
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 2026年4月12日(周日)
覆盖时间:2023年8月 — 2026年4月(含经典评测与 2025–2026 方法爆发期)
本期 AIGC 周末专题聚焦多镜头视频生成:整体式叙事、自回归记忆、电影级转场与跨镜头一致方向,精选 8 篇代表性论文进行深度解读。
方向分布:
含 CVPR 2026 × 4 篇 (HoloCine, OneStory, STAGE, + 其余 Gloria/Spatia);ICLR 2026 × 1 篇 (CineTrans);NeurIPS 2025 × 1 篇 (EchoShot);CVPR 2025 × 2 篇 (ShotAdapter, Mask²DiT)
| # | 论文 | 机构 | 核心贡献 | arXiv ID |
|---|---|---|---|---|
| 1 | HoloCine | HKUST / Ant Group / ZJU / CUHK / NTU | 首个分钟级整体式多镜头生成框架 | 2510.20822 |
| 2 | OneStory | Meta AI / University of Copenhagen | Frame Selection 模块选取语义最相关历史帧构建全局记忆 | 2512.07802 |
| 3 | ShotStream | CUHK MMLab / Kuaishou Technology | 首个因果流式多镜头生成系统——亚秒延迟、16 FPS | 2603.25746 |
| 4 | CineTrans | 复旦大学 / 上海人工智能实验室 | 首次揭示扩散模型注意力图与镜头转场的对应关系 | 2508.11484 |
| 5 | STAGE | 北京理工大学 / 北京大学 | 将关键帧范式重新建模为首尾帧对预测(STEP2) | 2512.12372 |
| 6 | StoryMem | ByteDance Intelligent Creation / NTU S-Lab | M2V 范式:关键帧记忆经 3D VAE 编码后与噪声潜变量拼接 | 2512.19539 |
| 7 | InfinityStory | Adobe Research / Virginia Tech / Dolby Labs / UMD / Cisco 等 | 位置锚定背景一致性:预生成场所参考图并在生成时注入 | 2603.03646 |
| 8 | EchoShot | 西安交通大学 / 阿里云 | Shot-aware RoPE:TcRoPE 保持跨镜头时间连续性建模身份关联 + TaRoPE 分配独立时间起点防止内 | 2506.15838 |
论文: HoloCine
arXiv: 2510.20822
机构: HKUST / Ant Group / ZJU / CUHK / NTU
核心问题: 单镜头 T2V 无法生成跨镜头连贯的叙事长视频
解耦范式(先关键帧再插值/逐镜头独立拼接)难以保证全局一致,整体式生成有望从根本上解决跨镜头连贯性。
前序工作及局限:
与前序工作的本质区别: HoloCine 整体式生成所有镜头,Window Cross-Attn + Sparse Inter-Shot SA 保证全局一致
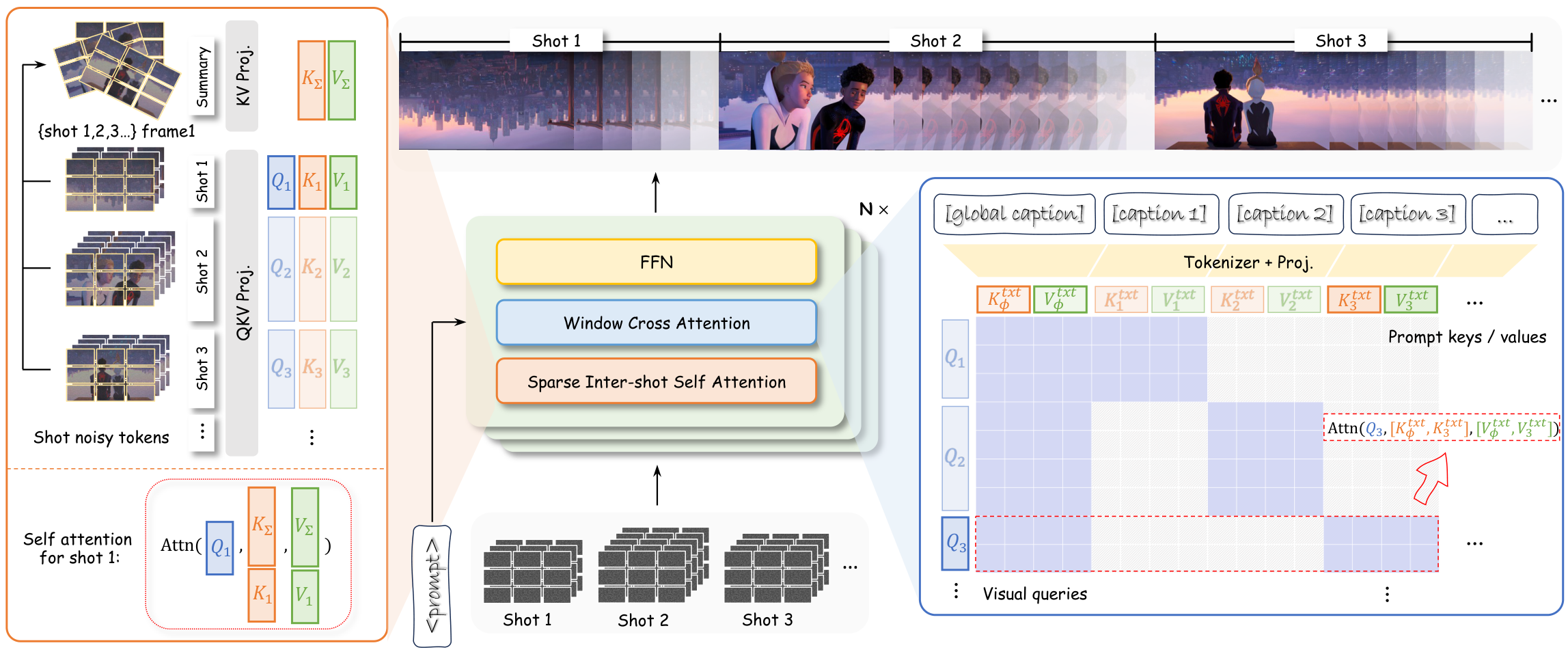
基于 Wan2.2 14B DiT;Window Cross-Attention 将逐镜头文本精确对应到视频帧区间;镜头内密集自注意力 + 镜头间稀疏自注意力组合;两阶段训练(高噪声 DiT 学结构 → 低噪声 DiT 精炼细节)。
优势:全局一致性最强,涌现电影技法理解。局限:受限于显存和计算,当前最长约 1 分钟;无法中途修改剧本。
技术演进定位: 整体式多镜头范式开拓者
可能的后续方向:
论文: OneStory
arXiv: 2512.07802
机构: Meta AI / University of Copenhagen
核心问题: 有限时间窗口或单关键帧条件导致长程上下文丢失
有限时间窗口或单关键帧条件导致长程上下文丢失,需要像人类记忆一样选择性保留关键视觉信息。
前序工作及局限:
与前序工作的本质区别: OneStory 自适应选帧 + 紧凑条件注入,模拟人类选择性记忆
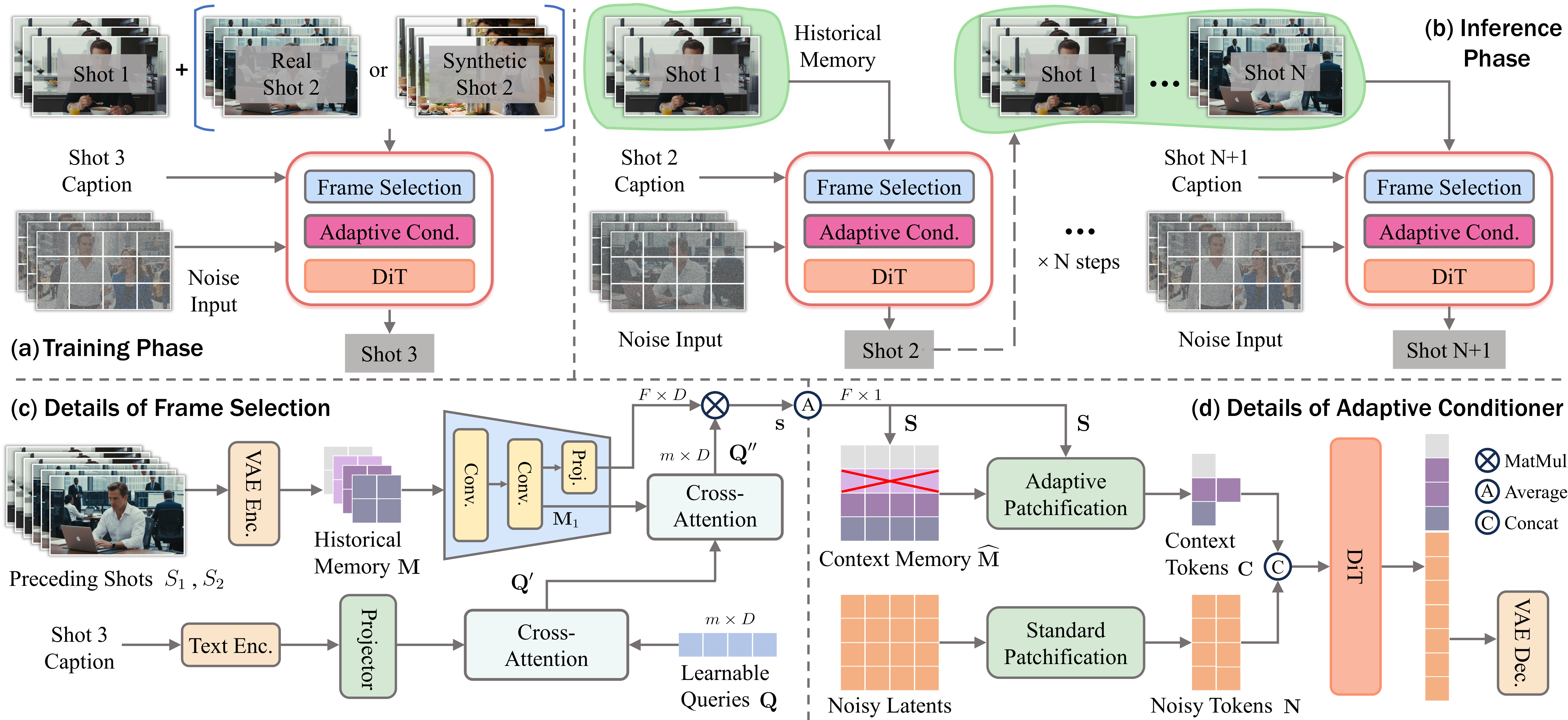
将多镜头建模为 next-shot 任务;Frame Selection 从历史帧中按信息量和相关性筛选;Adaptive Conditioner 压缩后直接注入生成器;60K 数据集的引用式字幕模拟真实叙事模式。

优势:自适应记忆选帧机制优雅高效,数据集设计贴合真实叙事。局限:复杂多角色场景下纯视觉记忆可能不足;引用式字幕生成依赖 LLM 质量。
技术演进定位: 自适应记忆自回归代表
可能的后续方向:
论文: ShotStream
arXiv: 2603.25746
机构: CUHK MMLab / Kuaishou Technology
核心问题: 双向整段生成延迟高、不可中途修改
双向整段生成延迟高且无法中途改剧本,创作者需要流式交互体验。
前序工作及局限:
与前序工作的本质区别: ShotStream 因果蒸馏 + 双缓存实现 16 FPS 流式多镜头
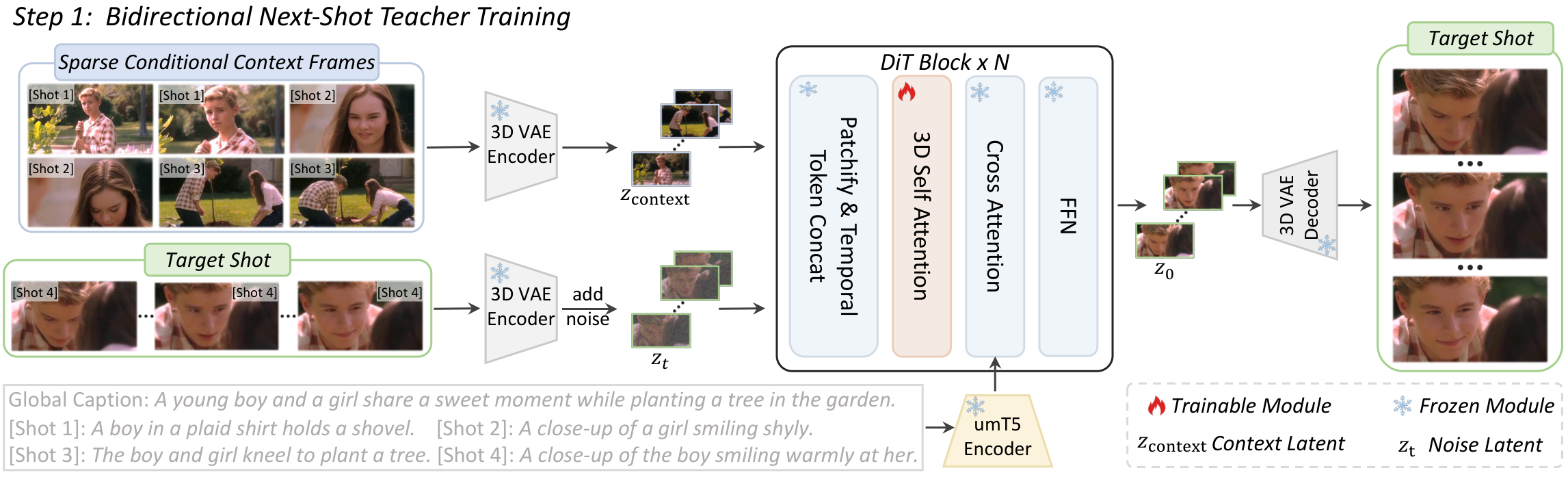
先训练双向 next-shot 教师,再 DMD 蒸馏为因果学生;全局上下文缓存服务跨镜头一致,局部上下文缓存服务镜头内时序;两阶段自强迫分别在镜头内和镜头间缩小训练-推理差距。

优势:交互叙事与工程指标平衡好,开源推动复现。局限:极长镜头链上因果信息量仍弱于全局双向;全局缓存随镜头增长占用上升。
技术演进定位: 交互式实时多镜头方向标杆
可能的后续方向:
论文: CineTrans
arXiv: 2508.11484
机构: 复旦大学 / 上海人工智能实验室
核心问题: 视频扩散模型的镜头转场能力原始且不稳定
即使大规模模型也无法稳定生成电影级镜头转场,转场能力原始且不稳定。
前序工作及局限:
与前序工作的本质区别: CineTrans 发现注意力-转场对应关系并用掩码实现电影级转场控制
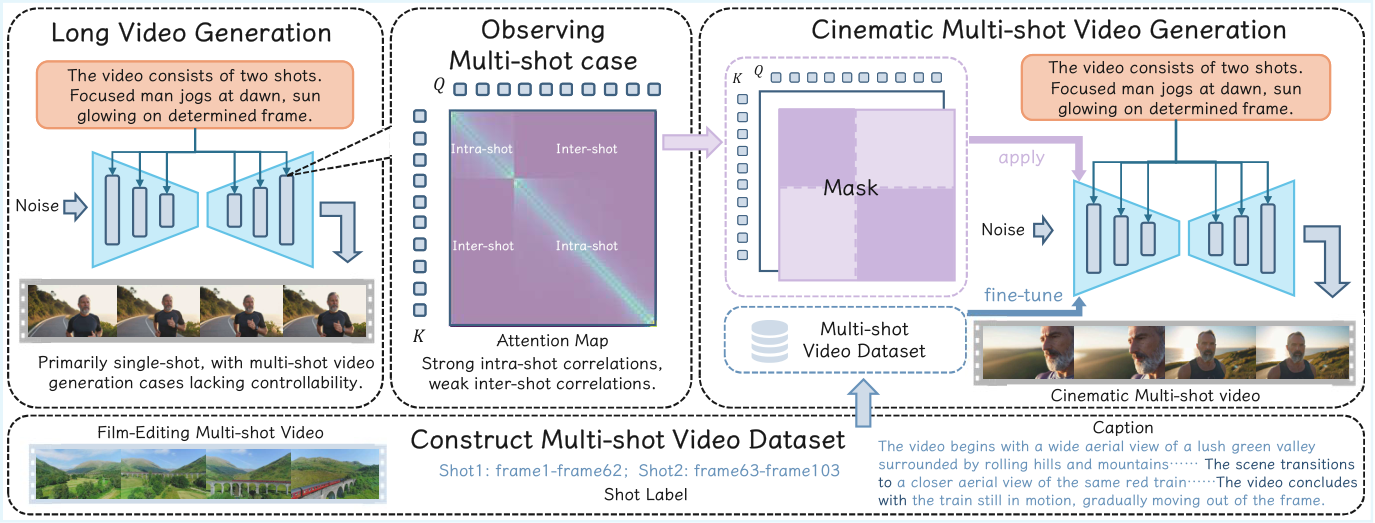
分析扩散模型注意力图发现概率分布在镜头切换位置出现变化;设计注意力掩码矩阵在指定帧引入转场;Cine250K 从 Vimeo 633K 视频多阶段清洗;在 SD1.4 和 Wan2.1 上均验证。

优势:注意力-转场对应的发现具有理论价值,掩码机制优雅且可迁移。局限:转场类型多样性仍需扩展;与自回归长视频的结合尚待验证。
技术演进定位: 电影转场控制开创性工作
可能的后续方向:
论文: STAGE
arXiv: 2512.12372
机构: 北京理工大学 / 北京大学
核心问题: 稀疏关键帧无法同时保证跨镜头一致和电影级过渡
稀疏关键帧无法维持跨镜头一致性且难以捕捉电影语言中的过渡。
前序工作及局限:
与前序工作的本质区别: STAGE 预测首尾帧对作为结构化故事板 + DPO 偏好对齐学习电影语言

STEP2 迭代预测每镜头首帧和尾帧组成结构化故事板;多镜头记忆包打包历史帧对为上下文;双编码分别处理镜头内起止和镜头间过渡;两阶段训练 + DPO 偏好对齐优化转场质量。

优势:首尾帧对比单一关键帧提供更强结构约束,DPO 引入电影偏好。局限:STEP2 预测质量上限受限于训练数据的电影片段质量;复杂叙事(多线并行)需进一步验证。
技术演进定位: 故事板锚定范式代表
可能的后续方向:
论文: StoryMem
arXiv: 2512.19539
机构: ByteDance Intelligent Creation / NTU S-Lab
核心问题: 预训练单镜头模型缺乏跨镜头记忆能力
如何让预训练单镜头模型以最小改动获得跨镜头记忆能力。
前序工作及局限:
与前序工作的本质区别: StoryMem M2V 潜变量拼接 + 负 RoPE 偏移,LoRA 微调成本极低
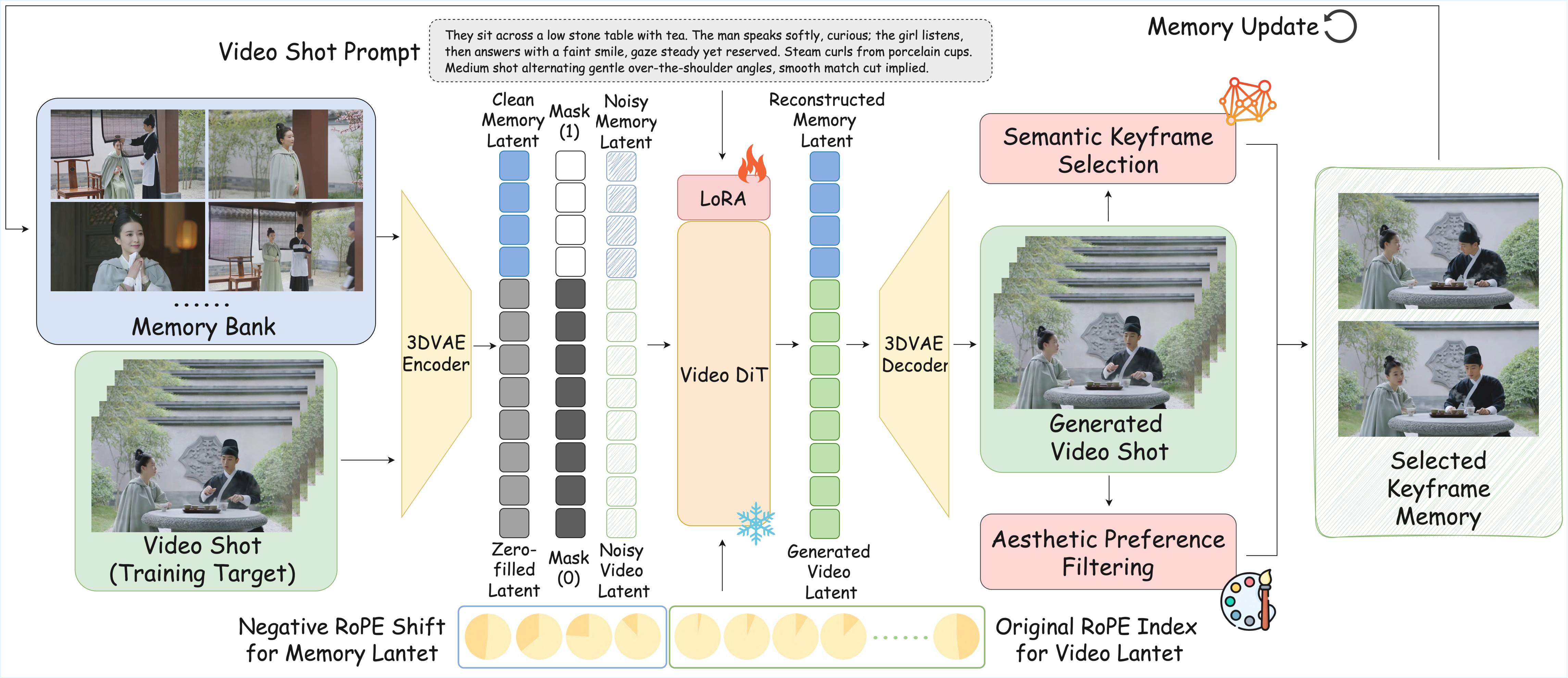
维护动态更新的关键帧记忆库;记忆帧经 3D VAE 编码后与噪声视频潜变量和二值掩码拼接送入 Video DiT;负 RoPE 偏移编码历史属性;LoRA 微调 Wan2.2;MM2V 扩展支持平滑过渡。

优势:M2V 范式简洁高效,LoRA 微调成本极低,开源生态好。局限:纯视觉记忆在复杂多角色场景下可能不足;记忆更新策略偏启发式。
技术演进定位: 最低成本多镜头启用方案
可能的后续方向:
论文: InfinityStory
arXiv: 2603.03646
机构: Adobe Research / Virginia Tech / Dolby Labs / UMD / Cisco 等
核心问题: 长叙事中背景漂移和多主体转场断裂
场景漂移和多主体转场断裂是长叙事视频的两个被低估的痛点。
前序工作及局限:
与前序工作的本质区别: InfinityStory 位置锚定背景 + 10K 合成数据训练多主体过渡模型
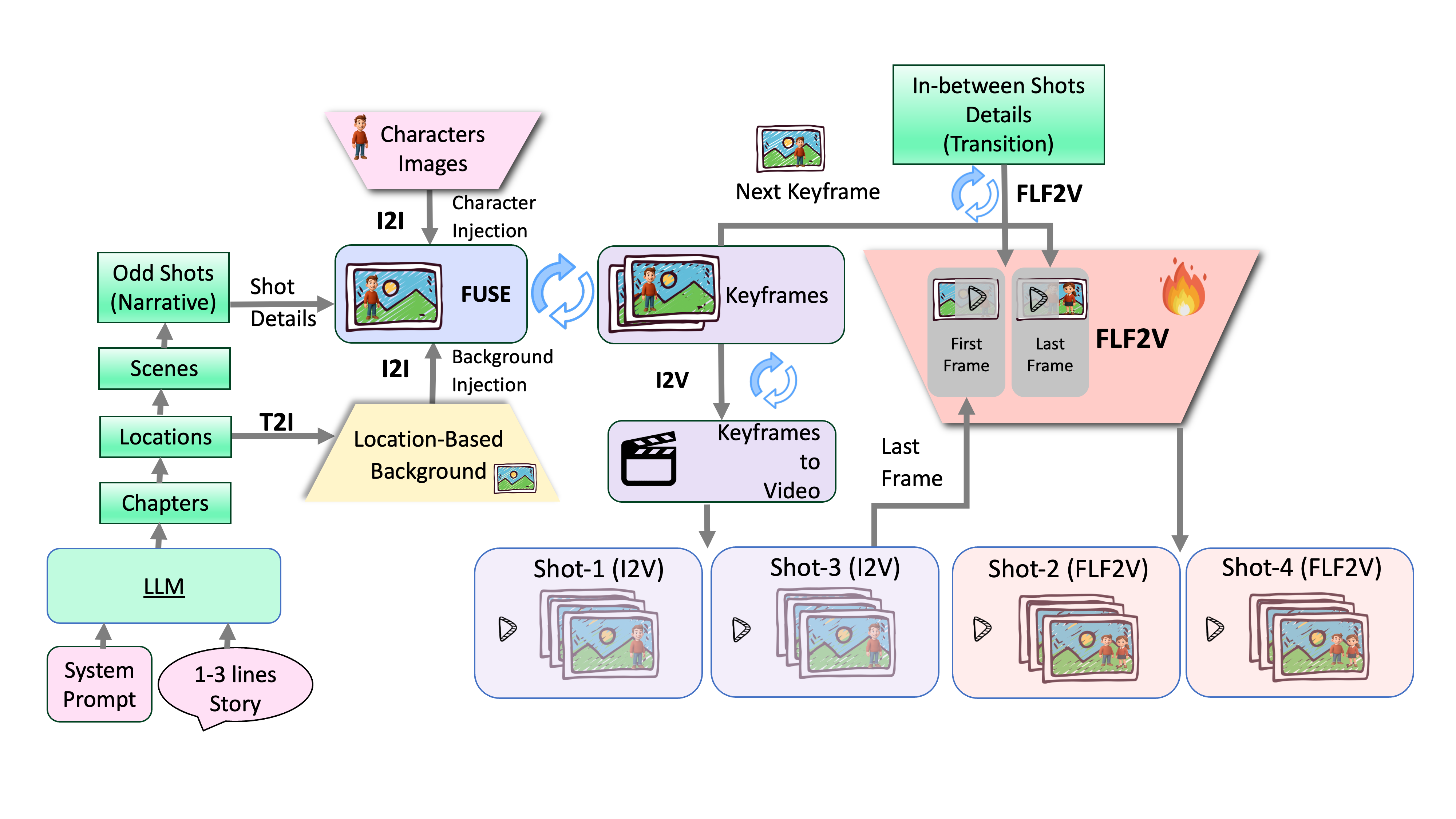
为每个场所预生成背景参考图注入生成过程保证世界一致;构建 10K 多主体过渡序列覆盖入场/退场/替换;训练 FLF2V 过渡模型实现平滑衔接;LLM 多智能体系统分解故事。
优势:同时解决背景漂移和多主体过渡两大痛点,VBench SOTA。局限:级联管线各模块错误可累积;背景参考图预生成增加前置成本。
技术演进定位: 世界一致性 + 多主体过渡先驱
可能的后续方向:
论文: EchoShot
arXiv: 2506.15838
机构: 西安交通大学 / 阿里云
核心问题: 人像多镜头需要精确面部 ID 一致同时允许属性变化
人像多镜头需要精确面部身份一致同时允许表情、动作、服装灵活变化,外部条件注入方案开销大且控制粗糙。
前序工作及局限:
与前序工作的本质区别: EchoShot 在 RoPE 层面原生建模多镜头结构,TcRoPE + TaRoPE 零额外开销
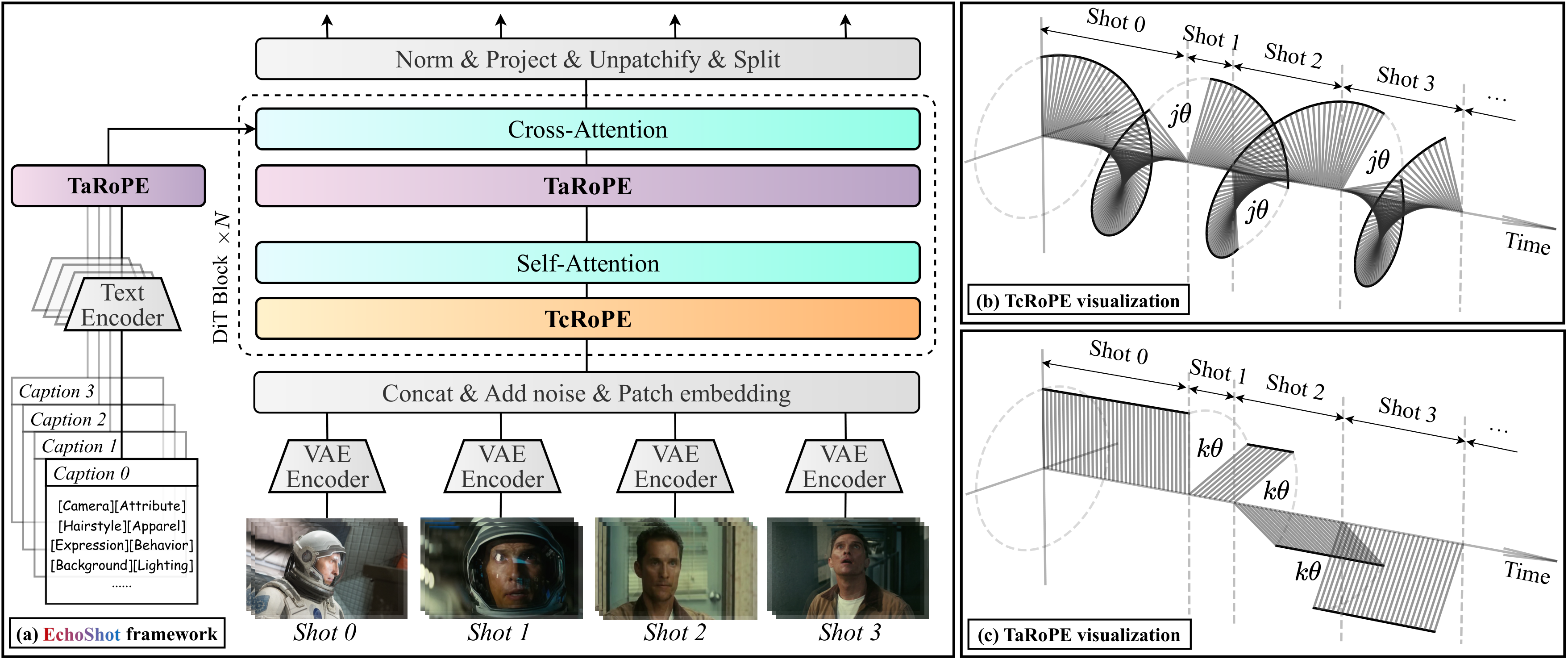
在 DiT 的 RoPE 层面原生区分镜头边界;TcRoPE 在注意力层保持跨镜头时间连续性;TaRoPE 在另一些层分配独立起点;多镜头视频作为长序列直接训练;PortraitGala 提供精细人像字幕。
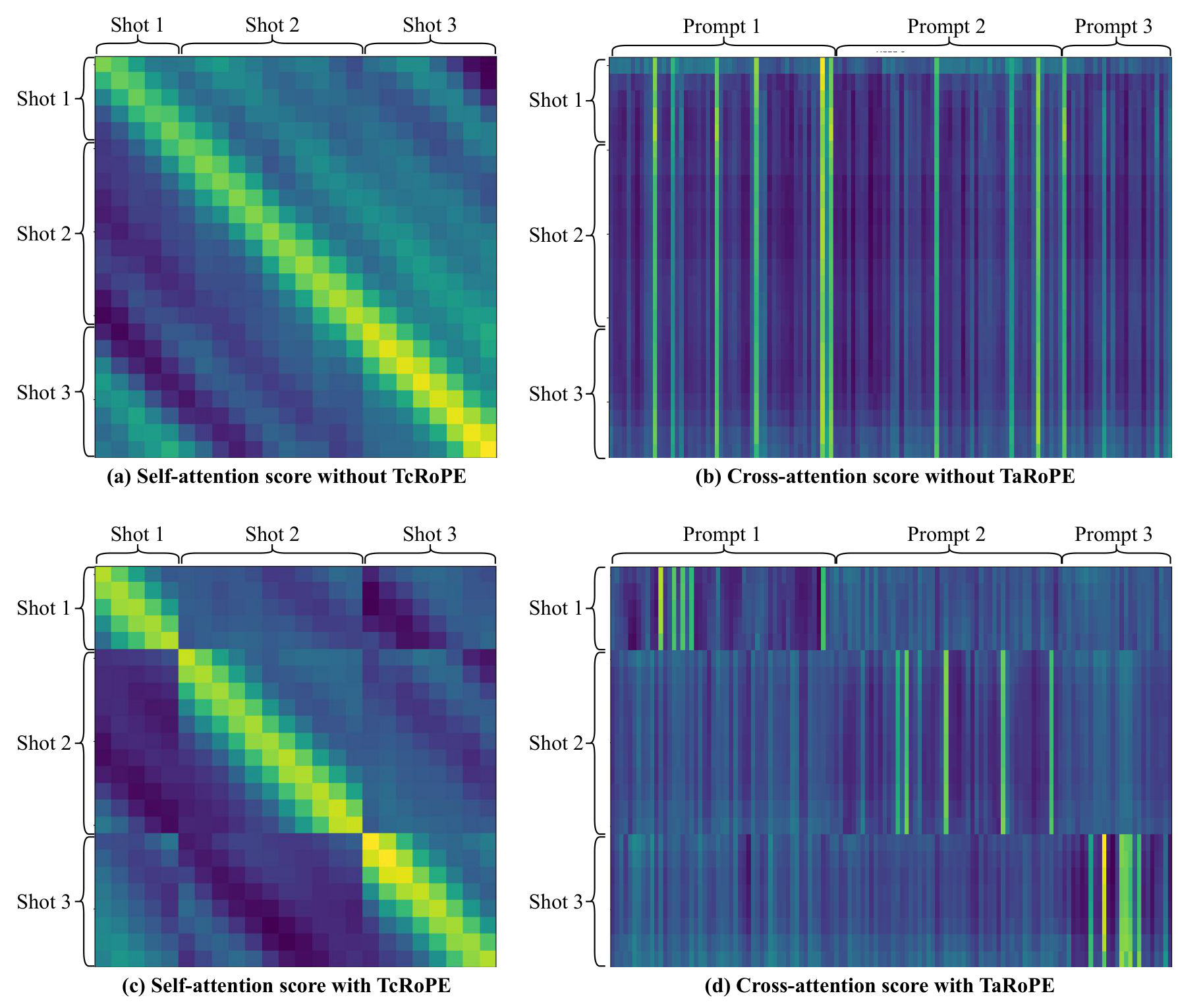
优势:RoPE 层面建模零额外开销,可推广到非人像。局限:当前仅在 1.3B 模型上验证,14B 级别的效果待确认;人像以外的泛化性需更多数据。
技术演进定位: 人像垂直场景原生多镜头范式
可能的后续方向:
ShotAdapter: Text-to-Multi-Shot Video Generation with Diffusion Models | Adobe / UIUC | arXiv:2505.07652
关键词: CVPR 2025, 掩码微调, 数据管线
贡献: 过渡 token + 局部注意力掩码,~5K 步微调 T2V 即可多镜头
效果: 低门槛多镜头启用路线代表
Mask²DiT: Dual Mask-based Diffusion Transformer for Multi-Scene Long Video Generation | USTC / ByteDance | arXiv:2503.19881
关键词: CVPR 2025, 双掩码, 自回归
贡献: 对称二值掩码 + 段级条件掩码,多场景长视频自回归扩展
效果: 掩码类方法在 DiT 上的完整实现
MultiShotMaster: A Controllable Multi-Shot Video Generation Framework | 高校+工业联合 | arXiv:2512.03041
关键词: 位置编码, 可控性, 数据自动化
贡献: Multi-Shot RoPE + ST Position-Aware RoPE + 自动标注管线
效果: RoPE 扩展路线代表
ShotVerse: Advancing Cinematic Camera Control for Text-Driven Multi-Shot Video Creation | 多机构 | arXiv:2603.11421
关键词: VLM 规划, 轨迹标定, 相机适配器
贡献: VLM 规划电影相机轨迹 + 相机适配器 + ShotVerse-Bench 三轨评测
效果: 电影级相机控制关键拼图
ShotDirector: Directorially Controllable Multi-Shot Video Generation with Cinematographic Transitions | 复旦 / 上海 AI Lab | arXiv:2512.10286
关键词: 6-DoF, 编辑模式, ShotWeaver40K
贡献: 6-DoF 相机控制 + 层级编辑模式提示 + ShotWeaver40K
效果: 导演级转场控制
FilmWeaver: Cache-Guided Autoregressive Diffusion for Multi-Shot Video | Kuaishou Technology | arXiv:2512.11274
关键词: 缓存, 自回归, 跨镜头一致
贡献: 缓存引导自回归扩散,任意镜头数 + 身份/背景一致性
效果: 工业级叙事生成
CoAgent: Collaborative Planning and Consistency Agent for Coherent Video Generation | 多机构 | arXiv:2512.22536
关键词: 多智能体, 闭环验证, 叙事规划
贡献: 协作闭环管线:剧本规划→全局实体记忆→合成→验证 Agent→节奏编辑
效果: Agent 驱动多镜头生成
VideoGen-of-Thought: Step-by-step generating multi-shot video with minimal manual intervention | NUS / UCF 等 | arXiv:2412.02259
关键词: NeurIPS 2025 WS, training-free, 身份传播
贡献: 训练无关管线,单句→多镜头自动化,面部一致性 +20.4%
效果: 零训练多镜头管线先驱
SkyReels-V2: Infinite-length Film Generative Model | Skywork AI | arXiv:2504.13074
关键词: Diffusion Forcing, RL, 开源生态
贡献: 无限长度电影模型,MLLM + Diffusion Forcing + RL + SkyCaptioner
效果: 工业级开源长视频系统(6.7K stars)
CINEMA: Coherent Multi-Subject Video Generation via MLLM-Based Guidance | ByteDance | arXiv:2503.10391
关键词: MLLM, 多主体, MM-DiT
贡献: MLLM 引导多主体连贯视频,消除主体-文本显式对应需求
效果: 多主体场景解决方案
Gloria: Content Anchors for Long-Time Character-Consistent Video Generation | USTC | arXiv:2603.29931
关键词: CVPR 2026, 内容锚点, 超集锚定
贡献: 三类内容锚点(全局/视角/表情),10min+ 角色一致
效果: 角色中心长视频一致
MemRoPE: Training-Free Infinite Video Generation with Dual-Stream Memory Tokens and Online RoPE | USC | arXiv:2603.12513
关键词: 无训练, Memory Token, Online RoPE
贡献: 无训练双流记忆 + Online RoPE,长视频身份防漂移
效果: 无训练长上下文推理参考
Spatia: Video Generation with Updatable Spatial Memory | Sydney / MSR | arXiv:2512.15716
关键词: CVPR 2026, 3D 点云, Visual SLAM
贡献: 3D 点云空间记忆 + Visual SLAM 迭代更新,长距空间一致
效果: 几何级空间一致方案
MSVBench: Towards Human-Level Evaluation of Multi-Shot Video Generation | 多机构 | arXiv:2602.23969
关键词: 评测基准, LMM+专家模型, 136 故事
贡献: 首个多镜头视频生成综合评测基准,20 方法对比,94.4% 人类相关性
效果: 多镜头评测标准化基础设施
StoryBench: A Multifaceted Benchmark for Continuous Story Visualization | Google Research / DeepMind | arXiv:2308.11606
关键词: NeurIPS 2023, 三任务, 人机评估
贡献: 连续故事可视化三任务基准
效果: 故事可视化评测基石
PackForcing: Three-Partition KV-cache Long Video Autoregressive | Alaya Studio / Shandong University | arXiv:2603.25730
关键词: KV-cache, 长视频, 自回归
贡献: 有界 KV-cache 极长自回归外推
效果: 长序列生成内存侧方案
Movie Gen: A Cast of Media Foundation Models | Meta | arXiv:2410.13720
关键词: 基础模型, 长上下文, 工业标杆
贡献: 超长上下文媒体基础模型
效果: 多镜头工业能力上限参考
DreamFactory: Pioneering Multi-Scene Long Video Generation with a Multi-Agent Framework | 清华等 | arXiv:2408.11788
关键词: 多场景, 多智能体, 长视频
贡献: 多智能体 + 关键帧迭代生成多场景长视频
效果: 多镜头叙事与 LLM 编排先驱
MovieFactory: Automatic Movie Creation from Text using Large Generative Models | 多机构 | arXiv:2306.07257
关键词: 级联管线, 脚本生成, 多场景
贡献: 早期脚本→多镜头有声影片级联管线
效果: 早期文本到电影流水线代表
| 论文 | 核心范式 | 跨镜头一致机制 | 交互/延迟 | 训练成本 | 会议 |
|---|---|---|---|---|---|
| HoloCine | 整体式双向 | 稀疏自注意力 | 离线整段 | 高 | CVPR 2026 |
| OneStory | 自回归 next-shot | 自适应选帧+紧凑注入 | 逐镜头 | 中 | CVPR 2026 |
| ShotStream | 因果蒸馏 next-shot | 全局+局部双缓存 | 实时 16 FPS | 高(蒸馏) | — |
| CineTrans | 掩码控制微调 | 注意力掩码 | 离线 | 中 | ICLR 2026 |
| STAGE | 故事板→插值 | 记忆包+双编码 | 逐镜头 | 中 | CVPR 2026 |
| StoryMem | M2V 潜变量拼接 | 关键帧记忆库 | 逐镜头 | 低(LoRA) | — |
| InfinityStory | 级联多模块 | 位置锚定+过渡模型 | 逐镜头 | 中 | — |
| EchoShot | 原生长序列 | TcRoPE+TaRoPE | 离线 | 低 | NeurIPS 2025 |
整体式与自回归各有未来
HoloCine 证明整体式在分钟级可行且一致性最强,但计算瓶颈限制扩展。自回归天然支持无限镜头和交互修改。两者可能走向融合。
记忆机制是决胜关键
StoryMem 的 M2V、ShotStream 的双缓存、OneStory 的自适应选帧、InfinityStory 的位置锚定——「记什么/怎么压缩/何时更新」是核心维度。
电影语言成为差异化壁垒
CineTrans 揭示注意力-转场对应、STAGE 引入 DPO 偏好、ShotDirector 定义编辑层级——从「拼得连贯」推向「剪得专业」。
数据集构建是隐形竞赛
Cine250K、ConStoryBoard、PortraitGala、ShotWeaver40K、10K CMTS——每篇顶会论文自带数据集,数据工程可能比模型创新更稀缺。
开源生态加速成熟
基于 Wan2.2 微调已成共识。ShotStream、StoryMem、HoloCine、SkyReels-V2 均开源。ComfyUI 多镜头插件标志着走向创作者工具链。
人工智能炼丹师 整理 | 数据来源:arXiv 2023年8月 — 2026年4月(含经典评测与 2025–2026 方法爆发期)
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)