
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
通义千问新旗舰——百亿参数全模态理解与生成一体化,215项评测SOTA | Alibaba | arXiv:2604.15804
关键词: 全模态模型, 生成理解一体化, Thinker-Talker, TMRoPE, 音视频交互, MoE, SOTA
核心问题: 如何在单一模型中同时实现文本/图像/视频/音频的顶级理解与生成能力
现有多模态大模型通常在某些模态上表现优异但在其他模态上性能退化,难以做到'全能不偏科'。以往的全模态模型要么理解强但生成弱,要么文本强但语音弱。Qwen团队希望构建一个真正统一的端到端模型,同时实现所有模态的顶级理解与生成能力,特别是实时流式语音交互——这对于下一代人机交互至关重要。前代Qwen2.5-Omni虽然开创了Thinker-Talker架构,但在模型规模和多模态推理深度上仍有提升空间。Qwen3.5-Omni将模型规模扩展到百亿参数级别,并在训练方法论上做出重大改进。
前序工作及局限:
与前序工作的本质区别: 首个在所有模态上同时达到SOTA且无偏科的全模态模型,TMRoPE时间对齐和MoE理解/生成分离是关键创新
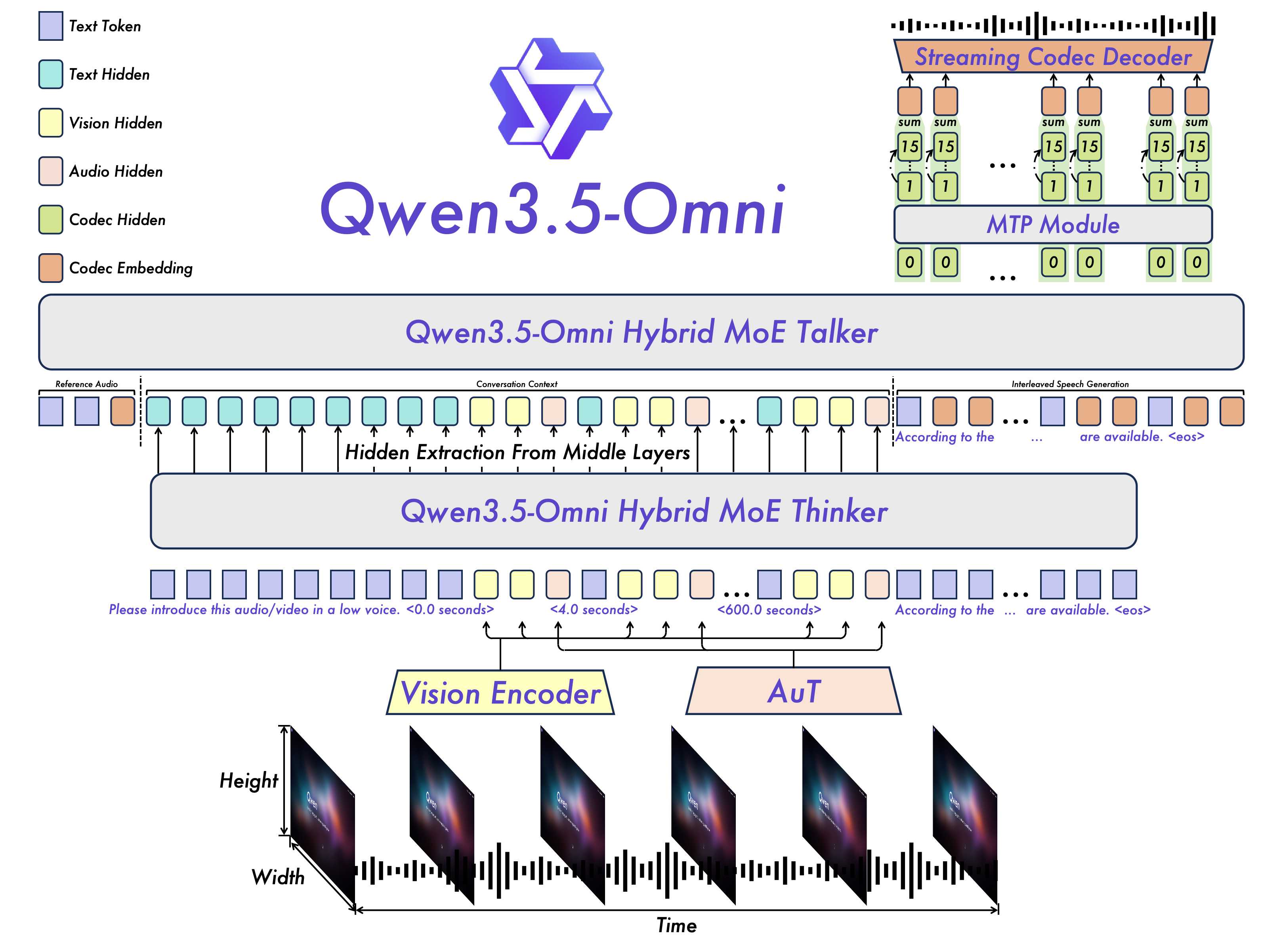
Qwen3.5-Omni采用Thinker-Talker双核架构设计:
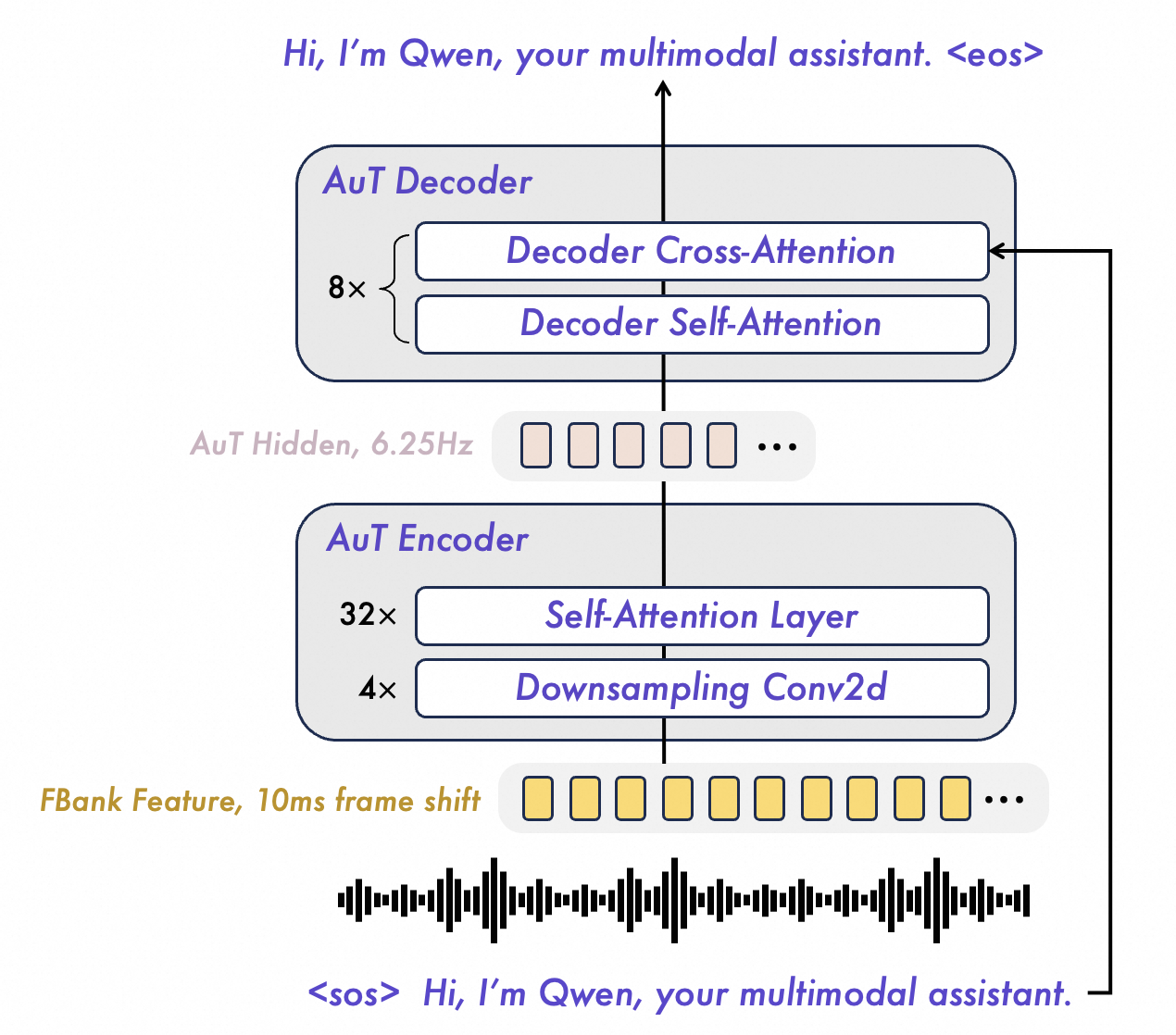
(1) Thinker模块(大脑):接收文本、图像、视频、音频等多模态输入,使用统一的Transformer编码器处理所有模态。视觉编码器和音频编码器均采用分块处理(block-wise)策略实现实时流式输入。输出高层语义表征和对应文本内容。引入MoE混合专家机制,为理解和生成任务分配独立专家组。
(2) Talker模块(发声器官):以流式方式接收Thinker实时输出的语义表征和文本token,流畅合成离散语音单元(speech tokens),再通过解码器转换为自然语音波形。整个过程是端到端的,延迟极低。
(3) TMRoPE位置编码:创新性地在RoPE基础上引入时间对齐机制,使视频帧和音频片段在同一时间轴上精准对齐。这对于理解音视频同步内容(如带字幕的视频、会议录音配PPT)至关重要。
(4) 三阶段预训练:第一阶段视觉与音频编码器独立训练;第二阶段联合全参数训练与多模态整合;第三阶段长序列数据训练提升理解能力。后训练阶段对Thinker和Talker分别进行SFT和DPO优化。
(5) 模型系列包含Base和Plus两个版本,Plus版本进一步增大参数量和训练数据。
Qwen3.5-Omni-Plus性能亮点:
音频理解:在215项音频和音视频理解/推理/交互子任务和基准上达到SOTA,在关键音频任务上超越Gemini-3.1 Pro
文本→文本:通用文本理解和推理能力保持SOTA水平
图像→文本:多模态理解评估中达到一流水平
视频→文本:视频理解在主要benchmark上表现突出
语音生成:零样本语音合成质量超越多数现有方案,自然度和流畅度均达SOTA
实时交互:支持完全实时的流式音视频交互,延迟控制在百毫秒级
支持256K超长上下文窗口,113种语言识别
深度点评:
技术演进定位: 全模态统一模型的重要里程碑,证明了'一个模型搞定一切'的技术可行性
可能的后续方向:
Seedance 2.0: Advancing Video Generation for World Complexity | ByteDance | arXiv:2604.14148
关键词: 视频生成·音视频联合·多模态·动作质量·音频同步
贡献: 字节跳动发布Seedance 2.0技术报告,统一多模态音视频联合生成架构,支持文字/图片/音频/视频四模态输入,集成业界最全面的多模态内容参考和编辑能力。在动作质量和音视频同步两个维度达到3.75分(领先第二名0.65分),音频维度全面领先竞品。
效果: 在VBench等多个基准上超越Sora、Kling等模型,动作质量、音视频同步和音频生成三个维度均达行业最高水平。
Generative Refinement Networks for Visual Synthesis | ByteDance Research | arXiv:2604.13030
关键词: 图像生成·精炼网络·HBQ量化·ImageNet SOTA·视觉合成
贡献: 提出生成精炼网络(GRN),核心创新:(1)用理论近无损的分层二进制量化(HBQ)替代传统VQ-VAE等有损离散化,构建高质量连续级潜空间;(2)设计全局精炼机制像人类画家一样逐步完善输出;(3)熵引导采样实现复杂度感知的自适应步数生成。
效果: 在ImageNet上创造图像重建新纪录(0.56 rFID)和类别条件生成新纪录(1.81 gFID),并扩展至文生图和文生视频。
VideoFlexTok: Flexible-Length Coarse-to-Fine Video Tokenization | Apple, EPFL | arXiv:2604.12887
关键词: 视频token化·粗到细·灵活长度·高效生成·长视频
贡献: Apple与EPFL提出VideoFlexTok,将视频表示为灵活长度、从粗到细的token序列。前几个token自动捕获抽象语义信息,后续token逐步补充细节。首次实现在81帧10秒视频上训练文生视频模型。
效果: 生成模型规模缩小5-10倍,所需训练token数量减少5-10倍,同时保持生成质量,大幅降低长视频生成的计算成本。
Ride the Wave: Precision-Allocated Sparse Attention for Smooth Video Generation | Unknown | arXiv:2604.12219
关键词: 稀疏注意力·视频生成加速·DiT·免训练·推理优化
贡献: 提出精准分配稀疏注意力(PASA),一个面向视频扩散Transformer的免训练加速框架。针对现有稀疏注意力方法导致的运动不连续和闪烁问题,PASA根据去噪阶段和注意力头的重要性动态分配计算精度,保证关键时域信息完整传递。
效果: 在不损失生成质量的前提下显著降低Video DiT的注意力计算开销,解决了稀疏注意力导致的视频平滑性问题。
Audio-Omni: Extending Multi-modal Understanding to Versatile Audio Generation and Editing | HKUST | arXiv:2604.10708
关键词: 音频生成·音频编辑·音乐合成·多模态·统一框架
贡献: 香港科技大学提出Audio-Omni,首个统一音频理解、生成和编辑的端到端框架。覆盖通用声音、音乐和语音三大领域,解耦推理与合成实现知识增强生成和跨语言控制等复杂任务。
效果: 在音频理解、音乐生成和语音合成三个领域的多个基准上均达到竞争力水平,首次在单一模型内统一全音频任务。
RationalRewards: Reasoning Rewards Scale Visual Generation Both Training and Test Time | Unknown | arXiv:2604.11626
关键词: 奖励模型·视觉生成评测·推理·可解释·偏好学习
贡献: 提出RationalRewards——推理式奖励模型范式。传统视觉生成奖励模型将人类偏好压缩为单一分数,丢失了判断的推理过程。RationalRewards教会奖励模型像人类一样'思考后评分',在训练时提升生成质量,在推理时实现更可解释的评估。
效果: 在视觉生成的训练和测试两个阶段均实现显著提升,构建了可扩展且可解释的奖励建模新范式。
MAST: Mask-Guided Attention Mass Allocation for Training-Free Multi-Style Transfer | Unknown | arXiv:2604.12281
关键词: 风格迁移·无训练·注意力分配·扩散模型·图像编辑
贡献: 提出MAST——面向多风格迁移的无训练框架。通过掩码引导的注意力质量分配(Attention Mass Allocation)显式控制内容和风格信号的注意力交互,解决了扩散模型多风格迁移中的边界伪影、不稳定风格化和结构失真问题。
效果: 在多风格迁移场景下实现无伪影、结构保持的风格化效果,无需额外训练即可应用于现有扩散模型。
LottieGPT: Tokenizing Vector Animation for Autoregressive Generation | CVPR 2026 | arXiv:2604.11792
关键词: 矢量动画·自回归生成·Lottie·CVPR 2026·可编辑
贡献: CVPR 2026入选论文。提出LottieGPT,首次实现矢量动画的自回归生成。构建包含1500万样本的大规模Lottie矢量动画数据集LottieAnimation-660K,将矢量动画结构token化后微调Qwen-VL生成连贯可编辑的矢量动画。
效果: 首次将视频生成扩展到矢量动画领域,生成的动画可直接编辑、分辨率无关,开辟了动画生成新方向。
Efficient Video Diffusion Models: Advancements and Challenges | Unknown | arXiv:2604.15911
关键词: 视频扩散·推理加速·稀疏注意力·综述·部署优化
贡献: 系统性综述视频扩散模型的高效推理技术。提出统一分类法将现有方法分为四大加速范式:步骤减少(step reduction)、注意力稀疏化(attention sparsification)、缓存复用(caching)和架构优化(architecture optimization)。全面梳理部署导向的高效化路线。
效果: 首个面向部署的视频扩散模型高效化综述,为研究者和从业者提供了清晰的技术路线图和开源代码仓库。
人工智能炼丹君 整理 | 2026-04-21
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)