
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇
今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
全模态统一大扩散语言模型:首个掩码扩散全模态基础模型 | Seoul National University (AIDAS Lab) | arXiv:2604.00007
关键词: 全模态统一, 掩码扩散, 文本/图像/视频/语音, 理解+生成一体化, 模态解纠缠合并
核心问题: 如何在单一架构中原生统一文本、图像、视频、语音的理解与生成,避免自回归序列化瓶颈和组合式模型的外部依赖
当前全模态统一模型存在两条路线:自回归模型需要序列化异构模态导致效率低下,组合式模型依赖外部解码器增加系统复杂度。Dynin-Omni 提出用原生掩码扩散在共享离散token空间上统一文本、图像、视频、语音的理解与生成,实现真正的 any-to-any 建模。
前序工作及局限:
与前序工作的本质区别: 用原生掩码扩散替代自回归或组合式架构,通过共享离散token空间和模态感知解码策略实现真正的any-to-any建模
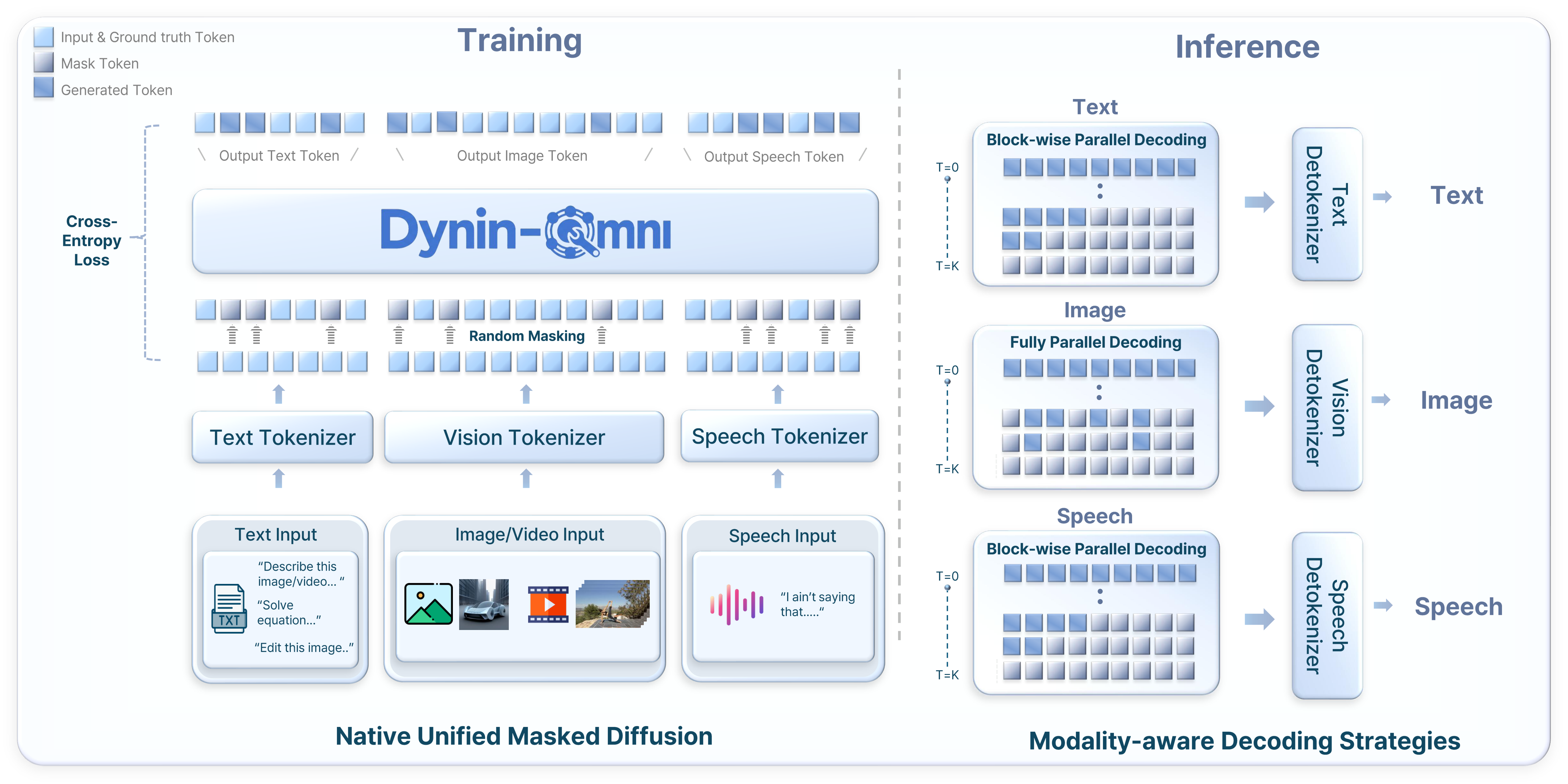
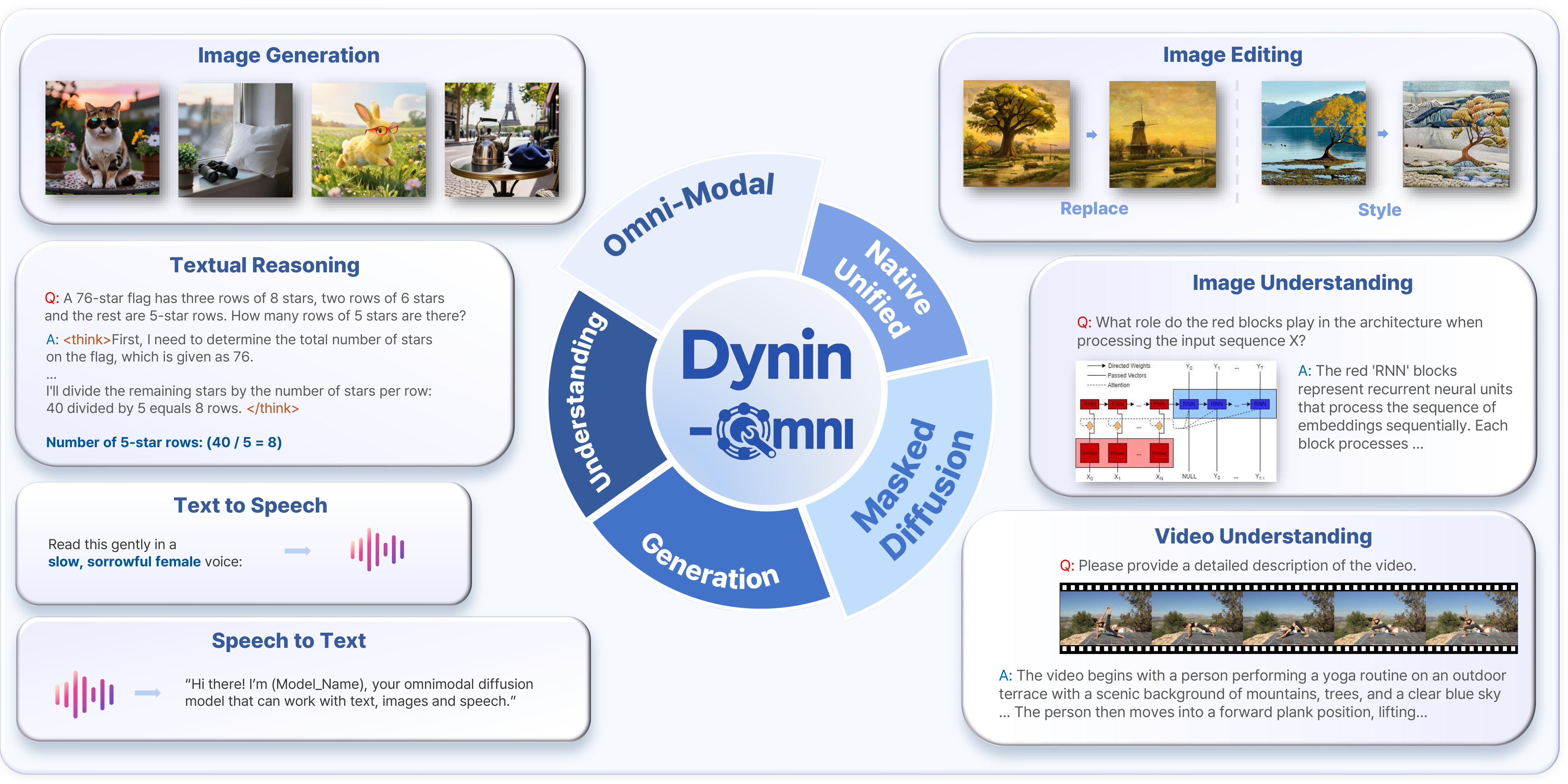
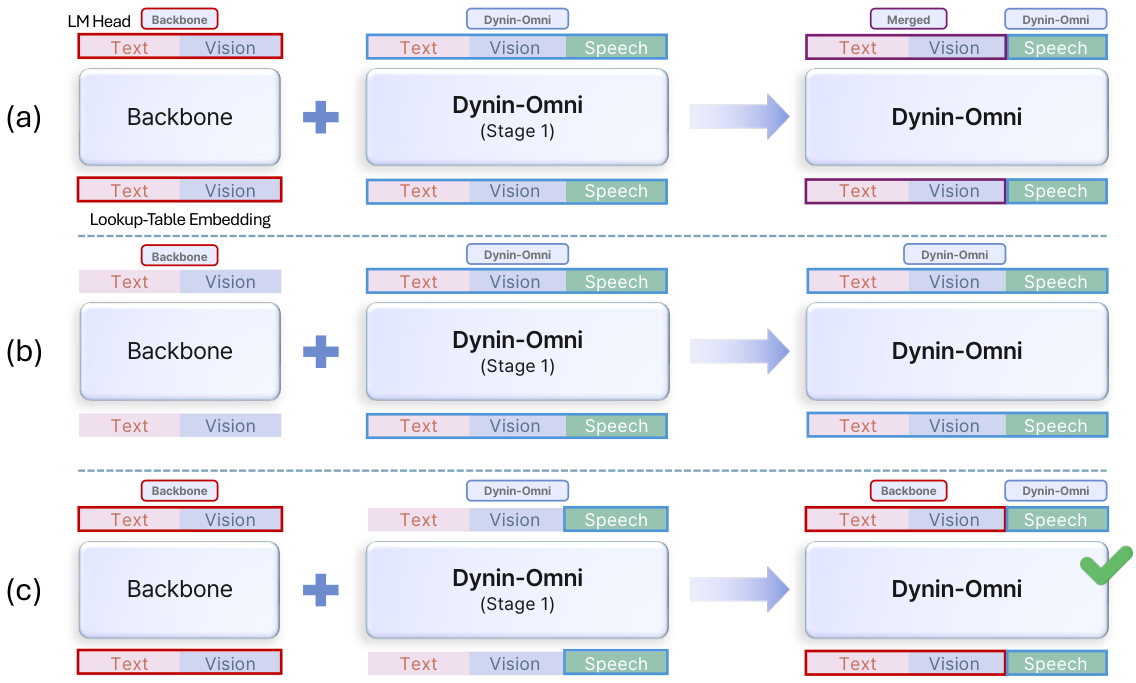
Dynin-Omni 的核心是将所有模态(文本、图像、视频、语音)映射到统一的离散token空间,通过掩码扩散进行训练和推理。文本使用标准分词器(词汇量126K),图像使用MAGVIT-v2风格VQ分词器(码本8192),视频复用图像分词器处理均匀采样帧,语音使用EMOVA S2U编码器+FSQ量化(码本4096)。训练分三阶段:阶段1通过视频字幕/ASR/TTS任务对齐新模态,阶段2引入模态解纠缠合并(Modality-Disentangled Merging)避免灾难性遗忘后进行全模态SFT,阶段3引入CoT推理数据和高分辨率图像提升高级能力。推理时采用模态感知解码策略:文本和语音用块状并行解码,图像用全并行解码,配合置信度重掩码机制迭代细化。
全模态架构对比:三种统一建模范式
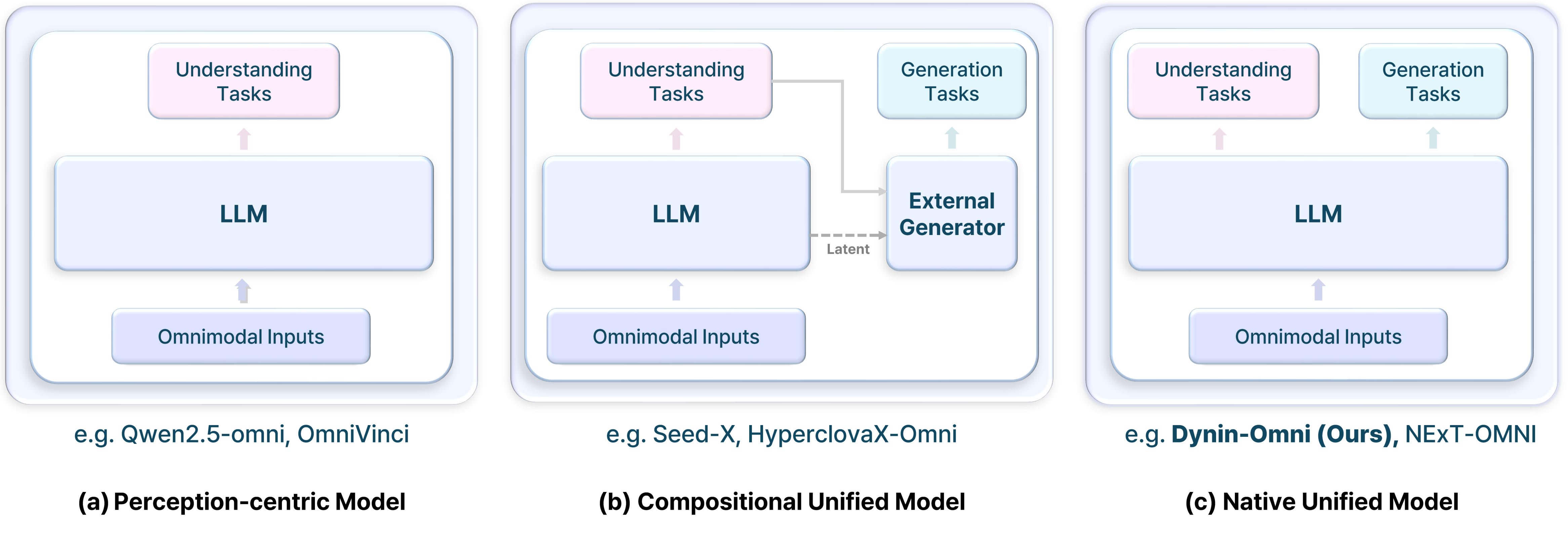
对比了三种全模态建模范式:(a)感知中心模型如Qwen2.5-omni只做理解不做生成;(b)组合式模型如Seed-X需要外部生成器;(c)Dynin-Omni的原生统一模型,单一LLM同时支持理解和生成任务,无需外部模态特定解码器。
全模态性能对比:理解与生成双维度
展示Dynin-Omni在7个核心基准上与HyperCLOVAX-Omni、Qwen2.5-Omni、Show-o2、BAGLE的对比。理解维度:GSM8K 87.6、MME 1734、VideoMME 61.4;生成维度:GenEval 87.0、ImgEdit 3.77、TTS 97.9。
采样步数消融:不同任务的步数-性能曲线

四个子图展示GSM8K、GenEval、DPGBench、ImgEdit随采样步数的性能变化。文本推理需512+步才收敛,图像生成32-64步饱和,图像编辑8-32步即可保持强劲性能。
深度点评:
技术演进定位: 全模态统一建模的第三条路线——原生掩码扩散范式,证明了其可行性和竞争力
可能的后续方向:
OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models
关键词: TTS·600+语言·扩散语言模型·零样本·多码本
贡献: 首个支持600+语言的大规模零样本TTS模型,直接文本→多码本声学token映射,跳过语义中间表示
效果: 基于58.1万小时开源多语言数据训练,中英文及多语种基准SOTA。全码本随机掩码策略+预训练LLM初始化确保清晰度
MambaVoiceCloning: Efficient and Expressive TTS via State-Space Modeling and Diffusion Control
关键词: TTS·Mamba/SSM·声音克隆·线性复杂度·ICLR 2026
贡献: 首个完全基于SSM(无注意力/RNN)条件路径的扩散TTS系统,ICLR 2026
效果: 编码器参数仅21M,吞吐量提升1.6x。MOS/CMOS/F0 RMSE/MCD均优于StyleTTS2和VITS
AceTone: Bridging Words and Colors for Conditional Image Grading
关键词: 调色·3D-LUT·VQ-VAE·RLHF·CVPR 2026
贡献: 首个统一多模态条件调色方法,文本/参考图→3D-LUT生成,CVPR 2026
效果: VQ-VAE将3x32^3 LUT压缩为64离散token(deltaE<2)。800K数据集+VLM预测+RL对齐,LPIPS提升50%
RawGen: Learning Camera Raw Image Generation
关键词: Raw图像生成·逆ISP·扩散模型·相机适配
贡献: 首个基于扩散的text-to-raw和sRGB-to-raw图像生成框架,支持任意目标相机
效果: 利用大规模sRGB扩散先验+专用解码器,多对一逆ISP数据集训练,显著优于传统逆ISP方法
DuoTok: Source-Aware Dual-Track Tokenization for Multi-Track Music Language Modeling
关键词: 音乐生成·Tokenizer·双轨·扩散解码·语言建模
贡献: 源感知双轨音乐Tokenizer,分阶段解纠缠平衡保真度/可预测性/跨轨对应
效果: 0.75kbps比特率下竞争力重建+最低cnBPT,扩散解码器重建高频细节
Diff-VS: Efficient Audio-Aware Diffusion U-Net for Vocals Separation
关键词: 人声分离·扩散U-Net·EDM·STFT·ICASSP 2026
贡献: 基于EDM框架的生成式人声分离模型,处理复数STFT频谱图,ICASSP 2026
效果: 客观指标匹配判别式基线,感知质量接近SOTA系统
MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation
关键词: VLA·扩散模型·多模态统一·指令跟随·西湖大学
贡献: 统一多模态指令和生成的大型扩散VLA模型(西湖大学)
效果: 单一扩散模型框架同时处理视觉理解、语言生成和动作预测
Measuring Prosody Diversity in Zero-Shot TTS: A New Metric, Benchmark, and Exploration
关键词: TTS评测·韵律多样性·DS-WED·Seed-TTS·基准测试
贡献: 首个零样本TTS韵律多样性量化评测框架,提出DS-WED新指标
效果: ProsodyEval数据集(1000样本+2000 PMOS),发现大型音频语言模型在韵律变化捕捉仍有局限
ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners?
关键词: 生成模型评测·视觉推理·I2I·视频·压力测试
贡献: 视觉生成模型推理能力统一评测框架,跨I2I/视频双轨评估+证据锚定自动评判
效果: 测试20+领先模型,揭示SOTA系统仍存在显著推理缺陷(美团等机构)
人工智能炼丹师 整理 | 2026-04-03
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注


评论 (0)