
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
含 3 篇 CVPR 2026 接收论文
首个分数步蒸馏框架——打破整数步约束实现33倍加速 | Unknown | arXiv:2604.04018
关键词: 蒸馏加速, 分布匹配蒸馏, 分数步推理, CFG控制, 块级缓存, SD3
核心问题: 扩散模型迭代去噪计算量大,分布匹配蒸馏在极端少步时多样性崩溃
扩散模型生成高质量图像,但迭代去噪计算量大。分布匹配蒸馏(DMD)是少步蒸馏的有前途路径,但在 2 步或更少时遭遇多样性崩溃和保真度下降。作者发现两个核心问题:(1) 教师模型 CFG 在高噪声时域驱使学生过早坍缩到少数主导模式;(2) 极端少步蒸馏下,单一目标函数无法同时兼顾全局结构和细节。
前序工作及局限:
与前序工作的本质区别: 首次将分布匹配蒸馏与块级缓存统一,发现并解决 CFG 导致模式崩溃的根因,提出分数步蒸馏打破整数步约束
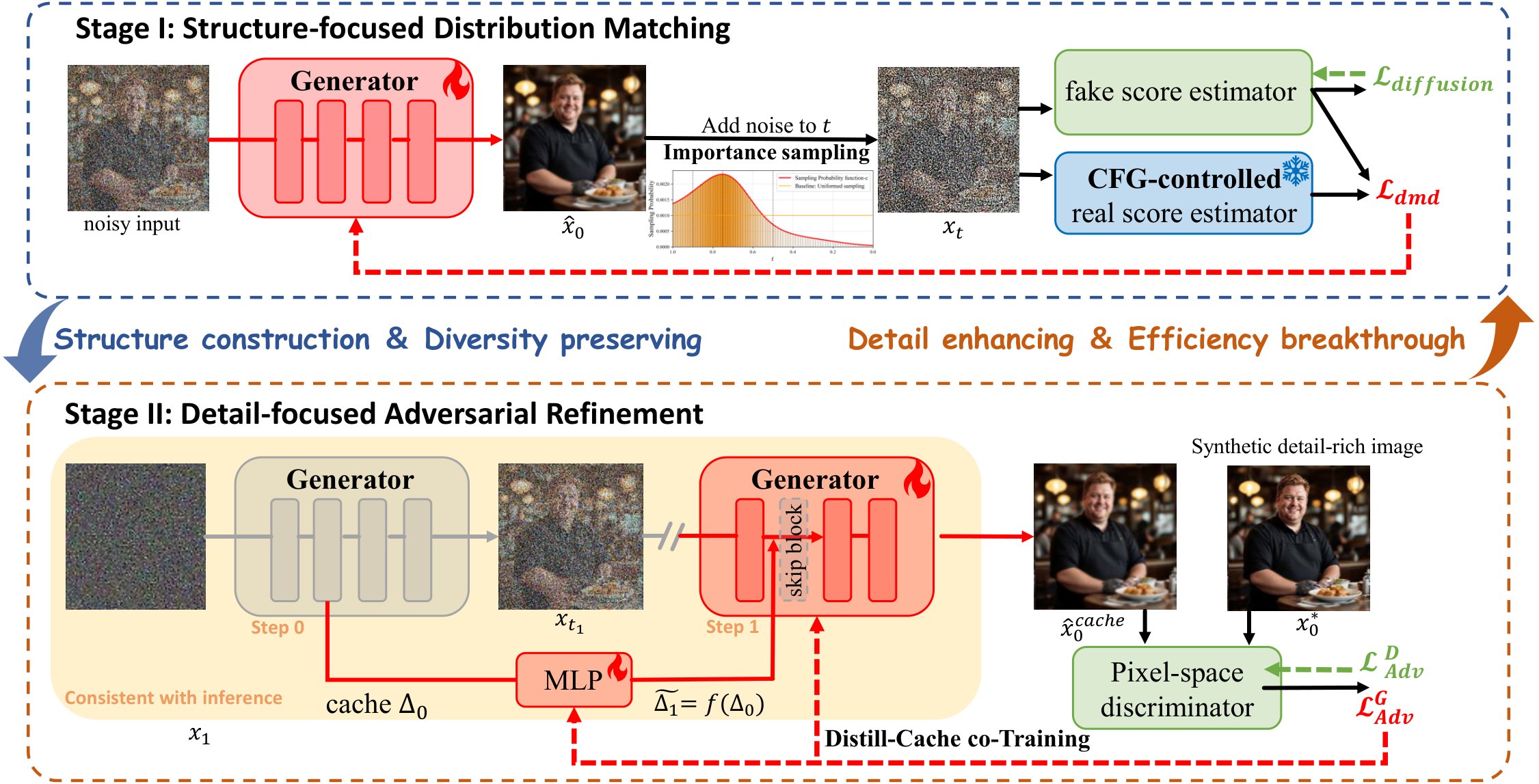
1.x-Distill 框架包含三个核心创新:
(1) 时间步感知 CFG 控制:在高噪声时域(t>alpha)禁用教师 CFG,使用纯条件分数引导学生覆盖更多模式;低噪声时域保留 CFG 保证细节质量。alpha=0.94 为最优阈值。
(2) 分阶段聚焦蒸馏(SFD):Stage I 结构导向分布匹配,采用重要性采样偏向 t=0.75 附近结构信息丰富的时域,避免低噪声区的过度纹理扰动;Stage II 细节导向对抗精炼,在学生的少步推理路径上生成样本,使用冻结 ConvNeXt 特征提取器 + 可训练分类头作为判别器,无需外部图像数据集。
(3) 蒸馏-缓存协同训练(DCT):观察到早期 DiT 块跨步骤时间冗余大,缓存块贡献 Delta_t = O_m - I_n,第二步跳过 6-8 个块。引入轻量级残差 MLP 预测修正缓存误差。Stage II 自然支持缓存训练,对抗损失直接监督缓存加速推理。

SD3-Medium (24 DiT blocks):
SD3.5-Large (38 DiT blocks):
DPG-Bench:蒸馏模型在复杂提示下总分超越多步教师模型
多样性(LPIPS):显著高于 Flash 和 TDM 等基线
用户研究:20 位评估者在 3200 提示上明确偏好 1.x-Distill
方法核心:块级缓存设计
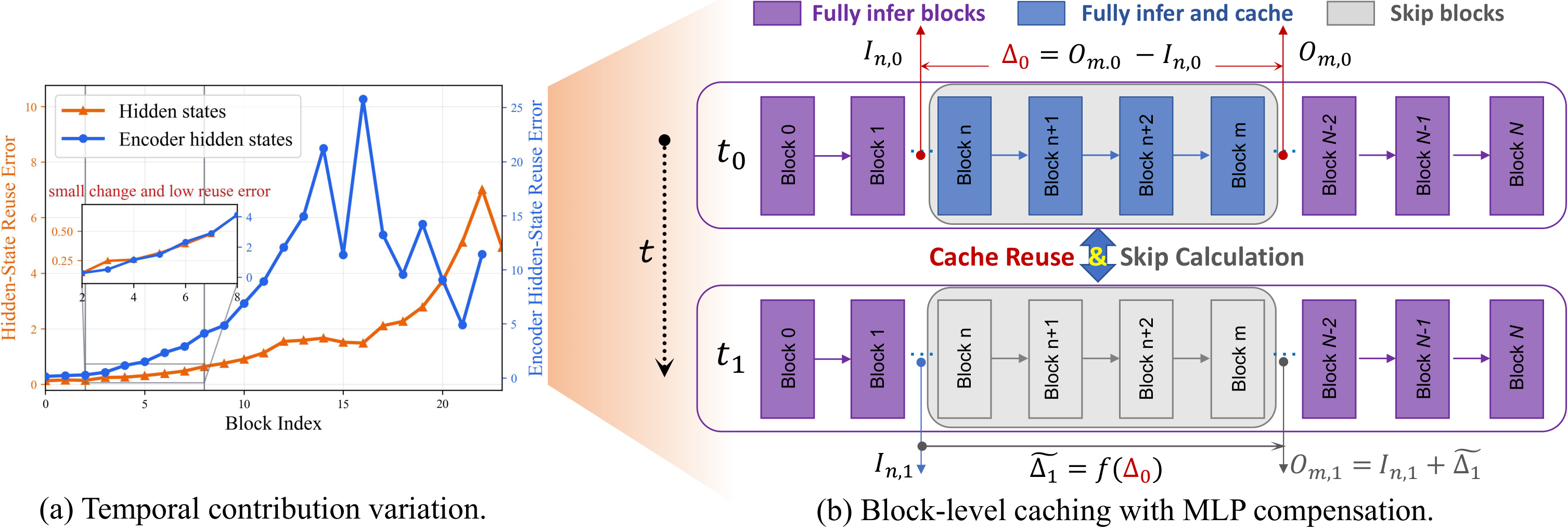
左图展示各 DiT 块的跨步复用误差(早期块冗余大),右图展示缓存机制:第一步完整计算并缓存块贡献,第二步跳过并用 MLP 修正恢复
CFG 在蒸馏中的作用分析
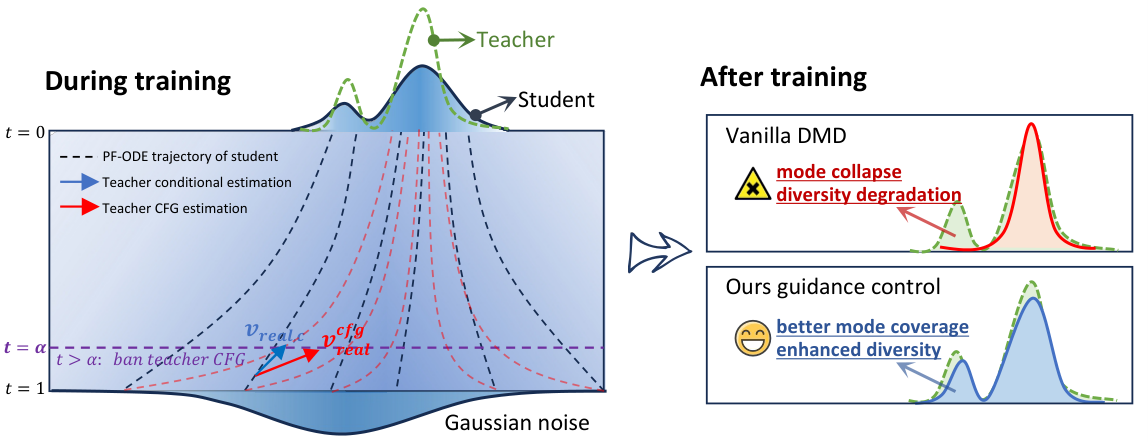
高噪声时域强 CFG 驱使学生过早模式坍缩;1.x-Distill 在高噪声区禁用 CFG,低噪声区保留 CFG
定性对比结果
SD3-Medium 上多种方法的生成质量对比,1.x-Distill 在 1.67 NFE 下仍保持连贯结构和丰富细节
深度点评:
技术演进定位: 分布匹配蒸馏领域的重要推进,开辟 1.x 步生成新范式
可能的后续方向:
SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing
关键词: 图像编辑·空间变换·几何保真度·合成数据·基准评测
贡献: 提出首个专门评估细粒度空间编辑的基准SpatialEdit-Bench,通过联合度量感知合理性和几何保真度系统评估空间操作能力。构建500K合成训练数据集SpatialEdit-500k,使用可控Blender管线生成精确的相机轨迹和物体变换真值。基于此训练16B参数的SpatialEdit-16B基线模型。
效果: SpatialEdit-16B在通用编辑任务中取得有竞争力的性能,同时在空间操作任务上大幅超越现有方法。
Training-Free Refinement of Flow Matching with Divergence-based Sampling
关键词: Flow Matching·采样优化·无训练·散度引导·即插即用
贡献: 提出流分歧采样器FDS,无需训练即可提升Flow Matching模型质量。核心发现:边缘速度场的散度可量化采样误导程度,利用该信号在每个求解步骤前将中间状态引导至歧义更小的区域。
效果: 作为即插即用框架,FDS兼容标准求解器和现有Flow模型,在文本到图像合成和逆问题等多种任务中一致提升保真度。
OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text
关键词: 音频生成·视频到音频·Flow Matching·MoE·CVPR 2026
贡献: 提出通用整体音频生成任务UniHAGen,首次统一生成屏幕内环境音、屏幕外环境音和人类语音。设计TriAttn-DiT架构,通过三路交叉注意力同时处理三种音频条件,配合MoE门控机制自适应平衡。构建UniHAGen-Bench基准覆盖三种代表性场景。CVPR 2026。
效果: 在客观指标和人类评估上均一致超越现有最先进方法,建立了通用整体音频生成的强基线。
OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models
关键词: GRPO·Flow Matching·离线策略·训练效率·后训练优化
贡献: 首个专为Flow-Matching模型设计的离线GRPO框架。主动选择高质量轨迹并自适应加入回放缓冲区重复使用;提出序列级重要性采样修正减轻分布偏移;发现并解决晚期去噪步骤的病态离线比率问题。
效果: 仅用平均34.2%的训练步骤即达到Flow-GRPO同等或更优性能,在图像和视频生成基准上均验证有效。
Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision
关键词: 虚拟试穿·视频生成·扩散Transformer·人体动画·CVPR 2026
贡献: 提出统一框架从单张人像、服装图和姿态视频一步生成换装动画视频。构建大规模三元组监督数据,引入视频扩散Transformer的双模块架构稳定训练,支持零样本服装插值。CVPR 2026。
效果: 克服传统两阶段方案的身份漂移和服装扭曲问题,实现高保真、身份一致的服装迁移动画。
Training-Free Image Editing with Visual Context Integration and Concept Alignment
关键词: 图像编辑·免训练·视觉上下文·概念对齐·后验采样
贡献: 提出VicoEdit——免训练且无需反演的视觉上下文注入图像编辑方法。直接基于视觉上下文将源图转换为目标图,消除扩散反演可能导致的轨迹偏离。设计概念对齐引导的后验采样方法增强编辑一致性。
效果: 免训练方法在编辑性能上甚至超越最先进的基于训练的模型。
Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning
关键词: 图像生成·推理过程·交错生成·可解释AI·多步细化
贡献: 提出过程驱动图像生成范式,将合成分解为思想-动作交错推理轨迹。每次迭代包含文本规划、视觉草拟、文本反思、视觉细化四个阶段。通过密集逐步监督维持空间和语义一致性。
效果: 使生成过程变得明确、可解释且可直接监督,在多种文本到图像基准上验证有效性。
Beyond Few-Step Inference: Accelerating Video Diffusion Transformer Model Serving with Inter-Request Caching Reuse
关键词: 视频生成·推理加速·跨请求缓存·DiT·模型服务
贡献: 提出Chorus——利用跨请求相似性加速视频扩散Transformer服务的缓存方法。采用三阶段缓存策略:完全复用阶段、区域级跨请求缓存阶段和令牌引导注意力放大阶段。在单请求内缓存无效的4步蒸馏模型上仍有效。
效果: 在工业级4步蒸馏视频DiT模型上实现高达45%的推理加速,同时维持语义对齐质量。
CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models
关键词: 生成理解一体化·退化图像·统一多模态·强化学习·GRPO
贡献: 提出CLEAR框架连接统一多模态模型的生成和理解能力以处理退化图像。三步渐进策略:感知退化SFT建立先生成后回答推理模式;潜在表示桥替代解码-重编码绕路;交错GRPO联合优化文本推理和视觉生成。构建MMD-Bench覆盖六个基准三级退化。
效果: 显著提升退化输入鲁棒性同时保持清晰图像性能。发现移除像素级重建监督可获得更高感知质量的中间视觉状态。
人工智能炼丹师 整理 | 2026-04-08
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)