
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 2026年3月15日(周日)
覆盖时间:2026年3月2日 — 2026年3月14日
本周 AIGC 领域最热门的方向莫过于统一多模态模型(Unified Multimodal Models, UMMs)——将视觉理解(图像识别、VQA、推理)与视觉生成(文生图、图像编辑)统一在同一个模型框架内。过去一周内,arXiv 上涌现了超过 8 篇高质量论文,从架构设计、训练范式、评测基准、长序列生成到强化学习后训练,全方位推动了这一方向的发展。
传统的多模态 AI 系统中,"理解"和"生成"是两套独立的系统:
统一多模态模型的目标是让同一个模型既能"看懂"图片,又能"画出"图片,甚至让两种能力相互促进。
| # | 论文 | 机构 | 核心贡献 | arXiv ID |
|---|---|---|---|---|
| 1 | DREAM | MIT + Amazon | 联合判别-生成训练框架,Masking Warmup + 语义对齐解码 | 2603.02667 |
| 2 | GvU (CVPR 2026) | 北大 + 百度 | 理解驱动内在奖励,自监督 RL 缩小生成-理解差距 | 2603.06043 |
| 3 | Omni-Diffusion | 腾讯 + CASIA | 首个全离散扩散统一模型,文本+语音+图像 any-to-any | 2603.06577 |
| 4 | InternVL-U | 上海AI Lab + 商汤 | 4B 参数统一模型,CoT 推理增强生成,超越 14B 基线 | 2603.09877 |
| 5 | UniCom | 阿里达摩院 | 压缩连续语义表征,Transfusion 架构,SOTA 生成 | 2603.10702 |
| 6 | UniG2U-Bench | 多机构联合 | 首个系统性 G2U 评测基准,7 种机制 30 个子任务 | 2603.03241 |
| 7 | UniLongGen | Adobe + PolyU | 长序列交错生成的主动遗忘策略,解决视觉污染 | 2603.07540 |
| 8 | GRPO-Interleaved | 华为 + 复旦 | GRPO 扩展到多模态交错生成,过程级奖励 | 2603.09538 |
论文: DREAM: Where Visual Understanding Meets Text-to-Image Generation
arXiv: 2603.02667
机构: MIT CSAIL, Amazon
发布日期: 2026年3月3日
在多模态学习中,视觉理解(如 CLIP 的对比学习)和图像生成(如 MAE 的掩码重建)一直是两个独立的优化目标。直接联合训练会导致两个目标相互冲突——对比学习需要低掩码率保留全局语义,而生成训练需要高掩码率学习重建。
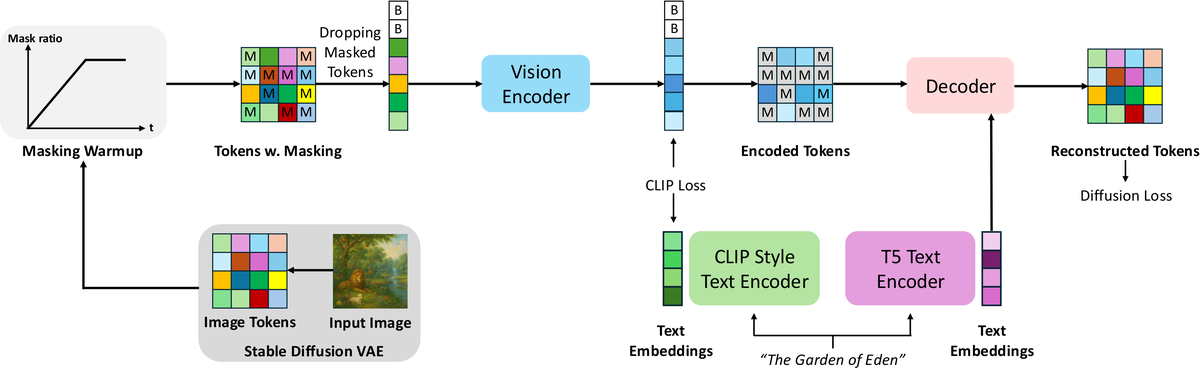
DREAM 提出了两项关键技术来解决这一矛盾:
(1)Masking Warmup(掩码预热)策略
训练分为两个阶段:
这种渐进式调度避免了"同时从零开始学两件事"的不稳定性。
(2)Semantically Aligned Decoding(语义对齐解码)
推理时,模型生成多个部分掩码的候选图像,然后用模型自身的理解分支计算每个候选与目标文本的语义对齐分数,选择最佳候选继续解码。这相当于在不引入外部重排序器的情况下,用理解能力"把关"生成质量。
仅在 CC12M(1200 万图文对)上训练:
DREAM 证明了判别目标和生成目标之间存在协同效应,而非简单的零和竞争。关键在于训练策略的设计——让模型先学好"看",再学"画"。
论文: Learning to Generate via Understanding: Understanding-Driven Intrinsic Rewarding for Unified Multimodal Models
arXiv: 2603.06043
机构: 北京大学, 百度
发布日期: 2026年3月6日 | 会议: CVPR 2026
现有的统一多模态模型存在一个显著的"能力不对称"问题:理解能力强,生成能力弱。模型能准确描述图片中的每个细节,但让它根据文字画图时却经常"丢三落四"。这种差距的根源在于理解和生成过程在训练中是解耦的。
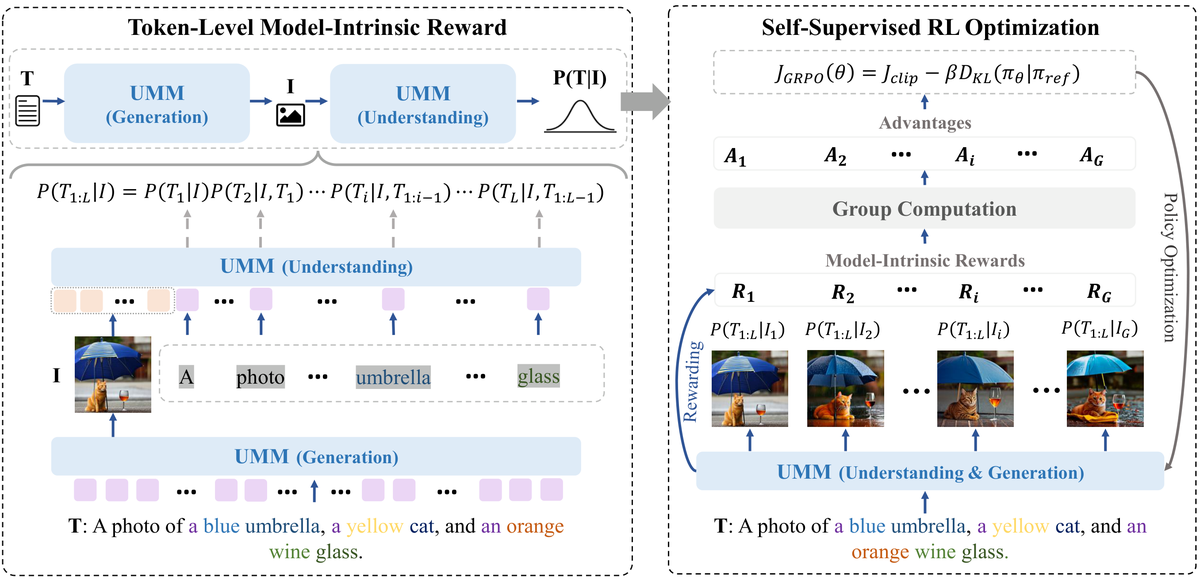
GvU 的核心思想非常精妙——让模型用自己的理解能力来指导自己的生成能力:
Token 级内在文本-图像对齐奖励:
自监督强化学习框架:
GvU 开创了一种"自我进化"范式:模型不依赖外部信号,仅通过内部的理解-生成循环就能持续改进。这与 LLM 领域的 Self-Play 思想异曲同工,但在多模态领域是首次实现。
论文: Omni-Diffusion: Unified Multimodal Understanding and Generation with Masked Discrete Diffusion
arXiv: 2603.06577
机构: 腾讯, 中科院自动化所
发布日期: 2026年3月6日
现有的统一多模态模型几乎都采用自回归(Autoregressive)架构作为骨干。但自回归架构存在固有局限:
离散扩散模型(Discrete Diffusion)是一种新兴的替代方案,它通过逐步去掩码的方式并行生成,但之前从未被用于构建统一的多模态系统。
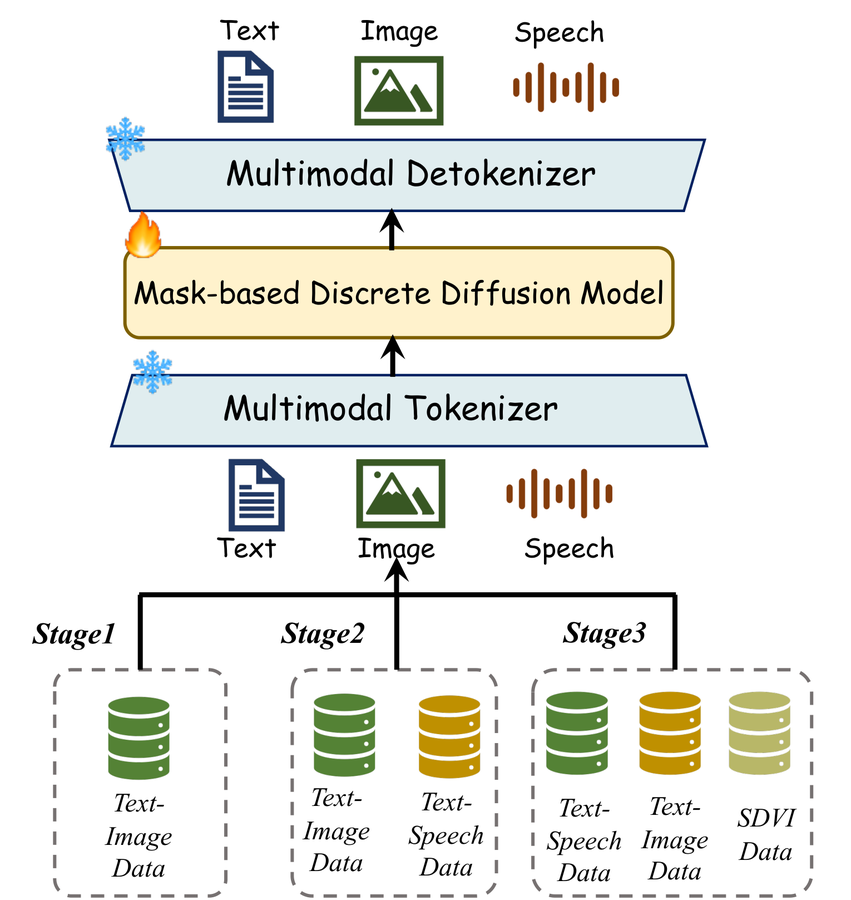
Omni-Diffusion 是首个完全基于掩码离散扩散模型的 any-to-any 多模态语言模型:
统一的掩码-去掩码框架:
支持的任务:
在多项基准测试上:
Omni-Diffusion 打破了"统一多模态模型 = 自回归"的思维定式,证明了离散扩散模型可以作为下一代多模态基础模型的骨干架构。这为并行生成、更灵活的条件控制和更高效的推理打开了新的可能性。
论文: InternVL-U: Democratizing Unified Multimodal Models for Understanding, Reasoning, Generation and Editing
arXiv: 2603.09877
机构: 上海 AI Lab, 商汤, 港中文
发布日期: 2026年3月10日
现有的统一多模态模型在追求全能的过程中往往面临"鱼与熊掌不可兼得"的困境——要么理解能力强但生成一般(如 Janus),要么生成漂亮但理解退化。而且大部分方案需要巨大的参数量(10B+)才能取得不错效果。
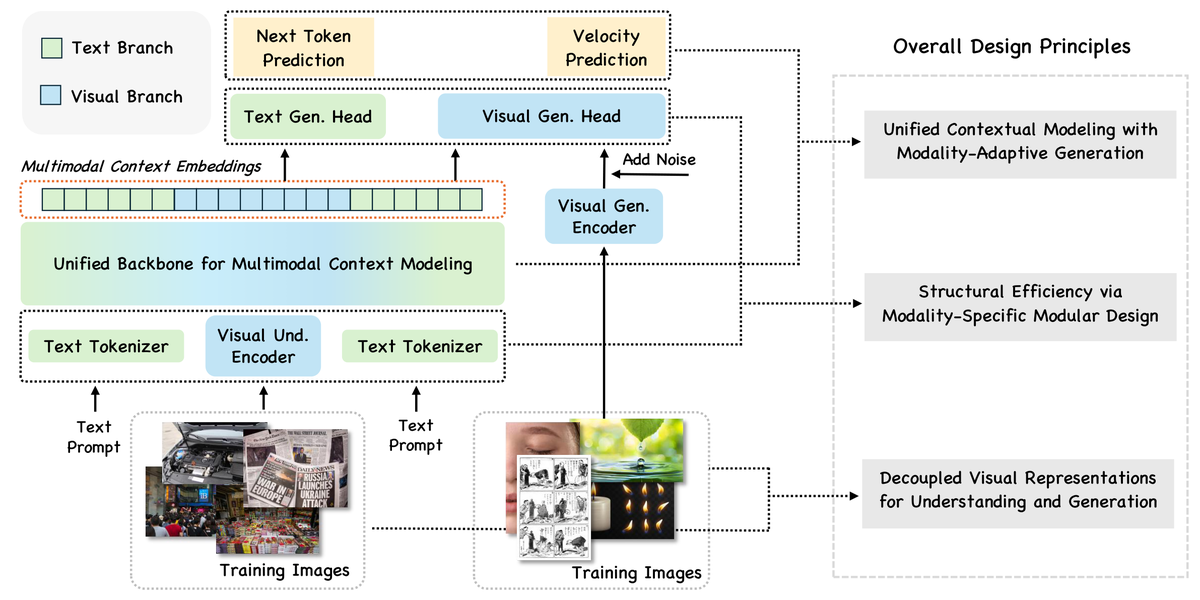
InternVL-U 通过三个关键设计突破了这一瓶颈:
(1)解耦视觉表征 + 模态特定模块化
(2)以推理为中心的数据合成流水线
(3)渐进式训练策略
仅 4B 参数的 InternVL-U:
InternVL-U 表明精心的架构设计和数据工程可以弥补参数量的不足。特别是 CoT 推理增强生成的范式——让模型先推理再生成——可能是统一模型走向实用的关键路径。
论文: UniCom: Unified Multimodal Modeling via Compressed Continuous Semantic Representations
arXiv: 2603.10702
机构: 阿里巴巴达摩院
发布日期: 2026年3月11日
统一多模态模型的一个核心技术选择是视觉表征形式:
| 方案 | 优势 | 劣势 |
|---|---|---|
| 离散 Token(VQ-VAE) | 与 LLM 天然兼容 | 信息损失大,理解能力弱 |
| 连续表征(CLIP) | 语义信息丰富 | 高维空间难以建模生成 |
UniCom 的目标是找到一个"甜蜜点"——在保留丰富语义的同时降低建模难度。
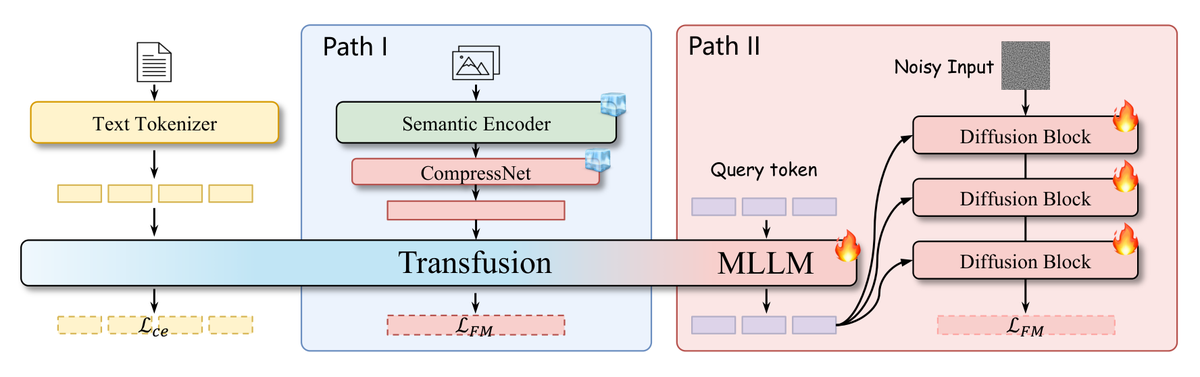
核心发现:通道压缩优于空间下采样
通过系统的消融实验,UniCom 团队发现:
基于注意力的语义压缩器:
Transfusion 架构选择:
UniCom 为"离散 vs 连续"之争提供了一个折中方案:压缩后的连续表征既保留了语义丰富性,又降低了生成建模的难度。这可能是未来统一模型视觉表征的主流选择。
论文: UniG2U-Bench: Do Unified Models Advance Multimodal Understanding?
arXiv: 2603.03241
机构: 多机构联合
发布日期: 2026年3月3日
统一模型的一个核心 Promise 是"生成能力能够反过来增强理解能力"。但这个 Promise 到底在多大程度上成立?在什么任务上成立?现有基准测试无法系统性地回答这些问题。
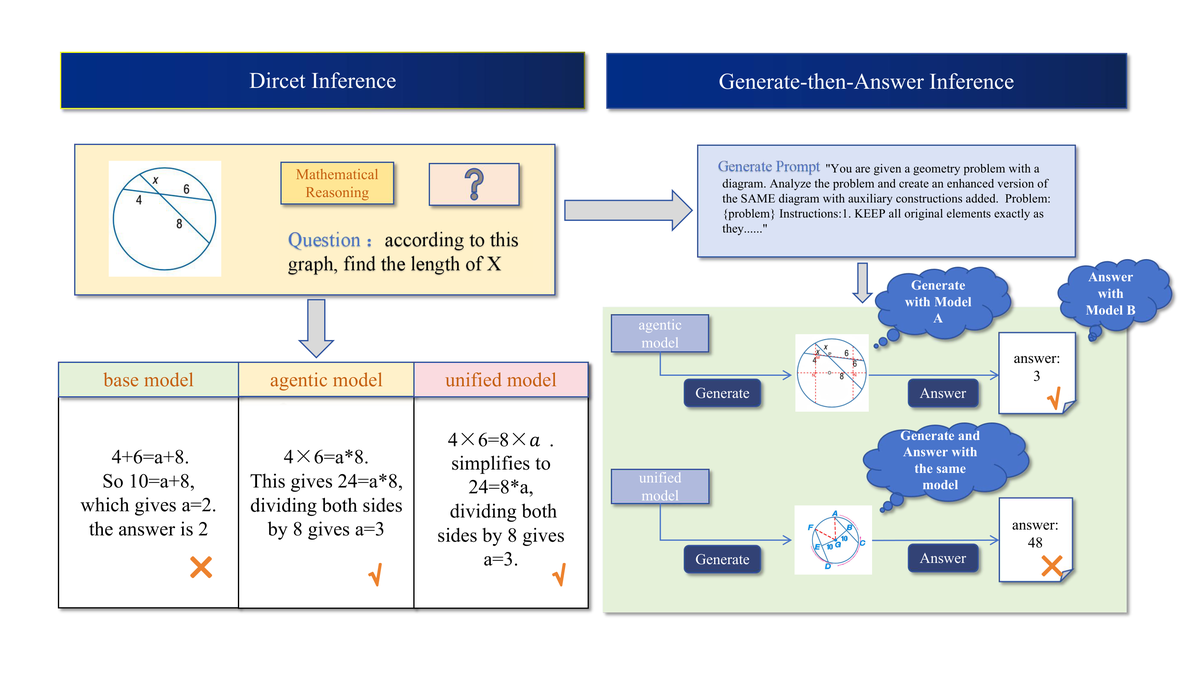
UniG2U-Bench 将"生成到理解"(G2U)评测分解为:
7 种机制:
30 个子任务,需要不同程度的隐式或显式视觉变换。
对 30+ 个模型的评估揭示了三个重要结论:
发现 1:统一模型通常不如其基础 VLM,"生成后回答"(Generate-then-Answer)推理通常比直接推理更差。
发现 2:但在特定场景下,生成确实能增强理解:
发现 3:具有相似推理结构的任务和相似架构的模型表现出相关的行为模式,说明 G2U 耦合是由训练数据和架构共同决定的归纳偏差。
UniG2U-Bench 给出了一个清醒的结论:生成增强理解并非万能药,而是在特定场景下才有效。这为未来的统一模型设计提供了明确的优化方向——聚焦于空间推理和多步推理场景。
论文: How Long Can Unified Multimodal Models Generate Images Reliably? Taming Long-Horizon Interleaved Image Generation via Context Curation
arXiv: 2603.07540
机构: Adobe Research, 香港理工大学
发布日期: 2026年3月8日
统一多模态模型的一个重要应用是交错生成——在一个长序列中交替生成文本和图像,用于视觉故事讲述、分步教程等场景。但现有模型面临一个严重问题:随着序列增长,生成质量急剧崩溃。
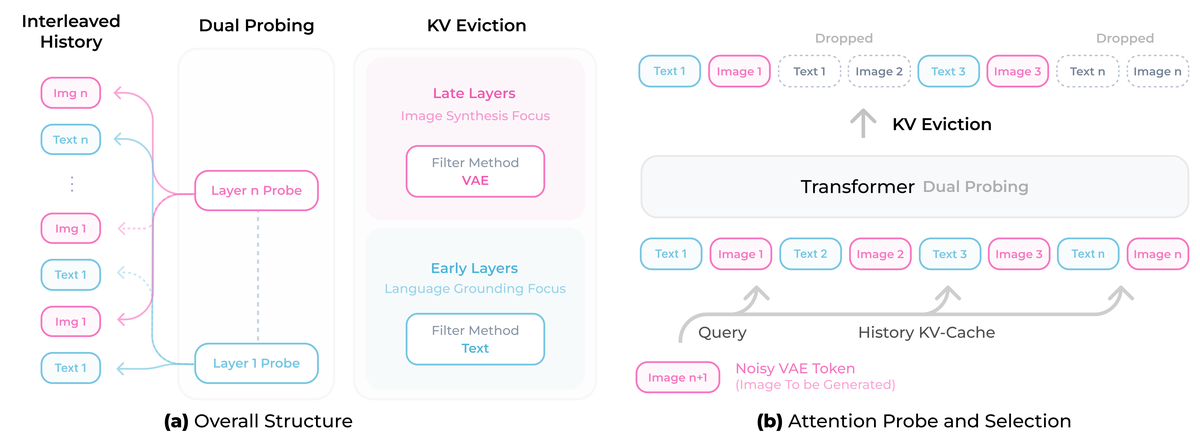
关键发现:视觉历史是"主动污染"源
论文通过深入分析发现:
UniLongGen:无训练的推理策略
核心思想——主动遗忘:
UniLongGen 揭示了一个反直觉的事实:在长序列生成中,"记住所有东西"反而是有害的。这与人类的认知机制类似——我们在创作长篇叙事时,也需要有选择性地"忽略"之前的细节,聚焦于当前的创作。
论文: Towards Unified Multimodal Interleaved Generation via Group Relative Policy Optimization
arXiv: 2603.09538
机构: 华为, 复旦大学
发布日期: 2026年3月10日
现有的统一多模态模型在理解和单模态生成上表现不错,但在多模态交错输出(如交替生成文本和图像的长叙事)上严重不足。原因是高质量的交错训练数据极度稀缺。
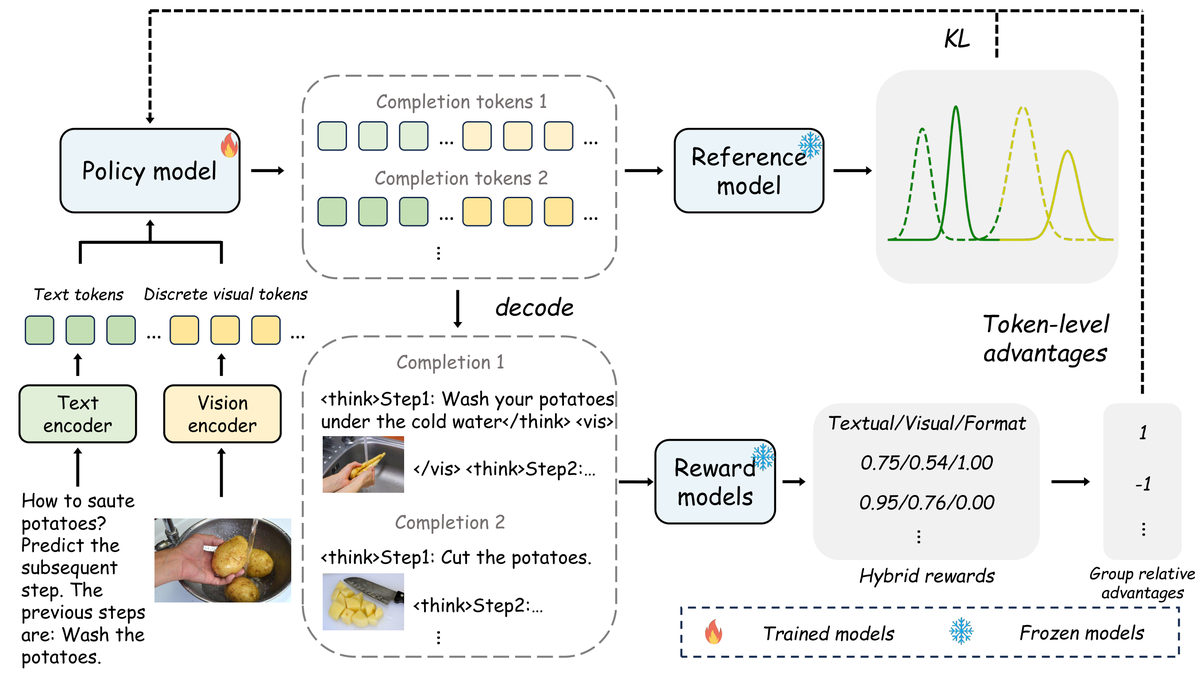
两阶段训练范式:
阶段 1:混合数据预热
阶段 2:群组相对策略优化(GRPO)
将 GRPO(源自 DeepSeek-R1 的 RL 方法)扩展到多模态:
过程级奖励:
在 MMIE 和 InterleavedBench 上:
GRPO-Interleaved 证明了强化学习后训练(RL Post-Training)是解锁统一模型新能力的有效手段。这延续了 LLM 领域 RLHF/DPO 的成功经验,将其推广到多模态交错生成这一更复杂的场景。
| 论文 | 骨干架构 | 视觉表征 | 理解-生成耦合方式 |
|---|---|---|---|
| DREAM | ViT + MAE | 连续(掩码重建) | 共享编码器 + 联合训练 |
| GvU | LLM + VQ-VAE | 离散 Token | 自监督 RL 桥接 |
| Omni-Diffusion | 离散扩散 LM | 离散 Token | 统一扩散过程 |
| InternVL-U | InternViT + MMDiT | 解耦表征 | 共享上下文 + 模态模块化 |
| UniCom | LLM + Transfusion | 压缩连续表征 | 通道压缩 + Transfusion |
| 论文 | 训练方法 | 外部监督 | 数据需求 |
|---|---|---|---|
| DREAM | 渐进式联合预训练 | 无 | CC12M(12M 图文对) |
| GvU | 自监督 RL 后训练 | 无(内在奖励) | 极少额外数据 |
| Omni-Diffusion | 统一扩散预训练 | 无 | 大规模多模态数据 |
| InternVL-U | 三阶段渐进训练 + CoT 数据合成 | 合成数据 | 中等规模 |
| UniCom | Transfusion 预训练 | 无 | 大规模多模态数据 |
| GRPO-Interleaved | GRPO 后训练 | 混合奖励函数 | 极少交错数据 |
趋势 1:从"对抗"到"协同"
早期的统一模型中,理解和生成是竞争关系(共享参数导致能力冲突)。本周的论文普遍转向"协同"思维——用理解增强生成(GvU),或证明两者可以共赢(DREAM)。
趋势 2:后训练成为关键杠杆
GvU 和 GRPO-Interleaved 都表明,在预训练模型上做少量 RL 后训练,就能显著解锁新能力。这与 LLM 领域 ChatGPT 的成功路径一致。
趋势 3:离散扩散的崛起
Omni-Diffusion 首次证明了离散扩散可以替代自回归成为统一模型的骨干,为并行生成和更灵活的架构设计开辟了道路。
趋势 4:表征形式的创新
从纯离散(VQ-VAE)到纯连续(CLIP),再到 UniCom 的"压缩连续",表征设计正在走向更精细化的折中方案。
趋势 5:长序列和交错生成的突破
UniLongGen 和 GRPO-Interleaved 共同推动了交错生成的进步,让统一模型距离实际应用(视觉叙事、交互式内容创作)更近了一步。
统一多模态模型技术路线
├── 架构设计
│ ├── 自回归统一 → DREAM, InternVL-U, UniCom
│ ├── 扩散统一 → Omni-Diffusion
│ └── 混合架构 → Transfusion (UniCom), 解耦模块化 (InternVL-U)
├── 视觉表征
│ ├── 离散 Token → Omni-Diffusion, GvU
│ ├── 连续表征 → DREAM
│ └── 压缩连续 → UniCom (NEW 最优折中)
├── 训练范式
│ ├── 联合预训练 → DREAM, Omni-Diffusion
│ ├── 渐进式训练 → InternVL-U (3 阶段)
│ └── RL 后训练 → GvU (自监督), GRPO-Interleaved (混合奖励)
├── 评测与分析
│ └── G2U 系统评测 → UniG2U-Bench (7 机制 30 任务)
└── 应用扩展
├── 长序列交错生成 → UniLongGen (主动遗忘)
└── 多模态交错生成 → GRPO-Interleaved (过程级 RL)本周的 8 篇论文共同描绘了统一多模态模型的全景图。以下是几个值得关注的未来方向:
统一多模态模型正处于从"概念验证"走向"实际可用"的关键转折点。生成与理解的融合不再是一个遥远的愿景,而是一个正在快速成形的现实。
人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月2日—14日

评论 (0)