
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 2026年4月11日(周六)
本期 AIGC 周末专题聚焦音视频联合生成与编辑前沿进展方向,精选 8 篇代表性论文进行深度解读。
方向分布:
含 CVPR 2026 × 2 篇, ICLR 2026 × 1 篇
| # | 论文 | 机构 | 核心贡献 | arXiv ID |
|---|---|---|---|---|
| 1 | MOVA | 上海 AI Lab, OpenMOSS | 首个全面开源的可扩展联合音视频生成系统 | 2602.08794 |
| 2 | JavisDiT++ | Rochester, 上海科技大学 | 系统性地将人类偏好优化引入联合音视频生成 | 2602.19163 |
| 3 | OmniForcing | 基于LTX-2蒸馏 | 首个实时联合音视频流式生成系统,单GPU约25 FPS | 2603.11647 |
| 4 | CCL | SenseTime | 首次系统分析双流联合生成框架的三个核心技术瓶颈 | 2603.18600 |
| 5 | Identity as Presence | 首个同时支持面部外观和声音音色联合个性化的音视频生成系统 | 2603.17889 | |
| 6 | FoleyDirector | 首个在DiT基V2A上实现精确时序引导的方法 | 2603.19857 | |
| 7 | OmniSonic | 首次在统一框架中覆盖三类视频音频(屏内环境音/屏外环境音/人类语音) | 2604.04348 | |
| 8 | FoleyDesigner | Shanghai University, University of Surrey | 首个电影级立体声拟音自动生成系统 | 2604.05731 |
论文: MOVA
arXiv: 2602.08794
机构: 上海 AI Lab, OpenMOSS
核心问题: 级联音视频生成管线导致成本增加、错误累积、质量下降
音频是真实世界视频不可或缺的部分,但现有生成模型大多忽略音频。级联管线(先视频后音频)带来成本增加、错误累积、质量下降三大问题。Veo 3和Sora 2虽展示了同步生成的价值,但闭源特性阻碍了学术推进。MOVA旨在构建开源的、可扩展的联合音视频生成系统。
前序工作及局限:
与前序工作的本质区别: MOVA采用双流DiT+渐进式三阶段训练,构建首个全面开源的联合音视频生成系统
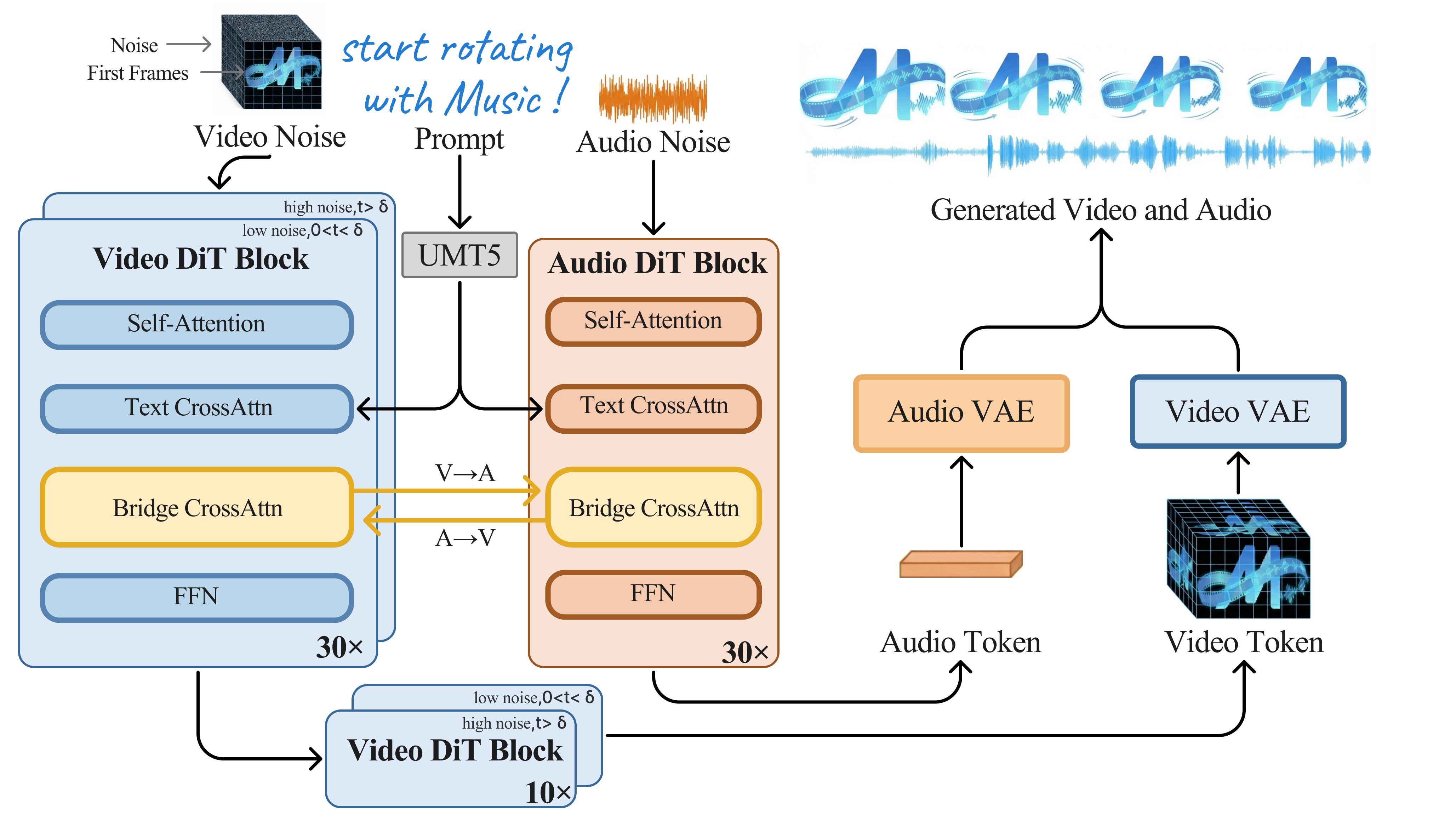
MOVA采用双流DiT架构:
(1) 独立模态流+跨模态交互:视频流和音频流分别基于预训练模型初始化,通过跨模态注意力层在每个Transformer块中建立音视频对齐。
(2) 渐进式训练策略:阶段一冻结主干仅训练跨模态注意力层,阶段二全模型联合微调,阶段三高质量数据精调。
(3) 大规模数据管线:自动化音视频配对数据清洗,多维度质量过滤。
优势:系统工程完整,开源贡献大;渐进式训练有效。局限:双流架构的跨模态对齐存在固有上限;数据规模仍不及商业系统。
技术演进定位: 开源联合音视频生成的技术基线
可能的后续方向:
论文: JavisDiT++
arXiv: 2602.19163
机构: Rochester, 上海科技大学
核心问题: 联合音视频生成的质量与商业系统仍有差距,缺乏人类偏好对齐
联合音视频生成已成为多模态合成基础任务,但与Veo 3等商业系统相比,开源方法在生成质量、时序同步和人类偏好对齐三个维度上仍存在明显差距。JavisDiT++从统一建模和系统优化两个层面同时发力。
前序工作及局限:
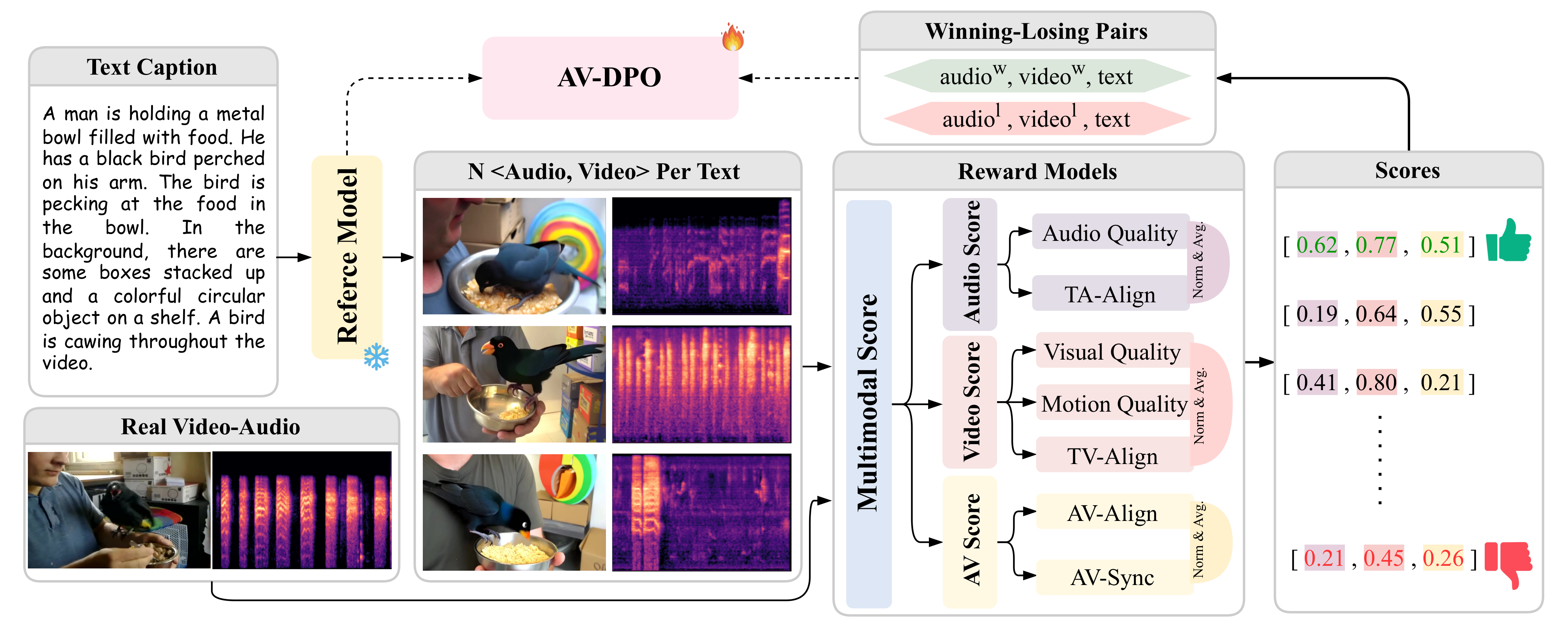
与前序工作的本质区别: JavisDiT++首次将DPO人类偏好优化引入联合音视频生成,配合时间对齐RoPE
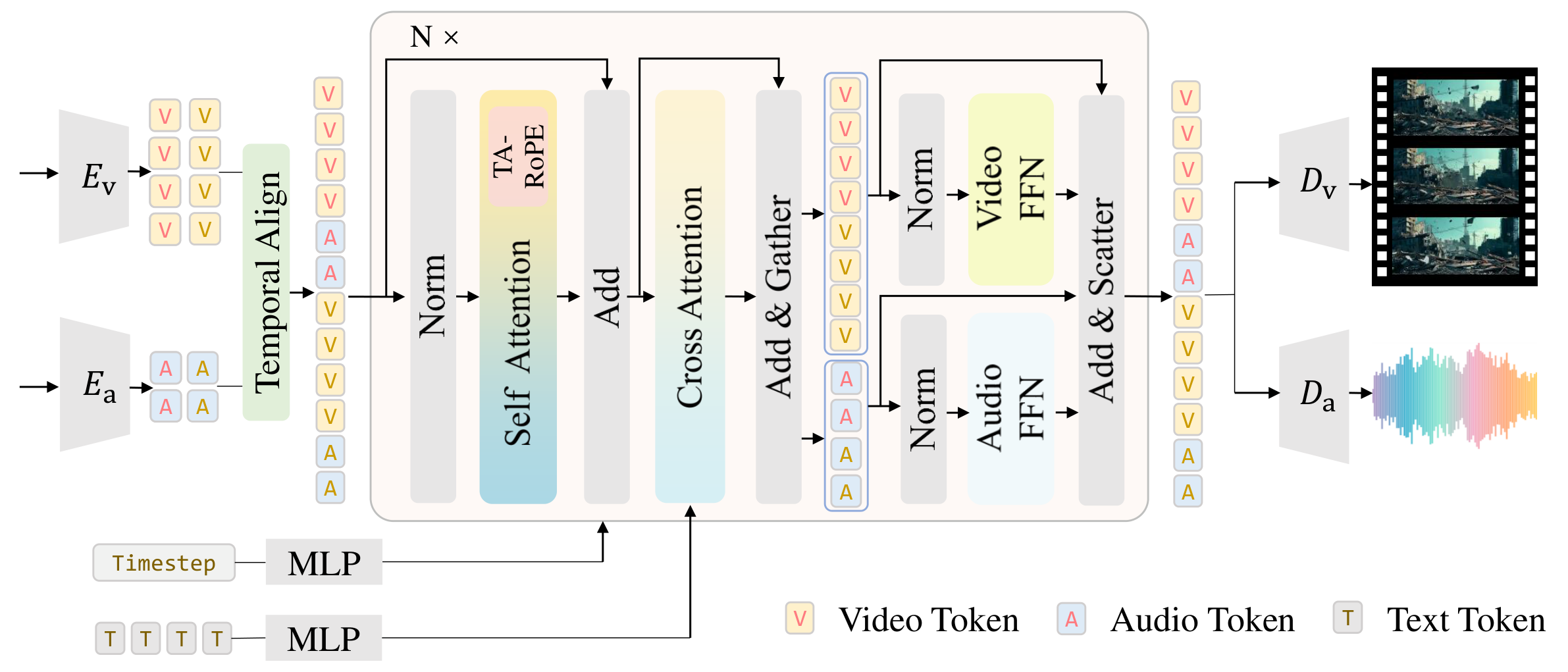
JavisDiT++的核心设计:
(1) 统一双流DiT架构:基于预训练视频DiT和音频DiT,跨模态注意力实现联合推理,时间对齐RoPE解决时间分辨率不匹配。
(2) 多阶段优化:跨模态注意力预训练→全模型联合微调→人类偏好对齐(DPO/RLHF)。
(3) 高质量数据策略:精心策划的多源音视频训练数据,基于同步性的质量过滤。
优势:首次在JAVG中引入DPO后训练,方法论完整。局限:人类偏好标注成本高;DPO对齐效果受奖励模型质量制约。
技术演进定位: 联合音视频生成的偏好对齐开拓者
可能的后续方向:
论文: OmniForcing
arXiv: 2603.11647
机构: 基于LTX-2蒸馏
核心问题: 联合音视频生成局限于离线模式,无法支持交互式应用
现有联合音视频生成系统都是离线的,严重限制交互式应用(游戏NPC、虚拟直播、实时对话)。OmniForcing提出核心问题:能否实现实时的、流式的联合音视频生成?
前序工作及局限:
与前序工作的本质区别: OmniForcing将离线双向扩散蒸馏为25FPS流式自回归生成器
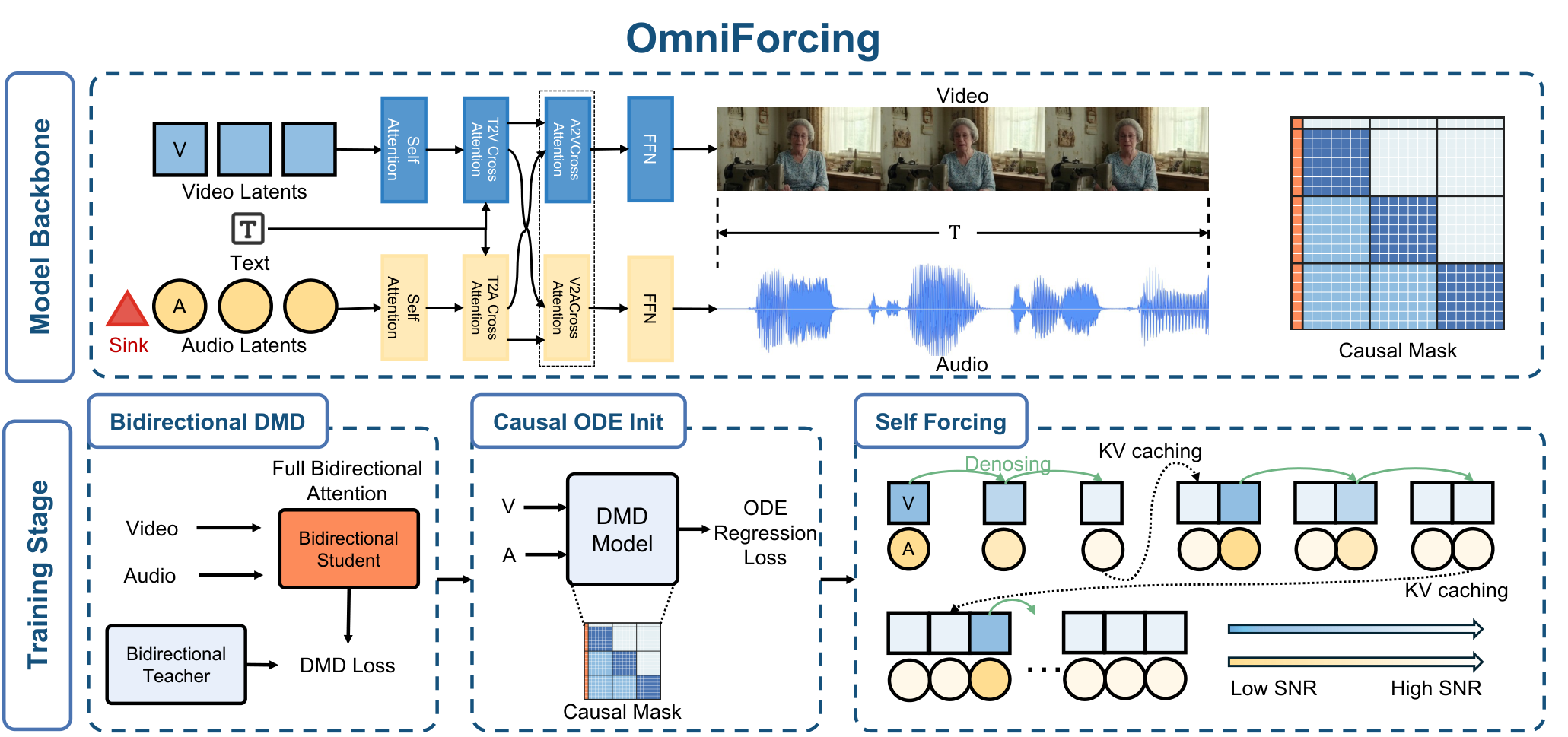
OmniForcing的核心设计:
(1) Joint Self-Forcing Distillation:以离线双向扩散模型为教师,蒸馏为流式自回归学生,在长序列上自纠正跨模态误差。
(2) Asymmetric Block-Causal Alignment + Zero-truncation Global Prefix:确保流式生成中音视频同步。
(3) Audio Sink Token + Identity RoPE:缓解音频token稀疏的梯度问题。
(4) 模态无关滚动KV-Cache:支持任意长度流式生成。
优势:实时生成突破意义重大,对交互式应用有直接影响。局限:蒸馏质量上限受教师模型制约;LTX-2训练成本高。
技术演进定位: 首个实时联合音视频流式生成系统
可能的后续方向:
论文: CCL
arXiv: 2603.18600
机构: SenseTime
核心问题: 双流联合生成框架存在门控流形变化、背景偏差、CFG冲突三大瓶颈
双流Transformer已成为联合音视频生成主流范式,但存在三个关键问题:(1)门控机制引起的模型流形变化;(2)跨模态注意力引入的多模态背景区域偏差;(3)多模态CFG的训练-推理不一致性。
前序工作及局限:
与前序工作的本质区别: CCL系统性提出TARP/LCT+DCR/UCG三个模块精准解决三大瓶颈
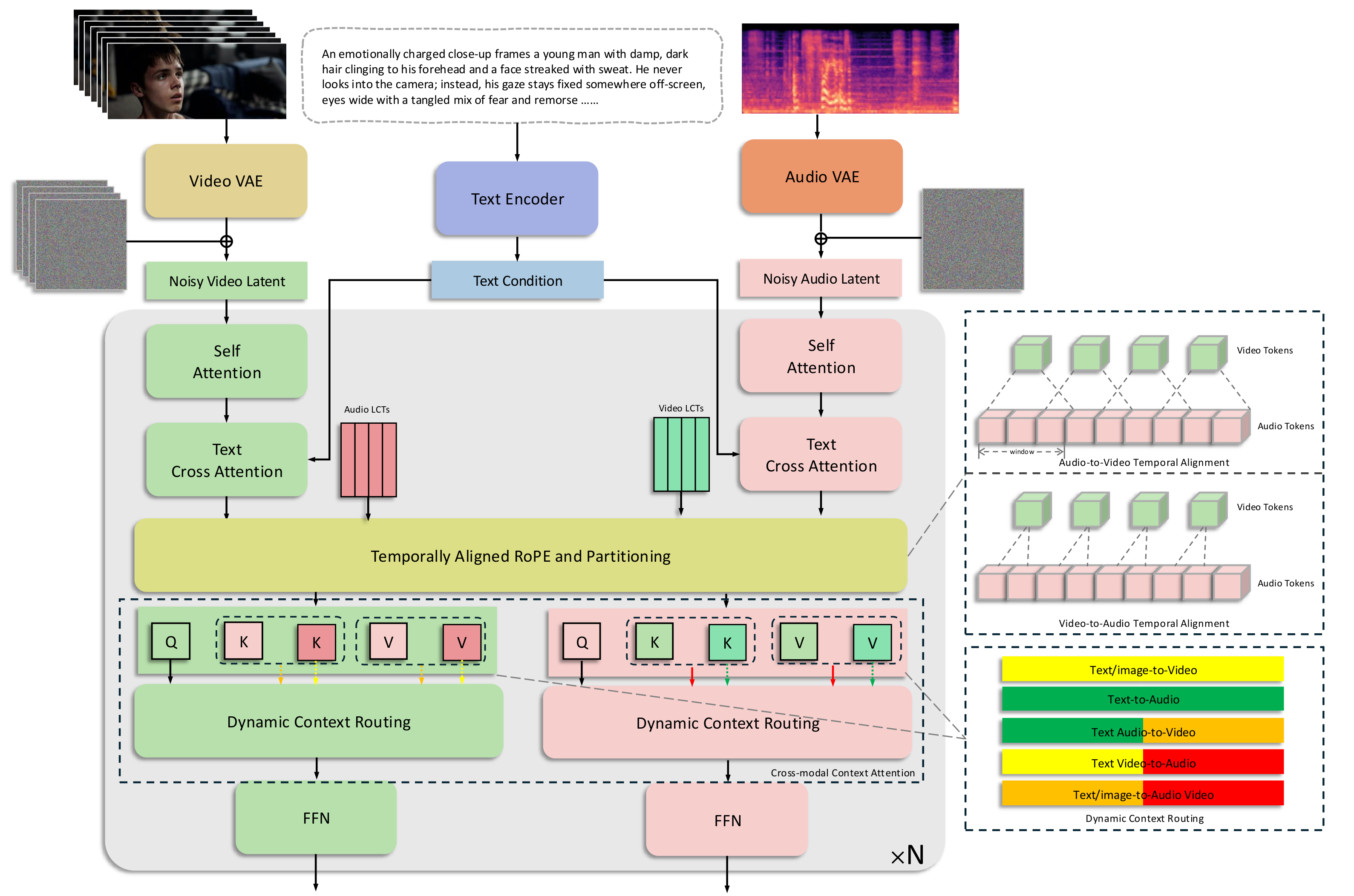
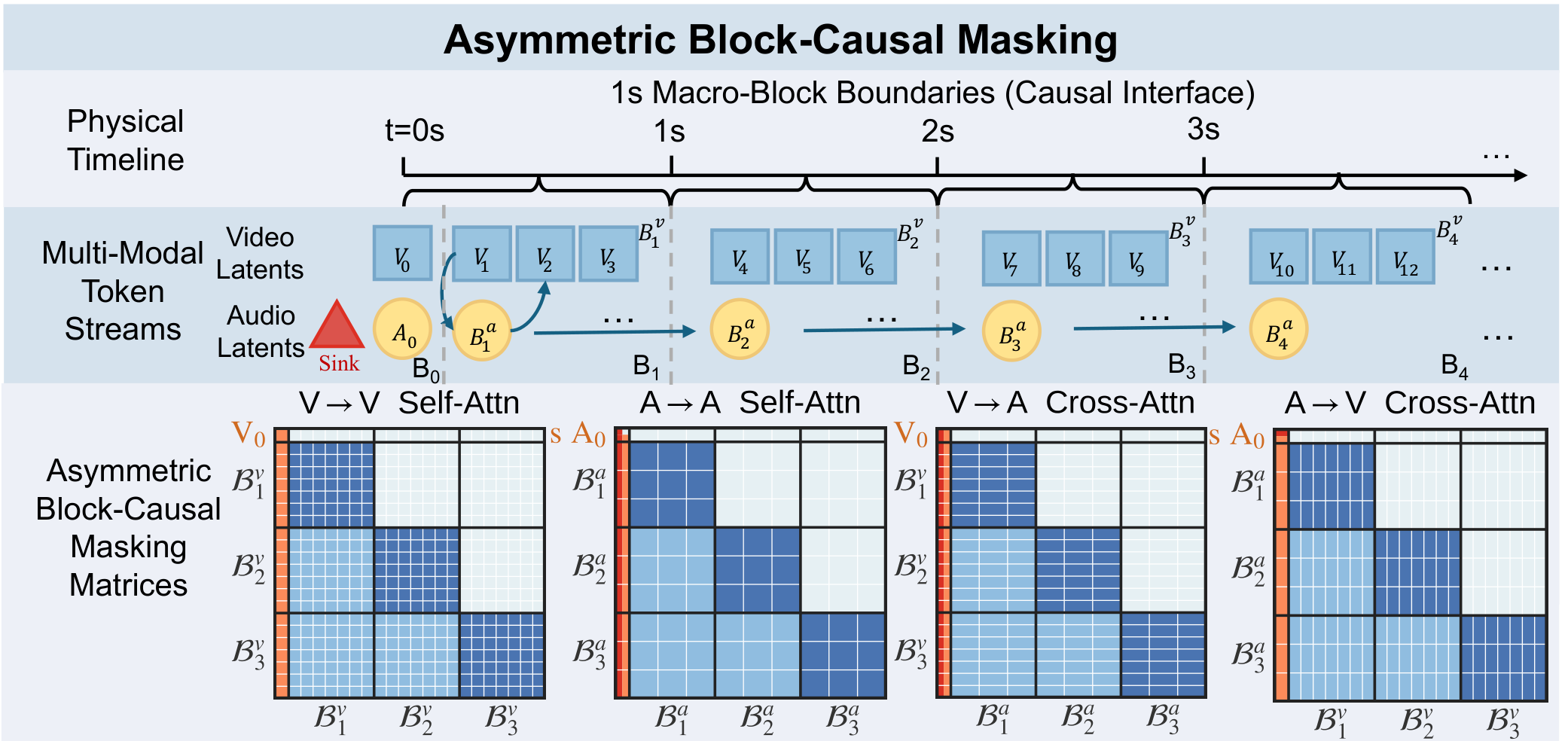
CCL提出三个模块:
(1) TARP(时间对齐RoPE和分区):在RoPE位置编码层面实现音视频精确时间对齐。
(2) LCT(可学习上下文标记)+DCR(动态上下文路由):LCT提供稳定锚点缓解流形变化,DCR根据生成模式动态路由。
(3) UCG(无条件上下文引导):利用LCT在推理时提供稳定的无条件支持,改善训练-推理一致性。
优势:问题分析精准,三个模块各自解决一个核心问题,设计优雅。局限:仍基于双流范式,未突破架构本身的上限。
技术演进定位: 双流范式优化的精巧方案
可能的后续方向:
论文: Identity as Presence
arXiv: 2603.17889
核心问题: 联合音视频生成产出匿名内容,无法指定特定人物的外貌和声音
现有联合音视频生成产出的都是'匿名'内容——无法指定特定人物的外貌和声音。然而在虚拟人、个性化视频、AI配音等应用中,身份可控是核心需求。
前序工作及局限:
与前序工作的本质区别: Identity as Presence首次实现面部外观+声音音色的联合个性化
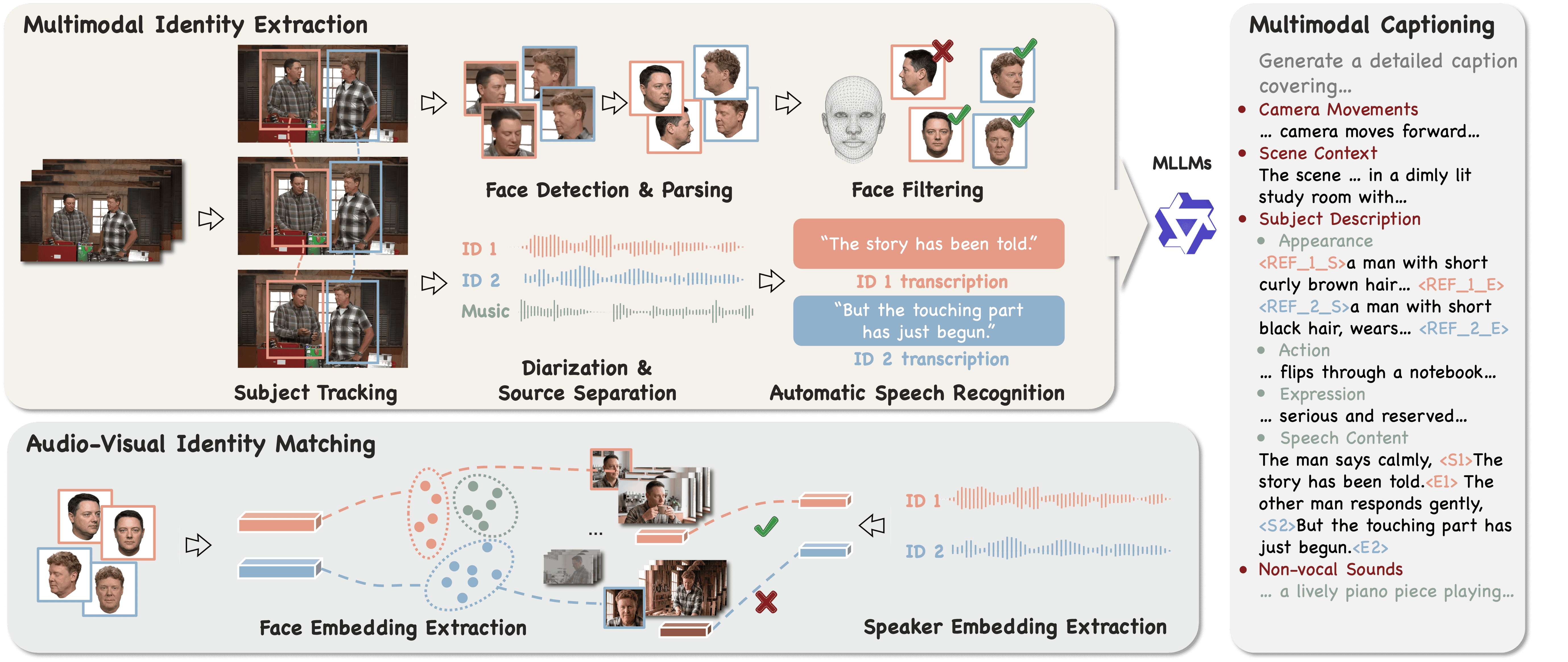
核心设计:
(1) 自动化身份数据策划管线:从大规模音视频数据中自动提取配对身份信息。
(2) 双模态身份注入:面部外观通过IP-Adapter风格特征注入,声音音色通过音频编码器+适配层注入。
(3) 多阶段训练:阶段一单模态身份预训练,阶段二联合微调学习外观-声音协同保持。
优势:问题定义清晰,双模态身份注入设计实用。局限:身份保持精度受特征编码器上限制约;多人场景下的身份混淆问题待深入分析。
技术演进定位: 联合生成走向身份可控的关键工作
可能的后续方向:
论文: FoleyDirector
arXiv: 2603.19857
核心问题: V2A缺乏精细时序控制,用户无法指定具体时间点的声音事件
当前V2A方法无法实现精细的时序控制——用户希望在特定时间点产生不同音效、控制画内/画外声的切换。现有V2A系统缺乏导演级别的精细调度能力。
前序工作及局限:
与前序工作的本质区别: FoleyDirector引入结构化时序脚本(STS)实现导演级精确控制
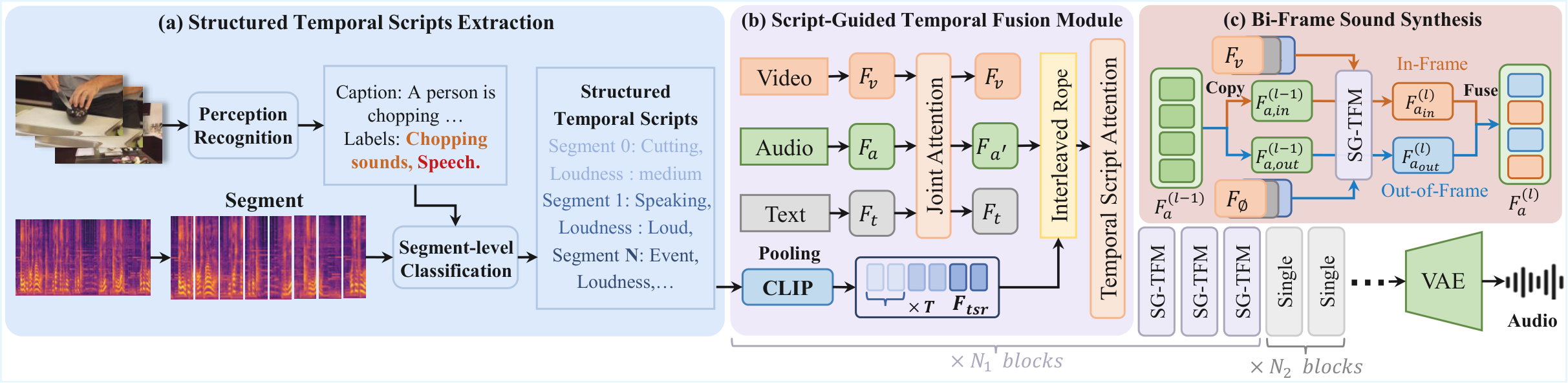
核心设计:
(1) 结构化时序脚本(STS):用户精确指定在第N秒到第M秒产生某种声音,支持画内/画外声独立控制。
(2) Temporal Script Attention:在DiT中引入时序脚本注意力层,融合STS与视频特征。
(3) Bi-Frame Sound Synthesis:并行生成画内声和画外声,精确对齐后混合输出。
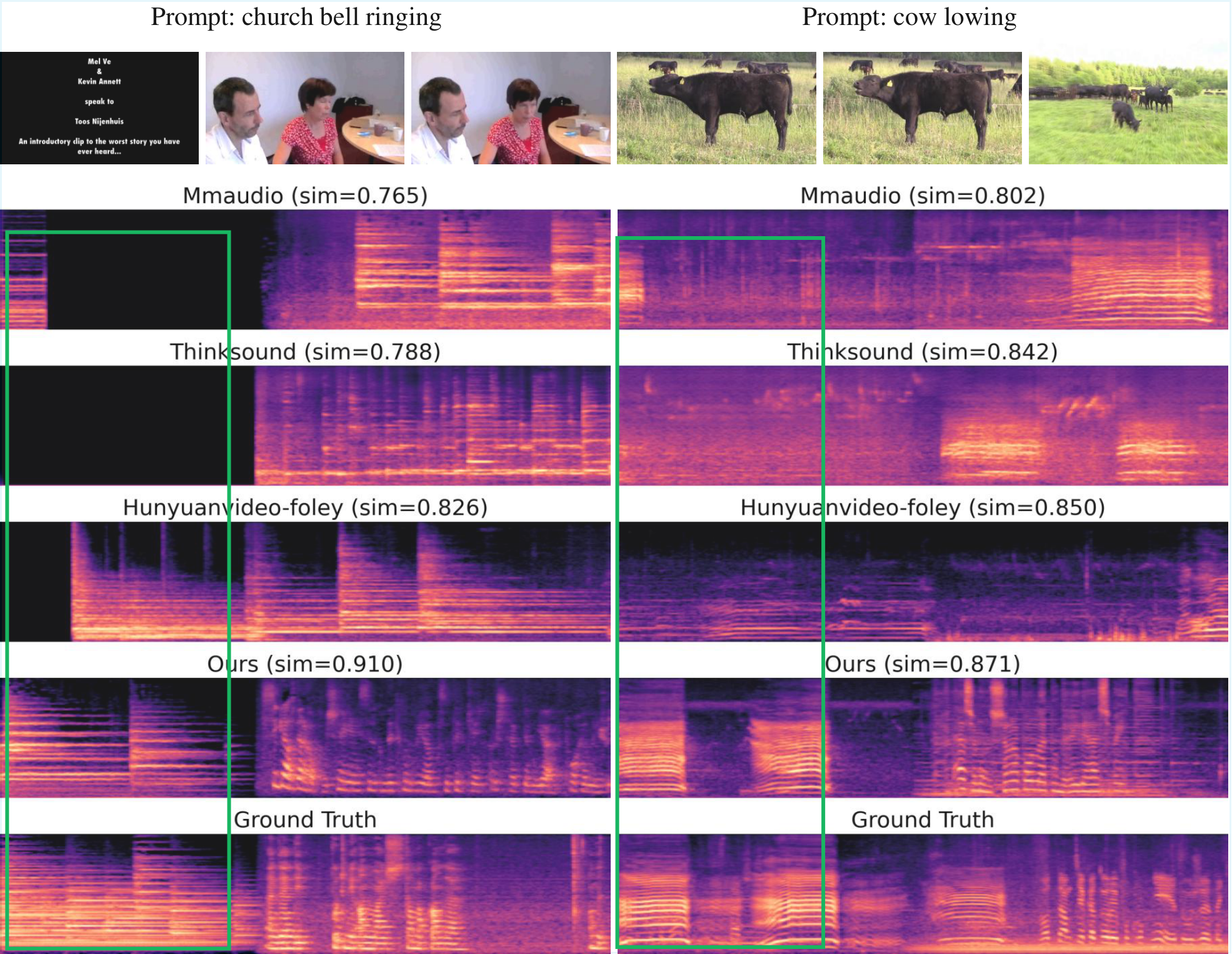
优势:时序脚本是优雅的控制接口,CVPR 2026验证了方法质量。局限:STS常需手工编写,大规模自动化可用性待验证。
技术演进定位: V2A精细控制的CVPR 2026代表作
可能的后续方向:
论文: OmniSonic
arXiv: 2604.04348
核心问题: V2A只关注单一类型音频,无法覆盖真实视频中的全部声音场景
现有V2A方法通常只关注单一类型音频。但真实视频中同时包含屏内环境音、屏外环境音和人类语音三类声音。OmniSonic首次提出Universal Holistic Audio Generation任务。
前序工作及局限:
与前序工作的本质区别: OmniSonic首次统一屏内环境音/屏外环境音/人类语音三类音频的生成
核心设计:
(1) UniHAGen任务:统一屏内环境音、屏外环境音、人类语音三类音频的生成。
(2) TriAttn-DiT架构:基于Flow Matching的DiT,三路交叉注意力(视频/文本/音频类型条件),MoE门控不同专家处理不同类型音频。
(3) UniHAGen-Bench:首个覆盖三类音频的统一评测基准。
优势:任务定义前瞻,全场景覆盖填补领域空白,CVPR 2026验证了质量。局限:三类音频的联合生成质量仍有提升空间。
技术演进定位: 全场景V2A的CVPR 2026开拓者
可能的后续方向:
论文: FoleyDesigner
arXiv: 2604.05731
机构: Shanghai University, University of Surrey
核心问题: 自动Foley生成产出单声道音频,缺乏空间感和沉浸式体验
拟音艺术是电影沉浸式听觉体验的关键。现有自动Foley生成方法产生的都是单声道音频,且时空对齐精度有限。FoleyDesigner首次将Foley生成推向立体声甚至5.1环绕声。
前序工作及局限:
与前序工作的本质区别: FoleyDesigner首次将Foley生成推向立体声/5.1环绕声,LLM驱动空间混音
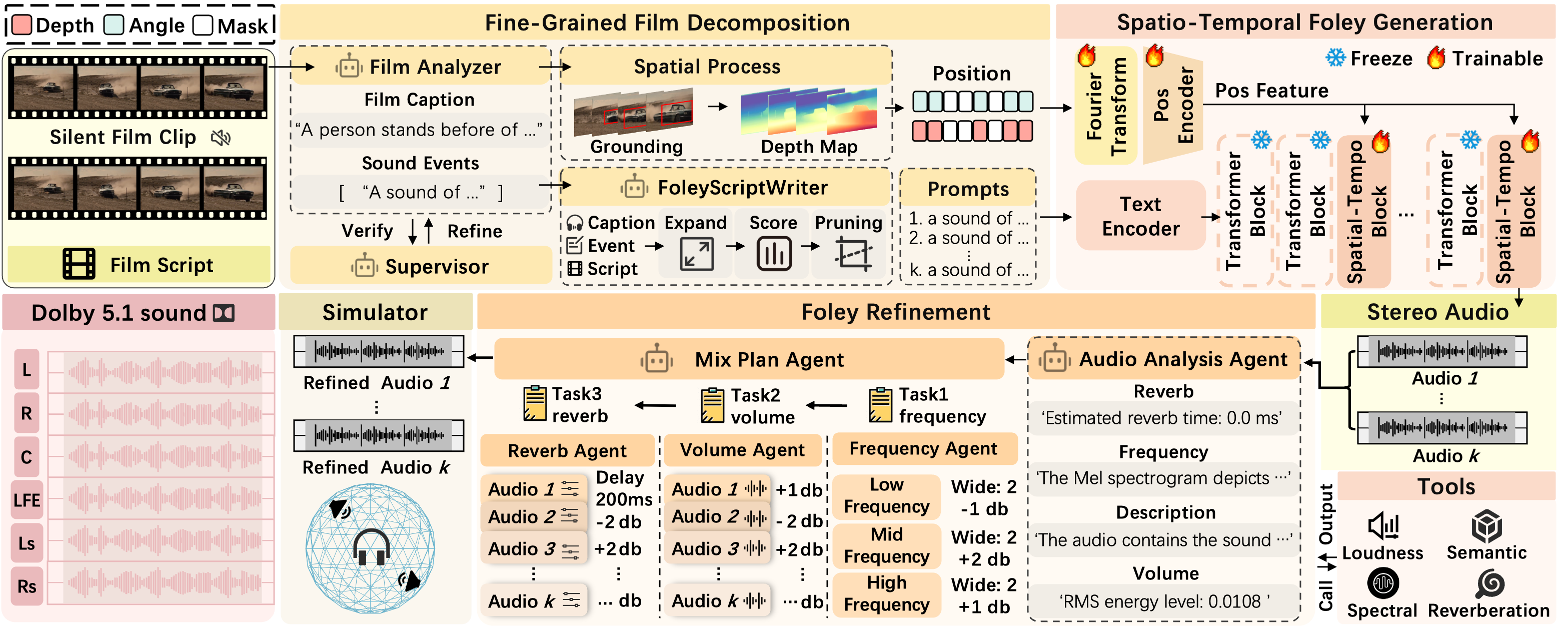
核心设计:
(1) 多智能体时空分析:使用多个AI Agent分析视频中的声音事件,精确标注时间窗口和空间位置。
(2) 潜在扩散音频合成:基于潜在扩散模型生成时序精确对齐的高质量音频。
(3) LLM驱动混音引擎:利用LLM理解声音空间分布,自动完成立体声/5.1声道空间混音。
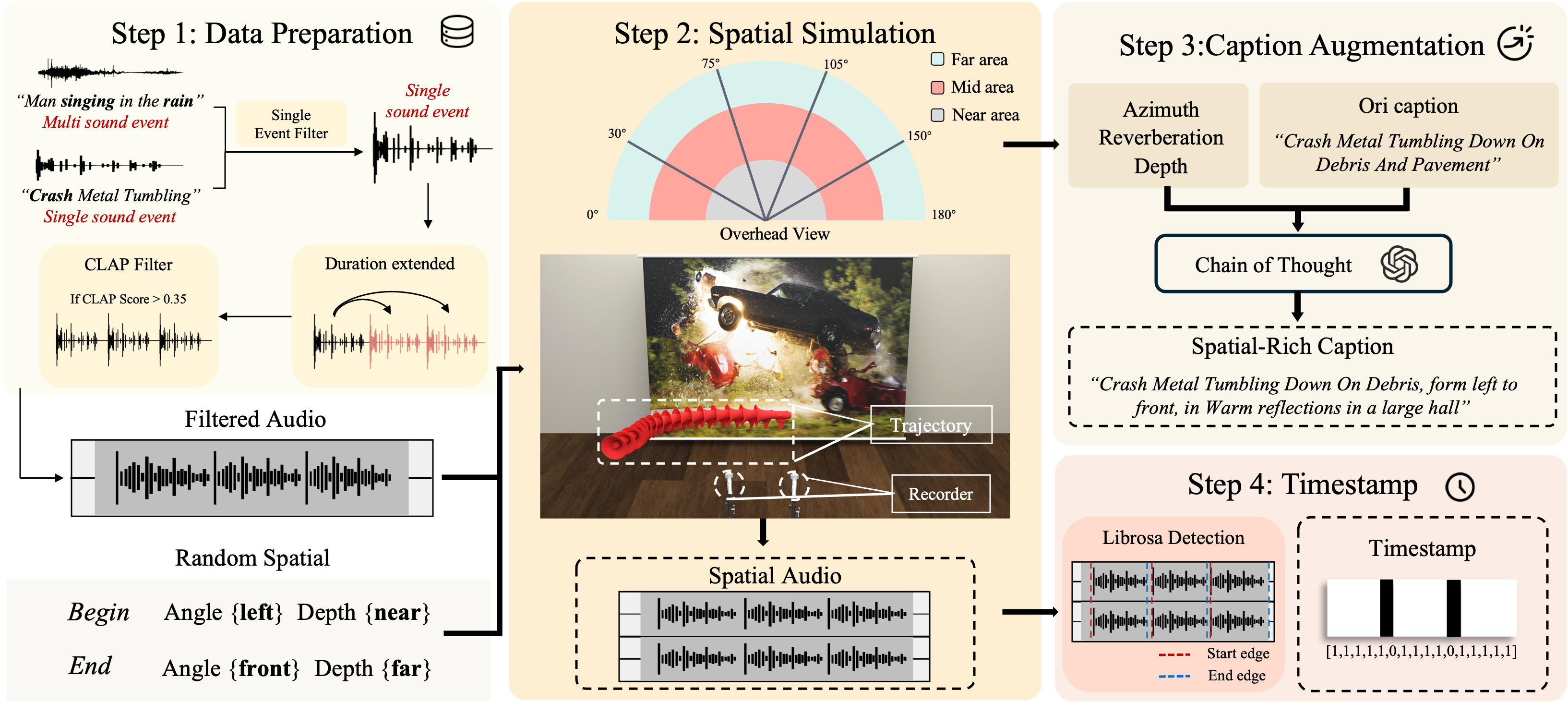
优势:立体声方向前瞻,LLM混音设计新颖。局限:LLM混音的精度和可控性仍需提升;FilmStereo数据集规模有限。
技术演进定位: 立体声拟音方向的探索先驱
可能的后续方向:
ALIVE: Animate Your World with Lifelike Audio-Video Generation | arXiv:2602.08682
关键词: T2VA, 动画, MMDiT
贡献: 将预训练T2V模型适配为联合音视频生成+动画,MMDiT架构增强音视频同步
效果: T2VA和参考图动画双能力
Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model | Sand.ai | arXiv:2603.21986
关键词: 单流架构, 人物中心, 统一token
贡献: 首个单流Transformer联合音视频生成,统一token序列+自注意力,避免多流/跨注意力复杂性
效果: 架构简洁,易于优化,开源
DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation | arXiv:2602.12160
关键词: 统一框架, 多身份, 人物中心
贡献: 统一R2AV/RV2AV/RA2V三种人物中心任务,实现多身份解耦控制
效果: 首个统一多人物音视频控制框架
OmniCustom: Sync Audio-Video Customization Via Joint Audio-Video Generation Model | 腾讯, HKU | arXiv:2602.12304
关键词: 音视频定制, 身份+音色, 新任务定义
贡献: 提出同步音视频定制新任务,同时定制视频身份+音频音色
效果: 同步音视频身份定制
AVControl: Efficient Framework for Training Audio-Visual Controls | arXiv:2603.24793
关键词: 模块化控制, LoRA, LTX-2
贡献: 基于LTX-2的模块化音视频控制,每模态独立LoRA,低训练成本
效果: 模块化控制SOTA
Woosh: A Sound Effects Foundation Model | Sony AI | arXiv:2604.01929
关键词: T2A+V2A, 基础模型, 蒸馏加速
贡献: 统一文本音效+视频条件音效的基础模型,蒸馏5-8x加速
效果: AudioCaps/Clotho上FAD与SOTA相当,V2A同步分数高于基线
AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer | ICLR 2026
关键词: 参考音频, V2A, ICLR 2026
贡献: 以参考音频(非文本)控制V2A生成,实现更细粒度音色迁移
效果: 参考音频条件下Foley生成SOTA
DynFOA: Generating First-Order Ambisonics with Conditional Diffusion for Dynamic 360-Degree Videos | arXiv:2604.02781
关键词: 360°视频, 空间音频, 3DGS, Ambisonics
贡献: 结合3DGS与条件扩散,为360°视频生成物理一致的一阶Ambisonics空间音频
效果: 空间准确性和声学保真持续优于基线
V2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation | arXiv:2603.11042
关键词: 视频转音乐, 零样本, 时间对齐
贡献: 无需配对数据实现视频到音乐的时间对齐生成
效果: 零样本跨模态音乐生成
GLANCE: A Global-Local Coordination Multi-Agent Framework for Music-Grounded Non-Linear Video Editing | Virginia Tech, Meta AI | arXiv:2604.05076
关键词: 音乐驱动, 视频编辑, 多智能体
贡献: 音乐驱动非线性视频编辑,全局-局部协调多智能体,双循环长期规划+逐片段精修
效果: 比最强基线高33.2%
Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models | arXiv:2602.20981
关键词: V2A, 长度泛化, MMHNet
贡献: 解决V2A模型的长度泛化问题,提出MMHNet多模态层次网络
效果: 短训练长推理的长度泛化
AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation | arXiv:2604.08540
关键词: 评测基准, T2AV, 多粒度
贡献: 首个多粒度文本-音视频联合生成评测基准,11个任务类别
效果: 填补T2AV评测空白
| 论文 | 架构设计 | 训练范式 | 推理模式 | 控制粒度 |
|---|---|---|---|---|
| MOVA | 双流DiT | 渐进式三阶段 | 离线 | 语义级 |
| JavisDiT++ | 双流DiT | 多阶段+DPO | 离线 | 语义级+偏好 |
| OmniForcing | 流式自回归 | 蒸馏 | 实时25FPS | 语义级 |
| CCL | 双流DiT | 轻量训练 | 离线 | 语义级 |
| FoleyDirector | DiT V2A | 监督训练 | 离线 | 时序脚本精确控制 |
| OmniSonic | TriAttn-DiT+MoE | 监督训练 | 离线 | 音频类型级 |
| FoleyDesigner | 扩散+LLM | 多阶段 | 离线 | 时空精确控制 |
| Identity as Presence | 双模态注入 | 多阶段 | 离线 | 身份级 |
从级联到联合,从离线到实时
联合音视频生成从'先视频后音频'的级联方式快速进化为端到端同步生成,OmniForcing的实时流式生成标志着从离线工具向交互式应用的关键转变
双流vs单流架构之争
双流DiT(MOVA/JavisDiT++/CCL)通过复用预训练模型降低训练成本但引入对齐复杂性,单流设计(daVinci-MagiHuman)更简洁,两种范式的优劣将在半年内见分晓
V2A走向导演级精细控制
从粗粒度语义匹配到FoleyDirector的时序脚本精确控制、OmniSonic的全场景覆盖、FoleyDesigner的立体声/空间音频,V2A正从玩具走向专业后期工具
个性化是产品化的关键
Identity as Presence/DreamID-Omni/OmniCustom将联合生成从匿名内容创作推向身份可控的个性化创作,这是从研究到消费产品的关键一步
评测体系亟需标准化
AVGen-Bench的出现说明社区已认识到联合音视频生成缺乏统一评测标准的痛点,标准化评测是推动领域进步的关键基础设施
人工智能炼丹师 整理 | 2026-04-11

评论 (0)