
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹君 整理 | 2026年5月10日(周日)
覆盖时间:2025-09 ~ 2026-05
本期 AIGC 周末专题聚焦视觉生成推理加速:从量化蒸馏到系统级并行的全栈优化方向,精选 8 篇代表性论文进行深度解读。
方向分布:
含 MLSys 2026 × 1, ICML 2026 Spotlight × 1
描述:FlashAttention 优化内存访问、LCM/Consistency Model 减少步数——各技术独立发展,实现 2-8 倍加速。
关键节点:
描述:SageAttention + 步数蒸馏 + 量化开始联合使用,加速 10-30 倍;StreamDiffusion 开启流式生成探索。
关键节点:
描述:TurboDiffusion 验证四技术正交叠加 100-200x;DC-VideoGen 提出后训练深度压缩新范式 14.8x。
关键节点:
描述:Mamoda2.5 部署广告场景 95.9x;SDVG 开辟连续投机解码;E2E-1D 重构训练范式提升效率上限。
关键节点:
论文: TurboDiffusion:100-200 倍视频生成加速框架
arXiv: 2512.16093
机构: Tsinghua University TSAIL Lab, Shengshu Technology
核心问题: 视频扩散模型推理极慢(14B 需 27 分钟),单一加速技术收益有限
视频扩散模型(Wan2.1-14B 等)生成质量持续提升但推理开销巨大——14B 模型生成 5 秒 480p 视频需 27 分钟。现有加速方法各自独立优化某一维度(如仅量化或仅蒸馏),缺乏系统性的多技术正交叠加方案。TurboDiffusion 提出:能否找到一组相互正交的加速技术,在单卡上实现数量级加速?
前序工作及局限:
与前序工作的本质区别: TurboDiffusion 首次系统验证四类正交技术(量化注意力+稀疏+步数蒸馏+W8A8)可叠加实现 100-200x 加速
TurboDiffusion 系统性地组合四类正交加速技术:
(1) 注意力加速—SageAttention2++:将注意力计算的 Q/K 量化到低比特(INT4/INT8)直接利用 Tensor Core 运算,相比标准 FlashAttention 提速 2-3 倍。
(2) 稀疏注意力加速—SLA:设计可训练的稀疏线性注意力核函数替代全注意力,与 SageAttention 正交使用(SLA 减少 token 数 + SageAttention 加速每次运算),提供额外 3-5 倍加速。
(3) 步数蒸馏—RCM:基于 Rectified Consistency Model 将教师模型的多步去噪蒸馏为学生模型的 4 步生成,保持生成质量。
(4) W8A8 量化:将非注意力线性层的权重和激活均量化至 INT8,进一步压缩计算和显存。
关键洞见:四项技术分别优化计算的不同维度——注意力精度/注意力稀疏度/时间步数/线性层精度,因此可正交叠加而不互相干扰。
[{'point': 'SLA 的质量-稀疏度权衡', 'detail': '极端稀疏率下对复杂多物体场景的细节保留程度未充分评估'}, {'point': '蒸馏数据依赖', 'detail': 'RCM 蒸馏需要教师模型生成大量数据对,前期计算投入可观'}, {'point': '硬件绑定', 'detail': 'SageAttention2++ 强依赖 Ada Lovelace/Hopper 架构 Tensor Core,旧显卡受益有限'}]
技术演进定位: 全栈加速框架的集大成者,验证正交叠加路线的工程可行性
可能的后续方向:
论文: DC-VideoGen:深度压缩 VAE 实现 14.8 倍视频生成加速
arXiv: 2509.25182
机构: MIT, NVIDIA, Tsinghua University
核心问题: latent 空间分辨率大是推理瓶颈,标准 8x 压缩下 1080p 视频 latent 仍很大
视频扩散模型的推理延迟主要由 latent 空间分辨率决定——标准 8x 空间压缩下,1080p 视频仍需在巨大的 latent map 上执行数十步去噪。如果能将 VAE 压缩比从 8x 提升至 32x/64x,latent 尺寸缩小 16-64 倍,扩散模型的计算量将急剧降低。
前序工作及局限:
与前序工作的本质区别: DC-VideoGen 实现 32x/64x 空间 + 4x 时间深度压缩且保持质量,后训练适配仅需 10 GPU-day
DC-VideoGen 提出后训练加速范式——不修改扩散模型架构,而是通过改变 latent 空间来加速:(1) 深度压缩视频 VAE 采用 Chunk-Causal 时间设计实现 32x/64x 空间和 4x 时间压缩;(2) AE-Adapt-V 策略通过渐进式训练解决预训练模型迁移到新 latent 空间的稳定性问题;(3) latent 面积减小 16-64 倍使 DiT 自注意力计算量平方级降低,最终实现 14.8x 推理加速。
[{'point': '极端压缩下的细节损失', 'detail': '64x 空间压缩对高频纹理的重建能力下降明显'}, {'point': 'Chunk-Causal 的边界伪影', 'detail': 'chunk 边界处因果卷积可能引入时间不连续'}, {'point': '与步数蒸馏的兼容性', 'detail': 'DC-VideoGen + TurboDiffusion 类步数蒸馏联合效果未探索'}]
技术演进定位: 后训练加速的新范式开创者——不修改扩散模型本身
可能的后续方向:
论文: StreamDiffusionV2:实时流式视频生成系统
arXiv: 2511.07399
机构: UT Austin, UC Berkeley, Stanford University, MIT, Nunchaku AI
核心问题: 视频扩散模型无法满足实时直播的严格延迟要求(TTFF/每帧截止/低抖动)
视频扩散模型在离线生成中质量突出,但无法满足实时直播场景的严格要求:首帧延迟需低于 0.5 秒、每帧必须在固定截止时间内完成、多 GPU 扩展需保持低抖动。现有方法优化吞吐而忽略延迟 SLO。
前序工作及局限:
与前序工作的本质区别: StreamDiffusionV2 首次在 14B 模型上实现 58 FPS + 满足产品级 SLO 的完整流式系统
StreamDiffusionV2 将离线视频生成改造为满足实时 SLO 的流式系统:SLO 感知调度确保 TTFF 最小化和低抖动;Sink-Token KV Cache 在无限长生成中保持锚点参考;Motion-Aware Noise Controller 按运动强度自适应去噪策略;Pipeline Orchestration 实现去噪步级+层级两维并行的近线性 GPU 扩展。
[{'point': '质量 vs 延迟的量化评估不足', 'detail': '1-2 步去噪的生成质量定量差距未系统报告'}, {'point': '硬件门槛', 'detail': '58 FPS 需 4×H100,对普通用户不可及'}, {'point': '真实直播场景验证缺失', 'detail': '缺少真实交互式直播场景的端到端用户体验报告'}]
技术演进定位: 首个将视频生成推入交互式实时产品级的完整工程系统
可能的后续方向:
论文: HiAR:分层去噪实现高效长视频自回归生成
arXiv: 2603.08703
机构: University of Science and Technology of China (USTC)
核心问题: 长视频 AR 生成中,高度去噪的条件会高保真传播误差导致渐进退化
自回归扩散面临根本矛盾:保证时序连续性需以高度去噪的历史帧作为条件,但高确定性条件会将预测误差高保真传播,导致渐进式质量退化。现有方法困于'连续性 vs 退化'的跷跷板。
前序工作及局限:
与前序工作的本质区别: HiAR 证明共享噪声水平条件即可保证连贯性,颠覆逐块串行范式并解锁流水线并行
HiAR 核心洞见:受双向扩散模型启发,以相同噪声水平的上下文为条件就足够保证连贯性。分层去噪颠覆传统逐块生成——在每个去噪步对所有块执行一步因果生成,当前块条件始终是同噪声水平上下文。该结构天然支持流水线并行。引入 forward-KL regulariser 对抗 self-rollout distillation 的低运动捷径。
[{'point': '语义连续性的局限', 'detail': '无外部记忆模块,极长序列下语义一致性受影响'}, {'point': '仅验证小模型', 'detail': '基于 Wan-1.3B 蒸馏,14B 大模型效果未验证'}, {'point': '加速幅度有限', 'detail': '1.8x 相比 TurboDiffusion 100x+ 显得保守'}]
技术演进定位: 从去噪顺序层面根本解决长视频退化问题的理论突破
可能的后续方向:
论文: Mamoda2.5:DiT-MoE 统一模型 + 4 步蒸馏实现 95.9 倍加速
arXiv: 2605.02641
机构: ByteDance
核心问题: 统一多模态模型的质量-效率矛盾:Dense 架构容量与推理速度不可兼得
统一多模态模型在质量和效率之间存在根本矛盾:更大模型容量带来更好生成质量但更慢推理。传统 Dense 架构无法兼顾。视频编辑场景 30 步去噪对实时应用不可接受。
前序工作及局限:
与前序工作的本质区别: Mamoda2.5 首次在 DiT 中嵌入 128 专家 MoE(25B/3B激活)+ 联合蒸馏RL 将 30步压至 4步
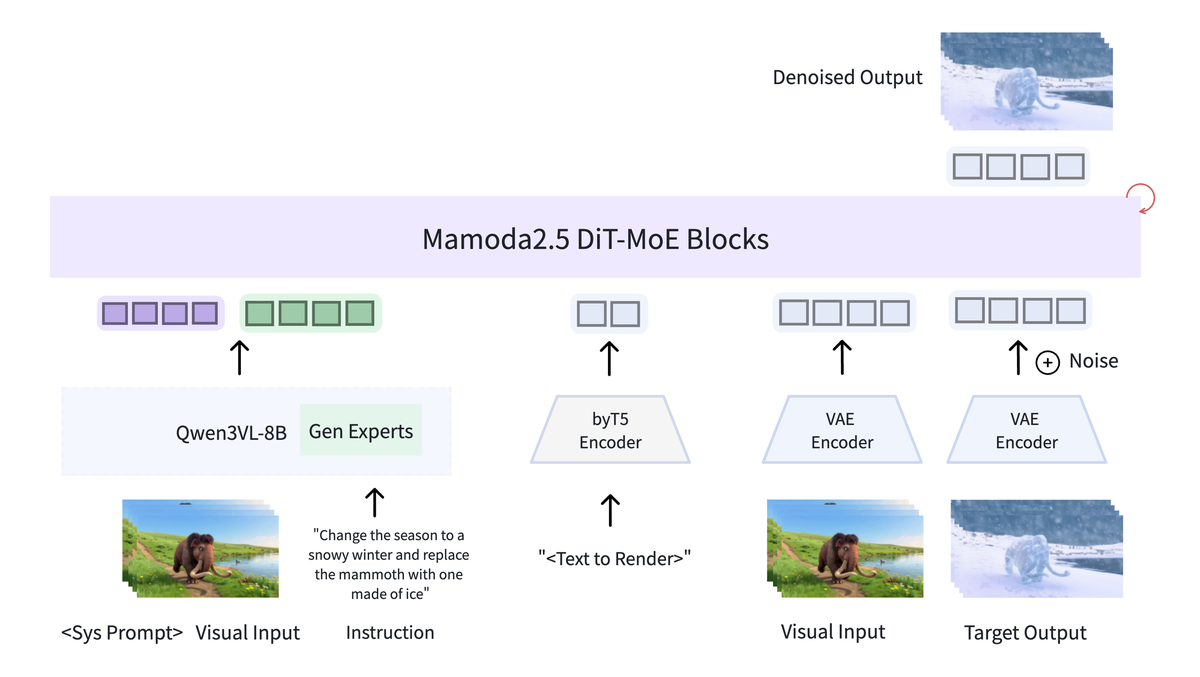
Mamoda2.5 从两个维度解决统一模型效率瓶颈:(1) MoE 架构扩展——DiT FFN 层替换为 128 专家 Top-8 MoE,25B 参数仅激活 3B;(2) 联合蒸馏+RL——先用 DMD 将 30 步压至 4 步,再用视频质量奖励模型 RL 微调弥补蒸馏质量损失。VBench 2.0 达顶级性能,OpenVE-Bench 匹配 Kling O1。
[{'point': 'MoE 路由不稳定性', 'detail': '128 专家 Top-8 路由训练早期易出现专家坍塌'}, {'point': '蒸馏+RL 的训练成本', 'detail': '推理快 95.9x 但蒸馏和 RL 阶段 GPU 资源未披露'}, {'point': '开源完整度不明', 'detail': '字节商业系统的模型权重开源程度存疑'}]
技术演进定位: MoE + 蒸馏 + RL 三合一在视频编辑中的工程典范
可能的后续方向:
论文: SDVG:投机解码加速自回归视频生成
arXiv: 2604.17397
机构: Tsinghua University
核心问题: 投机解码是 LLM 最成功的加速策略,但视频是连续张量无法精确拒绝采样
自回归视频扩散正成为主流范式,步数蒸馏是当前主要加速手段。但投机解码——LLM 中最成功的加速策略——能否迁移至视频生成?核心挑战:视频块是连续时空张量,无 token 级分布用于精确拒绝采样。
前序工作及局限:
与前序工作的本质区别: SDVG 首次用 ImageReward+worst-frame 聚合替代 token 验证,将投机解码迁移至连续视频空间
SDVG 将 LLM 投机解码的 propose-then-verify 范式迁移至连续视频空间:(1) 1.3B drafter 快速提议候选块;(2) Image-Quality Router 替代 token verification——VAE 解码后用 ImageReward 评分;(3) worst-frame 聚合(取最低帧分)捕获单帧伪影;(4) τ 阈值平滑调节质量-速度 Pareto 前沿。无需训练、无架构修改。
[{'point': '加速比有限', 'detail': '1.59-2.09x 相比 TurboDiffusion 100x 显得保守'}, {'point': 'ImageReward 偏差', 'detail': '作为 quality router 可能对某些风格有系统性偏好'}, {'point': '与步数蒸馏的冲突', 'detail': '若 target 已蒸馏为 4 步,投机解码收益可能消失'}]
技术演进定位: 连续空间投机解码的开创性验证,开辟 LLM 加速技术向视觉迁移新方向
可能的后续方向:
论文: Adjoint Matching:确定性控制框架微调 Flow 生成模型
arXiv: 2605.06583
机构: Columbia University
核心问题: Flow-based 模型的偏好对齐需全轨迹反传梯度,计算昂贵且不稳定
Flow-based 生成模型的偏好对齐依赖 RLHF/DPO,但在 ODE 速度场上训练不稳定且计算昂贵——需在整条轨迹上反向传播梯度。能否找到更稳定高效的对齐方案?
前序工作及局限:
与前序工作的本质区别: Adjoint Matching 将对齐重构为最优控制+截断伴随方案,节省 50-70% 计算且更稳定
Adjoint Matching 从最优控制理论出发:(1) 将偏好对齐视为确定性最优控制——速度场修正量为控制变量,终端奖励为目标;(2) 确定性伴随匹配直接回归 value-gradient 目标,无需全轨迹反传;(3) 截断伴随方案仅计算末端 30-50% 轨迹节省 50-70% 计算;(4) 泛化至 f-divergence 正则族。
[{'point': '适用范围受限', 'detail': '仅适用于确定性 ODE flow 模型,不适配 SDE 扩散或 AR 模型'}, {'point': '缺乏视频实验', 'detail': '仅在图像模型验证,视频 flow 模型适配效果未知'}, {'point': '奖励模型瓶颈', 'detail': '仍依赖外部奖励模型质量'}]
技术演进定位: 首次从最优控制理论统一 flow model 偏好对齐
可能的后续方向:
论文: 端到端自回归图像生成:联合优化 1D 语义 Tokenizer
arXiv: 2605.00503
机构: ByteDance SEED, Caltech, Stanford University
核心问题: AR 图像生成的两阶段训练(先 tokenizer 再 AR)导致目标不对齐,限制生成质量
自回归图像生成依赖 tokenizer 将图像压缩为 token 序列。传统两阶段训练(先独立训练 tokenizer 再固定训练 AR 模型)导致两者目标不对齐——tokenizer 优化重建而非下游生成质量。
前序工作及局限:
与前序工作的本质区别: E2E-1D-Tokenizer 首次端到端联合优化 + APR 损失解决 codebook 坍塌,达 FID 1.48 SOTA
本工作挑战两阶段训练范式:(1) 端到端联合优化使 AR 生成损失直接回传到 tokenizer,自动对齐两者目标;(2) APR 损失将 AR 预测解码回像素空间计算重建损失,桥接离散预测和像素质量,解决 codebook 坍塌;(3) 视觉基础模型特征辅助 1D tokenizer 语义压缩。达 ImageNet 256 FID 1.48 SOTA。
[{'point': '仅验证类条件生成', 'detail': 'text-to-image 等复杂场景效果未验证'}, {'point': '端到端训练计算开销', 'detail': '联合优化梯度链更长,训练成本增加幅度未量化'}, {'point': '1D tokenizer 分辨率瓶颈', 'detail': '序列长度随分辨率线性增长,高分辨率 AR 推理仍慢'}]
技术演进定位: 端到端训练 AR 图像生成的里程碑验证,证明联合优化显著超越两阶段
可能的后续方向:
| 论文 | 加速倍数 | 方法类型 | 是否需要训练 | 适用模型 | 开源程度 | 产业落地 |
|---|---|---|---|---|---|---|
| TurboDiffusion | 100-200x | 全栈叠加(量化+稀疏+蒸馏+W8A8) | SLA+RCM需训练 | 任意视频DiT | 完全开源 | ComfyUI集成 |
| DC-VideoGen | 14.8x | 深度压缩VAE+后训练适配 | 轻量微调(10 GPU-day) | 任意视频扩散模型 | 开源 | 单卡4K生成 |
| StreamDiffusionV2 | 58 FPS@14B | 系统级调度+流水线并行 | 无需训练 | AR视频扩散 | 完全开源(pip) | 直播/创作平台 |
| HiAR | 1.8x | 分层去噪+流水线并行 | 蒸馏训练 | AR视频扩散 | 代码开源 | 长视频生成 |
| Mamoda2.5 | 95.9x | MoE稀疏+4步蒸馏+RL | 全训练 | 专用统一模型 | 部分开源 | 字节广告场景 |
| SDVG | 1.59-2.09x | 投机解码(小模型propose+大模型verify) | 无需训练 | AR视频扩散 | 待开源 | 通用AR管线 |
| Adjoint Matching | 节省50-70%对齐计算 | 最优控制+截断伴随 | 对齐训练 | Flow模型 | 开源 | FLUX/SiT对齐 |
| E2E-1D-Tokenizer | FID 1.48(联合优化) | 端到端联合训练 | 全训练 | AR图像模型 | 代码待开源 | 高质量AR生成 |
100x+ 加速不再是幻想:注意力量化+稀疏+步数蒸馏+W8A8 四重叠加
TurboDiffusion 证明 SageAttention + Sparse-Linear Attention + RCM 步数蒸馏 + W8A8 量化四项技术正交叠加可在单卡 RTX 5090 上实现 Wan2.1-14B 的 100-200 倍加速
深度压缩 VAE 开辟后训练加速新范式
DC-VideoGen 通过 32x/64x 空间 + 4x 时间的深度压缩 VAE + AE-Adapt-V 策略,仅用 10 GPU-day 即实现 14.8x 推理加速并解锁单卡 4K 生成
实时流式生成从理论走向工程落地
StreamDiffusionV2 首次在 14B 模型上实现 58 FPS 实时生成,HiAR 解锁流水线并行推理,标志着视频生成正式进入交互式应用时代
投机解码与自蒸馏正在重塑视频生成的推理范式
SDVG 首次将 LLM 的 Speculative Decoding 迁移至连续视频空间,Mamoda2.5 联合蒸馏+RL 将 30 步压至 4 步,新范式正快速替代暴力增算力
1. 质量-速度帕累托逼近极限
100x+ 加速后微小质量损失被放大为可感知退化,维持人眼不可区分质量是核心难题
2. 技术叠加的干扰效应
量化+稀疏+蒸馏+压缩 VAE 理论正交但实际联合可能产生非线性退化,缺乏组合效应分析框架
3. 长视频/高分辨率稳健性
大多方法在短视频/低分辨率验证,4K/分钟级视频的误差累积和显存管理仍是工程挑战
4. 硬件碎片化与可及性
顶级方案依赖最新硬件(RTX5090/H100),消费级 GPU 有意义加速是产业化关键
| 问题 | 紧迫度 | 描述 |
|---|---|---|
| 是否存在统一加速理论框架 | ⭐⭐⭐ | 各加速技术各自为政,能否建立信息论/控制论框架指导最优组合? |
| 端到端训练能否根本改变加速上限 | ⭐⭐⭐ | 联合优化的中间表征是否天然适配高效推理,避免后训练压缩质量损失? |
| 投机解码在连续空间的理论最优加速比 | ⭐⭐ | SDVG 实现 2x,连续空间投机解码的理论上界是什么? |
| 实时生成的质量下界何时被商业接受 | ⭐⭐ | 1-2 步模式质量如何?产品经理能接受的最低质量下界对应何种技术配置? |
| 加速技术的泛化性 vs 模型特异性 | ⭐⭐ | TurboDiffusion 为 Wan 系列优化,能否无损迁移至其他架构? |
| MoE 路由与稀疏注意力的统一稀疏性 | ⭐⭐ | 能否设计统一稀疏策略在参数/注意力/时间步三个维度同时稀疏? |
视觉生成推理加速正从单一技术突破进入全栈正交叠加时代。TurboDiffusion 证明注意力量化+稀疏+步数蒸馏+W8A8 四重叠加可达 100-200x 加速;DC-VideoGen 开辟深度压缩 VAE 后训练新范式;StreamDiffusionV2 和 HiAR 从系统并行维度将实时生成变为现实。与此同时,SDVG 将投机解码引入连续空间,Mamoda2.5 通过 MoE+蒸馏+RL 实现工业部署级 95.9x 加速,E2E-1D-Tokenizer 则从训练范式根本重构生成效率。
未来趋势明确:加速技术的组合优化(而非单一维度极致)、训练-推理联合设计(端到端优化中间表征)、以及系统级流水线并行(跨卡/跨模块协同)将成为三大主线。实时视频生成(>30 FPS)已从学术概念变为工程可行,下一阶段的竞争焦点将转向质量-成本-延迟的帕累托最优。
人工智能炼丹君 整理 | 数据来源:arXiv 2025-09 ~ 2026-05
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描下方二维码关注


评论 (0)