
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇
今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。
方向分布:
含2篇CVPR 2026 (HetCache, HAM)
用视频扩散先验解锁32K超高分辨率图像生成 | Harbin Institute of Technology, Li Auto | arXiv:2603.24270
关键词: 32K图像生成, 视频扩散先验, 极端纵横比, 超分辨率
当前扩散模型在生成常规尺寸图像时表现出色,但在极端纵横比(如8:1)的超高分辨率图像合成中,往往出现灾难性的结构失败——物体重复和空间碎片化。这根本原因在于静态文生图模型缺乏鲁棒的空间先验。ScrollScape 提出了一个全新范式:将超大画布的空间扩展映射到视频帧的时序演变,利用视频模型的时序一致性作为强大的全局约束。

ScrollScape 框架包含三个核心创新:
1)扫描位置编码(ScanPE):将全局空间坐标分布到各帧,充当灵活的移动相机,支持线性和蛇形扫描模式
2)滚动超分辨率(ScrollSR):在潜在空间利用视频超分辨率扩散先验逐帧增强细节,绕过内存瓶颈
3)轨迹锚定分区(TAP):确保3D VAE解码器的解码状态与坐标系统对齐,消除帧间闪烁和边界伪影
4)中值共识选择(MCS)+加权融合:从每个时间块选择最具代表性的帧,通过距离权重融合生成无缝全景图

Fig.1 ScrollScape 32K生成效果展示

这是论文的标题图(Teaser),展示了ScrollScape在极端纵横比下的32K超高分辨率生成效果。
关键观察点:
• 顶部:传统中国山水卷轴画风格的32K全景,展现了连绵山脉、水墨渲染和精细植被纹理
• 底部:照片级真实感的自然风光全景
• 放大区域(红色方框):展示了局部细节的清晰度,即使在32K分辨率下依然保持锐利
核心证据:画面中没有出现物体重复现象,每个元素都是独一无二的,同时整体保持了连贯的景深和光影效果。这直观证明了ScrollScape解决了现有方法的两大痛点——物体重复和空间碎片化。
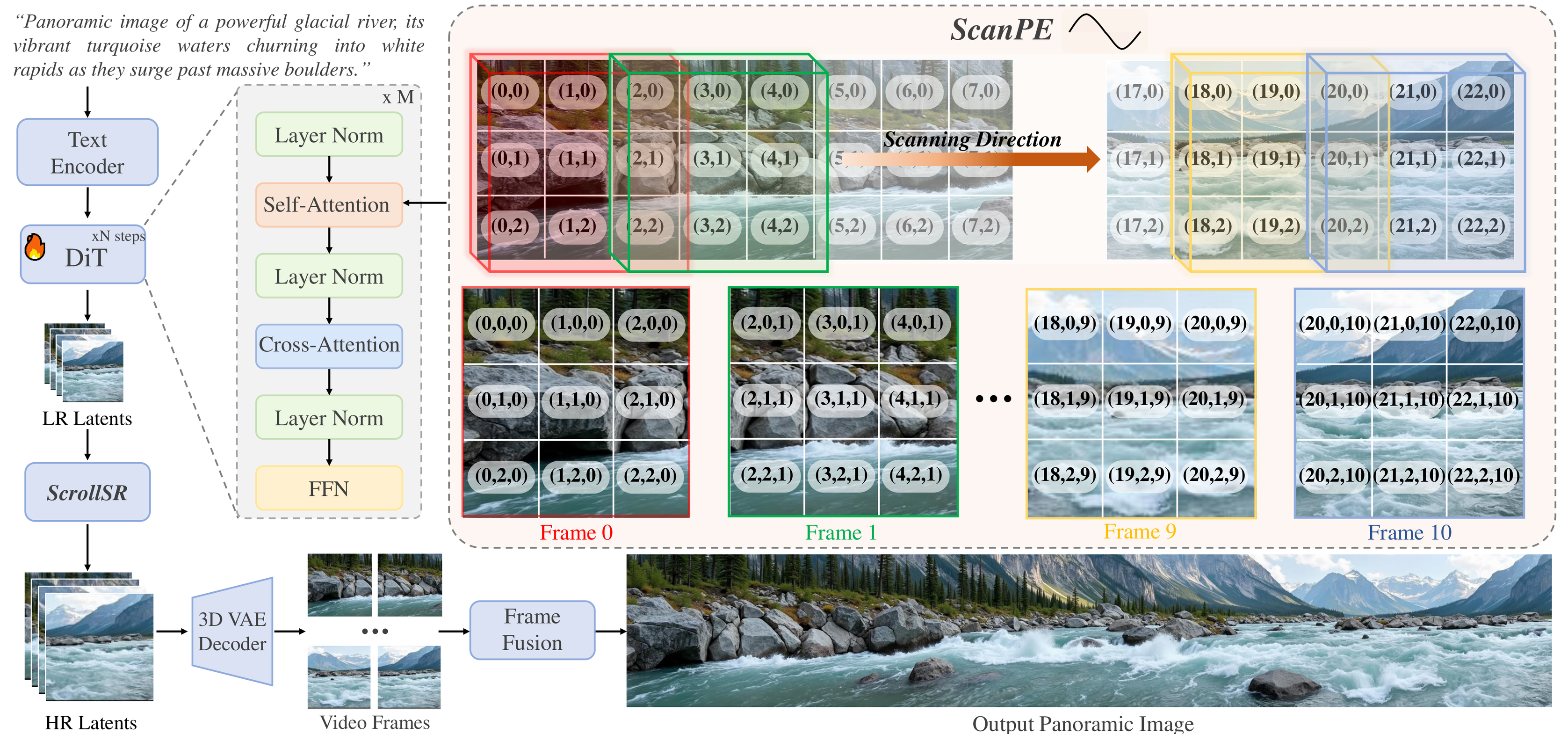
Fig.2 方法框架总览图 (Pipeline Overview)
这是ScrollScape的核心方法框架图,展示了从文本到32K图像的完整流程。
流程从左到右分为四个阶段:
Fig.3-4 定性对比:水平/垂直全景生成

左侧为水平8:1全景对比,右侧为垂直1:8全景对比。
基线方法的典型问题:
• FLUX-Krea:出现明显的语义重复——相同的建筑结构在不同位置反复出现
• MultiDiffusion:重叠区域出现可见的接缝和风格不一致
• DyPE:极端比例下结构崩溃,画面碎片化
ScrollScape的优势:
• 严格的结构连贯性:从画面一端到另一端保持统一的透视和布局
• 丰富的内容多样性:每个区域都有独特的细节,没有重复模式
• 水平和垂直两个方向都表现优越
Fig.5 8K高保真生成效果
展示了ScrollScape在8K分辨率下的高保真生成能力,覆盖多种主题。
关键细节:
• 甲虫外壳:精细的金属光泽纹理和微观结构清晰可见
• 冰晶结构:透明材质的折射和反射效果逼真
• 广阔景观:从前景植被到远景山脉的多层景深自然过渡
放大的补丁区域(zoom-in boxes)证明了即使在8K分辨率下,ScrollScape仍能保持微观纹理的清晰度和宏观构图的合理性。
Fig.6 ScanPE 消融实验定性对比

这是最重要的消融实验可视化,直观展示了每个组件的贡献。
四组对比:
(a) 原始Wan2.1:严重的内容重复,每个段落几乎是前一段的复制。GSD-DINOv2高达0.975证实重复
(b) +ScanPE但未训练:成功打破了重复模式(证明ScanPE本身的坐标约束有效),但纹理变得混乱
(c) 去掉TAP对齐:出现明显的模糊和结构崩溃,证明解码器状态对齐至关重要
(d) 完整ScrollScape:产生无缝且细节丰富的全景图
关键结论:ScanPE和TAP缺一不可。ScanPE负责全局坐标一致,TAP负责解码器状态对齐。
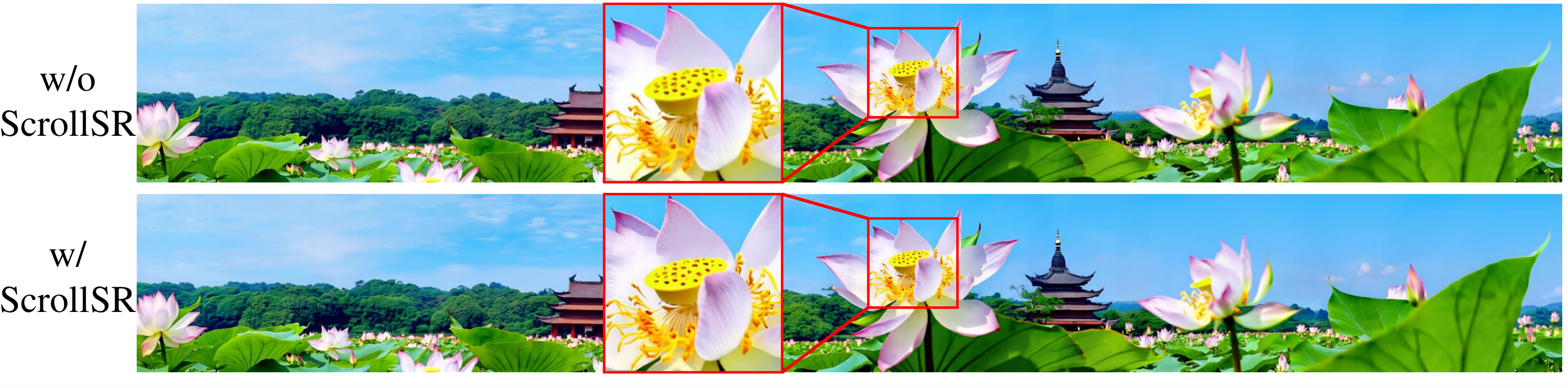
Fig.7 ScrollSR 超分模块消融对比

对比有无ScrollSR超分模块的视觉效果差异。
上方(无ScrollSR):莲花瓣的纹理模糊,细粒度结构缺失,整体感知质量较低
下方(有ScrollSR):成功恢复了花瓣的精细纹理、叶脉结构和微观细节
放大区域清楚展示了ScrollSR带来的锐利度提升。
定量数据支持:CLIP从26.5提升到30.0,证明超分模块显著提升了视觉质量与文本匹配度。
技术细节:ScrollSR基于修改后的FlashVSR,在潜在空间操作,利用视频超分扩散先验逐帧增强,避免了像素空间的高昂内存开销。
核心问题: 极端纵横比下的超高分辨率图像生成面临物体重复和空间碎片化问题
前序工作及局限:
与前序工作的本质区别: ScrollScape首次将空间扩展问题转化为视频时序问题,利用视频模型天然的时序一致性替代人工设计的空间融合策略
技术演进定位: 处于图像生成与视频生成的交叉点,开创了用视频先验赋能图像合成的新范式
可能的后续方向:
将32K图像生成重新表述为视频扫描是极具想象力的创新。ScanPE用移动相机隐喻优雅解决了全局坐标一致性问题。
仅3000张训练数据且集中在风景/山水画。人物、城市等复杂场景能力未验证。8:1评估协议的合理性值得讨论。
2×A100训练+单卡推理32K。训练数据仅3K张,极低门槛适合学术实验室和创业团队。
| # | 论文 | 机构 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|---|
| 1 | OmniWeaving (OmniWeaving: Towards Unified Video Generation with Free-form Composition and Reasoning) | Zhejiang University, Tencent Hunyuan, NTU | 统一视频生成·推理增强·MLLM·腾讯混元 | 提出统一视频生成模型OmniWeaving,采用MLLM+MMDiT+VAE架构,通过激活思维模式实现推理增强视频生成,并引入IntelligentVBench评测基准。在开源统一模型中达到SOTA。 | 在IntelligentVBench上,开启思维模式的OmniWeaving在Implicit I2V和Compositional MI2V指标上分别达到3.93和4.31(AVG),显著超越VACE-LTX和VINO等基线。 |
| 2 | HetCache (Accelerating Diffusion-based Video Editing via Heterogeneous Caching (CVPR 2026)) | NTU, SJTU, PolyU HK | 视频编辑加速·异构缓存·DiT·CVPR2026 | 提出免训练扩散加速框架HetCache,通过将DiT中的时空Token分为上下文Token和生成Token并选择性缓存,实现了2.67倍延迟加速和FLOPs削减。 | 实现2.67x延迟加速和FLOPs削减,编辑质量几乎无损。已被CVPR 2026接收。 |
| 3 | HAM (HAM: A Training-Free Style Transfer Approach via Heterogeneous Attention Modulation (CVPR 2026)) | Hangzhou Dianzi University | 风格迁移·注意力调制·免训练·CVPR2026 | 提出免训练风格迁移方法HAM,通过全局注意力调节(GAR)和局部注意力移植(LAT)两种异构注意力调制策略,解决扩散模型风格迁移中的风格-内容平衡难题。 | 在多项定量指标上达到SOTA性能,成功在保持内容身份的同时捕获复杂风格参考。已被CVPR 2026接收。 |
| 4 | DepthArb (DepthArb: Training-Free Depth-Arbitrated Generation for Occlusion-Robust Image Synthesis) | Xi'an Jiaotong University | 遮挡生成·深度仲裁·免训练·组合生成 | 提出免训练框架DepthArb,通过注意力仲裁调制(AAM)和空间紧凑性控制(SCC)两种机制解决文生图模型的遮挡关系歧义问题,并引入OcclBench评测基准。 | 在遮挡准确性和视觉保真度上一致超越SOTA基线,作为即插即用方法可无缝增强扩散模型的组合能力。 |
| 5 | GenMask (GenMask: Adapting DiT for Segmentation via Direct Mask Generation) | Shanghai Jiao Tong University, Alibaba | DiT分割·生成式分割·掩码生成·统一架构 | 提出GenMask,首次让DiT直接在RGB空间生成黑白分割掩码和彩色图像,发现VAE对二值掩码的潜在表示具有独特的噪声鲁棒性和线性可分特征,设计了针对性的时间步采样策略。 | 在referring和reasoning分割基准上达到SOTA性能,完全保持DiT原始架构不变。 |
| 6 | Anti-I2V (Anti-I2V: Safeguarding your photos from malicious image-to-video generation) | VinAI Research | 对抗防御·图转视频·安全保护·DiT防御 | 提出Anti-I2V防御框架,在LAB和频域空间操作对抗噪声,保护照片免受恶意图像转视频模型的滥用,首次系统性针对DiT架构的视频扩散模型进行防御。 | 在多种视频扩散模型上展现SOTA防御效果,有效降低生成视频的时序一致性和保真度。 |
| 7 | HAVIC (Leave No Stone Unturned: Uncovering Holistic Audio-Visual Intrinsic Coherence for Deepfake Detection) | Harbin Institute of Technology | 深伪检测·音视频一致性·跨模态·数据集 | 提出HAVIC深度伪造检测器,基于音视频固有一致性先验(模态内结构一致性+跨模态微观/宏观一致性),并发布HiFi-AVDF高保真音视频深度伪造数据集。 | 在最具挑战的跨数据集场景中,AP和AUC分别提升9.39%和9.37%,显著超越现有SOTA方法。 |
| 8 | ArrayDPS-Refine (ArrayDPS-Refine: Generative Refinement of Discriminative Multi-Channel Speech Enhancement) | Meta Reality Labs | 语音增强·扩散先验·多通道·免训练 | 提出ArrayDPS-Refine,利用干净语音扩散先验来精炼判别式多通道语音增强模型的输出。无需重训练,阵列无关,可直接提升任意判别式模型的性能。 | 一致性提升多种判别式模型(含波形域和STFT域SOTA模型)的语音增强性能。 |
| 9 | ViHOI (ViHOI: Human-Object Interaction Synthesis with Visual Priors) | South China University of Technology | 人物交互·视觉先验·运动生成·VLM | 提出ViHOI框架,从2D图像中提取交互先验来增强3D人物-物体交互运动生成,利用VLM作为先验提取引擎,设计Q-Former适配器压缩高维特征为紧凑先验Token。 | 在多个基准上达到SOTA,展现优越的泛化能力(可推广到未见物体和交互类别)。 |
人工智能炼丹师 整理 | 2026-03-27


评论 (0)