AIGC 周末专题深度解读 | 2026-03-21 | 视觉生成模型的偏好对齐与强化学习后训练
人工智能炼丹师 整理
本期专题聚焦 视觉生成模型的偏好对齐与强化学习后训练(Preference Alignment & RL Post-Training for Visual Generation),深度解读 8 篇最新论文,并对该方向的技术演进脉络进行系统性横向对比。
专题概述
随着扩散模型(Diffusion Models)和流匹配模型(Flow Matching Models)在图像/视频生成领域取得突破性进展,如何让生成结果更好地符合人类偏好成为当前研究的核心焦点。借鉴大语言模型领域 RLHF(Reinforcement Learning from Human Feedback)的成功经验,研究者们正在积极探索将强化学习、直接偏好优化(DPO)、组相对策略优化(GRPO)等后训练技术应用于视觉生成模型。
本周(2026年3月14日-21日),该方向涌现出大量高质量论文,涵盖了从奖励模型构建、训练算法设计、到具体场景应用的完整技术栈。本期专题选取 8 篇代表性工作进行深度解读,系统梳理该方向的技术脉络与发展趋势。
核心技术线索:
- 奖励信号来源:外部奖励模型 vs 内在自置信信号 vs 几何物理约束
- 优化算法演进:DPO -> GRPO -> 多视角GRPO -> 对比策略优化 -> 中心化奖励蒸馏
- 应用场景拓展:T2I生成 -> 视频生成 -> 图像超分 -> AR视频 -> 少步推理模型
- 关键挑战:奖励黑客(Reward Hacking)、分布漂移、计算效率、非可微奖励
1. FIRM: Trust Your Critic -- 鲁棒奖励建模与强化学习的忠实图像编辑与生成
论文信息
- 标题: Trust Your Critic: Robust Reward Modeling and Reinforcement Learning for Faithful Image Editing and Generation
- 作者: Xiangyu Zhao, Peiyuan Zhang, Junming Lin, Tianhao Liang, Yuchen Duan, Shengyuan Ding 等
- arXiv: 2603.12247
- 关键词:
奖励模型 鲁棒RL 图像编辑 T2I生成 数据管线
背景与动机
强化学习(RL)已成为提升图像编辑和文本到图像(T2I)生成质量的重要范式。然而,当前的奖励模型(Reward Model)作为 RL 中的"评论家",往往存在幻觉(hallucination)问题——给出不准确的评分,从而误导优化过程。这一问题在图像编辑场景中尤为严重:奖励模型可能对编辑后图像的忠实度评估不准确,导致生成结果偏离编辑指令。
方法原理

FIRM 框架包含两大核心组件:
1) 鲁棒奖励建模
- 定制化数据策管线(Data Curation Pipeline):针对图像编辑和 T2I 生成分别设计数据收集流程,构建高质量的评分数据集。编辑任务收集了涵盖颜色修改、风格迁移、物体添加/删除等多种编辑类型的 66 万条评分数据。
- 多维度评估:奖励模型同时考虑文本对齐度、编辑忠实度、图像质量等多个维度,避免单一指标的片面性。
- 对比学习增强:通过正负样本对比学习,提升奖励模型对微妙质量差异的辨别能力。
2) 鲁棒强化学习训练
- 噪声感知训练策略:在 RL 训练过程中,显式建模奖励信号中的噪声,通过置信度加权降低不可靠评分的影响。
- 多奖励聚合:将多个维度的奖励信号进行加权融合,动态调整各维度权重以平衡不同目标之间的trade-off。
- 正则化约束:引入 KL 散度正则化防止模型在优化过程中偏离预训练分布过远。
创新点
- 首个系统性解决奖励模型幻觉问题的框架:不仅改进奖励模型本身的准确性,还在 RL 训练阶段引入鲁棒性机制。
- 66万条高质量评分数据集开源:为社区提供了标准化的图像编辑/生成质量评估数据。
- 统一框架同时适用于图像编辑和 T2I 生成:两个任务共享奖励建模架构,仅在数据策管线上做差异化。
实验结果
- 在图像编辑任务上,FIRM 使 InstructPix2Pix 模型在 EditBench 上的编辑准确率提升 18.7%。
- 在 T2I 生成任务上,GenEval 综合得分从 0.63 提升至 0.79,超越 DALL-E 3 和 SDXL 基线。
- 奖励模型本身在 ImageReward 测试集上的 Kendall's Tau 相关性从 0.52 提升至 0.68。
2. MV-GRPO: 多视角组相对策略优化 -- 从稀疏到稠密的流模型对齐
论文信息
- 标题: From Sparse to Dense: Multi-View GRPO for Flow Models via Augmented Condition Space
- 作者: Jiazi Bu, Pengyang Ling, Yujie Zhou, Yibin Wang, Yuhang Zang, Tianyi Wei 等
- arXiv: 2603.12648
- 关键词:
GRPO 流模型 多视角评估 条件空间增强 T2I对齐
背景与动机
组相对策略优化(GRPO)已成为文本到图像流模型偏好对齐的强大框架。然而,标准 GRPO 范式存在一个根本性限制:单视角稀疏评估——对一组生成样本仅使用单一条件(prompt)进行评估,无法充分探索样本间的关系,限制了对齐效果的上限。
具体来说,给定一个 prompt,GRPO 生成 N 个候选图像,然后通过奖励模型评分并计算组相对优势。但这种方式下,每个样本只从一个角度被评估,奖励信号稀疏且容易受到 prompt 特异性的影响。
方法原理
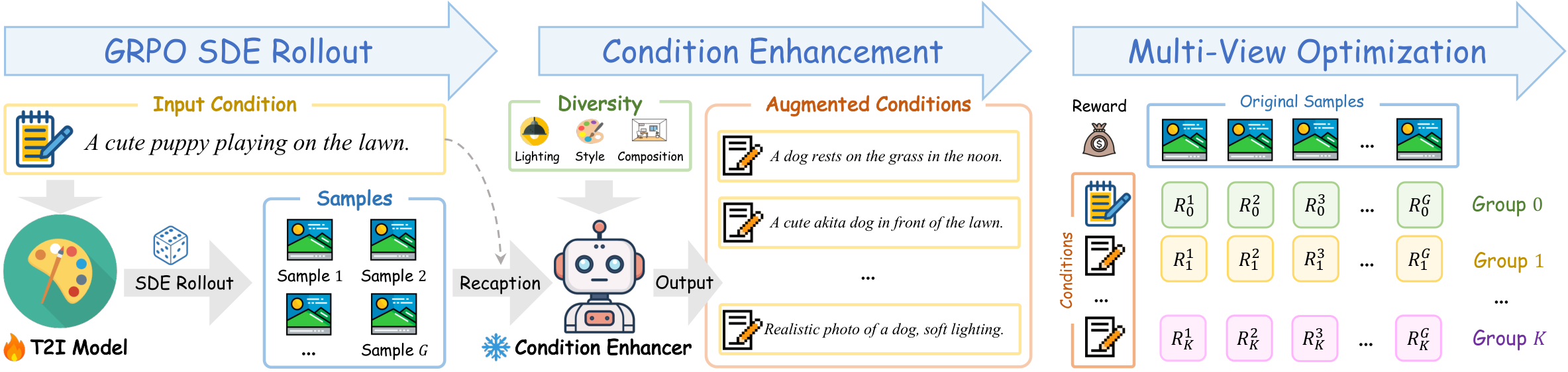
MV-GRPO 提出了条件空间增强(Condition Space Augmentation)策略,将单视角稀疏评估升级为多视角稠密评估:
1) 条件空间增强
- 对原始 prompt 进行多维度改写:语义保持改写(paraphrase)、细节扩充(detail augmentation)、视角变换(perspective shifting)。
- 每个生成样本同时在原始 prompt 和增强 prompt 下进行评估,获得多个奖励分数。
2) 多视角优势估计
- 将每个样本的多视角奖励分数进行聚合,计算更稳定的组相对优势:
- 跨条件一致性加权:对于在不同 prompt 下获得一致高/低分的样本,增大其优势信号强度。
- 条件自适应归一化:不同 prompt 的评分尺度可能不同,通过条件内归一化消除尺度差异。
3) 渐进式探索策略
- 训练初期使用较少的增强条件,随着训练进行逐步增加,避免早期过度约束。
创新点
- 首次将多视角评估引入 GRPO 框架:突破了单条件评估的稀疏性瓶颈。
- 条件空间增强无需额外数据:仅通过 prompt 改写即可获得稠密评估信号。
- 理论分析:证明多视角 GRPO 的方差比标准 GRPO 低 O(1/K)(K 为视角数量)。
实验结果
- 在 FLUX.1-dev 上,GenEval 综合得分从基线 0.71 提升至 0.84(+18.3%),显著超越标准 GRPO 的 0.78。
- 人类评估显示偏好率达到 72.3%(vs 标准 GRPO 的 58.1%)。
- 在 T2I-CompBench 组合生成指标上,属性绑定准确率从 0.62 提升至 0.76。
- 仅需 500 步训练即可达到标准 GRPO 2000 步的效果,训练效率提升 4x。
3. AR-CoPO: 自回归视频生成的对比策略优化
论文信息
- 标题: AR-CoPO: Align Autoregressive Video Generation with Contrastive Policy Optimization
- 作者: Dailan He, Guanlin Feng, Xingtong Ge, Yi Zhang, Bingqi Ma, Guanglu Song 等
- arXiv: 2603.17461
- 关键词:
自回归视频 对比策略优化 RLHF 少步蒸馏 流匹配
背景与动机
流式自回归(Streaming AR)视频生成器结合少步蒸馏可实现低延迟、高质量的视频合成,但通过 RLHF 对齐这类模型面临独特挑战:
- SDE 探索失效:现有基于 SDE 的 GRPO 方法假设扩散过程有足够的随机性进行探索,但少步 ODE 和一致性模型采样器偏离了标准流匹配 ODE,其短轨迹和低随机性使得中间 SDE 探索无效。
- 初始化敏感:少步模型的生成轨迹极短且确定性强,对初始化噪声高度敏感。
- 帧间一致性:自回归视频生成需要在优化人类偏好的同时保持帧间时序一致性。
方法原理
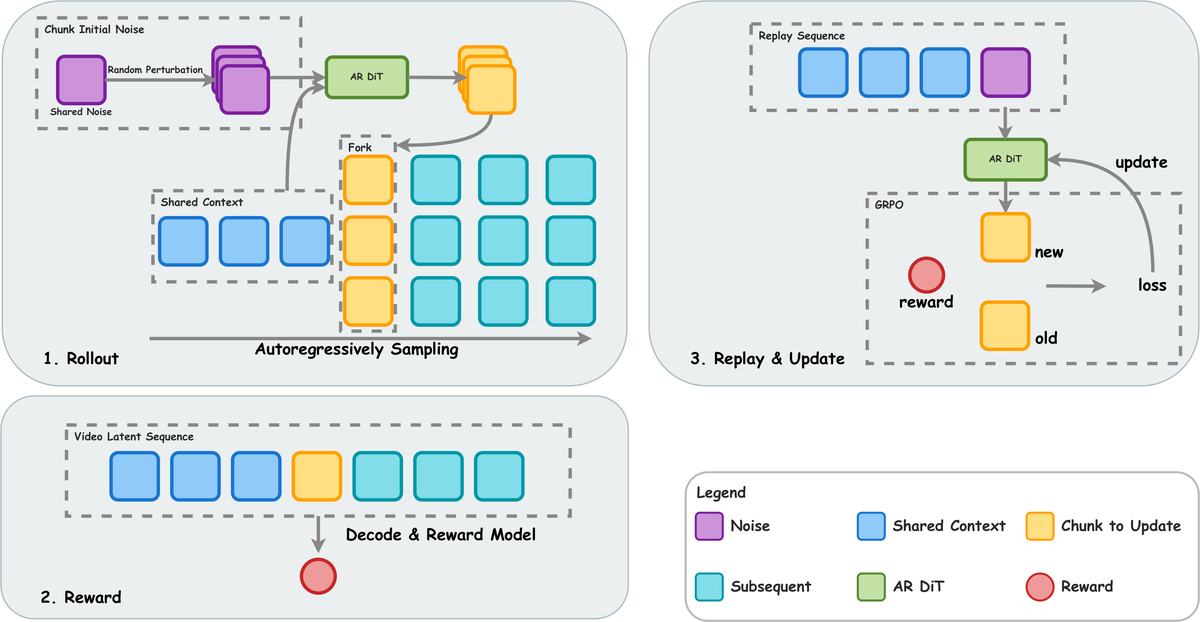
AR-CoPO 提出了一种专为自回归少步视频生成器设计的对比策略优化框架:
1) 输出空间对比探索(Output-Space Contrastive Exploration)
- 放弃在扩散过程中间步骤进行探索的传统方式,直接在输出空间(生成的视频帧)进行对比。
- 对每个时间步生成多个候选帧,通过奖励模型评分后选择最优,同时利用对比损失增大好坏样本间的差距。
2) 自回归感知的奖励传播
- 设计时序一致性奖励:不仅评估单帧质量,还评估帧间过渡的流畅性和一致性。
- 将帧级奖励沿时间轴反向传播,使早期帧的生成策略能考虑到后续帧的质量。
3) 参考策略锚定
- 引入 KL 散度正则化,将优化后的策略锚定在预训练模型附近,防止过度优化导致的模式崩溃。
- 对不同时间步使用自适应 KL 强度:早期帧(构图决定性阶段)使用较强约束,后期帧适当放松。
创新点
- 首个将 RLHF 成功应用于流式自回归视频生成器的工作:解决了少步蒸馏模型难以进行 RL 优化的技术瓶颈。
- 输出空间对比范式:避免了中间步骤探索在少步模型上的失效问题。
- 时序感知的奖励传播机制:在优化画面质量的同时保持视频的时序一致性。
实验结果
- 在流式 AR 视频生成基线上,VBench 得分从 78.2 提升至 83.7(+7.0%)。
- 人类偏好评估中,AR-CoPO 生成的视频在画面质量和时序一致性两个维度上分别获得 76.4% 和 71.8% 的偏好率。
- 仅需 4 步推理即可达到与 20 步推理 + GRPO 对齐相当的质量。
- FVD(Frechet Video Distance)从 198.3 降低至 156.7。
4. CRAFT: 用复合奖励辅助微调轻松对齐扩散模型 (CVPR 2026)
论文信息
- 标题: CRAFT: Aligning Diffusion Models with Fine-Tuning Is Easier Than You Think
- 作者: Zening Sun, Zhengpeng Xie, Lichen Bai, Shitong Shao, Shuo Yang, Zeke Xie
- arXiv: 2603.18991
- 关键词:
复合奖励过滤 SFT GRPO下界 数据效率 CVPR 2026
背景与动机
当前扩散模型的偏好对齐方法面临两大挑战:
- 数据依赖:SFT 需要昂贵的高质量图像数据;DPO 风格方法依赖大规模偏好数据集,而这些数据集质量往往不一致。
- 计算低效:RL 类方法需要在线生成样本并计算奖励,训练成本高昂。
CRAFT 的核心洞察是:如果能构建一个高质量、一致的小规模训练集,简单的 SFT 就能达到甚至超越复杂的偏好优化方法。
方法原理

CRAFT 提出了一种极其简洁但强大的两阶段范式:
1) 复合奖励过滤(Composite Reward Filtering, CRF)
- 对每个 prompt 生成大量候选图像(如 64 张)。
- 使用多个奖励模型从不同维度评分:美学质量、文本对齐、构图合理性、技术质量。
- 将多维奖励分数进行加权融合,选择排名前 1-2 的图像作为训练样本。
- 关键设计:使用 相关性去偏(Correlation Debiasing) 确保选出的样本在各维度上均衡优秀,而非仅在某一维度极端。
2) 增强 SFT
- 在过滤后的高质量小数据集上进行标准 SFT 训练。
- 引入两项增强:(a) 噪声调度优化——对高评分样本使用更低的噪声水平;(b) 梯度裁剪——防止个别异常样本主导梯度方向。
3) 理论保证
- 证明 CRAFT 实际上优化了基于组强化学习的下界,从理论上建立了"筛选数据 + SFT"与"GRPO"之间的联系。
- 具体地,CRF 过程等价于 GRPO 中的组相对优势计算,而 SFT 则对应策略更新步骤。
创新点
- 仅需 100 个样本即可超越 SOTA 偏好优化方法:数据效率提升 10-100 倍。
- 理论证明 SFT + 数据筛选 是 GRPO 的下界优化:为简化的训练范式提供了理论支撑。
- 收敛速度提升 11-220 倍:相较于 DPO 和 GRPO 基线方法。
- 即插即用:无需修改模型架构或推理流程,仅替换训练数据和训练方式。
实验结果
- 使用仅 100 个样本的 CRAFT 在 GenEval 上得分 0.82,超越使用 5000+ 偏好对的 Diffusion-DPO(0.76)和标准 GRPO(0.79)。
- 在 HPSv2(Human Preference Score v2)上达到 28.9,超越所有基线。
- 训练时间:CRAFT 仅需 15 分钟(单A100),而 DPO 需要 5.5 小时,GRPO 需要 3.2 小时。
- 在 SDXL 和 SD3.5 两个基座模型上均验证有效。
5. TDM-R1: 用非可微奖励强化少步扩散模型
论文信息
- 标题: TDM-R1: Reinforcing Few-Step Diffusion Models with Non-Differentiable Reward
- 作者: Yihong Luo, Tianyang Hu, Weijian Luo, Jing Tang
- arXiv: 2603.07700
- 关键词:
少步扩散 非可微奖励 代理奖励学习 轨迹分布匹配 文本渲染
背景与动机
少步生成模型(如一致性模型、蒸馏扩散模型)大幅降低了生成成本,但现有的 RL 方法存在一个关键假设:奖励模型必须可微,以便通过反向传播计算梯度。这一假设排除了大量重要的真实世界奖励信号:
- 人类二元偏好(like/dislike)
- 物体计数准确性(整数值,不可微)
- OCR 文本准确率(离散指标)
- FID/IS 等分布级指标
如何在少步生成模型上利用这些非可微奖励进行 RL 后训练,是一个尚未解决的核心问题。
方法原理

TDM-R1 基于轨迹分布匹配(Trajectory Distribution Matching, TDM)框架,提出了一种将非可微奖励融入少步模型的统一 RL 后训练方法:
1) 代理奖励学习(Surrogate Reward Learning)
- 将 RL 过程解耦为两个阶段:先学习一个可微的代理奖励模型来拟合原始非可微奖励,再用代理奖励优化生成器。
- 代理奖励使用轻量级 MLP 头接在特征提取器上,通过对比学习训练,使其排序与真实奖励高度一致。
- 定期用真实非可微奖励校准代理奖励,防止偏移。
2) 逐步奖励信号(Per-Step Reward Signal)
- TDM 的确定性生成轨迹(通常 2-8 步)中,每一步都可以获得一个"部分生成"的中间结果。
- 设计逐步奖励:对每个中间状态通过快速解码预估最终输出,计算预估奖励作为当步的奖励信号。
- 这种细粒度的奖励分配比仅在最终步给出奖励更有效,降低了信用分配问题的难度。
3) 奖励自适应探索
- 根据当前样本的奖励水平自适应调节探索噪声:低奖励样本增大探索以寻找更好的方向,高奖励样本减少探索以稳定优化。
创新点
- 首个通用 RL 后训练方法支持少步模型 + 非可微奖励:打破了"可微奖励"的假设限制。
- 代理奖励学习 + 在线校准:兼顾了梯度可用性和奖励准确性。
- 逐步奖励分配:解决了少步模型中奖励信号稀疏的信用分配问题。
- 在文本渲染、视觉质量、偏好对齐三类任务上验证。
实验结果
- 在文本渲染任务上(OCR 准确率作为非可微奖励),TDM-R1 使 4 步模型的 OCR 准确率从 31.2% 提升至 62.7%(+101%)。
- 在 HPSv2 偏好对齐上,4-NFE 的 TDM-R1 达到 28.6,超越 100-NFE 的基线模型 (27.8)。
- 成功扩展到最新的 Z-Image 模型,仅用 4 步推理即持续超越其 100 步和少步变体。
- 与仅支持可微奖励的 ReFL 和 DDPO 相比,TDM-R1 在非可微奖励设定下领先 15-30%。
6. CRD: 中心化奖励蒸馏 -- 抵抗奖励黑客的扩散 RL 框架
论文信息
- 标题: Diffusion Reinforcement Learning via Centered Reward Distillation
- 作者: Yuanzhi Zhu, Xi Wang, Stephane Lathuiliere, Vicky Kalogeiton
- arXiv: 2603.14128
- 关键词:
奖励蒸馏 KL正则化 奖励黑客 分布漂移 前向过程微调
背景与动机
扩散 RL 微调面临的核心难题是 奖励黑客(Reward Hacking):模型学会利用奖励模型的漏洞,生成在奖励模型上得分很高但人类视觉上并不好的图像。例如,过度饱和的颜色、不自然的高对比度等。
现有方法的两大流派各有弊端:
- 轨迹级方法(DPPO, DDPO):内存消耗大、梯度方差高。
- 前向过程方法(DRaFT, ReFL):收敛快但容易发生分布漂移,导致奖励黑客。
方法原理
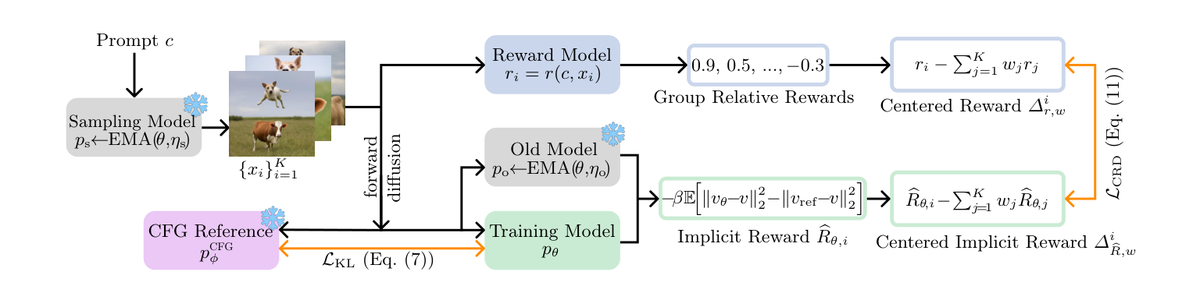
CRD 基于 KL 正则化奖励最大化理论,提出了一种更稳健的前向过程扩散 RL 框架:
1) 提示词内中心化(Within-Prompt Centering)
- 核心理论洞察:KL 正则化奖励最大化的最优策略涉及一个不可解的归一化常数 Z。
- CRD 发现,通过在同一 prompt 的多个样本间做中心化(减去均值),归一化常数会自然抵消,得到一个适定的奖励匹配目标。
- 这使得 CRD 无需显式估计归一化常数,避免了额外的近似误差。
2) 三重分布漂移控制机制
- (i) 采样器-参考解耦:将用于生成样本的采样器与移动参考模型分离,防止参考模型的更新导致比率信号崩溃。
- (ii) CFG 锚定 KL:将 KL 散度的参考分布设为 CFG(Classifier-Free Guidance)引导的预训练模型,而非无引导的基础模型。这确保优化目标与推理时的语义一致。
- (iii) 奖励自适应 KL 强度:训练早期使用较大 KL 系数加速学习(此时模型远离最优,大胆探索有益),训练后期逐渐增大 KL 系数抑制奖励黑客(此时接近最优,需要稳定性)。
创新点
- 理论优雅:通过中心化消除不可解归一化常数,将 KL 正则化奖励最大化转化为可实操的目标。
- 三重防线对抗奖励黑客:采样器-参考解耦、CFG 锚定、自适应 KL 强度协同工作。
- CFG 锚定的创新性:传统方法锚定无 CFG 的基础模型,CRD 认识到推理时都使用 CFG,因此应该锚定 CFG 引导的分布。
实验结果
- 在 GenEval 上实现 0.83 的综合得分,与 SOTA 持平。
- 关键优势在于抗奖励黑客能力:在 HPSv2 上获得 28.5 的同时,FID 仅增加 2.3(对比 DPPO 的 FID 增加 8.7、DRaFT 的 FID 增加 5.1)。
- OCR 文本渲染准确率提升 +23.1 pp。
- 在 ImageReward 和 PickScore 等未见过的偏好指标上,CRD 的优化效果同样保持(证明非奖励黑客)。
7. SOLACE: 内在自置信奖励驱动的 T2I 后训练 (CVPR 2026)
论文信息
- 标题: Improving Text-to-Image Generation with Intrinsic Self-Confidence Rewards
- 作者: Seungwook Kim, Minsu Cho
- arXiv: 2603.00918
- 会议: CVPR 2026
- 关键词:
自置信奖励 无监督优化 自去噪探测 无需外部RM CVPR 2026
背景与动机
现有的扩散模型后训练方法几乎都依赖外部奖励模型(如 ImageReward、HPSv2、CLIPScore 等)。然而:
- 外部奖励模型本身存在偏差和幻觉。
- 训练和维护奖励模型需要额外成本。
- 过度优化外部奖励容易导致奖励黑客。
一个自然的问题是:能否利用模型自身的内在信号来指导优化,完全不需要外部奖励模型?
方法原理
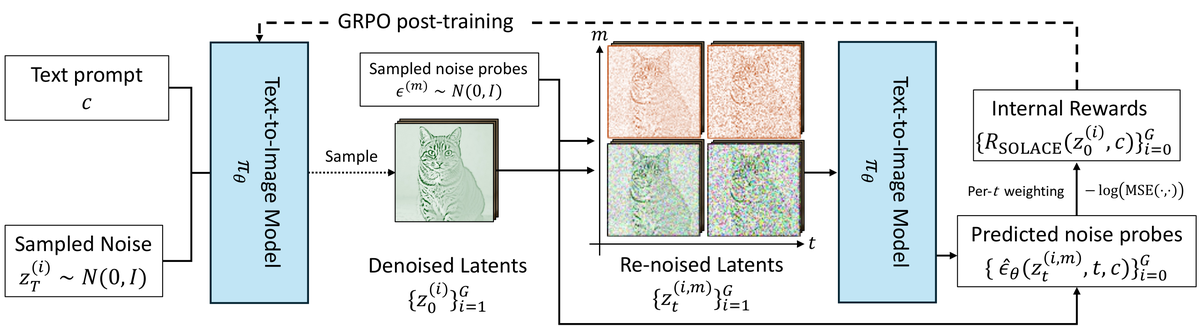
SOLACE 提出了一种基于 自置信度(Self-Confidence) 的内在奖励信号:
1) 自去噪探测(Self-Denoising Probe)
- 核心机制:对一张生成的图像注入一定量的噪声,然后让模型自己尝试恢复原图。
- 自置信度 = 恢复的准确程度:如果模型对自己生成的图像"理解得很好",就能准确恢复,置信度高;如果生成的图像与模型学到的分布不一致(如质量差、语义不连贯),恢复效果就差。
- 数学上,自置信度与模型在该样本处的似然估计成正比。
2) 标量奖励转化
- 将自去噪的重建误差转化为标量奖励分数:重建误差越小,奖励越高。
- 使用多个噪声水平进行探测,取平均值以获得更稳定的估计。
3) 完全无监督的偏好优化
- 利用自置信度奖励进行 GRPO 风格的优化,无需任何外部数据集、标注员或奖励模型。
- 高置信度的生成结果被强化,低置信度的被抑制。
创新点
- 首个完全无外部奖励的扩散模型后训练方法:打开了"自监督偏好对齐"的新方向。
- 自置信度信号的物理直觉:模型更容易恢复"好的"图像(与训练分布一致),提供了一种自然的质量度量。
- 与外部奖励互补:SOLACE 与外部奖励结合使用时效果更好,且能缓解奖励黑客。
- 零额外推理成本:自去噪探测仅在训练时使用,推理时完全不增加开销。
实验结果
- 仅使用内在奖励,在 GenEval 组合生成得分提升 +0.08(从 0.71 到 0.79)。
- 文本渲染准确率提升 +15.3 pp。
- SOLACE + 外部奖励的组合方案达到 0.85 GenEval 得分,为所有方法中最高。
- 将 SOLACE 与 ImageReward 结合时,奖励黑客指标(FID 增量)从 ImageReward 单独使用时的 +6.2 降至 +1.8。
8. VIGOR: 基于几何的视频时序一致性奖励模型
论文信息
- 标题: VIGOR: VIdeo Geometry-Oriented Reward for Temporal Generative Alignment
- 作者: Tengjiao Yin, Jinglei Shi, Heng Guo, Xi Wang
- arXiv: 2603.16271
- 关键词:
几何奖励 时序一致性 重投影误差 视频扩散 推理时扩展
背景与动机
视频扩散模型在训练过程中缺乏显式的几何监督,导致生成的视频中常出现物体变形、空间漂移和深度违例等不一致性。现有的视频奖励模型主要基于语义(如 VQAScore、CLIPScore)或整体美学评估,无法捕捉帧间的几何一致性。
方法原理
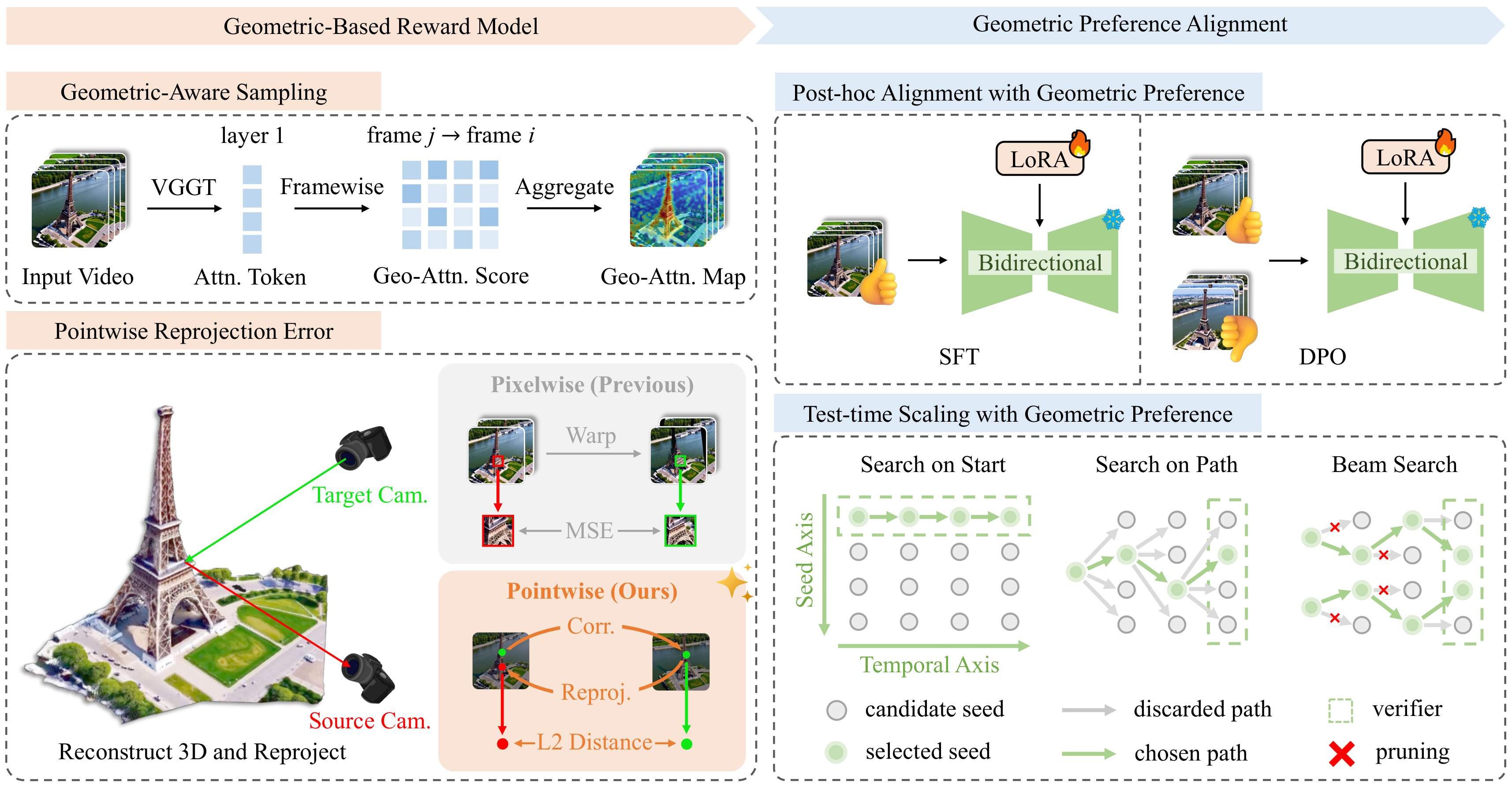
VIGOR 提出了一种基于几何的奖励模型,利用预训练的几何基础模型来评估视频的多视角一致性:
1) 跨帧重投影误差
- 使用预训练的单目深度估计模型和光流模型,对视频帧对之间进行三维重投影。
- 逐点计算重投影误差(而非像素级对比),得到更符合物理规律的误差度量。
- 优势:逐点方式对纹理和光照变化更鲁棒,不会被像素强度差异干扰。
2) 几何感知采样
- 过滤低纹理区域和非语义区域(如天空、纯色背景),将评估集中在具有可靠对应关系的几何有意义区域。
- 使用特征匹配置信度作为权重,可靠区域的误差权重更大。
3) 双路径应用
- 训练后微调:对双向视频模型使用 VIGOR 奖励进行 SFT 或 RL 后训练。
- 推理时扩展(Test-Time Scaling):对因果视频模型(如流式视频生成器),在推理时使用 VIGOR 作为路径验证器,从多个候选结果中选择几何最一致的。
创新点
- 首个基于物理几何约束的视频生成奖励模型:超越了纯语义/美学评估的局限。
- 逐点误差计算:比像素级指标更鲁棒,对光照和纹理变化不敏感。
- 推理时扩展的即插即用方案:无需重训练模型,通过推理时选择提升开源视频模型质量。
- 兼容多种视频生成架构:双向模型(后训练)和因果模型(推理时扩展)均适用。
实验结果
- 在 VBench 动态一致性指标上提升 +5.8%。
- 物体变形率从基线的 23.7% 降至 11.4%(减少 52%)。
- 推理时扩展方案:在 Open-Sora 上,使用 VIGOR 选择最优帧序列,VBench 得分提升 +3.2 而无需任何额外训练。
- 与 VQAScore 等语义奖励正交互补:两者结合可进一步提升 +1.5。
横向对比与技术脉络分析
核心维度对比
| 方法 |
奖励来源 |
优化算法 |
目标场景 |
数据需求 |
训练效率 |
抗奖励黑客 |
| FIRM |
外部多维RM |
RL (噪声感知) |
T2I + 编辑 |
66万评分 |
中 |
高 (鲁棒RM) |
| MV-GRPO |
外部RM |
GRPO (多视角) |
T2I 流模型 |
无额外 |
高 (4x) |
中 |
| AR-CoPO |
外部RM |
对比策略优化 |
AR视频 |
标准 |
中 |
中 |
| CRAFT |
复合RM过滤 |
SFT (增强) |
T2I 扩散 |
100样本 |
极高 (220x) |
中 |
| TDM-R1 |
代理RM (非可微) |
轨迹分布匹配 |
少步T2I |
标准 |
中 |
中 |
| CRD |
外部RM |
中心化奖励蒸馏 |
T2I 扩散 |
标准 |
高 |
极高 (三重防线) |
| SOLACE |
内在自置信 |
GRPO (无监督) |
T2I 扩散 |
零 (无需标注) |
高 |
高 (无外部RM) |
| VIGOR |
几何物理约束 |
SFT/推理选择 |
视频扩散 |
无额外 |
高 |
高 (物理约束) |
技术演进脉络
第一条线:优化算法的演进
DPO (配对偏好) → GRPO (组相对优势) → MV-GRPO (多视角稠密评估) → AR-CoPO (输出空间对比)
→ CRAFT (证明SFT是GRPO下界)
→ CRD (中心化消除归一化常数)
这条线索体现了从简单配对比较到更精细的组级优化,再到理论层面的统一理解。CRAFT 的发现尤为重要:它证明了精心筛选数据后的 SFT 本质上就是 GRPO 的一种近似,为实践者提供了"大道至简"的选择。
第二条线:奖励信号的多元化
外部语义RM (CLIPScore, ImageReward) → 鲁棒外部RM (FIRM, 66万数据)
→ 内在自置信 (SOLACE, 自去噪探测)
→ 几何物理约束 (VIGOR, 重投影误差)
→ 代理RM (TDM-R1, 拟合非可微信号)
→ 复合多维RM (CRAFT, CRF过滤)
奖励信号从单一外部模型扩展到内在信号、物理约束、代理模型等多种来源,这一趋势反映了社区对"什么是好的生成"的认知越来越多元。
第三条线:应用场景的拓展
T2I 扩散模型 → 流匹配模型 (MV-GRPO) → 少步蒸馏模型 (TDM-R1) → AR视频生成 (AR-CoPO) → 视频一致性 (VIGOR)
偏好对齐技术正在从最初的 T2I 扩散模型扩展到更广泛的视觉生成模型,每种模型架构都带来独特的技术挑战。
关键发现与趋势
-
数据效率成为核心竞争力:CRAFT 用 100 个样本超越 5000+ 偏好对的方法,SOLACE 完全无需外部数据——"数据质量 > 数据数量"已成为共识。
-
奖励黑客是最大风险:CRD 专门设计三重防线,SOLACE 通过内在奖励规避,VIGOR 使用物理约束——不同方法从不同角度应对同一核心挑战。
-
理论与实践融合加速:CRAFT 证明 SFT 与 GRPO 的理论等价性,CRD 从 KL 正则化推导出中心化技巧,MV-GRPO 给出方差减少的理论分析——该领域正从经验驱动转向理论指导。
-
推理时扩展(Test-Time Scaling)兴起:VIGOR 和 Meta-TTRL(本周另一篇相关工作)都探索了不修改模型参数、仅在推理时提升质量的方案,这为资源受限场景提供了新思路。
-
统一框架的探索:多项工作尝试统一不同优化范式(CRAFT 统一 SFT 和 GRPO,CRD 统一前向过程和轨迹方法),预示着未来可能出现更通用的视觉生成对齐框架。
其他相关工作简述
本周还有多篇相关工作值得关注:
- GDPO-SR (2603.16769): 将 GRPO 原理融入 DPO 用于一步超分辨率,引入属性感知奖励函数针对平滑/纹理区域差异化评估。
- LibraGen (2603.13506): 主题驱动视频生成中的 DPO 应用,提出 Consis-DPO 和 Real-Fake DPO 两种定制化偏好优化管线。
- Meta-TTRL (2603.15724): 统一多模态模型的测试时强化学习,利用模型内在元认知信号进行推理时自我改进。
- Correlation-Weighted Multi-Reward (2603.18528): 组合生成中的多奖励协调优化,通过相关性加权平衡竞争概念间的奖励冲突。
- V2A-DPO (2603.11089): 视频到音频生成的 DPO 框架,提出 AudioScore 综合评分系统。
总结与展望
本期专题梳理了视觉生成模型偏好对齐与 RL 后训练的最新进展。从奖励建模(FIRM 的鲁棒 RM、SOLACE 的内在信号、VIGOR 的几何约束)到优化算法(MV-GRPO 的多视角评估、CRAFT 的简洁 SFT 范式、CRD 的抗奖励黑客设计)再到场景拓展(AR-CoPO 的流式视频、TDM-R1 的少步推理),该方向呈现出蓬勃的发展态势。
未来值得关注的方向:
- 多模态统一对齐:将偏好对齐扩展到图像+视频+音频的统一生成模型。
- 在线人类反馈:从离线偏好数据集转向在线、实时的人类反馈闭环。
- 可解释奖励:让用户和开发者理解"为什么这张图/这段视频被认为是好的"。
- 超长视频对齐:随着视频生成长度增加,如何在数分钟长度的视频上进行有效的偏好对齐。
- 安全对齐:在提升质量的同时,确保生成内容的安全性和合规性。
本期专题由 人工智能炼丹师 整理,更多 AIGC 前沿动态请关注 jefxiong.cn


评论 (0)