
版权属于:
人工智能炼丹君
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

本文对截止到2020年各大顶会的分割论文,包括语义分割,实例分割, 全景分割,视频分割等领域发展进行小结,不定期更新。
Strip Pooling: Rethinking Spatial Pooling for Scene Parsing [Paper] [Code]
Semi-Supervised Segmentation based on Error-Correcting Supervision [Paper]
Synthesize then Compare: Detecting Failures and Anomalies for Semantic Segmentation [Paper]
Object-Contextual Representations for Semantic Segmentation[Paper] [Code]
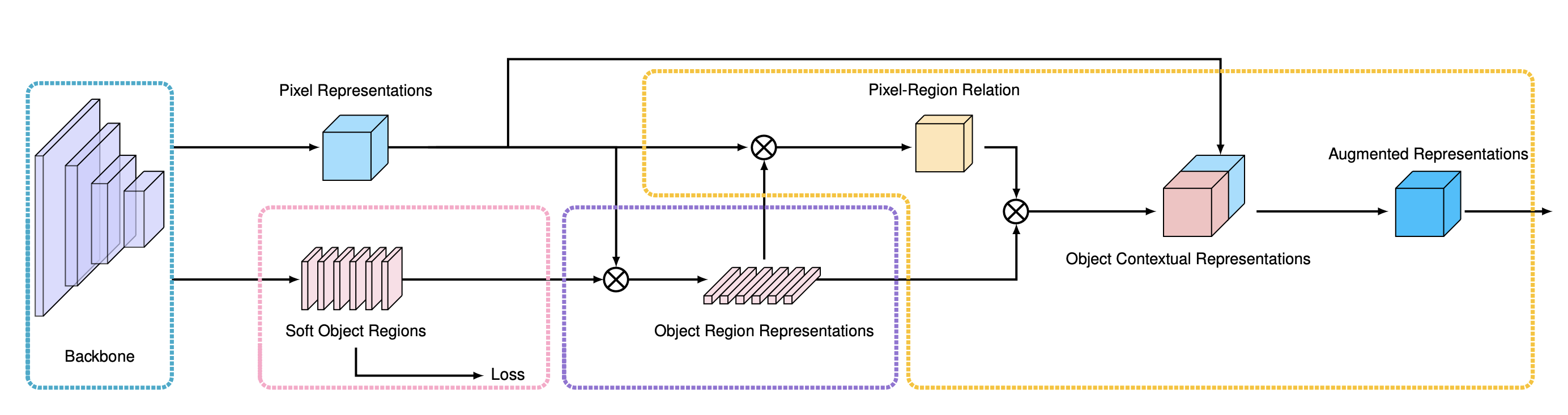
coarse2fine、attentionIntra-class Feature Variation Distillation for Semantic Segmentation [Paper] [Code]
Learning to Predict Context-adaptive Convolution for Semantic Segmentation[Paper] [[Code]()]
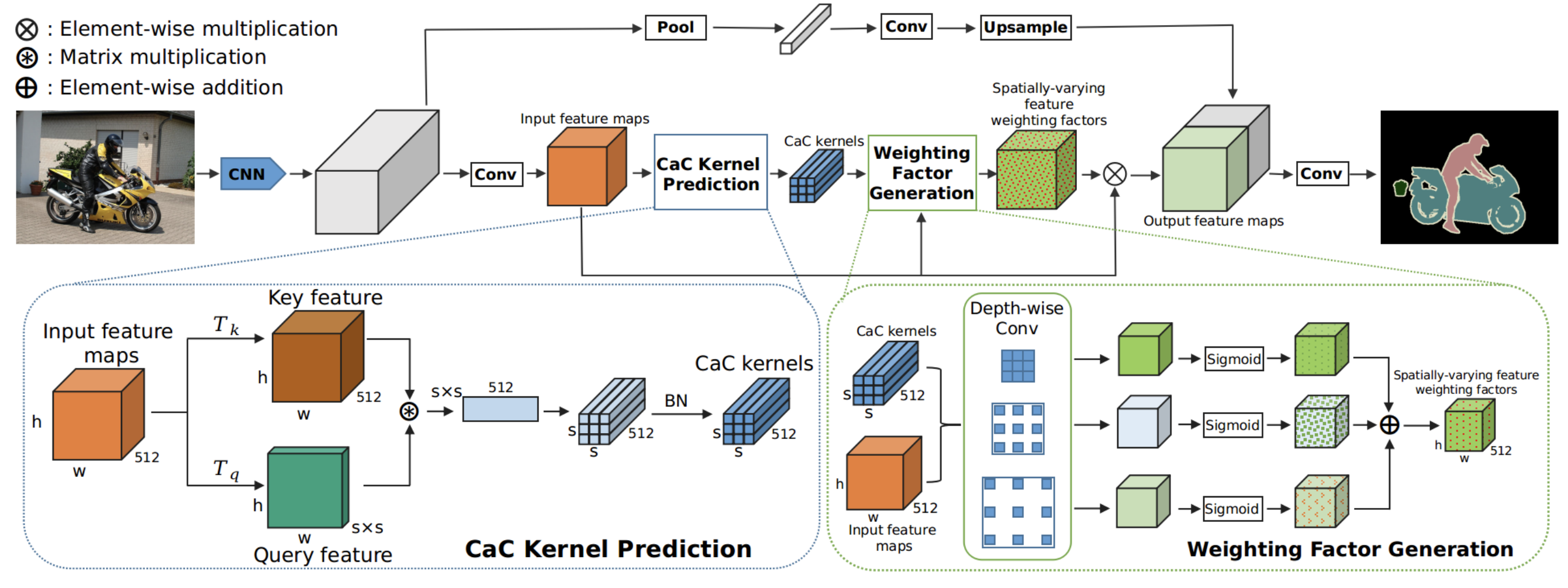
Tensor Low-Rank Reconstruction for Semantic Segmentation [Paper] [Code]
SegFix: Model-Agnostic Boundary Refinement for Segmentation [Paper]
Improving Semantic Segmentation via Decoupled Body and Edge Supervision [Paper] [Code]
EfficientFCN: Holistically-guided Decoding for Semantic Segmentation [Paper]
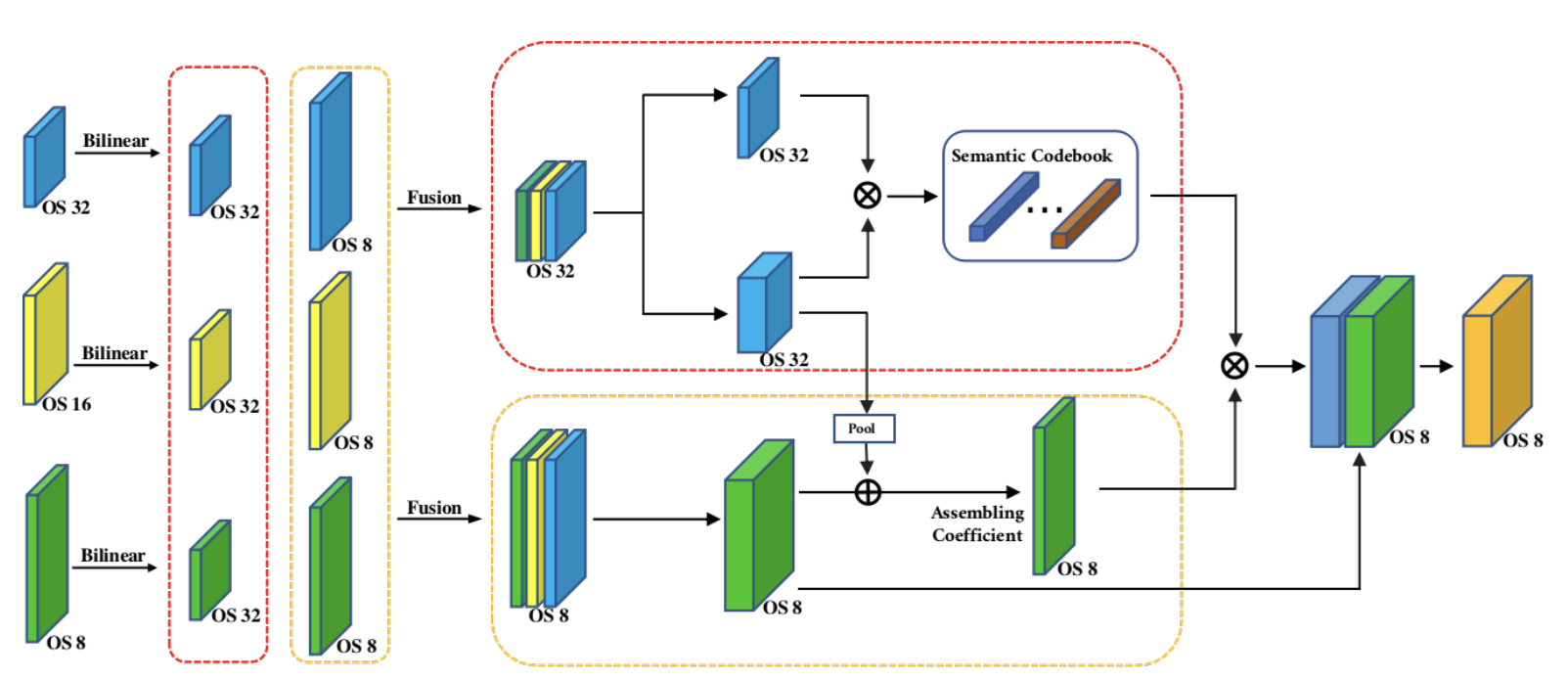
Class-wise Dynamic Graph Convolution for Semantic Segmentation [Paper]
[ICNet]: ICNet for Real-Time Semantic Segmentation on High-Resolution Images. [Paper] [Code(Tensorflow)]
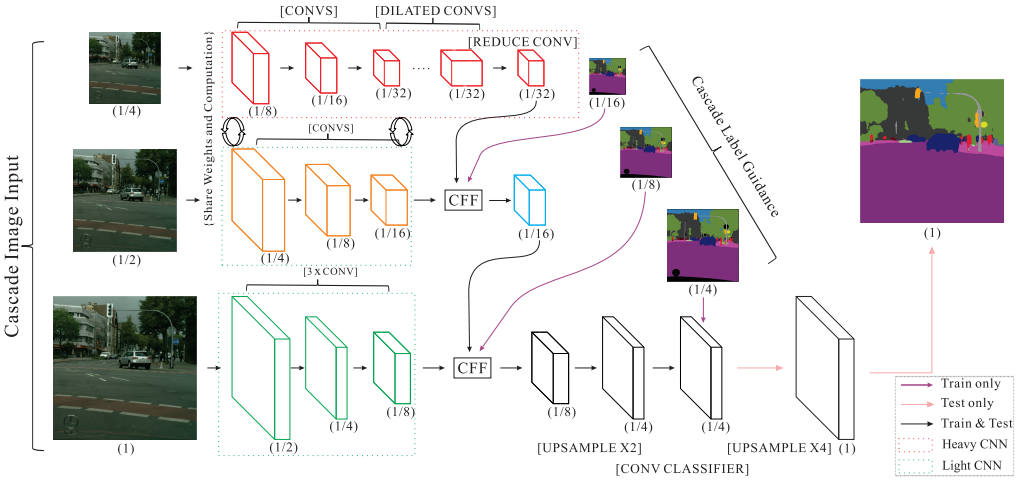
PSPNet(~1FPS)的加速版本,能够达到实时,30FPS; Image Cascade Network(ICNet)
为什么不直接在最后一个分辨率下,实现1/16和1/32的降采样,然后多尺度特征图融合(UNet结构),再加上多个尺度上的监督,也就是DeepLabV3+的简化模型版本?
[ExFuse]: Enhancing Feature Fusion for Semantic Segmentation(Face++).[Paper]
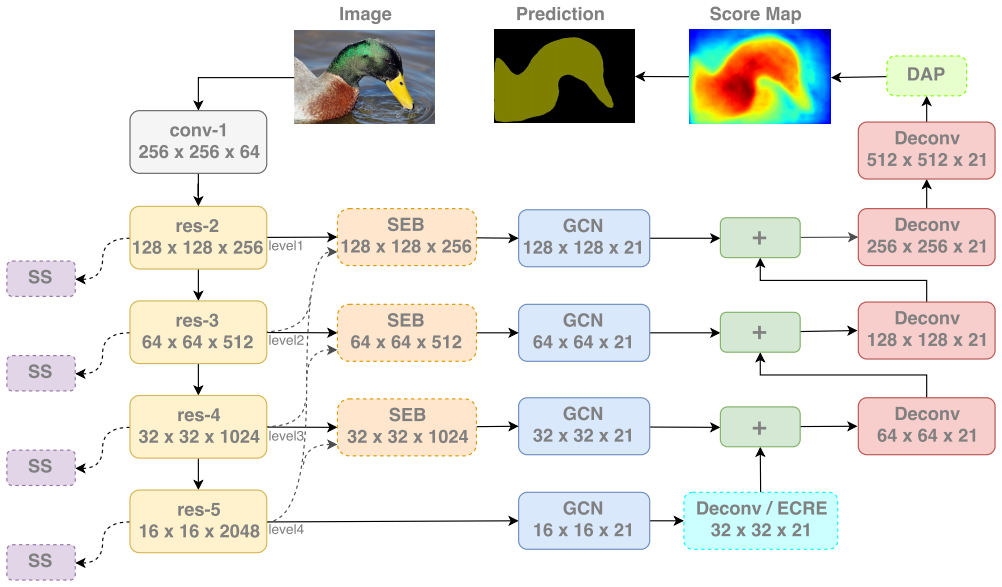
semantic supervision(SS): 在backbone的预训练的过程,在网络的中间层加入多个分类损失,使得中间层带有更多的语义信息
layer rearrangement(LR): 调整backbone中不同block的通道数的分布,使得深层和浅层具有相近的通道数,即丰富底层特征,有利于后续步骤中深层和浅层的融合
explicit channel resolution embedding(ECRE):借鉴超分辨率中的上采样方式(sub-pixel Upsample)
semantic embedding branch(SEB): 将不同深层特征进行上采样,然后与浅层特征相乘融合
densely adjacent prediction(DEP): 可以理解为卷积核为$k \times k$固定参数$\frac{1}{k \times k}$的group conv
[DeepLabv3+]: Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation.
Adaptive Affinity Fields for Semantic Segmentation
[PSANet]: Point-wise Spatial Attention Network for Scene Parsing
[ESPNet]: Efficient Spatial Pyramid of Dilated Convolutions for Semantic Segmentation
[BiSeNet]: Bilateral Segmentation Network for Real-time Semantic Segmentation
BlendMask: Top-Down Meets Bottom-Up for Instance Segmentation GITHUB CODE
PolarMask: Single Shot Instance Segmentation with Polar Representation GITHUB CODE
Hybrid Task Cascade for Instance Segmentation. [Paper] [Code(pytorch)]
Mask Scoring R-CNN. [Paper]
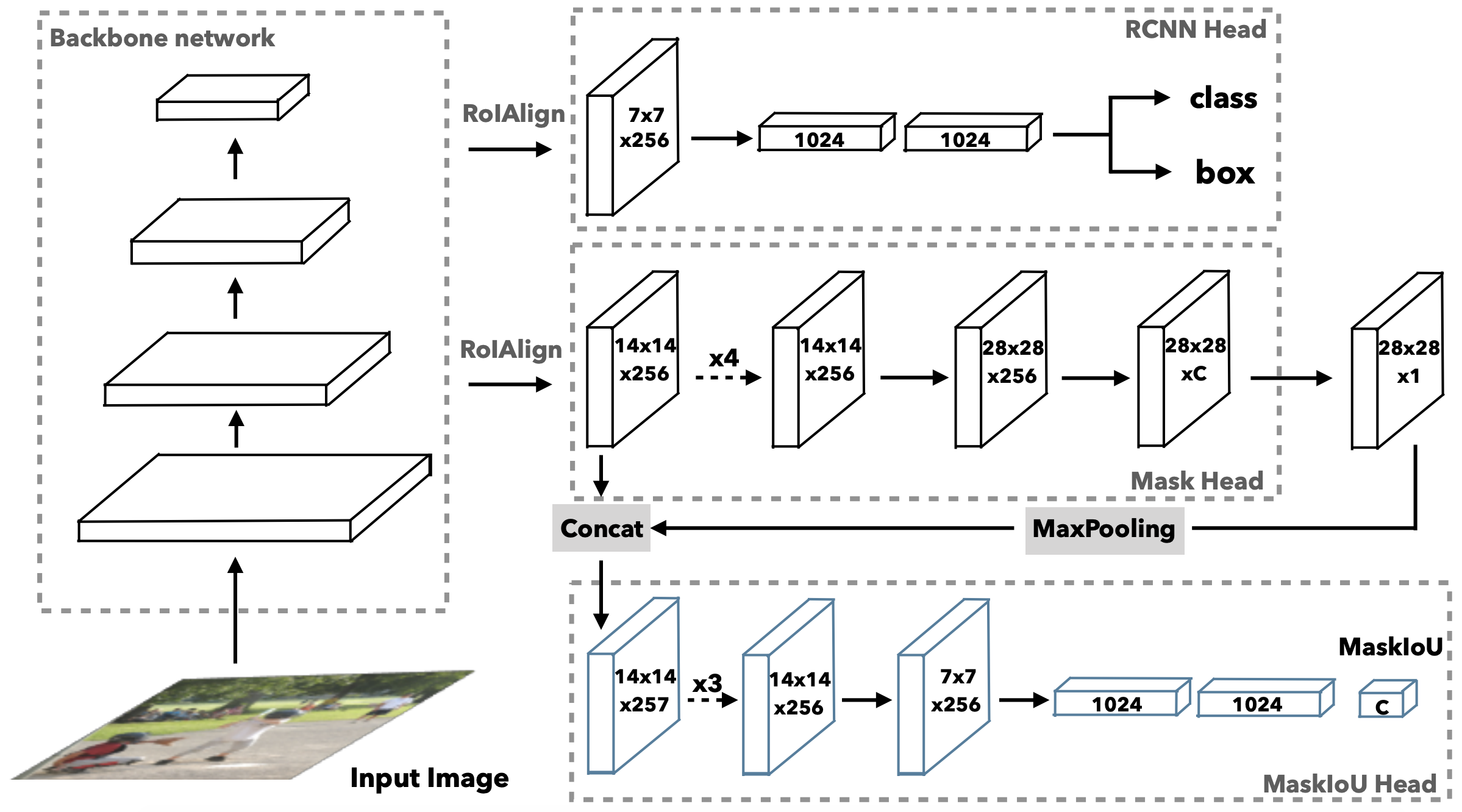
算法简介:Mask Scoring R-CNN是对Mask-RCNN的改进,文章的出发点在于mask-rcnn采用分类的得分作为检测结果和分割结果与GT重合程度的得分,但是在实际应用中常常出现,分类得分高,但是检测结果和分割结果并不好的问题。为了更准确的评估分割结果的好坏,文章在Mask-RCNN的基础上提出一个MaskIOU分支,该分支以ROI区域的分割Mask和ROIAlign的特征作为输入,预测输出该ROI predicted mask与GT mask 之间的IOU score。结合IOU score 和classification score,判断该ROI输出mask的精确程度值得借鉴的点: 视频分割 VS 语义图片分割: 相邻帧得到相似的结果(时间冗余度和视觉抖动)
| Algorithm | DAVIS(16val/17) | YouTube-VOS | Youtube-Obj(mIOU) | Speed(FPS) |
|---|---|---|---|---|
| RVOS(CVPR19) | -/48.0 | - | - | 22.7 |
| STCNN(CVPR19) | 83.8/58.7 | - | 79.6 | 0.256 |
| FEELOVS(CVPR19) | 81.1/- | 1.96 | ||
| SiamMask(CVPR19) | 35 | |||
| FAVOS(CVPR18) | -/54.6 | - | - | - |
| OSVOS(CVPR17) | 79.8/56.6 | - | - | 0.1~5 |
| MaskTrack(CVPR17) | 80.3/- | - | 71.7 | <1.0 |
| OnAVOS(BMVC17) | 86.1/- |
RVOS: End-to-End Recurrent Network for Video Object Segmentation. [Paper] [Code(pytorch)]
STCNN: Spatiotemporal CNN for Video Object Segmentation. [Paper] [Code(pytorch)]
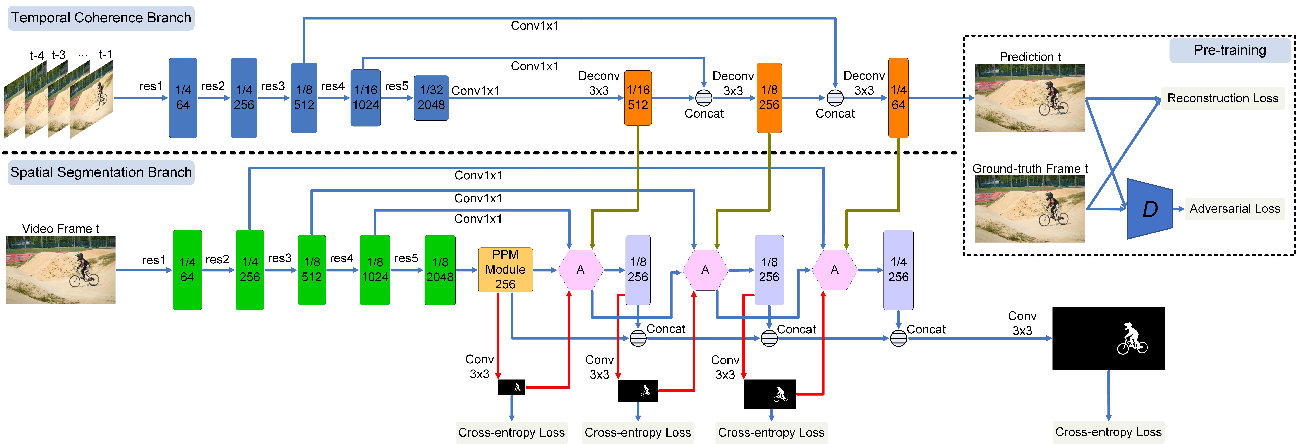
FEELOVS: Fast End-to-End Embedding Learning for Video Object Segmentation. [Google] [Paper] [Code(tensorflow)]
SiamMask: Fast Online Object Tracking and Segmentation: A Unifying Approach. [Paper] [Code(Pytorch)]
MHP-VOS: Multiple Hypotheses Propagation for Video Object Segmentation. [Paper]
Accel: A Corrective Fusion Network for Efficient Semantic Segmentation on Video. [Paper]
A Generative Appearance Model for End-To-End Video Object Segmentation. [Paper] [Code(Pytorch)]
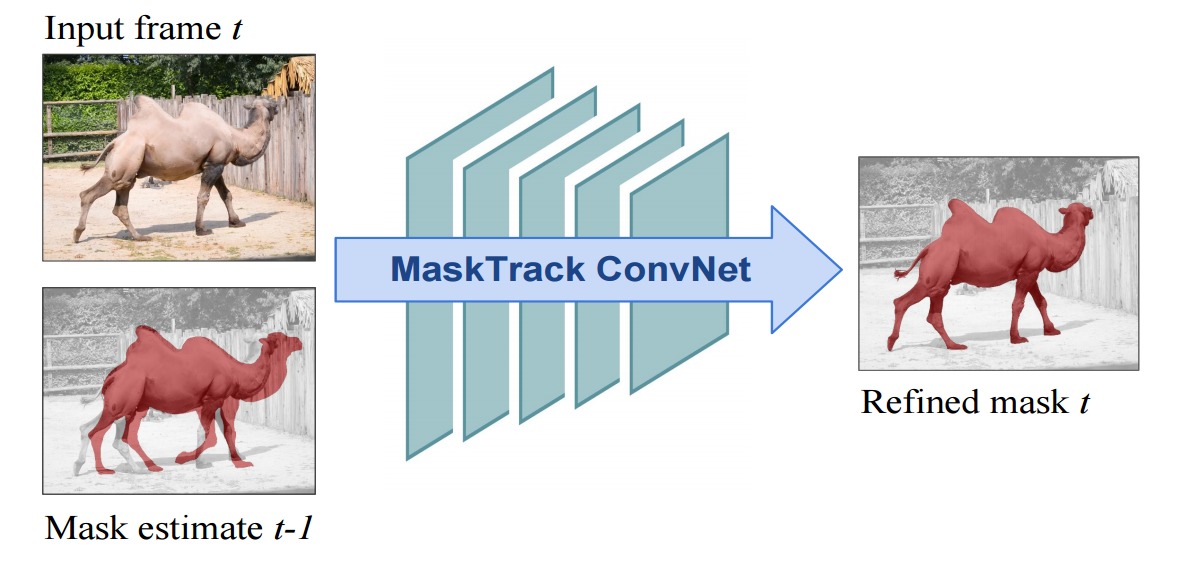
OSVOS 可以认为是将语义分割方法适用到视频目标分割最直接的方法,由离线训练二分类网络(物体分割)+在线finetune构成。FusionSeg和MaskTrack用了光流信息和RGB输入图像进行互补,通过在网络的输入中加入传统方法计算的光流。FusionSeg的光流支路进行重新训练,和MaskTrack 直接沿用RGB支路的模型,前者的光流支路结果通过可学习的1*1卷积进行融合,而后者直接将光流支路得到的结果叠加求平均。
OSVOS: One-Shot Video Object Segmentation.[Paper] [Code(pytorch)] [Code(TensorFlow)]
算法流程图:ImageNet预训练+视频分割数据集DAVIS二分类训练+在线测试Finetune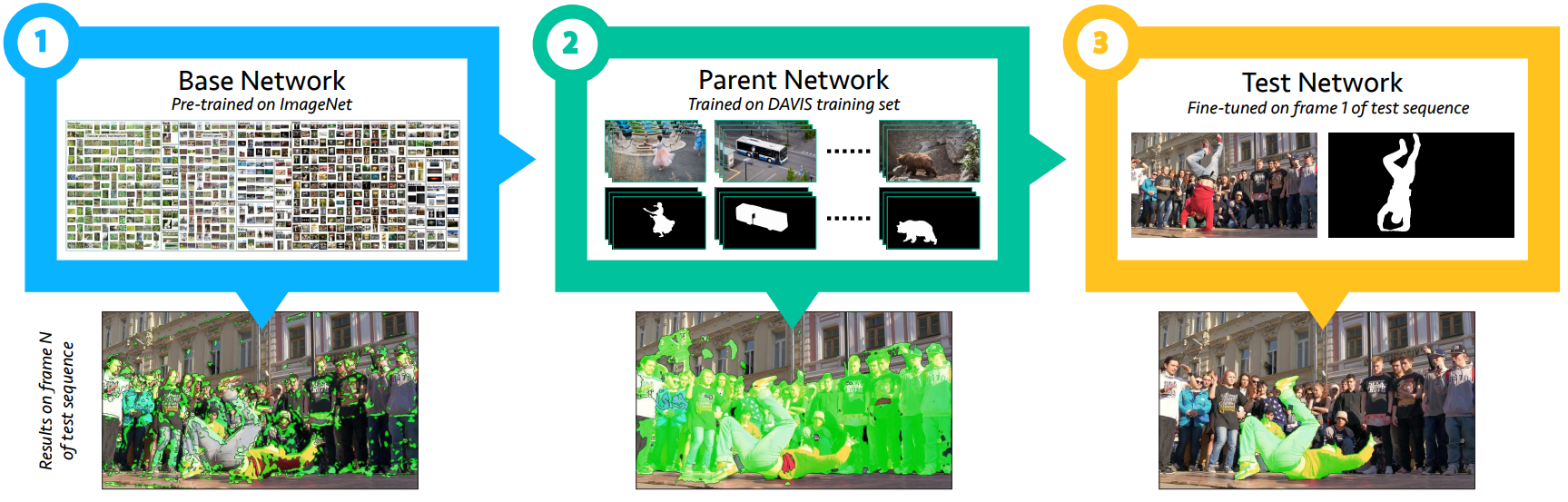
特点:单帧处理,没有累计误差;通过Finetune+物体边缘损失约束,用时间换准确率
FusionSeg: Learning to combine motion and appearance for fully automatic segmentation of generic objects in videos.[Paper] [Code(caffe)]
利用外观信息和运动信息构成two stream结构,实现视频目标分割
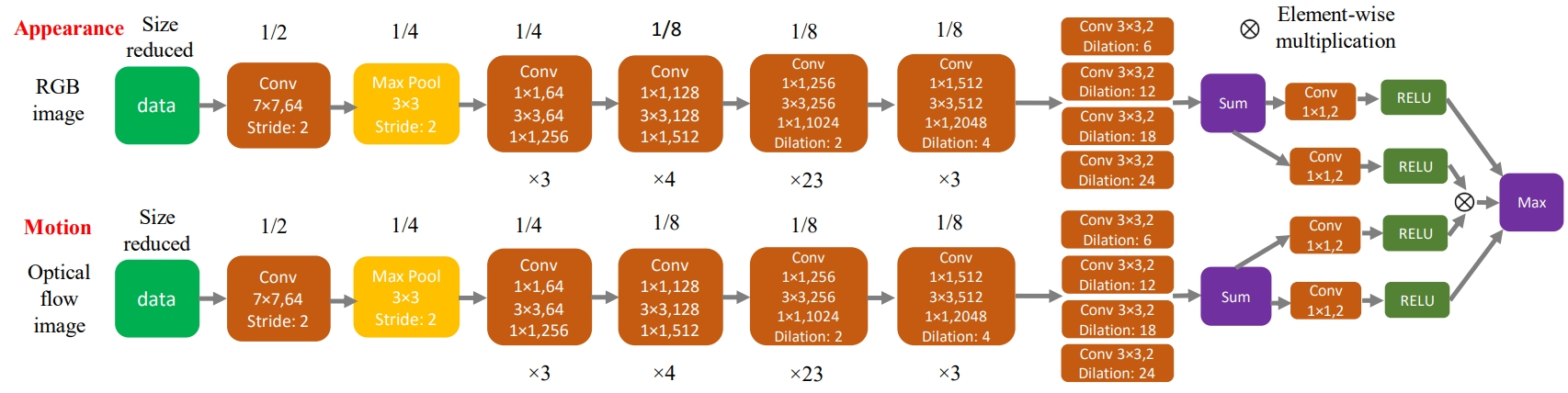
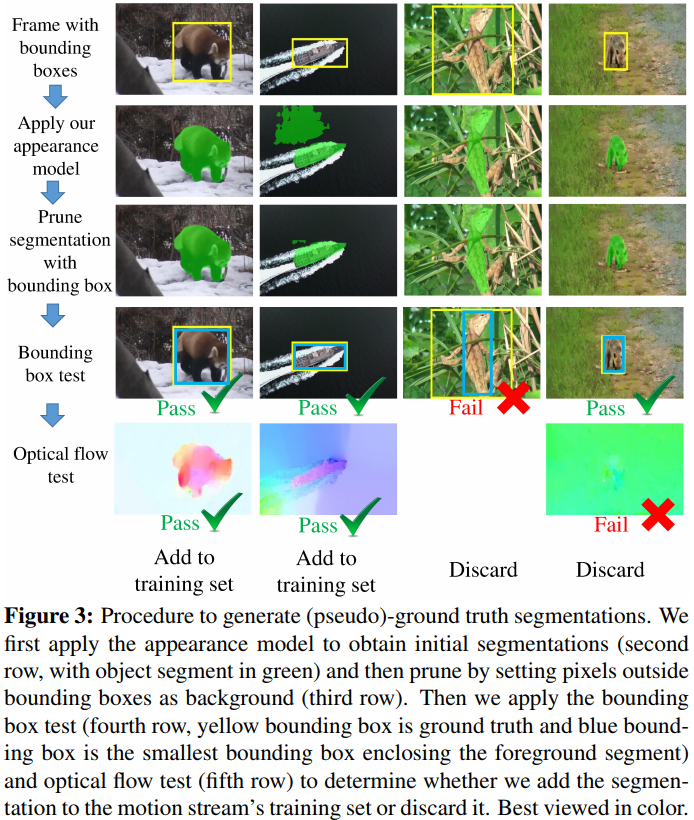
缺点:光流采用传统方法估计得到,得到的带有噪声的光流输入图像可能使得训练不稳定,且会影响最后的输出结果
MaskTrack: Learning video object segmentation from static images. [Paper] [Code]
评论 (0)