
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

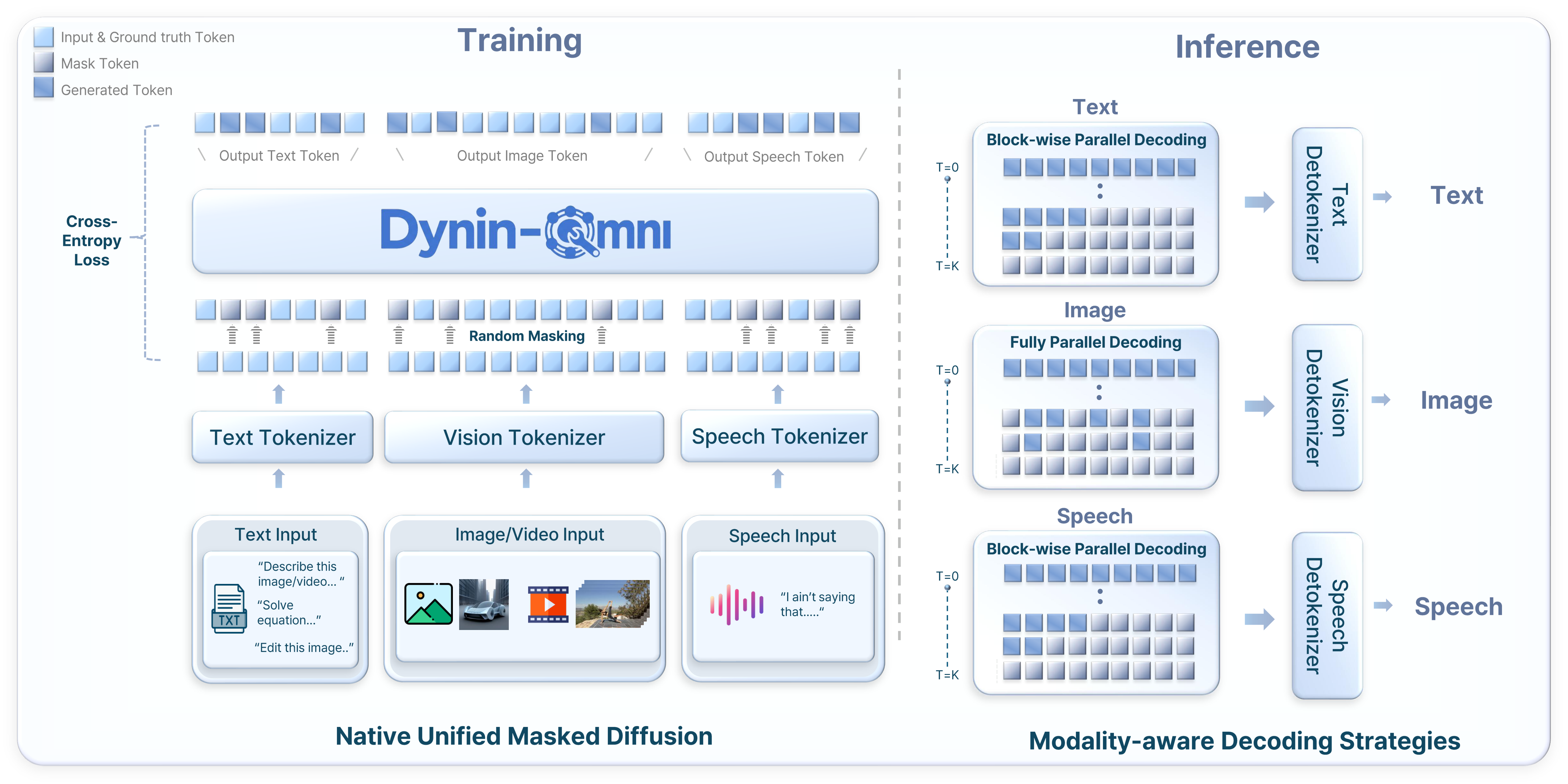
今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
CVPR 2026 × 1 | ACL 2026 × 1
多实例图像编辑的基准测试与区域对齐框架 | Telecom Paris, Institut Polytechnique de Paris | arXiv:2604.05180
关键词: 多实例编辑, 区域对齐, 并行去噪, 无训练
核心问题: 多实例图像编辑中的过度编辑与空间错位
当前最先进的图像编辑模型(如 FLUX.2、Qwen-Image-Edit)在处理包含多个相似实例且每个实例需要独立编辑的复杂场景时,会出现严重的过度编辑(Overediting)和空间错位(Spatial Misalignment)问题。例如,要求分别修改桌上三个杯子的颜色时,模型往往会错误地修改非目标区域,或在背景中引入意外变化。
前序工作及局限:
与前序工作的本质区别: 从单指令全局编辑到多指令区域对齐编辑,引入VLM指令解析+多分支并行去噪,实现实例级精确修改
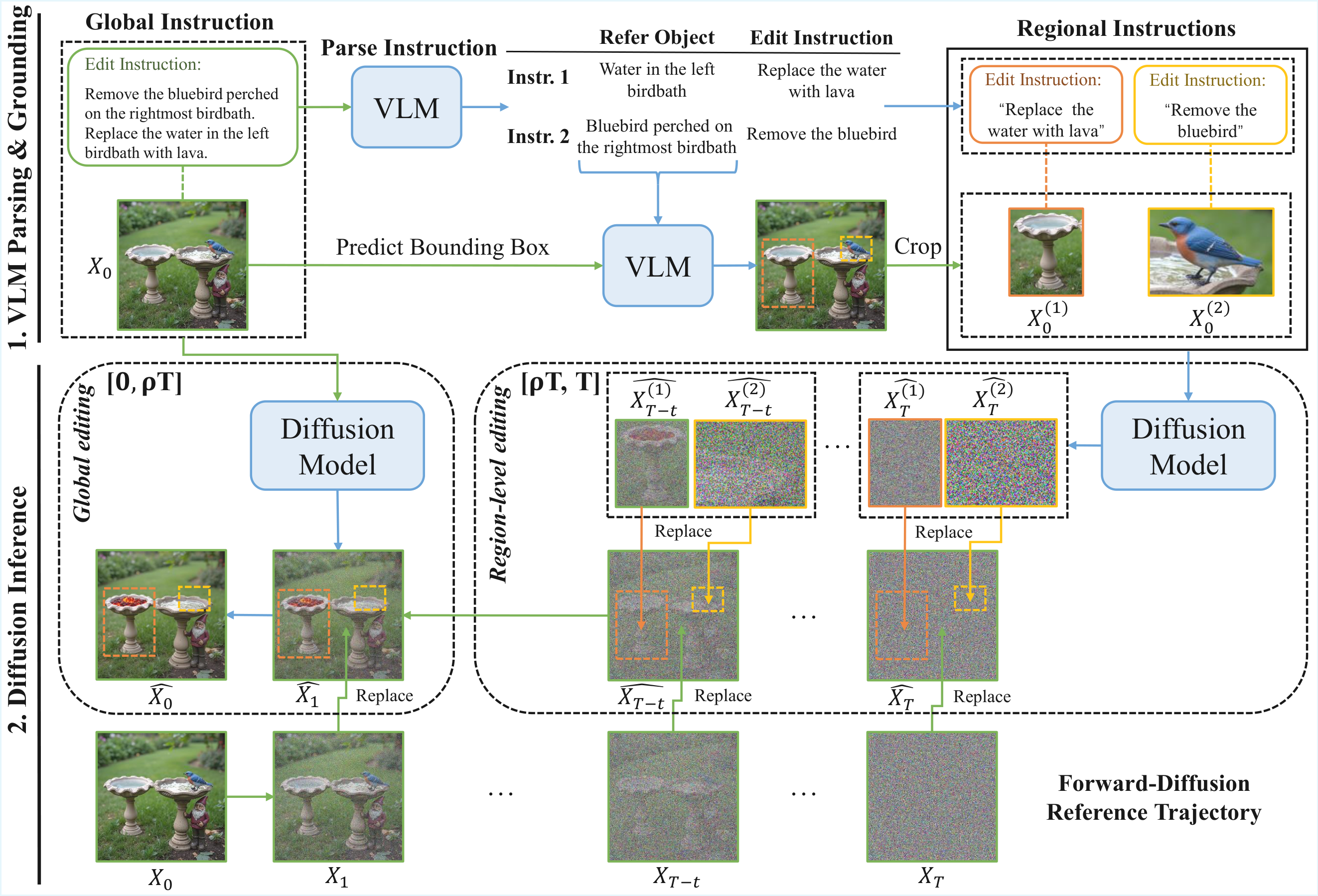
MIRAGE(Multi-Instance Regional Alignment via Guided Editing)提出了一个无需训练的框架,由两个核心模块组成:(1)指令解析与目标定位:利用视觉语言模型(VLM,如 Qwen3-VL)将全局组合指令分解为K个区域级原子编辑子任务,通过指代表达式定位(Referring Expression Grounding)提取每个编辑目标的边界框和子区域。(2)多分支并行局部编辑:构建一个全局分支和K个区域分支进行并行去噪。在早期时间步(t > 0.6T),各区域分支独立执行扩散编辑,将局部潜在表示空间映射回全局空间并覆盖对应位置,同时背景严格遵循参考轨迹防止漂移。在后期时间步(t <= 0.6T),终止所有区域分支,仅全局分支进行条件去噪,仅在目标区域内应用更新。

MIRA-Bench 构建流程
基准构建三步流程:FLUX.2生成多实例图像,VLM提取编辑指令和指代表达式,SAM2细化边界框为精确掩码
现有模型的过度编辑问题
展示当前SOTA模型在多实例编辑中的局限性:蓝色圆圈表示目标区域内一致性保持失败,绿色圆圈突出背景中的意外修改
指令复杂度增加时的性能变化
随着编辑指令数从1到5增加,标准模型一致性下降明显,而集成MIRAGE后性能更稳定
深度点评:
技术演进定位: 多实例编辑子领域的开创性工作,填补了基准和方法两个空白
可能的后续方向:
FoleyDesigner: Immersive Stereo Foley Generation with Precise Spatio-Temporal Alignment for Film Clips
关键词: 拟音生成 · 立体声 · 时空对齐 · 电影后期
贡献: 提出电影级立体声拟音生成框架,集成多智能体时空分析、潜在扩散模型和LLM驱动混音,支持杜比全景声5.1声道输出
效果: 首个专业立体声拟音数据集FilmStereo(8类/精确时间戳),时空对齐精度优于所有基线
GLANCE: A Global-Local Coordination Multi-Agent Framework for Music-Grounded Non-Linear Video Editing
关键词: 视频编辑 · 多智能体 · 音乐驱动 · 非线性编辑
贡献: 提出全局-局部协调多智能体框架,用于音乐驱动的非线性视频编辑,双循环架构实现长期规划和逐片段精细编辑
效果: 使用GPT-4o-mini骨干在两种任务设定上分别超越最强基线33.2%和15.6%,并发布MVEBench评估基准
OrthoFuse: Training-free Riemannian Fusion of Orthogonal Style-Concept Adapters for Diffusion Models
关键词: 适配器融合 · 正交微调 · 黎曼几何 · 免训练
贡献: 首个无训练合并正交适配器(OFT)的方法,利用黎曼流形测地线近似实现风格和概念适配器的免训练融合
效果: 在主题驱动生成中有效融合不同适配器的概念和风格特征,无需额外训练开销
Cross-Resolution Diffusion Models via Network Pruning
关键词: 扩散模型 · 跨分辨率 · 网络剪枝 · CVPR 2026
贡献: 发现扩散模型中的分辨率依赖参数行为问题,通过逐块修剪不利权重实现跨分辨率一致性,CVPR 2026 Findings
效果: 在未见分辨率上提升感知保真度和语义连贯性,同时保持默认分辨率性能不下降
Single-Stage Signal Attenuation Diffusion Model for Low-Light Image Enhancement and Denoising
关键词: 低光照增强 · 扩散模型 · 信号衰减 · 单阶段
贡献: 提出信号衰减扩散模型,将低光照退化的物理先验编码到扩散前向过程中,单阶段同时完成亮度恢复和噪声抑制
效果: 消除了两阶段管线和辅助校正网络的依赖,在恢复质量和计算效率间取得平衡
DARE: Diffusion Large Language Models Alignment and Reinforcement Executor
关键词: 扩散语言模型 · 后训练 · 强化学习 · 开源框架
贡献: 开源扩散语言模型后训练框架,统一SFT/PEFT/偏好优化/RL,支持LLaDA/Dream/SDAR等多个模型家族
效果: 解决dLLM生态碎片化问题,提供可复现基准和加速功能,加速扩散语言模型研究迭代
Expert-Choice Routing Enables Adaptive Computation in Diffusion Language Models
关键词: MoE · 专家选择路由 · 扩散语言模型 · 自适应计算
贡献: 证明Expert-Choice路由比Token-Choice更适合扩散语言模型MoE,引入时间步依赖的专家容量实现自适应计算
效果: 低掩码比率步骤学习效率高一个数量级,预训练TC模型可仅替换路由器改造为EC模型
Controllable Singing Style Conversion with Boundary-Aware Information Bottleneck
关键词: 歌唱转换 · 风格迁移 · Whisper瓶颈 · 语音合成
贡献: 提出歌唱风格转换系统,通过边界感知Whisper瓶颈、帧级技术矩阵和高频补全策略实现精细风格控制
效果: SVCC2025挑战赛参赛系统,在自然度和说话人相似度上取得优异成绩
Anchored Cyclic Generation: A Novel Paradigm for Long-Sequence Symbolic Music Generation
关键词: 音乐生成 · 符号音乐 · 锚定循环 · ACL 2026
贡献: 提出锚定循环生成范式及分层框架Hi-ACG,解决自回归模型生成长序列音乐时的误差累积问题,ACL 2026 Findings
效果: 显著提升长序列音乐质量和结构完整性,超越现有自回归方法
人工智能炼丹师 整理 | 2026-04-09
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)