
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日 arXiv cs.CV 视觉生成相关论文共 10 篇。
方向分布:
AdvDMD:对抗奖励融合蒸馏实现高质量少步生成 | Unknown | arXiv:2604.28126
关键词: 蒸馏加速·DMD·对抗奖励·少步生成·SD3.5
前序工作问题: 扩散模型蒸馏加速方法将 DMD 与 RL 简单拼接,两种优化目标相互干扰导致训练不稳定且加速倍率有限
贡献: 将 DMD2 的对抗判别器直接复用为 RL 奖励模型,通过统一 SDE 反向模拟对中间态和终态联合监督,实现 DMD 与 RL 的无缝融合
效果: 4 步 AdvDMD 在 SD3.5 上 DPG-Bench 超越原模型 40 步表现;2 步版本在 Qwen-Image 上超越 TwinFlow
批判点评: 对抗判别器随蒸馏模型在线更新增加训练复杂度;在极端 1 步生成场景下质量衰减幅度未报告
Edit-R1:验证器驱动强化学习提升图像编辑 | ByteDance Seed | arXiv:2604.27505
关键词: 图像编辑·奖励模型·CoT验证器·GRPO·FLUX
前序工作问题: 图像编辑缺乏可靠通用奖励模型,现有模型仅给整体评分无法逐条验证编辑指令是否满足
贡献: 提出推理奖励模型 RRM,通过 CoT 将指令拆分为独立原则逐条验证并聚合为细粒度可解释奖励,用 GCPO+GRPO 两阶段训练
效果: Edit-RRM 超越 Seed-1.5-VL/1.6-VL 等强 VLM 作为编辑奖励模型;3B→7B 清晰涨点;赋能 FLUX.1-kontext 编辑器
批判点评: CoT 推理链增加奖励计算成本,实际部署中每次编辑需额外 VLM 推理;仅在 FLUX 上验证泛化性有限
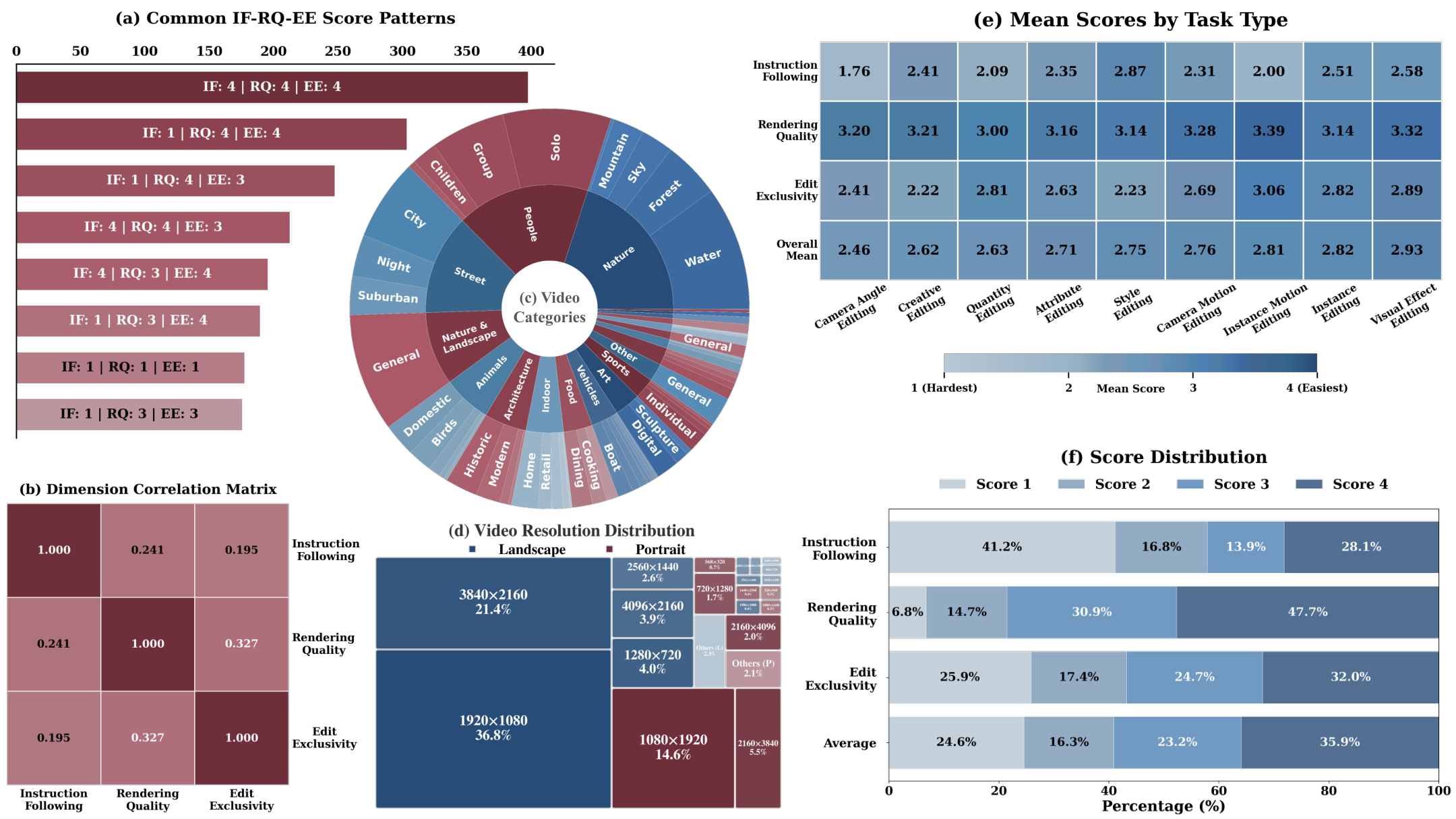
AesRM:专家级美学反馈提升视频生成质量 | Unknown | arXiv:2604.28078
关键词: 视频美学·奖励模型·分层评测·CoT推理·Wan2.2
前序工作问题: 视频生成评估过度关注保真度而忽视电影级美学(构图、光影、色彩和谐),缺乏系统化美学评价体系
贡献: 构建 3 维 15 细项美学评分体系与约 2500 对专家标注数据集 AesVideo-Bench,训练 AesRM-Base 和 AesRM-CoT 两版奖励模型
效果: 在多个美学基准上超越基线,位置偏差更低更鲁棒;成功对齐 Wan2.2 视频生成模型的美学输出
批判点评: 2500 视频对规模偏小可能限制泛化;美学本质上主观性强,专家标注的跨文化一致性未讨论
RFL:表征空间 Fréchet 距离作为训练损失提升生成质量 | Unknown | arXiv:2604.28190
关键词: FD损失·表征空间·一步生成·蒸馏替代·ImageNet
前序工作问题: Fréchet 距离一直仅用于评估而非训练,因为其需要大规模样本估计群体统计量与小批量梯度计算矛盾
贡献: 解耦 FD 估计所需群体规模(50k)与梯度计算批量(1024),提出 FD-loss 使 Fréchet 距离可直接作为训练目标
效果: ImageNet 256x256 上一步生成器达 0.72 FID;无需教师蒸馏或对抗训练即可将多步模型转化为强一步生成器
批判点评: FD-loss 对表征空间选择敏感,不同表征可能导致矛盾优化方向;维护 50k 统计量的内存开销在高分辨率场景未讨论
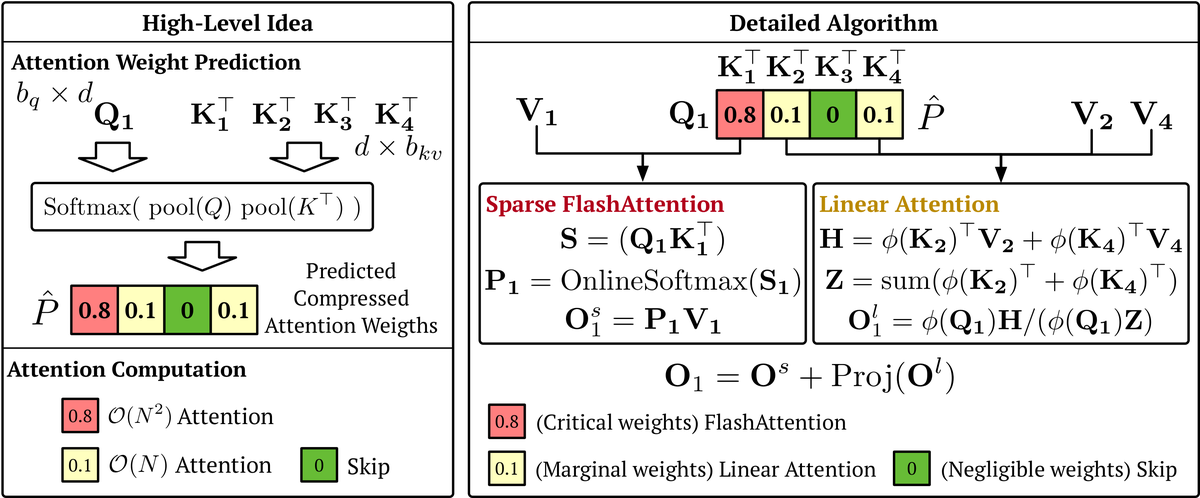
YOSE:按需选择关键 Token 加速 DiT 视频去物 | CVPR 2026 | arXiv:2604.27322
关键词: 视频去物·Token选择·DiT加速·掩码感知·线性缩放
前序工作问题: DiT 视频去物方法对全时空 Token 密集计算,即使仅小区域需修复也需处理完整 Token 空间,推理极慢(约 10 FPS)
贡献: 提出批量变长索引 BVI 按掩码自适应选择关键 Token,配合 DiffSim 模块为未掩码 Token 模拟扩散注意力影响
效果: 70% 场景实现 2.5 倍加速,推理时间与掩码区域大小近似线性缩放,生成质量保持可比
批判点评: 加速比强依赖掩码面积,大面积去物场景加速有限;DiffSim 的近似可能在复杂运动区域引入伪影
PhyCo:学习可控物理先验实现物理真实视频生成 | CMU / NEC Labs / UCSD | CVPR 2026 | arXiv:2604.28169
关键词: 物理先验·可控生成·摩擦力·弹性·视频扩散
前序工作问题: 视频扩散模型擅长外观合成但物理一致性差:物体漂移、碰撞无回弹、材料响应不真实
贡献: 从简单模拟(滑块/弹球)中学习连续可解释的物理先验(摩擦/弹性/形变/力),推理时无需物理引擎即可注入视频扩散
效果: 实现连续可控的物理参数调节,生成物理真实的碰撞回弹和材料变形效果,CVPR 2026 收录
批判点评: 训练仅用简单几何体模拟数据,对复杂真实场景(如流体、布料)的泛化能力存疑;推理时物理参数需手动指定
视觉生成新纪元:从原子映射到智能体世界建模(综述) | Multi-institution (27 authors) | arXiv:2604.28185
关键词: 综述·五级分类·Flow Matching·后训练·奖励模型·世界模型
前序工作问题: 视觉生成模型在空间推理、状态持续、长期一致性和因果理解上仍有系统性缺陷,但缺乏统一评价框架
贡献: 提出五级渐进式分类体系(原子→条件→上下文→智能体→世界建模),系统梳理流匹配、统一模型、后训练、奖励建模等技术驱动力
效果: HF Daily Papers 82 票热度最高,提供能力导向的视角理解和推进下一代智能视觉生成系统
批判点评: 27 人综述难免覆盖面广但深度不足;五级分类边界模糊(如 Level 3 与 Level 4 区分标准主观)
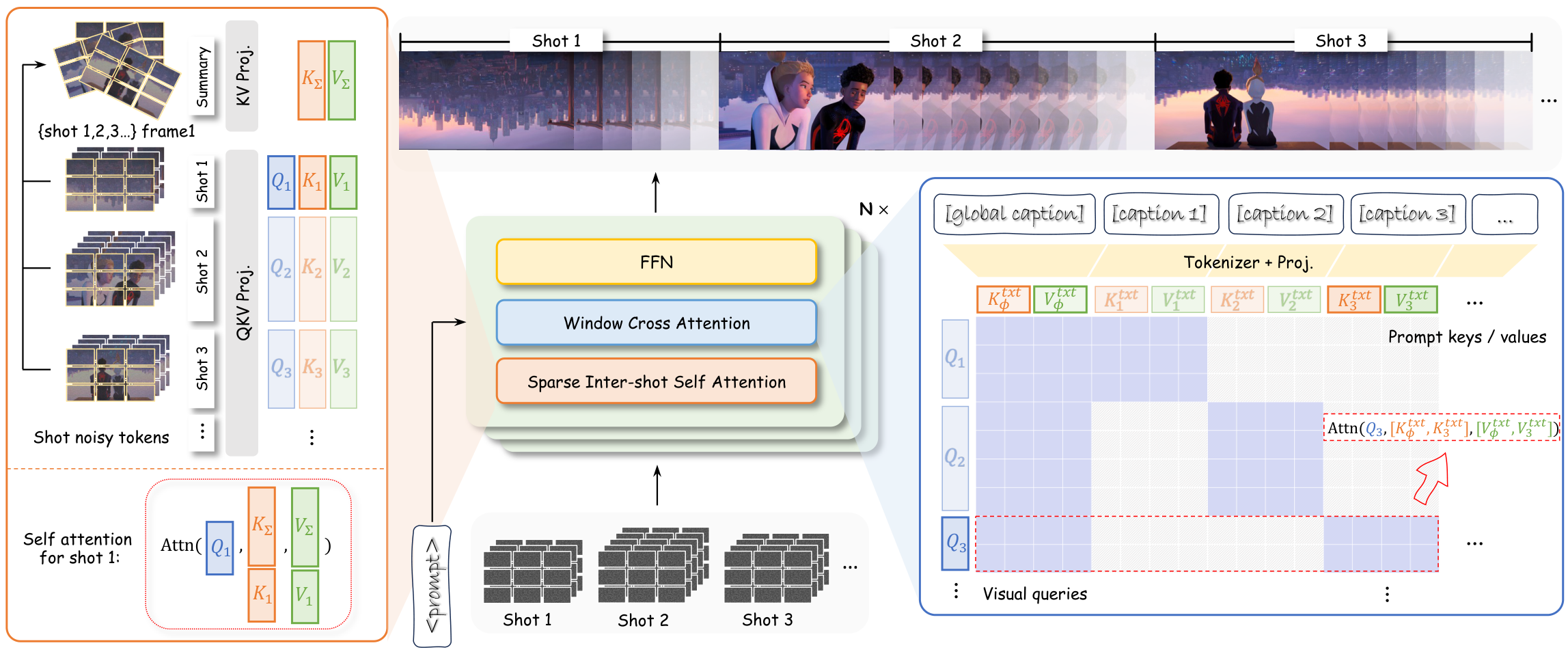
TAVR:从跨场景视频参考生成高保真说话头像 | HeyGen Research | arXiv:2604.27918
关键词: 说话头·跨场景·视频参考·Token选择·身份强化学习
前序工作问题: 现有说话头生成方法依赖同场景静态图参考,跨场景视频参考时身份保持和背景适应能力差
贡献: 提出视频参考范式 TAVR,含 Token 选择处理长时上下文、三阶段训练(同场景预训练→跨场景微调→身份 RL),构建 158 对跨场景评测基准
效果: 量化和定性评估均超越现有基线,已部署于 HeyGen Avatar-V 产品上线
批判点评: 强依赖参考视频质量和时长;身份 RL 奖励可能过拟合特定人脸特征分布,非正面角度效果存疑
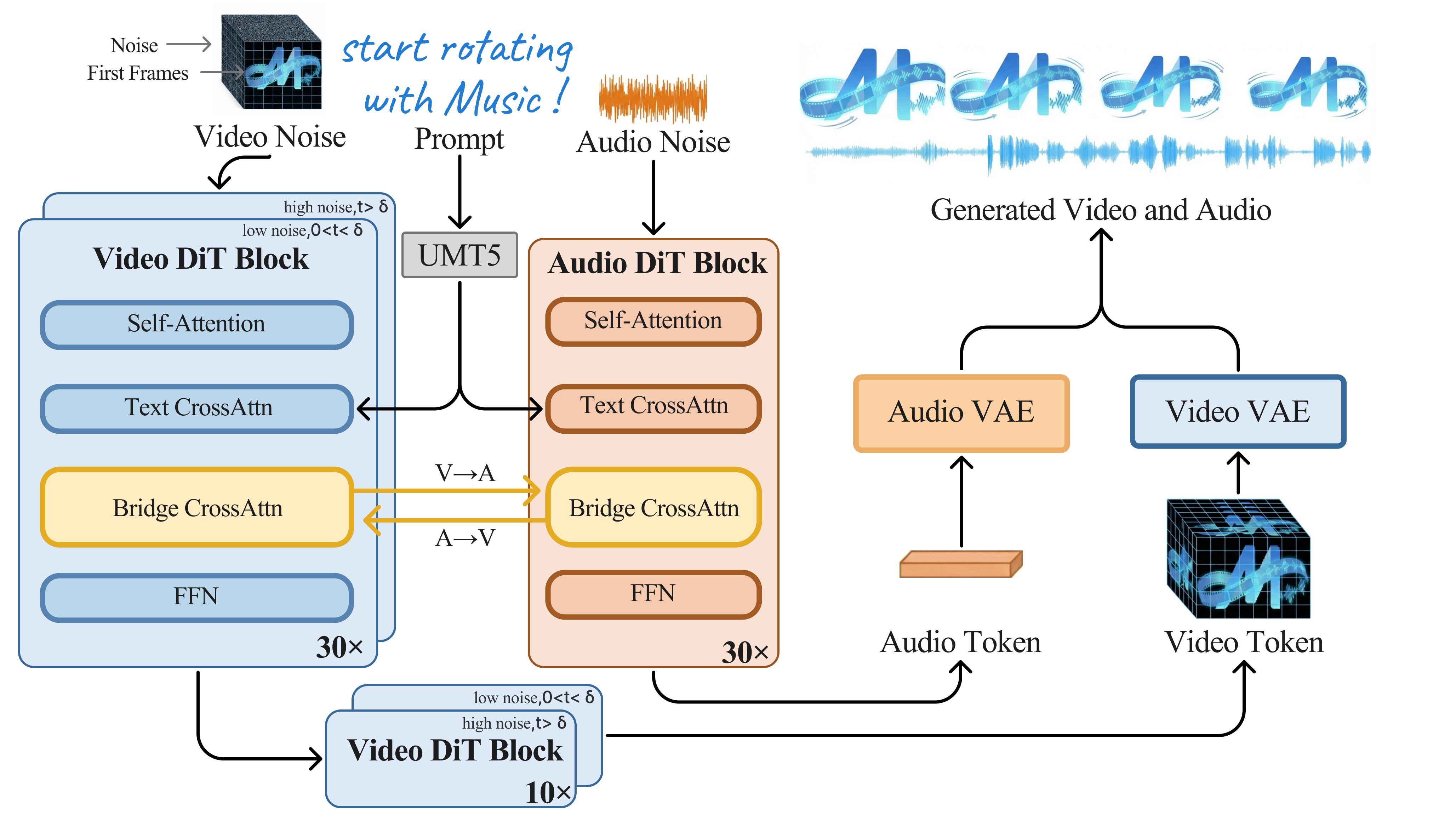
Nemotron 3 Nano Omni:NVIDIA 高效开源全模态模型 | NVIDIA | arXiv:2604.24954
关键词: 多模态·音频视觉文本·文档理解·Agent·开源
前序工作问题: 智能体系统需分别调用视觉、语音和语言模型,模型间数据传递耗时且丢失跨模态上下文
贡献: 首次原生支持音频+文本+图像+视频四模态输入,在文档理解、长音视频理解和 Agent 计算机操控上刷新效率基准
效果: 在 6 项权威榜单名列前茅;较前代在所有模态上准确率一致提升;已被 Foxconn 等企业采用
批判点评: 仅支持理解而无生成能力,不属于生成-理解统一模型;Nano 级别参数量在复杂推理场景可能受限
ExoActor:第三人称视频生成驱动通用人形机器人控制 | BAAI | arXiv:2604.27711
关键词: 人形控制·视频生成·第三人称·交互动力学·零样本泛化
前序工作问题: 人形机器人需同时建模空间上下文、时序动力学、动作和任务意图的交互,现有方法难以大规模获取多样化数据
贡献: 复用大规模视频生成模型作为交互动力学的统一接口,两阶段流程:先生成第三人称执行视频,再通过运动估计转为可执行动作
效果: 无需额外真实数据即可泛化到新场景,展示视频生成模型在机器人领域的全新应用范式
批判点评: 两阶段流程中运动估计误差会逐级累积;视频生成的物理真实性不足可能导致不可执行的动作序列
人工智能炼丹君 整理 | 2026-05-04
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描下方二维码关注

评论 (0)