
版权属于:
人工智能炼丹师 - AIGC论文速读
作品采用:
《
署名-非商业性使用-相同方式共享 4.0 国际 (CC BY-NC-SA 4.0)
》许可协议授权

人工智能炼丹师 整理 | 共 8 篇论文 | 重点深度解读 8 篇
今日 arXiv cs.CV 视觉生成相关论文共 8 篇,重点解读 8 篇。
方向分布:
来源: arXiv 2026-03-29 ~ 2026-04-04
潜空间统一模型:释放交错跨模态推理潜力 | 清华/上交 | Tsinghua University, Shanghai Jiao Tong University | arXiv:2604.02097
关键词: 统一模型, 潜空间, 跨模态推理, 视觉空间规划, 自反思生成
核心问题: 如何在统一多模态模型中消除像素空间中介,实现高效的交错跨模态推理
统一多模态模型(UMs)具有理解和生成异质模态内容的能力,但现有 UMs 面临关键瓶颈:视觉理解和生成使用不同的表示空间(如 CLIP 特征用于理解、VQGAN Token 用于生成),导致跨模态推理时必须经过像素空间解码作为中介,既低效又引入编解码器偏差(codec bias)。这严重限制了交错跨模态推理(interleaved cross-modal reasoning)的能力——例如需要密集视觉思考的理解任务、通过自反思改进生成、以及通过逐步动作干预建模物理世界动态等场景。
前序工作及局限:
与前序工作的本质区别: 提出共享语义潜空间,所有模态在同一表示中建模,消除像素空间解码中介
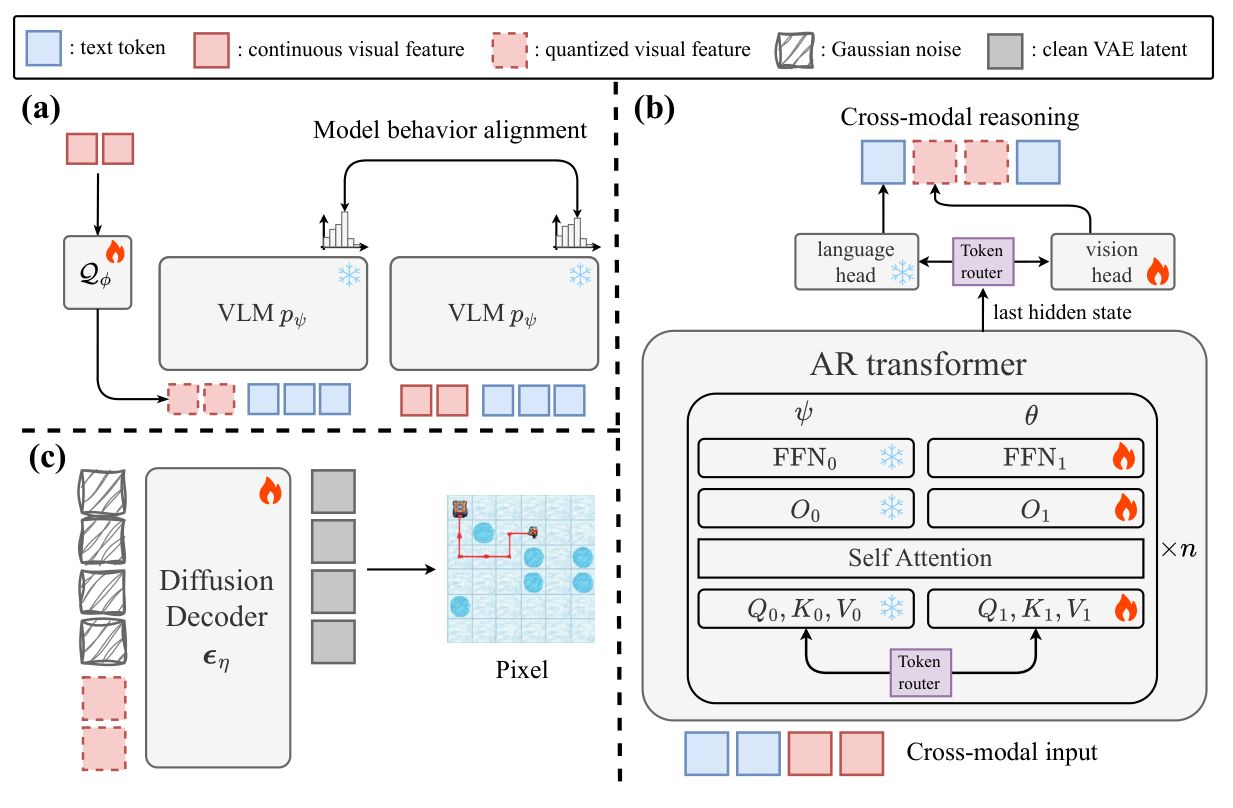
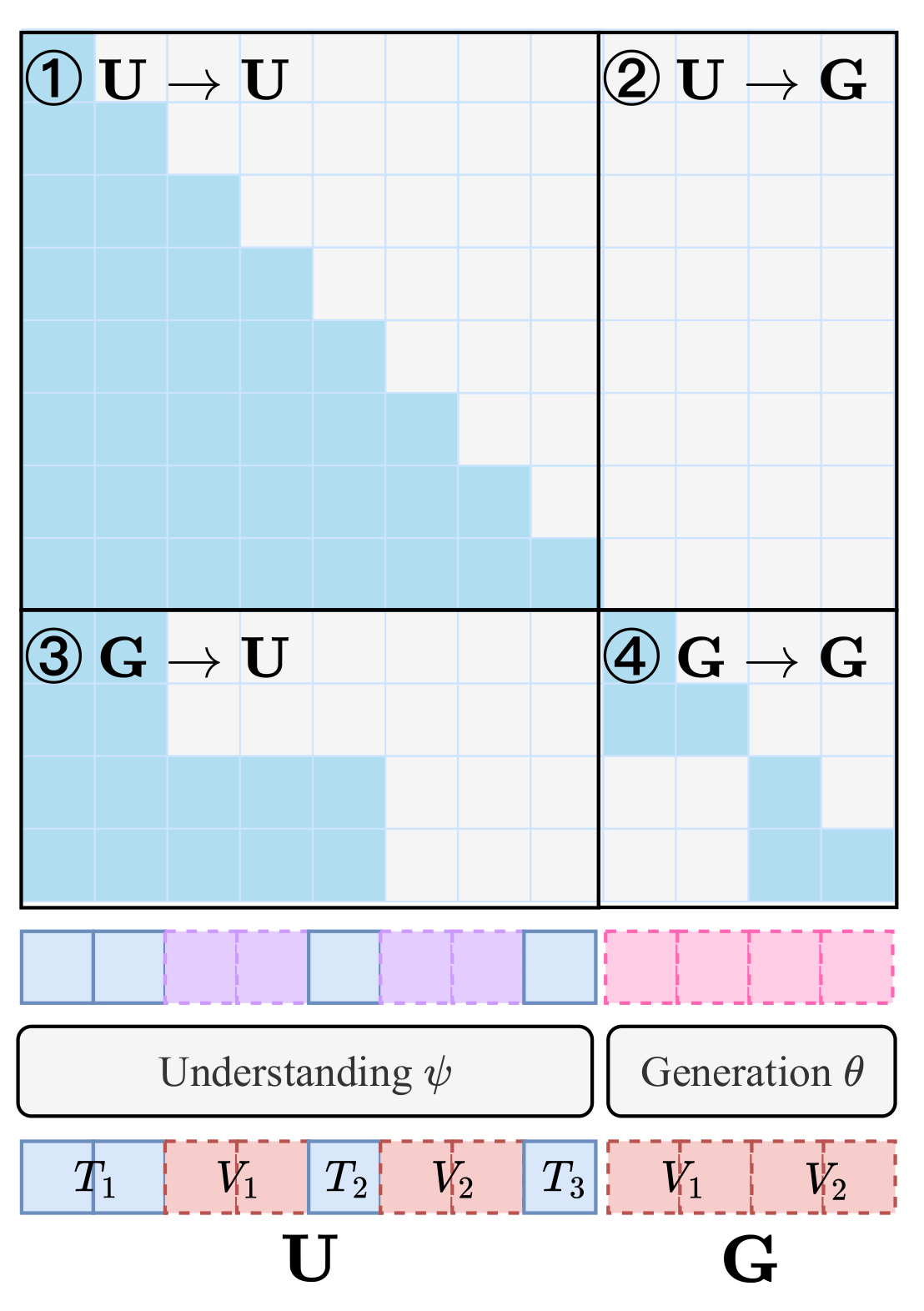
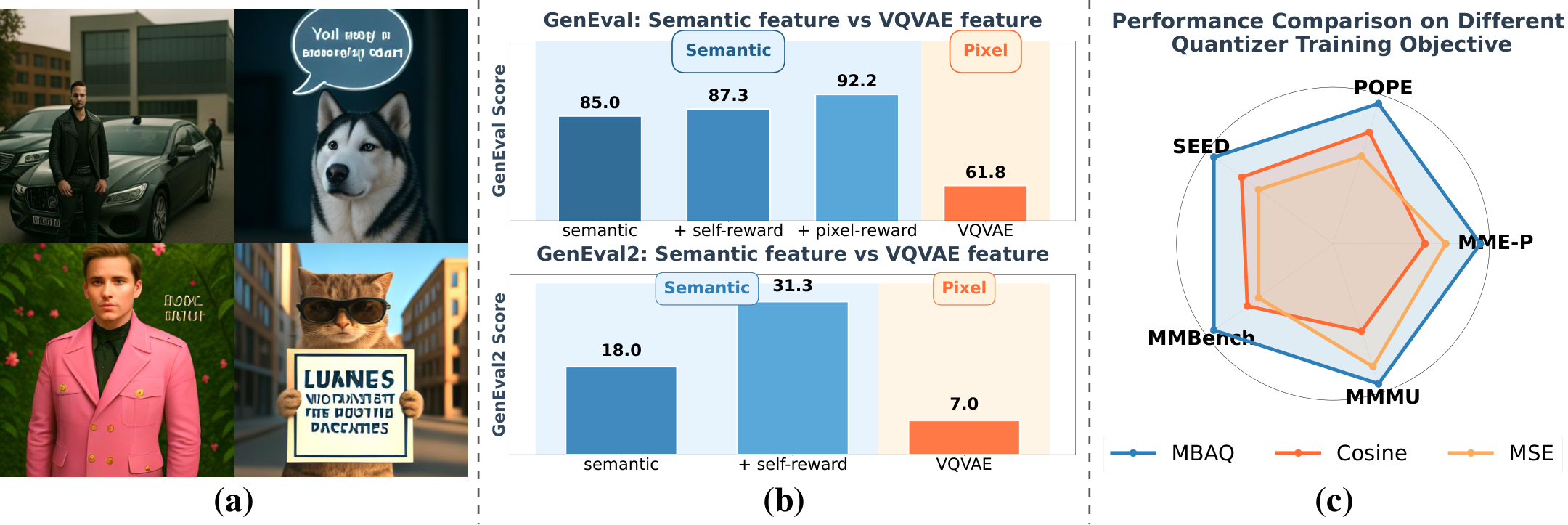
LatentUM 提出将所有模态统一到共享语义潜空间(shared semantic latent space)中表示,完全消除像素空间中介的需要。核心设计:(1) 共享潜空间表示:视觉理解和生成共用同一组潜向量,无需在两个不同的视觉编码器之间切换;(2) 交错生成与推理:模型可以在文本推理和视觉生成之间自由交替,每步的视觉输出直接作为下一步推理的输入,无需解码到像素再重新编码;(3) 自反思机制:模型能在潜空间中评估自己的生成结果,通过迭代优化提升视觉生成质量。这种设计不仅提高了计算效率,还大幅缓解了编解码器偏差,增强了跨模态对齐。
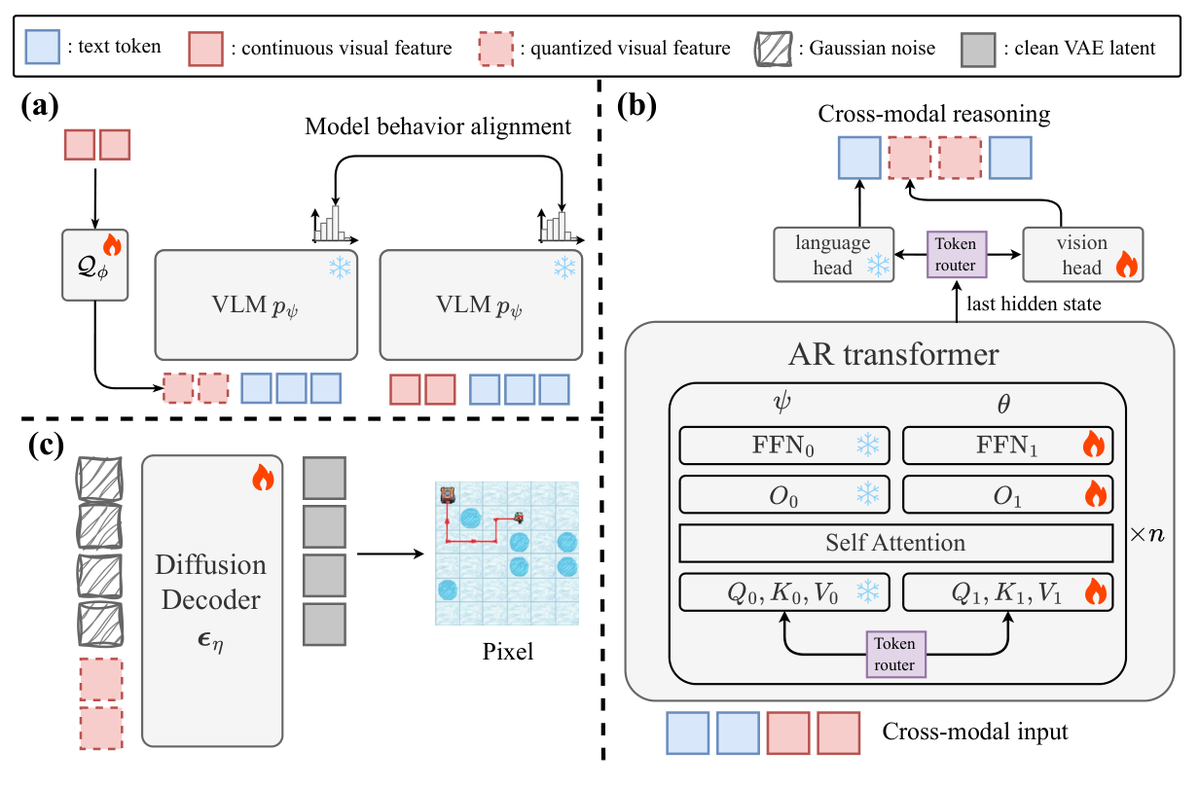
交错跨模态推理示例
展示 LatentUM 如何在文本推理和视觉生成之间自由交替。模型每一步的视觉输出直接作为下一步推理的输入,无需解码到像素再重新编码。图中对比了传统统一模型(需要像素中介)和 LatentUM(共享潜空间)的差异,清晰展示了潜空间融合带来的效率优势。
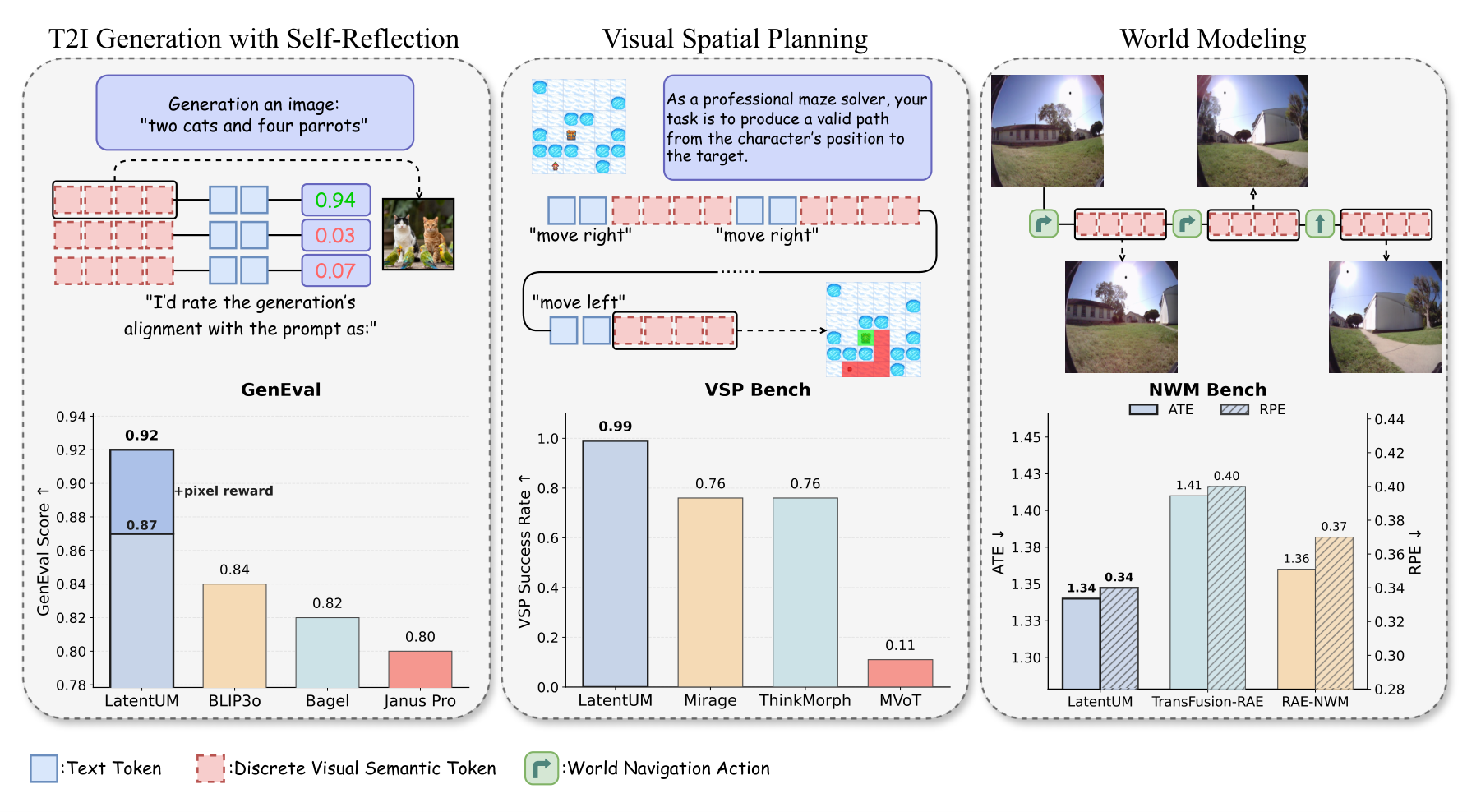
自反思机制效果对比
展示 LatentUM 的自反思机制如何提升视觉生成质量。通过在潜空间中评估自己的生成结果,模型可以迭代优化输出。图中对比了有无自反思机制下的生成效果,验证了潜空间评估和迭代改进的有效性。
深度点评:
技术演进定位: 统一模型从表面统一到深层语义融合的关键一步
可能的后续方向:
上下文空间排斥:让DiT生成更多样 | Tel Aviv University | Tel Aviv University | arXiv:2603.28762
关键词: 多样性, DiT, 文生图, 排斥机制, 注意力干预
核心问题: 如何在不牺牲质量的前提下提升DiT生成的多样性
现代文生图(T2I)扩散模型在语义对齐上已达到很高水平,但一个普遍且被低估的问题是:对同一文本提示,模型倾向于收敛到一组狭窄的视觉解决方案——即典型性偏差(typicality bias)。这对需要丰富多样创意输出的应用场景(如设计、广告、艺术创作)构成严重限制。现有提升多样性的方法面临根本权衡:修改模型输入需要昂贵的优化来融入生成路径反馈;而直接干预已空间定型的中间潜变量则会破坏正在形成的视觉结构,产生伪影。
前序工作及局限:
与前序工作的本质区别: 在注意力中间层的上下文空间施加排斥,找到了结构已建立但构图未固定的精准干预时机

本文提出在上下文空间(Contextual Space)中施加排斥力来实现 Diffusion Transformer 的丰富多样性。核心创新在于干预多模态注意力通道:在 Transformer 的前向传播中,在文本条件已融合新兴图像结构但构图尚未固定的 block 之间注入即时排斥(on-the-fly repulsion)。具体来说,当生成多张图像时,通过在上下文表示(即注意力中间层的特征)之间施加排斥力,使不同图像的生成轨迹在语义层面相互远离,从而产生多样化的视觉输出。这种方法的关键优势在于:(1) 干预发生在结构已被初步确定但构图尚未固定的层,避免了低层干预造成的伪影;(2) 计算开销极小;(3) 甚至对 Turbo 和蒸馏模型等传统轨迹干预失效的模型也有效。
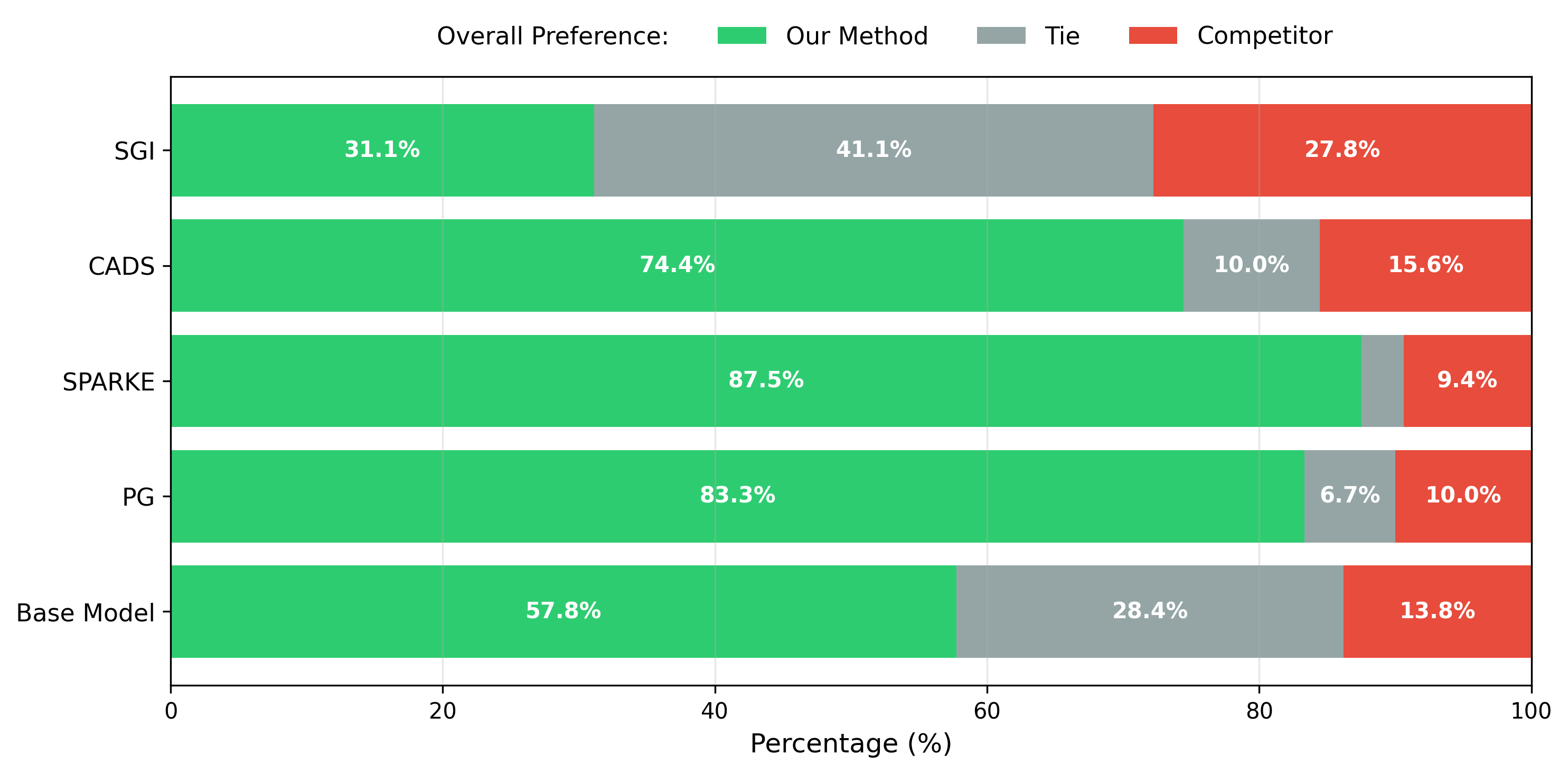
用户研究:多样性偏好评估
用户研究结果展示了上下文空间排斥方法生成的图像在多样性方面的优势。参与者被要求比较使用 ContextRepulsion 和基线方法生成的图像组,结果显示用户更偏好具有丰富多样性的输出,同时不牺牲语义对齐和视觉保真度。
上下文空间排斥原理图

ContextRepulsion 的核心原理示意图:在 DiT 的上下文空间(注意力中间层)施加排斥力。图中展示了当并行生成多张图像时,通过在上下文表示之间施加排斥力,使不同图像的生成轨迹在语义层面相互远离,从而产生多样化的视觉输出。干预时机精准:结构已被初步确定但构图尚未固定的层。
深度点评:
技术演进定位: 多样性控制从轨迹空间提升到特征空间的新维度
可能的后续方向:
门控条件注入:线性注意力的可控扩散生成 | NUS | National University of Singapore | arXiv:2603.27666
关键词: 线性注意力, 可控生成, 端侧部署, SANA, 门控调制
核心问题: 如何在线性注意力扩散模型上实现高效可控生成
基于扩散的可控视觉生成已取得显著进展,但这些模型通常需要部署在云端服务器上,引发用户数据隐私的严重担忧。要实现安全高效的端侧生成,线性注意力架构(如 SANA)是理想选择——它具备优越的可扩展性和效率。然而实验发现,现有的可控生成框架(如 ControlNet、OminiControl)在线性注意力模型上存在严重问题:要么缺乏灵活性,无法支持多种异构条件类型;要么收敛极慢。这揭示了一个被忽视的gap:可控生成方法主要为标准自注意力设计,未充分考虑线性注意力的特殊性。
前序工作及局限:
与前序工作的本质区别: 用门控调制替代多模态注意力,双路管线分别处理对齐和非对齐条件

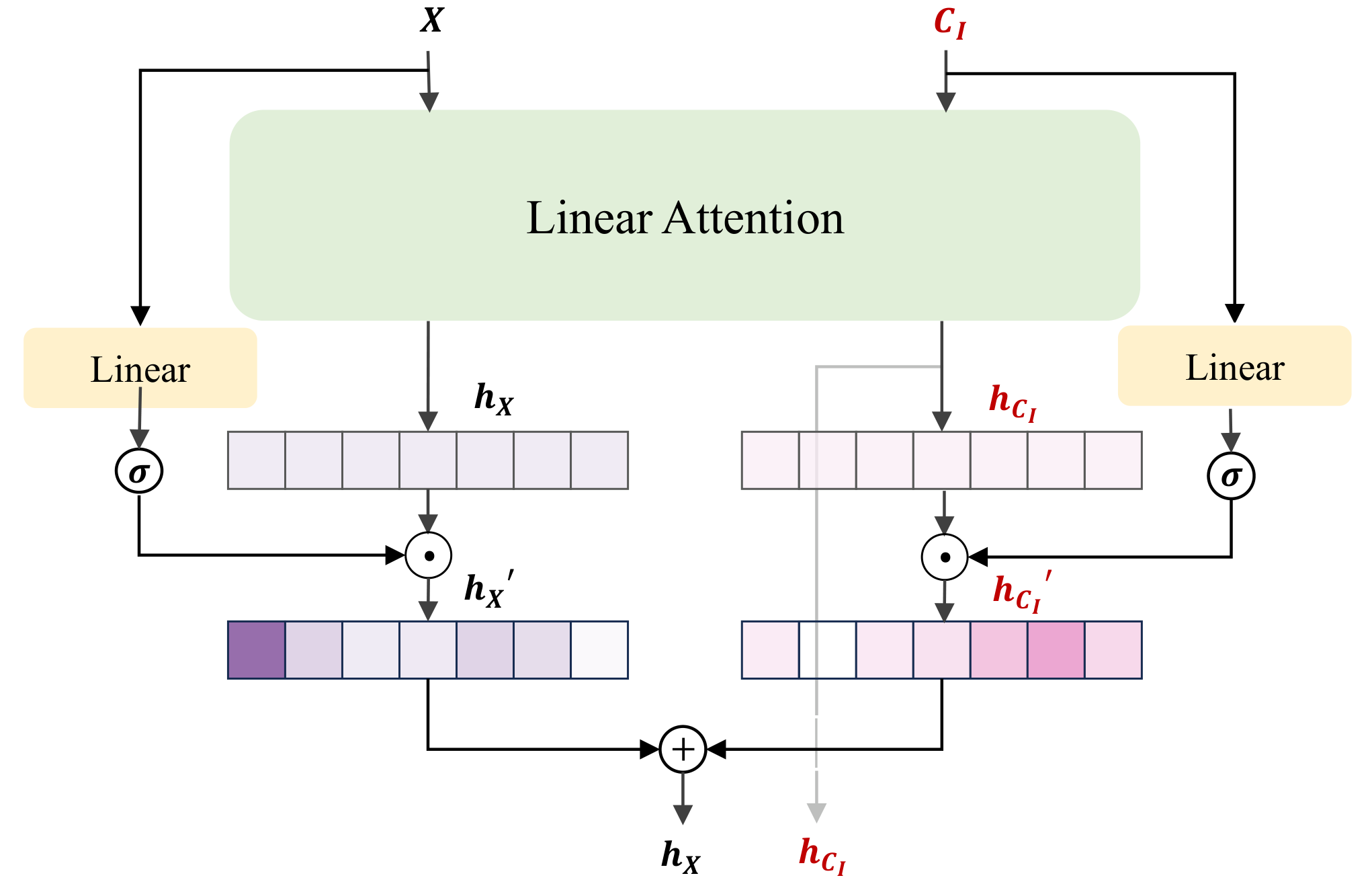
本文提出专为线性注意力骨干(如 SANA)定制的可控扩散框架。核心是统一门控条件模块(unified gated conditioning module)工作在双路管线(dual-path pipeline)中:(1) 空间对齐条件路径:处理 depth map、edge map、segmentation 等空间对齐的控制信号;(2) 非对齐条件路径:处理参考图像、风格图等非空间对齐的控制信号。两条路径通过门控机制有效融合到线性注意力的扩散过程中。关键设计是门控调制(gated modulation)替代传统多模态注意力(multimodal attention),避免了线性注意力中跨模态注意力的低效问题。
GatedControl 门控条件模块架构
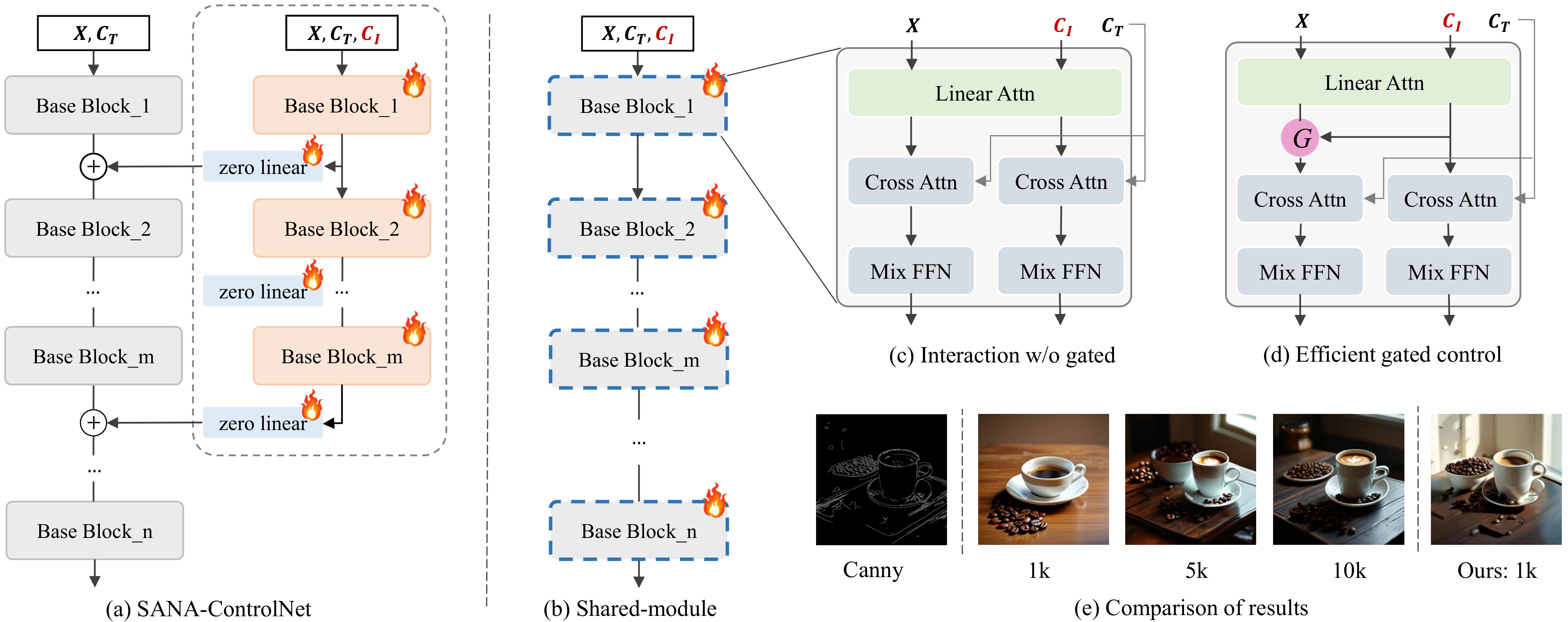
GatedControl 的核心架构:统一门控条件模块工作在双路管线中。空间对齐条件路径处理 depth map、edge map 等空间对齐信号;非对齐条件路径处理参考图像、风格图等非空间对齐信号。门控调制替代传统多模态注意力,更适合线性注意力的特性。
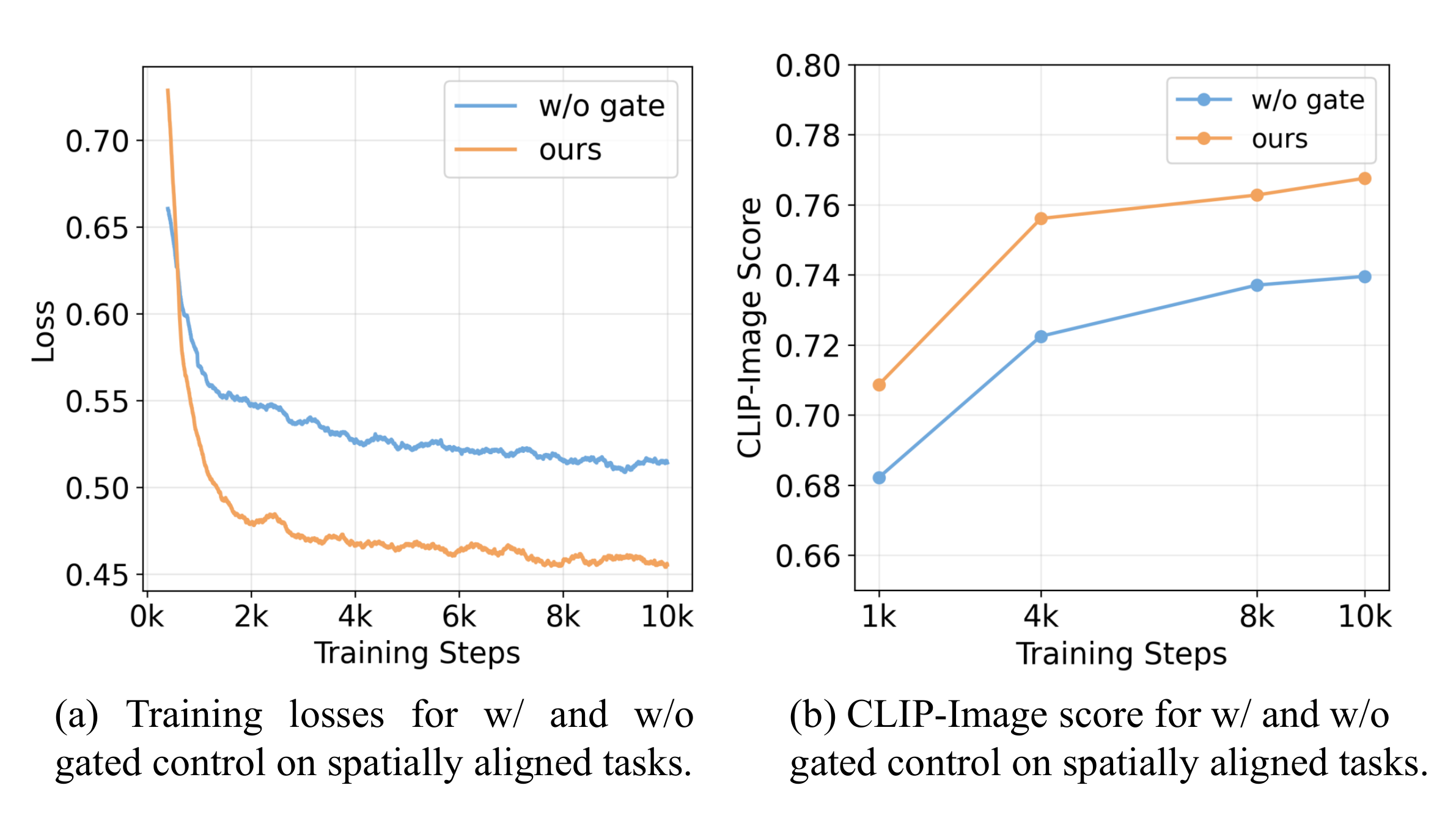
空间对齐条件消融实验
消融实验验证 GatedControl 在多种空间对齐条件下的性能。图中展示了深度条件、边缘条件、分割条件等不同控制信号下的生成效果对比。门控调制在线性注意力架构上的收敛速度和生成质量均优于传统多模态注意力方案。
深度点评:
技术演进定位: 首次将可控生成适配到线性注意力架构,打通端侧部署瓶颈
可能的后续方向:
0.39B端侧统一模型:生成+编辑不到1秒 | Xiaomi | Xiaomi | arXiv:2603.28713
关键词: 端侧推理, 模型压缩, 统一模型, 步蒸馏, 强化学习
核心问题: 如何在端侧设备上用单一紧凑模型同时支持图像生成和编辑
扩散模型在文生图和图像编辑上取得了显著进展,但通常需要数十亿参数,导致高延迟和部署困难。现有的端侧扩散模型虽然提升了效率,但几乎全部聚焦于文生图生成,缺乏对图像编辑的支持。这意味着用户需要同时安装两个独立模型才能完成生成和编辑——在存储和计算资源受限的移动设备上极不现实。
前序工作及局限:
与前序工作的本质区别: 剪枝U-Net + 上下文拼接统一格式 + 渐进预训练 + RL + 4步蒸馏
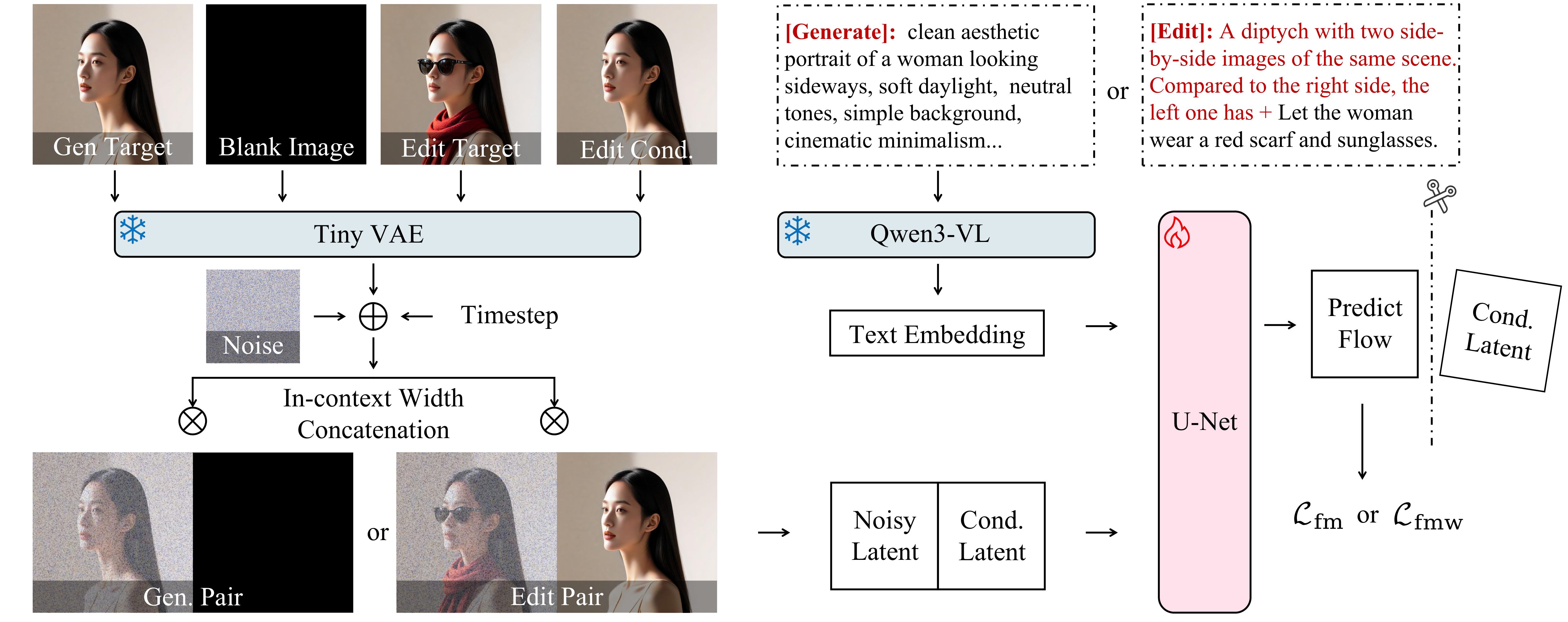
DreamLite 是一个仅 0.39B 参数的紧凑统一端侧扩散模型,在单一网络中同时支持文生图生成和文本引导图像编辑。核心设计:(1) 基础架构:基于剪枝后的 mobile U-Net 骨干,通过上下文空间拼接(in-context spatial concatenation)统一条件输入——生成任务使用 (target | blank) 配置,编辑任务使用 (target | source) 配置;(2) 任务渐进联合预训练策略:按顺序依次训练 T2I → 编辑 → 联合任务,稳定紧凑模型的训练过程;(3) 高质量 SFT + 强化学习微调;(4) 步蒸馏将去噪步数压缩到仅 4 步,在小米 14 手机上生成/编辑 1024x1024 图像不到 1 秒。
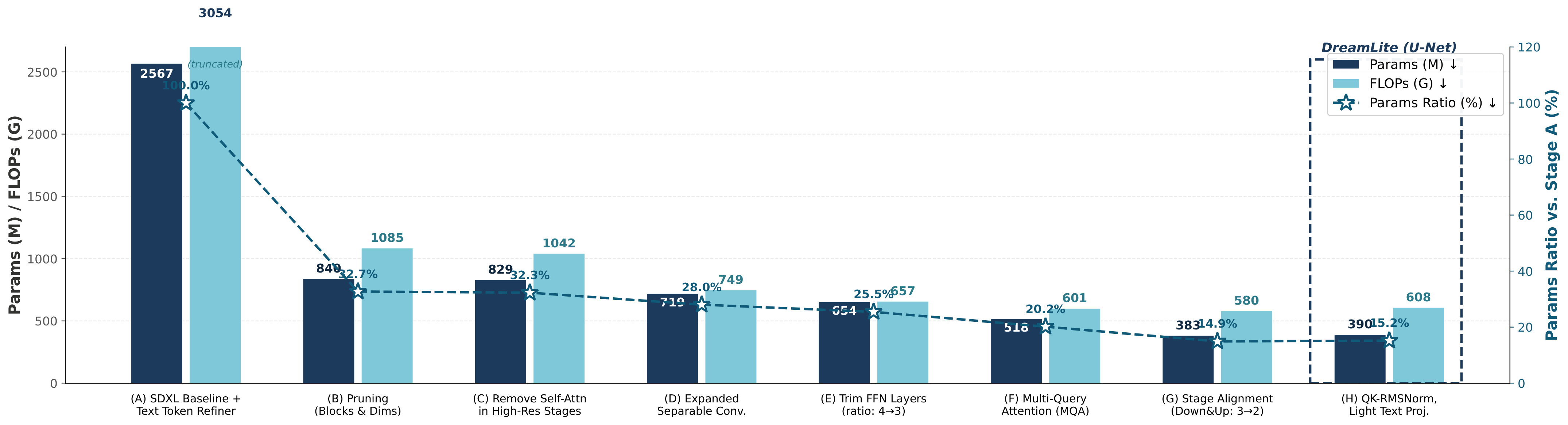
DreamLite 消融实验结果

消融实验验证 DreamLite 各组件的贡献。对比实验展示了渐进预训练、强化学习微调、步蒸馏等技术对最终性能的影响。DreamLite 在 GenEval 上取得 0.72 分(文生图),在 ImgEdit 上取得 4.11 分(图像编辑),超越所有现有端侧模型。
深度点评:
技术演进定位: 端侧扩散模型从单纯加速到功能完备的里程碑
可能的后续方向:
多Patch全局-局部DiT:计算量减半性能不降 | Rutgers | Rutgers University | arXiv:2603.26357
关键词: DiT, 多尺度Patch, 高效架构, Flow Matching, 全局到局部
核心问题: 如何降低DiT的计算成本同时保持生成质量
Transformer 架构(尤其是 Diffusion Transformers / DiTs)因其优于卷积 UNet 的性能已成为扩散和 Flow Matching 模型的主流选择。然而,DiT 的各向同性设计(isotropic design)在每个 block 中处理相同数量的 patch 化 token,导致训练过程中计算量居高不下。这是 DiT 效率的核心瓶颈:浅层和深层使用相同分辨率的 token,浅层做粗粒度全局感知时浪费了计算,深层做细粒度局部细化时又受限于粗 token。
前序工作及局限:
与前序工作的本质区别: 多Patch层级设计:早期粗patch全局感知,后期细patch局部精细化
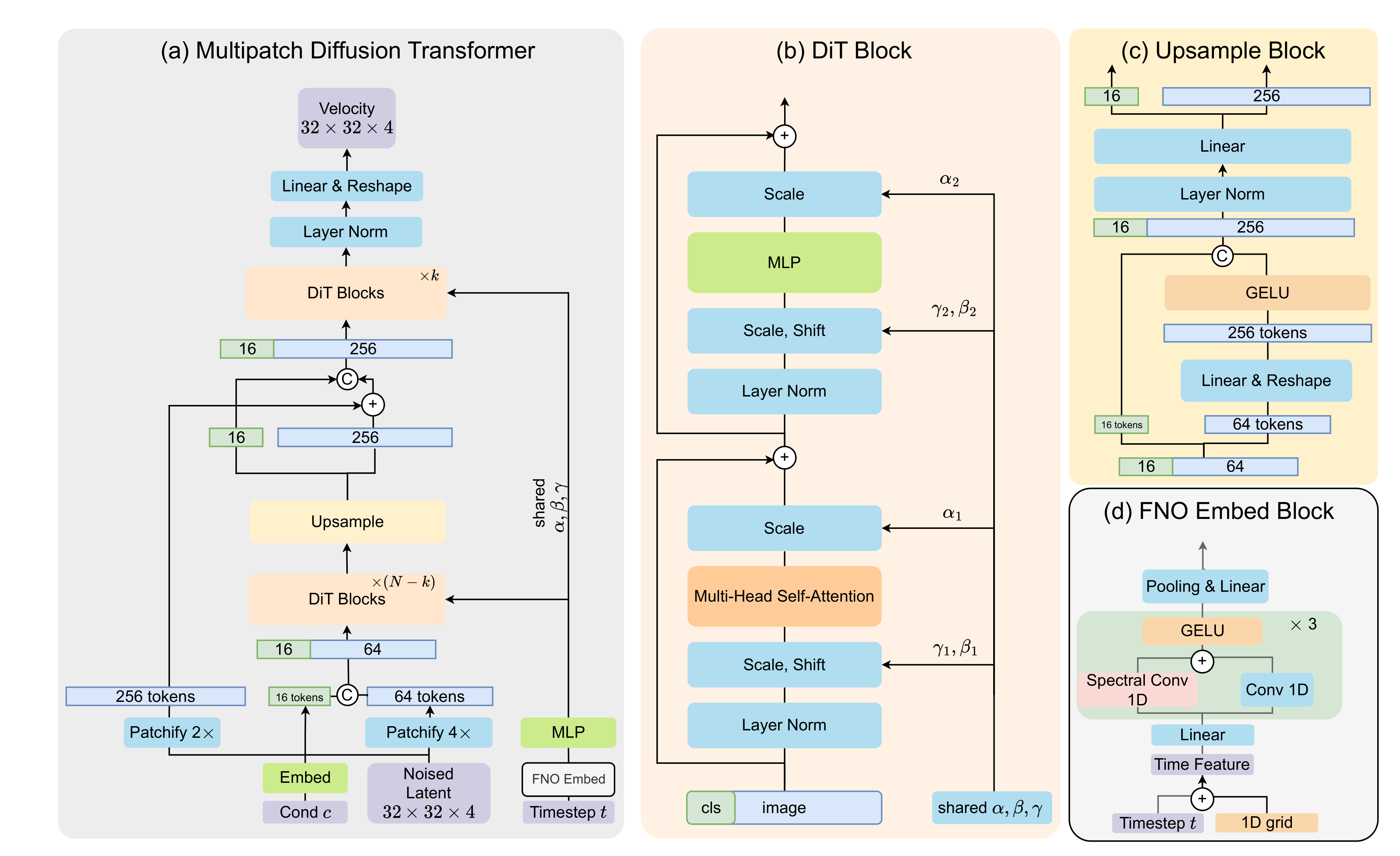
MPDiT 引入多 Patch Transformer 设计:早期 block 操作更大的 patch(粗粒度)以高效捕获全局上下文,后期 block 使用更小的 patch(细粒度)精细化局部细节。这种从粗到细的层级设计理念类似于 CNN 中经典的金字塔结构,但首次系统应用于 DiT。同时还提出了改进的时间步和类别嵌入设计,加速训练收敛。整体架构在保持生成质量的同时,将计算量(GFLOPs)降低最多 50%。

MPDiT 多Patch架构设计

MPDiT 的核心创新:多 Patch Transformer 设计。早期 block 操作更大的 patch(粗粒度)以高效捕获全局上下文,后期 block 使用更小的 patch(细粒度)精细化局部细节。这种从粗到细的层级设计理念类似于 CNN 中经典的金字塔结构,但首次系统应用于 DiT。
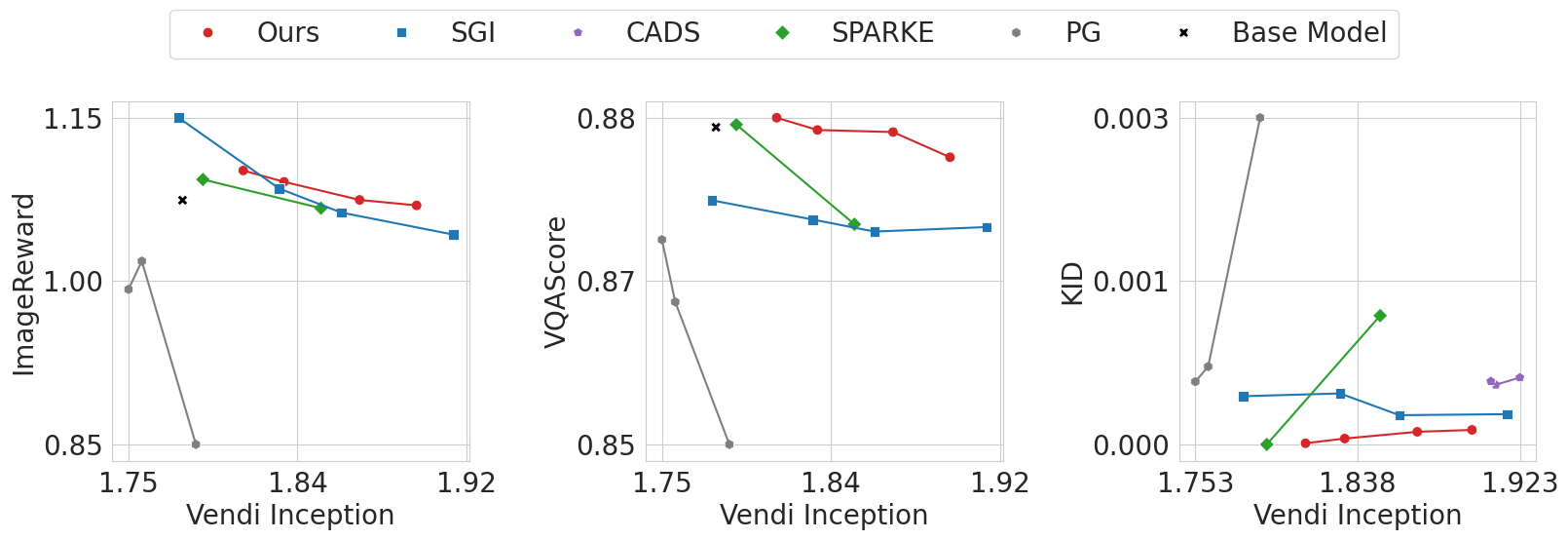
ImageNet 512x512 生成效果对比

ImageNet 数据集上的生成效果对比实验。MPDiT 在保持与标准 DiT 相当的生成质量的同时,计算量(GFLOPs)最多降低 50%。图中展示了不同分辨率下的 FID、IS 等指标对比,验证了多 Patch 设计的有效性。
MPDiT 系统架构图

MPDiT 的完整系统架构,展示了 patch 过渡机制和改进的时间步/类别嵌入设计。图中清晰说明了如何从大 patch token 重组为小 patch token,以及新的嵌入设计如何加速训练收敛。
深度点评:
技术演进定位: DiT效率优化的正交维度——从token数量角度降低计算量
可能的后续方向:
合成运动数据学习动态视频生成 | POSTECH/Microsoft | POSTECH, Microsoft Research Asia | arXiv:2604.01666
关键词: 视频生成, 合成数据, 光流, 动态运动, 运动控制
核心问题: 如何解决视频生成中高动态运动训练数据的稀缺问题
尽管视频扩散模型取得了长足进步,但在合成涉及高动态运动或需要精细运动控制的真实视频时仍然力不从心。核心限制在于:常用训练数据集中严重缺乏此类样本——真实世界的高动态运动视频(如剧烈人体运动、极端相机运动)极为稀缺,且难以标注精细的运动控制信号。
前序工作及局限:
与前序工作的本质区别: 用合成光流而非合成视频训练,运动与外观解耦避免域差距
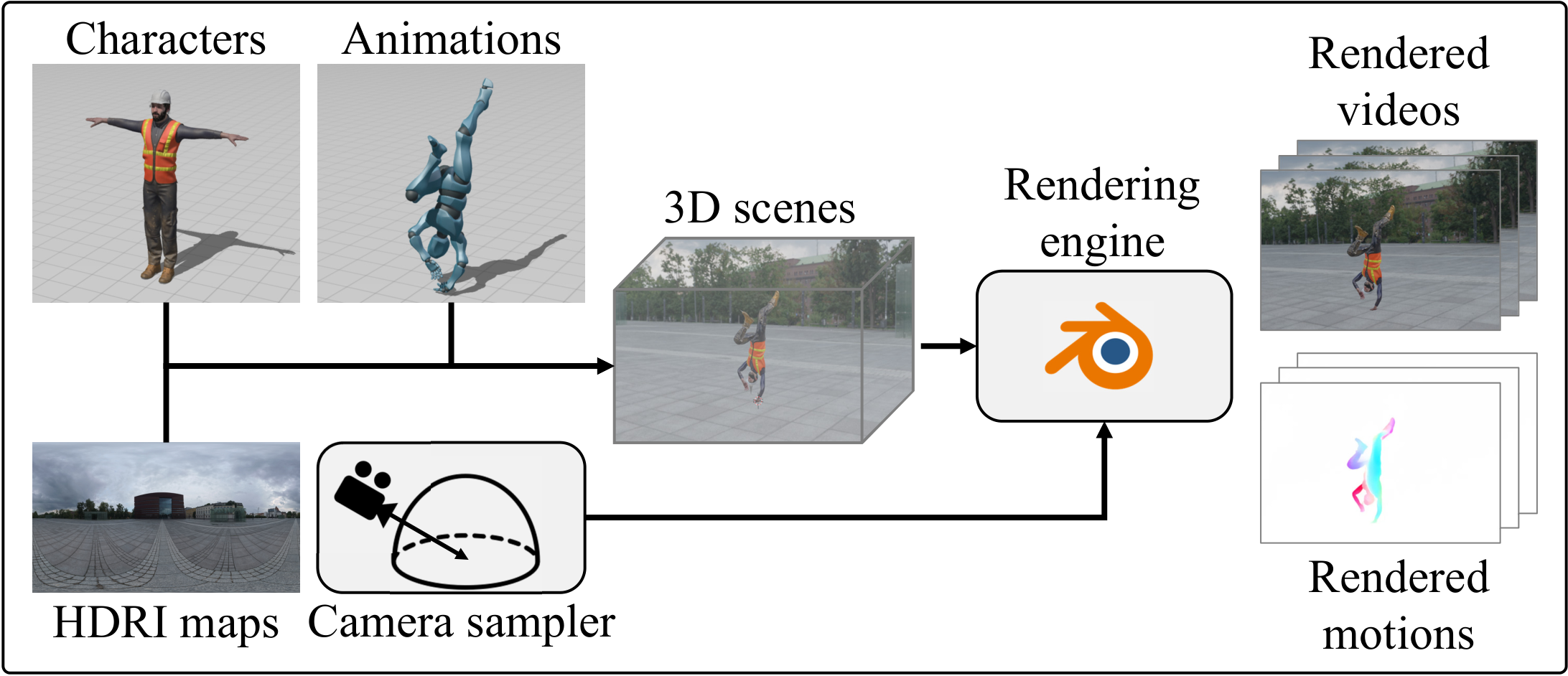
DynaVid 提出利用合成运动数据训练视频生成模型的框架。核心思路:(1) 运动以光流(optical flow)形式表示,通过计算机图形管线渲染合成——合成光流仅编码运动信息,与外观解耦,避免模型学到合成视频的不自然外观;(2) 两阶段生成框架:运动生成器先合成光流运动,运动引导的视频生成器再根据光流生成视频帧;(3) 这种解耦设计使模型能从合成数据学习动态运动模式,同时从真实视频保留视觉真实感。在两个具有挑战性的场景上验证:剧烈人体运动生成和极端相机运动控制。
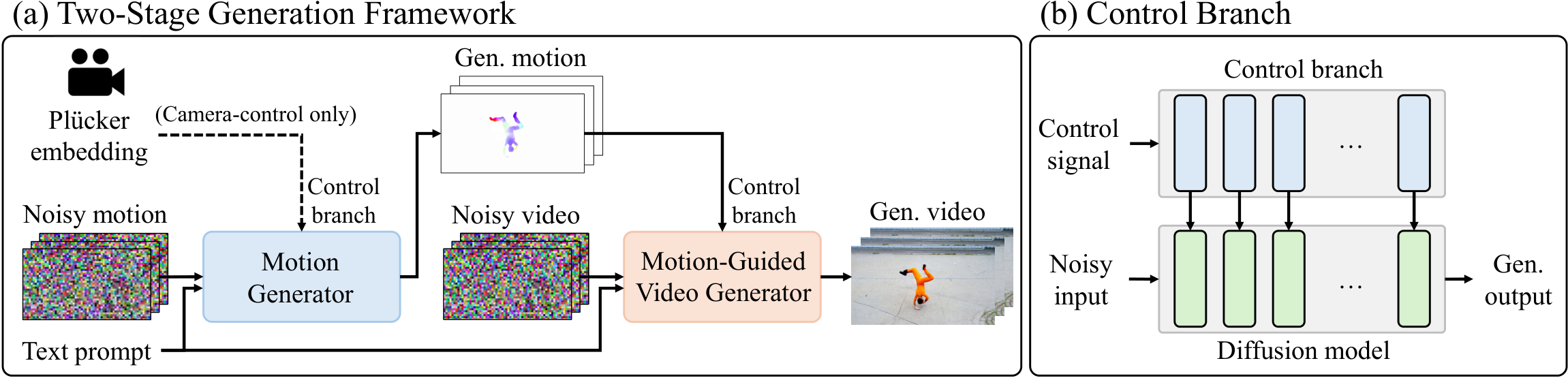
DynaVid 消融实验结果

消融实验验证 DynaVid 合成运动数据的贡献。对比实验展示了仅使用真实数据训练 vs. 结合合成光流训练的性能差异。在剧烈人体运动生成和极端相机运动控制两个挑战性场景上,合成运动数据带来了明显的性能提升。
深度点评:
技术演进定位: 利用合成数据增强视频生成动态性的新范式
可能的后续方向:
3.6K条件集+20K标注:压力测试图像生成模型 | Waterloo | University of Waterloo | arXiv:2603.27862
关键词: 评测基准, 人类评估, 可解释评测, 多任务, 图像生成
核心问题: 如何构建全面且可解释的图像生成评测基准
扩散、自回归和混合模型已实现了高质量图像合成,但现有评测基准存在严重不足:要么聚焦孤立任务,要么仅覆盖狭窄领域,要么只提供不透明的分数而无法解释失败模式。缺乏一个全面的、可解释的评测体系来系统性压力测试图像生成模型在真实世界开放式任务上的表现。
前序工作及局限:
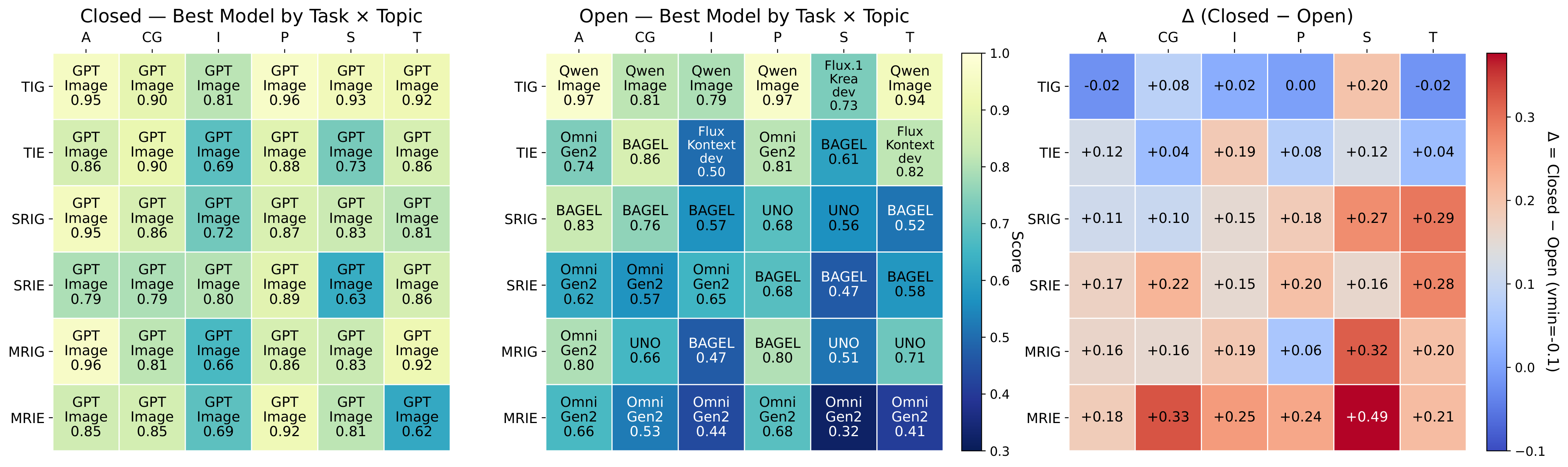
与前序工作的本质区别: 3.6K条件集×6任务×6域 + 20K细粒度人类标注 + 可解释错误归因
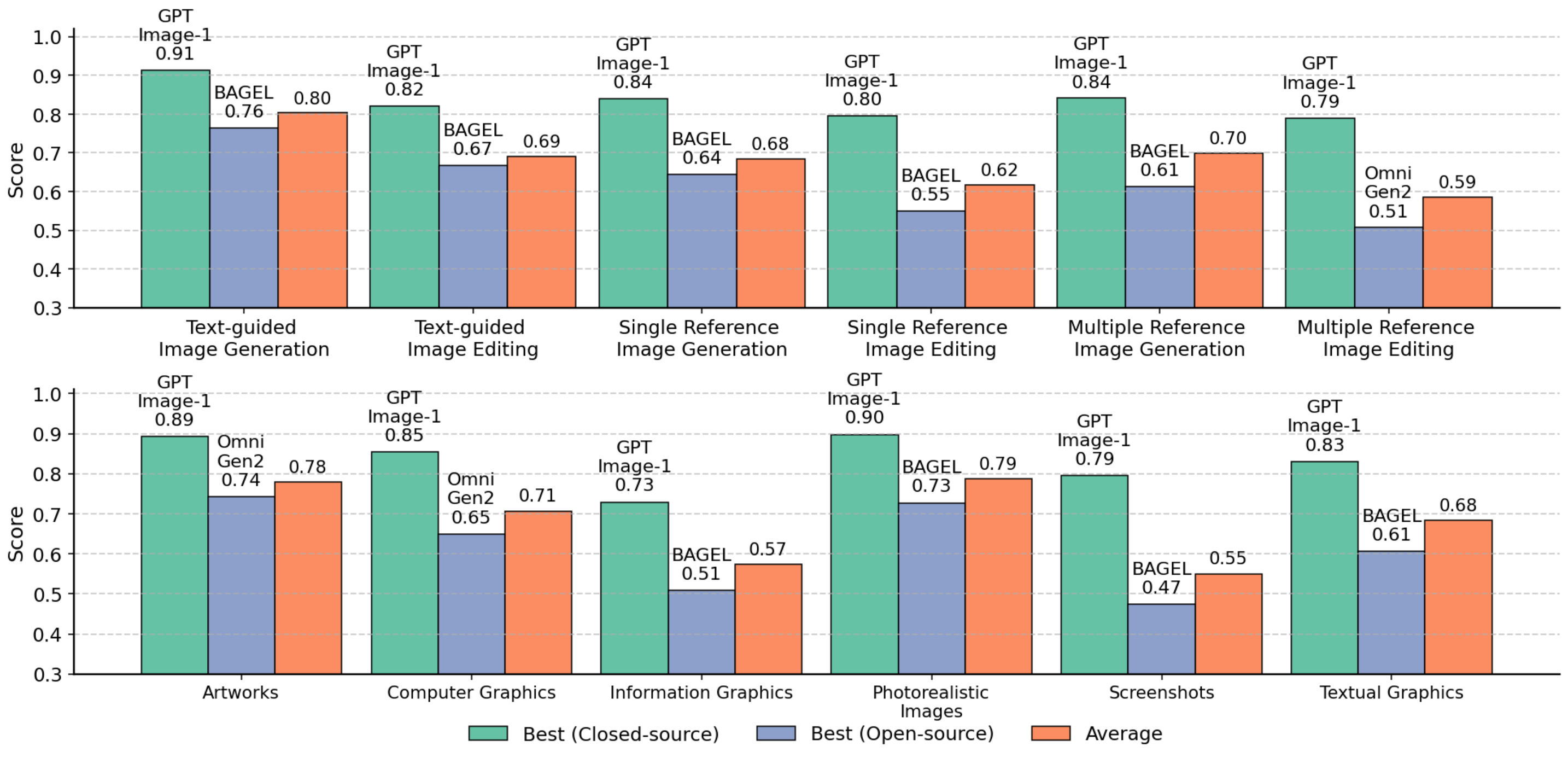
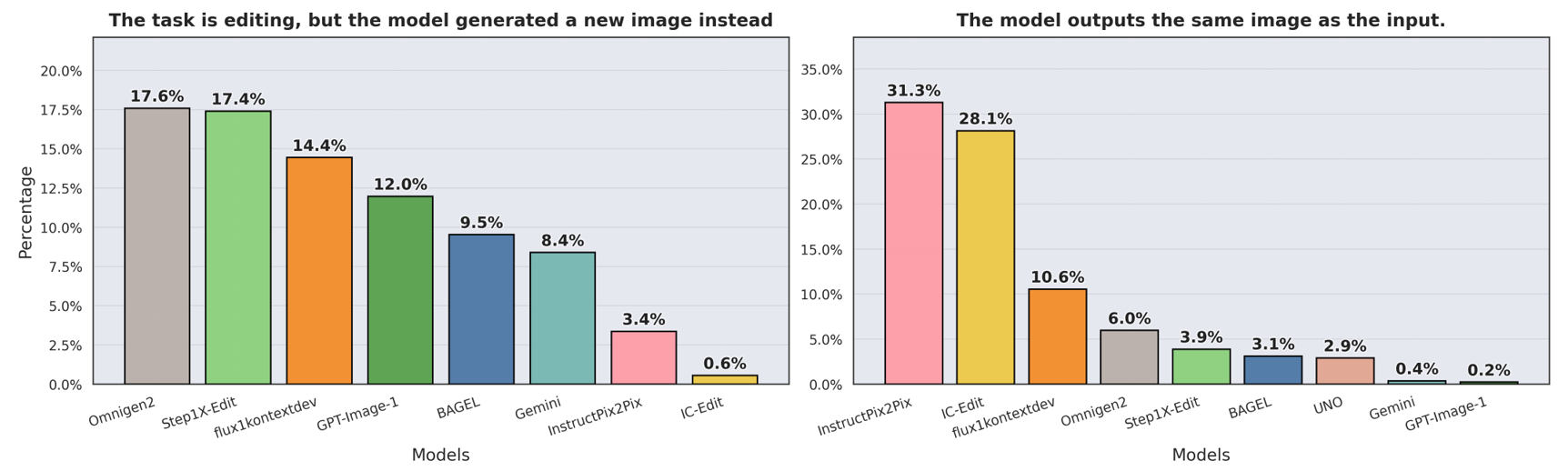
ImagenWorld 构建了一个包含 3.6K 条件集的评测基准,横跨六大核心任务(生成和编辑,含单/多参考)和六大主题域(艺术品、照片级真实、信息图表、文字图形、计算机图形、截图)。配套 20K 细粒度人类标注和可解释评测方案——标注局部化的目标级和区域级错误类型,补充自动化 VLM 指标。对 14 个模型的大规模评估揭示了关键洞察:(1) 编辑任务(尤其是局部编辑)显著难于生成任务;(2) 模型在艺术和照片级场景中表现优秀,但在符号密集和文字密集域(截图、信息图表)中挣扎;(3) 闭源系统总体领先,但定向数据策展(如 Qwen-Image)缩小了文字密集场景的差距;(4) VLM 指标最高达 Kendall 精度 0.79,但无法做到细粒度可解释错误归因。
ImagenWorld 标注界面
ImagenWorld 的细粒度人类标注界面,支持目标级和区域级错误类型标注。标注者可以在图像上框选特定区域,标注具体的错误类型(如文本错误、结构错误、语义错误等),实现局部化错误归因而不仅仅是给出一个总分。
ImagenWorld 评测框架架构
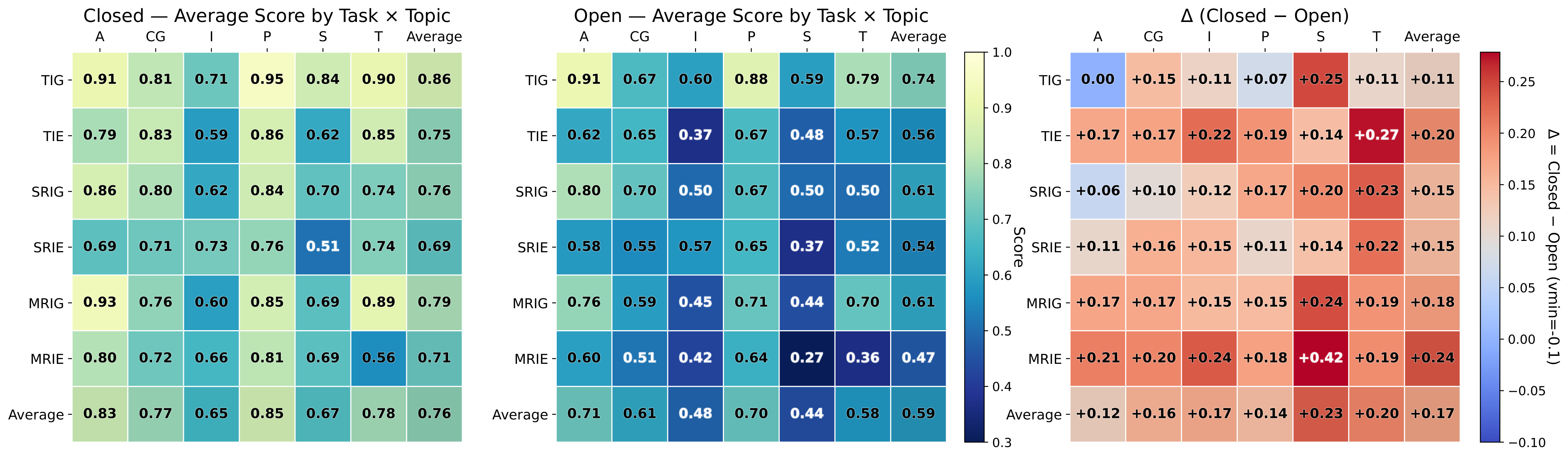
ImagenWorld 的评测框架架构,横跨六大核心任务(生成和编辑,含单/多参考)和六大主题域(艺术品、照片级真实、信息图表、文字图形、计算机图形、截图)。框架支持 VLM 自动评测和人类细粒度标注两种模式。
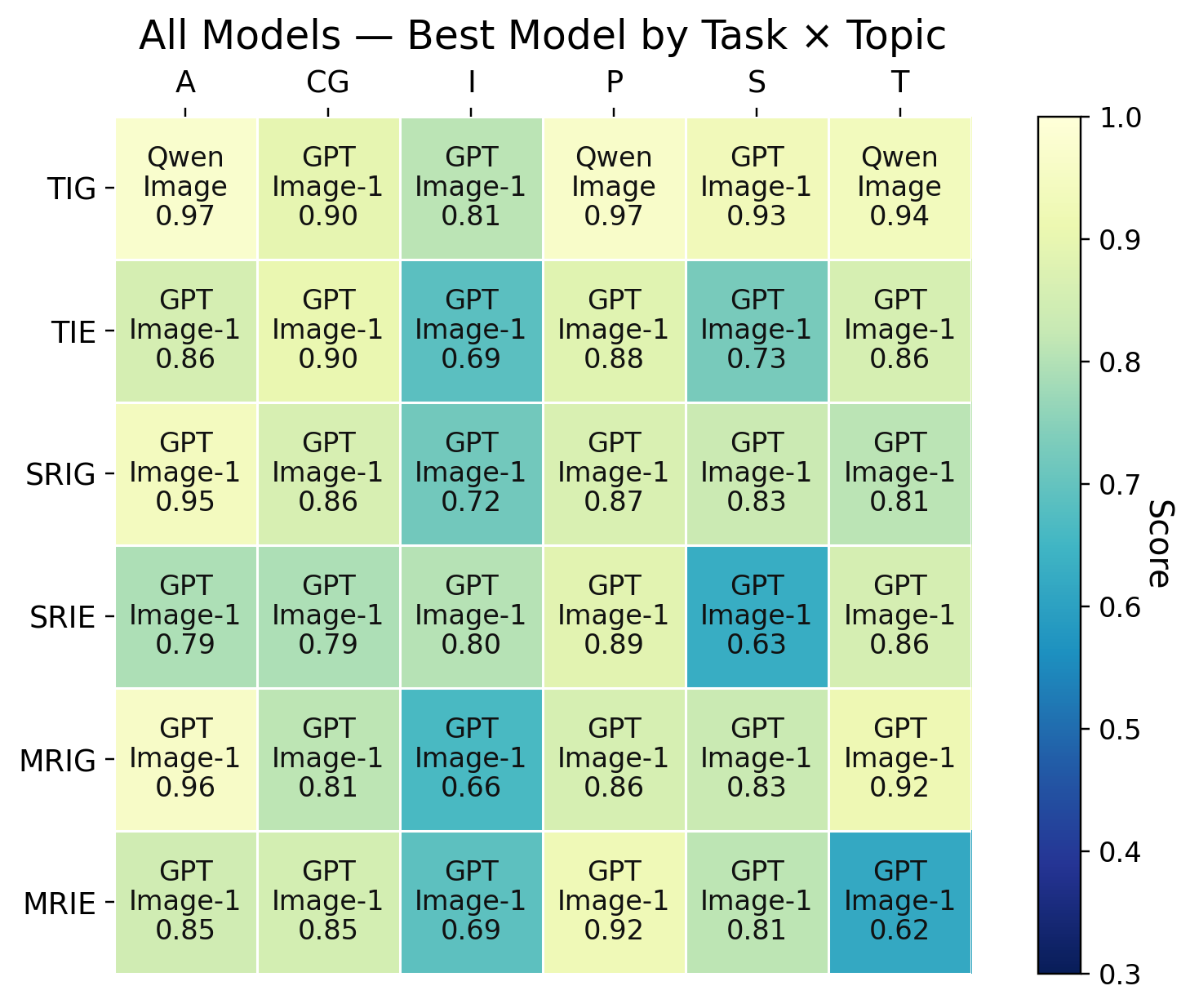
14 模型性能热力图
14 个图像生成模型在 ImagenWorld 基准上的性能热力图。图中清晰展示了各模型在不同任务和领域上的表现差异。关键洞察:编辑任务(尤其是局部编辑)显著难于生成任务;模型在艺术和照片级场景优秀但在文字/符号域挣扎。
深度点评:
技术演进定位: 图像生成评测从粗粒度分数走向细粒度可解释诊断
可能的后续方向:
Sony AI开源音效基础模型 | Sony Research | Sony AI, Sony Research | arXiv:2604.01929
关键词: 音效生成, 基础模型, Text-to-Audio, Video-to-Audio, 开源
核心问题: 如何为音频AIGC社区提供完整的开源基础模型
音频研究社区依赖开源生成模型作为构建新方法和建立基线的基础工具。然而,现有的开源音频生成模型(如 StableAudio-Open、TangoFlux)在音效(sound effects)领域的表现仍有提升空间,且缺乏全栈的音频编解码器、文本-音频对齐模型和生成模型的统一开源方案。
前序工作及局限:
与前序工作的本质区别: 首个涵盖编解码器+对齐模型+T2A+V2A的四组件完整开源方案
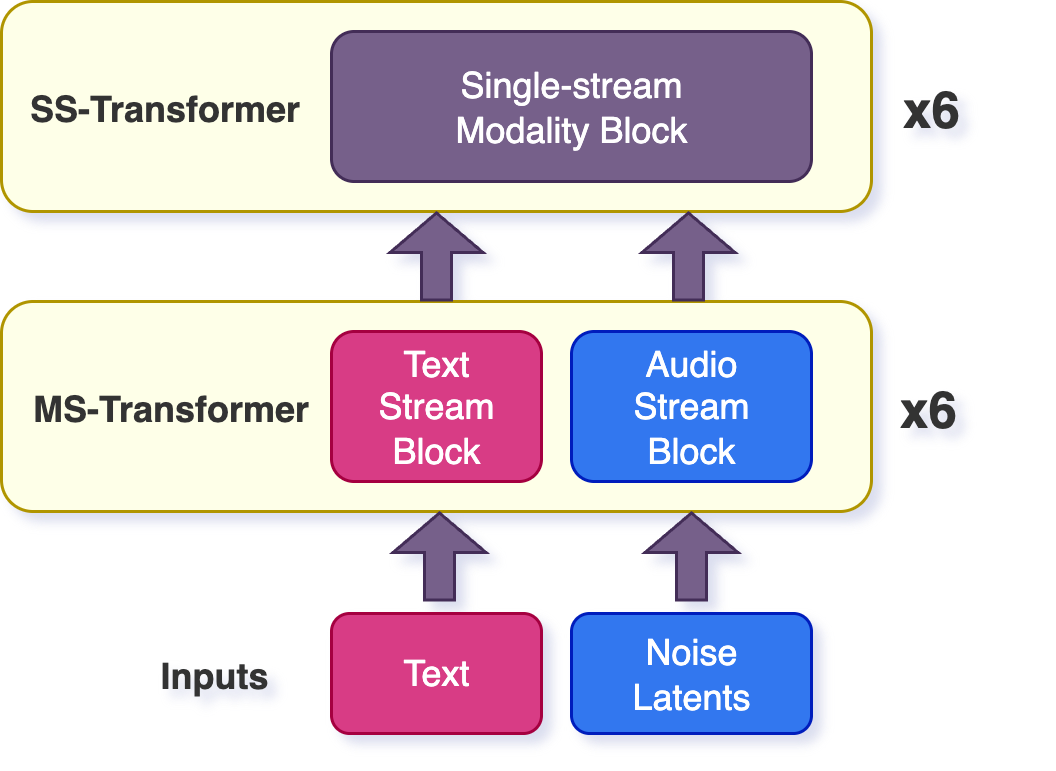
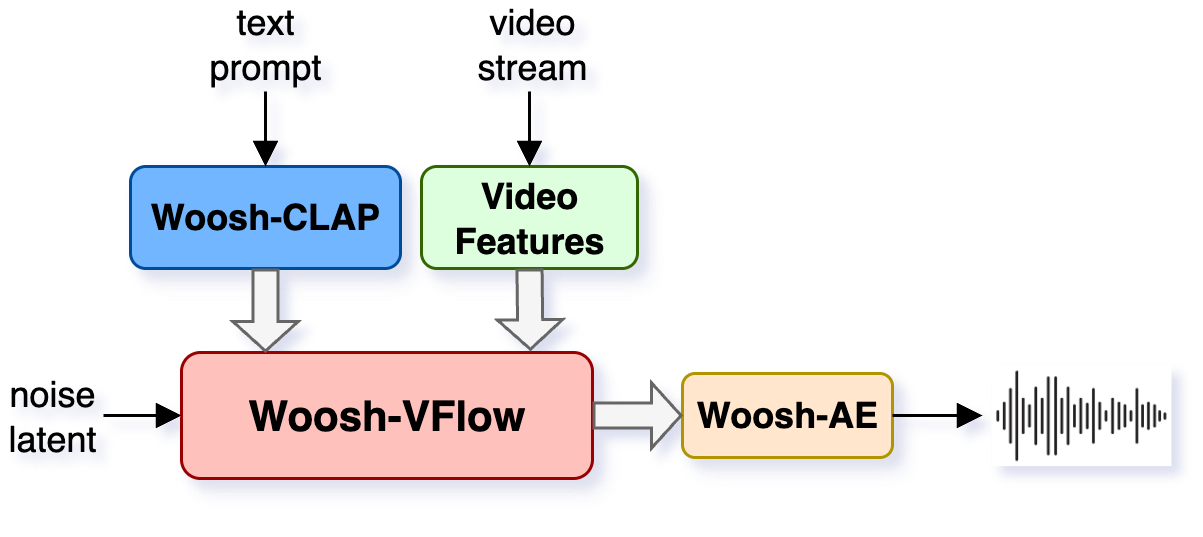
Woosh 是 Sony AI 公开发布的音效基础模型,提供完整的四组件开源方案:(1) 高质量音频编码器/解码器模型——将音频映射到潜空间再重建;(2) 文本-音频对齐模型——用于条件生成的语义对齐;(3) 文本到音频(T2A)生成模型——基于扩散的音效合成;(4) 视频到音频(V2A)生成模型——根据视频内容自动生成匹配的音效。还提供了蒸馏版本的 T2A 和 V2A 模型,支持低资源设备和快速推理。
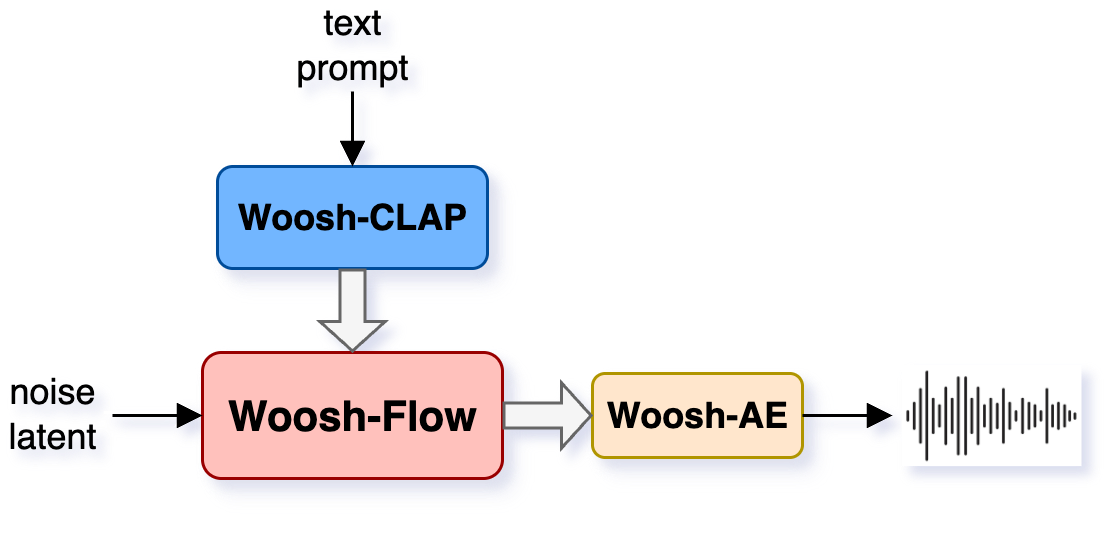
CLAP 文本-音频对齐模型
Woosh 提供的文本-音频对齐模型架构,基于 CLAP(Contrastive Language-Audio Pretraining)实现。该模型将文本描述和音频映射到同一语义空间,为条件生成提供语义对齐基础。支持文本描述驱动的音效合成。
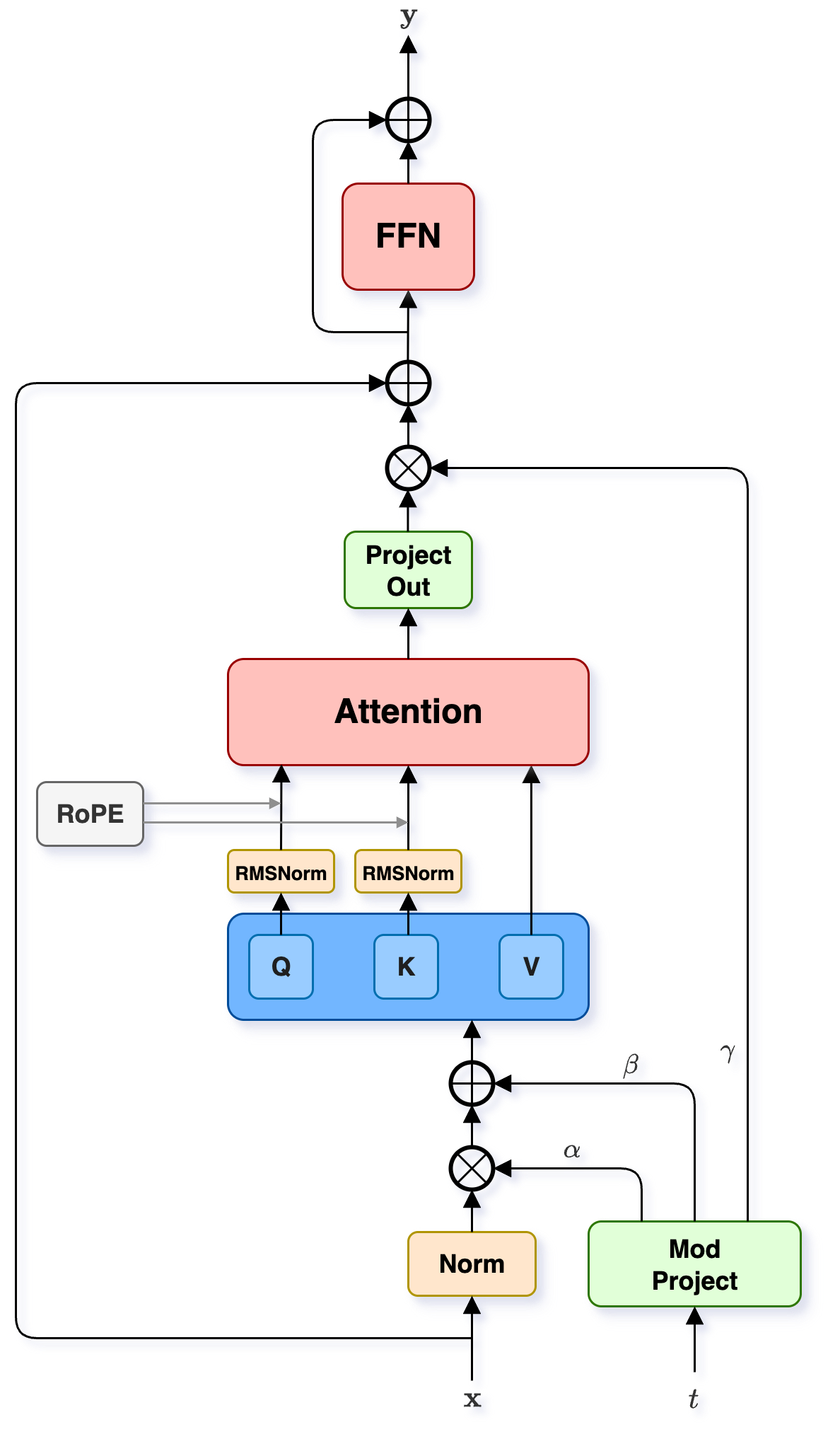
MMMSSFlux 音效生成架构
Woosh 的核心生成模型 MMMSSFlux 的架构设计。基于扩散模型的音效合成架构,支持文本到音频(T2A)生成。图中展示了多流处理机制和扩散去噪过程,专门针对音效领域优化。
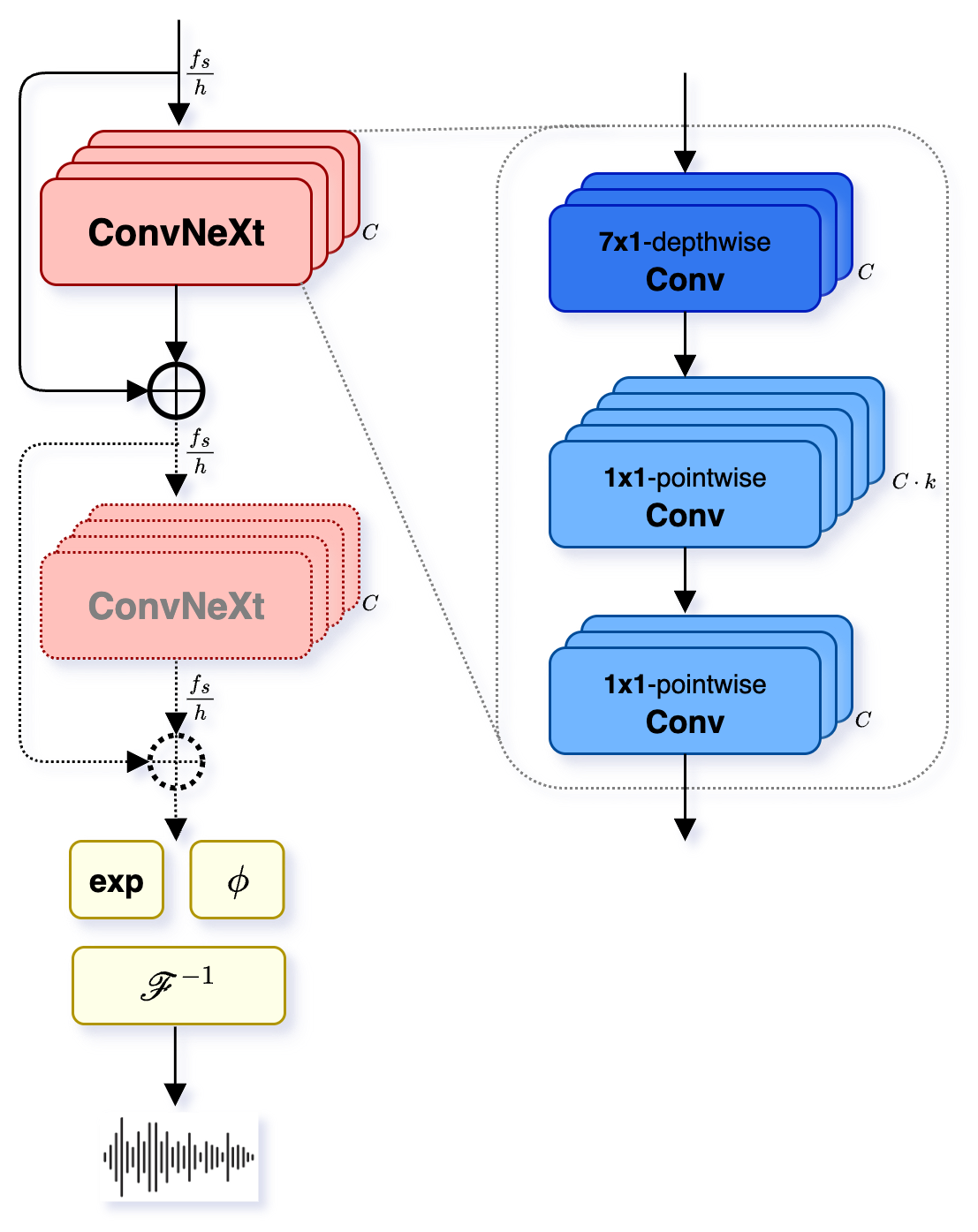
多流处理机制详解
MMMSSFlux 的多流处理机制详解。图中展示了如何并行处理不同类型的音频特征,通过多流架构提升音效生成的质量和多样性。蒸馏版本支持低资源设备快速推理。
深度点评:
技术演进定位: 音频AIGC从单一模型走向完整生态的重要一步
可能的后续方向:
人工智能炼丹师 整理 | 2026-04-04
更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」
每日更新 · 论文精选 · 深度解读 · 技术脉络
微信搜索 人工智能炼丹君 或扫描文末二维码关注
评论 (0)