
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇
今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
掩码扩散模型统一语音合成与零样本编辑——50小时微调实现2倍加速 | Unknown (TTS Research Lab) | arXiv:2603.26364
关键词: TTS, 掩码扩散, 零样本编辑, 并行生成, 语音合成
核心问题: 自回归TTS推理速度受限于逐token生成,且不支持灵活的语音编辑
基于大语言模型的文本转语音(TTS)系统通过自回归(AR)解码实现了出色的自然度,但生成N个语音token需要N个顺序步骤,推理延迟与序列长度线性相关,严重限制了实时应用。AR解码的顺序依赖性是TTS系统部署的核心瓶颈。同时,现有TTS系统缺乏零样本语音编辑能力——无法对已生成的语音进行词级别的插入、删除和替换操作。这两个问题根源在于AR架构的单向注意力机制限制。
前序工作及局限:
与前序工作的本质区别: LLaDA-TTS发现AR与掩码扩散仅是注意力掩码的差异,提出从AR预训练权重直接迁移到MDM的理论框架,仅需50小时微调即可获得2倍推理加速和零样本编辑能力
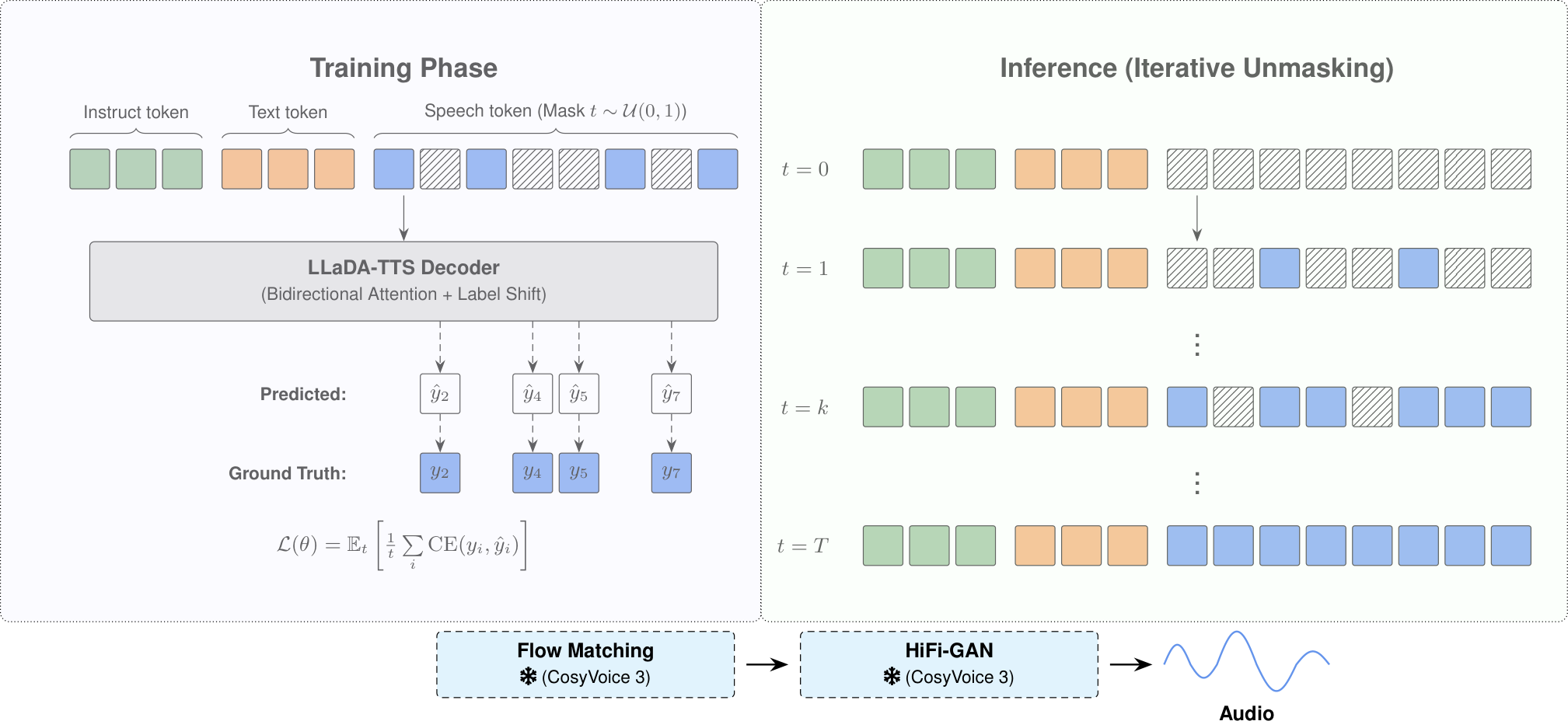
LLaDA-TTS将AR LLM中的自回归解码替换为掩码扩散模型(Masked Diffusion Model),在固定数量的并行步骤中完成生成,从而将推理延迟与序列长度解耦。核心创新点:(1) 仅使用50小时微调数据,通过双向注意力(bidirectional attention)将预训练的AR检查点迁移到掩码扩散范式;(2) 双向架构天然支持零样本语音编辑——包括词级插入、删除和替换,无需额外训练;(3) 该方法仅修改注意力掩码和训练目标,可无缝应用于任何基于LLM的AR TTS系统。理论上证明了AR预训练权重在声学token的局部性属性下,对双向掩码预测是接近最优的,解释了快速收敛。
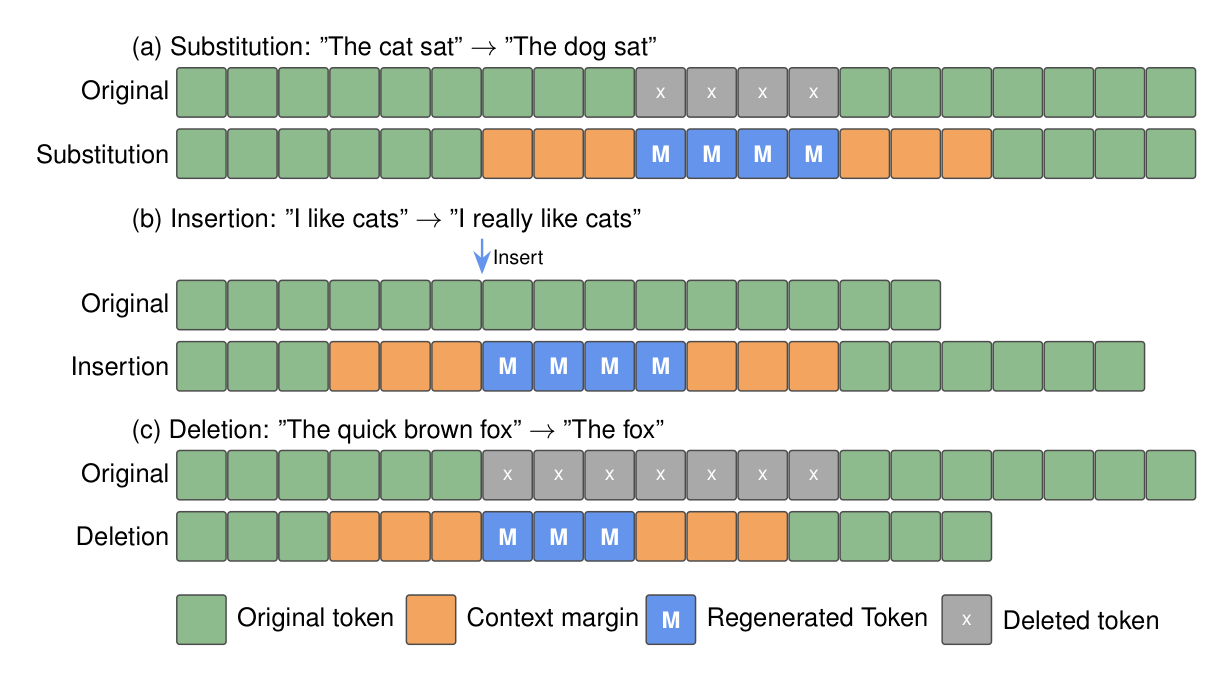
零样本语音编辑示意
LLaDA-TTS的零样本语音编辑能力示意:双向注意力架构天然支持在给定上下文中进行掩码区域的重新生成。通过在目标位置设置掩码,模型可以利用前后双向上下文信息生成新的语音token,从而实现词级别的插入(在指定位置插入新词)、删除(掩码后重新生成跳过目标词)和替换(掩码目标词后用新词重新生成)。
实验结果对比
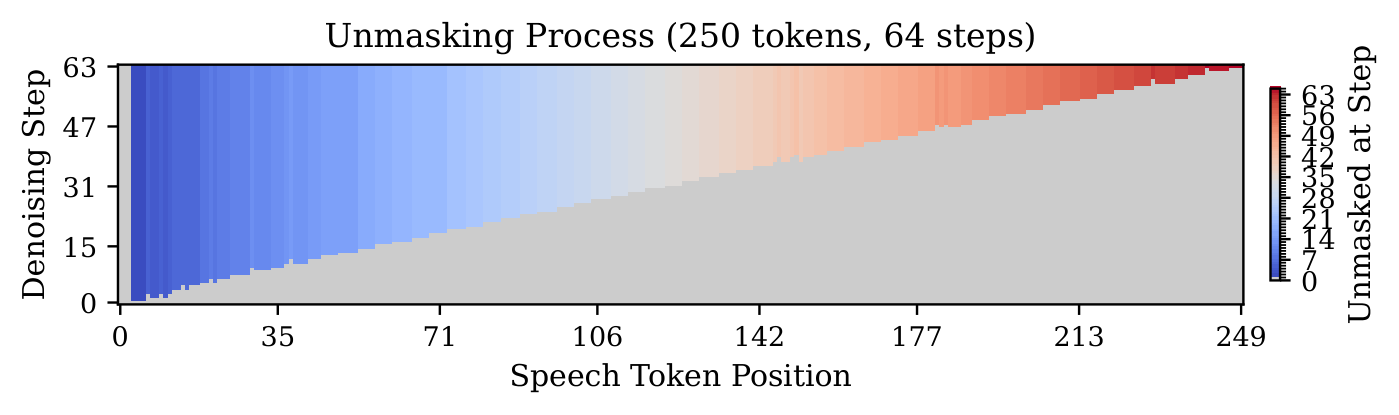
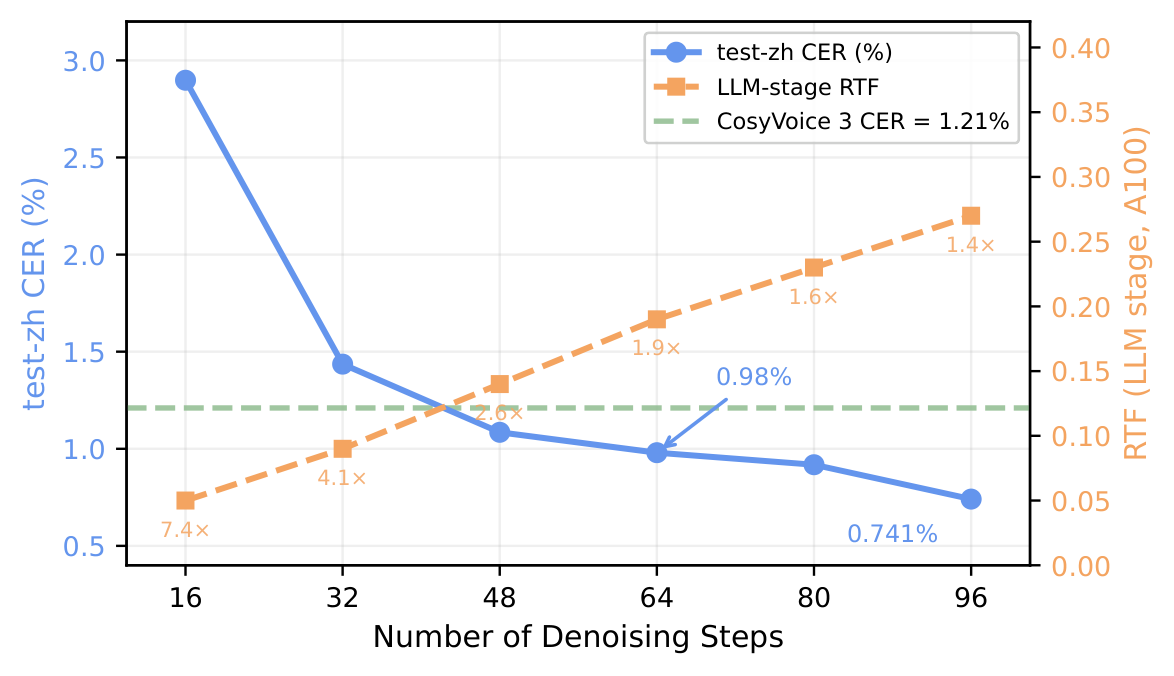
在Seed-TTS-Eval基准上的性能对比。LLaDA-TTS在64步生成时达到中文CER 0.98%和英文WER 1.96%,与原始CosyVoice 3 AR基线持平。但在LLM阶段实现了显著的2倍加速——这是在没有KV缓存(AR系统严重依赖的优化)的情况下取得的。同时展示了不同步数下的质量-速度权衡曲线。
深度点评:
技术演进定位: 处于AR TTS向并行生成范式过渡的关键节点——既保留了AR预训练的质量优势,又获得了扩散模型的并行性和可编辑性
可能的后续方向:
| # | 论文 | 机构 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|---|
| 1 | ShotStream (ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling) | Unknown | 流式视频生成·多镜头叙事·因果架构·蒸馏·实时 | 首个流式多镜头视频生成框架,通过因果架构实现交互式叙事。双缓存记忆(全局+局部)保持跨镜头一致性,两阶段蒸馏消除误差累积。 | 单GPU 16 FPS生成,亚秒延迟,质量匹配或超越更慢的双向模型。HF 110赞。 |
| 2 | PackForcing (PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference) | Shanda AI Research Tokyo | 长视频生成·KV缓存压缩·时间外推·自回归扩散·32倍压缩 | 提出三分区KV缓存策略(Sink/Mid/Recent tokens)实现分层上下文压缩,仅4GB有界KV缓存即可生成2分钟长视频。Mid tokens通过双分支网络实现32倍token压缩。 | 单H200 GPU生成2分钟832x480@16FPS视频,24倍时间外推(5s→120s)。VBench时间一致性26.07,动态度56.25,均为SOTA。 |
| 3 | DiReCT (DiReCT: Disentangled Regularization of Contrastive Trajectories for Physics-Refined Video Generation) | Ohio State University | 物理视频生成·对比流匹配·语义解纠缠·物理常识·后训练 | 揭示了对比流匹配中的语义-物理纠缠问题,提出宏观+微观双尺度对比正则化,LLM扰动构建物理困难负样本(运动学、力、材料、交互)。 | 应用于Wan 2.1-1.3B,VideoPhy物理常识得分比基线提高16.7%,比SFT提高11.3%,无额外训练时间。 |
| 4 | HyDRA (Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models) | HUST, Kuaishou | 视频世界模型·混合记忆·动态物体跟踪·视野外连续性·数据集 | 提出混合记忆范式,要求视频世界模型同时作为静态背景档案员和动态物体跟踪器。构建HM-World数据集(59K片段,17场景49主体),提出HyDRA时空相关检索架构。 | 动态物体一致性和整体生成质量显著优于SOTA。HF 133赞(当日最高)。 |
| 5 | ViGoR-Bench (ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners?) | Tsinghua University, Meituan | 生成评测·推理基准·跨模态·细粒度诊断·性能幻象 | 提出ViGoR统一评测框架,通过四大创新(跨模态覆盖、双轨评估、证据驱动自动评判、细粒度诊断)系统揭示生成模型的推理缺陷。 | 评测20+领先模型,发现即使SOTA系统仍存在显著推理缺陷。首次建立生成模型推理能力的系统性压力测试。 |
| 6 | Identity Collapse (When Identities Collapse: A Stress-Test Benchmark for Multi-Subject Personalization) | Unknown | 多主体个性化·身份崩溃·压力测试·SCR指标·CVPR 2026 | 揭示多主体个性化的可扩展性幻觉:模型在2-4主体时表现良好但6-10主体时灾难性崩溃。构建75提示压力测试基准,提出SCR(主体崩溃率)新指标。 | MOSAIC/XVerse/PSR等SOTA模型在10主体时SCR接近100%。CVPR 2026 Workshop。 |
| 7 | NLCE (Neighbor-Aware Localized Concept Erasure in Text-to-Image Diffusion Models) | Unknown | 概念擦除·免训练·邻近感知·扩散模型安全·CVPR 2026 | 提出邻近感知局部概念擦除(NLCE)三阶段免训练框架:频谱加权嵌入调制→注意力引导空间门控→空间门控硬擦除,在移除目标概念时保护邻近概念。 | 在Oxford Flowers/Stanford Dogs上擦除目标概念的同时更好保留相关类别。CVPR 2026。 |
| 8 | TaxaAdapter (TaxaAdapter: Vision Taxonomy Models are Key to Fine-grained Image Generation over the Tree of Life) | Ohio State University, MIT | 细粒度生成·视觉分类·BioCLIP·物种保真·适配器 | 将视觉分类模型(BioCLIP)嵌入注入冻结的T2I扩散模型,在保持姿势/风格文本控制的同时提升物种级保真度。引入MLLM-based形态一致性指标。 | 形态保真度和物种身份准确性始终优于基线。少样本和零样本物种生成均有效泛化。 |
| 9 | AV-CASS (Cinematic Audio Source Separation Using Visual Cues) | KAIST | 电影音频分离·视听生成·条件流匹配·CVPR 2026·跨模态 | 首个视听电影音频源分离(AV-CASS)框架,用条件流匹配将CASS表述为条件生成建模,设计双流视觉编码器(面部+场景)增强分离质量。 | 完全合成数据训练即可泛化到真实电影内容。CVPR 2026。 |
人工智能炼丹师 整理 | 2026-03-31
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注


评论 (0)