
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日 arXiv cs.CV 视觉生成相关论文共 8 篇,重点解读 1 篇。
方向分布:
重新审视可控扩散训练目标——直接x₀监督实现2倍加速 | CEA-LIST | arXiv:2604.05761
关键词: 可控生成, 训练加速, x₀预测, ControlNet, 扩散模型, SDXL
核心问题: 可控扩散模型沿用 ε-预测训练目标,导致控制分支训练低效
文本到图像扩散模型在视觉保真度和文本对齐上取得显著进步,但用户需要精确控制图像布局时,自然语言无法可靠表达。可控生成方法通过附加条件增强T2I模型,但先前工作简单沿用与基础模型相同的ε-预测训练损失。作者发现这种做法会导致某些控制条件下训练极慢——特别是当条件信号和干净图像之间的映射关系在不同噪声水平下差异很大时,ε-预测目标给予高噪声时域过大权重,导致训练效率低下。
前序工作及局限:
与前序工作的本质区别: 首次从去噪动态角度分析可控生成中训练目标的低效性,给出理论清晰的 x₀-supervision 方案
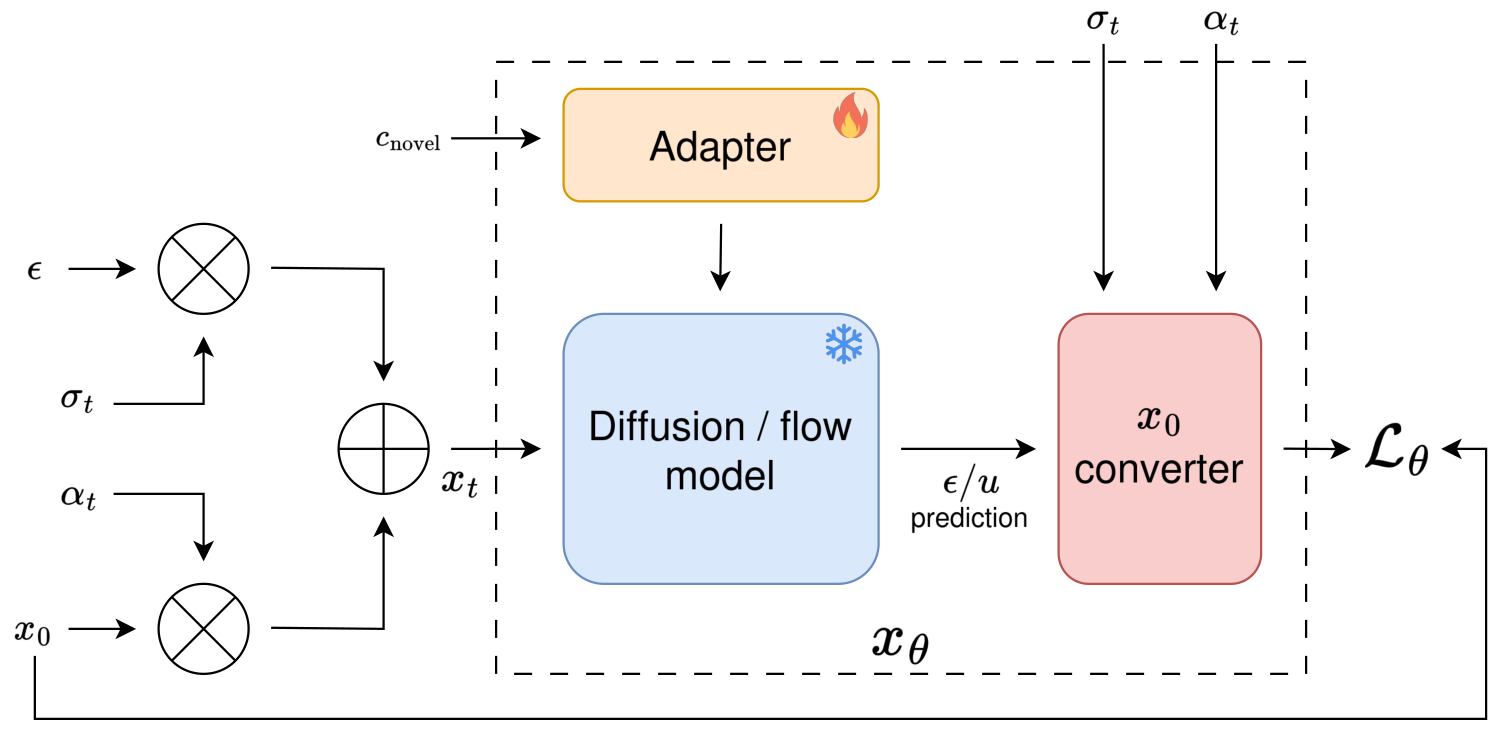
x₀-Supervision框架通过两个核心改进加速可控扩散训练:
(1) 训练目标重构:将标准ε-预测损失替换为x₀-预测损失,直接监督网络预测干净图像x₀。数学上等价于对ε-预测损失施加信噪比(SNR)相关的权重调制——低SNR(高噪声)时域权重降低,高SNR(低噪声)时域权重提升。这使得控制分支在训练早期就能获得有效的条件→图像映射信号。
(2) 去噪动态分析:作者系统分析了可控生成中基础模型和控制分支的去噪贡献。发现控制分支在低噪声时域贡献更大(此时条件信号和目标图像的关联最直接),而ε-预测目标恰恰在此区域给予低权重。x₀-supervision修正了这一不匹配。
(3) 评估方法创新:提出mAUCC指标(mean Area Under the Convergence Curve),综合衡量训练过程中的收敛速度,而非仅看最终性能。在ControlNet和T2I-Adapter两种架构上基于SDXL进行验证。
ControlNet (SDXL):
T2I-Adapter (SDXL):
消融实验:
训练收敛速度对比
5 种控制条件下 x₀-supervision(蓝线)vs ε-prediction(橙线)的 mAUCC 收敛曲线,展示全条件下的一致加速效果
SNR 权重分析
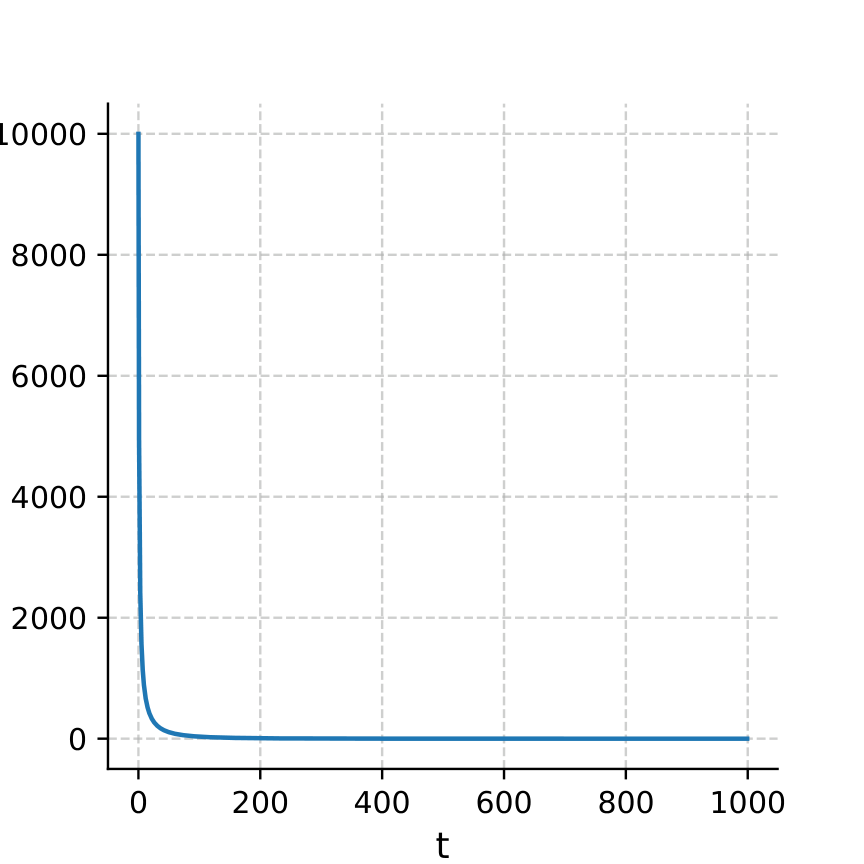
信噪比 SNR 与损失权重的关系图,说明 x₀-预测等价于对 ε-预测施加 SNR 相关的权重调制
生成质量定性对比

不同控制条件下 ε-prediction vs x₀-supervision 的生成结果对比,展示 x₀ 在保真度和条件遵循上的优势
深度点评:
技术演进定位: 扩散模型训练方法论的重要补充,特别是可控生成训练效率的里程碑式分析
可能的后续方向:
Lighting-grounded Video Generation with Renderer-based Agent Reasoning | Peking University, Beijing University of Posts and Telecommunications | arXiv:2604.07966
关键词: 视频生成·3D场景控制·光照解耦·Agent推理·可控生成
贡献: 提出LiVER——首个基于显式3D场景属性(布局、光照、相机轨迹)条件化的可控视频生成框架。构建大规模密集标注数据集,通过统一3D表示渲染控制信号实现场景因素解耦。设计场景Agent自动将自然语言指令转换为3D控制信号。
效果: 在光照、布局和相机轨迹控制上实现SOTA光真实感和时间一致性,支持image-to-video和video-to-video的全场景可编辑合成。
Not all tokens contribute equally to diffusion learning | Beijing Jiaotong University | arXiv:2604.07026
关键词: 视频生成·语义对齐·注意力重加权·分布校正·CFG优化
贡献: 揭示文本到视频扩散模型中语义重要token被忽视的问题——源于训练数据长尾分布偏差和交叉注意力空间失配。提出DARE统一框架:DR-CFG(分布校正CFG)动态抑制低语义密度token,SRA(空间表征对齐)按token重要性自适应重加权注意力图。
效果: 在多个基准上一致提升生成保真度和语义对齐,显著改善被忽视语义的生成质量。
VersaVogue: Visual Expert Orchestration and Preference Alignment for Unified Fashion Synthesis | Nanjing University of Science and Technology | arXiv:2604.07210
关键词: 时尚合成·虚拟试穿·MoE·偏好优化·DPO·图像生成
贡献: 提出VersaVogue——统一服装生成和虚拟换装的多条件可控时尚合成框架。核心:特征路由注意力(TA)模块通过MoE机制动态路由视觉属性(纹理/形状/颜色)到最兼容的专家层;多视角偏好优化(MPO)管线自动构建偏好数据进行DPO优化。
效果: 在服装生成和虚拟换装两个基准上均超越现有方法,实现更优的视觉保真度和细粒度可控性。
ImVideoEdit: Image-learning Video Editing via 2D Spatial Difference Attention Blocks | Zhejiang University | arXiv:2604.07958
关键词: 视频编辑·图像学习·空间差分注意力·免掩码·轻量训练
贡献: 提出ImVideoEdit——仅从图像对学习视频编辑能力的高效框架。冻结预训练3D注意力模块,将图像视为单帧视频解耦空间学习,保留原始时序动态。核心是Predict-Update空间差分注意力模块配合文本引导动态语义门控,不依赖外部掩码。
效果: 仅用13K图像对训练5个epoch,极低计算开销下达到与大规模视频数据集训练模型可比的编辑保真度和时序一致性。
Personalizing Text-to-Image Generation to Individual Taste | KU Leuven, University of Tübingen | arXiv:2604.07427
关键词: 个性化生成·奖励模型·审美评估·偏好学习·文生图
贡献: 提出PAMELA——个性化图像评估数据集和框架。收集70K评分数据(5000张Flux/Nano Banana生成图,每张15位用户评分),训练个性化奖励模型预测个体偏好。通过简单提示优化即可引导生成符合个人审美的图像。
效果: 个性化偏好预测准确率超越大多数SOTA方法的群体级预测性能,数据集和模型已开源。
Cross-Modal Emotion Transfer for Emotion Editing in Talking Face Video | KAIST | arXiv:2604.07786
关键词: 情感编辑·说话人生成·跨模态·语音驱动·表情迁移
贡献: 提出C-MET——跨模态情感迁移方法,通过在语音和视觉特征空间之间建模情感语义向量实现说话人面部表情编辑。利用大规模预训练音频编码器和解耦表情编码器学习跨模态情感差分向量,支持未见过的扩展情感(如讽刺)。
效果: 在MEAD和CREMA-D数据集上情感准确率提升14%,同时生成高表现力的说话人视频。代码和模型已开源。
MAR-GRPO: Stabilized GRPO for AR-diffusion Hybrid Image Generation | USTC, Alibaba | arXiv:2604.06966
关键词: AR-扩散混合·GRPO·强化学习·MAR·训练稳定性·图像生成
贡献: 首个为AR-扩散混合模型(MAR)设计的稳定GRPO框架。发现扩散头产生噪声梯度导致训练不稳定。提出多轨迹期望(MTE)对多扩散轨迹取平均降噪梯度;token级不确定性估计对高不确定token选择性优化;一致性感知token选择过滤低对齐AR token。
效果: 在多个基准上持续提升视觉质量、训练稳定性和空间结构理解能力,代码已开源。
人工智能炼丹师 整理 | 2026-04-10
评论 (0)