搜索到
4
篇与
generation
的结果
-
 AIGC 每日速读|2026-04-22|一步生成到投机解码-视频加速多路并进 今日核心看点 解耦记忆长视频 MemWN 一步文本生成 EMF 投机解码加速 2.09x 多事件视频+33.5% 编辑 RLHF 后训练 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇。 方向分布: 视频生成(4篇):长视频空间一致性 MemWN、多事件生成 TS-Attn、人体视频 ReImagine、视频到音乐 Video-Robin 推理加速(3篇):投机解码 SDVG、稀疏注意力聚类 AdaCluster、Patch 级自适应采样 Patch Forcing 图像生成与编辑(3篇):一步文本生成 EMF、人类偏好编辑 HP-Edit、扩散引导检测 DGSSM 含 CVPR 2026 接收,多篇开源代码,覆盖视频/图像/音频三大生成方向 今日论文速览 1. MemWN:提出解耦记忆控制框架 MemWN Memorize When Needed: Decoupled Memory Control for Spatially Consistent Long-Horizon Video Generation | Wuhan University | arXiv:2604.18215 关键词: 长视频生成·空间一致性·解耦记忆·相机轨迹·按需记忆 贡献: 提出解耦记忆控制框架 MemWN,将记忆建模与视频生成分离。混合记忆表示捕获时间+空间双重线索,逐帧交叉注意力精准注入记忆,相机感知门控智能判断何时使用记忆。 效果: 在长视频生成基准上取得 SOTA,场景重访空间一致性大幅提升,训练成本显著降低。 2. EMF:首次将 MeanFlow 框架从类别标签扩展到文本条件 EMF: Extending One-Step Image Generation from Class Labels to Text via Discriminative Text Representation | Nankai University, Alibaba AMAP-ML | arXiv:2604.18168 关键词: 一步生成·MeanFlow·文本条件·LLM编码器·图像合成 贡献: 首次将 MeanFlow 框架从类别标签扩展到文本条件,实现高效的一步文本到图像生成。揭示了 MeanFlow 少步生成中文本特征需要高区分度的关键洞察,开发了基于 LLM 文本编码器的解决方案。 效果: 在 MeanFlow 框架下首次实现文本条件的一步图像生成,同时在扩散模型上也展示了显著的生成性能提升。代码已开源。 3. TS-Attn:提出免训练的时间可分离注意力机制(TS-Attn) TS-Attn: Temporal-wise Separable Attention for Multi-Event Video Generation | PKU, ZJU, Nankai, MIT, NJU, UCSB | arXiv:2604.19473 关键词: 多事件视频·免训练·时间注意力·Wan2.1·即插即用 贡献: 提出免训练的时间可分离注意力机制(TS-Attn),解决多事件视频生成中动作保真度与时间一致性的固有矛盾。可即插即用到 Wan2.1-T2V-14B 等预训练模型中。 效果: 在 Wan2.1-T2V-14B 上 StoryEval-Bench 提升 33.5%,在 Wan2.2-T2V-A14B 上提升 16.4%,推理开销仅 +2%。代码已开源。 4. SDVG:首次将投机解码引入自回归视频扩散模型加速 Speculative Decoding for Autoregressive Video Generation | Independent Research | arXiv:2604.17397 关键词: 投机解码·自回归视频·加速推理·ImageReward·免训练 贡献: 首次将投机解码引入自回归视频扩散模型加速。用 1.3B 小模型起草候选块,ImageReward 路由器以最差帧评分筛选,实现免训练、无需架构修改的视频生成加速。 效果: 在 MovieGenVideoBench 上,保持 98.1% 质量实现 1.59× 加速,或 2.09× 加速保持 95.7% 质量,始终比纯 Draft 高 >17%。 5. ReImagine:提出先图像后视频的人体视频生成范式 ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis | CUHK(SZ), SSE, FNii | arXiv:2604.18300 关键词: 人体视频·SMPL-X·图像先验·视角控制·免训练精炼 贡献: 提出先图像后视频的人体视频生成范式,将高质量人体外观学习与时序一致性解耦。结合 SMPL-X 姿态引导和预训练视频扩散模型的免训练时序精炼。 效果: 在多样化姿态和视角下生成高质量、时序一致的人体视频。发布了标准化人体数据集和辅助合成模型。代码已开源。 6. DGSSM:提出扩散引导的状态空间模型框架 DGSSM: Diffusion Guided State-Space Models for Multimodal Salient Object Detection | IIT Guwahati | arXiv:2604.18500 关键词: 显著性检测·Mamba·扩散先验·多模态·边界感知 贡献: 提出扩散引导的状态空间模型框架,将多模态显著性检测建模为渐进去噪过程。融合 Mamba 高效全局推理与扩散结构先验。 效果: 在 13 个公开基准(RGB、RGB-D、RGB-T)上全面超越现有 SOTA,同时保持紧凑的模型尺寸。 7. Patch Forcing:探索 patch 级别的噪声调度用于图像合成 Denoising, Fast and Slow: Difficulty-Aware Adaptive Sampling for Image Generation | CompVis @ LMU Munich | arXiv:2604.19141 关键词: 自适应去噪·Patch级调度·难度感知·计算优化·扩散模型 贡献: 探索 patch 级别的噪声调度用于图像合成,提出 Patch Forcing 框架,让简单区域先行去噪为困难区域提供上下文。引入自适应难度头按需分配计算资源。 效果: 在 class-conditional ImageNet 上实现优于基线的生成质量,与表示对齐和引导方法正交,可扩展到文本到图像合成。 8. Video-Robin:提出 Video-Robin Video-Robin: Autoregressive Diffusion Planning for Intent-Grounded Video-to-Music Generation | UMD, Microsoft | arXiv:2604.18700 关键词: 视频到音乐·自回归规划·扩散合成·文本条件·DiT 贡献: 提出 Video-Robin,结合自回归规划与扩散合成的文本条件视频到音乐生成模型。自回归模块建模全局结构并对齐视觉与文本语义。 效果: 在分布内和分布外基准上均超越仅接受视频输入和额外特征条件的基线,推理速度比 SOTA 快 2.21 倍。 9. HP-Edit:提出 HP-Edit 人类偏好对齐的图像编辑后训练框架 HP-Edit: A Human-Preference Post-Training Framework for Image Editing | HIT, vivo AI Lab | arXiv:2604.19406 关键词: 图像编辑·人类偏好·RLHF·VLM评分器·后训练 贡献: 提出 HP-Edit 人类偏好对齐的图像编辑后训练框架,发布 RealPref-50K 真实世界偏好数据集覆盖 8 类编辑任务。训练 HP-Scorer 自动评分器作为 RLHF 奖励函数。 效果: 显著增强 Qwen-Image-Edit-2509 等模型的输出,使其更贴合人类偏好。同时发布 RealPref-Bench 基准。 10. AdaCluster:提出免训练的自适应聚类稀疏注意力框架 AdaCluster AdaCluster: Adaptive Query-Key Clustering for Sparse Attention in Video Generation | NUS, ByteDance | arXiv:2604.18348 关键词: 稀疏注意力·自适应聚类·视频DiT·加速推理·免训练 贡献: 提出免训练的自适应聚类稀疏注意力框架 AdaCluster,针对视频 DiT 的二次注意力复杂度问题。Q/K 分别采用角度和欧氏距离保持的聚类策略。 效果: 在 CogVideoX-2B、HunyuanVideo 和 Wan-2.1 上实现 1.67-4.31× 加速,质量损失可忽略不计,仅需单张 A40 GPU。 趋势观察 视频生成推理加速多路并进 — 投机解码(SDVG)、自适应稀疏注意力(AdaCluster)和 patch 级自适应采样(Patch Forcing)三种不同思路同时涌现,视频生成的实用化进程加速 免训练方法成为即插即用新常态 — TS-Attn、AdaCluster、ReImagine 的时序精炼均为免训练设计,降低部署门槛的同时保持了高效果 人类偏好对齐从生成扩展到编辑 — HP-Edit 将 RLHF 引入图像编辑后训练,配合 RealPref-50K 数据集和 VLM 评分器,预示编辑模型也将进入偏好对齐时代 长视频与多事件生成攻克一致性 — MemWN 用解耦记忆解决空间一致性,TS-Attn 用时间可分离注意力解决多事件时间一致性,分别从空间和时间维度推进长视频质量 视频-音乐跨模态生成走向可控 — Video-Robin 首次引入文本条件+自回归规划到 V2M 任务,从单纯视觉对齐升级为语义意图驱动的音乐创作 人工智能炼丹君 整理 | 2026-04-22 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
AIGC 每日速读|2026-04-22|一步生成到投机解码-视频加速多路并进 今日核心看点 解耦记忆长视频 MemWN 一步文本生成 EMF 投机解码加速 2.09x 多事件视频+33.5% 编辑 RLHF 后训练 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇。 方向分布: 视频生成(4篇):长视频空间一致性 MemWN、多事件生成 TS-Attn、人体视频 ReImagine、视频到音乐 Video-Robin 推理加速(3篇):投机解码 SDVG、稀疏注意力聚类 AdaCluster、Patch 级自适应采样 Patch Forcing 图像生成与编辑(3篇):一步文本生成 EMF、人类偏好编辑 HP-Edit、扩散引导检测 DGSSM 含 CVPR 2026 接收,多篇开源代码,覆盖视频/图像/音频三大生成方向 今日论文速览 1. MemWN:提出解耦记忆控制框架 MemWN Memorize When Needed: Decoupled Memory Control for Spatially Consistent Long-Horizon Video Generation | Wuhan University | arXiv:2604.18215 关键词: 长视频生成·空间一致性·解耦记忆·相机轨迹·按需记忆 贡献: 提出解耦记忆控制框架 MemWN,将记忆建模与视频生成分离。混合记忆表示捕获时间+空间双重线索,逐帧交叉注意力精准注入记忆,相机感知门控智能判断何时使用记忆。 效果: 在长视频生成基准上取得 SOTA,场景重访空间一致性大幅提升,训练成本显著降低。 2. EMF:首次将 MeanFlow 框架从类别标签扩展到文本条件 EMF: Extending One-Step Image Generation from Class Labels to Text via Discriminative Text Representation | Nankai University, Alibaba AMAP-ML | arXiv:2604.18168 关键词: 一步生成·MeanFlow·文本条件·LLM编码器·图像合成 贡献: 首次将 MeanFlow 框架从类别标签扩展到文本条件,实现高效的一步文本到图像生成。揭示了 MeanFlow 少步生成中文本特征需要高区分度的关键洞察,开发了基于 LLM 文本编码器的解决方案。 效果: 在 MeanFlow 框架下首次实现文本条件的一步图像生成,同时在扩散模型上也展示了显著的生成性能提升。代码已开源。 3. TS-Attn:提出免训练的时间可分离注意力机制(TS-Attn) TS-Attn: Temporal-wise Separable Attention for Multi-Event Video Generation | PKU, ZJU, Nankai, MIT, NJU, UCSB | arXiv:2604.19473 关键词: 多事件视频·免训练·时间注意力·Wan2.1·即插即用 贡献: 提出免训练的时间可分离注意力机制(TS-Attn),解决多事件视频生成中动作保真度与时间一致性的固有矛盾。可即插即用到 Wan2.1-T2V-14B 等预训练模型中。 效果: 在 Wan2.1-T2V-14B 上 StoryEval-Bench 提升 33.5%,在 Wan2.2-T2V-A14B 上提升 16.4%,推理开销仅 +2%。代码已开源。 4. SDVG:首次将投机解码引入自回归视频扩散模型加速 Speculative Decoding for Autoregressive Video Generation | Independent Research | arXiv:2604.17397 关键词: 投机解码·自回归视频·加速推理·ImageReward·免训练 贡献: 首次将投机解码引入自回归视频扩散模型加速。用 1.3B 小模型起草候选块,ImageReward 路由器以最差帧评分筛选,实现免训练、无需架构修改的视频生成加速。 效果: 在 MovieGenVideoBench 上,保持 98.1% 质量实现 1.59× 加速,或 2.09× 加速保持 95.7% 质量,始终比纯 Draft 高 >17%。 5. ReImagine:提出先图像后视频的人体视频生成范式 ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis | CUHK(SZ), SSE, FNii | arXiv:2604.18300 关键词: 人体视频·SMPL-X·图像先验·视角控制·免训练精炼 贡献: 提出先图像后视频的人体视频生成范式,将高质量人体外观学习与时序一致性解耦。结合 SMPL-X 姿态引导和预训练视频扩散模型的免训练时序精炼。 效果: 在多样化姿态和视角下生成高质量、时序一致的人体视频。发布了标准化人体数据集和辅助合成模型。代码已开源。 6. DGSSM:提出扩散引导的状态空间模型框架 DGSSM: Diffusion Guided State-Space Models for Multimodal Salient Object Detection | IIT Guwahati | arXiv:2604.18500 关键词: 显著性检测·Mamba·扩散先验·多模态·边界感知 贡献: 提出扩散引导的状态空间模型框架,将多模态显著性检测建模为渐进去噪过程。融合 Mamba 高效全局推理与扩散结构先验。 效果: 在 13 个公开基准(RGB、RGB-D、RGB-T)上全面超越现有 SOTA,同时保持紧凑的模型尺寸。 7. Patch Forcing:探索 patch 级别的噪声调度用于图像合成 Denoising, Fast and Slow: Difficulty-Aware Adaptive Sampling for Image Generation | CompVis @ LMU Munich | arXiv:2604.19141 关键词: 自适应去噪·Patch级调度·难度感知·计算优化·扩散模型 贡献: 探索 patch 级别的噪声调度用于图像合成,提出 Patch Forcing 框架,让简单区域先行去噪为困难区域提供上下文。引入自适应难度头按需分配计算资源。 效果: 在 class-conditional ImageNet 上实现优于基线的生成质量,与表示对齐和引导方法正交,可扩展到文本到图像合成。 8. Video-Robin:提出 Video-Robin Video-Robin: Autoregressive Diffusion Planning for Intent-Grounded Video-to-Music Generation | UMD, Microsoft | arXiv:2604.18700 关键词: 视频到音乐·自回归规划·扩散合成·文本条件·DiT 贡献: 提出 Video-Robin,结合自回归规划与扩散合成的文本条件视频到音乐生成模型。自回归模块建模全局结构并对齐视觉与文本语义。 效果: 在分布内和分布外基准上均超越仅接受视频输入和额外特征条件的基线,推理速度比 SOTA 快 2.21 倍。 9. HP-Edit:提出 HP-Edit 人类偏好对齐的图像编辑后训练框架 HP-Edit: A Human-Preference Post-Training Framework for Image Editing | HIT, vivo AI Lab | arXiv:2604.19406 关键词: 图像编辑·人类偏好·RLHF·VLM评分器·后训练 贡献: 提出 HP-Edit 人类偏好对齐的图像编辑后训练框架,发布 RealPref-50K 真实世界偏好数据集覆盖 8 类编辑任务。训练 HP-Scorer 自动评分器作为 RLHF 奖励函数。 效果: 显著增强 Qwen-Image-Edit-2509 等模型的输出,使其更贴合人类偏好。同时发布 RealPref-Bench 基准。 10. AdaCluster:提出免训练的自适应聚类稀疏注意力框架 AdaCluster AdaCluster: Adaptive Query-Key Clustering for Sparse Attention in Video Generation | NUS, ByteDance | arXiv:2604.18348 关键词: 稀疏注意力·自适应聚类·视频DiT·加速推理·免训练 贡献: 提出免训练的自适应聚类稀疏注意力框架 AdaCluster,针对视频 DiT 的二次注意力复杂度问题。Q/K 分别采用角度和欧氏距离保持的聚类策略。 效果: 在 CogVideoX-2B、HunyuanVideo 和 Wan-2.1 上实现 1.67-4.31× 加速,质量损失可忽略不计,仅需单张 A40 GPU。 趋势观察 视频生成推理加速多路并进 — 投机解码(SDVG)、自适应稀疏注意力(AdaCluster)和 patch 级自适应采样(Patch Forcing)三种不同思路同时涌现,视频生成的实用化进程加速 免训练方法成为即插即用新常态 — TS-Attn、AdaCluster、ReImagine 的时序精炼均为免训练设计,降低部署门槛的同时保持了高效果 人类偏好对齐从生成扩展到编辑 — HP-Edit 将 RLHF 引入图像编辑后训练,配合 RealPref-50K 数据集和 VLM 评分器,预示编辑模型也将进入偏好对齐时代 长视频与多事件生成攻克一致性 — MemWN 用解耦记忆解决空间一致性,TS-Attn 用时间可分离注意力解决多事件时间一致性,分别从空间和时间维度推进长视频质量 视频-音乐跨模态生成走向可控 — Video-Robin 首次引入文本条件+自回归规划到 V2M 任务,从单纯视觉对齐升级为语义意图驱动的音乐创作 人工智能炼丹君 整理 | 2026-04-22 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注 -
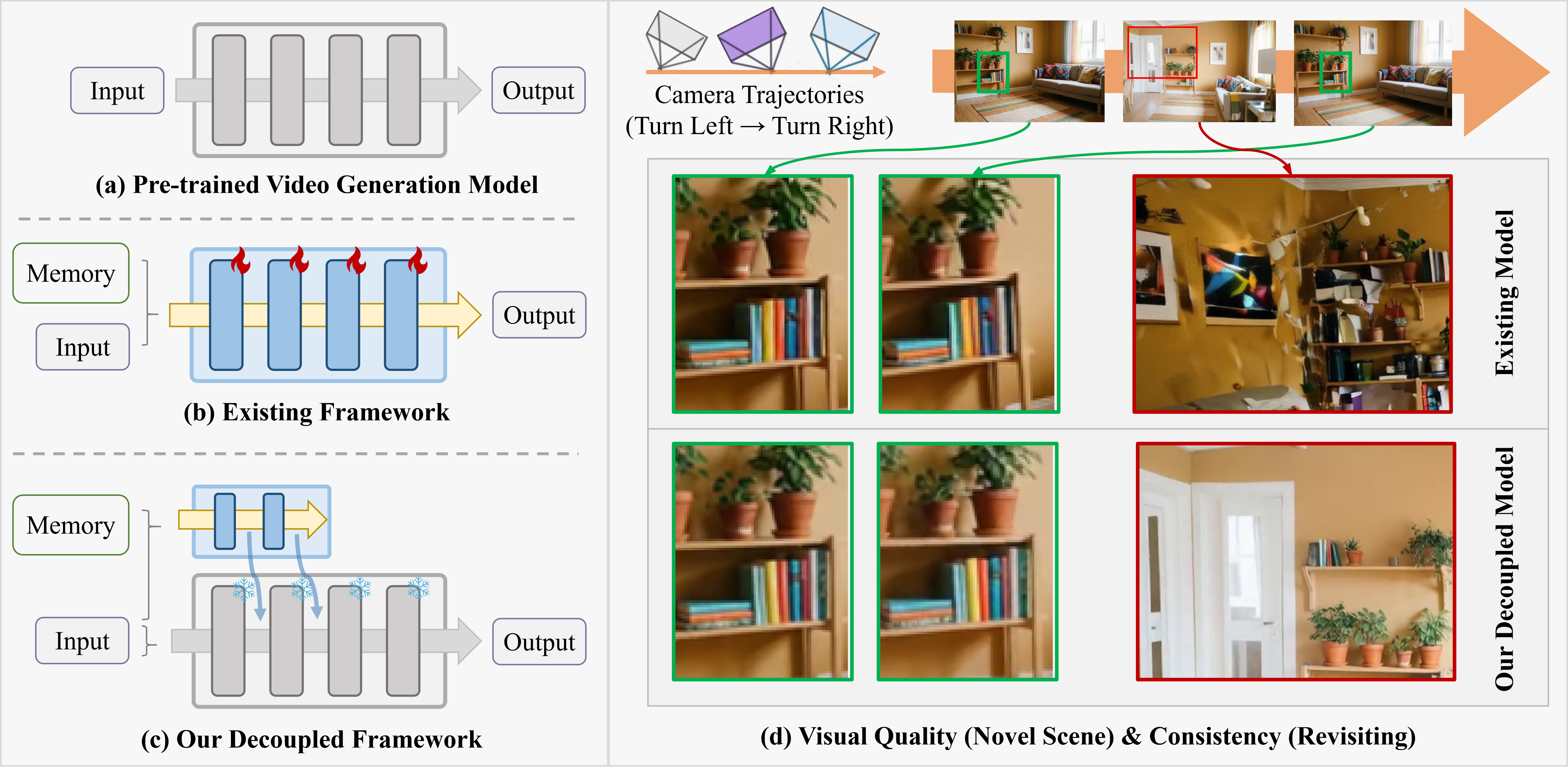
AIGC 每日速读|2026-04-22|解耦记忆控制长视频一致性-MemWN 今日核心看点 解耦记忆控制 长视频空间一致性新范式 一步图像生成 MeanFlow扩展到文本条件 投机解码首次用于视频生成加速 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 视频生成(4篇):长视频空间一致性、多事件生成、人体视频、视频到音乐 推理加速(3篇):投机解码、稀疏注意力聚类、Patch级自适应采样 图像生成与编辑(3篇):一步文本生成、人类偏好编辑、扩散引导检测 含多篇开源代码,覆盖视频/图像/音频三大生成方向 重点论文深度解读 1. Memorize When Needed: Decoupled Memory Control for Spatially Consistent Long-Horizon Video Generation 解耦记忆控制——用轻量级独立记忆分支实现空间一致性长视频生成 | HKPU, ByteDance | arXiv:2604.18215 关键词: 长视频生成, 空间一致性, 解耦记忆, 相机轨迹 研究动机 核心问题: 长视频生成中场景重访的空间不一致问题 沿预定义相机轨迹生成空间一致的长视频是当前视频生成领域的重要挑战。现有方法大多将记忆建模与视频生成耦合在一起,导致场景重访时出现内容不一致,而在探索新区域时生成能力下降。即使在大规模标注数据上训练,这些问题仍然存在。因此,亟需一种能同时保持空间一致性和新场景生成能力的新框架。 前序工作及局限: WorldDreamer (2024):无法保持场景重访时的空间一致性 SEVA (2025):记忆与生成耦合导致新场景生成能力下降 DFoT (2025):全局记忆注入干扰了不相关区域的生成 AC3D (2025):训练数据需求大,仍存在重访不一致问题 与前序工作的本质区别: 将记忆与生成彻底解耦,用轻量独立分支和门控机制实现按需记忆 方法原理 提出解耦框架,将记忆条件与生成过程分离。核心设计包括三个组件: 混合记忆表示(Hybrid Memory Representation):从已生成帧中捕获互补的时间与空间线索,构建丰富的历史信息表示。 逐帧交叉注意力(Per-Frame Cross-Attention):确保每一帧仅基于与其空间最相关的历史信息进行条件生成,精准注入记忆到生成模型中。 相机感知门控机制(Camera-Aware Gating):在生成新场景时,动态调节记忆模块与生成模块的交互,仅当存在有意义的历史参考时才启用记忆条件,避免无用记忆干扰新区域的探索。 轻量级独立记忆分支从生成过程中学习精确的空间一致性,训练成本大幅降低。 核心创新 首次将记忆条件与视频生成彻底解耦,用独立的轻量记忆分支替代耦合建模 混合记忆表示捕获时间+空间双重线索,比单一表示更全面 相机感知门控机制(Camera-Aware Gating)智能判断何时使用记忆、何时自由生成 高数据效率:相比现有方法在训练数据需求上大幅减少 实验结果 在长视频生成基准上取得 SOTA 表现:视觉质量和空间一致性均优于现有方法。相比耦合式方法,训练成本显著降低,同时在新场景探索和已见场景重访两方面均表现出色。 图表详解 概念对比图:解耦记忆控制 vs. 耦合式框架 图示展示三种框架对比:(a) 标准预训练视频生成模型无记忆能力,(b) 现有方法将记忆与生成耦合导致一致性问题,(c) 本文解耦框架用独立记忆分支实现按需记忆。右侧对比了两种方法在场景重访时的一致性表现。 解耦框架完整架构:混合记忆 + 交叉注意力 + 相机感知门控 完整方法架构图:左上角输入之前生成的帧和相机位姿,通过 FOV 引导检索和编码器生成混合记忆表示。记忆控制分支通过逐帧交叉注意力机制让每帧仅关注最相关的历史信息,相机感知门控决定是否注入到预训练 DiT 视频生成模型中。 与多种方法的视觉对比:前向探索 + 回访一致性 Visual comparison. Our method generates clearly structured staircases in unseen regions (pink boxes) and faithfully reproduces fine-grained details such as the two chairs when revisiting the original scene (red boxes). 与 WorldPlay、VMem、SEVA、DFoT、AC3D 五种方法的详细视觉对比。在前向旋转探索阶段所有方法都能生成合理内容,但在回访已见场景时本文方法保持了精确的空间一致性。 批判性点评 新颖性: 解耦记忆+门控的设计理念新颖,Camera-Aware Gating 是关键创新点 可复现性: 方法依赖预训练视频模型,轻量记忆分支可独立训练,复现性较好 影响力: 为长视频空间一致性问题提供了新范式,轻量解耦设计可广泛应用于世界模型和导航生成 深度点评: 解耦记忆 vs 耦合记忆 — Camera-Aware Gating 的设计理念出色,真正实现按需记忆而非全局注入 推理加速三路并进 — 投机解码 SDVG、稀疏注意力 AdaCluster 和 Patch Forcing 分别代表不同加速范式 RLHF 进入图像编辑时代 — HP-Edit 用 VLM 训练自动评分器作为奖励函数,推动编辑模型偏好对齐 技术演进定位: 在空间一致长视频生成方向上实现了 SOTA,向世界模型迈进 可能的后续方向: 与 3D 场景图结合实现精确空间定位 集成到世界模型中支持交互式场景生成 其余论文速览 1. EMF:首次将 MeanFlow 框架从类别标签扩展到文本条件 EMF: Extending One-Step Image Generation from Class Labels to Text via Discriminative Text Representation | Nankai University, Alibaba AMAP 关键词: 一步生成·MeanFlow·文本条件·LLM编码器·图像合成 贡献: 首次将 MeanFlow 框架从类别标签扩展到文本条件,实现高效的一步文本到图像生成。揭示了 MeanFlow 少步生成中文本特征需要高区分度的关键洞察,开发了基于 LLM 文本编码器的解决方案。 效果: 在 MeanFlow 框架下首次实现文本条件的一步图像生成,同时在扩散模型上也展示了显著的生成性能提升。代码已开源。 2. TS-Attn:提出免训练的时间可分离注意力机制(TS-Attn) TS-Attn: Temporal-wise Separable Attention for Multi-Event Video Generation | Peking University, Zhejiang University, Nankai University, MIT, NJU, UCSB 关键词: 多事件视频·免训练·时间注意力·Wan2.1·即插即用 贡献: 提出免训练的时间可分离注意力机制(TS-Attn),解决多事件视频生成中动作保真度与时间一致性的固有矛盾。可即插即用到 Wan2.1-T2V-14B 等预训练模型中。 效果: 在 Wan2.1-T2V-14B 上 StoryEval-Bench 提升 33.5%,在 Wan2.2-T2V-A14B 上提升 16.4%,推理开销仅 +2%。代码已开源。 3. SDVG:首次将投机解码(Speculative Decoding)引入自回归视… Speculative Decoding for Autoregressive Video Generation | Tsinghua University 关键词: 投机解码·自回归视频·加速推理·ImageReward·免训练 贡献: 首次将投机解码(Speculative Decoding)引入自回归视频扩散模型加速。用 1.3B 小模型起草候选块,ImageReward 路由器以最差帧评分筛选,实现免训练、无需架构修改的视频生成加速。 效果: 在 MovieGenVideoBench 上,保持 98.1% 质量实现 1.59× 加速,或 2.09× 加速保持 95.7% 质量,始终比纯 Draft 高 >17%。 4. ReImagine:提出先图像后视频的人体视频生成范式 ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis | CUHK(SZ), SSE, FNii 关键词: 人体视频·SMPL-X·图像先验·视角控制·免训练精炼 贡献: 提出先图像后视频的人体视频生成范式,将高质量人体外观学习与时序一致性解耦。结合 SMPL-X 姿态引导和预训练视频扩散模型的免训练时序精炼。 效果: 在多样化姿态和视角下生成高质量、时序一致的人体视频。发布了标准化人体数据集和辅助合成模型。代码已开源。 5. DGSSM:提出扩散引导的状态空间模型框架 DGSSM: Diffusion Guided State-Space Models for Multimodal Salient Object Detection | IIT Guwahati 关键词: 显著性检测·Mamba·扩散先验·多模态·边界感知 贡献: 提出扩散引导的状态空间模型框架,将多模态显著性检测建模为渐进去噪过程。融合 Mamba 高效全局推理与扩散结构先验。 效果: 在 13 个公开基准(RGB、RGB-D、RGB-T)上全面超越现有 SOTA,同时保持紧凑的模型尺寸。 6. Patch Forcing:探索 patch 级别的噪声调度用于图像合成 Denoising, Fast and Slow: Difficulty-Aware Adaptive Sampling for Image Generation | CompVis @ LMU Munich 关键词: 自适应去噪·Patch级调度·难度感知·计算优化·扩散模型 贡献: 探索 patch 级别的噪声调度用于图像合成,提出 Patch Forcing 框架,让简单区域先行去噪为困难区域提供上下文。引入自适应难度头按需分配计算资源。 效果: 在 class-conditional ImageNet 上实现优于基线的生成质量,与表示对齐和引导方法正交,可扩展到文本到图像合成。 7. Video-Robin:提出 Video-Robin Video-Robin: Autoregressive Diffusion Planning for Intent-Grounded Video-to-Music Generation | UMD, Microsoft 关键词: 视频到音乐·自回归规划·扩散合成·文本条件·DiT 贡献: 提出 Video-Robin,结合自回归规划与扩散合成的文本条件视频到音乐生成模型。自回归模块建模全局结构并对齐视觉与文本语义。 效果: 在分布内和分布外基准上均超越仅接受视频输入和额外特征条件的基线,推理速度比 SOTA 快 2.21 倍。 8. HP-Edit:提出 HP-Edit 人类偏好对齐的图像编辑后训练框架 HP-Edit: A Human-Preference Post-Training Framework for Image Editing | Harbin Institute of Technology, ByteDance 关键词: 图像编辑·人类偏好·RLHF·VLM评分器·后训练 贡献: 提出 HP-Edit 人类偏好对齐的图像编辑后训练框架,发布 RealPref-50K 真实世界偏好数据集覆盖 8 类编辑任务。训练 HP-Scorer 自动评分器作为 RLHF 奖励函数。 效果: 显著增强 Qwen-Image-Edit-2509 等模型的输出,使其更贴合人类偏好。同时发布 RealPref-Bench 基准。 9. AdaCluster:提出免训练的自适应聚类稀疏注意力框架 AdaCluster AdaCluster: Adaptive Query-Key Clustering for Sparse Attention in Video Generation | USTC, Hefei Science Center, University of Macau 关键词: 稀疏注意力·自适应聚类·视频DiT·加速推理·免训练 贡献: 提出免训练的自适应聚类稀疏注意力框架 AdaCluster,针对视频 DiT 的二次注意力复杂度问题。Q/K 分别采用角度和欧氏距离保持的聚类策略。 效果: 在 CogVideoX-2B、HunyuanVideo 和 Wan-2.1 上实现 1.67-4.31× 加速,质量损失可忽略不计,仅需单张 A40 GPU。 趋势观察 视频生成推理加速多路并进 — 投机解码(SDVG)、自适应稀疏注意力(AdaCluster)和 patch 级自适应采样(Patch Forcing)三种不同思路同时涌现,视频生成的实用化进程加速 免训练方法成为即插即用新常态 — TS-Attn、AdaCluster、ReImagine 的时序精炼均为免训练设计,降低部署门槛的同时保持了高效果 人类偏好对齐从生成扩展到编辑 — HP-Edit 将 RLHF 引入图像编辑后训练,配合 RealPref-50K 数据集和 VLM 评分器,预示编辑模型也将进入偏好对齐时代 长视频与多事件生成攻克一致性 — Memorize When Needed 用解耦记忆解决空间一致性,TS-Attn 用时间可分离注意力解决多事件时间一致性,分别从空间和时间维度推进长视频质量 视频-音乐跨模态生成走向可控 — Video-Robin 首次引入文本条件+自回归规划到 V2M 任务,从单纯视觉对齐升级为语义意图驱动的音乐创作 人工智能炼丹君 整理 | 2026-04-22 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
-
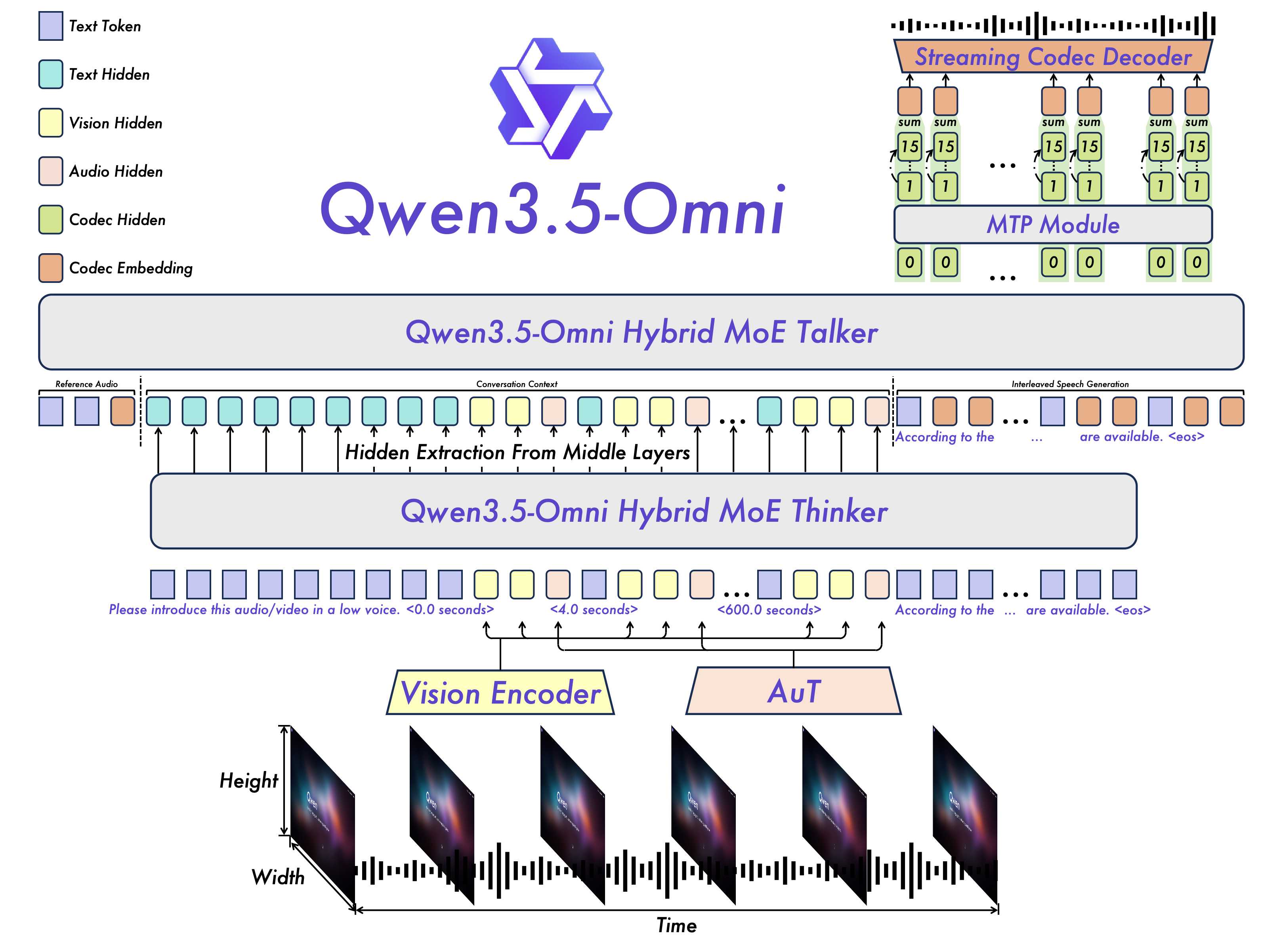
AIGC 每日速读|2026-04-21|Qwen3.5-Omni全模态215项SOTA 今日核心看点 全模态215项SOTA(Qwen3.5-Omni) 音视频联合生成(Seedance 2.0) ImageNet生成新纪录(GRN) 灵活视频Token化(VideoFlexTok) 推理式奖励模型(RationalRewards) 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 全模态理解与生成一体化: 3篇 (Qwen3.5-Omni, Audio-Omni, Seedance 2.0) 图像生成与风格迁移: 2篇 (GRN, MAST) 视频生成推理加速: 2篇 (PASA, EfficientVideoDiffusion综述) 视频Token化与高效表示: 1篇 (VideoFlexTok) 视觉生成评测与奖励模型: 1篇 (RationalRewards) 矢量动画生成: 1篇 (LottieGPT) 重点论文深度解读 1. Qwen3.5-Omni 通义千问新旗舰——百亿参数全模态理解与生成一体化,215项评测SOTA | Alibaba | arXiv:2604.15804 关键词: 全模态模型, 生成理解一体化, Thinker-Talker, TMRoPE, 音视频交互, MoE, SOTA 研究动机 核心问题: 如何在单一模型中同时实现文本/图像/视频/音频的顶级理解与生成能力 现有多模态大模型通常在某些模态上表现优异但在其他模态上性能退化,难以做到'全能不偏科'。以往的全模态模型要么理解强但生成弱,要么文本强但语音弱。Qwen团队希望构建一个真正统一的端到端模型,同时实现所有模态的顶级理解与生成能力,特别是实时流式语音交互——这对于下一代人机交互至关重要。前代Qwen2.5-Omni虽然开创了Thinker-Talker架构,但在模型规模和多模态推理深度上仍有提升空间。Qwen3.5-Omni将模型规模扩展到百亿参数级别,并在训练方法论上做出重大改进。 前序工作及局限: GPT-4o:开创端到端全模态交互,但闭源且细节未公开 Gemini Pro系列:Google全模态模型,多模态理解强但音频生成相对弱 Qwen2.5-Omni:首创Thinker-Talker架构,但模型规模和性能有提升空间 Mixtral MoE:MoE在语言模型中的成功应用,启发了多模态场景的专家设计 与前序工作的本质区别: 首个在所有模态上同时达到SOTA且无偏科的全模态模型,TMRoPE时间对齐和MoE理解/生成分离是关键创新 方法原理 Qwen3.5-Omni采用Thinker-Talker双核架构设计: (1) Thinker模块(大脑):接收文本、图像、视频、音频等多模态输入,使用统一的Transformer编码器处理所有模态。视觉编码器和音频编码器均采用分块处理(block-wise)策略实现实时流式输入。输出高层语义表征和对应文本内容。引入MoE混合专家机制,为理解和生成任务分配独立专家组。 (2) Talker模块(发声器官):以流式方式接收Thinker实时输出的语义表征和文本token,流畅合成离散语音单元(speech tokens),再通过解码器转换为自然语音波形。整个过程是端到端的,延迟极低。 (3) TMRoPE位置编码:创新性地在RoPE基础上引入时间对齐机制,使视频帧和音频片段在同一时间轴上精准对齐。这对于理解音视频同步内容(如带字幕的视频、会议录音配PPT)至关重要。 (4) 三阶段预训练:第一阶段视觉与音频编码器独立训练;第二阶段联合全参数训练与多模态整合;第三阶段长序列数据训练提升理解能力。后训练阶段对Thinker和Talker分别进行SFT和DPO优化。 (5) 模型系列包含Base和Plus两个版本,Plus版本进一步增大参数量和训练数据。 核心创新 提出Qwen3.5-Omni,新一代全模态大模型,首次在文本/图像/视频/音频四模态理解与生成中同时达到SOTA 采用Thinker-Talker双核架构:Thinker负责多模态推理生成高层语义表征,Talker以流式方式合成自然语音 提出TMRoPE(Time-aligned Multimodal RoPE)位置编码,通过时间轴对齐实现音视频输入精准同步 引入MoE混合专家设计,在推理和生成各自使用独立专家组,避免能力冲突 Qwen3.5-Omni-Plus在215项音频和音视频理解/推理/交互子任务上达到SOTA,超越Gemini-3.1 Pro 支持256K超长上下文窗口,113种语言识别,完全实时的音视频交互 实验结果 Qwen3.5-Omni-Plus性能亮点: 音频理解:在215项音频和音视频理解/推理/交互子任务和基准上达到SOTA,在关键音频任务上超越Gemini-3.1 Pro 文本→文本:通用文本理解和推理能力保持SOTA水平 图像→文本:多模态理解评估中达到一流水平 视频→文本:视频理解在主要benchmark上表现突出 语音生成:零样本语音合成质量超越多数现有方案,自然度和流畅度均达SOTA 实时交互:支持完全实时的流式音视频交互,延迟控制在百毫秒级 支持256K超长上下文窗口,113种语言识别 批判性点评 新颖性: Thinker-Talker架构延续自Qwen2.5-Omni,3.5版本在规模和训练上做了全面升级。TMRoPE时间对齐和MoE分离理解/生成是有意义的技术创新。整体更偏工程突破而非范式革新。 可复现性: 技术报告详尽但训练数据未完全公开。模型有开源版本(Qwen3.5-Omni)可供复现。基于Transformer+MoE的主体架构可重现性良好。 影响力: 极高——全模态统一模型代表了多模态AI的发展方向,215项SOTA彰显了综合实力。对产业界的实时交互应用(智能助手、客服、教育)有直接推动作用。 深度点评: 215项评测全SOTA — Qwen3.5-Omni 在音频、音视频理解和交互的 215 项子任务上全面达到 SOTA,超越 Gemini-3.1 Pro 全模态三路并进 — Qwen3.5-Omni(Alibaba) + Seedance 2.0(ByteDance) + Audio-Omni(HKUST) 三款全模态统一模型同期发布 高效化全面渗透 — VideoFlexTok(5-10x压缩) + PASA(免训练稀疏注意力) + GRN(自适应步数) 覆盖生成管线每个环节 技术演进定位: 全模态统一模型的重要里程碑,证明了'一个模型搞定一切'的技术可行性 可能的后续方向: 向更大规模(千亿参数)扩展 多模态Agent能力集成 端侧部署的轻量化版本 更丰富的生成模态(3D、代码等) 其余论文速览 1. Seedance 2.0:字节跳动发布Seedance 2.0技术报告 Seedance 2.0: Advancing Video Generation for World Complexity | ByteDance | arXiv:2604.14148 关键词: 视频生成·音视频联合·多模态·动作质量·音频同步 贡献: 字节跳动发布Seedance 2.0技术报告,统一多模态音视频联合生成架构,支持文字/图片/音频/视频四模态输入,集成业界最全面的多模态内容参考和编辑能力。在动作质量和音视频同步两个维度达到3.75分(领先第二名0.65分),音频维度全面领先竞品。 效果: 在VBench等多个基准上超越Sora、Kling等模型,动作质量、音视频同步和音频生成三个维度均达行业最高水平。 2. GRN:提出生成精炼网络(GRN) Generative Refinement Networks for Visual Synthesis | ByteDance Research | arXiv:2604.13030 关键词: 图像生成·精炼网络·HBQ量化·ImageNet SOTA·视觉合成 贡献: 提出生成精炼网络(GRN),核心创新:(1)用理论近无损的分层二进制量化(HBQ)替代传统VQ-VAE等有损离散化,构建高质量连续级潜空间;(2)设计全局精炼机制像人类画家一样逐步完善输出;(3)熵引导采样实现复杂度感知的自适应步数生成。 效果: 在ImageNet上创造图像重建新纪录(0.56 rFID)和类别条件生成新纪录(1.81 gFID),并扩展至文生图和文生视频。 3. VideoFlexTok:Apple与EPFL提出VideoFlexTok VideoFlexTok: Flexible-Length Coarse-to-Fine Video Tokenization | Apple, EPFL | arXiv:2604.12887 关键词: 视频token化·粗到细·灵活长度·高效生成·长视频 贡献: Apple与EPFL提出VideoFlexTok,将视频表示为灵活长度、从粗到细的token序列。前几个token自动捕获抽象语义信息,后续token逐步补充细节。首次实现在81帧10秒视频上训练文生视频模型。 效果: 生成模型规模缩小5-10倍,所需训练token数量减少5-10倍,同时保持生成质量,大幅降低长视频生成的计算成本。 4. PASA:提出精准分配稀疏注意力(PASA) Ride the Wave: Precision-Allocated Sparse Attention for Smooth Video Generation | Unknown | arXiv:2604.12219 关键词: 稀疏注意力·视频生成加速·DiT·免训练·推理优化 贡献: 提出精准分配稀疏注意力(PASA),一个面向视频扩散Transformer的免训练加速框架。针对现有稀疏注意力方法导致的运动不连续和闪烁问题,PASA根据去噪阶段和注意力头的重要性动态分配计算精度,保证关键时域信息完整传递。 效果: 在不损失生成质量的前提下显著降低Video DiT的注意力计算开销,解决了稀疏注意力导致的视频平滑性问题。 5. Audio-Omni:香港科技大学提出Audio-Omni Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing | HKUST | arXiv:2604.10708 关键词: 音频生成·音频编辑·音乐合成·多模态·统一框架 贡献: 香港科技大学提出Audio-Omni,首个统一音频理解、生成和编辑的端到端框架。覆盖通用声音、音乐和语音三大领域,解耦推理与合成实现知识增强生成和跨语言控制等复杂任务。 效果: 在音频理解、音乐生成和语音合成三个领域的多个基准上均达到竞争力水平,首次在单一模型内统一全音频任务。 6. RationalRewards:提出RationalRewards——推理式奖励模型范式 RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time | Unknown | arXiv:2604.11626 关键词: 奖励模型·视觉生成评测·推理·可解释·偏好学习 贡献: 提出RationalRewards——推理式奖励模型范式。传统视觉生成奖励模型将人类偏好压缩为单一分数,丢失了判断的推理过程。RationalRewards教会奖励模型像人类一样'思考后评分',在训练时提升生成质量,在推理时实现更可解释的评估。 效果: 在视觉生成的训练和测试两个阶段均实现显著提升,构建了可扩展且可解释的奖励建模新范式。 7. MAST:提出MAST——面向多风格迁移的无训练框架 MAST: Mask-Guided Attention Mass Allocation for Training-Free Multi-Style Transfer | Unknown | arXiv:2604.12281 关键词: 风格迁移·无训练·注意力分配·扩散模型·图像编辑 贡献: 提出MAST——面向多风格迁移的无训练框架。通过掩码引导的注意力质量分配(Attention Mass Allocation)显式控制内容和风格信号的注意力交互,解决了扩散模型多风格迁移中的边界伪影、不稳定风格化和结构失真问题。 效果: 在多风格迁移场景下实现无伪影、结构保持的风格化效果,无需额外训练即可应用于现有扩散模型。 8. LottieGPT:CVPR 2026入选论文 LottieGPT: Tokenizing Vector Animation for Autoregressive Generation | CVPR 2026 | arXiv:2604.11792 关键词: 矢量动画·自回归生成·Lottie·CVPR 2026·可编辑 贡献: CVPR 2026入选论文。提出LottieGPT,首次实现矢量动画的自回归生成。构建包含1500万样本的大规模Lottie矢量动画数据集LottieAnimation-660K,将矢量动画结构token化后微调Qwen-VL生成连贯可编辑的矢量动画。 效果: 首次将视频生成扩展到矢量动画领域,生成的动画可直接编辑、分辨率无关,开辟了动画生成新方向。 9. EfficientVideoDiffusion:系统性综述视频扩散模型的高效推理技术 Efficient Video Diffusion Models: Advancements and Challenges | Unknown | arXiv:2604.15911 关键词: 视频扩散·推理加速·稀疏注意力·综述·部署优化 贡献: 系统性综述视频扩散模型的高效推理技术。提出统一分类法将现有方法分为四大加速范式:步骤减少(step reduction)、注意力稀疏化(attention sparsification)、缓存复用(caching)和架构优化(architecture optimization)。全面梳理部署导向的高效化路线。 效果: 首个面向部署的视频扩散模型高效化综述,为研究者和从业者提供了清晰的技术路线图和开源代码仓库。 趋势观察 全模态统一模型竞赛白热化 — Qwen3.5-Omni(Alibaba)、Seedance 2.0(ByteDance)、Audio-Omni(HKUST)三款模型同时瞄准多模态理解与生成一体化——全模态统一成为大厂兵家必争之地 高效化技术全面提速 — VideoFlexTok(5-10倍压缩)、PASA(免训练稀疏注意力)、GRN(自适应步数)——从token化到注意力到生成步骤,视频生成的每个环节都在被优化 人工智能炼丹君 整理 | 2026-04-21 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
-
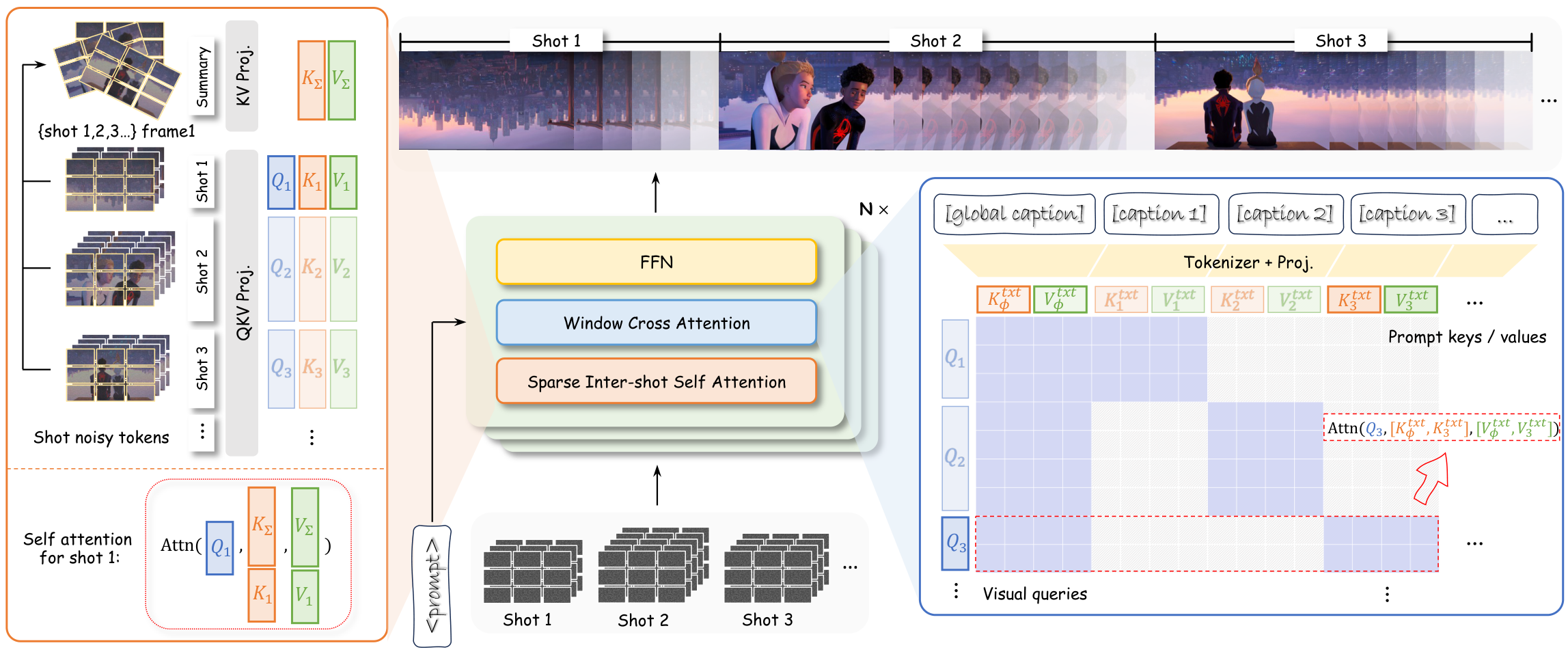
AIGC 周末专题|2026-04-12|多镜头视频生成: 开源Seedance2的进阶之路 AIGC 周末专题深度解读:多镜头视频生成:整体式叙事、自回归记忆、电影级转场与跨镜头一致 人工智能炼丹师 整理 | 2026年4月12日(周日) 覆盖时间:2023年8月 — 2026年4月(含经典评测与 2025–2026 方法爆发期) 本期概述 本期 AIGC 周末专题聚焦多镜头视频生成:整体式叙事、自回归记忆、电影级转场与跨镜头一致方向,精选 8 篇代表性论文进行深度解读。 方向分布: 整体式双向生成: 1篇 — HoloCine (CVPR 2026) 自回归 next-shot: 3篇 — OneStory (CVPR 2026), ShotStream, StoryMem 电影级转场控制: 1篇 — CineTrans (ICLR 2026) 故事板锚定: 1篇 — STAGE (CVPR 2026) 世界一致+多主体过渡: 1篇 — InfinityStory 人像垂直场景: 1篇 — EchoShot (NeurIPS 2025) 其余参考: 19篇(含 ShotAdapter CVPR'25, Mask²DiT CVPR'25, Gloria CVPR'26, Spatia CVPR'26, SkyReels-V2, MSVBench 等) 含 CVPR 2026 × 4 篇 (HoloCine, OneStory, STAGE, + 其余 Gloria/Spatia);ICLR 2026 × 1 篇 (CineTrans);NeurIPS 2025 × 1 篇 (EchoShot);CVPR 2025 × 2 篇 (ShotAdapter, Mask²DiT) 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 HoloCine HKUST / Ant Group / ZJU / CUHK / NTU 首个分钟级整体式多镜头生成框架 2510.20822 2 OneStory Meta AI / University of Copenhagen Frame Selection 模块选取语义最相关历史帧构建全局记忆 2512.07802 3 ShotStream CUHK MMLab / Kuaishou Technology 首个因果流式多镜头生成系统——亚秒延迟、16 FPS 2603.25746 4 CineTrans 复旦大学 / 上海人工智能实验室 首次揭示扩散模型注意力图与镜头转场的对应关系 2508.11484 5 STAGE 北京理工大学 / 北京大学 将关键帧范式重新建模为首尾帧对预测(STEP2) 2512.12372 6 StoryMem ByteDance Intelligent Creation / NTU S-Lab M2V 范式:关键帧记忆经 3D VAE 编码后与噪声潜变量拼接 2512.19539 7 InfinityStory Adobe Research / Virginia Tech / Dolby Labs / UMD / Cisco 等 位置锚定背景一致性:预生成场所参考图并在生成时注入 2603.03646 8 EchoShot 西安交通大学 / 阿里云 Shot-aware RoPE:TcRoPE 保持跨镜头时间连续性建模身份关联 + TaRoPE 分配独立时间起点防止内 2506.15838 1. HoloCine:整体式生成电影级多镜头长叙事——Window Cross-Attention + Sparse Inter-Shot Self-Attention 论文: HoloCine arXiv: 2510.20822 机构: HKUST / Ant Group / ZJU / CUHK / NTU 1.1 研究动机 核心问题: 单镜头 T2V 无法生成跨镜头连贯的叙事长视频 解耦范式(先关键帧再插值/逐镜头独立拼接)难以保证全局一致,整体式生成有望从根本上解决跨镜头连贯性。 前序工作及局限: 单镜头 T2V:Wan2.2, HunyuanVideo 拼接/级联方案:VideoStudio, MovieFactory 与前序工作的本质区别: HoloCine 整体式生成所有镜头,Window Cross-Attn + Sparse Inter-Shot SA 保证全局一致 1.2 方法原理 The architecture of our holistic generation pipeline, where all shot latents are processed jointly. The Window Cross-Attention provides precise directorial control by aligning each shot to its specific text prompt. The Sparse Inter-shot Self-Attention drastically reduces computational cost while preserving long-range consistency. 基于 Wan2.2 14B DiT;Window Cross-Attention 将逐镜头文本精确对应到视频帧区间;镜头内密集自注意力 + 镜头间稀疏自注意力组合;两阶段训练(高噪声 DiT 学结构 → 低噪声 DiT 精炼细节)。 1.3 核心创新 首个分钟级整体式多镜头生成框架 Window Cross-Attention 实现逐镜头文本控制 Sparse Inter-Shot Self-Attention 内密外疏实现高效跨镜头一致 涌现角色持久记忆和电影技法理解 1.4 实验结果 Qualitative comparison on a complex multi-shot prompt. Our method successfully generates a coherent sequence of distinct shots aligned with per-shot descriptions, while baseline methods fail in maintaining consistency, prompt fidelity, or handling shot transitions. 在叙事连贯性上显著优于 Wan2.2 直接生成、StoryDiffusion+Wan2.2、IC-LoRA+Wan2.2 等基线;与 Kling 2.5 Turbo 等商业模型在多镜头连贯性指标上具有优势;代码和模型已开源。 1.5 关键洞察 优势:全局一致性最强,涌现电影技法理解。局限:受限于显存和计算,当前最长约 1 分钟;无法中途修改剧本。 技术演进定位: 整体式多镜头范式开拓者 可能的后续方向: 扩展至 5 分钟以上长度 与自回归范式融合 2. OneStory:自适应记忆驱动的连贯多镜头叙事——Frame Selection + Adaptive Conditioner 论文: OneStory arXiv: 2512.07802 机构: Meta AI / University of Copenhagen 2.1 研究动机 核心问题: 有限时间窗口或单关键帧条件导致长程上下文丢失 有限时间窗口或单关键帧条件导致长程上下文丢失,需要像人类记忆一样选择性保留关键视觉信息。 前序工作及局限: 单关键帧条件:I2V 模型 滑动窗口:LongLive 等 与前序工作的本质区别: OneStory 自适应选帧 + 紧凑条件注入,模拟人类选择性记忆 2.2 方法原理 Overview of the proposed~ourmodel. Our model reframes multi-shot video generation (MSV) as a next-shot generation task. (a)~During training, the model learns to generate the final shot conditioned on the preceding two; when only two shots are available, we inflate with a synthetic shot to enable unified three-shot training. (b)~At inference, it maintains a memory bank of past shots and generates multi-shot videos autoregressively. The model is comprised of two key components: (c)~a Frame Selection module that selects semantically-relevant frames from preceding shots to construct a global context, and (d)~an Adaptive Conditioner that dynamically compresses the selected context and injects it directly into the generator for efficient conditioning. Together, ~realizes adaptive memory modeling, enabling global yet compact cross-shot context for coherent narrative generation. 将多镜头建模为 next-shot 任务;Frame Selection 从历史帧中按信息量和相关性筛选;Adaptive Conditioner 压缩后直接注入生成器;60K 数据集的引用式字幕模拟真实叙事模式。 2.3 核心创新 Frame Selection 模块选取语义最相关历史帧构建全局记忆 Adaptive Conditioner 通过重要性引导 patchification 紧凑注入 K 多镜头数据集带引用式字幕 Next-shot 自回归范式复用 I2V 预训练 2.4 实验结果 Qualitative results. For a fair comparison, the given multi-shot generations share the same first shot (generated by Wan2.2) as the initial condition, except for StoryDiff.+Wan2.1, which does not rely on visual conditioning. The baseline methods fail to maintain narrative consistency across shots, struggling with prompt adherence, reappearance, and compositional scenes, whereas ~(ours) faithfully follows shot-level captions and produces coherent shots. A representative segment of each prompt is given with the corresponding shot. T2MSV 和 I2MSV 设定下均 SOTA;角色一致性 0.5851、环境一致性 0.5716 均为最高;分钟级 10 镜头视频。 2.5 关键洞察 优势:自适应记忆选帧机制优雅高效,数据集设计贴合真实叙事。局限:复杂多角色场景下纯视觉记忆可能不足;引用式字幕生成依赖 LLM 质量。 技术演进定位: 自适应记忆自回归代表 可能的后续方向: 实体级结构化记忆 多角色场景扩展 3. ShotStream:因果流式多镜头——双缓存记忆 + 两阶段自强迫蒸馏实现 16 FPS 实时 论文: ShotStream arXiv: 2603.25746 机构: CUHK MMLab / Kuaishou Technology 3.1 研究动机 核心问题: 双向整段生成延迟高、不可中途修改 双向整段生成延迟高且无法中途改剧本,创作者需要流式交互体验。 前序工作及局限: 双向多镜头:HoloCine, FilmWeaver 级联管线:MovieFactory 与前序工作的本质区别: ShotStream 因果蒸馏 + 双缓存实现 16 FPS 流式多镜头 3.2 方法原理 Architecture of the Bidirectional Next-Shot Teacher Model. To realize ShotStream, we first fine-tune a text-to-video model into a bidirectional next-shot model, which generates subsequent shots conditioned on sparse context frames from preceding shots. These conditional context frames are encoded into latents via a 3D VAE and injected by concatenating them with noise latents along the temporal dimension. Notably, only the 3D spatial-temporal attention layers within the DiT Blocks are optimized during fine-tuning. A 4-shot example is shown here for illustration. 先训练双向 next-shot 教师,再 DMD 蒸馏为因果学生;全局上下文缓存服务跨镜头一致,局部上下文缓存服务镜头内时序;两阶段自强迫分别在镜头内和镜头间缩小训练-推理差距。 3.3 核心创新 首个因果流式多镜头生成系统——亚秒延迟、16 FPS 全局+局部双缓存记忆 + RoPE 不连续标记 两阶段自强迫蒸馏(镜头内→镜头间)缓解误差累积 Distribution Matching Distillation 双向→因果 3.4 实验结果 Qualitative Comparison. We present the initial frames of each shot generated by all compared methods. Our approach not only adheres strictly to the prompts and maintains high visual coherence, but also produces natural transitions between shots. MovieGen、StoryBench 设定下 FCD、IC-LPIPS 等指标与双向模型持平或更优;相比因果长视频模型吞吐量提升约 25 倍;支持动态改写提示;代码/模型开源。 3.5 关键洞察 优势:交互叙事与工程指标平衡好,开源推动复现。局限:极长镜头链上因果信息量仍弱于全局双向;全局缓存随镜头增长占用上升。 技术演进定位: 交互式实时多镜头方向标杆 可能的后续方向: 与实时配乐融合 更长镜头链的缓存优化 4. CineTrans:注意力图驱动的电影级转场生成——掩码控制 + Cine250K 数据集 论文: CineTrans arXiv: 2508.11484 机构: 复旦大学 / 上海人工智能实验室 4.1 研究动机 核心问题: 视频扩散模型的镜头转场能力原始且不稳定 即使大规模模型也无法稳定生成电影级镜头转场,转场能力原始且不稳定。 前序工作及局限: 无转场控制:标准 T2V 手动拼接:传统后期 与前序工作的本质区别: CineTrans 发现注意力-转场对应关系并用掩码实现电影级转场控制 4.2 方法原理 分析扩散模型注意力图发现概率分布在镜头切换位置出现变化;设计注意力掩码矩阵在指定帧引入转场;Cine250K 从 Vimeo 633K 视频多阶段清洗;在 SD1.4 和 Wan2.1 上均验证。 4.3 核心创新 首次揭示扩散模型注意力图与镜头转场的对应关系 注意力掩码控制任意位置的电影级转场(训练无关可迁移) Cine250K:250K 视频-文本对,帧级镜头标签 + 转场类型标注 专用评测指标:转场控制、时序一致性、整体质量 4.4 实验结果 在转场控制、时序一致性、整体质量三维度全面超越基线;UNet(SD 1.4)和 DiT(Wan2.1)版本均有效;代码和数据集已开源。 4.5 关键洞察 优势:注意力-转场对应的发现具有理论价值,掩码机制优雅且可迁移。局限:转场类型多样性仍需扩展;与自回归长视频的结合尚待验证。 技术演进定位: 电影转场控制开创性工作 可能的后续方向: 更多转场类型 与自回归长视频结合 5. STAGE:故事板锚定的电影叙事生成——STEP2 首尾帧对预测 + DPO 偏好对齐 论文: STAGE arXiv: 2512.12372 机构: 北京理工大学 / 北京大学 5.1 研究动机 核心问题: 稀疏关键帧无法同时保证跨镜头一致和电影级过渡 稀疏关键帧无法维持跨镜头一致性且难以捕捉电影语言中的过渡。 前序工作及局限: 关键帧插值:DynamiCrafter 等 单帧条件:I2V 模型 与前序工作的本质区别: STAGE 预测首尾帧对作为结构化故事板 + DPO 偏好对齐学习电影语言 5.2 方法原理 STEP2 迭代预测每镜头首帧和尾帧组成结构化故事板;多镜头记忆包打包历史帧对为上下文;双编码分别处理镜头内起止和镜头间过渡;两阶段训练 + DPO 偏好对齐优化转场质量。 5.3 核心创新 将关键帧范式重新建模为首尾帧对预测(STEP2) 多镜头记忆包 + 双编码策略 DPO 偏好对齐学习电影级转场语言 ConStoryBoard 数据集(电影片段+精细标注+人类偏好) 5.4 实验结果 在结构化叙事控制和跨镜头连贯性上显著优于 SOTA;人类评测中叙事可控性和电影美学获最高偏好。 5.5 关键洞察 优势:首尾帧对比单一关键帧提供更强结构约束,DPO 引入电影偏好。局限:STEP2 预测质量上限受限于训练数据的电影片段质量;复杂叙事(多线并行)需进一步验证。 技术演进定位: 故事板锚定范式代表 可能的后续方向: 多线叙事支持 与 VLM 自动规划结合 6. StoryMem:记忆驱动的分钟级叙事视频——M2V 潜变量拼接 + 负 RoPE 偏移 + LoRA 论文: StoryMem arXiv: 2512.19539 机构: ByteDance Intelligent Creation / NTU S-Lab 6.1 研究动机 核心问题: 预训练单镜头模型缺乏跨镜头记忆能力 如何让预训练单镜头模型以最小改动获得跨镜头记忆能力。 前序工作及局限: 无记忆的逐段生成:标准自回归 外部条件注入:IP-Adapter 等 与前序工作的本质区别: StoryMem M2V 潜变量拼接 + 负 RoPE 偏移,LoRA 微调成本极低 6.2 方法原理 Overview of~ours. ~generates each shot conditioned on a memory bank that stores keyframes from previously generated shots. During generation, the selected memory frames are encoded by a 3D VAE, fused with noisy video latents and binary masks, and fed into a LoRA-finetuned memory-conditioned Video DiT to synthesize the current shot. After generating each shot, semantic keyframe selection and aesthetic preference filtering are applied to obtain informative and reliable memory frames, enabling long-range cross-shot consistency and natural narrative progression. By iteratively generating shots with memory updates, ~produces coherent minute-long, multi-shot story videos. 维护动态更新的关键帧记忆库;记忆帧经 3D VAE 编码后与噪声视频潜变量和二值掩码拼接送入 Video DiT;负 RoPE 偏移编码历史属性;LoRA 微调 Wan2.2;MM2V 扩展支持平滑过渡。 6.3 核心创新 M2V 范式:关键帧记忆经 3D VAE 编码后与噪声潜变量拼接 负 RoPE 偏移区分记忆帧「历史」与当前帧「现在」 轻量 LoRA 微调完整保留基础模型能力 ST-Bench:30 故事×8-12 镜头评测基准 6.4 实验结果 Qualitative comparison. Our~~generates coherent multi-scene, multi-shot story videos aligned with per-shot descriptions. In contrast, the pretrained model and keyframe-based baselines fail to preserve long-term character and scene consistency, while HoloCine~meng2025holocine exhibits noticeable degradation in visual quality. ST-Bench 上角色一致性和叙事连贯性均最优;继承 Wan2.2 高美学水平;开源代码与模型(GitHub 714 stars),社区复现活跃。 6.5 关键洞察 优势:M2V 范式简洁高效,LoRA 微调成本极低,开源生态好。局限:纯视觉记忆在复杂多角色场景下可能不足;记忆更新策略偏启发式。 技术演进定位: 最低成本多镜头启用方案 可能的后续方向: 实体感知记忆 过渡建模增强 7. InfinityStory:世界一致性与多主体平滑过渡——位置锚定 + CMTS 过渡模型 论文: InfinityStory arXiv: 2603.03646 机构: Adobe Research / Virginia Tech / Dolby Labs / UMD / Cisco 等 7.1 研究动机 核心问题: 长叙事中背景漂移和多主体转场断裂 场景漂移和多主体转场断裂是长叙事视频的两个被低估的痛点。 前序工作及局限: 隐式一致性:注意力级一致 单主体过渡:SEINE 等 与前序工作的本质区别: InfinityStory 位置锚定背景 + 10K 合成数据训练多主体过渡模型 7.2 方法原理 Overview of the proposed storytelling video generation pipeline. Green shapes: are the output of the agentic pipeline. Purple Shapes: Narrative odd shots generate keyframe images which are used to generate video shots using I2V. Red shapes: While the transition in-between (even) shots take the next keyframe and the last frame from the generated I2V shot to generate a First-Last-Frame-to-Video (FLF2V) which smoothly bridges consecutive narrative shots. The output video would be stitched together to form one coherent video, i.e., shot-1 (I2V) $$ shot-2 (FLF2V) $$ shot-3 (I2V) $$ shot-4 (FLF2V) $$ .. and so on. 为每个场所预生成背景参考图注入生成过程保证世界一致;构建 10K 多主体过渡序列覆盖入场/退场/替换;训练 FLF2V 过渡模型实现平滑衔接;LLM 多智能体系统分解故事。 7.3 核心创新 位置锚定背景一致性:预生成场所参考图并在生成时注入 CMTS:10K 多主体过渡序列合成数据 + First-Last-Frame-to-Video 过渡模型 层级多智能体叙事规划 可扩展到小时级叙事 7.4 实验结果 Results show that we outperform other methods on human studies. VBench 最高背景一致性(88.94)和主体一致性(82.11);综合平均排名第一(2.80);可扩展到数百镜头小时级叙事。 7.5 关键洞察 优势:同时解决背景漂移和多主体过渡两大痛点,VBench SOTA。局限:级联管线各模块错误可累积;背景参考图预生成增加前置成本。 技术演进定位: 世界一致性 + 多主体过渡先驱 可能的后续方向: 真实电影过渡数据 动态环境变化 8. EchoShot:面向人像的原生多镜头生成——Shot-aware RoPE (TcRoPE + TaRoPE) 论文: EchoShot arXiv: 2506.15838 机构: 西安交通大学 / 阿里云 8.1 研究动机 核心问题: 人像多镜头需要精确面部 ID 一致同时允许属性变化 人像多镜头需要精确面部身份一致同时允许表情、动作、服装灵活变化,外部条件注入方案开销大且控制粗糙。 前序工作及局限: 外部 ID 注入:IP-Adapter 等 通用多镜头:ShotAdapter 等 与前序工作的本质区别: EchoShot 在 RoPE 层面原生建模多镜头结构,TcRoPE + TaRoPE 零额外开销 8.2 方法原理 (a) The overall architecture of EchoShot, a multi-shot video generation paradigm, which features two intricate RoPE mechanisms. (b)TcRoPE, a 3D-RoPE which rotates an extra angular rotation at every inter-shot boundary along the time dimension. (c)TaRoPE, a 1D-RoPE which differentiates between matching and non-matching shot-caption pairs. Note that the visualization displays only one rotational component, with others excluded for simplicity. 在 DiT 的 RoPE 层面原生区分镜头边界;TcRoPE 在注意力层保持跨镜头时间连续性;TaRoPE 在另一些层分配独立起点;多镜头视频作为长序列直接训练;PortraitGala 提供精细人像字幕。 8.3 核心创新 Shot-aware RoPE:TcRoPE 保持跨镜头时间连续性建模身份关联 + TaRoPE 分配独立时间起点防止内容混淆 零额外计算开销的原生多镜头建模 PortraitGala 大规模人像视频数据集 可推广为通用多镜头建模范式 8.4 实验结果 Visualization of self-attention score matrix w/ and w/o TcRoPE and cross-attention score matrix w/ and w/o TaRoPE. 身份一致性和属性级可控性均优于现有方法;细粒度控制(表情、服装、动作)效果显著;基于 Wan2.1-T2V-1.3B,模型已开源。 8.5 关键洞察 优势:RoPE 层面建模零额外开销,可推广到非人像。局限:当前仅在 1.3B 模型上验证,14B 级别的效果待确认;人像以外的泛化性需更多数据。 技术演进定位: 人像垂直场景原生多镜头范式 可能的后续方向: 14B 级别验证 非人像场景泛化 其余论文速览 1. ShotAdapter:过渡 token + 局部注意力掩码 ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models | Adobe / UIUC | arXiv:2505.07652 关键词: CVPR 2025, 掩码微调, 数据管线 贡献: 过渡 token + 局部注意力掩码,~5K 步微调 T2V 即可多镜头 效果: 低门槛多镜头启用路线代表 2. Mask²DiT:对称二值掩码 + 段级条件掩码 Mask²DiT: Dual Mask-based Diffusion Transformer for Multi-Scene Long Video Generation | USTC / ByteDance | arXiv:2503.19881 关键词: CVPR 2025, 双掩码, 自回归 贡献: 对称二值掩码 + 段级条件掩码,多场景长视频自回归扩展 效果: 掩码类方法在 DiT 上的完整实现 3. MultiShotMaster:Multi-Shot RoPE + ST Position-Aware… MultiShotMaster: A Controllable Multi-Shot Video Generation Framework | 高校+工业联合 | arXiv:2512.03041 关键词: 位置编码, 可控性, 数据自动化 贡献: Multi-Shot RoPE + ST Position-Aware RoPE + 自动标注管线 效果: RoPE 扩展路线代表 4. ShotVerse:VLM 规划电影相机轨迹 + 相机适配器 + ShotVerse-Bench… ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation | 多机构 | arXiv:2603.11421 关键词: VLM 规划, 轨迹标定, 相机适配器 贡献: VLM 规划电影相机轨迹 + 相机适配器 + ShotVerse-Bench 三轨评测 效果: 电影级相机控制关键拼图 5. ShotDirector:6-DoF 相机控制 + 层级编辑模式提示 + ShotWeaver40K ShotDirector: Directorially Controllable Multi-Shot Video Generation with Cinematographic Transitions | 复旦 / 上海 AI Lab | arXiv:2512.10286 关键词: 6-DoF, 编辑模式, ShotWeaver40K 贡献: 6-DoF 相机控制 + 层级编辑模式提示 + ShotWeaver40K 效果: 导演级转场控制 6. FilmWeaver:缓存引导自回归扩散 FilmWeaver: Cache-Guided Autoregressive Diffusion for Multi-Shot Video | Kuaishou Technology | arXiv:2512.11274 关键词: 缓存, 自回归, 跨镜头一致 贡献: 缓存引导自回归扩散,任意镜头数 + 身份/背景一致性 效果: 工业级叙事生成 7. CoAgent:协作闭环管线:剧本规划 CoAgent: Collaborative Planning and Consistency Agent for Coherent Video Generation | 多机构 | arXiv:2512.22536 关键词: 多智能体, 闭环验证, 叙事规划 贡献: 协作闭环管线:剧本规划→全局实体记忆→合成→验证 Agent→节奏编辑 效果: Agent 驱动多镜头生成 8. VideoGen-of-Thought:训练无关管线 VideoGen-of-Thought: Step-by-step generating multi-shot video with minimal manual intervention | NUS / UCF 等 | arXiv:2412.02259 关键词: NeurIPS 2025 WS, training-free, 身份传播 贡献: 训练无关管线,单句→多镜头自动化,面部一致性 +20.4% 效果: 零训练多镜头管线先驱 9. SkyReels-V2:无限长度电影模型 SkyReels-V2: Infinite-length Film Generative Model | Skywork AI | arXiv:2504.13074 关键词: Diffusion Forcing, RL, 开源生态 贡献: 无限长度电影模型,MLLM + Diffusion Forcing + RL + SkyCaptioner 效果: 工业级开源长视频系统(6.7K stars) 10. CINEMA:MLLM 引导多主体连贯视频 CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance | ByteDance | arXiv:2503.10391 关键词: MLLM, 多主体, MM-DiT 贡献: MLLM 引导多主体连贯视频,消除主体-文本显式对应需求 效果: 多主体场景解决方案 11. Gloria:三类内容锚点(全局/视角/表情) Gloria: Content Anchors for Long-Time Character-Consistent Video Generation | USTC | arXiv:2603.29931 关键词: CVPR 2026, 内容锚点, 超集锚定 贡献: 三类内容锚点(全局/视角/表情),10min+ 角色一致 效果: 角色中心长视频一致 12. MemRoPE:无训练双流记忆 + Online RoPE MemRoPE: Training-Free Infinite Video Generation with Dual-Stream Memory Tokens and Online RoPE | USC | arXiv:2603.12513 关键词: 无训练, Memory Token, Online RoPE 贡献: 无训练双流记忆 + Online RoPE,长视频身份防漂移 效果: 无训练长上下文推理参考 13. Spatia:3D 点云空间记忆 + Visual SLAM 迭代更新 Spatia: Video Generation with Updatable Spatial Memory | Sydney / MSR | arXiv:2512.15716 关键词: CVPR 2026, 3D 点云, Visual SLAM 贡献: 3D 点云空间记忆 + Visual SLAM 迭代更新,长距空间一致 效果: 几何级空间一致方案 14. MSVBench:首个多镜头视频生成综合评测基准 MSVBench: Towards Human-Level Evaluation of Multi-Shot Video Generation | 多机构 | arXiv:2602.23969 关键词: 评测基准, LMM+专家模型, 136 故事 贡献: 首个多镜头视频生成综合评测基准,20 方法对比,94.4% 人类相关性 效果: 多镜头评测标准化基础设施 15. StoryBench:连续故事可视化三任务基准 StoryBench: A Multifaceted Benchmark for Continuous Story Visualization | Google Research / DeepMind | arXiv:2308.11606 关键词: NeurIPS 2023, 三任务, 人机评估 贡献: 连续故事可视化三任务基准 效果: 故事可视化评测基石 16. PackForcing:有界 KV-cache 极长自回归外推 PackForcing: Three-Partition KV-cache Long Video Autoregressive | Alaya Studio / Shandong University | arXiv:2603.25730 关键词: KV-cache, 长视频, 自回归 贡献: 有界 KV-cache 极长自回归外推 效果: 长序列生成内存侧方案 17. Movie Gen:超长上下文媒体基础模型 Movie Gen: A Cast of Media Foundation Models | Meta | arXiv:2410.13720 关键词: 基础模型, 长上下文, 工业标杆 贡献: 超长上下文媒体基础模型 效果: 多镜头工业能力上限参考 18. DreamFactory:多智能体 + 关键帧迭代生成多场景长视频 DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework | 清华等 | arXiv:2408.11788 关键词: 多场景, 多智能体, 长视频 贡献: 多智能体 + 关键帧迭代生成多场景长视频 效果: 多镜头叙事与 LLM 编排先驱 19. MovieFactory:早期脚本 MovieFactory: Automatic Movie Creation from Text using Large Generative Models | 多机构 | arXiv:2306.07257 关键词: 级联管线, 脚本生成, 多场景 贡献: 早期脚本→多镜头有声影片级联管线 效果: 早期文本到电影流水线代表 横向对比与技术脉络总结 横向对比:多镜头视频生成技术路线 论文 核心范式 跨镜头一致机制 交互/延迟 训练成本 会议 HoloCine 整体式双向 稀疏自注意力 离线整段 高 CVPR 2026 OneStory 自回归 next-shot 自适应选帧+紧凑注入 逐镜头 中 CVPR 2026 ShotStream 因果蒸馏 next-shot 全局+局部双缓存 实时 16 FPS 高(蒸馏) — CineTrans 掩码控制微调 注意力掩码 离线 中 ICLR 2026 STAGE 故事板→插值 记忆包+双编码 逐镜头 中 CVPR 2026 StoryMem M2V 潜变量拼接 关键帧记忆库 逐镜头 低(LoRA) — InfinityStory 级联多模块 位置锚定+过渡模型 逐镜头 中 — EchoShot 原生长序列 TcRoPE+TaRoPE 离线 低 NeurIPS 2025 核心技术趋势 整体式与自回归各有未来 HoloCine 证明整体式在分钟级可行且一致性最强,但计算瓶颈限制扩展。自回归天然支持无限镜头和交互修改。两者可能走向融合。 记忆机制是决胜关键 StoryMem 的 M2V、ShotStream 的双缓存、OneStory 的自适应选帧、InfinityStory 的位置锚定——「记什么/怎么压缩/何时更新」是核心维度。 电影语言成为差异化壁垒 CineTrans 揭示注意力-转场对应、STAGE 引入 DPO 偏好、ShotDirector 定义编辑层级——从「拼得连贯」推向「剪得专业」。 数据集构建是隐形竞赛 Cine250K、ConStoryBoard、PortraitGala、ShotWeaver40K、10K CMTS——每篇顶会论文自带数据集,数据工程可能比模型创新更稀缺。 开源生态加速成熟 基于 Wan2.2 微调已成共识。ShotStream、StoryMem、HoloCine、SkyReels-V2 均开源。ComfyUI 多镜头插件标志着走向创作者工具链。 人工智能炼丹师 整理 | 数据来源:arXiv 2023年8月 — 2026年4月(含经典评测与 2025–2026 方法爆发期) 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注