
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇
今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。
方向分布:
含 2 篇 CVPR 2026 + 1 篇 ICLR 2026
首个高维离散扩散生成 | HKU + Google + ByteDance | arXiv:2603.19232
关键词: 离散扩散, 高维表示, 统一生成理解, ImageNet SOTA
离散 Token 视觉生成因能与语言模型共享统一的 Token 预测范式而备受关注,但当前方法局限于低维潜在 Token(通常 8-32 维),牺牲了对理解任务至关重要的语义丰富性。高维预训练表示(768-1024 维)理论上可弥补这一鸿沟,然而其离散化生成面临根本性挑战——维度爆炸导致码本大小和生成步数均不可控。
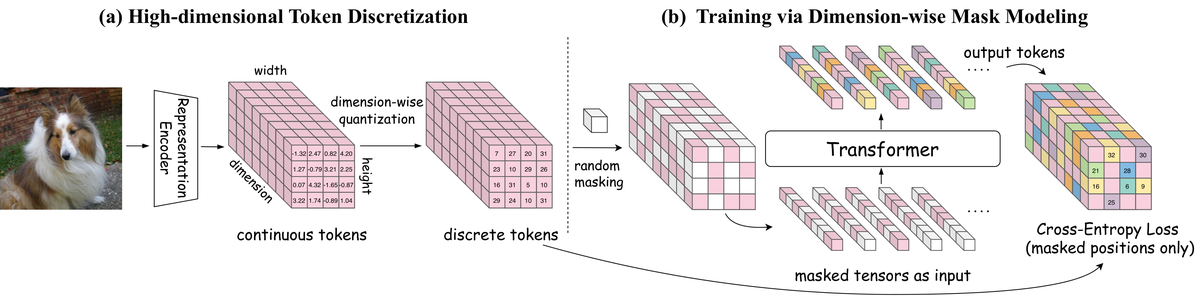
CubiD 提出在高维离散表示上进行「细粒度掩码扩散」。核心思想是:对高维离散表示的任意维度、任意位置都可以独立掩码和预测。具体包括:(1) 将预训练的 768/1024 维连续表示通过残差向量量化离散化;(2) 在扩散过程中,每个空间位置的每个维度都可被独立掩码,模型从部分观测中预测缺失维度;(3) 这使模型能学习空间位置内部和跨位置的丰富关联,且生成步数固定为 T(T 远小于 h×w×d),不随维度增长;(4) 从 900M 扩展到 3.7B 参数展现出强 Scaling 行为。
核心问题: 离散 Token 生成局限于低维(8-32维),无法利用高维预训练表示
前序工作及局限:
与前序工作的本质区别: CubiD 首次突破维度限制,在 768-1024 维上实现细粒度维度级掩码扩散,且生成步数不随维度增长
技术演进定位: 开辟了「高维离散扩散」新赛道,为 vision-language 统一架构提供了新范式
可能的后续方向:
架构无关扩散加速 | 武汉大学 | arXiv:2603.19939
关键词: 扩散加速, 块掩码, 架构无关, 特征复用
扩散概率模型在图像生成方面取得了巨大成功,但迭代去噪的特性导致推理延迟较高。现有加速方法要么需要全链反向传播(内存开销大),要么绑定特定架构。如何实现一种内存高效、架构无关的扩散加速方法是核心问题。
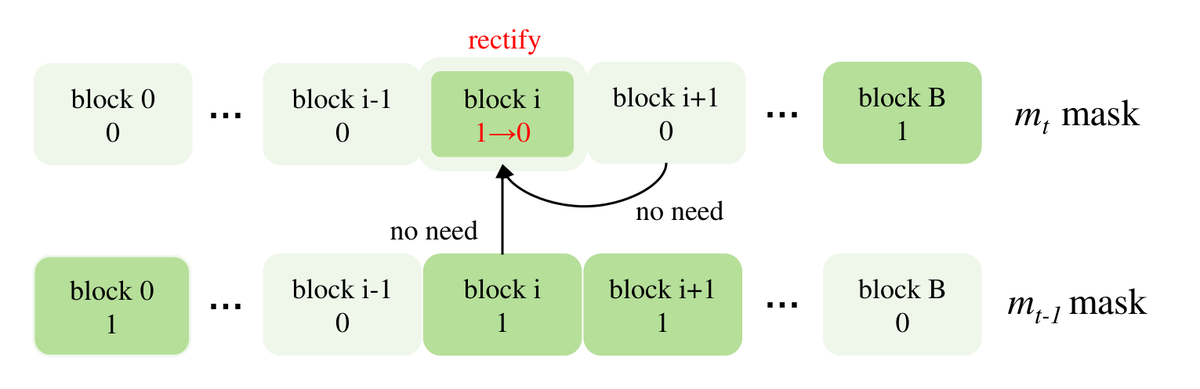
提出时间步感知块掩码(Timestep-Aware Block Masking)框架。核心思路:对预训练扩散模型的计算图进行逐时间步优化。(1) 学习时间步特异性掩码(per-timestep masks),在每个推理阶段动态决定哪些 Block 执行完整计算、哪些通过特征复用绕过;(2) 独立优化每个时间步的掩码(而非全链反向传播),确保内存高效训练;(3) 引入时间步感知损失缩放机制,在敏感的去噪阶段优先保证特征保真度;(4) 辅以知识引导的掩码修正策略,修剪冗余的时空依赖关系。
核心问题: 扩散模型推理慢,现有加速方法绑定特定架构或需高内存全链优化
前序工作及局限:
与前序工作的本质区别: Timestep-Aware Block Masking 是架构无关的:同一框架直接适用于 DDPM/LDM/DiT/PixArt,且通过逐步独立优化避免全链反向传播的内存瓶颈
技术演进定位: 在扩散加速领域建立了首个「架构无关」通用框架的先例
可能的后续方向:
细粒度 V2A 时序控制 | CVPR 2026 | arXiv:2603.19857
关键词: V2A, 时序控制, DiT音频, CVPR 2026
视频到音频(V2A)方法已能合成高质量音频,但在多事件场景或视觉线索不足时(小区域、画外音、遮挡物体),细粒度时序控制仍是难题。现有方法无法精确指定每个时间段应生成什么声音,限制了创作灵活性。
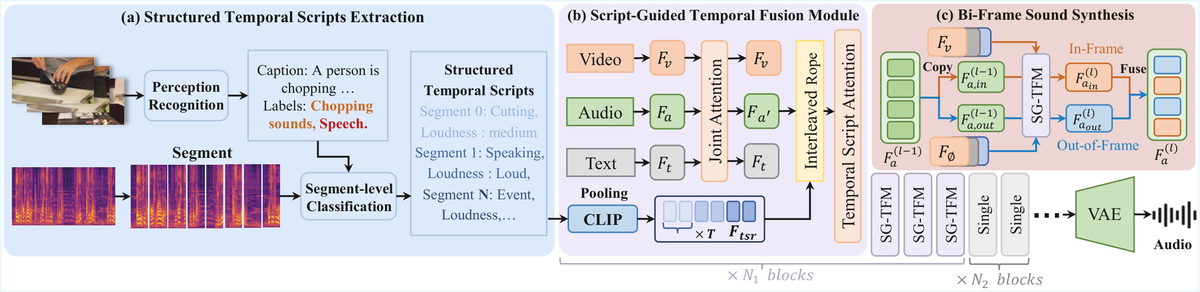
FoleyDirector 是首个在 DiT 基架构上实现精确时序引导的 V2A 生成框架。核心创新包括:(1) 结构化时序脚本(STS):将音频描述分解为对应短时间片段的字幕集合,提供丰富的时序信息;(2) 脚本引导时序融合模块:使用 Temporal Script Attention 将 STS 特征与视频特征连贯融合;(3) 双帧声音合成(Bi-Frame Sound Synthesis):并行生成画面内和画面外音频,处理复杂多事件场景;(4) 构建 DirectorSound 数据集和 DirectorBench 评测基准。
核心问题: V2A 生成缺乏细粒度时序控制,多事件场景和画外音难以处理
前序工作及局限:
与前序工作的本质区别: FoleyDirector 通过结构化时序脚本(STS)首次在 DiT 基 V2A 模型上实现时间段级精确控制,并创新性地并行生成画内和画外音频
技术演进定位: 将 V2A 从「全局条件生成」推进到「导演级时序控制」,显著拓展了实用价值
可能的后续方向:
CubiD 验证高维离散 Token 兼顾理解和生成,但 3.7B 模型的训练成本和实际 T2I 质量仍有待验证
Block Masking 覆盖四种架构值得称赞,但每种架构的最优掩码配置不同,通用性是否以牺牲极致性能为代价?
FoleyDirector 的 STS 需要手工编写结构化脚本,大规模自动化场景下的可用性值得关注
| # | 论文 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|
| 1 | LumosX (Relate Any Identities with Their Attributes for Personalized Video Generation) | 个性化视频生成 · 身份对齐 · ICLR 2026 | 提出关系自注意力和关系交叉注意力机制,在多对象个性化视频生成中实现精确的身份-属性对齐。通过 MLLM 推断对象间依赖关系,强化群组内聚性和跨对象分离。ICLR 2026。 | 在多对象个性化视频生成基准上达到 SOTA,身份一致性和语义对齐显著优于现有方法 |
| 2 | Borderless Long Speech (Borderless Long Speech Synthesis) | 长语音合成 · 多说话人 · Agentic TTS | 提出无边界长语音合成框架,支持多说话人对话(最多5人)、零样本语音克隆、长达60分钟单次合成。创新的 Global-Sentence-Token 多级标注体系和 Chain-of-Thought 推理增强复杂条件下的指令遵循。 | 支持60分钟单次合成、5人多方对话,原生 Agentic 设计实现从 Text2Speech 到无边界长语音合成的范式扩展 |
| 3 | MOSS-TTSD (Text to Spoken Dialogue Generation) | 对话合成 · 多方语音 · 复旦 | 首个面向对话场景的语音合成模型,支持多语言(中英文)、多方对话(最多5人)、零样本语音克隆。增强长上下文建模实现 60 分钟单次生成。提出 TTSD-eval 客观评测框架。复旦大学团队。 | 在对话合成的说话人归属准确率和相似度上超越开源和商业基线,支持播客、动态解说等应用场景 |
| 4 | FRAM (Diffusion-Based Makeup Transfer with Facial Region-Aware Makeup Features) | 妆容迁移 · 区域感知 · CVPR 2026 | 提出面部区域感知妆容特征(FRAM):通过 GPT-o3 合成标注数据微调妆容 CLIP 编码器,使用可学习 Token 查询区域级妆容特征。ControlNet Union 同时编码源图像及 3D 网格实现身份保持。CVPR 2026。 | 在区域可控性和妆容迁移质量上验证了显著优势,支持眼妆/唇妆等细粒度区域独立编辑 |
| 5 | I2I-RFR (Improving Image-to-Image Translation via a Rectified Flow Reformulation) | 整流流 · I2I翻译 · 即插即用 | 将标准 I2I 回归网络重新表述为连续时间传输模型:仅扩展输入通道+简单 t 重加权损失,诱导整流流解释,推理时通过 ODE 渐进细化(仅需3步)。无需蒸馏即可显著提升感知质量。 | 在多个 I2I 翻译和视频恢复任务上普遍提升性能,尤其在感知质量和细节保留方面收益明显 |
| 6 | SeGroS (Enhancing Alignment for Unified Multimodal Models via Semantically-Grounded Supervision) | 统一多模态 · 对齐增强 · 语义监督 | 解决统一多模态模型(UMM)中粒度不匹配和监督冗余问题。提出视觉定位图构建互补监督信号:语义视觉提示补偿文本稀疏性 + 语义定位的损坏输入将重建损失限制在核心文本对齐区域。 | 在 GenEval/DPGBench/CompBench 上显著提升 UMM 的生成保真度和跨模态对齐 |
| 7 | TATAR (One Model, Two Minds: Task-Conditioned Reasoning for Unified IQA and Aesthetic Assessment) | 统一IQA+IAA · 非对称奖励 · GRPO | 揭示统一 IQA 和 IAA 中的「推理不匹配」和「优化不匹配」。提出 TATAR 框架:快慢任务推理构建 + 两阶段 SFT+GRPO 学习 + 非对称奖励(IQA 高斯整形/IAA 瑟斯顿排名)。 | 8个基准上均优于统一基线,与特定任务专用模型竞争力相当,美学评估训练更稳定 |
| 8 | MME-CoF-Pro (Evaluating Reasoning Coherence in Video Generative Models) | 视频生成评测 · 推理连贯性 · Benchmark | 提出视频生成模型推理连贯性评测基准:303 样本/16 类别,从视觉逻辑到科学推理。引入「推理分数」评估中间步骤,三种设置(无提示/文本/视觉)控制研究。评测 7 个模型揭示推理连贯性与生成质量解耦。 | 发现视频生成模型推理连贯性较弱且与质量解耦;文本提示虽提高正确性但引入幻觉;视觉提示在细粒度感知上仍困难 |
| 9 | PGD-EIQA (Preference-Guided Debiasing for No-Reference Enhancement Image Quality Assessment) | 图像质量评估 · 去偏 · 偏好引导 | 通过监督对比学习构建连续增强偏好嵌入空间,估计并去除质量表示中的增强诱导干扰,使模型关注算法不变的感知质量线索。两阶段训练:偏好空间学习 → 去偏质量预测。 | 在公共 EIQA 基准上有效缓解算法诱导偏差,跨增强算法泛化能力显著优于现有方法 |
人工智能炼丹师 整理 | 2026-03-24


评论 (0)