
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

专题方向:视频 DiT 中的稀疏注意力、线性注意力与推理加速
覆盖时间:2026年3月2日 — 2026年3月13日
整理:人工智能炼丹师
日期:2026年3月14日(周六)
本周是视频扩散 Transformer(Video DiT)高效推理方向的"论文爆发周"。短短一周内,arXiv 上出现了 9 篇 高度聚焦于视频 DiT 注意力加速与推理优化的论文,覆盖了从稀疏注意力、线性注意力、结构化注意力,到蒸馏压缩、缓存+剪枝、系统级并行优化的完整技术栈。
当前主流视频生成模型(Wan 2.1/2.2、HunyuanVideo、Mochi 等)均采用 Diffusion Transformer(DiT)架构,其核心瓶颈在于 全注意力(Full 3D Attention)的 O(N²) 复杂度。一段 5 秒 720P 视频的 token 序列长度可达数十万,全注意力的计算量和显存占用极其惊人。因此,如何在保持生成质量的前提下大幅降低注意力计算成本,成为本周研究的核心主题。
| # | 论文 | 方法类别 | 核心思路 | 加速比 | 提交日期 |
|---|---|---|---|---|---|
| 1 | CalibAtt | 稀疏注意力(免训练) | 离线校准块级稀疏模式 | 1.58x E2E | 3月5日 |
| 2 | SVG-EAR | 稀疏注意力 + 线性补偿(免训练) | 误差感知路由 + 聚类质心补偿 | 1.77-1.93x | 3月9日 |
| 3 | SODA | 缓存 + 剪枝(免训练) | 敏感度导向的动态加速 | SOTA fidelity | 3月7日 |
| 4 | FrameDiT | 结构化注意力(需训练) | 帧级矩阵注意力 | ~Local FA | 3月10日 |
| 5 | VMonarch | 结构化注意力(轻量微调) | Monarch 矩阵分解 | 5x attn, 17.5x FLOPs↓ | 1月29日 |
| 6 | SALAD | 稀疏 + 线性混合(轻量微调) | 门控线性注意力并行分支 | 1.72x, 90%稀疏 | 1月23日 |
| 7 | SLA | 稀疏 + 线性融合(微调) | 三级权重分类 + 自定义 kernel | 2.2x E2E, 13.7x attn | 2025.9 (ICLR'26) |
| 8 | FastLightGen | 蒸馏 + 剪枝 | 步数+参数同时压缩 | 4步+30%剪枝 | 3月2日 |
| 9 | Diagonal Distillation | 自回归蒸馏 | 对角蒸馏 + 隐式光流 | 277.3x, 31 FPS | 3月10日 |
标题:Accelerating Text-to-Video Generation with Calibrated Sparse Attention
作者:Shai Yehezkel, Shahar Yadin, Noam Elata 等
机构:以色列理工
日期:2026年3月5日
arXiv:2603.05503
关键词:稀疏注意力 免训练 离线校准 块级模式 Wan 2.1 Mochi
视频 DiT 中的全注意力计算是推理速度的主要瓶颈。已有的稀疏注意力方法要么需要训练(如 SLA、SALAD),要么是在线动态判断每个 token 的重要性(开销大)。作者观察到一个关键现象:大量 token-to-token 连接在不同输入上一致地产生可忽略的注意力分数,且这些模式在不同查询间重复出现。
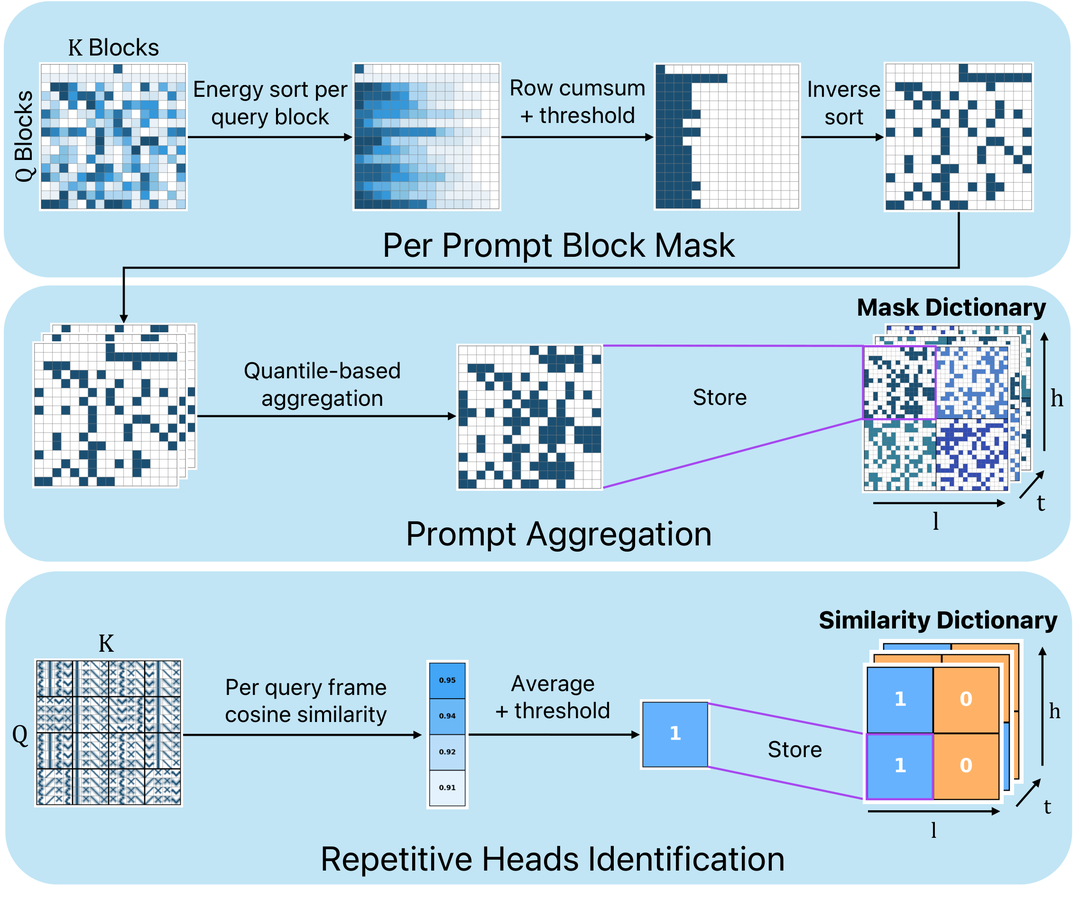
CalibAtt 采用"离线校准 + 在线高效推理"的两阶段策略:
Sparse VideoGen (2024) → Sparse VideoGen2 (2025.5) → CalibAtt (2026.3)。从在线动态稀疏 → 离线校准静态稀疏,核心洞察是"稀疏模式跨输入稳定"。
标题:SVG-EAR: Parameter-Free Linear Compensation for Sparse Video Generation via Error-aware Routing
作者:Xuanyi Zhou, Qiuyang Mang, Shuo Yang 等 (UC Berkeley, Ion Stoica 组)
日期:2026年3月9日
arXiv:2603.08982
关键词:稀疏注意力 线性补偿 误差感知路由 聚类质心 免训练 Wan 2.2 HunyuanVideo
现有稀疏注意力方法面临两难:(1) 直接丢弃被跳过的注意力块会丢失信息;(2) 用学习型预测器来近似它们又引入训练开销和分布偏移。能否在不训练的情况下恢复被跳过块的贡献?
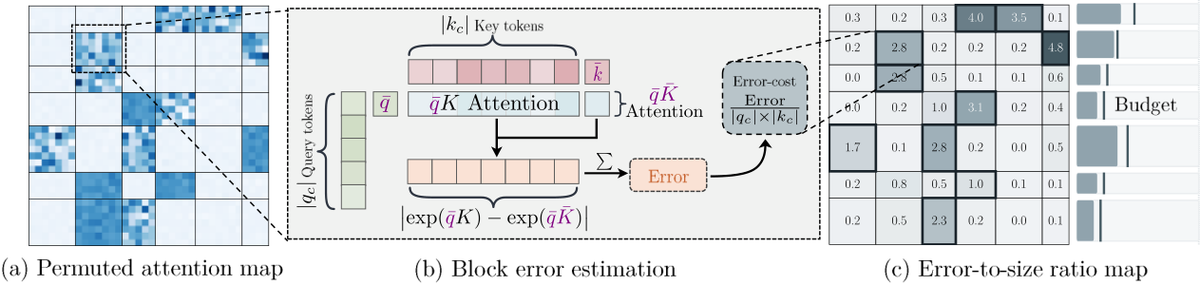
SVG-EAR 的核心洞察:经过语义聚类后,同一块内的 key 和 value 具有高度相似性,可以用少量聚类质心准确概括。
Sparse VideoGen → SVG2 → SVG-EAR(同一系列的第三代,Ion Stoica / Berkeley 团队的持续推进)
标题:SODA: Sensitivity-Oriented Dynamic Acceleration for Diffusion Transformer
作者:Tong Shao, Yusen Fu 等
日期:2026年3月7日
arXiv:2603.07057
关键词:缓存 剪枝 敏感度分析 动态规划 免训练 DiT-XL PixArt-α OpenSora
特征缓存(caching)和 token 剪枝(pruning)是两种互补的加速手段:缓存加速效率高但影响保真度,剪枝相反。现有方法用固定的启发式策略组合两者,无法捕捉模型对加速操作的细粒度敏感度变化。
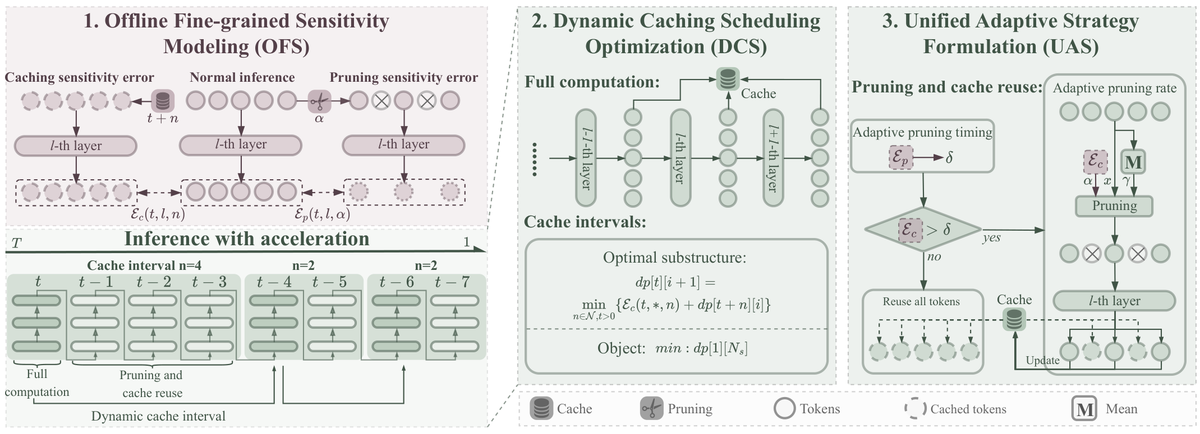
FasterCache (2024) → ∆-DiT (2024) → PAB → SODA (2026.3)
标题:VMonarch: Efficient Video Diffusion Transformers with Structured Attention
作者:Cheng Liang, Haoxian Chen, Liang Hou 等 (南京大学 + 腾讯)
日期:2026年1月29日
arXiv:2601.22275
关键词:Monarch矩阵 结构化稀疏 交替最小化 FlashAttention 在线熵 5x加速
视频 DiT 的注意力模式天然具有高度稀疏的时空结构,但现有稀疏方法(Top-K、局部窗口)要么不灵活,要么丢失全局信息。能否找到一种数学上优雅的方式来表示这些稀疏模式?
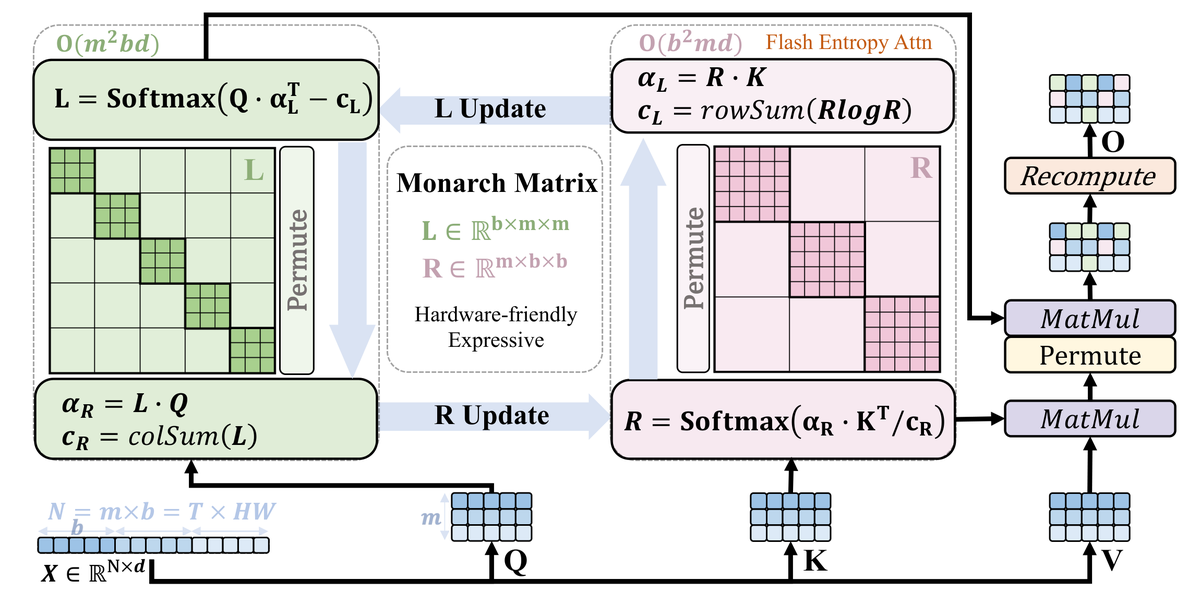
VMonarch 将视频 DiT 的稀疏注意力模式建模为 Monarch 矩阵 —— 一类具有灵活稀疏性的结构化矩阵。
Monarch Mixer (2023) → Monarch in LLM → VMonarch (视频 DiT 首次应用)
标题:SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention
作者:Jintao Zhang 等 (清华 + Berkeley)
日期:2025年9月28日(ICLR 2026 Oral)
arXiv:2509.24006
关键词:稀疏注意力 线性注意力 融合 自定义GPU kernel 95%计算减少 ICLR 2026
注意力权重可以分为两部分:少量大权重(高秩)和大量小权重(低秩)。这天然暗示:对大权重用稀疏注意力(O(N²) 但只算少量),对小权重用线性注意力(O(N))。
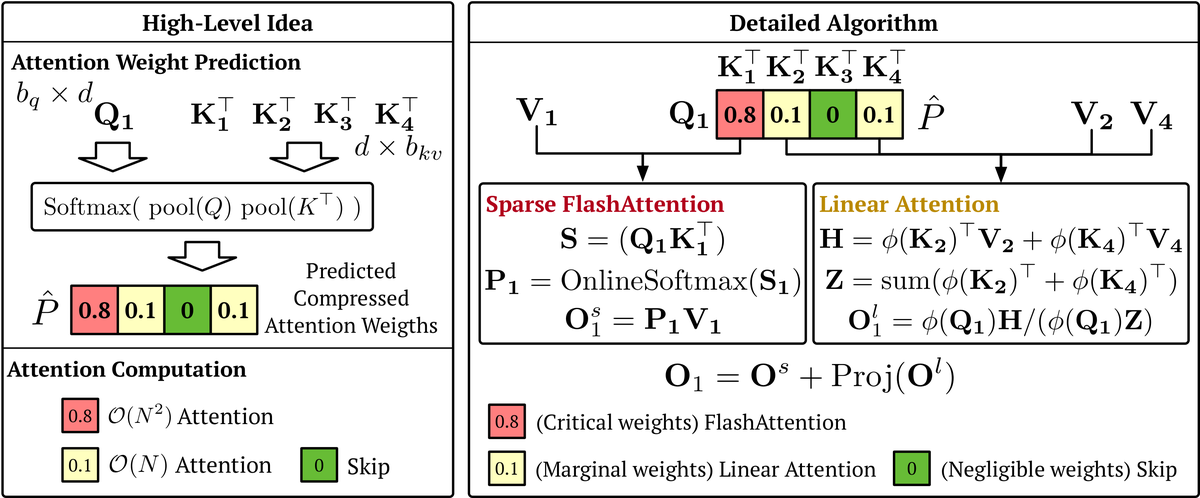
稀疏注意力 + 线性注意力两条独立技术路线 → SLA 首次统一融合(ICLR 2026 Oral)
标题:SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer
作者:Tongcheng Fang 等 (清华 + 腾讯)
日期:2026年1月23日
arXiv:2601.16515
关键词:线性注意力 门控机制 高稀疏度 轻量微调 2000样本
免训练稀疏注意力受限于有限的稀疏度(通常 50-70%),而训练型方法需要大量数据和计算。能否用极轻量的微调达到极高稀疏度?
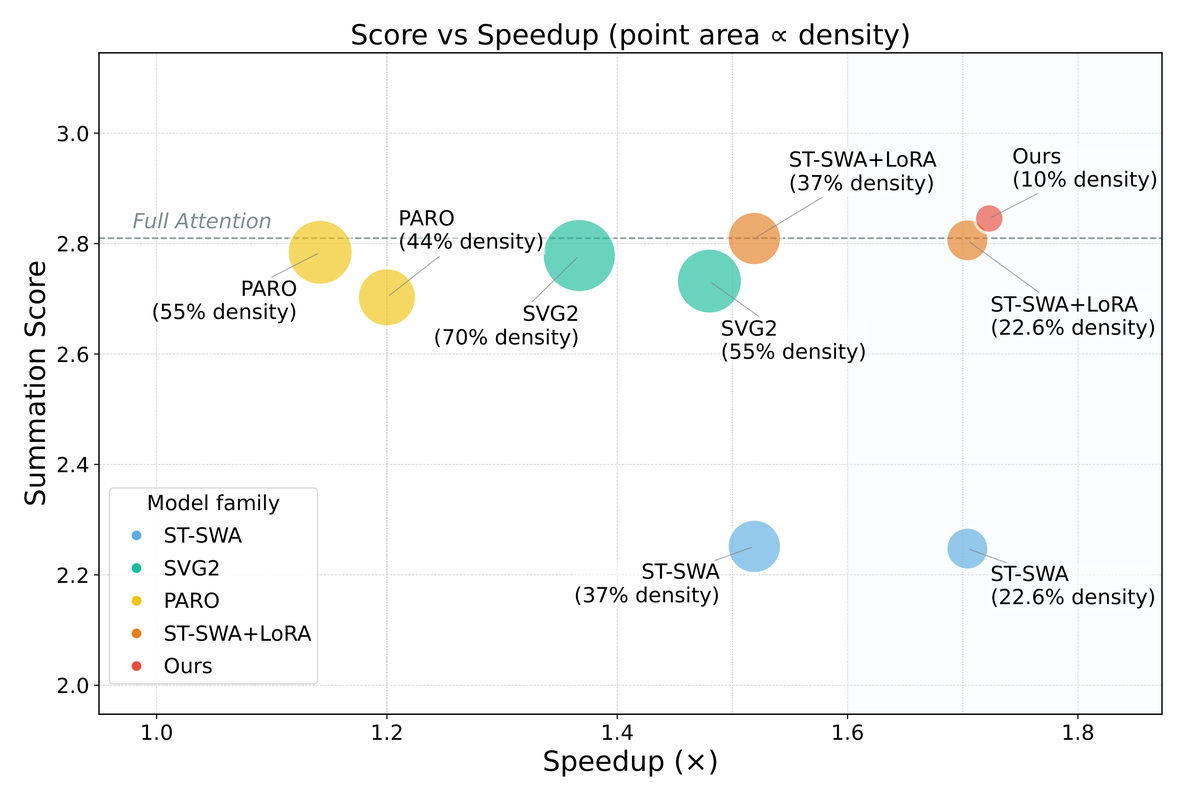
标题:FastLightGen: Fast and Light Video Generation with Fewer Steps and Parameters
作者:Shitong Shao, Yufei Gu, Zeke Xie
日期:2026年3月2日
arXiv:2603.01685
关键词:蒸馏 剪枝 步数压缩 参数压缩 HunyuanVideo WanX
以往的加速研究要么减少采样步数(蒸馏),要么减少模型参数(剪枝),但从未同时压缩两者。
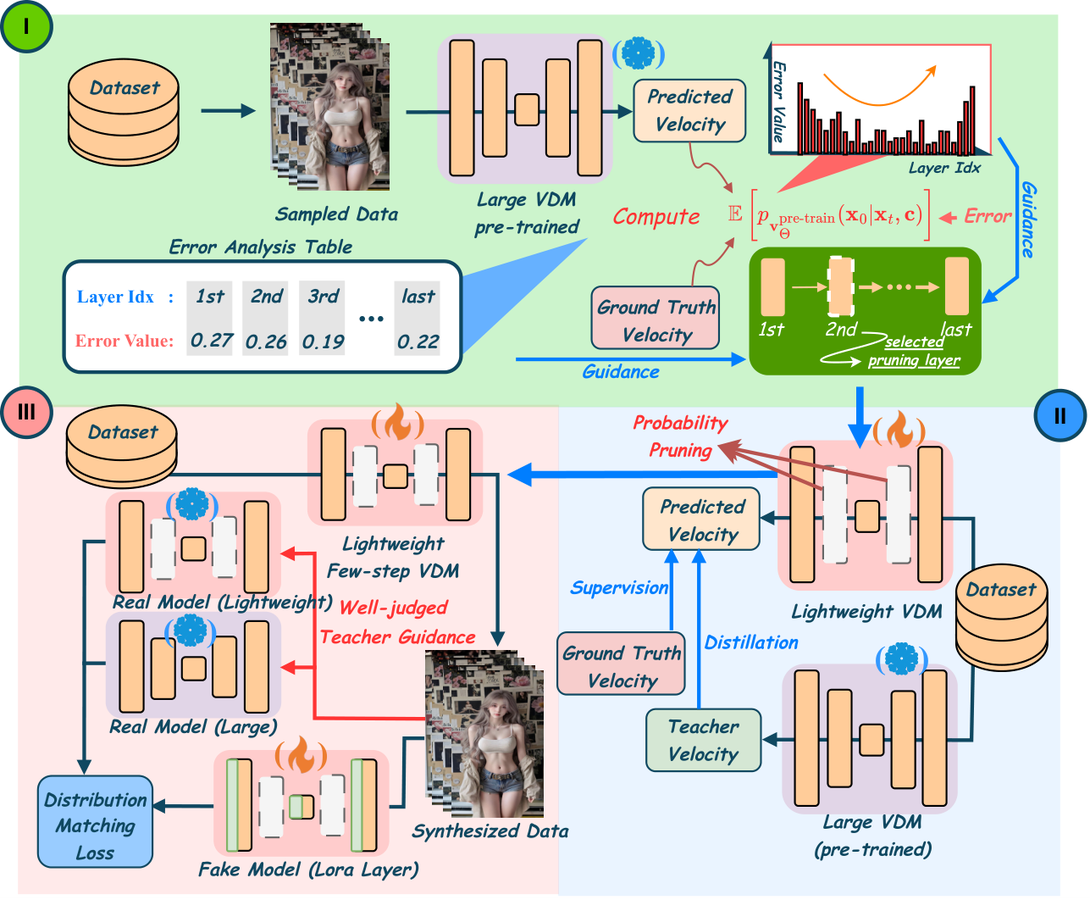
FastLightGen 的核心:构建一个"最优教师模型",在协同框架中同时蒸馏步数和参数。
标题:Streaming Autoregressive Video Generation via Diagonal Distillation
作者:Jinxiu Liu 等 (HKUST, Ming-Hsuan Yang)
日期:2026年3月10日
arXiv:2603.09488
关键词:自回归 蒸馏 流式生成 光流建模 277x加速 31 FPS
扩散蒸馏将多步模型压缩为少步变体,但现有方法主要针对图像设计,忽略了视频的时间依赖性,导致运动不连贯和长序列误差累积。
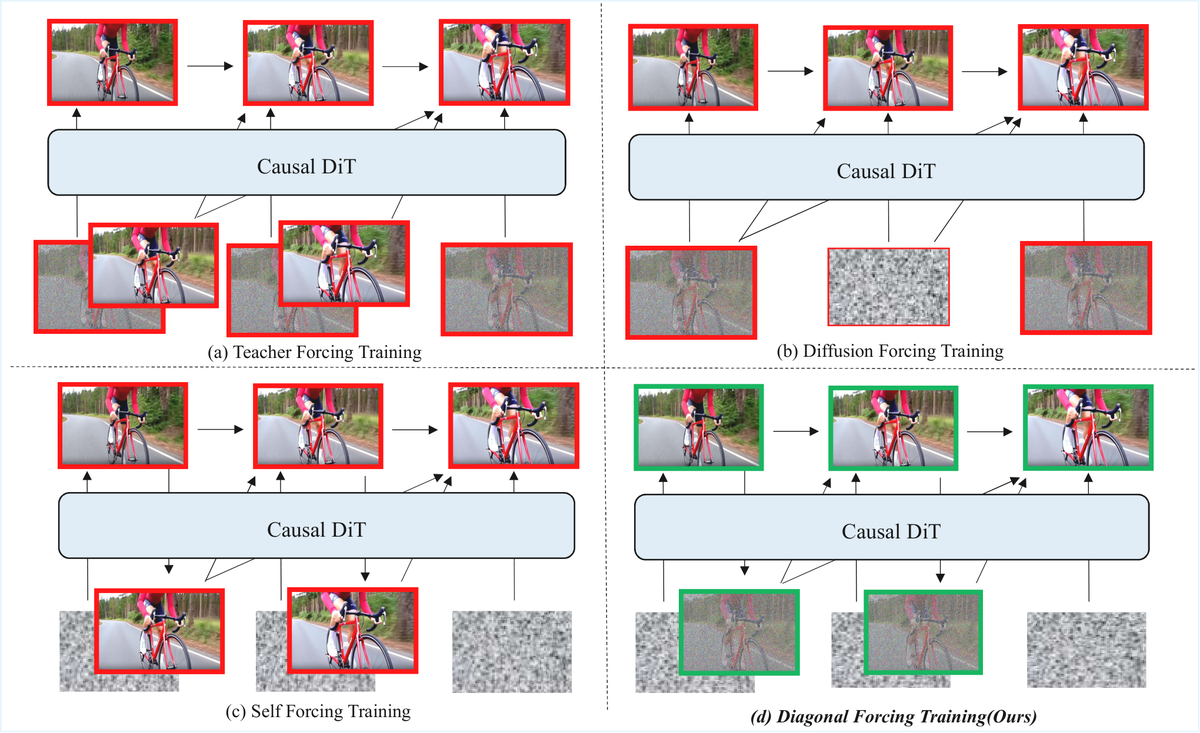
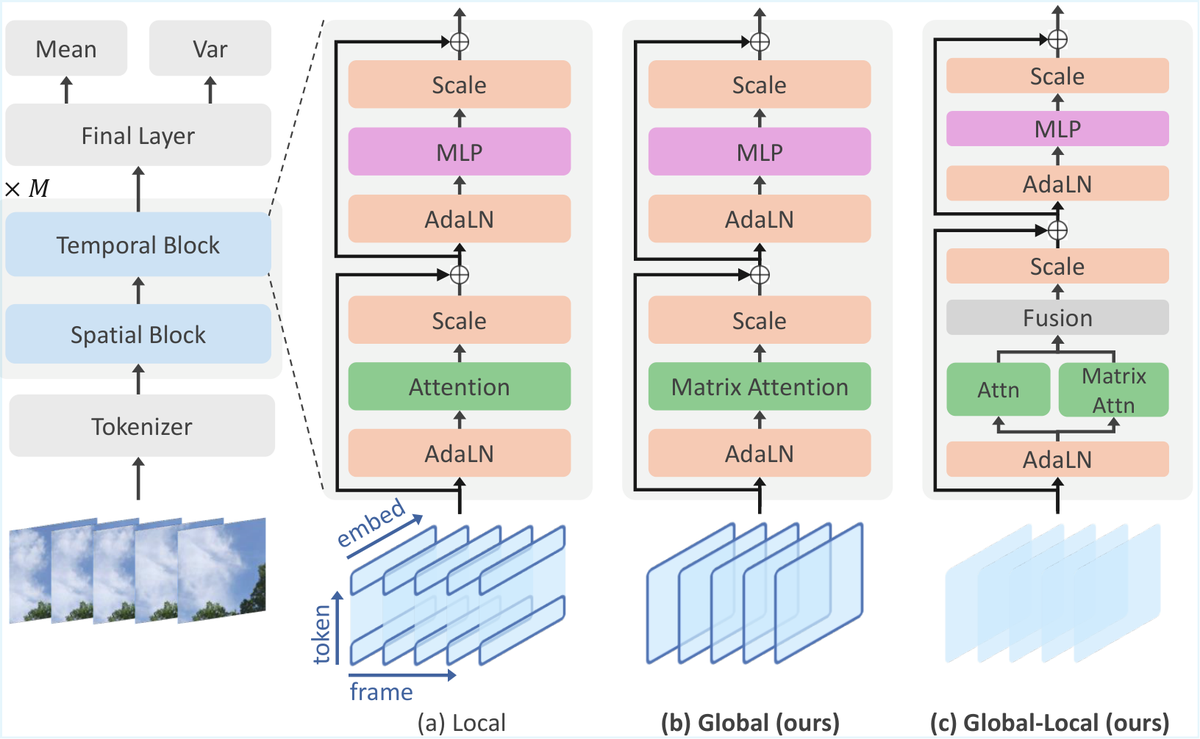
标题:FrameDiT: Diffusion Transformer with Frame-Level Matrix Attention for Efficient Video Generation
作者:Minh Khoa Le 等
日期:2026年3月10日
arXiv:2603.09721
关键词:帧级注意力 矩阵注意力 时空结构 Local Factorized
现有方法面临 Full 3D Attention(强但贵)vs Local Factorized Attention(快但丢失全局信息)的两难。
本周的 9 篇论文可以按 "是否需要训练" 和 "加速策略" 两个维度分类:
免训练 轻量微调 训练/蒸馏
┌─────────┐ ┌─────────┐ ┌─────────┐
稀疏注意力 │CalibAtt │ │ SALAD │ │ SLA │
│SVG-EAR │ │VMonarch │ │ │
├─────────┤ ├─────────┤ ├─────────┤
缓存+剪枝 │ SODA │ │ │ │ │
├─────────┤ ├─────────┤ ├─────────┤
蒸馏+压缩 │ │ │ │ │FastLight│
│ │ │ │ │DiagDist │
├─────────┤ ├─────────┤ ├─────────┤
结构化注意力 │ │ │ │ │FrameDiT │
└─────────┘ └─────────┘ └─────────┘| 方法 | 注意力加速 | 端到端加速 | 需要训练? | 测试模型 | 质量保持 |
|---|---|---|---|---|---|
| CalibAtt | - | 1.58x | 否 | Wan 2.1 14B, Mochi | ★★★★ |
| SVG-EAR | - | 1.77-1.93x | 否 | Wan 2.2, HunyuanVideo | ★★★★ |
| SODA | - | 可控 | 否 | DiT-XL, PixArt-α, OpenSora | ★★★★★ |
| VMonarch | 5x | - | 轻量微调 | VBench | ★★★★ |
| SALAD | - | 1.72x | 2000样本 | - | ★★★★ |
| SLA | 13.7x | 2.2x | 少量微调 | Wan 2.1 1.3B | ★★★★★ |
| FastLightGen | - | 显著 | 蒸馏 | HunyuanVideo, WanX | ★★★★ |
| Diagonal Dist. | - | 277.3x | 蒸馏 | 自回归模型 | ★★★ |
| FrameDiT | ~FA级 | ~FA级 | 训练 | 多个benchmark | ★★★★ |
本周的论文清晰地展现了四条技术路线的演进:
路线 A:免训练稀疏注意力
路线 B:稀疏 + 线性注意力融合
路线 C:缓存 + 剪枝
路线 D:蒸馏 + 压缩
免训练方法的天花板在 ~2x:CalibAtt (1.58x) 和 SVG-EAR (1.93x) 代表了免训练稀疏注意力的当前上限。突破需要引入轻量训练。
稀疏 + 线性融合是最佳平衡点:SLA 通过自定义 kernel 实现 2.2x E2E 加速且质量无损,是目前注意力加速的最优解。ICLR 2026 Oral 的认可也说明了这一点。
蒸馏方法的加速比远超注意力优化:Diagonal Distillation 的 277x 说明,如果能接受一定质量损失,蒸馏是最强力的加速手段。但注意力优化的优势是"质量无损"。
多种方法可叠加:注意力优化 + 蒸馏可以叠加使用。CalibAtt 已在蒸馏模型上验证有效。理论上 SLA + 步数蒸馏可能实现 5-10x 无损加速。
Wan 和 HunyuanVideo 成为标准测试平台:本周几乎所有论文都在这两个模型上测试,说明它们已成为视频生成的事实标准。
从算法到系统的全栈优化:SODA 的序列并行推理提醒我们,纯算法优化之外,系统级优化(多 GPU 并行、算子融合等)同样重要。
人工智能炼丹师 整理 | 2026-03-14

评论 (0)