
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇
今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
收录会议: CVPR 2026 × 3
双向 Flow Matching 统一少步图像生成与编辑 | ANU (Australian National University) | arXiv:2603.24942
关键词: Flow Matching, Few-Step, Image Editing, Bidirectional, CVPR 2026
核心问题: 扩散模型和 Flow Matching 在少步采样时编辑质量严重退化:现有少步反演方法依赖预训练辅助模块,跨架构泛化能力差。如何在单一模型中实现少步高质量的生成与编辑?
扩散模型和 Flow Matching 在图像生成和编辑中表现出色,但少步采样时编辑质量严重下降。现有少步反演方法依赖预训练生成器和辅助模块,限制了跨架构的可扩展性。BiFM 提出在单一模型内联合学习正向(图像到噪声)和反向(噪声到图像)两个方向的流匹配,实现统一的少步生成与编辑。
前序工作及局限:
与前序工作的本质区别: BiFM 在单一模型中同时学习正向和反向的平均速度场,引入连续时间间隔监督和双向一致性目标,实现了架构无关的少步生成-编辑统一框架
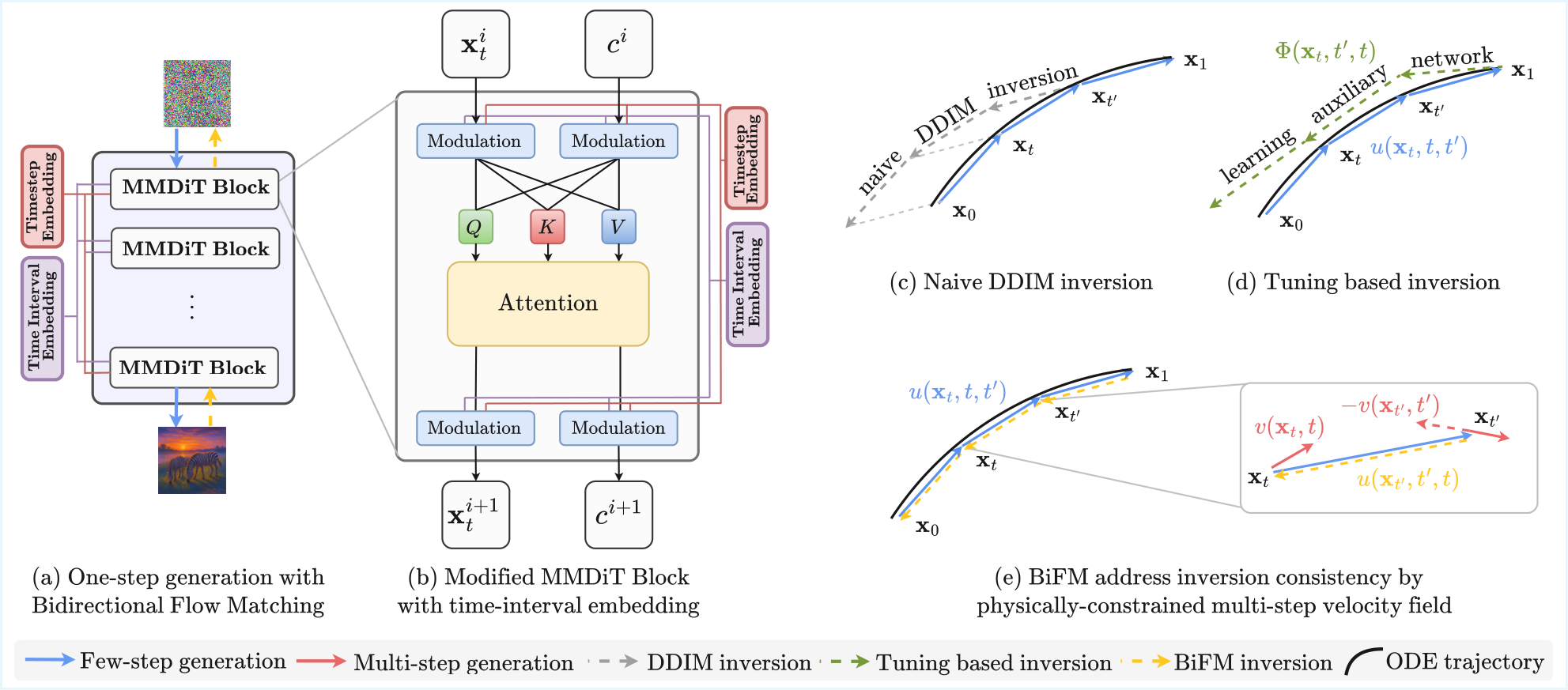
BiFM 的核心思想是在单一模型中同时估计图像到噪声和噪声到图像两个方向的平均速度场。具体而言:(1) 双向速度场估计:模型直接学习 x->noise 和 noise->x 两个方向的平均速度场,受共享瞬时速度场约束;(2) 连续时间间隔监督:引入新的训练策略,使用连续时间间隔进行监督,而非传统的离散时间步;(3) 双向一致性目标:通过双向一致性损失和轻量级时间间隔嵌入来稳定训练;(4) 单步反演能力:双向公式天然支持单步图像反演,无需额外的编码器或辅助网络;(5) 架构无关:可无缝集成到主流扩散和 Flow Matching 骨干网络中。

深度点评:
技术演进定位: 确立了双向 Flow Matching 作为统一少步生成与编辑的标准范式。启示:生成和反演不是两个独立任务,可以在共享模型中互相增强。
可能的后续方向:
| # | 论文 | 机构 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|---|
| 1 | Wan-Weaver (Wan-Weaver: Interleaved Multi-modal Generation via Decoupled Training) | 交错生成·解耦训练·多模态·长程一致性·CVPR 2026 | 解耦训练框架实现交错多模态生成,无需真实交错数据即可生成长程一致的图文交错内容 | CVPR 2026,优于现有方法。规划器生成文本描述,可视化器合成一致图像 | |
| 2 | PackForcing (PackForcing: Short Video Training Suffices for Long Video Sampling) | 长视频生成·KV-cache压缩·时间外推·自回归扩散·24倍 | 三分区 KV-cache 策略实现 24 倍时间外推,仅用 5 秒训练片段生成 2 分钟连贯视频 | VBench SOTA,4GB 有界 KV 缓存,单 H200 GPU 生成 832x480@16FPS 长视频 | |
| 3 | Voxtral TTS (Voxtral TTS: Expressive Multilingual Text-to-Speech by Mistral) | TTS·多语言·Flow Matching·语音克隆·Mistral | 混合架构结合自回归语义 Token 生成与 Flow Matching 声学解码,仅需 3 秒参考音频 | 人类评估胜率 68.4% 超 ElevenLabs Flash v2.5,CC BY-NC 开源 | |
| 4 | TRACE (TRACE: Object Motion Editing in Videos with First-Frame Trajectory Guidance) | 视频编辑·运动路径·轨迹引导·物体中心·两阶段 | 用户在首帧设计轨迹即可编辑视频物体运动路径,跨视图运动变换处理相机运动 | 在多样化真实视频上生成更连贯、逼真、可控的运动编辑效果 | |
| 5 | xLARD (Self-Corrected Image Generation with Explainable Latent Rewards) | 自纠正·潜在奖励·MLLM·语义对齐·CVPR 2026 | MLLM 驱动的自纠正生成框架,通过可解释潜在奖励信号实现生成时自我评估和修正 | CVPR 2026,在语义对齐和视觉保真度上显著提升,保持生成先验 | |
| 6 | DCARL (DCARL: A Divide-and-Conquer Framework for Autoregressive Long-Trajectory Video Generation) | 长视频·分治·关键帧·自回归·32秒 | 分治自回归框架结合关键帧生成器和插值生成器,有效解决长视频视觉漂移问题 | 32 秒高保真长视频生成,FID/FVD/相机跟随性均优于 SOTA 基线 | |
| 7 | AVControl (AVControl: Efficient Framework for Training Audio-Visual Controls) | 音视频控制·LoRA·LTX-2·模块化·并行画布 | 基于 LTX-2 联合模型的模块化音视频控制,每个模态作为独立 LoRA 并行训练 | VACE 基准 SOTA,首个模块化联合音视频控制,训练步骤仅需数百到数千步 | |
| 8 | CIAR (CIAR: Interval-based Collaborative Decoding for Image Generation Acceleration) | 加速·协作解码·概率区间·自回归·云端协同 | 云端协作框架通过 Token 不确定性量化和概率区间实现自回归图像生成加速 | 2.18 倍加速,减少 70% 云请求,保持图像质量和语义一致性 | |
| 9 | Z-Erase (Z-Erase: Enabling Concept Erasure in Single-Stream Diffusion Transformers) | 概念擦除·单流DiT·安全性·扩散Transformer·Z-Image | 首个针对单流扩散 Transformer 的概念擦除方法,解决生成模型安全性问题 | 有效移除不需要的生成概念,同时保持对其他概念的生成质量 |
人工智能炼丹师 整理 | 2026-03-30



评论 (0)