
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

为什么要做半监督(SSL)+带噪学习(Noisy Label):
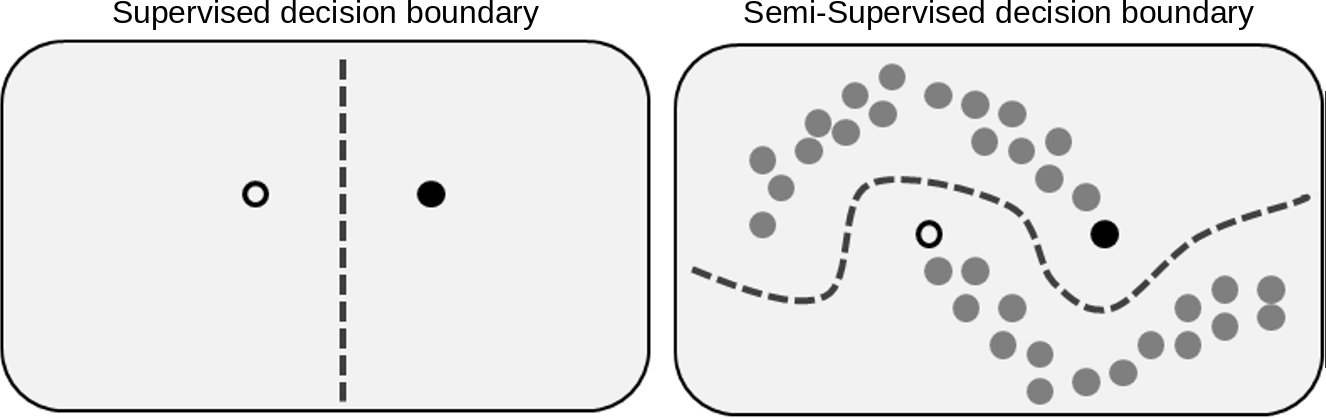
1. 定义: 半监督模型主要研究如何利用大量未标注的数据,提升模型的泛化能力,并且利用少量标注数据,减少标注人力。半监督之所以能够有效的关键原因在于,未标注数据提供了更多的数据分布信息,使得决策边界可以避免穿过数据高密度区域,提升模型的泛化性能,如下图所示,黑白点为单个有标注的两个类别数据,灰色为未标注的标签数据。只利用两个有标注数据学习出来的决策边界,在右图的数据分布下不会是一个好的决策边界:
半监督方法可大致分为以下几种:

本文主要介绍前四种主流算法, 基于生成式和图方法的两个研究方向虽然有不少相关论文,但是模型的性能不及前四种研究方法。早期方法以一致性约束和伪标签方法为主,混合方法结合一致性约束和伪标签两类方法提升精度。近期自监督+半监督相结合的方法,成为了新的SOTA。针对半监督领域的一些分支研究方向,比如半监督学习下的样本极度匮乏和类别不均衡的长尾问题,没有在本文的调研范围之内。
评估数据集
| DataSet | Class | Image Size | Train | Validation | Unlabeled | 备注 |
|---|---|---|---|---|---|---|
| SVHN-10 | 10 | 32x32 | 7.3w | 2.6w | 53w | 谷歌街景房屋号码,预测号码中的中间数字 |
| STL-10 | 10 | 96×96 | 5k | 8k | 1w张未标注数据(包含不属于10类的其他相近类别物体) | - |
| CIFAR-10 | 10 | 32x32 | 5w | 1w | 没有未标注数据 | 10分类,动物/交通工具等 |
| CIFAR-100 | 100 | 32x32 | 5w | 1w | 没有未标注数据 | 100分类,论文中通常采样一部分比例作为有标注数据,丢弃剩下的数据标签作为无标注数据 |
| ImageNet | 1000 | 任意大小 | 120w | 15w | 15w | 论文通常采用1%,10%的数据做训练,其余当作未标注数据验证半监督算法 |
| JFT300B | 18291 | - | 3亿 | - | - | 用作预训练,在ImageNet上做评估,半监督算法通常抛弃原有标签,把整个数据集当作无标签数据集使用 |
算法对比概览(数据集准确率选取top5/top1 acc展示,更多数据见 LeaderBoard of SSL)
| 算法 | backbone | 算法归类 | 数据增广 | 半监督损失 | ImageNet-10%(Top5/top1 acc) | CIFAR10-4k(err) |
|---|---|---|---|---|---|---|
| SimCLRv2 | ResNet-152 x3, SK | SSSS | simple | CE | 95.5/80.9 | - |
| SimCLRv2 | ResNet-50 | SSSS | simple | CE | 93.4/77.5 | - |
| CoMatch | Moco v2 | SSSS | RandAugment | CE | 91.4/73.7 | - |
| Meta Pseudo Labels | ResNet-50 | PL | RandAugment(15种随机方式) | CE | 91.38/73.89 | 3.89± 0.07 |
| Noisy Student | EfficientNet-L2 | PL | RandAugment | CE | -/- | - |
| MixMatch | - | HM | Mixup/simple | MSE | -/- | 6.24 |
| FixMatch | - | HM | RandAugment CTAugment |
CE | 89.13/- | 4.31 |
| DivideMix | - | HM | Mixup/simple | MSE | -/- | - |
| UDA | - | CR | RandAugment | CE | 88.52/- | 5.27 |
| VAT | - | CR | Adversarial Noise | MSE | -/- | 11.36 |
| Mean Teacher | - | CR | simple | MSE | -/- | 6.28 |
| PI Model/Temporal Ensembeling | - | CR | simple | MSE | -/- | 12.16/- |
一致性约束方法主要思想:约束同一样本的在不同变换下(网络扰动、数据扰动、对抗扰动等)的标签预测概率的一致性。一致性约束主要研究的方向是通过合理的方式构造一致性样本对(正样本对)
网络扰动: Dropout(PI Model, ICLR2017)/EMA(Mean Teacher, NIPS2017)
数据扰动: Temporal Ensembling/输入高斯噪声/数据增广(AutoAugment/RandomAugment)
对抗噪声: 输入的梯度方向(VAT, PAMI2019)
Temporal Ensembling for Semi-Supervised Learning
Authors: Samuli Laine, Timo Aila
Institute: Nvidia
论文简介: 半监督领域早期较为经典的一篇文章,提出了PI Model和temporal ensembling两个一致性约束方法
算法细节:
a. 模型结构

PI Model: 模型损失由两部分构成:有监督分类损失和一致性约束损失。对于有标注的数据,直接计算交叉熵损失函数,对于同一个未标注数据x,进行两次模型前向并约束网络的输出结果相同(由于网络扰动和数据增广两次结果会不一致),一致性约束的损失函数采用MSE
Temporal Ensembeling: PI Model需要进行两次模型前向才能构成一致性样本对,Temporal Ensembeling提出记录每个样本输出概率的滑动平均($Z_{t}=\alpha*Z_{t-1} + (1-\alpha)*z_{t}$),作为一致性约束的目标。节约了一次前向时间,并且滑动平均能够对噪声更加鲁棒。

Temporal Ensembeling的主要缺点在于需要维护整个数据集样本的输出预测概率,在大规模数据集上需要过大的存储空间
b . 半监督损失时变系数w(t)的重要性: 一致性损失函数的权重采用 $w(t)=e^{-5*(1-t)^2}$,即在网络的初期以优化监督损失为主,当模型训练精度提升后再开始逐步减小一致性约束。论文中指出,逐步增大一致性约束损失很有必要,否则会导致模型陷入收敛到没有意义的结果(比如模型预测为恒定常数)
Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results
Authors: Antti Tarvainen, Harri Valpola
Institute: The Curious AI Company
论文简介: 为解决Temporal Ensembling中数据存储的问题,Mean Teacher提出进行模型参数滑动平均替代样本概率滑动平均
算法细节:

借鉴意义:
Unsupervised Data Augmentation for Consistency Training 【Code】
Authors: Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, Quoc V. Le
Institute: Google Research
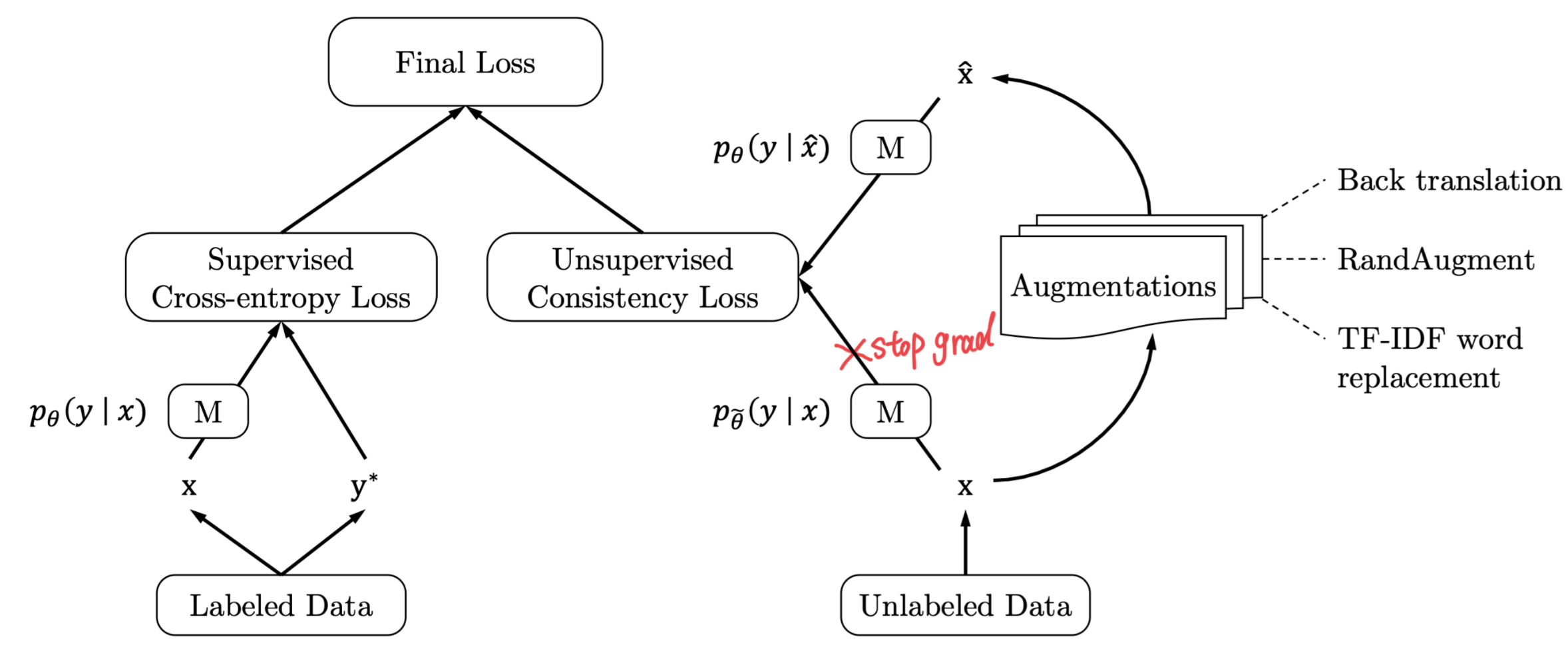
论文简介: 以往方法采用的构造一致性约束样本对的扰动方式过于简单(如数据高斯噪声和dropout等),论文尝试引入图像/文本领域内的SOTA数据增广方式(图像RandAugment/文本反向翻译)方式,提升基于一致性约束方法的性能
算法细节:
a. 模型结构:模型结构和PI Model一致,只是数据增广方式进行了扩展
Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning
Authors: Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, Shin Ishii
Institute: Google Research
论文简介: 对抗训练在有监督学习中被采用做数据增广提升模型泛化性,本文提出在未标注数据上的对抗训练方法,不依赖样本GT
算法细节:
(1). VAT算法整体和PI model(ICLR2017)相似,只是将数据增广方式变成了对抗噪声
(2) 未标注数据对抗噪声: 对抗训练在有监督中实现方式是,根据标注数据GT和模型预测,找到输入x的梯度方向即为噪声。在未标注数据中,采用如下方法近似方法进行估计:
(3) 未标注数据一致性损失
$$
\mathcal{L}_{u}=w \frac{1}{\left|\mathcal{D}_{u}\right|} \sum_{x \in \mathcal{D}_{u}} d_{\mathrm{MSE}}\left(f_{\theta}(x), f_{\theta}\left(x+r_{a d v}\right)\right)
$$
VAT方法的优缺点:
优点:和输入x的类型无关,可以用于RGB图片/已经提取好的特征/文本模态等等
缺点: 相比于数据增广方法,VAT扰动生成数据视觉上不够真实,对比一些SOTA的图片数据增广算法性能较差

最简单的伪标签方法的流程可分为三步:
为简化流程,更多的伪标签算法采用同步训练的方式: 即在一个batch内同时计算有标注样本的交叉熵损失,对于未标注样本通过模型预测出概率分布后,通过将概率分布通过阈值的方式转变为one-hot编码方式并计算交叉熵损失或MSE(对噪声更鲁棒)。
伪标签的最大挑战是: Teacher网络对未标注数据的预测存在噪声( confirmation bias),目前研究主要通过以下方法解决:
启发式方法: 通常采用固定卡阈值(threshold=0.9)方法;时变系数损失权重
迭代训练,逐步提升Teacher网络预测的伪标签精度: Noisy Student(CVPR2021)
动态阈值解决固定阈值问题: FlexMatch(NIPS2021)
Meta Pseudo Label(CVPR2021)通过Student网络在标注数据上的损失,反馈调整Teacher网络参数。Meta Pseudo Label通过学习如何修正pseudo label来提升Student网络在有标注验证集上的精度,可用于半监督和Noisy label的数据修正
不只用模型预测出的分类score,预测标签可信度: UPS(ICLR2021)
Self-training with Noisy Student improves ImageNet classification 【Code】
Authors: Qizhe Xie, Minh-Thang Luong, Eduard Hovy, Quoc V. Le
Institute: Google Research
论文简介: 结合self-training、蒸馏、数据增广/网络结构噪声等策略,提升模型性能。论文方法简单,消融实验丰富,可提供较多训练的经验指导,在ImageNet top1-acc上达到88.4%(结合3亿JFT未标注数据,达到了当时的SOTA,目前最高90.88%)。
算法流程:
模型训练流程: 1) 标注数据上训练Teacher网络 ;2)未标注数据上用Teacher网络预测伪标签;3) 利用伪标签数据和标注数据,结合网络和数据噪声,训练学生网络;4)迭代训练,重复2)3)两个步骤
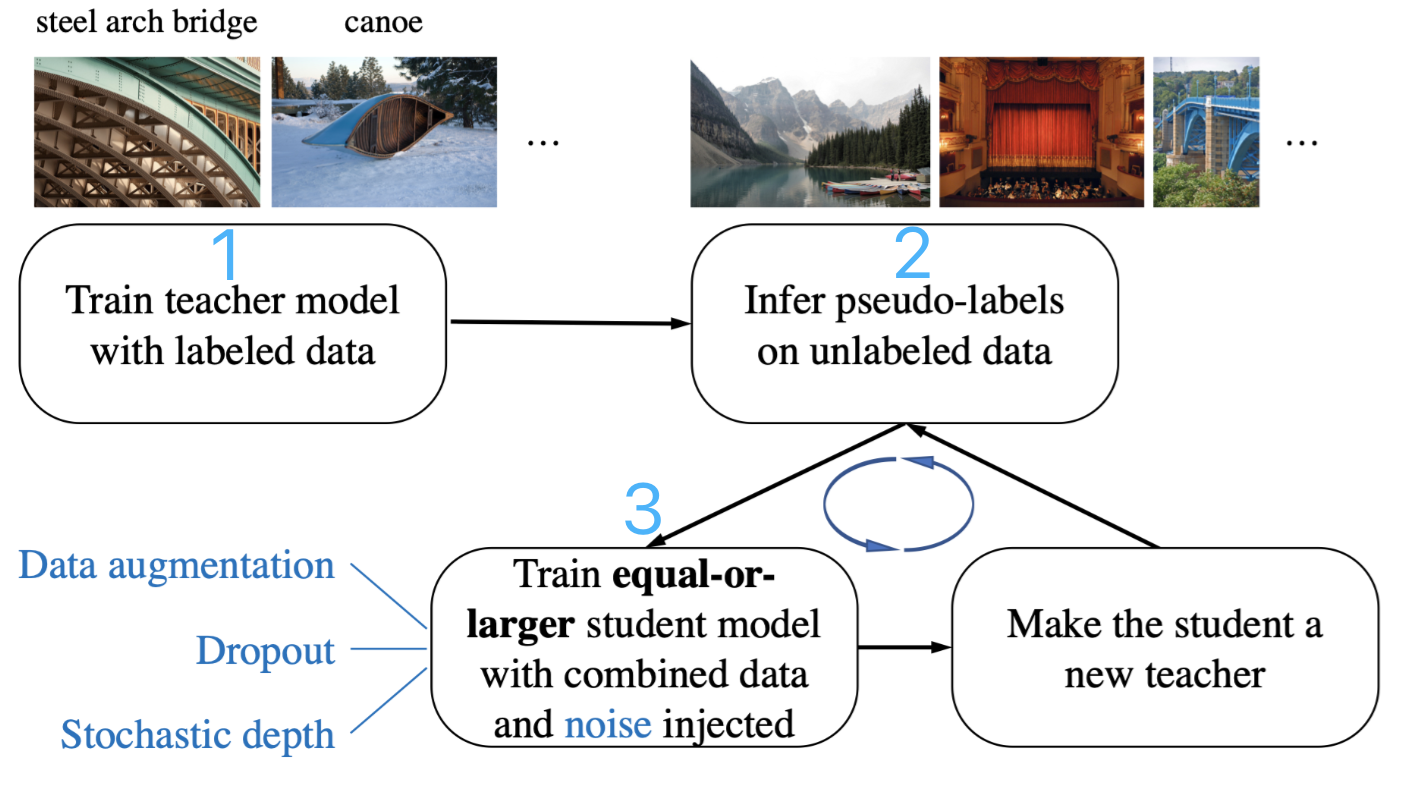
一系列模型训练Trick合集:
未标注数据类别平衡的重要性: 重复类别少的未标注数据(810w->1300w)
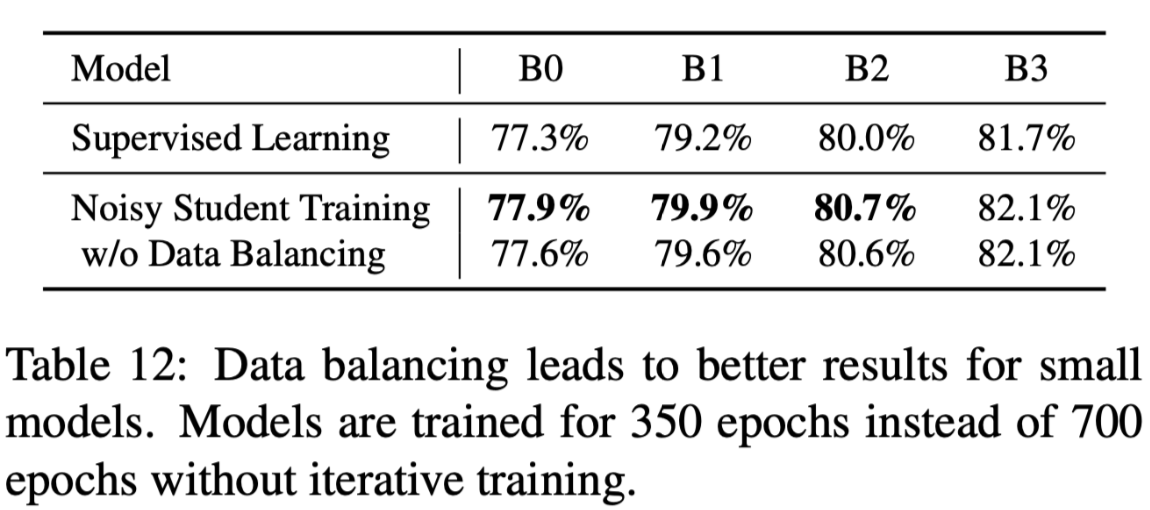
控制有标注样本和无标注样本比例:使用大比例的无标注数据batch_size

过滤未标注数据中的OOD(out-of-distribution)样本: 利用模型预测,并过滤最大分类概率小于0.3的样本
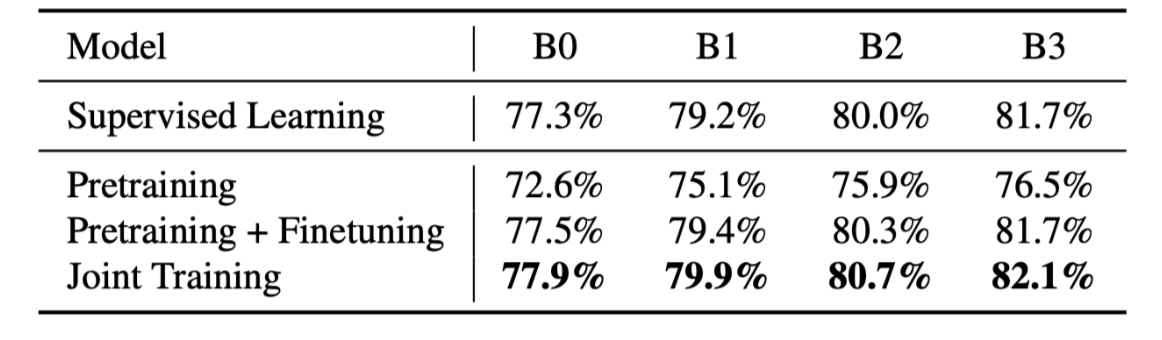
有标注/无标注(soft-label)的两类数据联合训练的优点:在标注数据和未标注数据联合训练,比在未标注数据上预训练再到有标注数据分步训练的方式好
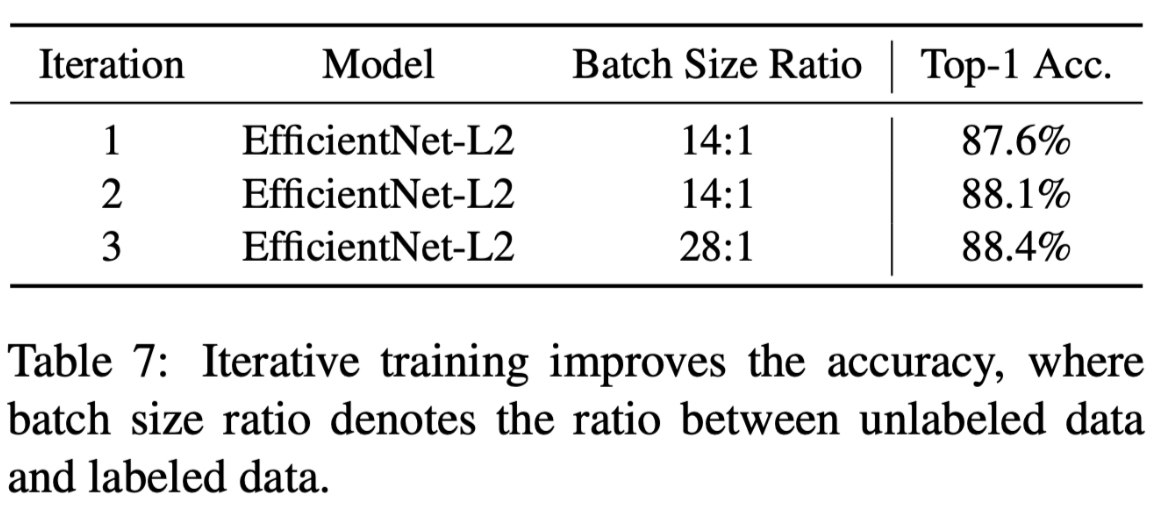
迭代训练逐步提升精度(ImageNet top1-acc +0.8%)
Meta Pseudo Labels 【Code】
Authors: Hieu Pham, Zihang Dai, Qizhe Xie, Minh-Thang Luong, Quoc V. Le
Institute: Google AI, Brain Team
论文简介: 伪标签方法中的Teacher网络不准确引入错误的预测伪标签GT(确认偏差, confimation bias),进而影响Student模型训练。为了修正Teacher模型预测伪标签的精度,本文提出采用元伪标签方法,根据Student网络在有标签数据集上的损失优化Teacher网络,利用未标注数据JET进行半监督,在ImageNet上top1-acc达到90.2%(首个在ImageNet上突破90% )
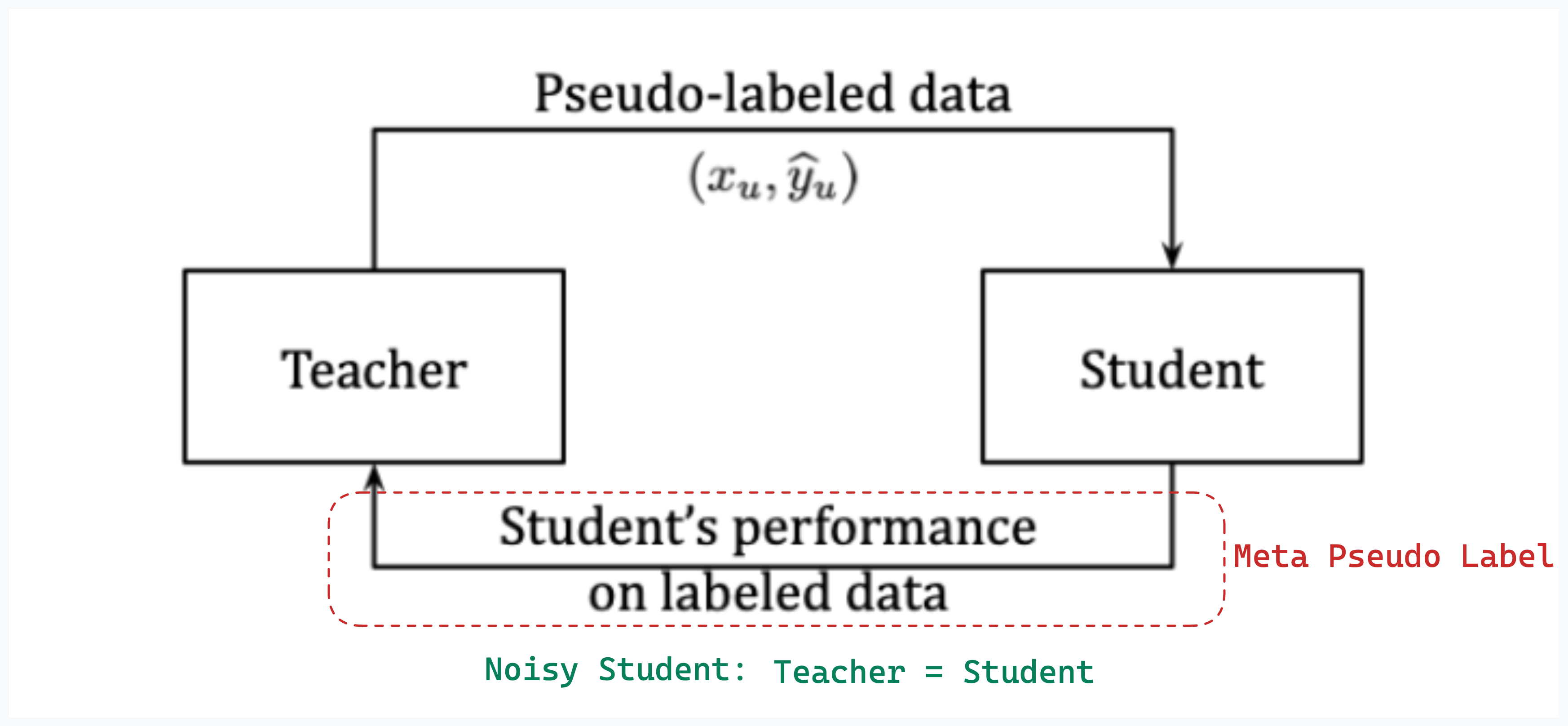
算法细节:
算法流程:

$$
\begin{array}{cl}
\min _{\theta_{T}} & \mathcal{L}_{l}\left(\theta_{S}^{\mathrm{PL}}\left(\theta_{T}\right)\right) \\
\text { where } & \theta_{S}^{\mathrm{PL}}\left(\theta_{T}\right)=\underset{\theta_{S}}{\operatorname{argmin}} \mathcal{L}_{u}\left(\theta_{T}, \theta_{S}\right)
\end{array}
$$
借鉴意义
混合方法采用一致性约束和伪标签算法中的一些算法模块,提升模型性能。
MixMatch: A Holistic Approach to Semi-Supervised Learning [Code]
Authors: David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, Colin Raffel
Institute: Google Research
论文简介: 统一当前主流半监督算法在一个算法中,包括一致性约束、最小化熵和MixUp正则化方法
算法流程:
(1) 构建未标注样本概率分布(soft-label): 通过多次数据增强的平均预测提升精度(一致性约束),并结合Sharpen函数降低预测概率分布的不确定性(最小化熵)
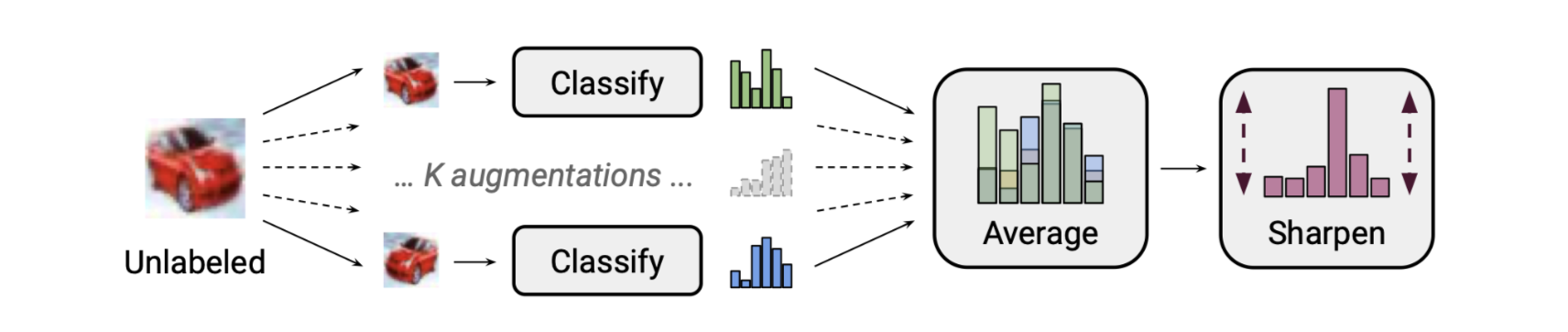
$$
\operatorname{Sharpen}(p, T)_{i}:=p_{i}^{\frac{1}{T}} / \sum_{j=1}^{L} p_{j}^{\frac{1}{T}}
$$
当T=1时,为identity;当T取<1时,概率分布向one-hot方式改变,论文中T取0.5
(2) 在标注样本和未标注样本(带有soft-label)的两类数据上做MixUp正则化:
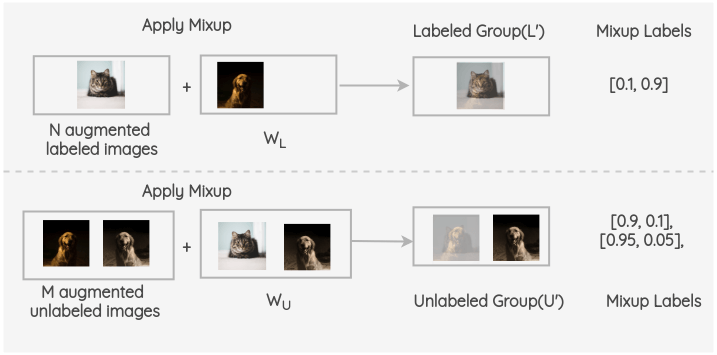
MixMatch中的Mixup与原论文的不同点在于: 下面公式中的第二项,保证了合成的样本 $x{'}$相比$x_{2}$而言与$x_{1}$更接近。让合成的样本保持和前者更接近是为了在计算损失的时候,对于Labeled Group和Unlabel Group两种类型数据,采用不同的监督方式。
$$
\begin{aligned}
\lambda & \sim \operatorname{Beta}(\alpha, \alpha) \\
\lambda^{\prime} &=\max (\lambda, 1-\lambda) \\
x^{\prime} &=\lambda^{\prime} x_{1}+\left(1-\lambda^{\prime}\right) x_{2} \\
p^{\prime} &=\lambda^{\prime} p_{1}+\left(1-\lambda^{\prime}\right) p_{2}
\end{aligned}
$$
(3) 针对Labeled Group和Unlabel Group两种类型数据,分别采用交叉熵和MSE进行监督。
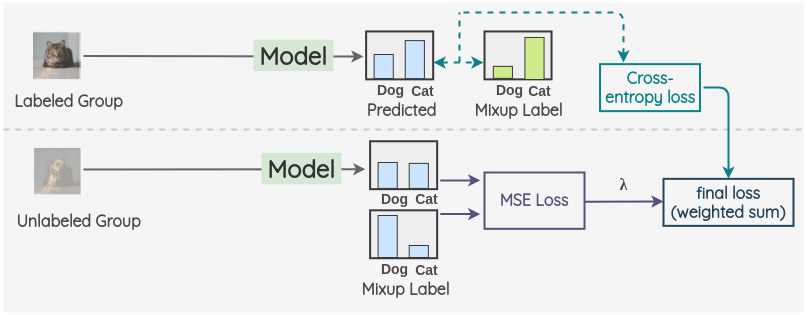
未标注样本损失函数的选取:对于无标签数据的监督优化,采用MSE替换常规的KL散度/交叉熵等分类损失函数,因为MSE对噪声更鲁棒。MSE损失函数相比较于KL散度的缺点是收敛慢,论文在对MSE损失函数的权重乘以100以加快收敛速度(我推测的)。
算法细节:
(1) 消融实验:

借鉴意义:
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence [Code]
Authors: Kihyuk Sohn
Institute: Google Research
论文简介: FixMatch简化同期MixMatch/ReMatch等混合方法中复杂的设计,并超越MixMatch/ReMatch等方法
算法流程:
(1) 在有标注样本上计算交叉熵损失
(2) 利用弱数据增广(flip-and-shift)为无标注样本生成伪标签,并进行高阈值过滤,转变为one-hot伪标签概率分布
(3) 对同一样本进行强数据增广(RandomAugment/Cutout),并用上一步得到的one-hot伪标签进行交叉熵损失计算。对于最大概率低于阈值的样本,不参与损失计算
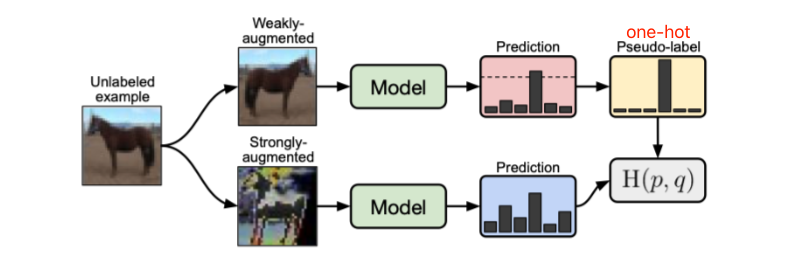
算法细节:
为什么需要将数据增广分类为强/弱两种:弱数据增广用于提供更准确的伪标签,强数据增广让网络能够适配更多的数据变化。如果将第一条支路的弱数据数据增广替换为强数据增广,实验中发现训练会变得不稳定(训练过程中准确率突然从45%突变到12%)
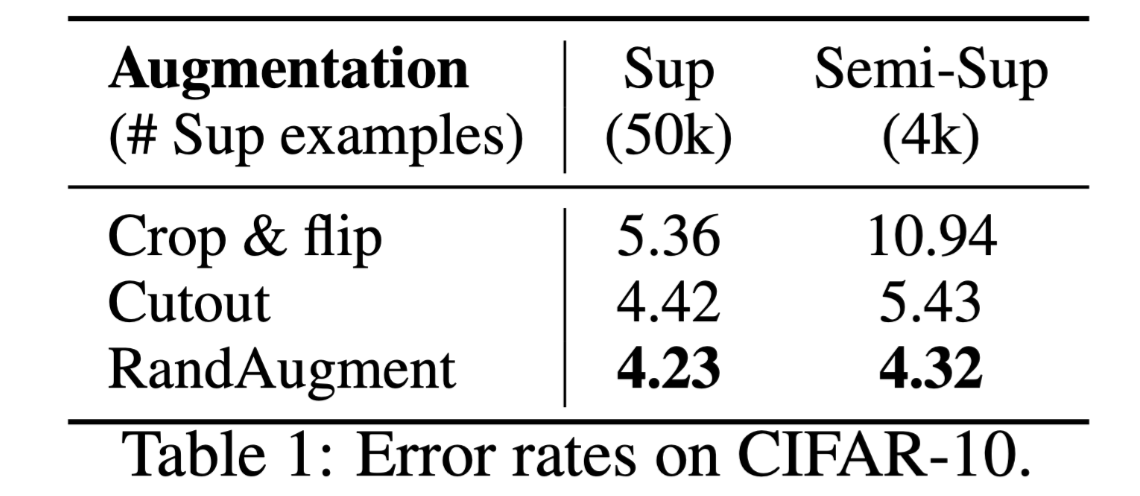
对比实验数据
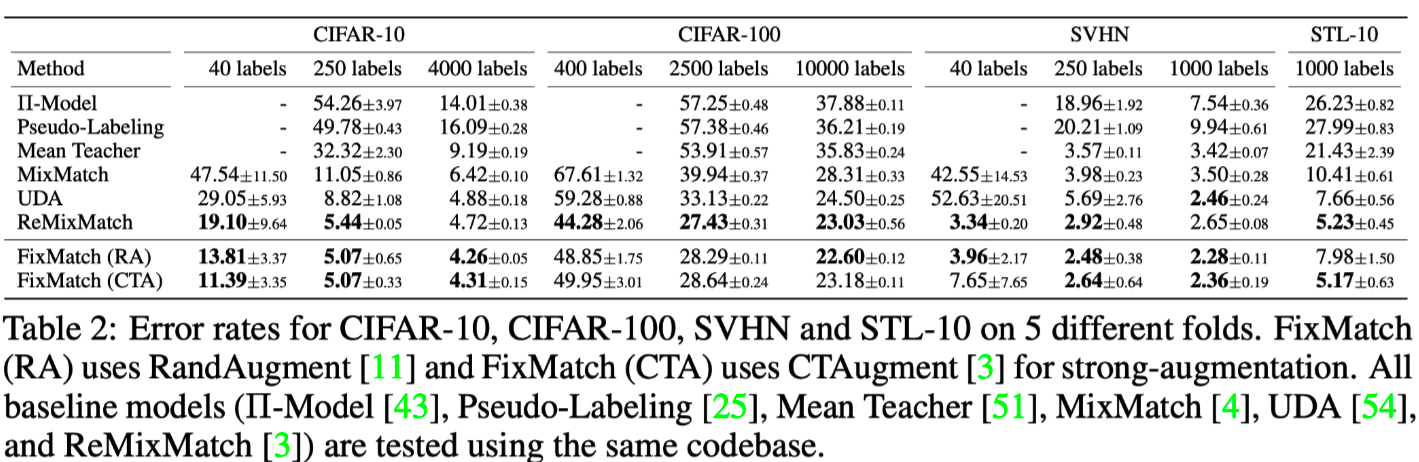
借鉴意义:
DivideMix: Learning with Noisy Labels as Semi-supervised Learning [Code]
Authors: Junnan Li, Richard Socher, Steven C.H. Hoi
Institute: Salesforce Research
论文简介: 基于噪声样本通常表现为loss较大的前提假设,将带噪样本问题转换为半监督问题处理
算法流程:
(1) 在有监督数据上进行warmup训练
(2) 通过高斯混合模型(GMM)建模每样样本损失的分布(随着训练过程变化),将训练集分为有标签的干净数据集和有噪声的未标注数据集

样本属于干净样本的概率:样本loss属于均值小的高斯分布的概率。通过卡阈值可以Clean/Noisy样本划分
模型细节:

- Co-Refine: 对于样本的类别概率$$p_{gt}$$,通过加权求和进行更新,加权系数w为样本属于干净样本的概率 $p_{gt}^{’}= w*p_{gt}+ (1 − w)*p_{new}$
- Co-Guess: 对于未标注样本伪标签概率分布,通过两个网络的预测平均作为该样本输入到MixMatch的伪标签
借鉴意义:
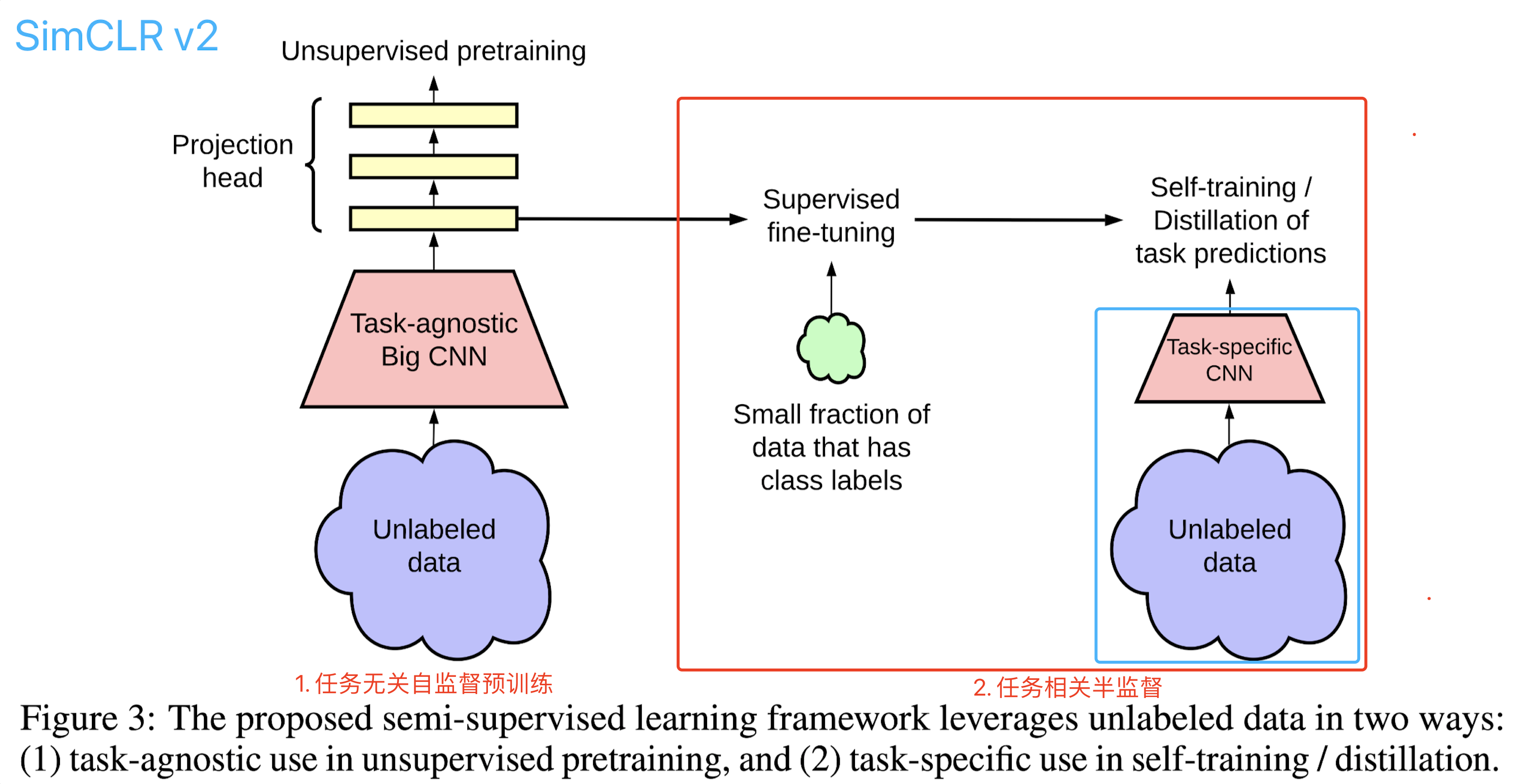
Big Self-Supervised Models are Strong Semi-Supervised Learners 【Code】
Authors:Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, Geoffrey Hinton
Institute: Google Research, Brain Team
论文简介: 自监督预训练任务没有考虑具体下游任务,采用预训练特征+少量标注样本Finetune的方式没有充分在下游任务上
算法流程:
(1) 在未标注数据上利用对比损失函数进行自监督预训练,正类(同一样本的数据增广)拉近特征距离,负类(不同样本)推远。
Normalized Temperature-scaled cross entropy loss,sim为余弦相似性
$$
\ell_{i, j}^{\text {NT-Xent }}=-\log \frac{\exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{j}\right) / \tau\right)}{\sum_{k=1}^{2 N} \mathbb{1}_{[k \neq i]} \exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{k}\right) / \tau\right)}
$$
(2) 有标签数据上进行模型Finetune
(3) 再次使用未标注数据,利用Finetune的模型进行蒸馏(soft label + CrossEntropy),适配当前下游任务。 训练包含有标注数据的监督损失和未标注数据的蒸馏损失
$$
\mathcal{L}=-(1-\alpha) \sum_{\left(\boldsymbol_{i}, y_{i}\right) \in \mathcal{D}^{L}}\left[\log P^{S}\left(y_{i} \mid \boldsymbol_{i}\right)\right]-\alpha \sum_{\boldsymbol_{i} \in \mathcal{D}}\left[\sum_{y} P^{T}\left(y \mid \boldsymbol_{i} ; \tau\right) \log P^{S}\left(y \mid \boldsymbol_{i} ; \tau\right)\right]
$$
算法细节:
(1) 在越少的标注样本下,越大的模型性能越好,即使存在过拟合的风险
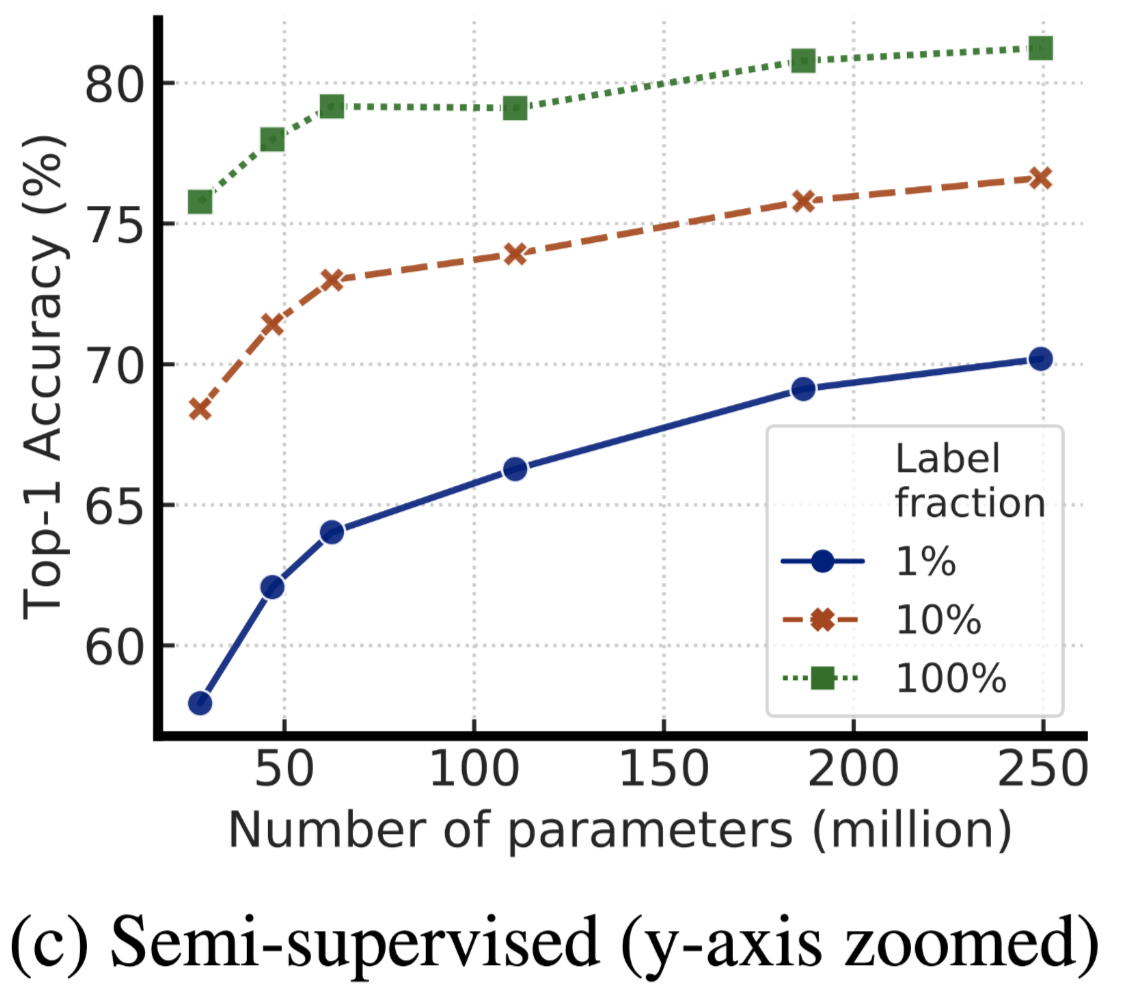
(2) 针对具体分类任务使用未标注的数据,能够提升模型在具体任务下的性能

借鉴意义:
CoMatch: Semi-supervised Learning with Contrastive Graph Regularization 【Code】
Authors: Junnan Li, Caiming Xiong, Steven Hoi
Institute: Salesforce Research
利用不同样本的特征相似性: 融合特征相近样本的标签,用于提升伪标签精度
利用不同样本的标签信息提升特征对比学习: 如果样本标签一致,则拉近两个样本的特征emb,反之推远


模型细节
消融实验

借鉴意义
真好呢