
版权属于:
人工智能炼丹师
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇
今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。
方向分布:
顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇
场景/主体/运动统一控制 | Adobe Research | arXiv:2603.15614
关键词: 视频扩散, 统一控制, 多视图主体, 3D感知, Adobe
当前视频扩散模型在视觉质量上取得了显著进步,但精细控制仍是关键瓶颈。AI视频创作者需要三种关键控制:场景构图、多视图主体定制、和相机/物体运动调整。现有方法通常孤立处理这些维度,缺乏统一架构支持多维联合控制。
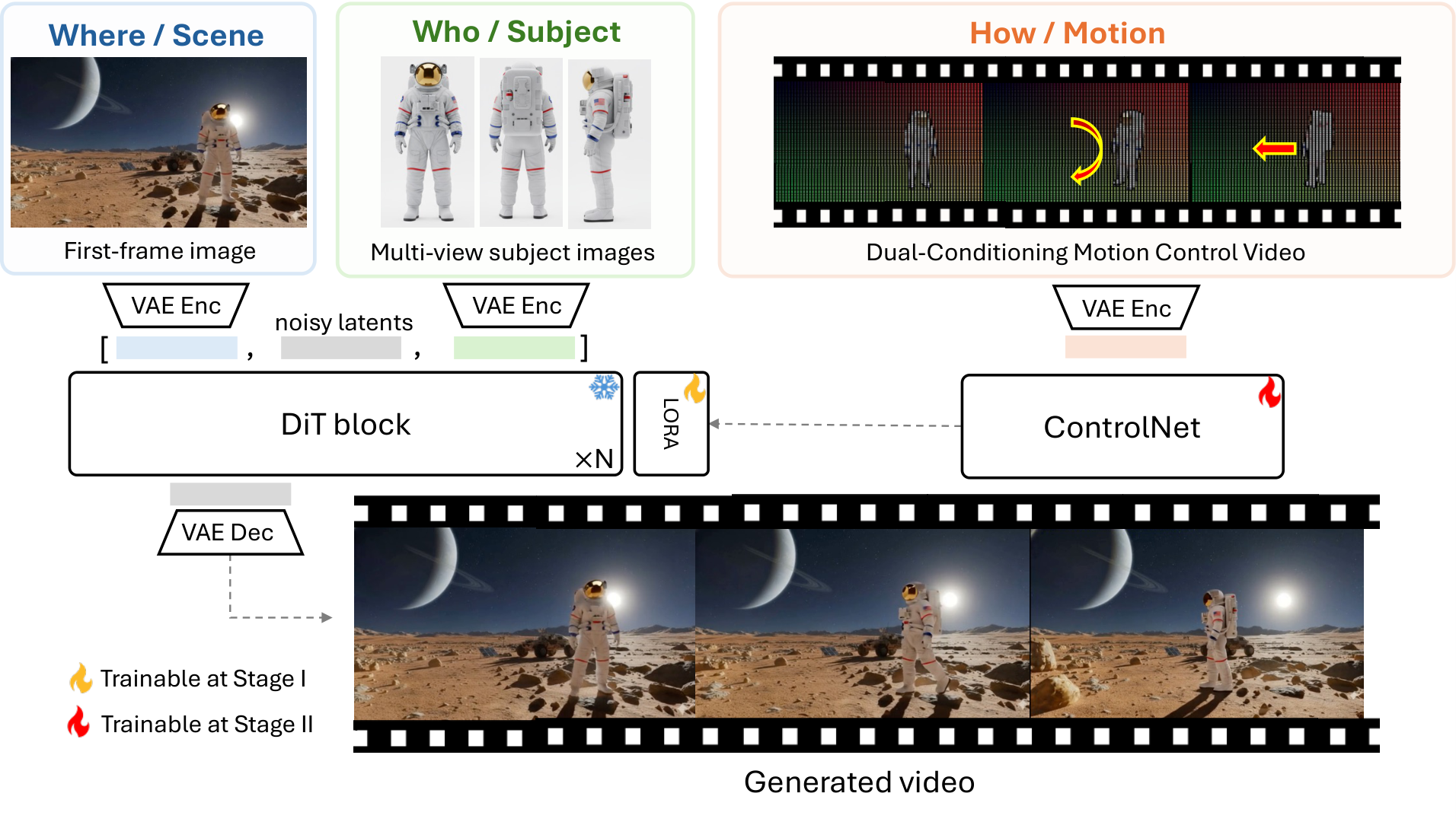
提出 Tri-Prompting 统一框架和两阶段训练范式,集成场景构图、多视图主体一致性和运动控制。核心是双条件运动模块:使用 3D 跟踪点控制背景场景,使用下采样 RGB 线索控制前景主体。进一步提出推理时 ControlNet 尺度调度策略,平衡可控性与视觉真实感。支持 3D 感知主体插入任意场景、操纵图像中已有主体等全新工作流。
核心问题: 视频扩散模型缺乏对场景、主体和运动的统一精细控制
前序工作及局限:
与前序工作的本质区别: 首次统一场景构图+多视图主体+运动控制三维度,双条件运动模块分别用3D跟踪点和下采样RGB控制前景背景
技术演进定位: 范式统一——从孤立控制到三维联合控制,为AI视频创作提供完整控制栈
可能的后续方向:
交互式流式视频扩散 | 锚点记忆+三区域RoPE | arXiv:2603.13405
关键词: 流式视频, 交互式生成, 锚点记忆, 三区域RoPE, 长视频
交互式长视频生成需要支持提示词切换以引入新主体或事件,同时在扩展范围内保持感知保真度和连贯运动。现有蒸馏流式视频扩散模型通过滚动 KV 缓存实现长程生成,但存在两个核心失败模式:提示词切换时缓存维护无法同时保留语义上下文和近期潜在线索;蒸馏过程中无界时间索引导致位置分布偏移。
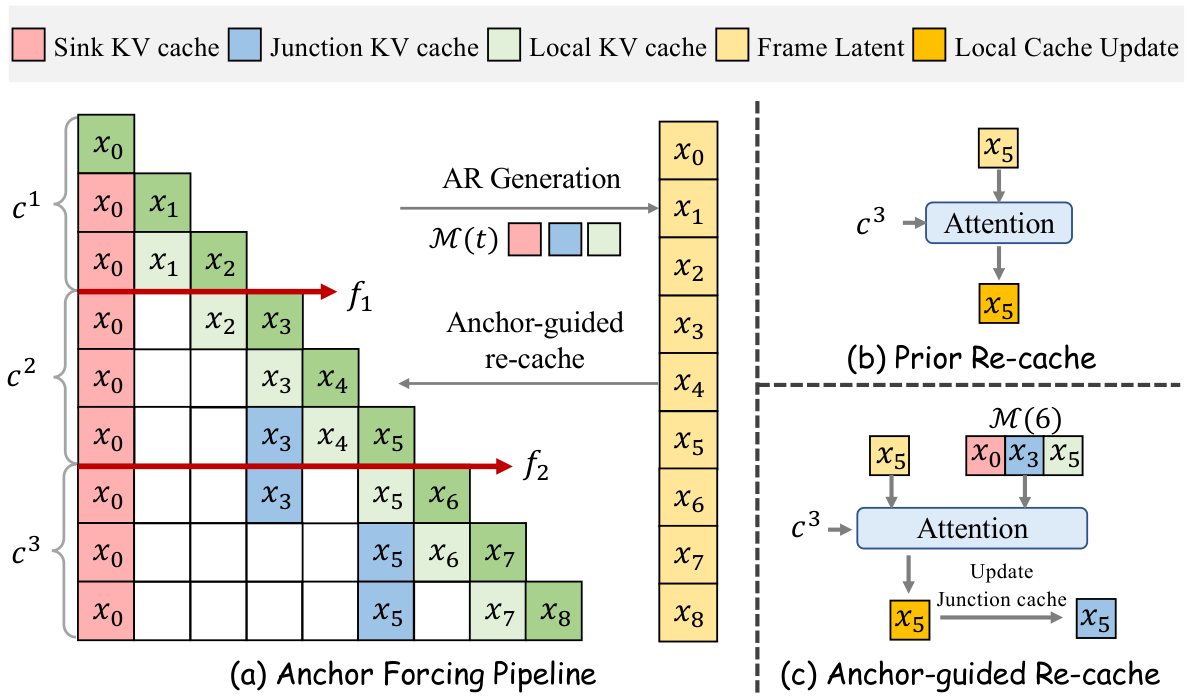
提出 Anchor Forcing 缓存中心框架。第一,锚点引导重缓存机制:在锚点缓存中存储 KV 状态,每次提示词切换时从锚点热启动重缓存,减少切换后的证据损失并稳定感知质量。第二,三区域 RoPE:设计区域特定的参考原点,配合 RoPE 重对齐蒸馏,将无界流式索引与预训练 RoPE 体制协调,更好地保留运动先验。
核心问题: 交互式长视频生成中提示词切换导致质量退化和运动失真
前序工作及局限:
与前序工作的本质区别: 锚点引导重缓存热启动解决切换边界问题,三区域RoPE重对齐解决无界索引的位置分布偏移
技术演进定位: 关键补全——与MemRoPE互补,一个解决长程记忆一个解决交互切换,共同构建流式视频基础设施
可能的后续方向:
无训练速度场分解图像编辑 | Flux.1 Kontext | arXiv:2603.13388
关键词: 图像编辑, 无训练, 速度场分解, Flow Matching, 连续控制
基于指令的图像编辑旨在根据文本指令修改源内容。然而,基于 Flow Matching 的现有方法常因去噪重建误差导致非编辑区域漂移,难以保持一致性。此外,它们通常缺乏对编辑强度的细粒度控制。
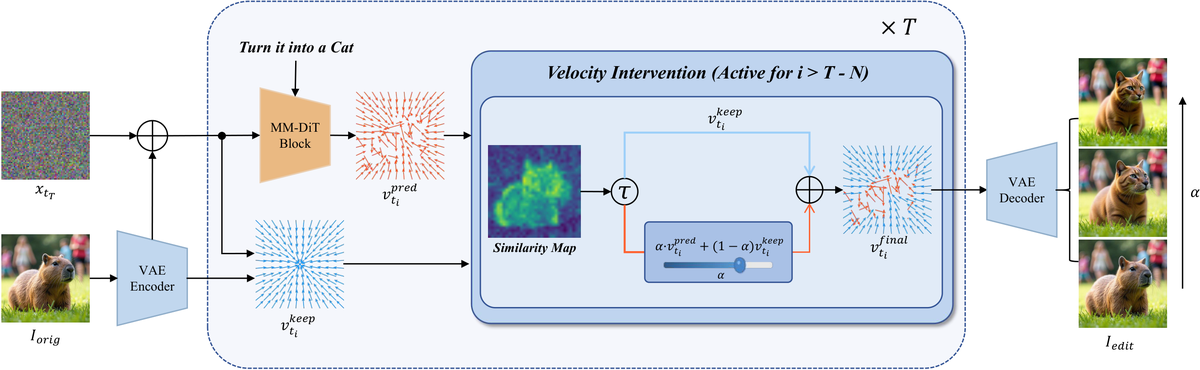
提出 VeloEdit:一种无训练方法,通过量化保持源内容的速度场与驱动目标编辑的速度场之间的差异,动态识别编辑区域。基于此分区,在保留区域用源恢复速度替代编辑速度以强制一致性,在目标区域通过速度插值实现编辑强度的连续调制。直接操作速度场,不依赖复杂注意力操纵或辅助可训练模块。
核心问题: Flow Matching时代图像编辑的区域一致性和强度控制困难
前序工作及局限:
与前序工作的本质区别: 直接操作速度场而非注意力,通过v_edit与v_src差异量化实现动态区域识别和连续强度插值
技术演进定位: 新范式——速度场分解是FM时代原生编辑方法,比移植U-Net时代注意力操纵更自然
可能的后续方向:
聚类最优传输 Flow Matching | CVPR 2026 | arXiv:2603.13395
关键词: Flow Matching, 最优传输, 加速采样, CVPR 2026, 即插即用
Flow Matching 模型由于随机或批级耦合常产生弯曲轨迹,增加离散化误差并降低样本质量。如何让生成轨迹更直从而减少采样步数,是加速 FM 的核心问题。
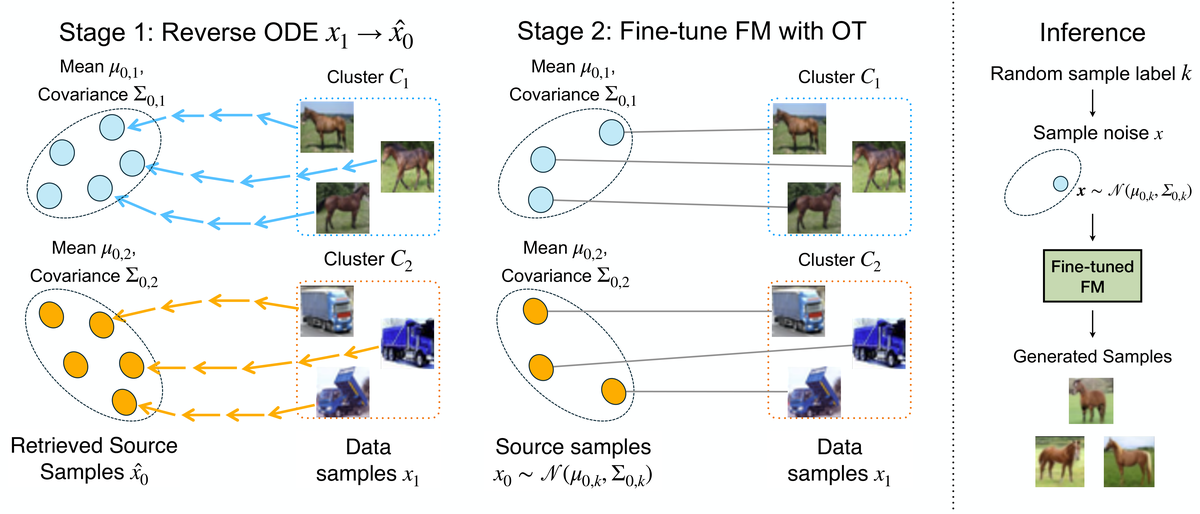
提出 COT-FM 通用框架,通过聚类目标样本并为每个聚类分配专用源分布(通过反转预训练 FM 模型获得)来重塑概率路径。这种分而治之策略产生更精确的局部传输和显著更直的向量场,且不改变模型架构。作为即插即用方法,可直接应用于任何预训练 FM 模型。
核心问题: Flow Matching的随机耦合导致弯曲轨迹和采样质量损失
前序工作及局限:
与前序工作的本质区别: 聚类级分而治之策略,为每个簇反转FM获取专用源分布,实现比全局OT更精确的局部传输
技术演进定位: 方法论创新——CVPR 2026 接收,聚类OT是FM加速的第三条路线(与蒸馏、直化互补)
可能的后续方向:
扩散语言模型高效文生图 | 4x 加速 | arXiv:2603.13450
关键词: 扩散LLM, 高效推理, 局部感知, 4x加速, 无训练
离散扩散语言模型已成为统一多模态生成的引人注目范式,但迭代解码导致高推理延迟。现有加速策略要么需要昂贵重训练,要么未能利用视觉数据固有的 2D 空间冗余性。
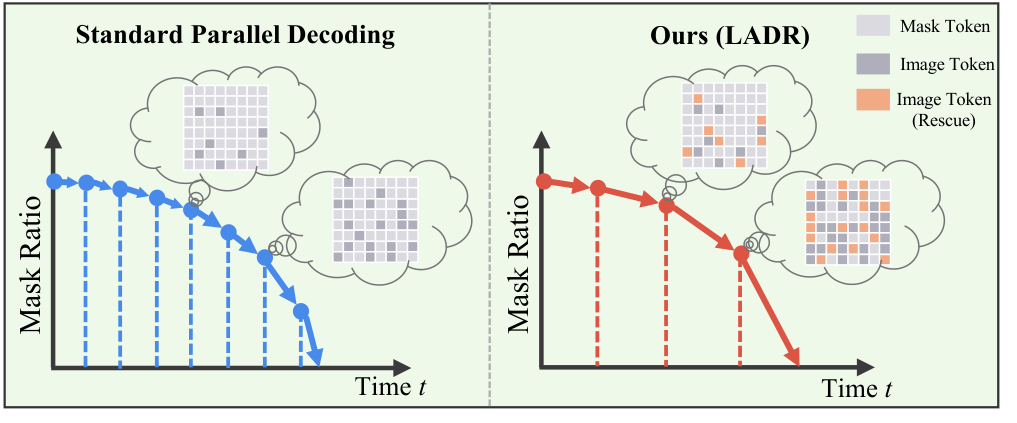
提出 LADR(局部感知动态拯救),利用图像的空间马尔可夫性质加速推理。优先恢复'生成前沿'处的标记(与已观察像素空间相邻的区域),最大化信息增益。集成形态学邻居识别定位候选标记、有界风险过滤防止错误传播、流形一致逆调度加速掩码密度与扩散轨迹对齐。
核心问题: 离散扩散语言模型的迭代解码导致T2I推理极慢
前序工作及局限:
与前序工作的本质区别: 首次利用图像空间马尔可夫性质,生成前沿优先恢复最大化信息增益,4x加速无质量损失
技术演进定位: 实用突破——扩散LLM从理论演示走向实际部署,4x加速是关键里程碑
可能的后续方向:
Tri-Prompting 和 Anchor Forcing 代表视频生成控制的两个关键方向:前者统一了场景/主体/运动三维度的精细控制,后者解决了交互式流式生成的边界质量问题。结合昨天的 MemRoPE,我们看到一个完整的流式视频控制栈正在形成:MemRoPE 负责长程记忆,Anchor Forcing 负责交互切换,Tri-Prompting 负责精细控制。
VeloEdit 的速度场分解和 COT-FM 的聚类最优传输分别从编辑和采样两个角度深化 Flow Matching 生态。VeloEdit 表明 FM 的速度场可以直接操作来实现编辑(比移植注意力操纵更自然),COT-FM 则为 FM 加速开辟了蒸馏和直化之外的第三条路线。FM 正从'替代扩散'走向'建立自己的方法论体系'。
LADR 的 4x 无训练加速表明离散扩散 LLM 的推理效率问题正被认真对待。空间马尔可夫性质是一个精彩的发现——图像 token 的空间局部性可以被利用来避免冗余恢复。这与 DiT 连续扩散的加速(JiT、AccelAes)形成互补,两条技术路线共同推动视觉生成模型的实际部署。
| # | 论文 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|
| 1 | LibraGen (Playing a Balance Game in Subject-Driven Video Generation) | 主体驱动 . S2V . DPO . 平衡博弈 | 将S2V视为平衡博弈,Consis-DPO + Real-Fake DPO + 时间依赖动态CFG | 仅千量级数据超越开源和商业S2V模型 |
| 2 | NumColor (Precise Numeric Color Control in Text-to-Image Generation) | 精确颜色 . 数字控制 . Lab空间 . 零样本 | Color Token Aggregator + 6707个可学习ColorBook嵌入,CIE Lab空间映射 | 数字颜色准确度提升4-9x,零样本迁移5个模型 |
| 3 | EVD (Event-Driven Video Generation) | 事件驱动 . 交互幻觉 . 门控采样 . DiT | 事件头预测token级活动,事件门控采样减少交互幻觉 | 状态持久/空间准确/支撑关系/接触稳定全面改善 |
| 4 | FlashMotion (Few-Step Controllable Video Generation with Trajectory Guidance (CVPR 2026)) | 轨迹引导 . 少步生成 . CVPR 2026 . 蒸馏 | 轨迹适配器+联合蒸馏实现少步可控视频生成 | CVPR 2026,代码已开源 |
| 5 | GlyphPrinter (Region-Grouped DPO for Glyph-Accurate Visual Text Rendering (CVPR 2026)) | 文本渲染 . DPO . 字形准确 . CVPR 2026 | 区域分组DPO文本渲染,无需显式奖励模型 | CVPR 2026,字形准确渲染SOTA |
| 6 | Spectrum Matching (A Unified Perspective for Superior Diffusability in Latent Diffusion) | VAE . 扩散性 . 频谱匹配 . 潜在扩散 | 频谱匹配假说统一理解VAE在潜在扩散中的可学习性 | 两个实用方法显著提升VAE扩散性 |
| 7 | SERUM (Simple Efficient Robust Unifying Marking for Diffusion Image Gen (ICLR 2026)) | 水印 . 扩散标记 . ICLR 2026 . 鲁棒 | 初始噪声中添加水印噪声,训练轻量检测器 | ICLR 2026,1% FPR下最高TPR,支持多用户 |
| 8 | DC-Diffusion (High-Fidelity T2I from VLM via Distribution-Conditioned Diffusion Decoding) | VLM . 扩散解码 . 分布条件 . 高保真 | Logit-to-Code分布映射将VLM token logits转连续条件信号 | 仅ImageNet-1K短训练即提升VLM视觉保真度 |
人工智能炼丹师 整理 | 2026-03-18
评论 (0)