
版权属于:
人工智能炼丹师
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 13 篇论文 | 重点深度解读 5 篇
今日 arXiv cs.CV 视觉生成相关论文共 13 篇,重点解读 5 篇。
方向分布:
顶会收录: CVPR 2026 x 3 篇 + ICLR 2026 x 1 篇
无训练无限视频生成 | USC | arXiv:2603.12513
关键词: 无限视频生成, Memory Tokens, RoPE, Training-Free
自回归扩散模型已经实现了实时帧流式传输,但现有的滑动窗口缓存策略会丢弃过去的上下文,导致长视频生成中出现保真度下降、身份漂移和运动停滞的问题。现有方法保留一组固定的早期 token 作为注意力汇,但这种静态锚点无法反映不断增长的视频内容的演变。
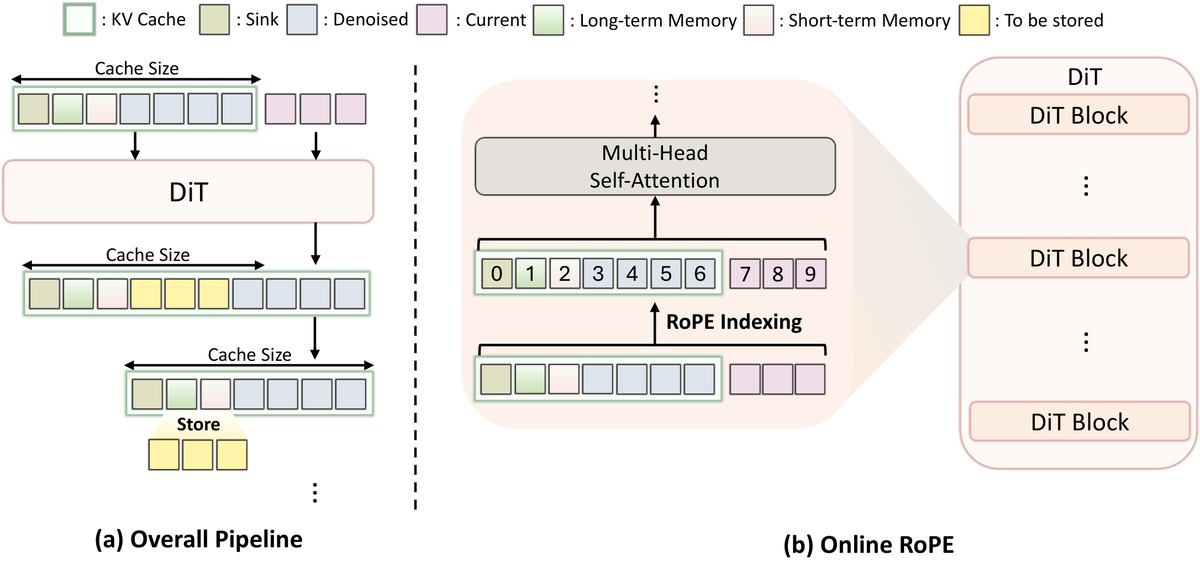
提出 MemRoPE 框架,包含两个协同设计的组件:(1) Memory Tokens(记忆令牌)通过指数移动平均将所有过去的键压缩为双重长期流和短期流,在固定大小的缓存中同时保持全局身份和最近的动态;(2) Online RoPE Indexing(在线 RoPE 索引)缓存未旋转的键,在注意力计算时动态应用位置嵌入,确保聚合过程不会产生冲突的位置相位。两个机制相互促进:位置解耦使时间聚合定义明确,聚合使固定缓存可用于无限生成。
核心问题: 自回归视频生成中滑动窗口缓存丢弃历史上下文,导致长视频质量退化
前序工作及局限:
与前序工作的本质区别: 双流 EMA 记忆机制动态压缩全部历史到固定缓存,在线 RoPE 索引解决聚合后的位置编码冲突
技术演进定位: 范式突破--从有限窗口到无限上下文,为长视频生成打开新空间
可能的后续方向:
美学感知 DiT 加速 2.11x | Sydney | arXiv:2603.12575
关键词: DiT 加速, 美学增强, Training-Free, AesMask
扩散 Transformer 因强大的可扩展性成为高保真 T2I 生成的主干,但密集空间 token 上的二次自注意力导致推理延迟高。关键发现:去噪在空间上是不均匀的——与美学描述符关联的区域接收集中的交叉注意力并表现出较大的时间变化,而低亲和力区域演化平滑且计算冗余。
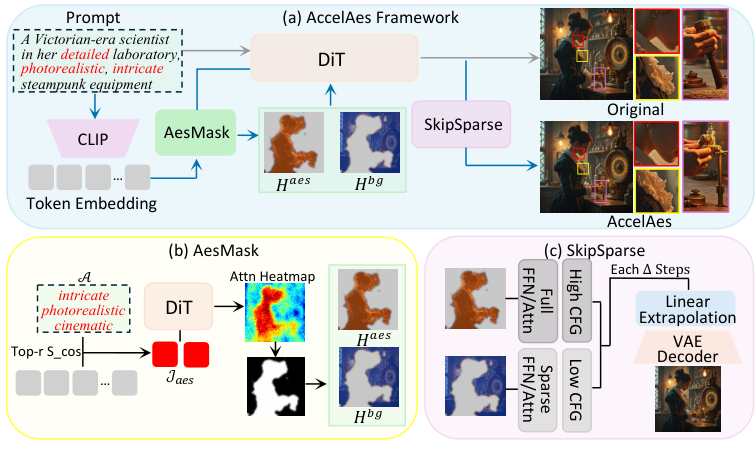
提出 AccelAes,通过美学感知的时空缩减来加速 DiT 同时提升感知美学效果。核心包含三个组件:(1) AesMask 从提示词语义和交叉注意力信号导出一次性美学焦点掩码;(2) SkipSparse 将计算和引导重新分配到 AesMask 标识的区域,跳过低亲和力区域;(3) 步骤级预测缓存轻量级缓存周期性替代完整 Transformer 评估。
核心问题: DiT 模型空间注意力的二次复杂度导致推理缓慢
前序工作及局限:
与前序工作的本质区别: 首次将美学语义与计算分配关联--高美学亲和力区域完整计算,低亲和力区域跳过,不仅加速还提升美学
技术演进定位: 范式创新--从无损加速到加速+增强双赢,开辟语义感知加速新方向
可能的后续方向:
首个实时音视频联合生成 | 25 FPS | arXiv:2603.11647
关键词: 音视频联合生成, 实时流式, 蒸馏, 25 FPS
联合音视频扩散模型虽能生成高质量内容,但因双向注意力依赖导致高延迟,无法实时应用。如何将高质量双向扩散模型转化为实时流式生成器是关键挑战。
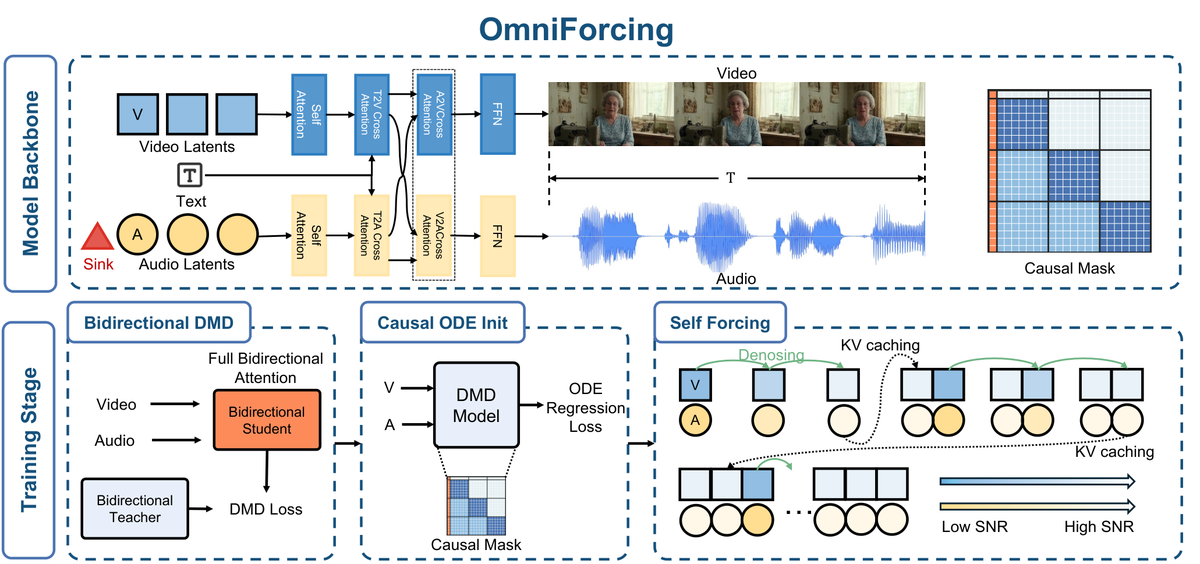
提出 OmniForcing,首个将离线双流双向扩散模型蒸馏为高保真流式自回归生成器的框架。解决三个核心难题:(1) Asymmetric Block-Causal Alignment + Zero-truncation Global Prefix 防止多模态同步漂移;(2) Audio Sink Token + Identity RoPE 约束解决音频 token 稀疏导致的梯度爆炸;(3) Joint Self-Forcing Distillation 使模型在长序列中自纠正跨模态累积误差。推理时采用模态无关的滚动 KV-cache。
核心问题: 联合音视频扩散模型延迟高,无法实时生成
前序工作及局限:
与前序工作的本质区别: 首次将大规模双向音视频扩散模型蒸馏为实时流式自回归生成器,三个创新解决模态不对称/稀疏/累积误差
技术演进定位: 里程碑--实时音视频联合生成从0到1,为沉浸式内容创作铺路
可能的后续方向:
四智能体协作组合生成 | CVPR 2026 | arXiv:2603.12829
关键词: 多智能体, 组合生成, 布局规划, CVPR 2026
文本到图像生成在复杂场景中忠实地组合多个对象并保留其属性仍是一大挑战。现有单模型方法在组合复杂性增加时准确率急剧下降。
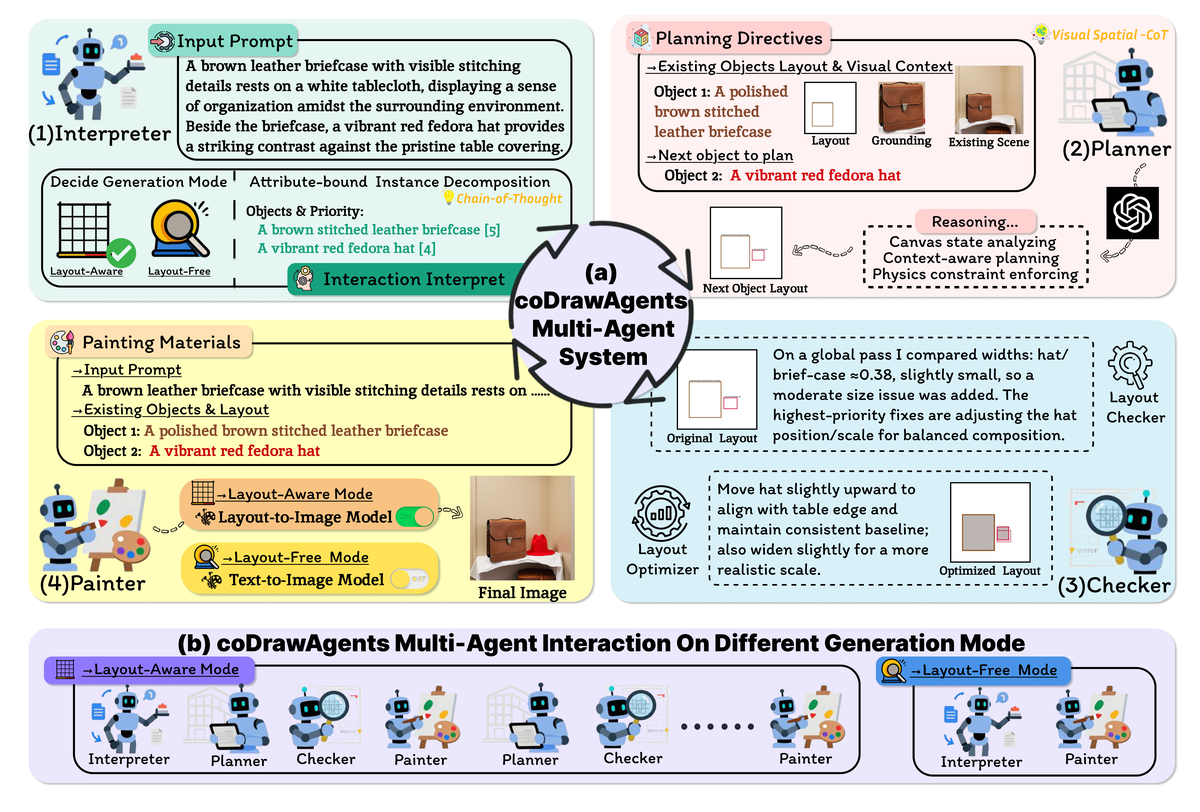
提出 coDrawAgents,包含四个专门智能体:(1) Interpreter 自适应决定直接 T2I 还是布局感知流程,将提示解析为富属性对象描述符并排序分组;(2) Planner 采用分治策略在画布视觉上下文中增量提出布局;(3) Checker 验证空间一致性和属性对齐,在渲染前细化布局;(4) Painter 逐步合成图像将新对象合并到画布中。
核心问题: T2I 模型在复杂组合场景中属性绑定和空间关系容易出错
前序工作及局限:
与前序工作的本质区别: 四智能体协作闭环--解释/规划/检查/绘制,Checker 提供渲染前显式错误纠正
技术演进定位: 新范式--多智能体方法论进入 T2I 组合生成领域,CVPR 2026 认可
可能的后续方向:
多视图偏好对齐 | 上海AI实验室+清华 | arXiv:2603.12648
关键词: GRPO, 偏好对齐, Flow Models, 多视图奖励
标准 GRPO 将一组生成样本与单一条件评估,这种稀疏的单视图评估方案未能充分探索样本间关系,限制了对齐效果和性能上限。
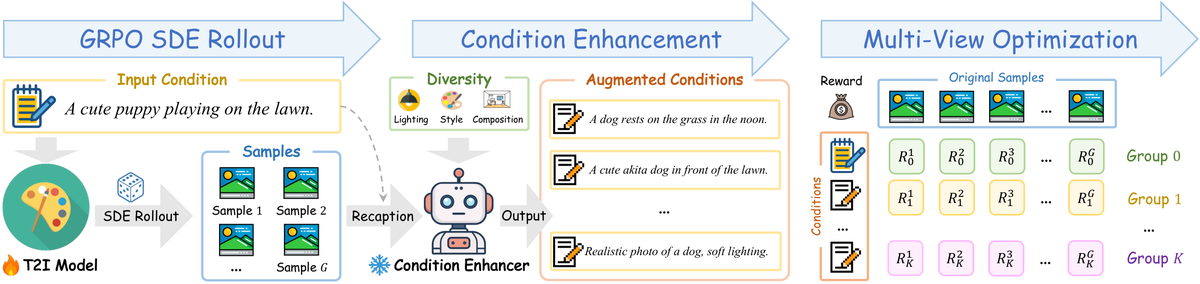
提出 Multi-View GRPO (MV-GRPO),通过增强条件空间来创建密集的多视图奖励映射。对于从单个提示生成的一组样本,利用条件增强器生成语义相邻但多样化的描述进行多视图优势重估计。关键技巧:通过推导条件概率分布,无需重新生成样本即可获得多视图信号。
核心问题: 标准 GRPO 单视图评估稀疏,限制偏好对齐效果
前序工作及局限:
与前序工作的本质区别: 通过条件空间增强创建密集多视图奖励映射,无需重新生成样本即可获得丰富优化信号
技术演进定位: 方法论创新--多视图思想引入偏好优化,提升 GRPO 的信号密度和对齐上限
可能的后续方向:
MemRoPE 揭示了自回归视频生成的核心瓶颈不在模型能力,而在上下文管理。双流 EMA 记忆巧妙地在信息保持和计算开销之间取得平衡。这标志着视频生成从'短视频'向'长视频/流式视频'的范式转换正式开始。
AccelAes 和 JiT 都瞄准 DiT 推理加速但思路不同。JiT 是'去冗余',AccelAes 是'重分配'且不仅加速还提升美学——暗示现有 DiT 在低美学区域存在'过度计算'。合并两种方法有望实现 3-4x 无损加速。
OmniForcing 的 25 FPS 实时联合生成是里程碑。AIGC 不再局限于离线创作,游戏 NPC 对话、虚拟直播、交互式叙事等场景将直接受益。但蒸馏方法的质量天花板和 LTX-2 高训练成本是需关注的问题。
| # | 论文 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|
| 1 | VQQA (Agentic Approach for Video Evaluation and Quality Improvement) | 视频生成评估 . 智能体 . 闭环优化 | 多智能体框架通过 VLM 批判作为语义梯度实现闭环提示优化 | T2V-CompBench +11.57%, VBench2 +8.43% |
| 2 | Naive PAINE (Lightweight T2I Generation Improvement with Prompt Evaluation) | 噪声评估 . 生成质量预测 . 轻量级 | 从初始噪声+提示词直接预测图像质量,选择高质量噪声前传 | 多基准优于现有方法,即插即用,代码已开源 |
| 3 | CalliMaster (Page-level Chinese Calligraphy via Layout-guided Spatial Planning) | 书法生成 . 布局规划 . Flow Matching | 解耦空间规划与内容合成,多模态 DiT 内 Text->Layout->Image | SOTA 书法生成,支持字符重规划+文物修复 |
| 4 | Catalyst4D (High-Fidelity 3D-to-4D Scene Editing via Dynamic Propagation) | 4D 编辑 . 3DGS . 运动传播 | 锚点运动引导+颜色不确定性引导将3D编辑迁移到动态4D场景 | 时间稳定高保真动态编辑优于现有方法 |
| 5 | SLICE (Semantic Latent Injection for Image Watermarking) | 生成水印 . 语义篡改检测 . 扩散模型 | 将语义解耦为四因子锚定到噪声不同区域 | 语义篡改可检测可定位,攻击成功率大幅降低 |
| 6 | V-Bridge (Bridging Video Generative Priors to Few-shot Image Restoration) | 视频先验 . 图像修复 . Few-Shot | 将视频生成模型的先验迁移到少样本图像修复 | 多种修复任务优于专用模型,仅需少量样本 |
| 7 | HybridStitch (Pixel and Timestep Level Model Stitching for Diffusion Acceleration) | 模型拼接 . 扩散加速 . 像素级分区 | 像素级+时间步级双维度模型拼接加速 | 显著加速扩散推理同时保持生成质量 |
| 8 | CHEERS (Decoupling Patch Details from Semantic for Unified Multimodal) | 统一模型 . 理解+生成 . 语义解耦 | 解耦 patch 细节与语义表征,统一视觉理解与生成 | 理解和生成双任务性能同时提升,代码已开源 |
人工智能炼丹师 整理 | 2026-03-17
评论 (0)