
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日 arXiv cs.CV 视觉生成相关论文共 10 篇。
方向分布:
含 CVPR 2026 接收,多篇开源代码,覆盖视频/图像/音频三大生成方向
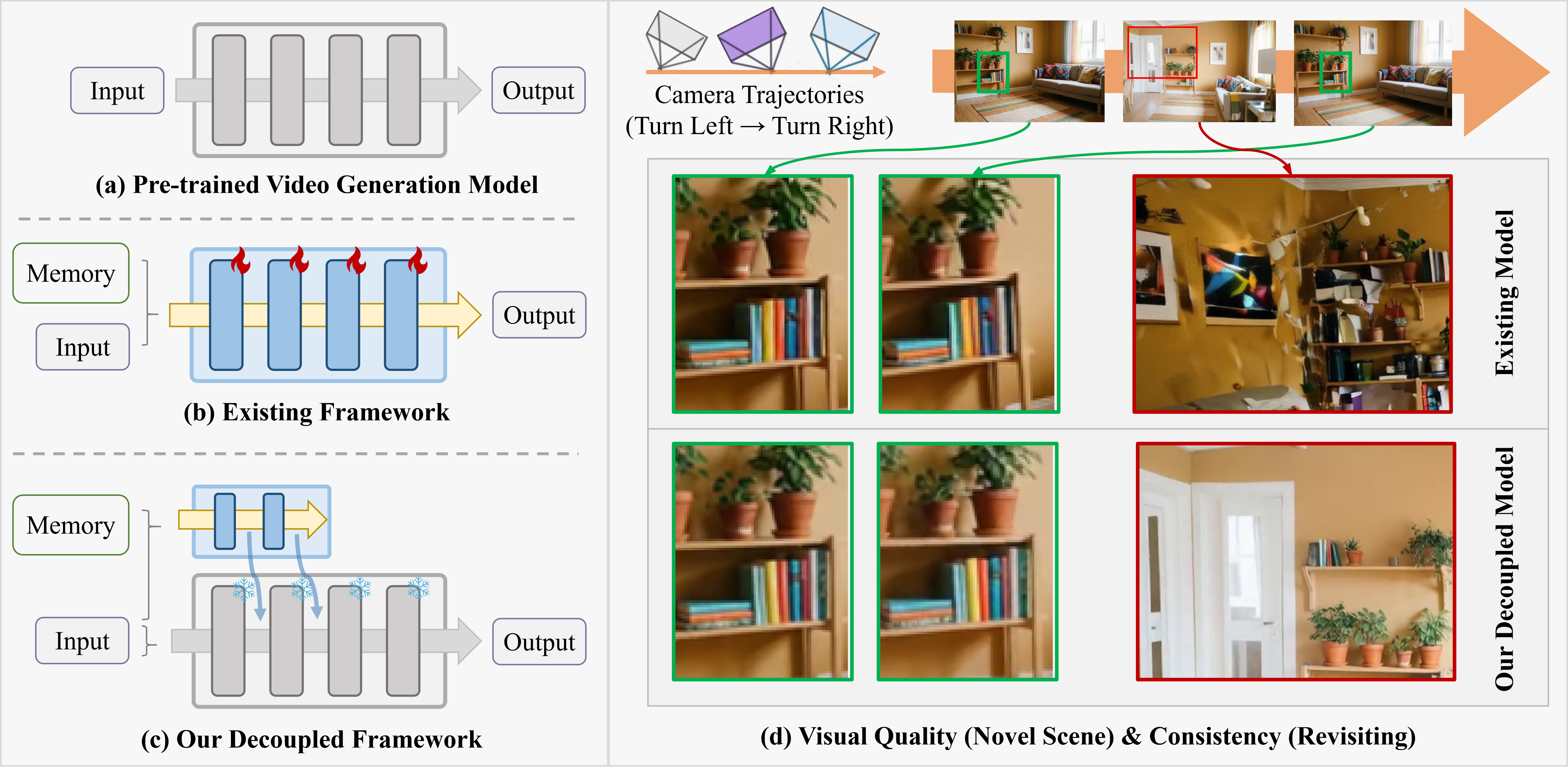
Memorize When Needed: Decoupled Memory Control for Spatially Consistent Long-Horizon Video Generation | Wuhan University | arXiv:2604.18215
关键词: 长视频生成·空间一致性·解耦记忆·相机轨迹·按需记忆
贡献: 提出解耦记忆控制框架 MemWN,将记忆建模与视频生成分离。混合记忆表示捕获时间+空间双重线索,逐帧交叉注意力精准注入记忆,相机感知门控智能判断何时使用记忆。
效果: 在长视频生成基准上取得 SOTA,场景重访空间一致性大幅提升,训练成本显著降低。
EMF: Extending One-Step Image Generation from Class Labels to Text via Discriminative Text Representation | Nankai University, Alibaba AMAP-ML | arXiv:2604.18168
关键词: 一步生成·MeanFlow·文本条件·LLM编码器·图像合成
贡献: 首次将 MeanFlow 框架从类别标签扩展到文本条件,实现高效的一步文本到图像生成。揭示了 MeanFlow 少步生成中文本特征需要高区分度的关键洞察,开发了基于 LLM 文本编码器的解决方案。
效果: 在 MeanFlow 框架下首次实现文本条件的一步图像生成,同时在扩散模型上也展示了显著的生成性能提升。代码已开源。
TS-Attn: Temporal-wise Separable Attention for Multi-Event Video Generation | PKU, ZJU, Nankai, MIT, NJU, UCSB | arXiv:2604.19473
关键词: 多事件视频·免训练·时间注意力·Wan2.1·即插即用
贡献: 提出免训练的时间可分离注意力机制(TS-Attn),解决多事件视频生成中动作保真度与时间一致性的固有矛盾。可即插即用到 Wan2.1-T2V-14B 等预训练模型中。
效果: 在 Wan2.1-T2V-14B 上 StoryEval-Bench 提升 33.5%,在 Wan2.2-T2V-A14B 上提升 16.4%,推理开销仅 +2%。代码已开源。
Speculative Decoding for Autoregressive Video Generation | Independent Research | arXiv:2604.17397
关键词: 投机解码·自回归视频·加速推理·ImageReward·免训练
贡献: 首次将投机解码引入自回归视频扩散模型加速。用 1.3B 小模型起草候选块,ImageReward 路由器以最差帧评分筛选,实现免训练、无需架构修改的视频生成加速。
效果: 在 MovieGenVideoBench 上,保持 98.1% 质量实现 1.59× 加速,或 2.09× 加速保持 95.7% 质量,始终比纯 Draft 高 >17%。
ReImagine: Rethinking Controllable High-Quality Human Video Generation via Image-First Synthesis | CUHK(SZ), SSE, FNii | arXiv:2604.18300
关键词: 人体视频·SMPL-X·图像先验·视角控制·免训练精炼
贡献: 提出先图像后视频的人体视频生成范式,将高质量人体外观学习与时序一致性解耦。结合 SMPL-X 姿态引导和预训练视频扩散模型的免训练时序精炼。
效果: 在多样化姿态和视角下生成高质量、时序一致的人体视频。发布了标准化人体数据集和辅助合成模型。代码已开源。
DGSSM: Diffusion Guided State-Space Models for Multimodal Salient Object Detection | IIT Guwahati | arXiv:2604.18500
关键词: 显著性检测·Mamba·扩散先验·多模态·边界感知
贡献: 提出扩散引导的状态空间模型框架,将多模态显著性检测建模为渐进去噪过程。融合 Mamba 高效全局推理与扩散结构先验。
效果: 在 13 个公开基准(RGB、RGB-D、RGB-T)上全面超越现有 SOTA,同时保持紧凑的模型尺寸。
Denoising, Fast and Slow: Difficulty-Aware Adaptive Sampling for Image Generation | CompVis @ LMU Munich | arXiv:2604.19141
关键词: 自适应去噪·Patch级调度·难度感知·计算优化·扩散模型
贡献: 探索 patch 级别的噪声调度用于图像合成,提出 Patch Forcing 框架,让简单区域先行去噪为困难区域提供上下文。引入自适应难度头按需分配计算资源。
效果: 在 class-conditional ImageNet 上实现优于基线的生成质量,与表示对齐和引导方法正交,可扩展到文本到图像合成。
Video-Robin: Autoregressive Diffusion Planning for Intent-Grounded Video-to-Music Generation | UMD, Microsoft | arXiv:2604.18700
关键词: 视频到音乐·自回归规划·扩散合成·文本条件·DiT
贡献: 提出 Video-Robin,结合自回归规划与扩散合成的文本条件视频到音乐生成模型。自回归模块建模全局结构并对齐视觉与文本语义。
效果: 在分布内和分布外基准上均超越仅接受视频输入和额外特征条件的基线,推理速度比 SOTA 快 2.21 倍。
HP-Edit: A Human-Preference Post-Training Framework for Image Editing | HIT, vivo AI Lab | arXiv:2604.19406
关键词: 图像编辑·人类偏好·RLHF·VLM评分器·后训练
贡献: 提出 HP-Edit 人类偏好对齐的图像编辑后训练框架,发布 RealPref-50K 真实世界偏好数据集覆盖 8 类编辑任务。训练 HP-Scorer 自动评分器作为 RLHF 奖励函数。
效果: 显著增强 Qwen-Image-Edit-2509 等模型的输出,使其更贴合人类偏好。同时发布 RealPref-Bench 基准。
AdaCluster: Adaptive Query-Key Clustering for Sparse Attention in Video Generation | NUS, ByteDance | arXiv:2604.18348
关键词: 稀疏注意力·自适应聚类·视频DiT·加速推理·免训练
贡献: 提出免训练的自适应聚类稀疏注意力框架 AdaCluster,针对视频 DiT 的二次注意力复杂度问题。Q/K 分别采用角度和欧氏距离保持的聚类策略。
效果: 在 CogVideoX-2B、HunyuanVideo 和 Wan-2.1 上实现 1.67-4.31× 加速,质量损失可忽略不计,仅需单张 A40 GPU。
人工智能炼丹君 整理 | 2026-04-22
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)