
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 2026年4月4日(周六)
覆盖时间:2026年3月29日 — 2026年4月4日
本期 AIGC 周末专题聚焦视频生成与编辑前沿:从统一框架到长视频、物理一致性与高效推理方向,精选 6 篇代表性论文进行深度解读。
方向分布:
| # | 论文 | 机构 | 核心贡献 | arXiv ID |
|---|---|---|---|---|
| 1 | OmniWeaving | Tencent Hunyuan, Zhejiang University | 提出 OmniWeaving 统一视频生成框架,通过 MLLM 实现多模态理解与推理,支持文本、多图像、视频的自由组合输 | 2603.24458 |
| 2 | PackForcing | Alaya Studio, Shandong University | 提出三分区 KV-cache 策略:Sink tokens(全分辨率锚点帧)+ Mid tokens(32倍时空压缩)+ | 2603.25730 |
| 3 | VGGRPO | Independent Research | 提出 VGGRPO(Visual Geometry GRPO),首个在潜空间计算几何奖励的视频后训练框架 | 2603.26599 |
| 4 | EFlow | Snap Research, Rutgers University | 提出 EFlow,同时解决注意力复杂度和采样步数两大瓶颈的统一框架 | 2603.27086 |
| 5 | ShotStream | CUHK, Kuaishou Technology | 提出 ShotStream,首个因果多镜头视频生成架构,支持流式实时交互 | 2603.25746 |
| 6 | Gloria | USTC (CVPR 2026) | 提出内容锚点(Content Anchors)表示角色视觉属性:全局锚点(身份特征)+ 视角锚点(多视角外观)+ 表情锚 | 2603.29931 |
论文: OmniWeaving
arXiv: 2603.24458
机构: Tencent Hunyuan, Zhejiang University
核心问题: 开源视频生成模型碎片化,无法在单一框架内统一 T2V/I2V/V2V 等多任务
当前开源视频生成模型高度碎片化,无法在单一框架内统一文生视频、图生视频、视频编辑等多种任务。商业系统(如 Seedance-2.0)遥遥领先,开源社区急需一个全能统一方案。
前序工作及局限:
与前序工作的本质区别: 首个开源全能统一视频生成框架,MLLM+DiT 双模块架构支持自由多模态组合输入和推理驱动的视频创作
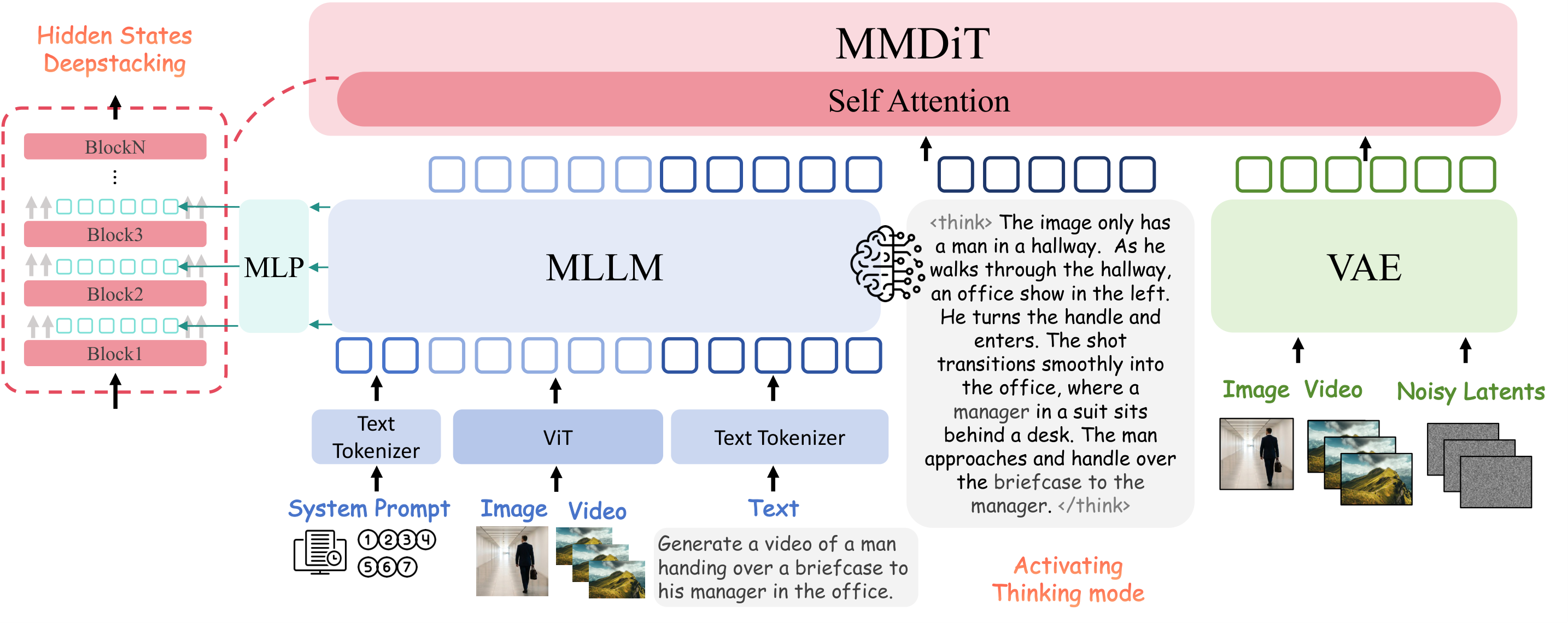
OmniWeaving 由两个核心模块组成:(1) 多模态大语言模型(MLLM)负责理解和推理复杂的用户意图,将文本、图像、视频等多模态输入统一编码为条件表示;(2) 视频扩散模型接收条件表示生成高质量视频。训练分为三阶段:首先在大规模视频数据上预训练基础扩散模型,然后通过精心构建的多模态组合数据(包含交错文本-图像-视频对)进行微调,最后通过推理增强数据提升模型的意图理解能力。关键创新在于训练数据构建管线:自动从海量视频中提取多模态组合场景,生成需要推理才能完成的复杂视频创作任务。
训练数据构建管线依赖大量自动化标注,数据质量可能存在噪声。IntelligentVBench 作为自家提出的评测基准,客观性有待社区验证。与 Seedance-2.0 等商业系统相比仍有差距,但开源意义重大。
技术演进定位: 开源统一视频生成的里程碑,填补了开源社区在全能视频框架上的空白
可能的后续方向:
论文: PackForcing
arXiv: 2603.25730
机构: Alaya Studio, Shandong University
核心问题: 自回归视频扩散模型的 KV-cache 线性增长导致长视频生成内存爆炸
自回归视频扩散模型在长视频生成中面临三大瓶颈:KV-cache 线性增长导致内存爆炸、时间重复(temporal repetition)和误差累积。现有方法无法在有限 GPU 内存下生成超过30秒的连贯视频。
前序工作及局限:
与前序工作的本质区别: 三分区 KV-cache 策略(Sink+Mid+Recent)实现 32 倍压缩和有界 4GB 内存,仅用 5 秒短视频训练即可 24 倍时间外推到 2 分钟
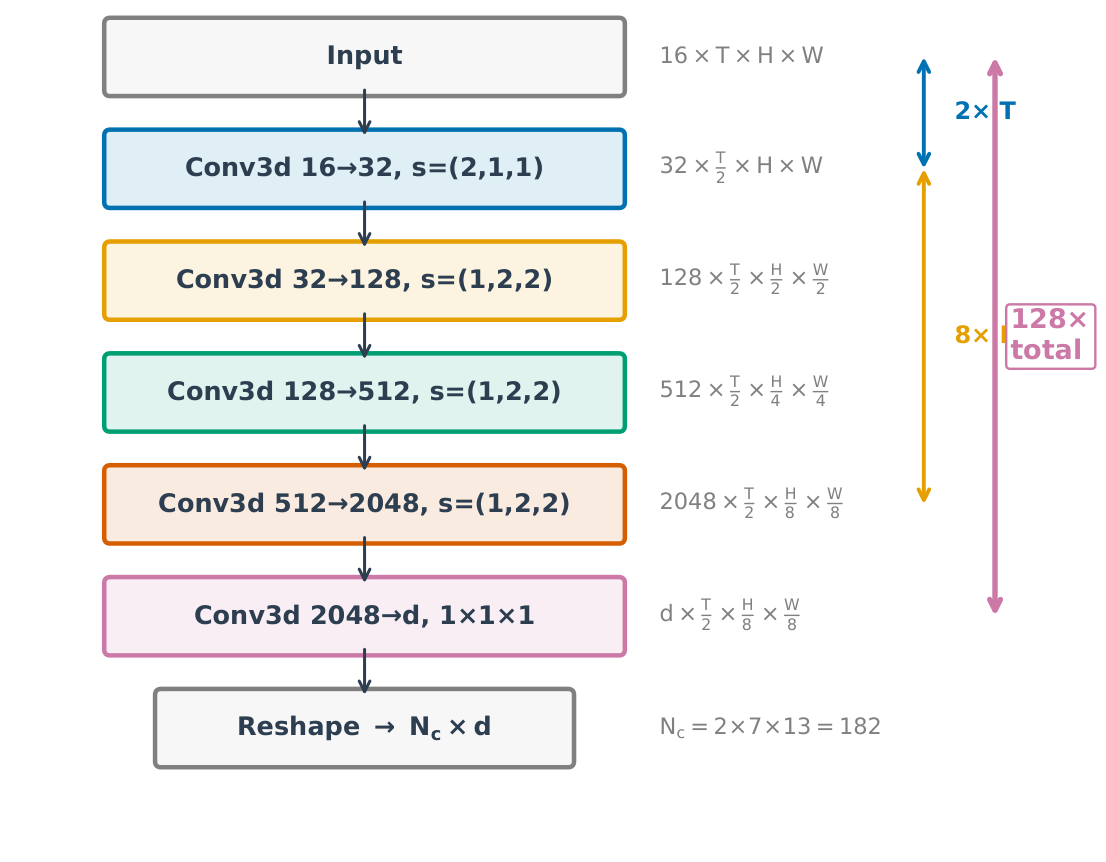
PackForcing 将自回归视频扩散中的历史上下文分为三类:(1) Sink tokens 保留最早的若干帧作为全局语义锚点;(2) Mid tokens 通过双分支网络将中间帧压缩为极少 token——一个分支是渐进式 3D 卷积逐步降低时空分辨率,另一个分支将帧重编码为低分辨率 VAE latent,两者通过门控机制融合;(3) Recent tokens 保持最近帧的全分辨率以确保局部连贯性。当 Mid tokens 过多时,动态 top-k 机制选择最重要的 token 保留,同时通过连续 RoPE 重编码消除位置间隙。整个框架可在仅 5 秒短视频片段上训练,推理时自回归扩展到 2 分钟。
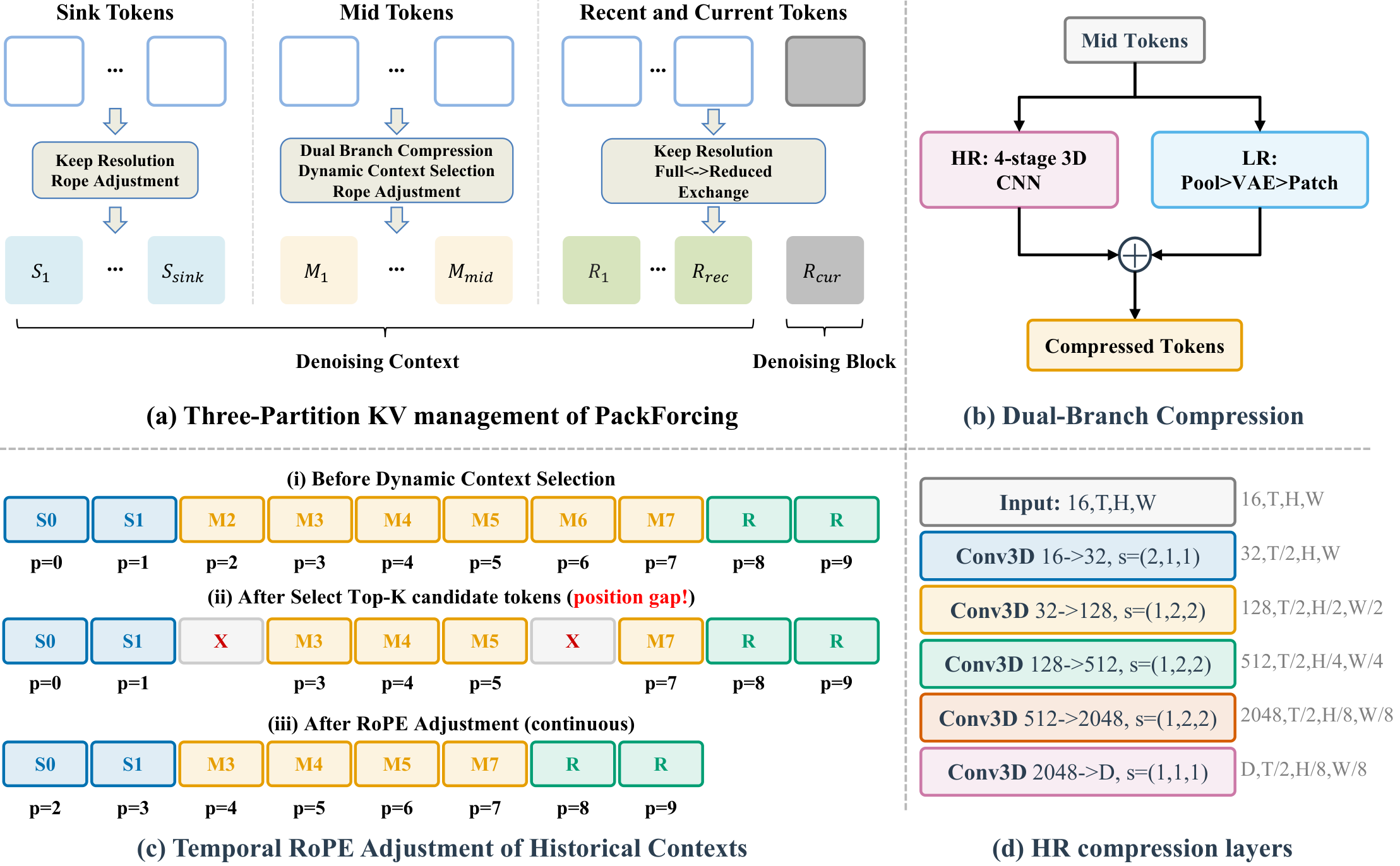
双分支 Mid token 压缩引入额外计算开销,需要验证其在更高分辨率(1080p+)下的可扩展性。目前仅在 16FPS 下验证,更高帧率场景待测试。分区策略中的超参数(Sink/Mid/Recent 比例)需要仔细调节。
技术演进定位: 当前最高效的长视频生成方案,首次在单 GPU 上实现 2 分钟连贯视频
可能的后续方向:
论文: VGGRPO
arXiv: 2603.26599
机构: Independent Research
核心问题: 视频扩散模型虽然视觉效果好但经常违反几何规律(相机抖动、多视角不一致)
大规模视频扩散模型虽然视觉质量出色,但经常违反几何一致性:相机抖动、多视角几何不一致、物理规律违反。现有方法要么修改架构(损害泛化能力),要么在 RGB 空间计算几何奖励(昂贵且仅限静态场景)。需要一种不修改架构、计算高效且支持动态场景的方案。
前序工作及局限:
与前序工作的本质区别: 首次在潜空间计算几何奖励(绕过 VAE 解码),通过 4D 重建扩展到动态场景,GRPO 策略梯度优化几何一致性
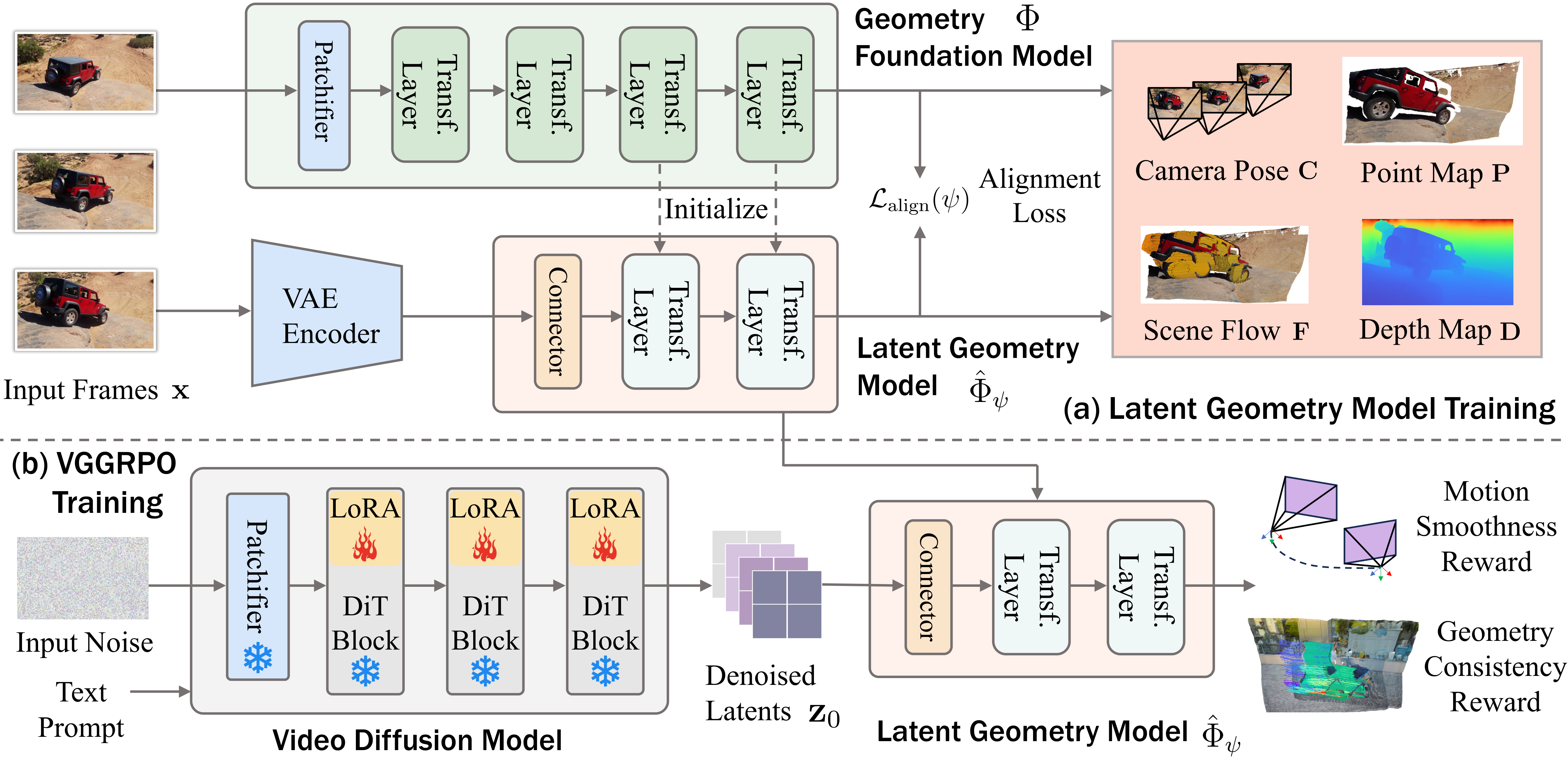
VGGRPO 分为两步:(1) 训练潜在几何模型 LGM,它是一个轻量级网络,直接从视频扩散的 latent 空间解码场景的深度和法线信息,不需要经过 VAE 解码到 RGB 空间。LGM 通过冻结 VAE encoder-decoder 对和几何基础模型(如 DPT/Metric3D)蒸馏训练。(2) 使用 Group Relative Policy Optimization(GRPO)进行视频扩散模型的后训练。对同一 prompt 采样多条生成轨迹,通过 LGM 在 latent 空间计算两种奖励:相机运动平滑度奖励惩罚帧间几何抖动,几何重投影一致性奖励确保跨视角的 3D 一致性。GRPO 根据奖励差异更新策略梯度。4D 扩展通过时序多帧几何重建实现。
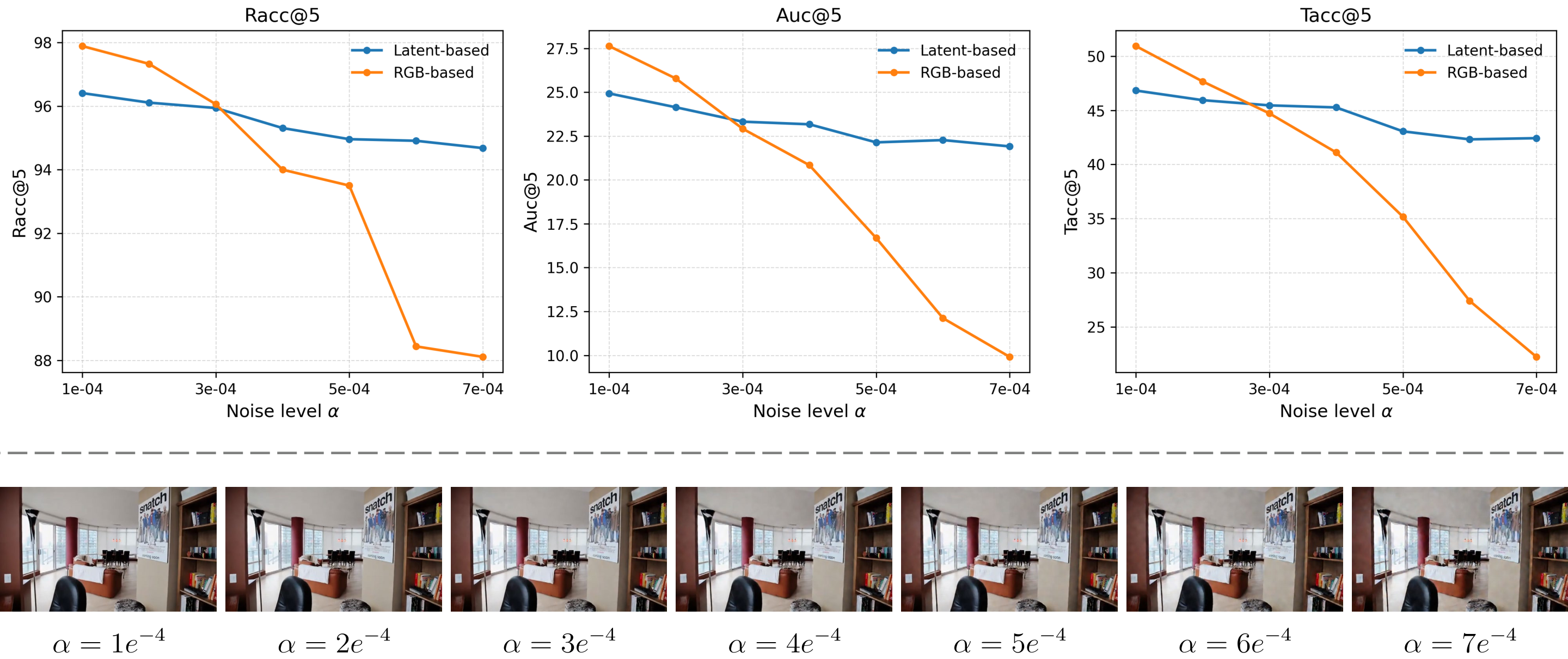
LGM 的训练质量直接影响奖励信号的准确性,如果几何基础模型本身有偏差会传播到视频模型。当前奖励仅考虑几何一致性,未涉及物理动力学(如碰撞、重力)。GRPO 的多轨迹采样增加了训练成本。
技术演进定位: 开创了视频几何后训练的新范式,证明 RLHF 类方法可有效提升视频的物理合理性
可能的后续方向:
论文: EFlow
arXiv: 2603.27086
机构: Snap Research, Rutgers University
核心问题: 视频扩散 Transformer 面临每步二次注意力复杂度和多步迭代采样的双重瓶颈
视频扩散 Transformer 面临两个复合成本瓶颈:每步的二次注意力复杂度 O(n^2) 和多步迭代采样。现有加速方法通常只解决其中一个——蒸馏减少步数但不降低单步成本,高效注意力降低单步成本但不减少步数。需要同时解决两个瓶颈的统一方案。
前序工作及局限:
与前序工作的本质区别: 同时解决注意力复杂度(Gated L-G Attention + token dropping)和采样步数(solution-flow + MVA 正则化),从头训练无需教师模型
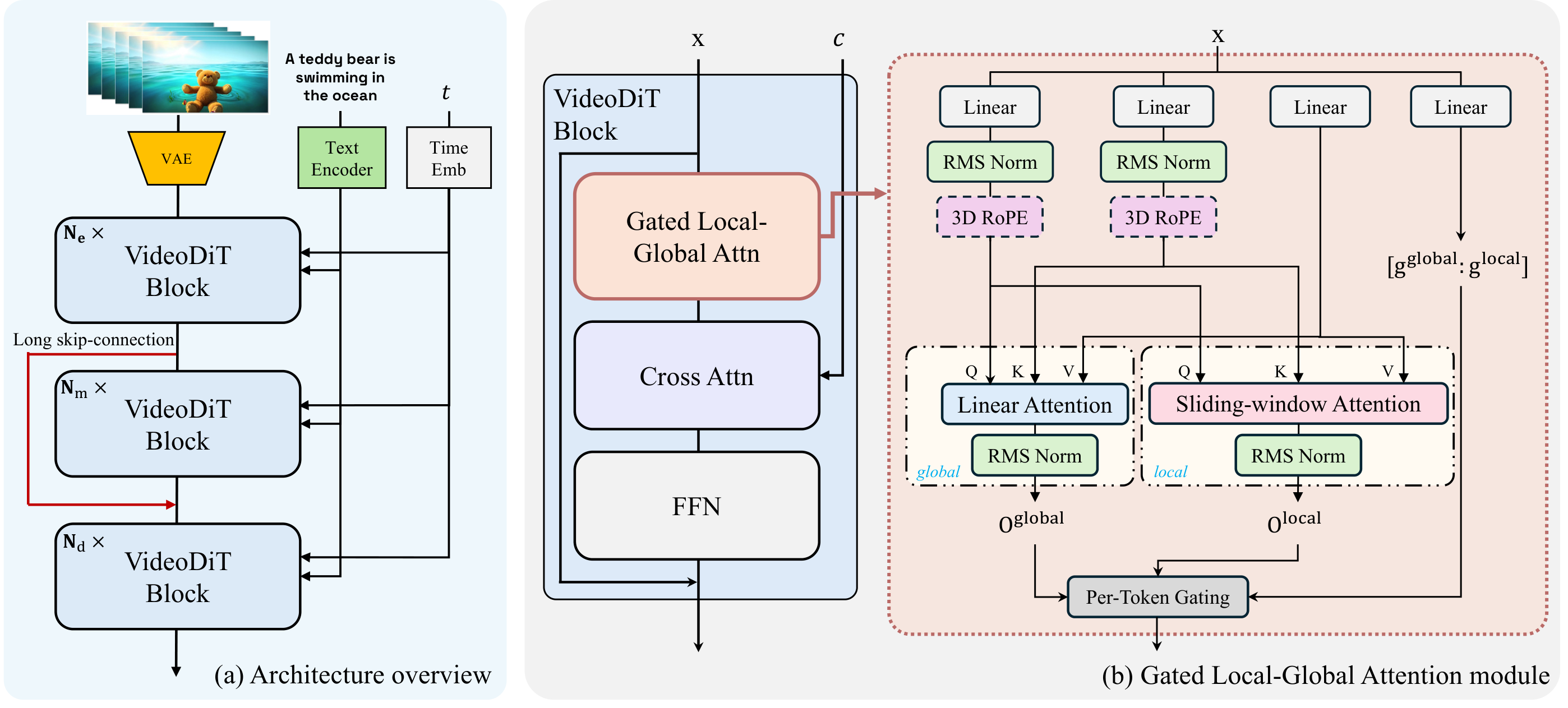
EFlow 基于 solution-flow 目标,学习将时刻 t 的噪声状态直接映射到时刻 s(跨越多个扩散步)。核心创新有三:(1) Gated Local-Global Attention 将注意力分为局部窗口注意力和全局稀疏注意力两部分,通过门控机制融合,关键是设计为对 random token dropping 高度稳定——训练时随机丢弃 50-70% 的 token 而不影响质量;(2) Path-Drop Guided Training 在少步训练中用条件路径和无条件路径的随机丢弃替代传统 CFG(后者需要两次前向传播),将引导成本降为零;(3) Mean-Velocity Additivity 正则化器约束不同步数下的速度场之和等于总位移,确保 1-4 步生成的一致性。从头训练流程支持直接训练少步模型,无需先训练多步模型再蒸馏。
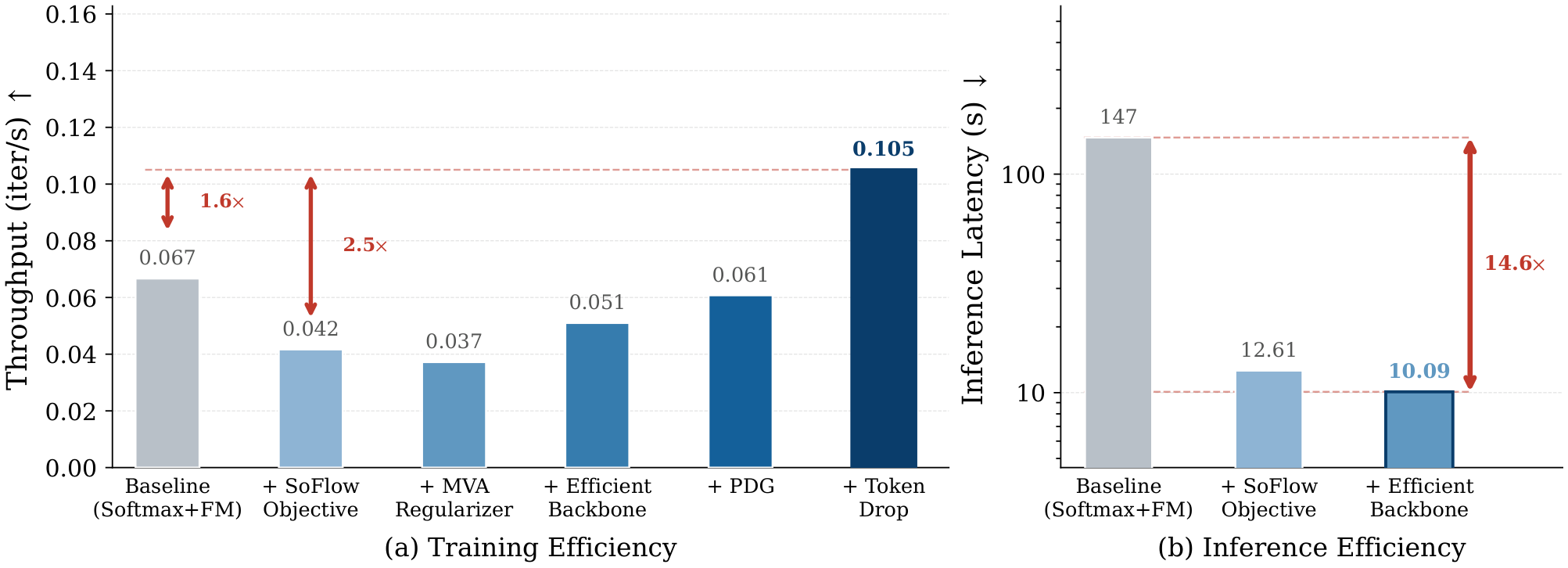
随机 token dropping 在极端比例下可能影响细节质量。Path-Drop Guided 是否在所有场景下都能替代 CFG 有待更多验证。从头训练的计算量仍然很大(虽然吞吐量提升了2.5倍)。目前主要在较短视频上验证。
技术演进定位: 首个同时解决两大瓶颈的统一加速框架,45.3 倍推理加速具有部署实用价值
可能的后续方向:
论文: ShotStream
arXiv: 2603.25746
机构: CUHK, Kuaishou Technology
核心问题: 多镜头视频生成的双向架构导致交互性差、延迟高,用户无法实时参与创作
多镜头视频生成是长叙事视频的关键,但当前双向扩散架构(如全序列并行生成)存在交互性差和延迟高的问题——用户无法在生成过程中动态调整叙事方向,且需要等待整个序列生成完成才能看到结果。
前序工作及局限:
与前序工作的本质区别: 首个因果流式多镜头架构,通过双缓存记忆和两阶段蒸馏实现 16 FPS 实时交互式叙事
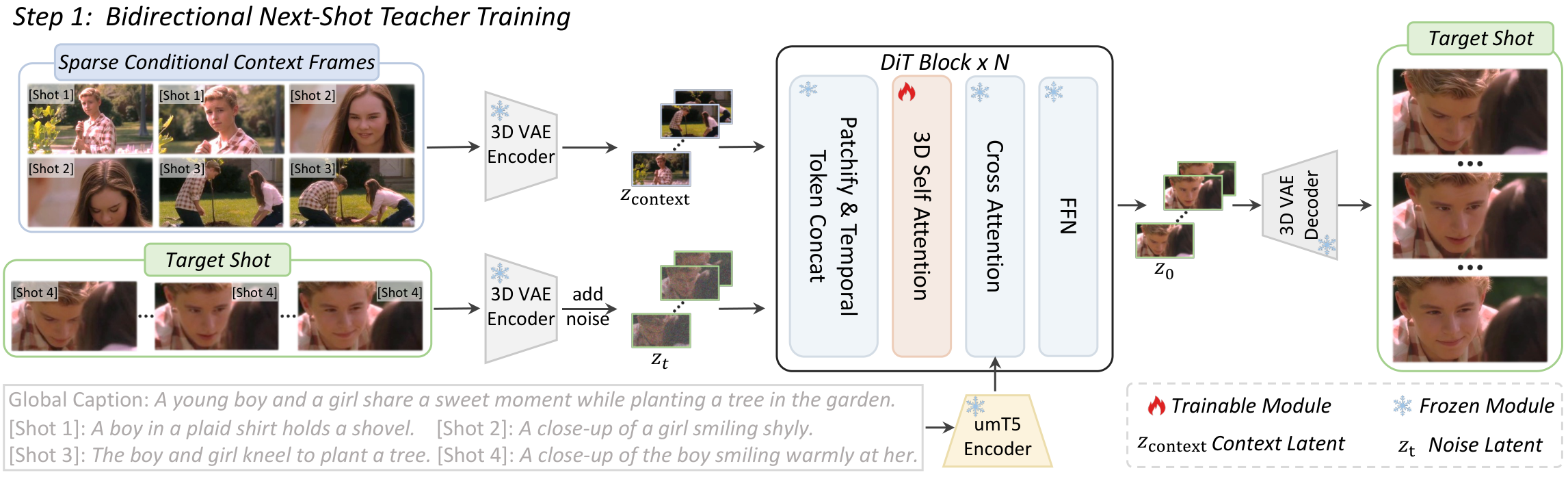
ShotStream 的流程分为训练和推理两阶段。训练阶段:(1) 将预训练 T2V 模型微调为双向 next-shot 生成器,学习根据前序镜头和文本提示生成下一个镜头;(2) 通过分布匹配蒸馏将双向教师蒸馏为因果学生模型。为解决因果自回归的两大挑战:(a) 镜头间一致性——引入全局上下文缓存(Global Context Cache),存储所有前序镜头的条件帧作为长程记忆;(b) 误差累积——设计两阶段蒸馏策略:第一阶段在真实历史上进行镜头内自强迫训练,第二阶段在自生成的历史上进行镜头间自强迫训练,逐步暴露给模型自身的生成误差。RoPE 不连续性指示器通过在全局和局部缓存之间插入位置编码跳跃来消除歧义。

因果架构天然信息量少于双向架构,长程一致性在超长叙事(10+镜头)下可能衰减。蒸馏质量依赖双向教师模型。全局上下文缓存随镜头数增长可能成为新的内存瓶颈。
技术演进定位: 开创了流式交互式视频叙事的新范式,是 AI 视频工具从离线走向实时的关键一步
可能的后续方向:
论文: Gloria
arXiv: 2603.29931
机构: USTC (CVPR 2026)
核心问题: 长时间角色视频生成中身份漂移严重,多视角和表情一致性难以保持
数字角色是现代媒体的核心,但生成长时间、多视角一致且表情丰富的角色视频仍是开放挑战。现有方法面临两类问题:要么参考信息不足导致身份漂移,要么使用非角色中心的记忆信息导致一致性次优。
前序工作及局限:
与前序工作的本质区别: 通过三类内容锚点(全局/视角/表情)提供稳定参考,超集锚定防止复制粘贴,实现 10+ 分钟级别的角色一致性
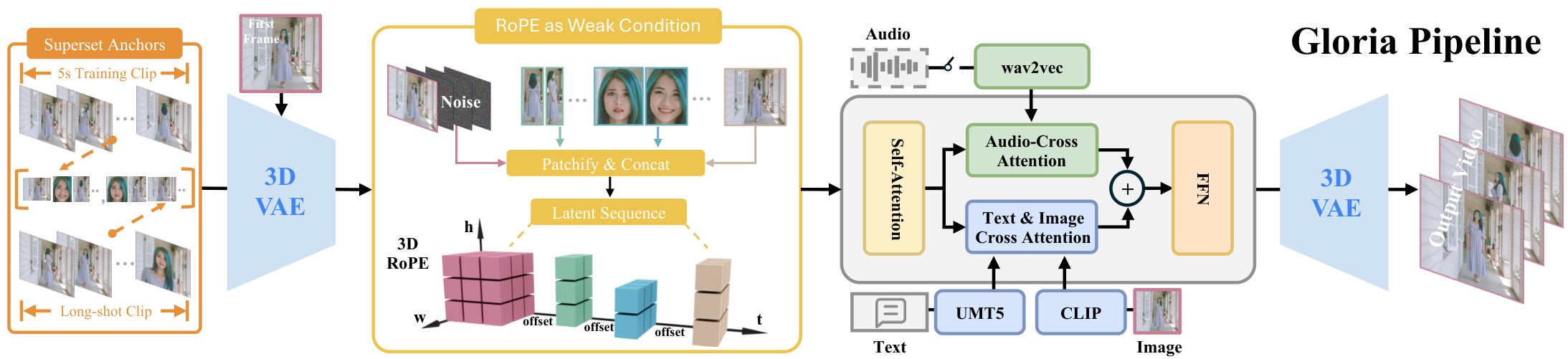
Gloria 将角色视频生成类比为由外向内观察的场景。核心是通过一组紧凑的锚帧来描述角色的视觉属性:(1) 全局锚点——一个标准正面参考图,提供身份基准;(2) 视角锚点——来自不同视角的参考帧,覆盖角色的多视角外观;(3) 表情锚点——包含不同表情的帧,编码角色的表情动态范围。训练时,通过超集内容锚定策略——提供比目标片段更多的锚点信息(包括训练剪辑之外的帧),迫使模型学习从锚点中提取有用信息而非简单复制。同时使用 RoPE 位置偏移作为弱条件区分不同锚点帧,让模型知道哪些帧来自哪个视角。数据管线方面,从海量视频中自动检测角色区域、跟踪身份、提取关键帧作为锚点。
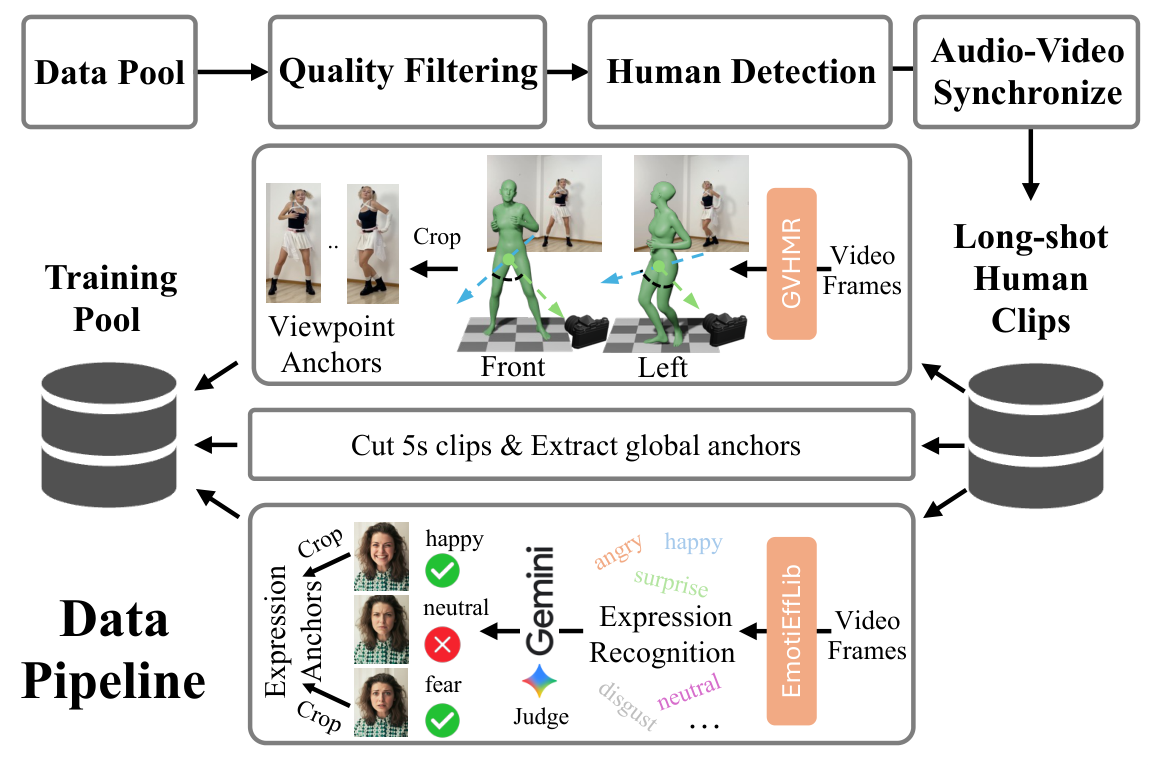
锚点提取管线依赖角色检测和跟踪的准确性,遮挡严重的场景可能失败。超集锚定策略增加了训练复杂度。对非人物角色(如动漫、卡通角色)的泛化能力需要更多验证。10 分钟的一致性主要在受控场景下验证。
技术演进定位: 角色一致性视频生成的新标杆,锚点机制为长视频角色保持提供了有效范式(CVPR 2026)
可能的后续方向:
| 论文 | 核心架构 | 主要任务 | 关键创新 | 输入形式 |
|---|---|---|---|---|
| OmniWeaving | MLLM + DiT | T2V/I2V/V2V 统一 | 推理驱动+组合数据 | 文本+多图+视频自由组合 |
| PackForcing | 自回归 DiT | 长视频生成 | 三分区 KV-cache | 文本 → 2分钟视频 |
| VGGRPO | DiT + LGM | 几何一致性后训练 | 4D 潜空间几何奖励 | 文本 → 几何一致视频 |
| EFlow | Gated L-G DiT | 高效少步生成 | token dropping + MVA | 文本 → 4步高质量视频 |
| ShotStream | 因果 DiT | 流式多镜头叙事 | 双缓存+两阶段蒸馏 | 逐镜头文本 → 实时视频 |
| Gloria | DiT + 锚点 | 角色一致性生成 | 三类内容锚点 | 角色参考图 → 10min视频 |
| 论文 | 训练范式 | 外部监督 | 推理效率 | 核心瓶颈解决 |
|---|---|---|---|---|
| OmniWeaving | 三阶段渐进训练 | 组合数据+推理增强 | 标准 DiT 速度 | 任务碎片化 |
| PackForcing | 短视频训练+时间外推 | 无(5秒视频) | 单 GPU 2分钟 | 内存爆炸(KV-cache→4GB) |
| VGGRPO | GRPO 后训练 | LGM 伪标签 | 与基线相同 | 几何违反(相机稳定↑23%) |
| EFlow | Solution-flow 从头训练 | 无需教师模型 | 45.3× 加速 | 注意力O(n²)+多步采样 |
| ShotStream | 两阶段蒸馏 | 双向教师蒸馏 | 16 FPS 实时 | 延迟高+不可交互 |
| Gloria | 端到端锚点训练 | 自动锚点提取 | 标准 DiT 速度 | 长时身份漂移 |
趋势 1:视频生成从碎片化走向统一
OmniWeaving 证明了 MLLM+DiT 架构可以在单一框架内处理 T2V/I2V/V2V 等多种视频任务。推理驱动的数据构建策略使模型能理解复杂的多模态组合意图,这预示着未来的视频 AI 将是全能型的。
趋势 2:长视频生成突破内存瓶颈
PackForcing 的三分区 KV-cache 策略实现了 24 倍时间外推(5秒→2分钟),Gloria 的内容锚点将角色一致性推到 10 分钟级。两者共同表明长视频生成的关键不在于生成能力本身,而在于上下文管理和信息压缩。
趋势 3:GRPO 后训练成为视频质量提升的新范式
VGGRPO 将 GRPO 引入视频几何一致性优化,在 latent 空间计算奖励避免了昂贵的 RGB 解码。这延续了 LLM 领域 RLHF/DPO 的成功经验,后训练对齐正成为视频扩散模型质量提升的关键杠杆。
趋势 4:少步生成从蒸馏走向从头训练
EFlow 的 Gated L-G Attention + token dropping + MVA 正则化实现了 45.3 倍推理加速,且无需教师模型。这种从头训练少步模型的路线比蒸馏更灵活,可能成为效率优化的主流方案。
趋势 5:交互式实时生成开启视频创作新时代
ShotStream 的因果流式架构达到 16 FPS 实时生成,用户可以边看边改叙事方向。这标志着视频 AI 从「离线工具」向「实时合作者」的转变,对短视频平台和游戏行业有重要意义。
视频生成与编辑技术路线
├── 统一框架
│ └── MLLM + DiT 双模块 → OmniWeaving(多模态组合+推理驱动)
├── 长视频生成
│ ├── KV-cache 压缩 → PackForcing(三分区策略,24x 外推)
│ └── 角色一致性 → Gloria(三类内容锚点,10min 级别)
├── 质量对齐
│ └── 后训练 GRPO → VGGRPO(4D 潜空间几何奖励)
├── 推理效率
│ └── 从头训练少步 → EFlow(45.3x 加速,无需蒸馏)
└── 交互式生成
└── 因果流式架构 → ShotStream(16 FPS 实时多镜头叙事)本期专题的 6 篇论文共同描绘了视频生成与编辑领域的前沿全景图。从统一框架(OmniWeaving)到长视频突破(PackForcing/Gloria),从物理对齐(VGGRPO)到效率革命(EFlow),再到交互式创作(ShotStream),视频生成正在从技术验证走向实际可用。几个值得关注的未来方向:
人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月29日 — 2026年4月4日
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注



评论 (0)