
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

如果对视频语义分割采用逐帧进行图像语义分割的方法存在两个问题:1. 逐帧处理没有考虑分割结果的时空一致性,造成视觉上分割结果在边缘上的剧烈抖动;2. 同一视频中的不同帧之间非常相似,用图像分割网络提取特征存在大量的计算冗余。基于这两点视频语义分割目前主要有两个研究方向:
提升精度,利用时序信息提升精度视频数据生成辅助训练(少量标注); 利用时序视频帧自监督学习时序特征:star:
光流法用于图像/特征/标签的propagation;光流图用于网络输入:star:
在对图像逐帧分割后的refinement操作(后处理):optimization based label propagation(CRF); Filtering based label propagation(e.g. Bilateral filtering)
CRF作为深度神经网络中的Layer进行端到端学习
提升速度,对时序上的特征进行重用(同一视频相邻时刻的图像帧的高层语义特征相似),以减少推断时间消耗。具体过程分为两步:先通过视频关键帧选择的策略(固定时间间隔、根据网络输出score判断、强化学习策略等策略),选择少量的视频帧作为关键帧,只在这些帧上进行特征提取(主要耗时操作);对于非关键帧,通过feature propagation(包括naive copy or warping based on optical flow or spatially variant convolution等)方法变换得到,以达到减少计算量的目的视频处理中常采用的方法(不限于视频语义分割任务):
- 3D CNN: 用于行为识别,视频预测任务。参数量大
- two stream(spatial stream, temporal stream): 将多帧光流和图像帧作为网络输入,两条支路处理
- optial flow: 用作图像/语意标签/特征等的变换(双线性插值方法)
- RNN/LSTM: 长时时序信息传递
Improving Semantic Segmentation via Video Propagation and Label Relaxation. CVPR19
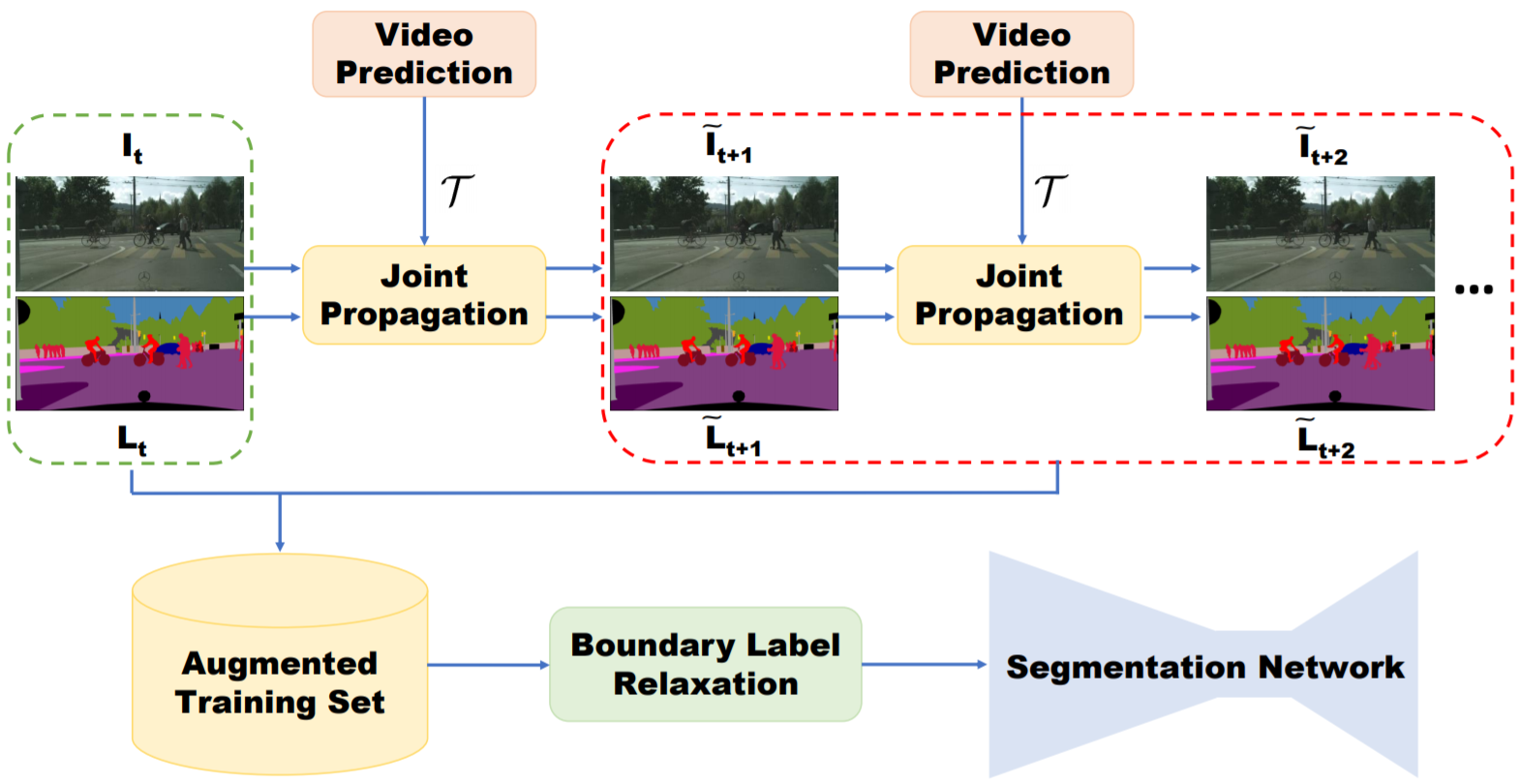
算法简介:主要提出了一种通过视频预测进行数据扩充的方法。给定稀疏标注的数据集(每隔一定视频帧数才进行标注,总标注语言标签帧数小于总视频帧数),利用视频帧$I_{1:t+1}$和光流$F_{2:t+1}$得到运动向量(利用3D卷积实现),再结合当前帧$I_{t}$进行插值,输出预测的图像帧$\tilde{I_{t+1}}$,对于语义标签$\tilde{L_{t+1}}$同理,最后将预测得到的图像帧$\tilde{I_{t+1}}$、语义标签$\tilde{L_{t+1}}$加入分割图像训练集辅助训练。此外,为了避免生成的数据在边界上的标签不准确,本文提出Boundary Label Relaxation,即将边界上的像素概率从one-hot编码变成多类别(像素周围区域类别集合)概率和为1的监督信号;该方法最后仍然使用图像语义分割网络DeeplabV3+逐帧处理视频可以借鉴的点:视频生成用于视频数据训练集扩充;Boundary Label Relaxation改善边界预测问题(在物体边缘的标注不准确引起的问题)PEARL: Video Scene Parsing with Predictive Feature Learning. ICCV2017
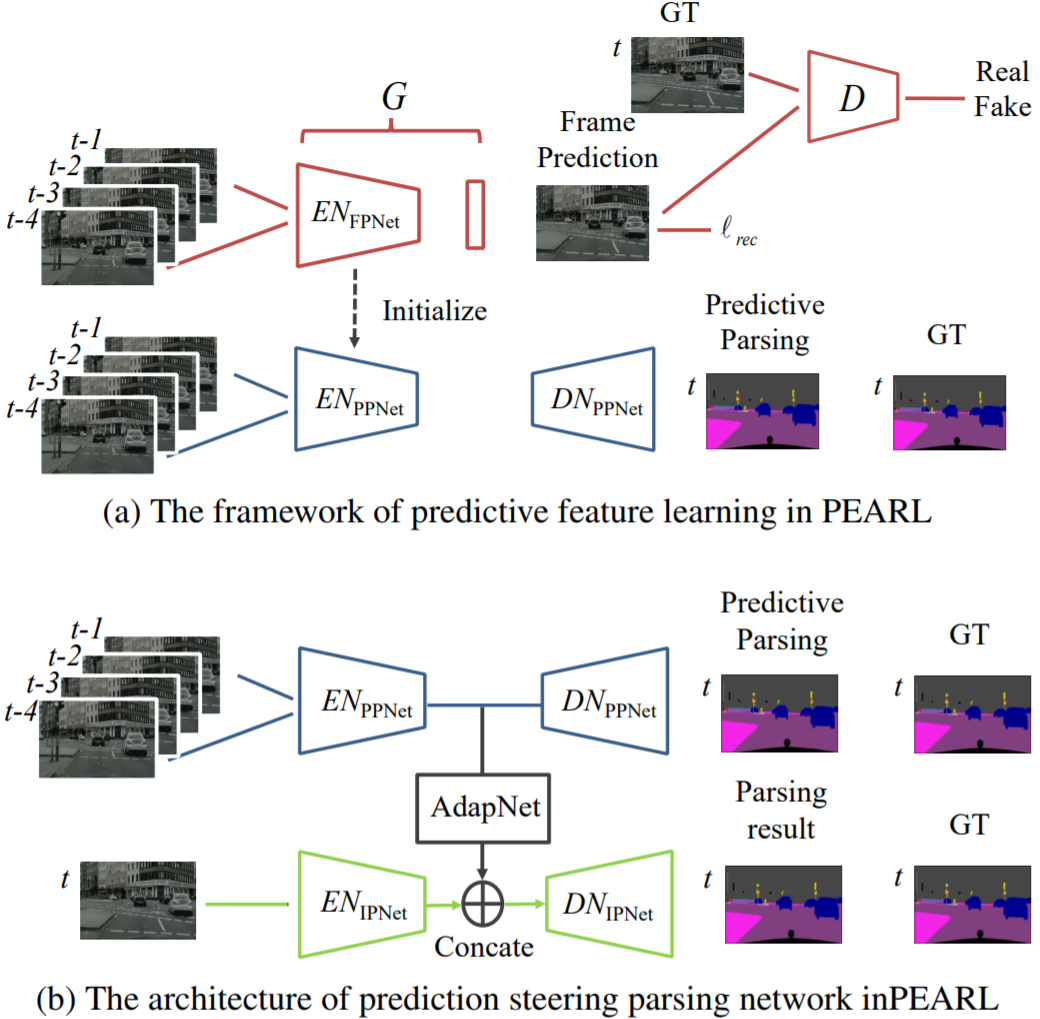
算法简介:该方案以历史图像帧预测未来图像帧(Frame Prediction),引导网络学习出时序相关(结构变化,运动变化)的特征。该学习过程利用视频图像帧进行自监督,不需要进行标注,适用于目前视频语义分割数据集匮乏的现状。视频预测任务采用GAN进行实现(生成器的第一层卷积层采用Group conv以适应多帧输入)。为了使得学习到的特征进一步适应语义分割任务,提出了利用历史帧预测未来图像帧的语义标签任务(Predictive Parsing),并采用上一过程中的生成器作为初始化参数。最后通过AdapNet(单层带ReLU的1x1卷积)融合时序信息特征$EN_{PPNet}$和当前帧的特征$EN_{IPNet}$,预测当前帧的分割结果。mIOU结果在cityscape数据集上提升6%可以借鉴的点:利用历史帧预测当前帧学习到的特征能够挖掘视频中的时序信息,并且该方法不需要人工标注,对于处理视频任务是一种值得借鉴的预训练方法,隐式地将时序信息(运动信息/外观信息)集成在特征上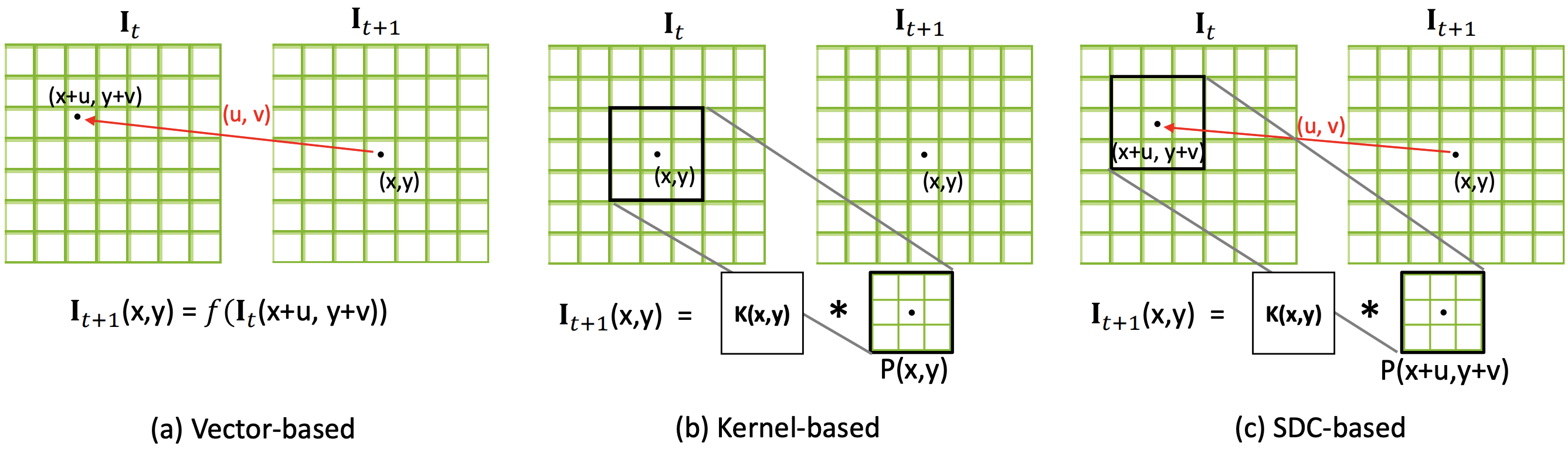
| 方法 | 优点 | 缺点 |
|---|---|---|
| 光流法(a) | 可以用于大位移预测 | 受限于光流估计算法的精度,光流估计错误会出现累计误差;双线性插值的方法只考虑四个点,容易受到噪声影响;对于遮挡部分在下一帧出现的情况,遮挡部位的光流向量未定义造成错误 |
| predicted sampling kernel(b) | 变换时能够很好地保证物体形状的一致性(边缘预测准确) | 由于所预测的位移范围与kernel尺寸相关,所以该方法不能处理大位移,否则大位移时需要大量显存 |
| spatially-displaced convolution(c) | 结合二者特点,能够在小kenel size的情况下预测大位移,节省计算资源 | - |
光流法的问题: 被遮挡部分再次出现问题
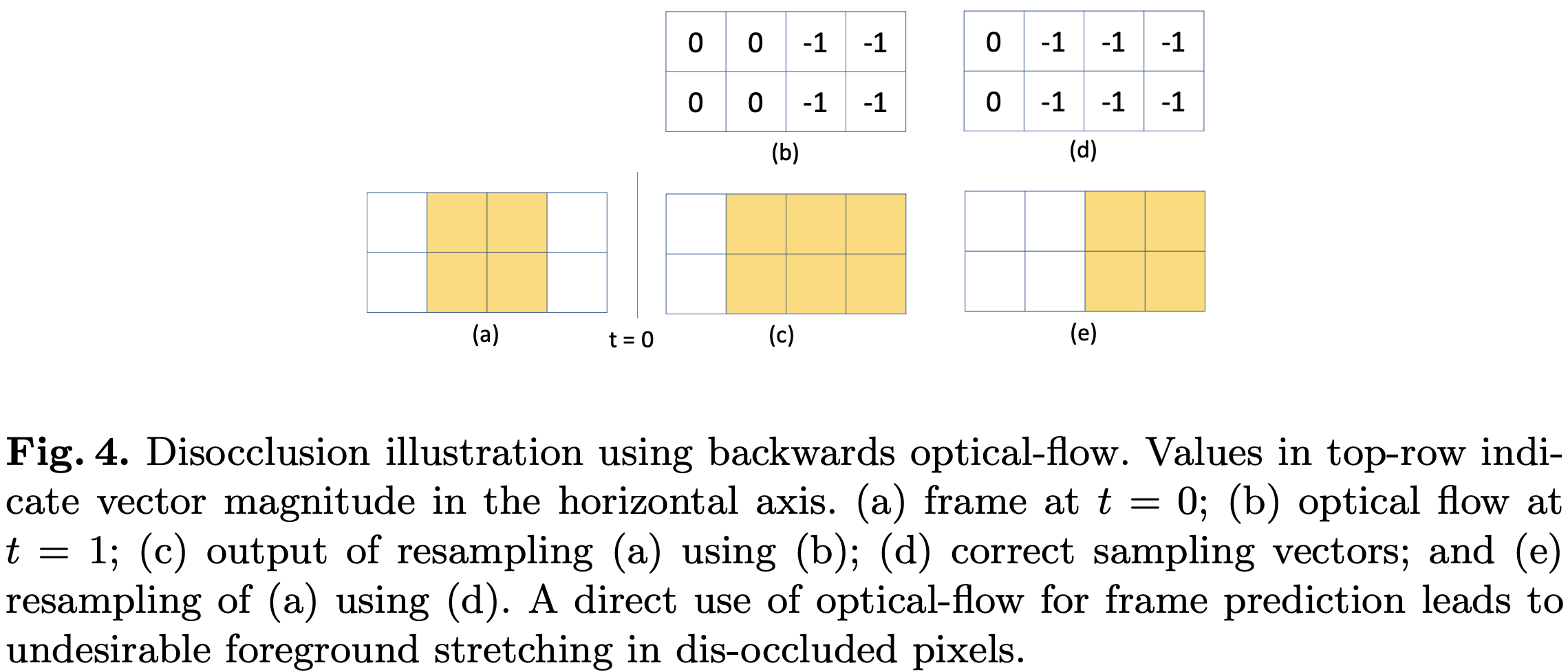
Semantic Video CNNs through Representation Warping. ICCV17
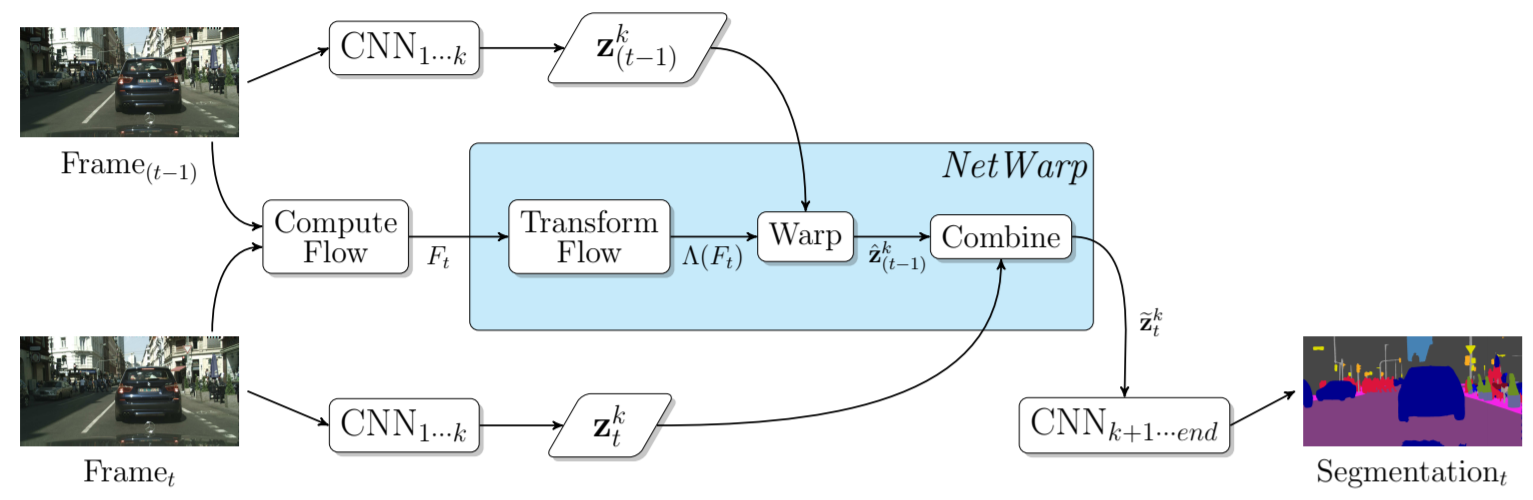
算法特点:本方案的基本思想是通过光流对前一帧图像的卷积特征进行warp操作,通过双线性插值方法得到与当前图像帧特征在空间上对齐的特征,然后将二者进行线性加权叠加。这里光流的计算采用DISFlow(5ms@CPU,原始光流)+FlowCNN(输入原始光流和图像对,输出refined的光流估计,通过语义分割标签图进行监督学习)可以借鉴的点: 相比较于视频逐帧图像分割流程,该方法引入了历史帧特征提升性能,并且只增加了少量计算量(光流计算和双线性插值操作); 该算法只用到了两帧之间的光流,即只考虑了极短时间内图像的变化,结合多帧进行长时间和短时间的图像特征融合可以考虑作为改进的方向光流法:目前现有视频语义分割文献中光流估计以FlowNet2网络为主流(300 ms/frame),考虑到效率时使用其它非深度网络方法
Semantic Video Segmentation by Gated Recurrent Flow Propagation. CVPR18
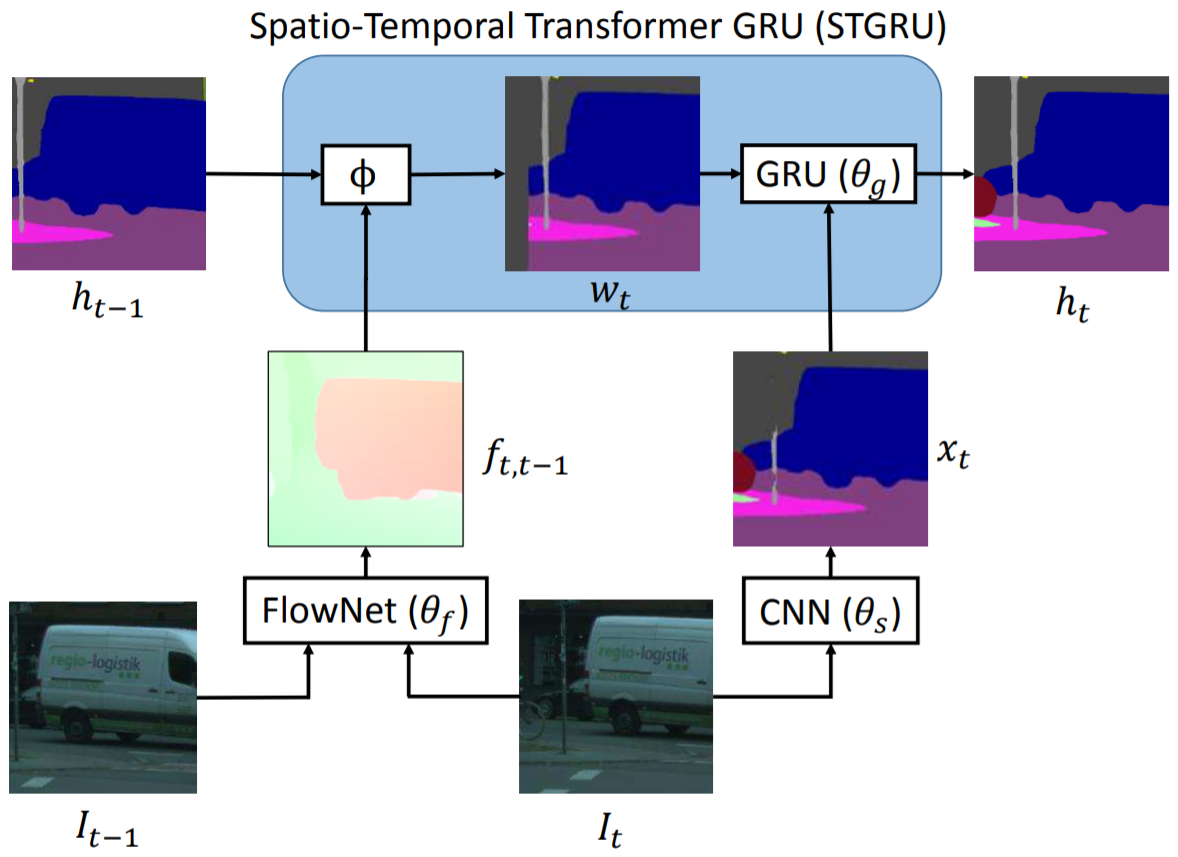
算法简介:通过光流法进行插值的方法得到的结果不总是可靠,例如被遮挡物体在下一帧重新出现的情况,被遮挡区域处的光流值是不定的,因为前后帧之间找不到对应点。本文采用GRU(Gated Recueeent Unit, LSTM的变种)门限思想,对于不准确的光流估计,通过Gate限制信息流动。光流估计的准确性通过$I_{t}$和$\hat{I_{t}}$(利用$I_{t-1}$和计算的光流结果wrap得到)之间的差值判断。与Netwrap不同光流插值方式不同,STGRU不对CNN的中间特征变换,而是直接对历史帧预测的语义分割概率$h_{t-1}$进行warp。利用光流网络(FlowNet)将前一帧预测的语义分割概率$h_{t-1}$与当前帧对齐得到$w_t$,结合当前帧语义分割结果$x_t$作为GRU的输入,最后得到当前帧的输出类别概率估计。可以借鉴的点: 对光流估计进行置信度估计,避免不准确的光流估计对结果造成影响。Deep Spatio-Temporal Random Fields for Efficient Video Segmentation. CVPR18
算法简介:将CRF作为深度神经网络中的一层,参与前向反向传播,区别于3D-CRF;用线性方程解替代平均场近似;可以借鉴的点:CRF参与网络端到端训练,在性能和速度上均优于CRF后处理的方法。Feature space optimization for semantic video segmentation. CVPR16
算法简介:将2D-CRF(特征维度: 位置,颜色)扩展成3D-CRF(特征维度: 位置,颜色,时刻),论文主要贡献在于对CRF中的特征空间选择(难点: 特征空间上,同一时刻的同一物体和不同时刻的同一个物体内的点的在特征空间上应该是邻近的,但是由于遮挡、摄像头运动等原因难以满足要求)可以借鉴的点:: 对语义分割网络逐帧处理结果的后处理操作,该算法比较耗时(10秒/帧),不适合大规模数据处理Video Propagation Networks. CVPR17 Paper

算法简介: 文章提出一种双边滤波器网络对逐帧处理得到的分割结果进行refine的方法Video Propagation Networks(VPN,可以理解为图像语义分割在时间维度上的后处理操作,在时间维度上的平滑滤波)。VPN由双边滤波器网络(Bilateral Network)和常规卷积网络(Spatial Network)构成。VPN以当前帧之前的历史帧的分割结果$O_{t-T:t-1}$和历史帧图像$I_{t-T:t}$为输入,输出当前帧的预测结果$O_{t}$。狭义的双边滤波器采用高斯核函数和位置颜色(x,y,r,g,b)作为特征,本文采用可学习的滤波器组和位置颜色时间(x,y,r,g,b,t)作为特征。本文利用permutohedral lattice(一种对双边滤波的加速方法,可进行反向传播)双边滤波器网络进行加速。可以借鉴的点:该方法属于后处理操作,任意的视频分割方法均可采用该方法进行结果提升。基于双边滤波的后处理方法相比较于基于优化的方法(CRF)而言,具有速度快的优势。缺点是网络的输入为分割网络的输出结果,不能进行端到端学习。狭义上的双边滤波器(边缘保持滤波器):滤波器参数由空间域和像素域的核函数乘积构成。在平坦区域,不同位置像素域数值接近,主要由空间核函数作用;在边缘区域,不同位置像素值差别大,主要由像素域核函数起作用,所以起到了保留边缘的平滑滤波器效果。
提升速度方向的文章,算法流程基本分两步:
视频语义分割算法的主要耗时在步骤1中的深度网络特征提取,提升速度方向的算法通过高效的特征传递方法减少特征提取计算量
Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video. CVPR19
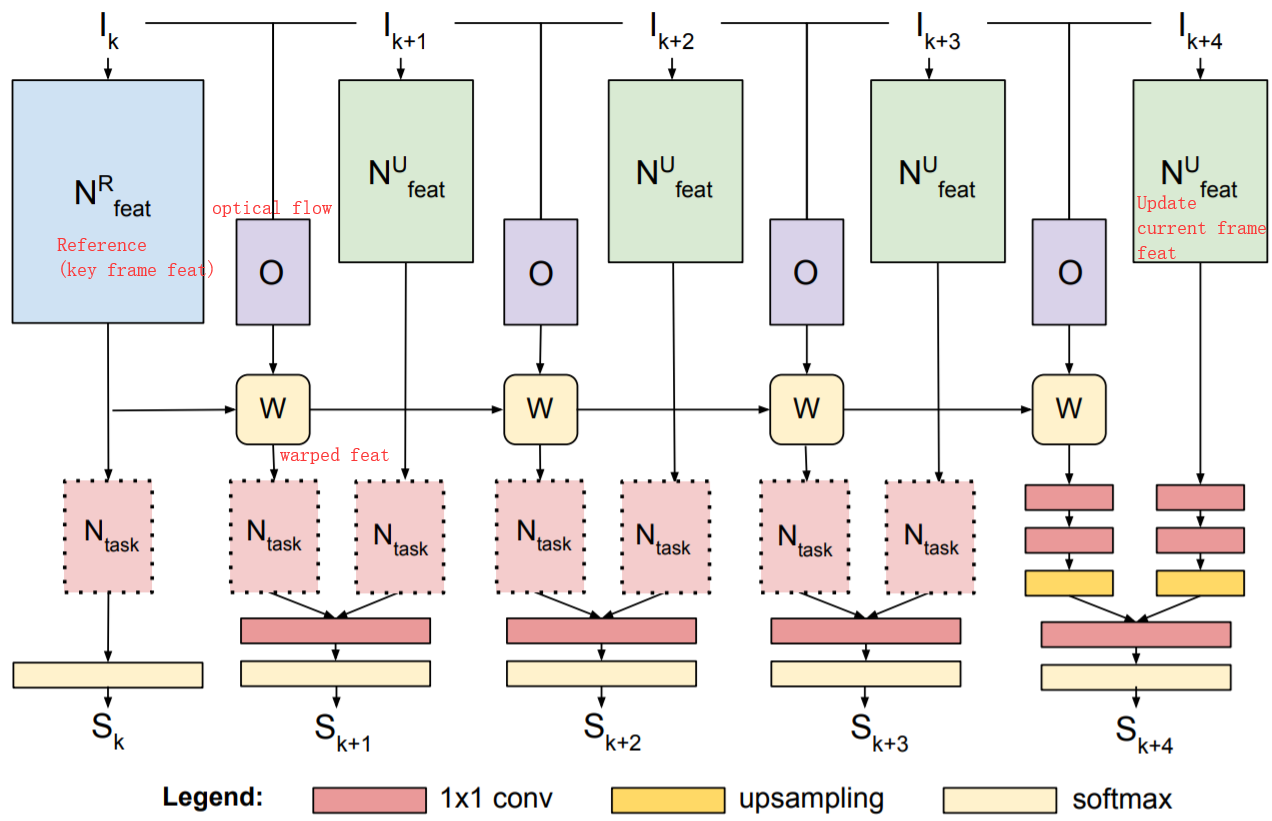
算法简介:每隔几帧,从视频中选择关键帧。关键帧的卷积网络特征(高准确率的特征网络)在一定的时间间隔内通过光流进行特征的重利用,与当前帧的卷积特征(Update Branch,轻量级特征网络)进行融合,输出当前帧的预测结果; 与DFF的区别在于,Accel进行了关键帧特征在一段时间内的累积wrap,而DFF直接从关键帧特征wrap到当前帧。可以借鉴的点: 针对任务的要求(效率 vs 准确率),可以模块化定制选择不同Update feat特征网络;关键帧特征在多帧间逐步变换DFF: Deep feature flow for video recognition. CVPR17
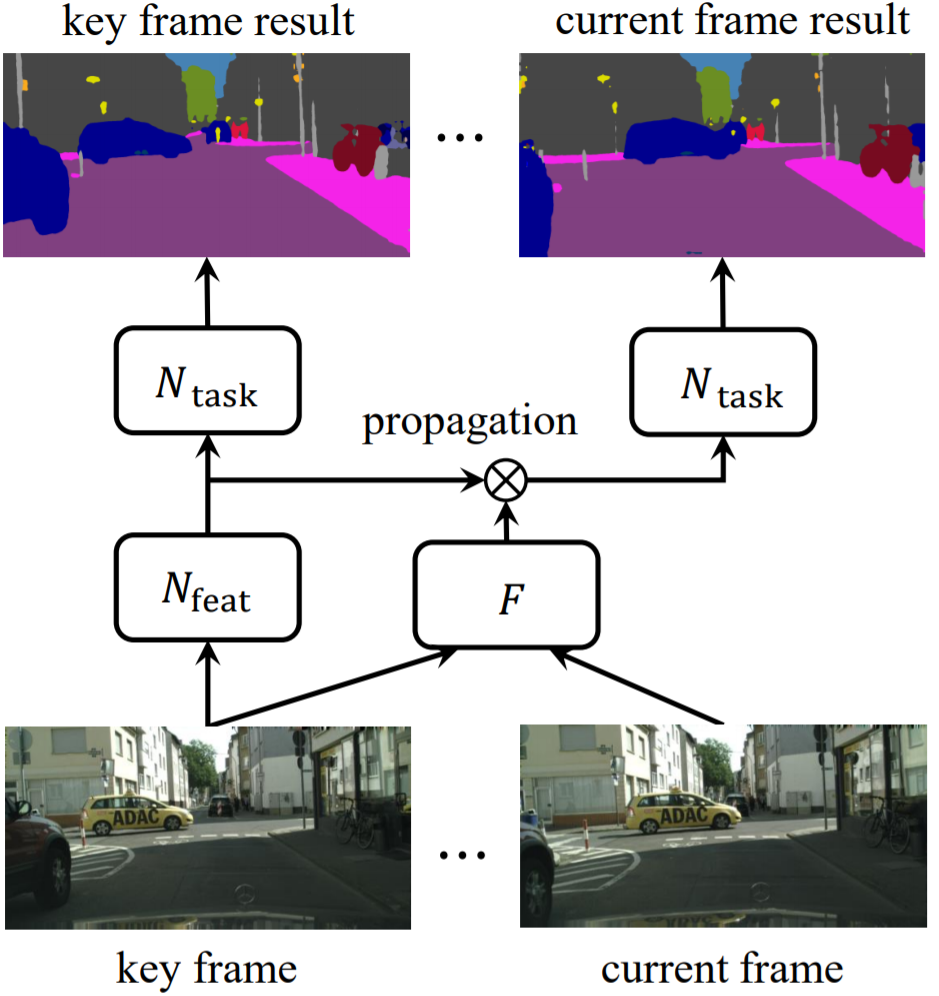
算法简介:每隔几帧,从视频中选择关键帧。利用关键帧特征和光流进行特征重用,避免对当前帧进行特征提取。特征传递不是逐帧依次累计进行,而是直接计算关键帧,和当前帧的光流进行变换。可以借鉴的点: 算法丢弃了对当前帧进行特征提取,而是直接由关键帧特征变换得到。在视频内容变化快的情况下,会忽略当前视频帧中的细节,因此适用于场景变化慢、细节变化小的场景。Low-Latency Video Semantic Segmentation. CVPR18
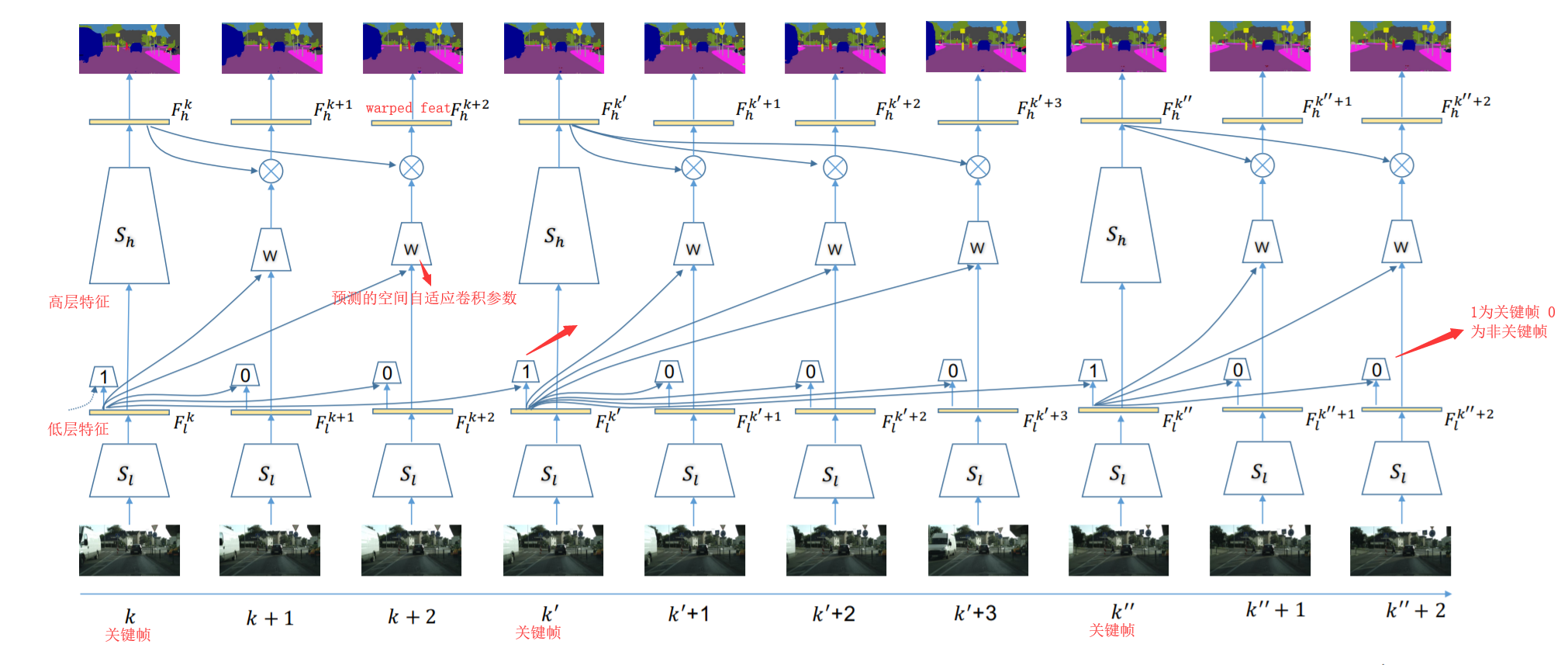
算法简介:文章主要有两个贡献点: 1. 特征传递 ;2.基于预测图像差异的关键帧选择策略。1.关键帧选择策略:以关键帧和当前帧低层卷积特征之差为输入,预测图像的差异来决定是否更新关键帧(gt为语义标注的差异)。 2.特征传递:为了能够减少计算当前图像帧的高层卷积特征,采用spatially variant convolution(自适应空间卷积,每一个位置的卷积权重不同,且卷积权重通过网络预测得到)将关键帧的高层卷积特征propagate到当前帧可以借鉴的点::提出一种不同于光流法的特征传递方法,较光流法的优点在于具有空间的约束先验(关键帧中某一物体在当前帧的对应位置的固定邻域范围内,具有空间上的约束); 缺点是不能用于快速运动,运动范围受限于预测卷积kernel的大小,而kernel过大会导致过高的显存消耗DVSNet: Dynamic Video Segmentation Network. CVPR18
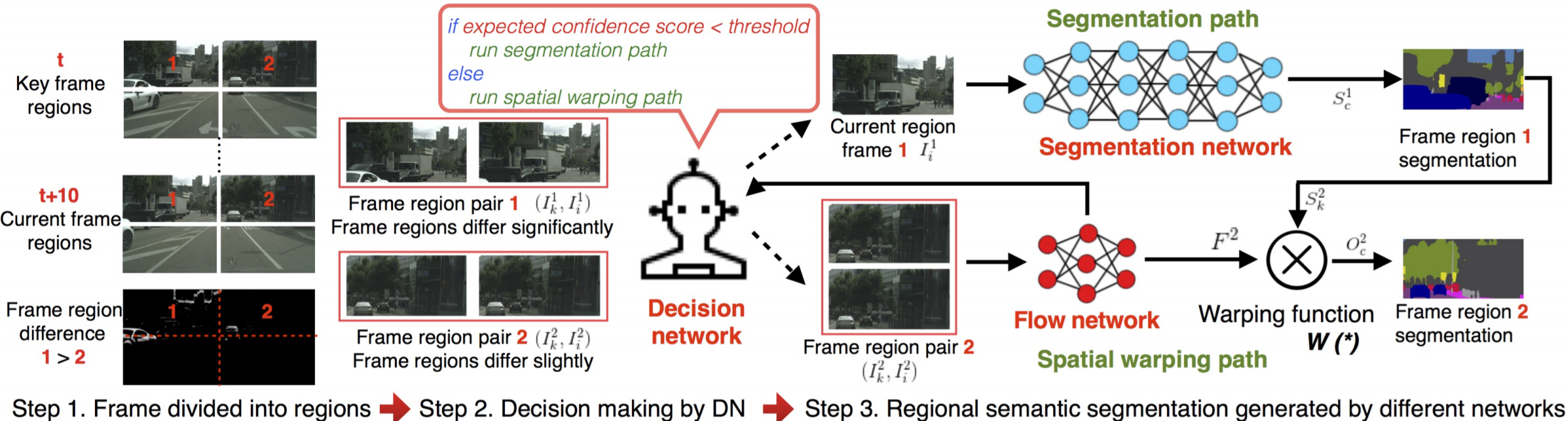
算法简介:文章的主要出发点是视频中的图像帧,不同图像区域随着时间的变化,图像区域变化的程度不同。首先将图片划分成多个区域,再利用关键帧和当前帧的特征传递思想,对于变化慢的区域可以采用光流wrap关键帧对应区域的分割结果(小模型,速度快)得到当前帧中该区域的预测结果;对于变化区域快的区域可以直接通过分割网络(大模型,慢)得到该区域的预测结果。为了能够评估区域变化的快慢,采用Decision network(输入为光流网络特征,回归wraped语义结果图与GT之间的相似度)进行对光流法wrap操作准确性的估计。如果估计得分高,选择spatial warping path,否则选择segmentation path。可以借鉴的点:相比较于逐帧处理,速度提升大(约10倍,直接wrap预测结果而不是卷积网络的中间特征层),效果变差明显(mIOU下降7%),适用于视频中不同区域内容变化差异大的场景。Budget-Aware Deep Semantic Video Segmentation. CVPR17
算法简介: 本文通过只计算关键帧图像分割概率,非关键帧通过单层卷积求得(输出最邻近关键帧与非关键帧的图像差分和关键帧的分割概率,输出非关键帧的预测概率结果),其中关键帧的选择通过强化学习进行决策可以借鉴的点:在对计算资源有严格的限制的情况下适用Clockwork Convnets for Video Semantic Segmentation. ECCV16
算法简介:直接复制特征(卷积网络深层特征在一段时间间隔内的特征复用),简单粗暴,牺牲精度换效率可以借鉴的点: 为了提升速度牺牲了过多精度,不推荐
评论 (0)