搜索到
64
篇与
人工智能炼丹师
的结果
-
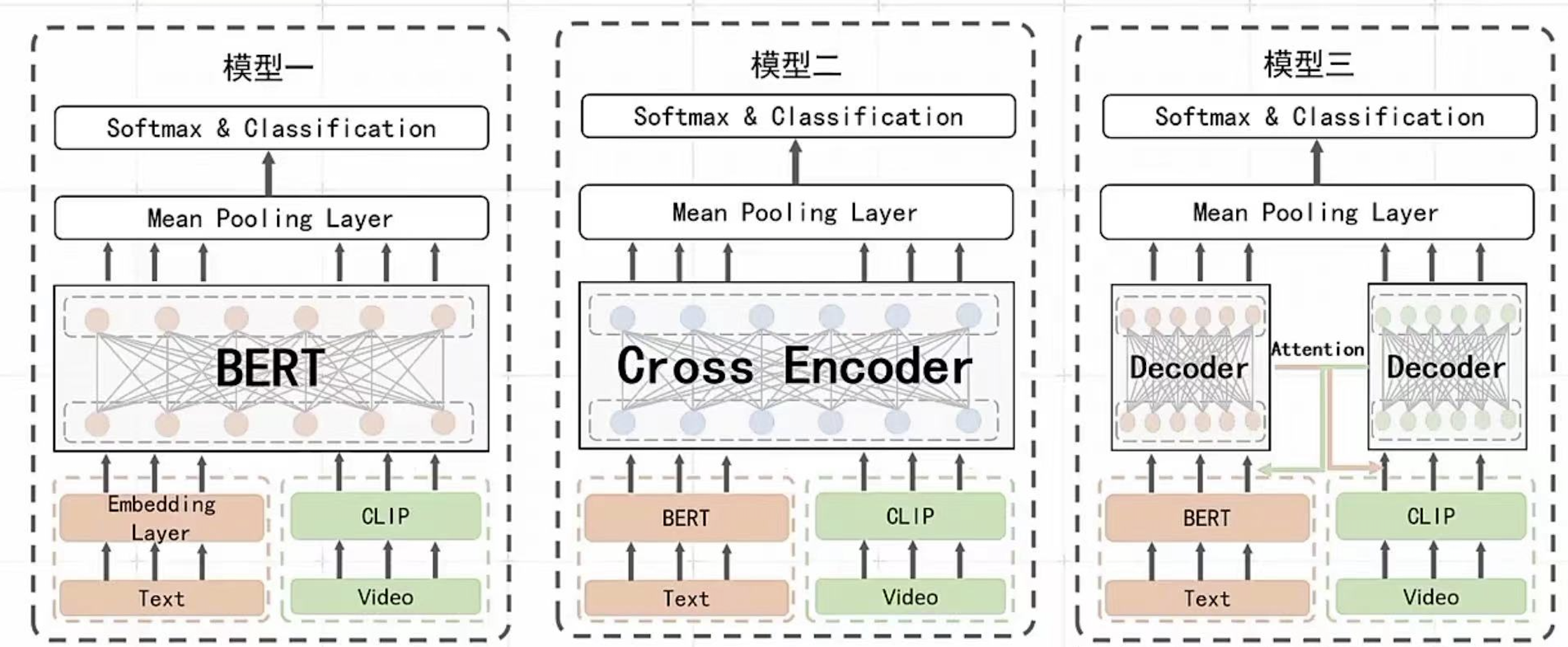
 2022年微信大数据比赛(多模态短视频分类)总结 写在前面 今天(2022.09.17), 微信大数据比赛进行了现场决赛答辩。由于工作内容和比赛比较相关,所以一直有关注。简单总结下听完线上现场答辩直播后的一些感受。近年来随着短视频的发展,多模态视频分类任务变得越来越火,多模态分类算法方案从最开始的: 多模态特征提取后简单concat拼接的baseline方案,演进到目前主流采用在大规模数据下进行预训练方式,来充分利用无标注数据获取更好的特征表示和将不同模态特征对齐,参赛选手都是基于预训练+Finetune方式来做的,但答辩现场给我影响最深刻的就是,评委张正友老师谈到的: 选手针对赛题本身问题做的优化太少。我们在做算法优化的时候,应该优先去做哪些算法优化点, 我相信这也是算法工程师经常遇到的问题。本文主要围绕这个谈谈个人的想法,最后总结下比赛中多模态分类里的一些上分优化点。 从数据分析问题出发还是“无脑堆好模型”? 这道赛题的难点如果去做数据分析,我们大概率会发现是这些问题:1) 数据类别分布不均衡;2) ASR/OCR/Title文本数据存在噪声(识别不准确 + 标签党视频文本不匹配等等),直接做对视频/文本对比学习可能噪声大;3)ASR/OCR相比较于标题而言噪声更大,如何区分处理不同类型的文本;4)标签体系是层次的,包括一级分类和二级分类,做层次分类可能对比模型精度能够有提升 5)标注数据GT是有噪声的, 如何做带噪学习训练,和标签数据清洗等方面。6) 如何利用大量无标注数据。这类问题每个都能找到很多论文来解决,但到底最后能对最终的评测指标能有多少提升却很难准确预估。 比赛的第一名GDY的方案,最大的不同的地方是利用单流/双流等差异性足够大的模型做集成,最后再利用模型蒸馏的想法将未标注的数据集利用起来。想法其实也很简单,利用好而不同的模型集成和模型蒸馏也是教科书里面会涉及的知识点,但就是这拉开了和其他选手之间的比分差距。对于数据分析能表现出来的问题,没有在最终方案中体现出来。比如数据不均衡问题,第一名没有做特殊处理优化,只是简单地使用了训练数据类别重采样,和利用蒸馏得到的伪标签样本进行类别平衡。 所以,这就引发我思考: 我们在做算法优化的时候,应该优先去做哪些算法优化。基于数据分析问题出发,还是直接无脑把先各种最好的模型堆叠起来,去快速不断尝试刷新指标。如果基于数据分析到的问题来解决问题,我们可能会采取以下一些方案: 比如标注数据GT带噪,可能最无脑的方式是顾一大批人,来人工把数据智能清洗一遍(有钱好办事) 更高效一点的方式,是利用聚类算法,基于规则对数据进行清洗 偏学术的做法,基于带噪训练的框架, 选择对噪声更鲁邦的损失函数等 这些针对具体问题出发的解决方法和“选择一个更好的模型”,那个应该优先做?对于选手来说,在限定时间的比赛阶段来看,能够快速做模型迭代是很重要的。对在岗工程师而言,如果抓不住主要矛盾,而导致项目不能在deadline前完成也不好交差。 一些想法(欢迎留言讨论) 我觉得 数据分析 + 堆好模型两个都很重要,在不同的时期,需要给两者分配不同的权重 1.项目初期: 数据分析很重要,把事情做对而不是做最好。在工业界做算法开发,不像参加比赛,已经有人给我们准备好了训练和测试集。这些都需要我们自己构建(或外包标注团队),标注数据很可能有错标/缺失的问题,这个时候我们需要结合数据分析把数据做对,而不是疯狂堆好模型。不同的模型在有问题的数据上的测试结果可能就是随机数,不可信。 2.项目中期: 抓住主要矛盾,优先做最大投入产出比的事。 这个时候不能陷入到细节中,要有大局意识,找到投入产出比最大的方面进行优化。但如何找到主要矛盾也是门学问,我觉得主要依赖两点: 足够的经验积累和有效的数据分析。在比赛中,我们无法通过数据分析提前知道模型蒸馏是不是投入产出比最大的优化点,这部分只能试,但试的前提的有自己的insight,知道为什么试这个方案,这个方案预期能带来哪些增益,这就依赖于我们历史积累的经验和读过的论文来大致估计这部分的增益。数据分析也是项目中期需要特别关心的。包括混淆矩阵/PR指标/具体badcase归类等。 3.项目后期: 问题针对性优化,到这个时候已经基本满足业务需求了,基本是精益求精的时候,就更需要结合具体问题逐个击破(对于业务而言,这个时候再做任何模型优化,可能投入产出比并不大~) 多模态分类算法优化点总结 下面主要从数据处理、模型选取、优化tricks、模型集成等方面归纳总结下方案 1.数据处理: 视频抽帧在训练阶段随机采样,增加训练的多样性 文本可以采用分词而不是分字的方式,缓解文本长度过长问题,roberta-base-word-chinese-cluecorpussmall 2.模型选取: 模型选取,能选large就不选base,选择预训练数据集大和模型规模大的模型(clip-large) R2D2 参考BEIT3等 3.优化tricks防止过拟合: EMA模型平均,这个按经验一般有1%左右提升 FGM 文本对抗训练 Finetune时加预训练任务防止过拟合 RDrop: 一致性约束 4.模型集成: 好而不同,选择差异性大的好模型进行集成(单流&双流), 有利于模型蒸馏; 只用单个模型预测的伪标签,自己学自己,提升效果可能不理想 5.模型加速 TensorRT量化,可用选择对backbone模型进行量化,具体的分类模型在量化后的特征上进行训练,以保证精度不降的情况下提升模型推理效率 FasterTransformer Fp16推理 6.预训练任务选择 选手基本都是基于后验评测指标来综合考虑是否加mlm/mfm/vtm等预训练任务 参考链接 复赛结束后微信群内参赛选手讨论内容
2022年微信大数据比赛(多模态短视频分类)总结 写在前面 今天(2022.09.17), 微信大数据比赛进行了现场决赛答辩。由于工作内容和比赛比较相关,所以一直有关注。简单总结下听完线上现场答辩直播后的一些感受。近年来随着短视频的发展,多模态视频分类任务变得越来越火,多模态分类算法方案从最开始的: 多模态特征提取后简单concat拼接的baseline方案,演进到目前主流采用在大规模数据下进行预训练方式,来充分利用无标注数据获取更好的特征表示和将不同模态特征对齐,参赛选手都是基于预训练+Finetune方式来做的,但答辩现场给我影响最深刻的就是,评委张正友老师谈到的: 选手针对赛题本身问题做的优化太少。我们在做算法优化的时候,应该优先去做哪些算法优化点, 我相信这也是算法工程师经常遇到的问题。本文主要围绕这个谈谈个人的想法,最后总结下比赛中多模态分类里的一些上分优化点。 从数据分析问题出发还是“无脑堆好模型”? 这道赛题的难点如果去做数据分析,我们大概率会发现是这些问题:1) 数据类别分布不均衡;2) ASR/OCR/Title文本数据存在噪声(识别不准确 + 标签党视频文本不匹配等等),直接做对视频/文本对比学习可能噪声大;3)ASR/OCR相比较于标题而言噪声更大,如何区分处理不同类型的文本;4)标签体系是层次的,包括一级分类和二级分类,做层次分类可能对比模型精度能够有提升 5)标注数据GT是有噪声的, 如何做带噪学习训练,和标签数据清洗等方面。6) 如何利用大量无标注数据。这类问题每个都能找到很多论文来解决,但到底最后能对最终的评测指标能有多少提升却很难准确预估。 比赛的第一名GDY的方案,最大的不同的地方是利用单流/双流等差异性足够大的模型做集成,最后再利用模型蒸馏的想法将未标注的数据集利用起来。想法其实也很简单,利用好而不同的模型集成和模型蒸馏也是教科书里面会涉及的知识点,但就是这拉开了和其他选手之间的比分差距。对于数据分析能表现出来的问题,没有在最终方案中体现出来。比如数据不均衡问题,第一名没有做特殊处理优化,只是简单地使用了训练数据类别重采样,和利用蒸馏得到的伪标签样本进行类别平衡。 所以,这就引发我思考: 我们在做算法优化的时候,应该优先去做哪些算法优化。基于数据分析问题出发,还是直接无脑把先各种最好的模型堆叠起来,去快速不断尝试刷新指标。如果基于数据分析到的问题来解决问题,我们可能会采取以下一些方案: 比如标注数据GT带噪,可能最无脑的方式是顾一大批人,来人工把数据智能清洗一遍(有钱好办事) 更高效一点的方式,是利用聚类算法,基于规则对数据进行清洗 偏学术的做法,基于带噪训练的框架, 选择对噪声更鲁邦的损失函数等 这些针对具体问题出发的解决方法和“选择一个更好的模型”,那个应该优先做?对于选手来说,在限定时间的比赛阶段来看,能够快速做模型迭代是很重要的。对在岗工程师而言,如果抓不住主要矛盾,而导致项目不能在deadline前完成也不好交差。 一些想法(欢迎留言讨论) 我觉得 数据分析 + 堆好模型两个都很重要,在不同的时期,需要给两者分配不同的权重 1.项目初期: 数据分析很重要,把事情做对而不是做最好。在工业界做算法开发,不像参加比赛,已经有人给我们准备好了训练和测试集。这些都需要我们自己构建(或外包标注团队),标注数据很可能有错标/缺失的问题,这个时候我们需要结合数据分析把数据做对,而不是疯狂堆好模型。不同的模型在有问题的数据上的测试结果可能就是随机数,不可信。 2.项目中期: 抓住主要矛盾,优先做最大投入产出比的事。 这个时候不能陷入到细节中,要有大局意识,找到投入产出比最大的方面进行优化。但如何找到主要矛盾也是门学问,我觉得主要依赖两点: 足够的经验积累和有效的数据分析。在比赛中,我们无法通过数据分析提前知道模型蒸馏是不是投入产出比最大的优化点,这部分只能试,但试的前提的有自己的insight,知道为什么试这个方案,这个方案预期能带来哪些增益,这就依赖于我们历史积累的经验和读过的论文来大致估计这部分的增益。数据分析也是项目中期需要特别关心的。包括混淆矩阵/PR指标/具体badcase归类等。 3.项目后期: 问题针对性优化,到这个时候已经基本满足业务需求了,基本是精益求精的时候,就更需要结合具体问题逐个击破(对于业务而言,这个时候再做任何模型优化,可能投入产出比并不大~) 多模态分类算法优化点总结 下面主要从数据处理、模型选取、优化tricks、模型集成等方面归纳总结下方案 1.数据处理: 视频抽帧在训练阶段随机采样,增加训练的多样性 文本可以采用分词而不是分字的方式,缓解文本长度过长问题,roberta-base-word-chinese-cluecorpussmall 2.模型选取: 模型选取,能选large就不选base,选择预训练数据集大和模型规模大的模型(clip-large) R2D2 参考BEIT3等 3.优化tricks防止过拟合: EMA模型平均,这个按经验一般有1%左右提升 FGM 文本对抗训练 Finetune时加预训练任务防止过拟合 RDrop: 一致性约束 4.模型集成: 好而不同,选择差异性大的好模型进行集成(单流&双流), 有利于模型蒸馏; 只用单个模型预测的伪标签,自己学自己,提升效果可能不理想 5.模型加速 TensorRT量化,可用选择对backbone模型进行量化,具体的分类模型在量化后的特征上进行训练,以保证精度不降的情况下提升模型推理效率 FasterTransformer Fp16推理 6.预训练任务选择 选手基本都是基于后验评测指标来综合考虑是否加mlm/mfm/vtm等预训练任务 参考链接 复赛结束后微信群内参赛选手讨论内容 -
-
图像自监督预训练小结(2016-2021) 早期方案(2016-2018)通过设计代理任务实现自监督训练,包括预测周围图像块的相对位置(转化为九宫格的分类问题),预测图像的旋转角度等 中期方案(2019-2021)基于对比学习的方法,通过构造正负样本对(正样本对为同一张图片的不同数据增广构成的两张图片,负样本对为不同图片),拉近正样本对特征之间的距离,拉远负样本对特征之间之间的距离。采用InfoNCE作为损失函数。主要包括像MoCo(v1-v3)、SimCLR、BYOL、SwAV、SimSiam 近期方案(2021-现在)主要将NLP中掩码机制(mask部分区域,模型对masked的区域进行预测,类似完形填空)成功地借鉴到CV领域,按照时间顺序,主要有BEiT、MAE、SimMIM、MaskFeat等系列工作 参考文献 自监督学习系列(一):基于 Pretext Task 自监督学习系列(二):基于 Contrastive Learning 自监督学习系列(三):基于 Masked Image Modeling 自监督学习代码库 MMSelfSup
-
Pytorch DDP 1. Pytorch DDP 使用大致流程 使用 torch.distributed.init_process_group 初始化进程组 使用 torch.nn.parallel.DistributedDataParallel 创建 分布式模型 使用 torch.utils.data.distributed.DistributedSampler 创建 DataLoader 2. Pytorch DDP 训练报错信息 [W reducer.cpp:346] Warning: Grad strides do not match bucket view strides. This may indicate grad was not created according to the gradient layout contract, or that the param's strides changed since DDP was constructed. This is not an error, but may impair performance. Expected to mark a variable ready only once. RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. 3. DDP多卡训练需要主要事项? 为每个进程设置不同的随机种子 使用syncBN DistributedSampler 多进程的日志管理,文件创建管理,目录创建管理等 4. DDP 单机多卡卡住问题(hang/stuck/dead lock) 现象: GPU利用率100%,但是程序一直没有输出。 (1) 限制单进程并发数(无效) torch.set_num_threads(4) (2) 设置find_unused_parameters为True model = torch.nn.parallel.DistributedDataParallel(model, device_ids=[int(args.local_rank)], output_device=int(args.local_rank), find_unused_parameters=True) # find_unused_parameters 的含义: 查找未用于计算损失的参数 (3) 排查NCCL问题? # 设置环境变量,看是否有更多的信息输出,更多环境变量参考 # https://docs.nvidia.com/deeplearning/nccl/user-guide/docs/env.html export NCCL_DEBUG=INFO export NCCL_DEBUG_SUBSYS=ALL (4) 在不同GPU上,部分分支的输出结果未参与损失计算 报错信息: RuntimeError: Expected to have finished reduction in the prior iteration before starting a new one. 由于过滤了样本,只有当样本满足一定条件下才计算损失(比如回归任务中,只有当pred与gt在一定范围内才计算损失),会导致不同GPU上,缺少梯度计算,导致导致程序假死 参考文献 Pytorch官方文档 Pytorch官方教程 Pytorch多gpu并行训练教程 DDP系列第一篇:入门教程 DDP系列第二篇:实现原理与源代码解析 DDP系列第三篇:实战与技巧 pytorch 多机多卡卡住问题汇总 PyTorch 源码解读之 DP & DDP:模型并行和分布式训练解析 https://discuss.pytorch.org/t/distributed-data-parallel-freezes-without-error-message/8009
-
Video Understanding Dataset 1. 视频理解数据集概览 2. 数据集详情介绍 SoccerNet HVU ICCV 2019, tag list THUMOS14 THUMOS Challenge 2014 训练集:UCF101,101种动作类别,共13320剪辑的视频片段;验证集:1010未剪辑视频,其中200个有时序标注(3007个行为段,包含20类行为);测试集:1574未剪辑视频,其中213个有时序标注(3358个行为段)。 ActivityNet CVPR2015 包含分类、检测任务,包含200个动作类别,20000多视频(训练10024+验证4926+测试5044)。 Charades 2016 主要包含9848个未剪辑的室内视频(训练7985+1863测试),包含157个类别及267不同的人物,每段视频大约30秒。 AVA 2018 包含430个15分钟电影剪辑片段及标注80类动作。有386,000个标记的片段,614,000个标记的边界框和81,000条人迹。 总共有158万个带有标签的动作,每个人经常有多个标签。 MovieNet ECCV2020 Moments-in-time ICCV2019 Opps CVPR2020 异常动作时间定位数据集 3. 参考文献 视频理解公开数据集
-
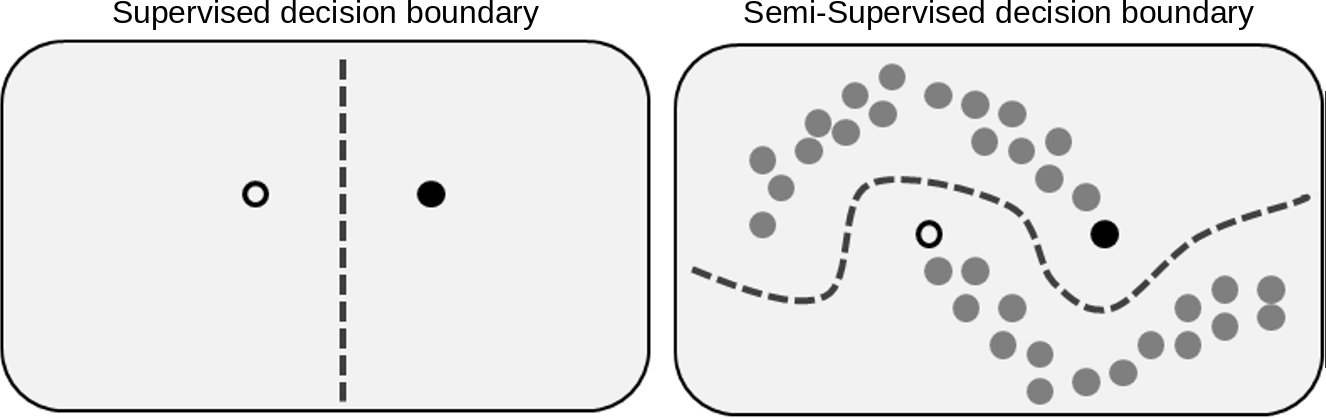
Semi-Supervised + Noisy Label 为什么要做半监督(SSL)+带噪学习(Noisy Label): 标注成本高,数据标注周期长。真实业务场景拥有大量无标注数据。探索自监督(任务无关)+半监督(任务相关)相结合的训练范式 标签体系调整带来的训练数据整合问题。最直接的想法是利用少量新增标签标注数据训练,并在原有体系上预测出伪标签进行数据整合,本质是半监督学习的一种最简单、常用的方法(Pseudo Label) 多标签容易出现漏标、错标问题。即使有多次人工审核的情况下。大多数半监督算法(例如伪标签)生成的标签通常的带有噪声,进而影响模型训练 图片半监督学习 半监督学习SSL (Semi-Supervised Learning)概览 1. 定义: 半监督模型主要研究如何利用大量未标注的数据,提升模型的泛化能力,并且利用少量标注数据,减少标注人力。半监督之所以能够有效的关键原因在于,未标注数据提供了更多的数据分布信息,使得决策边界可以避免穿过数据高密度区域,提升模型的泛化性能,如下图所示,黑白点为单个有标注的两个类别数据,灰色为未标注的标签数据。只利用两个有标注数据学习出来的决策边界,在右图的数据分布下不会是一个好的决策边界: **2. 两种主流使用未标注数据的方式:半监督学习 vs 自监督学习。**半监督学习相关工作主要研究集中在视觉领域,而自监督学习预训练 + 下游特定任务Finetune, 是在NLP领域被广泛应用的方式。二者的相同点都是利用无标签的数据进行学习,不同点在于半监督学习是结合具体下游任务进行训练的,而自监督学习是学习一个通用的特征表示,和下游任务无关,导致预训练任务学习的特征在下游任务并不完全适用(**主流基于对比学习的自监督方法,同一个类别的不同样本,被强制拉远特征之间的距离,可能与下游分类任务相违背**)。自监督预训练和半监督学习结合进行下游任务适配学习,会是更好的解决方案(SimCLR v2, NIPS 2020; CoMatch, ICCV2021) ## 主要研究方向 半监督方法可大致分为以下几种: 本文主要介绍前四种主流算法, 基于生成式和图方法的两个研究方向虽然有不少相关论文,但是模型的性能不及前四种研究方法。早期方法以一致性约束和伪标签方法为主,混合方法结合一致性约束和伪标签两类方法提升精度。近期自监督+半监督相结合的方法,成为了新的SOTA。针对半监督领域的一些分支研究方向,比如半监督学习下的样本极度匮乏和类别不均衡的长尾问题,没有在本文的调研范围之内。 评估数据集 DataSet Class Image Size Train Validation Unlabeled 备注 SVHN-10 10 32x32 7.3w 2.6w 53w 谷歌街景房屋号码,预测号码中的中间数字 STL-10 10 96×96 5k 8k 1w张未标注数据(包含不属于10类的其他相近类别物体) - CIFAR-10 10 32x32 5w 1w 没有未标注数据 10分类,动物/交通工具等 CIFAR-100 100 32x32 5w 1w 没有未标注数据 100分类,论文中通常采样一部分比例作为有标注数据,丢弃剩下的数据标签作为无标注数据 ImageNet 1000 任意大小 120w 15w 15w 论文通常采用1%,10%的数据做训练,其余当作未标注数据验证半监督算法 JFT300B 18291 - 3亿 - - 用作预训练,在ImageNet上做评估,半监督算法通常抛弃原有标签,把整个数据集当作无标签数据集使用 算法对比概览(数据集准确率选取top5/top1 acc展示,更多数据见 LeaderBoard of SSL) 半监督加自监督: SSSS (Self-Supervised+Semi-Supvised) 伪标签: PL (Pseudo-Label ) 一致性约束: CR (Consistency Regularization) 混合方法: HM (Hybrid Methods) 算法 backbone 算法归类 数据增广 半监督损失 ImageNet-10%(Top5/top1 acc) CIFAR10-4k(err) SimCLRv2 ResNet-152 x3, SK SSSS simple CE 95.5/80.9 - SimCLRv2 ResNet-50 SSSS simple CE 93.4/77.5 - CoMatch Moco v2 SSSS RandAugment CE 91.4/73.7 - Meta Pseudo Labels ResNet-50 PL RandAugment(15种随机方式) CE 91.38/73.89 3.89± 0.07 Noisy Student EfficientNet-L2 PL RandAugment CE -/- - MixMatch - HM Mixup/simple MSE -/- 6.24 FixMatch - HM RandAugmentCTAugment CE 89.13/- 4.31 DivideMix - HM Mixup/simple MSE -/- - UDA - CR RandAugment CE 88.52/- 5.27 VAT - CR Adversarial Noise MSE -/- 11.36 Mean Teacher - CR simple MSE -/- 6.28 PI Model/Temporal Ensembeling - CR simple MSE -/- 12.16/- 一致性约束方法 一致性约束方法主要思想:约束同一样本的在不同变换下(网络扰动、数据扰动、对抗扰动等)的标签预测概率的一致性。一致性约束主要研究的方向是通过合理的方式构造一致性样本对(正样本对) 网络扰动: Dropout(PI Model, ICLR2017)/EMA(Mean Teacher, NIPS2017) 数据扰动: Temporal Ensembling/输入高斯噪声/数据增广(AutoAugment/RandomAugment) 对抗噪声: 输入的梯度方向(VAT, PAMI2019) PI Model/Temporal Ensembling【ICLR2017】 Temporal Ensembling for Semi-Supervised Learning Authors: Samuli Laine, Timo Aila Institute: Nvidia 论文简介: 半监督领域早期较为经典的一篇文章,提出了PI Model和temporal ensembling两个一致性约束方法 算法细节: a. 模型结构 PI Model: 模型损失由两部分构成:有监督分类损失和一致性约束损失。对于有标注的数据,直接计算交叉熵损失函数,对于同一个未标注数据x,进行两次模型前向并约束网络的输出结果相同(由于网络扰动和数据增广两次结果会不一致),一致性约束的损失函数采用MSE Temporal Ensembeling: PI Model需要进行两次模型前向才能构成一致性样本对,Temporal Ensembeling提出记录每个样本输出概率的滑动平均($Z_{t}=\alpha*Z_{t-1} + (1-\alpha)*z_{t}$),作为一致性约束的目标。节约了一次前向时间,并且滑动平均能够对噪声更加鲁棒。 Temporal Ensembeling的主要缺点在于需要维护整个数据集样本的输出预测概率,在大规模数据集上需要过大的存储空间 b . 半监督损失时变系数w(t)的重要性: 一致性损失函数的权重采用 $w(t)=e^{-5*(1-t)^2}$,即在网络的初期以优化监督损失为主,当模型训练精度提升后再开始逐步减小一致性约束。论文中指出,逐步增大一致性约束损失很有必要,否则会导致模型陷入收敛到没有意义的结果(比如模型预测为恒定常数) Mean Teacher【NIPS 2017】 Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results Authors: Antti Tarvainen, Harri Valpola Institute: The Curious AI Company 论文简介: 为解决Temporal Ensembling中数据存储的问题,Mean Teacher提出进行模型参数滑动平均替代样本概率滑动平均 算法细节: 借鉴意义: 模型参数的滑动平均,可以认为是一种简单的模型集成。在监督学习和半监督领域都适用,通常能够起到防止过拟合的作用 模型的EMA能够稳定网络训练,在自监督预训练模型BYOL(NIPS2020)也被运用 UDA【NIPS 2020】 Unsupervised Data Augmentation for Consistency Training 【Code】 Authors: Qizhe Xie, Zihang Dai, Eduard Hovy, Minh-Thang Luong, Quoc V. Le Institute: Google Research 论文简介: 以往方法采用的构造一致性约束样本对的扰动方式过于简单(如数据高斯噪声和dropout等),论文尝试引入图像/文本领域内的SOTA数据增广方式(图像RandAugment/文本反向翻译)方式,提升基于一致性约束方法的性能 算法细节: a. 模型结构:模型结构和PI Model一致,只是数据增广方式进行了扩展 b. 消融实验: 有效的数据增广方式对基于一致性约束方法十分重要。 VAT【PAMI2019】 Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning Authors: Takeru Miyato, Shin-ichi Maeda, Masanori Koyama, Shin Ishii Institute: Google Research 论文简介: 对抗训练在有监督学习中被采用做数据增广提升模型泛化性,本文提出在未标注数据上的对抗训练方法,不依赖样本GT 算法细节: (1). VAT算法整体和PI model(ICLR2017)相似,只是将数据增广方式变成了对抗噪声 (2) 未标注数据对抗噪声: 对抗训练在有监督中实现方式是,根据标注数据GT和模型预测,找到输入x的梯度方向即为噪声。在未标注数据中,采用如下方法近似方法进行估计: $r \sim \mathcal{N}\left(0, \frac{\xi}{\sqrt{\operatorname{dim}(x)}} I\right)$ $\operatorname{grad}_{r}=\nabla_{r} d_{\mathrm{KL}}\left(f_{\theta}(x), f_{\theta}(x+r)\right)$ $r_{a d v}=\epsilon \frac{g r a d_{r}}{\left\|g r a d_{r}\right\|}$ (3) 未标注数据一致性损失 $$ \mathcal{L}_{u}=w \frac{1}{\left|\mathcal{D}_{u}\right|} \sum_{x \in \mathcal{D}_{u}} d_{\mathrm{MSE}}\left(f_{\theta}(x), f_{\theta}\left(x+r_{a d v}\right)\right) $$ VAT方法的优缺点: 优点:和输入x的类型无关,可以用于RGB图片/已经提取好的特征/文本模态等等 缺点: 相比于数据增广方法,VAT扰动生成数据视觉上不够真实,对比一些SOTA的图片数据增广算法性能较差 伪标签方法(self-training) 最简单的伪标签方法的流程可分为三步: 在有标注数据集上训练Teacher模型 在未标注数据上进行预测得到数据的分类(soft-label/hard-label) 最后Student模型在有标注数据和伪标签数据上进行联合训练 为简化流程,更多的伪标签算法采用同步训练的方式: 即在一个batch内同时计算有标注样本的交叉熵损失,对于未标注样本通过模型预测出概率分布后,通过将概率分布通过阈值的方式转变为one-hot编码方式并计算交叉熵损失或MSE(对噪声更鲁棒)。 伪标签的最大挑战是: Teacher网络对未标注数据的预测存在噪声( confirmation bias),目前研究主要通过以下方法解决: 启发式方法: 通常采用固定卡阈值(threshold=0.9)方法;时变系数损失权重 迭代训练,逐步提升Teacher网络预测的伪标签精度: Noisy Student(CVPR2021) 动态阈值解决固定阈值问题: FlexMatch(NIPS2021) Meta Pseudo Label(CVPR2021)通过Student网络在标注数据上的损失,反馈调整Teacher网络参数。Meta Pseudo Label通过学习如何修正pseudo label来提升Student网络在有标注验证集上的精度,可用于半监督和Noisy label的数据修正 不只用模型预测出的分类score,预测标签可信度: UPS(ICLR2021) Noisy Student【CVPR2020】 Self-training with Noisy Student improves ImageNet classification 【Code】 Authors: Qizhe Xie, Minh-Thang Luong, Eduard Hovy, Quoc V. Le Institute: Google Research 论文简介: 结合self-training、蒸馏、数据增广/网络结构噪声等策略,提升模型性能。论文方法简单,消融实验丰富,可提供较多训练的经验指导,在ImageNet top1-acc上达到88.4%(结合3亿JFT未标注数据,达到了当时的SOTA,目前最高90.88%)。 算法流程: 模型训练流程: 1) 标注数据上训练Teacher网络 ;2)未标注数据上用Teacher网络预测伪标签;3) 利用伪标签数据和标注数据,结合网络和数据噪声,训练学生网络;4)迭代训练,重复2)3)两个步骤 一系列模型训练Trick合集: 未标注数据类别平衡的重要性: 重复类别少的未标注数据(810w->1300w) 控制有标注样本和无标注样本比例:使用大比例的无标注数据batch_size 过滤未标注数据中的OOD(out-of-distribution)样本: 利用模型预测,并过滤最大分类概率小于0.3的样本 有标注/无标注(soft-label)的两类数据联合训练的优点:在标注数据和未标注数据联合训练,比在未标注数据上预训练再到有标注数据分步训练的方式好 迭代训练逐步提升精度(ImageNet top1-acc +0.8%) Meta Pseudo Labels【CVPR2021】 Meta Pseudo Labels 【Code】 Authors: Hieu Pham, Zihang Dai, Qizhe Xie, Minh-Thang Luong, Quoc V. Le Institute: Google AI, Brain Team 论文简介: 伪标签方法中的Teacher网络不准确引入错误的预测伪标签GT(确认偏差, confimation bias),进而影响Student模型训练。为了修正Teacher模型预测伪标签的精度,本文提出采用元伪标签方法,根据Student网络在有标签数据集上的损失优化Teacher网络,利用未标注数据JET进行半监督,在ImageNet上top1-acc达到90.2%(首个在ImageNet上突破90% ) 算法细节: 算法流程: Student网络产生的Loss对Teacher反馈信号: 目标函数如下,利用元学习中MAML的方法进行近似求解梯度 $$ \begin{array}{cl} \min _{\theta_{T}} & \mathcal{L}_{l}\left(\theta_{S}^{\mathrm{PL}}\left(\theta_{T}\right)\right) \\ \text { where } & \theta_{S}^{\mathrm{PL}}\left(\theta_{T}\right)=\underset{\theta_{S}}{\operatorname{argmin}} \mathcal{L}_{u}\left(\theta_{T}, \theta_{S}\right) \end{array} $$ 借鉴意义 在半监督和带噪学习中的可用性: Student网络利用干净标签数据进行Loss评估,Teacher网络学习如何生成干净样本,使得Student网络在干净样本上的精度得到提升,是一条可探索的路,但不能一定确保获得好正向结果。 混合方法 混合方法采用一致性约束和伪标签算法中的一些算法模块,提升模型性能。 MixMatch【NIPS2019】 MixMatch: A Holistic Approach to Semi-Supervised Learning [Code] Authors: David Berthelot, Nicholas Carlini, Ian Goodfellow, Nicolas Papernot, Avital Oliver, Colin Raffel Institute: Google Research 论文简介: 统一当前主流半监督算法在一个算法中,包括一致性约束、最小化熵和MixUp正则化方法 算法流程: (1) 构建未标注样本概率分布(soft-label): 通过多次数据增强的平均预测提升精度(一致性约束),并结合Sharpen函数降低预测概率分布的不确定性(最小化熵) $$ \operatorname{Sharpen}(p, T)_{i}:=p_{i}^{\frac{1}{T}} / \sum_{j=1}^{L} p_{j}^{\frac{1}{T}} $$ 当T=1时,为identity;当T取<1时,概率分布向one-hot方式改变,论文中T取0.5 (2) 在标注样本和未标注样本(带有soft-label)的两类数据上做MixUp正则化: MixMatch中的Mixup与原论文的不同点在于: 下面公式中的第二项,保证了合成的样本 $x{'}$相比$x_{2}$而言与$x_{1}$更接近。让合成的样本保持和前者更接近是为了在计算损失的时候,对于Labeled Group和Unlabel Group两种类型数据,采用不同的监督方式。 $$ \begin{aligned} \lambda & \sim \operatorname{Beta}(\alpha, \alpha) \\ \lambda^{\prime} &=\max (\lambda, 1-\lambda) \\ x^{\prime} &=\lambda^{\prime} x_{1}+\left(1-\lambda^{\prime}\right) x_{2} \\ p^{\prime} &=\lambda^{\prime} p_{1}+\left(1-\lambda^{\prime}\right) p_{2} \end{aligned} $$ (3) 针对Labeled Group和Unlabel Group两种类型数据,分别采用交叉熵和MSE进行监督。 未标注样本损失函数的选取:对于无标签数据的监督优化,采用MSE替换常规的KL散度/交叉熵等分类损失函数,因为MSE对噪声更鲁棒。MSE损失函数相比较于KL散度的缺点是收敛慢,论文在对MSE损失函数的权重乘以100以加快收敛速度(我推测的)。 算法细节: (1) 消融实验: K 表示数据增广的次数,MixMatch默认采用K=2,K越大效果越好但是也增加了模型的前向时间 概率分布Sharpen影响精度较大(在4000labels情况下约4.5%), 考虑低熵预测的其他方式, 如果将sharpen替换为one-hot编码效果会怎样? Mixup对算法的贡献最大(4.97%), 在样本数少的情况下越明显 借鉴意义: Mixup作为一种与模态无关的非常有效的数据增广方法,不止在图片中可以用,对于其他模态(甚至是预先提取好的embedding)也是适用的 一致性损失函数的选择可以考虑其他对噪声鲁棒的SOTA损失函数替换,解决MSE监督概率分布收敛慢的问题 FixMatch【NIPS2020】 FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence [Code] Authors: Kihyuk Sohn Institute: Google Research 论文简介: FixMatch简化同期MixMatch/ReMatch等混合方法中复杂的设计,并超越MixMatch/ReMatch等方法 算法流程: (1) 在有标注样本上计算交叉熵损失 (2) 利用弱数据增广(flip-and-shift)为无标注样本生成伪标签,并进行高阈值过滤,转变为one-hot伪标签概率分布 (3) 对同一样本进行强数据增广(RandomAugment/Cutout),并用上一步得到的one-hot伪标签进行交叉熵损失计算。对于最大概率低于阈值的样本,不参与损失计算 算法细节: 为什么需要将数据增广分类为强/弱两种:弱数据增广用于提供更准确的伪标签,强数据增广让网络能够适配更多的数据变化。如果将第一条支路的弱数据数据增广替换为强数据增广,实验中发现训练会变得不稳定(训练过程中准确率突然从45%突变到12%) 对比实验数据 在各个数据集上超越之前方法,尤其是在样本数少的时候,e.g. 40个样本的CIFAR-10实验 借鉴意义: 整体结构简单有效,存在改进的地方是算法中采用固定的阈值过滤的超参数,对于难却分的类别(通常表现为预测score低)是不友好的,难样本会被过滤掉,动态估计阈值方法在(FlexMatch, NIPS2021)中进行了改进 DivideMix【ICLR2020】 DivideMix: Learning with Noisy Labels as Semi-supervised Learning [Code] Authors: Junnan Li, Richard Socher, Steven C.H. Hoi Institute: Salesforce Research 论文简介: 基于噪声样本通常表现为loss较大的前提假设,将带噪样本问题转换为半监督问题处理 算法流程: (1) 在有监督数据上进行warmup训练 (2) 通过高斯混合模型(GMM)建模每样样本损失的分布(随着训练过程变化),将训练集分为有标签的干净数据集和有噪声的未标注数据集 样本属于干净样本的概率:样本loss属于均值小的高斯分布的概率。通过卡阈值可以Clean/Noisy样本划分 (3) 在干净有标签样本集上计算有监督损失函数,和带噪的样本上利用MixMatch进行半监督训练(丢弃噪声GT) 模型细节: 为了缓解单个网络出现确认偏差问题(预测为错误样本,且在伪标签上loss低),论文提出两个网络联合训练的方法 - Co-Divide: 两个网络互相为对方进行Clean(labeled) 和Noisy(unlabeled)的数据划分 - Co-Refine: 对于样本的类别概率$$p_{gt}$$,通过加权求和进行更新,加权系数w为样本属于干净样本的概率 $p_{gt}^{’}= w*p_{gt}+ (1 − w)*p_{new}$ - Co-Guess: 对于未标注样本伪标签概率分布,通过两个网络的预测平均作为该样本输入到MixMatch的伪标签 借鉴意义: 缺点:需要同时优化两个网络,对训练时间和显存需求会翻倍;Multi-task和Multi-Label的设定下,不能只有一个loss评估样本,需要分任务,分标签进行区分; 完全丢弃原始标签信息,可能会造成信息丢失 优点: 同时考虑了半监督和带噪训练,在实际应用场景会更实用 SOTA: 自监督 + 半监督 SimCLR V2【NIPS2020】 Big Self-Supervised Models are Strong Semi-Supervised Learners 【Code】 Authors:Ting Chen, Simon Kornblith, Kevin Swersky, Mohammad Norouzi, Geoffrey Hinton Institute: Google Research, Brain Team 论文简介: 自监督预训练任务没有考虑具体下游任务,采用预训练特征+少量标注样本Finetune的方式没有充分在下游任务上 算法流程: (1) 在未标注数据上利用对比损失函数进行自监督预训练,正类(同一样本的数据增广)拉近特征距离,负类(不同样本)推远。 Normalized Temperature-scaled cross entropy loss,sim为余弦相似性 $$ \ell_{i, j}^{\text {NT-Xent }}=-\log \frac{\exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{j}\right) / \tau\right)}{\sum_{k=1}^{2 N} \mathbb{1}_{[k \neq i]} \exp \left(\operatorname{sim}\left(\boldsymbol{z}_{i}, \boldsymbol{z}_{k}\right) / \tau\right)} $$ (2) 有标签数据上进行模型Finetune (3) 再次使用未标注数据,利用Finetune的模型进行蒸馏(soft label + CrossEntropy),适配当前下游任务。 训练包含有标注数据的监督损失和未标注数据的蒸馏损失 $$ \mathcal{L}=-(1-\alpha) \sum_{\left(\boldsymbol{x}_{i}, y_{i}\right) \in \mathcal{D}^{L}}\left[\log P^{S}\left(y_{i} \mid \boldsymbol{x}_{i}\right)\right]-\alpha \sum_{\boldsymbol{x}_{i} \in \mathcal{D}}\left[\sum_{y} P^{T}\left(y \mid \boldsymbol{x}_{i} ; \tau\right) \log P^{S}\left(y \mid \boldsymbol{x}_{i} ; \tau\right)\right] $$ 算法细节: (1) 在越少的标注样本下,越大的模型性能越好,即使存在过拟合的风险 (2) 针对具体分类任务使用未标注的数据,能够提升模型在具体任务下的性能 借鉴意义: 优点: 自监督很重要,结合半监督训练比单纯在少量标注样本上Finetune效果更好 缺点: 简单利用无标注数据进行知识蒸馏的方法还有较大提升的空间。相对而言,CoMatch(ICCV2021)的解决方案更有针对性 SimCLR V2效果非常好的原因在于用了参数量非常大的Teacher模型,需要较多计算资源用于自监督预训练 CoMatch【ICCV2021】 CoMatch: Semi-supervised Learning with Contrastive Graph Regularization 【Code】 Authors: Junnan Li, Caiming Xiong, Steven Hoi Institute: Salesforce Research 算法简介: self-training的自监督预训练能够得到一个较好的特征表示,但是在特定任务上不一定适用(对于同一个类别的不同样本,被强制拉远特征距离)。CoMatch提出将数据的特征表示层和标签预测层分离,再进行信息交互: 利用不同样本的特征相似性: 融合特征相近样本的标签,用于提升伪标签精度 利用不同样本的标签信息提升特征对比学习: 如果样本标签一致,则拉近两个样本的特征emb,反之推远 算法流程: (1) 算法流程图 模型细节 消融实验 在没有预训练的情况下,半监督方法CoMatch比监督训练好11.2%(91.6 vs 80.4) 在有监督预训练情况下,CoMatch半监督方法比直接finetune好1.29% 参数量大的SimCLR v2有较强的优势,结合蒸馏到小模型,比同量级模型(25.6M vs 29.8M)高出2% 借鉴意义 结合下游任务标签数据,将对比学习预训练中,不合理的负样本(不同的样本,但属于同一个类别)特征拉远问题进行优化 图片半监督调研小结 自监督预训练很有效但还不够。自监督结合任务相关的半监督训练方法可以较大幅度提升模型精度,达到SOTA水平(SimCLR v2, CoMatch等) 数据增广方式在一致性约束中扮演重要的作用,一种有效的视频数据增广方式是一致性方法得以应用在视频理解任务里面的关键;一些sota的数据增广方式比如,AutoAugument,RandomAugment等只在图片中适用。与模态无关的数据增广方式包括Mixup和VAT对抗扰动噪声,从实验精度来看,mixup数据增广的效果比对抗扰动更好。在预先提取好视频帧的情况下,可以优先考虑mixup方法和其变种来实现数据增广 对无标签的预测标签分布后处理,多数算法选择对概率分布进行sharpen操作,甚至直接转换为one-hot的形式,本质都是在鼓励低熵预测,即让样本尽可能远离分类边界。保持soft-label的方法在蒸馏中会被采用,soft-label在无标注样本可能存在OOD(out-of-distribution)的情况下适用(允许类别概率是均匀分布)。 值得尝试的方向:1.带噪训练和半监督方法如何更好得结合: 比如【DividMix, ICLR2020】/【 Robust LR,Top1 on WebVision】方法; 2.Meta Pseudo Label为代表,Teacher网络学习如何生成“高质量”的伪标签提升Student网络的精度,结合meta learning的方法也可能较大提升精度的一个方向; 3. 自监督+半监督相结合的策略 方法迁移应用于多标签问题:图片半监督算法基本都是在研究多分类问题,要适配到多标签任务需要额外的设计(比如,根据类别概率最大值去过滤样本、根据loss进行样本划分等) 参考文献 【Survey】A Survey on Deep Semi-supervised Learning⭐️ 【Survey】An Overview of Deep Semi-Supervised Learning⭐️ 【Github】 Awesome-Learning-with-Label-Noise ⭐️ 【Github】 awesome-semi-supervised-learning ⭐️⭐️ 【LeaderBoard of SSL on Paper with Code】⭐️⭐️ 【Github】半监督学习开源库 TorchSSL ⭐️⭐️ 【Blog】OPENAI, Learning with not Enough Data Part 1: Semi-Supervised Learning ⭐️ 【Blog】Semi-Supervised Learning in Computer Vision ⭐️ 【Blog】PaperWeekly 半监督学习技术近年来的发展历程及典型算法框架的演进 【Blog】vivo-带噪学习研究及其在内容审核业务下的工业级应用 【Blog】淘宝,主动学习入门篇:如何能够显著地减少标注代价 【Blog】网易,知物由学 | “半监督”与“自监督”:多方法结合让AI模型训练事半功倍 【Blog】Meta Pseudo Label A Survey of Label-noise Representation Learning: Past, Present and Future
-
Transformer-based Segmentation Unet系列Transformer模型(医学图像分割) 结合全局(self-attention) 和 局部(Unet) 的特点,构建分割网络 如何在小样本数据集上,使得分割work,有效训练大参数量的transformer模型 Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation [Code] 1. Metric: 2. Motivation: Swin transformer 的优点: 解决长序列问题;窗口内Attention + 窗口间信息交互; UNet的优点: 局部信息, ShortCut 3. Main Contributions: Based on Swin Transformer block, we build a symmetric Encoder-Decoder architecture with skip connections. In the encoder, self-attention from local to global is realized; in the decoder, the global features are up-sampled to the input resolution for corresponding pixel-level segmentation prediction. A patch expanding layer is developed to achieve up-sampling and feature dimension increase without using convolution or interpolation operation. It is found in the experiment that skip connection is also effective for Transformer, so a pure Transformer-based U-shaped Encoder-Decoder architecture with skip connection is finally constructed, named Swin-Unet. 4. Model Structure: 5. Take Home Message: 上采样方式patch expanding layer Medical Transformer: Gated Axial-Attention for Medical Image Segmentation [Code] 主流语义分割Transformer模型 SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers [Code] MaskFormer: Per-Pixel Classification is Not All You Need for Semantic Segmentation [Code]
-
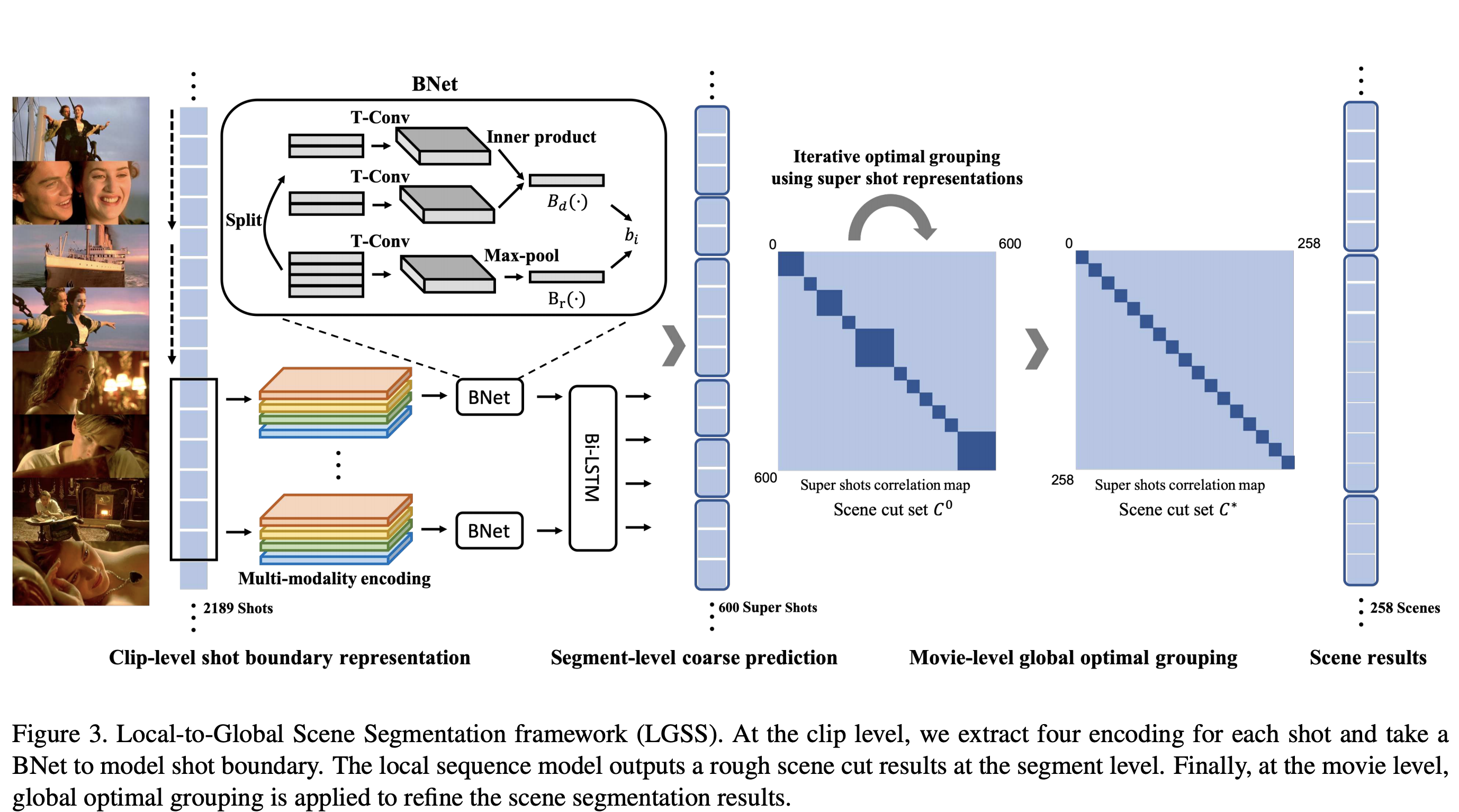
视频时序切分 将视频在时序维度(镜头 + 场景)进行理解, 相关公开数据集和benchmark:SoccerNet-v2、 Kinetics-GEBD、MovieNet ViTT-AACL2020 1. 镜头分割(Shot Boundray Segmentation) 镜头切分benchmark: ClipShots、TRECVID、SoccerNet-v2 1.1 TransNet 1.2 TransNet V2 1.3 DSBD 2. 场景分割(Scene Boundray Segmentation) 2.1 SceneSeg A Local-to-Global Approach to Multi-modal Movie Scene Segmentation [CVPR 2020] 论文简介:提出一个场景切分数据集MovieNet(380个电影),此外提出了一个局部到全局的场景切分算法 Github Code 算法整体流程: 镜头切分,公开的源代码采用了传统方法做镜头切分,可以考虑用深度学习方法做优化,如TransNet等 对每个镜头提取多个模态特征(动作、地点、语音等维度) 进行局部到全局的特征聚合,利用BNet(boundary Network)实现局部的特征融合 a. Clip-level: BNet由两个部分构成: 通过内积建模镜头之间(4个镜头)的差异,通过temporal conv + max pooling建模镜头之间的联系,二者concat b. Segment-level: 通过bi-LSTM实现序列到序列的功能,其中序列长度选取10(远小于镜头数目,为了减少内存消耗) c. global optimal grouping: 通过过动态规划,实现后处理优化(优点:考虑了所有镜头特征,考虑了长时的上下文依赖,缺点: 没有能够实现端到端的优化,与前面的模型时独立的), 具体细节参考StoryGraph 2.2 Shot Type Classification A Unified Framework for Shot Type Classification Based on Subject Centric Lens[ECCV2020] 镜头拍摄风格识别 Deep Relationship Analysis in Video with Multimodal Feature Fusion [ACM MM 2020] 多模态场景理解 2.3 自监督预训练 Shot Contrastive Self-Supervised Learning for Scene Boundary Detection [CVPR2021] Amazon BaSSL: Boundary-aware Self-supervised Learning for Video Scene Segmentation UBoCo : Unsupervised Boundary Contrastive Learning for Generic Event Boundary Detection Scene Consistency Representation Learning for Video Scene Segmentation 3. 事件分割(Event Segmentation) Generic Event Boundary Detection: A Benchmark for Event Segmentation 提出了一种新的边界切分定义,包括: 环境、物体、镜头发生变化。 A Benchmark for Multi-shot Temporal Event Localization Temporal Perceiver: A General Architecture for Arbitrary Boundary Detection Progressive Attention on Multi-Level Dense Difference Maps for Generic Event Boundary Detection
-
Pytorch 常见问题 1.CUDA_VISIBLE_DEVICES设置无效,始终占用GPU0? 1. 在import torch前设置环境变量 2. CUDA_DEVICE_ORDER=PCI_BUS_ID CUDA_VISIBLE_DEVICES=3 python train.py 2.RuntimeError: CUDA error: device-side assert triggered 设置环境变量,让报错显示更具体的代码行 import os os.environ["CUDA_LAUNCH_BLOCKING"] = "1" 3.RuntimeError: DataLoader worker (pid xxx) is killed by signal: Aborted. what(): CUDA error: initialization error pytorch github issue ref google找到的文章,大多怀疑是内存问题 尝试修改pin_memory没有效用 尝试修改shm没有效果,mount -o remount,size=32g /dev/shm 尝试改小num_worker无效果(16->8)将num_workers设置为0可以解决问题,但肯定不是最优解!!! 4.resume training时,出现GPU OOM的问题 在DDP训练场景下进行resume training可能出现该问题,原因在于每个进程torch.load都加载在同一块卡上,导致最后OOM。解决方案: map_location指定加载在哪块卡上 checkpoint = torch.load(checkpoint_path, map_location='cuda:{}'.format(opts.local_rank)) 5.CUDNN和pytorch版本不匹配 可以从torch_stable.html下载安装 6 . unrecognized arguments: --local_rank,由于torch2.0升级导致,修复方案: python -m torch.distributed.launch xxx 替换为 torchrun xxx
-
Shell 常用命令总结 shell常用命令 查看CPU # 总核数 = 物理CPU个数 X 每颗物理CPU的核数 # 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数 # 查看物理CPU个数 cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l # 查看每个物理CPU中core的个数(即核数) cat /proc/cpuinfo| grep "cpu cores"| uniq # 查看逻辑CPU的个数 cat /proc/cpuinfo| grep "processor"| wc -l # 查看CPU使用情况 mpstat -P ALL 显示目录下文件,按文件大小排序 ls -Shlr #按文件大小(-S)从小到大(-r)排序显示(-hl) 查找文件中包含字符串 cat file.txt|grep -B 2 key # 查找包含key,并显示前两行 cat file.txt|grep -A 2 key # 查找包含key,并显示后两行 cat file.txt|grep -2 key # 查找包含key,并显示前后两行 查找包含字符串的文件: grep -rn "keyword" [files/dir] 查找符合条件的进程并kiil ps aux | grep "python test.py" | awk '{print $2}' | xargs kill -9 #适用于批量删除进程 查看硬盘占用情况 du -hs dir_name # h(human readable) s (而不列出子目录) df -h #列出文件系统的整体磁盘使用量 判断符合条件的文件是否存在 test -f 多线程下载数据 axel -n num_threads -q download_url rync+sshpass免密码同步数据 * rsync -av -e "sshpass -p [your_password] ssh -p [your_port]" src_path dst_path --exclude=exclude_pattern --include=include_pattern` rysnc 同步文件 rsync -avh --progress source_directory destination_directory 定时服务 `30 23 * * * find /data/home/jefxiong/PenguinID/videos/* -mtime +8 -exec rm {} \;` #每天23:00定时删除超过8天的数据 shm 不足 mount -o remount,size=32g /dev/shm mount 解决git无法加入软连接问题 mount --bind src dst 按规则删除指定文件命令 find . -name '*.DS_Store' -type f -delete #删除Mac下.DS文件 find . -name "*" -type f -size 0c | xargs -n 1 rm -f #删除空文件 find . -size 1k -exec rm {} \; #删除小于1k数据 按规则移动文件命令 find . -iname *.npy -exec mv {} dst_dir \; #移动numpy文件到指定目录下 多个python版本共用时,在脚本中指定python PYTHON=${PYTHON:-python} #PYTHON默认值为python,可以在命令行前设置为其他覆盖 #e.g. PYTHON=python3 (bash scripts/xxx.sh, 脚本中用$PYTHON替代 python awk awk '{print $1}' input.txt > out.txt #取input.txt 文件第一列保存到output.txt中 awk '{print $1,$2}' input.txt > out.txt #取input.txt 文件第一列和第二列保存到output.txt中 cat input.txt|awk '{sum+=$1} END {print "Average = ", sum/NR}' #求平均值 cat input.txt|awk '{sum+=$1} END {print "Sum = ", sum}' #求和 awk -F '[|]' '{print $1}' file.txt # 对fil.txt文件利用|进行分割,并取第1个元素输出 # awk 处理字符串: https://www.jianshu.com/p/8cb01a334527 批量加后缀、前缀重命名 for file in ./* ; do mv "$file" "$(basename "$file").mp4"; done; #批量加后缀名.mp4 删除特殊字符文件 # 1. 文件名为 a&b.c, 通过转义\和""解决 rm a\&b.c rm "a&b.c" # 2. 文件名为 -ab.c,通过加入参数-- rm -- -ab.c shell 编程 for i in ${list[@]}; do ... ; done for i in ${list[*]}; do ... ; done for i in exp1 exp2; do ... ; done for i in $(seq 1 100); do ...;done for((i=1; i<100; i++)); do ... ; done # c-like list=(12 34 56) echo ${#list[@]} # 获取数组大小 echo $# #获取执行命令参数个数 免密登陆 # 生成密钥对(若未生成过) ssh-keygen -t rsa -b 4096 # 复制公钥到远程服务器 ssh-copy-id -p {ssh_port} {remote_host} git免密 git config --global credential.helper store 丢弃本地更改,同步远程 git checkout master_leo git fetch origin git reset --hard origin/master_leo
-
Python 工具库使用 用 magic vs filetype 实现视频类型判断 magic 比filetype更好用,能判断更多的类型,能够直接从文件buffer中判断 import magic # pip install python-magic import filetype # pip install filetype src_file = "x.some" print(filetype.guess(src_file)) print(magic.from_file(src_file, mime=True)) print(magic.from_buffer(open(src_file, 'rb'), mime=True)) jupyterlab IDE 函数定义跳转工具 jupyterlab-lsp parallel_apply[依赖pandarallel库] 对于多CPU机器,加速DataFrame的apply方法 安装python包,不更新其他依赖[--no-dependencies] pip3 install torch-fidelity --no-dependencies
-
数据结构/算法学习之LeetCode 数据结构 链表/树 典型链表/树问题 大数相加 反转链表 前序,中序,后序: 递归和迭代的遍历方式 平衡二叉树 二叉搜索树 树/链表参考文章 花花酱-树/链表 字符串 典型字符串问题 KMP Edit Distance 堆栈 典型堆栈问题 前缀表达式 利用栈的迭代解法 队列 典型队列问题 BFS 优先队列(heap) 图 典型图问题 DFS/BFS 最短路径 最小生成树(Kruskal, Prim两种算法) 图参考文章 花花酱-图 算法 查找 二分查找、哈希查找、常用set/map 排序 O(n^2)与O(nlogn)的排序算法,特点、冒泡/选择/插入,归并/快排/堆排序 回溯法 排列、组合 BFS/DFS 动态规划/贪心算法 从递归到动态规划 暴力解,复杂度: 指数级别时间复杂度 定义状态函数, 写状态转移方程(最优子结构)--递归实现: 指数级别时间复杂度 记忆化搜索: 递归实现 + 记忆化搜索 (自顶而下的方法): 多项式级别时间复杂度 自底而上求解--动态规划: 多项式级别时间复杂度 优化空间复杂度(例如对索引%2,只保留两行数据) 典型动态规划问题 斐波那序列 爬台阶 0-1背包问题/(无限使用背包问题,多维约束,物品依赖与排斥) 最长上升子序列: 动态规划时间复杂度$O(n^2)$ 最长公共子序列 单源最短路径算法 动态规划参考文章 花花酱-贪心/动态规划 参考链接 花花酱B站视频 拉钩+leetcode培训视频 geeksforgeeks 数据结构 Leetcode All in One 编程之法:面试和算法心得