
版权属于:
人工智能炼丹师
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇
今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。
方向分布:
共计 12 篇,重点解读 3 篇
统一 Layout-Image 生成与理解 | arXiv:2603.18001
关键词: Layout-to-Image, Image Grounding, 循环一致性, GRPO, 统一框架
Layout-to-image 生成和 Image grounding 是两个互补但传统上独立训练的任务:前者从布局生成图像,后者从图像定位物体。生成任务具有强大的视觉创造力但布局准确性有限,而 grounding 任务具有精确的文本和布局理解能力但缺乏生成能力。联合训练可以互相补偿,但现有方法在优化时面临严重的任务冲突和性能受限问题。
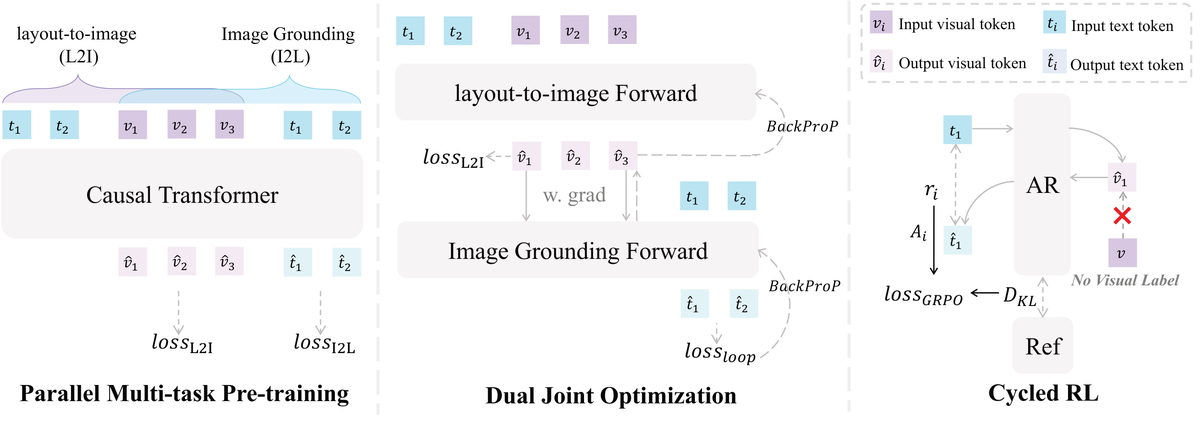
提出 EchoGen 统一框架,包含三阶段渐进式训练策略:
核心问题: Layout-to-Image 生成与 Image Grounding 互补但独立训练,联合训练面临优化冲突
前序工作及局限:
与前序工作的本质区别: 首次利用循环一致性将生成和定位构建为互补闭环,GRPO 策略消除视觉监督依赖,实现真正的双任务协同
技术演进定位: 方法论创新——循环 RL 策略为多任务生成理解统一提供了新的训练范式
可能的后续方向:
无文本反转攻击揭示概念擦除漏洞 | arXiv:2603.17828
关键词: 概念擦除, Unlearning, DDIM Inversion, 安全性, 对抗攻击
Text-to-Image 扩散模型的概念擦除(Concept Erasure)是保障模型安全部署的关键技术。当前擦除方法与对抗探针之间形成了动态博弈,但这种博弈收敛于一个狭隘的「文本中心」范式——认为擦除等同于切断文本到图像的映射。然而底层视觉知识是否真正被删除?这个根本问题从未被认真验证过。
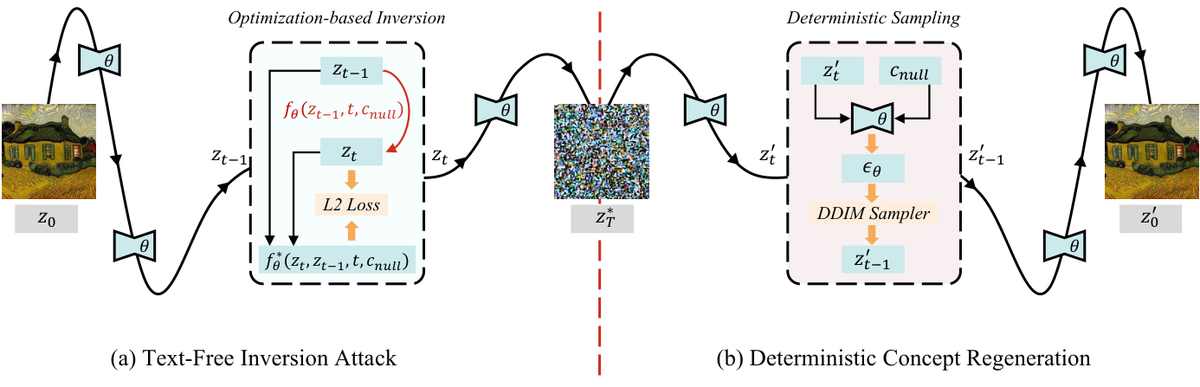
提出 TINA(Text-free INversion Attack),一种全新的无文本反转攻击方法:
核心问题: 概念擦除方法仅切断文本映射,底层视觉知识是否真正删除未被验证
前序工作及局限:
与前序工作的本质区别: 完全从视觉角度出发,null-text DDIM 反转绕过所有文本防御,首次证明视觉知识残留是普遍现象
技术演进定位: 范式挑战——揭示当前概念擦除研究的根本盲点,推动从文本中心向视觉中心的范式转移
可能的后续方向:
自回归视频生成的对比策略优化 | arXiv:2603.17461
关键词: 自回归视频生成, RLHF, GRPO, 流式生成, 偏好对齐
流式自回归(AR)视频生成器结合少步蒸馏已实现低延迟、高质量的视频合成,但通过 RLHF 进行对齐仍然困难。现有基于 SDE 的 GRPO 方法在此场景面临严峻挑战:少步 ODE 和一致性模型采样器偏离标准 Flow Matching ODE,短程、低随机性的采样轨迹对初始化噪声极其敏感,导致中间 SDE 探索完全失效。
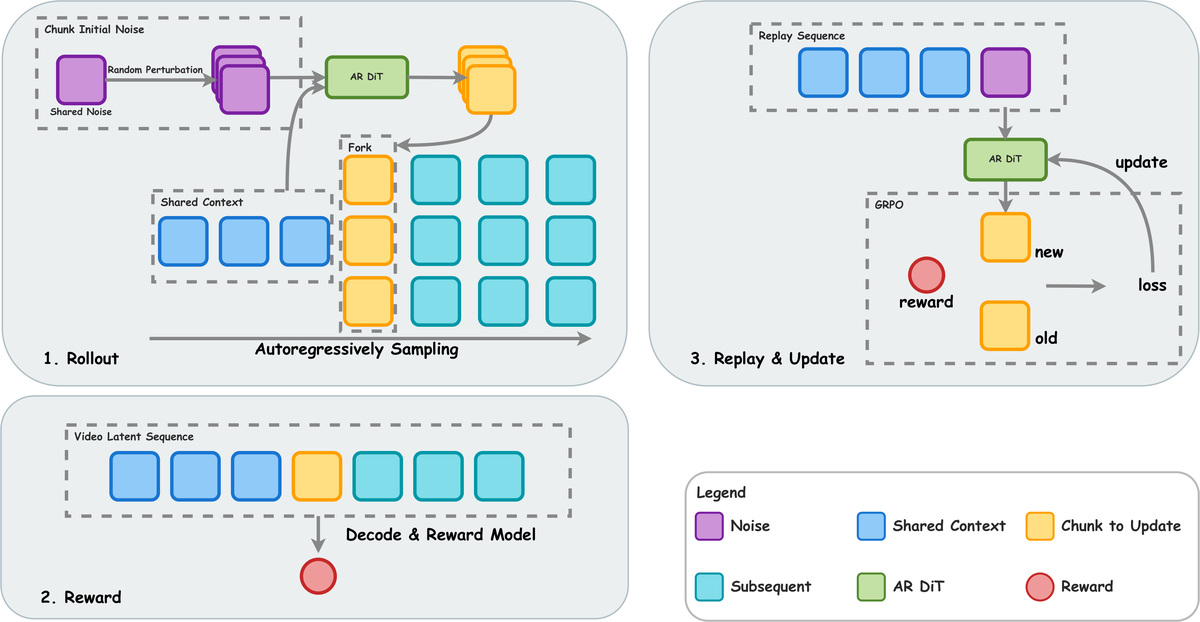
提出 AR-CoPO(AutoRegressive Contrastive Policy Optimization)框架:
核心问题: 流式 AR 视频生成的少步 ODE 采样对 RLHF 对齐极其困难
前序工作及局限:
与前序工作的本质区别: chunk-level forking 巧妙解决少步 ODE 的探索困难,半 on-policy 策略平衡效率与质量
技术演进定位: 技术突破——首次打通流式 AR 视频生成的 RLHF 对齐路径
可能的后续方向:
TINA 用 85%+ 的攻击成功率证明了当前所有 SOTA 概念擦除方法都仅仅遮蔽了文本映射而非删除视觉知识。这意味着我们对'安全部署'的理解可能需要根本性修正——仅操作文本条件路径是不够的,必须直接处理模型内部的视觉表征。这对整个生成模型安全性研究方向是一个重大挑战。
AR-CoPO 的 chunk-level forking 机制解决了一个被认为几乎不可能的问题:在少步 ODE 采样的低随机性条件下进行有效的偏好对齐。这标志着视频生成从'能生成'向'能对齐人类偏好'的重要进步。但半 on-policy 策略的微妙平衡可能在不同奖励模型下表现不一致,泛化性是关键的下一步验证。
EchoGen 用 15%/12% 的协同增益令人信服地证明了生成和理解任务之间存在真实的互补性。循环一致性作为无监督奖励信号的设计简洁而有效。这个发现可能远超 layout-image 这一个场景——视觉生成领域中还有多少任务对偶性可以被挖掘?这开辟了一个值得深入探索的新方向。
| # | 论文 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|
| 1 | STAS (Steering Video Diffusion Transformers with Massive Activations) | Video Diffusion · Massive Activations · 训练无关 · 自引导 | 发现视频扩散 Transformer 中 Massive Activations 的结构化时间层次模式,提出训练无关的 STAS 自引导方法 | 跨多个 T2V 模型一致提升视频质量和时间连贯性,额外推理开销 < 1% |
| 2 | ChopGrad (Pixel-Wise Losses for Latent Video Diffusion via Truncated Backprop) | 视频扩散 · 截断反传 · O(1)显存 · 像素级损失 | 截断反向传播实现 O(1) 常量显存训练,理论保证误差有界,支持像素级损失微调视频扩散模型 | 视频超分/修复/增强/受控生成四项任务均达 SOTA,显存不随帧数增长 |
| 3 | Motion-Adaptive (Motion-Adaptive Temporal Attention for Lightweight Video Generation with Stable Diffusion) | 轻量视频生成 · 运动自适应 · 时间注意力 · SD | 提出运动自适应时间注意力机制:高运动序列局部注意力保留快速变化细节,低运动序列全局注意力保持场景一致性 | 仅增加 2.9% (25.8M) 参数量,在 WebVid 验证集上达到竞争性结果 |
| 4 | SHIFT (SHIFT: Motion Alignment in Video Diffusion Models with Adversarial Hybrid Fine-Tuning) | 视频扩散 · 运动对齐 · 奖励微调 · RLHF | 提出像素运动奖励 + Smooth Hybrid Fine-tuning (SHIFT) 框架,解决视频扩散模型微调后运动保真度下降的问题 | 有效解决 dynamic-degree collapse,对抗性优势加速收敛并缓解 reward hacking |
| 5 | Text Embedding Interpolation (The Unreasonable Effectiveness of Text Embedding Interpolation for Continuous Image Steering) | 连续编辑 · Steering Vector · 训练无关 · 跨模态 | 训练无关框架:用 LLM 自动构建去偏对比 prompt 对,在文本嵌入空间计算 steering vector 实现连续可控编辑 | 效果可比肩训练方法,优于其他训练无关方案,支持图像和视频编辑 |
| 6 | Proxy-GRM (Rationale Matters: Learning Transferable Rubrics via Proxy-Guided Critique for VLM Reward Models) | Reward Model · VLM · 评分标准 · RLHF | 引入代理引导的评分标准验证到 RL 训练中,训练轻量代理预测偏好序,以标准质量作为奖励信号 | 仅 50K 数据即达 VL-RewardBench/MM-RLHF-Bench SOTA,优于 4 倍数据量方法 |
| 7 | UOT-Unlearn (Unlearning for One-Step Generative Models via Unbalanced Optimal Transport) | 一步生成 · 遗忘学习 · 最优传输 · 安全部署 | 首次为一步生成模型(Flow Map Models)提出遗忘学习框架,基于非平衡最优传输的即插即用方案 | CIFAR-10/ImageNet-256 上遗忘成功率 (PUL) 和保留质量 (u-FID) 均显著超越基线 |
| 8 | DynaEdit (Versatile Editing of Video Content, Actions, and Dynamics without Training) | 视频编辑 · 训练无关 · 动态编辑 · Flow Model | 训练无关视频编辑方法,基于 inversion-free 方法实现动作修改、物体插入交互、全局效果添加等复杂编辑 | 在复杂文本视频编辑任务上达到 SOTA,支持修改动作、插入交互物体和引入全局效果 |
| 9 | LaDe (LaDe: Unified Multi-Layered Graphic Media Generation and Decomposition) | 图层设计 · 多任务统一 · RGBA VAE · 图形设计 | 潜在扩散框架 + LLM prompt 扩展 + 4D RoPE + RGBA VAE,统一文本到图像、文本到图层和设计分解三个任务 | 文本到图层任务上文本-图层对齐度优于 Qwen-Image-Layered(GPT-4o mini 和 Qwen3-VL 评估) |
人工智能炼丹师 整理 | 2026-03-19
评论 (0)