
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹君 整理 | 2026年4月25日(周六)
覆盖时间:2024年8月 — 2026年4月(涵盖 AAAI/WACV/ICLR/ICCV 2025-2026 评测基准爆发期)
本期 AIGC 周末专题聚焦视频编辑评测方法全景:从传统指标到 Reward Model 的范式跃迁方向,精选 7 篇代表性论文进行深度解读。
方向分布:
| # | 论文 | 机构 | 核心贡献 | arXiv ID |
|---|---|---|---|---|
| 1 | VEFX-Bench | 未披露(2026 年 4 月最新工作) | 首个同时包含编辑输出+人工标注+多维标签的大规模视频编辑数据集 | 2604.16272 |
| 2 | IVEBench | 浙江大学 / 腾讯优图 / 上海交通大学 / 新加坡国立大学 | 首个专为指令引导视频编辑设计的现代化综合基准 | 2510.11647 |
| 3 | FiVE-Bench | HKUST / 其他合作机构 | 首个细粒度物体级视频编辑基准 | 2503.13684 |
| 4 | EditReward | TIGER-AI Lab (Waterloo) | 首个大规模人类偏好数据集 EditReward-Data(200K+ 偏好对) | 2509.26346 |
| 5 | VE-Bench | 北京大学 | 首个专为视频编辑设计的 VQA 数据集(VE-Bench DB) | 2408.11481 |
| 6 | SST-EM | 未披露 | 首个组合 VLM + 目标检测 + ViT 的视频编辑评估框架 | 2501.07554 |
| 7 | VEditBench | NUS / Intel / UC Berkeley | 真实世界视频覆盖短(2-4s)和长(10-20s)两种时长 |
论文: VEFX-Bench
arXiv: 2604.16272
机构: 未披露(2026 年 4 月最新工作)
核心问题: 视频编辑模型缺乏统一评测标准,不同论文使用不同指标和数据集导致结论不可比
现有评测数据集规模小、缺少编辑输出或人工质量标签,通用 VLM 评审器未针对编辑质量优化,导致无法公正对比不同编辑系统。
前序工作及局限:
与前序工作的本质区别: 从单一指标到多维度评测框架,从通用视频质量到编辑特异性评估(指令遵循+编辑排他性+渲染质量三维解耦)
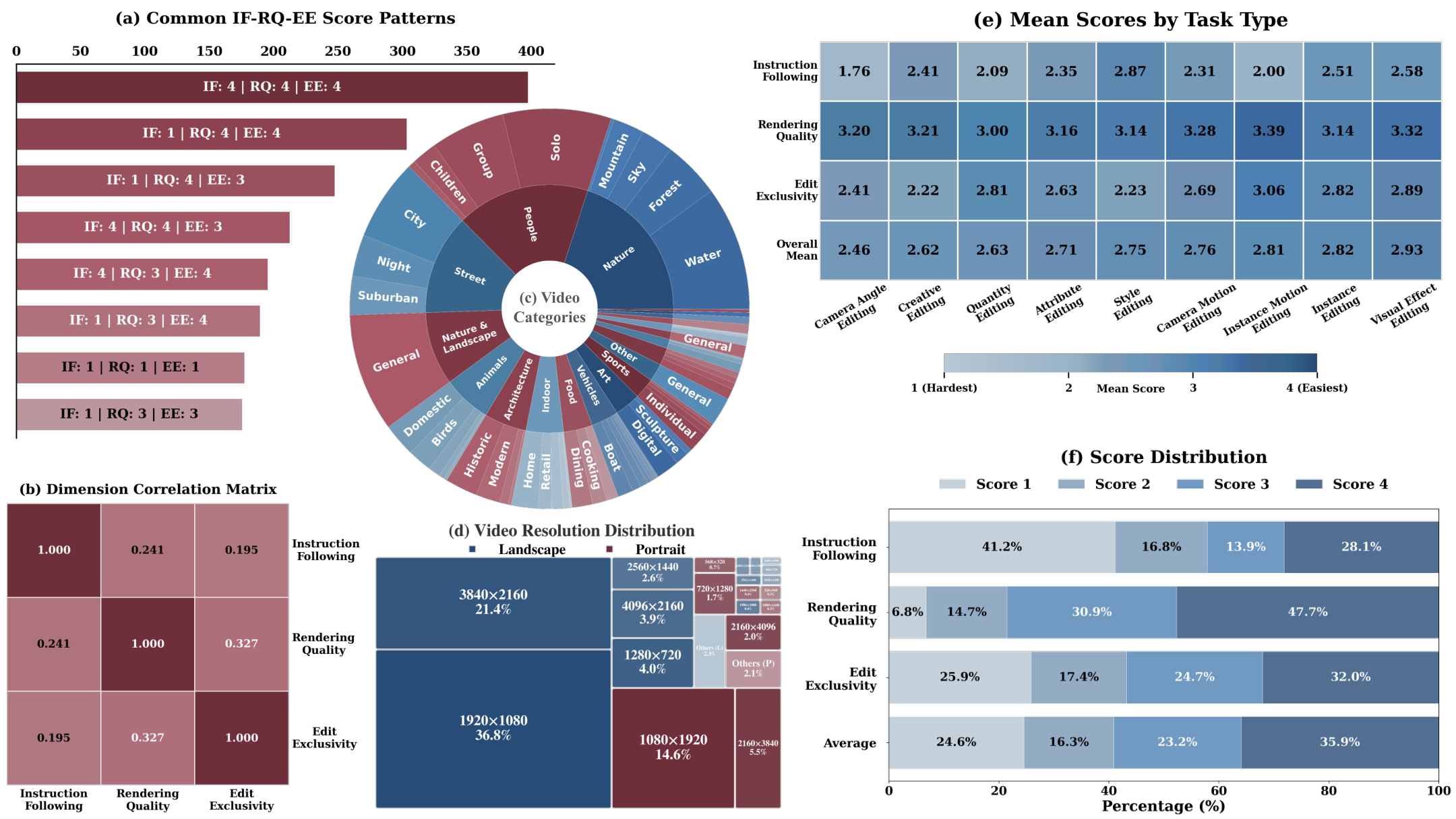
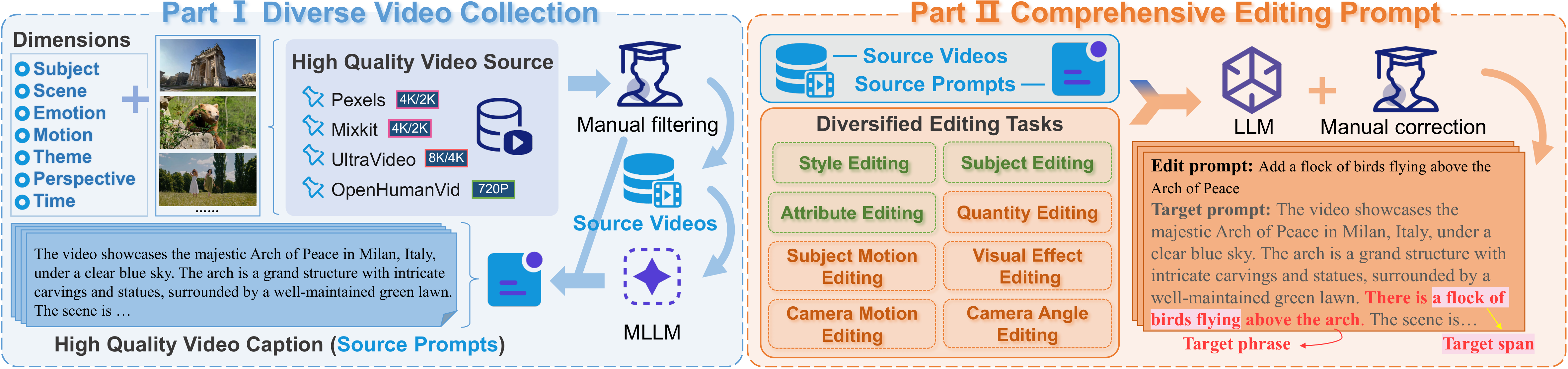
数据集:5049 个视频编辑样本,9 大类(相机角度/实例运动/数量/相机运动/属性/创意/实例/视觉特效/风格)32 子类,每个样本由 3 个解耦维度独立标注(4 分制)。Reward Model:基于 Qwen3-VL-Instruct(4B/32B),联合处理原始视频+编辑指令+编辑视频,3 个可学习特殊 token 查询各维度分数,采用序数回归(ordinal regression)而非标量回归,训练时条件二值交叉熵保持有序约束。两阶段训练:Stage 1 冻结预训练权重仅训练 reward head,Stage 2 解冻语言骨干微调。推理时将有序概率转换为 [1,4] 连续分数。
优势:三维解耦设计精准捕捉不同失败模式,序数回归比标量回归更适合有序评分。局限:数据集仅来自少量编辑系统,可能存在偏差;标注者间 IF 完全一致率仅 75.2%,说明指令遵循评估本身存在歧义。
技术演进定位: 2024 下半年 VE-Bench 开创编辑专用 VQA,2025 年 FiVE-Bench/IVEBench/VEditBench 细化任务分类,2026 年 VEFX-Bench 引入 Reward Model 实现自动+人类对齐评估。
可能的后续方向:
论文: IVEBench
arXiv: 2510.11647
机构: 浙江大学 / 腾讯优图 / 上海交通大学 / 新加坡国立大学
核心问题: 传统手工指标(CLIP/LPIPS/FVD)与人类感知严重偏离
现有视频编辑基准无法支撑指令引导编辑的评估需求:数据来源单一、任务覆盖面窄、评估指标不完整。
前序工作及局限:
与前序工作的本质区别: 从手工指标到学习型评估器,从单一分数到多维度解耦评分,从通用质量到编辑专用
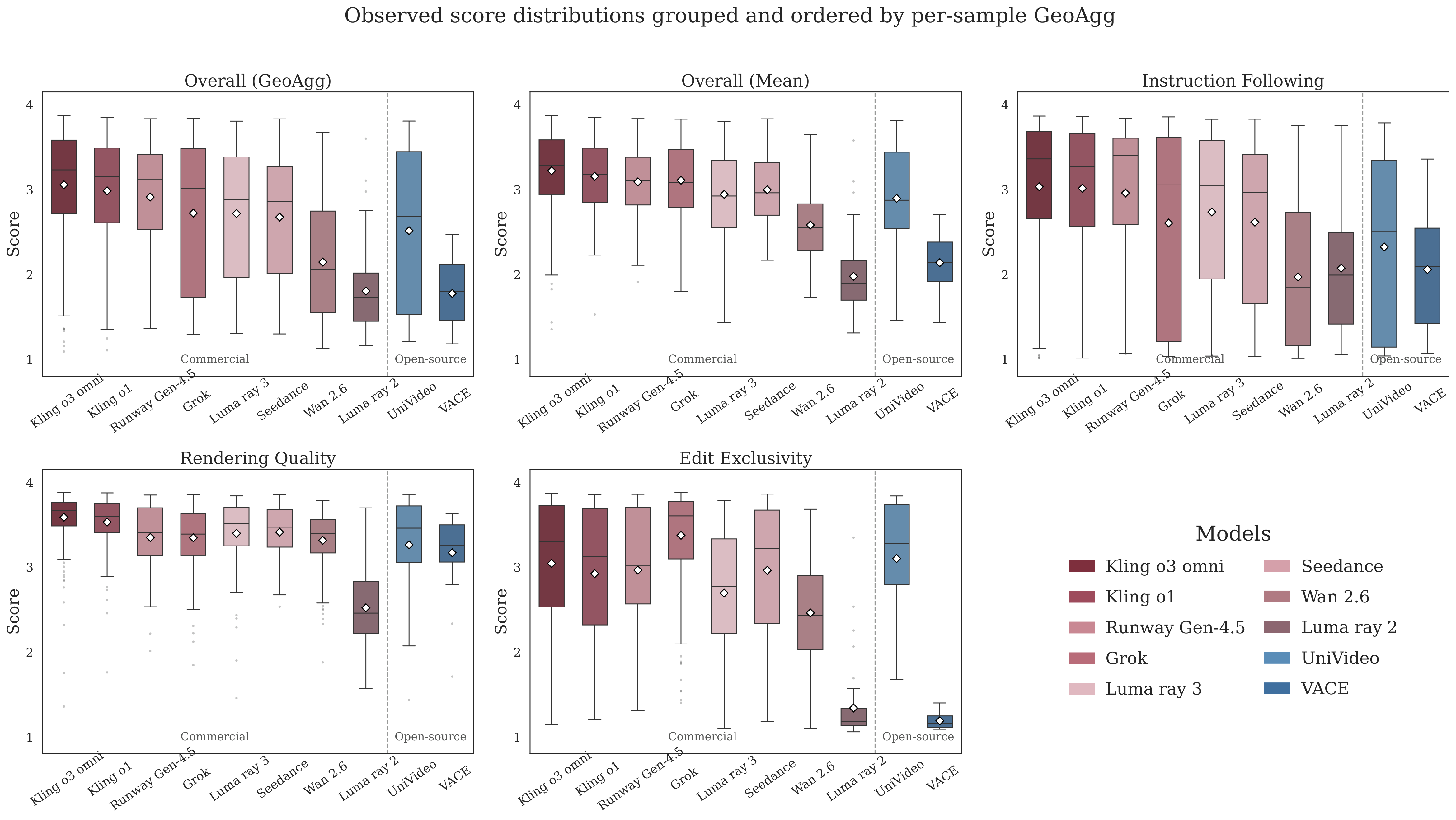
数据集构建:600 高质量源视频,覆盖 7 个语义维度和 30 个主题,帧长从 32 到 1024 帧。编辑任务:8 大类(风格/特效/主体/相机角度/主体运动/相机运动/属性/视觉特效)35 子类,通过 LLM 生成+专家审核获取提示对(源/编辑/目标三元组)。评估协议三维度:(1) 视频质量(主体一致性、背景一致性、时间闪烁、运动平滑度、VTSS);(2) 指令遵循(整体/短语语义一致性、指令满足度、数量准确性);(3) 视频保真度(语义/运动/内容保真度)。
优势:任务覆盖面最广(8 类 35 子类),MLLM + 传统指标双通道评估提升可靠性。局限:评估依赖特定 MLLM(如 Qwen3-VL),模型版本变化可能影响复现性;缺少人工标注的 ground truth 偏好数据。
技术演进定位: EditReward 和 VEFX-Reward 代表 Reward Model 范式在编辑评测中的应用,可能成为未来 RLHF/DPO 后训练的核心组件。
可能的后续方向:
论文: FiVE-Bench
arXiv: 2503.13684
机构: HKUST / 其他合作机构
核心问题: 评测维度设计如何平衡全面性和可操作性
缺乏标准化细粒度基准导致方法间无法公平比较,也无法评估模型对超参数的敏感度。
前序工作及局限:
与前序工作的本质区别: VEFX-Bench 的三维解耦(IF/RQ/EE)是目前最佳平衡点:维度足够区分失败模式(相关性 0.19-0.33),又不至于过多导致标注困难。
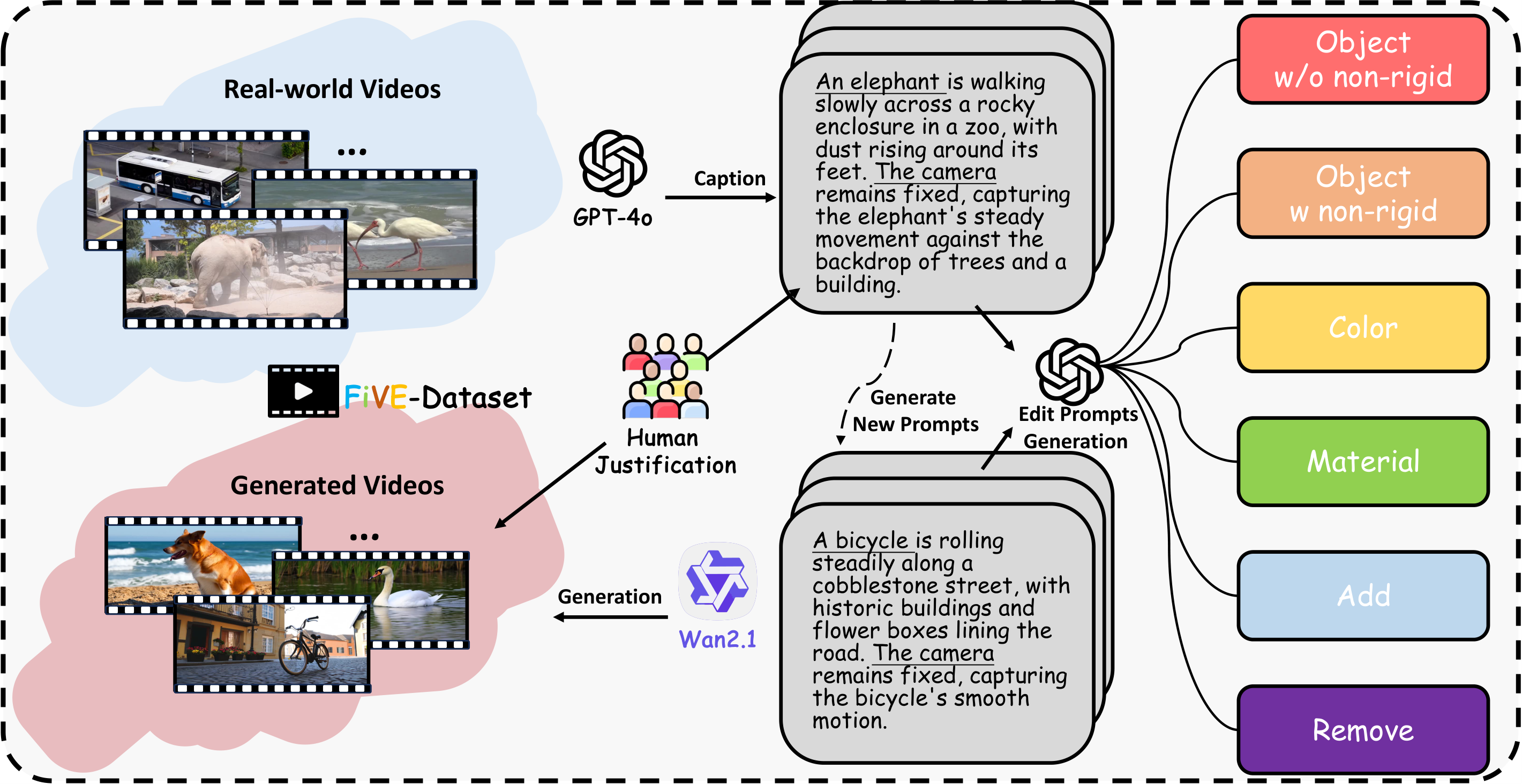
数据集:74 真实视频 + 26 生成视频,6 类细粒度编辑(物体替换/添加/删除/属性修改/背景替换/动作修改),420 组源-目标提示对含精确 Mask。评估指标 14 项覆盖 5 维度:(1) 背景保留(PSNR/SSIM/LPIPS);(2) 文本-视频相似度(CLIP-T/PickScore);(3) 时间一致性(Warp Error/CLIP-I);(4) 视频质量(FVD/FID/MUSIQ);(5) 运行时间。新指标 FiVE-Acc 利用 VLM 判定编辑是否成功。FlowEdit 方法:将注入噪声视为 ODE 反向过程,在 RF 模型上无需 DDIM 反转。
优势:Mask 标注使评估更精确,FiVE-Acc 利用 VLM 判定成功率是有意义的创新。局限:100 视频规模偏小;FlowEdit 同时是基准作者提出的方法,存在裁判-运动员角色冲突。
技术演进定位: 三维解耦已成为新的共识范式(IVEBench 的三维评估协议与之高度一致)。
可能的后续方向:
论文: EditReward
arXiv: 2509.26346
机构: TIGER-AI Lab (Waterloo)
核心问题: 评测数据集如何兼顾规模、多样性和标注质量
开源编辑模型落后于闭源的核心瓶颈在于缺乏可靠的 Reward Model 来规模化高质量合成训练数据。
前序工作及局限:
与前序工作的本质区别: 从几十个视频到数千标注样本,从单一来源到多系统输出收集。
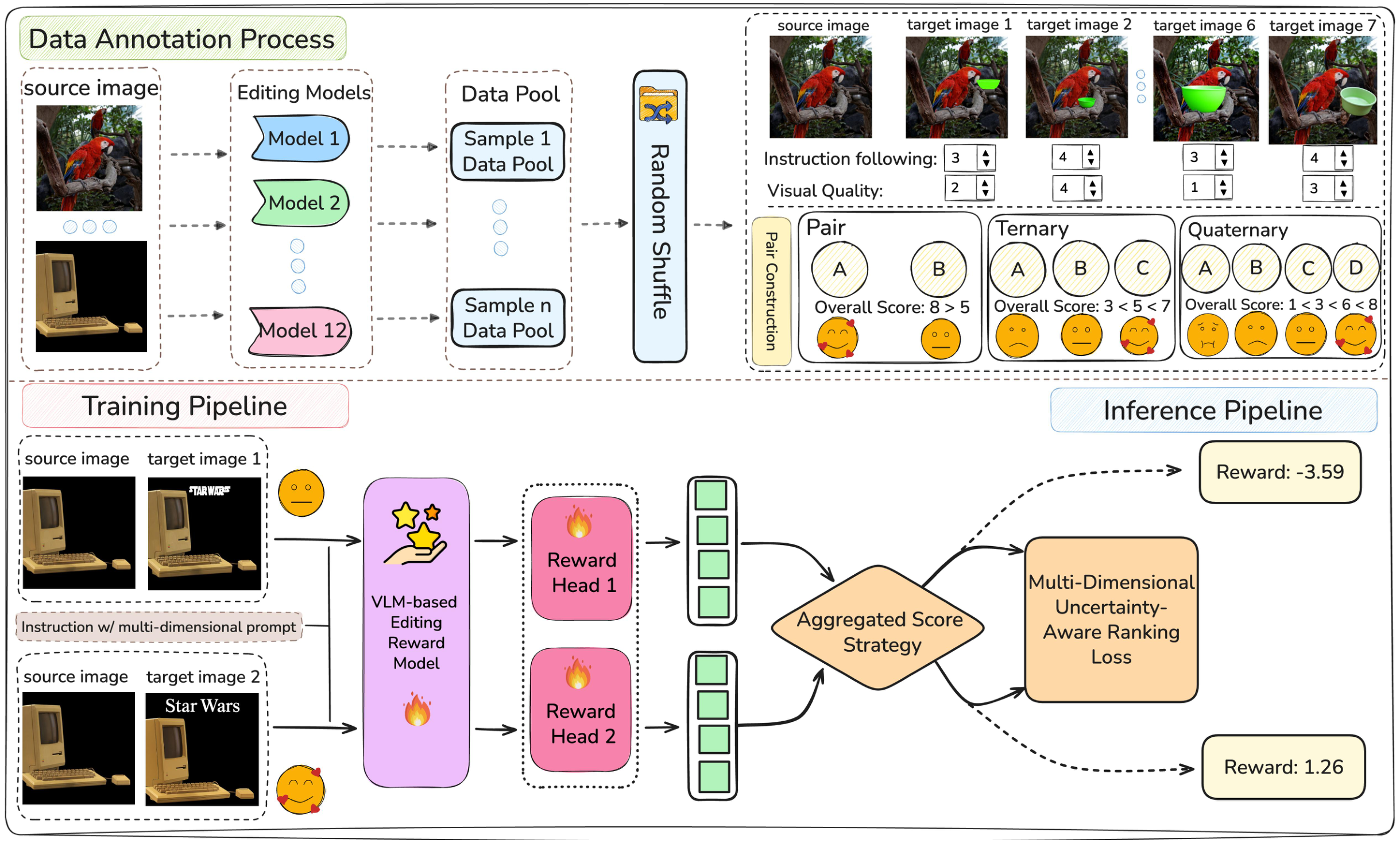
数据集构建:200K+ 偏好对,由训练有素的专家按严格标注协议标注。Reward Model 基于 VLM 架构,输入为编辑指令+源图+编辑图,输出人类偏好对齐的质量分数。下游验证:用 EditReward 从有噪声的 ShareGPT-4o-Image 数据集中筛选高质量子集,在该子集上训练 Step1X-Edit 显著优于在完整数据集上的训练效果。
优势:规模最大的专家标注偏好数据集,验证了 Reward Model 作为数据筛选器的实用价值(闭环验证)。局限:主要聚焦图像编辑,视频编辑的适用性需进一步验证;VEFX-Bench 的对比显示其在 RQ 维度相关性为负值(-0.211),暴露图-视频 domain gap。
技术演进定位: VEFX-Dataset(5049 样本)和 EditReward-Data(200K 偏好对)代表当前规模的上限。
可能的后续方向:
论文: VE-Bench
arXiv: 2408.11481
机构: 北京大学
核心问题: VLM-as-Judge 范式的可靠性和一致性
传统 VQA 方法只关注画面质量,忽略编辑特有的文本对齐和源视频关联性,导致评估结果与人类感知严重偏离。
前序工作及局限:
与前序工作的本质区别: 从通用 VLM 零样本评审到编辑专用微调 Reward Model,人类相关性大幅提升。
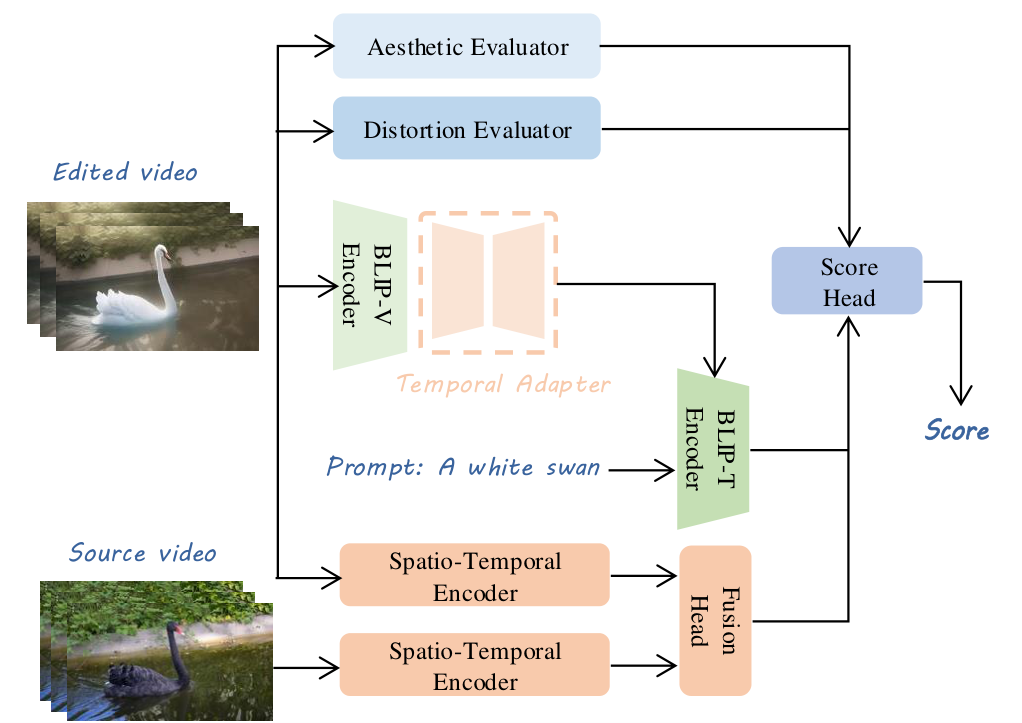
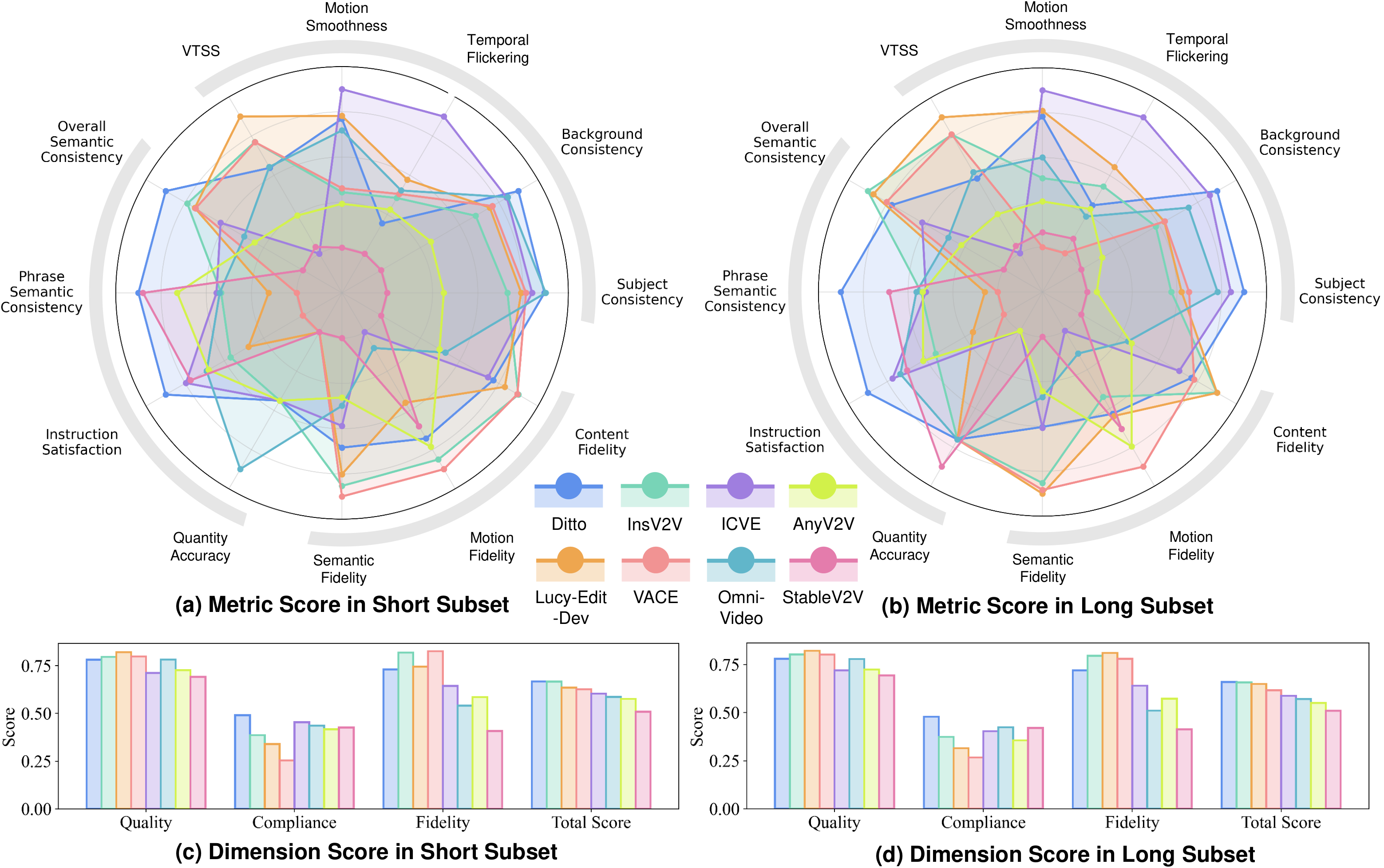
VE-Bench DB:收集多样化源视频(不同运动模式和主题),为每个视频设计多种编辑提示,收集 8 个模型的编辑输出,24 名标注者给出 MOS(Mean Opinion Score)。VE-Bench QA 评估网络:在传统 VQA 的美学/失真维度之上,新增文本-视频对齐建模和源-编辑视频关联建模两个分支,输出综合质量分数。编辑任务覆盖 3 类:风格编辑、语义编辑、结构编辑。

优势:首个视频编辑专用 VQA 数据集,为后续研究奠定了基础。局限:单一综合分数无法区分不同失败模式(如指令遵循好但渲染差);8 个模型均为 SD 系列(2024 年),缺乏最新系统评测。
技术演进定位: VEFX-Reward 证明专用 Reward Model > 通用 VLM Judge > 传统手工指标。
可能的后续方向:
论文: SST-EM
arXiv: 2501.07554
机构: 未披露
核心问题: 编辑任务分类法如何标准化
CLIP 文本分数受训练数据和层级依赖限制,图像分数无法评估时间一致性,需要一个同时覆盖语义、空间和时间维度的综合指标。
前序工作及局限:
与前序工作的本质区别: IVEBench 8 类 35 子类和 VEFX-Bench 9 类 32 子类代表当前最细化的分类。
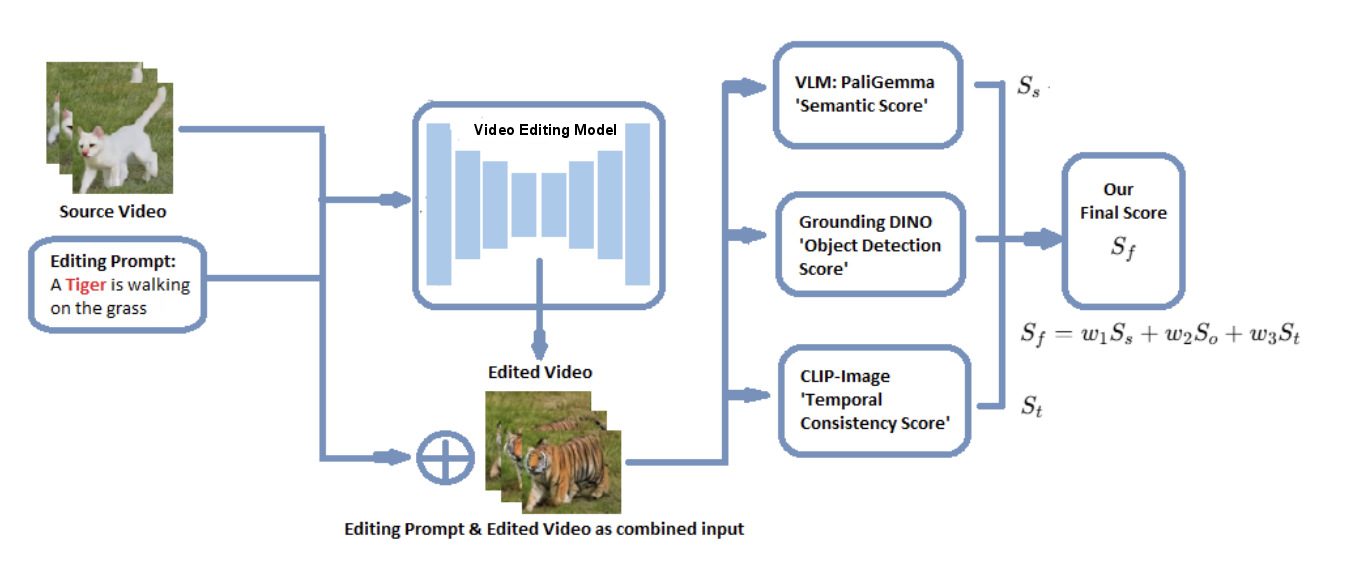
四组件管线:(1) VLM 提取每帧语义信息;(2) 目标检测追踪主要物体位置;(3) LLM Agent 精炼物体识别和上下文理解;(4) ViT 评估帧间时间一致性。统一指标权重通过人类评估数据 + 回归分析标定。最终输出语义保真度和时间平滑度的综合分数。

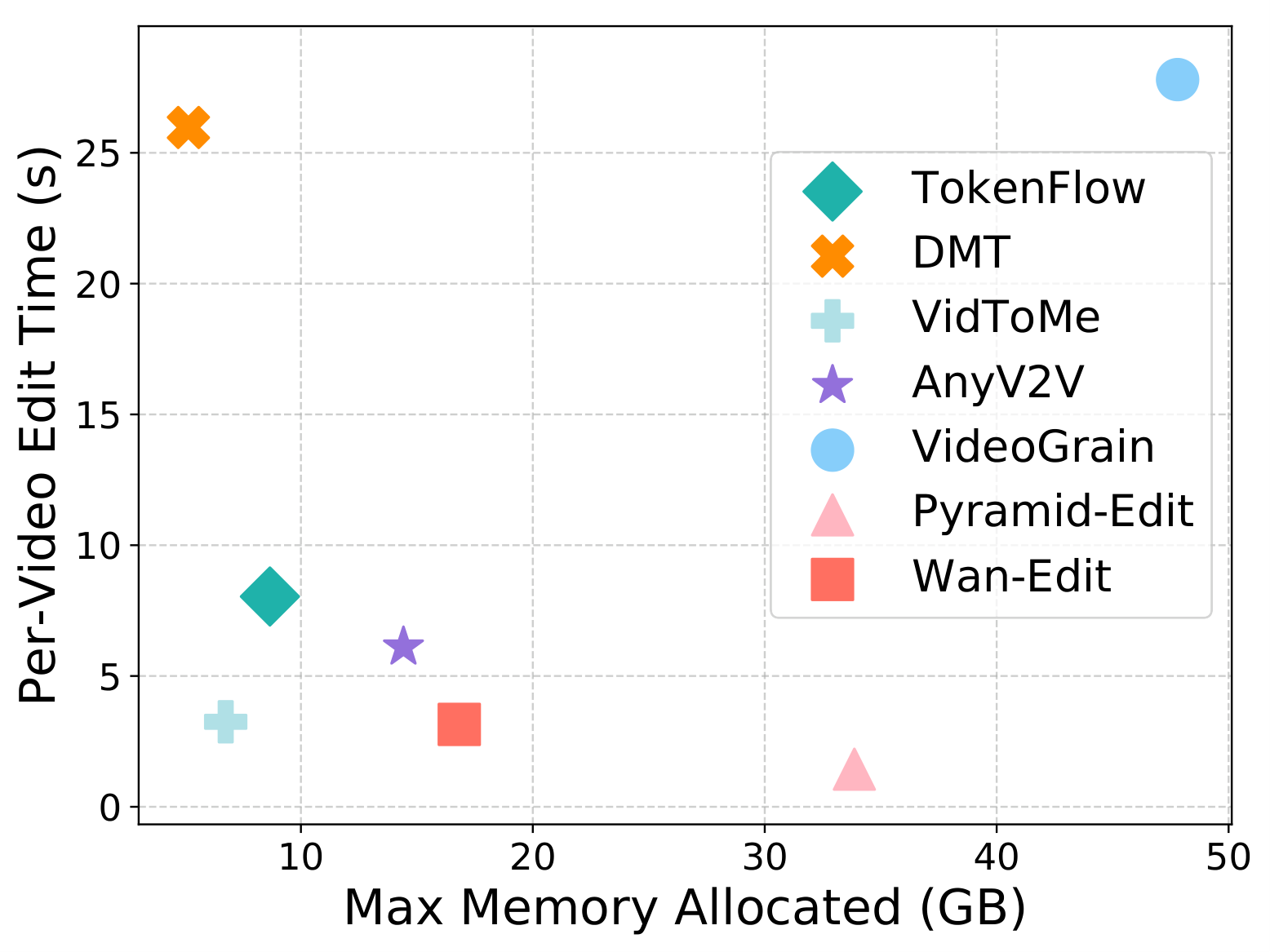
优势:管线式设计模块化程度高,每个组件可独立替换升级。局限:四阶段串行推理速度慢;依赖多个外部模型(VLM + 检测器 + LLM + ViT),部署成本高;权重标定依赖特定人类评估数据集,泛化性存疑。
技术演进定位: 分类法正在趋向收敛:相机控制、实例操作、属性修改、风格变换、视觉特效已成为公认的核心类别。
可能的后续方向:
论文: VEditBench
arXiv: []()
机构: NUS / Intel / UC Berkeley
核心问题: 长视频编辑的评测挑战
缺乏一个在通用视频编辑框架下同时覆盖多种编辑任务和时长范围的标准化基准。
前序工作及局限:
与前序工作的本质区别: 发现长视频编辑性能普遍下降 5-15%,但现有指标未充分捕捉时序退化模式。
数据集:420 真实视频(300 短 2-4s + 120 长 10-20s),覆盖多种场景和内容类别。任务设计 6 类:物体插入、物体删除、物体替换、场景替换、运动变化、风格转换。评估 9 维度覆盖:语义对齐(编辑语义/原始语义)、视觉质量(美学/失真/时间一致性)、额外维度(编辑精度/背景保留等)。
优势:短+长视频双覆盖设计实用,6 类任务分类简洁清晰。局限:420 视频规模中等;评估维度未明确区分编辑特有 vs 通用画质指标;缺少人工标注偏好数据。
技术演进定位: 长视频评测仍是开放挑战,需要新的时间维度指标。
可能的后续方向:
EditBoard: Towards A Comprehensive Evaluation Benchmark for Text-Based Video Editing Models | Cornell University / Nanjing University / University of Oxford | arXiv:2409.09668
关键词: 综合评测基准·多维度指标·文本视频编辑
前序工作问题: 当前视频编辑模型评估缺乏全面基准,现有方法仅用单一分数概括性能,无法细致分析模型在不同编辑任务中的表现。
贡献: 提出 EditBoard 综合评测基准,设计 4 个维度 9 个自动评估指标的评估框架,覆盖 4 个任务类别,标准化视频编辑评估流程。
效果: 为视频编辑模型提供了标准化评估工具,能够细致分析模型在不同编辑任务中的表现,推动视频编辑技术的标准化和进一步发展。
批判点评: 优势:填补了视频编辑模型评估基准的空白,多维度评估框架设计合理。局限:数据集规模未明确说明;评估维度未充分考虑时序一致性这一视频特有挑战。
I2EBench: A Comprehensive Benchmark for Instruction-based Image Editing | Xiamen University / 鹏城实验室 / 北京大学 | arXiv:2408.14180
关键词: 图像编辑评测·16维度·人类感知对齐·NeurIPS 2024
前序工作问题: 指令驱动的图像编辑(IIE)模型缺乏综合评测基准,现有指标无法全面覆盖高层次语义理解和低层次图像质量。
贡献: 构建 I2EBench 基准,包含 2000+ 待编辑图像和 4000+ 条指令,设计 16 个评估维度,并通过大量用户研究确保基准与人类感知高度一致。
效果: 为图像编辑模型提供了首个综合评测基准,16 个维度覆盖语义理解和图像质量,分析方法为视频编辑评测提供了可迁移方法论。
批判点评: 优势:16 维度设计全面,人类感知对齐做得好。局限:针对图像编辑而非视频编辑;部分维度(如时序一致性)在图像场景中不存在,迁移到视频需要适配。
T2VEval: Benchmark Dataset and Objective Evaluation Method for T2V-generated Videos | 中国传媒大学 信息与通信工程学院 | arXiv:2501.08545
关键词: 文本生成视频·多维度评测·主观客观融合·中国传媒大学
前序工作问题: 文本生成视频(T2V)模型缺乏统一的多维度评测基准,主观评价和客观评价方法各自存在局限性,无法全面评估生成视频质量。
贡献: 构建 T2VEval-Bench 多维度评测基准数据集,包含 148 个文本提示和 1783 个生成视频;提出 T2VEval 评估模型,从质量、真实感、一致性三个分支进行客观评估,达到 SOTA 人类相关性。
效果: 为文本生成视频提供了大规模评测基准,三分支评估模型可部分迁移到视频编辑评测场景,尤其是一致性评估维度与编辑排他性高度相关。
批判点评: 优势:主观+客观融合评估思路先进,数据集规模较大。局限:针对文本生成视频而非编辑场景;一致性分支主要评估生成稳定性,与编辑场景的源视频保真度存在差异。
| 论文 | 发表 | 数据规模 | 评测维度 | 自动指标类型 | 人工标注 | 任务分类 | 核心创新 |
|---|---|---|---|---|---|---|---|
| VEFX-Bench | 2026.04 | 5049 样本 | 3 维解耦 | Reward Model | 三维 4 分制 | 9 类 32 子类 | 序数回归 RM |
| IVEBench | ICLR 2026 | 600 视频 | 3 维评估 | 传统+MLLM | 无 | 8 类 35 子类 | MLLM 融合 |
| FiVE-Bench | ICCV 2025 | 100 视频 | 5 维 14 指标 | 传统+VLM | 无 | 6 类 | FiVE-Acc |
| EditReward | ICLR 2026 | 200K 偏好对 | 综合 | Reward Model | 专家偏好 | 通用 | 200K 数据 |
| VE-Bench | AAAI 2025 | ~170 视频 | 综合 | 评估网络 | MOS 24人 | 3 类 | 首个 VQA |
| SST-EM | WACV 2025 | - | 3 维管线 | VLM+检测+ViT | 权重标定 | - | 组合式评估 |
| VEditBench | ICLR 2025 | 420 视频 | 9 维 | 传统 | 无 | 6 类 | 短+长视频 |
三维解耦评测成为共识
IF(指令遵循)/ RQ(渲染质量)/ EE(编辑排他性)三维独立评估已成为 VEFX-Bench 和 IVEBench 的共同设计,正在取代单一综合分数。
Reward Model 取代手工指标
从 CLIP-Score/LPIPS/FVD 到学习型 Reward Model(VEFX-Reward/EditReward),评测精度大幅提升,且可直接用于下游 RLHF/DPO 训练。
MLLM 深度融入评测管线
IVEBench 和 SST-EM 将 MLLM 评估融入标准管线,FiVE-Acc 用 VLM 判定编辑成功率。但 MLLM 版本变化导致的结果漂移是待解决的风险。
评测任务分类趋向精细化
从 3-4 类到 8-9 大类 32-35 子类,相机控制、实例操作、属性修改、风格变换、视觉特效成为公认核心类别。
长视频评测成为开放挑战
VEditBench 首次发现长视频编辑性能下降 5-15%,但现有指标未充分捕捉时序退化模式,需要新的时间维度评估方法。
人工智能炼丹君 整理 | 数据来源:arXiv 2024年8月 — 2026年4月(涵盖 AAAI/WACV/ICLR/ICCV 2025-2026 评测基准爆发期)
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注

评论 (0)