搜索到
1
篇与
音视频生成
的结果
-
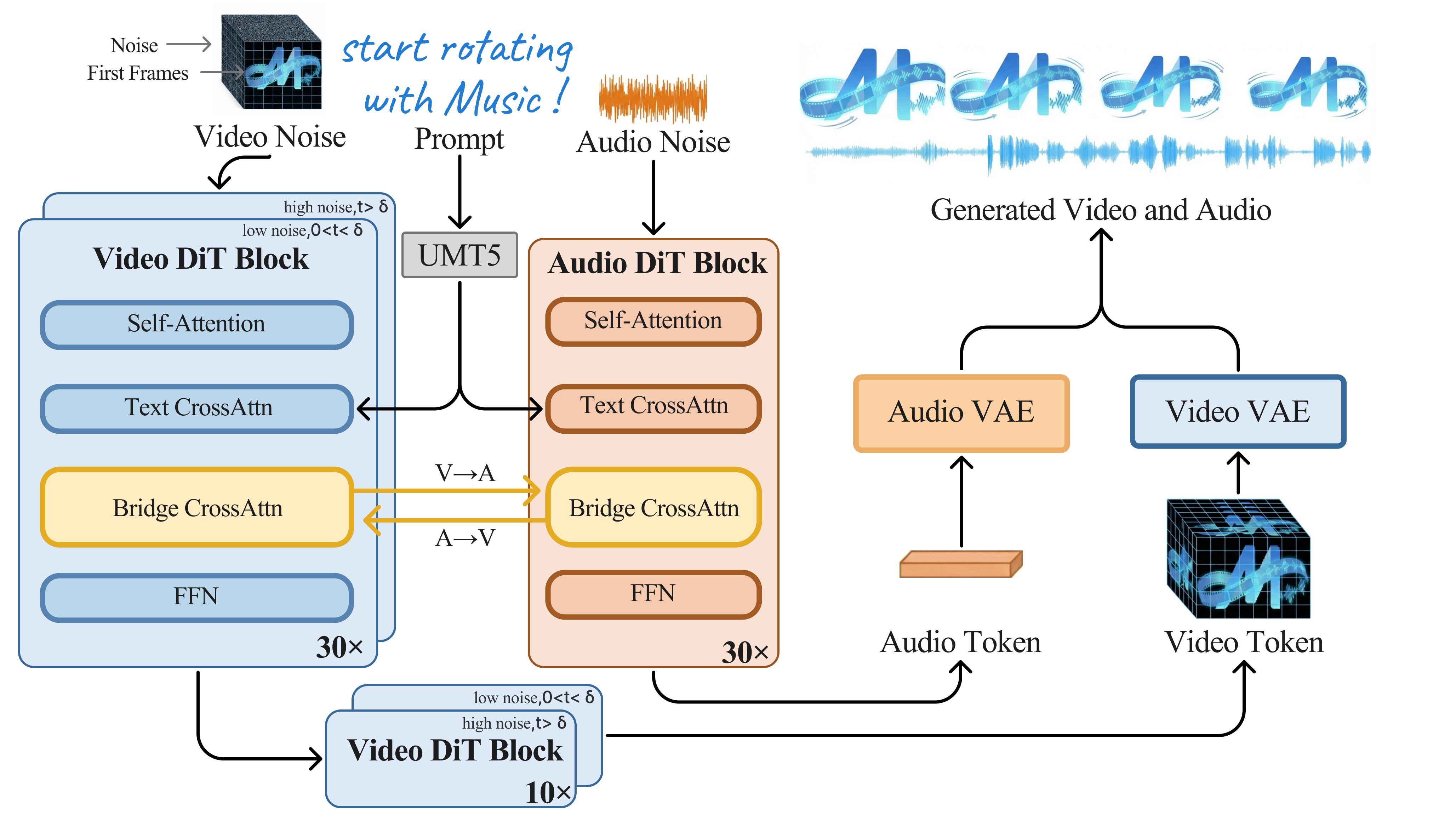
 AIGC 周末专题|2026-04-11|音视频联合生成与编辑前沿进展: 开源Seedance2的进阶之路 AIGC 周末专题深度解读:音视频联合生成与编辑前沿进展 人工智能炼丹师 整理 | 2026年4月11日(周六) 本期概述 本期 AIGC 周末专题聚焦音视频联合生成与编辑前沿进展方向,精选 8 篇代表性论文进行深度解读。 方向分布: 联合音视频生成: 4篇 — MOVA, JavisDiT++, OmniForcing, CCL V2A/音频生成: 3篇 — FoleyDirector(CVPR 2026), OmniSonic(CVPR 2026), FoleyDesigner 个性化: 1篇 — Identity as Presence 其余工作: 12篇 — 涵盖音视频定制、空间音频、音乐驱动编辑、评测基准等 含 CVPR 2026 × 2 篇, ICLR 2026 × 1 篇 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 MOVA 上海 AI Lab, OpenMOSS 首个全面开源的可扩展联合音视频生成系统 2602.08794 2 JavisDiT++ Rochester, 上海科技大学 系统性地将人类偏好优化引入联合音视频生成 2602.19163 3 OmniForcing 基于LTX-2蒸馏 首个实时联合音视频流式生成系统,单GPU约25 FPS 2603.11647 4 CCL SenseTime 首次系统分析双流联合生成框架的三个核心技术瓶颈 2603.18600 5 Identity as Presence 首个同时支持面部外观和声音音色联合个性化的音视频生成系统 2603.17889 6 FoleyDirector 首个在DiT基V2A上实现精确时序引导的方法 2603.19857 7 OmniSonic 首次在统一框架中覆盖三类视频音频(屏内环境音/屏外环境音/人类语音) 2604.04348 8 FoleyDesigner Shanghai University, University of Surrey 首个电影级立体声拟音自动生成系统 2604.05731 1. MOVA:开源可扩展的同步视频-音频联合生成系统——渐进式双流DiT训练管线 论文: MOVA arXiv: 2602.08794 机构: 上海 AI Lab, OpenMOSS 1.1 研究动机 核心问题: 级联音视频生成管线导致成本增加、错误累积、质量下降 音频是真实世界视频不可或缺的部分,但现有生成模型大多忽略音频。级联管线(先视频后音频)带来成本增加、错误累积、质量下降三大问题。Veo 3和Sora 2虽展示了同步生成的价值,但闭源特性阻碍了学术推进。MOVA旨在构建开源的、可扩展的联合音视频生成系统。 前序工作及局限: CoDi / NExT-GPT:早期多模态生成尝试 Veo 3 / Sora 2:商业系统展示联合生成价值但闭源 与前序工作的本质区别: MOVA采用双流DiT+渐进式三阶段训练,构建首个全面开源的联合音视频生成系统 1.2 方法原理 Model Structure Overview. MOVA couples an A14B video DiT backbone and a 1.3B audio DiT backbone via a 2.6B bidirectional Bridge module. MOVA采用双流DiT架构: (1) 独立模态流+跨模态交互:视频流和音频流分别基于预训练模型初始化,通过跨模态注意力层在每个Transformer块中建立音视频对齐。 (2) 渐进式训练策略:阶段一冻结主干仅训练跨模态注意力层,阶段二全模型联合微调,阶段三高质量数据精调。 (3) 大规模数据管线:自动化音视频配对数据清洗,多维度质量过滤。 1.3 核心创新 首个全面开源的可扩展联合音视频生成系统 采用双流DiT架构,独立模态流+跨模态注意力交互 渐进式三阶段训练策略缓解多模态联合训练的稳定性问题 大规模音视频配对数据清洗管线支撑高质量生成 1.4 实验结果 Ablation study on human preference. 在音视频同步性、音频质量、视频质量等多维度达到开源SOTA 与Veo 3等商业系统在部分指标上具有竞争力 代码和模型全面开源 1.5 关键洞察 优势:系统工程完整,开源贡献大;渐进式训练有效。局限:双流架构的跨模态对齐存在固有上限;数据规模仍不及商业系统。 技术演进定位: 开源联合音视频生成的技术基线 可能的后续方向: 双流→单流架构演进 更大规模数据与模型 2. JavisDiT++:统一建模与人类偏好对齐——联合音视频生成的系统性优化 论文: JavisDiT++ arXiv: 2602.19163 机构: Rochester, 上海科技大学 2.1 研究动机 核心问题: 联合音视频生成的质量与商业系统仍有差距,缺乏人类偏好对齐 联合音视频生成已成为多模态合成基础任务,但与Veo 3等商业系统相比,开源方法在生成质量、时序同步和人类偏好对齐三个维度上仍存在明显差距。JavisDiT++从统一建模和系统优化两个层面同时发力。 前序工作及局限: MOVA:开源联合生成基线 DPO / RLHF:语言模型偏好对齐技术 与前序工作的本质区别: JavisDiT++首次将DPO人类偏好优化引入联合音视频生成,配合时间对齐RoPE 2.2 方法原理 Architecture of . We use shared attention layers to encourage audio-visual mutual information modeling, with modality-specific FFN layers to enhance intra-modal aggregation. The Temporal-Aligned RoPE strategy is applied to ensure audio-video synchrony. The audio/video embedder layer and prediction head that bridge DiT and VAEs are hidden for simplicity. JavisDiT++的核心设计: (1) 统一双流DiT架构:基于预训练视频DiT和音频DiT,跨模态注意力实现联合推理,时间对齐RoPE解决时间分辨率不匹配。 (2) 多阶段优化:跨模态注意力预训练→全模型联合微调→人类偏好对齐(DPO/RLHF)。 (3) 高质量数据策略:精心策划的多源音视频训练数据,基于同步性的质量过滤。 2.3 核心创新 系统性地将人类偏好优化引入联合音视频生成 时间对齐RoPE解决异构时间分辨率问题 支持多种生成模式:T2AV/V2A/A2V 多阶段优化管线包含DPO后训练 2.4 实验结果 Illustration of preference data collection and training pipeline of audio-video DPO. 在多个JAVG基准上取得开源SOTA 人类偏好对齐后用户偏好率显著提升 同步质量和感知质量综合提升 2.5 关键洞察 优势:首次在JAVG中引入DPO后训练,方法论完整。局限:人类偏好标注成本高;DPO对齐效果受奖励模型质量制约。 技术演进定位: 联合音视频生成的偏好对齐开拓者 可能的后续方向: 更精细的音视频同步奖励模型 人类偏好驱动的质量提升 3. OmniForcing:首个实时联合音视频流式生成——Self-Forcing蒸馏实现25FPS 论文: OmniForcing arXiv: 2603.11647 机构: 基于LTX-2蒸馏 3.1 研究动机 核心问题: 联合音视频生成局限于离线模式,无法支持交互式应用 现有联合音视频生成系统都是离线的,严重限制交互式应用(游戏NPC、虚拟直播、实时对话)。OmniForcing提出核心问题:能否实现实时的、流式的联合音视频生成? 前序工作及局限: LTX-2:高质量离线双流联合生成教师模型 Self-Forcing:流式生成蒸馏范式 与前序工作的本质区别: OmniForcing将离线双向扩散蒸馏为25FPS流式自回归生成器 3.2 方法原理 The three-stage OmniForcing distillation pipeline. Stage I employs Distribution Matching Distillation (DMD)~yin2024one,yin2024improved to adapt the model for few-step, fast denoising. Stage II utilizes causal ODE regression to adapt the network weights to the asymmetric block-causal mask. Stage III implements joint Self-Forcing~huang2025self training by autoregressively unrolling the generation process to mitigate exposure bias. OmniForcing的核心设计: (1) Joint Self-Forcing Distillation:以离线双向扩散模型为教师,蒸馏为流式自回归学生,在长序列上自纠正跨模态误差。 (2) Asymmetric Block-Causal Alignment + Zero-truncation Global Prefix:确保流式生成中音视频同步。 (3) Audio Sink Token + Identity RoPE:缓解音频token稀疏的梯度问题。 (4) 模态无关滚动KV-Cache:支持任意长度流式生成。 3.3 核心创新 首个实时联合音视频流式生成系统,单GPU约25 FPS 将离线双流双向扩散蒸馏为流式自回归生成器 Joint Self-Forcing Distillation在长序列上自纠正跨模态误差 非对称块因果对齐+全局前缀确保流式同步 Audio Sink Token缓解音频token稀疏问题 3.4 实验结果 Asymmetric Block-Causal Masking. The vertical axis denotes query tokens and the horizontal axis denotes key tokens. Modalities are synchronized via 1s macro-blocks. Each audio block ($B^a$) contains 25 latent frames (one token each), whereas each video block ($B^v$) contains 3 latent frames patchified into $3 384$ tokens. Unmasked tokens include the Global Prefix (orange, $V_0/A_0$) and Audio Sink tokens (red, $s$). Blue regions denote allowed attention (bidirectional intra-block, strictly causal inter-block), while white regions mask future keys to prevent information leakage. 单GPU约25 FPS实时生成 同步质量和视觉质量与双向教师模型持平 显著优于已有流式方法 项目代码开源 3.5 关键洞察 优势:实时生成突破意义重大,对交互式应用有直接影响。局限:蒸馏质量上限受教师模型制约;LTX-2训练成本高。 技术演进定位: 首个实时联合音视频流式生成系统 可能的后续方向: 实时生成的质量进一步提升 交互式音视频创作工具 4. CCL:系统解决双流联合生成三大瓶颈——跨模态上下文学习 论文: CCL arXiv: 2603.18600 机构: SenseTime 4.1 研究动机 核心问题: 双流联合生成框架存在门控流形变化、背景偏差、CFG冲突三大瓶颈 双流Transformer已成为联合音视频生成主流范式,但存在三个关键问题:(1)门控机制引起的模型流形变化;(2)跨模态注意力引入的多模态背景区域偏差;(3)多模态CFG的训练-推理不一致性。 前序工作及局限: 双流DiT范式:当前联合音视频生成的主流架构 TARP / RoPE:位置编码对齐技术 与前序工作的本质区别: CCL系统性提出TARP/LCT+DCR/UCG三个模块精准解决三大瓶颈 4.2 方法原理 The pipeline of our proposed Cross-Modal Context Learning. CCL follows the conventional dual-stream transformer architecture, equipped with several novel-designed modules, enabling efficient and effective joint audio-video generation with high consistency. The figure illustrates the implementation details of proposed modules. For Dynamic Context Routing, the various colors denote that the corresponding colored paths on the left are in an activated state. CCL提出三个模块: (1) TARP(时间对齐RoPE和分区):在RoPE位置编码层面实现音视频精确时间对齐。 (2) LCT(可学习上下文标记)+DCR(动态上下文路由):LCT提供稳定锚点缓解流形变化,DCR根据生成模式动态路由。 (3) UCG(无条件上下文引导):利用LCT在推理时提供稳定的无条件支持,改善训练-推理一致性。 4.3 核心创新 首次系统分析双流联合生成框架的三个核心技术瓶颈 TARP解决异构时间分辨率的精确对齐 可学习上下文标记(LCT)+动态上下文路由(DCR)稳定跨模态交互 无条件上下文引导(UCG)解决多模态CFG训练-推理不一致 4.4 实验结果 The gating mechanism alters the optimization objective during training, which affects training efficiency. 实现开源SOTA联合音视频生成 所需训练资源远少于对比方法 音视频同步质量和整体生成质量均显著提升 4.5 关键洞察 优势:问题分析精准,三个模块各自解决一个核心问题,设计优雅。局限:仍基于双流范式,未突破架构本身的上限。 技术演进定位: 双流范式优化的精巧方案 可能的后续方向: 跨模态对齐机制的进一步演化 5. Identity as Presence:外观+声音联合个性化——音视频生成的身份可控新范式 论文: Identity as Presence arXiv: 2603.17889 5.1 研究动机 核心问题: 联合音视频生成产出匿名内容,无法指定特定人物的外貌和声音 现有联合音视频生成产出的都是'匿名'内容——无法指定特定人物的外貌和声音。然而在虚拟人、个性化视频、AI配音等应用中,身份可控是核心需求。 前序工作及局限: IP-Adapter:图像特征注入技术 联合音视频生成基线:不支持身份控制 与前序工作的本质区别: Identity as Presence首次实现面部外观+声音音色的联合个性化 5.2 方法原理 Overview of data curation pipeline for constructing identity-labeled audio-visual data from raw videos. The process involves isolating both visual and auditory identity-specific signals from raw videos, synthesizing comprehensive captions via MLLMs, and rigorously matching audio-visual identities to guarantee precise alignment across video clips to ensure high-fidelity identity consistency. 核心设计: (1) 自动化身份数据策划管线:从大规模音视频数据中自动提取配对身份信息。 (2) 双模态身份注入:面部外观通过IP-Adapter风格特征注入,声音音色通过音频编码器+适配层注入。 (3) 多阶段训练:阶段一单模态身份预训练,阶段二联合微调学习外观-声音协同保持。 5.3 核心创新 首个同时支持面部外观和声音音色联合个性化的音视频生成系统 自动化身份数据策划管线 多阶段训练处理音视觉表征差异 支持单人和多人场景 5.4 实验结果 身份保持、音画一致性、生成质量多维度优于基线 多主体场景下保持高保真身份一致性 5.5 关键洞察 优势:问题定义清晰,双模态身份注入设计实用。局限:身份保持精度受特征编码器上限制约;多人场景下的身份混淆问题待深入分析。 技术演进定位: 联合生成走向身份可控的关键工作 可能的后续方向: 多身份精细解耦控制 虚拟人产品化 6. FoleyDirector:导演级V2A精细控制——时序脚本驱动的画内/画外声并行合成 论文: FoleyDirector arXiv: 2603.19857 6.1 研究动机 核心问题: V2A缺乏精细时序控制,用户无法指定具体时间点的声音事件 当前V2A方法无法实现精细的时序控制——用户希望在特定时间点产生不同音效、控制画内/画外声的切换。现有V2A系统缺乏导演级别的精细调度能力。 前序工作及局限: Diff-Foley / SonicVisionLM:早期V2A方法,粗粒度语义匹配 Make-An-Audio / AudioLDM:文本到音频生成基线 与前序工作的本质区别: FoleyDirector引入结构化时序脚本(STS)实现导演级精确控制 6.2 方法原理 Overview of our method. (a) Extraction pipeline of segment-level ~features. (b) Structure of the ~module, where Temporal Script Attention introduces control signals. (c) , which leverages the controllability of our method in T2A and V2A to enable parallel rendering of in-frame and out-of-frame sounds. Fused block represents the single-modal transformer block in MMAudio. 核心设计: (1) 结构化时序脚本(STS):用户精确指定在第N秒到第M秒产生某种声音,支持画内/画外声独立控制。 (2) Temporal Script Attention:在DiT中引入时序脚本注意力层,融合STS与视频特征。 (3) Bi-Frame Sound Synthesis:并行生成画内声和画外声,精确对齐后混合输出。 6.3 核心创新 首个在DiT基V2A上实现精确时序引导的方法 结构化时序脚本(STS)提供导演级控制 画内/画外声并行合成(Bi-Frame Sound Synthesis) 构建DirectorSound数据集和DirectorBench评测基准 CVPR 2026接收 6.4 实验结果 Visual Results in VGGSound-Director. We present several results from VGGSound-Director, comparing the mel-spectrograms generated by our method with those from other approaches and with the ground-truth audio. We also compute the L1 similarity between each generated mel-spectrogram and the ground truth. VGGSoundDirector和DirectorBench上时序控制SOTA 高保真与精确时序可控性兼顾 CVPR 2026接收 6.5 关键洞察 优势:时序脚本是优雅的控制接口,CVPR 2026验证了方法质量。局限:STS常需手工编写,大规模自动化可用性待验证。 技术演进定位: V2A精细控制的CVPR 2026代表作 可能的后续方向: STS自动化生成 V2A与联合生成的融合 7. OmniSonic:首个全场景V2A——统一屏内/屏外/语音三类音频的通用生成 论文: OmniSonic arXiv: 2604.04348 7.1 研究动机 核心问题: V2A只关注单一类型音频,无法覆盖真实视频中的全部声音场景 现有V2A方法通常只关注单一类型音频。但真实视频中同时包含屏内环境音、屏外环境音和人类语音三类声音。OmniSonic首次提出Universal Holistic Audio Generation任务。 前序工作及局限: FoleyDirector:V2A精细时序控制 环境音/语音/音乐分离模型:单类型音频处理 与前序工作的本质区别: OmniSonic首次统一屏内环境音/屏外环境音/人类语音三类音频的生成 7.2 方法原理 (A) Overview of our proposed OmniSonic, which mainly consists of an environmental text encoder (FLAN-T5), a speech transcription encoder (SpeechT5), a visual encoder (CLIP visual encoder), an audio VAE, and our specially designed TriAttn-DiT blocks. The input example demonstrates the scenario of on-screen speech with off-screen environmental sound. The input conditions include visual frames, speech transcription, an on-screen environmental sound caption (represented by a placeholder ""), and an off-screen environmental sound caption. (B) Details of our proposed TriAttn-DiT block. 核心设计: (1) UniHAGen任务:统一屏内环境音、屏外环境音、人类语音三类音频的生成。 (2) TriAttn-DiT架构:基于Flow Matching的DiT,三路交叉注意力(视频/文本/音频类型条件),MoE门控不同专家处理不同类型音频。 (3) UniHAGen-Bench:首个覆盖三类音频的统一评测基准。 7.3 核心创新 首次在统一框架中覆盖三类视频音频(屏内环境音/屏外环境音/人类语音) TriAttn-DiT+MoE的专家化架构设计 构建UniHAGen-Bench评测体系 CVPR 2026接收 7.4 实验结果 Visualization of the spectrograms of generated audios and the ground-truth. 客观指标和人工评估一致超越现有SOTA 在全部三类音频生成上均取得最优性能 CVPR 2026接收 7.5 关键洞察 优势:任务定义前瞻,全场景覆盖填补领域空白,CVPR 2026验证了质量。局限:三类音频的联合生成质量仍有提升空间。 技术演进定位: 全场景V2A的CVPR 2026开拓者 可能的后续方向: 三类音频联合质量提升 空间音频集成 8. FoleyDesigner:电影级立体声拟音——多智能体时空分析+LLM空间混音 论文: FoleyDesigner arXiv: 2604.05731 机构: Shanghai University, University of Surrey 8.1 研究动机 核心问题: 自动Foley生成产出单声道音频,缺乏空间感和沉浸式体验 拟音艺术是电影沉浸式听觉体验的关键。现有自动Foley生成方法产生的都是单声道音频,且时空对齐精度有限。FoleyDesigner首次将Foley生成推向立体声甚至5.1环绕声。 前序工作及局限: OmniSonic / FoleyDirector:单声道V2A方法 杜比全景声:专业空间音频标准 与前序工作的本质区别: FoleyDesigner首次将Foley生成推向立体声/5.1环绕声,LLM驱动空间混音 8.2 方法原理 FoleyDesigner Architecture. Our pipeline for automated Foley generation consists of three stages, (1) Fine-Grained Film Decomposition: analyzes silent video and generates hierarchical Foley scripts; (2) Spatio-Temporal Foley Generation: produces spatially-controlled stereo audio using DiT-based diffusion conditioned on visual cues; (3) Foley Refinement: applies multi-agent processing to refine audio quality and generate 5.1 surround output. 核心设计: (1) 多智能体时空分析:使用多个AI Agent分析视频中的声音事件,精确标注时间窗口和空间位置。 (2) 潜在扩散音频合成:基于潜在扩散模型生成时序精确对齐的高质量音频。 (3) LLM驱动混音引擎:利用LLM理解声音空间分布,自动完成立体声/5.1声道空间混音。 8.3 核心创新 首个电影级立体声拟音自动生成系统 多智能体+LLM驱动的空间混音方案 支持杜比5.1环绕声输出 构建FilmStereo数据集 8.4 实验结果 FilmStereo Dataset Pipeline. The process begins with sourcing data using randomly sampled parameters to define sound event attributes, followed by a simulated sound design scenario in Step 2 to generate film foley annotations. The resulting data undergoes manual verification to ensure quality and accuracy. 时空对齐精度优于所有基线方法 生成的立体声音频具有沉浸式空间感 支持杜比5.1环绕声输出 8.5 关键洞察 优势:立体声方向前瞻,LLM混音设计新颖。局限:LLM混音的精度和可控性仍需提升;FilmStereo数据集规模有限。 技术演进定位: 立体声拟音方向的探索先驱 可能的后续方向: 空间音频/立体声标准化 专业Foley工具产品化 其余论文速览 1. ALIVE:将预训练T2V模型适配为联合音视频生成+动画 ALIVE: Animate Your World with Lifelike Audio-Video Generation | arXiv:2602.08682 关键词: T2VA, 动画, MMDiT 贡献: 将预训练T2V模型适配为联合音视频生成+动画,MMDiT架构增强音视频同步 效果: T2VA和参考图动画双能力 2. daVinci-MagiHuman:首个单流Transformer联合音视频生成 Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model | Sand.ai | arXiv:2603.21986 关键词: 单流架构, 人物中心, 统一token 贡献: 首个单流Transformer联合音视频生成,统一token序列+自注意力,避免多流/跨注意力复杂性 效果: 架构简洁,易于优化,开源 3. DreamID-Omni:统一R2AV/RV2AV/RA2V三种人物中心任务 DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation | arXiv:2602.12160 关键词: 统一框架, 多身份, 人物中心 贡献: 统一R2AV/RV2AV/RA2V三种人物中心任务,实现多身份解耦控制 效果: 首个统一多人物音视频控制框架 4. OmniCustom:提出同步音视频定制新任务 OmniCustom: Sync Audio-Video Customization Via Joint Audio-Video Generation Model | 腾讯, HKU | arXiv:2602.12304 关键词: 音视频定制, 身份+音色, 新任务定义 贡献: 提出同步音视频定制新任务,同时定制视频身份+音频音色 效果: 同步音视频身份定制 5. AVControl:基于LTX-2的模块化音视频控制 AVControl: Efficient Framework for Training Audio-Visual Controls | arXiv:2603.24793 关键词: 模块化控制, LoRA, LTX-2 贡献: 基于LTX-2的模块化音视频控制,每模态独立LoRA,低训练成本 效果: 模块化控制SOTA 6. Woosh:统一文本音效+视频条件音效的基础模型 Woosh: A Sound Effects Foundation Model | Sony AI | arXiv:2604.01929 关键词: T2A+V2A, 基础模型, 蒸馏加速 贡献: 统一文本音效+视频条件音效的基础模型,蒸馏5-8x加速 效果: AudioCaps/Clotho上FAD与SOTA相当,V2A同步分数高于基线 7. AC-Foley:以参考音频(非文本)控制V2A生成 AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer | ICLR 2026 关键词: 参考音频, V2A, ICLR 2026 贡献: 以参考音频(非文本)控制V2A生成,实现更细粒度音色迁移 效果: 参考音频条件下Foley生成SOTA 8. DynFOA:结合3DGS与条件扩散 DynFOA: Generating First-Order Ambisonics with Conditional Diffusion for Dynamic 360-Degree Videos | arXiv:2604.02781 关键词: 360°视频, 空间音频, 3DGS, Ambisonics 贡献: 结合3DGS与条件扩散,为360°视频生成物理一致的一阶Ambisonics空间音频 效果: 空间准确性和声学保真持续优于基线 9. V2M-Zero:无需配对数据实现视频到音乐的时间对齐生成 V2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation | arXiv:2603.11042 关键词: 视频转音乐, 零样本, 时间对齐 贡献: 无需配对数据实现视频到音乐的时间对齐生成 效果: 零样本跨模态音乐生成 10. GLANCE:音乐驱动非线性视频编辑 GLANCE: A Global-Local Coordination Multi-Agent Framework for Music-Grounded Non-Linear Video Editing | Virginia Tech, Meta AI | arXiv:2604.05076 关键词: 音乐驱动, 视频编辑, 多智能体 贡献: 音乐驱动非线性视频编辑,全局-局部协调多智能体,双循环长期规划+逐片段精修 效果: 比最强基线高33.2% 11. Echoes Over Time:解决V2A模型的长度泛化问题 Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models | arXiv:2602.20981 关键词: V2A, 长度泛化, MMHNet 贡献: 解决V2A模型的长度泛化问题,提出MMHNet多模态层次网络 效果: 短训练长推理的长度泛化 12. AVGen-Bench:首个多粒度文本-音视频联合生成评测基准 AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation | arXiv:2604.08540 关键词: 评测基准, T2AV, 多粒度 贡献: 首个多粒度文本-音视频联合生成评测基准,11个任务类别 效果: 填补T2AV评测空白 横向对比与技术脉络总结 横向对比:音视频联合生成与编辑方法的技术路线对比 论文 架构设计 训练范式 推理模式 控制粒度 MOVA 双流DiT 渐进式三阶段 离线 语义级 JavisDiT++ 双流DiT 多阶段+DPO 离线 语义级+偏好 OmniForcing 流式自回归 蒸馏 实时25FPS 语义级 CCL 双流DiT 轻量训练 离线 语义级 FoleyDirector DiT V2A 监督训练 离线 时序脚本精确控制 OmniSonic TriAttn-DiT+MoE 监督训练 离线 音频类型级 FoleyDesigner 扩散+LLM 多阶段 离线 时空精确控制 Identity as Presence 双模态注入 多阶段 离线 身份级 核心技术趋势 从级联到联合,从离线到实时 联合音视频生成从'先视频后音频'的级联方式快速进化为端到端同步生成,OmniForcing的实时流式生成标志着从离线工具向交互式应用的关键转变 双流vs单流架构之争 双流DiT(MOVA/JavisDiT++/CCL)通过复用预训练模型降低训练成本但引入对齐复杂性,单流设计(daVinci-MagiHuman)更简洁,两种范式的优劣将在半年内见分晓 V2A走向导演级精细控制 从粗粒度语义匹配到FoleyDirector的时序脚本精确控制、OmniSonic的全场景覆盖、FoleyDesigner的立体声/空间音频,V2A正从玩具走向专业后期工具 个性化是产品化的关键 Identity as Presence/DreamID-Omni/OmniCustom将联合生成从匿名内容创作推向身份可控的个性化创作,这是从研究到消费产品的关键一步 评测体系亟需标准化 AVGen-Bench的出现说明社区已认识到联合音视频生成缺乏统一评测标准的痛点,标准化评测是推动领域进步的关键基础设施 人工智能炼丹师 整理 | 2026-04-11
AIGC 周末专题|2026-04-11|音视频联合生成与编辑前沿进展: 开源Seedance2的进阶之路 AIGC 周末专题深度解读:音视频联合生成与编辑前沿进展 人工智能炼丹师 整理 | 2026年4月11日(周六) 本期概述 本期 AIGC 周末专题聚焦音视频联合生成与编辑前沿进展方向,精选 8 篇代表性论文进行深度解读。 方向分布: 联合音视频生成: 4篇 — MOVA, JavisDiT++, OmniForcing, CCL V2A/音频生成: 3篇 — FoleyDirector(CVPR 2026), OmniSonic(CVPR 2026), FoleyDesigner 个性化: 1篇 — Identity as Presence 其余工作: 12篇 — 涵盖音视频定制、空间音频、音乐驱动编辑、评测基准等 含 CVPR 2026 × 2 篇, ICLR 2026 × 1 篇 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 MOVA 上海 AI Lab, OpenMOSS 首个全面开源的可扩展联合音视频生成系统 2602.08794 2 JavisDiT++ Rochester, 上海科技大学 系统性地将人类偏好优化引入联合音视频生成 2602.19163 3 OmniForcing 基于LTX-2蒸馏 首个实时联合音视频流式生成系统,单GPU约25 FPS 2603.11647 4 CCL SenseTime 首次系统分析双流联合生成框架的三个核心技术瓶颈 2603.18600 5 Identity as Presence 首个同时支持面部外观和声音音色联合个性化的音视频生成系统 2603.17889 6 FoleyDirector 首个在DiT基V2A上实现精确时序引导的方法 2603.19857 7 OmniSonic 首次在统一框架中覆盖三类视频音频(屏内环境音/屏外环境音/人类语音) 2604.04348 8 FoleyDesigner Shanghai University, University of Surrey 首个电影级立体声拟音自动生成系统 2604.05731 1. MOVA:开源可扩展的同步视频-音频联合生成系统——渐进式双流DiT训练管线 论文: MOVA arXiv: 2602.08794 机构: 上海 AI Lab, OpenMOSS 1.1 研究动机 核心问题: 级联音视频生成管线导致成本增加、错误累积、质量下降 音频是真实世界视频不可或缺的部分,但现有生成模型大多忽略音频。级联管线(先视频后音频)带来成本增加、错误累积、质量下降三大问题。Veo 3和Sora 2虽展示了同步生成的价值,但闭源特性阻碍了学术推进。MOVA旨在构建开源的、可扩展的联合音视频生成系统。 前序工作及局限: CoDi / NExT-GPT:早期多模态生成尝试 Veo 3 / Sora 2:商业系统展示联合生成价值但闭源 与前序工作的本质区别: MOVA采用双流DiT+渐进式三阶段训练,构建首个全面开源的联合音视频生成系统 1.2 方法原理 Model Structure Overview. MOVA couples an A14B video DiT backbone and a 1.3B audio DiT backbone via a 2.6B bidirectional Bridge module. MOVA采用双流DiT架构: (1) 独立模态流+跨模态交互:视频流和音频流分别基于预训练模型初始化,通过跨模态注意力层在每个Transformer块中建立音视频对齐。 (2) 渐进式训练策略:阶段一冻结主干仅训练跨模态注意力层,阶段二全模型联合微调,阶段三高质量数据精调。 (3) 大规模数据管线:自动化音视频配对数据清洗,多维度质量过滤。 1.3 核心创新 首个全面开源的可扩展联合音视频生成系统 采用双流DiT架构,独立模态流+跨模态注意力交互 渐进式三阶段训练策略缓解多模态联合训练的稳定性问题 大规模音视频配对数据清洗管线支撑高质量生成 1.4 实验结果 Ablation study on human preference. 在音视频同步性、音频质量、视频质量等多维度达到开源SOTA 与Veo 3等商业系统在部分指标上具有竞争力 代码和模型全面开源 1.5 关键洞察 优势:系统工程完整,开源贡献大;渐进式训练有效。局限:双流架构的跨模态对齐存在固有上限;数据规模仍不及商业系统。 技术演进定位: 开源联合音视频生成的技术基线 可能的后续方向: 双流→单流架构演进 更大规模数据与模型 2. JavisDiT++:统一建模与人类偏好对齐——联合音视频生成的系统性优化 论文: JavisDiT++ arXiv: 2602.19163 机构: Rochester, 上海科技大学 2.1 研究动机 核心问题: 联合音视频生成的质量与商业系统仍有差距,缺乏人类偏好对齐 联合音视频生成已成为多模态合成基础任务,但与Veo 3等商业系统相比,开源方法在生成质量、时序同步和人类偏好对齐三个维度上仍存在明显差距。JavisDiT++从统一建模和系统优化两个层面同时发力。 前序工作及局限: MOVA:开源联合生成基线 DPO / RLHF:语言模型偏好对齐技术 与前序工作的本质区别: JavisDiT++首次将DPO人类偏好优化引入联合音视频生成,配合时间对齐RoPE 2.2 方法原理 Architecture of . We use shared attention layers to encourage audio-visual mutual information modeling, with modality-specific FFN layers to enhance intra-modal aggregation. The Temporal-Aligned RoPE strategy is applied to ensure audio-video synchrony. The audio/video embedder layer and prediction head that bridge DiT and VAEs are hidden for simplicity. JavisDiT++的核心设计: (1) 统一双流DiT架构:基于预训练视频DiT和音频DiT,跨模态注意力实现联合推理,时间对齐RoPE解决时间分辨率不匹配。 (2) 多阶段优化:跨模态注意力预训练→全模型联合微调→人类偏好对齐(DPO/RLHF)。 (3) 高质量数据策略:精心策划的多源音视频训练数据,基于同步性的质量过滤。 2.3 核心创新 系统性地将人类偏好优化引入联合音视频生成 时间对齐RoPE解决异构时间分辨率问题 支持多种生成模式:T2AV/V2A/A2V 多阶段优化管线包含DPO后训练 2.4 实验结果 Illustration of preference data collection and training pipeline of audio-video DPO. 在多个JAVG基准上取得开源SOTA 人类偏好对齐后用户偏好率显著提升 同步质量和感知质量综合提升 2.5 关键洞察 优势:首次在JAVG中引入DPO后训练,方法论完整。局限:人类偏好标注成本高;DPO对齐效果受奖励模型质量制约。 技术演进定位: 联合音视频生成的偏好对齐开拓者 可能的后续方向: 更精细的音视频同步奖励模型 人类偏好驱动的质量提升 3. OmniForcing:首个实时联合音视频流式生成——Self-Forcing蒸馏实现25FPS 论文: OmniForcing arXiv: 2603.11647 机构: 基于LTX-2蒸馏 3.1 研究动机 核心问题: 联合音视频生成局限于离线模式,无法支持交互式应用 现有联合音视频生成系统都是离线的,严重限制交互式应用(游戏NPC、虚拟直播、实时对话)。OmniForcing提出核心问题:能否实现实时的、流式的联合音视频生成? 前序工作及局限: LTX-2:高质量离线双流联合生成教师模型 Self-Forcing:流式生成蒸馏范式 与前序工作的本质区别: OmniForcing将离线双向扩散蒸馏为25FPS流式自回归生成器 3.2 方法原理 The three-stage OmniForcing distillation pipeline. Stage I employs Distribution Matching Distillation (DMD)~yin2024one,yin2024improved to adapt the model for few-step, fast denoising. Stage II utilizes causal ODE regression to adapt the network weights to the asymmetric block-causal mask. Stage III implements joint Self-Forcing~huang2025self training by autoregressively unrolling the generation process to mitigate exposure bias. OmniForcing的核心设计: (1) Joint Self-Forcing Distillation:以离线双向扩散模型为教师,蒸馏为流式自回归学生,在长序列上自纠正跨模态误差。 (2) Asymmetric Block-Causal Alignment + Zero-truncation Global Prefix:确保流式生成中音视频同步。 (3) Audio Sink Token + Identity RoPE:缓解音频token稀疏的梯度问题。 (4) 模态无关滚动KV-Cache:支持任意长度流式生成。 3.3 核心创新 首个实时联合音视频流式生成系统,单GPU约25 FPS 将离线双流双向扩散蒸馏为流式自回归生成器 Joint Self-Forcing Distillation在长序列上自纠正跨模态误差 非对称块因果对齐+全局前缀确保流式同步 Audio Sink Token缓解音频token稀疏问题 3.4 实验结果 Asymmetric Block-Causal Masking. The vertical axis denotes query tokens and the horizontal axis denotes key tokens. Modalities are synchronized via 1s macro-blocks. Each audio block ($B^a$) contains 25 latent frames (one token each), whereas each video block ($B^v$) contains 3 latent frames patchified into $3 384$ tokens. Unmasked tokens include the Global Prefix (orange, $V_0/A_0$) and Audio Sink tokens (red, $s$). Blue regions denote allowed attention (bidirectional intra-block, strictly causal inter-block), while white regions mask future keys to prevent information leakage. 单GPU约25 FPS实时生成 同步质量和视觉质量与双向教师模型持平 显著优于已有流式方法 项目代码开源 3.5 关键洞察 优势:实时生成突破意义重大,对交互式应用有直接影响。局限:蒸馏质量上限受教师模型制约;LTX-2训练成本高。 技术演进定位: 首个实时联合音视频流式生成系统 可能的后续方向: 实时生成的质量进一步提升 交互式音视频创作工具 4. CCL:系统解决双流联合生成三大瓶颈——跨模态上下文学习 论文: CCL arXiv: 2603.18600 机构: SenseTime 4.1 研究动机 核心问题: 双流联合生成框架存在门控流形变化、背景偏差、CFG冲突三大瓶颈 双流Transformer已成为联合音视频生成主流范式,但存在三个关键问题:(1)门控机制引起的模型流形变化;(2)跨模态注意力引入的多模态背景区域偏差;(3)多模态CFG的训练-推理不一致性。 前序工作及局限: 双流DiT范式:当前联合音视频生成的主流架构 TARP / RoPE:位置编码对齐技术 与前序工作的本质区别: CCL系统性提出TARP/LCT+DCR/UCG三个模块精准解决三大瓶颈 4.2 方法原理 The pipeline of our proposed Cross-Modal Context Learning. CCL follows the conventional dual-stream transformer architecture, equipped with several novel-designed modules, enabling efficient and effective joint audio-video generation with high consistency. The figure illustrates the implementation details of proposed modules. For Dynamic Context Routing, the various colors denote that the corresponding colored paths on the left are in an activated state. CCL提出三个模块: (1) TARP(时间对齐RoPE和分区):在RoPE位置编码层面实现音视频精确时间对齐。 (2) LCT(可学习上下文标记)+DCR(动态上下文路由):LCT提供稳定锚点缓解流形变化,DCR根据生成模式动态路由。 (3) UCG(无条件上下文引导):利用LCT在推理时提供稳定的无条件支持,改善训练-推理一致性。 4.3 核心创新 首次系统分析双流联合生成框架的三个核心技术瓶颈 TARP解决异构时间分辨率的精确对齐 可学习上下文标记(LCT)+动态上下文路由(DCR)稳定跨模态交互 无条件上下文引导(UCG)解决多模态CFG训练-推理不一致 4.4 实验结果 The gating mechanism alters the optimization objective during training, which affects training efficiency. 实现开源SOTA联合音视频生成 所需训练资源远少于对比方法 音视频同步质量和整体生成质量均显著提升 4.5 关键洞察 优势:问题分析精准,三个模块各自解决一个核心问题,设计优雅。局限:仍基于双流范式,未突破架构本身的上限。 技术演进定位: 双流范式优化的精巧方案 可能的后续方向: 跨模态对齐机制的进一步演化 5. Identity as Presence:外观+声音联合个性化——音视频生成的身份可控新范式 论文: Identity as Presence arXiv: 2603.17889 5.1 研究动机 核心问题: 联合音视频生成产出匿名内容,无法指定特定人物的外貌和声音 现有联合音视频生成产出的都是'匿名'内容——无法指定特定人物的外貌和声音。然而在虚拟人、个性化视频、AI配音等应用中,身份可控是核心需求。 前序工作及局限: IP-Adapter:图像特征注入技术 联合音视频生成基线:不支持身份控制 与前序工作的本质区别: Identity as Presence首次实现面部外观+声音音色的联合个性化 5.2 方法原理 Overview of data curation pipeline for constructing identity-labeled audio-visual data from raw videos. The process involves isolating both visual and auditory identity-specific signals from raw videos, synthesizing comprehensive captions via MLLMs, and rigorously matching audio-visual identities to guarantee precise alignment across video clips to ensure high-fidelity identity consistency. 核心设计: (1) 自动化身份数据策划管线:从大规模音视频数据中自动提取配对身份信息。 (2) 双模态身份注入:面部外观通过IP-Adapter风格特征注入,声音音色通过音频编码器+适配层注入。 (3) 多阶段训练:阶段一单模态身份预训练,阶段二联合微调学习外观-声音协同保持。 5.3 核心创新 首个同时支持面部外观和声音音色联合个性化的音视频生成系统 自动化身份数据策划管线 多阶段训练处理音视觉表征差异 支持单人和多人场景 5.4 实验结果 身份保持、音画一致性、生成质量多维度优于基线 多主体场景下保持高保真身份一致性 5.5 关键洞察 优势:问题定义清晰,双模态身份注入设计实用。局限:身份保持精度受特征编码器上限制约;多人场景下的身份混淆问题待深入分析。 技术演进定位: 联合生成走向身份可控的关键工作 可能的后续方向: 多身份精细解耦控制 虚拟人产品化 6. FoleyDirector:导演级V2A精细控制——时序脚本驱动的画内/画外声并行合成 论文: FoleyDirector arXiv: 2603.19857 6.1 研究动机 核心问题: V2A缺乏精细时序控制,用户无法指定具体时间点的声音事件 当前V2A方法无法实现精细的时序控制——用户希望在特定时间点产生不同音效、控制画内/画外声的切换。现有V2A系统缺乏导演级别的精细调度能力。 前序工作及局限: Diff-Foley / SonicVisionLM:早期V2A方法,粗粒度语义匹配 Make-An-Audio / AudioLDM:文本到音频生成基线 与前序工作的本质区别: FoleyDirector引入结构化时序脚本(STS)实现导演级精确控制 6.2 方法原理 Overview of our method. (a) Extraction pipeline of segment-level ~features. (b) Structure of the ~module, where Temporal Script Attention introduces control signals. (c) , which leverages the controllability of our method in T2A and V2A to enable parallel rendering of in-frame and out-of-frame sounds. Fused block represents the single-modal transformer block in MMAudio. 核心设计: (1) 结构化时序脚本(STS):用户精确指定在第N秒到第M秒产生某种声音,支持画内/画外声独立控制。 (2) Temporal Script Attention:在DiT中引入时序脚本注意力层,融合STS与视频特征。 (3) Bi-Frame Sound Synthesis:并行生成画内声和画外声,精确对齐后混合输出。 6.3 核心创新 首个在DiT基V2A上实现精确时序引导的方法 结构化时序脚本(STS)提供导演级控制 画内/画外声并行合成(Bi-Frame Sound Synthesis) 构建DirectorSound数据集和DirectorBench评测基准 CVPR 2026接收 6.4 实验结果 Visual Results in VGGSound-Director. We present several results from VGGSound-Director, comparing the mel-spectrograms generated by our method with those from other approaches and with the ground-truth audio. We also compute the L1 similarity between each generated mel-spectrogram and the ground truth. VGGSoundDirector和DirectorBench上时序控制SOTA 高保真与精确时序可控性兼顾 CVPR 2026接收 6.5 关键洞察 优势:时序脚本是优雅的控制接口,CVPR 2026验证了方法质量。局限:STS常需手工编写,大规模自动化可用性待验证。 技术演进定位: V2A精细控制的CVPR 2026代表作 可能的后续方向: STS自动化生成 V2A与联合生成的融合 7. OmniSonic:首个全场景V2A——统一屏内/屏外/语音三类音频的通用生成 论文: OmniSonic arXiv: 2604.04348 7.1 研究动机 核心问题: V2A只关注单一类型音频,无法覆盖真实视频中的全部声音场景 现有V2A方法通常只关注单一类型音频。但真实视频中同时包含屏内环境音、屏外环境音和人类语音三类声音。OmniSonic首次提出Universal Holistic Audio Generation任务。 前序工作及局限: FoleyDirector:V2A精细时序控制 环境音/语音/音乐分离模型:单类型音频处理 与前序工作的本质区别: OmniSonic首次统一屏内环境音/屏外环境音/人类语音三类音频的生成 7.2 方法原理 (A) Overview of our proposed OmniSonic, which mainly consists of an environmental text encoder (FLAN-T5), a speech transcription encoder (SpeechT5), a visual encoder (CLIP visual encoder), an audio VAE, and our specially designed TriAttn-DiT blocks. The input example demonstrates the scenario of on-screen speech with off-screen environmental sound. The input conditions include visual frames, speech transcription, an on-screen environmental sound caption (represented by a placeholder ""), and an off-screen environmental sound caption. (B) Details of our proposed TriAttn-DiT block. 核心设计: (1) UniHAGen任务:统一屏内环境音、屏外环境音、人类语音三类音频的生成。 (2) TriAttn-DiT架构:基于Flow Matching的DiT,三路交叉注意力(视频/文本/音频类型条件),MoE门控不同专家处理不同类型音频。 (3) UniHAGen-Bench:首个覆盖三类音频的统一评测基准。 7.3 核心创新 首次在统一框架中覆盖三类视频音频(屏内环境音/屏外环境音/人类语音) TriAttn-DiT+MoE的专家化架构设计 构建UniHAGen-Bench评测体系 CVPR 2026接收 7.4 实验结果 Visualization of the spectrograms of generated audios and the ground-truth. 客观指标和人工评估一致超越现有SOTA 在全部三类音频生成上均取得最优性能 CVPR 2026接收 7.5 关键洞察 优势:任务定义前瞻,全场景覆盖填补领域空白,CVPR 2026验证了质量。局限:三类音频的联合生成质量仍有提升空间。 技术演进定位: 全场景V2A的CVPR 2026开拓者 可能的后续方向: 三类音频联合质量提升 空间音频集成 8. FoleyDesigner:电影级立体声拟音——多智能体时空分析+LLM空间混音 论文: FoleyDesigner arXiv: 2604.05731 机构: Shanghai University, University of Surrey 8.1 研究动机 核心问题: 自动Foley生成产出单声道音频,缺乏空间感和沉浸式体验 拟音艺术是电影沉浸式听觉体验的关键。现有自动Foley生成方法产生的都是单声道音频,且时空对齐精度有限。FoleyDesigner首次将Foley生成推向立体声甚至5.1环绕声。 前序工作及局限: OmniSonic / FoleyDirector:单声道V2A方法 杜比全景声:专业空间音频标准 与前序工作的本质区别: FoleyDesigner首次将Foley生成推向立体声/5.1环绕声,LLM驱动空间混音 8.2 方法原理 FoleyDesigner Architecture. Our pipeline for automated Foley generation consists of three stages, (1) Fine-Grained Film Decomposition: analyzes silent video and generates hierarchical Foley scripts; (2) Spatio-Temporal Foley Generation: produces spatially-controlled stereo audio using DiT-based diffusion conditioned on visual cues; (3) Foley Refinement: applies multi-agent processing to refine audio quality and generate 5.1 surround output. 核心设计: (1) 多智能体时空分析:使用多个AI Agent分析视频中的声音事件,精确标注时间窗口和空间位置。 (2) 潜在扩散音频合成:基于潜在扩散模型生成时序精确对齐的高质量音频。 (3) LLM驱动混音引擎:利用LLM理解声音空间分布,自动完成立体声/5.1声道空间混音。 8.3 核心创新 首个电影级立体声拟音自动生成系统 多智能体+LLM驱动的空间混音方案 支持杜比5.1环绕声输出 构建FilmStereo数据集 8.4 实验结果 FilmStereo Dataset Pipeline. The process begins with sourcing data using randomly sampled parameters to define sound event attributes, followed by a simulated sound design scenario in Step 2 to generate film foley annotations. The resulting data undergoes manual verification to ensure quality and accuracy. 时空对齐精度优于所有基线方法 生成的立体声音频具有沉浸式空间感 支持杜比5.1环绕声输出 8.5 关键洞察 优势:立体声方向前瞻,LLM混音设计新颖。局限:LLM混音的精度和可控性仍需提升;FilmStereo数据集规模有限。 技术演进定位: 立体声拟音方向的探索先驱 可能的后续方向: 空间音频/立体声标准化 专业Foley工具产品化 其余论文速览 1. ALIVE:将预训练T2V模型适配为联合音视频生成+动画 ALIVE: Animate Your World with Lifelike Audio-Video Generation | arXiv:2602.08682 关键词: T2VA, 动画, MMDiT 贡献: 将预训练T2V模型适配为联合音视频生成+动画,MMDiT架构增强音视频同步 效果: T2VA和参考图动画双能力 2. daVinci-MagiHuman:首个单流Transformer联合音视频生成 Speed by Simplicity: A Single-Stream Architecture for Fast Audio-Video Generative Foundation Model | Sand.ai | arXiv:2603.21986 关键词: 单流架构, 人物中心, 统一token 贡献: 首个单流Transformer联合音视频生成,统一token序列+自注意力,避免多流/跨注意力复杂性 效果: 架构简洁,易于优化,开源 3. DreamID-Omni:统一R2AV/RV2AV/RA2V三种人物中心任务 DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation | arXiv:2602.12160 关键词: 统一框架, 多身份, 人物中心 贡献: 统一R2AV/RV2AV/RA2V三种人物中心任务,实现多身份解耦控制 效果: 首个统一多人物音视频控制框架 4. OmniCustom:提出同步音视频定制新任务 OmniCustom: Sync Audio-Video Customization Via Joint Audio-Video Generation Model | 腾讯, HKU | arXiv:2602.12304 关键词: 音视频定制, 身份+音色, 新任务定义 贡献: 提出同步音视频定制新任务,同时定制视频身份+音频音色 效果: 同步音视频身份定制 5. AVControl:基于LTX-2的模块化音视频控制 AVControl: Efficient Framework for Training Audio-Visual Controls | arXiv:2603.24793 关键词: 模块化控制, LoRA, LTX-2 贡献: 基于LTX-2的模块化音视频控制,每模态独立LoRA,低训练成本 效果: 模块化控制SOTA 6. Woosh:统一文本音效+视频条件音效的基础模型 Woosh: A Sound Effects Foundation Model | Sony AI | arXiv:2604.01929 关键词: T2A+V2A, 基础模型, 蒸馏加速 贡献: 统一文本音效+视频条件音效的基础模型,蒸馏5-8x加速 效果: AudioCaps/Clotho上FAD与SOTA相当,V2A同步分数高于基线 7. AC-Foley:以参考音频(非文本)控制V2A生成 AC-Foley: Reference-Audio-Guided Video-to-Audio Synthesis with Acoustic Transfer | ICLR 2026 关键词: 参考音频, V2A, ICLR 2026 贡献: 以参考音频(非文本)控制V2A生成,实现更细粒度音色迁移 效果: 参考音频条件下Foley生成SOTA 8. DynFOA:结合3DGS与条件扩散 DynFOA: Generating First-Order Ambisonics with Conditional Diffusion for Dynamic 360-Degree Videos | arXiv:2604.02781 关键词: 360°视频, 空间音频, 3DGS, Ambisonics 贡献: 结合3DGS与条件扩散,为360°视频生成物理一致的一阶Ambisonics空间音频 效果: 空间准确性和声学保真持续优于基线 9. V2M-Zero:无需配对数据实现视频到音乐的时间对齐生成 V2M-Zero: Zero-Pair Time-Aligned Video-to-Music Generation | arXiv:2603.11042 关键词: 视频转音乐, 零样本, 时间对齐 贡献: 无需配对数据实现视频到音乐的时间对齐生成 效果: 零样本跨模态音乐生成 10. GLANCE:音乐驱动非线性视频编辑 GLANCE: A Global-Local Coordination Multi-Agent Framework for Music-Grounded Non-Linear Video Editing | Virginia Tech, Meta AI | arXiv:2604.05076 关键词: 音乐驱动, 视频编辑, 多智能体 贡献: 音乐驱动非线性视频编辑,全局-局部协调多智能体,双循环长期规划+逐片段精修 效果: 比最强基线高33.2% 11. Echoes Over Time:解决V2A模型的长度泛化问题 Echoes Over Time: Unlocking Length Generalization in Video-to-Audio Generation Models | arXiv:2602.20981 关键词: V2A, 长度泛化, MMHNet 贡献: 解决V2A模型的长度泛化问题,提出MMHNet多模态层次网络 效果: 短训练长推理的长度泛化 12. AVGen-Bench:首个多粒度文本-音视频联合生成评测基准 AVGen-Bench: A Task-Driven Benchmark for Multi-Granular Evaluation of Text-to-Audio-Video Generation | arXiv:2604.08540 关键词: 评测基准, T2AV, 多粒度 贡献: 首个多粒度文本-音视频联合生成评测基准,11个任务类别 效果: 填补T2AV评测空白 横向对比与技术脉络总结 横向对比:音视频联合生成与编辑方法的技术路线对比 论文 架构设计 训练范式 推理模式 控制粒度 MOVA 双流DiT 渐进式三阶段 离线 语义级 JavisDiT++ 双流DiT 多阶段+DPO 离线 语义级+偏好 OmniForcing 流式自回归 蒸馏 实时25FPS 语义级 CCL 双流DiT 轻量训练 离线 语义级 FoleyDirector DiT V2A 监督训练 离线 时序脚本精确控制 OmniSonic TriAttn-DiT+MoE 监督训练 离线 音频类型级 FoleyDesigner 扩散+LLM 多阶段 离线 时空精确控制 Identity as Presence 双模态注入 多阶段 离线 身份级 核心技术趋势 从级联到联合,从离线到实时 联合音视频生成从'先视频后音频'的级联方式快速进化为端到端同步生成,OmniForcing的实时流式生成标志着从离线工具向交互式应用的关键转变 双流vs单流架构之争 双流DiT(MOVA/JavisDiT++/CCL)通过复用预训练模型降低训练成本但引入对齐复杂性,单流设计(daVinci-MagiHuman)更简洁,两种范式的优劣将在半年内见分晓 V2A走向导演级精细控制 从粗粒度语义匹配到FoleyDirector的时序脚本精确控制、OmniSonic的全场景覆盖、FoleyDesigner的立体声/空间音频,V2A正从玩具走向专业后期工具 个性化是产品化的关键 Identity as Presence/DreamID-Omni/OmniCustom将联合生成从匿名内容创作推向身份可控的个性化创作,这是从研究到消费产品的关键一步 评测体系亟需标准化 AVGen-Bench的出现说明社区已认识到联合音视频生成缺乏统一评测标准的痛点,标准化评测是推动领域进步的关键基础设施 人工智能炼丹师 整理 | 2026-04-11