
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇
今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
掩码增强1D连续Tokenizer——仅64/128 tokens实现SOTA图像生成, CVPR 2026 | East China Normal University / Shanghai AI Lab | arXiv:2603.29634
关键词: 连续Tokenizer, 后验崩溃, 掩码增强, DINO语义引导, 图像生成
核心问题: 连续图像Tokenizer在极少token(64/128个)下发生后验崩溃,编码器无法有效编码信息到高度压缩的潜在空间
连续图像Tokenizer通过变分框架学习平滑结构化的潜在表示,是高效视觉生成的核心组件。然而,当使用极少量token(如64或128个)时,基于KL正则化的变分方法普遍面临后验崩溃(posterior collapse)问题——编码器无法将有意义的信息编码进高度压缩的潜在空间,导致所有输入映射到近似相同的潜在分布。这意味着token数量与生成质量之间存在一个痛苦的权衡:要么使用大量token保证质量(如256/512个),要么接受极低token数带来的严重质量下降。MacTok旨在打破这一权衡,实现仅用64/128 tokens就达到甚至超越高token数方案的生成质量。
前序工作及局限:
与前序工作的本质区别: MacTok系统性组合双重掩码策略(随机+DINO语义)和全局-局部表示对齐,首次在64 tokens这一极端压缩级别实现SOTA图像生成质量(gFID 1.44)
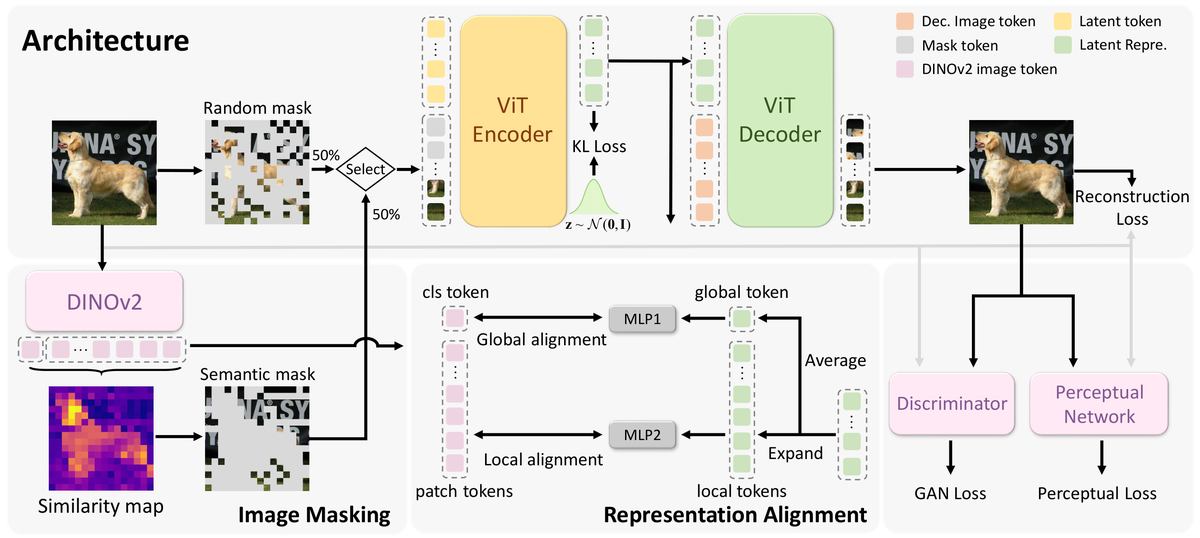
MacTok(Masked Augmenting 1D Continuous Tokenizer)通过三个核心机制解决后验崩溃问题:(1) 双重掩码策略:随机掩码(Random Masking)作为正则化手段防止编码器走捷径,DINO引导的语义掩码(Semantic Masking)强调图像中信息量最高的区域——利用预训练DINO模型的注意力图识别语义重要区域,迫使编码器从不完整的视觉输入中提取鲁棒语义。(2) 全局-局部表示对齐(Global-Local Representation Alignment):全局对齐确保整体语义保留,局部对齐保证细粒度判别信息不丢失,两者协同在高度压缩的1D潜在空间中维持丰富的表征能力。(3) 1D连续潜在空间设计:将图像压缩为极紧凑的1D token序列(仅64或128个token),配合上述掩码和对齐机制确保信息密度。MacTok与SiT-XL(Scalable Interpolant Transformer)配合使用进行图像生成。
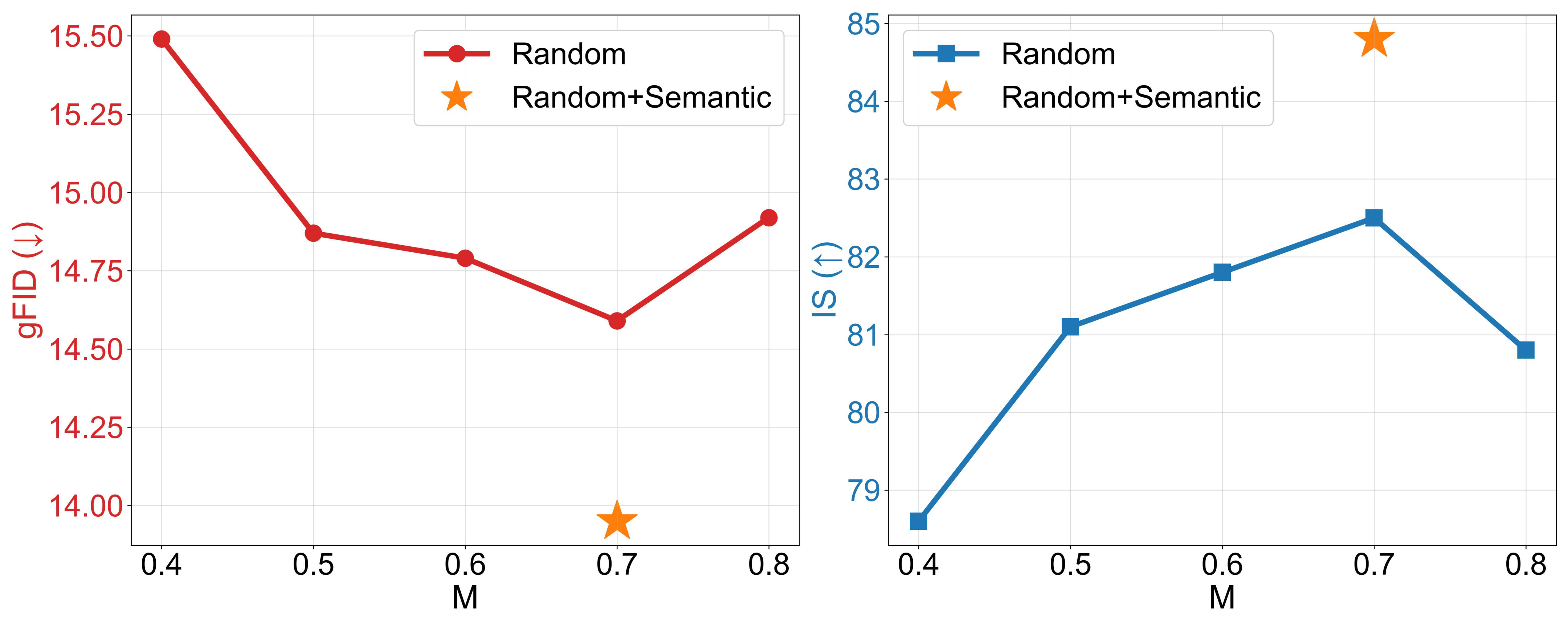
掩码策略对比——从后验崩溃到有效编码
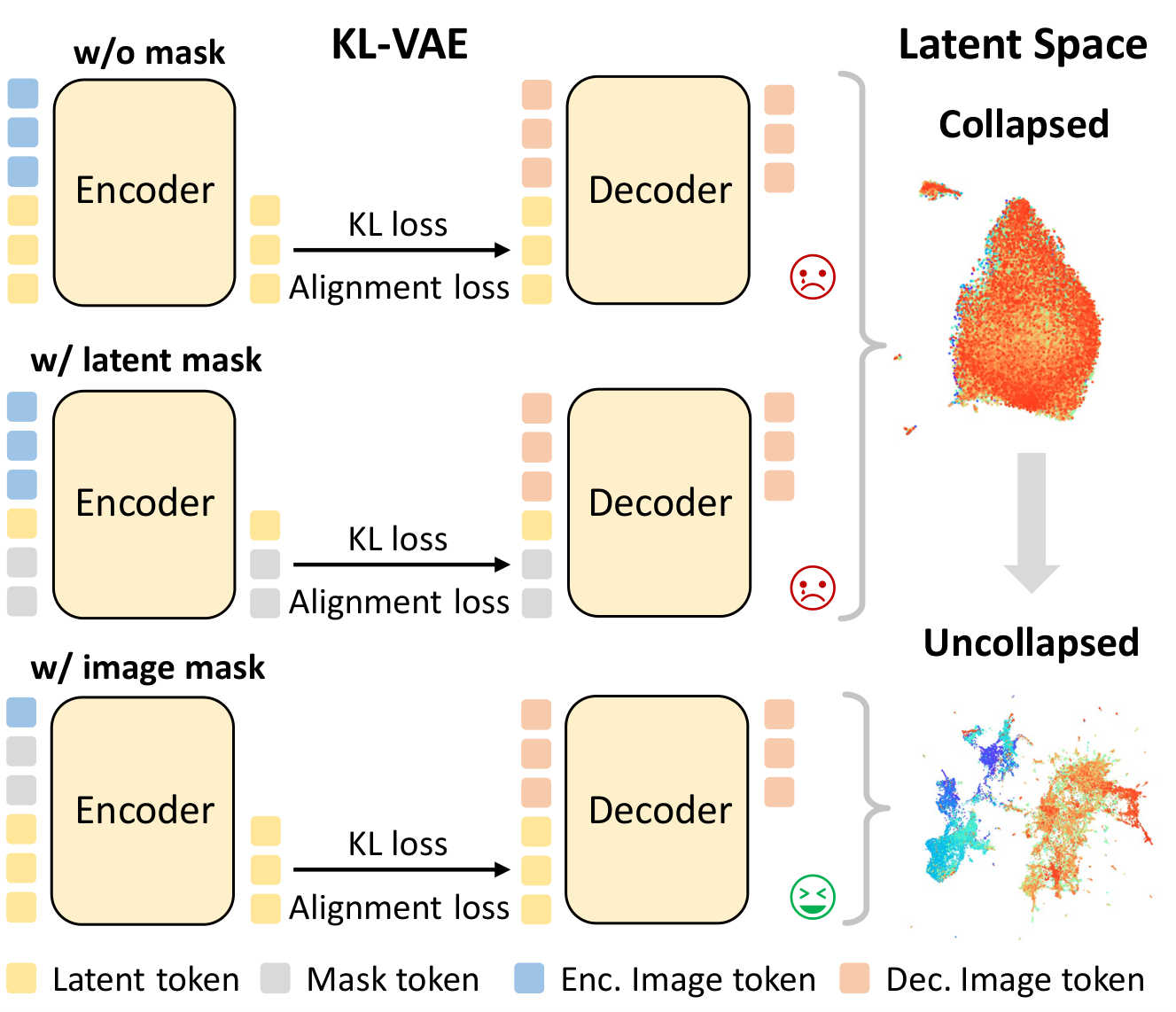
这张图直观展示了掩码策略如何解决后验崩溃问题。图中对比了三种设置:上方是无掩码的KL-VAE,中间是潜在空间掩码,下方是MacTok的图像空间掩码。右侧是对应的潜在空间t-SNE可视化。无掩码时(上方),潜在空间严重崩溃——所有图像被映射到近似相同的区域(红色团簇),编码器完全放弃了编码有意义的信息。潜在空间掩码(中间)虽然有改善但仍不理想。MacTok的图像空间掩码(下方)成功解决了崩溃问题——潜在空间中不同类别的图像被映射到分散的、有区分度的区域(多色散布)。这证明了在图像输入端施加掩码是防止后验崩溃最有效的策略。绿色笑脸和红色哭脸直观标注了每种方案的效果好坏。
gFID训练曲线对比——MacTok收敛速度与最终质量领先
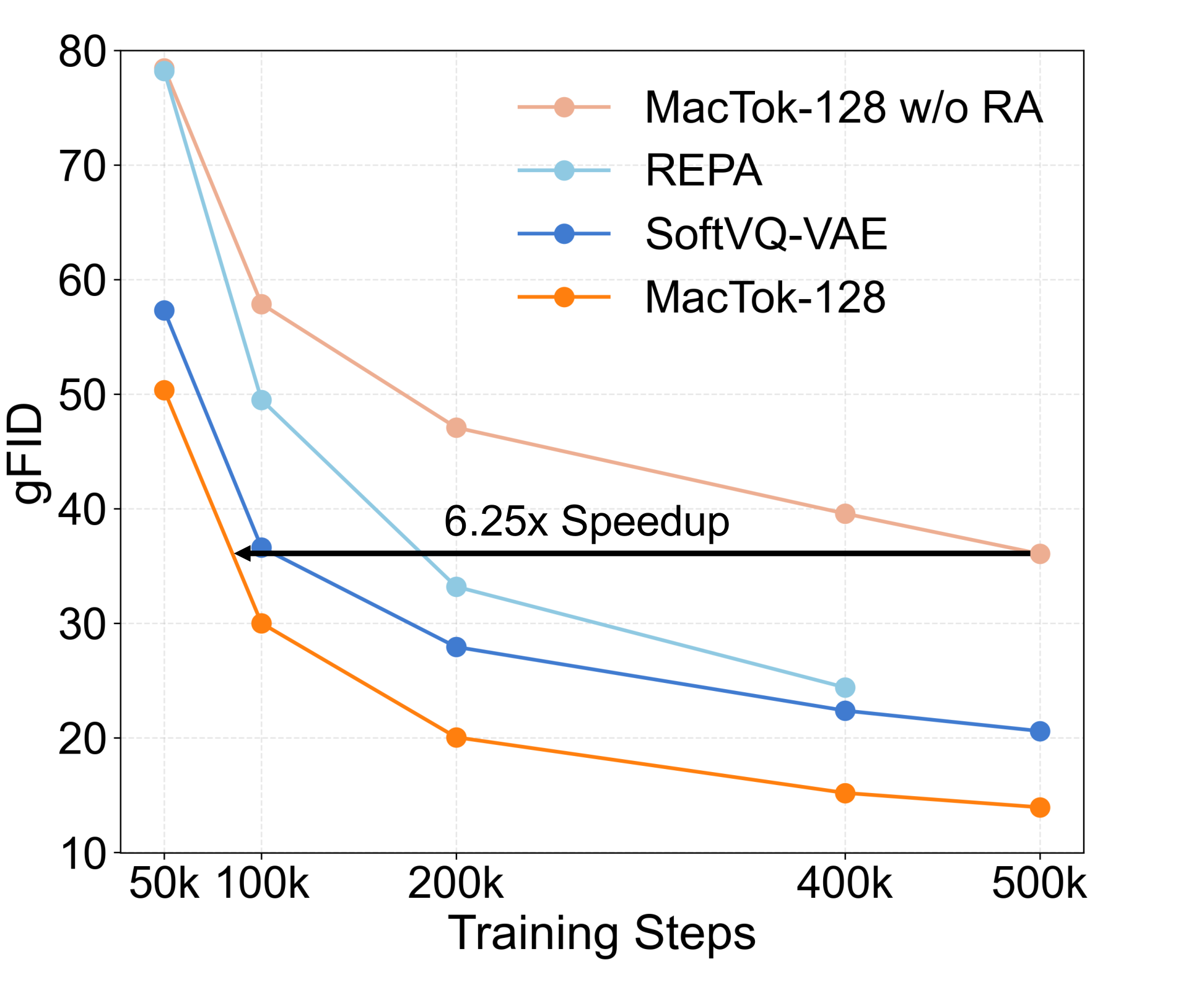
这张图展示了MacTok与REPA、SoftVQ-VAE等基线在ImageNet上的gFID随训练步数变化曲线。横轴是Training Steps(从50k到500k),纵轴是gFID(越低越好)。MacTok-128(橙色线)在所有训练阶段都保持最低的gFID,最终在500k步时达到约14的极低gFID。SoftVQ-VAE(深蓝线)和REPA(浅蓝线)虽然也在持续下降,但最终gFID分别约20和21。MacTok-128 w/o RA(去除表示对齐)则明显更差,约36,证明表示对齐的关键贡献。图中标注了6.25x Speedup——MacTok在100k步就达到了其他方法500k步的性能,训练效率提升了6.25倍。这对资源有限的团队来说意义重大。
消融实验:gFID与分类准确率的权衡分析
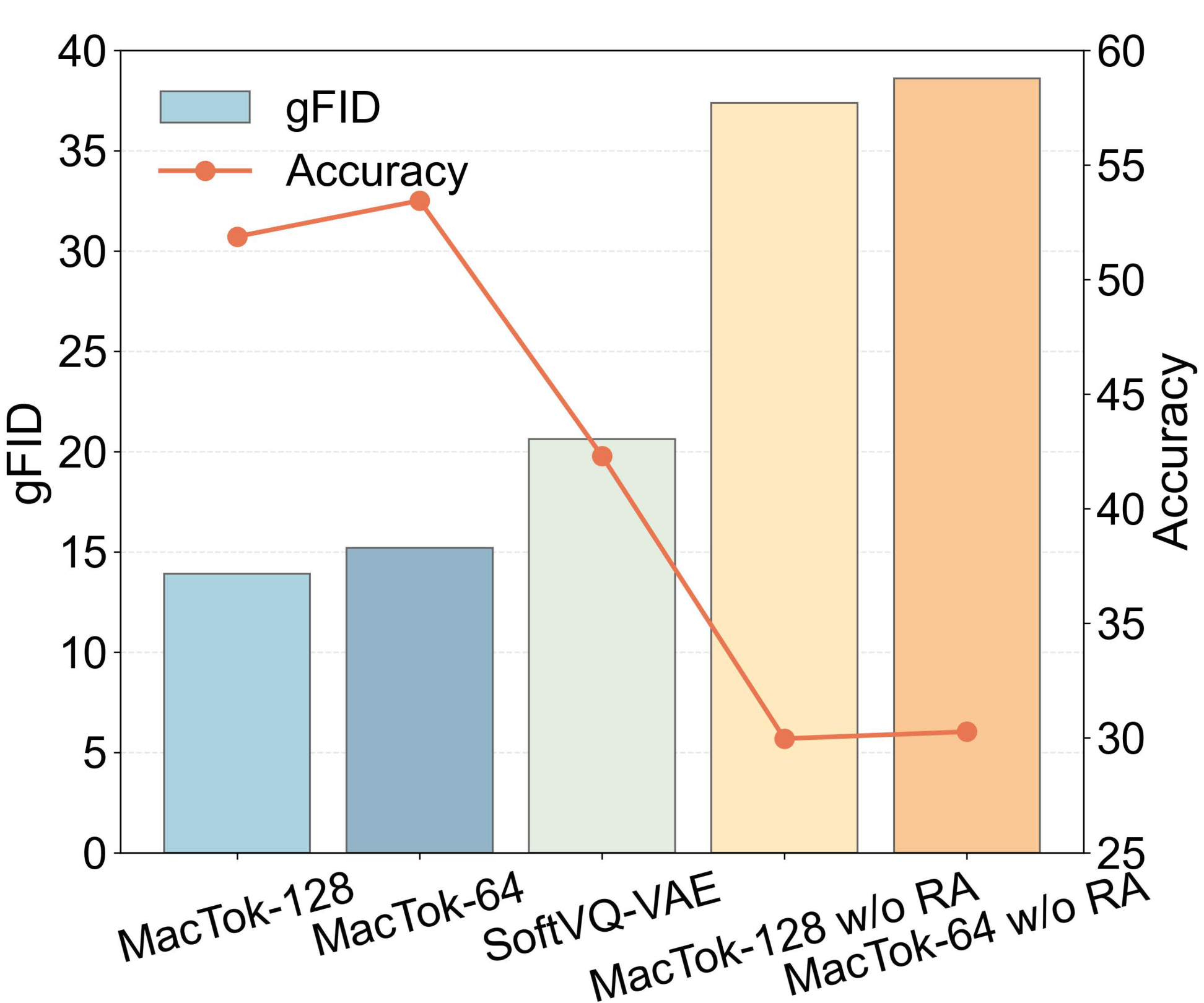
这张消融实验柱状图展示了MacTok各配置的gFID(柱状)和分类准确率Accuracy(折线)对比。MacTok-128(最左)达到最低gFID约14和最高准确率约52%,是最优配置。MacTok-64紧随其后,gFID约15,准确率约53%,证明极低token数也能保持高质量。SoftVQ-VAE作为基线,gFID约21,准确率约44%,明显不如MacTok。关键对比:MacTok-128 w/o RA(去除表示对齐)的gFID骤升至37,准确率暴跌到约31%,MacTok-64 w/o RA更差,gFID接近39。这组数据明确证明了表示对齐(Representation Alignment)是MacTok成功的关键——没有全局-局部对齐,即使有掩码策略也无法在极低token数下保持质量。gFID和Accuracy的双重下降说明去除对齐后编码器不仅生成质量差,连语义判别能力也大幅退化。
MacTok生成样例展示(256x256 & 512x512)

这组图展示了MacTok配合SiT-XL在ImageNet各类别上的生成样例。可以看到仅用64个连续token,模型就能生成高度逼真的图像——动物(如金毛犬、猎豹)的毛发纹理细腻清晰,自然场景(如瀑布、花田)的光影层次丰富,人造物品(如跑车、教堂)的几何结构准确。这些样例视觉质量与使用数百个token的方案几乎无法区分,充分证明了MacTok在极高压缩比下保持生成质量的能力。特别值得注意的是细节部分——如动物眼睛的反光、建筑的对称性——这些在后验崩溃情况下通常最先丢失的细节都被很好地保留了。
深度点评:
技术演进定位: 处于图像Tokenizer从高冗余向极致压缩演进的突破点——64倍token压缩使得高效视觉生成从理论走向实践
可能的后续方向:
Towards World-Consistent Video Generation with 4D Latent Reward
Unknown (Multi-institution)
关键词: 视频生成·几何一致·GRPO·4D奖励·潜在空间
贡献: 提出VGGRPO框架,通过潜在几何模型(LGM)连接视频扩散潜在空间与几何基础模型,直接从潜在空间解码场景几何实现4D几何一致的视频后训练,克服先前方法仅限静态场景的局限
效果: 消除昂贵的VAE解码,相机稳定性和几何一致性显著提升,首次支持动态场景几何引导
Lexicalizing Modalities as Discrete Tokens — Meituan Unified Multimodal Model
Meituan (美团)
关键词: 离散自回归·多模态统一·任意分辨率·美团·开源
贡献: 提出离散原生自回归框架,在共享离散空间表示文本/视觉/音频多模态,核心创新是离散原生任意分辨率ViT实现任意分辨率分词/解词,解决离散视觉建模在理解任务上的性能天花板
效果: 单一自回归目标统一观察/绘画/对话,多模态基准全面强劲,已开源模型和Tokenizer
Agent-Native Multimodal Generation with Memory and Skills
Unknown
关键词: Agent生成·闭环优化·记忆系统·技能扩展·6B超越SOTA
贡献: 提出Agent-Native多模态生成框架,包含Agent Loop(闭环迭代优化)、Agent Memory(轨迹级持久记忆)和Agent Skill(可扩展领域专业知识),突破基础模型固有局限
效果: 6B模型Z-Image-Turbo在GenEval2上超越SOTA Nano Banana 2,证明智能体控制可大幅扩展模型能力
World Wandering via Long-Horizon Panoramic Video Generation
Unknown (Multi-institution)
关键词: 全景视频·长距生成·轨迹控制·场景漫游·3D重建
贡献: 提出可控全景视频生成框架,利用全景表示的丰富场景覆盖和固有时空一致性,通过预览-精炼两阶段实现长距场景漫游,支持实时视频生成和3D重建扩展
效果: 在视觉质量/可控性/长期场景一致性上全面优于SOTA,支持实时生成和3D重建
Agentic Hours-Long Video Editing via Music Synchronization
GVC Lab
关键词: 视频编辑·音乐同步·多智能体·长视频·自动剪辑
贡献: 提出多智能体框架自动将数小时原始素材剪辑为音乐同步短视频,包含分层多模态分解、编剧Agent(叙事一致性)、编辑Agent+审查Agent(美学/语义标准协作优化)
效果: 在节奏对齐和视频质量上显著超越SOTA基线,大幅减少视频编辑人工时间
Vector-wise Sparse Attention for Accelerating Long Context Inference
Unknown
关键词: 稀疏注意力·向量选择·视频加速·CVPR 2026·2.65x加速
贡献: 发现视频注意力图存在强垂直向量稀疏模式,提出逐向量稀疏注意力框架,通过轻量级重要向量选择+优化稀疏注意力内核动态处理信息向量,CVPR 2026
效果: 比全注意力加速2.65倍,比SOTA稀疏方法加速1.83倍,精度与全注意力相当
Multi-Patch Global-to-Local Transformer for Efficient Flow Matching and Diffusion
Rutgers University
关键词: 高效DiT·多Patch·全局到局部·50%加速·开源
贡献: 提出多Patch DiT设计:早期模块用大Patch捕获全局上下文,后期模块用小Patch精炼局部细节,打破DiT各向同性设计的计算冗余,另提出改进的时间和类别嵌入加速收敛
效果: GFLOPs计算成本降低50%,生成性能保持良好,已开源代码
Continuous Attribute Control in Text-to-Video via Spatiotemporal Token Offsets
Adobe Research / CMU
关键词: 视频属性控制·token偏移·滑块式编辑·免训练·Adobe
贡献: 提出通过时空token偏移实现T2V模型的连续滑块式属性控制,发现中间token空间中的加性偏移形成语义控制方向,无需重训练即可调节外观和运动属性
效果: 比SOTA基线实现更强可控性和更高编辑质量,人类研究验证有效性
Synthetic Meta Evaluation Benchmark for Text-to-Long Video Generation
Unknown
关键词: 长视频评测·元评估·合成降质·CVPR 2026·3小时视频
贡献: 提出长视频生成元评估基准(最长10486秒约3小时),通过合成降质创建控制的质量对比视频对,覆盖10个评估维度,用众包筛选建立可靠测试平台,CVPR 2026
效果: 人类准确率84.7%-96.8%,揭示9/10维度现有评估系统不及人类,暴露长视频评估短板
人工智能炼丹师 整理 | 2026-04-02


评论 (0)