
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇
今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。
方向分布:
CVPR 2026 × 3 篇 (InverFill, GroupEditing, FG-Portrait)
统一推理驱动视觉生成 | Shanghai AI Lab / The University of Sydney | arXiv:2603.23500
关键词: 统一生成模型, GRPO, FlowGRPO, 推理驱动生成, 强化学习
统一生成模型(交错文本和图像生成)已成为多模态AI的重要范式,但如何有效地进行后训练优化以同时提升推理和视觉生成质量仍是开放挑战。现有的强化学习方法要么只针对文本推理,要么只针对视觉生成,缺乏统一的优化框架来联合优化两种模态。
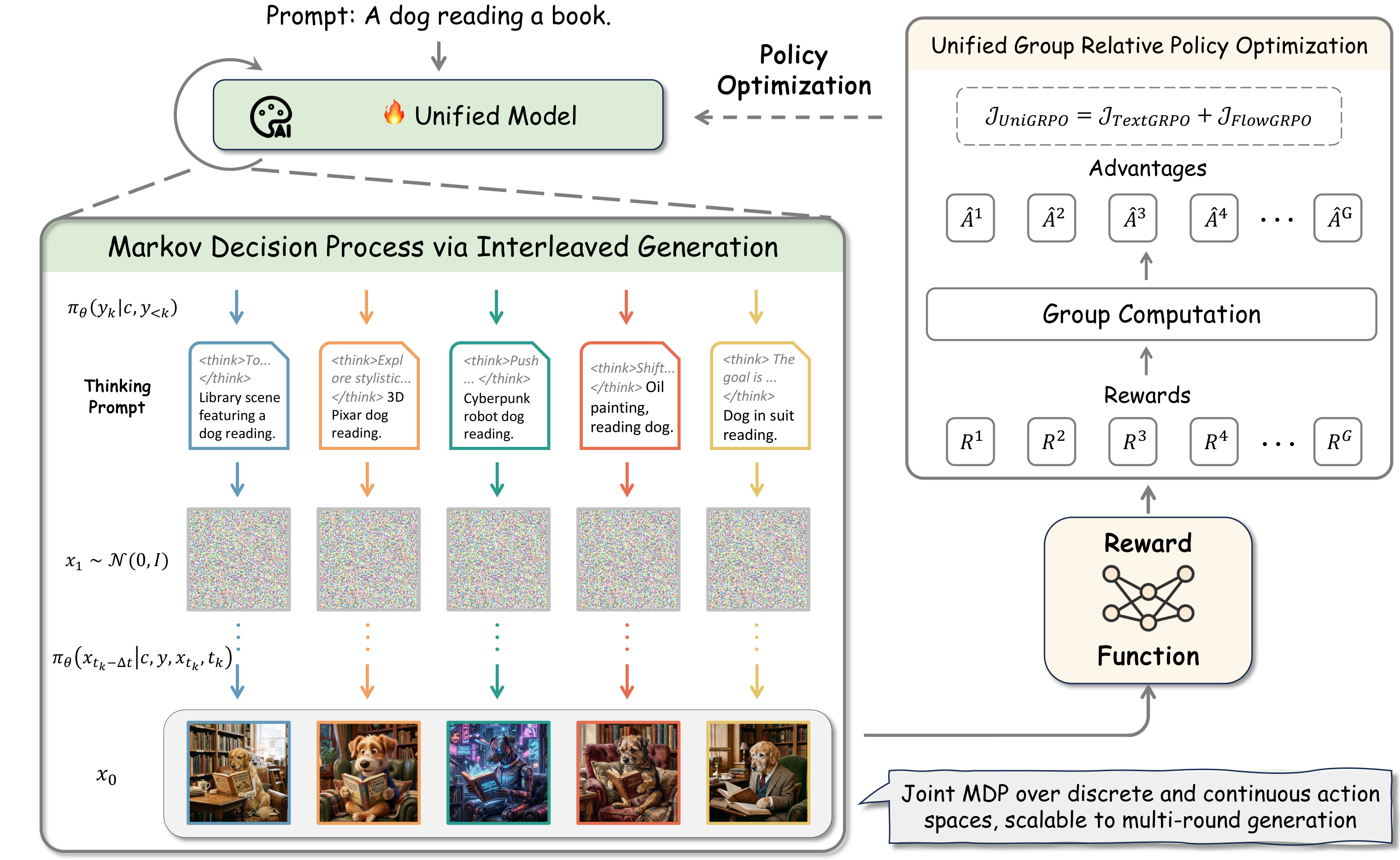
提出 UniGRPO,将交错生成建模为具有稀疏终端奖励的马尔可夫决策过程,联合优化文本推理和视觉生成策略。无缝集成文本推理的标准 GRPO 和视觉合成的 FlowGRPO。引入两个关键改进:(1) 消除 Classifier-Free Guidance 以维持线性非分支轨迹,使框架可扩展到多轮交互和条件生成(如编辑);(2) 用速度场上的 MSE 惩罚替代标准潜在 KL 惩罚,提供更稳健的正则化信号来缓解奖励黑客攻击。
核心问题: 如何统一优化交错文本推理和视觉生成
前序工作及局限:
与前序工作的本质区别: UniGRPO 首次将两者无缝集成,消除 CFG 实现线性轨迹,速度场 MSE 替代 KL 惩罚
技术演进定位: 统一生成模型后训练优化的开拓性基线工作
可能的后续方向:
纯图像驱动超高分辨率视频合成 | SJTU | arXiv:2603.23326
关键词: 超高分辨率, 视频合成, Relay LoRA, 高频感知, 纯图像训练
基于 Transformer 的视频扩散模型依赖 3D 空间-时间注意力,其二次方复杂度使得超高分辨率视频的端到端训练成本极高。直接用高分辨率图像微调视频模型会因图像-视频模态差距引入明显噪声。如何在不使用任何视频训练数据的情况下,让预训练的视频扩散模型生成超高分辨率视频?
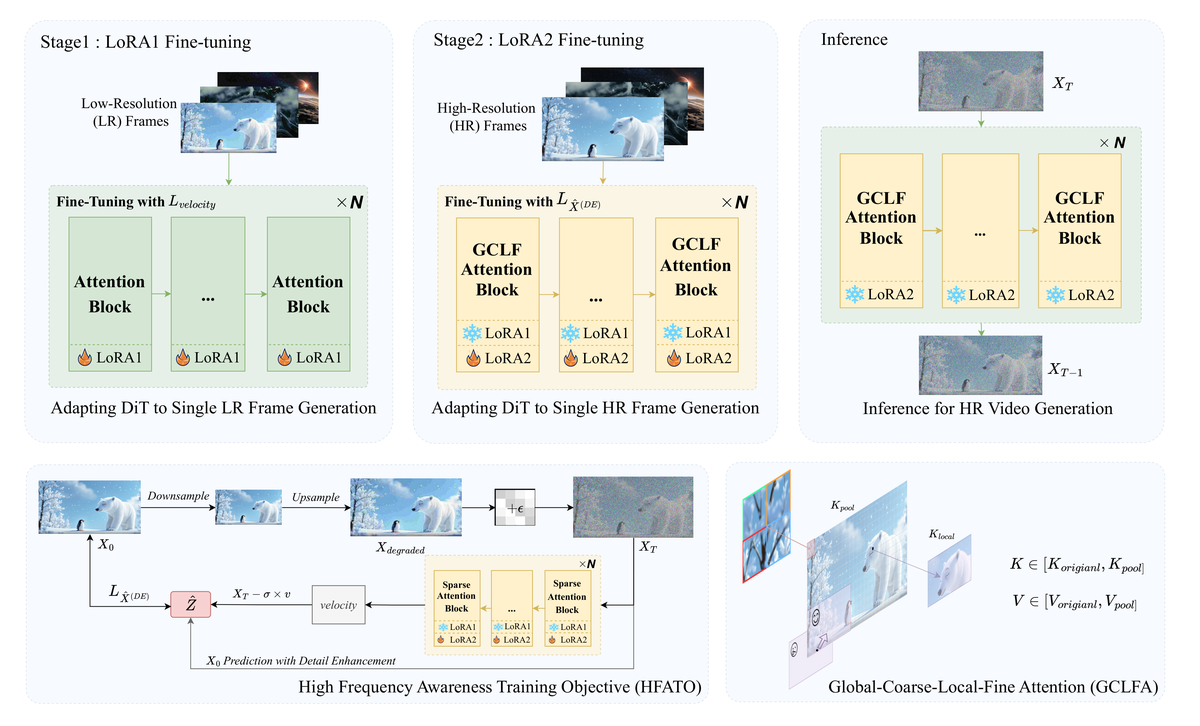
提出纯图像适应框架,通过 Relay LoRA 两阶段策略升级视频 DiT。第一阶段:用低分辨率图像将视频扩散模型适应到图像域,弥合模态差距。第二阶段:用高分辨率图像进一步适应以获得空间外推能力。推理时仅保留高分辨率适应,保持视频生成模态。另外提出高频感知训练目标(HF-ATO),通过专用重建损失显式鼓励模型从退化潜在表示中恢复高频细节。
核心问题: 如何在不使用视频数据的情况下实现超高分辨率视频合成
前序工作及局限:
与前序工作的本质区别: ViBe 提出 Relay LoRA 两阶段策略解耦模态对齐和空间外推,HF-ATO 恢复高频细节
技术演进定位: 挑战了视频训练的必要性,开辟了纯图像数据提升视频质量的新路径
可能的后续方向:
一步逆变换加速少步扩散修复 | VinAI Research | CVPR 2026 | arXiv:2603.23463
关键词: 图像修复, 少步扩散, 一步逆变换, 语义对齐噪声, CVPR 2026
基于扩散的图像修复模型虽然实现了照片级真实感,但需要大量采样步骤。少步文本到图像模型提供更快生成速度,但直接用于修复会导致背景和修复区域之间的协调性差和伪影。问题根源在于随机高斯噪声初始化,在低函数评估次数下会导致语义错位和保真度降低。
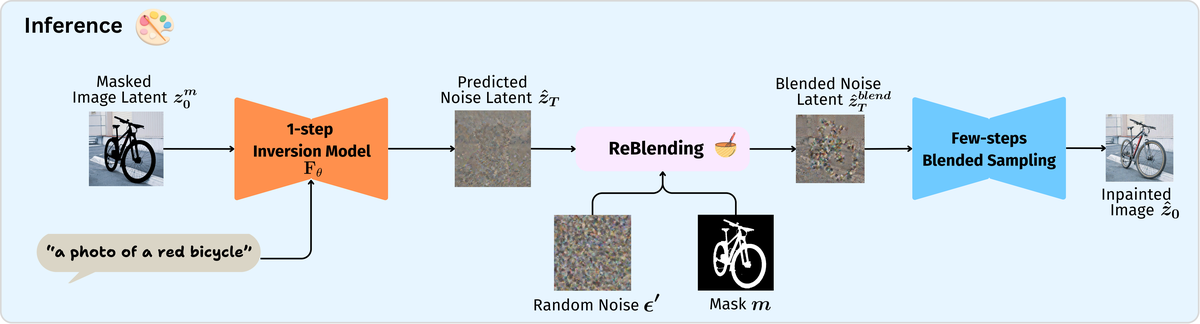
提出 InverFill,一种专为修复定制的一步逆变换方法。将输入掩码图像的语义信息注入到初始噪声中,实现高保真少步修复。利用少步 T2I 模型在混合采样管线中处理,以语义对齐噪声作为输入。不需要训练修复模型,不需要真实图像监督,只增加极小推理开销。
核心问题: 如何在极少采样步数下实现高质量图像修复
前序工作及局限:
与前序工作的本质区别: InverFill 通过一步逆变换将掩码图像语义注入噪声,解决少步下的语义错位
技术演进定位: 少步扩散修复的即插即用加速方案,CVPR 2026
可能的后续方向:
UniGRPO 的极简集成策略展示了一条清晰的技术路线:在统一模型中,针对不同模态使用各自成熟的优化方法,通过共享奖励信号统一训练。这种模块化思路可能比重新设计全新算法更实用。
ViBe 证明了纯图像数据+精心设计的适应策略就能超越用视频数据训练的模型。这一发现可能引发对数据策略的重新思考:高质量图像数据的价值可能被低估了。
InverFill 揭示了少步扩散中一个长期被忽视的问题——随机噪声初始化是质量下降的根本原因。这一洞察可能推动更多研究关注「智能初始化」而非仅仅关注采样策略。
| # | 论文 | 机构 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|---|
| 1 | Group Editing (Edit Multiple Images in One Go) | 多图编辑 · 几何对应 · CVPR 2026 | 利用 VGGT 几何对应和伪视频时序先验实现多图一致性编辑,构建大规模 GroupEditData 数据集,CVPR 2026 论文。 | 首次实现多视图一致性编辑,在多图编辑质量和一致性上显著超越现有方法 | |
| 2 | Dress-ED (Instruction-Guided Editing for Virtual Try-On and Try-Off) | 虚拟试穿 · 服装编辑 · 大规模基准 | 首个统一虚拟试穿、脱衣和文本引导服装编辑的大规模基准(146K 四元组),含多模态扩散基线框架。 | 提供 146K 高质量四元组数据集,多模态扩散基线在三项任务上达到强性能 | |
| 3 | VHS (Tiny Inference-Time Scaling with Latent Verifiers) | 推理加速 · 潜在验证器 · DiT | 直接在 DiT 中间隐藏状态上操作轻量验证器进行推理时缩放,无需完整解码即可评估生成质量。 | 减少 63% 推理时间和 51% FLOPs,GenEval 提升 2.7%,高效推理时质量筛选 | |
| 4 | FG-Portrait (3D Flow Guided Editable Portrait Animation) | 肖像动画 · 3D 流引导 · CVPR 2026 | 引入 3D 流作为几何驱动运动对应,通过深度引导采样和 3D 流编码实现高保真可编辑肖像动画,CVPR 2026。 | 在肖像动画质量和可编辑性上超越现有方法,支持表情/头部姿态精细控制 | |
| 5 | InterDyad (Interactive Dyadic Speech-to-Video Generation) | 语音到视频 · 双人交互 · MLLM | 基于 MLLM 提取语言意图和角色感知双高斯引导,实现交互式双人语音到视频生成的自然动力学合成。 | 首次实现双人交互式语音到视频生成,自然对话动力学模拟逼真 | |
| 6 | Zero-Shot Personalization (Personalization of Objects via Textual Inversion) | 零样本个性化 · 文本逆变换 · 免训练 | 学习网络预测物体专属文本逆变换嵌入,单次前向实现任意物体的零样本个性化生成,首个通用免训练方案。 | 单次前向即可实现高质量个性化生成,无需每个物体微调,通用性强 | |
| 7 | MuQ-Eval (Open-Source Per-Sample Quality Metric for AI Music Generation) | 音乐质量评估 · 开源指标 · MuQ | 开源的逐样本 AI 音乐质量评估指标,基于冻结 MuQ-310M 特征实现高精度质量评分。 | 系统级 SRCC=0.957,单曲级 SRCC=0.838,为 AI 音乐评估提供标准工具 | |
| 8 | Q-Tacit (Image Quality Assessment via Latent Visual Reasoning) | 图像质量评估 · 潜在推理 · 结构化先验 | 提出潜在质量空间推理新范式,注入结构化视觉质量先验并校准推理轨迹,用更少 token 实现强 IQA 性能。 | 用更少 token 达到 SOTA 级图像质量评估性能,推理效率显著提升 | |
| 9 | RealMaster (Lifting Rendered Scenes into Photorealistic Video) | 渲染转真实 · 视频扩散 · IC-LoRA | 利用视频扩散模型将 3D 引擎渲染视频提升为逼真视频,通过锚点传播和 IC-LoRA 保持完整几何对齐。 | 将合成渲染视频转化为逼真视频,保持完整几何对齐和时间一致性 |
人工智能炼丹师 整理 | 2026-03-26


评论 (0)