
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

共 10 篇 | 覆盖 4 个方向 | 含 Fudan / ETH / MIT / Baidu 等机构
| 方向 | 篇数 | 代表论文 |
|---|---|---|
| 视频/数字人 | 5 | Hallo-Live(实时流式)、Talker-T2AV、EAD-Net、BurstGP、MotionHiFlow |
| 采样优化 | 2 | Z2-Sampling(零成本锯齿)、Oracle Noise(球面对齐) |
| 图片编辑 | 2 | REDEdit(无掩码局部编辑)、Geometry-Conditioned Diffusion |
| 模型对齐 | 1 | V-GRPO(在线RL偏好对齐) |
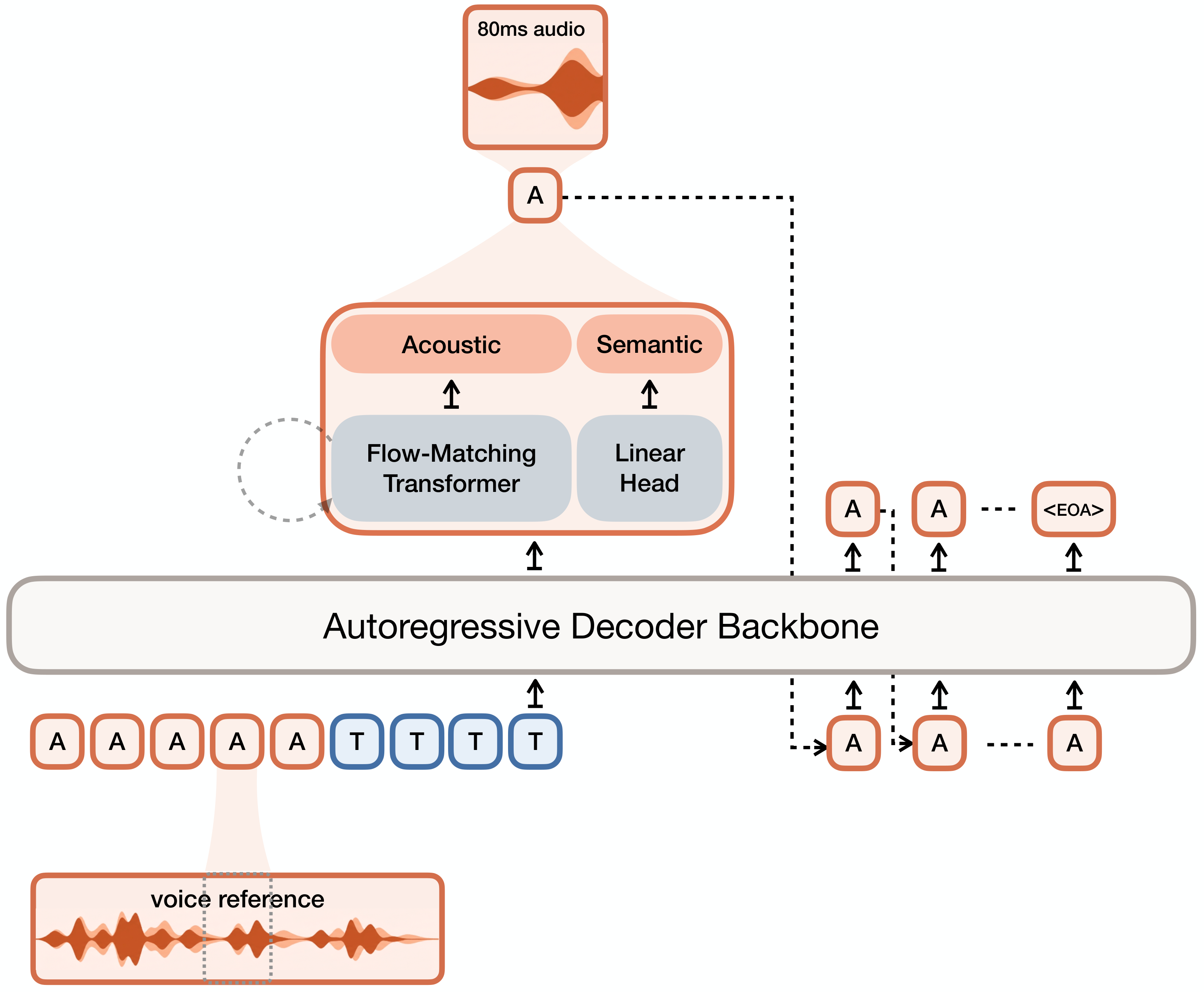
Hallo-Live: Real-Time Streaming Joint Audio-Video Avatar Generation with Asynchronous Dual-Stream and Human-Centric Preference Distillation | Shanghai Innovation Institute, Fudan University, University of Science and Technology of China, Nanjing University, Baidu
关键词: 实时生成, 音视频数字人, 双流扩散, 偏好蒸馏
前序工作问题: 现有音视频扩散模型推理速度太慢,无法满足实时交互式数字人生成的需求,激进加速后质量严重退化。
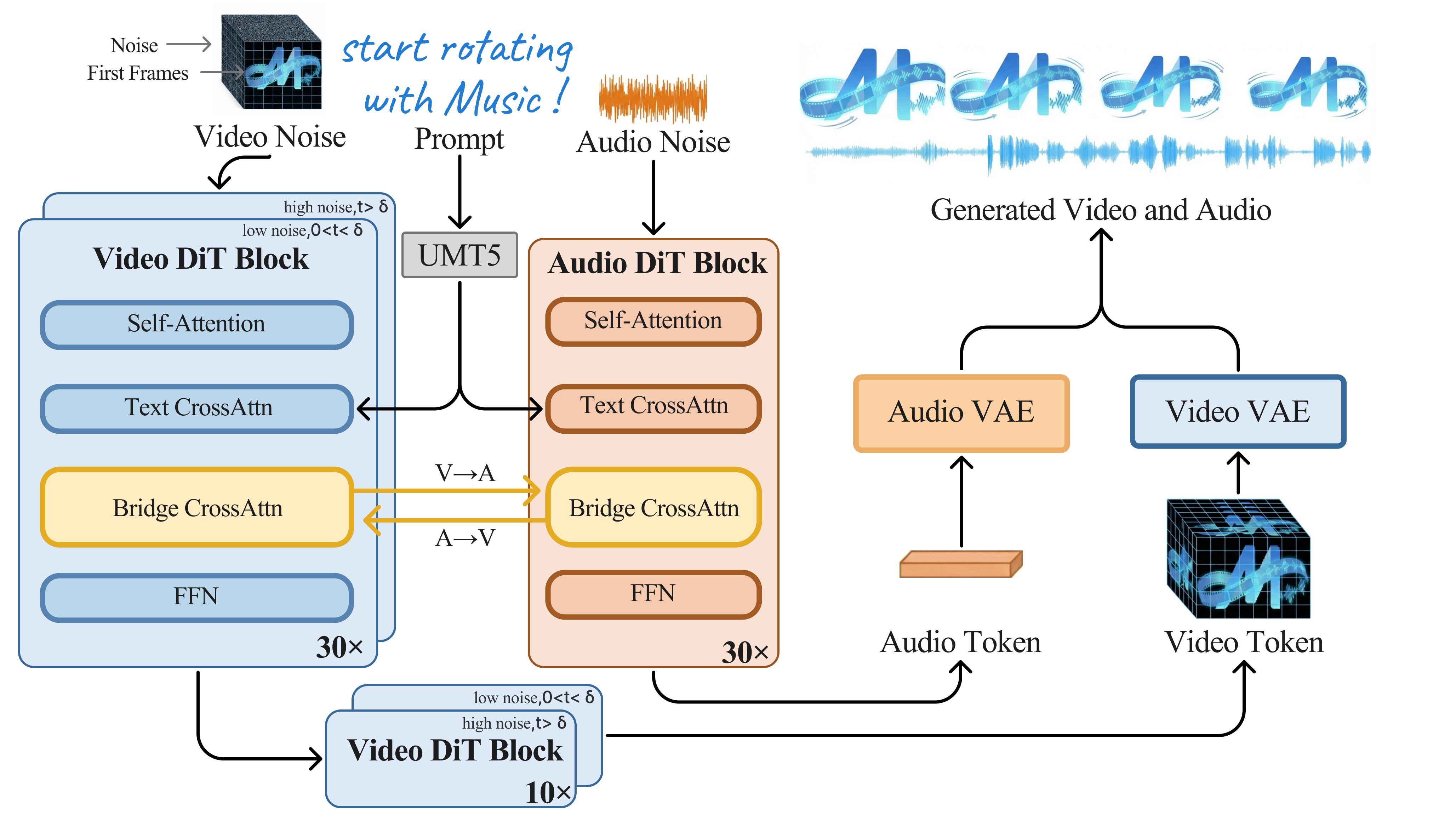
贡献: 提出 Hallo-Live 框架,通过异步双流扩散架构(视频流与音频流独立去噪 + Future-Expanding Attention)和以人为本偏好蒸馏(HP-DMD),实现首个实时流式联合音视频数字人生成。
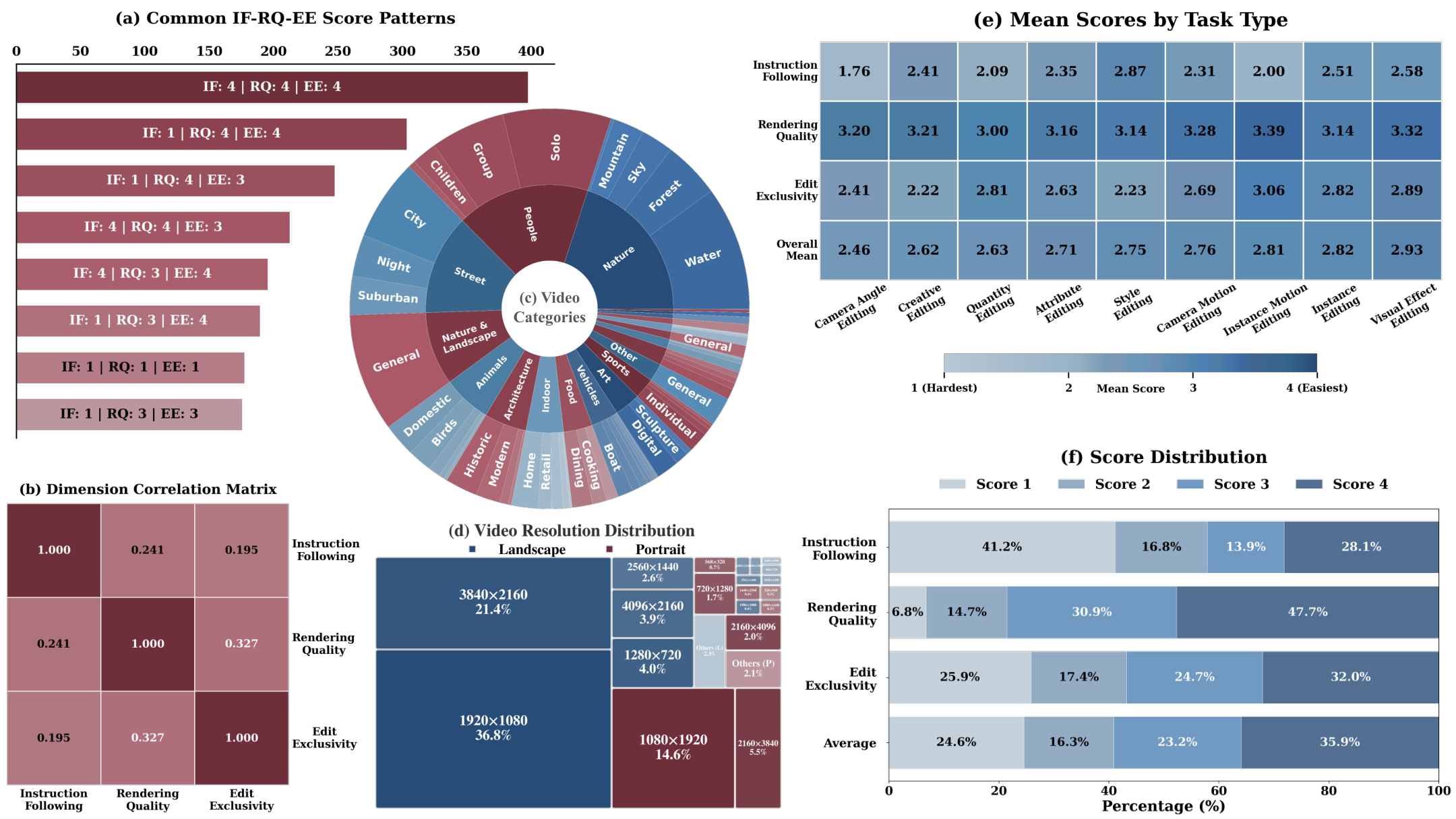
效果: 在两块 H200 GPU 上达到 20.38 FPS、0.94 秒延迟,较教师模型吞吐量提升 16 倍、延迟降低 99.3 倍。VideoAlign 整体分数和 Sync 分数均超越教师模型。
批判点评: 双H200的硬件门槛不低,20FPS实时性令人印象深刻但工程复杂度高,偏好蒸馏的泛化性有待更多场景验证
BurstGP: Enhancing Raw Burst Image Super Resolution with Generative Priors | ETH
关键词: 突发超分, 扩散先验, 退化感知
前序工作问题: 传统 Burst 超分方法在复杂纹理上过度平滑,难以从多帧低分辨率图像重建精细视觉细节。
贡献: 提出 BurstGP,利用预训练视频扩散模型的生成先验来增强多帧突发(Burst)图像超分辨率,解决传统方法在复杂纹理上过度平滑的问题。
效果: 引入退化感知条件机制控制细节合成力度,以及鲁棒的 sRGB-to-lRGB 反转模块以利用视频先验。在感知指标(MUSIQ、LPIPS)上达到 SOTA,纹理恢复和结构细节显著提升。
批判点评: 视频扩散先验用于Burst超分思路新颖,但退化感知机制的鲁棒性在极端退化场景下可能受限
$Z^2$-Sampling: Zero-Cost Zigzag Trajectories for Semantic Alignment in Diffusion Models | MIT, ETH
关键词: 采样优化, CFG增强, 零成本
前序工作问题: 标准 CFG 仅利用瞬时梯度,忽略历史去噪轨迹中的语义对齐信息,限制了扩散模型的生成质量。
贡献: 理论证明 Z-Sampling 的显式锯齿轨迹可拓扑约简,提出 Z²-Sampling(零成本锯齿采样),在不增加 NFE 开销的情况下显著提升扩散模型的语义对齐质量。
效果: 利用概率流 ODE 的时间连续性,将隐式代数坍缩与动态缓存结合,零额外计算成本实现与 Z-Sampling 相当的语义对齐提升,消除离流形评估误差。
批判点评: 零成本提升语义对齐的理论贡献扎实,但实际增益幅度需看具体任务和模型架构
Oracle Noise: Faster Semantic Spherical Alignment for Interpretable Latent Optimization | MIT, ETH
关键词: 噪声优化, 球面对齐, 语义增强
前序工作问题: 文生图扩散模型在复杂文本提示下语义对齐不精确,传统初始噪声优化方法会破坏高斯先验导致伪影。
贡献: 提出 Oracle Noise 方法,通过球面对齐优化初始噪声来提升文生图模型的语义对齐,避免传统欧几里得梯度上升破坏高斯先验导致的伪影。
效果: 在球面流形上进行约束优化,保持噪声的高斯分布性质,消除颜色过饱和等伪影,实现更快速的语义对齐收敛。
批判点评: 球面约束优化思路优雅,2秒预算内的收敛速度是亮点,但对高分辨率生成的扩展性存疑
Talker-T2AV: Joint Talking Audio-Video Generation with Autoregressive Diffusion Modeling
关键词: Talking Head, 自回归扩散, 音视频联合
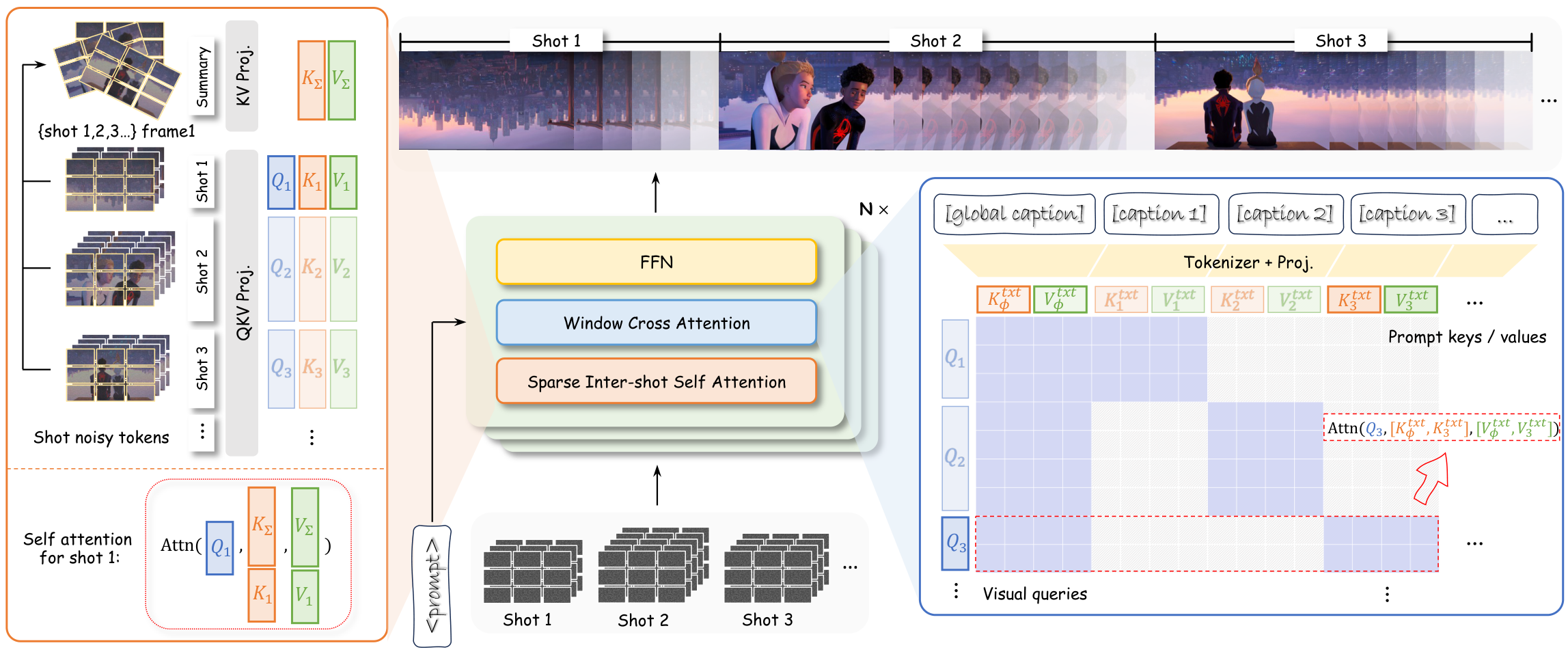
前序工作问题: 现有联合音视频生成模型在整个去噪过程中耦合模态,无法有效解耦语义关联与底层渲染。
贡献: 提出 Talker-T2AV,采用自回归扩散建模实现联合说话音视频生成,将语义关联与底层渲染解耦。
效果: 高层语义跨模态关联,低层音频信号和视觉纹理独立渲染,减少不必要的纠缠,提升说话头像合成中的音画质量和唇形同步精度。
批判点评: 语义-渲染解耦设计合理,但双头架构的训练稳定性和音视频同步精度需更大规模验证
MotionHiFlow: Text-to-motion via hierarchical flow matching | MIT
关键词: 动作生成, 分层流匹配, 文本驱动
前序工作问题: 文本驱动动作生成在复杂动作的层级理解和精细细节保真方面仍有不足,单一层次建模难以兼顾语义对齐与物理合理性。
贡献: 提出 MotionHiFlow,一种用于文本驱动动作生成的分层 Flow Matching 框架,模拟人类认知中对复杂动作的层级理解。
效果: 在多个时间尺度上逐层生成动作,从粗粒度语义到细粒度细节,提升语义对齐和时间连贯性,生成更自然的 3D 人体运动。
批判点评: 分层Flow Matching概念清晰,跨尺度过渡机制是关键创新,但3D动作的物理合理性评估不够充分
EAD-Net: Emotion-Aware Talking Head Generation with Spatial Refinement and Temporal Coherence | MIT, ETH
关键词: 情感驱动, Talking Head, 时间连贯
前序工作问题: 情感说话头像生成依赖简单情感标签语义不足,且引入情感表达往往导致唇形同步质量退化。
贡献: 提出 EAD-Net,情感感知的说话头像生成方法,解决简单情感标签语义不足和唇形同步退化问题。
效果: 引入高层语义情感信息增强表情表达力,同时通过空间精化和时间连贯性模块平衡计算效率与全局运动感知,减轻长视频中的闪烁伪影。
批判点评: 情感标签→LLM文本描述的升级方向正确,但STDA的计算开销可能限制长视频实用性
V-GRPO: Online Reinforcement Learning for Denoising Generative Models Is Easier than You Think | MIT, ETH
关键词: GRPO, 偏好对齐, 在线RL
前序工作问题: 将去噪生成模型与人类偏好对齐仍面临方差大、训练不稳定等挑战,现有策略梯度方法效率有限。
贡献: 提出 V-GRPO,用在线强化学习对齐去噪生成模型与人类偏好,基于 ELBO 似然代理实现高效稳定的策略优化。
效果: 关键发现:ELBO 似然代理在足够的 KL 正则化下效果与精确似然相当。V-GRPO 在视觉生成任务上优于 MDP 轨迹优化方法,训练更高效。
批判点评: ELBO代理+GRPO的组合简洁高效,2-3倍加速实用价值高,但奖励模型的质量仍是瓶颈
Geometry-Conditioned Diffusion for Occlusion-Robust In-Bed Pose Estimation | MIT, ETH
关键词: 姿态估计, 遮挡鲁棒, 条件扩散
前序工作问题: 毯子遮挡下的床上人体姿态估计缺乏可靠标注数据,现有多模态方法成本高且适应性差。
贡献: 将遮挡感知数据增强重新定义为几何条件生成建模任务,提出姿态条件扩散模型用于被毯子遮挡的床上姿态估计。
效果: 系统比较确定性遮罩、非配对翻译、配对扩散翻译和姿态条件生成四种方案,实现不依赖多模态传感器的鲁棒遮挡姿态估计。
批判点评: 从骨架直接生成遮挡图像消除了配对数据依赖,但应用场景较窄,泛化到其他遮挡类型需验证
Edit Where You Mean: Region-Aware Adapter Injection for Mask-Free Local Image Editing
关键词: 局部编辑, 无掩码, DiT适配器
前序工作问题: 大型 DiT 模型的联合注意力架构缺乏显式空间控制,局部编辑指令会不可避免地泄漏到无关区域。
贡献: 提出 REDEdit,指令与区域感知的适配器框架,让冻结的 DiT 变成精确的局部编辑器,无需修改骨干网络权重。
效果: 通过 Block Adapter 在每个 Transformer 块注入结构化条件流,将「编辑什么」与「在哪编辑」分离,解决 DiT 局部编辑泄漏到无关区域的问题,无需掩码输入。
批判点评: Block Adapter免训练骨干的设计实用性强,MaskPredictor自动定位编辑区域是亮点,但复杂多区域编辑场景未充分探索
人工智能炼丹君 整理 | 2026-04-28
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描下方二维码关注

评论 (0)