AIGC 视觉生成领域 · 每日论文解读 (2026-03-28)
人工智能炼丹师 整理 | 共 9 篇论文 | 重点深度解读 8 篇
今日核心看点
- UniGRPO 统一后训练
- FIRM 忠实奖励建模
- EditHF-1M 29M偏好对
- MV-GRPO 多视图评估
- VIGOR 视频几何奖励
- VHS CVPR2026 推理扩展
- TATAR 不对称奖励
- SeGroS 语义锚定监督
今日概览
今日 arXiv cs.CV 视觉生成相关论文共 9 篇,重点解读 8 篇。
方向分布:
后训练框架: UniGRPO(统一多模态后训练), MV-GRPO(多视图GRPO), SeGroS(语义锚定监督)
奖励模型与评估: FIRM(编辑+生成), EditHF-1M(29M偏好对), VIGOR(视频几何), TATAR(质量+美学), VHS(潜在验证器)
重点论文深度解读
1. UniGRPO
统一策略优化实现推理驱动视觉生成 | 上海AI Lab/港中文 | Shanghai AI Lab, CUHK | arXiv:2603.23500
关键词: 统一后训练, GRPO, 推理驱动生成, Flow Matching, 交错生成
研究动机
核心问题: 统一多模态模型(自回归文本+Flow Matching图像)缺乏后训练方法
统一多模态模型正朝着交错生成(interleaved generation)发展——自回归建模文本、Flow Matching 建模图像。然而,如何对这种混合架构进行强化学习后训练?现有 GRPO 只针对单一模态,且 FlowGRPO 依赖 Classifier-Free Guidance(CFG)导致轨迹分叉,难以扩展到多轮交互场景。核心挑战是:如何在一个统一的 RL 框架中同时优化推理(文本)和生成(图像)两个阶段的策略?
前序工作及局限:
- GRPO (DeepSeek 2025):大语言模型的群体相对策略优化
- FlowGRPO (2026):将GRPO扩展到Flow Matching视觉生成
- Transfusion (Meta 2024):统一自回归+扩散的多模态架构
与前序工作的本质区别: UniGRPO首次统一优化文本推理和图像合成,消除CFG保持线性轨迹
方法原理
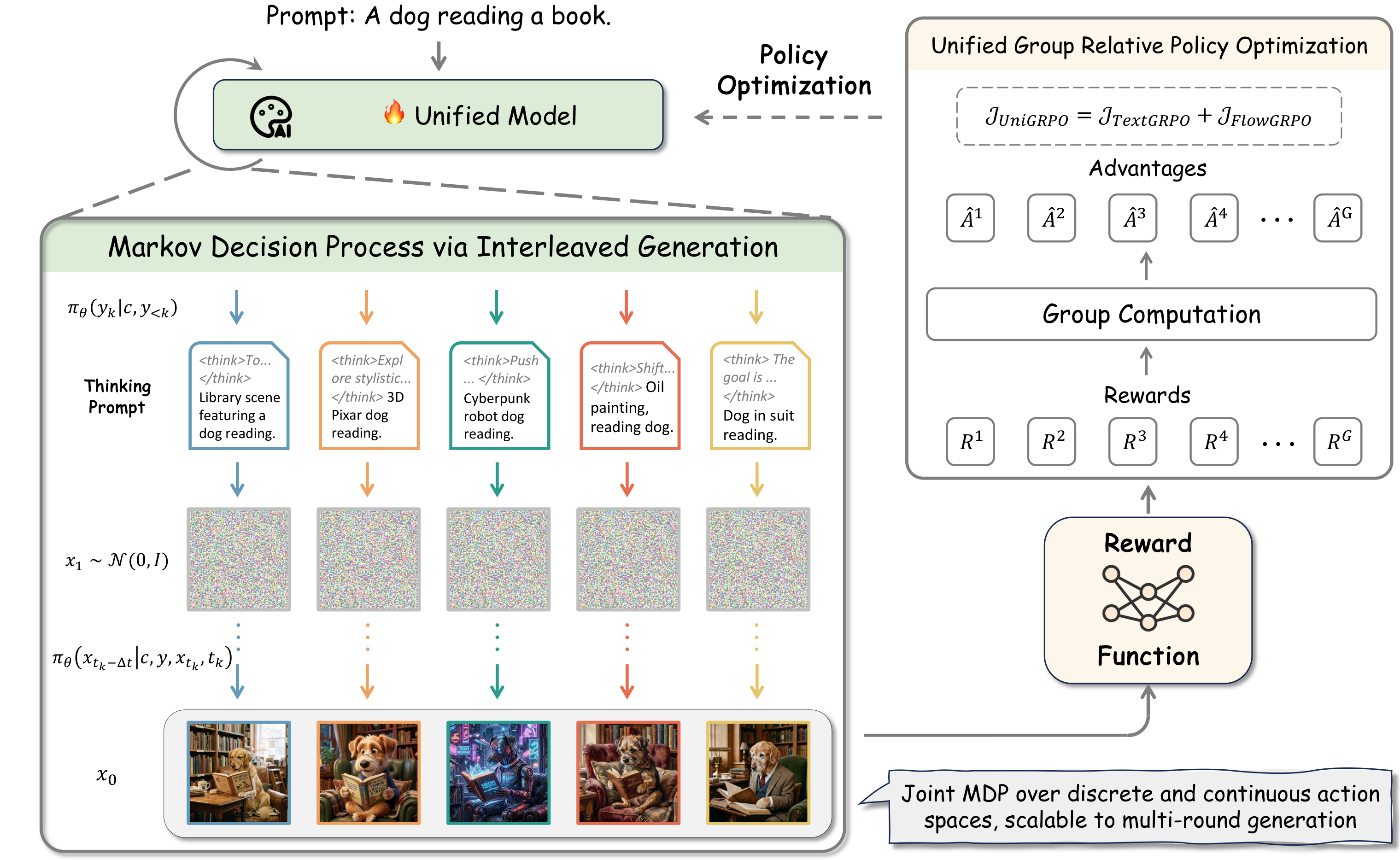
UniGRPO 将多模态生成建模为稀疏终端奖励的马尔可夫决策过程(MDP),联合优化文本推理和图像合成两个阶段。框架采用极简设计原则:(1) 文本推理阶段使用标准 GRPO,让模型学会扩展用户提示为详细推理链;(2) 图像合成阶段使用 FlowGRPO,在 Flow Matching 的速度场上进行策略优化。关键改进有两点:第一,消除 Classifier-Free Guidance(CFG),保持线性、未分叉的生成轨迹,这对多轮交互和多条件生成(如编辑)至关重要;第二,将标准的潜空间 KL 惩罚替换为直接作用于速度场的 MSE 惩罚,提供更鲁棒的正则化信号,有效缓解 Reward Hacking。两种模态的优化通过统一的 MDP 框架无缝集成。
核心创新
- 首个统一的多模态生成后训练框架:联合优化自回归文本推理和 Flow Matching 图像合成
- 消除 CFG 保持线性轨迹:使框架可扩展到多轮交错生成场景
- 速度场 MSE 正则化替代 KL 惩罚:直接在速度场空间约束策略偏移,更鲁棒地防止 Reward Hacking
- 极简设计原则:无缝集成标准 GRPO + FlowGRPO,避免过度工程化
- 为完全交错式多模态模型的后训练建立了可扩展基线
实验结果
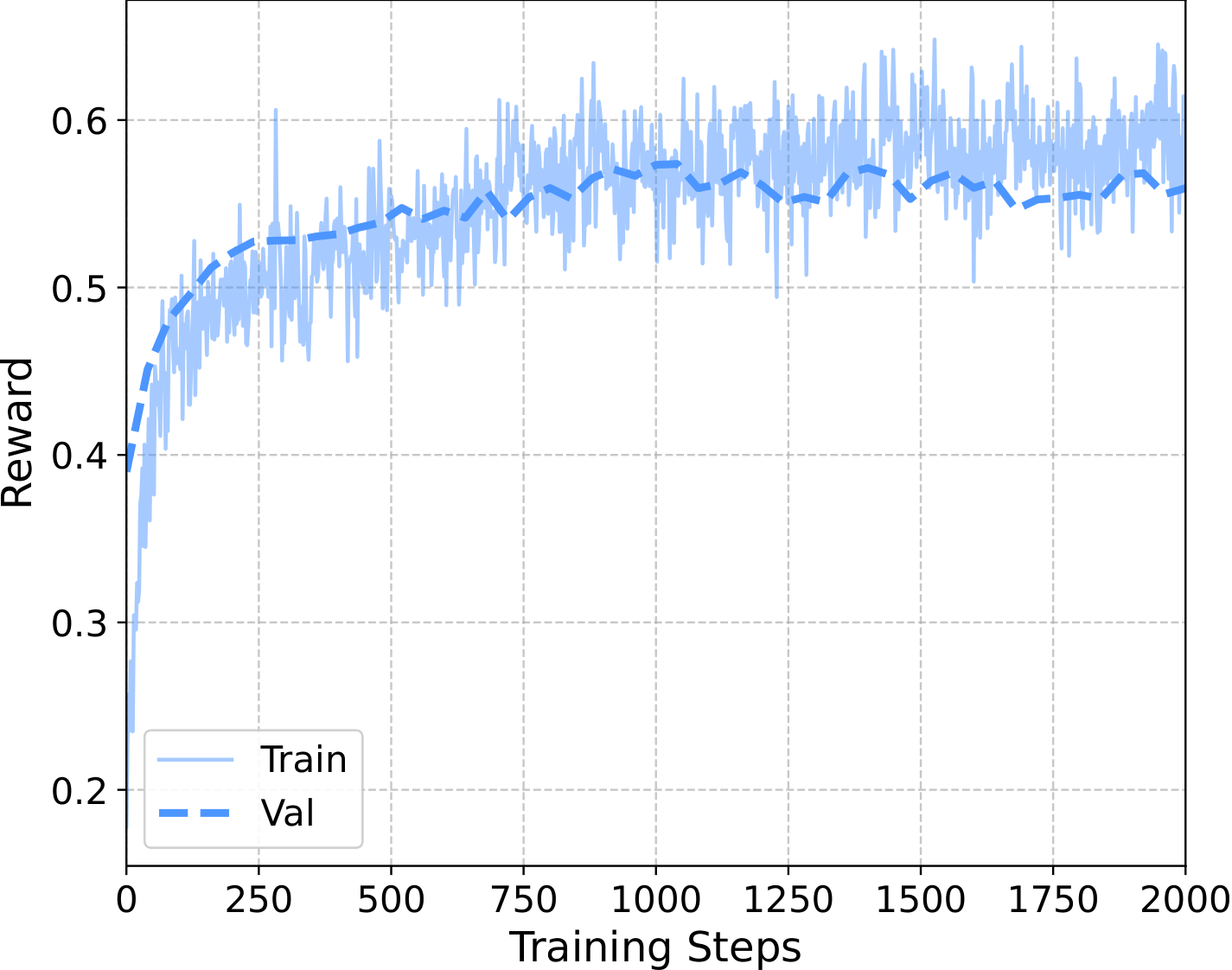
- 实验表明,UniGRPO 的统一训练方案显著提高了推理驱动图像生成的质量。在标准评估基准上,文本推理质量和图像生成保真度均获得一致提升。消除 CFG 后的模型在多轮交互场景中表现更稳定,MSE 速度场正则化有效避免了训练后期的 Reward Hacking 现象。该框架为未来完全交错模型的后训练提供了鲁棒且可扩展的基线。
批判性点评
- 新颖性: 首次将GRPO统一应用于文本推理+图像Flow Matching的交错生成,消除CFG保持线性轨迹的设计优雅且实用。但概念上是GRPO和FlowGRPO的自然组合,原创突破性有限。
- 可复现性: 基于开源Janus-Pro-7B模型,论文提供了完整的算法伪代码和超参数设置。但训练使用80张H100,资源门槛较高。代码和模型权重已开源。
- 影响力: 为统一多模态模型的后训练建立了可扩展基线,对Chameleon、Transfusion等架构有直接参考价值。极简设计降低了社区跟进门槛。
深度点评:
- GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式
- 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化
- 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径
技术演进定位: 交错生成后训练的可扩展基线
可能的后续方向:
- 多轮交互场景的后训练
- 视频+音频交错生成
- 在线持续学习
2. FIRM
忠实图像奖励建模:鲁棒奖励模型+RL优化 | 上交/港中文/上海AI Lab | SJTU, CUHK, Shanghai AI Lab | arXiv:2603.12247
关键词: 奖励模型, 图像编辑, 文生图, RLHF, 开源数据集
研究动机
核心问题: 图像编辑和生成的奖励模型存在幻觉,评分不忠实
RL 已成为增强图像编辑和文生图生成的重要范式,但现有奖励模型存在严重的幻觉问题——产生噪声评分,误导优化方向。核心痛点是:缺乏专门针对图像编辑和生成的大规模高质量评分数据集,导致奖励模型无法提供忠实、准确的反馈信号。
前序工作及局限:
- ImageReward (Xu 2023):首个文生图人类偏好奖励模型
- HPSv2 (Wu 2023):人类偏好评分模型v2
- PickScore (Kirstain 2023):Pick-a-Pic数据驱动的偏好评分
与前序工作的本质区别: FIRM专门解决编辑+生成双赛道的忠实性,提出Base-and-Bonus奖励策略
方法原理

FIRM 框架从数据、模型、策略三层解决奖励模型的忠实性问题:(1) 数据层:设计专业化数据整理管线,构建 FIRM-Edit-370K(编辑评分数据,评估执行力+一致性)和 FIRM-Gen-293K(生成评分数据,评估指令遵循),总计 66.3 万条评分数据;(2) 模型层:基于上述数据训练 FIRM-Edit-8B 和 FIRM-Gen-8B 两个 8B 参数的专业奖励模型,并发布 FIRM-Bench 评测基准;(3) 策略层:提出 Base-and-Bonus 奖励策略——对编辑任务使用 CME(Consistency-Modulated Execution,一致性调制执行),对生成任务使用 QMA(Quality-Modulated Alignment,质量调制对齐),巧妙平衡相互竞争的优化目标。
核心创新
- 首个系统性解决图像编辑和生成奖励建模的综合框架
- 发布 FIRM-Edit-370K + FIRM-Gen-293K 全套开源评分数据集
- Base-and-Bonus 奖励策略:CME 平衡编辑的执行力与一致性,QMA 平衡生成的质量与对齐
- FIRM-Bench 编辑+生成批评评测基准
- 消除奖励幻觉:比现有通用指标更准确匹配人类判断
实验结果
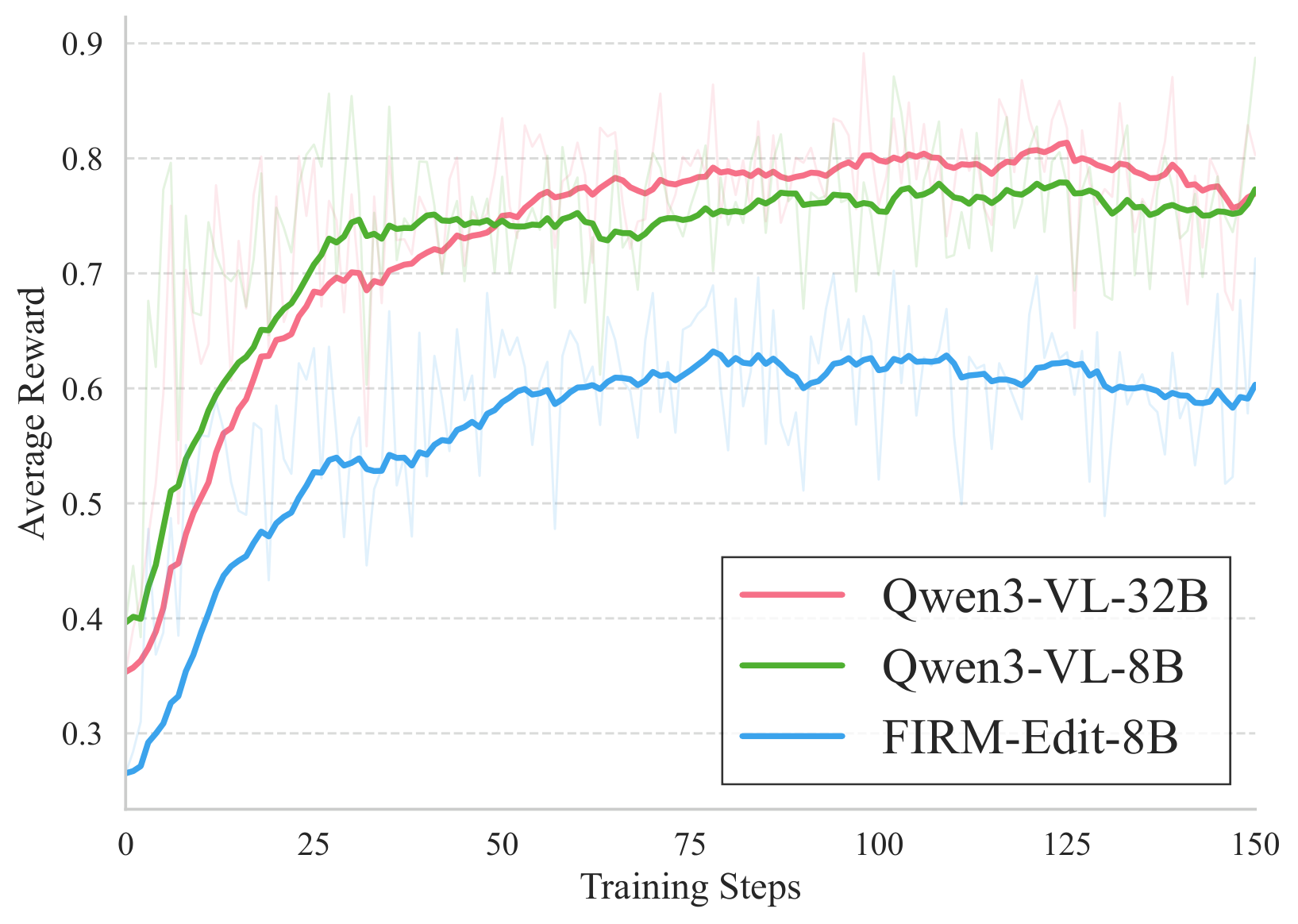
- FIRM 系列奖励模型在 FIRM-Bench 上显著超越现有指标对人类判断的匹配度。基于 FIRM 的 RL 优化产出 FIRM-Qwen-Edit 和 FIRM-SD3.5,在忠实度和指令遵循方面确立了新标准。所有数据集、模型和代码均已公开发布。
批判性点评
- 新颖性: 从数据-模型-策略三层全栈构建忠实奖励体系,Base-and-Bonus策略巧妙解决了编辑和生成任务间的优化矛盾。CME和QMA两个具体策略设计有针对性且有理论支撑。
- 可复现性: 全套数据集(FIRM-Edit 37万+FIRM-Gen 29.3万)、模型权重和代码均已开源。基于InternVL2-8B训练,硬件需求可控。社区复现门槛低。
- 影响力: 视觉生成RLHF奖励建模的新标准。全栈开源的做法对社区价值巨大。Base-and-Bonus策略可泛化到其他多任务RL场景。
深度点评:
- GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式
- 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化
- 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径
技术演进定位: 视觉生成RLHF奖励建模的新标准
可能的后续方向:
3. EditHF-1M
百万级图像编辑人类偏好反馈数据集 | 上交 | Shanghai Jiao Tong University | arXiv:2603.14916
关键词: 编辑偏好数据集, 29M偏好对, MLLM评估模型, 奖励信号, RL优化
研究动机
核心问题: 图像编辑缺乏大规模多维度人类偏好数据集
文本引导的图像编辑取得了显著进展,但编辑结果仍常出现伪影、意外编辑、不美观等问题。现有编辑评估方法缺乏大规模可扩展的评估模型,这严重限制了编辑领域人类反馈奖励模型的发展。核心瓶颈是:缺少百万级规模、多维度评估的人类偏好数据集。
前序工作及局限:
- InstructPix2Pix (Brooks 2023):GPT-4生成编辑指令,数据规模有限
- MagicBrush (Zhang 2024):人工标注编辑数据集,规模较小
- FIRM-Edit-370K:专业化编辑评分数据
与前序工作的本质区别: EditHF-1M将规模推至29M偏好对,三维度(质量+对齐+保持)评估体系
方法原理
EditHF-1M 体系包含三个层次:(1) 数据集层:构建百万级图像编辑偏好数据集,包含超过 2900 万人类偏好对和 14.8 万人类主观评分(MOS),均从视觉质量、指令对齐、属性保持三个维度进行评估;(2) 模型层:基于 EditHF-1M 训练 EditHF——一个基于多模态大语言模型(MLLM)的评估模型,提供与人类对齐的编辑反馈;(3) 应用层:引入 EditHF-Reward,将 EditHF 作为奖励信号,通过强化学习优化文本引导图像编辑模型 Qwen-Image-Edit。
核心创新
- 迄今最大的图像编辑偏好数据集:29M偏好对 + 148K MOS评分
- 三维度评估体系:视觉质量 + 指令对齐 + 属性保持
- 基于MLLM的编辑评估模型 EditHF
- EditHF-Reward:将评估模型转化为RL奖励信号
- 在 Qwen-Image-Edit 上验证显著性能提升
实验结果
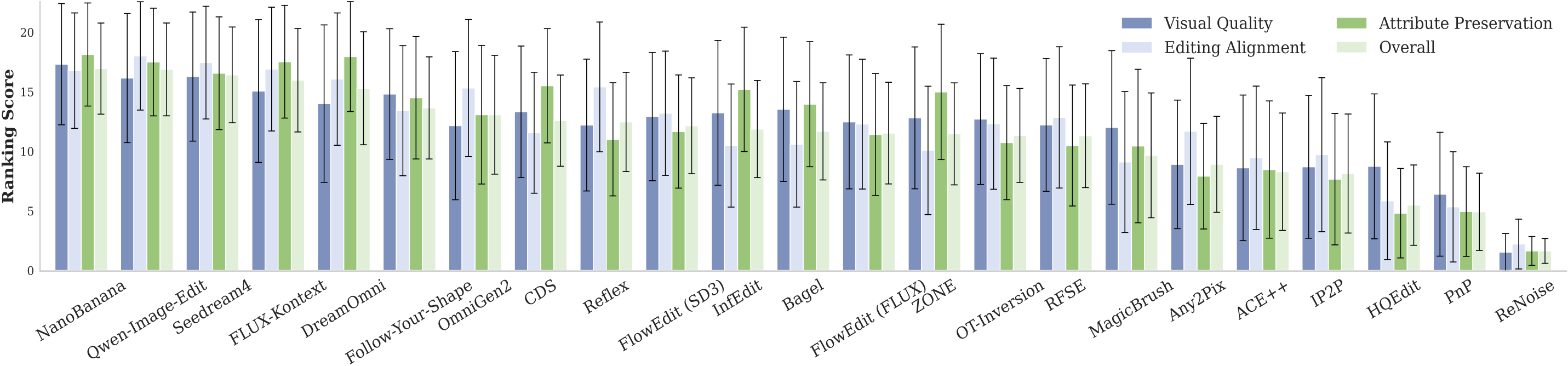
- EditHF 在与人类偏好对齐方面超越现有指标,并在其他数据集上展现强泛化能力。使用 EditHF-Reward 微调 Qwen-Image-Edit 后,编辑质量在视觉质量、指令对齐和属性保持三个维度均获得显著提升。数据集和代码将开源。
批判性点评
- 新颖性: 在偏好数据集的规模和评估维度设计上均为领先。三维度(质量+对齐+保持)评估体系比单标量更精准。但核心方法(人类标注+Bradley-Terry模型训练)较传统,创新更多在工程规模上。
- 可复现性: 数据集规模庞大(29M对)使得完整复现成本极高。评估模型基于公开架构训练,技术上可复现但资源需求大。数据集已部分开放。
- 影响力: 为图像编辑偏好建模提供了最大规模的公开基准。三维度评估范式可能成为社区标准。对未来编辑模型的开发和评估有直接推动作用。
深度点评:
- GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式
- 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化
- 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径
技术演进定位: 迄今最大的图像编辑偏好数据集
可能的后续方向:
4. MV-GRPO
多视图GRPO:增强条件空间实现密集奖励映射 | 港中文/上海AI Lab | CUHK, Shanghai AI Lab | arXiv:2603.12648
关键词: 多视图评估, GRPO改进, 条件增强, 偏好对齐, Flow Matching
研究动机
核心问题: 标准GRPO的单视图评估方案限制了偏好对齐效果
标准 GRPO 采用单一条件评估一组生成样本——这种稀疏的单视图评估方案未能充分探索样本间关系,限制了对齐有效性和性能上限。直觉上,同一组样本在不同语义视角下可能展现出完全不同的优劣排序。如何构建密集的多视图奖励映射以更充分地利用每次采样?
前序工作及局限:
- GRPO (DeepSeek 2025):单条件评估一组样本
- DPO (Rafailov 2023):直接偏好优化但依赖配对数据
- FlowGRPO (2026):Flow Matching上的GRPO
与前序工作的本质区别: MV-GRPO通过条件增强实现多视图密集评估,无需样本再生成
方法原理
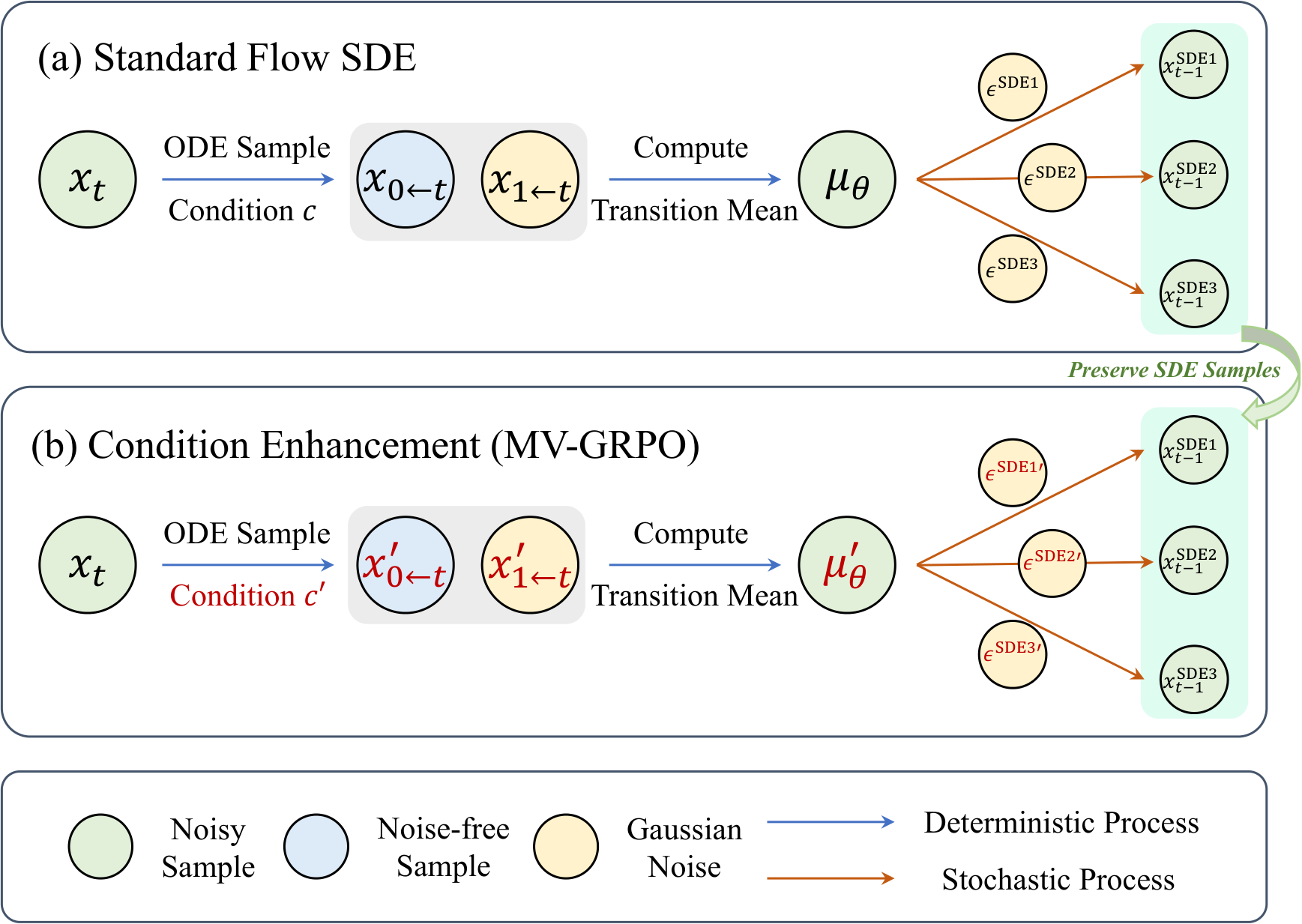
MV-GRPO 通过增强条件空间将稀疏单视图评估转化为密集多视图评估:(1) 对于由一个提示生成的一组样本,利用灵活的条件增强器生成语义相邻但多样化的标题(captions);(2) 这些多视图标题提供不同语义属性的评估角度,捕捉更丰富的优化信号;(3) 通过推导原始样本在新标题条件下的概率分布,无需昂贵的样本再生成即可将多视图评估纳入训练;(4) 多视图优势重估计产生密集的奖励映射,显著增强关系探索。
核心创新
- 首次将多视图评估引入GRPO框架
- 条件增强器生成语义相邻的多样化标题
- 无需样本再生成的多视图优势重估计
- 从稀疏单视图到密集多视图的范式转换
- 在文生图Flow Matching模型上超越SOTA
实验结果
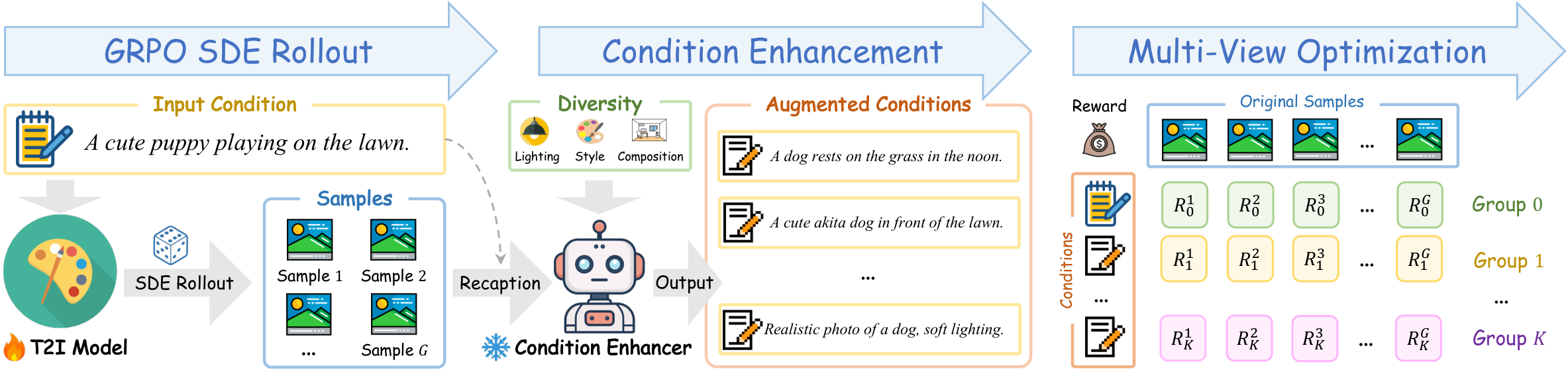
- 大量实验表明,MV-GRPO 在偏好对齐性能上优于标准 GRPO 和其他最先进方法。多视图评估提供的密集奖励信号有效提升了文生图 Flow Matching 模型在多个评估维度上的表现。
批判性点评
- 新颖性: 通过概率分布推导将多视图评估转化为无需再生成的数学等价形式,理论推导优雅。从稀疏到密集评估的范式转换思路具有一般性。但增强策略的设计空间未充分探索。
- 可复现性: 基于开源SDXL/PixArt-α模型,算法伪代码清晰。条件增强器使用现有LLM改写,技术门槛低。计算开销仅增加奖励模型推理,几乎零额外训练成本。
- 影响力: 为GRPO框架提供了一种低成本且通用的性能增强方案。密集评估思路可扩展到其他RL-based生成优化。在标注预算受限时尤其有价值。
深度点评:
- GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式
- 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化
- 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径
技术演进定位: GRPO框架的重要扩展,从稀疏到密集
可能的后续方向:
5. VIGOR
视频几何奖励模型:跨帧重投影误差评估时序一致性 | arXiv:2603.16271
关键词: 视频奖励模型, 几何一致性, 重投影误差, 推理时扩展, SFT/RL后训练
研究动机
核心问题: 视频生成缺乏几何一致性评估和优化信号
视频扩散模型训练缺乏几何监督,生成视频中频繁出现物体变形、空间漂移和深度违反等伪影。现有视频评估指标在像素空间度量不一致性,容易被像素强度差异干扰。需要一种更符合物理规律、更鲁棒的视频质量评估方法来驱动后训练优化。
前序工作及局限:
- VBench (Huang 2024):视频生成综合评测基准
- VideoScore (He 2024):基于MLLM的视频质量评分
- VisionReward (2025):细粒度多维度视频偏好模型
与前序工作的本质区别: VIGOR首次引入基于几何的跨帧重投影误差作为视频奖励信号
方法原理
VIGOR 利用预训练几何基础模型构建基于几何的视频奖励:(1) 通过跨帧重投影误差评估多视图一致性——以点对点方式计算误差,比像素空间度量更符合物理规律且更鲁棒;(2) 引入几何感知采样策略,过滤低纹理和非语义区域,聚焦具有可靠对应关系的几何有意义区域;(3) 将此奖励通过两条互补途径应用:SFT 或 RL 进行双向模型后训练;以及推理时作为路径验证器实现因果视频模型的 test-time scaling。
核心创新
- 首个基于几何的视频生成奖励模型
- 跨帧重投影误差比像素级度量更鲁棒
- 几何感知采样:过滤低纹理区域聚焦可靠对应
- 双路径应用:后训练(SFT/RL) + 推理时扩展(test-time scaling)
- 为开源视频模型提供低成本增强方案
实验结果
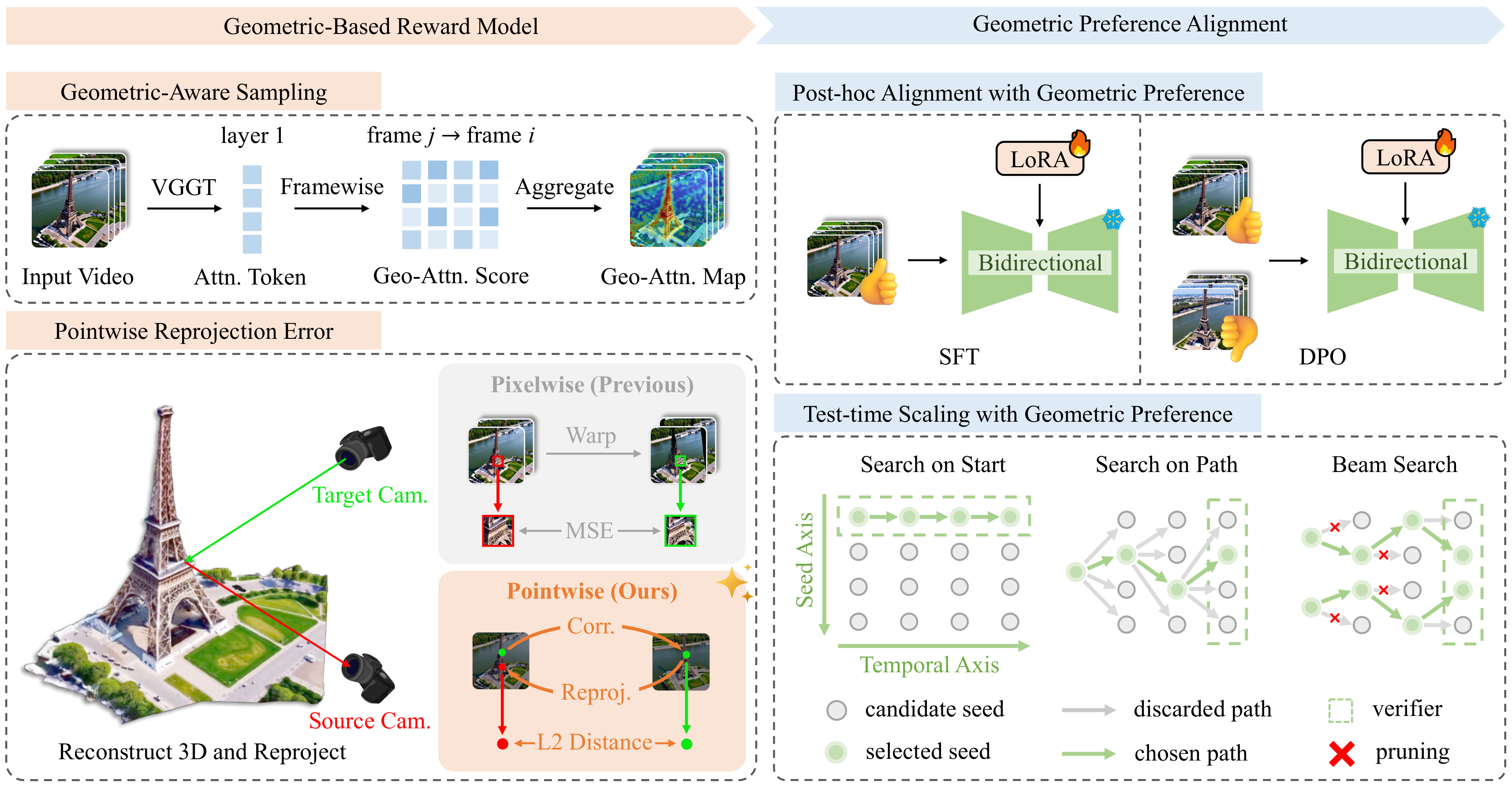
- 实验验证了 VIGOR 基于几何的奖励在鲁棒性上显著优于其他变体。通过推理时扩展,VIGOR 为开源视频模型提供了实用的增强方案,无需大量计算资源进行重训练。后训练路径同样展现了一致的质量改善。
批判性点评
- 新颖性: 首次将几何重投影误差作为视频生成的奖励信号,利用预训练几何基础模型避免了昂贵的3D标注。双路径应用模式增加了实用性。但在non-rigid场景(如流体、火焰)中的适用性未讨论。
- 可复现性: 基于开源视频扩散模型和MoGe几何模型。技术方案描述详细,几何奖励计算流程可复现。但完整训练流程的超参数和计算资源需求描述不够详细。
- 影响力: 为视频生成质量评估引入了物理层面的几何先验,与现有像素级和语义级指标互补。对开源视频模型的质量提升提供了新的优化信号来源。
深度点评:
- GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式
- 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化
- 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径
技术演进定位: 视频生成几何一致性优化的开创性工作
可能的后续方向:
- 物理一致性奖励
- 音视频同步奖励
- 4D时空一致性评估
6. VHS
潜在空间验证器实现高效推理时扩展 | CVPR 2026 | University of Modena | arXiv:2603.22492
关键词: 推理时扩展, 潜在验证器, DiT, CVPR 2026, 高效验证
研究动机
核心问题: 推理时扩展(test-time scaling)的验证器计算成本过高
推理时扩展(inference-time scaling)通过验证器对候选输出评分选择来改进生成质量。但常用的 MLLM 验证器需要将候选从潜空间解码到像素空间再编码为视觉嵌入——冗余且昂贵。如何在不解码到像素空间的情况下直接评估生成质量?
前序工作及局限:
- Best-of-N (2024):MLLM验证器对候选评分选择
- MLLM Verifier:需要解码到像素空间再编码为视觉嵌入
- DiT单步生成器:内部hidden states包含丰富质量信号
与前序工作的本质区别: VHS直接在DiT隐藏状态上验证,跳过像素解码-重编码
方法原理
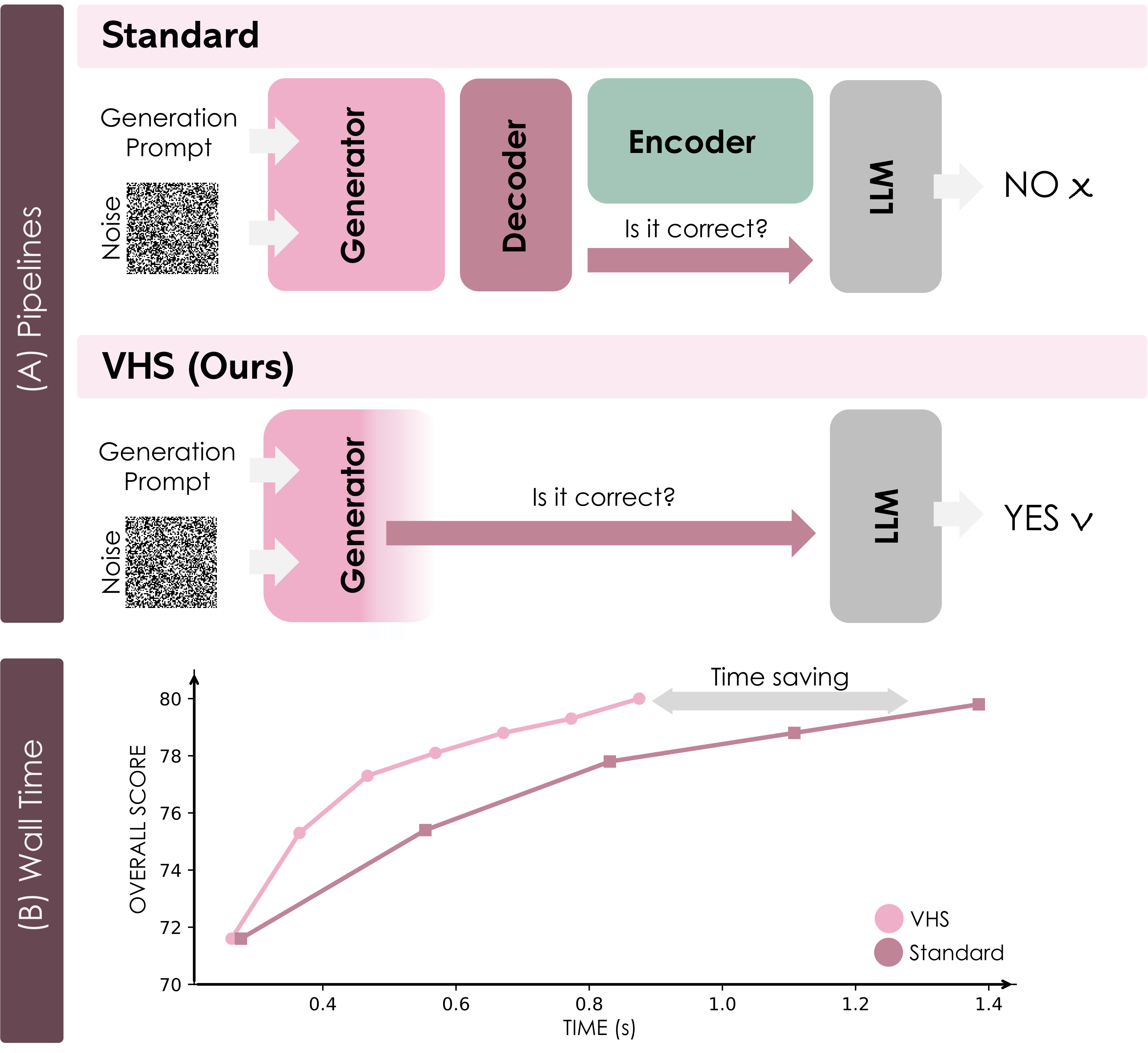
VHS(Verifier on Hidden States)直接在扩散 Transformer(DiT)单步生成器的中间隐藏表示上进行验证:(1) 分析生成器的特征表示而无需解码到像素空间;(2) 训练一个轻量级验证器网络直接在 DiT 的 hidden states 上评分;(3) 在极小推理预算(少量候选者)下实现比 MLLM 验证器更高效的推理时扩展。
核心创新
- 首个直接在DiT隐藏状态上操作的生成验证器
- 跳过像素解码-重编码的冗余流程
- CVPR 2026,推理时间-63.3%,FLOPs-51%,VRAM-14.5%
- 极小推理预算下超越MLLM验证器
- GenEval性能+2.7%同时节省大量计算资源
实验结果
- 与标准 MLLM 验证器相比,VHS 将联合生成和验证时间减少 63.3%,FLOPs 减少 51%,VRAM 使用量减少 14.5%,并在相同推理时间预算下实现 GenEval 性能 +2.7% 的提升。CVPR 2026 接收。
批判性点评
- 新颖性: 直接在DiT隐藏状态上训练验证器的思路简单但有效,避免了传统的编码-解码往返。揭示了DiT中间表示包含丰富质量信号的重要发现。方法设计简洁但insight深刻。
- 可复现性: 基于开源DMD2-SDXL模型,验证器网络结构简单(线性探针+小MLP)。训练数据通过自采样获取,计算成本可控。整体复现门槛低。
- 影响力: CVPR接收验证了学术价值。隐藏状态验证器的效率优势对推理时扩展的实际部署意义重大。可能启发更多利用扩散模型中间表示的工作。
深度点评:
- GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式
- 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化
- 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径
技术演进定位: CVPR 2026, 高效推理时扩展的新范式
可能的后续方向:
- 多步DiT的流式验证
- 与后训练的协同优化
- 移动端部署
7. TATAR
一个模型两种思维:统一IQA+美学评估的任务条件推理 | arXiv:2603.19779
关键词: 图像质量评估, 美学评估, GRPO, 不对称奖励, 任务条件推理
研究动机
核心问题: IQA和IAA使用相同推理逻辑和奖励机制存在根本性错位
将图像质量评估(IQA)和图像美学评估(IAA)统一在单一 MLLM 中是有前景的方向,但现有方法对两个任务使用相同的推理逻辑和奖励机制——这存在根本性错位:IQA 依赖客观感知线索,需要简明推理;IAA 需要深思熟虑的语义判断。统一框架如何针对不同任务特性提供差异化的推理和优化?
前序工作及局限:
- Q-Instruct (Wu 2024):统一质量评估指令调优
- LIQE (Zhang 2023):CLIP增强的图像质量评估
- AestheticScore:单一标量美学评分
与前序工作的本质区别: TATAR揭示推理错位和优化错位,提出快慢推理+不对称奖励
方法原理
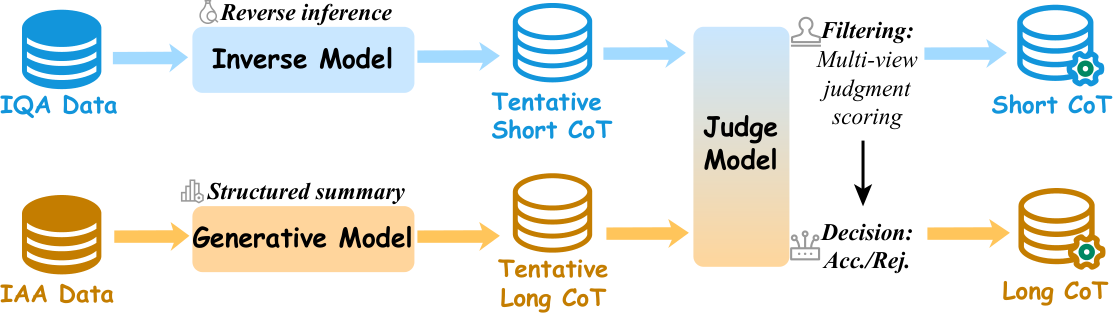
TATAR 共享视觉-语言主干,但在后训练阶段针对任务特性进行条件调节:(1) 快慢推理构建:IQA 配对简明感知理由,IAA 配对深思熟虑的美学叙述;(2) 两阶段学习:先 SFT 建立任务感知行为先验,再 GRPO 进行奖励驱动细化;(3) 不对称奖励设计:IQA 使用高斯分数塑造,IAA 使用 Thurstone 风格的完成度排名。
核心创新
- 揭示IQA和IAA的推理错位和优化错位问题
- 快慢任务特定推理:IQA简明+IAA深思熟虑
- SFT+GRPO两阶段学习建立任务感知行为
- 不对称奖励:高斯分数塑造(IQA)+Thurstone排名(IAA)
- 八个基准上统一超越任务专用模型
实验结果
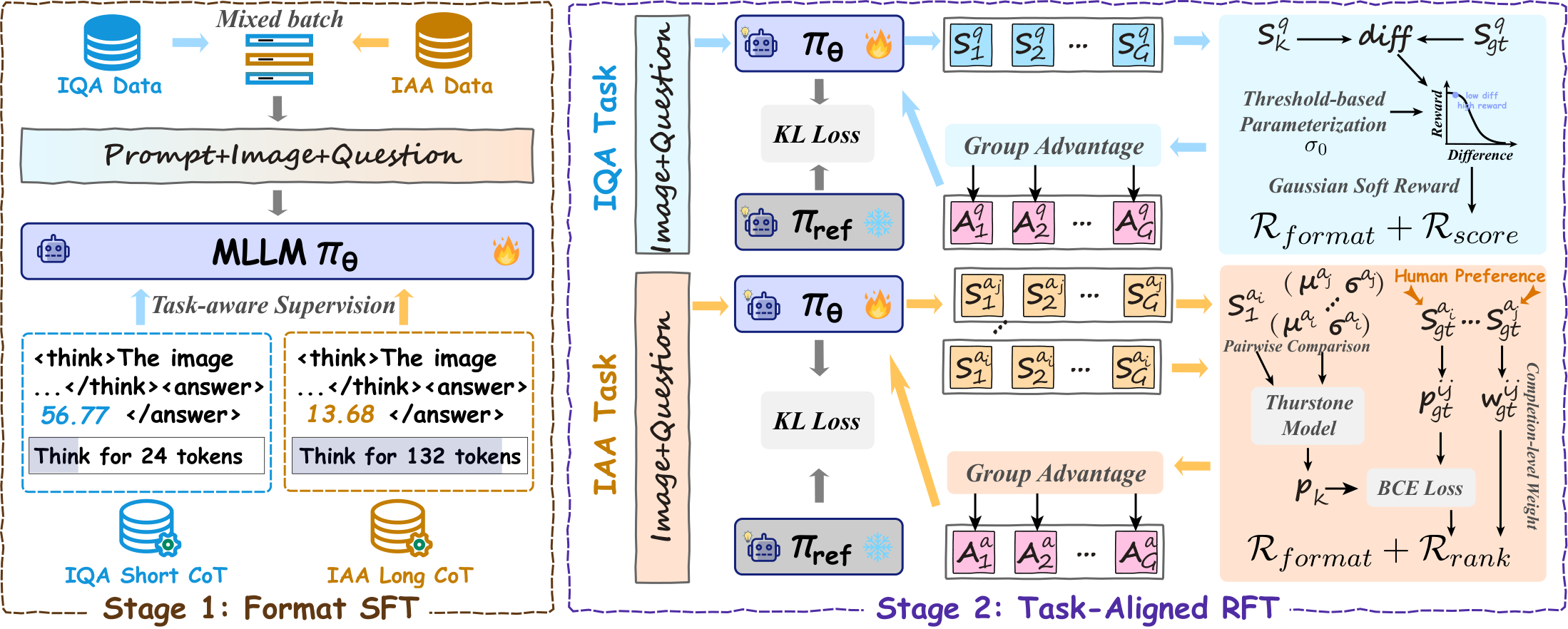
- 在八个基准上,TATAR 在域内和跨域设置下均显著超越先前统一基线,同时保持与特定任务专业模型竞争力的性能。美学评估的训练动态也更加稳定。代码已开源。
批判性点评
- 新颖性: 揭示IQA和IAA需要不同推理模式(快/慢思维)是有价值的洞见。不对称奖励设计——IQA用高斯分数塑造、IAA用Thurstone排名——理论动机清晰。SFT+GRPO两阶段框架设计合理。
- 可复现性: 基于开源MLLM骨干(如InternVL系列),训练数据来自公开IQA/IAA数据集。不对称奖励计算流程有完整公式推导。整体可复现性好。
- 影响力: 统一IQA和IAA评估对视觉生成的质量控制有直接应用价值。不对称奖励设计的思路可泛化到其他需要差异化优化策略的多任务场景。
深度点评:
- GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式
- 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化
- 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径
技术演进定位: 统一感知评分的任务条件后训练新范式
可能的后续方向:
- 视频质量+美学统一评估
- 多粒度感知推理
- 人类偏好对齐
8. SeGroS
语义锚定监督增强统一多模态模型对齐 | arXiv:2603.19807
关键词: 语义锚定, 统一多模态, 视觉提示, 掩码重建, 生成对齐
研究动机
核心问题: 统一多模态模型的生成训练存在粒度不匹配和监督冗余
统一多模态模型集成了理解和生成,但当前生成训练范式存在粒度不匹配和监督冗余两大局限:文本提示的稀疏性无法充分指导细粒度视觉生成,全图重建损失在非语义关键区域浪费了大量监督信号。如何通过更精准的监督信号提升生成保真度和跨模态对齐?
前序工作及局限:
- Show-o (Xie 2024):统一文本到图像理解和生成
- Transfusion (Meta 2024):融合自回归+扩散
- Chameleon (Meta 2024):完全自回归的多模态模型
与前序工作的本质区别: SeGroS通过视觉定位图构建语义锚定监督,解决文本稀疏+监督冗余
方法原理
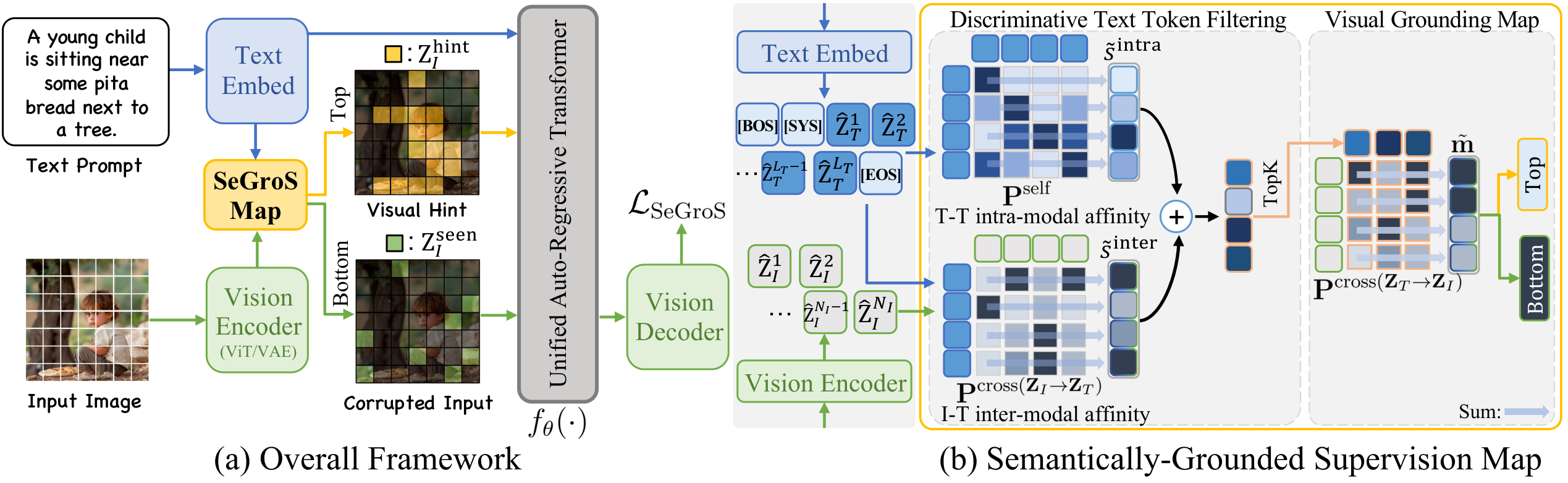
SeGroS 提出语义锚定监督框架:(1) 构建视觉定位图(visual grounding map),将文本提示与图像的语义关键区域关联;(2) 基于定位图构建语义化视觉提示,补偿文本提示的稀疏性,为生成过程提供更丰富的空间引导;(3) 生成语义锚定的损坏输入,通过将重建损失限制在核心文本对齐区域,显式增强掩码重建的监督效果,减少非语义区域的监督冗余。
核心创新
- 揭示统一多模态模型的粒度不匹配和监督冗余问题
- 视觉定位图:文本-图像语义关键区域关联
- 语义化视觉提示:补偿文本提示稀疏性
- 语义锚定损坏输入:重建损失聚焦核心对齐区域
- 在GenEval/DPGBench/CompBench上显著提升对齐
实验结果
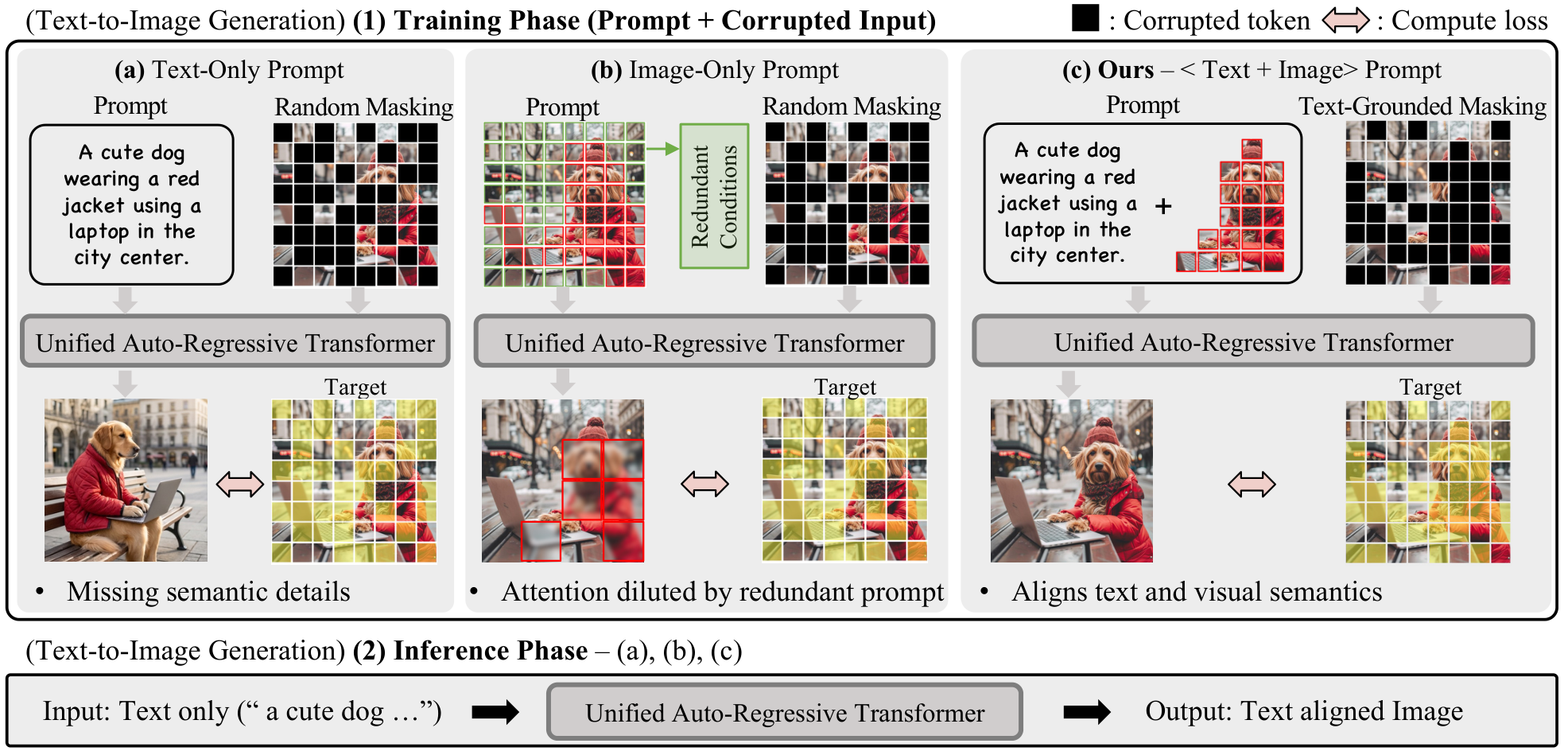
- 在 GenEval、DPGBench 和 CompBench 上的广泛评估表明,SeGroS 显著提高了多种统一多模态模型架构的生成保真度和跨模态对齐能力。
批判性点评
- 新颖性: 视觉定位图将文本-区域关联显式化,解决了统一模型中的文本稀疏和监督冗余两个关键问题。方案设计直觉清晰,理论动机充分。但定位图生成依赖外部模型(如GroundingDINO)。
- 可复现性: 基于开源Show-o架构。视觉定位图生成管线依赖GroundingDINO等开源工具。训练流程和超参数描述清晰。整体可复现性较好,但pipeline复杂度较高。
- 影响力: 为统一多模态模型的对齐训练提供了新的监督信号设计范式。视觉定位图的概念可能启发更多空间感知的训练策略。对Show-o、Chameleon等架构有直接参考价值。
深度点评:
- GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式
- 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化
- 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径
技术演进定位: 统一多模态模型的生成对齐增强方法
可能的后续方向:
- 视频多模态的语义锚定
- 自适应监督区域选择
- 动态粒度调整
其余论文 · 贡献与效果总结
| # |
论文 |
机构 |
关键词 |
主要贡献 |
效果 |
| 1 |
_placeholder (Weekend Survey - No Rest Papers) |
|
N/A |
N/A |
N/A |
趋势观察
- GRPO 成为视觉生成后训练的主流范式 — 从标准 GRPO 到 UniGRPO(统一多模态)、MV-GRPO(多视图评估)、FlowGRPO(Flow Matching),GRPO 的变体已覆盖文生图、文生视频、交错生成等全场景。
- 专业化奖励模型快速涌现 — FIRM(编辑+生成双赛道)、EditHF-1M(百万级编辑偏好)、VIGOR(视频几何)、TATAR(质量+美学双任务)——不同子领域开始构建各自的专业化奖励体系。
- 推理时扩展成为后训练的互补方案 — VHS 和 VIGOR 都探索了推理时 test-time scaling——通过验证器在推理阶段筛选候选,不修改模型权重即可提升质量,与后训练形成互补。
- 数据规模驱动奖励质量 — EditHF-1M 的 29M 偏好对、FIRM 的 66.3 万评分数据——大规模人类偏好数据正在成为训练高质量奖励模型的关键竞争壁垒。
人工智能炼丹师 整理 | 2026-03-28
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注



评论 (0)