
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日 arXiv cs.CV 视觉生成相关论文共 10 篇。
方向分布:
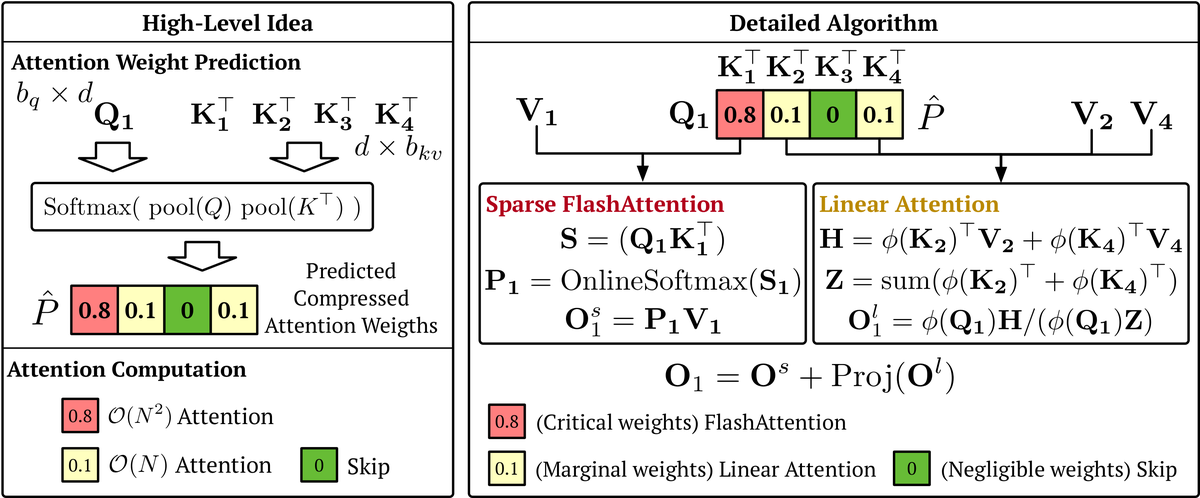
Mamoda2.5:DiT-MoE统一多模态模型,25B参数仅激活3B,视频编辑加速95.9x | Unknown (Industry) | arXiv:2605.02641
关键词: 统一多模态·DiT-MoE·AR-Diffusion·视频生成·蒸馏加速
前序工作问题: 多模态理解与生成模型通常分离训练,缺乏统一框架;视频编辑推理速度慢难以部署
贡献: 提出统一AR-Diffusion框架,为Diffusion Transformer配备细粒度MoE(128专家Top-8路由),25B参数仅激活3B;联合少步蒸馏与强化学习将30步压缩为4步
效果: VBench 2.0视频生成顶尖,视频编辑创新高;匹敌Kling O1等闭源模型;编辑推理加速95.9x,广告场景成功率98%
批判点评: 128专家路由的负载均衡和专家坍缩问题未详细分析;仅激活3B参数是否在复杂多模态推理任务上存在能力天花板待验证
MotionCache:运动感知缓存加速自回归视频生成6.28x | Xiamen University | arXiv:2605.01725
关键词: 视频生成加速·运动感知·缓存复用·SkyReels-V2·MAGI-1
前序工作问题: 自回归视频生成因逐步去噪计算量巨大难以部署;现有缓存策略采用粗粒度块级跳步,忽略像素级运动动态
贡献: 形式化证明缓存误差与残差不稳定性的关联,提出利用帧间差分作为像素级运动代理的粗到细策略:预热阶段建立语义连贯,随后按运动权重动态调整每Token更新频率
效果: SkyReels-V2加速6.28x(VBench仅降1%),MAGI-1加速1.64x(VBench仅降0.01%),代码已开源
批判点评: 帧间差分作为运动代理过于简单,无法区分相机运动与物体运动;预热阶段长度为超参数,对不同内容敏感
用TTT线性化SD3.5:1小时微调实现1.47x推理加速 | Tsinghua University / ICML 2026 | arXiv:2605.02772
关键词: 线性注意力·TTT·SD3.5·推理加速·权重迁移
前序工作问题: Softmax注意力二次复杂度限制高分辨率生成效率;从头训练线性注意力模型成本过高
贡献: 发现TTT的两层动态公式与Softmax注意力结构对齐,可直接继承预训练权重;引入Key实例归一化和轻量局部性增强模块保持表征一致性
效果: 4xH20 GPU仅1小时微调,文生图质量与原模型可比;1K分辨率1.32x加速,2K分辨率1.47x加速(ICML 2026)
批判点评: 1.47x加速幅度相比FlashAttention等工程优化的叠加优势有限;TTT的额外在线学习开销在批处理场景的表现未报告
Khala:64层RVQ统一声学Token语言建模,无需语义Token阶段 | Tsinghua University | arXiv:2605.01790
关键词: 音乐生成·声学Token·RVQ·语言建模·粗到细
前序工作问题: 现有音乐生成将语义Token与声学Token分离为异构表示空间,系统复杂且信息传递断裂
贡献: 证明文本-声学对齐可在纯声学Token语言建模中涌现无需语义Token阶段;设计64层RVQ统一表示,两阶段粗到细框架固定62步推理,混合注意力训练
效果: 高保真音乐生成,文本-人声对齐自然涌现;超分辨率模型从骨干迁移学习显著提升收敛和质量
批判点评: 64层RVQ的编码复杂度和码本利用率未详细分析;固定62步推理对不同长度音乐的效率适配性待验证
BRITE:首个含音视频对齐的T2V评测基准,实测Sora 2/Veo 3.1/Gen4.5 | Unknown | arXiv:2605.00873
关键词: T2V评测·不合理场景·音视频对齐·人工循环·QA可解释
前序工作问题: 现有T2V评测忽视不合理场景和音视频对齐维度;全自动MLLM评测易受幻觉和歧义影响
贡献: 统一不合理场景提示、细粒度音视频一致性评估和QA式可解释评测三大组件;人工循环协议保障可靠性
效果: 实测Sora 2/Veo 3.1/Runway Gen4.5/Pixverse V5.5/Qwen3Max五大模型,发现物体-动作绑定和音视频同步存在显著性能缺口
批判点评: 仅评测5个模型样本量有限,结论的统计显著性和可推广性存疑;人工循环协议扩展成本高
TOC-SR:贝叶斯优化发现紧凑扩散架构,6.6x参数压缩单步超分 | Unknown (Industry) | arXiv:2605.02767
关键词: 图像超分·紧凑扩散·贝叶斯优化·蒸馏·单步推理
前序工作问题: 扩散超分模型因大参数量和多步采样难以在边缘设备部署
贡献: 从16通道隐扩散模型出发,通过特征级生成蒸馏构建高效替代块,用epsilon约束贝叶斯优化搜索最优紧凑架构,再将多步过程蒸馏为单步生成器
效果: 参数量压缩6.6x,计算量减少2.8x,单步推理保持强重建质量
批判点评: NAS搜索成本本身较高,一次性投入是否划算取决于部署规模;蒸馏后模型在困难退化场景的鲁棒性未评估
ScribbleEdit:涂鸦+文本联合编辑大规模合成数据集 | UC Berkeley | arXiv:2605.01135
关键词: 图像编辑·涂鸦输入·合成数据·空间对齐·多模态控制
前序工作问题: 用户难以同时传达精确空间布局和语义细节;缺乏涂鸦-文本联合编辑的专用训练数据
贡献: 设计自动生成管线:通过修复生成源-目标图像对,配对人工涂鸦和VLM生成的文本指令,构建大规模合成数据集
效果: 微调后模型在空间对齐和语义一致性上显著提升,扩散和自回归两类模型均受益
批判点评: 合成涂鸦与真实用户涂鸦分布差异可能导致域迁移问题;VLM生成的文本指令质量依赖VLM能力上限
BlenderRAG:检索增强代码合成生成高保真3D对象 | University of Bologna | arXiv:2605.00632
关键词: 3D生成·RAG·Blender代码·LLM·检索增强
前序工作问题: LLM直接生成3D建模代码编译成功率低且几何一致性差,无需微调的3D生成方案匮乏
贡献: 构建500例专家验证的多模态数据集(50类别),RAG检索语义相似示例辅助LLM生成可执行Blender代码,无需微调或特殊硬件
效果: 编译成功率从40.8%提升至70%(+29.2%),CLIP语义对齐从0.41提升至0.77,跨4个LLM一致有效
批判点评: 500例数据集规模有限,复杂场景和组合对象的覆盖度不足;代码生成方式难以表达光滑曲面等连续几何
HumanSplatHMR:闭环联合优化人体Mesh恢复与高斯泼溅化身 | University of Michigan | arXiv:2605.02784
关键词: 人体重建·高斯泼溅·Mesh恢复·闭环优化·新视角合成
前序工作问题: 现有方法将姿态估计与外观重建解耦,姿态误差累积到渲染中无法修正
贡献: 通过可微渲染闭环,将光度/分割/深度损失反向传播到姿态参数和全局位置,实现姿态-外观联合优化
效果: 全局3D姿态恢复精度和新视角渲染质量均超越解耦基线,无需动捕设备即可从视频重建高质量化身
批判点评: 闭环优化增加训练时间;对遮挡严重或极端姿态的鲁棒性未充分验证
Pixel Perfect:自监督关系型IQA,无需人工标注的空间感知质量评估 | Unknown | arXiv:2605.02863
关键词: 图像质量评估·自监督·关系型·空间感知·对比学习
前序工作问题: 传统IQA依赖MOS人工标注,成本高且无法提供可解释的局部反馈
贡献: 从绝对质量预测转向关系型方向性评估;自监督合成失真引擎生成训练数据;反对称目标训练失真预测网络输出空间感知解耦图;对比学习训练评分网络
效果: 完全无需人工标注,提供失真类型/强度/方向的空间感知映射,可针对性优化图像处理算法
批判点评: 合成失真与真实世界失真分布差距可能影响泛化;关系型评估难以与传统MOS指标直接对比
人工智能炼丹君 整理 | 2026-05-06
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描下方二维码关注

评论 (0)