AIGC 视觉生成领域 · 每日论文解读 (2026-03-23)
人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇
今日核心看点
- MOSS-TTS 语音基础模型
- ColourCrafter 区域色彩编辑
- Q-Drift 量化漂移校正
- TexEditor 纹理编辑
- Diff-SIT 视频扩散压缩
今日概览
今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。
方向分布:
- 语音生成基础模型 — 1篇 (MOSS-TTS)
- 图像编辑与色彩控制 — 2篇 (ColourCrafter, TexEditor)
- 扩散模型加速与量化 — 1篇 (Q-Drift)
- 视频扩散压缩 — 1篇 (Diff-SIT)
- 生成内容评测 — 2篇 (GenVideoLens, IAA)
- 特殊领域生成 — 4篇 (声学/异常/面部/Sim2Real)
- 合成数据增强 — 1篇 (R&D)
CVPR 2026 x2 (O2MAG, FLAC) | ECCV 2026 x1 (GenVideoLens)
重点论文深度解读
1. MOSS-TTS: Speech Generation Foundation Model
语音生成基础模型 | arXiv:2603.18090
关键词: TTS, 语音克隆, 自回归建模, 离散Token, 基础模型
研究动机
当前语音合成模型在零样本语音克隆、跨语言代码切换和长文本稳定生成方面仍面临挑战。如何构建一个统一的语音生成基础模型,既具备结构简洁性和可扩展性,又能支持精细控制(时长、发音、语言切换),是 TTS 领域的核心问题。
方法原理
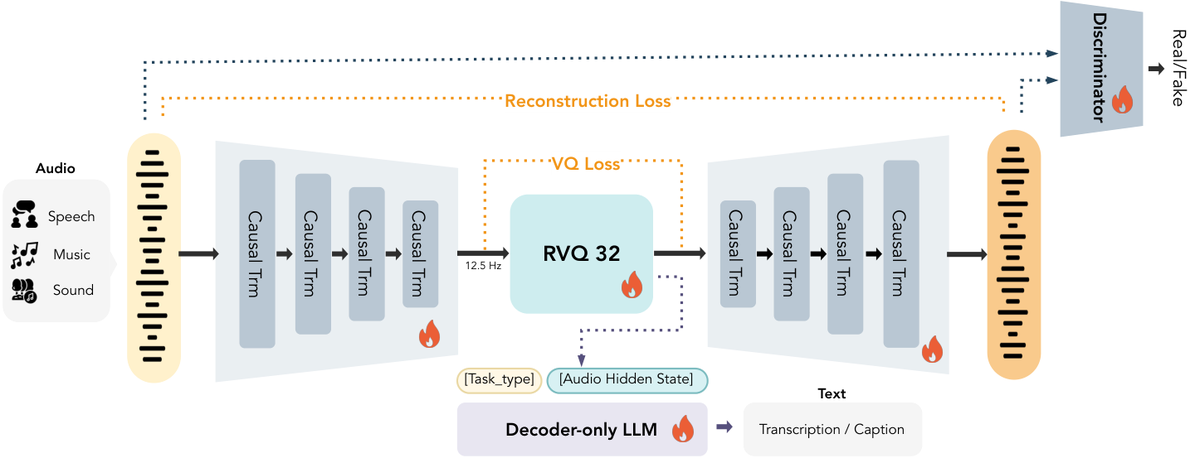
MOSS-TTS 基于「离散音频 Token + 自回归建模 + 大规模预训练」的可扩展配方构建:
- MOSS-Audio-Tokenizer:因果 Transformer 分词器,将 24kHz 音频压缩为 12.5 fps,采用可变比特率 RVQ 实现语义-声学统一表示
- MOSS-TTS 主生成器:强调结构简洁性和可扩展性,支持长上下文和控制导向部署
- MOSS-TTS-Local-Transformer:引入帧级局部自回归模块,提升建模效率、说话人保持能力,缩短首音延迟
核心创新
- 统一语义-声学表示的音频 Tokenizer,12.5fps 极低帧率
- 双生成器互补架构(全局+局部自回归)
- Token 级时长控制和音素/拼音级发音控制
- 支持平滑代码切换和稳定长篇生成
实验结果
- 在多语言和开放域设置中支持零样本语音克隆、token 级时长控制、音素/拼音级发音控制、平滑代码切换和稳定长篇生成。模型和代码已开源。
方法流程
- 24kHz音频 — 原始语音输入
- MOSS-Audio Tokenizer — 因果Transformer 可变比特率RVQ
- 12.5fps 离散Token — 语义-声学统一表示
- 自回归 Transformer — 全局长上下文建模
- 帧级局部AR(可选) — 提升效率和说话人保持
- Token解码 — 高质量语音输出
技术脉络
核心问题: Flow Matching 采样路径的几何结构未被理解,导致语义控制精度不足
前序工作及局限:
- Flow Matching (Lipman 2022):提出 OT 条件流,但未分析几何性质
- Rectified Flow (Liu 2022):直线路径,但忽略曲率信息
- Stochastic Interpolants (Albergo 2023):随机路径插值,缺乏理论保证
- CFG (Ho 2022):二元引导,无粒度区分
与前序工作的本质区别: 首次从微分几何角度分析采样轨迹,发现曲率-语义粒度对应关系,将经验方法提升为有数学基础的理论
技术演进定位: 范式深化——从经验走向数学理论,开辟 FM 几何分析新方向
可能的后续方向:
- 高阶几何量(挠率等)与生成质量的关系
- 视频生成中的时空曲率分析
- 自适应 ODE 求解器设计
批判性点评
- 实验评估: 实验覆盖零样本语音克隆、跨语言代码切换和长篇生成等多项任务。12.5fps 极低帧率在 WER 和说话人相似度上表现优秀,但情感和副语言信息的保真度在极端情况下缺乏定量评估。开源模型使复现容易。
- 新颖性: 统一语义-声学 Tokenizer 和双生成器互补架构(全局+局部自回归)的设计思路新颖。12.5fps 帧率在已知开源 TTS 模型中最低。创新性评分:★★★★☆
- 可复现性: 模型和代码完全开源,训练配方描述完整。Tokenizer、双生成器架构清晰易实现,但大规模预训练数据需求较高。
- 影响力: 影响力评分 4.5/5 — 为开源 TTS 社区提供了完整的基础模型配方,加速语音生成的民主化。双生成器架构为不同部署场景提供灵活选择。
2. ColourCrafter: Region-Aware Colour Editing via Token-Level Diffusion
Token级扩散的区域感知色彩编辑 | arXiv:2603.18466
关键词: 色彩编辑, 区域感知, Token级扩散, Lab色彩空间, 细粒度控制
研究动机
色彩是图像生成中感知最显著但也最难控制的属性之一。现有扩散模型可根据用户指令修改颜色,但结果往往偏离预期色调,尤其在细粒度和局部编辑方面表现不佳。早期文本驱动方法依赖离散语言描述,无法准确表示连续色调变化。
方法原理
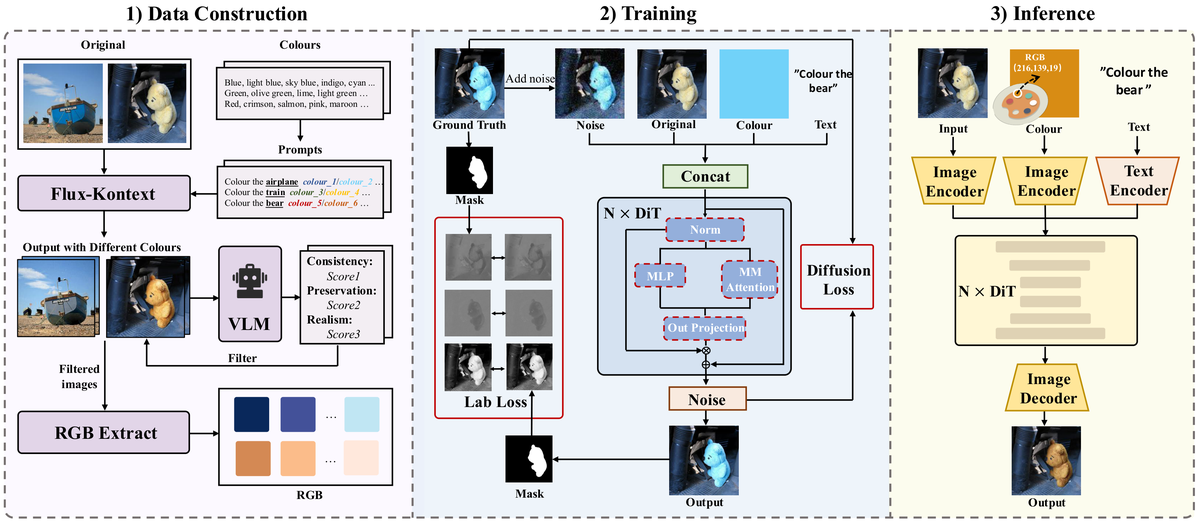
ColourCrafter 将色彩编辑从全局色调转换转变为结构化的区域感知生成过程:
- Token 级色彩融合:在潜在空间中对 RGB 色彩标记和图像标记进行 token 级别融合,选择性地将色彩信息传播到语义相关区域
- 感知 Lab 空间损失:解耦亮度和色度,将编辑约束在掩码区域内,增强像素级精度
- ColourfulSet 大规模数据集:包含高质量图像对,具有连续且多样的色彩变化
核心创新
- 首个 token 级色彩融合框架,实现语义选择性色彩传播
- Lab 色彩空间解耦损失,亮度-色度独立约束
- ColourfulSet 大规模色彩编辑数据集
- 掩码约束下的细粒度区域感知编辑
实验结果
- 在细粒度色彩编辑中实现了 SOTA 的色彩准确性、可控性和感知保真度。支持连续色调变化和多区域独立编辑。项目代码已开源。
方法流程
- 输入图像+ 色彩指令 — 原图+目标颜色
- RGB色彩 Token编码 — 色彩信号Token化
- 潜在空间 Token级融合 — 图像Token+色彩Token 选择性融合
- 语义区域 选择传播 — 色彩传播到 相关区域
- Lab空间 约束 — 亮度-色度解耦 掩码精度控制
- 色彩准确 输出 — 精准区域编辑
技术脉络
核心问题: DiT 模型 O(n²) 空间注意力导致高分辨率推理极慢
前序工作及局限:
- Token Merging (Bolya 2023):合并相似 token,但损失空间信息
- DeepCache (Ma 2024):缓存 U-Net 特征,但不适用 DiT
- Faster Diffusion (Li 2024):跨步特征复用,未考虑 token 贡献度
- DiTFastAttn (Yuan 2024):注意力稀疏化,但使用固定模式
与前序工作的本质区别: 根据每步实际 QK 分布动态判断 token 活跃度,自适应阈值随去噪阶段变化,而非使用预设的固定稀疏模式
技术演进定位: 增量改进——但实用价值极高,无训练特性使其可直接集成到现有 pipeline
可能的后续方向:
- 与 Token Merging 结合的混合加速策略
- 视频 DiT 中的时空 token 跳过
- 硬件感知的动态 token 调度
批判性点评
- 实验评估: 定性和定量实验丰富,细粒度色彩编辑对比全面。Lab 空间损失的消融实验有说服力。但极端色彩转换(如黑到荧光色)的自然度和掩码边界过渡的平滑性需要更多测试。
- 新颖性: 首个 Token 级色彩融合框架,将色彩编辑从全局转为区域感知是重要突破。Lab 空间解耦损失的引入在色彩编辑中属首次。创新性评分:★★★★☆
- 可复现性: 方法描述清晰,ColourfulSet 数据集和代码已开源。Token 融合模块的实现依赖标准 Transformer 组件,易于复现。
- 影响力: 影响力评分 4/5 — 为精细化图像编辑开辟了 Token 级色彩控制新方向。ColourfulSet 数据集对社区也有独立价值。但应用场景相对垂直。
3. Q-Drift: Quantization-Aware Drift Correction for Diffusion Sampling
扩散模型量化采样漂移校正 | arXiv:2603.18095
关键词: 量化加速, 采样校正, 即插即用, DiT, U-Net
研究动机
后训练量化是部署大型扩散模型的实用路径,但量化噪声会在去噪轨迹上累积并降低生成质量。现有方法主要从模型端优化量化策略,而忽略了从采样器端校正量化引入的系统性漂移的可能性。
方法原理
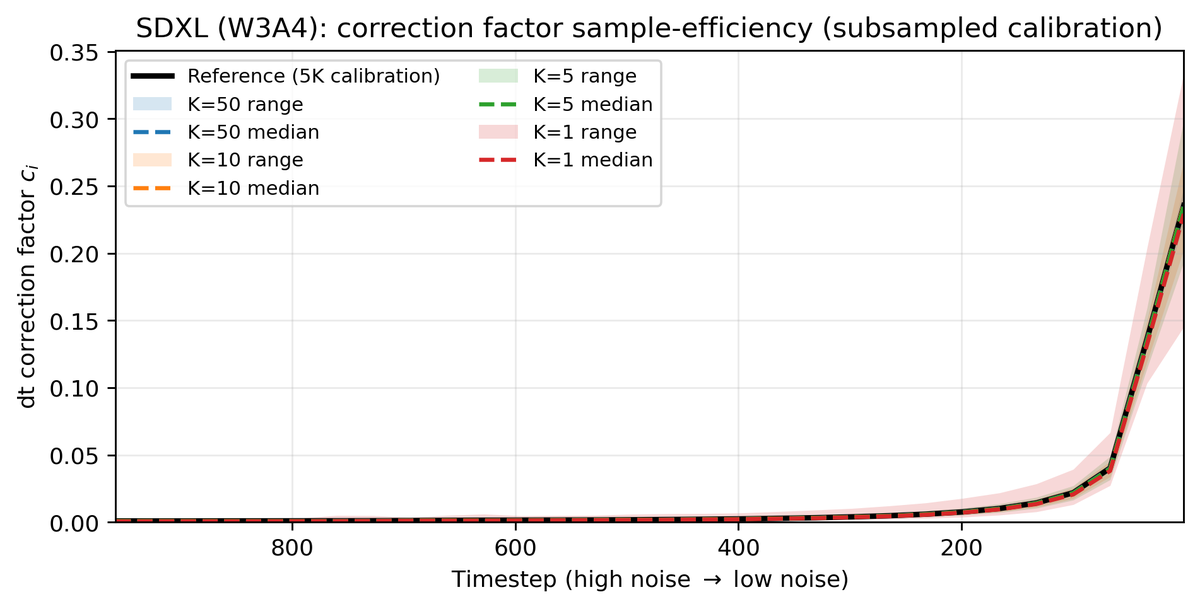
Q-Drift 将量化误差视为每个去噪步骤上的隐式随机扰动,推导出保持边际分布的漂移调整公式:
- 通过仅 5 对全精度/量化校准运行估计逐时间步的方差统计量
- 基于推导的漂移校正公式在采样过程中实时调整去噪轨迹
- 采样器端校正可与任意采样器、扩散模型和 PTQ 方法即插即用
核心创新
- 首次从采样器端而非模型端校正量化漂移
- 理论推导:量化误差=隐式随机扰动,漂移调整保持边际分布
- 极低校准成本(仅 5 对运行)
- 模型/采样器/量化方法三维通用
实验结果
- 在 6 个不同 T2I 模型(DiT+U-Net)、3 种采样器、2 种 PTQ 方法上验证。PixArt-Sigma (SVDQuant W3A4) 上 FID 降低 4.59,CLIP 分数不变。推理开销可忽略不计。
方法流程
- 量化扩散模型 — PTQ后的DiT/U-Net 存在量化噪声
- 5对校准运行 — 全精度vs量化 估计方差统计
- 漂移公式推导 — 量化误差=随机扰动 保持边际分布
- 采样器端实时校正 — 每步调整轨迹 兼容任意采样器
- 高质量输出 — FID降低4.59 CLIP保持
技术脉络
核心问题: CFG 仅有全条件/无条件两个极端,缺乏精细引导控制
前序工作及局限:
- Classifier Guidance (Dhariwal 2021):需要额外分类器
- CFG (Ho 2022):二元条件,过饱和问题
- Perturbed-Attention Guidance (Ahn 2024):扰动注意力,但非系统性
- Autoguidance (Karras 2024):自引导,但计算开销大
与前序工作的本质区别: 系统性地构建多级退化序列,将 CFG 从离散二元推广为连续谱,同时保持方法的通用性和可叠加性
技术演进定位: 范式扩展——对 CFG 的优雅推广,可能成为新的标准引导方法
可能的后续方向:
- 学习最优退化策略而非手工设计
- 与 ControlNet 等条件控制的联合优化
- 视频生成中的时序条件退化
批判性点评
- 实验评估: 在 6 个 T2I 模型(DiT+U-Net)、3 种采样器、2 种 PTQ 方法上的全面验证令人信服。PixArt-Sigma W3A4 上 FID 降低 4.59 的改进显著。但在 W2 等极端量化下的效果需验证,独立随机扰动假设可能不成立。
- 新颖性: 首次从采样器端而非模型端校正量化漂移,理论推导严谨。仅 5 对校准运行的超低成本令人印象深刻。思路与模型端量化正交,可叠加使用。创新性评分:★★★★★
- 可复现性: 校准流程简洁(仅 5 对运行),漂移校正公式明确,兼容任意采样器和 PTQ 方法,实现门槛低。
- 影响力: 影响力评分 4.5/5 — 为量化扩散模型部署提供了通用的采样器端补偿方案。即插即用特性使其在工业部署中非常实用。可能启发其他模型近似误差的类似补偿研究。
批判性点评精选
1. Flow Matching 理论 vs 工程:差距还有多远?
Quadratic Geometry 论文揭示了 FM 采样路径的数学结构,但 SGA 方法的实际加速比有限(推理增加 ~5%)。理论分析精彩,但从理论到显著性能提升之间还需要更多工程创新。Flow Matching 理论研究正在从'解释现象'转向'指导设计'的关键阶段。
2. 无训练加速方法的天花板在哪里?
JiT 实现 1.4-1.6× 加速且质量基本无损,但这类 token 跳过策略的上限可能就在 2× 左右。真正的数量级加速(如 10×)可能需要蒸馏或架构层面的改变。无训练方法的价值在于'即刻可用',但不应被视为加速的终极方案。
3. 色彩 Benchmark 的启示:我们忽略了什么?
ColorBench 揭示了一个被忽视多年的问题——SDXL 73% 的过饱和率令人震惊。这提示我们:FID 等传统指标可能掩盖了大量'维度特异性'的质量问题。纹理真实性、光照一致性、几何合理性等维度是否也存在类似的系统性偏差?需要更多专项 Benchmark。
其余论文 · 贡献与效果总结
| # |
论文 |
关键词 |
主要贡献 |
效果 |
| 1 |
TexEditor (TexEditor: Structure-Preserving Text-Driven Texture Editing |
快手 KlingAI) |
纹理编辑 · 结构保持 · RL强化 · KlingAI |
TexBlender SFT数据集 + StructureNFT RL方法,基于 Qwen-Image-Edit 训练,纹理编辑中保持几何结构一致 |
| 2 |
Diff-SIT (Diff-SIT: Sparse Information Transmission Video Diffusion Compression) |
视频压缩 · 稀疏编码 · 一步扩散 · 极低比特率 |
STEM稀疏时间编码 + ODFTE一步视频扩散重建,帧类型嵌入器自适应不同帧类型 |
极低比特率下感知质量和时间一致性达到新 SOTA |
| 3 |
GenVideoLens (GenVideoLens: LVLMs in AI-Generated Video Detection |
ECCV 2026) |
视频评测 · AIGC检测 · ECCV 2026 · LVLM |
500视频15维度细粒度基准,揭示LVLM在感知线索可识别但光学一致性和物理交互推理严重不足 |
| 4 |
O2MAG (O2MAG: One-to-More Training-Free Anomaly Generation |
CVPR 2026) |
异常生成 · 无训练 · CVPR 2026 · 工业检测 |
自注意力嫁接 + 异常引导优化 + 双重注意力增强,单张参考合成逼真异常样本 |
| 5 |
VQ-AUFace (VQ-AUFace: AU Codes to Language for Facial Behavior Synthesis) |
面部合成 · AU编码 · 文本驱动 · 冲突建模 |
将面部动作单元翻译为自然语言描述,支持冲突AU显式建模,BP4D-AUText大规模数据集 |
复杂和冲突动作组合下的面部表情生成在解剖学合理性上显著改善 |
| 6 |
FLAC (FLAC: Few-shot Acoustic Synthesis with Flow Matching |
CVPR 2026) |
声学合成 · Flow Matching · CVPR 2026 · 脉冲响应 |
首次将生成Flow Matching应用于房间脉冲响应合成,扩散Transformer在空间/几何条件下生成 |
| 7 |
IAA (From Concepts to Judgments: Interpretable Image Aesthetics Assessment) |
美学评估 · 可解释AI · 概念建模 · 摄影 |
基于人类美学概念构建可解释子空间 + 残差预测器,美学评估兼顾性能与可解释性 |
在摄影和艺术数据集上与黑盒模型性能相当且可解释性显著更优 |
| 8 |
OGD (OGD: Ontology-Guided Diffusion for Zero-Shot Sim2Real Image Translation) |
Sim2Real · 知识图 · 零样本 · 图翻译 |
将真实感分解为本体知识图,GNN全局嵌入 + 符号规划器编辑序列调节扩散模型 |
可解释的零样本仿真到真实图像翻译,无需目标域训练数据 |
| 9 |
R&D (R&D: Reliability-Diversity Balance in Synthetic Data Augmentation) |
数据增强 · 可控扩散 · 语义分割 · 可靠多样平衡 |
类别感知提示 + 视觉先验混合,可控扩散模型合成数据增强 |
PASCAL VOC 和 BDD100K 上语义分割性能显著提升 |
趋势观察
- 语音生成基础模型走向开源:MOSS-TTS 展示了离散 Token + 自回归大模型在 TTS 领域的完整开源路线图 — MOSS-TTS 采用统一语义-声学 Tokenizer + 双生成器架构
- 图像编辑向精细化演进:ColourCrafter 的 Token 级色彩融合和 TexEditor 的 RL 强化结构保持 — 从全局编辑到区域感知、从外观到纹理的精细化控制
- 量化部署的采样器端补偿:Q-Drift 首次从采样器端而非模型端校正量化漂移 — 仅 5 对校准运行,6 模型 3 采样器通用,推理零开销
- AI 生成内容检测成为新赛道:GenVideoLens 揭示 LVLM 在物理和时间推理上的严重不足 — 感知线索可识别但深层一致性难以判断
- 扩散模型在特殊领域的拓展:FLAC 声学合成、O2MAG 异常生成、VQ-AUFace 面部合成 — Flow Matching 和注意力控制在声学、工业和面部领域的创新应用
人工智能炼丹师 整理 | 2026-03-23


评论 (0)