
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日 arXiv cs.CV 视觉生成相关论文共 10 篇。
方向分布:
源自 arXiv 4月25日 107 篇候选中精选
VARestorer: One-Step VAR Distillation for Real-World Image Super-Resolution | Tsinghua University | arXiv:2604.21450
关键词: VAR蒸馏·图像超分·一步推理·参数高效
前序工作问题: 视觉自回归模型(VAR)的逐尺度预测机制在超分任务中因因果注意力限制无法利用全局低质量上下文,导致输出模糊,且多步迭代引发误差累积
贡献: 提出蒸馏框架将预训练文生图VAR模型转化为一步超分模型,引入金字塔图像条件+跨尺度注意力实现双向尺度交互,仅微调1.2%参数
效果: DIV2K上MUSIQ 72.32、CLIPIQA 0.7669达SOTA,推理速度提升10倍
批判点评: 蒸馏依赖教师模型质量,对极端退化场景(如严重压缩伪影)的泛化能力待验证
Linear Image Generation by Synthesizing Exposure Brackets | Adobe Research / NTU | arXiv:2604.21008
关键词: 线性图像·曝光包围·HDR生成·DiT流匹配
前序工作问题: 现有生成模型只能合成经色调映射的显示参考图像,丢失场景真实辐照信息,限制后期编辑空间
贡献: 首次提出文本到线性图像生成任务,将线性图像表示为曝光包围序列,设计DiT流匹配架构生成多曝光bracket保留完整动态范围
效果: 生成高质量场景参考线性图像,支持文本引导编辑和ControlNet结构条件生成等下游应用
批判点评: 曝光包围表示增加推理开销,线性图像评估标准尚未建立,实用性需更多专业摄影师反馈验证
GeoRelight: Learning Joint Geometrical Relighting and Reconstruction with Multi-Modal DiT | Meta / University of Toronto | arXiv:2604.20715
关键词: 重光照·3D重建·多模态DiT·深度估计
前序工作问题: 单张照片重光照是病态问题,现有方法要么串行流水线误差累积,要么忽略3D几何导致物理不一致
贡献: 提出统一多模态DiT同时求解几何估计和重光照,设计各向同性NDC正交深度(iNOD)表示兼容潜在扩散模型,合成+真实数据混合训练
效果: 几何和重光照互相增益,性能超越串行模型和忽略几何的方法
批判点评: 对复杂遮挡和极端光照条件的鲁棒性需进一步验证,单张输入的几何歧义仍是固有限制
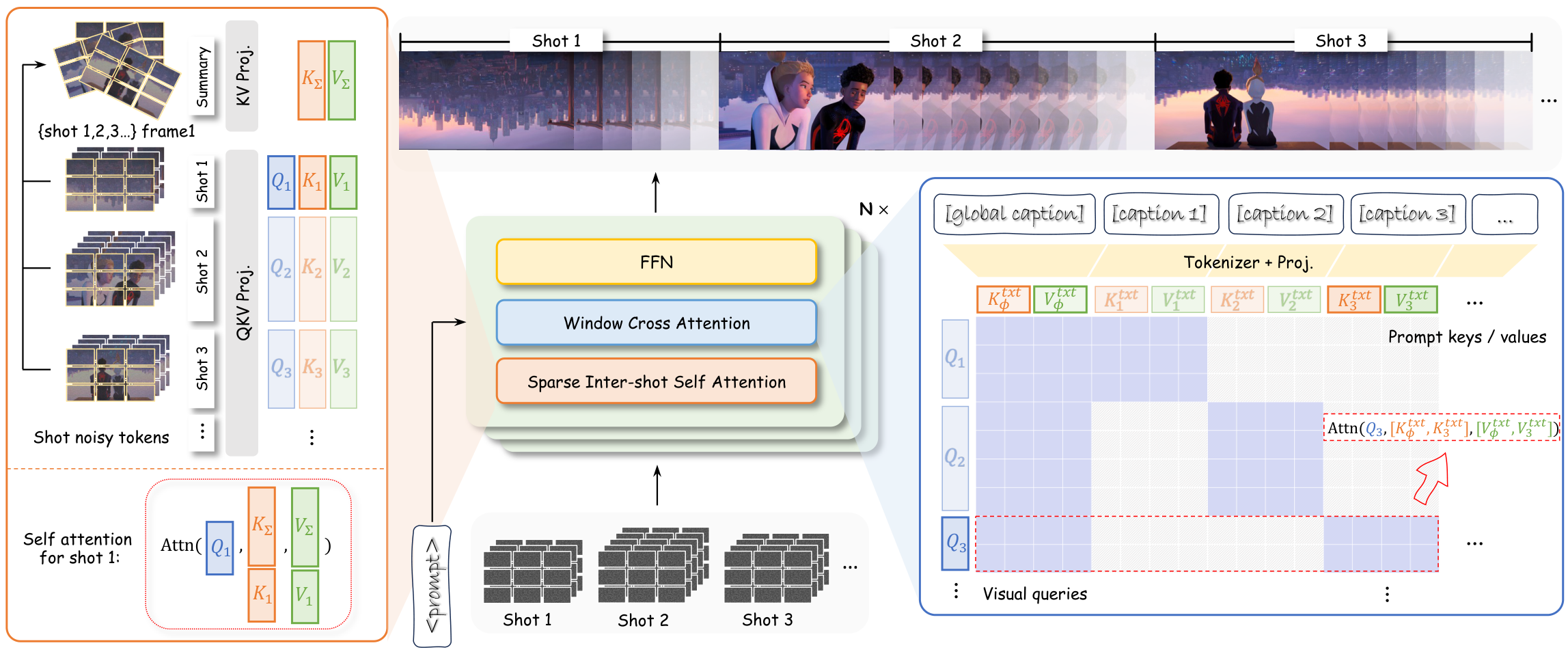
KD-CVG: A Knowledge-Driven Approach for Creative Video Generation | Xi'an Jiaotong University / ByteDance | arXiv:2604.21362
关键词: 创意视频·广告生成·知识图谱·语义对齐
前序工作问题: T2V模型在广告创意视频生成中存在语义对齐模糊和运动适应性不足两大问题
贡献: 构建广告创意知识库(ACKB),提出语义感知检索(SAR)+多模态知识参考(MKR)两阶段方法,用图注意力网络和RL反馈增强卖点-视频关联理解
效果: 在语义对齐和运动适应性指标上超越现有方法,代码和数据集将开源
批判点评: 知识库构建成本高且依赖特定广告领域,泛化到其他创意场景需额外适配
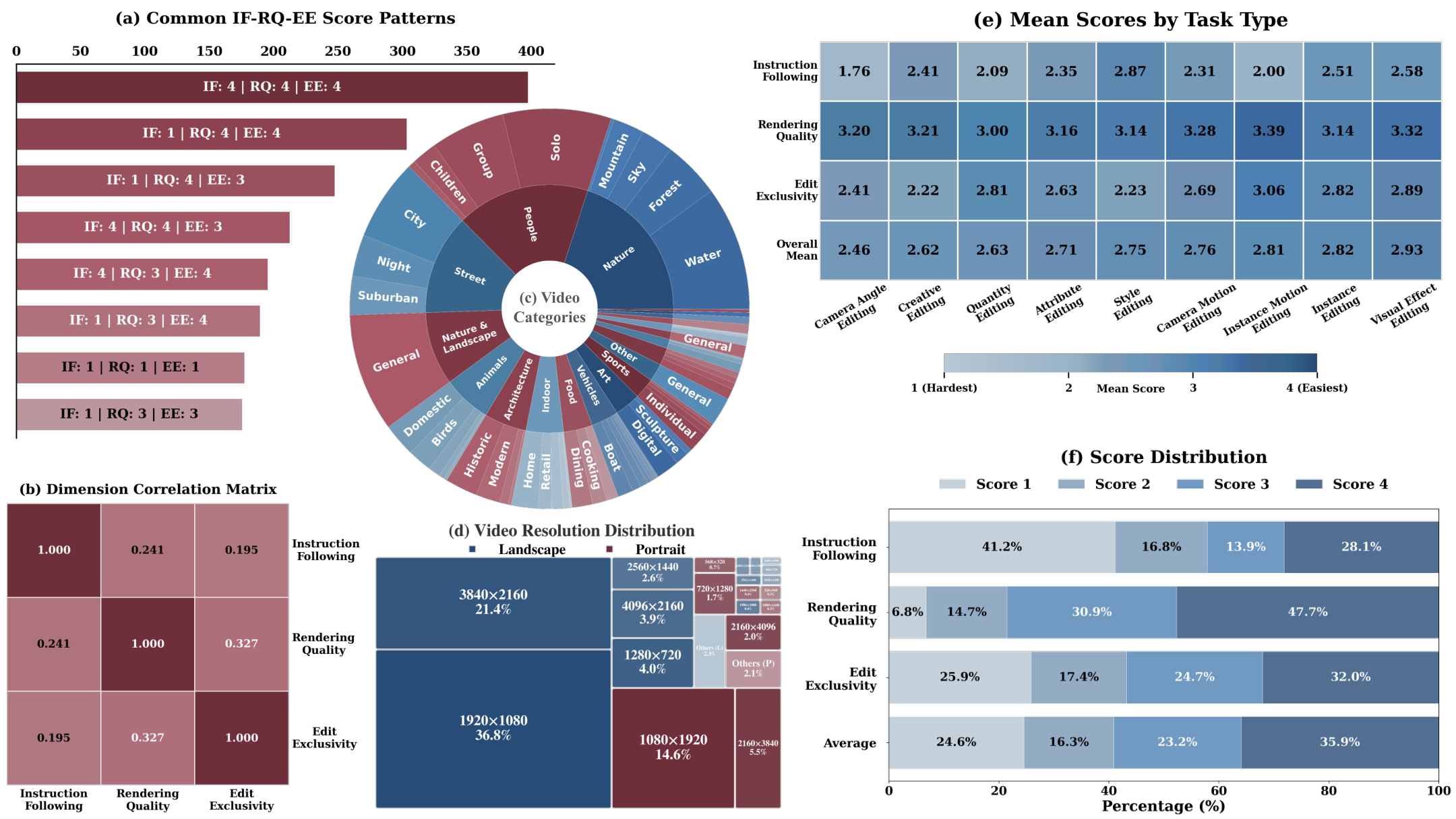
Building a Precise Video Language with Human-AI Oversight | CMU / Stanford | arXiv:2604.21718
关键词: 视频描述·CHAI框架·人机协同·Wan微调
前序工作问题: 现有视频语言模型缺乏精确描述运动、空间和摄像机动态的能力,标注数据质量参差不齐
贡献: 定义结构化视频描述规范(数百个视觉原语),提出CHAI人机协同框架让专家对模型预标注进行批判修正,支持SFT/DPO/推理时Scaling
效果: 在适度人工监督下开源模型超越Gemini-3.1-Pro;微调Wan实现400词长提示的精准视频生成控制
批判点评: 专家监督仍需大量人力投入,视觉原语定义的通用性和可扩展性有待社区验证
ParetoSlider: Diffusion Models Post-Training for Continuous Reward Control | Tel Aviv University / NVIDIA | arXiv:2604.20816
关键词: 多目标RL·Pareto前沿·扩散后训练·推理时控制
前序工作问题: RL后训练依赖单一标量奖励,早期标量化将多目标折叠为固定加权和,无法在推理时控制冲突目标间的权衡
贡献: 提出多目标RL框架训练单个扩散模型逼近整个Pareto前沿,通过连续变化偏好权重条件化实现推理时精细权衡导航
效果: 在SD3.5、FluxKontext、LTX-2三个骨干上单模型匹配或超越多个独立训练的基线
批判点评: Pareto前沿近似精度受训练采样密度影响,目标数量增加时训练稳定性可能下降
AttentionBender: Manipulating Cross-Attention in Video Diffusion Transformers | University of the Arts London | arXiv:2604.20936
关键词: 注意力操控·视频DiT·创意工具·可解释AI
前序工作问题: 视频生成模型只能通过提示词控制,艺术家无法直观理解和操控模型内部机制以突破默认生成倾向
贡献: 基于Network Bending设计工具,对视频DiT的交叉注意力图施加2D变换(旋转/缩放/平移),4500+视频实验验证操控效果
效果: 揭示交叉注意力高度纠缠特性,产生超越模型学习表征空间的新颖glitch美学效果
批判点评: 操控效果高度非线性且难以预测,作为实用工具的可控性和易用性较弱
Exploring the Role of Synthetic Data Augmentation in Controllable Human-Centric Video Generation | Alibaba Group | arXiv:2604.21291
关键词: 合成数据·人体视频·Sim2Real·动作控制
前序工作问题: 大规模、多样且隐私安全的人体视频数据集稀缺,合成数据的Sim2Real差距使其对生成模型的实际贡献不明确
贡献: 系统研究合成数据对可控人体视频生成的影响,提出扩散框架支持外观和动作精细控制,分析合成-真实数据训练交互
效果: 揭示合成与真实数据互补角色,高效合成样本选择可增强运动真实性、时序一致性和身份保持
批判点评: 合成数据质量依赖渲染引擎和资产库,跨域泛化效果受特定合成工具限制
DCMorph: Face Morphing via Dual-Stream Cross-Attention Diffusion | Fraunhofer IGD / TU Darmstadt | arXiv:2604.21627
关键词: 人脸变形·双流扩散·身份注入·安全对抗
前序工作问题: 图像级融合方法有拼接痕迹,GAN方法重建保真度有限,现有扩散方法缺乏显式双身份条件注入
贡献: 提出双流框架:(1)解耦交叉注意力插值注入双源人脸特征,(2)DDIM反演+球面插值获取几何一致初始隐表示
效果: 在四个SOTA人脸识别系统上攻击成功率最高,同时对现有检测方案具有挑战性
批判点评: 该技术潜在安全风险值得关注,论文主要聚焦攻击而非防御,伦理讨论不够充分
WorldMark: A Unified Benchmark Suite for Interactive Video World Models | Alibaba Group | arXiv:2604.21686
关键词: 世界模型·交互视频·评测基准·WASD控制
前序工作问题: 交互式视频生成模型各自使用私有场景和轨迹评测,缺乏统一标准化测试条件进行公平跨模型比较
贡献: 提出首个统一评测基准:(1)统一动作映射层将WASD操作翻译为各模型控制格式,(2)500个测试用例覆盖多视角/风格/难度,(3)模块化评估工具包
效果: 在6个主流模型上实现公平对比,发布World Model Arena在线对战平台(warena.ai)
批判点评: WASD离散动作难以覆盖连续控制场景,500个测试用例对真正全面评测可能仍不足
人工智能炼丹君 整理 | 2026-04-27
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)