
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇
今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
顶会收录: CVPR 2026 (DynaVid)
因果推理驱动的视频对象与交互删除:物理一致性视频编辑新范式 | Netflix, INSAIT (Sofia University) | arXiv:2604.02296
关键词: 视频编辑, 对象删除, 因果推理, 物理一致性, 反事实生成
核心问题: 视频对象移除后如何保持物理一致性?现有方法只能修复外观伪影,无法重写因果交互。
现有视频对象移除方法只能修复外观层面的伪影(如阴影和反射),当被移除对象与场景存在物理交互(如碰撞、支撑)时,无法推理并重写下游物理动态,导致结果不合物理常识。VOID 提出用因果推理指导视频扩散模型,在对象移除后生成物理一致的反事实场景。
前序工作及局限:
与前序工作的本质区别: VOID 首次引入因果推理:通过反事实数据监督 + VLM 空间推理 + 四色掩码编码,让视频扩散模型学会重写下游物理交互,而非简单填充。
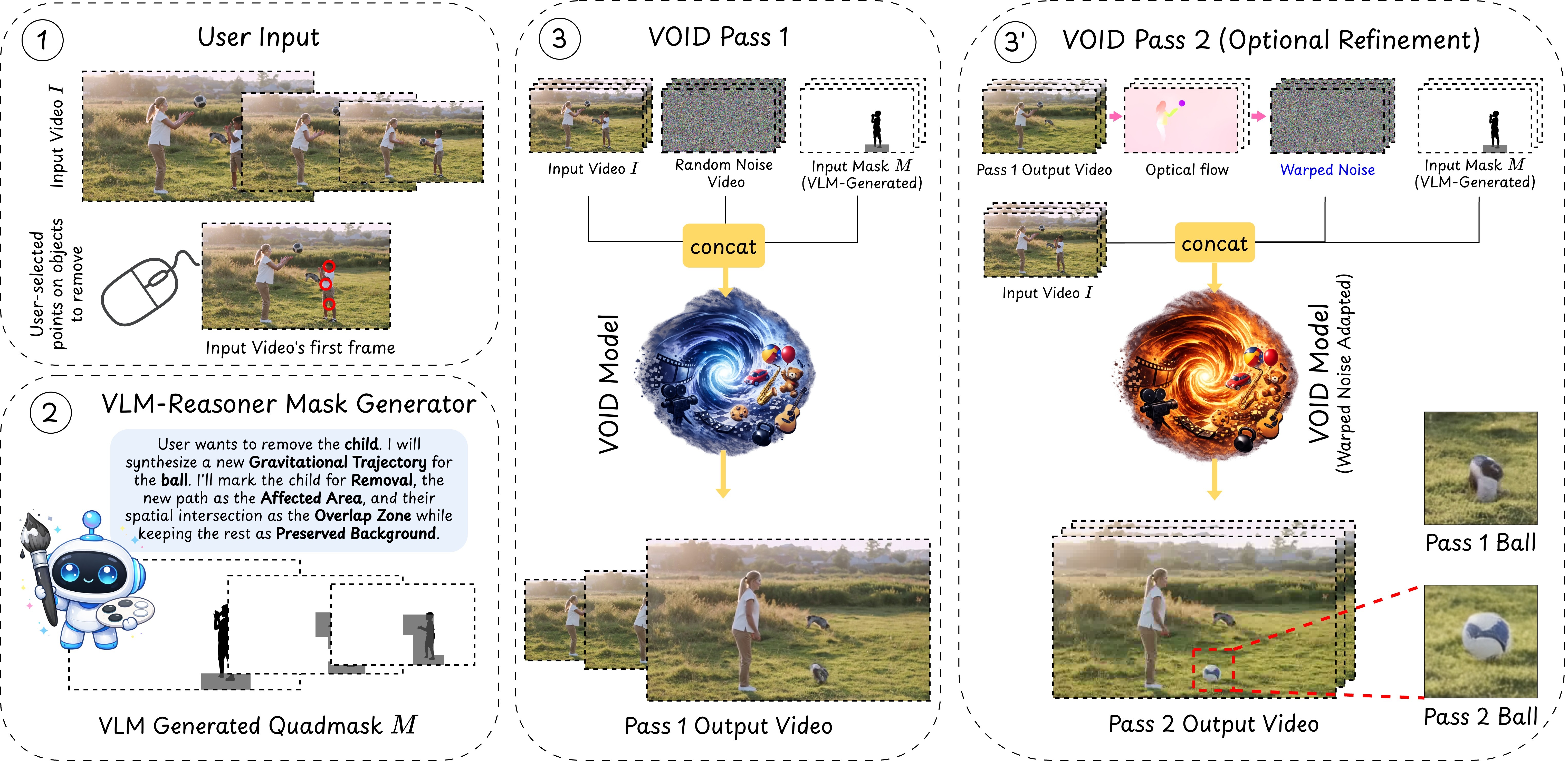
VOID 基于 CogVideoX 扩散 Transformer 构建,采用两遍生成策略。核心创新包括:(1) 反事实数据集监督——使用 Kubric 刚体动力学和 HUMOTO 人体运动捕捉数据,生成约 6400 组配对反事实视频(有/无目标对象),提供物理一致的训练监督。(2) 四色掩码(Quadmask)条件——扩展传统三色掩码为四色:黑色(待移除对象)、深灰(对象与受影响区域重叠)、浅灰(受影响区域)、白色(保持不变),消除掩码歧义。(3) VLM 引导推理——推理时使用视觉语言模型(Gemini 3 Pro)识别受移除对象影响的区域,结合 SAM3 分割,预测反事实轨迹并生成四色掩码。(4) 第二遍 Flow-Warped Noise 稳定——第一遍生成正确的反事实轨迹但可能出现变形,第二遍使用光流对齐噪声保持物体刚性。VLM 自动判断是否需要第二遍。
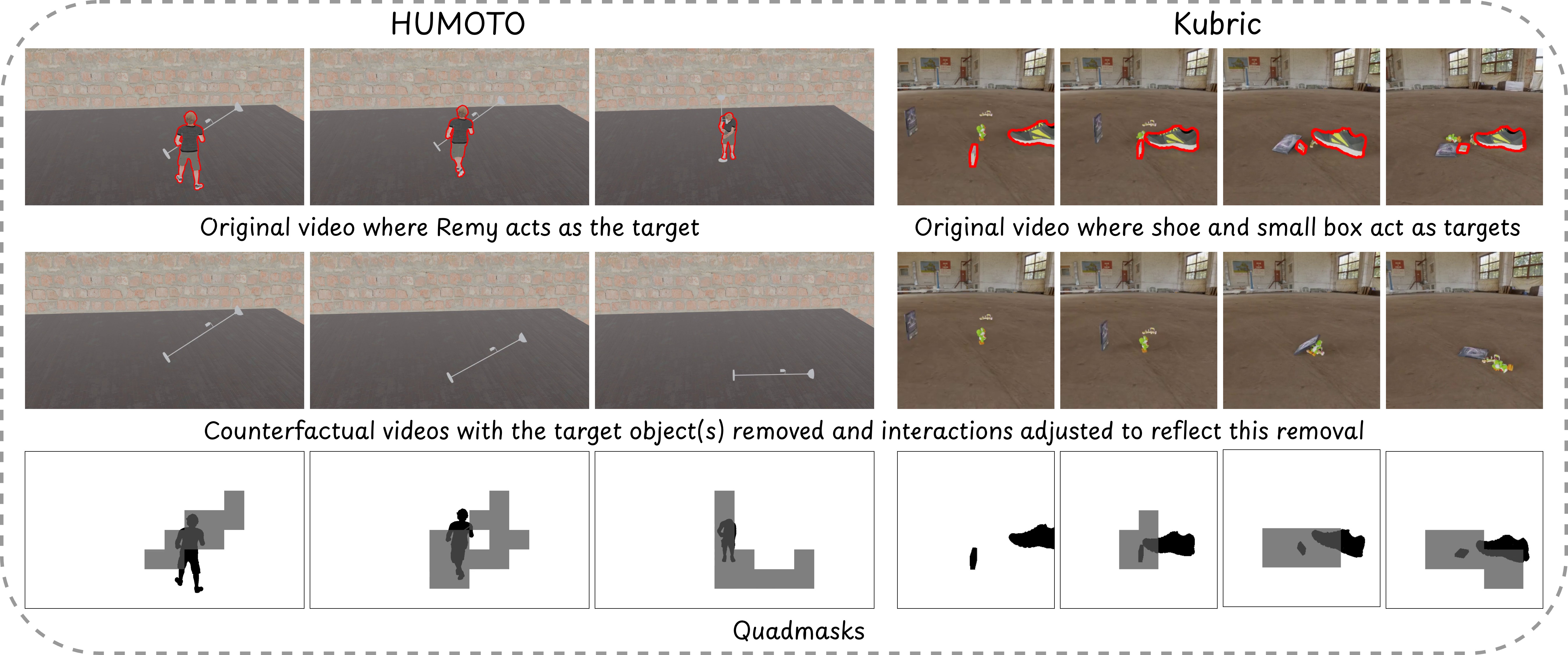
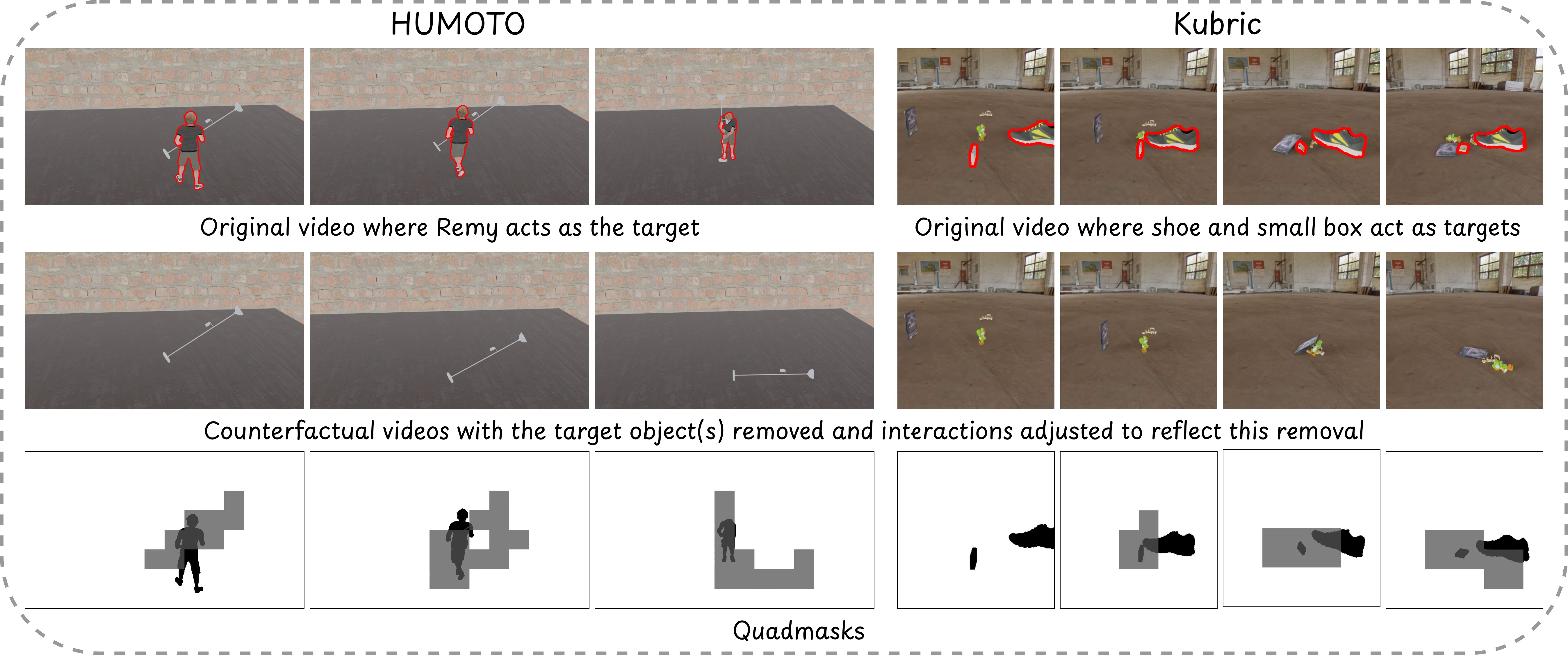
反事实数据集样例

Kubric 刚体碰撞和 HUMOTO 人体运动捕捉的配对反事实视频。上排为原始视频(红色标注目标对象),下排为移除对象后的反事实模拟,展示物理交互如何被正确重写。
双遍生成效果对比

左列第一遍生成正确的反事实轨迹但出现结构变形(吉他弯曲、球体拉伸),右列第二遍使用光流对齐噪声后保持了物体刚性,细节显著改善。
真实场景定性比较

与 Runway/Gen-Omnimatte/ProPainter 的对比:壶铃移除后枕头应弹回、浮标移除后无碰撞、双车相撞移除后正确还原。VOID 在物理一致性和伪影消除上全面领先。
多场景泛化结果
VOID 泛化到训练数据未涵盖的真实场景:积木多米诺骨牌停止、气球浮起、保龄球碰撞、搅拌机不启动等,展示强大的物理推理能力。
深度点评:
技术演进定位: 开创视频编辑从外观修复到世界模拟的新方向。证明合成物理模拟数据可以让模型泛化到真实世界的因果推理。
可能的后续方向:
DynaVid: Learning to Generate Highly Dynamic Videos using Synthetic Motion Data
关键词: 视频生成·合成运动数据·光流·运动解耦·CVPR 2026
贡献: 合成光流数据→运动-外观解耦→高动态视频生成,两阶段框架(运动生成+视频渲染),CVPR 2026
效果: 利用 CG 管线渲染光流训练运动生成器,保留真实视频视觉真实感。在剧烈人体运动和极端相机运动场景验证有效
SteerFlow: Steering Rectified Flows for Faithful Inversion-Based Image Editing
关键词: 图像编辑·Rectified Flow·免训练·保真度·多轮编辑
贡献: 基于 Rectified Flow 的免训练图像编辑框架,摊销定点求解器+轨迹插值+自适应掩码,理论保证源保真度
效果: 在 FLUX.1-dev 和 SD 3.5 Medium 上超越现有方法。支持多轮编辑不累积漂移
LatentUM: Unleashing the Potential of Interleaved Cross-Modal Reasoning via a Latent-Space Unified Model
关键词: 统一模型·潜在空间·跨模态推理·视觉生成·世界建模
贡献: 潜在空间统一多模态模型,消除视觉理解和生成之间的像素空间中介,支持交错跨模态推理
效果: 视觉空间规划 SOTA,自我反思改进视觉生成,支持世界建模预测未来视觉状态
FlowSlider: Training-Free Continuous Image Editing via Fidelity-Steering Decomposition
关键词: 图像编辑·连续控制·正交分解·免训练·Rectified Flow
贡献: 将编辑更新分解为正交的保真度项+导向项,实现滑块式连续强度控制的免训练图像编辑
效果: 基于 Rectified Flow 模型无需后训练,保真度项保持身份结构,导向项驱动语义编辑,平滑可靠
ActionParty: Multi-Subject Action Binding in Generative Video Games
关键词: 世界模型·多主体控制·动作绑定·视频游戏·状态token
贡献: 首个可同时控制多达 7 名玩家的视频世界模型,引入主体状态 token + 空间偏置解耦全局渲染与动作控制
效果: 在 Melting Pot 46 个环境中验证,动作跟随准确性和身份一致性显著提升,Snap Research
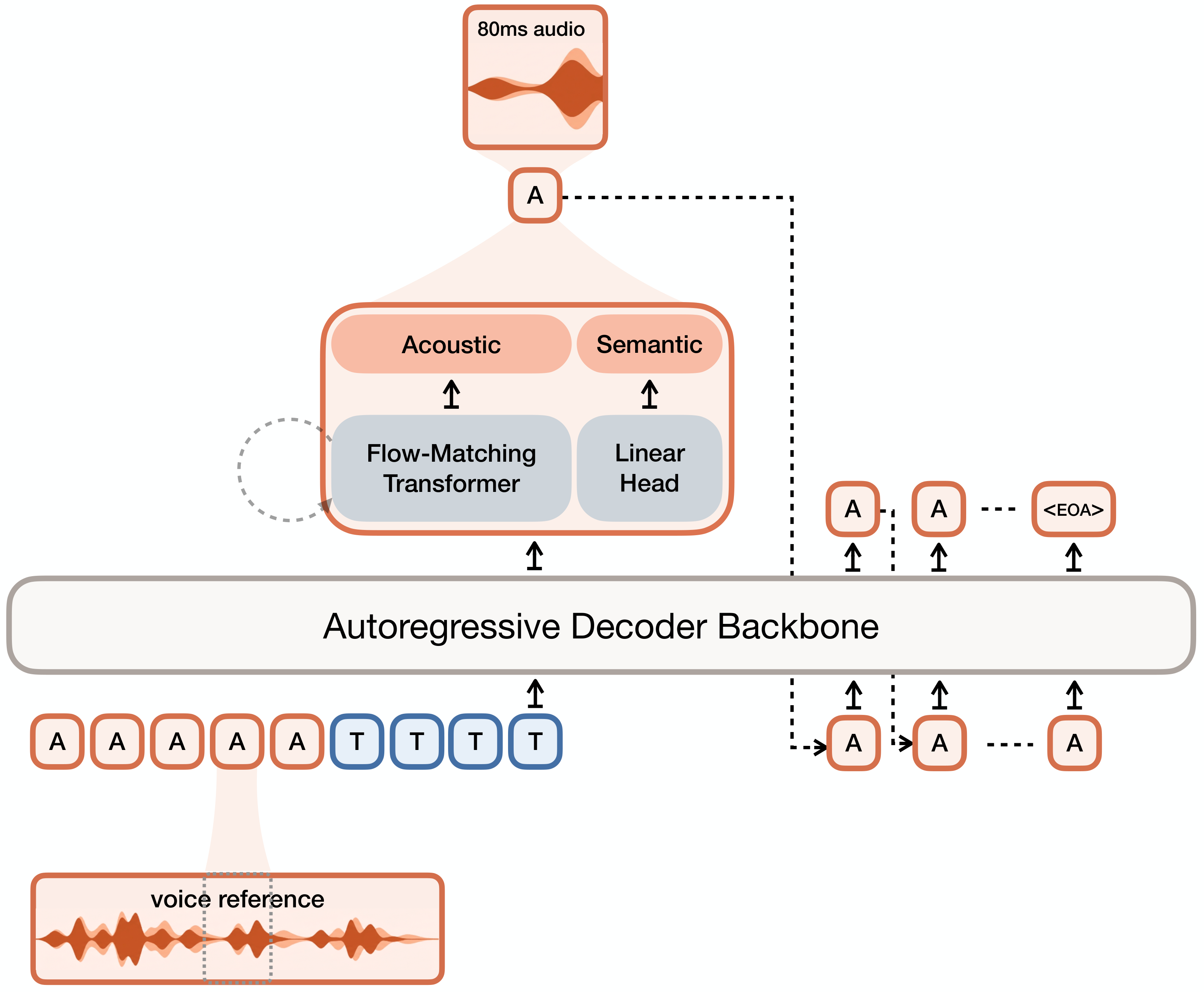
PFluxTTS: Hybrid Flow-Matching TTS with Robust Cross-Lingual Voice Cloning and Inference-Time Model Fusion
关键词: TTS·Flow Matching·跨语言克隆·双解码器·48kHz
贡献: 双解码器混合流匹配 TTS,推理时向量场融合+FLUX 解码器跨语言克隆+48kHz PeriodWave 声码器
效果: MOS 4.11 持平 ChatterBox,WER 降低 23%(6.9% vs 9.0%),说话人相似度超越 ElevenLabs(+0.32 SMOS)
Can Video Diffusion Models Predict Past Frames? Bidirectional Cycle Consistency for Reversible Interpolation
关键词: 视频插值·循环一致性·双向扩散·方向token·课程学习
贡献: 视频扩散双向循环一致性框架,可学习方向 token 统一前向合成和后向重建,课程学习从短到长
效果: 37帧和73帧插值任务均 SOTA,推理无额外开销(循环约束仅训练时),运动平滑度和动态控制大幅提升
CLPIPS: A Personalized Metric for AI-Generated Image Similarity
关键词: 评测指标·图像相似度·个性化·LPIPS·人类对齐
贡献: LPIPS 的个性化扩展,通过人类排序数据微调层组合权重,对齐 AI 生成图像评估与人类判断
效果: Spearman 等级相关和 ICC 均优于原始 LPIPS,证明有限人类数据微调即可显著提升感知对齐
Reflection Generation for Composite Image Using Diffusion Model
关键词: 反射生成·合成图像·扩散模型·DEROBA数据集·类型感知
贡献: 首个大规模物体反射数据集 DEROBA + 扩散模型反射生成方法,注入反射位置和外观先验,类型感知设计
效果: 生成物理一致、视觉逼真的反射效果,为合成图像反射生成建立新基准
人工智能炼丹师 整理 | 2026-04-06
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)