
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 2026年4月5日(周日)
覆盖时间:2026年3月29日 — 2026年4月5日
本期 AIGC 周末专题聚焦语音合成与音频生成前沿:从编解码器语言模型到扩散 TTS、音效生成与指令驱动语音设计方向,精选 6 篇代表性论文进行深度解读。
方向分布:
| # | 论文 | 机构 | 核心贡献 | arXiv ID |
|---|---|---|---|---|
| 1 | Voxtral TTS | Mistral AI | 提出 Voxtral TTS 混合架构:自回归语义 token 建模 + 流匹配声学 token 生成,兼顾语义连贯性和 | 2603.25551 |
| 2 | LongCat-AudioDiT | Meituan | 在波形潜空间(而非频谱或 token 空间)进行扩散 TTS,保留完整音频信息 | 2603.29339 |
| 3 | T5Gemma-TTS | 回归编码器-解码器架构:T5 编码器(2B)理解文本、Gemma 解码器(2B)生成语音 token | 2604.01760 | |
| 4 | Woosh | Sony AI | 构建完整音效基础模型:音频编解码器 + 文本-音频对齐 + T2A 生成 + V2A 生成 | 2604.01929 |
| 5 | MOSS-VoiceGenerator | Fudan University | 指令驱动语音生成:自然语言描述控制语音风格、情感和表达方式 | 2603.28086 |
| 6 | Prosody-Aware TTS | Independent Research | 多阶段预训练:MLM 预训练 + SigLIP 跨模态对比学习 | 2604.01247 |
论文: Voxtral TTS
arXiv: 2603.25551
机构: Mistral AI
核心问题: 语音合成在零样本克隆音色保真度和多语言支持上不足,开源与商业差距大
当前语音合成系统在零样本语音克隆的音色保真度、韵律自然度和长文本稳定性上仍有差距。商业系统如 ElevenLabs 领先,开源社区需要更强大的基座模型。
前序工作及局限:
与前序工作的本质区别: 混合 AR 语义建模 + Flow Matching 声学生成,Voxtral Codec 双层量化,68.4% 胜率超越 ElevenLabs
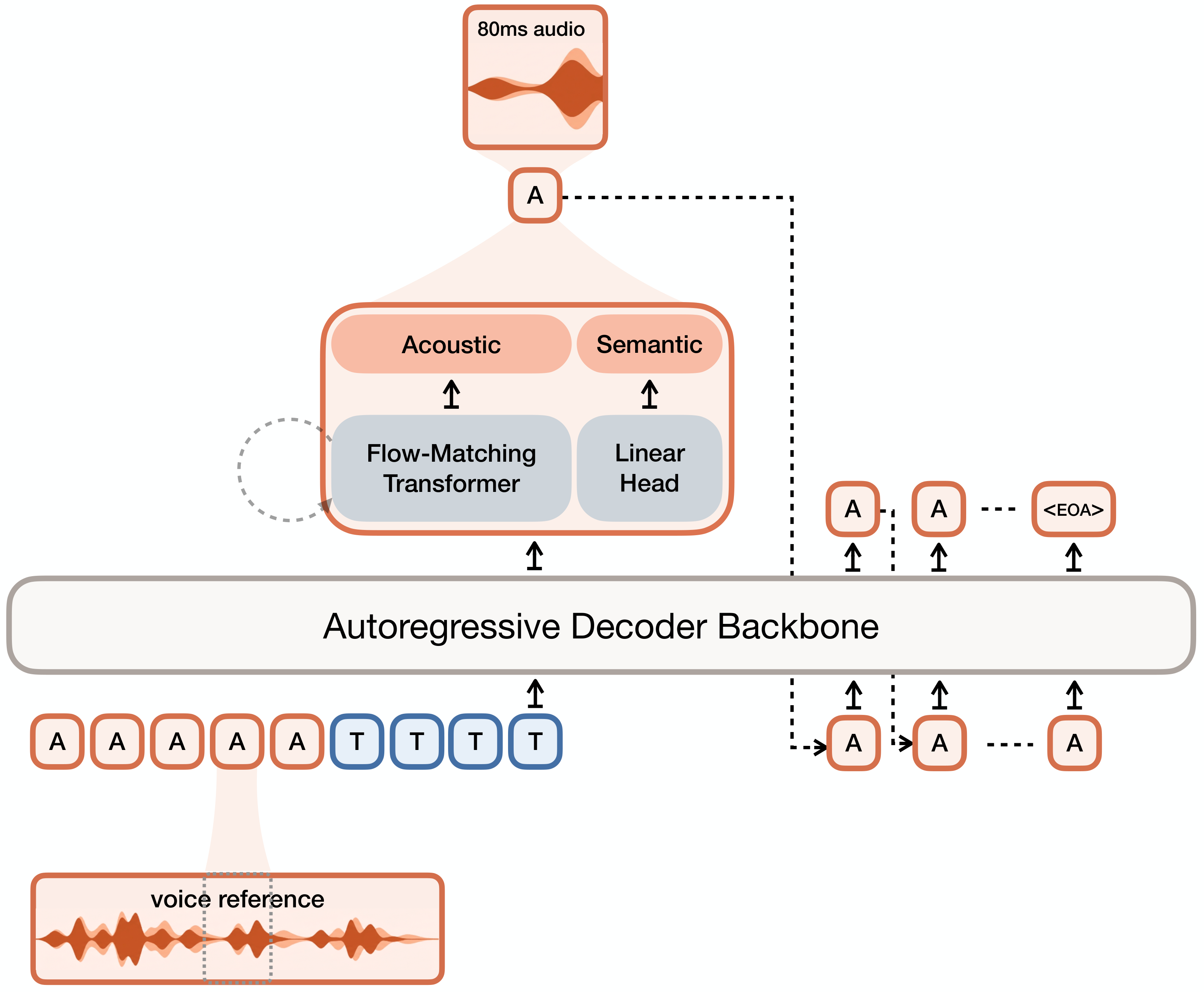
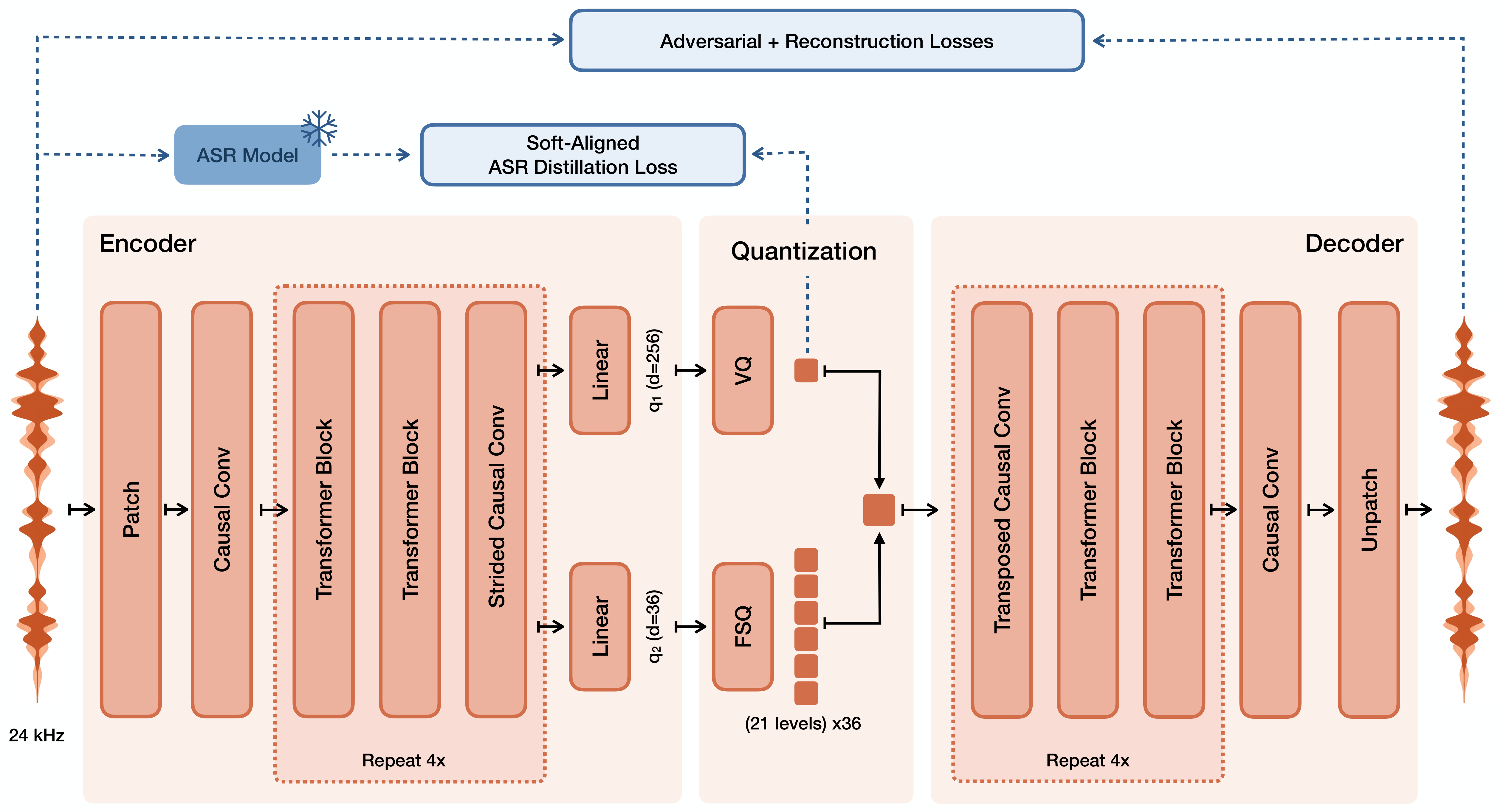
Voxtral TTS 的核心是两阶段生成管线。第一阶段使用自回归 Transformer 预测语义 token 序列,这些语义 token 由 Voxtral Codec 的 VQ 层提取,编码语音的语言内容和韵律模式。第二阶段使用条件流匹配模型以语义 token 为条件生成声学 token,FSQ 层编码精细的音色纹理。Voxtral Codec 是关键创新:编码器将音频压缩为双层表示(VQ 语义层 + FSQ 声学层),解码器从两层 token 重建高保真音频。
CC BY-NC 限制商业应用。两阶段推理增加延迟。与 ElevenLabs Turbo 系列未对比。训练数据未完全公开。
技术演进定位: 开源 TTS 新标杆,证明混合架构路线有效性
可能的后续方向:
论文: LongCat-AudioDiT
arXiv: 2603.29339
机构: Meituan
核心问题: 自回归 TTS 误差累积和延迟,非自回归方法音色克隆质量不足
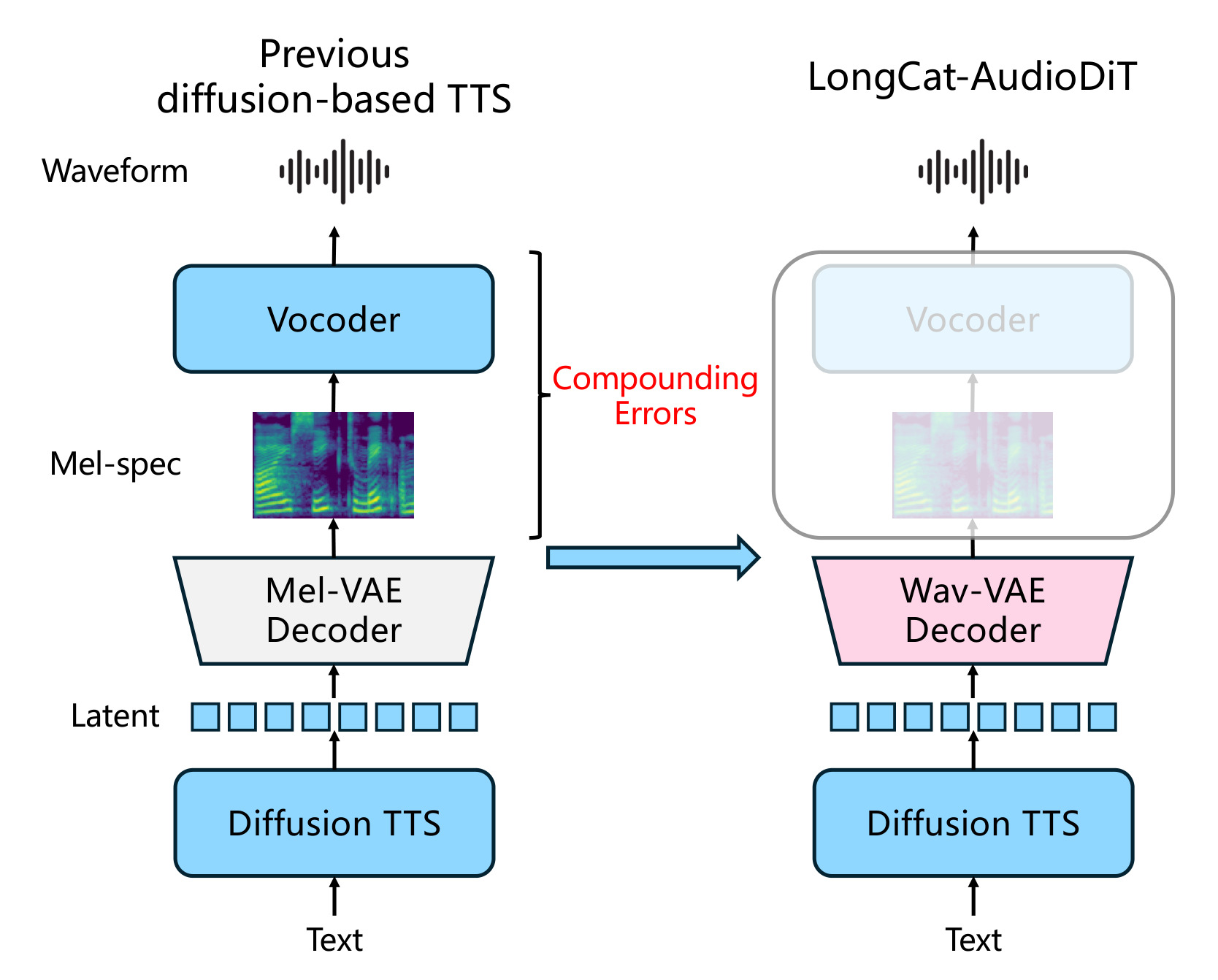
自回归 TTS 面临误差累积和推理延迟问题,非自回归方法在音色克隆上通常不如自回归。需要既能高效并行生成又达到自回归级别质量的方案。
前序工作及局限:
与前序工作的本质区别: 首个波形潜空间扩散 TTS,Wav-VAE 保留相位信息,APG 替代 CFG
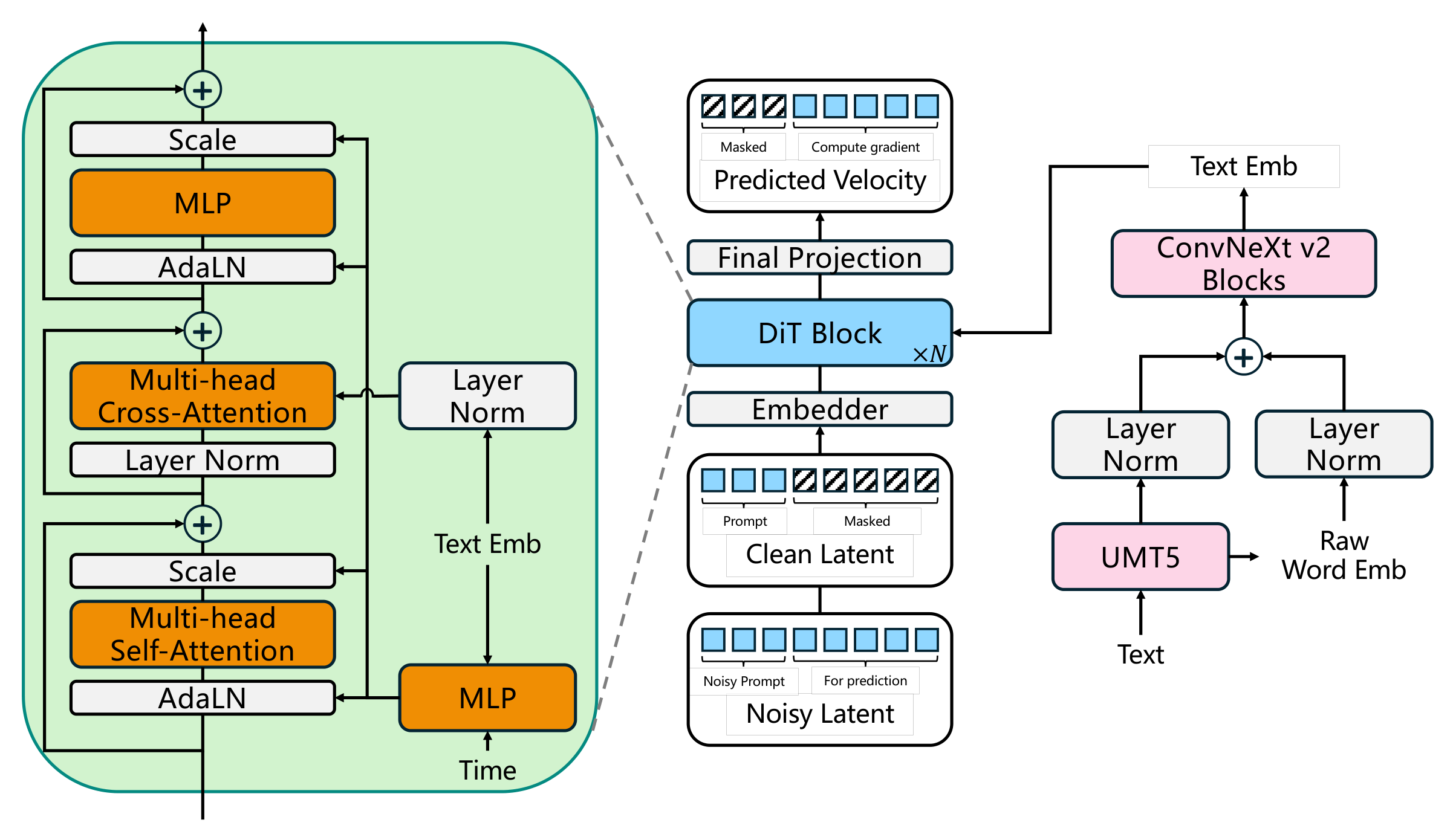
三个核心组件:(1) Wav-VAE 在波形域工作,多尺度卷积编码器压缩波形到连续潜空间,保留相位和细节信息。(2) 扩散 DiT 在潜空间去噪,文本和说话人条件通过交叉注意力注入。(3) APG 将无条件预测投影到条件预测的正交补空间,避免 CFG 的过饱和问题。非自回归一次性生成完整潜表示。
Wav-VAE 波形域压缩计算量较大。APG 增加少量推理开销。极长文本稳定性待验证。作者机构未明确标注。
技术演进定位: 非自回归 TTS 新高度,SIM 0.818 超越 Seed-TTS
可能的后续方向:
论文: T5Gemma-TTS
arXiv: 2604.01760
机构: Google
核心问题: Decoder-only Codec LM TTS 在文本理解和时长控制上的局限
当前 Codec LM TTS 主流采用 decoder-only 架构,但文本理解和语音生成是性质不同的任务,统一序列建模可能不是最优方案。多语言场景下的时长控制不够精确。
前序工作及局限:
与前序工作的本质区别: 编码器-解码器各司其职,PM-RoPE 音素/词素位置精细时长控制,4B 参数 scaling
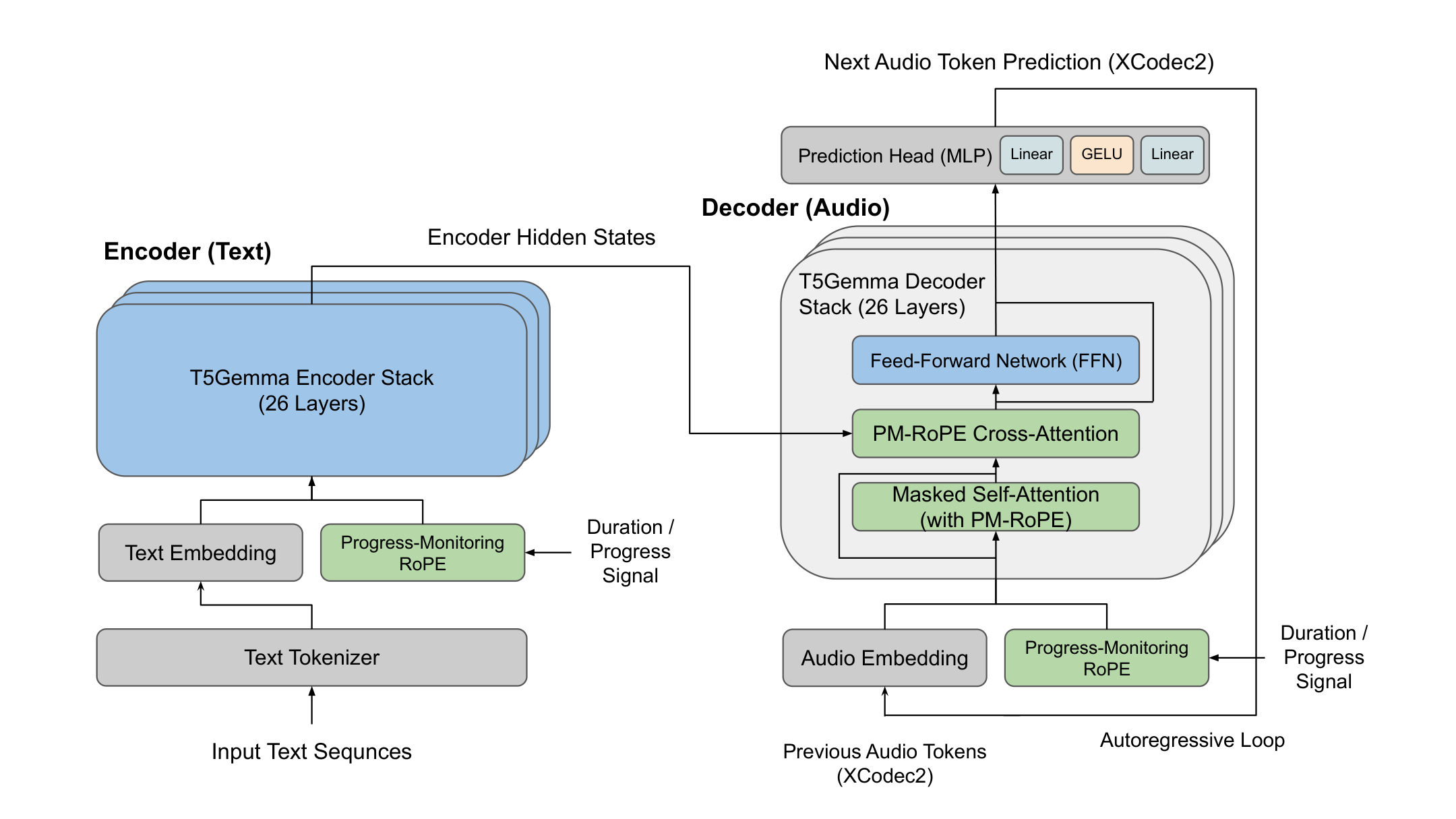
T5 编码器接收文本生成上下文化表示,Gemma 解码器以交叉注意力为条件自回归生成 Codec token。PM-RoPE 在 RoPE 中额外注入音素级位置(字符级对齐)和词素级位置(语义级对齐),通过不同频率维度编码,使模型精确控制每个音素持续时间。
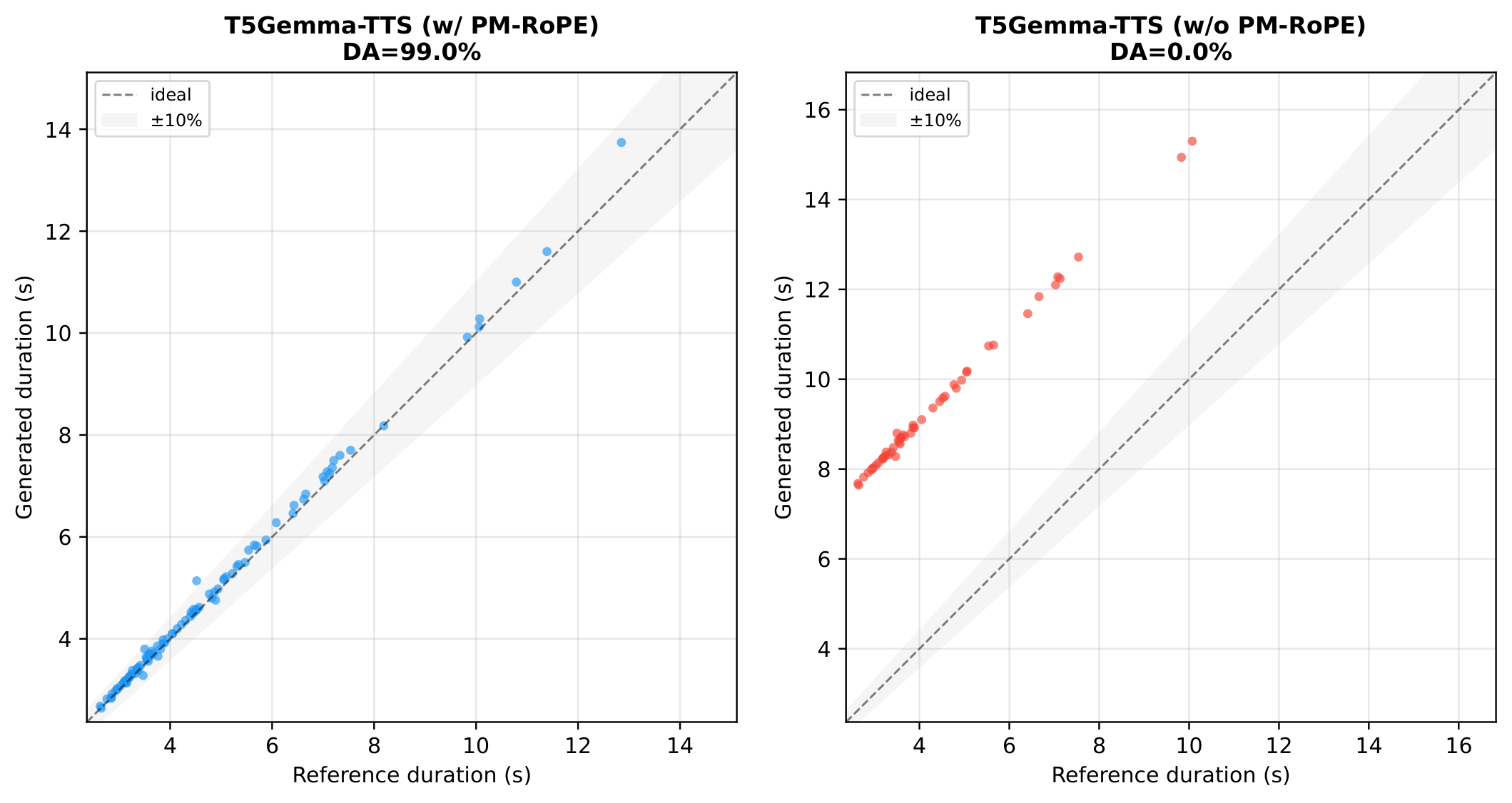
4B 参数推理成本高。交叉注意力增加内存占用。PM-RoPE 需要音素/词素标注。与 Google 自家闭源系统仍有差距。
技术演进定位: 挑战 decoder-only 主流,编码器-解码器架构在大规模 TTS 上有效
可能的后续方向:
论文: Woosh
arXiv: 2604.01929
机构: Sony AI
核心问题: 音效生成模型分散,T2A 和 V2A 各自独立,缺乏统一基础模型
音效生成模型分散,T2A 和 V2A 各自独立,缺乏统一基础模型。现有模型推理速度慢,难以满足交互式创作需求。
前序工作及局限:
与前序工作的本质区别: 完整音效基础模型统一 T2A+V2A,蒸馏版本快速推理
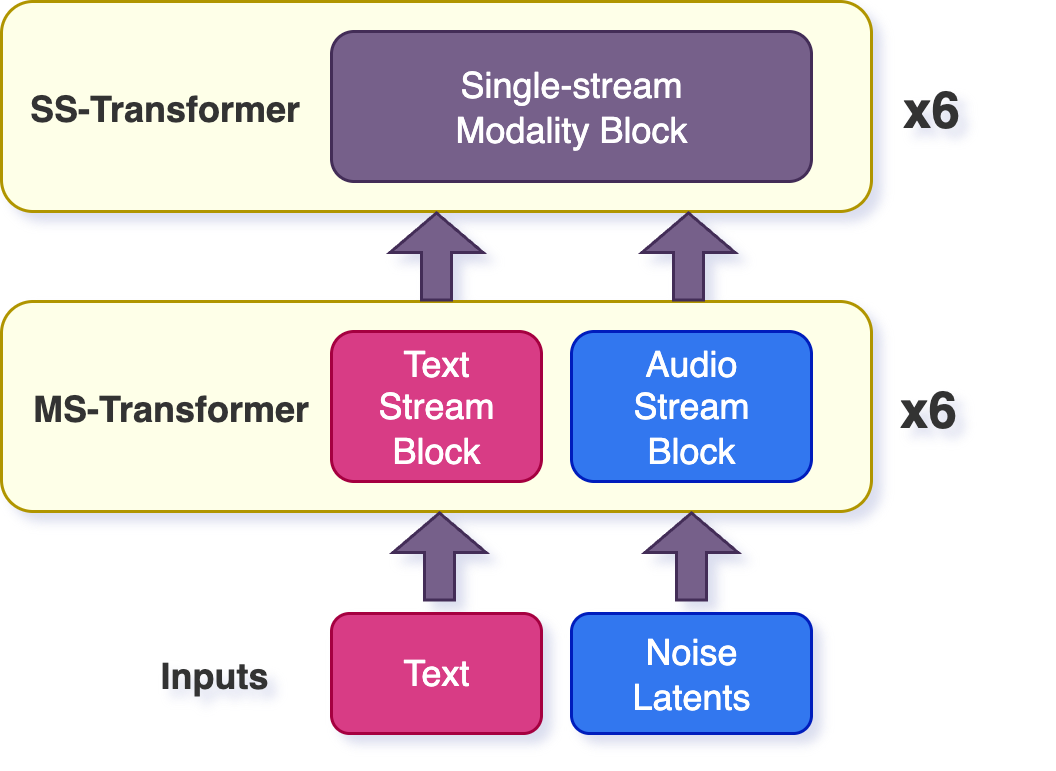
模块化设计四组件:(1) 音频编解码器压缩/重建音频 (2) CLAP 风格对比学习建立文本-音频对齐 (3) T2A 扩散模型以文本为条件生成 (4) V2A 扩散模型以视频帧为条件生成同步音效。蒸馏版通过知识蒸馏实现少步生成。
模块化增加系统复杂度。T2A 和 V2A 未完全统一。蒸馏版复杂音效质量下降。与闭源音效模型仍有差距。
技术演进定位: 音效生成从单任务走向基础模型
可能的后续方向:
论文: MOSS-VoiceGenerator
arXiv: 2603.28086
机构: Fudan University
核心问题: 语音风格控制依赖参考音频,无法用自然语言灵活描述
传统 TTS 需要参考音频克隆风格,但很多创意场景中用户想用自然语言描述期望的语音风格。现有系统对复杂风格描述的理解能力有限。
前序工作及局限:
与前序工作的本质区别: 电影语音数据训练,多维风格空间,自然语言直接映射
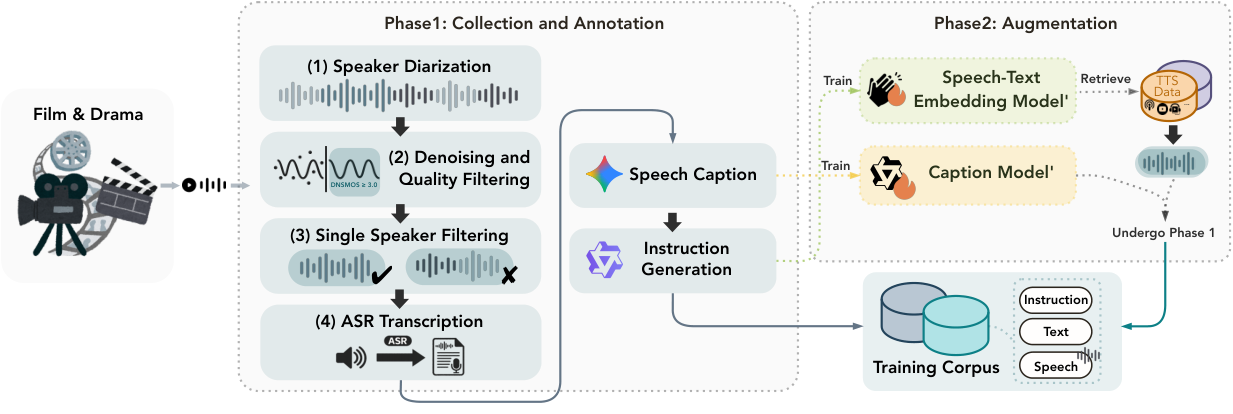
两模块设计:(1) 风格理解模块用预训练 LLM 将自然语言风格描述编码为嵌入向量,涵盖音色/情感/语速/场景多维度。(2) 条件语音生成模块以文本和风格嵌入为条件,在梅尔频谱空间扩散生成。训练数据来自电影语音,自动标注情感、风格和角色属性。
风格理解依赖 LLM 能力,抽象描述可能失效。电影语音数据版权问题。MOS 3.89 距顶级 TTS 仍有差距。缺少与最新系统直接对比。
技术演进定位: 指令驱动语音设计代表工作,开辟人机交互式语音创作
可能的后续方向:
论文: Prosody-Aware TTS
arXiv: 2604.01247
机构: Independent Research
核心问题: 扩散 TTS 韵律平淡缺乏表现力,缺少显式韵律建模
韵律是自然语音的关键要素,但扩散 TTS 往往生成韵律平淡的语音,缺乏对韵律结构的显式建模。
前序工作及局限:
与前序工作的本质区别: MLM+SigLIP 两阶段韵律预训练,即插即用不增推理开销
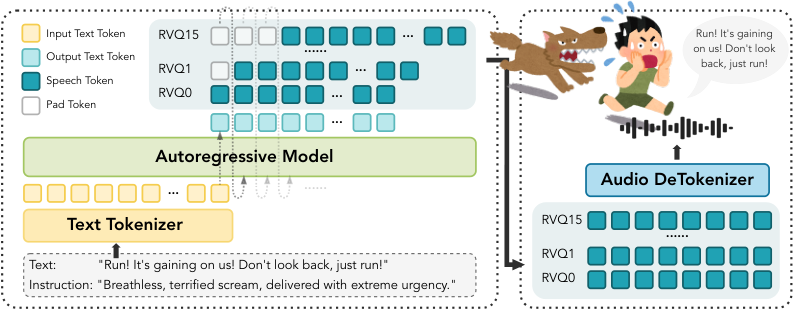
三阶段:(1) MLM 预训练韵律编码器,掩码韵律 token 预测,学习韵律结构。(2) SigLIP 对比学习,建立文本语义和语音韵律跨模态对齐。(3) 将韵律编码器集成到扩散 TTS,韵律嵌入作为额外条件注入去噪。韵律编码器仅增加 5% 参数。
多阶段预训练增加训练复杂度。SigLIP 效果依赖正负样本质量。仅验证两种架构。韵律特征提取依赖信号处理工具。
技术演进定位: 通用韵律预训练策略可提升任意扩散 TTS
可能的后续方向:
| 论文 | 核心架构 | 主要任务 | 关键创新 | 核心指标 |
|---|---|---|---|---|
| Voxtral TTS | AR + Flow Matching | 多语言 TTS | Voxtral Codec 双层量化 | 68.4% 胜率 vs ElevenLabs |
| LongCat-AudioDiT | Wav-VAE + DiT | 零样本 TTS | 波形潜空间 + APG | SIM 0.818 超 Seed-TTS |
| T5Gemma-TTS | T5 + Gemma (4B) | 多语言 TTS | PM-RoPE 时长控制 | 日语 SIM 0.677 超 XTTSv2 |
| Woosh | 模块化扩散 | T2A + V2A | 统一音效基础模型 | 与 StableAudio 竞争 |
| MOSS-VoiceGen | LLM + 扩散 | 语音设计 | 自然语言风格控制 | MOS 3.89, 一致性 81.3% |
| Prosody-Aware | 预训练 + 扩散 | 韵律增强 | MLM + SigLIP 预训练 | F0 RMSE 降低 18% |
| 论文 | 训练范式 | 数据规模/特色 | 推理特点 | 目标场景 |
|---|---|---|---|---|
| Voxtral TTS | 两阶段生成管线 | 大规模多语言 | 两步推理 | 通用高质量 TTS |
| LongCat-AudioDiT | Wav-VAE + DiT 联合 | 大规模中英文 | 一步并行, 快5-10x | 高保真零样本克隆 |
| T5Gemma-TTS | 编码器-解码器微调 | 170K 小时多语言 | 自回归, 4B 参数 | 多语言精细控制 |
| Woosh | 模块化分阶段 | 大规模音效数据 | 蒸馏版 5-8x 加速 | 影视/游戏音效 |
| MOSS-VoiceGen | 电影语音微调 | 电影对白(情感丰富) | 标准扩散速度 | 有声书/游戏配音 |
| Prosody-Aware | 三阶段预训练 | 标准 TTS 数据 | 不增推理开销 | 通用韵律增强插件 |
趋势 1:混合架构成为语音合成最优解
Voxtral TTS 的 AR+Flow Matching 和 T5Gemma-TTS 的编码器-解码器都证明,将不同任务交给不同模块比统一架构更有效。混合方案在语义连贯性和声学保真度之间取得最佳平衡。
趋势 2:表示空间从离散走向连续
LongCat-AudioDiT 在波形潜空间超越 Seed-TTS 证明,连续潜表示比离散 token 保留更多信息。Voxtral Codec 的双层设计也体现了语义(离散)和声学(连续)的最优分工。
趋势 3:音效生成走向基础模型化
Woosh 统一 T2A 和 V2A 是音效领域的重要尝试。类似于视觉领域从单任务模型走向基础模型,音频领域也在整合不同任务到统一框架。蒸馏加速为交互式应用铺路。
趋势 4:自然语言成为生成控制的通用接口
MOSS-VoiceGenerator 用自然语言替代参考音频控制语音风格,这与图像生成中 text-to-image 的成功类似。自然语言作为人机接口的通用性正在从文本/图像扩展到音频领域。
趋势 5:模块化预训练策略的崛起
Prosody-Aware TTS 的韵律预训练可即插即用提升任意扩散 TTS。这种模块化的预训练策略——独立训练某个能力模块再嵌入主框架——可能成为能力增强的通用范式。
语音合成与音频生成技术路线
├── TTS 架构创新
│ ├── 混合架构 → Voxtral TTS(AR + Flow Matching,68.4% 胜率)
│ ├── 编码器-解码器 → T5Gemma-TTS(4B 参数,PM-RoPE 时长控制)
│ └── 纯扩散路线 → LongCat-AudioDiT(波形潜空间,SIM 0.818)
├── 表示空间探索
│ ├── 波形潜空间 → Wav-VAE(保留相位信息)
│ └── 双层量化 → Voxtral Codec(VQ 语义 + FSQ 声学)
├── 音效生成
│ └── 统一基础模型 → Woosh(T2A + V2A + 蒸馏加速)
└── 交互与控制
├── 自然语言控制 → MOSS-VoiceGenerator(指令驱动风格设计)
└── 韵律增强 → Prosody-Aware TTS(MLM + SigLIP 即插即用)本期专题的 6 篇论文共同描绘了语音合成与音频生成的前沿全景图。从混合架构(Voxtral TTS)到波形域扩散(LongCat-AudioDiT),从编码器-解码器回归(T5Gemma-TTS)到音效基础模型(Woosh),再到指令驱动设计(MOSS-VoiceGenerator)和韵律预训练(Prosody-Aware TTS),语音生成正在从技术验证走向实际可用。值得关注的未来方向:
人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月29日 — 2026年4月5日
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注

评论 (0)