搜索到
6
篇与
attention
的结果
-
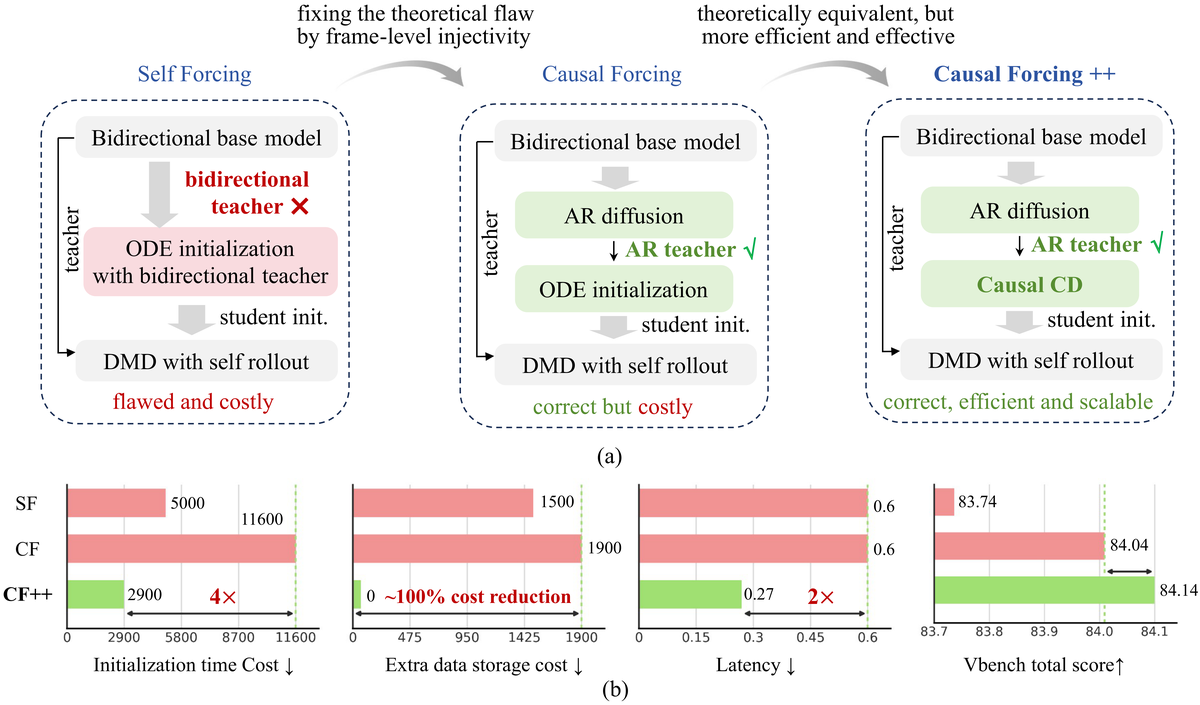
 AIGC 每日速读|2026-05-29|生数科技minWM开源实时交互视频世界模型 今日 AIGC 论文速览 今日共 8 篇 · 视频世界模型 3 篇 · 流式视频生成 1 篇 · 音视频联合生成 1 篇 · 可控图像生成与数据 2 篇 · 大模型记忆与微调 1 篇 重点论文标题列表 minWM:实时交互视频世界模型全栈开源 NAVA:原生音视频对齐联合生成6.3B Gamma-World:多智能体生成式世界模型 AdaState:流式视频生成自演化锚点 YoCausal:视频生成因果性认知基准 今日论文速览 1. minWM:实时交互视频世界模型全栈开源 minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models | 生数科技, 清华大学 | arXiv:2605.30263 关键词:视频世界模型·实时交互·自回归蒸馏·开源·生数科技 前序问题:视频扩散基础模型已能高质量出片,但把它变成实时交互视频世界模型仍然难:交互世界模型需要可控、因果、低延迟的 rollout,实践上要打通数据构造、可控微调、自回归训练、少步蒸馏、流式推理整条链路,而开源社区一直缺一套能跑通的端到端 recipe 本文贡献:minWM:全栈开源框架,把现成的双向 T2V/TI2V 视频基础模型转成「相机可控 + 少步自回归」的世界模型。先对双向扩散做相机控制微调,再用 Causal Forcing / Causal Forcing++ 流程(AR diffusion 训练 + causal ODE/consistency 蒸馏 + 非对称 DMD)蒸成少步自回归生成器做低延迟 rollout。框架模块化、架构可扩展:在 Wan2.1-T2V-1.3B(cross-attention 条件注入)和 HY1.5-TI2V-8B(MMDiT)上分别实例化,还能把 HY-WorldPlay 等已有世界模型适配到新数据分布、训练配方与延迟目标 实验效果:不止放出可运行脚本、checkpoint、文档和推理代码,还给出相机轨迹质量、可控性训练步数、最小 batch size 等实战 ablation——是这个方向少见的「能跑起来、可复现、可扩展」的实时交互视频世界模型配方 (github.com/shengshu-ai/minWM) 批判点评:「全栈开源 + 跨两种主流架构(Wan2.1 cross-attn / HY1.5 MMDiT)实例化 + 可适配已有世界模型」三点让它成为这个方向稀缺的工程基建,对想做实时交互视频的团队意义重大。但框架 / recipe 类工作的核心价值在工程完整度而非单点创新;Causal Forcing++ 与非对称 DMD 联训的稳定性、长 rollout 的累积漂移控制还可以披露更多 2. NAVA:原生音视频对齐联合生成6.3B Native Audio-Visual Alignment for Generation | 百度 ERNIE | arXiv:2605.30073 关键词:音视频联合生成·原生对齐·MMDiT·音色可控·百度 前序问题:联合音视频生成要做到时序同步 + 语义连贯,但现有开源方案要么走「双塔 + 后验对齐」(弱化细粒度音视频协同演化),要么走「三模态全统一」(把语义条件和底层同步耦死在一起)——两条路线都有结构性缺陷 本文贡献:NAVA:context-conditioned 的原生音视频对齐框架。先在专用交互空间建立音视频对应关系,再用外部 context 条件化联合去噪。用 Align-then-Fuse MMDiT 架构实例化,从「模态感知的音视频对齐」平滑过渡到「模态共享的联合去噪」;并提出 Timbre-in-Context Conditioning,把参考音色线索关联到对应语音片段,实现可控语音音色 实验效果:在 Verse-Bench 和 Seed-TTS 上配合用户研究表明:仅用 6.3B 参数即取得更优视频质量、精确的音视频同步、有竞争力的音频质量,以及更强的参考音色可控性 批判点评:「先对齐后融合」而非「一上来全统一」的设计直击双塔 / 三模态两条路线的痛点,6.3B 拿下多项指标性价比很高;Timbre-in-Context 把音色可控做进 context 是干净的设计。但「专用交互空间 + 联合去噪」的两阶段是否引入额外训练复杂度、对更长音视频的扩展性仍需观察 3. Gamma-World:多智能体生成式世界模型 Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players | NVIDIA, 清华大学 | arXiv:2605.28816 关键词:多智能体·世界模型·RoPE·稀疏注意力·NVIDIA 前序问题:交互式视频世界模型大多聚焦单 agent(从单一控制信号生成未来观测),但很多生成环境需要多 agent 同时在共享空间行动(多玩家 / 机器人 / 具身体)。扩到多 agent 需要原则性设计:各 agent 独立可控、排列对称、推理高效,同时跨时间和视角保持一致 本文贡献:生成式多智能体世界模型。提出 Simplex Rotary Agent Encoding:3D RoPE 的无参扩展,把 agent 表示成旋转角空间里正单纯形的顶点,给每个 agent 不同相位又保持排列等价——无需学习 per-slot 身份或固定排序即可扩展 agent 身份;提出 Sparse Hub Attention:用可学习 hub token 中介跨 agent 交互,把跨 agent 注意力从二次降到线性。再把全上下文扩散 teacher 蒸成因果 student,带 KV cache 顺序生成时间块,实现 24FPS 的动作响应生成 实验效果:多人虚拟环境实验中,在视频保真度、动作可控性、agent 间一致性上超越 slot-based 和 dense-attention 基线,且无需额外训练即可从 2 玩家泛化到 4 玩家 批判点评:「用正单纯形顶点的旋转相位编码 agent 身份」是极优雅的无参设计——天然排列对称又可扩展;Sparse Hub Attention 把多 agent 注意力线性化是务实工程;从 2 人零样本泛化到 4 人很有说服力。但 hub token 数量与 agent 数的可扩展上限、长时序多 agent 一致性的退化曲线需要更大规模验证 4. AdaState:流式视频生成自演化锚点 AdaState: Self-Evolving Anchors for Streaming Video Generation | 弗吉尼亚理工 Virginia Tech | arXiv:2605.30349 关键词:流式视频生成·自回归扩散·自演化锚点·KV cache·时间相对 前序问题:自回归视频扩散逐块生成、每块条件于已生成内容,但模型结构性地「锚定在第一帧」:首帧 KV 占据注意力 cache 的特权位置、作为整段主场景参考。作为最干净无误差的位置,这个锚点吸走过多注意力,压制视频动态、把场景构图锁死在初始视角,结果是「时间上很浅」的视频——运动、镜头、场景推进都被静态一致性压制 本文贡献:用「自适应 state」替换静态锚点——一个隐 latent,模型每块和内容一起去噪但从不渲染。模型不再参考冻结的首帧,而是每步通过同时关注「前一 state + 当前内容」自己生成场景锚点,产出随生成内容演化的参考。不同于编码绝对时间的标准视频生成,本方法把时间当相对量:每个生成步看到相同的位置结构、state transition 每块都相同。这给生成过程引入了递归——去噪即 transition 函数,KV cache 即载体,无需任何外部模块 实验效果:实验表明自适应 state 大幅改善视频动态,让生成视频内出现更丰富的运动和更自然的场景推进 批判点评:「首帧 KV 锚点偷走注意力 → 视频时间上变浅」的诊断非常精准,用「可去噪但不渲染的隐 state」做自演化锚点是优雅的零外部模块方案,把时间从绝对改成相对的视角很有启发。但「丰富运动」与「时序一致性」本就是 trade-off,自演化锚点会不会牺牲长程一致性需要定量;缺与显式 memory / anchor 方法的正面对比 5. YoCausal:视频生成因果性认知基准 YoCausal: How Far is Video Generation from World Model? A Causality Perspective | 上海 AI Lab, 阳明交大 NYCU | arXiv:2605.30346 关键词:视频生成·世界模型·因果性·评测基准·上海AILab 前序问题:视频扩散模型(VDM)正走向世界模型,关键问题是:它们真懂因果,还是只过拟合统计时序模式?现有基准大多依赖合成数据,受 sim-to-real gap 限制真实世界泛化 本文贡献:YoCausal:受认知科学「违反预期(VoE)」范式启发的两级基准。零成本地把真实世界视频时序反转,作为天然反事实样本,建立可任意扩展的评测协议。Level 1 提出 Reverse Surprise Index (RSI),用去噪 loss 量化「时间箭头」感知;Level 2 提出 Causality Cognition Index (CCI),用 VLM 把数据分层成因果 / 非因果子集,把真正的因果推理从时序偏置中解耦 实验效果:评测 13 个 SOTA VDM 发现:感知到时间箭头并不意味着理解因果,且相对人类级因果认知仍存在显著差距 批判点评:「时序反转真实视频做零成本反事实」是极聪明的基准构造,RSI / CCI 两级指标把「时间感知」与「因果认知」分层解耦的思路很清晰,给「视频生成→世界模型」泼了必要的冷水。但用去噪 loss 衡量「惊讶度」是否完全等价于因果理解仍可争议;VLM 分层本身的可靠性会传导到 CCI 的结论 6. GenClaw:代码驱动的智能体图像生成 GenClaw: Code-Driven Agentic Image Generation | 中山大学 | arXiv:2605.30248 关键词:图像生成·智能体·代码驱动·可控生成·中山大学 前序问题:图像生成已从「文本条件像素合成」走向「具备视觉理解 + 工具调用的多模态 agent」,但现有 agent 仍受制于底层黑盒图像模型——工作流困在「为优化生成反复改 prompt」的循环里,没有直接操控画布的机制。LLM 作为精确视觉构建「画笔」的潜力基本未被开发 本文贡献:GenClaw:代码驱动的智能体图像生成范式,让 agent 像人类艺术家一样创作——先构思、再起草、最后上色。agent 先通过搜索和推理构建概念知识与上下文;再用代码(SVG / HTML / Three.js)渲染可执行的视觉草图;最后用图像生成模型补充纹理、材质、真实感。代码在此作为可控的中间画布,桥接语言推理与像素合成,把程序逻辑与生成模型的视觉表现力无缝整合 实验效果:把图像生成从黑盒范式转成类似真实人类创作的分阶段过程,朝着高度可控、可解释的视觉生成系统迈出一步 批判点评:「代码作中间画布」是把可控性问题转译成「可执行草图」的聪明思路——SVG / HTML / Three.js 草图天然结构化、可精确编辑,比反复改 prompt 强太多;构思-起草-上色的拟人流程也很有叙事性。但代码草图能表达的视觉复杂度有上限(精细写实场景难用 SVG 起草),最终仍依赖底层生成模型的「上色」能力;端到端延迟和失败率需要量化 7. GPIC:28万亿像素许可级图像语料 GPIC: A Giant Permissive Image Corpus for Visual Generation | 斯坦福 李飞飞团队 | arXiv:2605.30341 关键词:图像语料·视觉生成·许可数据集·flow matching·斯坦福 前序问题:研究可扩展的视觉生成方法需要大、可获取、稳定的数据集,但开放且许可清晰的大规模图像语料长期稀缺 本文贡献:GPIC:约 28 万亿像素的巨型许可图像语料。由 SOTA 视觉语言模型为多样互联网图像生成 caption,含 1 亿训练 + 20 万验证 + 100 万测试样本。所有图像均「研究 + 商用」许可宽松,经安全过滤、去重,集中托管于 Hugging Face。提供生成建模的 benchmark 协议,并给出像素空间 flow matching 的参考 baseline 实验效果:数据集、benchmark、模型全部开放(stanford-vision-lab/gpic);为视觉生成提供「大规模 + 许可清晰 + 稳定可复现」的公共底座 批判点评:「许可宽松 + 商用可用 + 安全去重 + 集中托管」直击当前生成数据集的版权 / 可复现痛点——这种基础设施工作对整个社区的长尾价值很高,28 万亿像素 + 完整 benchmark + baseline 让它即插即用。但「VLM 自动 caption」的质量上限会限制可训出的文本对齐能力;与 LAION 类已有大语料的去重重叠和质量差异需要更透明 8. Parametric Memory Law:LoRA参数记忆的幂律定律 How LoRA Remembers? A Parametric Memory Law for LLM Finetuning | 浙江大学, 阿里 | arXiv:2605.30260 关键词:LoRA·参数记忆·幂律·LLM微调·浙大 前序问题:LLM 需持续学习更新知识,LoRA 被广泛用于记忆更新,但现有研究多靠定性下游评测,对「精确参数记忆」的定量容量极限和底层动力学几乎没探索 本文贡献:用 LoRA 作为受控的记忆容量探针,在 latent 空间系统量化精确参数记忆。提出 Parametric Memory Law:把 loss 下降 ΔL 与有效参数量、序列长度联系起来的稳健幂律。token 级细粒度分析揭示确定性相变——证明预测概率 p>0.5 是 greedy decoding 下逐字召回的充分条件。据此提出 MemFT:阈值引导的优化策略,把训练预算动态重分配到次阈值 token 实验效果:实证表明 MemFT 能提升记忆保真度和效率;为「LoRA 到底记住多少、怎么记」给出可量化的定律而非定性结论 (github.com/zjunlp/ParametricMemoryLaw) 批判点评:「用 LoRA 当记忆容量探针 + 找出幂律 + p>0.5 相变的充分条件」是把模糊的「记忆能力」做成可量化科学定律的扎实工作,MemFT 把定律反哺成实际训练策略形成漂亮闭环。但幂律的普适性需要跨更多模型规模 / 任务验证;「逐字召回」的记忆与「泛化知识」的记忆是两回事,定律对后者的适用边界要谨慎 趋势观察 视频生成正在「世界模型化」:从出片段走向实时交互、多智能体、可因果 — minWM 把双向 T2V/TI2V 蒸成相机可控的少步自回归世界模型并全栈开源;Gamma-World 用单纯形旋转编码 + 稀疏 hub 注意力把世界模型从单 agent 扩到多 agent(2→4 人零样本泛化、24FPS);YoCausal 用时序反转真实视频做反事实基准,量出 13 个 SOTA VDM 距离「真懂因果」仍有显著差距——视频生成的下一站从「画面好」转向「能交互、有因果、多主体」 自回归流式视频生成开始解决「时间太浅」的结构病 — AdaState 诊断出首帧 KV 锚点偷走注意力、把场景锁死在初始视角,改用「可去噪但不渲染的自演化隐 state」做相对时间锚点,显著改善运动和场景推进——流式视频生成从「保一致」转向「敢动起来」 音视频联合生成走向「先对齐后融合」的原生范式 — NAVA 指出双塔后验对齐弱化协同、三模态全统一耦合语义与同步两条路都有缺陷,提出 Align-then-Fuse MMDiT 先在交互空间建音视频对应、再 context 条件化联合去噪,6.3B 拿下多项 SOTA + 可控音色——音视频生成的架构共识正在形成 图像生成的可控性升级:代码做中间画布、许可数据做底座 — GenClaw 用 SVG/HTML/Three.js 可执行草图作中间画布,把「反复改 prompt」换成「构思-起草-上色」的拟人可控流程;GPIC 放出 28 万亿像素、研究+商用许可宽松、安全去重的图像语料 + benchmark + flow matching baseline——可控生成的「方法」和「数据底座」被同时推进 大模型记忆与微调走向「可量化定律」 — How LoRA Remembers 用 LoRA 当记忆探针,给出 loss 下降 ΔL 与有效参数 / 序列长度的 Parametric Memory Law,发现 p>0.5 是逐字召回的充分条件,并据此提出阈值引导的 MemFT——把「LoRA 记多少」从定性评测推到可解析的幂律 人工智能炼丹君 整理 | 2026-05-29 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描下方二维码关注
AIGC 每日速读|2026-05-29|生数科技minWM开源实时交互视频世界模型 今日 AIGC 论文速览 今日共 8 篇 · 视频世界模型 3 篇 · 流式视频生成 1 篇 · 音视频联合生成 1 篇 · 可控图像生成与数据 2 篇 · 大模型记忆与微调 1 篇 重点论文标题列表 minWM:实时交互视频世界模型全栈开源 NAVA:原生音视频对齐联合生成6.3B Gamma-World:多智能体生成式世界模型 AdaState:流式视频生成自演化锚点 YoCausal:视频生成因果性认知基准 今日论文速览 1. minWM:实时交互视频世界模型全栈开源 minWM: A Full-Stack Open-Source Framework for Real-Time Interactive Video World Models | 生数科技, 清华大学 | arXiv:2605.30263 关键词:视频世界模型·实时交互·自回归蒸馏·开源·生数科技 前序问题:视频扩散基础模型已能高质量出片,但把它变成实时交互视频世界模型仍然难:交互世界模型需要可控、因果、低延迟的 rollout,实践上要打通数据构造、可控微调、自回归训练、少步蒸馏、流式推理整条链路,而开源社区一直缺一套能跑通的端到端 recipe 本文贡献:minWM:全栈开源框架,把现成的双向 T2V/TI2V 视频基础模型转成「相机可控 + 少步自回归」的世界模型。先对双向扩散做相机控制微调,再用 Causal Forcing / Causal Forcing++ 流程(AR diffusion 训练 + causal ODE/consistency 蒸馏 + 非对称 DMD)蒸成少步自回归生成器做低延迟 rollout。框架模块化、架构可扩展:在 Wan2.1-T2V-1.3B(cross-attention 条件注入)和 HY1.5-TI2V-8B(MMDiT)上分别实例化,还能把 HY-WorldPlay 等已有世界模型适配到新数据分布、训练配方与延迟目标 实验效果:不止放出可运行脚本、checkpoint、文档和推理代码,还给出相机轨迹质量、可控性训练步数、最小 batch size 等实战 ablation——是这个方向少见的「能跑起来、可复现、可扩展」的实时交互视频世界模型配方 (github.com/shengshu-ai/minWM) 批判点评:「全栈开源 + 跨两种主流架构(Wan2.1 cross-attn / HY1.5 MMDiT)实例化 + 可适配已有世界模型」三点让它成为这个方向稀缺的工程基建,对想做实时交互视频的团队意义重大。但框架 / recipe 类工作的核心价值在工程完整度而非单点创新;Causal Forcing++ 与非对称 DMD 联训的稳定性、长 rollout 的累积漂移控制还可以披露更多 2. NAVA:原生音视频对齐联合生成6.3B Native Audio-Visual Alignment for Generation | 百度 ERNIE | arXiv:2605.30073 关键词:音视频联合生成·原生对齐·MMDiT·音色可控·百度 前序问题:联合音视频生成要做到时序同步 + 语义连贯,但现有开源方案要么走「双塔 + 后验对齐」(弱化细粒度音视频协同演化),要么走「三模态全统一」(把语义条件和底层同步耦死在一起)——两条路线都有结构性缺陷 本文贡献:NAVA:context-conditioned 的原生音视频对齐框架。先在专用交互空间建立音视频对应关系,再用外部 context 条件化联合去噪。用 Align-then-Fuse MMDiT 架构实例化,从「模态感知的音视频对齐」平滑过渡到「模态共享的联合去噪」;并提出 Timbre-in-Context Conditioning,把参考音色线索关联到对应语音片段,实现可控语音音色 实验效果:在 Verse-Bench 和 Seed-TTS 上配合用户研究表明:仅用 6.3B 参数即取得更优视频质量、精确的音视频同步、有竞争力的音频质量,以及更强的参考音色可控性 批判点评:「先对齐后融合」而非「一上来全统一」的设计直击双塔 / 三模态两条路线的痛点,6.3B 拿下多项指标性价比很高;Timbre-in-Context 把音色可控做进 context 是干净的设计。但「专用交互空间 + 联合去噪」的两阶段是否引入额外训练复杂度、对更长音视频的扩展性仍需观察 3. Gamma-World:多智能体生成式世界模型 Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players | NVIDIA, 清华大学 | arXiv:2605.28816 关键词:多智能体·世界模型·RoPE·稀疏注意力·NVIDIA 前序问题:交互式视频世界模型大多聚焦单 agent(从单一控制信号生成未来观测),但很多生成环境需要多 agent 同时在共享空间行动(多玩家 / 机器人 / 具身体)。扩到多 agent 需要原则性设计:各 agent 独立可控、排列对称、推理高效,同时跨时间和视角保持一致 本文贡献:生成式多智能体世界模型。提出 Simplex Rotary Agent Encoding:3D RoPE 的无参扩展,把 agent 表示成旋转角空间里正单纯形的顶点,给每个 agent 不同相位又保持排列等价——无需学习 per-slot 身份或固定排序即可扩展 agent 身份;提出 Sparse Hub Attention:用可学习 hub token 中介跨 agent 交互,把跨 agent 注意力从二次降到线性。再把全上下文扩散 teacher 蒸成因果 student,带 KV cache 顺序生成时间块,实现 24FPS 的动作响应生成 实验效果:多人虚拟环境实验中,在视频保真度、动作可控性、agent 间一致性上超越 slot-based 和 dense-attention 基线,且无需额外训练即可从 2 玩家泛化到 4 玩家 批判点评:「用正单纯形顶点的旋转相位编码 agent 身份」是极优雅的无参设计——天然排列对称又可扩展;Sparse Hub Attention 把多 agent 注意力线性化是务实工程;从 2 人零样本泛化到 4 人很有说服力。但 hub token 数量与 agent 数的可扩展上限、长时序多 agent 一致性的退化曲线需要更大规模验证 4. AdaState:流式视频生成自演化锚点 AdaState: Self-Evolving Anchors for Streaming Video Generation | 弗吉尼亚理工 Virginia Tech | arXiv:2605.30349 关键词:流式视频生成·自回归扩散·自演化锚点·KV cache·时间相对 前序问题:自回归视频扩散逐块生成、每块条件于已生成内容,但模型结构性地「锚定在第一帧」:首帧 KV 占据注意力 cache 的特权位置、作为整段主场景参考。作为最干净无误差的位置,这个锚点吸走过多注意力,压制视频动态、把场景构图锁死在初始视角,结果是「时间上很浅」的视频——运动、镜头、场景推进都被静态一致性压制 本文贡献:用「自适应 state」替换静态锚点——一个隐 latent,模型每块和内容一起去噪但从不渲染。模型不再参考冻结的首帧,而是每步通过同时关注「前一 state + 当前内容」自己生成场景锚点,产出随生成内容演化的参考。不同于编码绝对时间的标准视频生成,本方法把时间当相对量:每个生成步看到相同的位置结构、state transition 每块都相同。这给生成过程引入了递归——去噪即 transition 函数,KV cache 即载体,无需任何外部模块 实验效果:实验表明自适应 state 大幅改善视频动态,让生成视频内出现更丰富的运动和更自然的场景推进 批判点评:「首帧 KV 锚点偷走注意力 → 视频时间上变浅」的诊断非常精准,用「可去噪但不渲染的隐 state」做自演化锚点是优雅的零外部模块方案,把时间从绝对改成相对的视角很有启发。但「丰富运动」与「时序一致性」本就是 trade-off,自演化锚点会不会牺牲长程一致性需要定量;缺与显式 memory / anchor 方法的正面对比 5. YoCausal:视频生成因果性认知基准 YoCausal: How Far is Video Generation from World Model? A Causality Perspective | 上海 AI Lab, 阳明交大 NYCU | arXiv:2605.30346 关键词:视频生成·世界模型·因果性·评测基准·上海AILab 前序问题:视频扩散模型(VDM)正走向世界模型,关键问题是:它们真懂因果,还是只过拟合统计时序模式?现有基准大多依赖合成数据,受 sim-to-real gap 限制真实世界泛化 本文贡献:YoCausal:受认知科学「违反预期(VoE)」范式启发的两级基准。零成本地把真实世界视频时序反转,作为天然反事实样本,建立可任意扩展的评测协议。Level 1 提出 Reverse Surprise Index (RSI),用去噪 loss 量化「时间箭头」感知;Level 2 提出 Causality Cognition Index (CCI),用 VLM 把数据分层成因果 / 非因果子集,把真正的因果推理从时序偏置中解耦 实验效果:评测 13 个 SOTA VDM 发现:感知到时间箭头并不意味着理解因果,且相对人类级因果认知仍存在显著差距 批判点评:「时序反转真实视频做零成本反事实」是极聪明的基准构造,RSI / CCI 两级指标把「时间感知」与「因果认知」分层解耦的思路很清晰,给「视频生成→世界模型」泼了必要的冷水。但用去噪 loss 衡量「惊讶度」是否完全等价于因果理解仍可争议;VLM 分层本身的可靠性会传导到 CCI 的结论 6. GenClaw:代码驱动的智能体图像生成 GenClaw: Code-Driven Agentic Image Generation | 中山大学 | arXiv:2605.30248 关键词:图像生成·智能体·代码驱动·可控生成·中山大学 前序问题:图像生成已从「文本条件像素合成」走向「具备视觉理解 + 工具调用的多模态 agent」,但现有 agent 仍受制于底层黑盒图像模型——工作流困在「为优化生成反复改 prompt」的循环里,没有直接操控画布的机制。LLM 作为精确视觉构建「画笔」的潜力基本未被开发 本文贡献:GenClaw:代码驱动的智能体图像生成范式,让 agent 像人类艺术家一样创作——先构思、再起草、最后上色。agent 先通过搜索和推理构建概念知识与上下文;再用代码(SVG / HTML / Three.js)渲染可执行的视觉草图;最后用图像生成模型补充纹理、材质、真实感。代码在此作为可控的中间画布,桥接语言推理与像素合成,把程序逻辑与生成模型的视觉表现力无缝整合 实验效果:把图像生成从黑盒范式转成类似真实人类创作的分阶段过程,朝着高度可控、可解释的视觉生成系统迈出一步 批判点评:「代码作中间画布」是把可控性问题转译成「可执行草图」的聪明思路——SVG / HTML / Three.js 草图天然结构化、可精确编辑,比反复改 prompt 强太多;构思-起草-上色的拟人流程也很有叙事性。但代码草图能表达的视觉复杂度有上限(精细写实场景难用 SVG 起草),最终仍依赖底层生成模型的「上色」能力;端到端延迟和失败率需要量化 7. GPIC:28万亿像素许可级图像语料 GPIC: A Giant Permissive Image Corpus for Visual Generation | 斯坦福 李飞飞团队 | arXiv:2605.30341 关键词:图像语料·视觉生成·许可数据集·flow matching·斯坦福 前序问题:研究可扩展的视觉生成方法需要大、可获取、稳定的数据集,但开放且许可清晰的大规模图像语料长期稀缺 本文贡献:GPIC:约 28 万亿像素的巨型许可图像语料。由 SOTA 视觉语言模型为多样互联网图像生成 caption,含 1 亿训练 + 20 万验证 + 100 万测试样本。所有图像均「研究 + 商用」许可宽松,经安全过滤、去重,集中托管于 Hugging Face。提供生成建模的 benchmark 协议,并给出像素空间 flow matching 的参考 baseline 实验效果:数据集、benchmark、模型全部开放(stanford-vision-lab/gpic);为视觉生成提供「大规模 + 许可清晰 + 稳定可复现」的公共底座 批判点评:「许可宽松 + 商用可用 + 安全去重 + 集中托管」直击当前生成数据集的版权 / 可复现痛点——这种基础设施工作对整个社区的长尾价值很高,28 万亿像素 + 完整 benchmark + baseline 让它即插即用。但「VLM 自动 caption」的质量上限会限制可训出的文本对齐能力;与 LAION 类已有大语料的去重重叠和质量差异需要更透明 8. Parametric Memory Law:LoRA参数记忆的幂律定律 How LoRA Remembers? A Parametric Memory Law for LLM Finetuning | 浙江大学, 阿里 | arXiv:2605.30260 关键词:LoRA·参数记忆·幂律·LLM微调·浙大 前序问题:LLM 需持续学习更新知识,LoRA 被广泛用于记忆更新,但现有研究多靠定性下游评测,对「精确参数记忆」的定量容量极限和底层动力学几乎没探索 本文贡献:用 LoRA 作为受控的记忆容量探针,在 latent 空间系统量化精确参数记忆。提出 Parametric Memory Law:把 loss 下降 ΔL 与有效参数量、序列长度联系起来的稳健幂律。token 级细粒度分析揭示确定性相变——证明预测概率 p>0.5 是 greedy decoding 下逐字召回的充分条件。据此提出 MemFT:阈值引导的优化策略,把训练预算动态重分配到次阈值 token 实验效果:实证表明 MemFT 能提升记忆保真度和效率;为「LoRA 到底记住多少、怎么记」给出可量化的定律而非定性结论 (github.com/zjunlp/ParametricMemoryLaw) 批判点评:「用 LoRA 当记忆容量探针 + 找出幂律 + p>0.5 相变的充分条件」是把模糊的「记忆能力」做成可量化科学定律的扎实工作,MemFT 把定律反哺成实际训练策略形成漂亮闭环。但幂律的普适性需要跨更多模型规模 / 任务验证;「逐字召回」的记忆与「泛化知识」的记忆是两回事,定律对后者的适用边界要谨慎 趋势观察 视频生成正在「世界模型化」:从出片段走向实时交互、多智能体、可因果 — minWM 把双向 T2V/TI2V 蒸成相机可控的少步自回归世界模型并全栈开源;Gamma-World 用单纯形旋转编码 + 稀疏 hub 注意力把世界模型从单 agent 扩到多 agent(2→4 人零样本泛化、24FPS);YoCausal 用时序反转真实视频做反事实基准,量出 13 个 SOTA VDM 距离「真懂因果」仍有显著差距——视频生成的下一站从「画面好」转向「能交互、有因果、多主体」 自回归流式视频生成开始解决「时间太浅」的结构病 — AdaState 诊断出首帧 KV 锚点偷走注意力、把场景锁死在初始视角,改用「可去噪但不渲染的自演化隐 state」做相对时间锚点,显著改善运动和场景推进——流式视频生成从「保一致」转向「敢动起来」 音视频联合生成走向「先对齐后融合」的原生范式 — NAVA 指出双塔后验对齐弱化协同、三模态全统一耦合语义与同步两条路都有缺陷,提出 Align-then-Fuse MMDiT 先在交互空间建音视频对应、再 context 条件化联合去噪,6.3B 拿下多项 SOTA + 可控音色——音视频生成的架构共识正在形成 图像生成的可控性升级:代码做中间画布、许可数据做底座 — GenClaw 用 SVG/HTML/Three.js 可执行草图作中间画布,把「反复改 prompt」换成「构思-起草-上色」的拟人可控流程;GPIC 放出 28 万亿像素、研究+商用许可宽松、安全去重的图像语料 + benchmark + flow matching baseline——可控生成的「方法」和「数据底座」被同时推进 大模型记忆与微调走向「可量化定律」 — How LoRA Remembers 用 LoRA 当记忆探针,给出 loss 下降 ΔL 与有效参数 / 序列长度的 Parametric Memory Law,发现 p>0.5 是逐字召回的充分条件,并据此提出阈值引导的 MemFT——把「LoRA 记多少」从定性评测推到可解析的幂律 人工智能炼丹君 整理 | 2026-05-29 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描下方二维码关注 -
AIGC 每日速读|2026-05-28|北大OSP-Next视频生成跨硬件加速 今日 AIGC 论文速览 今日共 11 篇 · 视频生成全栈加速 4 篇 · 视频生成新能力 2 篇 · 音频统一生成 2 篇 · 语音合成与编辑 2 篇 · 扩散模型对齐 1 篇 重点论文标题列表 OSP-Next:稀疏+量化+RL全栈视频生成1.64x PARE:视频DiT结构剪枝+动态路由 ⚡ Quantized Keys Steal Attention:KV缓存量化的Jensen偏差校正 SVDQuant-GPTQ:W4A4量化Wan2.2-I2V省内存59.3% Dasheng AudioGen:首个文生混合音频场景统一模型 今日论文速览 1. OSP-Next:稀疏+量化+RL全栈视频生成1.64x OSP-Next: Efficient High-Quality Video Generation with Sparse Sequence Parallelism, HiF8 Quantization, and Reinforcement Learning | 北大袁粒组, 华为 | arXiv:2605.28691 关键词:视频生成·稀疏注意力·序列并行·HiF8·北大袁粒组 ⚠️ 前序问题:Diffusion Transformer 在视频生成上已经能出好东西,但 full attention 二次开销死死压住效率。前人方案各做一段(稀疏 / 量化 / 蒸馏),缺一套能同时打通通信、计算、精度的端到端方案——尤其在「多卡序列并行」上和「跨国产硬件」上 本文贡献:OSP-Next:把稀疏注意力 + 序列并行 + 量化 + RL 后训练全栈打通的高效 T2V 框架。Skiparse-2D Attention 在空间维做 token-wise + group-wise 稀疏并保留 FlashAttention 兼容;提出 Sparse Sequence Parallelism (SSP) 用一次 All-to-All 切换稀疏模式,相比 Ulysses SP 通信量降低 75%;HiF8 量化支持 8-bit 联合训练 + 稀疏 fine-tune;Mix-GRPO 后训练弥补稀疏模型的质量回退 实验效果:VBench 总分 83.73% 超越 Wan2.1 基线;5 秒 720P/768P 设置下,H200 单 GPU 加速 1.64×,8 GPU 加速 1.52×;OSP-Next-HiF8 仅掉 0.4% 分数即可在国产昇腾 Ascend 950PR 上拿到 1.69× 和 2.27× 加速——是少见的同时验证国际/国产硬件的视频生成加速方案 批判点评:「稀疏注意力 + 序列并行 + 量化 + RL」四件套全栈打通,每一件单独不算新,但 SSP 把通信量直接打掉 75% 是非常硬的工程数字;跨 H200 + 昇腾的双硬件验证为国产硬件视频生成提供了稀缺的实证。但 Skiparse-2D 是 fixed pattern,对极复杂运动场景的可适配性需要看;Mix-GRPO 与 SSP 联训的稳定性细节披露还可以更多 2. PARE:视频DiT结构剪枝+动态路由 PARE: Pruning and Adaptive Routing for Efficient Video Generation | 港中文 CUHK, 上海 AI Lab, 悉尼大学 | arXiv:2605.27336 关键词:视频 DiT·结构剪枝·动态路由·Wan2.1-14B·上海 AI Lab ⚠️ 前序问题:Video DiT 又宽(block 宽)又深(架构深)又要多步采样,部署成本极高。前人通过压宽/压深/压步数减成本,但都 commit 到固定架构——不能针对单个输入或不同去噪阶段动态调整 本文贡献:PARE:把宽度剪枝和深度自适应路由联合做。宽度上观察到 attention head 自然分化为空间 vs 时序角色,设计区分两类的 importance scoring 避免「运动关键的 temporal head」被过早剪掉;深度上训轻量 router 以 denoising timestep + 视觉内容为条件,动态选择每步执行哪些 block——实现「按输入动态计算」而非静态删除。两阶段 progressive pipeline 先用蒸馏修复宽度剪枝的质量损失,再联合优化 student + router 解耦学习目标 实验效果:在 Wan2.1-14B 上对 I2V 和 T2V 都大幅降低每步算力且保住 VBench 各维度质量;与 step 蒸馏天然可组合进一步加速——把「静态剪枝」时代翻篇成「动态路由按需算」 批判点评:「区分空间/时序 head 重要性 + denoising-step 条件的 block router」两个洞察都直击 Video DiT 的结构性冗余。动态路由实现「按输入按 timestep 算」是 efficient video gen 的下一阶段方向。但 router 本身的训练稳定性、推理时的额外 overhead、以及与 OSP-Next 类静态稀疏组合后的边际收益需要更细 ablation 3. Quantized Keys Steal Attention:KV缓存量化的Jensen偏差校正 Quantized Keys Steal Attention: Bias Correction for KV-Cache Compression in Video Diffusion | 慕尼黑工大 TUM, Tensordyne | arXiv:2605.26266 关键词:视频扩散·KV cache·INT2 量化·Jensen 偏差·长视频 ⚠️ 前序问题:chunk-wise 自回归视频扩散依赖前序 chunk 的 KV cache 避免重复计算,但视频越长 cache 越大,量化 KV 到低 bit 又会显著掉画质。掉画质的根因是什么?以前没人说清楚 本文贡献:首次明确指出根因:softmax 注意力中 exp 的凸性让量化噪声系统性放大「被 cache 的 keys」对注意力的贡献——作者命名为 Jensen bias(量化的 keys 会偷走当前 chunk 的注意力质量)。给出 per-attention-score 的解析修正项,在 expectation 上消除该 bias,只用量化 step size 和 query norm 即可在线算;用二阶 Taylor 近似让额外计算开销可忽略、无需额外显存 实验效果:在 MAGI-1 / SkyReels-V2 / HY-WorldPlay 三个长视频模型上 INT2 量化即可恢复大部分掉的质量、接近 BF16;用 50% 更少显存的 INT2 反而能超过 INT4——长视频 KV cache 压缩拿到新的帕累托前沿 批判点评:把「量化掉画质」从经验问题改写成「Jensen 偏差」这一可解析的统计现象是真正的科学贡献——一行公式校正、零额外显存就拿到 INT2 ≈ BF16 的质量。这种「找根因 + 闭式解」的工作含金量高。但局限在 chunk-wise AR 视频扩散,对非 AR 的全局扩散 KV 压缩不直接适用;与 SmoothQuant 等激活/权重路线的组合策略还可探索 4. SVDQuant-GPTQ:W4A4量化Wan2.2-I2V省内存59.3% Timestep-Aware SVDQuant-GPTQ for W4A4 Quantization of Wan2.2-I2V | 华中科技大学 HUST | arXiv:2605.27003 关键词:W4A4 量化·Wan2.2·MoE DiT·SVDQuant·华中科大 ⚠️ 前序问题:把大型视频 DiT 推到 W4A4 量化可以省一大块显存,但两道坎卡死:(1) 稀疏的「大幅激活 outlier」;(2) 不同去噪 timestep 的激活分布漂移很大。这两个问题在 Wan2.2-I2V 双专家 MoE DiT(高噪/低噪两个 expert 量化敏感度完全不同)下被进一步放大——单一全局校准策略根本拿不下 本文贡献:Timestep-Aware SVDQuant-GPTQ:(1) SVDQuant-based 低秩 outlier 补偿处理激活大幅 outlier;(2) GPTQ 重建感知残差权重量化;(3) timestep-bin-wise 逐层激活 clipping-ratio 搜索,对每个 MoE expert 独立完成。三件套合起来就是「按 expert + 按 timestep」精细化校准的 PTQ 框架 实验效果:在 OpenS2V-Eval 上相对 BF16 把峰值 GPU 内存降 59.3%,VBench 平均分仅掉 0.9%,Imaging Quality 仅掉 2.3%——证明「expert + timestep 双感知校准」是 MoE 视频 DiT 量化高保真的必要条件 批判点评:把 MoE DiT 量化从「全局校准」拉到「按 expert + 按 timestep」是正确的颗粒度切分——双专家的量化敏感度本来就不同,强行全局必然掉点。59.3% 内存降 + <1% 质量损是漂亮的工业数字。但 PTQ 路线天然依赖 calibration set 质量,长视频/复杂运动的覆盖度需要追踪;与昨天 RT-Lynx 类激活稀疏的组合潜力值得探索 5. Dasheng AudioGen:首个文生混合音频场景统一模型 Dasheng AudioGen: A Unified Model for Generating Coherent Audio Scenes from Text | 小米, 上海交大 | arXiv:2605.27838 关键词:音频场景生成·multi-view caption·flow matching·小米·DiT ⚠️ 前序问题:音频生成长期被「按域切分」——语音、音乐、音效各有独立模型——做不到从一句描述生成「同时包含人声 + 背景音乐 + 环境音效」的连贯混合音频场景。两大障碍:缺真实混合音频的细粒度监督;声学表示难以同时承载多个并发音频组件 本文贡献:Dasheng AudioGen:首个统一生成混合音频场景的端到端框架。两个核心:(i) structured multi-view captions——把复杂声学场景显式解耦成互补的描述视图,让每个音频层都有细粒度控制;(ii) 高维统一「语义-声学」表示作为共享 latent,注入语义先验加速跨模态训练收敛,同时高维特征空间提供解耦并发声音组件的容量。在此基础上一个简单的 flow-matching DiT 就能跑出端到端高质量音频场景生成 实验效果:在混合音频类别接近真实录音质量,单类型生成(speech/music/SFX)也与专用模型打平——首次把「视觉生成里图文统一」的思路真正落到音频场景上;配套建立音频场景生成的综合评测 pipeline 批判点评:「structured multi-view captions + 高维语义-声学统一 latent」是非常对症的两个设计——把音频域的「描述粒度」和「表示容量」都拉到能容纳混合场景的层次。flow-matching DiT 的工程极简性也很好。但 multi-view caption 的自动构造成本/质量、高维 latent 增加的 DiT 训练开销,以及与商用 ElevenLabs Sound Effect / Stable Audio 2 的端到端对比都需要更细评测 6. HarmoVid:视频肖像重打光和谐化稳定不闪烁 HarmoVid: Relightful Video Portrait Harmonization | Adobe Research, UNC | arXiv:2605.28811 关键词:视频肖像·relight 和谐化·deflicker·alpha mask·Adobe ⚠️ 前序问题:把人物前景视频和谐到目标背景场景(同步阴影、色调、光照强度——relightful harmonization)的硬伤是:视频域没法采集「同一动作不同光照」的成对标注数据。最直接的方案——「按帧调用图像和谐模型」——会带来严重时序抖动(flicker) 本文贡献:HarmoVid 给出整套视频和谐化方案:(i) 全新的 lighting deflickering 模型稳定全局和局部光照 flicker,把「逐帧 image-harmonization」的输出升级成可监督的 paired 视频数据;(ii) 视频扩散模型在 deflickered 真实 + 合成视频上学习;(iii) asymmetric alpha mask conditioning 让模型从真实视频里学到干净的边界 实验效果:在时序连贯、自然度、边界干净度、物理合理光照行为多个维度超越此前所有 image-based 和 video-based 和谐化方法;relighting 表现力也保住——人物视频合成 / 后期合成的标准工业链路被显著升级 批判点评:用「先 deflicker 再训练」绕开「无成对数据」的死结是非常聪明的——deflicker 把单帧图像和谐输出转化成可用监督,是真正的杠杆点。asymmetric alpha mask 也很实用。但 deflicker 模型本身的失败模式(强光/复杂阴影)会传导到下游;与 Adobe 自家的商业级合成工具的真实对比需要更细评测 7. SmartDirector:多关键帧条件电影级视频叙事控制 SmartDirector: Keyframe-Conditioned Cinematic Video Generation with Narrative Pacing Control | 国内视频生成团队 | arXiv:2605.27891 关键词:电影级视频·多关键帧·叙事节奏·两阶段·Director-Gen/SR ⚠️ 前序问题:视频的「叙事质量」决定感知价值,但现有视频生成方法主要靠 text prompt 或首尾帧这类稀疏 condition——对叙事结构和时序节奏的精确控制非常有限,导出不了真正「有 pacing 的电影感视频」 本文贡献:SmartDirector:以多关键帧增强视频生成的叙事能力。支持单镜头、多镜头叙事合成、视频延展三类场景。两阶段:(i) Director-Gen 在低分辨率上以关键帧为条件生成;(ii) Director-SR 利用高分辨率关键帧作为语义锚点把细粒度细节补回来。配套数据管线从电影中精选单镜头/多镜头序列以支撑多关键帧训练 实验效果:在多个评测上大幅超越 SOTA,把视频生成从「按 prompt 出 5 秒片段」升级到「按多关键帧出有节奏的多镜头序列」——电影级视频生成的可控性接近真实创作工作流 批判点评:「多关键帧 + 两阶段先粗后细」直击「电影级叙事控制」的实际痛点——单 prompt / 首尾帧确实远远不够。两阶段把分辨率 vs 叙事控制解耦是合理设计。但「关键帧」的获取成本(人工/AI辅助)和叙事节奏的可量化评测仍是模糊地带;多镜头切换的时空一致性细节需要更深 ablation 8. LoSATok:1280维语义压缩到128维统一audio LoSATok: Low-dimensional Semantic-Acoustic Tokenizer for Cross-Domain Audio Understanding and Generation | 清华深圳, 面壁智能 | arXiv:2605.27840 关键词:audio tokenizer·128 维·语义瓶颈·清华深圳·面壁 ⚠️ 前序问题:音频 tokenizer 是统一「音频理解」和「音频生成」的根基。理解需要高层语义;生成需要语义 + 声学细节。现有统一 tokenizer 在高维连续 latent 里同时编码——这增加了 DiT 生成端的建模负担 本文贡献:LoSATok:观察到 1280 维语义 encoder 特征是可压缩的,引入 Semantic Bottleneck 压到 128 维,并用 time-relation loss 保时序特征一致性;再用「双层级语义监督」同时利用高维/低维语义信号——让 tokenizer 在紧凑 latent 空间里同时承载语义和声学细节 实验效果:在 speech / music / 通用 audio 上 SemBo 保住强低维语义容量,LoSATok 与多个语义表示比较 understanding 性能仍有竞争力;在 DiT 端的 speech / music / audio 生成上一致改进——证明「低维 audio 表示也能同时支撑理解与生成」 批判点评:把「audio 统一 tokenizer」的维度从 1280 砍到 128 是非常硬的容量压缩——若真的不掉理解还能提升生成,那就解掉了「audio 统一表示卡 DiT」的关键梗。time-relation loss + 双层级语义监督是合理工程。但 128 维下声学细节的极限(音乐复杂混音、长 reverb)需要更细测试;与 Dasheng AudioGen 高维路线的端到端比较是行业级议题 9. CosyEdit2:GRPO语音编辑反哺零样本TTS CosyEdit2: Speech-Editing-Oriented Reinforcement Learning Unlocks Better Zero-Shot TTS | 南开大学 | arXiv:2605.25930 关键词:语音编辑·GRPO·zero-shot TTS·南开大学·post-training ⚠️ 前序问题:语音编辑和 zero-shot TTS 同源于「prompt 驱动的语音生成」,但语音编辑对「与周围未编辑内容的局部声学一致性」要求严苛得多。SFT 让 TTS 模型获得编辑能力的路线被卡在「成对编辑数据不完美 + 优化信号粗粒度」 本文贡献:CosyEdit2:建立「先 SFT 初始化 → 再 editing-oriented GRPO 后训练」的两阶段框架。GRPO 阶段在「无目标语音」的数据上做,把语音编辑当作 RL 任务优化,让模型从粗粒度匹配走向精细局部声学一致 实验效果:不仅在语音编辑上显著提升,还反哺 zero-shot TTS 能力——揭示「编辑任务 ↔ 合成任务」之间隐藏的相互增益;GRPO 在 audio 域被验证是有效的 post-training 范式 批判点评:把 GRPO 引入 audio 域、并用「编辑反哺合成」这个新角度证明两个任务的深层互助,是非常聪明的科学故事。无目标语音的 RL 设计也比依赖成对数据更可扩展。但 GRPO 的 reward 设计细节、跨语种/多说话人鲁棒性、以及对 prosody 细节的影响需要更系统评测 10. PilotTTS:高德200K小时开源TTS竞品级 PilotTTS: A Disciplined Modular Recipe for Competitive Speech Synthesis | 高德 AMAP | arXiv:2605.27258 关键词:TTS·200K 小时·开源·Q-Former·高德 AMAP ⚠️ 前序问题:SOTA TTS 系统通常需要数百万小时专有数据 + 多阶段复杂架构——这对资源受限的研究团队是几乎跨不过去的门槛。开源社区想自己训出竞品级 TTS 一直缺成熟 recipe 本文贡献:PilotTTS:高德 AMAP 用「最小化架构 + 严格数据工程」做出竞品级轻量自回归 TTS。仅用 200K 小时数据 + 全开源工具处理。两大贡献:(i) 可复现的多阶段数据处理 pipeline(质量评估 + 标签标注 + 过滤);(ii) Q-Former conditioning 紧凑模型架构,通过 cross-sample paired training 解耦说话人身份与说话风格。统一框架支持 zero-shot voice cloning / 11 类情感合成 / 4 类副语言合成 / 14 种中文方言 实验效果:在 Seed-TTS Eval 上 test-en WER 1.50%(最低)、test-zh CER 0.87%;两个测试集说话人相似度都最高(0.862 / 0.815)——超越使用大得多数据集训出来的系统。完整 data pipeline + 预训练权重 + 代码全开源 (AMAPVOICE/PilotTTS) 批判点评:「200K 小时 + 开源工具 + 极简架构」做出超越百万小时专有数据系统的 TTS——是非常有信号量的开源胜利,对中小团队意义重大。Q-Former 解耦说话人/风格的设计也是 clean。但 PilotTTS 主打数据工程而非架构创新,复现门槛仍在「数据处理 pipeline 的工程细节」;与昨天 LongCat-Avatar 类「audio + 视频联合」的下一步集成是开放问题 11. LAIR:扩散模型从成对偏好升级到列表对齐 Beyond Pairwise Preferences: Listwise Reward-Aware Alignment for Diffusion Models | 斯坦福, 加州理工 Caltech | arXiv:2605.26491 关键词:diffusion 对齐·listwise preference·advantage-weighted·Stanford·Ermon ⚠️ 前序问题:preference optimization 已成 RLHF 之外对齐 T2I 扩散的高效替代,但现有方法基本都把监督降到 binary pairwise——这在「同 prompt 有多张候选 + 有连续 reward 分数」时严重浪费信息(一个 winner-loser 标签远远没用上 reward 分布) 本文贡献:Diffusion LAIR:reward-aware listwise preference optimization。每个 prompt 把候选组的 reward 分数转成中心化 advantage 权重,再优化「advantage-weighted regression」目标——目标定义在 implicit reward(当前模型 vs 固定参考模型的 denoising-loss 改进量)上,配二次惩罚正则隐式 reward 幅度。结果是同时用所有候选而非选 pair,并保持保守。LAIR 目标在 implicit-reward 空间有 bounded closed-form 最优解,把正则强度 → 偏好更新幅度的关系写清楚 实验效果:在 SD1.5 / SDXL 上对 T2I 生成 / 组合生成 / 图像编辑 benchmark 都超越 strong pairwise preference optimization baseline;为 diffusion 对齐提供「更接近 RLHF reward 信息密度但不需在线 RL」的中间路线 批判点评:把 DPO 类 pairwise 升级到 listwise + 给出 closed-form 最优解的清晰表述是教科书级的方法工作——既保留 offline 偏好优化的稳定性,又用上了 reward score 的全部信息。但 listwise 数据采集成本高于 pairwise(要 N 张同 prompt 候选 + reward 分),实际落地的数据可得性是隐藏成本;与 in-context 在线 RL(GRPO 类)的端到端比较略浅 趋势观察 视频生成进入「全栈加速」时代:稀疏 + 量化 + 并行 + 路由 + RL 多管齐下 — OSP-Next 把稀疏注意力 + Sparse Sequence Parallelism(通信 -75%)+ HiF8 量化 + Mix-GRPO 一锅端,跨 H200 / 昇腾双硬件分别 1.64× / 2.27× 加速;PARE 联合宽度剪枝 + 动态深度路由,在 Wan2.1-14B 上按输入按 timestep 动态算;SVDQuant-GPTQ 把 Wan2.2 双专家 MoE DiT 推到 W4A4 显存降 59.3%——视频生成的工业部署正在被「全栈加速」改写 长视频 KV cache 压缩出现「找根因 + 闭式解」类突破 — Quantized Keys Steal Attention 首次把「量化 KV 掉画质」从经验现象写成 Jensen bias(exp 凸性放大 cache key 贡献)的可解析统计现象,一行公式校正零额外显存,让 MAGI-1 / SkyReels-V2 / HY-WorldPlay 在 INT2 上接近 BF16——把 chunk-wise AR 长视频的 KV 压缩从「玄学调参」推到「有理论的工程」 音频生成统一化:从「按域切分」走向「一句描述出混合场景」 — Dasheng AudioGen 是首个能从一句描述同时生成 speech + music + SFX 混合连贯场景的统一模型,关键是 structured multi-view captions + 高维语义-声学统一 latent;LoSATok 反过来把 1280 维语义压到 128 维统一 tokenizer 反哺 DiT 生成;CosyEdit2 在 audio 域用 GRPO 把「编辑」反哺「TTS」——audio 正在重走视觉「统一模型」的同一条路 视频生成的「叙事控制」与「视频后期」继续拓宽到工业链路 — SmartDirector 把视频生成从「按 prompt 出 5 秒片段」升级到「多关键帧 + 两阶段先粗后细」做电影级叙事节奏控制;HarmoVid 用 deflicker 模型破解「视频和谐化无成对数据」的死结,把视频肖像 relight 和谐化做到工业级稳定——视频生成的可控性从「内容」深入到「节奏」和「后期合成」 开源 TTS / 对齐方法补齐 audio + diffusion 的「最后一公里」 — 高德 PilotTTS 用 200K 小时 + 开源工具 + Q-Former 极简架构做出超越百万小时专有系统的开源 TTS(Seed-TTS Eval 第一);Diffusion LAIR 把 T2I 对齐从 pairwise 升级到 listwise,给出 implicit-reward 的 closed-form 最优解——开源社区在 audio 合成 + diffusion 对齐这两个长期被闭源霸占的方向同时迈出了「竞品级 + 理论级」的双台阶 人工智能炼丹君 整理 | 2026-05-28
-
AIGC 每日速读|2026-05-21|智能编辑成统一模型通用任务Uni-Edit 今日 AIGC 论文速览 今日共 13 篇 · 统一多模态与图像编辑 2 篇 · 视频生成与编辑 5 篇 · 高效推理与稀疏注意力 3 篇 · 安全与可控生成 2 篇 · 图像复原与评测 2 篇 重点论文标题列表 Uni-Edit:智能编辑成为统一模型唯一训练任务 FullFlow:只训LoRA把T2I升级成双向多模态 ⚡ DVG:时空联合自适应HunyuanVideo提速7倍 BA-Att:块预降采样稀疏注意力提速7倍 FlowLong:滑窗加流形约束推理期出长视频 今日论文速览 1. Uni-Edit:智能编辑成为统一模型唯一训练任务 Uni-Edit: Intelligent Editing Is A General Task For Unified Model Tuning | CUHK MMLab | arXiv:2605.21487 关键词:UMM 统一多模态·智能图像编辑·通用任务·BAGEL·Janus-Pro ⚠️ 前序问题:统一多模态模型(UMM,理解+生成+编辑三件事一起做)当前主要靠混合多任务训练。但任务之间天生冲突,逼出了复杂的多阶段 pipeline、海量数据混合和各种平衡 trick——结果只是性能折中而非真正互相增强 本文贡献:提出 Uni-Edit:智能图像编辑作为 UMM tuning 的「第一个通用任务」。一个任务、一个训练阶段、一个数据集就能同时提升理解/生成/编辑三种能力。为此构建首个自动化可扩展智能编辑数据合成 pipeline:把多样 VQA 数据转化为带嵌入问题和嵌套逻辑的复杂编辑指令,得到 Uni-Edit-148k 数据集(reasoning-intensive 指令 + 高质量编辑图像) 实验效果:BAGEL 与 Janus-Pro 上仅用 Uni-Edit 单任务训练即获得三种能力的全面增强,无需任何辅助操作;模型/数据/代码已开源在 HuggingFace 和 GitHub 批判点评:「编辑作为通用任务」的洞察是范式级——编辑天生需要「理解 + 生成」两件事,这是其作为通用任务的根本理由;但 Uni-Edit-148k 是 VQA 数据合成的,复杂场景下指令质量上限仍受 VQA 数据集决定;BAGEL/Janus-Pro 之外能否泛化到更多 UMM(OmniGen/UniGen)需要后续验证 2. FullFlow:只训LoRA把T2I升级成双向多模态 FullFlow: Upgrading Text-to-Image Flow Matching Models for Bidirectional Vision-Language Generation | ETH Zürich, Google Zurich | arXiv:2605.20316 关键词:统一多模态·LoRA 升级·Rectified Flow·双向生成·参数高效 ⚠️ 前序问题:现代 T2I 扩散模型有强视觉先验,但只暴露在单向 text→image 生成。从 T2I 衍生的统一视觉语言模型要么靠大规模联合预训练,要么大幅重训文本通路——两者都浪费了 T2I backbone 已经学到的强图像先验 本文贡献:提出 FullFlow 参数高效配方:只训 LoRA 适配器和轻量 text head 就把预训练的 rectified-flow T2I 模型升级成双向 vision-language 生成器。图像保持原生连续 flow,文本走离散 insertion 过程;图像/文本独立 timestep 让推理变成「二维生成空间」中的轨迹选择,单 backbone 同时支持 text→image / image→text / 联合采样 / partial-text 预测 实验效果:在 SD3 上同等可训参数和 LoRA rank 下,T2I FID 62.7 → 31.6,I2T CIDEr 2.0 → 99.4(远超之前 SOTA Dual Diffusion);峰值 VRAM 从 ~84GB 降到 ~38GB,吞吐 8×(双 RTX A5000 训 24h,仅训 ~5% backbone 参数);同样配方迁移到 FLUX.1-dev 并支持 partial-text 做下游 VQA 批判点评:5% 参数开销实现双向多模态是非常高 ROI 的工程贡献——把扩散视觉先验「升级 vs 重建」拉到了正确选择;但 image→text CIDEr 99.4 vs Dual Diffusion 2.0 的对比量级悬殊,可能反映 baseline 设置问题;与原生统一模型(BAGEL/Janus)的端到端能力对比缺失 3. DVG:时空联合自适应HunyuanVideo提速7倍 Dynamic Video Generation: Shaping Video Generation Across Time and Space | 上海交大, 华南理工, 清华大学 | arXiv:2605.21042 关键词:视频扩散加速·时空联合·渐进分辨率·HunyuanVideo·近无损 ⚠️ 前序问题:视频扩散每步要处理大量 token,迭代去噪极昂贵。最近渐进分辨率采样在早期阶段降 latent 分辨率取得加速,但 scale 到视频上仍困难——时序维度引入跨视频差异巨大的时空需求,只压一个维度要么加速有限要么质量退化 本文贡献:提出 DVG(Dynamic Video Generation)框架:跨时间和空间联合分配计算,自动选择内容感知(content-aware)的加速策略,无需手工调参或重训。通过学习每个视频的最佳时空降采样模式,实现近无损加速 实验效果:HunyuanVideo / HunyuanVideo-1.5 上达到 7× 加速;与蒸馏组合可达 18× 加速;近无损跨模型跨任务,可作为大规模高效视频生成系统的关键组件——代码开源 批判点评:把渐进分辨率从空间扩到时空联合是合理的下一步,自动 content-aware 策略避免了手工 schedule;但加速倍数高度依赖底模容量与内容多样性,对极端运动场景的 robustness 论文未充分披露;7×→18× 的复合是否保留各自的画质底线需更细粒度评测 4. BA-Att:块预降采样稀疏注意力提速7倍 Efficient Long-Context Modeling in Diffusion Language Models via Block Approximate Sparse Attention | 香港科大, 港大, 浙大, 港中文 | arXiv:2605.19726 关键词:扩散语言模型·稀疏注意力·块降采样·FlashAttention·长上下文 ⚠️ 前序问题:扩散语言模型(DLM)能做全局连贯、双向、可控文本生成,但 scale 到超长序列仍昂贵。现有 block-sparse attention 用固定采样模式(尾部、反斜对角条带)选块——这种 prior-driven 采样会漏关键 token、分布偏移下不稳定 本文贡献:提出 BA-Att 框架:block-wise 预降采样操作在压缩空间识别 informative 区域,避免依赖脆弱的位置先验。理论上定义 oracle post-downsample attention map,形式化前 vs 后降采样方案的近似误差;引入轻量 norm-sorting 模块和协方差补偿修正(用对角 QK 方差近似完整协方差),降复杂度 实验效果:比 FlashAttention 加速最高 6.95×;50% 稀疏度下保持接近 full-attention 性能,跨语言模型/多模态语言模型/视频生成模型一致——证明高效率和强泛化 批判点评:把 sparse attention 的「选块」从 prior-based 升级到 learned downsampled space 是非常正确的方向,6.95× 加速比 FlashAttention 还快是亮眼的工程数字;但 50% 稀疏率下「接近 full」的具体差距需更精细评测;对极长上下文(1M+)的渐近行为仅理论保证而无实测 5. FlowLong:滑窗加流形约束推理期出长视频 FlowLong: Inference-time Long Video Generation via Manifold-constrained Tweedie Matching | KAIST, Amazon | arXiv:2605.20910 关键词:长视频生成·推理期方法·Tweedie matching·滑窗·流形约束 ⚠️ 前序问题:把视频扩散模型生成时长扩到长序列一直没解决:双向模型扩展紧绑架构且长距退化严重,自回归模型有 exposure bias 累积漂移并产生重复运动。现有 training-free 方案没有同时跨这两条路线 本文贡献:提出 architecture-agnostic 推理期长视频生成方法:滑动重叠窗口生成长视频,相邻窗口预测的 clean sample 通过 Tweedie matching 在重叠区强制流形约束 + 时序一致;high-noise 阶段用 stochastic early-phase sampling,每次 Tweedie matching 校正后注入新噪声同步窗口轨迹,再切到 deterministic ODE sampling 保留细节 实验效果:可生成数倍于原生窗口长度的视频,时序一致性和视觉质量超越 training-free 与自回归两类基线;同一思路无微调即可扩展到音视频联合生成、文生 3DGS——证明这套方法是通用的 批判点评:Tweedie matching 在窗口边界做修正是 elegant 的解法,几乎是「无需训练」的最简扩展;但滑窗推理时延比单 pass 显著增加,长视频对内存的累积压力不算小;与原生因果模型(如 Causal Forcing++/Mutual Forcing)相比,缺少同等长度下的直接对比 6. StreamGVE:少步流式生成做训练免视频编辑 StreamGVE: Training-Free Video Editing via Few-Step Streaming Video Generation | UBC ECE | arXiv:2605.21466 关键词:视频编辑·训练免微调·少步流式生成·noise-to-data·双分支 ⚠️ 前序问题:视频编辑方法可行但要花很多昂贵迭代且编辑结果质量勉强。作者把症结归因到「data-to-data」范式——它和现代生成模型(noise-to-data)天生不兼容,绕远路反而拉低了编辑质量 本文贡献:从 noise-to-data 视角重做视频编辑:基于预训练的流式生成模型构建 StreamGVE,保留 few-step 采样并无缝注入源视频条件;引入双分支快速采样(self-attention bridge + cross-attention grounding/boosting)兼顾采样和条件;提出 source-oriented guidance 提目标质量,再加 visual prompting 增强编辑灵活性 实验效果:在多种视频编辑任务上一致超越现有方法,即使在 few-step 设置下也能以最少时间代价完成;方法对不同底模具有鲁棒性和泛化能力 批判点评:把视频编辑「从 data-to-data 转向 noise-to-data」是个范式级洞察,能直接复用流式生成模型的少步能力——很省工;但在风格迁移、物体替换等具体编辑任务上的优势是否一致需要更细分对比;source-oriented guidance 的强度调参成本未明 7. FlowErase-RL:首个GRPO范式的概念擦除框架 FlowErase-RL: Rethinking Concept Erasure as Reward Optimization in Flow Matching Models | 哈工大深圳, 清华深圳, 吉林大学, 鹏城实验室, 清华大学 | arXiv:2605.19739 关键词:Flow Matching·概念擦除·GRPO·安全生成·双路径奖励 ⚠️ 前序问题:Flow Matching 文生图模型质量飞涨同时安全风险也在加剧,要擦除有害/不想要的概念。现有方案要么是推理期干预(效果有限),要么靠 SFT(依赖精对齐数据 + 多概念扩展性差)——擦除问题一直缺少更优范式 本文贡献:首次把概念擦除重新表述为 reward optimization 问题,提出基于 GRPO 的 FlowErase-RL:(1) 双路径动态奖励——CE(Concept Erasure)奖励抑制目标概念,NS(Non-target Space)奖励保住生成质量;(2) 性能驱动的自适应切换策略,无需显式监督就能稳定训练;通用支持裸露/物体/艺术风格三类擦除 实验效果:裸露/物体/艺术风格三类擦除均达 SOTA,图像质量与语义对齐保持很好;对抗攻击鲁棒性强,多概念场景扩展性好——开辟了 Flow Matching 安全可控生成的新范式 批判点评:把擦除从 SFT 转向 RL 是聪明的——擦除本质是分布偏移而非分类,RL 的奖励更贴合;但 GRPO 训练成本不低,CE/NS 双奖励的权重边界对效果影响多大未深入消融;擦除概念之间的相互干扰(擦了概念 A 影响概念 B 的生成)这一长尾问题未充分讨论 8. CPC-VAR:首次给VAR模型做持续多概念个性化 CPC-VAR: Continual Personalized and Compositional Generation in Visual Autoregressive Models | 哈工大深圳, 清华深圳国际研究生院, 鹏城实验室, 华南理工 | arXiv:2605.19750 关键词:持续学习·VAR 个性化·概念神经元·多概念合成·解纠缠 ⚠️ 前序问题:Visual Autoregressive(VAR)做文生图效率高,但现有 VAR 个性化只能静态训单概念——序列学新概念时旧概念会被灾难性遗忘,多概念合成又会出现特征纠缠和属性不一致。这是 VAR 个性化生成的两个老大难 本文贡献:首次系统研究 VAR 持续个性化生成,提出统一框架。两个核心组件:(1) GCNS(Gradient-based Concept Neuron Selection),找到每个概念相关的神经元,只约束跨任务冲突参数,不扩展模型也能抗遗忘;(2) 上下文感知组合策略:多分支特征建模 + 空间条件引导的局部 cross-attention 融合,做精确解纠缠的多概念合成 实验效果:长序列持续个性化场景下显著领先现有 baseline,多概念图像合成上也优于现有方法,证明 VAR 完全有能力做可扩展可控的个性化生成 批判点评:VAR 个性化第一次被系统化研究是好事,神经元级别的 GCNS 设计也比经典扩散模型路线(DreamBooth/LoRA)更经济;但实验是否覆盖到 10+ 概念的真实长尾、跨概念组合的失败模式分析略浅,VAR 底模本身的天花板(vs 扩散模型)没有正面比较 9. DyMoS:一个标量旋钮控 I2V 运动幅度 Rebalancing Reference Frame Dominance to Improve Motion in Image-to-Video Models | 延世大学 Yonsei, GIST, Adobe Research | arXiv:2605.19398 关键词:I2V·运动控制·注意力 rebalance·训练免微调·DyMoS ⚠️ 前序问题:I2V(image-to-video)相比 T2V 生成的视频普遍过于静态。前人方案靠削弱或修改图像条件来增加运动,但要么需要额外训练,要么牺牲了对参考图像的保真度——「动起来 vs 像参考图」是个长期 tradeoff 本文贡献:识别出「reference-frame dominance」是动作抑制的核心机制:非参考帧对参考帧 key token 分配过多 self-attention,导致参考信息被过度跨时传播、压制了帧间动态。提出 DyMoS(Dynamic Motion Slider):训练免微调、模型无关,初始去噪步 rebalance 生成帧到参考帧的注意力路径,输入图和模型权重都不动,只引入一个标量参数连续控制运动强度 实验效果:多个 SOTA I2V backbone 上一致提升运动动态,同时保持视觉质量和对参考图的保真度;提供 user 一个可调的运动旋钮 批判点评:把「动起来 vs 像参考图」从冲突变成可调旋钮是非常实用的工程贡献;但 attention rebalance 的具体公式对不同架构可能需重新调,论文给出的 generality 主要在 SD 系列底模;标量旋钮是否能控制不同方向的运动(横向 vs 纵向)需要更细粒度评测 10. MSAVBench:首个多镜头音视频生成评测基准 MSAVBench: Towards Comprehensive and Reliable Evaluation of Multi-Shot Audio-Video Generation | 复旦大学, 港大, 阿里通义实验室, 浙大, 北大 | arXiv:2605.20183 关键词:多镜头音视频·评测基准·导演级控制·自适应分镜·MSAVBench ⚠️ 前序问题:视频生成正从单镜头扩展到复杂多镜头音视频(MSAV)叙事,但评测仍是基础性挑战——现有 benchmark 范围有限、数据多样性不足、评测流水线僵化,无法系统可靠地评估现代 MSAV 模型 本文贡献:推出 MSAVBench 首个面向多镜头音视频生成的综合评测基准 + 自适应混合评测框架。覆盖视频/音频/镜头/参考四个维度,多种任务设置,最多 15 个镜头,挑战性的非真实场景。评测框架的鲁棒性来自三件事:分镜分割的自适应 self-correction、主观指标的实例级 rubric、复杂判断的工具溯源证据抽取 实验效果:与人类判断的 Spearman 秩相关达 91.5%,对齐度极高;系统评测 19 个 SOTA 闭源/开源模型显示:当前系统在导演级控制和细粒度音视频同步上仍有困难,模块化/agentic 生成 pipeline 是缩小开源-闭源差距的有前途路径;benchmark 数据和评测代码将开源 批判点评:把音视频生成评测从「单镜头质量」推进到「多镜头叙事 + 导演级控制」是必要的下一步;91.5% Spearman 与人类对齐很高,自适应分镜 self-correction 是工程亮点;但 15 个镜头作为基准上限对真正的长视频(>5 分钟、几十个镜头)覆盖度有限;非真实场景的标注成本与一致性如何控制仍是开放问题 11. CogOmniControl:专用CogVLM认知创意意图引导生成 CogOmniControl: Reasoning-Driven Controllable Video Generation via Creative Intent Cognition | 澳门大学 SKL-IOTSC, 腾讯 Online-Video BU | arXiv:2605.19995 关键词:可控视频生成·专业 VLM·创意意图认知·闭环 harness·in-context ⚠️ 前序问题:视频扩散模型对 abstract / 稀疏 / 复杂条件依然脆弱——专业制作工作流(分镜草图、黏土渲染等)下表现差。现有方案要么用 adapter 注入条件,要么把通用 VLM 耦合到扩散 backbone——能力鸿沟仍在,难以输出对齐用户创意意图的视频 本文贡献:提出 CogOmniControl 推理驱动框架:把可控视频生成因式分解为「创意意图认知」+「生成」。专门用真实动漫制作数据训了一个专业版 CogVLM,比通用 VLM 更准确地从稀疏抽象条件中识别用户创意意图,转译成密集 reasoning 输出;CogOmniDiT 通过 in-context generation 统一多种条件,并用 RL 对齐到 CogVLM reasoning 输出。进一步利用 CogVLM 做评测与 Best-of-N 选择,整个框架是闭环 harness 架构。同时发布 CogReasonBench / CogControlBench 来自专业工作流的真实创意意图数据 实验效果:两个 benchmark 上一致超越现有开源模型,在分镜草图、黏土渲染等专业条件下尤其明显——证明专业 VLM 介入的认知能力对可控生成是有效的 批判点评:专业 VLM 当「创意意图认知器」是个新颖思路,引入 reasoning 缓解条件稀疏问题——但训练专业版 VLM 的数据规模有限,跨垂直域(动漫→真人/工业)泛化未验证;闭环 harness 架构推理时延偏高,落地工业流水线存在挑战 12. DiSI:单模型连续滑动失真感知权衡 Disentangling Generation and Regression in Stochastic Interpolants for Controllable Image Restoration | 同济大学, 复旦大学 | arXiv:2605.21381 关键词:图像复原·Stochastic Interpolant·生成-回归解耦·失真感知权衡·像素空间 ⚠️ 前序问题:图像复原(IR)领域生成式(Diffusion/Flow Matching)擅长合成真实纹理但慢且像素保真度差;经典回归式方法单步高效像素准确——两条路线长期不能兼得 本文贡献:提出 DiSI 统一框架:把底层 Stochastic Interpolant 过程显式解耦为独立的生成分量和回归分量。这种解耦让模型在「纯回归 → 全生成」之间连续可控过渡。技术上提供两条具体采样轨迹和统一 sampler 支持任意轨迹的少步推理;网络是像素空间的双分支 U-Net 风格 transformer(专用分支增强条件引导同时保高吞吐) 实验效果:在多种 IR 任务上以高效率取得有竞争力的结果;独有特性:单一模型推理期就能控制失真-感知 tradeoff(distortion-perception trade-off),不再需要训多个模型 批判点评:把 SI 过程拆成生成+回归两个可独立调用的分量,在理论上很优雅,给「失真-感知」连续控制提供了第一种统一手段;但实际 IR 任务中如何选择最佳轨迹(用户需指定 tradeoff?)的 UI/控制接口论文未深入讨论;与最新 OSEDiff/PASD 等方法的端到端对比有所欠缺 13. ABSS:初始几步注意力筛 seed 提画质 Boosting Text-to-Image Diffusion Models via Core Token Attention-Based Seed Selection | Brandeis University | arXiv:2605.19532 关键词:文生图·Seed Selection·Cross-Attention·训练免微调·SD ⚠️ 前序问题:文生图扩散模型的输出对随机 seed 极度敏感——不同 seed 同 prompt 画质和文图对齐差异巨大。但「该用哪个 seed」一直靠盲选,缺乏系统的预选机制 本文贡献:观察到一个关键现象:在前几步去噪过程中,对 prompt 中 core token(content-bearing words)的 cross-attention dynamic 强烈预测最终生成质量。基于此提出 ABSS(Attention-Based Seed Selection),训练免微调即插即用:候选 seed 跑前几步,用对 core token 的 cross-attention 打分排序,只保留 top-k 完成完整生成,不需要固定阈值 实验效果:三个 benchmark 上 Stable Diffusion 各变体的文图对齐和视觉质量一致提升,人工偏好与对齐指标都有改善;可作为现有 seed 优化 pipeline 的轻量预选附加组件叠加额外收益 批判点评:很经济的工程发现:把 seed 筛选问题转换为前几步 attention 信号读取,几乎没有计算开销;但这种基于 attention 的代理指标在跨架构(DiT/MMDiT)的可迁移性需要进一步验证;core token 的提取依赖 prompt parsing 的鲁棒性 趋势观察 「编辑」开始成为统一多模态模型的核心训练任务 — Uni-Edit 把智能编辑提为 UMM 单一通用训练任务,BAGEL/Janus-Pro 上一个数据集就能同时提理解/生成/编辑——「编辑作为通用任务」的认知正在替代「混合多任务训练」的范式。FullFlow 用同样的精简思路(只训 5% 参数)把 T2I 升级成双向多模态,从「重训」走向「升级」 视频生成加速进入「时空联合 + 稀疏注意力」阶段 — DVG 把渐进分辨率从单空间扩到时空联合,HunyuanVideo 上 7× 加速 + 蒸馏达 18×;BA-Att 用块预降采样稀疏注意力比 FlashAttention 还快 6.95×。视频扩散下一阶段的加速重心从单维度优化转向「时空 + 稀疏」组合拳 长视频生成从训练扩展走向「推理期方法」 — FlowLong 用 Tweedie matching 滑窗 training-free 把视频时长扩到数倍——这条 inference-time 路线和 Mutual Forcing/Causal Forcing++ 的训练侧路线形成互补,意味着长视频不一定要重新训模型 I2V 运动控制和文生图 seed 选择都被「单一标量旋钮 + Attention 信号」攻破 — DyMoS 用一个标量参数控 I2V 运动幅度(attention rebalance);ABSS 用初始几步 cross-attention 信号筛 seed——共同点是把「需要训练才能解决」的问题,转化为「读取已有 attention 信号」的免训练方案 概念擦除从 SFT 范式跨入 RL 范式 — FlowErase-RL 首次用 GRPO 做 Flow Matching 概念擦除,CE+NS 双路径动态奖励替代精对齐 SFT 数据——证明在 Flow Matching 时代,「擦除」本质上更适合用 RL 的分布偏移视角而非分类监督视角 人工智能炼丹君 整理 | 2026-05-21
-
AIGC 每日速读|2026-05-18|14B视频对齐单步训练Flash-GRPO 今日 AIGC 论文速览 今日共 7 篇 · 视频扩散对齐与定制 2 篇 · 图像生成几何与少步推理 2 篇 · 多镜头视频与实体一致性 1 篇 · 3D 重建与世界模型 2 篇 重点论文标题列表 Flash-GRPO:14B 视频对齐单步训练即超全轨迹 Spherical-FM:球面插值贴合潜空间路径 ⚡ Sphere-Latent-Enc:解耦图像编码器与球面去噪 EntityBench:多镜头视频实体一致性基准 FashionChameleon:单卡 23.8 FPS 实时换装 今日论文速览 1. Flash-GRPO:14B 视频对齐单步训练即超全轨迹 Flash-GRPO: Efficient Alignment for Video Diffusion via One-Step Policy Optimization | 浙江大学, 京东 | arXiv:2605.15980 关键词:视频扩散·GRPO 对齐·单步训练·时间步分组·14B 大模型 ⚠️ 前序问题:GRPO 已成为对齐视频扩散模型与人类偏好的关键工具,但训练 14B 视频扩散模型动辄需要数百 GPU 天;现有效率方法靠在时间步上做滑动窗口子采样,根本上破坏了优化稳定性,且无法逼近全轨迹训练的对齐质量 本文贡献:提出 Flash-GRPO 单步训练框架:(1) Iso-Temporal Grouping 通过 prompt 内部的时间一致性消除时间步混淆方差,把策略表现与时间步难度解耦;(2) Temporal Gradient Rectification 中和不同时间步的尺度因子,防止梯度幅值跨时间步剧烈漂移;最终单步 GRPO 即可超越全轨迹训练的对齐质量 实验效果:在 1.3B 到 14B 视频扩散模型上验证:训练显著加速、稳定性优于全轨迹基线,对齐质量达到 SOTA,让 14B 视频对齐从「数百 GPU 天」级实验变得可负担 批判点评:把视频 GRPO 的瓶颈精准定位到「时间步混淆 + 梯度尺度漂移」并各个击破,工程上极具实用性;但单步训练对教师 reward 噪声的鲁棒性、与 Causal Forcing 类少步 AR 视频的兼容性还需进一步验证 2. Spherical-FM:球面插值贴合潜空间路径 Aligning Latent Geometry for Spherical Flow Matching in Image Generation | Virginia Tech, fal | arXiv:2605.15193 关键词:Flow Matching·球面几何·潜空间·slerp·图像生成 ⚠️ 前序问题:潜空间 flow matching 通常在高斯噪声与 VAE 潜在变量之间走线性路径,但两端点都集中在薄薄的球壳上,欧式弦线在每一步都「离开了壳」——即使预处理对齐了半径,路径仍然不在真实的数据流形上 本文贡献:把每个潜在 token 分解为「径向 + 角度」两个分量,用 swap 探针证明感知和语义内容主要由方向承载、径向贡献远小于此;据此把数据潜变量投影到固定 token 半径,用高斯噪声的径向投影作为球面先验,冻结 encoder 微调 decoder,并把线性插值替换为球面插值(slerp)——测速目标因此在构造上变成纯角度,路径全程贴在球面上 实验效果:在多种图像 tokenizer 下一致改善 ImageNet-256 的类条件 FID;扩散网络结构无需改动、不引入辅助 encoder 或表征对齐目标,是一条极简但有效的几何修复路径 批判点评:回到流形几何本身解决「半径漂移」问题,理论清晰、实现极简——这是少有的「几乎零代码改动就涨点」的范式工作;但球面假设是否对所有 VAE 潜空间都成立、对 video latent 这种时空联合分布是否仍适用,还需更广验证 3. Sphere-Latent-Enc:解耦图像编码器与球面去噪 Efficient Image Synthesis with Sphere Latent Encoder | MBZUAI | arXiv:2605.15592 关键词:少步图像生成·球面潜空间·解耦训练·Sphere Encoder·推理加速 ⚠️ 前序问题:consistency 与 meanflow 类少步生成虽然推理便宜,但训练不稳定、可扩展性差;近期 Sphere Encoder 能少步出图,却需要在像素空间和潜空间间反复切换,重建与生成挤在同一架构里互相打架 本文贡献:把框架解耦为「固定预训练图像编码器 + 独立的球面潜在去噪模型」,完全在球面潜空间里训练去噪模型——训练和推理都不再需要反复跨像素/潜空间切换,重建和生成各自专精,互不掣肘 实验效果:在 Animal-Faces、Oxford-Flowers、ImageNet-1K 上同时显著超越 Sphere Encoder 的画质和推理速度,对比强力少步与多步基线也能取得有竞争力的结果,是一个高效少步图像合成的新基线 批判点评:「解耦」这个看似平凡的工程决策,反映出一个被忽略的事实:把重建和生成耦合在同一目标里很容易互相妥协;但跨数据集泛化、与扩散 Transformer 的兼容、以及球面潜空间的尺度上限仍需进一步研究 4. EntityBench:多镜头视频实体一致性基准 EntityBench: Towards Entity-Consistent Long-Range Multi-Shot Video Generation | ByteDance, Rice University | arXiv:2605.15199 关键词:多镜头视频·实体一致性·评测基准·记忆增强·叙事生成 ⚠️ 前序问题:多镜头视频生成把单镜头延伸到连贯叙事,但跨镜头维持角色、物体、地点的一致性长期是难题;现有评测用独立生成的 prompt 集,实体覆盖有限、一致性指标过于简单,难以做标准化比较 本文贡献:提出 EntityBench:从真实叙事媒体里抽取的 140 个 episode、2,491 个镜头,按易/中/难三档同时跟踪角色、物体、地点的实体调度(最长 50 镜头、13 跨镜头角色、22 跨镜头物体、回归间隔最长 48 镜头);配套三支柱评测套件解耦 intra-shot 质量、prompt 跟随、跨镜头一致性,并用保真度门控只让正确出现的实体进入跨镜头打分;另发布 EntityMem 基线:先把每实体的可信视觉参考存入持久记忆库,再生成 实验效果:实验显示现有方法的跨镜头实体一致性随回归距离急剧下降,显式 per-entity 记忆带来最高角色保真度(Cohen's d = +2.33)和实体出现率,为多镜头视频提供了能区分 SOTA 的标准评测 批判点评:把多镜头视频的「角色/物体/地点」标准化为可量化的 entity schedule 是社区一直缺的基础设施;但 140 个 episode 主要来自既有叙事媒体,对完全开放生成场景的覆盖度、评测自动化中视觉感知模型的偏差,仍是后续要补的环节 5. FashionChameleon:单卡 23.8 FPS 实时换装 FashionChameleon: Towards Real-Time and Interactive Human-Garment Video Customization | 厦门大学, 阿里巴巴 | arXiv:2605.15824 关键词:视频定制·实时交互·KV Cache·In-Context Learning·电商生成 ⚠️ 前序问题:服装级人物视频定制有巨大商业价值(电商、内容创作),但现有方法不支持低延迟交互式服装控制——用户无法在生成过程中实时切换服装,且多服装训练数据稀缺 本文贡献:提出 FashionChameleon 实时交互式自回归视频定制框架:(1) 不训多服装数据,用单参考-服装对配合 in-context learning 训练 Teacher Model,强制 reference/garment 失配迫使模型隐式保持单服装切换的连贯;(2) Streaming Distillation with In-Context Learning 用 in-context teacher forcing 微调,并用梯度重加权 distribution matching distillation 改善外推一致性;(3) Training-Free KV Cache Rescheduling 通过 garment KV refresh / historical KV withdraw / reference KV disentangle 实现切换时保留运动连贯 实验效果:支持长视频外推一致性 + 实时交互式服装切换,单 GPU 23.8 FPS 实时生成,比已有基线快 30-180 倍 批判点评:用「单服装数据 + KV 调度」绕过了多服装数据采集的瓶颈,是非常聪明的工程方案;但 KV 调度对极端切换(颜色/版型差异巨大)的视觉伪影、长时间交互后的累积漂移,仍是产品化的关键考验 6. VGGT-Ω:前馈 3D 重建首现 Scaling Law VGGT-Ω: Scaling Feed-Forward 3D Reconstruction | Meta FAIR, Oxford VGG | arXiv:2605.15195 关键词:前馈 3D 重建·register attention·scaling·动态场景·VLA ⚠️ 前序问题:VGGT 这类前馈式 3D 重建模型已经能与传统优化基线掰手腕,并提供几何感知特征服务下游任务;但要把这种模型 scale up 训练到更大的数据规模,原架构的显存占用与计算冗余成为最大障碍 本文贡献:提出 VGGT-Ω:(1) 用单一密集预测头 + 多任务监督简化原架构,去掉昂贵的高分辨率卷积层;(2) 用 register 把场景信息聚合为紧凑表示,并引入 register attention 把跨帧信息交换限定在 register 之间,部分替代全局 attention;(3) 配套高质量动态场景标注流水线 + 自监督协议;训练显存只需前代 30%,得以使用 15× 监督数据 + 大量无标注视频 实验效果:在静态与动态场景多个 benchmark 上一致刷 SOTA,例如 Sintel 上相机估计精度比之前最好结果提升 77%;学到的 register 还能改善 VLA 模型并支持语言对齐,证明重建可以作为空间理解的可扩展代理任务 批判点评:「重建模型也存在 scaling law」并通过架构精简一次性把训练规模拉满,是 VGGT 系列工作的关键里程碑;但 register 数量与表达能力的取舍、动态场景对真实开放视频的泛化,仍需在更复杂自由场景下追加验证 7. ReactiveGWM:解耦玩家与 NPC 跨游戏零样本 ReactiveGWM: Steering NPC in Reactive Game World Models | 腾讯, 新加坡国立大学, 港理工, 港科大广州 | arXiv:2605.15256 关键词:游戏世界模型·NPC 交互·零样本迁移·扩散主干·可控生成 ⚠️ 前序问题:现有游戏世界模型只从玩家主观视角模拟环境,把 NPC 当作背景像素,无法捕捉玩家与 NPC 的交互;本质上更像被动视频渲染器而非真正的仿真引擎,缺少建模动作引发的 NPC 反应所需的物理理解 本文贡献:提出 ReactiveGWM:显式解耦玩家控制与 NPC 行为——玩家动作通过轻量加性偏置注入扩散主干,NPC 高层响应(进攻/控制/防御)通过 cross-attention 模块 grounding;这些模块学到与游戏无关的交互逻辑表示,可零样本插入其他无标注游戏的世界模型,无需领域微调即可解锁可操控 NPC 交互 实验效果:在两款街头霸王上验证:保持精细玩家可控性的同时实现稳健、prompt 对齐的 NPC 策略遵循,为「策略丰富、可控的 NPC 交互」打开了零样本扩展的可能 批判点评:把「玩家 vs NPC」拆成两条解耦支路是非常优雅的设计,零样本迁移到其他游戏的能力让世界模型走出单一题材;但目前只验证了对战类游戏,开放世界 RPG 的多 NPC 协作、长时序情节一致性仍是开放问题 趋势观察 视频扩散对齐进入「单步训练」时代 — Flash-GRPO 把全轨迹 GRPO 压缩到单步训练,靠 iso-temporal grouping 与 temporal gradient rectification 修复时间步混淆与梯度漂移——14B 视频对齐从「数百 GPU 天」级实验降为可负担成本,视频扩散偏好对齐正在跨过工程化门槛 流匹配开始「修几何」而不是堆模型 — Spherical-FM 用径向/角度分解证明感知信息主要由方向承载,把线性插值改为球面插值即在多个 tokenizer 上一致涨点;Sphere Latent Encoder 进一步把生成完全搬到球面潜空间——少步图像生成的下一波收益来自「让路径贴上流形」 多镜头视频从「能拍」走向「记得住」 — EntityBench 把跨镜头角色/物体/地点一致性升级为可量化基础设施,配套 EntityMem 显式记忆库验证「记忆」是关键变量——多镜头视频生成的下一战场不是单镜头质量,而是叙事意义上的实体连续性 人物-服装视频生成走向实时交互 — FashionChameleon 用 in-context learning + KV cache 调度实现 23.8 FPS 单 GPU 实时换装,比基线快 30-180 倍——电商和内容创作的「实时交互式视频定制」从 demo 走向产品级 重建模型也存在 scaling law — VGGT-Ω 用 register attention 等架构精简把训练显存压到 30%,在 15× 数据上推到 77% Sintel 提升;ReactiveGWM 让世界模型零样本迁移到不同游戏——「重建+世界模型」开始从感知任务走向通用空间智能 人工智能炼丹君 整理 | 2026-05-18
-
AIGC 周末专题|2026-05-17|实时自回归视频生成加速 AIGC 周末专题深度解读:实时自回归视频生成:从蒸馏加速到流式交互的范式突破 人工智能炼丹君 整理 | 2026年5月17日(周日) 覆盖时间:2026-05-11 ~ 2026-05-16 本期概述 本期 AIGC 周末专题聚焦实时自回归视频生成:从蒸馏加速到流式交互的范式突破方向,精选 8 篇代表性论文进行深度解读。 方向分布: 自回归蒸馏加速 4 篇 (Causal Forcing++, AnyFlow, RAVEN, CDM) 流式推理与 KV Cache 优化 3 篇 (Forcing-KV, SWIFT, HSA) 世界模型与多镜头叙事 2 篇 (SANA-WM, CausalCine) 含 NVIDIA/MIT 联合 × 2 技术路线与时间线 基础蒸馏时代(2022.06 — 2024.06) 描述:Progressive Distillation 开创渐进蒸馏路线,Consistency Models 提出端点一致性映射,少步生成从理论走向实践。 关键节点: 2022.06:Progressive Distillation:渐进蒸馏开山作 2023.03:Consistency Models:一步生成理论突破 2023.12:DMD/DMD2:分布匹配蒸馏 2024.06:SD-Turbo/SDXL-Turbo:1-4 步商用 因果 AR 蒸馏兴起(2024.06 — 2025.12) 描述:Self Forcing 开创 AR 视频蒸馏范式,Causal Forcing 将 chunk-wise 4 步推向可用,流式视频生成原型出现。 关键节点: 2024.09:Self Forcing:AR 视频蒸馏开创 2025.02:Causal Forcing:chunk-wise 4 步实用 2025.06:Genie3:action-conditioned 世界模型 2025.12:LongLive:长视频流式生成 实时化爆发期(2026.01 — 2026.05) 描述:Frame-wise 蒸馏、KV Cache 压缩、无训练加速三线并进,实时交互式视频生成从实验室走向产品。 关键节点: 2026.03:CDM:连续时间分布匹配突破离散瓶颈 2026.05:Causal Forcing++:frame-wise 2 步实时 2026.05:AnyFlow:Flow Map 恢复步数可扩展性 2026.05:Forcing-KV/SWIFT:单卡 20-29 FPS 世界模型与叙事融合(2026.03 — 未来) 描述:实时 AR 视频生成与世界模型、多镜头叙事融合,从'生成画面'走向'仿真世界'。 关键节点: 2026.05:SANA-WM:消费级 GPU 分钟级世界模型 2026.05:CausalCine:多镜头叙事 AR 生成 未来:实时世界仿真 + 用户交互式导演 1. Causal Forcing++:因果一致性蒸馏实现 Frame-wise 2 步实时视频生成:清华 TSAIL 将因果 AR 蒸馏从 chunk-wise 4 步推进到 frame-wise 2 步,首帧延迟降低 50% 论文: Causal Forcing++:因果一致性蒸馏实现 Frame-wise 2 步实时视频生成 arXiv: 2605.15141 机构: Tsinghua TSAIL, 生数科技 (Shengshu) 1.1 研究动机 核心问题: Frame-wise AR 蒸馏的初始化策略与少步目标错位 实时交互式视频生成需要低延迟、流式、可控的 rollout。Causal Forcing 等先驱已经证明 chunk-wise 4 步蒸馏的可行性,但 chunk 粒度过粗——每生成 16 帧需 4 步 DiT forward pass,首帧延迟仍以秒计。如果能做到 frame-wise 1-2 步,每帧只需 1-2 次 forward pass,延迟可再降一个量级。问题是:现有蒸馏初始化策略要么目标错位、要么不能少步生成、要么算力大到无法 scale。 前序工作及局限: Causal Forcing:Chunk-wise 4 步成功但延迟仍高 Consistency Models:提供一致性蒸馏理论基础 与前序工作的本质区别: Causal CD 只需一次教师 ODE 步在线监督,三阶段初始化解决冷启动 1.2 方法原理 Causal Forcing++ 解决的核心问题是:如何在 frame-wise 粒度做高效的因果 AR 蒸馏?关键观察:Causal Consistency Distillation 学的流图与 Causal ODE 蒸馏完全等价,但训练信号更简洁——只需教师模型做一步 ODE 更新,学生学习匹配该更新结果。这避免了传统蒸馏需要预计算完整 PF-ODE 轨迹的巨大开销。 三阶段初始化解决冷启动:(1) 双向扩散预训练让模型学习高质量生成能力;(2) 因果适配将双向注意力切换为因果 mask,保持生成质量同时获得 AR 属性;(3) 少步蒸馏在上述基础上训练 frame-wise 1-2 步推理。 进一步将流水线扩展到 Genie3 风格 action-conditioned 世界模型,用相同 Causal CD 范式蒸馏交互式世界模型,支持动态 action 实时驱动。 1.3 核心创新 提出 Causal CD(因果一致性蒸馏)流水线:核心观察是 Causal CD 学习与 Causal ODE 蒸馏相同的 AR 条件流图,但只需在相邻时间步之间用一次教师 ODE 步在线提供监督,无需预计算完整 PF-ODE 轨迹——既高效又易优化。三阶段初始化策略彻底解决 frame-wise 蒸馏的冷启动问题。 1.4 实验结果 在 frame-wise 2 步设定下,全面超越 SOTA 4 步 chunk-wise Causal Forcing:VBench Total +0.1、VBench Quality +0.3、VisionReward +0.335。首帧延迟降低 50%。Stage 2 训练成本降至约 1/4。扩展到世界模型同样有效。 1.5 关键洞察 [{'point': '教师 ODE 误差放大', 'detail': '1-2 步生成使教师单步 ODE 的离散化误差直接影响学生最终输出,误差没有后续步骤修正的机会'}, {'point': '世界模型场景的 action 复杂度', 'detail': '在简单 action 下表现优秀,但面对复杂多步交互指令时的稳定性需要更多压力测试'}, {'point': '未开源', 'detail': '论文来自产业实验室,复现需等待官方代码公开'}] 技术演进定位: Frame-wise 因果 AR 蒸馏的实时交互级方案 可能的后续方向: Frame-wise 1 步 端到端无分阶段初始化 2. AnyFlow:任意步数视频蒸馏的 Flow Map 统一框架:NUS Show Lab + MIT + NVIDIA 首次基于 Flow Map 实现 4→32 步性能单调提升 论文: AnyFlow:任意步数视频蒸馏的 Flow Map 统一框架 arXiv: 2605.13724 机构: National University of Singapore Show Lab, MIT, NVIDIA 2.1 研究动机 核心问题: Consistency Distillation 步数增加时性能退化 过去一年的少步视频生成被一致性蒸馏(Consistency Distillation)统治——4-8 步即可出图。但一个致命问题:把步数从 4 加到 16/32,画质反而崩溃。为什么?CD 用一致性轨迹替换了原始 PF-ODE 轨迹,破坏了 ODE 采样在测试时的可扩展行为。用户需要'任意步数'推理的灵活性——算力充裕时多步出精品,紧急场景少步求速度——但 CD 做不到。 前序工作及局限: Consistency Models:端点映射 z_t→z_0 破坏 ODE 语义 Shortcut Models:任意区间跳跃但未系统化 与前序工作的本质区别: Flow Map z_t→z_r 目标 + FMBS on-policy 训练恢复步数可扩展性 2.2 方法原理 AnyFlow 的核心洞察:一致性蒸馏学的是 z_t→z_0 的端点映射,这迫使模型'一步到位'——当允许多步时,中间状态没有明确的 ODE 语义,因此步数越多反而越混乱。 Flow Map 解决方案:不学端点映射,而是学任意时间区间 [t, r] 的流图过渡 z_t→z_r。当 r=0 退化为一步生成,当 r>0 退化为多步 ODE 采样的某一段——自然统一了少步和多步。 FMBS 训练方法:传统蒸馏是 off-policy 的——用教师 ODE 生成配对 (z_t, z_r)。AnyFlow 提出 on-policy 方法:让学生自身做 Euler rollout,在 rollout 路径上反向模拟真实的流图过渡,用于训练。这解决了视频域因果生成的 exposure bias 问题。 在双向 DiT(Open-Sora Plan)和因果 AR(CausalVAR)两类骨干、1.3B 到 14B 全规模区间验证。 2.3 核心创新 提出 AnyFlow——首个基于 flow map 的任意步数视频扩散蒸馏框架。核心突破:(1) 将蒸馏目标从端点一致性 z_t→z_0 升级为流图过渡 z_t→z_r(任意时间区间),让学生学会任意区间跳跃;(2) Flow Map Backward Simulation (FMBS) 把完整 Euler rollout 拆为多段 shortcut,用 on-policy rollout 替代 off-policy 配对蒸馏。 2.4 实验结果 在双向和因果两类视频扩散骨干上一致达到或超越 consistency baseline。关键突破:步数从 4 提升到 16/32 时性能不再退化、反而单调上升,重新恢复了 ODE 采样的 test-time scaling 优势。在 14B 模型上同样有效。 2.5 关键洞察 [{'point': '复现门槛高', 'detail': '需要 1B-14B 级别教师模型 + 大规模 on-policy rollout,数据与算力两端门槛都不低'}, {'point': '具体数值缺失', 'detail': '论文未公开 VBench/UCF-FVD 等标准 benchmark 的绝对数值,难以与其他方法直接对比'}, {'point': '训练效率', 'detail': 'On-policy rollout 的训练时间和显存开销与 off-policy CD 的对比数据不够充分'}] 技术演进定位: 首次理论解释 CD 多步退化并给出 flow map 解决方案 可能的后续方向: 自适应步数调度 Flow Map + RL 结合 3. RAVEN:训练-测试对齐的实时自回归视频外推:帝国理工 AGI Lab 提出 CM-GRPO 在一致性核上直接做 RL 论文: RAVEN:训练-测试对齐的实时自回归视频外推 arXiv: 2605.15190 机构: Imperial College London AGI Lab 3.1 研究动机 核心问题: 因果视频蒸馏训练用真实 history、推理用自身 rollout 的分布 gap 因果自回归视频扩散模型通过蒸馏高保真双向教师已能实现少步推理。但一个根本性问题一直被忽视:训练时用真实 history(来自数据集)作为条件,推理时却用模型自身 rollout 的结果作为 history——两者分布不同。随着 rollout 长度增加,这个训练-测试分布 gap 会累积放大,导致长序列生成质量严重退化。 前序工作及局限: Self Forcing:self-rollout 训练但未系统性解决对齐 GRPO:RL 对齐但在扩散模型上公式复杂 与前序工作的本质区别: RAVEN rollout 重打包 + CM-GRPO 在一致性核上做 RL 3.2 方法原理 RAVEN 解决的核心问题是训练-测试分布不对齐。具体做法:训练时不再只用真实数据作为 history 条件,而是让模型先做一段 rollout 生成'假 history',然后把这个 rollout 的干净端点重新打包为条件输入,让模型在自身 rollout 分布上继续学习。这样训练时看到的 history 分布就与推理时一致。 CM-GRPO 的创新在于简化了 RL 在生成模型上的应用。传统 flow-model RL 需要构造 Euler-Maruyama 辅助过程来定义 policy gradient,复杂且不稳定。CM-GRPO 的观察:consistency model 的每步采样本质上是条件高斯转移 p(z_{t-1}|z_t) = N(μ(z_t), σ²I),可以直接在这个高斯核上定义 log-probability 并做 GRPO——公式简洁、梯度稳定。 两者组合:RAVEN 让模型在正确分布上训练,CM-GRPO 让模型朝奖励方向优化。 3.3 核心创新 提出 RAVEN training-time test 框架:把每次自身 rollout 重打包为(干净历史端点 + 噪声去噪状态)交错序列,让训练注意力对齐推理时的外推方式。进一步提出 CM-GRPO:把 consistency 采样步重新表达为条件高斯转移,直接在该核上做在线 RL,避免了 flow-model RL 中 Euler-Maruyama 辅助过程的复杂性。 3.4 实验结果 RAVEN 在质量、语义、动态度多维评测上超越近期因果视频蒸馏 baseline。CM-GRPO 与 RAVEN 组合后进一步提升性能。训练-测试对齐效果在长序列(>100 帧)上尤为显著。 3.5 关键洞察 [{'point': '内存开销', 'detail': 'RAVEN 重打包需要额外存储 rollout 结果,对长序列的内存占用影响未充分量化'}, {'point': '奖励设计敏感性', 'detail': 'CM-GRPO 的效果强依赖于奖励函数设计,在更复杂/多维奖励场景下的稳定性有待验证'}, {'point': '模型规模验证', 'detail': '在更大模型尺度(>5B)上是否同样有效需要进一步实验'}] 技术演进定位: 系统性解决因果视频蒸馏训练-测试对齐的首个完整方案 可能的后续方向: 多奖励 CM-GRPO 自适应 rollout 长度 4. Forcing-KV:注意力头特化驱动的 KV Cache 混合压缩:NVIDIA/MIT/ETH 联合发现注意力头功能特化规律,单卡 H200 达 29+ FPS 论文: Forcing-KV:注意力头特化驱动的 KV Cache 混合压缩 arXiv: 2605.09681 机构: NVIDIA, MIT, ETH Zurich, ZJU 4.1 研究动机 核心问题: AR 视频扩散历史帧 KV Cache 线性膨胀导致显存爆炸 自回归视频扩散模型(如 Self Forcing)通过流式生成实现了开放式长视频合成。但致命瓶颈来了:随着生成帧数增加,历史帧的 KV Cache 线性膨胀——注意力复杂度爆炸 + 显存不够用。一段 30 秒的 1080P 视频,KV Cache 就能吃掉整张 H100 的 80GB 显存。如果不压缩 KV Cache,流式视频生成就永远停留在几秒级别。 前序工作及局限: Flash Attention:算法层面加速但不压缩缓存 Token Merging:图像域 token 压缩 与前序工作的本质区别: 发现注意力头功能特化并据此设计静态/动态混合压缩 4.2 方法原理 Forcing-KV 的核心发现:在自回归视频扩散模型中,不同注意力头承担完全不同的功能角色,这种分工是稳定且可预测的。 静态头特征:注意力分布集中在远程 token(历史帧的关键区域),负责跨 chunk 的语义连续性和帧内的结构保真。这些头对'哪些远程 token 重要'的判断高度一致,因此可以做结构化剪枝——只保留少数高注意力权重的远程 token。 动态头特征:注意力集中在近邻 token(前几帧),负责帧间运动预测和局部一致性。近邻帧之间往往高度相似,因此可以做相似度驱动的动态剪枝——当相邻片段的 KV 向量相似度超过阈值时合并。 工程实现:KV-cache 同步机制确保压缩后的 cache 在多 head 之间保持一致的时间索引;缓存 Euler 更新将已压缩 token 的 denoising 中间状态缓存起来避免重复计算。 4.3 核心创新 首次发现视频扩散模型中注意力头具有稳定的功能特化:静态头(Static Heads)负责跨 chunk 过渡和帧内保真,关注远程 token;动态头(Dynamic Heads)负责帧间运动与一致性,关注近邻 token。基于此设计混合压缩:对静态头执行结构化剪枝(保留远程关键 token),对动态头执行基于片段相似度的动态剪枝(移除冗余近邻)。 4.4 实验结果 在 LongLive 和 Self Forcing 两个 AR 视频扩散模型上验证。480P 场景:1.35x/1.50x 加速。1080P 场景:加速比达 2.82x。单卡 H200 达到 29+ FPS 并减少 30% cache 显存。无需离线 profiling,运行时自动判断头类型。 4.5 关键洞察 [{'point': '架构通用性', 'detail': '仅在两个 AR 视频扩散模型上验证,是否推广到非 AR 架构(如 CogVideoX)有待检验'}, {'point': '头分类稳定性', 'detail': '静态/动态头的划分是否在新架构或不同训练阶段仍然成立存疑'}, {'point': '质量退化分析', 'detail': '在极端压缩比下(如 80%+ 裁剪)的视觉质量退化模式需要更多系统性分析'}] 技术演进定位: 首次揭示视频扩散注意力头分工并实现实时 29 FPS 可能的后续方向: 自适应头分类 hierarchical cache 5. SWIFT:无训练语义自适应记忆实现高效流式长视频:中科大/复旦/Georgia Tech 提出逐头语义注入,单卡 H100 达 22.6 FPS 论文: SWIFT:无训练语义自适应记忆实现高效流式长视频 arXiv: 2605.09442 机构: University of Science and Technology of China, Fudan University, Georgia Institute of Technology 5.1 研究动机 核心问题: 流式长视频 prompt 切换时 KV Cache 管理困难 流式长视频生成的核心挑战之一是语义切换——当 prompt 变化时(例如从'人走路'切换到'人跑步'),模型需要在保持视觉连贯性的同时响应新语义。现有方法在 prompt 边界处要么重建整个 KV Cache(慢),要么固定缓存大小无法适配语义变化(质量差)。 前序工作及局限: StreamingT2V:滑动窗口但无语义感知 ControlNet/P2P:注入控制但非流式 与前序工作的本质区别: 无训练语义注入代替缓存重建,逐头梯度化更新 5.2 方法原理 SWIFT 解决的问题:流式视频生成中 prompt 切换时如何高效更新记忆? 传统做法是在 prompt 边界处清空并重建 KV Cache,这造成两个问题:(1) 重建开销大,打断流式生成的实时性;(2) 清空历史信息可能导致前后帧视觉不连贯。 SWIFT 的做法完全不同:不清空缓存,而是把新 prompt 的语义'注入'到已有 cache 中。具体实现:计算每个注意力头当前 KV 状态与新 prompt 特征的对齐度(余弦相似度),对齐度高的头已经自然适配新语义(少注入),对齐度低的头需要更多新信息(多注入)。 自适应动态窗口:不同 prompt 阶段的记忆需求不同——刚切换时需要大窗口保持过渡平滑,稳定后可缩小窗口节省显存。SWIFT 根据生成帧数和语义稳定度自动调整窗口大小。 关键优势:完全无训练,可直接插入任何因果视频扩散模型。 5.3 核心创新 提出 SWIFT(Semantic Windowing and Injection for Flexible Transitions)无训练框架:(1) 语义注入缓存增强——不重建缓存,而是将新 prompt 语义注入已有缓存中;(2) 逐头语义注入——每个注意力头按自身与当前视频状态的对齐度决定接收多少新语义更新;(3) 自适应动态窗口——按 prompt 阶段分配时间记忆容量。 5.4 实验结果 在保持生成质量的同时,单卡 H100 上达到 22.6 FPS。多 prompt 长视频(>200 帧)的语义切换平滑度显著优于重建方案。与 Self Forcing 等 AR 模型即插即用兼容。 5.5 关键洞察 [{'point': '语义对齐度计算延迟', 'detail': '逐头计算语义对齐度本身引入额外延迟,在极端实时场景下可能成为瓶颈'}, {'point': '双向注意力适用性', 'detail': '仅在因果视频扩散模型上验证,对双向注意力架构是否同样有效存疑'}, {'point': '复杂语义切换', 'detail': '在多重、快速的语义切换场景下(如 5 秒内切换 3 次 prompt)的稳定性未充分验证'}] 技术演进定位: 首个无训练的流式语义切换方案 可能的后续方向: 与 KV 压缩组合 多模态条件注入 6. CDM:连续时间分布匹配蒸馏:阿里/南开提出动态连续调度,从离散锚定进化到连续流形优化 论文: CDM:连续时间分布匹配蒸馏 arXiv: 2605.06376 机构: Alibaba, Nankai University 6.1 研究动机 核心问题: DMD 离散锚定导致少步生成伪影 DMD(Distribution Matching Distillation)是少步扩散蒸馏的主流范式之一,但有个根本缺陷:它在离散时间步上做分布匹配——只在 {0, 0.25, 0.5, 0.75, 1.0} 等稀疏锚点对齐分布。这种离散锚定加上反向 KL 散度的模式寻求特性,容易产生视觉伪影和过度平滑。通常需要额外的 GAN 判别器或奖励模型来修补,系统复杂度极高。 前序工作及局限: DMD/DMD2:离散时间步分布匹配 Progressive Distillation:渐进蒸馏但步数固定 与前序工作的本质区别: 连续时间采样 + 轨迹偏离匹配,移除 GAN/奖励辅助 6.2 方法原理 ![Overview of Continuous-Time Distribution Matching (CDM). Top: Our approach employs a dynamic continuous time schedule during backward simulation, sampling intermediate anchors uniformly from $(0, 1]$. Bottom Left: CFG augmentation (CA) and distribution matching (DM) operate on this dynamic schedule to align text-image conditions and data distributions at on-trajectory anchors. Bottom Right: To address inter-anchor inconsistency, the proposed CDM objective explicitly extrapolates off-trajectory latents ($x_t_i'$) using the predicted velocity.](https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/AIGC/20260516/2605.06376_1.png) CDM 的核心洞察:DMD 之所以需要 GAN 和奖励模型修补,是因为离散锚定注定了'覆盖不全'——轨迹上 99% 的点没有监督信号,模型在这些无监督区域自由飘移。 解决方案:把分布匹配从离散点扩展到连续流形。具体实现:(1) 训练过程中不再用固定时间步集合 {t₁, t₂, ...},而是在 [0,1] 上连续采样匹配点,采样概率密度随训练动态调整——模型薄弱的区域被更频繁地采样;(2) 对齐目标不再局限于 ODE 轨迹上的点,还主动采样轨迹附近的'偏离点'——这迫使模型学习在轨迹邻域内也保持良好的分布匹配。 效果:连续调度消除了离散锚定的覆盖空洞,偏离匹配增强了模型在采样扰动下的鲁棒性。两者组合后,即使不用 GAN 和奖励模型,视觉质量也能匹配甚至超越带这些辅助模块的方案。 6.3 核心创新 将 DMD 框架从离散锚定首次迁移到连续优化:(1) 动态连续调度——允许在任意轨迹点(而非预设锚点)做分布匹配,采样点随训练自适应调整;(2) 连续时间对齐目标——主动在偏离 ODE 轨迹的位置做匹配,增强鲁棒性。无需 GAN、无需奖励模型等复杂辅助模块。 6.4 实验结果 ![Empirical evidence of schedule decoupling. (a) Conventional distillation strictly anchors backward simulation to predefined discrete inference timesteps. In contrast, our dynamic scheduling optimizes over uniformly sampled continuous timesteps $t (0, 1]$ at each iteration. (b) Visually, the dynamically scheduled model produces finer details and fewer artifacts than the strictly aligned baseline. (c) Quantitatively, it also attains a higher HPSv3 score, indicating that exact discrete alignment is not only unnecessary but in fact restrictive---motivating our continuous-time formulation.](https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/AIGC/20260516/2605.06376_2.png) 在 SD3-Medium 和 Longcat-Image 上展示了高度竞争力的少步生成视觉保真度。4 步 FID 达到接近 50 步教师的水平。代码已开源(GitHub)。无需 GAN 或奖励模型的极简架构降低了工程复杂度。 6.5 关键洞察 [{'point': '训练开销', 'detail': '连续调度增加了每步的采样复杂度,实际训练时间和显存开销的对比数据不够充分'}, {'point': '视频域验证缺失', 'detail': '仅在图像模型上验证,视频域的时序一致性是否同样受益未知'}, {'point': '与 CD 方法对比', 'detail': '与 Consistency Distillation 的直接对比较少,两者互补性未探讨'}] 技术演进定位: 分布匹配蒸馏从离散走向连续的进化 可能的后续方向: 视频域连续调度 自适应精度匹配 7. SANA-WM:2.6B 参数分钟级世界模型的算力民主化:NVIDIA/MIT/港科大提出 Hybrid Linear DiT,单卡 RTX 5090 生成 60s 720p 论文: SANA-WM:2.6B 参数分钟级世界模型的算力民主化 arXiv: 2605.15178 机构: NVIDIA, MIT, HKUST 7.1 研究动机 核心问题: 分钟级世界模型训练和推理都需要海量资源 分钟级世界模型是通往具身智能和虚拟环境仿真的必经之路。但现有方案面临三重困境:(1) 画质要求媲美产业级大模型(LingBot-World、HY-WorldPlay),(2) 训练需要海量闭源数据和数百张 GPU,(3) 推理需要多卡集群。结果是:开源社区几乎没有可用的分钟级世界模型。 前序工作及局限: Genie2/3:分钟级但闭源/昂贵 SANA:高效图像生成架构 与前序工作的本质区别: Hybrid Linear Attention + 公开数据 + 量化蒸馏 → 消费级 GPU 7.2 方法原理 SANA-WM 的核心挑战:如何用有限资源做出质量不差的分钟级世界模型? Hybrid Linear Attention:纯 softmax attention 的 O(n²) 复杂度在分钟级视频(数千帧)上不可承受。SANA-WM 将 frame-wise 的 Gated DeltaNet(线性复杂度,处理帧内 token)与跨帧的 softmax attention(处理时序依赖)混合——帧内用线性、帧间用 softmax,总复杂度接近 O(n)。 Dual-Branch Camera Control:世界模型需要精确的 6-DoF 相机控制。SANA-WM 设计双分支:一个分支处理相机轨迹的全局运动趋势,另一个处理局部帧间旋转/平移细节,两者融合后注入 DiT。 数据方案:不依赖闭源数据,而是从公开视频(WebVid 等)自动提取 metric-scale 6-DoF 相机姿态作为 action 标签。标注流水线基于 DUSt3R + SLAM,全自动无人工。 推理优化:蒸馏 + NVFP4 量化,在单张 RTX 5090 上 34 秒生成 60s 720p clip。 7.3 核心创新 提出 SANA-WM:首个面向分钟级视频生成的开源高效世界模型。三大技术突破:(1) Hybrid Linear Attention——frame-wise Gated DeltaNet 与 softmax attention 混合,长上下文内存 O(n) 可控;(2) Dual-Branch Camera Control——保证 6-DoF 轨迹精确跟随;(3) 鲁棒标注流水线——从公开视频自动提取 metric-scale 6-DoF 相机姿态。 7.4 实验结果 仅用约 213K 公开视频片段、64 张 H100 训练 15 天。单 GPU 即可生成 60s 720p clip。蒸馏量化版在单卡 RTX 5090 上 NVFP4 下 34 秒完成。在 1 分钟世界模型 benchmark 上动作跟随精度强于现有开源 baseline,画质相当但吞吐高 36 倍。 7.5 关键洞察 [{'point': 'Refiner 依赖', 'detail': '1 分钟生成仍依赖 stage-2 refiner 外置模块,端到端质量与商业闭源仍有差距'}, {'point': '场景多样性', 'detail': '213K 公开视频的场景覆盖度有限,复杂室内/多物体交互场景可能生成质量不稳定'}, {'point': '6-DoF 精度', 'detail': '自动标注的 6-DoF 姿态精度受限于 DUSt3R/SLAM 的能力,在快速运动或低纹理场景可能有偏差'}] 技术演进定位: 首个面向消费级硬件的开源分钟级世界模型 可能的后续方向: 多模态 action 物理引擎耦合 8. CausalCine:多镜头叙事的实时自回归视频生成:港科大/蚂蚁/上交提出内容感知记忆路由 CAMR 支持动态镜头切换 论文: CausalCine:多镜头叙事的实时自回归视频生成 arXiv: 2605.12496 机构: HKUST, Ant Group, SJTU 8.1 研究动机 核心问题: AR 视频模型无法处理多镜头叙事中的镜头转换 现有自回归视频模型解决了'开放式生成'——可以无限延伸画面。但电影叙事不是无限延伸单一场景——它需要事件演进、视角切换、镜头边界。当用户说'先拍远景,然后切到近景,再来个俯拍'时,现有 AR 模型将其视为单一长序列延伸,结果:运动停滞、语义漂移、无法处理镜头转换。 前序工作及局限: Self Forcing:单镜头流式生成 MovieGen:多镜头但非 AR/非实时 与前序工作的本质区别: CAMR 内容感知路由 + 多镜头训练数据构建 8.2 方法原理 CausalCine 解决的核心问题:如何让 AR 视频模型理解'镜头'概念? 传统 AR 视频模型把所有帧当作同质序列——前一帧和后一帧的关系是'延续'。CausalCine 引入镜头边界的概念:同一镜头内的帧关系是'延续',跨镜头帧关系是'切换'——两者需要完全不同的记忆策略。 CAMR (Content-Aware Memory Routing) 的具体做法:不使用固定的滑动窗口来管理历史 KV Cache,而是让每个新 token 通过注意力得分动态选择'回忆什么'。镜头切换时,与新镜头语义相关的历史(如同一人物的远景)被高权重检索,无关历史(如前一场景的背景细节)被低权重淡化。 这本质上是一种学习到的'选择性遗忘'——让模型在保持叙事连贯性(人物/故事线)的同时,允许视觉内容的突变(场景切换)。 最后蒸馏为少步实时生成器,保持交互式特性。 8.3 核心创新 将多镜头视频生成转化为在线导演过程:(1) 在原生多镜头序列上训练因果基础模型,学习复杂的镜头转换先验(淡入淡出/硬切/运镜等);(2) 提出 Content-Aware Memory Routing (CAMR)——按注意力相关性动态检索历史 KV 条目而非固定窗口,让镜头切换时记忆'该忘的忘、该记的记'。 8.4 实验结果 显著超越自回归基线,接近双向模型能力。多镜头叙事的连贯性(人物一致性、情节连续性)在主观评测中远超现有 AR 方案。支持动态 prompt 实时切换——生成中途改变指令,模型自动执行镜头切换。 8.5 关键洞察 [{'point': '训练数据获取', 'detail': '原生多镜头视频的镜头边界标注获取成本未讨论,是否需要大量人工标注'}, {'point': '蒸馏后多样性', 'detail': '蒸馏为少步生成器后,镜头转换的多样性(淡入/硬切/运镜等)是否被压缩到少数模式'}, {'point': '长叙事稳定性', 'detail': '超过 10 个镜头的长叙事中,人物一致性是否能稳定维持'}] 技术演进定位: 首个面向多镜头叙事的实时 AR 视频框架 可能的后续方向: 分镜自动规划 多角色追踪 横向对比与技术脉络总结 横向对比:本周实时视频生成技术路线对比 论文 核心方法 推理步数 单卡速度 是否需要训练 视频长度 是否开源 Causal Forcing++ 因果一致性蒸馏 Frame-wise 2 步 未公布 FPS 需蒸馏训练 开放式流式 未开源 AnyFlow Flow Map 任意步数蒸馏 4-32 步灵活 未公布 FPS 需蒸馏训练 标准长度 待开源 RAVEN 训练-测试对齐 + CM-GRPO 少步(具体步数未公布) 未公布 FPS 需 RL 训练 开放式流式 待开源 Forcing-KV KV Cache 混合压缩 与基模型一致 29+ FPS (H200) 无训练推理优化 开放式长视频 待开源 SWIFT 语义注入缓存 与基模型一致 22.6 FPS (H100) 完全无训练 多 prompt 长视频 待开源 CDM 连续时间分布匹配 4 步 标准推理 需蒸馏训练 图像(待扩展视频) 已开源 SANA-WM Hybrid Linear DiT 多步(+量化加速) 34s/60s clip (5090) 需完整训练 60s 分钟级 已开源 CausalCine 内容感知记忆路由 少步(蒸馏后) 实时级 需多镜头训练 多镜头叙事 待开源 核心技术趋势 因果自回归蒸馏从 chunk-wise 4 步推向 frame-wise 1-2 步,实时交互成为现实 Causal Forcing++ 证明因果一致性蒸馏可以在 frame 粒度实现高质量 2 步生成,首帧延迟降低 50%,解锁了真正的流式交互式视频生成 训练-推理分布对齐成为自回归视频蒸馏的核心议题 RAVEN 通过 rollout 重打包直接弥合训练时 teacher history 与推理时 student rollout 的分布 gap,配合 CM-GRPO 实现端到端对齐 KV Cache 压缩与自适应记忆方案使流式视频生成在单卡上实现 20-30 FPS Forcing-KV 发现注意力头的功能特化规律(静态/动态),SWIFT 提出无训练语义注入方案,两者分别在 H200 和 H100 单卡上实现实时吞吐 世界模型正在从封闭系统走向开源、从秒级走向分钟级 SANA-WM 以 2.6B 参数 + 213K 公开视频在单卡 RTX 5090 上生成 60s 720p 视频,吞吐比闭源方案高 36 倍,标志着世界模型的算力民主化 核心技术难点与开放问题 四大核心难点 1. 少步生成的质量天花板 当采样步数降到 1-2 步,模型本质上在做'条件预测'而非'迭代去噪'。Causal Forcing++ 在 2 步下已接近 4 步水平,但与 50 步教师仍有可见差距。AnyFlow 通过 flow map 让多步时性能恢复,但 1-2 步仍是瓶颈。核心问题:少步生成的理论质量上界在哪里? 2. 长序列的累积误差与遗忘 所有 AR 模型都面临长序列退化:RAVEN 通过训练-测试对齐缓解,Forcing-KV/SWIFT 通过 cache 管理控制,CausalCine 通过 CAMR 选择性遗忘。但 1000+ 帧的真正长视频中,这些方案能否持续有效?'选择性遗忘'与'不该遗忘'之间的精确边界难以界定。 3. 蒸馏与 RL 对齐的统一 本周出现三条竞争路线:Causal CD(蒸馏为主)、AnyFlow(flow map 蒸馏)、CM-GRPO(RL 对齐)。它们解决不同层面问题但目前各自为战——是否存在一个统一框架,先 flow map 蒸馏获得任意步数能力,再 CM-GRPO 对齐到人类偏好? 4. 实时生成的硬件民主化 Forcing-KV 在 H200、SWIFT 在 H100、SANA-WM 在 RTX 5090 上实现实时/近实时。但消费级 GPU(如 RTX 4090 甚至 RTX 4060)上呢?真正的用户端实时体验需要把算力需求再降一个量级,这可能需要蒸馏+量化+剪枝+cache 压缩的全栈优化。 今日讨论 自回归视频生成已经进入'实时'门槛——Forcing-KV 29 FPS、SWIFT 22.6 FPS、Causal Forcing++ frame-wise 2 步。下一步的核心问题是:实时生成的质量天花板在哪里?当采样步数降到 1-2 步,模型本质上在做'条件预测'而非'迭代去噪',这对视觉保真度的根本影响是什么?AnyFlow 通过 flow map 让步数可伸缩、RAVEN 通过 RL 对齐推理分布——这两条路线谁更有可能统一少步和多步的质量-速度曲线? 人工智能炼丹君 整理 | 数据来源:arXiv 2026-05-11 ~ 2026-05-16 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描下方二维码关注
-
AIGC 每日速读|2026-05-15|实时视频2步出帧Causal Forcing++ 今日 AIGC 论文速览 今日共 8 篇 · 实时 AR 视频与世界模型 3 篇 · 相机控制与视频生成 2 篇 · 图像编辑持续学习 1 篇 · 扩散模型 RL 后训练 1 篇 · 视频世界模型评测 1 篇 重点论文标题列表 Causal Forcing++:因果一致性蒸馏 Warp-as-History:把相机引起的形变直接转化为「相机扭曲 ACE-LoRA:动态正则化框架 RefDecoder:参考条件视频 VAE decoder DiffusionOPD:多任务训练范式 今日论文速览 1. Causal Forcing++:因果一致性蒸馏 Causal Forcing++: Scalable Few-Step Autoregressive Diffusion Distillation for Real-Time Interactive Video Generation | 清华 TSAIL, 生数科技 | arXiv:2605.15141 关键词:少步AR视频·因果一致性蒸馏·实时交互生成·世界模型·Genie3 前序问题:实时交互式视频生成需要低延迟、流式、可控的 rollout。现有自回归扩散蒸馏在 chunk-wise 4 步取得了不错效果,但 chunk 粒度过粗、采样延迟仍然不可忽略;当尝试更激进的 frame-wise 1-2 步时,少步 AR 学生的初始化策略要么目标错位、要么不能少步生成、要么算力代价大到无法 scale 本文贡献:提出 Causal Forcing++ 因果一致性蒸馏(Causal CD)流水线:核心观察是 Causal CD 学习与 Causal ODE 蒸馏相同的 AR-条件流图,但只需在相邻时间步之间用一次教师 ODE 步在线提供监督,无需预先计算并存储完整 PF-ODE 轨迹——既高效又易优化;进一步把流水线扩展到 Genie3 风格的 action-conditioned 世界模型 实验效果:在 frame-wise 2 步设定下,全面超越 SOTA 4 步 chunk-wise Causal Forcing:VBench Total +0.1、VBench Quality +0.3、VisionReward +0.335,同时首帧延迟降低 50%、Stage 2 训练成本降至约 1/4 批判点评:把蒸馏从 chunk-wise 4 步推进到 frame-wise 2 步,是实时交互式视频生成可用性上的关键一步——把瓶颈识别为「初始化」是非常贴切的诊断;但 1-2 步生成对教师 ODE 误差的放大效应、以及在更复杂 action 条件下的稳定性还需更多压力测试 2. Warp-as-History:把相机引起的形变直接转化为「相机扭曲 Warp-as-History: Generalizable Camera-Controlled Video Generation from One Training Video | 上海交大, 上海 AI Lab | arXiv:2605.15182 关键词:相机控制·视频生成·零样本·伪历史·LoRA 微调 前序问题:相机可控视频生成已经很成熟,但现有方法普遍需要在大规模带相机标注的视频上做后训练(额外的 camera encoder、控制分支、注意力/位置编码改造);training-free 方案则把代价转嫁到测试时优化或 denoising 时的额外 guidance,依然不便宜 本文贡献:提出 Warp-as-History:把相机引起的形变直接转化为「相机扭曲后的伪历史」,在 frozen 视频生成模型自带的「视觉历史」通路中喂进去——目标帧位置编码对齐、剔除没有有效观测来源的 token,无需训练或架构改动即可零样本服从相机轨迹;可选用一段相机标注视频做轻量 LoRA 微调进一步提升泛化能力 实验效果:在多个数据集上的实验显示:完全 training-free 即可让冻结视频生成模型获得不平凡的相机轨迹跟随能力;只用「一段」相机标注视频做 LoRA 微调,即可在未见视频上同时改善相机贴合度、画质与运动动态 批判点评:把相机可控问题视作「历史 warp」是一个非常优雅的视角,几乎不增加任何训练成本;但 zero-shot 能力依赖底模的「视觉历史」通路是否足够强,没有该通路的扩散视频模型迁移性可能受限;另外极端轨迹下的孔洞填充质量值得关注 3. ACE-LoRA:动态正则化框架 ACE-LoRA: Adaptive Orthogonal Decoupling for Continual Image Editing | 上海交大, vivo AI Lab | arXiv:2605.14948 关键词:持续学习·图像编辑·LoRA·正交解耦·CIE-Bench 前序问题:现有 SOTA 扩散模型靠参数高效微调(LoRA 等)适配各类图像编辑任务,但真实业务需要在不断到来的新任务上持续学习同时保留旧任务能力;图像编辑的持续学习问题至今几乎没人系统研究,灾难性遗忘问题严重 本文贡献:提出 ACE-LoRA 动态正则化框架:通过 Adaptive Orthogonal Decoupling 自动识别并正交化任务间干扰,再用 Rank-Invariant Historical Information Compression 解决持续更新中的可扩展性瓶颈;同时发布 CIE-Bench——业内首个面向图像编辑的持续学习评测基准 实验效果:在指令保真度、视觉真实感、抗遗忘鲁棒性上一致优于现有 baseline,建立了「图像编辑持续学习」这一子方向的标准方法+标准评测 批判点评:把「持续学习」首次正式带到图像编辑领域,问题设定和 benchmark 都非常务实;但 14 维基因式正交化的超参对任务序列分布的鲁棒性、以及面对几十个长尾编辑任务时压缩策略的极限,需要更长任务流的实测 4. RefDecoder:参考条件视频 VAE decoder RefDecoder: Enhancing Visual Generation with Conditional Video Decoding | University of Washington, UNC | arXiv:2605.15196 关键词:视频 VAE·参考条件 decoder·视频生成·即插即用·VBench 前序问题:主流 latent 视频扩散模型的 denoising 网络条件丰富,但 VAE decoder 几乎都是无条件的——这种结构性不对称导致细节流失、与输入参考图不一致,是当前视频生成「看起来糊糊的」的隐藏元凶 本文贡献:提出 RefDecoder 参考条件视频 VAE decoder:用一个轻量图像编码器把参考帧映射成细节丰富的高维 token,在 decoder 每个 upsampling stage 与去噪后的视频 latent token 共同处理(reference attention),让 decoder 也获得与 denoising 网络对等的条件信息 实验效果:在 Wan 2.1、VideoVAE+ 等多个 decoder backbone 上一致提升 PSNR 最多 +2.1dB(Inter4K / WebVid / Large Motion);可直接热插拔进现有视频生成系统,无需额外微调,VBench I2V 上主体一致性、背景一致性、综合质量全面提升;天然泛化到风格迁移、视频编辑精修等任务 批判点评:这是一项「补条件」的低风险高收益工作,可即插即用是工程师最爱的属性;但 decoder 端注入参考可能在大幅运动场景下与 latent 表示冲突,长视频累积误差与 reference token 选择策略仍有优化空间 5. DiffusionOPD:多任务训练范式 DiffusionOPD: A Unified Perspective of On-Policy Distillation in Diffusion Models | 阿里 Wan Team, 复旦 | arXiv:2605.15055 关键词:扩散模型 RL·On-Policy 蒸馏·多任务·Wan Team·文生图 前序问题:强化学习是改进文生图扩散模型的强力工具,但现有方法大多局限于单任务优化——多任务联合 RL 受困于跨任务干扰和不平衡,级联 RL 又笨重且易遗忘 本文贡献:提出 DiffusionOPD 多任务训练范式:先独立训练任务专属 teacher,再沿学生自己的 rollout 轨迹做 Online Policy Distillation 把多 teacher 能力蒸馏到统一学生;理论上首次把 OPD 框架从离散 token 提升到连续状态 Markov 过程,给出闭式 per-step KL 目标,统一 SDE 与 ODE refinement,方差更低、泛化更好 实验效果:一致超越多奖励 RL 与级联 RL 基线,训练效率与最终性能两端均占优,在所有评测基准上达到 SOTA 批判点评:把 OPD 严格地搬上连续扩散是漂亮的理论延伸,多任务版本对落地非常有价值;但 teacher 数量增加后蒸馏的 token-level KL 是否仍稳定、teacher 与学生 capacity 失配时的下界,仍需更大规模实验 6. RAVEN:框架 RAVEN: Real-time Autoregressive Video Extrapolation with Consistency-model GRPO | 帝国理工 AGI Lab | arXiv:2605.15190 关键词:实时 AR 视频·一致性模型·CM-GRPO·训练-测试对齐·流式生成 前序问题:因果自回归视频扩散模型靠把过去内容外推未来 chunk 实现实时流式生成,蒸馏自高保真双向教师后已能少步推理;但训练时 history 分布与推理时实际 rollout 分布之间的 gap 一直限制长序列的生成质量 本文贡献:提出 RAVEN training-time test 框架:把每次自身 rollout 重打包为「干净历史端点 + 噪声去噪状态」交错序列,让训练注意力对齐推理时的外推方式,同时让下游 chunk loss 监督未来预测所依赖的历史表示;进一步提出 CM-GRPO,把 consistency 采样步重新表达为条件高斯转移,直接在该核上做在线 RL,避免了之前 flow-model RL 公式中的 Euler-Maruyama 辅助过程 实验效果:RAVEN 在质量、语义、动态度多维评测上超越近期因果视频蒸馏 baseline;CM-GRPO 与 RAVEN 组合后进一步提升性能 批判点评:把 training-test 不一致问题正面解决并配套 CM-GRPO 是组合拳;但 RAVEN 重打包对长序列内存占用的影响、CM-GRPO 在更复杂奖励上的稳定性,还需要在更大模型尺度上验证 7. SANA-WM:2.6B 参数原生面向 1 SANA-WM: Efficient Minute-Scale World Modeling with Hybrid Linear Diffusion Transformer | NVIDIA, MIT, 港科大 | arXiv:2605.15178 关键词:世界模型·分钟级视频·Hybrid Linear Attention·6-DoF 相机·开源 前序问题:一分钟级别的世界模型既要画质媲美 LingBot-World、HY-WorldPlay 这些产业级大模型,又要在算力、数据、推理硬件三方面都「能用得起」——目前几乎没有开源方案能同时做到 本文贡献:提出 SANA-WM:2.6B 参数原生面向 1 分钟视频生成的开源世界模型——(1) Hybrid Linear Attention 把 frame-wise Gated DeltaNet 与 softmax attention 混合,长上下文内存可控;(2) Dual-Branch Camera Control 保证 6-DoF 轨迹精确跟随;(3) 两阶段生成 + long-video refiner;(4) 鲁棒标注流水线从公开视频中提取 metric-scale 6-DoF 相机姿态作为动作标签 实验效果:仅用约 213K 公开视频片段、64 张 H100 训练 15 天,每个 60s 720p clip 单 GPU 即可生成;蒸馏量化版可在单卡 RTX 5090 上 NVFP4 量化下 34 秒生成 60s 720p;在 1 分钟世界模型 benchmark 上动作跟随精度强于现有开源 baseline,画质相当但吞吐高 36 倍 批判点评:把「分钟级世界模型」做到能在单张消费卡上跑动,是世界模型走向开发者手里的关键一步;但 1 分钟仍然依赖「stage-2 refiner」这一外置模块,端到端 1 分钟生成质量与商业闭源仍有差距 8. PDI-Bench:几何一致性量化框架 Quantitative Video World Model Evaluation for Geometric-Consistency | UCSD, 港科大等 | arXiv:2605.15185 关键词:视频世界模型·几何一致性·评测基准·3D 重建·物理推理 前序问题:生成视频模型越来越被当作隐式世界模型来研究,但「生成视频是否产生了物理合理的 3D 结构与运动」一直缺乏客观度量——现有评测要么靠人工打分要么靠学习式 grader,对几何失败的诊断力都很弱 本文贡献:提出 PDI-Bench(Perspective Distortion Index)几何一致性量化框架:先用 SAM 2、MegaSaM、CoTracker3 抽取物体级观测,单目重建到 3D 世界坐标,再算三类射影几何残差——尺度-深度对齐、3D 运动一致性、3D 结构刚性;配套 PDI-Dataset 覆盖多种压力测试场景 实验效果:在多个 SOTA 视频生成器上揭示了通用感知指标完全捕获不到的「几何特定失败模式」,为「物理基础视频生成 / 物理世界模型」的进展提供了可诊断信号 批判点评:把视频世界模型评测从「看起来对不对」推进到「几何上对不对」是必要的下一步,依托成熟 3D 工具链让指标可复现;但单目重建本身的误差对 PDI 指标的噪声有多大、对真实开放世界长尾场景的覆盖度,是后续要补的关键证据 趋势观察 实时交互视频生成进入 frame-wise 时代 — Causal Forcing++ 把少步 AR 视频从 chunk-wise 4 步压缩到 frame-wise 2 步,首帧延迟降一半;RAVEN 用 training-time test + CM-GRPO 直击 history 分布漂移——实时交互视频已经从「能动」进入「秒级响应」 相机控制从「重训」走向「零样本 + 一段视频微调」 — Warp-as-History 把相机条件转译为 frozen 模型自带的视觉历史通路,零样本即跟随;只用一段视频做 LoRA 即可泛化到未见素材——相机可控视频生成从「依赖大规模标注」滑向「轻数据即用」 VAE decoder 不再是哑终端 — RefDecoder 指出主流视频扩散模型 decoder 长期处于「无条件」状态,导致细节流失;用 reference attention 给 decoder 也加上条件,PSNR 直接 +2.1dB——decoder 端的条件化正成为视频生成的下一个低悬果实 世界模型走向消费级硬件 — SANA-WM 用 Hybrid Linear Attention + 量化在单卡 RTX 5090 上跑出 34 秒生成 60 秒 720p——分钟级世界模型第一次具备了「开发者本地可玩」的硬件包络 评测从感知质量转向几何/物理一致性 — PDI-Bench 把视频世界模型的考评从「看起来真不真」转到「几何上对不对」,借助成熟 3D 工具链给出射影几何残差——这预示着视频生成下一阶段的评测竞赛是「物理可解释性」 人工智能炼丹君 整理 | 2026-05-15 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描下方二维码关注