
版权属于:
人工智能炼丹师
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇
今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。
方向分布:
顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇
弹性潜在接口 | Snap Research | DiT 通用加速 | arXiv:2603.12245
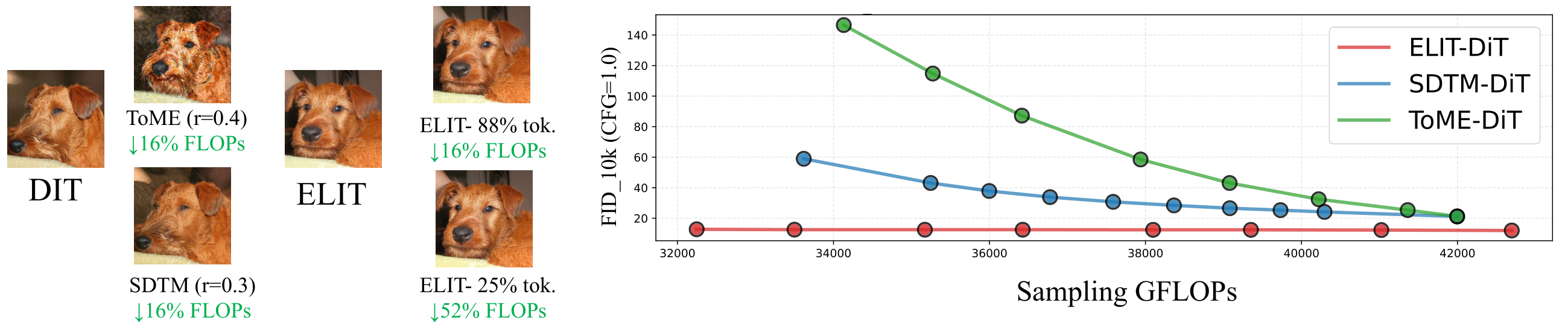
关键词: DiT 加速, 弹性推理, 跨架构通用, Snap Research
Diffusion Transformer (DiT) 的计算量与图像分辨率强绑定,无法灵活地在延迟与质量之间做权衡。更关键的是,DiT 对所有空间位置均匀分配计算资源,忽视了不同区域的重要性差异,导致大量算力浪费在低信息量区域。
提出 ELIT (Elastic Latent Interface Transformer):在 DiT 架构中插入一组可学习的、长度可变的潜在 Token 序列作为「潜在接口」。标准 Transformer 块在这组潜在 Token 上运算,而非直接处理空间 Token。通过轻量的 Read/Write 跨注意力层在空间 Token 和潜在 Token 之间传递信息,并自动优先处理重要区域。训练时随机丢弃尾部潜在 Token,迫使模型学会按重要性排序表示——前部 Token 编码全局结构,后部 Token 负责细节精修。推理时可动态调整潜在 Token 数量以匹配算力预算。
核心问题: DiT 计算量与分辨率强绑定,无法灵活权衡延迟与质量
前序工作及局限:
与前序工作的本质区别: 将空间 token 和计算完全解耦,通过可学习潜在接口实现按重要性排序的信息压缩
技术演进定位: 范式创新——从在空间 token 上省计算转变为在潜在接口上做计算
可能的后续方向:
全方位运动控制视频定制 | 潜在身份强化学习 | arXiv:2603.12257
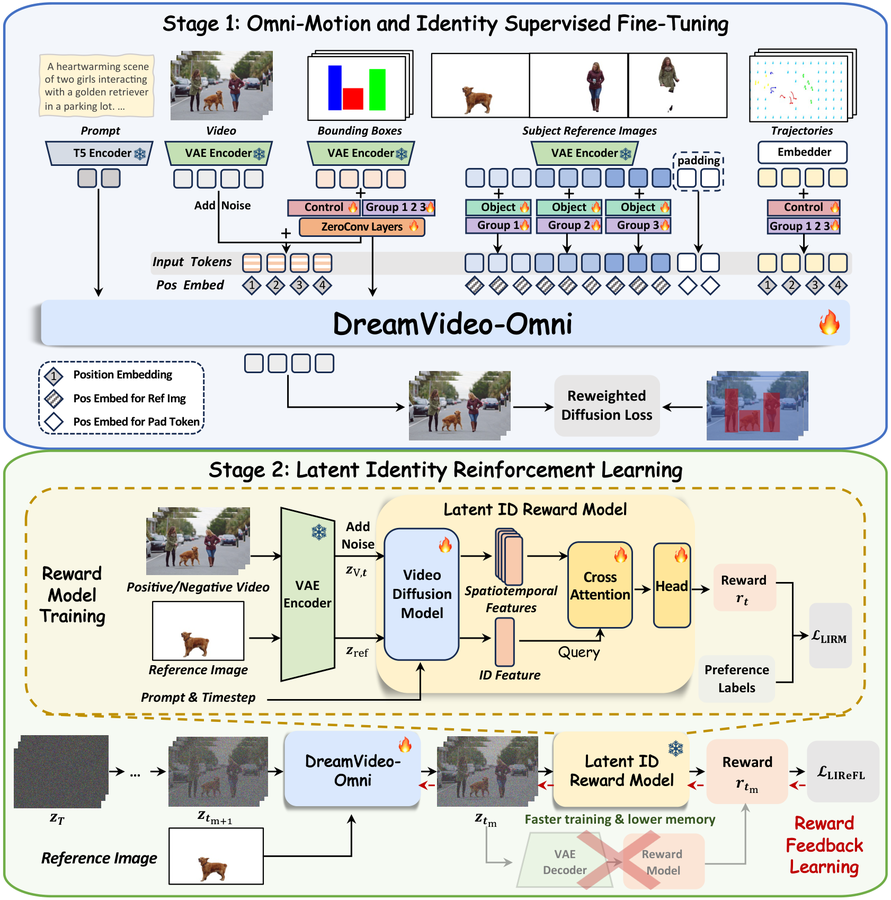
关键词: 视频定制, 多主体, 运动控制, 身份RL
大规模视频扩散模型已能生成高质量视频,但同时精确控制多个主体的身份和多粒度运动仍然是重大挑战。现有方法要么运动粒度有限、要么身份退化严重。
提出 DreamVideo-Omni 统一框架,采用渐进式两阶段训练。第一阶段:集成全面控制信号,引入条件感知 3D 旋转位置嵌入协调异构输入,分层运动注入策略增强全局运动引导,分组与角色嵌入将运动信号锚定到特定身份。第二阶段:设计潜在身份奖励反馈学习范式,在预训练视频扩散骨干上训练潜在身份奖励模型,在潜在空间提供运动感知的身份奖励。
核心问题: 多主体身份保持和多粒度运动控制难以兼顾
前序工作及局限:
与前序工作的本质区别: 统一多主体身份、全局运动、局部动态、相机控制,用潜在身份奖励 RL 解决身份退化
技术演进定位: 集大成者——统一视频定制分散的研究方向
可能的后续方向:
鲁棒奖励模型 | FIRM-Edit-370K | 全套开源 | arXiv:2603.12247

关键词: 奖励模型, 图像编辑, RLHF, Benchmark
RL 正成为提升图像编辑和 T2I 生成的主要范式,但当前奖励模型存在严重的幻觉问题,给出噪声评分从根本上误导优化方向。
提出 FIRM 框架:定制化数据策划管道构建高质量评分数据集(Edit-370K + Gen-293K),训练专业化奖励模型(Edit-8B + Gen-8B)。设计 Base-and-Bonus 奖励策略——编辑用一致性调制执行 CME,生成用质量调制对齐 QMA——平衡竞争目标。提出 FIRM-Bench 综合评测基准。
核心问题: RL 优化时奖励模型幻觉导致噪声评分误导优化
前序工作及局限:
与前序工作的本质区别: 首次为编辑和生成分别构建大规模评分数据集和专业化奖励模型
技术演进定位: 基础设施建设——为扩散模型 RL 提供可靠 Critic
可能的后续方向:
电影级多镜头视频创作 | Plan-then-Control | arXiv:2603.11421
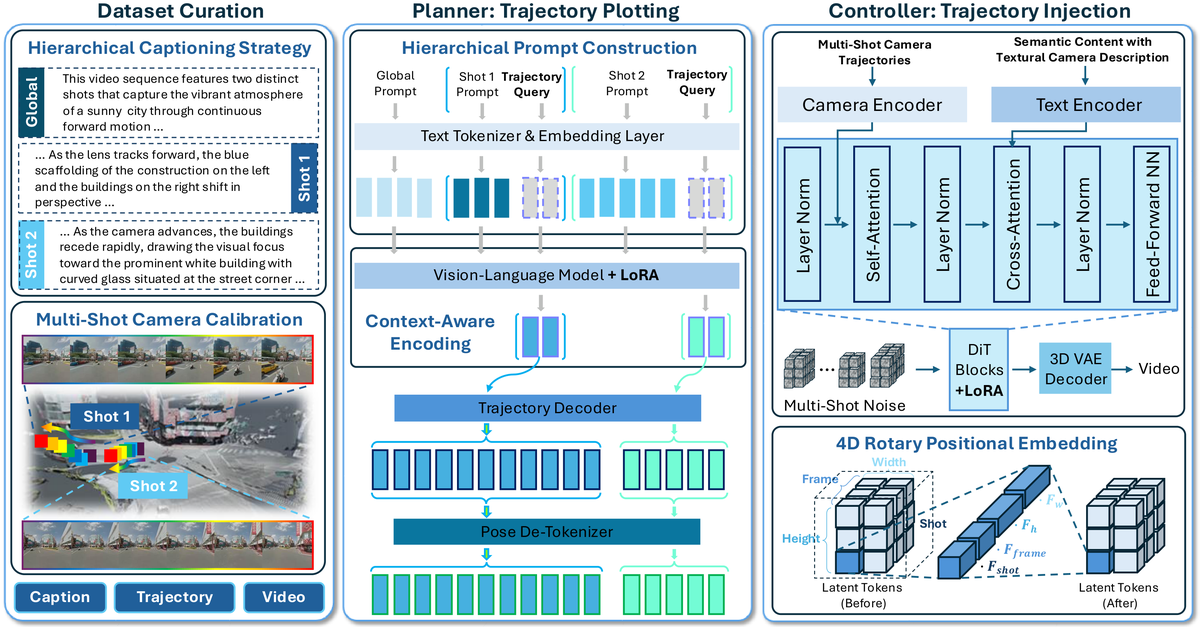
关键词: 多镜头视频, 相机控制, VLM 规划, 数据驱动
文本驱动视频生成在多镜头场景中的相机控制仍是关键瓶颈:隐式文本提示缺乏精确性,显式轨迹条件带来巨大手动开销且执行常失败。
提出以数据为核心的范式:对齐的 (Caption,Trajectory,Video) 三元组构成联合分布。构建 Plan-then-Control 框架:VLM 规划器从文本生成全局对齐轨迹,控制器通过相机适配器渲染多镜头视频。核心是自动化多镜头相机校准管线和 ShotVerse-Bench 数据集。
核心问题: 多镜头视频相机控制缺少文本自然表达和精确控制之间的桥梁
前序工作及局限:
与前序工作的本质区别: 数据驱动的联合分布学习,VLM 规划+控制器执行,实现端到端多镜头视频管线
技术演进定位: 应用创新——首次解决多镜头电影级相机控制
可能的后续方向:
扩散模型内生思维链 | MLLM+DiT 深度推理 | arXiv:2603.12252
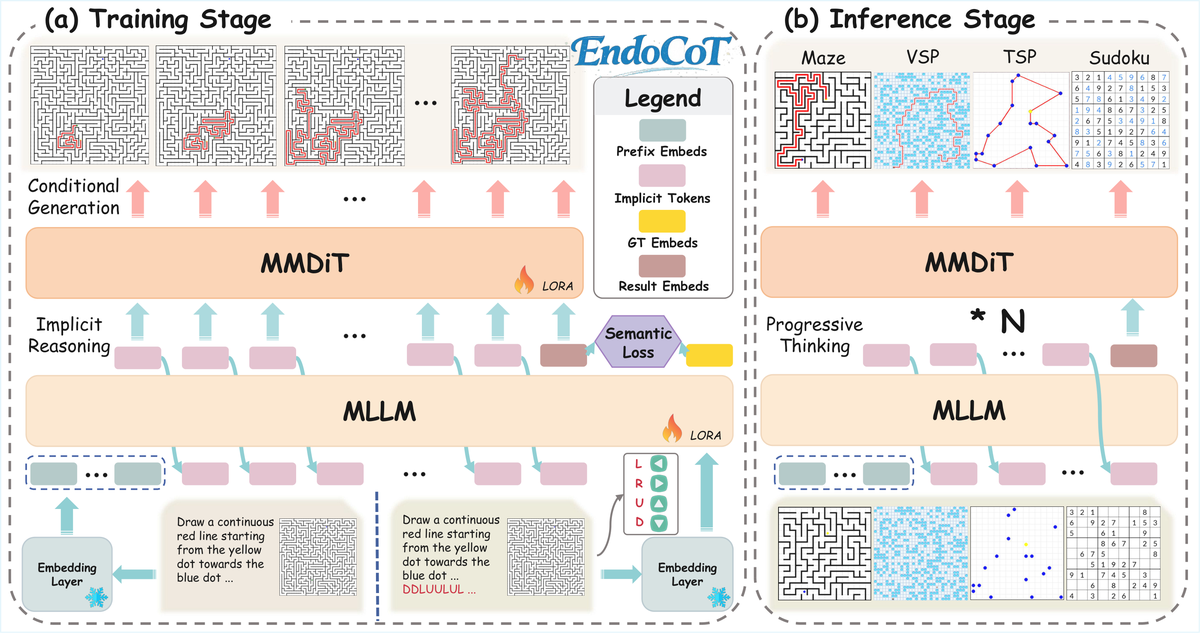
关键词: 思维链, 扩散模型, 空间推理, MLLM+DiT
MLLM 作为扩散框架的文本编码器时,单步编码无法激活思维链过程推理深度不足,且解码过程中引导固定不变。
提出 EndoCoT 框架:迭代思维引导模块在潜在空间中迭代优化思维状态,激活 MLLM 推理潜力并桥接到 DiT 去噪过程。终端思维锚定模块将最终状态与真实答案对齐,确保推理不漂移。两个组件让 MLLM 提供精心推理的引导,DiT 逐步执行复杂任务。
核心问题: MLLM 编码器单步编码推理深度不足,解码过程引导固定
前序工作及局限:
与前序工作的本质区别: 将 CoT 从外部规划内化到去噪过程中,MLLM 成为迭代推理器而非一次性编码器
技术演进定位: 范式转换——从外部推理+内部生成转为内源性推理-生成一体化
可能的后续方向:
ELIT 将 DiT 加速从 token 粒度提升到架构级别。关键问题:在 FLUX/SD3 上是否仍成立?
FIRM 66 万评分数据+全套开源,标志扩散模型从探索期进入基础设施建设期。
EndoCoT 让扩散模型拥有类似 o1 的推理能力,92.1% 证明方向可行。
| # | 论文 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|
| 1 | EVATok (Adaptive Length Video Tokenization for AR Generation) | 视频 Token . AR 生成 . CVPR 2026 | 自适应长度视频 Tokenizer,轻量路由器预测最优 Token 分配 | UCF-101 SOTA,Token 节省 24.4%+ (CVPR 2026) |
| 2 | MOG (Manifold-Optimal Guidance for Diffusion Models) | CFG 改进 . 黎曼几何 . 无训练 | 黎曼流形局部最优控制修复 CFG 离流形漂移,Auto-MOG 动态校准 | 消除 CFG 过饱和,几乎零额外开销 |
| 3 | WeEdit (Glyph-Guided Text-centric Image Editing) | 文本编辑 . 字形引导 . 多语言 | HTML 管道生成 33 万训练对(15 种语言),字形引导 SFT + 多目标 RL | 文本编辑准确率超越所有开源模型 |
| 4 | SoulX-LiveAct (Hour-Scale Real-Time Human Animation) | 实时动画 . AR 扩散 . 无限视频 | Neighbor Forcing(扩散步对齐) + ConvKV 固定内存无限视频 | 小时级 20FPS 实时(2x H100),唇形/情感 SOTA |
| 5 | PROMO (Promptable Virtual Try-On with Flow Matching DiT) | 虚拟试穿 . Flow Matching . DiT | VTON 重定义为结构化编辑,FM-DiT + 潜在多模态条件 + 自参考加速 | 保真度超所有 VTON 方法,速度质量最优 |
| 6 | CEI-3D (Collaborative Explicit-Implicit 3D Editing) | 3D 编辑 . SDF+点 . 属性解耦 | 隐式 SDF + 显式处理点协作,物理属性解耦独立控制 | 比 SOTA 更逼真精细,编辑时间更短 |
| 7 | OSCBench (Object State Change in T2V Generation) | T2V 评测 . 状态变化 . Benchmark | 首个评估 T2V 中对象状态变化的基准,组织为常规/新颖/组合场景 | 揭示当前 T2V 在状态变化上的重大不足 |
| 8 | Coarse-Guided VG (Visual Generation via h-Transform Sampling) | 引导采样 . h-Transform . 无训练 | h-Transform 约束扩散采样,噪声感知调度平衡引导与质量 | 多种图像视频任务验证有效 |
人工智能炼丹师 整理 | 2026-03-16
评论 (0)