
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 12 篇论文 | 重点深度解读 3 篇
今日 arXiv cs.CV 视觉生成相关论文共 12 篇,重点解读 3 篇。
方向分布:
CVPR 2026 × 2 | 新方法 × 10
最大开源图像编辑数据集 | 上交/港中文 | arXiv:2603.20644
关键词: 图像编辑数据集, 多智能体, 1200万样本, 23个任务族
基于指令的图像编辑是统一多模态模型(UMM)的关键能力,但构建大规模、多样化且高质量的编辑数据集面临两大挑战:依赖闭源API(如GPT-4V)标注成本极高,固定合成流水线质量有限且泛化能力差。现有开源编辑数据集规模和多样性远不能满足训练需求。
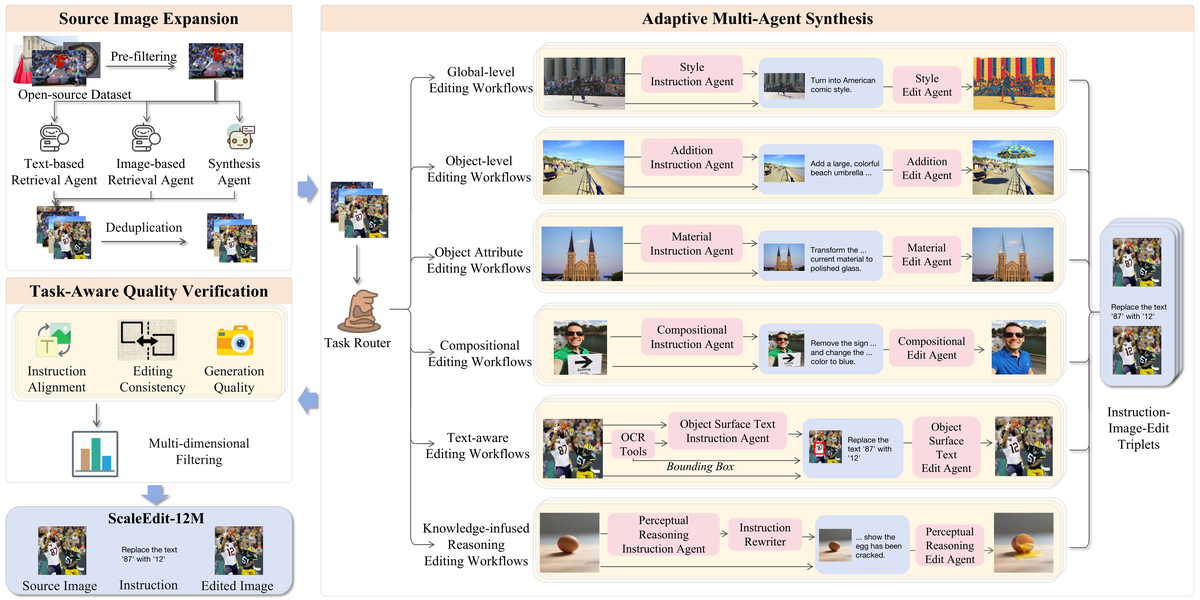
ScaleEditor 是一个完全开源的分层多智能体框架,实现端到端的大规模图像编辑数据集构建。整个流水线包含三个关键组件:(1) 融入世界知识的源图像扩展——通过多智能体协作从互联网和合成数据中收集覆盖多样场景的高质量源图像;(2) 自适应多智能体编辑指令-图像合成——多个专业化智能体分别负责生成编辑指令、执行图像变换、进行质量验证,根据不同编辑类型自适应选择最优工作流;(3) 任务感知的数据质量验证机制——针对23个编辑任务族设计差异化质量校验标准,确保每个样本的编辑准确性和自然度。最终整理出 ScaleEdit-12M,跨越23个任务族(包括颜色编辑、风格迁移、物体添加/删除、背景替换等),涵盖真实和合成域。
核心问题: 开源图像编辑数据集规模有限且依赖闭源API
前序工作及局限:
与前序工作的本质区别: ScaleEdit-12M 用全开源多智能体框架替代闭源API,规模扩大3x+,覆盖23个任务族
技术演进定位: 开源编辑数据集的新里程碑,降低整个社区的数据壁垒
可能的后续方向:
跨时间步自校准 | CVPR 2026 | arXiv:2603.20741
关键词: T2I对齐, 跨时间步校准, 交叉注意力, CVPR 2026
文生图扩散模型在文本与图像的精确对齐方面仍面临持续挑战。传统扩散损失仅提供隐式监督来建模细粒度的文本-图像对应关系,这是对齐困难的根本原因。随着时间步增大(噪声增多),建立准确的文本-图像对齐变得越来越困难,低噪声阶段形成的交叉注意力图是可靠的,但高噪声阶段的注意力图容易偏离,现有方法缺乏显式的跨时间步知识传递机制。
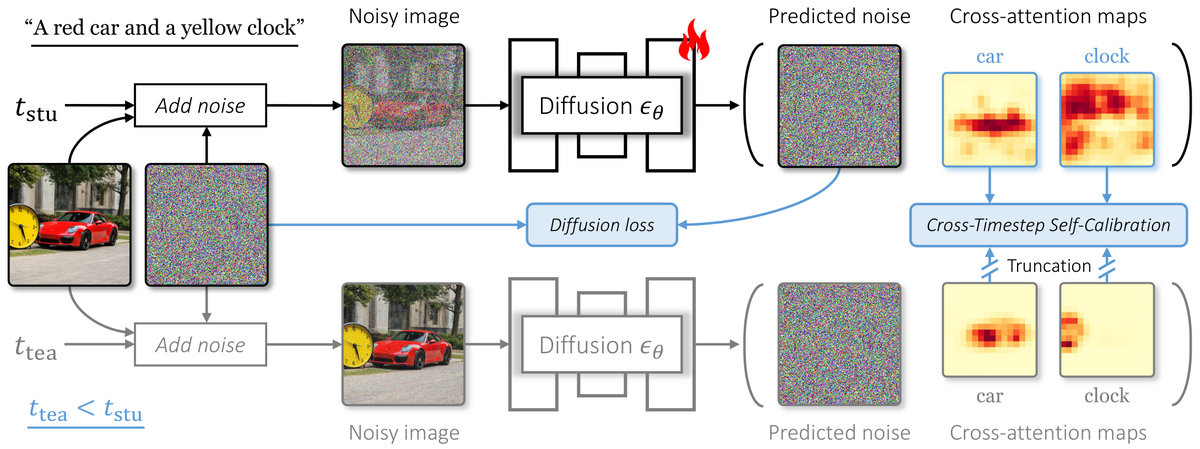
CTCal(Cross-Timestep Self-Calibration)利用低噪声时间步下形成的可靠文本-图像对齐来校准高噪声时间步的表示学习。核心原理:(1) 观察到交叉注意力图在小时间步(噪声少)时准确反映文本-图像对应关系,而大时间步(噪声多)时容易偏差;(2) 将小时间步的注意力图作为「自校准信号」,在训练期间为大时间步提供显式的对齐监督;(3) 提出时间步感知自适应加权机制,根据时间步动态调整 CTCal 损失与标准扩散损失的权重比例,在不同去噪阶段实现最优平衡;(4) 模型无关设计——可无缝集成到基于扩散的模型(如 SD 2.1)和基于 Flow 的模型(如 SD 3)。
核心问题: 扩散模型的文本-图像对齐在高噪声阶段容易偏差
前序工作及局限:
与前序工作的本质区别: CTCal 首次利用跨时间步注意力自校准提供显式对齐监督
技术演进定位: 训练阶段文图对齐优化的新范式
可能的后续方向:
内存高效微调扩散DiT | CVPR 2026 | arXiv:2603.20755
关键词: DiT微调, 内存高效, 块跳过, 设备端部署, CVPR 2026
扩散 Transformer(DiT)显著提升了文生图质量,使高质量个性化内容创作成为可能。然而,微调这些大模型需要巨大的计算复杂性和内存开销,严重限制了在资源受限环境(如智能手机、IoT 设备)下的实际部署。现有方法要么需要完整的梯度计算(内存爆炸),要么牺牲了个性化效果。
DiT-BlockSkip 提出一个内存高效的微调框架,集成两大核心机制:(1) 时间步感知动态补丁采样——根据扩散时间步自适应调整补丁大小:高时间步(早期去噪)用大补丁捕获全局结构,低时间步(后期细化)用小补丁聚焦细粒度细节,裁剪后的补丁统一调整为固定低分辨率,显著降低前向和反向的内存消耗;(2) 基于预计算残差的块跳过机制——利用交叉注意力掩码识别对个性化关键的 Transformer 块,仅对这些块进行微调,跳过的块使用预计算的残差特征(一次性离线计算),大幅减少训练内存。两个机制协同工作,实现在显著降低内存的同时保持竞争力的个性化性能。
核心问题: 大规模扩散Transformer微调内存开销过高
前序工作及局限:
与前序工作的本质区别: DiT-BlockSkip 将时间步感知与块选择结合,训练阶段大幅压缩内存
技术演进定位: DiT 设备端部署的重要一步
可能的后续方向:
ScaleEdit-12M 将开源编辑数据推至千万级,23 个任务族全覆盖,ImgEdit +10.4%
CTCal 跨时间步自校准——低噪声注意力图校准高噪声表示,模型无关
DiT-BlockSkip 动态补丁+块跳过双管齐下,推动 DiT 走向设备端
| # | 论文 | 关键词 | 主要贡献 | 效果 |
|---|---|---|---|---|
| 1 | InjectFlow (Weak Guides Strong via Orthogonal Injection for Flow Matching) | Flow Matching · 偏差修复 · 免训练 | 形式化了 Flow Matching 的「偏差流形」问题,提出 InjectFlow 通过在初始速度场中注入正交语义(无需训练/改种子)修复轨迹锁定。在 GenEval 上修复了标准 FM 模型 75% 的失败提示。 | GenEval 修复率 75%,免训练即插即用,为构建更公平鲁棒的视觉基础模型提供理论和实践方案 |
| 2 | Premier (Personalized Preference Modulation with Learnable User Embedding in T2I) | 个性化T2I · 偏好嵌入 · 哈工大 | 提出可学习用户偏好嵌入和偏好适配器,将用户偏好与文本提示融合调制生成过程。引入分散损失强制分离不同用户嵌入。新用户可通过已有嵌入线性组合快速泛化。哈工大团队。 | 在相同历史长度下超越先前方法,实现更强的偏好对齐和文本一致性 |
| 3 | SGG (Improving Diffusion Generalization with Weak-to-Strong Segmented Guidance) | 扩散引导 · 弱到强 · SD3 | 从弱到强原则分离 CFG 和 AutoGuidance 的有效操作区间,提出混合实例 SGG 结合两者优势。W2S 原则可迁移到训练目标,在 SD3 和 SD3.5 上超越现有免训练引导变体。 | SD3/SD3.5 上超越 CFG 和 AutoGuidance 等现有引导方法,开源代码 |
| 4 | DiffMark (Transferable Multi-Bit Watermarking Across Frozen Diffusion Models via Latent Consistency Bridges) | 扩散水印 · 跨模型迁移 · LCM | 即插即用的扩散模型多比特水印方法:利用 Latent Consistency Models 作为可微训练桥梁,梯度步数从 50 步压缩到 4 步。单次前向传递检测(16.4ms,比采样法快 45 倍),支持跨模型迁移。 | 16.4ms 检测速度(45x加速),保持鲁棒性,跨冻结扩散模型可迁移 |
| 5 | MFSR (MeanFlow Distillation for One Step Real-World Image Super Resolution) | 超分辨率 · 一步蒸馏 · MeanFlow | 基于 MeanFlow 蒸馏的一步式真实世界图像超分辨率。学生模型学习近似 PF-ODE 任意状态间的平均速度,配合教师 CFG 蒸馏保留精细细节。一步即可生成逼真结果,可选少步路径进一步细化。 | 一步生成质量与多步教师模型相当甚至更优,显著降低计算成本 |
| 6 | EARTalking (End-to-end GPT-style Autoregressive Talking Head Synthesis with Frame-wise Control) | 数字人生成 · 自回归 · 逐帧控制 | 端到端 GPT 风格自回归模型实现交互式音频驱动数字人生成。提出 Sink Frame Window Attention (SFA) 保持变长视频的身份一致性,Frame Condition In-Context (FCIC) 支持逐帧交互式控制信号注入。 | 性能优于现有自回归方法,与扩散方法相当,支持流式生成和实时交互控制 |
| 7 | OmniCodec (Low Frame Rate Universal Audio Codec with Semantic-Acoustic Disentanglement) | 音频编解码 · 语义解耦 · 低帧率 | 面向低帧率的通用神经音频编解码器。分层多码本设计,利用预训练理解模型音频编码器实现语义-声学解耦。自引导策略提升码本利用率。在相同比特率下超越 Mimi 编解码器,提供更优重建质量和更丰富语义表示。 | 相同比特率超越 Mimi,重建质量+语义丰富度双提升,利好下游 LLM 音频生成 |
| 8 | SqueezeComposer (Temporal Speed-up is A Simple Trick for Long-form Music Composing) | 长音乐生成 · 时间加速 · 扩散模型 | 提出「时间加速」策略:先让模型生成加速版本(2x-8x)的音乐以减少序列长度和资源需求,再恢复到原始速度。在加速域用扩散模型生成,在恢复域细化。简单技巧实现高效可扩展的长音乐生成。 | 高效生成长篇连贯音乐,资源需求与短音乐相当,质量保持 |
| 9 | SelfTTS (Cross-Speaker Style Transfer through Explicit Embedding Disentanglement and Self-Refinement) | 跨说话人TTS · 风格迁移 · 自细化 | 无需外部预训练编码器的跨说话人风格迁移 TTS。利用梯度反转层(GRL)+余弦相似度损失实现说话人与情感的显式解耦,多正对比学习(MPCL)诱导嵌入聚类,自增强自细化策略利用模型自身的语音转换能力提升自然度。 | 在跨说话人情感风格迁移上超越基线,无需外部预训练编码器,自包含设计 |
人工智能炼丹师 整理 | 2026-03-25
评论 (0)