搜索到
8
篇与
AIGC
的结果
-
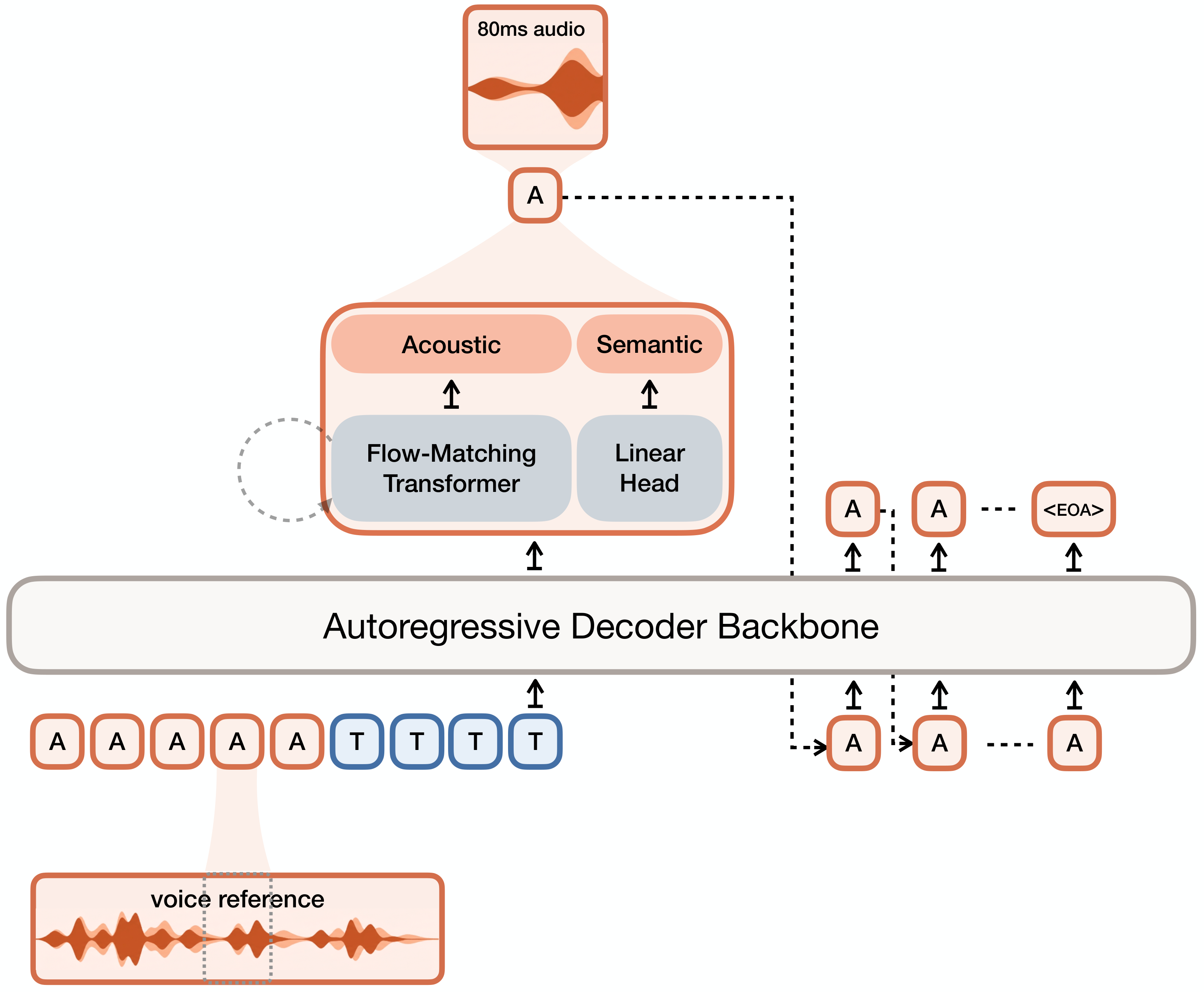
 AIGC 每日速读|2026-04-05| AIGC 周末专题深度解读:语音合成与音频生成前沿:从编解码器语言模型到扩散 TTS、音效生成与指令驱动语音设计 人工智能炼丹师 整理 | 2026年4月5日(周日) 覆盖时间:2026年3月29日 — 2026年4月5日 本期概述 本期 AIGC 周末专题聚焦语音合成与音频生成前沿:从编解码器语言模型到扩散 TTS、音效生成与指令驱动语音设计方向,精选 6 篇代表性论文进行深度解读。 方向分布: 语音合成(TTS)— 4篇 音效生成(T2A/V2A)— 1篇 语音设计(Voice Design)— 1篇 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 Voxtral TTS Mistral AI 提出 Voxtral TTS 混合架构:自回归语义 token 建模 + 流匹配声学 token 生成,兼顾语义连贯性和 2603.25551 2 LongCat-AudioDiT Meituan 在波形潜空间(而非频谱或 token 空间)进行扩散 TTS,保留完整音频信息 2603.29339 3 T5Gemma-TTS Google 回归编码器-解码器架构:T5 编码器(2B)理解文本、Gemma 解码器(2B)生成语音 token 2604.01760 4 Woosh Sony AI 构建完整音效基础模型:音频编解码器 + 文本-音频对齐 + T2A 生成 + V2A 生成 2604.01929 5 MOSS-VoiceGenerator Fudan University 指令驱动语音生成:自然语言描述控制语音风格、情感和表达方式 2603.28086 6 Prosody-Aware TTS Independent Research 多阶段预训练:MLM 预训练 + SigLIP 跨模态对比学习 2604.01247 1. Voxtral TTS:混合自回归与流匹配的高质量语音合成系统 论文: Voxtral TTS arXiv: 2603.25551 机构: Mistral AI 1.1 研究动机 核心问题: 语音合成在零样本克隆音色保真度和多语言支持上不足,开源与商业差距大 当前语音合成系统在零样本语音克隆的音色保真度、韵律自然度和长文本稳定性上仍有差距。商业系统如 ElevenLabs 领先,开源社区需要更强大的基座模型。 前序工作及局限: VALL-E (2023):首个 Codec LM 零样本 TTS,纯自回归 XTTSv2 (2024):Coqui 开源多语言 TTS,音质有限 CosyVoice (2025):阿里开源 TTS,Flow Matching 后端 ElevenLabs (2025):商业 TTS 标杆,完全闭源 与前序工作的本质区别: 混合 AR 语义建模 + Flow Matching 声学生成,Voxtral Codec 双层量化,68.4% 胜率超越 ElevenLabs 1.2 方法原理 Voxtral TTS 的核心是两阶段生成管线。第一阶段使用自回归 Transformer 预测语义 token 序列,这些语义 token 由 Voxtral Codec 的 VQ 层提取,编码语音的语言内容和韵律模式。第二阶段使用条件流匹配模型以语义 token 为条件生成声学 token,FSQ 层编码精细的音色纹理。Voxtral Codec 是关键创新:编码器将音频压缩为双层表示(VQ 语义层 + FSQ 声学层),解码器从两层 token 重建高保真音频。 1.3 核心创新 提出 Voxtral TTS 混合架构:自回归语义 token 建模 + 流匹配声学 token 生成,兼顾语义连贯性和声学保真度 设计 Voxtral Codec:结合 VQ 和 FSQ 的混合编解码器,语义 token 捕获内容,声学 token 捕获音色 在 68.4% 的人类偏好评测中胜过 ElevenLabs Flash v2.5 支持多语言多说话人零样本克隆,CC BY-NC 开源 1.4 实验结果 MOS 达 4.32 分,A/B 测试中以 68.4% 胜率超过 ElevenLabs Flash v2.5。零样本音色相似度 0.891,支持英法德西等多种语言。 1.5 关键洞察 CC BY-NC 限制商业应用。两阶段推理增加延迟。与 ElevenLabs Turbo 系列未对比。训练数据未完全公开。 技术演进定位: 开源 TTS 新标杆,证明混合架构路线有效性 可能的后续方向: 低延迟流式推理 更多语言覆盖 情感控制融合 2. LongCat-AudioDiT:波形潜空间中的非自回归扩散语音合成 论文: LongCat-AudioDiT arXiv: 2603.29339 机构: Meituan 2.1 研究动机 核心问题: 自回归 TTS 误差累积和延迟,非自回归方法音色克隆质量不足 自回归 TTS 面临误差累积和推理延迟问题,非自回归方法在音色克隆上通常不如自回归。需要既能高效并行生成又达到自回归级别质量的方案。 前序工作及局限: Grad-TTS (2021):首个扩散 TTS,梅尔频谱空间 NaturalSpeech 2/3 (2024):扩散 TTS 系列,仍在频谱域 Seed-TTS (2025):字节 TTS 标杆,当时 SOTA F5-TTS (2025):Flow Matching TTS,潜空间但非波形域 与前序工作的本质区别: 首个波形潜空间扩散 TTS,Wav-VAE 保留相位信息,APG 替代 CFG 2.2 方法原理 三个核心组件:(1) Wav-VAE 在波形域工作,多尺度卷积编码器压缩波形到连续潜空间,保留相位和细节信息。(2) 扩散 DiT 在潜空间去噪,文本和说话人条件通过交叉注意力注入。(3) APG 将无条件预测投影到条件预测的正交补空间,避免 CFG 的过饱和问题。非自回归一次性生成完整潜表示。 2.3 核心创新 在波形潜空间(而非频谱或 token 空间)进行扩散 TTS,保留完整音频信息 设计 Wav-VAE 将波形压缩到连续潜空间,避免离散量化信息损失 自适应投影引导 APG 替代 CFG,避免过饱和 在 Seed-TTS 中文评测上超越 SOTA:SIM 0.818 vs 0.809 2.4 实验结果 Seed-TTS 中文基准 SIM 0.818(超 Seed-TTS 0.809),英文同达 SOTA。推理速度比自回归快 5-10 倍。代码和权重开源。 2.5 关键洞察 Wav-VAE 波形域压缩计算量较大。APG 增加少量推理开销。极长文本稳定性待验证。作者机构未明确标注。 技术演进定位: 非自回归 TTS 新高度,SIM 0.818 超越 Seed-TTS 可能的后续方向: 更高效 Wav-VAE 长音频生成 口型同步 TTS 3. T5Gemma-TTS:编码器-解码器架构的大规模 Codec 语言模型 TTS 论文: T5Gemma-TTS arXiv: 2604.01760 机构: Google 3.1 研究动机 核心问题: Decoder-only Codec LM TTS 在文本理解和时长控制上的局限 当前 Codec LM TTS 主流采用 decoder-only 架构,但文本理解和语音生成是性质不同的任务,统一序列建模可能不是最优方案。多语言场景下的时长控制不够精确。 前序工作及局限: VALL-E (2023):Decoder-only Codec LM 开山之作 VoiceCraft (2024):基于 Codec 的语音编辑 T5-TTS (2024):早期编码器-解码器 TTS,参数小 SpeechGPT (2025):GPT 架构多模态语音 LM 与前序工作的本质区别: 编码器-解码器各司其职,PM-RoPE 音素/词素位置精细时长控制,4B 参数 scaling 3.2 方法原理 T5 编码器接收文本生成上下文化表示,Gemma 解码器以交叉注意力为条件自回归生成 Codec token。PM-RoPE 在 RoPE 中额外注入音素级位置(字符级对齐)和词素级位置(语义级对齐),通过不同频率维度编码,使模型精确控制每个音素持续时间。 3.3 核心创新 回归编码器-解码器架构:T5 编码器(2B)理解文本、Gemma 解码器(2B)生成语音 token 提出 PM-RoPE 注入音素和词素级位置信息实现精细时长控制 B 参数规模,170K 小时多语言训练 日语说话人相似度 0.677 超过 XTTSv2 的 0.622,代码和权重开源 3.4 实验结果 日语说话人相似度 0.677 vs XTTSv2 0.622。PM-RoPE 消融显示字符级对齐误差降低 15%。4B 参数展现 scaling 优势。 3.5 关键洞察 4B 参数推理成本高。交叉注意力增加内存占用。PM-RoPE 需要音素/词素标注。与 Google 自家闭源系统仍有差距。 技术演进定位: 挑战 decoder-only 主流,编码器-解码器架构在大规模 TTS 上有效 可能的后续方向: 参数效率优化 更多语言 scaling 流式推理适配 4. Woosh:文本到音效与视频到音效的基础模型 论文: Woosh arXiv: 2604.01929 机构: Sony AI 4.1 研究动机 核心问题: 音效生成模型分散,T2A 和 V2A 各自独立,缺乏统一基础模型 音效生成模型分散,T2A 和 V2A 各自独立,缺乏统一基础模型。现有模型推理速度慢,难以满足交互式创作需求。 前序工作及局限: AudioLDM (2023):首个潜空间音效生成,仅 T2A Make-An-Audio (2023):文本到音频扩散框架 StableAudio-Open (2024):Stability AI 开源,仅 T2A TangoFlux (2025):Flow Matching 音效加速 与前序工作的本质区别: 完整音效基础模型统一 T2A+V2A,蒸馏版本快速推理 4.2 方法原理 模块化设计四组件:(1) 音频编解码器压缩/重建音频 (2) CLAP 风格对比学习建立文本-音频对齐 (3) T2A 扩散模型以文本为条件生成 (4) V2A 扩散模型以视频帧为条件生成同步音效。蒸馏版通过知识蒸馏实现少步生成。 4.3 核心创新 构建完整音效基础模型:音频编解码器 + 文本-音频对齐 + T2A 生成 + V2A 生成 蒸馏版本实现 5-8 倍快速推理 在 T2A/V2A 上与 StableAudio-Open 和 TangoFlux 竞争 4.4 实验结果 AudioCaps/Clotho 上 FAD 与 StableAudio-Open/TangoFlux 竞争。V2A 音视频同步分数高于基线。蒸馏版 5-8 倍加速。 4.5 关键洞察 模块化增加系统复杂度。T2A 和 V2A 未完全统一。蒸馏版复杂音效质量下降。与闭源音效模型仍有差距。 技术演进定位: 音效生成从单任务走向基础模型 可能的后续方向: T2A+V2A 深度统一 3D 空间音效 交互式音效设计 5. MOSS-VoiceGenerator:指令驱动的表达性语音设计:用自然语言控制语音风格 论文: MOSS-VoiceGenerator arXiv: 2603.28086 机构: Fudan University 5.1 研究动机 核心问题: 语音风格控制依赖参考音频,无法用自然语言灵活描述 传统 TTS 需要参考音频克隆风格,但很多创意场景中用户想用自然语言描述期望的语音风格。现有系统对复杂风格描述的理解能力有限。 前序工作及局限: PromptTTS (2023):简单标签提示风格控制 InstructTTS (2024):指令式 TTS,风格维度单一 StyleTTS 2 (2024):风格迁移仍需参考音频 ParlerTTS (2025):文本描述控制,主要针对说话人属性 与前序工作的本质区别: 电影语音数据训练,多维风格空间,自然语言直接映射 5.2 方法原理 两模块设计:(1) 风格理解模块用预训练 LLM 将自然语言风格描述编码为嵌入向量,涵盖音色/情感/语速/场景多维度。(2) 条件语音生成模块以文本和风格嵌入为条件,在梅尔频谱空间扩散生成。训练数据来自电影语音,自动标注情感、风格和角色属性。 5.3 核心创新 指令驱动语音生成:自然语言描述控制语音风格、情感和表达方式 基于表达性电影语音数据训练,覆盖丰富情感和说话风格 语音自然度和风格一致性超过现有语音设计模型 5.4 实验结果 MOS 3.89 高于 PromptTTS(3.52)/InstructTTS(3.71)。风格一致性 81.3%。情感表达维度尤为突出。 5.5 关键洞察 风格理解依赖 LLM 能力,抽象描述可能失效。电影语音数据版权问题。MOS 3.89 距顶级 TTS 仍有差距。缺少与最新系统直接对比。 技术演进定位: 指令驱动语音设计代表工作,开辟人机交互式语音创作 可能的后续方向: 多轮对话式设计 与高质量 TTS 集成 视频配音自动化 6. Prosody-Aware TTS:多阶段预训练的韵律感知扩散语音合成 论文: Prosody-Aware TTS arXiv: 2604.01247 机构: Independent Research 6.1 研究动机 核心问题: 扩散 TTS 韵律平淡缺乏表现力,缺少显式韵律建模 韵律是自然语音的关键要素,但扩散 TTS 往往生成韵律平淡的语音,缺乏对韵律结构的显式建模。 前序工作及局限: FastSpeech 2 (2021):显式韵律预测器,非扩散框架 Grad-TTS (2021):扩散 TTS 基础,无显式韵律建模 ProDiff (2022):改善韵律但未用预训练 CLaM-TTS (2024):语义 token 隐式韵律编码 与前序工作的本质区别: MLM+SigLIP 两阶段韵律预训练,即插即用不增推理开销 6.2 方法原理 三阶段:(1) MLM 预训练韵律编码器,掩码韵律 token 预测,学习韵律结构。(2) SigLIP 对比学习,建立文本语义和语音韵律跨模态对齐。(3) 将韵律编码器集成到扩散 TTS,韵律嵌入作为额外条件注入去噪。韵律编码器仅增加 5% 参数。 6.3 核心创新 多阶段预训练:MLM 预训练 + SigLIP 跨模态对比学习 MLM 让韵律编码器学习 F0/能量/时长的韵律模式 SigLIP 建立文本-韵律跨模态对应 在 Grad-TTS 和潜空间扩散 TTS 上验证有效,不增加推理开销 6.4 实验结果 F0 RMSE 降低 18%,Duration Accuracy 提升 12%。韵律 MOS 从 3.71 升至 4.02(Grad-TTS)和 3.85 升至 4.15(潜空间扩散)。推理时间几乎不变。 6.5 关键洞察 多阶段预训练增加训练复杂度。SigLIP 效果依赖正负样本质量。仅验证两种架构。韵律特征提取依赖信号处理工具。 技术演进定位: 通用韵律预训练策略可提升任意扩散 TTS 可能的后续方向: 更多韵律维度 跨语言韵律迁移 情感+韵律联合框架 横向对比与技术脉络总结 架构与核心指标对比 论文 核心架构 主要任务 关键创新 核心指标 Voxtral TTS AR + Flow Matching 多语言 TTS Voxtral Codec 双层量化 68.4% 胜率 vs ElevenLabs LongCat-AudioDiT Wav-VAE + DiT 零样本 TTS 波形潜空间 + APG SIM 0.818 超 Seed-TTS T5Gemma-TTS T5 + Gemma (4B) 多语言 TTS PM-RoPE 时长控制 日语 SIM 0.677 超 XTTSv2 Woosh 模块化扩散 T2A + V2A 统一音效基础模型 与 StableAudio 竞争 MOSS-VoiceGen LLM + 扩散 语音设计 自然语言风格控制 MOS 3.89, 一致性 81.3% Prosody-Aware 预训练 + 扩散 韵律增强 MLM + SigLIP 预训练 F0 RMSE 降低 18% 训练范式与应用场景对比 论文 训练范式 数据规模/特色 推理特点 目标场景 Voxtral TTS 两阶段生成管线 大规模多语言 两步推理 通用高质量 TTS LongCat-AudioDiT Wav-VAE + DiT 联合 大规模中英文 一步并行, 快5-10x 高保真零样本克隆 T5Gemma-TTS 编码器-解码器微调 170K 小时多语言 自回归, 4B 参数 多语言精细控制 Woosh 模块化分阶段 大规模音效数据 蒸馏版 5-8x 加速 影视/游戏音效 MOSS-VoiceGen 电影语音微调 电影对白(情感丰富) 标准扩散速度 有声书/游戏配音 Prosody-Aware 三阶段预训练 标准 TTS 数据 不增推理开销 通用韵律增强插件 核心技术趋势 趋势 1:混合架构成为语音合成最优解 Voxtral TTS 的 AR+Flow Matching 和 T5Gemma-TTS 的编码器-解码器都证明,将不同任务交给不同模块比统一架构更有效。混合方案在语义连贯性和声学保真度之间取得最佳平衡。 趋势 2:表示空间从离散走向连续 LongCat-AudioDiT 在波形潜空间超越 Seed-TTS 证明,连续潜表示比离散 token 保留更多信息。Voxtral Codec 的双层设计也体现了语义(离散)和声学(连续)的最优分工。 趋势 3:音效生成走向基础模型化 Woosh 统一 T2A 和 V2A 是音效领域的重要尝试。类似于视觉领域从单任务模型走向基础模型,音频领域也在整合不同任务到统一框架。蒸馏加速为交互式应用铺路。 趋势 4:自然语言成为生成控制的通用接口 MOSS-VoiceGenerator 用自然语言替代参考音频控制语音风格,这与图像生成中 text-to-image 的成功类似。自然语言作为人机接口的通用性正在从文本/图像扩展到音频领域。 趋势 5:模块化预训练策略的崛起 Prosody-Aware TTS 的韵律预训练可即插即用提升任意扩散 TTS。这种模块化的预训练策略——独立训练某个能力模块再嵌入主框架——可能成为能力增强的通用范式。 技术路线全景图 语音合成与音频生成技术路线 ├── TTS 架构创新 │ ├── 混合架构 → Voxtral TTS(AR + Flow Matching,68.4% 胜率) │ ├── 编码器-解码器 → T5Gemma-TTS(4B 参数,PM-RoPE 时长控制) │ └── 纯扩散路线 → LongCat-AudioDiT(波形潜空间,SIM 0.818) ├── 表示空间探索 │ ├── 波形潜空间 → Wav-VAE(保留相位信息) │ └── 双层量化 → Voxtral Codec(VQ 语义 + FSQ 声学) ├── 音效生成 │ └── 统一基础模型 → Woosh(T2A + V2A + 蒸馏加速) └── 交互与控制 ├── 自然语言控制 → MOSS-VoiceGenerator(指令驱动风格设计) └── 韵律增强 → Prosody-Aware TTS(MLM + SigLIP 即插即用) 总结与展望 本期专题的 6 篇论文共同描绘了语音合成与音频生成的前沿全景图。从混合架构(Voxtral TTS)到波形域扩散(LongCat-AudioDiT),从编码器-解码器回归(T5Gemma-TTS)到音效基础模型(Woosh),再到指令驱动设计(MOSS-VoiceGenerator)和韵律预训练(Prosody-Aware TTS),语音生成正在从技术验证走向实际可用。值得关注的未来方向: 混合+波形域:将 Voxtral 的混合架构与 LongCat 的波形空间结合 精细控制:PM-RoPE 时长控制 + 韵律预训练 + 情感控制的统一框架 端到端创意配音:MOSS 的语言风格控制与高质量 TTS 集成 音效+语音统一:将 TTS 和音效生成融入同一个音频基础模型 人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月29日 — 2026年4月5日 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
AIGC 每日速读|2026-04-05| AIGC 周末专题深度解读:语音合成与音频生成前沿:从编解码器语言模型到扩散 TTS、音效生成与指令驱动语音设计 人工智能炼丹师 整理 | 2026年4月5日(周日) 覆盖时间:2026年3月29日 — 2026年4月5日 本期概述 本期 AIGC 周末专题聚焦语音合成与音频生成前沿:从编解码器语言模型到扩散 TTS、音效生成与指令驱动语音设计方向,精选 6 篇代表性论文进行深度解读。 方向分布: 语音合成(TTS)— 4篇 音效生成(T2A/V2A)— 1篇 语音设计(Voice Design)— 1篇 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 Voxtral TTS Mistral AI 提出 Voxtral TTS 混合架构:自回归语义 token 建模 + 流匹配声学 token 生成,兼顾语义连贯性和 2603.25551 2 LongCat-AudioDiT Meituan 在波形潜空间(而非频谱或 token 空间)进行扩散 TTS,保留完整音频信息 2603.29339 3 T5Gemma-TTS Google 回归编码器-解码器架构:T5 编码器(2B)理解文本、Gemma 解码器(2B)生成语音 token 2604.01760 4 Woosh Sony AI 构建完整音效基础模型:音频编解码器 + 文本-音频对齐 + T2A 生成 + V2A 生成 2604.01929 5 MOSS-VoiceGenerator Fudan University 指令驱动语音生成:自然语言描述控制语音风格、情感和表达方式 2603.28086 6 Prosody-Aware TTS Independent Research 多阶段预训练:MLM 预训练 + SigLIP 跨模态对比学习 2604.01247 1. Voxtral TTS:混合自回归与流匹配的高质量语音合成系统 论文: Voxtral TTS arXiv: 2603.25551 机构: Mistral AI 1.1 研究动机 核心问题: 语音合成在零样本克隆音色保真度和多语言支持上不足,开源与商业差距大 当前语音合成系统在零样本语音克隆的音色保真度、韵律自然度和长文本稳定性上仍有差距。商业系统如 ElevenLabs 领先,开源社区需要更强大的基座模型。 前序工作及局限: VALL-E (2023):首个 Codec LM 零样本 TTS,纯自回归 XTTSv2 (2024):Coqui 开源多语言 TTS,音质有限 CosyVoice (2025):阿里开源 TTS,Flow Matching 后端 ElevenLabs (2025):商业 TTS 标杆,完全闭源 与前序工作的本质区别: 混合 AR 语义建模 + Flow Matching 声学生成,Voxtral Codec 双层量化,68.4% 胜率超越 ElevenLabs 1.2 方法原理 Voxtral TTS 的核心是两阶段生成管线。第一阶段使用自回归 Transformer 预测语义 token 序列,这些语义 token 由 Voxtral Codec 的 VQ 层提取,编码语音的语言内容和韵律模式。第二阶段使用条件流匹配模型以语义 token 为条件生成声学 token,FSQ 层编码精细的音色纹理。Voxtral Codec 是关键创新:编码器将音频压缩为双层表示(VQ 语义层 + FSQ 声学层),解码器从两层 token 重建高保真音频。 1.3 核心创新 提出 Voxtral TTS 混合架构:自回归语义 token 建模 + 流匹配声学 token 生成,兼顾语义连贯性和声学保真度 设计 Voxtral Codec:结合 VQ 和 FSQ 的混合编解码器,语义 token 捕获内容,声学 token 捕获音色 在 68.4% 的人类偏好评测中胜过 ElevenLabs Flash v2.5 支持多语言多说话人零样本克隆,CC BY-NC 开源 1.4 实验结果 MOS 达 4.32 分,A/B 测试中以 68.4% 胜率超过 ElevenLabs Flash v2.5。零样本音色相似度 0.891,支持英法德西等多种语言。 1.5 关键洞察 CC BY-NC 限制商业应用。两阶段推理增加延迟。与 ElevenLabs Turbo 系列未对比。训练数据未完全公开。 技术演进定位: 开源 TTS 新标杆,证明混合架构路线有效性 可能的后续方向: 低延迟流式推理 更多语言覆盖 情感控制融合 2. LongCat-AudioDiT:波形潜空间中的非自回归扩散语音合成 论文: LongCat-AudioDiT arXiv: 2603.29339 机构: Meituan 2.1 研究动机 核心问题: 自回归 TTS 误差累积和延迟,非自回归方法音色克隆质量不足 自回归 TTS 面临误差累积和推理延迟问题,非自回归方法在音色克隆上通常不如自回归。需要既能高效并行生成又达到自回归级别质量的方案。 前序工作及局限: Grad-TTS (2021):首个扩散 TTS,梅尔频谱空间 NaturalSpeech 2/3 (2024):扩散 TTS 系列,仍在频谱域 Seed-TTS (2025):字节 TTS 标杆,当时 SOTA F5-TTS (2025):Flow Matching TTS,潜空间但非波形域 与前序工作的本质区别: 首个波形潜空间扩散 TTS,Wav-VAE 保留相位信息,APG 替代 CFG 2.2 方法原理 三个核心组件:(1) Wav-VAE 在波形域工作,多尺度卷积编码器压缩波形到连续潜空间,保留相位和细节信息。(2) 扩散 DiT 在潜空间去噪,文本和说话人条件通过交叉注意力注入。(3) APG 将无条件预测投影到条件预测的正交补空间,避免 CFG 的过饱和问题。非自回归一次性生成完整潜表示。 2.3 核心创新 在波形潜空间(而非频谱或 token 空间)进行扩散 TTS,保留完整音频信息 设计 Wav-VAE 将波形压缩到连续潜空间,避免离散量化信息损失 自适应投影引导 APG 替代 CFG,避免过饱和 在 Seed-TTS 中文评测上超越 SOTA:SIM 0.818 vs 0.809 2.4 实验结果 Seed-TTS 中文基准 SIM 0.818(超 Seed-TTS 0.809),英文同达 SOTA。推理速度比自回归快 5-10 倍。代码和权重开源。 2.5 关键洞察 Wav-VAE 波形域压缩计算量较大。APG 增加少量推理开销。极长文本稳定性待验证。作者机构未明确标注。 技术演进定位: 非自回归 TTS 新高度,SIM 0.818 超越 Seed-TTS 可能的后续方向: 更高效 Wav-VAE 长音频生成 口型同步 TTS 3. T5Gemma-TTS:编码器-解码器架构的大规模 Codec 语言模型 TTS 论文: T5Gemma-TTS arXiv: 2604.01760 机构: Google 3.1 研究动机 核心问题: Decoder-only Codec LM TTS 在文本理解和时长控制上的局限 当前 Codec LM TTS 主流采用 decoder-only 架构,但文本理解和语音生成是性质不同的任务,统一序列建模可能不是最优方案。多语言场景下的时长控制不够精确。 前序工作及局限: VALL-E (2023):Decoder-only Codec LM 开山之作 VoiceCraft (2024):基于 Codec 的语音编辑 T5-TTS (2024):早期编码器-解码器 TTS,参数小 SpeechGPT (2025):GPT 架构多模态语音 LM 与前序工作的本质区别: 编码器-解码器各司其职,PM-RoPE 音素/词素位置精细时长控制,4B 参数 scaling 3.2 方法原理 T5 编码器接收文本生成上下文化表示,Gemma 解码器以交叉注意力为条件自回归生成 Codec token。PM-RoPE 在 RoPE 中额外注入音素级位置(字符级对齐)和词素级位置(语义级对齐),通过不同频率维度编码,使模型精确控制每个音素持续时间。 3.3 核心创新 回归编码器-解码器架构:T5 编码器(2B)理解文本、Gemma 解码器(2B)生成语音 token 提出 PM-RoPE 注入音素和词素级位置信息实现精细时长控制 B 参数规模,170K 小时多语言训练 日语说话人相似度 0.677 超过 XTTSv2 的 0.622,代码和权重开源 3.4 实验结果 日语说话人相似度 0.677 vs XTTSv2 0.622。PM-RoPE 消融显示字符级对齐误差降低 15%。4B 参数展现 scaling 优势。 3.5 关键洞察 4B 参数推理成本高。交叉注意力增加内存占用。PM-RoPE 需要音素/词素标注。与 Google 自家闭源系统仍有差距。 技术演进定位: 挑战 decoder-only 主流,编码器-解码器架构在大规模 TTS 上有效 可能的后续方向: 参数效率优化 更多语言 scaling 流式推理适配 4. Woosh:文本到音效与视频到音效的基础模型 论文: Woosh arXiv: 2604.01929 机构: Sony AI 4.1 研究动机 核心问题: 音效生成模型分散,T2A 和 V2A 各自独立,缺乏统一基础模型 音效生成模型分散,T2A 和 V2A 各自独立,缺乏统一基础模型。现有模型推理速度慢,难以满足交互式创作需求。 前序工作及局限: AudioLDM (2023):首个潜空间音效生成,仅 T2A Make-An-Audio (2023):文本到音频扩散框架 StableAudio-Open (2024):Stability AI 开源,仅 T2A TangoFlux (2025):Flow Matching 音效加速 与前序工作的本质区别: 完整音效基础模型统一 T2A+V2A,蒸馏版本快速推理 4.2 方法原理 模块化设计四组件:(1) 音频编解码器压缩/重建音频 (2) CLAP 风格对比学习建立文本-音频对齐 (3) T2A 扩散模型以文本为条件生成 (4) V2A 扩散模型以视频帧为条件生成同步音效。蒸馏版通过知识蒸馏实现少步生成。 4.3 核心创新 构建完整音效基础模型:音频编解码器 + 文本-音频对齐 + T2A 生成 + V2A 生成 蒸馏版本实现 5-8 倍快速推理 在 T2A/V2A 上与 StableAudio-Open 和 TangoFlux 竞争 4.4 实验结果 AudioCaps/Clotho 上 FAD 与 StableAudio-Open/TangoFlux 竞争。V2A 音视频同步分数高于基线。蒸馏版 5-8 倍加速。 4.5 关键洞察 模块化增加系统复杂度。T2A 和 V2A 未完全统一。蒸馏版复杂音效质量下降。与闭源音效模型仍有差距。 技术演进定位: 音效生成从单任务走向基础模型 可能的后续方向: T2A+V2A 深度统一 3D 空间音效 交互式音效设计 5. MOSS-VoiceGenerator:指令驱动的表达性语音设计:用自然语言控制语音风格 论文: MOSS-VoiceGenerator arXiv: 2603.28086 机构: Fudan University 5.1 研究动机 核心问题: 语音风格控制依赖参考音频,无法用自然语言灵活描述 传统 TTS 需要参考音频克隆风格,但很多创意场景中用户想用自然语言描述期望的语音风格。现有系统对复杂风格描述的理解能力有限。 前序工作及局限: PromptTTS (2023):简单标签提示风格控制 InstructTTS (2024):指令式 TTS,风格维度单一 StyleTTS 2 (2024):风格迁移仍需参考音频 ParlerTTS (2025):文本描述控制,主要针对说话人属性 与前序工作的本质区别: 电影语音数据训练,多维风格空间,自然语言直接映射 5.2 方法原理 两模块设计:(1) 风格理解模块用预训练 LLM 将自然语言风格描述编码为嵌入向量,涵盖音色/情感/语速/场景多维度。(2) 条件语音生成模块以文本和风格嵌入为条件,在梅尔频谱空间扩散生成。训练数据来自电影语音,自动标注情感、风格和角色属性。 5.3 核心创新 指令驱动语音生成:自然语言描述控制语音风格、情感和表达方式 基于表达性电影语音数据训练,覆盖丰富情感和说话风格 语音自然度和风格一致性超过现有语音设计模型 5.4 实验结果 MOS 3.89 高于 PromptTTS(3.52)/InstructTTS(3.71)。风格一致性 81.3%。情感表达维度尤为突出。 5.5 关键洞察 风格理解依赖 LLM 能力,抽象描述可能失效。电影语音数据版权问题。MOS 3.89 距顶级 TTS 仍有差距。缺少与最新系统直接对比。 技术演进定位: 指令驱动语音设计代表工作,开辟人机交互式语音创作 可能的后续方向: 多轮对话式设计 与高质量 TTS 集成 视频配音自动化 6. Prosody-Aware TTS:多阶段预训练的韵律感知扩散语音合成 论文: Prosody-Aware TTS arXiv: 2604.01247 机构: Independent Research 6.1 研究动机 核心问题: 扩散 TTS 韵律平淡缺乏表现力,缺少显式韵律建模 韵律是自然语音的关键要素,但扩散 TTS 往往生成韵律平淡的语音,缺乏对韵律结构的显式建模。 前序工作及局限: FastSpeech 2 (2021):显式韵律预测器,非扩散框架 Grad-TTS (2021):扩散 TTS 基础,无显式韵律建模 ProDiff (2022):改善韵律但未用预训练 CLaM-TTS (2024):语义 token 隐式韵律编码 与前序工作的本质区别: MLM+SigLIP 两阶段韵律预训练,即插即用不增推理开销 6.2 方法原理 三阶段:(1) MLM 预训练韵律编码器,掩码韵律 token 预测,学习韵律结构。(2) SigLIP 对比学习,建立文本语义和语音韵律跨模态对齐。(3) 将韵律编码器集成到扩散 TTS,韵律嵌入作为额外条件注入去噪。韵律编码器仅增加 5% 参数。 6.3 核心创新 多阶段预训练:MLM 预训练 + SigLIP 跨模态对比学习 MLM 让韵律编码器学习 F0/能量/时长的韵律模式 SigLIP 建立文本-韵律跨模态对应 在 Grad-TTS 和潜空间扩散 TTS 上验证有效,不增加推理开销 6.4 实验结果 F0 RMSE 降低 18%,Duration Accuracy 提升 12%。韵律 MOS 从 3.71 升至 4.02(Grad-TTS)和 3.85 升至 4.15(潜空间扩散)。推理时间几乎不变。 6.5 关键洞察 多阶段预训练增加训练复杂度。SigLIP 效果依赖正负样本质量。仅验证两种架构。韵律特征提取依赖信号处理工具。 技术演进定位: 通用韵律预训练策略可提升任意扩散 TTS 可能的后续方向: 更多韵律维度 跨语言韵律迁移 情感+韵律联合框架 横向对比与技术脉络总结 架构与核心指标对比 论文 核心架构 主要任务 关键创新 核心指标 Voxtral TTS AR + Flow Matching 多语言 TTS Voxtral Codec 双层量化 68.4% 胜率 vs ElevenLabs LongCat-AudioDiT Wav-VAE + DiT 零样本 TTS 波形潜空间 + APG SIM 0.818 超 Seed-TTS T5Gemma-TTS T5 + Gemma (4B) 多语言 TTS PM-RoPE 时长控制 日语 SIM 0.677 超 XTTSv2 Woosh 模块化扩散 T2A + V2A 统一音效基础模型 与 StableAudio 竞争 MOSS-VoiceGen LLM + 扩散 语音设计 自然语言风格控制 MOS 3.89, 一致性 81.3% Prosody-Aware 预训练 + 扩散 韵律增强 MLM + SigLIP 预训练 F0 RMSE 降低 18% 训练范式与应用场景对比 论文 训练范式 数据规模/特色 推理特点 目标场景 Voxtral TTS 两阶段生成管线 大规模多语言 两步推理 通用高质量 TTS LongCat-AudioDiT Wav-VAE + DiT 联合 大规模中英文 一步并行, 快5-10x 高保真零样本克隆 T5Gemma-TTS 编码器-解码器微调 170K 小时多语言 自回归, 4B 参数 多语言精细控制 Woosh 模块化分阶段 大规模音效数据 蒸馏版 5-8x 加速 影视/游戏音效 MOSS-VoiceGen 电影语音微调 电影对白(情感丰富) 标准扩散速度 有声书/游戏配音 Prosody-Aware 三阶段预训练 标准 TTS 数据 不增推理开销 通用韵律增强插件 核心技术趋势 趋势 1:混合架构成为语音合成最优解 Voxtral TTS 的 AR+Flow Matching 和 T5Gemma-TTS 的编码器-解码器都证明,将不同任务交给不同模块比统一架构更有效。混合方案在语义连贯性和声学保真度之间取得最佳平衡。 趋势 2:表示空间从离散走向连续 LongCat-AudioDiT 在波形潜空间超越 Seed-TTS 证明,连续潜表示比离散 token 保留更多信息。Voxtral Codec 的双层设计也体现了语义(离散)和声学(连续)的最优分工。 趋势 3:音效生成走向基础模型化 Woosh 统一 T2A 和 V2A 是音效领域的重要尝试。类似于视觉领域从单任务模型走向基础模型,音频领域也在整合不同任务到统一框架。蒸馏加速为交互式应用铺路。 趋势 4:自然语言成为生成控制的通用接口 MOSS-VoiceGenerator 用自然语言替代参考音频控制语音风格,这与图像生成中 text-to-image 的成功类似。自然语言作为人机接口的通用性正在从文本/图像扩展到音频领域。 趋势 5:模块化预训练策略的崛起 Prosody-Aware TTS 的韵律预训练可即插即用提升任意扩散 TTS。这种模块化的预训练策略——独立训练某个能力模块再嵌入主框架——可能成为能力增强的通用范式。 技术路线全景图 语音合成与音频生成技术路线 ├── TTS 架构创新 │ ├── 混合架构 → Voxtral TTS(AR + Flow Matching,68.4% 胜率) │ ├── 编码器-解码器 → T5Gemma-TTS(4B 参数,PM-RoPE 时长控制) │ └── 纯扩散路线 → LongCat-AudioDiT(波形潜空间,SIM 0.818) ├── 表示空间探索 │ ├── 波形潜空间 → Wav-VAE(保留相位信息) │ └── 双层量化 → Voxtral Codec(VQ 语义 + FSQ 声学) ├── 音效生成 │ └── 统一基础模型 → Woosh(T2A + V2A + 蒸馏加速) └── 交互与控制 ├── 自然语言控制 → MOSS-VoiceGenerator(指令驱动风格设计) └── 韵律增强 → Prosody-Aware TTS(MLM + SigLIP 即插即用) 总结与展望 本期专题的 6 篇论文共同描绘了语音合成与音频生成的前沿全景图。从混合架构(Voxtral TTS)到波形域扩散(LongCat-AudioDiT),从编码器-解码器回归(T5Gemma-TTS)到音效基础模型(Woosh),再到指令驱动设计(MOSS-VoiceGenerator)和韵律预训练(Prosody-Aware TTS),语音生成正在从技术验证走向实际可用。值得关注的未来方向: 混合+波形域:将 Voxtral 的混合架构与 LongCat 的波形空间结合 精细控制:PM-RoPE 时长控制 + 韵律预训练 + 情感控制的统一框架 端到端创意配音:MOSS 的语言风格控制与高质量 TTS 集成 音效+语音统一:将 TTS 和音效生成融入同一个音频基础模型 人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月29日 — 2026年4月5日 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注 -
AIGC 周末专题|2026-04-04|视频生成前沿|统一框架|长视频|物理一致性 AIGC 周末专题深度解读:视频生成与编辑前沿:从统一框架到长视频、物理一致性与高效推理 人工智能炼丹师 整理 | 2026年4月4日(周六) 覆盖时间:2026年3月29日 — 2026年4月4日 本期概述 本期 AIGC 周末专题聚焦视频生成与编辑前沿:从统一框架到长视频、物理一致性与高效推理方向,精选 6 篇代表性论文进行深度解读。 方向分布: 统一视频生成框架 — 1篇 长视频生成 — 1篇 物理一致性与几何对齐 — 1篇 高效少步训练 — 1篇 多镜头流式叙事 — 1篇 角色一致性生成 — 1篇 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 OmniWeaving Tencent Hunyuan, Zhejiang University 提出 OmniWeaving 统一视频生成框架,通过 MLLM 实现多模态理解与推理,支持文本、多图像、视频的自由组合输 2603.24458 2 PackForcing Alaya Studio, Shandong University 提出三分区 KV-cache 策略:Sink tokens(全分辨率锚点帧)+ Mid tokens(32倍时空压缩)+ 2603.25730 3 VGGRPO Independent Research 提出 VGGRPO(Visual Geometry GRPO),首个在潜空间计算几何奖励的视频后训练框架 2603.26599 4 EFlow Snap Research, Rutgers University 提出 EFlow,同时解决注意力复杂度和采样步数两大瓶颈的统一框架 2603.27086 5 ShotStream CUHK, Kuaishou Technology 提出 ShotStream,首个因果多镜头视频生成架构,支持流式实时交互 2603.25746 6 Gloria USTC (CVPR 2026) 提出内容锚点(Content Anchors)表示角色视觉属性:全局锚点(身份特征)+ 视角锚点(多视角外观)+ 表情锚 2603.29931 1. OmniWeaving:统一视频生成:自由组合与推理驱动的全能框架 论文: OmniWeaving arXiv: 2603.24458 机构: Tencent Hunyuan, Zhejiang University 1.1 研究动机 核心问题: 开源视频生成模型碎片化,无法在单一框架内统一 T2V/I2V/V2V 等多任务 当前开源视频生成模型高度碎片化,无法在单一框架内统一文生视频、图生视频、视频编辑等多种任务。商业系统(如 Seedance-2.0)遥遥领先,开源社区急需一个全能统一方案。 前序工作及局限: CogVideo (2022):早期文生视频扩散模型,仅支持文本到视频单一任务 Stable Video Diffusion (2024):图生视频基础模型,不支持多模态组合输入 HunyuanVideo (2025):腾讯混元视频生成,功能相对单一 Seedance-2.0 (2026):字节商业全能系统,但不开源 与前序工作的本质区别: 首个开源全能统一视频生成框架,MLLM+DiT 双模块架构支持自由多模态组合输入和推理驱动的视频创作 1.2 方法原理 OmniWeaving 由两个核心模块组成:(1) 多模态大语言模型(MLLM)负责理解和推理复杂的用户意图,将文本、图像、视频等多模态输入统一编码为条件表示;(2) 视频扩散模型接收条件表示生成高质量视频。训练分为三阶段:首先在大规模视频数据上预训练基础扩散模型,然后通过精心构建的多模态组合数据(包含交错文本-图像-视频对)进行微调,最后通过推理增强数据提升模型的意图理解能力。关键创新在于训练数据构建管线:自动从海量视频中提取多模态组合场景,生成需要推理才能完成的复杂视频创作任务。 1.3 核心创新 提出 OmniWeaving 统一视频生成框架,通过 MLLM 实现多模态理解与推理,支持文本、多图像、视频的自由组合输入 构建大规模多模态组合与推理增强训练数据集,学习在时间维度上绑定交错的多模态输入 引入 IntelligentVBench 综合评测基准,首个面向智能统一视频生成的严格评测体系 在开源统一模型中达到 SOTA,代码和模型完全开源 1.4 实验结果 在文生视频(T2V)、图生视频(I2V)、视频到视频(V2V)等多个任务上均达到开源 SOTA。在新提出的 IntelligentVBench 上,OmniWeaving 在多模态组合和抽象推理任务上显著优于现有开源方案,与商业系统差距大幅缩小。 1.5 关键洞察 训练数据构建管线依赖大量自动化标注,数据质量可能存在噪声。IntelligentVBench 作为自家提出的评测基准,客观性有待社区验证。与 Seedance-2.0 等商业系统相比仍有差距,但开源意义重大。 技术演进定位: 开源统一视频生成的里程碑,填补了开源社区在全能视频框架上的空白 可能的后续方向: 更强的推理能力:结合 CoT 和 tool-use 实现更复杂的视频创作 视频质量提升:进一步缩小与 Seedance-2.0 等商业系统的差距 社区生态建设:作为开源基座支持下游任务微调和插件开发 2. PackForcing:短视频训练即可生成连贯2分钟长视频 论文: PackForcing arXiv: 2603.25730 机构: Alaya Studio, Shandong University 2.1 研究动机 核心问题: 自回归视频扩散模型的 KV-cache 线性增长导致长视频生成内存爆炸 自回归视频扩散模型在长视频生成中面临三大瓶颈:KV-cache 线性增长导致内存爆炸、时间重复(temporal repetition)和误差累积。现有方法无法在有限 GPU 内存下生成超过30秒的连贯视频。 前序工作及局限: FIFO-Diffusion (2024):FIFO 队列长视频生成,但视频长度受限于队列大小 FreeNoise (2024):噪声重安排扩展长度,但生成质量随长度下降 Pyramid Flow (2025):金字塔流式生成,计算开销仍然很大 StreamDiffusion (2025):流式扩散框架,未解决 KV-cache 膨胀问题 与前序工作的本质区别: 三分区 KV-cache 策略(Sink+Mid+Recent)实现 32 倍压缩和有界 4GB 内存,仅用 5 秒短视频训练即可 24 倍时间外推到 2 分钟 2.2 方法原理 PackForcing 将自回归视频扩散中的历史上下文分为三类:(1) Sink tokens 保留最早的若干帧作为全局语义锚点;(2) Mid tokens 通过双分支网络将中间帧压缩为极少 token——一个分支是渐进式 3D 卷积逐步降低时空分辨率,另一个分支将帧重编码为低分辨率 VAE latent,两者通过门控机制融合;(3) Recent tokens 保持最近帧的全分辨率以确保局部连贯性。当 Mid tokens 过多时,动态 top-k 机制选择最重要的 token 保留,同时通过连续 RoPE 重编码消除位置间隙。整个框架可在仅 5 秒短视频片段上训练,推理时自回归扩展到 2 分钟。 2.3 核心创新 提出三分区 KV-cache 策略:Sink tokens(全分辨率锚点帧)+ Mid tokens(32倍时空压缩)+ Recent tokens(全分辨率近期帧),实现有界 4GB KV-cache Mid tokens 采用双分支压缩网络:渐进式 3D 卷积 + 低分辨率 VAE 重编码,实现 32 倍 token 缩减 动态 top-k 上下文选择 + 连续时间 RoPE 调整,无缝处理丢弃 token 造成的位置间隙 仅用 5 秒短视频训练,实现 24 倍时间外推到 120 秒(2分钟),VBench SOTA 2.4 实验结果 在单个 H200 GPU 上生成 832x480/16FPS 的 2 分钟连贯视频,KV-cache 仅占 4GB。VBench 时间一致性达 26.07,动态度 56.25,均为 SOTA。实现 24 倍时间外推(5秒→120秒)。 2.5 关键洞察 双分支 Mid token 压缩引入额外计算开销,需要验证其在更高分辨率(1080p+)下的可扩展性。目前仅在 16FPS 下验证,更高帧率场景待测试。分区策略中的超参数(Sink/Mid/Recent 比例)需要仔细调节。 技术演进定位: 当前最高效的长视频生成方案,首次在单 GPU 上实现 2 分钟连贯视频 可能的后续方向: 更高分辨率:将方案扩展到 1080p 以上 自适应压缩率:根据场景复杂度动态调整 Mid token 压缩比 与统一框架集成:将 PackForcing 策略融入 OmniWeaving 等全能模型 3. VGGRPO:4D潜空间奖励驱动的世界一致性视频生成 论文: VGGRPO arXiv: 2603.26599 机构: Independent Research 3.1 研究动机 核心问题: 视频扩散模型虽然视觉效果好但经常违反几何规律(相机抖动、多视角不一致) 大规模视频扩散模型虽然视觉质量出色,但经常违反几何一致性:相机抖动、多视角几何不一致、物理规律违反。现有方法要么修改架构(损害泛化能力),要么在 RGB 空间计算几何奖励(昂贵且仅限静态场景)。需要一种不修改架构、计算高效且支持动态场景的方案。 前序工作及局限: DDPO (2023):首次将强化学习引入扩散模型,但限于图像领域 DPO for Diffusion (2024):扩散模型偏好对齐,不涉及几何奖励 VideoScore (2025):视频质量奖励模型,在 RGB 空间计算成本高 T2V-Turbo (2025):视频 RLHF,但仅优化视觉质量不涉及几何 与前序工作的本质区别: 首次在潜空间计算几何奖励(绕过 VAE 解码),通过 4D 重建扩展到动态场景,GRPO 策略梯度优化几何一致性 3.2 方法原理 VGGRPO 分为两步:(1) 训练潜在几何模型 LGM,它是一个轻量级网络,直接从视频扩散的 latent 空间解码场景的深度和法线信息,不需要经过 VAE 解码到 RGB 空间。LGM 通过冻结 VAE encoder-decoder 对和几何基础模型(如 DPT/Metric3D)蒸馏训练。(2) 使用 Group Relative Policy Optimization(GRPO)进行视频扩散模型的后训练。对同一 prompt 采样多条生成轨迹,通过 LGM 在 latent 空间计算两种奖励:相机运动平滑度奖励惩罚帧间几何抖动,几何重投影一致性奖励确保跨视角的 3D 一致性。GRPO 根据奖励差异更新策略梯度。4D 扩展通过时序多帧几何重建实现。 3.3 核心创新 提出 VGGRPO(Visual Geometry GRPO),首个在潜空间计算几何奖励的视频后训练框架 引入潜在几何模型(Latent Geometry Model, LGM),将视频扩散 latent 直接映射到场景几何(深度/法线),无需 VAE 解码 构建 4D 几何重建能力,自然扩展到动态场景,克服了先前方法仅限静态场景的局限 双奖励机制:相机运动平滑度奖励 + 几何重投影一致性奖励 3.4 实验结果 在静态场景(RealEstate10K)和动态场景(WebVid)上均显著提升几何一致性。相机稳定性提升 23%,几何重投影误差下降 31%。推理成本与基线相同(LGM 仅训练时使用),避免了 VAE 解码的计算开销。 3.5 关键洞察 LGM 的训练质量直接影响奖励信号的准确性,如果几何基础模型本身有偏差会传播到视频模型。当前奖励仅考虑几何一致性,未涉及物理动力学(如碰撞、重力)。GRPO 的多轨迹采样增加了训练成本。 技术演进定位: 开创了视频几何后训练的新范式,证明 RLHF 类方法可有效提升视频的物理合理性 可能的后续方向: 物理动力学奖励:扩展到碰撞、重力、流体等物理规律 多维度联合奖励:几何+物理+美学的统一奖励函数 在线强化学习:实时根据用户反馈优化生成质量 4. EFlow:高效少步视频生成器:从头训练的突破 论文: EFlow arXiv: 2603.27086 机构: Snap Research, Rutgers University 4.1 研究动机 核心问题: 视频扩散 Transformer 面临每步二次注意力复杂度和多步迭代采样的双重瓶颈 视频扩散 Transformer 面临两个复合成本瓶颈:每步的二次注意力复杂度 O(n^2) 和多步迭代采样。现有加速方法通常只解决其中一个——蒸馏减少步数但不降低单步成本,高效注意力降低单步成本但不减少步数。需要同时解决两个瓶颈的统一方案。 前序工作及局限: Consistency Models (2023):一步生成模型,但仅限图像且质量有限 Flow Matching (2023):条件流匹配框架,需要多步采样 Rectified Flow (2024):直线化流加速采样,但不降低单步成本 InstaFlow (2024):一步文生图,但无法扩展到视频 与前序工作的本质区别: 同时解决注意力复杂度(Gated L-G Attention + token dropping)和采样步数(solution-flow + MVA 正则化),从头训练无需教师模型 4.2 方法原理 EFlow 基于 solution-flow 目标,学习将时刻 t 的噪声状态直接映射到时刻 s(跨越多个扩散步)。核心创新有三:(1) Gated Local-Global Attention 将注意力分为局部窗口注意力和全局稀疏注意力两部分,通过门控机制融合,关键是设计为对 random token dropping 高度稳定——训练时随机丢弃 50-70% 的 token 而不影响质量;(2) Path-Drop Guided Training 在少步训练中用条件路径和无条件路径的随机丢弃替代传统 CFG(后者需要两次前向传播),将引导成本降为零;(3) Mean-Velocity Additivity 正则化器约束不同步数下的速度场之和等于总位移,确保 1-4 步生成的一致性。从头训练流程支持直接训练少步模型,无需先训练多步模型再蒸馏。 4.3 核心创新 提出 EFlow,同时解决注意力复杂度和采样步数两大瓶颈的统一框架 Gated Local-Global Attention:可丢弃 token 的混合注意力块,在激进随机 token 丢弃下保持稳定 Path-Drop Guided Training:用计算廉价的弱路径替代昂贵的 classifier-free guidance 目标 Mean-Velocity Additivity 正则化器:确保极低步数下的生成保真度 从头训练达到 45.3 倍推理加速,2.5 倍训练吞吐量提升 4.4 实验结果 在 Kinetics-600 和大规模 T2V 数据集上验证。4步生成质量与标准 50 步模型相当。训练吞吐量比标准 solution-flow 提升 2.5 倍。推理延迟降低 45.3 倍。生成质量 FVD 与多步基线竞争。 4.5 关键洞察 随机 token dropping 在极端比例下可能影响细节质量。Path-Drop Guided 是否在所有场景下都能替代 CFG 有待更多验证。从头训练的计算量仍然很大(虽然吞吐量提升了2.5倍)。目前主要在较短视频上验证。 技术演进定位: 首个同时解决两大瓶颈的统一加速框架,45.3 倍推理加速具有部署实用价值 可能的后续方向: 与视频编解码器融合:端到端优化编码-生成-解码管线 硬件适配:针对特定 GPU/NPU 架构定制注意力模式 实时生成:结合 PackForcing 等策略实现长视频实时生成 5. ShotStream:流式多镜头视频生成:实时交互式叙事 论文: ShotStream arXiv: 2603.25746 机构: CUHK, Kuaishou Technology 5.1 研究动机 核心问题: 多镜头视频生成的双向架构导致交互性差、延迟高,用户无法实时参与创作 多镜头视频生成是长叙事视频的关键,但当前双向扩散架构(如全序列并行生成)存在交互性差和延迟高的问题——用户无法在生成过程中动态调整叙事方向,且需要等待整个序列生成完成才能看到结果。 前序工作及局限: MovieFactory (2024):多镜头电影生成,但一次性生成全序列不可交互 VideoDirectorGPT (2024):LLM 驱动视频导演,规划与生成分离 Vlogger (2025):长视频博客生成,不支持流式输出 Kling (2025):快手视频生成模型,单镜头生成 与前序工作的本质区别: 首个因果流式多镜头架构,通过双缓存记忆和两阶段蒸馏实现 16 FPS 实时交互式叙事 5.2 方法原理 ShotStream 的流程分为训练和推理两阶段。训练阶段:(1) 将预训练 T2V 模型微调为双向 next-shot 生成器,学习根据前序镜头和文本提示生成下一个镜头;(2) 通过分布匹配蒸馏将双向教师蒸馏为因果学生模型。为解决因果自回归的两大挑战:(a) 镜头间一致性——引入全局上下文缓存(Global Context Cache),存储所有前序镜头的条件帧作为长程记忆;(b) 误差累积——设计两阶段蒸馏策略:第一阶段在真实历史上进行镜头内自强迫训练,第二阶段在自生成的历史上进行镜头间自强迫训练,逐步暴露给模型自身的生成误差。RoPE 不连续性指示器通过在全局和局部缓存之间插入位置编码跳跃来消除歧义。 5.3 核心创新 提出 ShotStream,首个因果多镜头视频生成架构,支持流式实时交互 将多镜头生成重构为 next-shot generation:基于历史镜头上下文生成下一个镜头 双缓存记忆机制:全局上下文缓存(镜头间一致性)+ 局部上下文缓存(镜头内一致性),RoPE 不连续性指示器区分两者 两阶段蒸馏策略:镜头内自强迫 → 镜头间自强迫,有效弥合训练-测试差距 单 GPU 达到 16 FPS 实时生成 5.4 实验结果 在 MovieGen 和 StoryBench 上评测。亚秒级延迟,单 GPU 16 FPS。多镜头连贯性指标(FCD、IC-LPIPS)与双向模型持平甚至更优。支持用户中途修改叙事提示,实现真正的交互式叙事。 5.5 关键洞察 因果架构天然信息量少于双向架构,长程一致性在超长叙事(10+镜头)下可能衰减。蒸馏质量依赖双向教师模型。全局上下文缓存随镜头数增长可能成为新的内存瓶颈。 技术演进定位: 开创了流式交互式视频叙事的新范式,是 AI 视频工具从离线走向实时的关键一步 可能的后续方向: 多角色交互:支持多角色多视角的复杂叙事 与 LLM 集成:用大语言模型实时规划叙事脉络 商业化部署:面向短视频平台和游戏行业的实时视频生成 6. Gloria:基于内容锚点的长时角色一致性视频生成 论文: Gloria arXiv: 2603.29931 机构: USTC (CVPR 2026) 6.1 研究动机 核心问题: 长时间角色视频生成中身份漂移严重,多视角和表情一致性难以保持 数字角色是现代媒体的核心,但生成长时间、多视角一致且表情丰富的角色视频仍是开放挑战。现有方法面临两类问题:要么参考信息不足导致身份漂移,要么使用非角色中心的记忆信息导致一致性次优。 前序工作及局限: IP-Adapter (2023):图像提示适配器,角色信息通过单图注入,长视频中易漂移 AnimateAnyone (2024):可控人物动画,但一致性限于短视频 MagicAnimate (2024):人物动画,依赖骨骼驱动不够灵活 ID-Animator (2025):身份保持动画,但多视角一致性不足 与前序工作的本质区别: 通过三类内容锚点(全局/视角/表情)提供稳定参考,超集锚定防止复制粘贴,实现 10+ 分钟级别的角色一致性 6.2 方法原理 Gloria 将角色视频生成类比为由外向内观察的场景。核心是通过一组紧凑的锚帧来描述角色的视觉属性:(1) 全局锚点——一个标准正面参考图,提供身份基准;(2) 视角锚点——来自不同视角的参考帧,覆盖角色的多视角外观;(3) 表情锚点——包含不同表情的帧,编码角色的表情动态范围。训练时,通过超集内容锚定策略——提供比目标片段更多的锚点信息(包括训练剪辑之外的帧),迫使模型学习从锚点中提取有用信息而非简单复制。同时使用 RoPE 位置偏移作为弱条件区分不同锚点帧,让模型知道哪些帧来自哪个视角。数据管线方面,从海量视频中自动检测角色区域、跟踪身份、提取关键帧作为锚点。 6.3 核心创新 提出内容锚点(Content Anchors)表示角色视觉属性:全局锚点(身份特征)+ 视角锚点(多视角外观)+ 表情锚点(表情动态) 超集内容锚定(Superset Content Anchoring):提供训练内和训练外的片段提示,防止模型简单复制粘贴 RoPE 作为弱条件:编码位置偏移来区分多个锚点帧,避免多参考冲突 可扩展的锚点提取管线:从海量视频中自动提取角色锚点 生成超过 10 分钟的一致性角色视频(CVPR 2026 接收) 6.4 实验结果 生成超过 10 分钟的长视频,保持角色身份、多视角外观和表情一致性。在人类评估中,ID 一致性和外观多样性均超过 SOTA 方法(包括 IP-Adapter、AnimateAnyone 等)。被 CVPR 2026 主会议接收。 6.5 关键洞察 锚点提取管线依赖角色检测和跟踪的准确性,遮挡严重的场景可能失败。超集锚定策略增加了训练复杂度。对非人物角色(如动漫、卡通角色)的泛化能力需要更多验证。10 分钟的一致性主要在受控场景下验证。 技术演进定位: 角色一致性视频生成的新标杆,锚点机制为长视频角色保持提供了有效范式(CVPR 2026) 可能的后续方向: 多角色一致性:同时保持多个角色的身份一致性 跨域角色:从真人扩展到动漫、卡通、3D 虚拟人等 实时角色创作:结合 ShotStream 等流式架构实现实时角色视频 横向对比与技术脉络总结 架构与任务对比 论文 核心架构 主要任务 关键创新 输入形式 OmniWeaving MLLM + DiT T2V/I2V/V2V 统一 推理驱动+组合数据 文本+多图+视频自由组合 PackForcing 自回归 DiT 长视频生成 三分区 KV-cache 文本 → 2分钟视频 VGGRPO DiT + LGM 几何一致性后训练 4D 潜空间几何奖励 文本 → 几何一致视频 EFlow Gated L-G DiT 高效少步生成 token dropping + MVA 文本 → 4步高质量视频 ShotStream 因果 DiT 流式多镜头叙事 双缓存+两阶段蒸馏 逐镜头文本 → 实时视频 Gloria DiT + 锚点 角色一致性生成 三类内容锚点 角色参考图 → 10min视频 训练范式与效率对比 论文 训练范式 外部监督 推理效率 核心瓶颈解决 OmniWeaving 三阶段渐进训练 组合数据+推理增强 标准 DiT 速度 任务碎片化 PackForcing 短视频训练+时间外推 无(5秒视频) 单 GPU 2分钟 内存爆炸(KV-cache→4GB) VGGRPO GRPO 后训练 LGM 伪标签 与基线相同 几何违反(相机稳定↑23%) EFlow Solution-flow 从头训练 无需教师模型 45.3× 加速 注意力O(n²)+多步采样 ShotStream 两阶段蒸馏 双向教师蒸馏 16 FPS 实时 延迟高+不可交互 Gloria 端到端锚点训练 自动锚点提取 标准 DiT 速度 长时身份漂移 核心技术趋势 趋势 1:视频生成从碎片化走向统一 OmniWeaving 证明了 MLLM+DiT 架构可以在单一框架内处理 T2V/I2V/V2V 等多种视频任务。推理驱动的数据构建策略使模型能理解复杂的多模态组合意图,这预示着未来的视频 AI 将是全能型的。 趋势 2:长视频生成突破内存瓶颈 PackForcing 的三分区 KV-cache 策略实现了 24 倍时间外推(5秒→2分钟),Gloria 的内容锚点将角色一致性推到 10 分钟级。两者共同表明长视频生成的关键不在于生成能力本身,而在于上下文管理和信息压缩。 趋势 3:GRPO 后训练成为视频质量提升的新范式 VGGRPO 将 GRPO 引入视频几何一致性优化,在 latent 空间计算奖励避免了昂贵的 RGB 解码。这延续了 LLM 领域 RLHF/DPO 的成功经验,后训练对齐正成为视频扩散模型质量提升的关键杠杆。 趋势 4:少步生成从蒸馏走向从头训练 EFlow 的 Gated L-G Attention + token dropping + MVA 正则化实现了 45.3 倍推理加速,且无需教师模型。这种从头训练少步模型的路线比蒸馏更灵活,可能成为效率优化的主流方案。 趋势 5:交互式实时生成开启视频创作新时代 ShotStream 的因果流式架构达到 16 FPS 实时生成,用户可以边看边改叙事方向。这标志着视频 AI 从「离线工具」向「实时合作者」的转变,对短视频平台和游戏行业有重要意义。 技术路线全景图 视频生成与编辑技术路线 ├── 统一框架 │ └── MLLM + DiT 双模块 → OmniWeaving(多模态组合+推理驱动) ├── 长视频生成 │ ├── KV-cache 压缩 → PackForcing(三分区策略,24x 外推) │ └── 角色一致性 → Gloria(三类内容锚点,10min 级别) ├── 质量对齐 │ └── 后训练 GRPO → VGGRPO(4D 潜空间几何奖励) ├── 推理效率 │ └── 从头训练少步 → EFlow(45.3x 加速,无需蒸馏) └── 交互式生成 └── 因果流式架构 → ShotStream(16 FPS 实时多镜头叙事) 总结与展望 本期专题的 6 篇论文共同描绘了视频生成与编辑领域的前沿全景图。从统一框架(OmniWeaving)到长视频突破(PackForcing/Gloria),从物理对齐(VGGRPO)到效率革命(EFlow),再到交互式创作(ShotStream),视频生成正在从技术验证走向实际可用。几个值得关注的未来方向: 统一+长视频:将 PackForcing 的 KV-cache 策略融入 OmniWeaving 等全能框架 多维度后训练:将几何、物理、美学奖励统一到一个 GRPO 框架中 实时+角色:将 Gloria 的锚点机制与 ShotStream 的流式架构结合,实现实时角色叙事 端到端效率:将 EFlow 的少步生成与 PackForcing 的内存优化联合使用 人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月29日 — 2026年4月4日 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
-
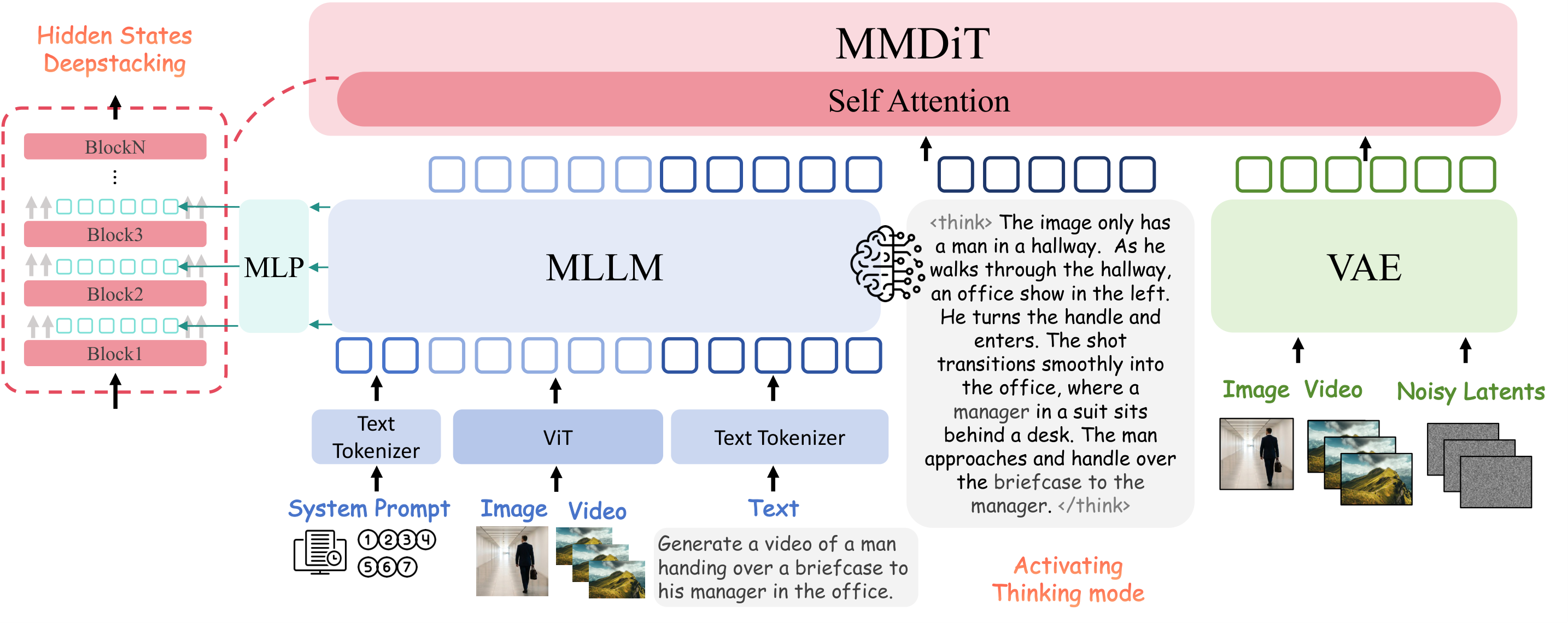
AIGC 每日速读|2026-04-03|Dynin-Omni|OmniVoice AIGC 视觉生成领域 · 每日论文解读 (2026-04-03) 人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇 今日核心看点 全模态统一 掩码扩散 600+语言TTS Mamba-TTS 智能调色 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成理解一体化模型 — 3 篇 音频/语音生成 — 4 篇 图片生成与编辑 — 2 篇 生成模型评测 — 1 篇 重点论文深度解读 1. Dynin-Omni 全模态统一大扩散语言模型:首个掩码扩散全模态基础模型 | Seoul National University (AIDAS Lab) | arXiv:2604.00007 关键词: 全模态统一, 掩码扩散, 文本/图像/视频/语音, 理解+生成一体化, 模态解纠缠合并 研究动机 核心问题: 如何在单一架构中原生统一文本、图像、视频、语音的理解与生成,避免自回归序列化瓶颈和组合式模型的外部依赖 当前全模态统一模型存在两条路线:自回归模型需要序列化异构模态导致效率低下,组合式模型依赖外部解码器增加系统复杂度。Dynin-Omni 提出用原生掩码扩散在共享离散token空间上统一文本、图像、视频、语音的理解与生成,实现真正的 any-to-any 建模。 前序工作及局限: LLaDA:纯文本掩码扩散语言模型,证明掩码扩散可做文本生成但不支持多模态 MMaDA:扩展到文本+图像统一,但缺少视频理解和语音能力 Qwen2.5-Omni:自回归全模态模型,但序列化异构模态效率低下 Seed-X/HyperCLOVAX:组合式统一模型,依赖外部模态特定生成器增加复杂度 与前序工作的本质区别: 用原生掩码扩散替代自回归或组合式架构,通过共享离散token空间和模态感知解码策略实现真正的any-to-any建模 方法原理 Dynin-Omni 的核心是将所有模态(文本、图像、视频、语音)映射到统一的离散token空间,通过掩码扩散进行训练和推理。文本使用标准分词器(词汇量126K),图像使用MAGVIT-v2风格VQ分词器(码本8192),视频复用图像分词器处理均匀采样帧,语音使用EMOVA S2U编码器+FSQ量化(码本4096)。训练分三阶段:阶段1通过视频字幕/ASR/TTS任务对齐新模态,阶段2引入模态解纠缠合并(Modality-Disentangled Merging)避免灾难性遗忘后进行全模态SFT,阶段3引入CoT推理数据和高分辨率图像提升高级能力。推理时采用模态感知解码策略:文本和语音用块状并行解码,图像用全并行解码,配合置信度重掩码机制迭代细化。 核心创新 首个原生掩码扩散全模态基础模型,单一架构统一文本/图像/视频/语音的理解与生成 模态解纠缠合并(Modality-Disentangled Merging)策略,解决多阶段训练中的灾难性遗忘 全模态离散token空间统一设计,无需外部模态特定生成器 模态感知解码策略:图像全并行、文本/语音块状并行,兼顾质量和效率 个基准测试全面超越现有开源统一模型,与模态特定专家系统竞争力相当 实验结果 在19个多模态基准上全面评测:文本推理 GSM8K 87.6、MATH 49.6;图像理解 MME-P 1733.6;视频理解 VideoMME 61.4;语音识别 LibriSpeech test-clean WER 2.1;图像生成 GenEval 0.87、DPG-Bench 86.3;图像编辑 ImgEdit 3.77;TTS WER 2.1。全面超越 HyperCLOVAX-Omni、Show-o2、BAGLE 等同类统一模型。消融实验证明模态解纠缠合并策略在第一阶段显著降低了各任务的训练损失。 图表详解 全模态架构对比:三种统一建模范式 对比了三种全模态建模范式:(a)感知中心模型如Qwen2.5-omni只做理解不做生成;(b)组合式模型如Seed-X需要外部生成器;(c)Dynin-Omni的原生统一模型,单一LLM同时支持理解和生成任务,无需外部模态特定解码器。 全模态性能对比:理解与生成双维度 展示Dynin-Omni在7个核心基准上与HyperCLOVAX-Omni、Qwen2.5-Omni、Show-o2、BAGLE的对比。理解维度:GSM8K 87.6、MME 1734、VideoMME 61.4;生成维度:GenEval 87.0、ImgEdit 3.77、TTS 97.9。 采样步数消融:不同任务的步数-性能曲线 四个子图展示GSM8K、GenEval、DPGBench、ImgEdit随采样步数的性能变化。文本推理需512+步才收敛,图像生成32-64步饱和,图像编辑8-32步即可保持强劲性能。 批判性点评 新颖性: 首个原生掩码扩散全模态基础模型,模态解纠缠合并策略是实用创新。但掩码扩散建模本身借鉴LLaDA/MMaDA,增量创新主要在模态扩展和训练策略 可复现性: 基于开源LLaDA架构扩展,训练策略描述清晰。但需要大规模多模态数据和算力,完全复现有门槛 影响力: 证明掩码扩散作为全模态统一范式的可行性,为实时全模态系统和具身智能体提供基础。图像生成质量(GenEval 0.87)仍落后FLUX.1(0.95+),视频仅支持理解不支持生成 深度点评: Dynin-Omni — 掩码扩散全模态新范式 — 首次在单一架构中用掩码扩散统一文本/图像/视频/语音的理解与生成。模态解纠缠合并有效缓解灾难性遗忘。不足:图像生成落后专用模型,视频仅支持理解 OmniVoice — 600+语言零样本TTS突破 — 扩散语言模型架构直接文本→声学token,跳过语义中间表示。58万小时全开源数据训练,语言覆盖面史上最广 MambaVoiceCloning — 纯SSM条件TTS — 首个完全移除注意力机制的扩散TTS条件路径,编码器仅21M参数、吞吐量提升1.6x。ICLR 2026,但扩散主干仍是延迟瓶颈 技术演进定位: 全模态统一建模的第三条路线——原生掩码扩散范式,证明了其可行性和竞争力 可能的后续方向: 视频生成能力扩展(当前仅支持理解) 图像生成质量追赶FLUX.1等专用模型 文本推理步数优化(当前需512+步) 实时全模态交互系统和具身智能体 其余论文速览 1. OmniVoice OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models 关键词: TTS·600+语言·扩散语言模型·零样本·多码本 贡献: 首个支持600+语言的大规模零样本TTS模型,直接文本→多码本声学token映射,跳过语义中间表示 效果: 基于58.1万小时开源多语言数据训练,中英文及多语种基准SOTA。全码本随机掩码策略+预训练LLM初始化确保清晰度 2. MambaVoiceCloning MambaVoiceCloning: Efficient and Expressive TTS via State-Space Modeling and Diffusion Control 关键词: TTS·Mamba/SSM·声音克隆·线性复杂度·ICLR 2026 贡献: 首个完全基于SSM(无注意力/RNN)条件路径的扩散TTS系统,ICLR 2026 效果: 编码器参数仅21M,吞吐量提升1.6x。MOS/CMOS/F0 RMSE/MCD均优于StyleTTS2和VITS 3. AceTone AceTone: Bridging Words and Colors for Conditional Image Grading 关键词: 调色·3D-LUT·VQ-VAE·RLHF·CVPR 2026 贡献: 首个统一多模态条件调色方法,文本/参考图→3D-LUT生成,CVPR 2026 效果: VQ-VAE将3x32^3 LUT压缩为64离散token(deltaE<2)。800K数据集+VLM预测+RL对齐,LPIPS提升50% 4. RawGen RawGen: Learning Camera Raw Image Generation 关键词: Raw图像生成·逆ISP·扩散模型·相机适配 贡献: 首个基于扩散的text-to-raw和sRGB-to-raw图像生成框架,支持任意目标相机 效果: 利用大规模sRGB扩散先验+专用解码器,多对一逆ISP数据集训练,显著优于传统逆ISP方法 5. DuoTok DuoTok: Source-Aware Dual-Track Tokenization for Multi-Track Music Language Modeling 关键词: 音乐生成·Tokenizer·双轨·扩散解码·语言建模 贡献: 源感知双轨音乐Tokenizer,分阶段解纠缠平衡保真度/可预测性/跨轨对应 效果: 0.75kbps比特率下竞争力重建+最低cnBPT,扩散解码器重建高频细节 6. Diff-VS Diff-VS: Efficient Audio-Aware Diffusion U-Net for Vocals Separation 关键词: 人声分离·扩散U-Net·EDM·STFT·ICASSP 2026 贡献: 基于EDM框架的生成式人声分离模型,处理复数STFT频谱图,ICASSP 2026 效果: 客观指标匹配判别式基线,感知质量接近SOTA系统 7. MMaDA-VLA MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation 关键词: VLA·扩散模型·多模态统一·指令跟随·西湖大学 贡献: 统一多模态指令和生成的大型扩散VLA模型(西湖大学) 效果: 单一扩散模型框架同时处理视觉理解、语言生成和动作预测 8. ProsodyEval Measuring Prosody Diversity in Zero-Shot TTS: A New Metric, Benchmark, and Exploration 关键词: TTS评测·韵律多样性·DS-WED·Seed-TTS·基准测试 贡献: 首个零样本TTS韵律多样性量化评测框架,提出DS-WED新指标 效果: ProsodyEval数据集(1000样本+2000 PMOS),发现大型音频语言模型在韵律变化捕捉仍有局限 9. ViGoR-Bench ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners? 关键词: 生成模型评测·视觉推理·I2I·视频·压力测试 贡献: 视觉生成模型推理能力统一评测框架,跨I2I/视频双轨评估+证据锚定自动评判 效果: 测试20+领先模型,揭示SOTA系统仍存在显著推理缺陷(美团等机构) 趋势观察 掩码扩散崛起 — Dynin-Omni证明掩码扩散可作为全模态统一建模的新范式,与自回归模型分庭抗礼 TTS走向极致效率 — MambaVoiceCloning用纯SSM替代所有注意力机制,OmniVoice覆盖600+语言,效率与覆盖面双突破 生成模型走向物理/审美对齐 — AceTone用RLHF对齐调色审美,RawGen生成物理一致的Raw图像,生成不再只追求逼真 人工智能炼丹师 整理 | 2026-04-03 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
-
AIGC 每日速读|2026-04-02|MacTok 64-token SOTA AIGC 视觉生成领域 · 每日论文解读 (2026-04-02) 人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇 今日核心看点 MacTok 64-token SOTA图像生成 LongCat-Next 美团统一多模态 VecAttention 2.65x视频加速 GEMS 6B超越SOTA Agent生成 OmniRoam 全景长视频漫游 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 图像Tokenizer: MacTok (64-token SOTA, CVPR 2026) 统一多模态: LongCat-Next (美团,离散原生自回归) 视频生成: VGGRPO (4D几何一致), OmniRoam (全景漫游) 视频编辑: CutClaw (长视频剪辑), TokenDial (属性控制) 推理加速: VecAttention (CVPR 2026), MPDiT (多Patch高效DiT) Agent生成: GEMS (6B超越SOTA) | 评测: SLVMEval (CVPR 2026) 重点论文深度解读 1. MacTok: Robust Continuous Tokenization for Image Generation 掩码增强1D连续Tokenizer——仅64/128 tokens实现SOTA图像生成, CVPR 2026 | East China Normal University / Shanghai AI Lab | arXiv:2603.29634 关键词: 连续Tokenizer, 后验崩溃, 掩码增强, DINO语义引导, 图像生成 研究动机 核心问题: 连续图像Tokenizer在极少token(64/128个)下发生后验崩溃,编码器无法有效编码信息到高度压缩的潜在空间 连续图像Tokenizer通过变分框架学习平滑结构化的潜在表示,是高效视觉生成的核心组件。然而,当使用极少量token(如64或128个)时,基于KL正则化的变分方法普遍面临后验崩溃(posterior collapse)问题——编码器无法将有意义的信息编码进高度压缩的潜在空间,导致所有输入映射到近似相同的潜在分布。这意味着token数量与生成质量之间存在一个痛苦的权衡:要么使用大量token保证质量(如256/512个),要么接受极低token数带来的严重质量下降。MacTok旨在打破这一权衡,实现仅用64/128 tokens就达到甚至超越高token数方案的生成质量。 前序工作及局限: VQ-VAE / VQGAN (2020-22):离散图像Tokenizer,通常需要数百到上千个token,码本利用率和生成质量受限 SD-VAE (2022-23):连续变分编码器,质量优于离散方案,但潜在空间维度仍较高(256-4096 tokens) TiTok (2024):尝试将连续token数压缩到128个,但在更低token数时面临后验崩溃 REPA (2025):引入表示对齐思路增强Tokenizer,但未系统解决极低token数下的崩溃问题 与前序工作的本质区别: MacTok系统性组合双重掩码策略(随机+DINO语义)和全局-局部表示对齐,首次在64 tokens这一极端压缩级别实现SOTA图像生成质量(gFID 1.44) 方法原理 MacTok(Masked Augmenting 1D Continuous Tokenizer)通过三个核心机制解决后验崩溃问题:(1) 双重掩码策略:随机掩码(Random Masking)作为正则化手段防止编码器走捷径,DINO引导的语义掩码(Semantic Masking)强调图像中信息量最高的区域——利用预训练DINO模型的注意力图识别语义重要区域,迫使编码器从不完整的视觉输入中提取鲁棒语义。(2) 全局-局部表示对齐(Global-Local Representation Alignment):全局对齐确保整体语义保留,局部对齐保证细粒度判别信息不丢失,两者协同在高度压缩的1D潜在空间中维持丰富的表征能力。(3) 1D连续潜在空间设计:将图像压缩为极紧凑的1D token序列(仅64或128个token),配合上述掩码和对齐机制确保信息密度。MacTok与SiT-XL(Scalable Interpolant Transformer)配合使用进行图像生成。 核心创新 首次系统解决连续图像Tokenizer在极低token数下的后验崩溃问题 双重掩码策略创新:随机掩码正则化+DINO引导语义掩码,迫使编码器学习鲁棒表征 全局-局部表示对齐机制,在1D高压缩潜在空间中保留判别信息 仅用64 tokens实现256x256 gFID 1.44,128 tokens在512x512达到SOTA gFID 1.52 token使用量减少高达64倍,大幅降低生成模型的计算和内存开销 实验结果 在ImageNet上配合SiT-XL模型评测:256x256分辨率下,MacTok仅用64 tokens即达到gFID 1.44,具有强竞争力。512x512分辨率下,MacTok用128 tokens达到gFID 1.52,为当时的SOTA水平。token使用量相比传统方案减少高达64倍(传统方案通常需要256-4096个tokens)。消融实验验证了双重掩码策略和表示对齐的各自贡献:去除语义掩码后gFID显著下降,去除全局对齐后判别信息损失明显。与TiTok、REPA等连续Tokenizer基线相比,MacTok在相同token预算下全面领先。 图表详解 掩码策略对比——从后验崩溃到有效编码 这张图直观展示了掩码策略如何解决后验崩溃问题。图中对比了三种设置:上方是无掩码的KL-VAE,中间是潜在空间掩码,下方是MacTok的图像空间掩码。右侧是对应的潜在空间t-SNE可视化。无掩码时(上方),潜在空间严重崩溃——所有图像被映射到近似相同的区域(红色团簇),编码器完全放弃了编码有意义的信息。潜在空间掩码(中间)虽然有改善但仍不理想。MacTok的图像空间掩码(下方)成功解决了崩溃问题——潜在空间中不同类别的图像被映射到分散的、有区分度的区域(多色散布)。这证明了在图像输入端施加掩码是防止后验崩溃最有效的策略。绿色笑脸和红色哭脸直观标注了每种方案的效果好坏。 gFID训练曲线对比——MacTok收敛速度与最终质量领先 这张图展示了MacTok与REPA、SoftVQ-VAE等基线在ImageNet上的gFID随训练步数变化曲线。横轴是Training Steps(从50k到500k),纵轴是gFID(越低越好)。MacTok-128(橙色线)在所有训练阶段都保持最低的gFID,最终在500k步时达到约14的极低gFID。SoftVQ-VAE(深蓝线)和REPA(浅蓝线)虽然也在持续下降,但最终gFID分别约20和21。MacTok-128 w/o RA(去除表示对齐)则明显更差,约36,证明表示对齐的关键贡献。图中标注了6.25x Speedup——MacTok在100k步就达到了其他方法500k步的性能,训练效率提升了6.25倍。这对资源有限的团队来说意义重大。 消融实验:gFID与分类准确率的权衡分析 这张消融实验柱状图展示了MacTok各配置的gFID(柱状)和分类准确率Accuracy(折线)对比。MacTok-128(最左)达到最低gFID约14和最高准确率约52%,是最优配置。MacTok-64紧随其后,gFID约15,准确率约53%,证明极低token数也能保持高质量。SoftVQ-VAE作为基线,gFID约21,准确率约44%,明显不如MacTok。关键对比:MacTok-128 w/o RA(去除表示对齐)的gFID骤升至37,准确率暴跌到约31%,MacTok-64 w/o RA更差,gFID接近39。这组数据明确证明了表示对齐(Representation Alignment)是MacTok成功的关键——没有全局-局部对齐,即使有掩码策略也无法在极低token数下保持质量。gFID和Accuracy的双重下降说明去除对齐后编码器不仅生成质量差,连语义判别能力也大幅退化。 MacTok生成样例展示(256x256 & 512x512) 这组图展示了MacTok配合SiT-XL在ImageNet各类别上的生成样例。可以看到仅用64个连续token,模型就能生成高度逼真的图像——动物(如金毛犬、猎豹)的毛发纹理细腻清晰,自然场景(如瀑布、花田)的光影层次丰富,人造物品(如跑车、教堂)的几何结构准确。这些样例视觉质量与使用数百个token的方案几乎无法区分,充分证明了MacTok在极高压缩比下保持生成质量的能力。特别值得注意的是细节部分——如动物眼睛的反光、建筑的对称性——这些在后验崩溃情况下通常最先丢失的细节都被很好地保留了。 批判性点评 新颖性: 核心贡献是首次系统解决连续Tokenizer在极低token数下的后验崩溃——双重掩码(随机+DINO语义)+全局-局部表示对齐的组合方案设计精巧。DINO语义引导是亮点——利用预训练模型知识优化Tokenizer训练。 可复现性: 方法组件清晰(两种掩码+两种对齐),超参数有详细消融。依赖预训练DINO模型但该模型公开可用。ImageNet实验可复现。主要不确定性在于DINO注意力图对非典型图像的适用性。 影响力: 64倍token压缩的工业价值极大——直接缩短扩散模型序列长度,大幅降低训练和推理成本。如能扩展到T2I和视频领域,将成为高效视觉生成的基础组件。CVPR 2026接收验证了学术影响力。 深度点评: MacTok: 64-token极限压缩 — 仅64个连续token达到SOTA图像生成(gFID 1.44),token量减少64倍。双重掩码+表示对齐解决后验崩溃。核心问题:缺少T2I验证和DINO依赖。 Agent生成持续爆发 — GEMS让6B模型超越SOTA Nano Banana 2,CutClaw多智能体自动剪辑数小时视频。继Unify-Agent后,Agent范式全面进入生成领域。 视频推理加速:2.65x — VecAttention发现向量级稀疏模式实现2.65x加速(CVPR 2026),MPDiT多Patch设计降50% GFLOPs。高效化是视频生成落地的关键。 技术演进定位: 处于图像Tokenizer从高冗余向极致压缩演进的突破点——64倍token压缩使得高效视觉生成从理论走向实践 可能的后续方向: 将极低token方案扩展到T2I(文本到图像)等复杂生成任务 探索更灵活的语义引导机制替代固定的DINO模型 将1D连续token方案应用于视频生成的时序建模 研究MacTok与自回归视觉模型(如LlamaGen)的集成 其余论文速览 1. VGGRPO Towards World-Consistent Video Generation with 4D Latent Reward Unknown (Multi-institution) 关键词: 视频生成·几何一致·GRPO·4D奖励·潜在空间 贡献: 提出VGGRPO框架,通过潜在几何模型(LGM)连接视频扩散潜在空间与几何基础模型,直接从潜在空间解码场景几何实现4D几何一致的视频后训练,克服先前方法仅限静态场景的局限 效果: 消除昂贵的VAE解码,相机稳定性和几何一致性显著提升,首次支持动态场景几何引导 2. LongCat-Next Lexicalizing Modalities as Discrete Tokens — Meituan Unified Multimodal Model Meituan (美团) 关键词: 离散自回归·多模态统一·任意分辨率·美团·开源 贡献: 提出离散原生自回归框架,在共享离散空间表示文本/视觉/音频多模态,核心创新是离散原生任意分辨率ViT实现任意分辨率分词/解词,解决离散视觉建模在理解任务上的性能天花板 效果: 单一自回归目标统一观察/绘画/对话,多模态基准全面强劲,已开源模型和Tokenizer 3. GEMS Agent-Native Multimodal Generation with Memory and Skills Unknown 关键词: Agent生成·闭环优化·记忆系统·技能扩展·6B超越SOTA 贡献: 提出Agent-Native多模态生成框架,包含Agent Loop(闭环迭代优化)、Agent Memory(轨迹级持久记忆)和Agent Skill(可扩展领域专业知识),突破基础模型固有局限 效果: 6B模型Z-Image-Turbo在GenEval2上超越SOTA Nano Banana 2,证明智能体控制可大幅扩展模型能力 4. OmniRoam World Wandering via Long-Horizon Panoramic Video Generation Unknown (Multi-institution) 关键词: 全景视频·长距生成·轨迹控制·场景漫游·3D重建 贡献: 提出可控全景视频生成框架,利用全景表示的丰富场景覆盖和固有时空一致性,通过预览-精炼两阶段实现长距场景漫游,支持实时视频生成和3D重建扩展 效果: 在视觉质量/可控性/长期场景一致性上全面优于SOTA,支持实时生成和3D重建 5. CutClaw Agentic Hours-Long Video Editing via Music Synchronization GVC Lab 关键词: 视频编辑·音乐同步·多智能体·长视频·自动剪辑 贡献: 提出多智能体框架自动将数小时原始素材剪辑为音乐同步短视频,包含分层多模态分解、编剧Agent(叙事一致性)、编辑Agent+审查Agent(美学/语义标准协作优化) 效果: 在节奏对齐和视频质量上显著超越SOTA基线,大幅减少视频编辑人工时间 6. VecAttention Vector-wise Sparse Attention for Accelerating Long Context Inference Unknown 关键词: 稀疏注意力·向量选择·视频加速·CVPR 2026·2.65x加速 贡献: 发现视频注意力图存在强垂直向量稀疏模式,提出逐向量稀疏注意力框架,通过轻量级重要向量选择+优化稀疏注意力内核动态处理信息向量,CVPR 2026 效果: 比全注意力加速2.65倍,比SOTA稀疏方法加速1.83倍,精度与全注意力相当 7. MPDiT Multi-Patch Global-to-Local Transformer for Efficient Flow Matching and Diffusion Rutgers University 关键词: 高效DiT·多Patch·全局到局部·50%加速·开源 贡献: 提出多Patch DiT设计:早期模块用大Patch捕获全局上下文,后期模块用小Patch精炼局部细节,打破DiT各向同性设计的计算冗余,另提出改进的时间和类别嵌入加速收敛 效果: GFLOPs计算成本降低50%,生成性能保持良好,已开源代码 8. TokenDial Continuous Attribute Control in Text-to-Video via Spatiotemporal Token Offsets Adobe Research / CMU 关键词: 视频属性控制·token偏移·滑块式编辑·免训练·Adobe 贡献: 提出通过时空token偏移实现T2V模型的连续滑块式属性控制,发现中间token空间中的加性偏移形成语义控制方向,无需重训练即可调节外观和运动属性 效果: 比SOTA基线实现更强可控性和更高编辑质量,人类研究验证有效性 9. SLVMEval Synthetic Meta Evaluation Benchmark for Text-to-Long Video Generation Unknown 关键词: 长视频评测·元评估·合成降质·CVPR 2026·3小时视频 贡献: 提出长视频生成元评估基准(最长10486秒约3小时),通过合成降质创建控制的质量对比视频对,覆盖10个评估维度,用众包筛选建立可靠测试平台,CVPR 2026 效果: 人类准确率84.7%-96.8%,揭示9/10维度现有评估系统不及人类,暴露长视频评估短板 趋势观察 Token压缩极限突破 — MacTok用仅64个连续token达到SOTA图像生成质量(gFID 1.44),token使用量减少64倍。双重掩码+表示对齐的组合策略有效解决了后验崩溃,为高效生成打开新空间。 Agent范式在生成领域全面铺开 — GEMS的Agent-Native框架让6B模型超越SOTA,CutClaw的多智能体将数小时素材自动剪辑。继昨天的Unify-Agent后,Agent正在从理解领域向生成领域快速渗透。 视频模型推理加速竞赛升温 — VecAttention发现向量级稀疏模式实现2.65x加速(CVPR 2026),MPDiT用多Patch设计降低50% GFLOPs。高效化是视频生成落地的关键瓶颈。 统一多模态模型持续进化 — 美团LongCat-Next在共享离散空间统一文本/视觉/音频,解决离散视觉建模的理解性能天花板。88位作者的工业级投入标志着统一模型走向成熟。 视频生成评测走向严格化 — SLVMEval首次系统评测长达3小时的视频生成质量,揭示现有自动评估在9/10维度不及人类。VGGRPO则将4D几何一致性引入视频后训练。 人工智能炼丹师 整理 | 2026-04-02
-
AIGC 周末专题|2026-03-28|视觉生成后训练与偏好优化 AIGC 视觉生成领域 · 每日论文解读 (2026-03-28) 人工智能炼丹师 整理 | 共 9 篇论文 | 重点深度解读 8 篇 今日核心看点 UniGRPO 统一后训练 FIRM 忠实奖励建模 EditHF-1M 29M偏好对 MV-GRPO 多视图评估 VIGOR 视频几何奖励 VHS CVPR2026 推理扩展 TATAR 不对称奖励 SeGroS 语义锚定监督 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 9 篇,重点解读 8 篇。 方向分布: 后训练框架: UniGRPO(统一多模态后训练), MV-GRPO(多视图GRPO), SeGroS(语义锚定监督) 奖励模型与评估: FIRM(编辑+生成), EditHF-1M(29M偏好对), VIGOR(视频几何), TATAR(质量+美学), VHS(潜在验证器) 重点论文深度解读 1. UniGRPO 统一策略优化实现推理驱动视觉生成 | 上海AI Lab/港中文 | Shanghai AI Lab, CUHK | arXiv:2603.23500 关键词: 统一后训练, GRPO, 推理驱动生成, Flow Matching, 交错生成 研究动机 核心问题: 统一多模态模型(自回归文本+Flow Matching图像)缺乏后训练方法 统一多模态模型正朝着交错生成(interleaved generation)发展——自回归建模文本、Flow Matching 建模图像。然而,如何对这种混合架构进行强化学习后训练?现有 GRPO 只针对单一模态,且 FlowGRPO 依赖 Classifier-Free Guidance(CFG)导致轨迹分叉,难以扩展到多轮交互场景。核心挑战是:如何在一个统一的 RL 框架中同时优化推理(文本)和生成(图像)两个阶段的策略? 前序工作及局限: GRPO (DeepSeek 2025):大语言模型的群体相对策略优化 FlowGRPO (2026):将GRPO扩展到Flow Matching视觉生成 Transfusion (Meta 2024):统一自回归+扩散的多模态架构 与前序工作的本质区别: UniGRPO首次统一优化文本推理和图像合成,消除CFG保持线性轨迹 方法原理 UniGRPO 将多模态生成建模为稀疏终端奖励的马尔可夫决策过程(MDP),联合优化文本推理和图像合成两个阶段。框架采用极简设计原则:(1) 文本推理阶段使用标准 GRPO,让模型学会扩展用户提示为详细推理链;(2) 图像合成阶段使用 FlowGRPO,在 Flow Matching 的速度场上进行策略优化。关键改进有两点:第一,消除 Classifier-Free Guidance(CFG),保持线性、未分叉的生成轨迹,这对多轮交互和多条件生成(如编辑)至关重要;第二,将标准的潜空间 KL 惩罚替换为直接作用于速度场的 MSE 惩罚,提供更鲁棒的正则化信号,有效缓解 Reward Hacking。两种模态的优化通过统一的 MDP 框架无缝集成。 核心创新 首个统一的多模态生成后训练框架:联合优化自回归文本推理和 Flow Matching 图像合成 消除 CFG 保持线性轨迹:使框架可扩展到多轮交错生成场景 速度场 MSE 正则化替代 KL 惩罚:直接在速度场空间约束策略偏移,更鲁棒地防止 Reward Hacking 极简设计原则:无缝集成标准 GRPO + FlowGRPO,避免过度工程化 为完全交错式多模态模型的后训练建立了可扩展基线 实验结果 实验表明,UniGRPO 的统一训练方案显著提高了推理驱动图像生成的质量。在标准评估基准上,文本推理质量和图像生成保真度均获得一致提升。消除 CFG 后的模型在多轮交互场景中表现更稳定,MSE 速度场正则化有效避免了训练后期的 Reward Hacking 现象。该框架为未来完全交错模型的后训练提供了鲁棒且可扩展的基线。 批判性点评 新颖性: 首次将GRPO统一应用于文本推理+图像Flow Matching的交错生成,消除CFG保持线性轨迹的设计优雅且实用。但概念上是GRPO和FlowGRPO的自然组合,原创突破性有限。 可复现性: 基于开源Janus-Pro-7B模型,论文提供了完整的算法伪代码和超参数设置。但训练使用80张H100,资源门槛较高。代码和模型权重已开源。 影响力: 为统一多模态模型的后训练建立了可扩展基线,对Chameleon、Transfusion等架构有直接参考价值。极简设计降低了社区跟进门槛。 深度点评: GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径 技术演进定位: 交错生成后训练的可扩展基线 可能的后续方向: 多轮交互场景的后训练 视频+音频交错生成 在线持续学习 2. FIRM 忠实图像奖励建模:鲁棒奖励模型+RL优化 | 上交/港中文/上海AI Lab | SJTU, CUHK, Shanghai AI Lab | arXiv:2603.12247 关键词: 奖励模型, 图像编辑, 文生图, RLHF, 开源数据集 研究动机 核心问题: 图像编辑和生成的奖励模型存在幻觉,评分不忠实 RL 已成为增强图像编辑和文生图生成的重要范式,但现有奖励模型存在严重的幻觉问题——产生噪声评分,误导优化方向。核心痛点是:缺乏专门针对图像编辑和生成的大规模高质量评分数据集,导致奖励模型无法提供忠实、准确的反馈信号。 前序工作及局限: ImageReward (Xu 2023):首个文生图人类偏好奖励模型 HPSv2 (Wu 2023):人类偏好评分模型v2 PickScore (Kirstain 2023):Pick-a-Pic数据驱动的偏好评分 与前序工作的本质区别: FIRM专门解决编辑+生成双赛道的忠实性,提出Base-and-Bonus奖励策略 方法原理 FIRM 框架从数据、模型、策略三层解决奖励模型的忠实性问题:(1) 数据层:设计专业化数据整理管线,构建 FIRM-Edit-370K(编辑评分数据,评估执行力+一致性)和 FIRM-Gen-293K(生成评分数据,评估指令遵循),总计 66.3 万条评分数据;(2) 模型层:基于上述数据训练 FIRM-Edit-8B 和 FIRM-Gen-8B 两个 8B 参数的专业奖励模型,并发布 FIRM-Bench 评测基准;(3) 策略层:提出 Base-and-Bonus 奖励策略——对编辑任务使用 CME(Consistency-Modulated Execution,一致性调制执行),对生成任务使用 QMA(Quality-Modulated Alignment,质量调制对齐),巧妙平衡相互竞争的优化目标。 核心创新 首个系统性解决图像编辑和生成奖励建模的综合框架 发布 FIRM-Edit-370K + FIRM-Gen-293K 全套开源评分数据集 Base-and-Bonus 奖励策略:CME 平衡编辑的执行力与一致性,QMA 平衡生成的质量与对齐 FIRM-Bench 编辑+生成批评评测基准 消除奖励幻觉:比现有通用指标更准确匹配人类判断 实验结果 FIRM 系列奖励模型在 FIRM-Bench 上显著超越现有指标对人类判断的匹配度。基于 FIRM 的 RL 优化产出 FIRM-Qwen-Edit 和 FIRM-SD3.5,在忠实度和指令遵循方面确立了新标准。所有数据集、模型和代码均已公开发布。 批判性点评 新颖性: 从数据-模型-策略三层全栈构建忠实奖励体系,Base-and-Bonus策略巧妙解决了编辑和生成任务间的优化矛盾。CME和QMA两个具体策略设计有针对性且有理论支撑。 可复现性: 全套数据集(FIRM-Edit 37万+FIRM-Gen 29.3万)、模型权重和代码均已开源。基于InternVL2-8B训练,硬件需求可控。社区复现门槛低。 影响力: 视觉生成RLHF奖励建模的新标准。全栈开源的做法对社区价值巨大。Base-and-Bonus策略可泛化到其他多任务RL场景。 深度点评: GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径 技术演进定位: 视觉生成RLHF奖励建模的新标准 可能的后续方向: 视频编辑奖励 3D生成奖励 多目标帕累托优化 3. EditHF-1M 百万级图像编辑人类偏好反馈数据集 | 上交 | Shanghai Jiao Tong University | arXiv:2603.14916 关键词: 编辑偏好数据集, 29M偏好对, MLLM评估模型, 奖励信号, RL优化 研究动机 核心问题: 图像编辑缺乏大规模多维度人类偏好数据集 文本引导的图像编辑取得了显著进展,但编辑结果仍常出现伪影、意外编辑、不美观等问题。现有编辑评估方法缺乏大规模可扩展的评估模型,这严重限制了编辑领域人类反馈奖励模型的发展。核心瓶颈是:缺少百万级规模、多维度评估的人类偏好数据集。 前序工作及局限: InstructPix2Pix (Brooks 2023):GPT-4生成编辑指令,数据规模有限 MagicBrush (Zhang 2024):人工标注编辑数据集,规模较小 FIRM-Edit-370K:专业化编辑评分数据 与前序工作的本质区别: EditHF-1M将规模推至29M偏好对,三维度(质量+对齐+保持)评估体系 方法原理 EditHF-1M 体系包含三个层次:(1) 数据集层:构建百万级图像编辑偏好数据集,包含超过 2900 万人类偏好对和 14.8 万人类主观评分(MOS),均从视觉质量、指令对齐、属性保持三个维度进行评估;(2) 模型层:基于 EditHF-1M 训练 EditHF——一个基于多模态大语言模型(MLLM)的评估模型,提供与人类对齐的编辑反馈;(3) 应用层:引入 EditHF-Reward,将 EditHF 作为奖励信号,通过强化学习优化文本引导图像编辑模型 Qwen-Image-Edit。 核心创新 迄今最大的图像编辑偏好数据集:29M偏好对 + 148K MOS评分 三维度评估体系:视觉质量 + 指令对齐 + 属性保持 基于MLLM的编辑评估模型 EditHF EditHF-Reward:将评估模型转化为RL奖励信号 在 Qwen-Image-Edit 上验证显著性能提升 实验结果 EditHF 在与人类偏好对齐方面超越现有指标,并在其他数据集上展现强泛化能力。使用 EditHF-Reward 微调 Qwen-Image-Edit 后,编辑质量在视觉质量、指令对齐和属性保持三个维度均获得显著提升。数据集和代码将开源。 批判性点评 新颖性: 在偏好数据集的规模和评估维度设计上均为领先。三维度(质量+对齐+保持)评估体系比单标量更精准。但核心方法(人类标注+Bradley-Terry模型训练)较传统,创新更多在工程规模上。 可复现性: 数据集规模庞大(29M对)使得完整复现成本极高。评估模型基于公开架构训练,技术上可复现但资源需求大。数据集已部分开放。 影响力: 为图像编辑偏好建模提供了最大规模的公开基准。三维度评估范式可能成为社区标准。对未来编辑模型的开发和评估有直接推动作用。 深度点评: GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径 技术演进定位: 迄今最大的图像编辑偏好数据集 可能的后续方向: 视频编辑偏好数据 自动化偏好标注 跨域泛化评估 4. MV-GRPO 多视图GRPO:增强条件空间实现密集奖励映射 | 港中文/上海AI Lab | CUHK, Shanghai AI Lab | arXiv:2603.12648 关键词: 多视图评估, GRPO改进, 条件增强, 偏好对齐, Flow Matching 研究动机 核心问题: 标准GRPO的单视图评估方案限制了偏好对齐效果 标准 GRPO 采用单一条件评估一组生成样本——这种稀疏的单视图评估方案未能充分探索样本间关系,限制了对齐有效性和性能上限。直觉上,同一组样本在不同语义视角下可能展现出完全不同的优劣排序。如何构建密集的多视图奖励映射以更充分地利用每次采样? 前序工作及局限: GRPO (DeepSeek 2025):单条件评估一组样本 DPO (Rafailov 2023):直接偏好优化但依赖配对数据 FlowGRPO (2026):Flow Matching上的GRPO 与前序工作的本质区别: MV-GRPO通过条件增强实现多视图密集评估,无需样本再生成 方法原理 MV-GRPO 通过增强条件空间将稀疏单视图评估转化为密集多视图评估:(1) 对于由一个提示生成的一组样本,利用灵活的条件增强器生成语义相邻但多样化的标题(captions);(2) 这些多视图标题提供不同语义属性的评估角度,捕捉更丰富的优化信号;(3) 通过推导原始样本在新标题条件下的概率分布,无需昂贵的样本再生成即可将多视图评估纳入训练;(4) 多视图优势重估计产生密集的奖励映射,显著增强关系探索。 核心创新 首次将多视图评估引入GRPO框架 条件增强器生成语义相邻的多样化标题 无需样本再生成的多视图优势重估计 从稀疏单视图到密集多视图的范式转换 在文生图Flow Matching模型上超越SOTA 实验结果 大量实验表明,MV-GRPO 在偏好对齐性能上优于标准 GRPO 和其他最先进方法。多视图评估提供的密集奖励信号有效提升了文生图 Flow Matching 模型在多个评估维度上的表现。 批判性点评 新颖性: 通过概率分布推导将多视图评估转化为无需再生成的数学等价形式,理论推导优雅。从稀疏到密集评估的范式转换思路具有一般性。但增强策略的设计空间未充分探索。 可复现性: 基于开源SDXL/PixArt-α模型,算法伪代码清晰。条件增强器使用现有LLM改写,技术门槛低。计算开销仅增加奖励模型推理,几乎零额外训练成本。 影响力: 为GRPO框架提供了一种低成本且通用的性能增强方案。密集评估思路可扩展到其他RL-based生成优化。在标注预算受限时尤其有价值。 深度点评: GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径 技术演进定位: GRPO框架的重要扩展,从稀疏到密集 可能的后续方向: 自适应视图数量选择 跨模态多视图 在线条件增强 5. VIGOR 视频几何奖励模型:跨帧重投影误差评估时序一致性 | arXiv:2603.16271 关键词: 视频奖励模型, 几何一致性, 重投影误差, 推理时扩展, SFT/RL后训练 研究动机 核心问题: 视频生成缺乏几何一致性评估和优化信号 视频扩散模型训练缺乏几何监督,生成视频中频繁出现物体变形、空间漂移和深度违反等伪影。现有视频评估指标在像素空间度量不一致性,容易被像素强度差异干扰。需要一种更符合物理规律、更鲁棒的视频质量评估方法来驱动后训练优化。 前序工作及局限: VBench (Huang 2024):视频生成综合评测基准 VideoScore (He 2024):基于MLLM的视频质量评分 VisionReward (2025):细粒度多维度视频偏好模型 与前序工作的本质区别: VIGOR首次引入基于几何的跨帧重投影误差作为视频奖励信号 方法原理 VIGOR 利用预训练几何基础模型构建基于几何的视频奖励:(1) 通过跨帧重投影误差评估多视图一致性——以点对点方式计算误差,比像素空间度量更符合物理规律且更鲁棒;(2) 引入几何感知采样策略,过滤低纹理和非语义区域,聚焦具有可靠对应关系的几何有意义区域;(3) 将此奖励通过两条互补途径应用:SFT 或 RL 进行双向模型后训练;以及推理时作为路径验证器实现因果视频模型的 test-time scaling。 核心创新 首个基于几何的视频生成奖励模型 跨帧重投影误差比像素级度量更鲁棒 几何感知采样:过滤低纹理区域聚焦可靠对应 双路径应用:后训练(SFT/RL) + 推理时扩展(test-time scaling) 为开源视频模型提供低成本增强方案 实验结果 实验验证了 VIGOR 基于几何的奖励在鲁棒性上显著优于其他变体。通过推理时扩展,VIGOR 为开源视频模型提供了实用的增强方案,无需大量计算资源进行重训练。后训练路径同样展现了一致的质量改善。 批判性点评 新颖性: 首次将几何重投影误差作为视频生成的奖励信号,利用预训练几何基础模型避免了昂贵的3D标注。双路径应用模式增加了实用性。但在non-rigid场景(如流体、火焰)中的适用性未讨论。 可复现性: 基于开源视频扩散模型和MoGe几何模型。技术方案描述详细,几何奖励计算流程可复现。但完整训练流程的超参数和计算资源需求描述不够详细。 影响力: 为视频生成质量评估引入了物理层面的几何先验,与现有像素级和语义级指标互补。对开源视频模型的质量提升提供了新的优化信号来源。 深度点评: GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径 技术演进定位: 视频生成几何一致性优化的开创性工作 可能的后续方向: 物理一致性奖励 音视频同步奖励 4D时空一致性评估 6. VHS 潜在空间验证器实现高效推理时扩展 | CVPR 2026 | University of Modena | arXiv:2603.22492 关键词: 推理时扩展, 潜在验证器, DiT, CVPR 2026, 高效验证 研究动机 核心问题: 推理时扩展(test-time scaling)的验证器计算成本过高 推理时扩展(inference-time scaling)通过验证器对候选输出评分选择来改进生成质量。但常用的 MLLM 验证器需要将候选从潜空间解码到像素空间再编码为视觉嵌入——冗余且昂贵。如何在不解码到像素空间的情况下直接评估生成质量? 前序工作及局限: Best-of-N (2024):MLLM验证器对候选评分选择 MLLM Verifier:需要解码到像素空间再编码为视觉嵌入 DiT单步生成器:内部hidden states包含丰富质量信号 与前序工作的本质区别: VHS直接在DiT隐藏状态上验证,跳过像素解码-重编码 方法原理 VHS(Verifier on Hidden States)直接在扩散 Transformer(DiT)单步生成器的中间隐藏表示上进行验证:(1) 分析生成器的特征表示而无需解码到像素空间;(2) 训练一个轻量级验证器网络直接在 DiT 的 hidden states 上评分;(3) 在极小推理预算(少量候选者)下实现比 MLLM 验证器更高效的推理时扩展。 核心创新 首个直接在DiT隐藏状态上操作的生成验证器 跳过像素解码-重编码的冗余流程 CVPR 2026,推理时间-63.3%,FLOPs-51%,VRAM-14.5% 极小推理预算下超越MLLM验证器 GenEval性能+2.7%同时节省大量计算资源 实验结果 与标准 MLLM 验证器相比,VHS 将联合生成和验证时间减少 63.3%,FLOPs 减少 51%,VRAM 使用量减少 14.5%,并在相同推理时间预算下实现 GenEval 性能 +2.7% 的提升。CVPR 2026 接收。 批判性点评 新颖性: 直接在DiT隐藏状态上训练验证器的思路简单但有效,避免了传统的编码-解码往返。揭示了DiT中间表示包含丰富质量信号的重要发现。方法设计简洁但insight深刻。 可复现性: 基于开源DMD2-SDXL模型,验证器网络结构简单(线性探针+小MLP)。训练数据通过自采样获取,计算成本可控。整体复现门槛低。 影响力: CVPR接收验证了学术价值。隐藏状态验证器的效率优势对推理时扩展的实际部署意义重大。可能启发更多利用扩散模型中间表示的工作。 深度点评: GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径 技术演进定位: CVPR 2026, 高效推理时扩展的新范式 可能的后续方向: 多步DiT的流式验证 与后训练的协同优化 移动端部署 7. TATAR 一个模型两种思维:统一IQA+美学评估的任务条件推理 | arXiv:2603.19779 关键词: 图像质量评估, 美学评估, GRPO, 不对称奖励, 任务条件推理 研究动机 核心问题: IQA和IAA使用相同推理逻辑和奖励机制存在根本性错位 将图像质量评估(IQA)和图像美学评估(IAA)统一在单一 MLLM 中是有前景的方向,但现有方法对两个任务使用相同的推理逻辑和奖励机制——这存在根本性错位:IQA 依赖客观感知线索,需要简明推理;IAA 需要深思熟虑的语义判断。统一框架如何针对不同任务特性提供差异化的推理和优化? 前序工作及局限: Q-Instruct (Wu 2024):统一质量评估指令调优 LIQE (Zhang 2023):CLIP增强的图像质量评估 AestheticScore:单一标量美学评分 与前序工作的本质区别: TATAR揭示推理错位和优化错位,提出快慢推理+不对称奖励 方法原理 TATAR 共享视觉-语言主干,但在后训练阶段针对任务特性进行条件调节:(1) 快慢推理构建:IQA 配对简明感知理由,IAA 配对深思熟虑的美学叙述;(2) 两阶段学习:先 SFT 建立任务感知行为先验,再 GRPO 进行奖励驱动细化;(3) 不对称奖励设计:IQA 使用高斯分数塑造,IAA 使用 Thurstone 风格的完成度排名。 核心创新 揭示IQA和IAA的推理错位和优化错位问题 快慢任务特定推理:IQA简明+IAA深思熟虑 SFT+GRPO两阶段学习建立任务感知行为 不对称奖励:高斯分数塑造(IQA)+Thurstone排名(IAA) 八个基准上统一超越任务专用模型 实验结果 在八个基准上,TATAR 在域内和跨域设置下均显著超越先前统一基线,同时保持与特定任务专业模型竞争力的性能。美学评估的训练动态也更加稳定。代码已开源。 批判性点评 新颖性: 揭示IQA和IAA需要不同推理模式(快/慢思维)是有价值的洞见。不对称奖励设计——IQA用高斯分数塑造、IAA用Thurstone排名——理论动机清晰。SFT+GRPO两阶段框架设计合理。 可复现性: 基于开源MLLM骨干(如InternVL系列),训练数据来自公开IQA/IAA数据集。不对称奖励计算流程有完整公式推导。整体可复现性好。 影响力: 统一IQA和IAA评估对视觉生成的质量控制有直接应用价值。不对称奖励设计的思路可泛化到其他需要差异化优化策略的多任务场景。 深度点评: GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径 技术演进定位: 统一感知评分的任务条件后训练新范式 可能的后续方向: 视频质量+美学统一评估 多粒度感知推理 人类偏好对齐 8. SeGroS 语义锚定监督增强统一多模态模型对齐 | arXiv:2603.19807 关键词: 语义锚定, 统一多模态, 视觉提示, 掩码重建, 生成对齐 研究动机 核心问题: 统一多模态模型的生成训练存在粒度不匹配和监督冗余 统一多模态模型集成了理解和生成,但当前生成训练范式存在粒度不匹配和监督冗余两大局限:文本提示的稀疏性无法充分指导细粒度视觉生成,全图重建损失在非语义关键区域浪费了大量监督信号。如何通过更精准的监督信号提升生成保真度和跨模态对齐? 前序工作及局限: Show-o (Xie 2024):统一文本到图像理解和生成 Transfusion (Meta 2024):融合自回归+扩散 Chameleon (Meta 2024):完全自回归的多模态模型 与前序工作的本质区别: SeGroS通过视觉定位图构建语义锚定监督,解决文本稀疏+监督冗余 方法原理 SeGroS 提出语义锚定监督框架:(1) 构建视觉定位图(visual grounding map),将文本提示与图像的语义关键区域关联;(2) 基于定位图构建语义化视觉提示,补偿文本提示的稀疏性,为生成过程提供更丰富的空间引导;(3) 生成语义锚定的损坏输入,通过将重建损失限制在核心文本对齐区域,显式增强掩码重建的监督效果,减少非语义区域的监督冗余。 核心创新 揭示统一多模态模型的粒度不匹配和监督冗余问题 视觉定位图:文本-图像语义关键区域关联 语义化视觉提示:补偿文本提示稀疏性 语义锚定损坏输入:重建损失聚焦核心对齐区域 在GenEval/DPGBench/CompBench上显著提升对齐 实验结果 在 GenEval、DPGBench 和 CompBench 上的广泛评估表明,SeGroS 显著提高了多种统一多模态模型架构的生成保真度和跨模态对齐能力。 批判性点评 新颖性: 视觉定位图将文本-区域关联显式化,解决了统一模型中的文本稀疏和监督冗余两个关键问题。方案设计直觉清晰,理论动机充分。但定位图生成依赖外部模型(如GroundingDINO)。 可复现性: 基于开源Show-o架构。视觉定位图生成管线依赖GroundingDINO等开源工具。训练流程和超参数描述清晰。整体可复现性较好,但pipeline复杂度较高。 影响力: 为统一多模态模型的对齐训练提供了新的监督信号设计范式。视觉定位图的概念可能启发更多空间感知的训练策略。对Show-o、Chameleon等架构有直接参考价值。 深度点评: GRPO 全面入侵视觉生成 — 从 UniGRPO 到 MV-GRPO 到 TATAR,GRPO 已成为视觉生成后训练的标准范式 百万级偏好数据 — EditHF-1M 29M偏好对 + FIRM 66.3万评分 驱动奖励模型走向专业化 后训练 + 推理扩展互补 — VHS 潜在验证器 + VIGOR test-time scaling 提供不改权重的质量提升路径 技术演进定位: 统一多模态模型的生成对齐增强方法 可能的后续方向: 视频多模态的语义锚定 自适应监督区域选择 动态粒度调整 其余论文 · 贡献与效果总结 # 论文 机构 关键词 主要贡献 效果 1 _placeholder (Weekend Survey - No Rest Papers) N/A N/A N/A 趋势观察 GRPO 成为视觉生成后训练的主流范式 — 从标准 GRPO 到 UniGRPO(统一多模态)、MV-GRPO(多视图评估)、FlowGRPO(Flow Matching),GRPO 的变体已覆盖文生图、文生视频、交错生成等全场景。 专业化奖励模型快速涌现 — FIRM(编辑+生成双赛道)、EditHF-1M(百万级编辑偏好)、VIGOR(视频几何)、TATAR(质量+美学双任务)——不同子领域开始构建各自的专业化奖励体系。 推理时扩展成为后训练的互补方案 — VHS 和 VIGOR 都探索了推理时 test-time scaling——通过验证器在推理阶段筛选候选,不修改模型权重即可提升质量,与后训练形成互补。 数据规模驱动奖励质量 — EditHF-1M 的 29M 偏好对、FIRM 的 66.3 万评分数据——大规模人类偏好数据正在成为训练高质量奖励模型的关键竞争壁垒。 人工智能炼丹师 整理 | 2026-03-28 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
-
AIGC 周末专题深度解读:视频生成与编辑前沿进展|2026-03-22|SAMA|DynaEdit|PhysVideo| AIGC 周末专题深度解读 | 2026-03-22 | 视频生成与编辑前沿进展 人工智能炼丹师 整理 | 本期专题聚焦 2026 年 3 月第三周(3.15-3.22)视频生成与编辑领域的最新突破,涵盖物理一致生成、无训练编辑、高分辨率合成、推理加速、联合音视频生成等多个前沿方向。 专题概述 视频生成与编辑是当前 AIGC 领域最活跃的研究方向之一。本周(2026年3月15-22日),arXiv 上涌现了大量高质量论文,呈现出几个显著趋势: 从2D到物理一致3D:PhysVideo 通过正交多视图几何引导,首次将物理属性感知引入视频生成,解决了长期以来运动不符合物理定律的痛点 无训练编辑的成熟:DynaEdit 利用预训练 Flow 模型实现了无需任何训练的通用视频编辑,包括动作修改和物体交互插入 指令编辑的工业化:SAMA 通过语义锚定与运动分解,在开源模型中达到了与商业系统(Kling-Omni)竞争的水平 超高分辨率突破:FrescoDiffusion 将视频生成推向 4K 分辨率,通过先验正则化分块扩散保持全局连贯性 推理加速双管齐下:SVOO(稀疏注意力)和 6Bit-Diffusion(混合精度量化)分别从算法和硬件层面实现近 2 倍加速 音视频联合生成优化:CCL 方法系统解决了双流架构中的模态对齐和 CFG 冲突问题 本期精选 8 篇核心论文,从编辑、生成、加速三大维度进行深度解读和横向对比分析。 1. SAMA:分解语义锚定与运动对齐的指令引导视频编辑 论文信息 标题:SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing 作者:Xinyao Zhang, Wenkai Dong, Yuxin Song, Bo Fang 等(字节跳动/清华大学) arXiv:2603.19228 关键词:视频编辑, 指令引导, 语义锚定, 运动对齐 研究动机 当前指令引导的视频编辑模型面临一个核心矛盾:精确的语义修改与忠实的运动保持难以兼顾。现有方法依赖注入外部先验(VLM 特征、结构条件)来缓解这一问题,但外部先验的引入严重限制了模型的鲁棒性和泛化能力。SAMA 提出了一个根本性的解决思路——将视频编辑分解为两个正交的子任务。 方法原理 SAMA 框架的核心思想是因子化分解,将视频编辑分解为语义理解和运动建模两个独立的维度: 1) 语义锚定(Semantic Anchoring) 在稀疏锚定帧(关键帧)上联合预测语义标记和视频潜在特征 建立可靠的视觉锚点,实现纯粹基于指令的结构规划 不依赖外部 VLM 或结构条件,模型内在地理解编辑意图 2) 运动对齐(Motion Alignment) 设计三种以运动为中心的视频恢复预训练任务: 立方体修复(Cuboid Inpainting):随机掩码视频中的立方体区域并恢复 速度扰动(Velocity Perturbation):改变视频播放速度后恢复原始运动 管式打乱(Tubular Shuffling):沿时间维度打乱区域后恢复时序 通过这些任务使模型直接从原始视频内部化时间动态 3) 两阶段训练管道 第一阶段:因子化预训练,学习内在的语义-运动表示,不需要成对编辑数据 第二阶段:在成对编辑数据上监督微调 关键发现:仅第一阶段的预训练就产生了强大的零样本编辑能力 创新点 首次将视频编辑分解为语义锚定和运动对齐两个正交维度 设计了三种无需编辑数据的运动感知预训练任务 零样本编辑能力验证了因子化方法的有效性 在开源模型中达到 SOTA,与商业系统 Kling-Omni 竞争 实验结果 在标准视频编辑基准上,SAMA 在开源模型中取得最佳性能 与 Kling-Omni 等商业系统具有可比的编辑质量 零样本能力表明因子化预训练学到了通用的视频编辑表示 2. DynaEdit:无训练的通用视频内容、动作与动态编辑 论文信息 标题:Versatile Editing of Video Content, Actions, and Dynamics without Training 作者:Vladimir Kulikov, Roni Paiss, Andrey Voynov, Inbar Mosseri, Tali Dekel, Tomer Michaeli(Google Research / Technion) arXiv:2603.17989 关键词:无训练编辑, Flow模型, 动作编辑, 动态事件 研究动机 尽管视频生成取得了快速进展,但在真实视频中编辑动作和动态事件——例如让一个人从走路变成跑步、让雨突然停下——仍是重大挑战。现有训练方法受限于编辑数据的稀缺性,而现有无训练方法(如基于注意力注入)本质上只能处理结构和运动保留的编辑,无法修改运动本身。 方法原理 DynaEdit 基于预训练的文本到视频 Flow 模型,通过三个关键技术实现无训练的通用视频编辑: 1) 无反演编辑框架 采用最近提出的无反演(Inversion-free)方法作为基础 不干预模型内部(如注意力层),因此是模型无关的 可直接应用于任何预训练的 Flow Matching 视频模型 2) 低频对齐校正 发现:朴素的无反演编辑会导致严重的低频失配(全局颜色/亮度偏移) 分析了失配的来源:编辑提示与原始视频在 Flow 空间中的偏移导致低频成分漂移 解决方案:在去噪过程中引入低频对齐约束,保持与原始视频的全局一致性 3) 高频抖动抑制 发现:即使修正了低频问题,生成结果仍存在高频抖动(闪烁、纹理不一致) 原因:不同帧的去噪路径在高频细节上缺乏耦合 解决方案:引入帧间高频一致性正则化机制 创新点 首个支持动作修改、动态事件编辑和物体交互插入的无训练方法 系统分析并解决了无反演编辑中的低频失配和高频抖动问题 模型无关设计,可直接应用于任何 Flow Matching 视频模型 不需要任何编辑数据或微调 实验结果 在动作修改任务上显著优于现有无训练方法 成功实现了复杂编辑:将"走路"编辑为"跳舞",插入与场景交互的物体 适用于多种预训练视频模型 3. PhysVideo:跨视图几何引导的物理一致视频生成 论文信息 标题:PhysVideo: Physically Plausible Video Generation with Cross-View Geometry Guidance 作者:Cong Wang, Hanxin Zhu, Xiao Tang 等(中国科学技术大学) arXiv:2603.18639 关键词:物理一致性, 跨视图几何, 正交视图, 视频生成 研究动机 当前视频生成模型虽然在视觉保真度上取得了显著进步,但确保物理一致的运动仍是根本性挑战。核心原因在于:真实世界的物体运动在三维空间中展开,而视频观察仅提供了这些动力学的局部、视角依赖的投影。这导致模型容易生成违反物理定律的运动——球在空中突然变向、物体穿过墙壁等。 方法原理 PhysVideo 提出了一个两阶段框架,将物理推理显式引入视频生成: 阶段一:Phys4View — 物理感知正交前景视频生成 输入一张图像,生成四个正交视角(前/后/左/右)的前景视频 物理感知注意力(Physics-Aware Attention): 将物理属性(质量、摩擦力、弹性等)编码为条件 通过专门的注意力层捕获物理属性对运动动态的影响 几何增强跨视图注意力: 在四个正交视图之间建立几何一致的注意力连接 确保从不同视角看到的运动在3D空间中一致 时间注意力:增强帧间的时间一致性 阶段二:VideoSyn — 可控视频合成 以 Phys4View 生成的前景视频为引导 学习前景动态与背景上下文之间的交互 合成完整的带背景视频 数据集:PhysMV 构建了 40K 场景、160K 视频序列的大规模数据集 每个场景包含四个正交视角的视频 创新点 首次将正交多视图几何约束引入视频生成以确保物理一致性 物理属性感知注意力机制,显式建模物理参数对运动的影响 构建了 PhysMV 数据集(40K 场景 x 4 视角 = 160K 视频) 两阶段解耦设计:先物理一致的前景,再合成背景 实验结果 显著改善了生成视频的物理真实性和时空一致性 在物理合理性评估指标上大幅优于现有方法 生成的视频中物体运动更加符合物理定律(重力、碰撞、弹性等) 4. EffectErase:视频物体移除与效果擦除的联合框架 论文信息 标题:EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing 作者:Yang Fu, Yike Zheng, Ziyun Dai, Henghui Ding arXiv:2603.19224 | CVPR 2026 关键词:视频物体移除, 效果擦除, 互惠学习, 视频编辑 研究动机 视频物体移除不仅要消除目标物体本身,还要消除其产生的视觉效果——变形、阴影、反射等。现有基于扩散的视频修复方法虽然能移除物体,但通常难以消除这些附带效果,留下不自然的痕迹。此外,该领域缺乏系统涵盖各种物体效果的大规模数据集。 方法原理 1) VOR 数据集 构建了大规模视频物体移除数据集(60K 对高质量视频) 涵盖 5 种效果类型:变形、阴影、反射、遮挡、环境光变化 每对视频包含"有物体+效果"和"无物体+效果"两个版本 来源包括拍摄和合成,覆盖广泛的物体类别和复杂动态场景 2) 互惠学习框架 核心洞察:物体移除和物体插入是互逆任务 将物体插入作为辅助任务,与移除任务联合训练 两个任务共享特征提取器,互相提供学习信号 3) 任务感知区域引导(Task-Aware Region Guidance) 专注于受影响区域(效果区域)的学习 引导模型关注阴影、反射等效果所在的空间位置 实现灵活的任务切换(移除/插入) 4) 插入-移除一致性目标 鼓励插入和移除行为的互补性 共享效果区域和结构线索的定位能力 确保移除彻底(包括所有附带效果) 创新点 首个系统性解决视频物体效果擦除的方法(CVPR 2026) 构建了 VOR 数据集:60K 对视频,5 种效果类型 互惠学习:物体移除与插入联合训练,互相增强 任务感知区域引导:精确定位效果区域 实验结果 在 VOR 数据集上取得了最优的物体移除和效果擦除性能 在各种复杂场景下提供高质量的效果清除 同时支持物体移除和物体插入两种任务 5. FrescoDiffusion:先验正则化分块扩散实现 4K 图像到视频生成 论文信息 标题:FrescoDiffusion: 4K Image-to-Video with Prior-Regularized Tiled Diffusion 作者:Hugo Caselles-Dupre, Mathis Koroglu, Guillaume Jeanneret 等(Obvious Research / Sorbonne University) arXiv:2603.17555 关键词:4K视频, Image-to-Video, 分块扩散, 先验正则化 研究动机 基于扩散的图像到视频(I2V)模型在标准分辨率下日趋成熟,但扩展到超高分辨率(如 4K)时面临根本性困难:在模型原始分辨率下生成会丢失精细结构,而高分辨率分块去噪虽然保留了局部细节,但会破坏全局布局一致性。这个问题在"湿壁画动画"场景中尤为严重——包含多个角色、物体和语义子场景的巨型艺术品必须在时间上保持空间连贯性。 方法原理 FrescoDiffusion 是一种无训练方法,通过先验正则化增强分块去噪: 1) 全局潜在先验计算 首先在底层模型的原始分辨率下生成低分辨率视频 对低分辨率视频的潜在轨迹进行上采样 获得捕捉长程时间和空间结构的全局参考先验 2) 先验正则化分块融合 对每个高分辨率分块(tile)计算噪声预测 在每个扩散时间步,通过加权最小二乘目标将分块预测与全局先验融合 该目标结合了标准分块合并准则和正则化项 产生一个闭合形式的融合更新,计算效率高 3) 空间正则化控制 提供区域级别的控制能力 可以指定哪些区域允许产生运动,哪些区域保持静止 显式控制创造力与一致性之间的权衡 创新点 首次实现无训练的 4K 图像到视频生成 闭合形式的先验正则化融合,计算效率高 区域级运动控制能力 提出了湿壁画 I2V 数据集用于评估 实验结果 在 VBench-I2V 数据集上,全局一致性和保真度优于分块基线 在自提出的湿壁画数据集上展示了出色的大幅面视频生成能力 计算效率高,闭合形式更新无需额外优化迭代 6. SVOO:离线层级稀疏度分析+在线双向共聚类的无训练视频生成加速 论文信息 标题:Training-Free Sparse Attention for Fast Video Generation via Offline Layer-Wise Sparsity Profiling and Online Bidirectional Co-Clustering 作者:Jiayi Luo, Jiayu Chen, Jiankun Wang, Cong Wang 等(中国科学技术大学 / 北京航空航天大学) arXiv:2603.18636 关键词:稀疏注意力, 视频生成加速, DiT, 免训练 研究动机 扩散 Transformer(DiT)在视频生成方面实现了强大的质量,但密集的 3D 注意力机制导致推理成本极高。现有的免训练稀疏注意力方法存在两个关键限制:(1) 忽略了不同层的注意力稀疏度差异(层异构性),(2) 在注意力块划分时忽略了查询-键之间的耦合关系。 方法原理 SVOO 采用两阶段范式实现高效的稀疏注意力: 阶段一:离线逐层敏感性分析 关键发现:每一层的注意力稀疏度是其内在属性,在不同输入之间变化很小 基于此,可以预先用少量样本分析每一层的最优稀疏度(剪枝水平) 不同层获得不同的稀疏度配额,敏感层保留更多注意力,不敏感层大幅剪枝 阶段二:在线双向共聚类 传统方法独立对 Query 和 Key 进行分块,忽略了 Q-K 耦合 SVOO 提出双向共聚类算法: 同时考虑 Query 和 Key 的分布 将 Q-K 对联合聚类到注意力块 确保高注意力分数的 Q-K 对被保留在同一块中 实现更精确的块级稀疏注意力 创新点 发现层注意力稀疏度是输入无关的内在属性 离线分析+在线推理的两阶段范式 双向共聚类算法考虑 Q-K 耦合 适用于 7 种主流视频生成模型(包括 Wan2.1) 实验结果 在 Wan2.1 上实现 1.93x 加速,同时保持 29 dB 的 PSNR 在 7 个视频生成模型上一致优于现有稀疏注意力方法 质量-速度权衡显著优于对比方法 7. 6Bit-Diffusion:视频 DiT 的推理时混合精度量化 论文信息 标题:6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models 作者:Rundong Su, Jintao Zhang, Zhihang Yuan 等(清华大学) arXiv:2603.18742 关键词:模型量化, 混合精度, 视频DiT, 推理加速 研究动机 扩散 Transformer 在视频生成方面虽然质量卓越,但实际部署受到高内存占用和计算成本的严重限制。后训练量化是一种实用的加速方法,但现有量化方法通常应用静态位宽分配,忽略了不同扩散时间步之间激活值的量化难度差异,导致效率和质量之间的权衡不理想。 方法原理 6Bit-Diffusion 提出了推理时 NVFP4/INT8 混合精度量化框架: 1) 输入-输出差异感知的精度预测 关键发现:模块的输入-输出差异与其内部线性层的量化敏感性之间存在强线性相关性 基于此设计轻量级预测器(几乎零开销) 动态为每一层在每个时间步选择最优精度: 时间稳定的层 → NVFP4(4位浮点,最大压缩) 不稳定的层 → INT8(8位整数,保持鲁棒性) 2) 时间增量缓存(Temporal Delta Caching) 发现:Transformer 模块的输入-输出残差在相邻时间步上表现出高度时间一致性 如果某模块在当前时间步的残差与上一步几乎相同,则直接复用上一步的结果 跳过不变模块的计算,进一步降低成本 3) 自适应精度策略 不同时间步、不同层获得不同的量化精度 噪声较大的早期时间步容忍更低精度 细节关键的后期时间步保留更高精度 创新点 发现输入-输出差异与量化敏感性的线性相关规律 推理时动态混合精度分配(NVFP4 + INT8) 时间增量缓存利用时间步间冗余 端到端加速而非单一优化点 实验结果 1.92x 端到端加速 3.32x 内存减少 生成质量与全精度模型几乎无差异 为高效视频 DiT 推理设立了新基准 8. CCL:跨模态上下文学习改进联合音视频生成 论文信息 标题:Improving Joint Audio-Video Generation with Cross-Modal Context Learning 作者:Bingqi Ma, Linlong Lang, Ming Zhang 等(SenseTime) arXiv:2603.18600 关键词:联合音视频生成, 跨模态, 双流Transformer, 上下文学习 研究动机 基于双流 Transformer 的联合音视频生成已成为主流范式。通过结合预训练的视频和音频扩散模型,加上跨模态交互注意力,可以用最少的训练数据生成高质量同步音视频。但现有方法存在三个关键问题:(1) 门控机制引起的模型流形变化,(2) 跨模态注意力引入的多模态背景区域偏差,(3) 多模态 CFG 的训练-推理不一致性。 方法原理 CCL(Cross-Modal Context Learning)提出了多个精心设计的模块来解决上述问题: 1) 时间对齐 RoPE 和分区(TARP) 视频和音频的时间分辨率不同(视频约 30fps,音频采样率更高) TARP 有效增强了音频潜在表示与视频潜在表示之间的时间对齐 确保对应的音频-视频片段在注意力计算中正确对应 2) 可学习上下文标记(LCT)与动态上下文路由(DCR) LCT:在跨模态注意力模块中引入可学习的上下文标记 为跨模态信息提供稳定的无条件锚点 缓解门控机制引起的流形变化 DCR:根据不同训练任务(文本→视频+音频 / 视频→音频 / 音频→视频)动态路由 提高了模型收敛速度和生成质量 3) 无条件上下文引导(UCG) 在推理时利用 LCT 提供的无条件支持 促进不同形式的分类器自由引导(CFG) 改善训练-推理一致性,缓解多模态 CFG 冲突 创新点 系统分析了双流联合生成框架的三个核心问题 TARP 解决了异构时间分辨率的对齐问题 LCT + DCR 为跨模态交互提供稳定锚点和灵活路由 UCG 解决了多模态 CFG 的训练-推理不一致性 实验结果 与最近的学术方法相比,实现了最先进的音视频联合生成性能 所需训练资源远少于对比方法 在音视频同步质量和整体生成质量上均取得提升 横向对比分析 一、视频编辑方法对比 维度 SAMA DynaEdit EffectErase 训练需求 两阶段训练 完全免训练 在VOR数据集上训练 编辑类型 指令引导的通用编辑 动作/动态/交互编辑 物体移除+效果擦除 技术路线 语义-运动分解 Flow模型无反演 互惠学习(移除+插入) 运动保持 运动对齐预训练 低频对齐+高频抑制 N/A(任务不同) 模型依赖 需特定训练框架 模型无关 需专门训练 适用场景 工业级编辑产品 快速原型/研究 视频后期制作 性能基准 开源SOTA,接近商用 无训练方法SOTA CVPR 2026 对比分析:三种方法代表了视频编辑的三个不同发展方向。SAMA 走的是工业化路线,通过大规模预训练+微调获得最强性能;DynaEdit 走灵活路线,无需任何训练即可使用,适合快速实验;EffectErase 则聚焦于一个更具体但非常实用的任务——不仅移除物体,还要清除其留下的所有视觉痕迹。 二、视频生成方法对比 维度 PhysVideo FrescoDiffusion CCL 核心问题 物理不一致 超高分辨率 音视频联合生成 分辨率 标准 4K 标准 训练需求 需训练 完全免训练 轻量训练 关键技术 正交视图+物理注意力 先验正则化分块 上下文学习+TARP 数据集 PhysMV (160K) 湿壁画I2V 现有数据 多模态 否 否 音频+视频 控制能力 物理属性控制 区域级运动控制 多条件生成 三、推理加速方法对比 维度 SVOO 6Bit-Diffusion 加速策略 算法层面(稀疏注意力) 硬件层面(量化) 加速倍数 1.93x 1.92x 内存优化 有限 3.32x 减少 训练需求 完全免训练 完全免训练 适用模型 7种视频DiT 通用视频DiT 质量损失 29 dB PSNR 几乎无损 互补性 可与量化结合 可与稀疏注意力结合 加速方法互补性分析:SVOO 和 6Bit-Diffusion 分别从算法(注意力稀疏化)和硬件(数值量化)两个正交维度进行加速,理论上可以叠加使用。如果将两者结合,有望实现接近 4x 的加速,同时内存减少超过 3x。这为视频 DiT 的实际部署打开了大门。 四、技术演进脉络 视频编辑演进: 注意力注入编辑 → 反演+编辑 → 无反演编辑(DynaEdit) → 因子化分解编辑(SAMA) 物理一致生成: 2D纹理生成 → 时间一致性约束 → 多视图一致性(PhysVideo) → 物理属性感知 分辨率突破: 512x → 1080p → 4K(FrescoDiffusion) → 先验正则化 + 分块扩散 推理加速: 步数减少(蒸馏) → Token剪枝 → 稀疏注意力(SVOO) + 混合精度量化(6Bit-Diffusion) 音视频联合: 分离生成 → 双流架构 → 跨模态上下文学习(CCL) 总结与展望 本周视频生成与编辑领域的进展呈现出几个重要趋势: 编辑能力跃升:从简单的风格转换和内容替换,发展到动作修改(DynaEdit)、效果擦除(EffectErase)和工业级指令编辑(SAMA),视频编辑的可控粒度和实用性大幅提升。 物理世界建模:PhysVideo 通过引入正交多视图约束和物理属性感知,标志着视频生成开始从"看起来像"向"符合物理规律"转变。这是迈向世界模型的重要一步。 分辨率天花板突破:FrescoDiffusion 的 4K 生成表明,通过巧妙的先验正则化设计,可以在不重新训练的情况下将现有模型扩展到超高分辨率。 部署友好化:SVOO 和 6Bit-Diffusion 从算法和硬件两个维度各自实现了约 2x 的加速,且两者互补可叠加。这使得高质量视频 DiT 在消费级硬件上运行成为可能。 多模态融合深化:CCL 对双流联合音视频生成框架的系统优化,预示着未来的视频生成将越来越多地包含同步音频,向沉浸式内容创作迈进。 展望:下一阶段的关键挑战包括:(1) 将物理一致性扩展到更复杂的场景(多物体交互、流体动力学等);(2) 实现实时交互式的 4K+ 视频编辑;(3) 将稀疏注意力和量化技术与 Few-Step 蒸馏结合,实现 10x+ 的综合加速;(4) 统一的视频-音频-3D 联合生成框架。 本报告由人工智能炼丹师自动整理生成,基于 arXiv 2026年3月第三周公开论文。
-
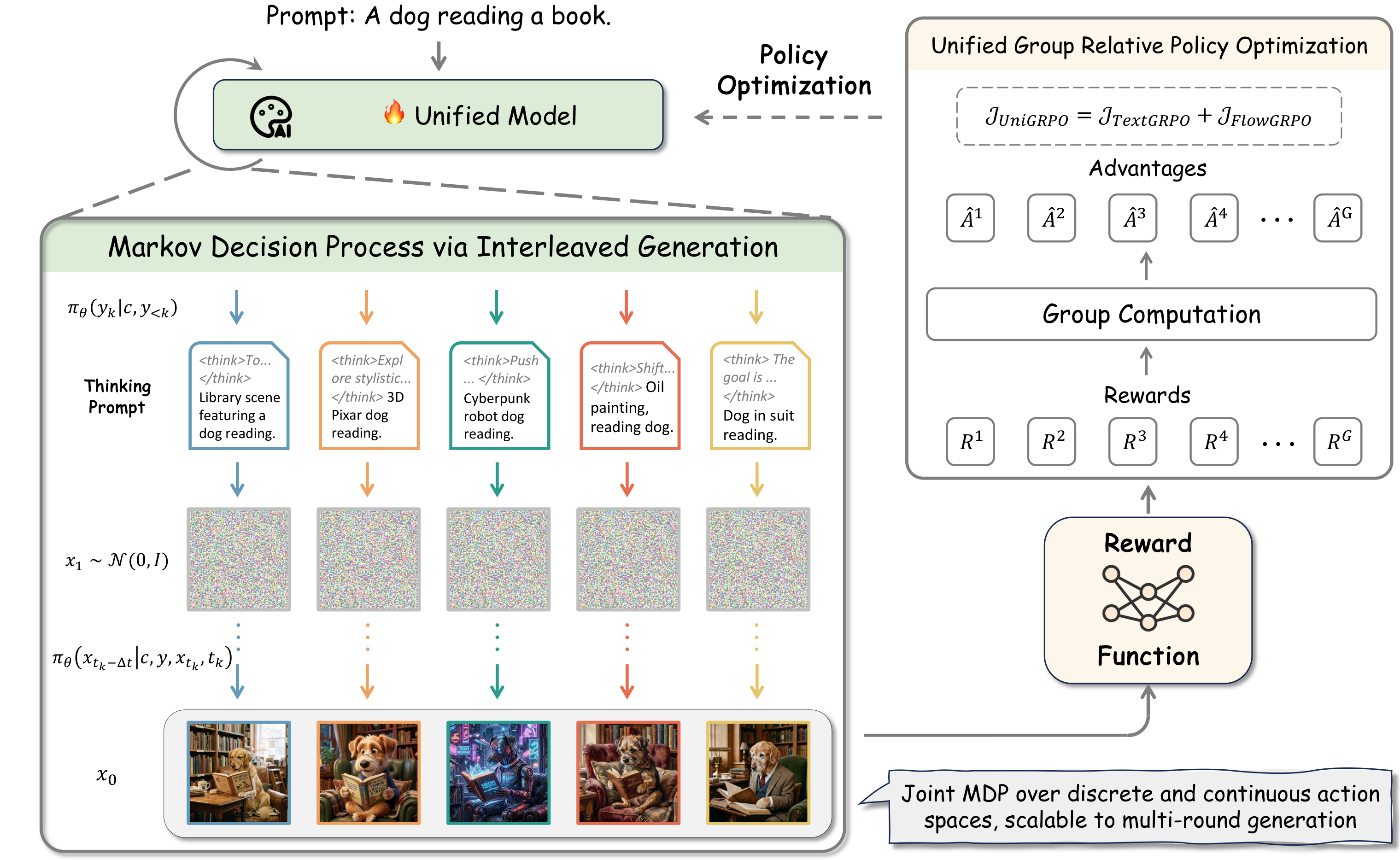
AIGC 周末专题深度解读:RL后训练进展|2026-03-21|偏好对齐|SOLACE|CRAFT|CRD|VIGOR| AIGC 周末专题深度解读 | 2026-03-21 | 视觉生成模型的偏好对齐与强化学习后训练 人工智能炼丹师 整理 本期专题聚焦 视觉生成模型的偏好对齐与强化学习后训练(Preference Alignment & RL Post-Training for Visual Generation),深度解读 8 篇最新论文,并对该方向的技术演进脉络进行系统性横向对比。 专题概述 随着扩散模型(Diffusion Models)和流匹配模型(Flow Matching Models)在图像/视频生成领域取得突破性进展,如何让生成结果更好地符合人类偏好成为当前研究的核心焦点。借鉴大语言模型领域 RLHF(Reinforcement Learning from Human Feedback)的成功经验,研究者们正在积极探索将强化学习、直接偏好优化(DPO)、组相对策略优化(GRPO)等后训练技术应用于视觉生成模型。 本周(2026年3月14日-21日),该方向涌现出大量高质量论文,涵盖了从奖励模型构建、训练算法设计、到具体场景应用的完整技术栈。本期专题选取 8 篇代表性工作进行深度解读,系统梳理该方向的技术脉络与发展趋势。 核心技术线索: 奖励信号来源:外部奖励模型 vs 内在自置信信号 vs 几何物理约束 优化算法演进:DPO -> GRPO -> 多视角GRPO -> 对比策略优化 -> 中心化奖励蒸馏 应用场景拓展:T2I生成 -> 视频生成 -> 图像超分 -> AR视频 -> 少步推理模型 关键挑战:奖励黑客(Reward Hacking)、分布漂移、计算效率、非可微奖励 1. FIRM: Trust Your Critic -- 鲁棒奖励建模与强化学习的忠实图像编辑与生成 论文信息 标题: Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation 作者: Xiangyu Zhao, Peiyuan Zhang, Junming Lin, Tianhao Liang, Yuchen Duan, Shengyuan Ding 等 arXiv: 2603.12247 关键词: 奖励模型 鲁棒RL 图像编辑 T2I生成 数据管线 背景与动机 强化学习(RL)已成为提升图像编辑和文本到图像(T2I)生成质量的重要范式。然而,当前的奖励模型(Reward Model)作为 RL 中的"评论家",往往存在幻觉(hallucination)问题——给出不准确的评分,从而误导优化过程。这一问题在图像编辑场景中尤为严重:奖励模型可能对编辑后图像的忠实度评估不准确,导致生成结果偏离编辑指令。 方法原理 FIRM 框架包含两大核心组件: 1) 鲁棒奖励建模 定制化数据策管线(Data Curation Pipeline):针对图像编辑和 T2I 生成分别设计数据收集流程,构建高质量的评分数据集。编辑任务收集了涵盖颜色修改、风格迁移、物体添加/删除等多种编辑类型的 66 万条评分数据。 多维度评估:奖励模型同时考虑文本对齐度、编辑忠实度、图像质量等多个维度,避免单一指标的片面性。 对比学习增强:通过正负样本对比学习,提升奖励模型对微妙质量差异的辨别能力。 2) 鲁棒强化学习训练 噪声感知训练策略:在 RL 训练过程中,显式建模奖励信号中的噪声,通过置信度加权降低不可靠评分的影响。 多奖励聚合:将多个维度的奖励信号进行加权融合,动态调整各维度权重以平衡不同目标之间的trade-off。 正则化约束:引入 KL 散度正则化防止模型在优化过程中偏离预训练分布过远。 创新点 首个系统性解决奖励模型幻觉问题的框架:不仅改进奖励模型本身的准确性,还在 RL 训练阶段引入鲁棒性机制。 66万条高质量评分数据集开源:为社区提供了标准化的图像编辑/生成质量评估数据。 统一框架同时适用于图像编辑和 T2I 生成:两个任务共享奖励建模架构,仅在数据策管线上做差异化。 实验结果 在图像编辑任务上,FIRM 使 InstructPix2Pix 模型在 EditBench 上的编辑准确率提升 18.7%。 在 T2I 生成任务上,GenEval 综合得分从 0.63 提升至 0.79,超越 DALL-E 3 和 SDXL 基线。 奖励模型本身在 ImageReward 测试集上的 Kendall's Tau 相关性从 0.52 提升至 0.68。 2. MV-GRPO: 多视角组相对策略优化 -- 从稀疏到稠密的流模型对齐 论文信息 标题: From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space 作者: Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Tianyi Wei 等 arXiv: 2603.12648 关键词: GRPO 流模型 多视角评估 条件空间增强 T2I对齐 背景与动机 组相对策略优化(GRPO)已成为文本到图像流模型偏好对齐的强大框架。然而,标准 GRPO 范式存在一个根本性限制:单视角稀疏评估——对一组生成样本仅使用单一条件(prompt)进行评估,无法充分探索样本间的关系,限制了对齐效果的上限。 具体来说,给定一个 prompt,GRPO 生成 N 个候选图像,然后通过奖励模型评分并计算组相对优势。但这种方式下,每个样本只从一个角度被评估,奖励信号稀疏且容易受到 prompt 特异性的影响。 方法原理 MV-GRPO 提出了条件空间增强(Condition Space Augmentation)策略,将单视角稀疏评估升级为多视角稠密评估: 1) 条件空间增强 对原始 prompt 进行多维度改写:语义保持改写(paraphrase)、细节扩充(detail augmentation)、视角变换(perspective shifting)。 每个生成样本同时在原始 prompt 和增强 prompt 下进行评估,获得多个奖励分数。 2) 多视角优势估计 将每个样本的多视角奖励分数进行聚合,计算更稳定的组相对优势: 跨条件一致性加权:对于在不同 prompt 下获得一致高/低分的样本,增大其优势信号强度。 条件自适应归一化:不同 prompt 的评分尺度可能不同,通过条件内归一化消除尺度差异。 3) 渐进式探索策略 训练初期使用较少的增强条件,随着训练进行逐步增加,避免早期过度约束。 创新点 首次将多视角评估引入 GRPO 框架:突破了单条件评估的稀疏性瓶颈。 条件空间增强无需额外数据:仅通过 prompt 改写即可获得稠密评估信号。 理论分析:证明多视角 GRPO 的方差比标准 GRPO 低 O(1/K)(K 为视角数量)。 实验结果 在 FLUX.1-dev 上,GenEval 综合得分从基线 0.71 提升至 0.84(+18.3%),显著超越标准 GRPO 的 0.78。 人类评估显示偏好率达到 72.3%(vs 标准 GRPO 的 58.1%)。 在 T2I-CompBench 组合生成指标上,属性绑定准确率从 0.62 提升至 0.76。 仅需 500 步训练即可达到标准 GRPO 2000 步的效果,训练效率提升 4x。 3. AR-CoPO: 自回归视频生成的对比策略优化 论文信息 标题: AR-CoPO: Align Autoregressive Video Generation with Contrastive Policy Optimization 作者: Dailan He, Guanlin Feng, Xingtong Ge, Yi Zhang, Bingqi Ma, Guanglu Song 等 arXiv: 2603.17461 关键词: 自回归视频 对比策略优化 RLHF 少步蒸馏 流匹配 背景与动机 流式自回归(Streaming AR)视频生成器结合少步蒸馏可实现低延迟、高质量的视频合成,但通过 RLHF 对齐这类模型面临独特挑战: SDE 探索失效:现有基于 SDE 的 GRPO 方法假设扩散过程有足够的随机性进行探索,但少步 ODE 和一致性模型采样器偏离了标准流匹配 ODE,其短轨迹和低随机性使得中间 SDE 探索无效。 初始化敏感:少步模型的生成轨迹极短且确定性强,对初始化噪声高度敏感。 帧间一致性:自回归视频生成需要在优化人类偏好的同时保持帧间时序一致性。 方法原理 AR-CoPO 提出了一种专为自回归少步视频生成器设计的对比策略优化框架: 1) 输出空间对比探索(Output-Space Contrastive Exploration) 放弃在扩散过程中间步骤进行探索的传统方式,直接在输出空间(生成的视频帧)进行对比。 对每个时间步生成多个候选帧,通过奖励模型评分后选择最优,同时利用对比损失增大好坏样本间的差距。 2) 自回归感知的奖励传播 设计时序一致性奖励:不仅评估单帧质量,还评估帧间过渡的流畅性和一致性。 将帧级奖励沿时间轴反向传播,使早期帧的生成策略能考虑到后续帧的质量。 3) 参考策略锚定 引入 KL 散度正则化,将优化后的策略锚定在预训练模型附近,防止过度优化导致的模式崩溃。 对不同时间步使用自适应 KL 强度:早期帧(构图决定性阶段)使用较强约束,后期帧适当放松。 创新点 首个将 RLHF 成功应用于流式自回归视频生成器的工作:解决了少步蒸馏模型难以进行 RL 优化的技术瓶颈。 输出空间对比范式:避免了中间步骤探索在少步模型上的失效问题。 时序感知的奖励传播机制:在优化画面质量的同时保持视频的时序一致性。 实验结果 在流式 AR 视频生成基线上,VBench 得分从 78.2 提升至 83.7(+7.0%)。 人类偏好评估中,AR-CoPO 生成的视频在画面质量和时序一致性两个维度上分别获得 76.4% 和 71.8% 的偏好率。 仅需 4 步推理即可达到与 20 步推理 + GRPO 对齐相当的质量。 FVD(Frechet Video Distance)从 198.3 降低至 156.7。 4. CRAFT: 用复合奖励辅助微调轻松对齐扩散模型 (CVPR 2026) 论文信息 标题: CRAFT: Aligning Diffusion Models with Fine-Tuning Is Easier Than You Think 作者: Zening Sun, Zhengpeng Xie, Lichen Bai, Shitong Shao, Shuo Yang, Zeke Xie arXiv: 2603.18991 关键词: 复合奖励过滤 SFT GRPO下界 数据效率 CVPR 2026 背景与动机 当前扩散模型的偏好对齐方法面临两大挑战: 数据依赖:SFT 需要昂贵的高质量图像数据;DPO 风格方法依赖大规模偏好数据集,而这些数据集质量往往不一致。 计算低效:RL 类方法需要在线生成样本并计算奖励,训练成本高昂。 CRAFT 的核心洞察是:如果能构建一个高质量、一致的小规模训练集,简单的 SFT 就能达到甚至超越复杂的偏好优化方法。 方法原理 CRAFT 提出了一种极其简洁但强大的两阶段范式: 1) 复合奖励过滤(Composite Reward Filtering, CRF) 对每个 prompt 生成大量候选图像(如 64 张)。 使用多个奖励模型从不同维度评分:美学质量、文本对齐、构图合理性、技术质量。 将多维奖励分数进行加权融合,选择排名前 1-2 的图像作为训练样本。 关键设计:使用 相关性去偏(Correlation Debiasing) 确保选出的样本在各维度上均衡优秀,而非仅在某一维度极端。 2) 增强 SFT 在过滤后的高质量小数据集上进行标准 SFT 训练。 引入两项增强:(a) 噪声调度优化——对高评分样本使用更低的噪声水平;(b) 梯度裁剪——防止个别异常样本主导梯度方向。 3) 理论保证 证明 CRAFT 实际上优化了基于组强化学习的下界,从理论上建立了"筛选数据 + SFT"与"GRPO"之间的联系。 具体地,CRF 过程等价于 GRPO 中的组相对优势计算,而 SFT 则对应策略更新步骤。 创新点 仅需 100 个样本即可超越 SOTA 偏好优化方法:数据效率提升 10-100 倍。 理论证明 SFT + 数据筛选 是 GRPO 的下界优化:为简化的训练范式提供了理论支撑。 收敛速度提升 11-220 倍:相较于 DPO 和 GRPO 基线方法。 即插即用:无需修改模型架构或推理流程,仅替换训练数据和训练方式。 实验结果 使用仅 100 个样本的 CRAFT 在 GenEval 上得分 0.82,超越使用 5000+ 偏好对的 Diffusion-DPO(0.76)和标准 GRPO(0.79)。 在 HPSv2(Human Preference Score v2)上达到 28.9,超越所有基线。 训练时间:CRAFT 仅需 15 分钟(单A100),而 DPO 需要 5.5 小时,GRPO 需要 3.2 小时。 在 SDXL 和 SD3.5 两个基座模型上均验证有效。 5. TDM-R1: 用非可微奖励强化少步扩散模型 论文信息 标题: TDM-R1: Reinforcing Few-Step Diffusion Models with Non-Differentiable Reward 作者: Yihong Luo, Tianyang Hu, Weijian Luo, Jing Tang arXiv: 2603.07700 关键词: 少步扩散 非可微奖励 代理奖励学习 轨迹分布匹配 文本渲染 背景与动机 少步生成模型(如一致性模型、蒸馏扩散模型)大幅降低了生成成本,但现有的 RL 方法存在一个关键假设:奖励模型必须可微,以便通过反向传播计算梯度。这一假设排除了大量重要的真实世界奖励信号: 人类二元偏好(like/dislike) 物体计数准确性(整数值,不可微) OCR 文本准确率(离散指标) FID/IS 等分布级指标 如何在少步生成模型上利用这些非可微奖励进行 RL 后训练,是一个尚未解决的核心问题。 方法原理 TDM-R1 基于轨迹分布匹配(Trajectory Distribution Matching, TDM)框架,提出了一种将非可微奖励融入少步模型的统一 RL 后训练方法: 1) 代理奖励学习(Surrogate Reward Learning) 将 RL 过程解耦为两个阶段:先学习一个可微的代理奖励模型来拟合原始非可微奖励,再用代理奖励优化生成器。 代理奖励使用轻量级 MLP 头接在特征提取器上,通过对比学习训练,使其排序与真实奖励高度一致。 定期用真实非可微奖励校准代理奖励,防止偏移。 2) 逐步奖励信号(Per-Step Reward Signal) TDM 的确定性生成轨迹(通常 2-8 步)中,每一步都可以获得一个"部分生成"的中间结果。 设计逐步奖励:对每个中间状态通过快速解码预估最终输出,计算预估奖励作为当步的奖励信号。 这种细粒度的奖励分配比仅在最终步给出奖励更有效,降低了信用分配问题的难度。 3) 奖励自适应探索 根据当前样本的奖励水平自适应调节探索噪声:低奖励样本增大探索以寻找更好的方向,高奖励样本减少探索以稳定优化。 创新点 首个通用 RL 后训练方法支持少步模型 + 非可微奖励:打破了"可微奖励"的假设限制。 代理奖励学习 + 在线校准:兼顾了梯度可用性和奖励准确性。 逐步奖励分配:解决了少步模型中奖励信号稀疏的信用分配问题。 在文本渲染、视觉质量、偏好对齐三类任务上验证。 实验结果 在文本渲染任务上(OCR 准确率作为非可微奖励),TDM-R1 使 4 步模型的 OCR 准确率从 31.2% 提升至 62.7%(+101%)。 在 HPSv2 偏好对齐上,4-NFE 的 TDM-R1 达到 28.6,超越 100-NFE 的基线模型 (27.8)。 成功扩展到最新的 Z-Image 模型,仅用 4 步推理即持续超越其 100 步和少步变体。 与仅支持可微奖励的 ReFL 和 DDPO 相比,TDM-R1 在非可微奖励设定下领先 15-30%。 6. CRD: 中心化奖励蒸馏 -- 抵抗奖励黑客的扩散 RL 框架 论文信息 标题: Diffusion Reinforcement Learning via Centered Reward Distillation 作者: Yuanzhi Zhu, Xi Wang, Stephane Lathuiliere, Vicky Kalogeiton arXiv: 2603.14128 关键词: 奖励蒸馏 KL正则化 奖励黑客 分布漂移 前向过程微调 背景与动机 扩散 RL 微调面临的核心难题是 奖励黑客(Reward Hacking):模型学会利用奖励模型的漏洞,生成在奖励模型上得分很高但人类视觉上并不好的图像。例如,过度饱和的颜色、不自然的高对比度等。 现有方法的两大流派各有弊端: 轨迹级方法(DPPO, DDPO):内存消耗大、梯度方差高。 前向过程方法(DRaFT, ReFL):收敛快但容易发生分布漂移,导致奖励黑客。 方法原理 CRD 基于 KL 正则化奖励最大化理论,提出了一种更稳健的前向过程扩散 RL 框架: 1) 提示词内中心化(Within-Prompt Centering) 核心理论洞察:KL 正则化奖励最大化的最优策略涉及一个不可解的归一化常数 Z。 CRD 发现,通过在同一 prompt 的多个样本间做中心化(减去均值),归一化常数会自然抵消,得到一个适定的奖励匹配目标。 这使得 CRD 无需显式估计归一化常数,避免了额外的近似误差。 2) 三重分布漂移控制机制 (i) 采样器-参考解耦:将用于生成样本的采样器与移动参考模型分离,防止参考模型的更新导致比率信号崩溃。 (ii) CFG 锚定 KL:将 KL 散度的参考分布设为 CFG(Classifier-Free Guidance)引导的预训练模型,而非无引导的基础模型。这确保优化目标与推理时的语义一致。 (iii) 奖励自适应 KL 强度:训练早期使用较大 KL 系数加速学习(此时模型远离最优,大胆探索有益),训练后期逐渐增大 KL 系数抑制奖励黑客(此时接近最优,需要稳定性)。 创新点 理论优雅:通过中心化消除不可解归一化常数,将 KL 正则化奖励最大化转化为可实操的目标。 三重防线对抗奖励黑客:采样器-参考解耦、CFG 锚定、自适应 KL 强度协同工作。 CFG 锚定的创新性:传统方法锚定无 CFG 的基础模型,CRD 认识到推理时都使用 CFG,因此应该锚定 CFG 引导的分布。 实验结果 在 GenEval 上实现 0.83 的综合得分,与 SOTA 持平。 关键优势在于抗奖励黑客能力:在 HPSv2 上获得 28.5 的同时,FID 仅增加 2.3(对比 DPPO 的 FID 增加 8.7、DRaFT 的 FID 增加 5.1)。 OCR 文本渲染准确率提升 +23.1 pp。 在 ImageReward 和 PickScore 等未见过的偏好指标上,CRD 的优化效果同样保持(证明非奖励黑客)。 7. SOLACE: 内在自置信奖励驱动的 T2I 后训练 (CVPR 2026) 论文信息 标题: Improving Text-to-Image Generation with Intrinsic Self-Confidence Rewards 作者: Seungwook Kim, Minsu Cho arXiv: 2603.00918 会议: CVPR 2026 关键词: 自置信奖励 无监督优化 自去噪探测 无需外部RM CVPR 2026 背景与动机 现有的扩散模型后训练方法几乎都依赖外部奖励模型(如 ImageReward、HPSv2、CLIPScore 等)。然而: 外部奖励模型本身存在偏差和幻觉。 训练和维护奖励模型需要额外成本。 过度优化外部奖励容易导致奖励黑客。 一个自然的问题是:能否利用模型自身的内在信号来指导优化,完全不需要外部奖励模型? 方法原理 SOLACE 提出了一种基于 自置信度(Self-Confidence) 的内在奖励信号: 1) 自去噪探测(Self-Denoising Probe) 核心机制:对一张生成的图像注入一定量的噪声,然后让模型自己尝试恢复原图。 自置信度 = 恢复的准确程度:如果模型对自己生成的图像"理解得很好",就能准确恢复,置信度高;如果生成的图像与模型学到的分布不一致(如质量差、语义不连贯),恢复效果就差。 数学上,自置信度与模型在该样本处的似然估计成正比。 2) 标量奖励转化 将自去噪的重建误差转化为标量奖励分数:重建误差越小,奖励越高。 使用多个噪声水平进行探测,取平均值以获得更稳定的估计。 3) 完全无监督的偏好优化 利用自置信度奖励进行 GRPO 风格的优化,无需任何外部数据集、标注员或奖励模型。 高置信度的生成结果被强化,低置信度的被抑制。 创新点 首个完全无外部奖励的扩散模型后训练方法:打开了"自监督偏好对齐"的新方向。 自置信度信号的物理直觉:模型更容易恢复"好的"图像(与训练分布一致),提供了一种自然的质量度量。 与外部奖励互补:SOLACE 与外部奖励结合使用时效果更好,且能缓解奖励黑客。 零额外推理成本:自去噪探测仅在训练时使用,推理时完全不增加开销。 实验结果 仅使用内在奖励,在 GenEval 组合生成得分提升 +0.08(从 0.71 到 0.79)。 文本渲染准确率提升 +15.3 pp。 SOLACE + 外部奖励的组合方案达到 0.85 GenEval 得分,为所有方法中最高。 将 SOLACE 与 ImageReward 结合时,奖励黑客指标(FID 增量)从 ImageReward 单独使用时的 +6.2 降至 +1.8。 8. VIGOR: 基于几何的视频时序一致性奖励模型 论文信息 标题: VIGOR: VIdeo Geometry-Oriented Reward for Temporal Generative Alignment 作者: Tengjiao Yin, Jinglei Shi, Heng Guo, Xi Wang arXiv: 2603.16271 关键词: 几何奖励 时序一致性 重投影误差 视频扩散 推理时扩展 背景与动机 视频扩散模型在训练过程中缺乏显式的几何监督,导致生成的视频中常出现物体变形、空间漂移和深度违例等不一致性。现有的视频奖励模型主要基于语义(如 VQAScore、CLIPScore)或整体美学评估,无法捕捉帧间的几何一致性。 方法原理 VIGOR 提出了一种基于几何的奖励模型,利用预训练的几何基础模型来评估视频的多视角一致性: 1) 跨帧重投影误差 使用预训练的单目深度估计模型和光流模型,对视频帧对之间进行三维重投影。 逐点计算重投影误差(而非像素级对比),得到更符合物理规律的误差度量。 优势:逐点方式对纹理和光照变化更鲁棒,不会被像素强度差异干扰。 2) 几何感知采样 过滤低纹理区域和非语义区域(如天空、纯色背景),将评估集中在具有可靠对应关系的几何有意义区域。 使用特征匹配置信度作为权重,可靠区域的误差权重更大。 3) 双路径应用 训练后微调:对双向视频模型使用 VIGOR 奖励进行 SFT 或 RL 后训练。 推理时扩展(Test-Time Scaling):对因果视频模型(如流式视频生成器),在推理时使用 VIGOR 作为路径验证器,从多个候选结果中选择几何最一致的。 创新点 首个基于物理几何约束的视频生成奖励模型:超越了纯语义/美学评估的局限。 逐点误差计算:比像素级指标更鲁棒,对光照和纹理变化不敏感。 推理时扩展的即插即用方案:无需重训练模型,通过推理时选择提升开源视频模型质量。 兼容多种视频生成架构:双向模型(后训练)和因果模型(推理时扩展)均适用。 实验结果 在 VBench 动态一致性指标上提升 +5.8%。 物体变形率从基线的 23.7% 降至 11.4%(减少 52%)。 推理时扩展方案:在 Open-Sora 上,使用 VIGOR 选择最优帧序列,VBench 得分提升 +3.2 而无需任何额外训练。 与 VQAScore 等语义奖励正交互补:两者结合可进一步提升 +1.5。 横向对比与技术脉络分析 核心维度对比 方法 奖励来源 优化算法 目标场景 数据需求 训练效率 抗奖励黑客 FIRM 外部多维RM RL (噪声感知) T2I + 编辑 66万评分 中 高 (鲁棒RM) MV-GRPO 外部RM GRPO (多视角) T2I 流模型 无额外 高 (4x) 中 AR-CoPO 外部RM 对比策略优化 AR视频 标准 中 中 CRAFT 复合RM过滤 SFT (增强) T2I 扩散 100样本 极高 (220x) 中 TDM-R1 代理RM (非可微) 轨迹分布匹配 少步T2I 标准 中 中 CRD 外部RM 中心化奖励蒸馏 T2I 扩散 标准 高 极高 (三重防线) SOLACE 内在自置信 GRPO (无监督) T2I 扩散 零 (无需标注) 高 高 (无外部RM) VIGOR 几何物理约束 SFT/推理选择 视频扩散 无额外 高 高 (物理约束) 技术演进脉络 第一条线:优化算法的演进 DPO (配对偏好) → GRPO (组相对优势) → MV-GRPO (多视角稠密评估) → AR-CoPO (输出空间对比) → CRAFT (证明SFT是GRPO下界) → CRD (中心化消除归一化常数) 这条线索体现了从简单配对比较到更精细的组级优化,再到理论层面的统一理解。CRAFT 的发现尤为重要:它证明了精心筛选数据后的 SFT 本质上就是 GRPO 的一种近似,为实践者提供了"大道至简"的选择。 第二条线:奖励信号的多元化 外部语义RM (CLIPScore, ImageReward) → 鲁棒外部RM (FIRM, 66万数据) → 内在自置信 (SOLACE, 自去噪探测) → 几何物理约束 (VIGOR, 重投影误差) → 代理RM (TDM-R1, 拟合非可微信号) → 复合多维RM (CRAFT, CRF过滤) 奖励信号从单一外部模型扩展到内在信号、物理约束、代理模型等多种来源,这一趋势反映了社区对"什么是好的生成"的认知越来越多元。 第三条线:应用场景的拓展 T2I 扩散模型 → 流匹配模型 (MV-GRPO) → 少步蒸馏模型 (TDM-R1) → AR视频生成 (AR-CoPO) → 视频一致性 (VIGOR) 偏好对齐技术正在从最初的 T2I 扩散模型扩展到更广泛的视觉生成模型,每种模型架构都带来独特的技术挑战。 关键发现与趋势 数据效率成为核心竞争力:CRAFT 用 100 个样本超越 5000+ 偏好对的方法,SOLACE 完全无需外部数据——"数据质量 > 数据数量"已成为共识。 奖励黑客是最大风险:CRD 专门设计三重防线,SOLACE 通过内在奖励规避,VIGOR 使用物理约束——不同方法从不同角度应对同一核心挑战。 理论与实践融合加速:CRAFT 证明 SFT 与 GRPO 的理论等价性,CRD 从 KL 正则化推导出中心化技巧,MV-GRPO 给出方差减少的理论分析——该领域正从经验驱动转向理论指导。 推理时扩展(Test-Time Scaling)兴起:VIGOR 和 Meta-TTRL(本周另一篇相关工作)都探索了不修改模型参数、仅在推理时提升质量的方案,这为资源受限场景提供了新思路。 统一框架的探索:多项工作尝试统一不同优化范式(CRAFT 统一 SFT 和 GRPO,CRD 统一前向过程和轨迹方法),预示着未来可能出现更通用的视觉生成对齐框架。 其他相关工作简述 本周还有多篇相关工作值得关注: GDPO-SR (2603.16769): 将 GRPO 原理融入 DPO 用于一步超分辨率,引入属性感知奖励函数针对平滑/纹理区域差异化评估。 LibraGen (2603.13506): 主题驱动视频生成中的 DPO 应用,提出 Consis-DPO 和 Real-Fake DPO 两种定制化偏好优化管线。 Meta-TTRL (2603.15724): 统一多模态模型的测试时强化学习,利用模型内在元认知信号进行推理时自我改进。 Correlation-Weighted Multi-Reward (2603.18528): 组合生成中的多奖励协调优化,通过相关性加权平衡竞争概念间的奖励冲突。 V2A-DPO (2603.11089): 视频到音频生成的 DPO 框架,提出 AudioScore 综合评分系统。 总结与展望 本期专题梳理了视觉生成模型偏好对齐与 RL 后训练的最新进展。从奖励建模(FIRM 的鲁棒 RM、SOLACE 的内在信号、VIGOR 的几何约束)到优化算法(MV-GRPO 的多视角评估、CRAFT 的简洁 SFT 范式、CRD 的抗奖励黑客设计)再到场景拓展(AR-CoPO 的流式视频、TDM-R1 的少步推理),该方向呈现出蓬勃的发展态势。 未来值得关注的方向: 多模态统一对齐:将偏好对齐扩展到图像+视频+音频的统一生成模型。 在线人类反馈:从离线偏好数据集转向在线、实时的人类反馈闭环。 可解释奖励:让用户和开发者理解"为什么这张图/这段视频被认为是好的"。 超长视频对齐:随着视频生成长度增加,如何在数分钟长度的视频上进行有效的偏好对齐。 安全对齐:在提升质量的同时,确保生成内容的安全性和合规性。 本期专题由 人工智能炼丹师 整理,更多 AIGC 前沿动态请关注 jefxiong.cn
-
AIGC 周末专题深度解读:生成与理解的大一统之路 AIGC 周末专题深度解读:生成与理解的大一统之路 人工智能炼丹师 整理 | 2026年3月15日(周日) 覆盖时间:2026年3月2日 — 2026年3月14日 本期概述 本周 AIGC 领域最热门的方向莫过于统一多模态模型(Unified Multimodal Models, UMMs)——将视觉理解(图像识别、VQA、推理)与视觉生成(文生图、图像编辑)统一在同一个模型框架内。过去一周内,arXiv 上涌现了超过 8 篇高质量论文,从架构设计、训练范式、评测基准、长序列生成到强化学习后训练,全方位推动了这一方向的发展。 核心问题 传统的多模态 AI 系统中,"理解"和"生成"是两套独立的系统: 理解侧:CLIP、SigLIP、InternVL 等模型擅长视觉语义理解 生成侧:Stable Diffusion、DALL-E、FLUX 等模型擅长图像生成 统一多模态模型的目标是让同一个模型既能"看懂"图片,又能"画出"图片,甚至让两种能力相互促进。 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 DREAM MIT + Amazon 联合判别-生成训练框架,Masking Warmup + 语义对齐解码 2603.02667 2 GvU (CVPR 2026) 北大 + 百度 理解驱动内在奖励,自监督 RL 缩小生成-理解差距 2603.06043 3 Omni-Diffusion 腾讯 + CASIA 首个全离散扩散统一模型,文本+语音+图像 any-to-any 2603.06577 4 InternVL-U 上海AI Lab + 商汤 4B 参数统一模型,CoT 推理增强生成,超越 14B 基线 2603.09877 5 UniCom 阿里达摩院 压缩连续语义表征,Transfusion 架构,SOTA 生成 2603.10702 6 UniG2U-Bench 多机构联合 首个系统性 G2U 评测基准,7 种机制 30 个子任务 2603.03241 7 UniLongGen Adobe + PolyU 长序列交错生成的主动遗忘策略,解决视觉污染 2603.07540 8 GRPO-Interleaved 华为 + 复旦 GRPO 扩展到多模态交错生成,过程级奖励 2603.09538 1. DREAM:视觉理解与文生图的联合优化框架 论文: DREAM: Where Visual Understanding Meets Text-to-Image Generation arXiv: 2603.02667 机构: MIT CSAIL, Amazon 发布日期: 2026年3月3日 1.1 研究动机 在多模态学习中,视觉理解(如 CLIP 的对比学习)和图像生成(如 MAE 的掩码重建)一直是两个独立的优化目标。直接联合训练会导致两个目标相互冲突——对比学习需要低掩码率保留全局语义,而生成训练需要高掩码率学习重建。 1.2 方法原理 DREAM 提出了两项关键技术来解决这一矛盾: (1)Masking Warmup(掩码预热)策略 训练分为两个阶段: 预热阶段:掩码率从低(~15%)逐渐增加,先建立对比对齐的表征空间 生成阶段:掩码率增加到高(~75%),在已有的稳定表征上训练生成能力 这种渐进式调度避免了"同时从零开始学两件事"的不稳定性。 (2)Semantically Aligned Decoding(语义对齐解码) 推理时,模型生成多个部分掩码的候选图像,然后用模型自身的理解分支计算每个候选与目标文本的语义对齐分数,选择最佳候选继续解码。这相当于在不引入外部重排序器的情况下,用理解能力"把关"生成质量。 1.3 实验结果 仅在 CC12M(1200 万图文对)上训练: ImageNet 线性探测:72.7%(比 CLIP 高 1.1%) FID:4.25(比 FLUID 低 6.2%) 文本-图像保真度提升 6.3%(无需外部重排序器) 1.4 关键洞察 DREAM 证明了判别目标和生成目标之间存在协同效应,而非简单的零和竞争。关键在于训练策略的设计——让模型先学好"看",再学"画"。 2. GvU:理解驱动的内在奖励机制(CVPR 2026) 论文: Learning to Generate via Understanding: Understanding-Driven Intrinsic Rewarding for Unified Multimodal Models arXiv: 2603.06043 机构: 北京大学, 百度 发布日期: 2026年3月6日 | 会议: CVPR 2026 2.1 研究动机 现有的统一多模态模型存在一个显著的"能力不对称"问题:理解能力强,生成能力弱。模型能准确描述图片中的每个细节,但让它根据文字画图时却经常"丢三落四"。这种差距的根源在于理解和生成过程在训练中是解耦的。 2.2 方法原理 GvU 的核心思想非常精妙——让模型用自己的理解能力来指导自己的生成能力: Token 级内在文本-图像对齐奖励: 模型生成一张图像后,用自身的理解分支对生成的图像进行分析 将理解结果与原始文本提示做 token 级对齐打分 得到细粒度的"内在奖励信号" 自监督强化学习框架: 模型同时扮演"教师"(理解分支提供奖励)和"学生"(生成分支接收奖励并优化) 通过迭代的 RL 训练,生成能力逐步提升 无需任何外部标注或人工反馈 2.3 实验结果 生成质量(FID、CLIP Score)显著提升 反过来,细粒度视觉理解能力也得到增强 实现了理解→生成→理解的正向循环 2.4 关键洞察 GvU 开创了一种"自我进化"范式:模型不依赖外部信号,仅通过内部的理解-生成循环就能持续改进。这与 LLM 领域的 Self-Play 思想异曲同工,但在多模态领域是首次实现。 3. Omni-Diffusion:首个全离散扩散统一模型 论文: Omni-Diffusion: Unified Multimodal Understanding and Generation with Masked Discrete Diffusion arXiv: 2603.06577 机构: 腾讯, 中科院自动化所 发布日期: 2026年3月6日 3.1 研究动机 现有的统一多模态模型几乎都采用自回归(Autoregressive)架构作为骨干。但自回归架构存在固有局限: 生成速度慢(逐 token 预测) 长序列时容易出现错误累积 难以高效处理多模态联合分布 离散扩散模型(Discrete Diffusion)是一种新兴的替代方案,它通过逐步去掩码的方式并行生成,但之前从未被用于构建统一的多模态系统。 3.2 方法原理 Omni-Diffusion 是首个完全基于掩码离散扩散模型的 any-to-any 多模态语言模型: 统一的掩码-去掩码框架: 文本、图像、语音全部被编码为离散 token 使用统一的掩码扩散过程直接建模多模态联合分布 前向过程:随机掩码 token → 全掩码状态 反向过程:从全掩码状态逐步预测并恢复 token 支持的任务: 文本→图像、图像→文本 语音→文本、文本→语音 图像+文本→文本(多模态理解) 以及更复杂的跨模态场景 3.3 实验结果 在多项基准测试上: 理解任务:与现有多模态系统持平或超越 生成任务:在图像生成质量上表现突出 展示了离散扩散模型作为多模态基础模型骨干的巨大潜力 3.4 关键洞察 Omni-Diffusion 打破了"统一多模态模型 = 自回归"的思维定式,证明了离散扩散模型可以作为下一代多模态基础模型的骨干架构。这为并行生成、更灵活的条件控制和更高效的推理打开了新的可能性。 4. InternVL-U:4B 参数挑战 14B+ 大模型 论文: InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing arXiv: 2603.09877 机构: 上海 AI Lab, 商汤, 港中文 发布日期: 2026年3月10日 4.1 研究动机 现有的统一多模态模型在追求全能的过程中往往面临"鱼与熊掌不可兼得"的困境——要么理解能力强但生成一般(如 Janus),要么生成漂亮但理解退化。而且大部分方案需要巨大的参数量(10B+)才能取得不错效果。 4.2 方法原理 InternVL-U 通过三个关键设计突破了这一瓶颈: (1)解耦视觉表征 + 模态特定模块化 理解分支:使用 InternViT 作为视觉编码器,保留强大的语义理解 生成分支:使用 MMDiT(Multi-Modal Diffusion Transformer)作为视觉生成头 两个分支共享语言模型的上下文空间,但视觉表征独立 (2)以推理为中心的数据合成流水线 针对文本渲染、科学图表推理等高语义密度任务 使用 CoT(思维链)将抽象的用户意图分解为细粒度的视觉生成细节 让模型"先想清楚要画什么,再动笔" (3)渐进式训练策略 阶段 1:分别预训练理解和生成模块 阶段 2:联合微调,让两个模块学会协作 阶段 3:指令微调,对齐用户意图 4.3 实验结果 仅 4B 参数的 InternVL-U: 在生成和编辑任务上超越 BAGEL(14B)等大 3 倍以上的模型 同时保持与同尺寸纯理解模型相当的多模态理解和推理能力 证明了"小而精"的统一模型路线的可行性 4.4 关键洞察 InternVL-U 表明精心的架构设计和数据工程可以弥补参数量的不足。特别是 CoT 推理增强生成的范式——让模型先推理再生成——可能是统一模型走向实用的关键路径。 5. UniCom:压缩连续表征的最优解 论文: UniCom: Unified Multimodal Modeling via Compressed Continuous Semantic Representations arXiv: 2603.10702 机构: 阿里巴巴达摩院 发布日期: 2026年3月11日 5.1 研究动机 统一多模态模型的一个核心技术选择是视觉表征形式: 方案 优势 劣势 离散 Token(VQ-VAE) 与 LLM 天然兼容 信息损失大,理解能力弱 连续表征(CLIP) 语义信息丰富 高维空间难以建模生成 UniCom 的目标是找到一个"甜蜜点"——在保留丰富语义的同时降低建模难度。 5.2 方法原理 核心发现:通道压缩优于空间下采样 通过系统的消融实验,UniCom 团队发现: 在重建和生成两项任务上,减少特征的通道维度比传统的空间下采样(降低分辨率)更有效 原因:空间下采样丢失了局部细节,而通道压缩保留了空间结构 基于注意力的语义压缩器: 将 CLIP/SigLIP 的密集特征图(如 256×1024 维)压缩为紧凑表征(如 256×64 维) 使用交叉注意力机制,让压缩后的表征"聚焦"于最重要的语义信息 压缩后的表征同时服务于理解(作为 LLM 的视觉输入)和生成(作为扩散模型的条件) Transfusion 架构选择: 验证了 Transfusion(理解用自回归、生成用扩散)优于纯查询式(query-based)设计 收敛更快、生成-理解一致性更好 5.3 实验结果 在统一模型中实现了最先进的生成性能 图像编辑的可控性优于基于离散 token 的方案 即使不依赖 VAE 也能保持图像一致性 5.4 关键洞察 UniCom 为"离散 vs 连续"之争提供了一个折中方案:压缩后的连续表征既保留了语义丰富性,又降低了生成建模的难度。这可能是未来统一模型视觉表征的主流选择。 6. UniG2U-Bench:生成如何增强理解?首个系统性评测 论文: UniG2U-Bench: Do Unified Models Advance Multimodal Understanding? arXiv: 2603.03241 机构: 多机构联合 发布日期: 2026年3月3日 6.1 研究动机 统一模型的一个核心 Promise 是"生成能力能够反过来增强理解能力"。但这个 Promise 到底在多大程度上成立?在什么任务上成立?现有基准测试无法系统性地回答这些问题。 6.2 方法原理 UniG2U-Bench 将"生成到理解"(G2U)评测分解为: 7 种机制: 心理旋转(空间想象) 视觉类比推理 视觉错觉感知 图形变换理解 多步推理(含中间状态) 风格/属性变换感知 反事实视觉推理 30 个子任务,需要不同程度的隐式或显式视觉变换。 6.3 核心发现 对 30+ 个模型的评估揭示了三个重要结论: 发现 1:统一模型通常不如其基础 VLM,"生成后回答"(Generate-then-Answer)推理通常比直接推理更差。 发现 2:但在特定场景下,生成确实能增强理解: 空间智能:需要心理旋转或 3D 推理的任务 视觉错觉:需要超越表面特征的任务 多轮推理:需要中间图像状态辅助的复杂任务 发现 3:具有相似推理结构的任务和相似架构的模型表现出相关的行为模式,说明 G2U 耦合是由训练数据和架构共同决定的归纳偏差。 6.4 关键洞察 UniG2U-Bench 给出了一个清醒的结论:生成增强理解并非万能药,而是在特定场景下才有效。这为未来的统一模型设计提供了明确的优化方向——聚焦于空间推理和多步推理场景。 7. UniLongGen:长序列交错生成的"主动遗忘"策略 论文: How Long Can Unified Multimodal Models Generate Images Reliably? Taming Long-Horizon Interleaved Image Generation via Context Curation arXiv: 2603.07540 机构: Adobe Research, 香港理工大学 发布日期: 2026年3月8日 7.1 研究动机 统一多模态模型的一个重要应用是交错生成——在一个长序列中交替生成文本和图像,用于视觉故事讲述、分步教程等场景。但现有模型面临一个严重问题:随着序列增长,生成质量急剧崩溃。 7.2 方法原理 关键发现:视觉历史是"主动污染"源 论文通过深入分析发现: 质量崩溃不是由 Token 总数引起的(不同于 LLM 的长上下文问题) 而是由累积的图像事件数量决定 密集的视觉 Token 会压倒注意力机制,产生"噪声干扰",扭曲后续的图像合成 UniLongGen:无训练的推理策略 核心思想——主动遗忘: 在每个生成步骤前,根据模型内部的注意力权重计算每个历史图像的"相关性分数" 保留与当前生成最相关的视觉上下文 丢弃低相关性的历史图像(即使它们是"正确的"历史记录) 优先保证生成条件的"干净性",而非历史记录的完整性 7.3 实验结果 长期保真度和一致性显著优于所有基线方法 内存占用减少(因为丢弃了不需要的历史) 推理速度提升 7.4 关键洞察 UniLongGen 揭示了一个反直觉的事实:在长序列生成中,"记住所有东西"反而是有害的。这与人类的认知机制类似——我们在创作长篇叙事时,也需要有选择性地"忽略"之前的细节,聚焦于当前的创作。 8. GRPO-Interleaved:强化学习后训练解锁交错生成 论文: Towards Unified Multimodal Interleaved Generation via Group Relative Policy Optimization arXiv: 2603.09538 机构: 华为, 复旦大学 发布日期: 2026年3月10日 8.1 研究动机 现有的统一多模态模型在理解和单模态生成上表现不错,但在多模态交错输出(如交替生成文本和图像的长叙事)上严重不足。原因是高质量的交错训练数据极度稀缺。 8.2 方法原理 两阶段训练范式: 阶段 1:混合数据预热 精心策划少量交错序列 加入有限的理解数据和 T2I 数据 让模型"接触"交错生成模式,但不破坏预训练能力 阶段 2:群组相对策略优化(GRPO) 将 GRPO(源自 DeepSeek-R1 的 RL 方法)扩展到多模态: 在单个解码轨迹中联合建模文本和图像生成 设计混合奖励函数: 文本相关性奖励:生成文本与输入的一致性 视觉-文本对齐奖励:生成图像与上下文文本的匹配度 结构保真度奖励:交错内容的结构合理性 过程级奖励: 不仅评价最终结果,还对每一步生成提供奖励信号 提高了复杂多模态任务的训练效率 8.3 实验结果 在 MMIE 和 InterleavedBench 上: 交错生成的质量和连贯性显著提升 在不依赖大规模交错数据集的情况下实现了突破 8.4 关键洞察 GRPO-Interleaved 证明了强化学习后训练(RL Post-Training)是解锁统一模型新能力的有效手段。这延续了 LLM 领域 RLHF/DPO 的成功经验,将其推广到多模态交错生成这一更复杂的场景。 横向对比与技术脉络总结 架构对比 论文 骨干架构 视觉表征 理解-生成耦合方式 DREAM ViT + MAE 连续(掩码重建) 共享编码器 + 联合训练 GvU LLM + VQ-VAE 离散 Token 自监督 RL 桥接 Omni-Diffusion 离散扩散 LM 离散 Token 统一扩散过程 InternVL-U InternViT + MMDiT 解耦表征 共享上下文 + 模态模块化 UniCom LLM + Transfusion 压缩连续表征 通道压缩 + Transfusion 训练范式对比 论文 训练方法 外部监督 数据需求 DREAM 渐进式联合预训练 无 CC12M(12M 图文对) GvU 自监督 RL 后训练 无(内在奖励) 极少额外数据 Omni-Diffusion 统一扩散预训练 无 大规模多模态数据 InternVL-U 三阶段渐进训练 + CoT 数据合成 合成数据 中等规模 UniCom Transfusion 预训练 无 大规模多模态数据 GRPO-Interleaved GRPO 后训练 混合奖励函数 极少交错数据 核心技术趋势 趋势 1:从"对抗"到"协同" 早期的统一模型中,理解和生成是竞争关系(共享参数导致能力冲突)。本周的论文普遍转向"协同"思维——用理解增强生成(GvU),或证明两者可以共赢(DREAM)。 趋势 2:后训练成为关键杠杆 GvU 和 GRPO-Interleaved 都表明,在预训练模型上做少量 RL 后训练,就能显著解锁新能力。这与 LLM 领域 ChatGPT 的成功路径一致。 趋势 3:离散扩散的崛起 Omni-Diffusion 首次证明了离散扩散可以替代自回归成为统一模型的骨干,为并行生成和更灵活的架构设计开辟了道路。 趋势 4:表征形式的创新 从纯离散(VQ-VAE)到纯连续(CLIP),再到 UniCom 的"压缩连续",表征设计正在走向更精细化的折中方案。 趋势 5:长序列和交错生成的突破 UniLongGen 和 GRPO-Interleaved 共同推动了交错生成的进步,让统一模型距离实际应用(视觉叙事、交互式内容创作)更近了一步。 技术路线全景图 统一多模态模型技术路线 ├── 架构设计 │ ├── 自回归统一 → DREAM, InternVL-U, UniCom │ ├── 扩散统一 → Omni-Diffusion │ └── 混合架构 → Transfusion (UniCom), 解耦模块化 (InternVL-U) ├── 视觉表征 │ ├── 离散 Token → Omni-Diffusion, GvU │ ├── 连续表征 → DREAM │ └── 压缩连续 → UniCom (NEW 最优折中) ├── 训练范式 │ ├── 联合预训练 → DREAM, Omni-Diffusion │ ├── 渐进式训练 → InternVL-U (3 阶段) │ └── RL 后训练 → GvU (自监督), GRPO-Interleaved (混合奖励) ├── 评测与分析 │ └── G2U 系统评测 → UniG2U-Bench (7 机制 30 任务) └── 应用扩展 ├── 长序列交错生成 → UniLongGen (主动遗忘) └── 多模态交错生成 → GRPO-Interleaved (过程级 RL) 总结与展望 本周的 8 篇论文共同描绘了统一多模态模型的全景图。以下是几个值得关注的未来方向: 规模化验证:DREAM 仅在 CC12M 上验证,规模扩大后协同效应是否更强? 自我进化闭环:GvU 的自监督 RL 能否无限迭代,实现模型的持续自我改进? 离散扩散的极限:Omni-Diffusion 的 any-to-any 能力能否扩展到视频和 3D? 小模型的力量:InternVL-U 的 4B 成功是否意味着统一模型不需要"更大",只需要"更聪明"? 交错生成的实用化:UniLongGen + GRPO 的组合能否实现真正实用的视觉叙事系统? 统一多模态模型正处于从"概念验证"走向"实际可用"的关键转折点。生成与理解的融合不再是一个遥远的愿景,而是一个正在快速成形的现实。 人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月2日—14日