
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹君 整理 | 2026年5月17日(周日)
覆盖时间:2026-05-11 ~ 2026-05-16
本期 AIGC 周末专题聚焦实时自回归视频生成:从蒸馏加速到流式交互的范式突破方向,精选 8 篇代表性论文进行深度解读。
方向分布:
含 NVIDIA/MIT 联合 × 2
描述:Progressive Distillation 开创渐进蒸馏路线,Consistency Models 提出端点一致性映射,少步生成从理论走向实践。
关键节点:
描述:Self Forcing 开创 AR 视频蒸馏范式,Causal Forcing 将 chunk-wise 4 步推向可用,流式视频生成原型出现。
关键节点:
描述:Frame-wise 蒸馏、KV Cache 压缩、无训练加速三线并进,实时交互式视频生成从实验室走向产品。
关键节点:
描述:实时 AR 视频生成与世界模型、多镜头叙事融合,从'生成画面'走向'仿真世界'。
关键节点:
论文: Causal Forcing++:因果一致性蒸馏实现 Frame-wise 2 步实时视频生成
arXiv: 2605.15141
机构: Tsinghua TSAIL, 生数科技 (Shengshu)
核心问题: Frame-wise AR 蒸馏的初始化策略与少步目标错位
实时交互式视频生成需要低延迟、流式、可控的 rollout。Causal Forcing 等先驱已经证明 chunk-wise 4 步蒸馏的可行性,但 chunk 粒度过粗——每生成 16 帧需 4 步 DiT forward pass,首帧延迟仍以秒计。如果能做到 frame-wise 1-2 步,每帧只需 1-2 次 forward pass,延迟可再降一个量级。问题是:现有蒸馏初始化策略要么目标错位、要么不能少步生成、要么算力大到无法 scale。
前序工作及局限:
与前序工作的本质区别: Causal CD 只需一次教师 ODE 步在线监督,三阶段初始化解决冷启动
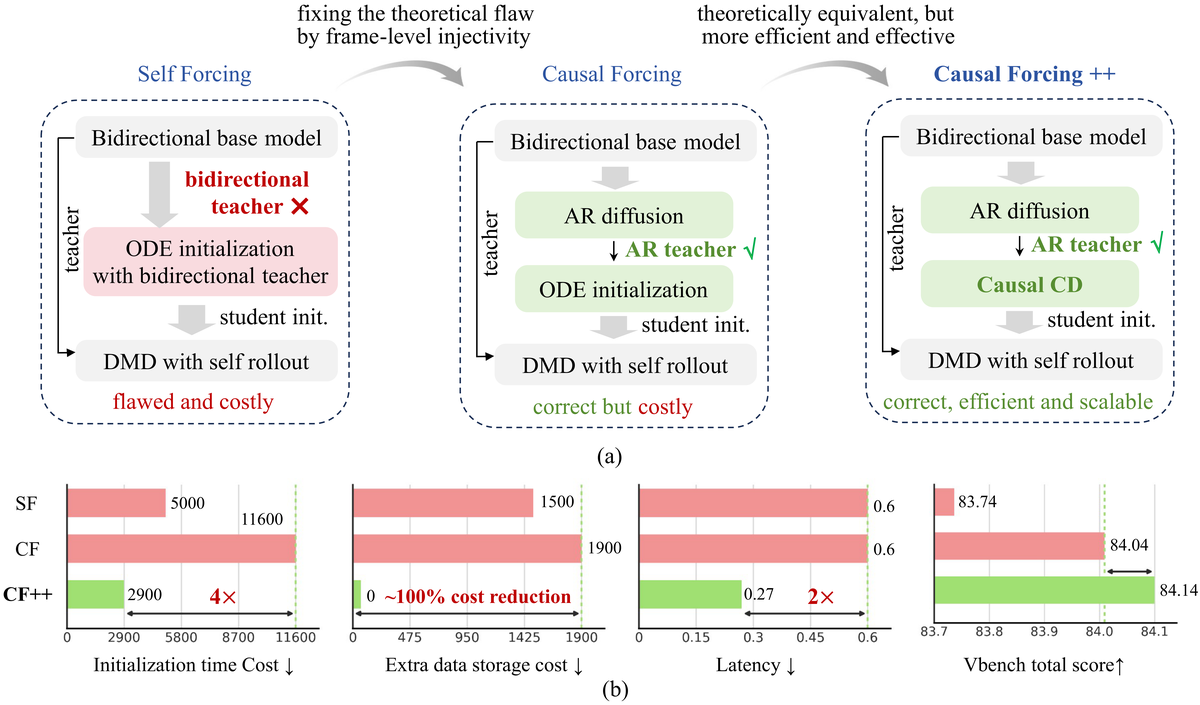
Causal Forcing++ 解决的核心问题是:如何在 frame-wise 粒度做高效的因果 AR 蒸馏?关键观察:Causal Consistency Distillation 学的流图与 Causal ODE 蒸馏完全等价,但训练信号更简洁——只需教师模型做一步 ODE 更新,学生学习匹配该更新结果。这避免了传统蒸馏需要预计算完整 PF-ODE 轨迹的巨大开销。
三阶段初始化解决冷启动:(1) 双向扩散预训练让模型学习高质量生成能力;(2) 因果适配将双向注意力切换为因果 mask,保持生成质量同时获得 AR 属性;(3) 少步蒸馏在上述基础上训练 frame-wise 1-2 步推理。
进一步将流水线扩展到 Genie3 风格 action-conditioned 世界模型,用相同 Causal CD 范式蒸馏交互式世界模型,支持动态 action 实时驱动。
[{'point': '教师 ODE 误差放大', 'detail': '1-2 步生成使教师单步 ODE 的离散化误差直接影响学生最终输出,误差没有后续步骤修正的机会'}, {'point': '世界模型场景的 action 复杂度', 'detail': '在简单 action 下表现优秀,但面对复杂多步交互指令时的稳定性需要更多压力测试'}, {'point': '未开源', 'detail': '论文来自产业实验室,复现需等待官方代码公开'}]
技术演进定位: Frame-wise 因果 AR 蒸馏的实时交互级方案
可能的后续方向:
论文: AnyFlow:任意步数视频蒸馏的 Flow Map 统一框架
arXiv: 2605.13724
机构: National University of Singapore Show Lab, MIT, NVIDIA
核心问题: Consistency Distillation 步数增加时性能退化
过去一年的少步视频生成被一致性蒸馏(Consistency Distillation)统治——4-8 步即可出图。但一个致命问题:把步数从 4 加到 16/32,画质反而崩溃。为什么?CD 用一致性轨迹替换了原始 PF-ODE 轨迹,破坏了 ODE 采样在测试时的可扩展行为。用户需要'任意步数'推理的灵活性——算力充裕时多步出精品,紧急场景少步求速度——但 CD 做不到。
前序工作及局限:
与前序工作的本质区别: Flow Map z_t→z_r 目标 + FMBS on-policy 训练恢复步数可扩展性
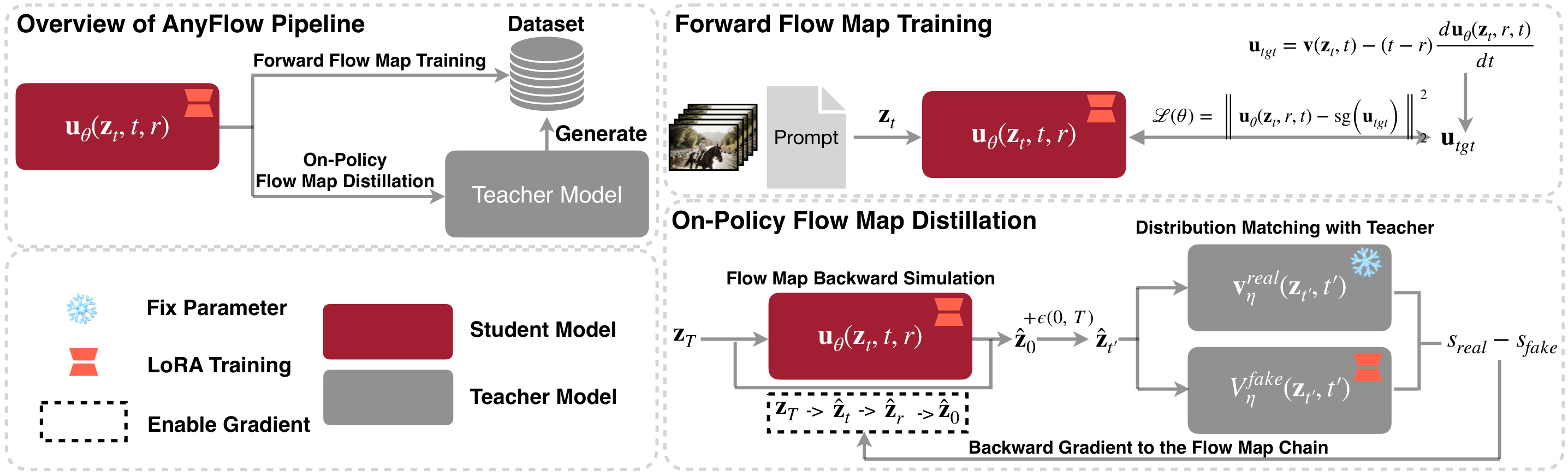
AnyFlow 的核心洞察:一致性蒸馏学的是 z_t→z_0 的端点映射,这迫使模型'一步到位'——当允许多步时,中间状态没有明确的 ODE 语义,因此步数越多反而越混乱。
Flow Map 解决方案:不学端点映射,而是学任意时间区间 [t, r] 的流图过渡 z_t→z_r。当 r=0 退化为一步生成,当 r>0 退化为多步 ODE 采样的某一段——自然统一了少步和多步。
FMBS 训练方法:传统蒸馏是 off-policy 的——用教师 ODE 生成配对 (z_t, z_r)。AnyFlow 提出 on-policy 方法:让学生自身做 Euler rollout,在 rollout 路径上反向模拟真实的流图过渡,用于训练。这解决了视频域因果生成的 exposure bias 问题。
在双向 DiT(Open-Sora Plan)和因果 AR(CausalVAR)两类骨干、1.3B 到 14B 全规模区间验证。
[{'point': '复现门槛高', 'detail': '需要 1B-14B 级别教师模型 + 大规模 on-policy rollout,数据与算力两端门槛都不低'}, {'point': '具体数值缺失', 'detail': '论文未公开 VBench/UCF-FVD 等标准 benchmark 的绝对数值,难以与其他方法直接对比'}, {'point': '训练效率', 'detail': 'On-policy rollout 的训练时间和显存开销与 off-policy CD 的对比数据不够充分'}]
技术演进定位: 首次理论解释 CD 多步退化并给出 flow map 解决方案
可能的后续方向:
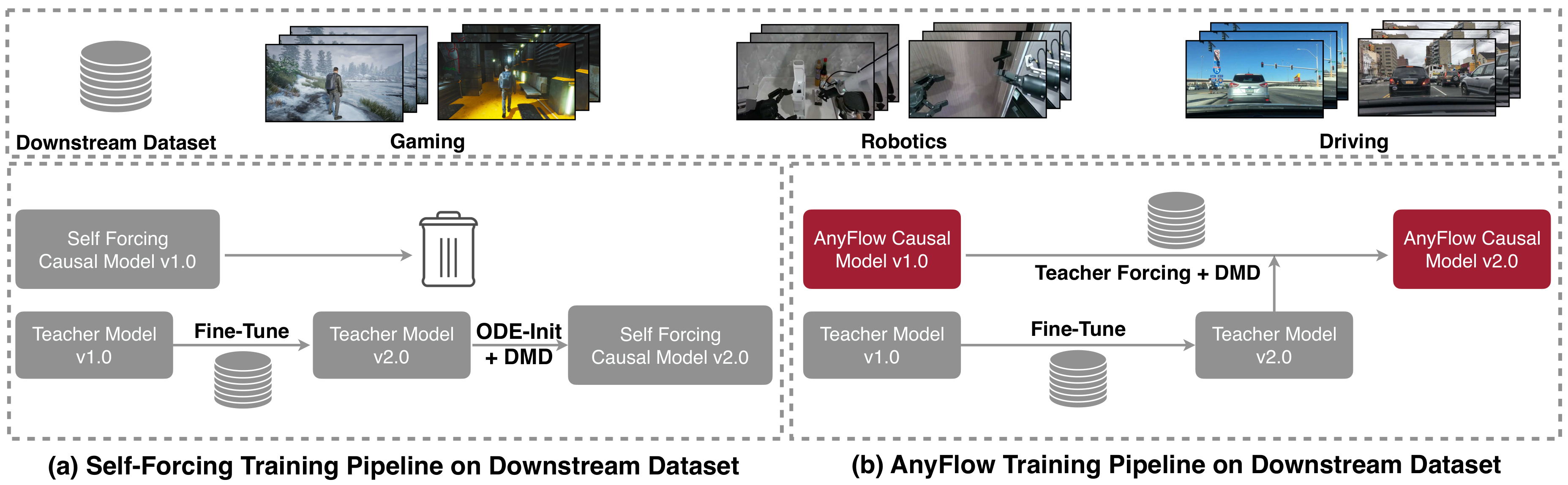
论文: RAVEN:训练-测试对齐的实时自回归视频外推
arXiv: 2605.15190
机构: Imperial College London AGI Lab
核心问题: 因果视频蒸馏训练用真实 history、推理用自身 rollout 的分布 gap
因果自回归视频扩散模型通过蒸馏高保真双向教师已能实现少步推理。但一个根本性问题一直被忽视:训练时用真实 history(来自数据集)作为条件,推理时却用模型自身 rollout 的结果作为 history——两者分布不同。随着 rollout 长度增加,这个训练-测试分布 gap 会累积放大,导致长序列生成质量严重退化。
前序工作及局限:
与前序工作的本质区别: RAVEN rollout 重打包 + CM-GRPO 在一致性核上做 RL
RAVEN 解决的核心问题是训练-测试分布不对齐。具体做法:训练时不再只用真实数据作为 history 条件,而是让模型先做一段 rollout 生成'假 history',然后把这个 rollout 的干净端点重新打包为条件输入,让模型在自身 rollout 分布上继续学习。这样训练时看到的 history 分布就与推理时一致。
CM-GRPO 的创新在于简化了 RL 在生成模型上的应用。传统 flow-model RL 需要构造 Euler-Maruyama 辅助过程来定义 policy gradient,复杂且不稳定。CM-GRPO 的观察:consistency model 的每步采样本质上是条件高斯转移 p(z_{t-1}|z_t) = N(μ(z_t), σ²I),可以直接在这个高斯核上定义 log-probability 并做 GRPO——公式简洁、梯度稳定。
两者组合:RAVEN 让模型在正确分布上训练,CM-GRPO 让模型朝奖励方向优化。
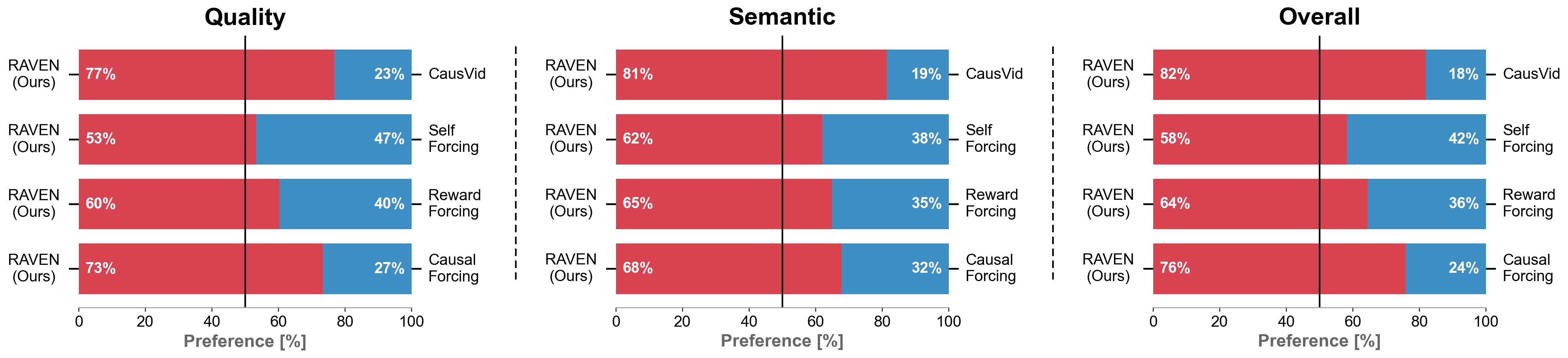
[{'point': '内存开销', 'detail': 'RAVEN 重打包需要额外存储 rollout 结果,对长序列的内存占用影响未充分量化'}, {'point': '奖励设计敏感性', 'detail': 'CM-GRPO 的效果强依赖于奖励函数设计,在更复杂/多维奖励场景下的稳定性有待验证'}, {'point': '模型规模验证', 'detail': '在更大模型尺度(>5B)上是否同样有效需要进一步实验'}]
技术演进定位: 系统性解决因果视频蒸馏训练-测试对齐的首个完整方案
可能的后续方向:
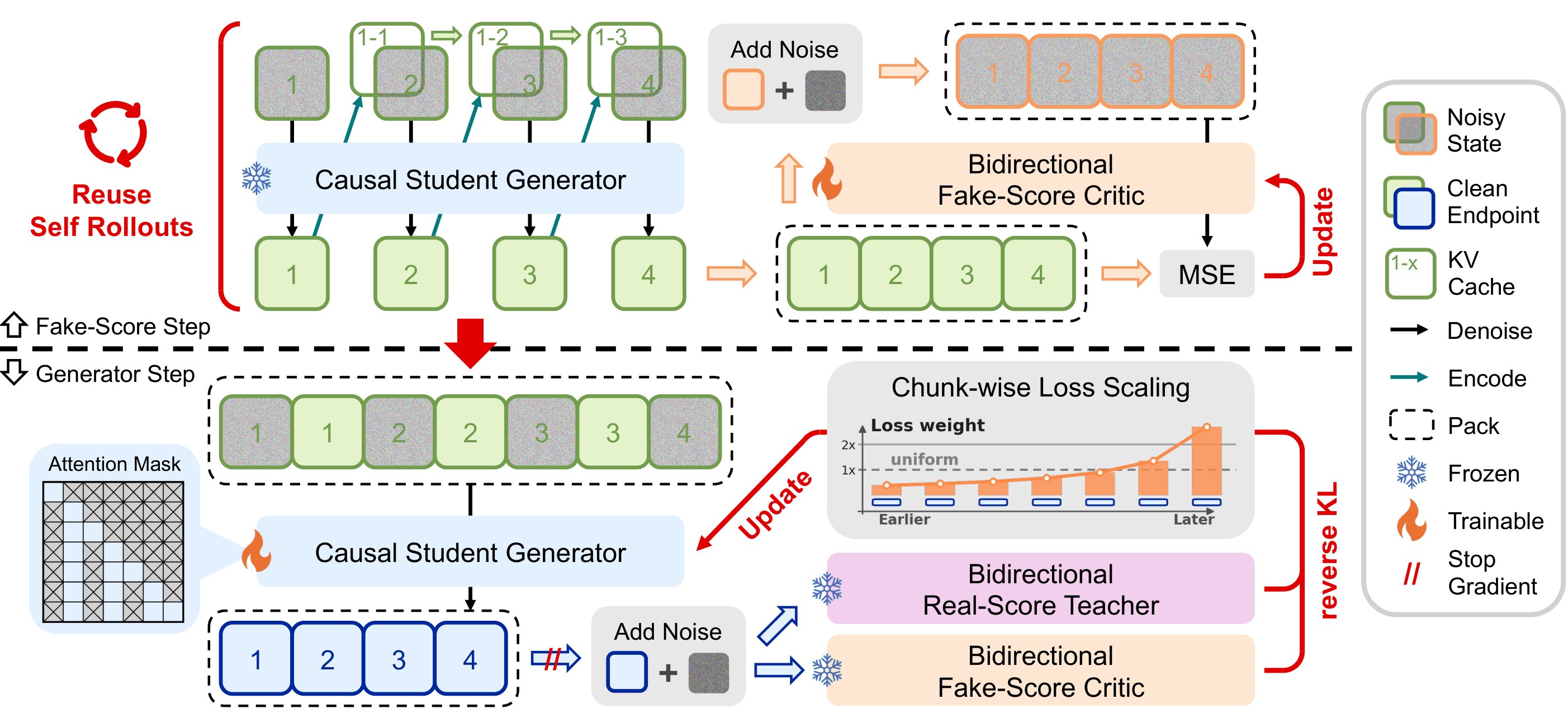
论文: Forcing-KV:注意力头特化驱动的 KV Cache 混合压缩
arXiv: 2605.09681
机构: NVIDIA, MIT, ETH Zurich, ZJU
核心问题: AR 视频扩散历史帧 KV Cache 线性膨胀导致显存爆炸
自回归视频扩散模型(如 Self Forcing)通过流式生成实现了开放式长视频合成。但致命瓶颈来了:随着生成帧数增加,历史帧的 KV Cache 线性膨胀——注意力复杂度爆炸 + 显存不够用。一段 30 秒的 1080P 视频,KV Cache 就能吃掉整张 H100 的 80GB 显存。如果不压缩 KV Cache,流式视频生成就永远停留在几秒级别。
前序工作及局限:
与前序工作的本质区别: 发现注意力头功能特化并据此设计静态/动态混合压缩
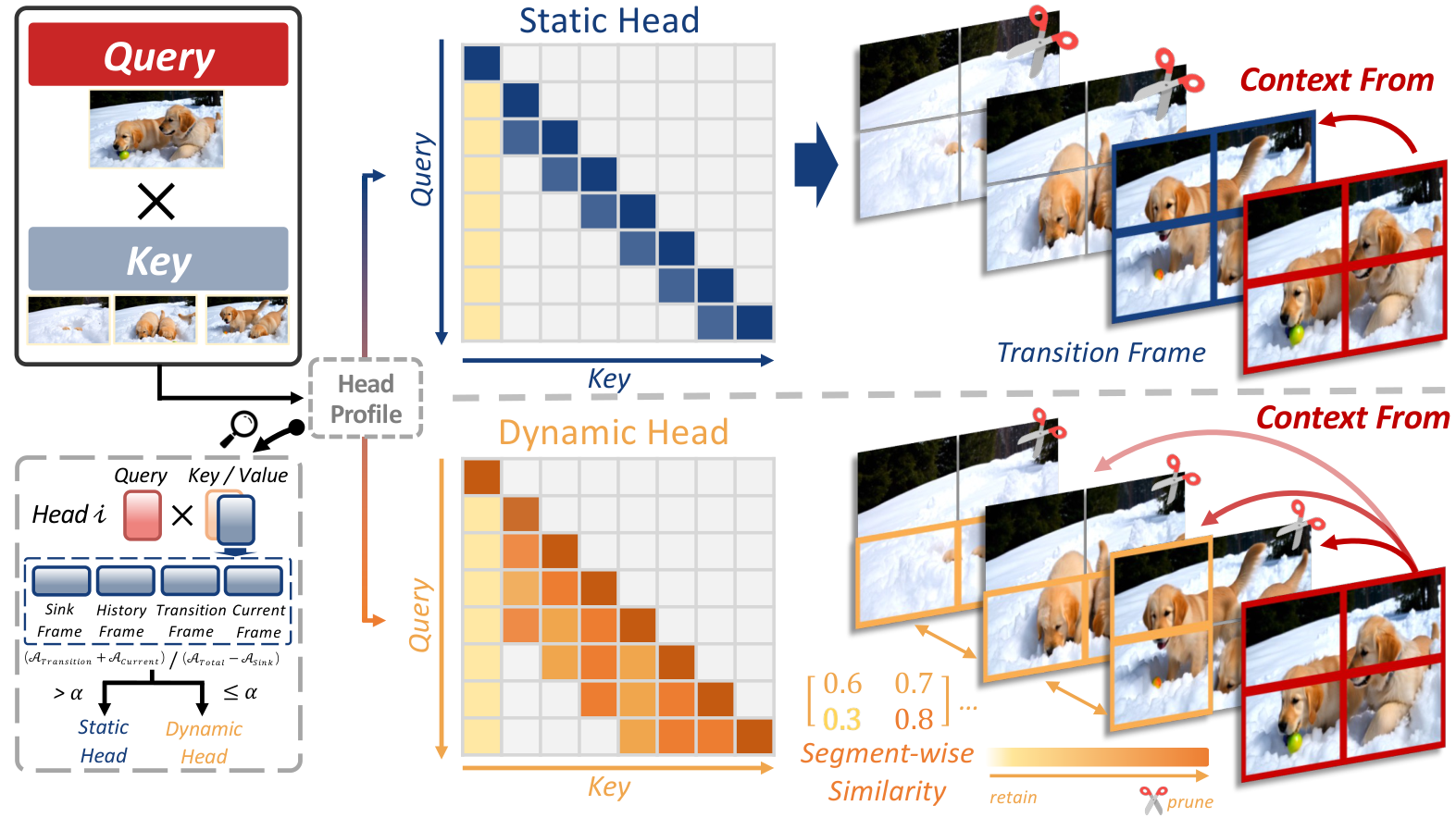
Forcing-KV 的核心发现:在自回归视频扩散模型中,不同注意力头承担完全不同的功能角色,这种分工是稳定且可预测的。
静态头特征:注意力分布集中在远程 token(历史帧的关键区域),负责跨 chunk 的语义连续性和帧内的结构保真。这些头对'哪些远程 token 重要'的判断高度一致,因此可以做结构化剪枝——只保留少数高注意力权重的远程 token。
动态头特征:注意力集中在近邻 token(前几帧),负责帧间运动预测和局部一致性。近邻帧之间往往高度相似,因此可以做相似度驱动的动态剪枝——当相邻片段的 KV 向量相似度超过阈值时合并。
工程实现:KV-cache 同步机制确保压缩后的 cache 在多 head 之间保持一致的时间索引;缓存 Euler 更新将已压缩 token 的 denoising 中间状态缓存起来避免重复计算。
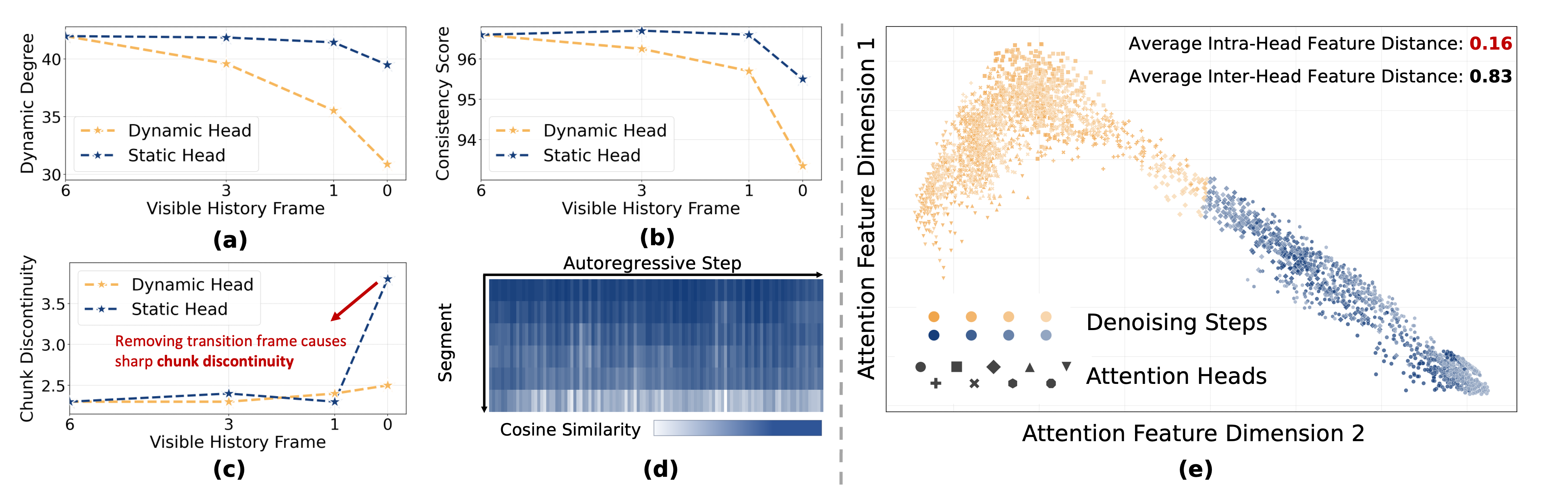
[{'point': '架构通用性', 'detail': '仅在两个 AR 视频扩散模型上验证,是否推广到非 AR 架构(如 CogVideoX)有待检验'}, {'point': '头分类稳定性', 'detail': '静态/动态头的划分是否在新架构或不同训练阶段仍然成立存疑'}, {'point': '质量退化分析', 'detail': '在极端压缩比下(如 80%+ 裁剪)的视觉质量退化模式需要更多系统性分析'}]
技术演进定位: 首次揭示视频扩散注意力头分工并实现实时 29 FPS
可能的后续方向:
论文: SWIFT:无训练语义自适应记忆实现高效流式长视频
arXiv: 2605.09442
机构: University of Science and Technology of China, Fudan University, Georgia Institute of Technology
核心问题: 流式长视频 prompt 切换时 KV Cache 管理困难
流式长视频生成的核心挑战之一是语义切换——当 prompt 变化时(例如从'人走路'切换到'人跑步'),模型需要在保持视觉连贯性的同时响应新语义。现有方法在 prompt 边界处要么重建整个 KV Cache(慢),要么固定缓存大小无法适配语义变化(质量差)。
前序工作及局限:
与前序工作的本质区别: 无训练语义注入代替缓存重建,逐头梯度化更新
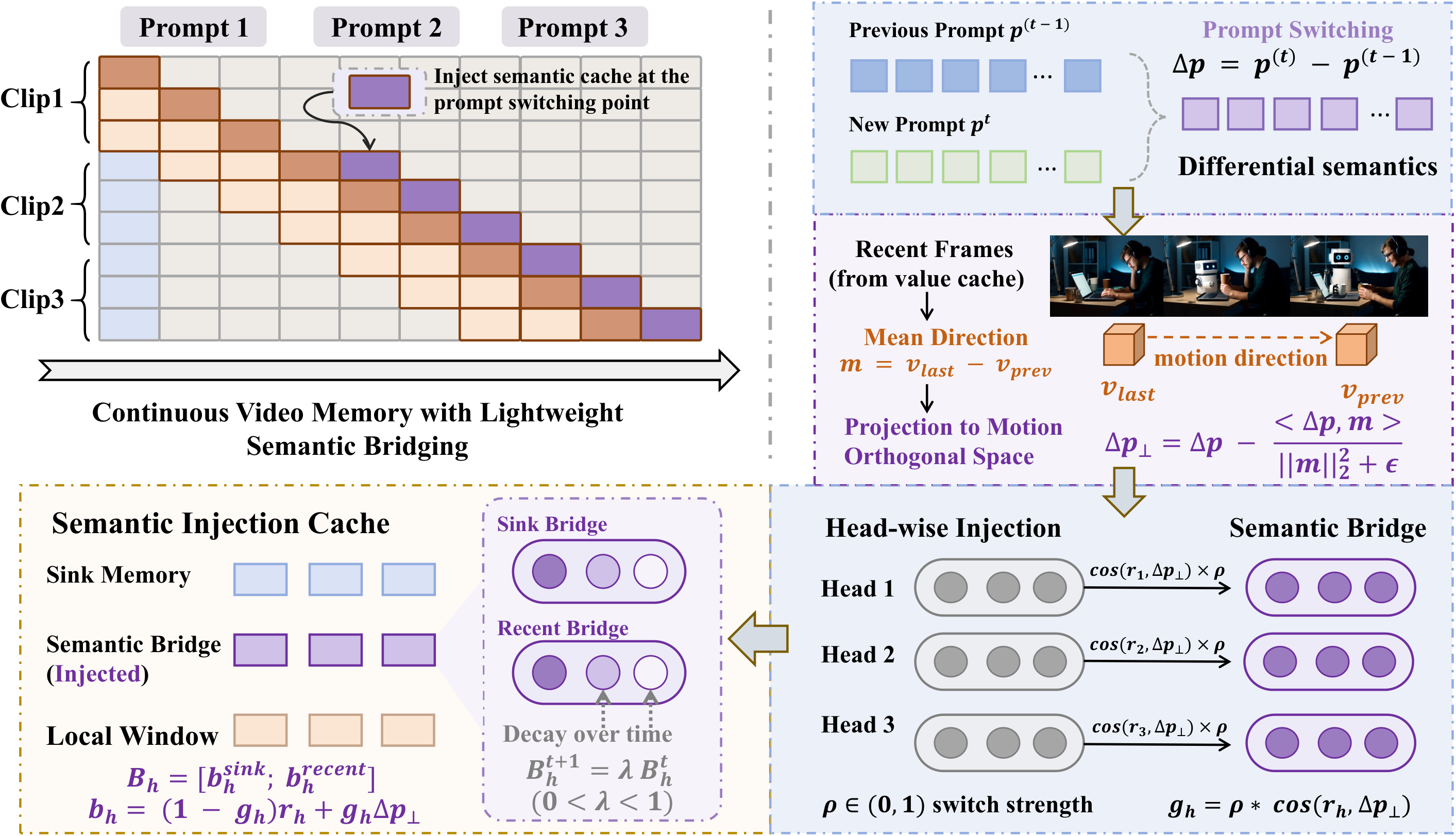
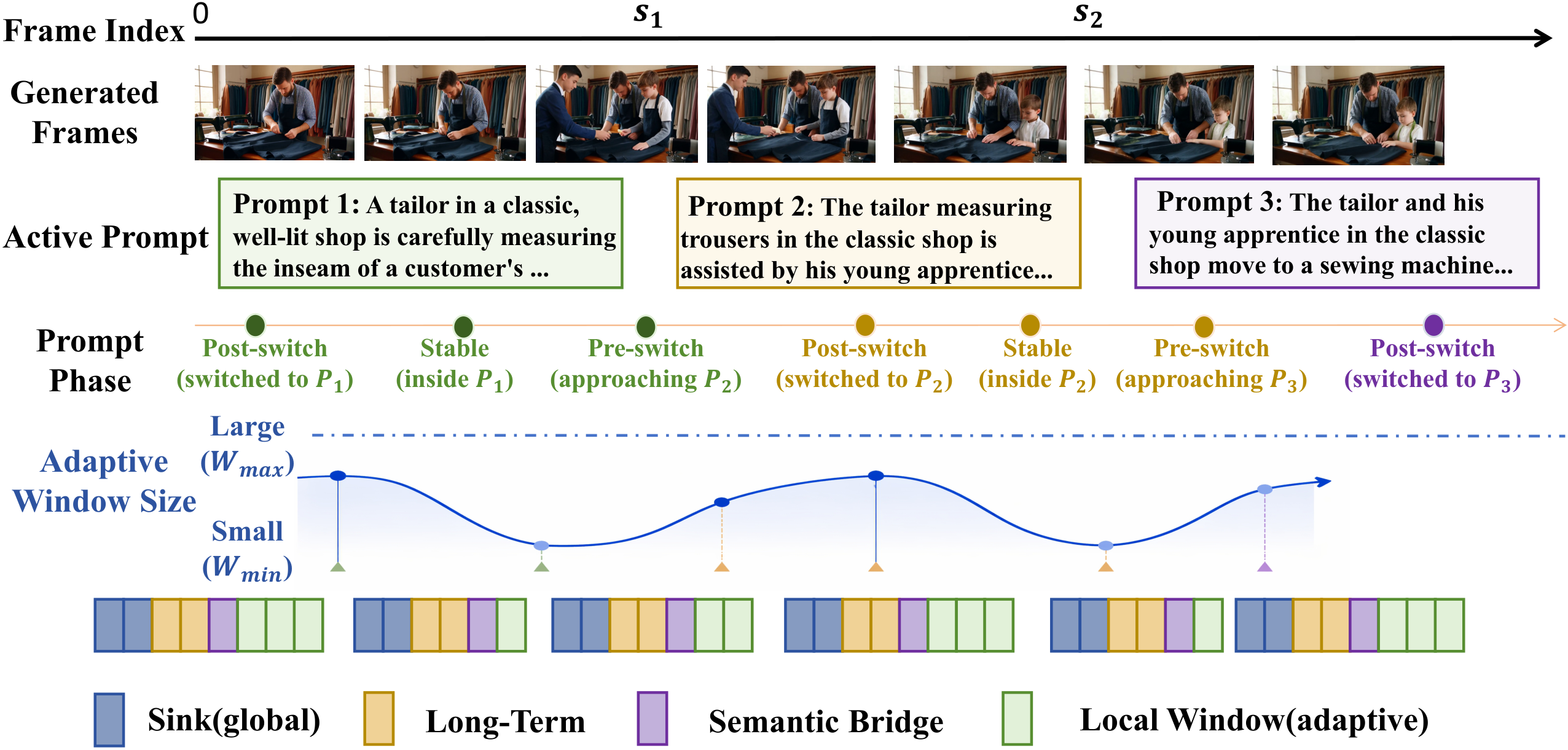
SWIFT 解决的问题:流式视频生成中 prompt 切换时如何高效更新记忆?
传统做法是在 prompt 边界处清空并重建 KV Cache,这造成两个问题:(1) 重建开销大,打断流式生成的实时性;(2) 清空历史信息可能导致前后帧视觉不连贯。
SWIFT 的做法完全不同:不清空缓存,而是把新 prompt 的语义'注入'到已有 cache 中。具体实现:计算每个注意力头当前 KV 状态与新 prompt 特征的对齐度(余弦相似度),对齐度高的头已经自然适配新语义(少注入),对齐度低的头需要更多新信息(多注入)。
自适应动态窗口:不同 prompt 阶段的记忆需求不同——刚切换时需要大窗口保持过渡平滑,稳定后可缩小窗口节省显存。SWIFT 根据生成帧数和语义稳定度自动调整窗口大小。
关键优势:完全无训练,可直接插入任何因果视频扩散模型。
[{'point': '语义对齐度计算延迟', 'detail': '逐头计算语义对齐度本身引入额外延迟,在极端实时场景下可能成为瓶颈'}, {'point': '双向注意力适用性', 'detail': '仅在因果视频扩散模型上验证,对双向注意力架构是否同样有效存疑'}, {'point': '复杂语义切换', 'detail': '在多重、快速的语义切换场景下(如 5 秒内切换 3 次 prompt)的稳定性未充分验证'}]
技术演进定位: 首个无训练的流式语义切换方案
可能的后续方向:
论文: CDM:连续时间分布匹配蒸馏
arXiv: 2605.06376
机构: Alibaba, Nankai University
核心问题: DMD 离散锚定导致少步生成伪影
DMD(Distribution Matching Distillation)是少步扩散蒸馏的主流范式之一,但有个根本缺陷:它在离散时间步上做分布匹配——只在 {0, 0.25, 0.5, 0.75, 1.0} 等稀疏锚点对齐分布。这种离散锚定加上反向 KL 散度的模式寻求特性,容易产生视觉伪影和过度平滑。通常需要额外的 GAN 判别器或奖励模型来修补,系统复杂度极高。
前序工作及局限:
与前序工作的本质区别: 连续时间采样 + 轨迹偏离匹配,移除 GAN/奖励辅助
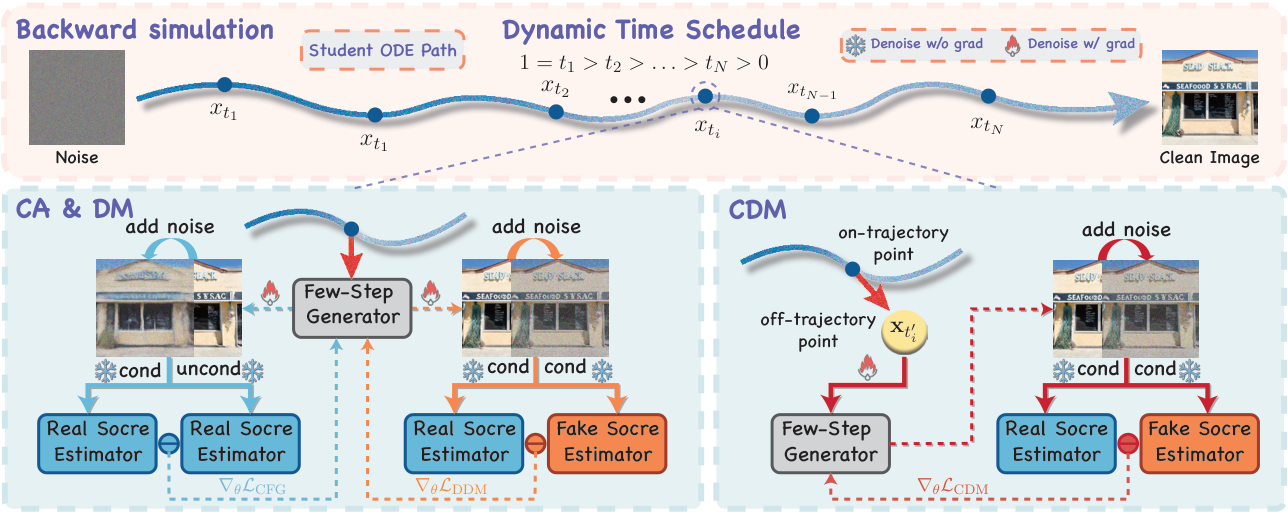
![Overview of Continuous-Time Distribution Matching (CDM).
Top: Our approach employs a dynamic continuous time schedule during backward simulation, sampling intermediate anchors uniformly from $(0, 1]$.
Bottom Left: CFG augmentation (CA) and distribution matching (DM) operate on this dynamic schedule to align text-image conditions and data distributions at on-trajectory anchors.
Bottom Right: To address inter-anchor inconsistency, the proposed CDM objective explicitly extrapolates off-trajectory latents ($x_t_i'$) using the predicted velocity.](https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/AIGC/20260516/2605.06376_1.png)
CDM 的核心洞察:DMD 之所以需要 GAN 和奖励模型修补,是因为离散锚定注定了'覆盖不全'——轨迹上 99% 的点没有监督信号,模型在这些无监督区域自由飘移。
解决方案:把分布匹配从离散点扩展到连续流形。具体实现:(1) 训练过程中不再用固定时间步集合 {t₁, t₂, ...},而是在 [0,1] 上连续采样匹配点,采样概率密度随训练动态调整——模型薄弱的区域被更频繁地采样;(2) 对齐目标不再局限于 ODE 轨迹上的点,还主动采样轨迹附近的'偏离点'——这迫使模型学习在轨迹邻域内也保持良好的分布匹配。
效果:连续调度消除了离散锚定的覆盖空洞,偏离匹配增强了模型在采样扰动下的鲁棒性。两者组合后,即使不用 GAN 和奖励模型,视觉质量也能匹配甚至超越带这些辅助模块的方案。
![Empirical evidence of schedule decoupling.
(a) Conventional distillation strictly anchors backward simulation to predefined discrete inference timesteps. In contrast, our dynamic scheduling optimizes over uniformly sampled continuous timesteps $t (0, 1]$ at each iteration.
(b) Visually, the dynamically scheduled model produces finer details and fewer artifacts than the strictly aligned baseline.
(c) Quantitatively, it also attains a higher HPSv3 score, indicating that exact discrete alignment is not only unnecessary but in fact restrictive---motivating our continuous-time formulation.](https://jefxiong-1304293246.cos.ap-shenzhen-fsi.myqcloud.com/AIGC/20260516/2605.06376_2.png)
[{'point': '训练开销', 'detail': '连续调度增加了每步的采样复杂度,实际训练时间和显存开销的对比数据不够充分'}, {'point': '视频域验证缺失', 'detail': '仅在图像模型上验证,视频域的时序一致性是否同样受益未知'}, {'point': '与 CD 方法对比', 'detail': '与 Consistency Distillation 的直接对比较少,两者互补性未探讨'}]
技术演进定位: 分布匹配蒸馏从离散走向连续的进化
可能的后续方向:
论文: SANA-WM:2.6B 参数分钟级世界模型的算力民主化
arXiv: 2605.15178
机构: NVIDIA, MIT, HKUST
核心问题: 分钟级世界模型训练和推理都需要海量资源
分钟级世界模型是通往具身智能和虚拟环境仿真的必经之路。但现有方案面临三重困境:(1) 画质要求媲美产业级大模型(LingBot-World、HY-WorldPlay),(2) 训练需要海量闭源数据和数百张 GPU,(3) 推理需要多卡集群。结果是:开源社区几乎没有可用的分钟级世界模型。
前序工作及局限:
与前序工作的本质区别: Hybrid Linear Attention + 公开数据 + 量化蒸馏 → 消费级 GPU
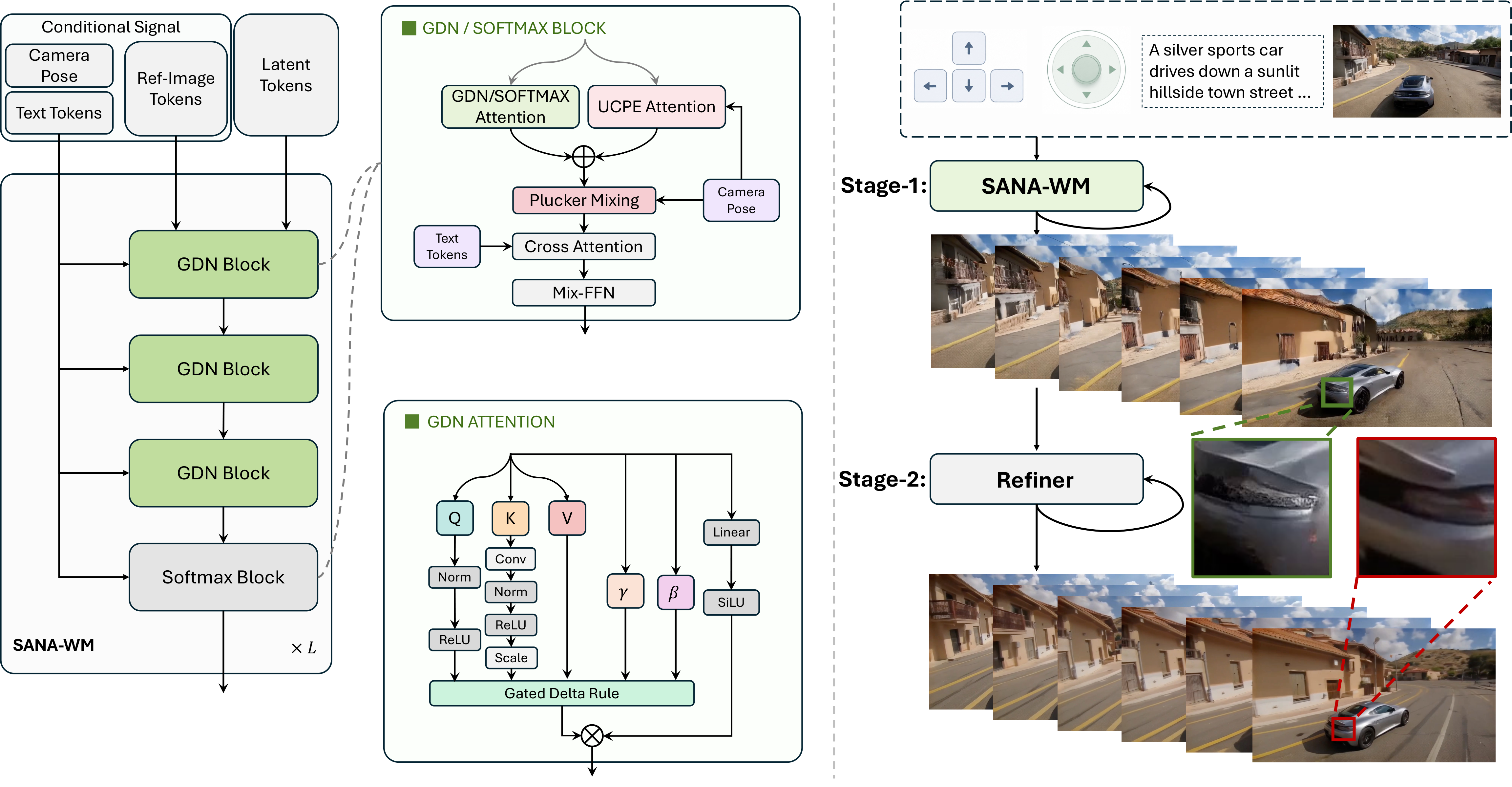
SANA-WM 的核心挑战:如何用有限资源做出质量不差的分钟级世界模型?
Hybrid Linear Attention:纯 softmax attention 的 O(n²) 复杂度在分钟级视频(数千帧)上不可承受。SANA-WM 将 frame-wise 的 Gated DeltaNet(线性复杂度,处理帧内 token)与跨帧的 softmax attention(处理时序依赖)混合——帧内用线性、帧间用 softmax,总复杂度接近 O(n)。
Dual-Branch Camera Control:世界模型需要精确的 6-DoF 相机控制。SANA-WM 设计双分支:一个分支处理相机轨迹的全局运动趋势,另一个处理局部帧间旋转/平移细节,两者融合后注入 DiT。
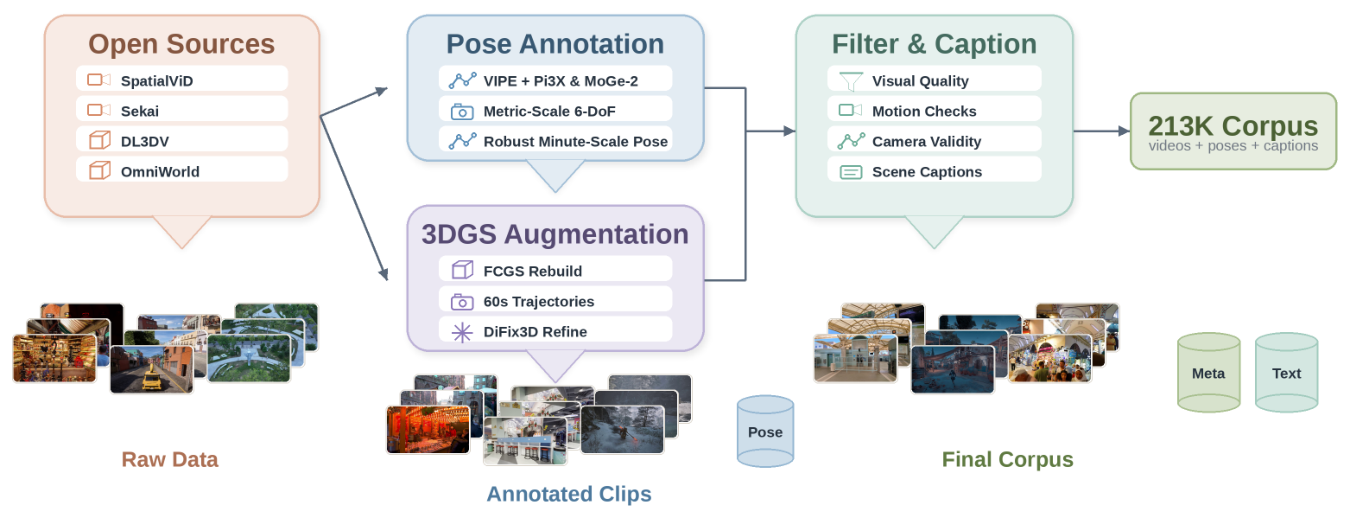
数据方案:不依赖闭源数据,而是从公开视频(WebVid 等)自动提取 metric-scale 6-DoF 相机姿态作为 action 标签。标注流水线基于 DUSt3R + SLAM,全自动无人工。
推理优化:蒸馏 + NVFP4 量化,在单张 RTX 5090 上 34 秒生成 60s 720p clip。
[{'point': 'Refiner 依赖', 'detail': '1 分钟生成仍依赖 stage-2 refiner 外置模块,端到端质量与商业闭源仍有差距'}, {'point': '场景多样性', 'detail': '213K 公开视频的场景覆盖度有限,复杂室内/多物体交互场景可能生成质量不稳定'}, {'point': '6-DoF 精度', 'detail': '自动标注的 6-DoF 姿态精度受限于 DUSt3R/SLAM 的能力,在快速运动或低纹理场景可能有偏差'}]
技术演进定位: 首个面向消费级硬件的开源分钟级世界模型
可能的后续方向:
论文: CausalCine:多镜头叙事的实时自回归视频生成
arXiv: 2605.12496
机构: HKUST, Ant Group, SJTU
核心问题: AR 视频模型无法处理多镜头叙事中的镜头转换
现有自回归视频模型解决了'开放式生成'——可以无限延伸画面。但电影叙事不是无限延伸单一场景——它需要事件演进、视角切换、镜头边界。当用户说'先拍远景,然后切到近景,再来个俯拍'时,现有 AR 模型将其视为单一长序列延伸,结果:运动停滞、语义漂移、无法处理镜头转换。
前序工作及局限:
与前序工作的本质区别: CAMR 内容感知路由 + 多镜头训练数据构建
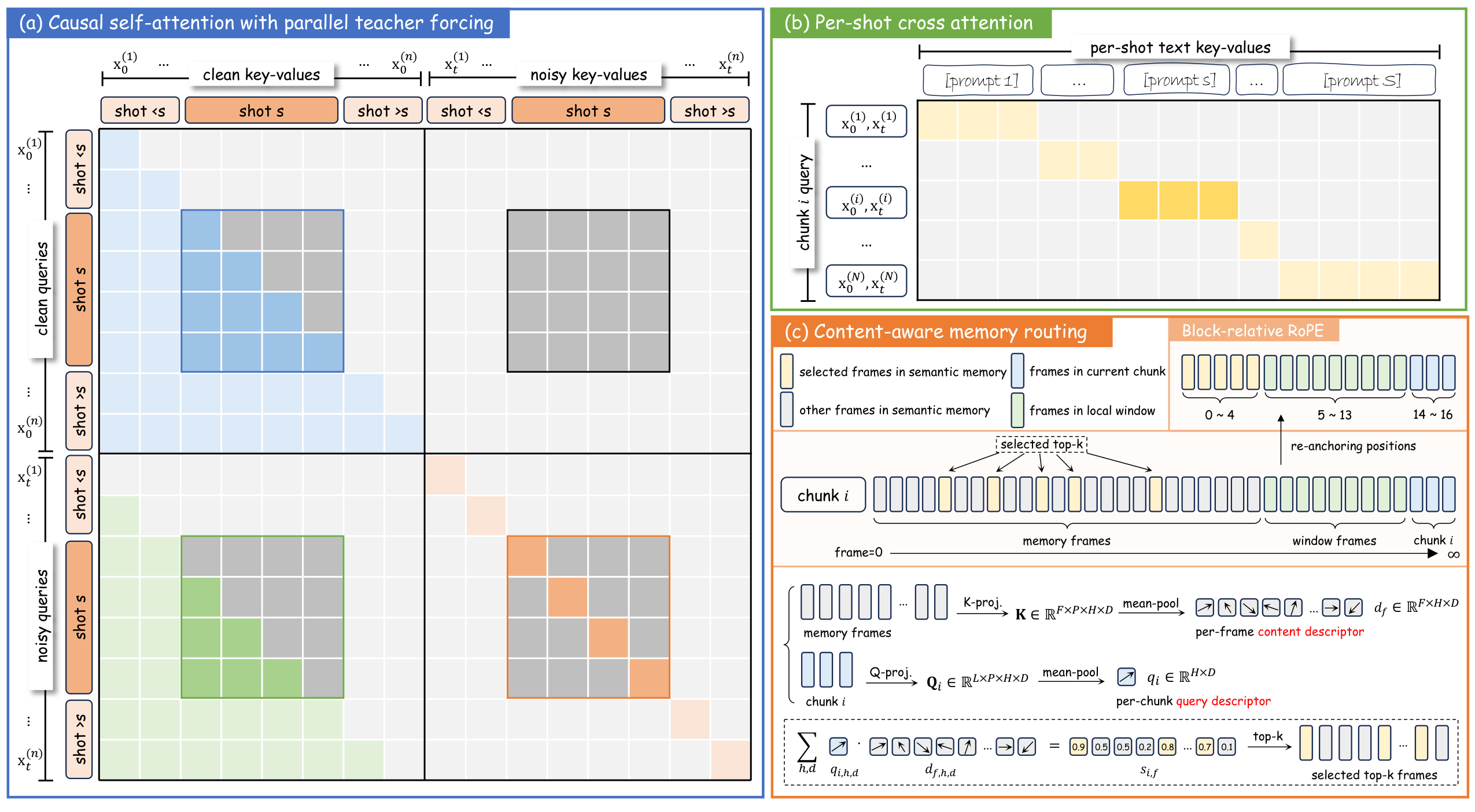
CausalCine 解决的核心问题:如何让 AR 视频模型理解'镜头'概念?
传统 AR 视频模型把所有帧当作同质序列——前一帧和后一帧的关系是'延续'。CausalCine 引入镜头边界的概念:同一镜头内的帧关系是'延续',跨镜头帧关系是'切换'——两者需要完全不同的记忆策略。
CAMR (Content-Aware Memory Routing) 的具体做法:不使用固定的滑动窗口来管理历史 KV Cache,而是让每个新 token 通过注意力得分动态选择'回忆什么'。镜头切换时,与新镜头语义相关的历史(如同一人物的远景)被高权重检索,无关历史(如前一场景的背景细节)被低权重淡化。
这本质上是一种学习到的'选择性遗忘'——让模型在保持叙事连贯性(人物/故事线)的同时,允许视觉内容的突变(场景切换)。
最后蒸馏为少步实时生成器,保持交互式特性。

[{'point': '训练数据获取', 'detail': '原生多镜头视频的镜头边界标注获取成本未讨论,是否需要大量人工标注'}, {'point': '蒸馏后多样性', 'detail': '蒸馏为少步生成器后,镜头转换的多样性(淡入/硬切/运镜等)是否被压缩到少数模式'}, {'point': '长叙事稳定性', 'detail': '超过 10 个镜头的长叙事中,人物一致性是否能稳定维持'}]
技术演进定位: 首个面向多镜头叙事的实时 AR 视频框架
可能的后续方向:
| 论文 | 核心方法 | 推理步数 | 单卡速度 | 是否需要训练 | 视频长度 | 是否开源 |
|---|---|---|---|---|---|---|
| Causal Forcing++ | 因果一致性蒸馏 | Frame-wise 2 步 | 未公布 FPS | 需蒸馏训练 | 开放式流式 | 未开源 |
| AnyFlow | Flow Map 任意步数蒸馏 | 4-32 步灵活 | 未公布 FPS | 需蒸馏训练 | 标准长度 | 待开源 |
| RAVEN | 训练-测试对齐 + CM-GRPO | 少步(具体步数未公布) | 未公布 FPS | 需 RL 训练 | 开放式流式 | 待开源 |
| Forcing-KV | KV Cache 混合压缩 | 与基模型一致 | 29+ FPS (H200) | 无训练推理优化 | 开放式长视频 | 待开源 |
| SWIFT | 语义注入缓存 | 与基模型一致 | 22.6 FPS (H100) | 完全无训练 | 多 prompt 长视频 | 待开源 |
| CDM | 连续时间分布匹配 | 4 步 | 标准推理 | 需蒸馏训练 | 图像(待扩展视频) | 已开源 |
| SANA-WM | Hybrid Linear DiT | 多步(+量化加速) | 34s/60s clip (5090) | 需完整训练 | 60s 分钟级 | 已开源 |
| CausalCine | 内容感知记忆路由 | 少步(蒸馏后) | 实时级 | 需多镜头训练 | 多镜头叙事 | 待开源 |
因果自回归蒸馏从 chunk-wise 4 步推向 frame-wise 1-2 步,实时交互成为现实
Causal Forcing++ 证明因果一致性蒸馏可以在 frame 粒度实现高质量 2 步生成,首帧延迟降低 50%,解锁了真正的流式交互式视频生成
训练-推理分布对齐成为自回归视频蒸馏的核心议题
RAVEN 通过 rollout 重打包直接弥合训练时 teacher history 与推理时 student rollout 的分布 gap,配合 CM-GRPO 实现端到端对齐
KV Cache 压缩与自适应记忆方案使流式视频生成在单卡上实现 20-30 FPS
Forcing-KV 发现注意力头的功能特化规律(静态/动态),SWIFT 提出无训练语义注入方案,两者分别在 H200 和 H100 单卡上实现实时吞吐
世界模型正在从封闭系统走向开源、从秒级走向分钟级
SANA-WM 以 2.6B 参数 + 213K 公开视频在单卡 RTX 5090 上生成 60s 720p 视频,吞吐比闭源方案高 36 倍,标志着世界模型的算力民主化
1. 少步生成的质量天花板
当采样步数降到 1-2 步,模型本质上在做'条件预测'而非'迭代去噪'。Causal Forcing++ 在 2 步下已接近 4 步水平,但与 50 步教师仍有可见差距。AnyFlow 通过 flow map 让多步时性能恢复,但 1-2 步仍是瓶颈。核心问题:少步生成的理论质量上界在哪里?
2. 长序列的累积误差与遗忘
所有 AR 模型都面临长序列退化:RAVEN 通过训练-测试对齐缓解,Forcing-KV/SWIFT 通过 cache 管理控制,CausalCine 通过 CAMR 选择性遗忘。但 1000+ 帧的真正长视频中,这些方案能否持续有效?'选择性遗忘'与'不该遗忘'之间的精确边界难以界定。
3. 蒸馏与 RL 对齐的统一
本周出现三条竞争路线:Causal CD(蒸馏为主)、AnyFlow(flow map 蒸馏)、CM-GRPO(RL 对齐)。它们解决不同层面问题但目前各自为战——是否存在一个统一框架,先 flow map 蒸馏获得任意步数能力,再 CM-GRPO 对齐到人类偏好?
4. 实时生成的硬件民主化
Forcing-KV 在 H200、SWIFT 在 H100、SANA-WM 在 RTX 5090 上实现实时/近实时。但消费级 GPU(如 RTX 4090 甚至 RTX 4060)上呢?真正的用户端实时体验需要把算力需求再降一个量级,这可能需要蒸馏+量化+剪枝+cache 压缩的全栈优化。
自回归视频生成已经进入'实时'门槛——Forcing-KV 29 FPS、SWIFT 22.6 FPS、Causal Forcing++ frame-wise 2 步。下一步的核心问题是:实时生成的质量天花板在哪里?当采样步数降到 1-2 步,模型本质上在做'条件预测'而非'迭代去噪',这对视觉保真度的根本影响是什么?AnyFlow 通过 flow map 让步数可伸缩、RAVEN 通过 RL 对齐推理分布——这两条路线谁更有可能统一少步和多步的质量-速度曲线?
人工智能炼丹君 整理 | 数据来源:arXiv 2026-05-11 ~ 2026-05-16
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描下方二维码关注


{kind=link}
{kind=link}
评论 (0)