
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

今日 arXiv cs.CV 视觉生成相关论文共 12 篇。
方向分布:
源自 arXiv 4月25日 141 篇候选 + HF Daily Papers,经多维评分排序精选
ParetoSlider: Diffusion Models Post-Training for Continuous Reward Control | Tel Aviv University / NVIDIA | arXiv:2604.20816
关键词: 多目标RL·Pareto前沿·扩散后训练·推理时控制
前序工作问题: RL后训练只能优化单一标量奖励,无法在推理时动态控制文本对齐度、美学、真实感等多个冲突目标间的权衡
贡献: 提出多目标RL框架训练单个扩散模型逼近整个Pareto前沿,通过偏好权重条件化+多目标GRPO实现推理时Slider实时调控
效果: 在SD3.5/FluxKontext/LTX-2三个骨干上单模型匹配或超越多个独立训练的基线,权衡导航平滑连续
批判点评: Pareto前沿维度灾难:目标数超过3-4个时近似质量可能下降,reward model覆盖度有限
Efficient Diffusion Distillation via Embedding Loss | Unknown | arXiv:2604.22379
关键词: 扩散蒸馏·嵌入损失·少步生成·训练效率
前序工作问题: 扩散蒸馏训练成本极高:回归损失需预生成大量教师样本,对抗损失训练不稳定且资源消耗大
贡献: 提出嵌入损失替代传统蒸馏目标,用预训练视觉编码器(DINO/CLIP)将师生输出映射到嵌入空间计算相似度,兼具稳定性和感知质量
效果: 训练效率相比对抗蒸馏提升数倍,生成质量保持或提升,即插即用适配多种蒸馏框架
批判点评: 嵌入损失上限受预训练编码器表达能力制约,与对抗损失的最优组合尚未探索
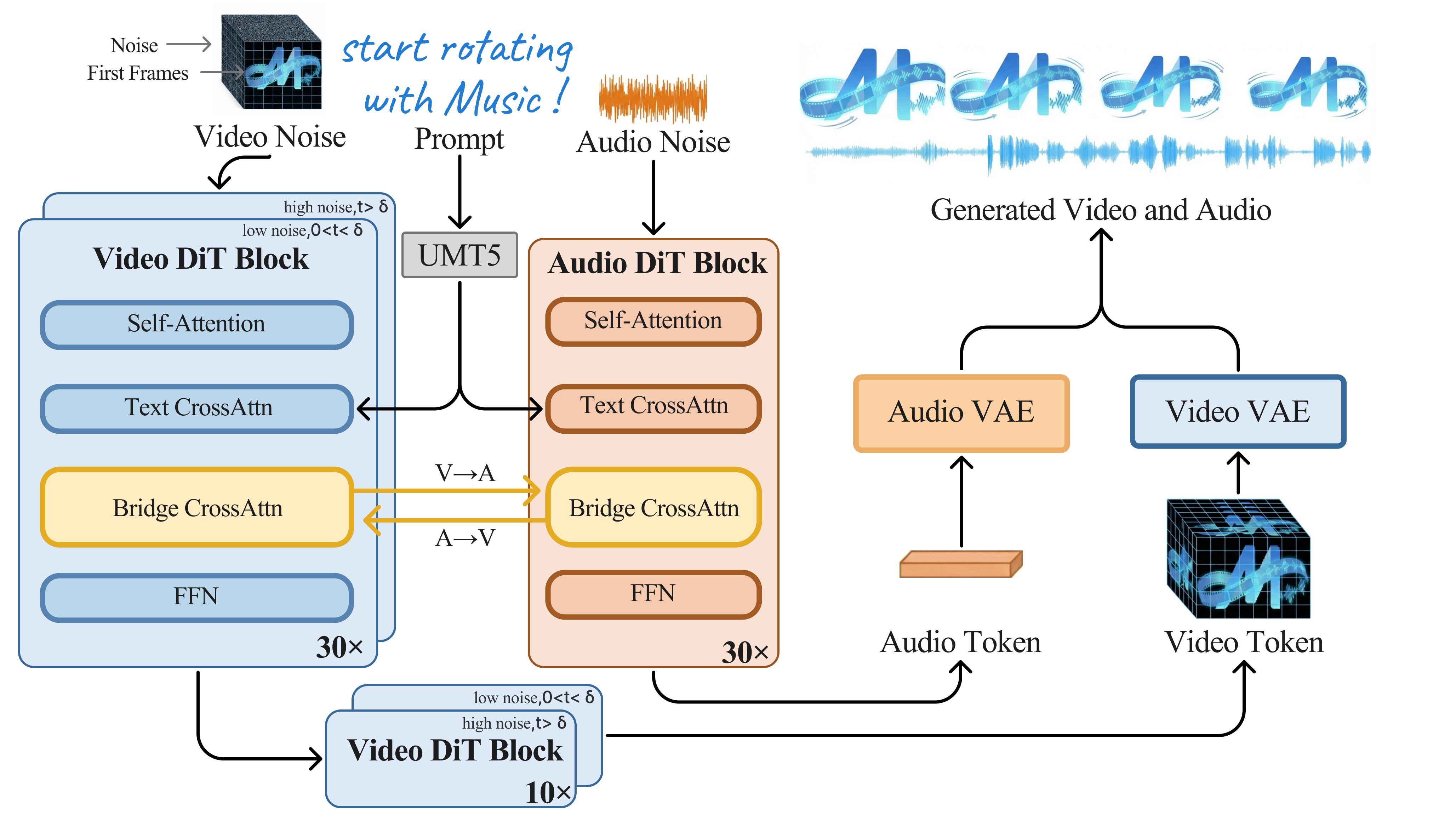
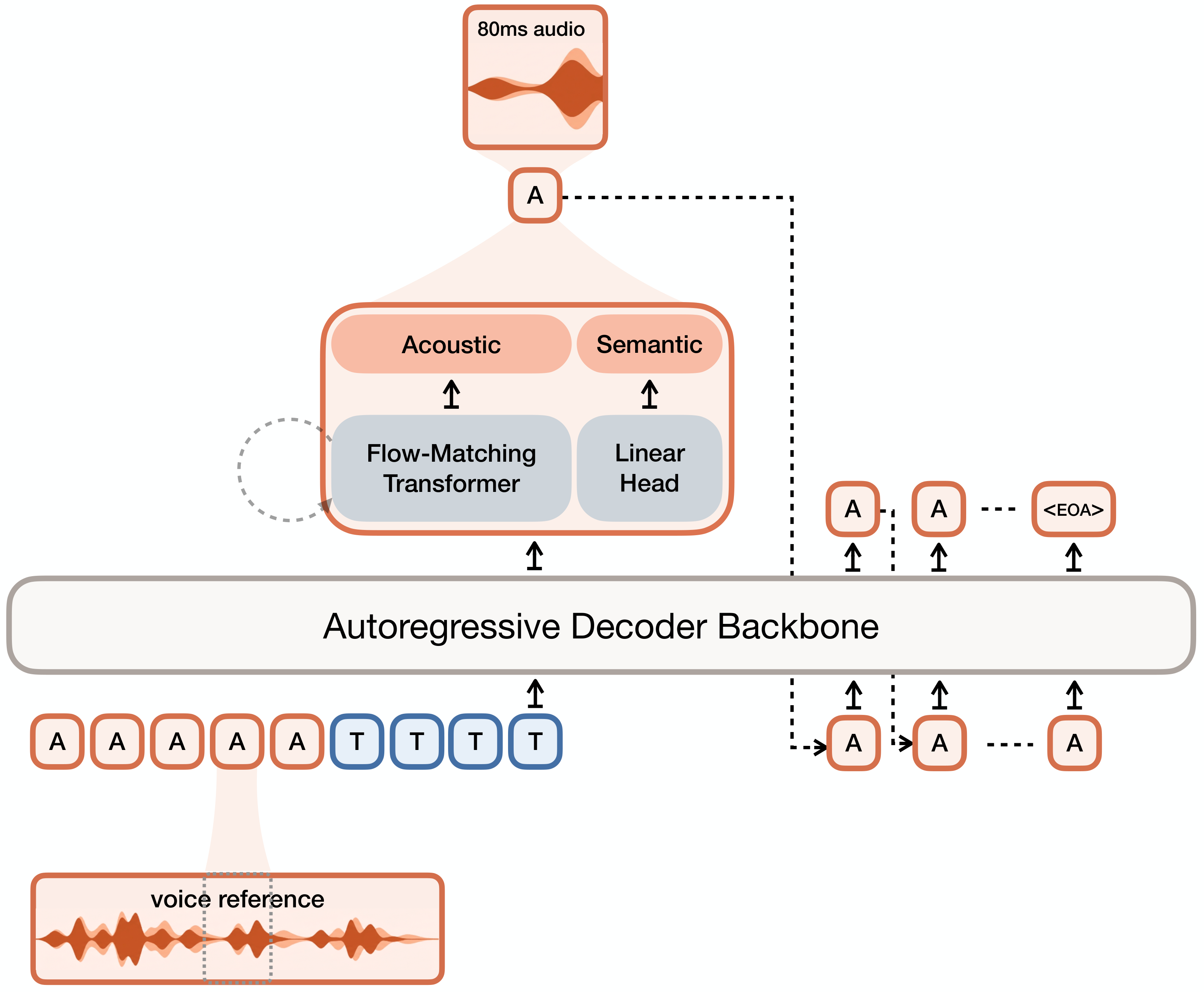
UniSonate: A Unified Model for Speech, Music, and Sound Effect Generation with Text Instructions | Tianjin University / Kling Team, Kuaishou / Chinese Academy of Sciences | arXiv:2604.22209
关键词: 统一音频生成·TTS·音乐生成·音效生成·快手Kling
前序工作问题: 音频生成被割裂为TTS、文生音乐、文生音效三个独立领域,结构化语义与非结构化声学纹理的统一面临根本挑战
贡献: 首个单模型统一三大音频任务,设计层次化token(语义+声学)+两阶段生成(语言模型+扩散),文本指令统一接口
效果: 单模型在语音/音乐/音效上接近专用模型性能,支持跨模态组合生成(如带背景音乐的语音)
批判点评: 系统复杂度高(多编码器+LM+扩散),复现门槛大,与专用SOTA的性能差距需详细量化
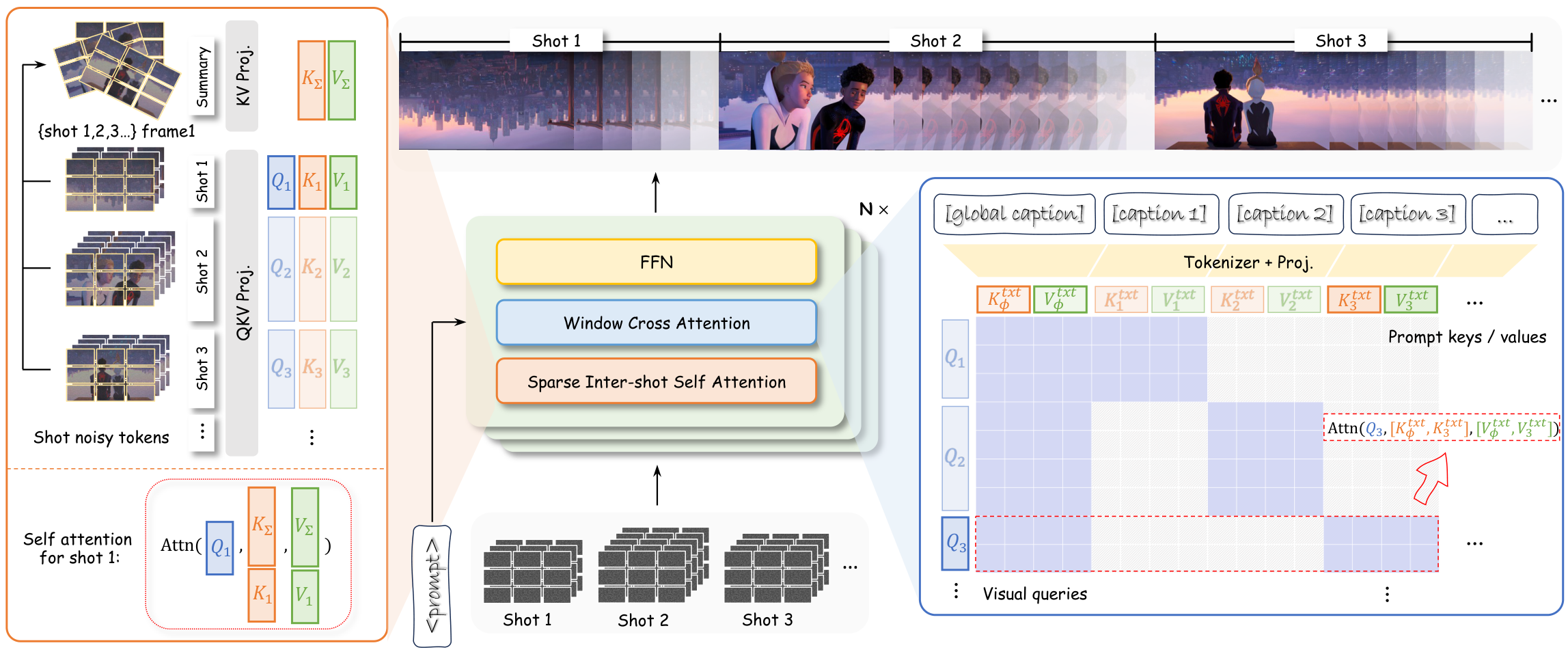
FlowAnchor: Stabilizing the Editing Signal for Inversion-Free Video Editing | Unknown | arXiv:2604.22586
关键词: 视频编辑·Flow-based·免反转·训练免费
前序工作问题: 免反转的flow-based视频编辑方法在多物体场景下信号不稳定,常出现失败
贡献: 提出FlowAnchor训练免费框架,通过锚定编辑信号稳定采样轨迹,实现高效结构保持的视频编辑
效果: 在多物体场景的视频编辑任务中显著提升稳定性和结构保真度
批判点评: 锚定策略的通用性需在更多编辑场景验证,对大幅度语义变化的支持可能有限
Sparse Forcing: Native Trainable Sparse Attention for Real-time Autoregressive Diffusion Video Generation | Unknown | arXiv:2604.21221
关键词: 稀疏注意力·视频扩散·自回归·实时生成
前序工作问题: 自回归视频扩散模型的注意力计算量随序列增长爆炸,无法实时生成长视频
贡献: 提出Sparse Forcing范式,利用注意力集中于显著视觉块的观察设计原生可训练稀疏注意力,同时提升生成质量和降低延迟
效果: 长视频生成质量提升的同时解码延迟显著降低,向实时自回归视频生成迈进
批判点评: 稀疏模式的选择依赖场景特性,对快速运动或场景切换的鲁棒性待验证
VARestorer: One-Step VAR Distillation for Real-World Image Super-Resolution | Tsinghua University | arXiv:2604.21450
关键词: VAR蒸馏·图像超分·一步推理·参数高效
前序工作问题: 视觉自回归模型(VAR)的逐尺度预测机制在超分任务中因因果注意力限制无法利用全局低质量上下文,导致输出模糊,且多步迭代引发误差累积
贡献: 提出蒸馏框架将预训练文生图VAR模型转化为一步超分模型,引入金字塔图像条件+跨尺度注意力实现双向尺度交互,仅微调1.2%参数
效果: DIV2K上MUSIQ 72.32、CLIPIQA 0.7669达SOTA,推理速度提升10倍
批判点评: 蒸馏依赖教师模型质量,对极端退化场景(如严重压缩伪影)的泛化能力待验证
Linear Image Generation by Synthesizing Exposure Brackets | Adobe Research / NTU | arXiv:2604.21008
关键词: 线性图像·曝光包围·HDR生成·DiT流匹配
前序工作问题: 现有生成模型只能合成经色调映射的显示参考图像,丢失场景真实辐照信息,限制后期编辑空间
贡献: 首次提出文本到线性图像生成任务,将线性图像表示为曝光包围序列,设计DiT流匹配架构生成多曝光bracket保留完整动态范围
效果: 生成高质量场景参考线性图像,支持文本引导编辑和ControlNet结构条件生成等下游应用
批判点评: 曝光包围表示增加推理开销,线性图像评估标准尚未建立,实用性需更多专业摄影师反馈验证
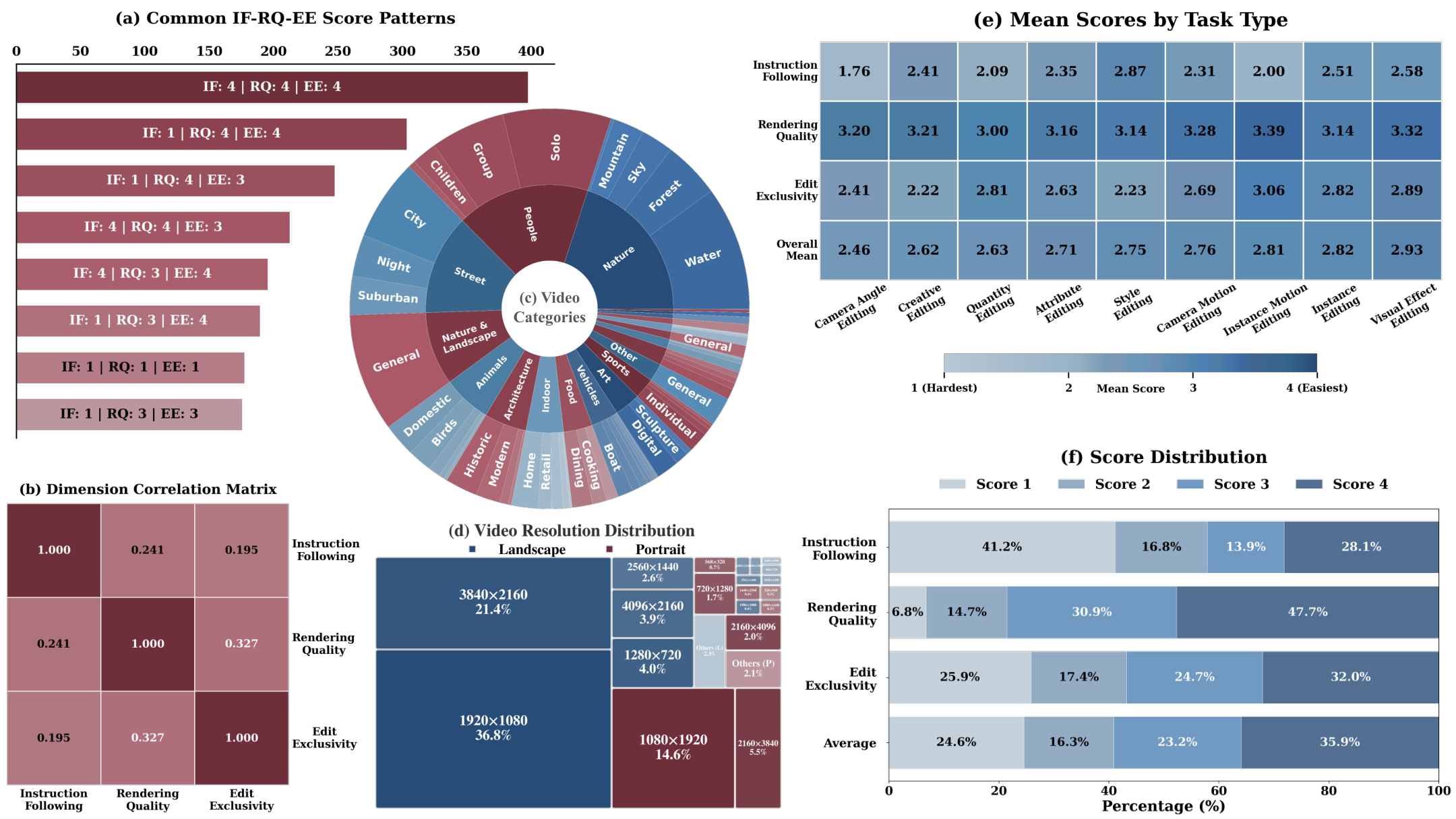
Building a Precise Video Language with Human-AI Oversight | CMU / Stanford | arXiv:2604.21718
关键词: 视频描述·CHAI框架·人机协同·Wan微调
前序工作问题: 现有视频语言模型缺乏精确描述运动、空间和摄像机动态的能力,标注数据质量参差不齐
贡献: 定义结构化视频描述规范(数百个视觉原语),提出CHAI人机协同框架让专家对模型预标注进行批判修正,支持SFT/DPO/推理时Scaling
效果: 在适度人工监督下开源模型超越Gemini-3.1-Pro;微调Wan实现400词长提示的精准视频生成控制
批判点评: 专家监督仍需大量人力投入,视觉原语定义的通用性和可扩展性有待社区验证
StyleVAR: Controllable Image Style Transfer via Visual Autoregressive Modeling | Unknown | arXiv:2604.21052
关键词: VAR框架·风格迁移·离散序列·VQ-VAE
前序工作问题: 现有风格迁移方法在内容保持与风格一致性之间难以平衡,基于扩散的方法推理慢
贡献: 基于VAR框架将风格迁移建模为条件离散序列生成,用VQ-VAE分解多尺度表示,Transformer自回归建模风格和内容条件下的目标token分布
效果: 在内容保持和风格一致性两方面取得良好平衡,推理速度优于扩散方法
批判点评: VQ-VAE的离散化可能导致细节损失,对抽象艺术风格的迁移效果待验证
AttentionBender: Manipulating Cross-Attention in Video Diffusion Transformers | University of the Arts London | arXiv:2604.20936
关键词: 注意力操控·视频DiT·创意工具·可解释AI
前序工作问题: 视频生成模型只能通过提示词控制,艺术家无法直观理解和操控模型内部机制以突破默认生成倾向
贡献: 基于Network Bending设计工具,对视频DiT的交叉注意力图施加2D变换(旋转/缩放/平移),4500+视频实验验证操控效果
效果: 揭示交叉注意力高度纠缠特性,产生超越模型学习表征空间的新颖glitch美学效果
批判点评: 操控效果高度非线性且难以预测,作为实用工具的可控性和易用性较弱
KD-CVG: A Knowledge-Driven Approach for Creative Video Generation | Xi'an Jiaotong University / ByteDance | arXiv:2604.21362
关键词: 创意视频·广告生成·知识图谱·语义对齐
前序工作问题: T2V模型在广告创意视频生成中存在语义对齐模糊和运动适应性不足两大问题
贡献: 构建广告创意知识库(ACKB),提出语义感知检索(SAR)+多模态知识参考(MKR)两阶段方法,用图注意力网络和RL反馈增强卖点-视频关联理解
效果: 在语义对齐和运动适应性指标上超越现有方法,代码和数据集将开源
批判点评: 知识库构建成本高且依赖特定广告领域,泛化到其他创意场景需额外适配
AttDiff-GAN: A Hybrid Diffusion-GAN Framework for Facial Attribute Editing | Unknown | arXiv:2604.21289
关键词: 人脸编辑·扩散GAN混合·属性解耦·高保真
前序工作问题: GAN方法可控性好但风格码与属性语义对齐弱,扩散方法图像真实但编辑精度受噪声纠缠限制
贡献: 提出混合Diffusion-GAN框架,融合GAN的可控性和扩散模型的高真实度,实现精确人脸属性编辑
效果: 在属性编辑精度和图像保真度上超越纯GAN和纯扩散基线
批判点评: 人脸属性编辑场景较窄,对非人脸图像编辑的泛化性未知
人工智能炼丹君 整理 | 2026-04-27
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)