搜索到
2
篇与
蒸馏
的结果
-
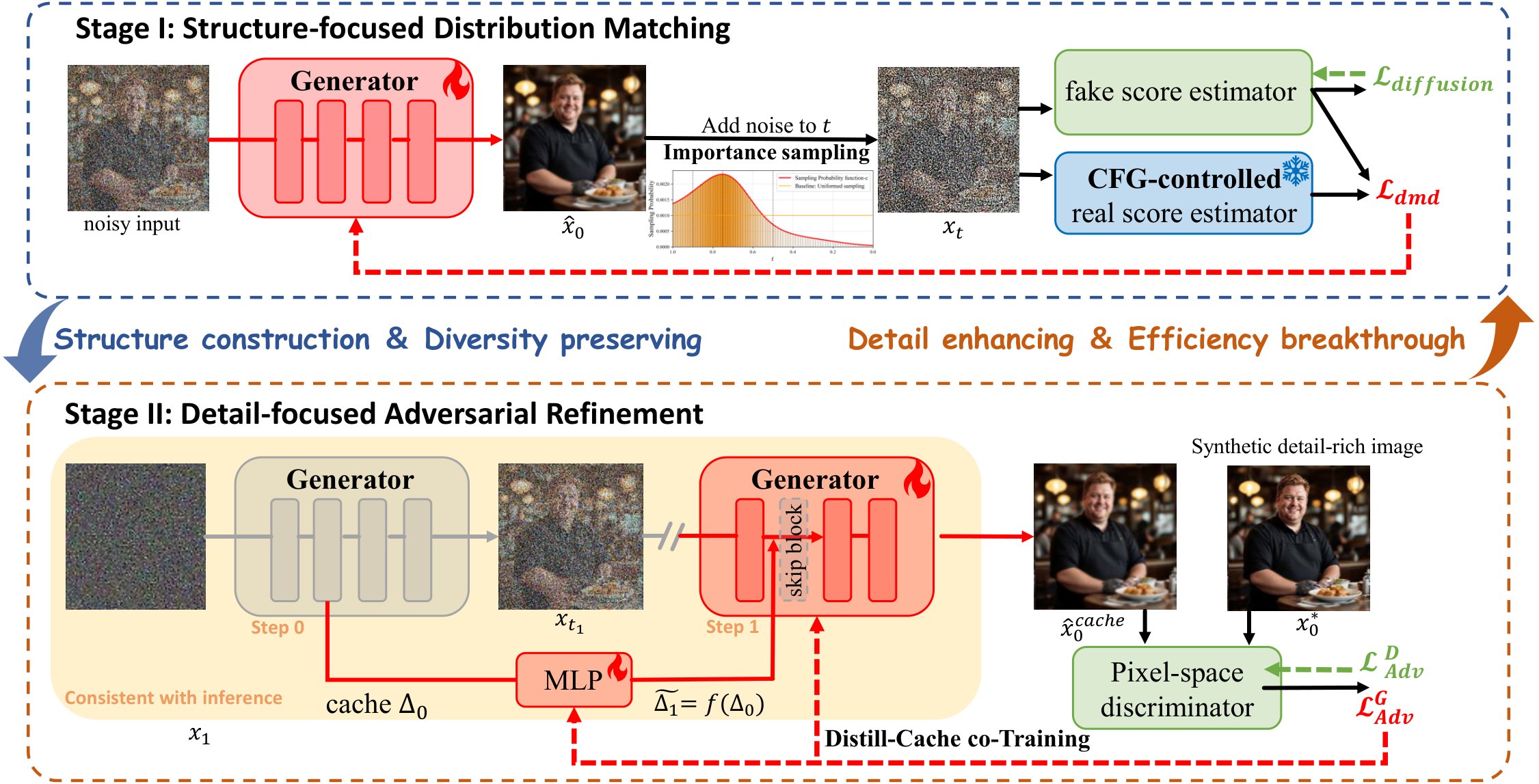
 AIGC 每日速读|2026-04-08|分数步蒸馏(1.x-Distill)实现33x推理加速 今日核心看点 分数步蒸馏(1.x-Distill) 空间编辑基准(SpatialEdit) 通用音频生成(OmniSonic) 视频DiT缓存(Chorus) 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成推理加速: 3篇 (1.x-Distill, Chorus, OP-GRPO) 图像编辑与评测: 3篇 (SpatialEdit, VicoEdit, Think-in-Strokes) 音频生成: 1篇 (OmniSonic, CVPR 2026) 视频生成: 1篇 (Vanast, CVPR 2026) 生成理解一体化: 1篇 (退化图像理解CLEAR) 含 3 篇 CVPR 2026 接收论文 重点论文深度解读 1. 1.x-Distill 首个分数步蒸馏框架——打破整数步约束实现33倍加速 | Unknown | arXiv:2604.04018 关键词: 蒸馏加速, 分布匹配蒸馏, 分数步推理, CFG控制, 块级缓存, SD3 研究动机 核心问题: 扩散模型迭代去噪计算量大,分布匹配蒸馏在极端少步时多样性崩溃 扩散模型生成高质量图像,但迭代去噪计算量大。分布匹配蒸馏(DMD)是少步蒸馏的有前途路径,但在 2 步或更少时遭遇多样性崩溃和保真度下降。作者发现两个核心问题:(1) 教师模型 CFG 在高噪声时域驱使学生过早坍缩到少数主导模式;(2) 极端少步蒸馏下,单一目标函数无法同时兼顾全局结构和细节。 前序工作及局限: DMD/DMD2:分布匹配蒸馏的先驱,但 2 步以下多样性严重崩溃 TDM/SenseFlow:无图像训练蒸馏,但未发现 CFG 导致模式坍缩的根因 DDIM/一致性模型:少步采样加速,但受限于整数步约束 DeepCache/Learning-to-Cache:DiT 块级缓存加速,但未与蒸馏训练过程整合 与前序工作的本质区别: 首次将分布匹配蒸馏与块级缓存统一,发现并解决 CFG 导致模式崩溃的根因,提出分数步蒸馏打破整数步约束 方法原理 1.x-Distill 框架包含三个核心创新: (1) 时间步感知 CFG 控制:在高噪声时域(t>alpha)禁用教师 CFG,使用纯条件分数引导学生覆盖更多模式;低噪声时域保留 CFG 保证细节质量。alpha=0.94 为最优阈值。 (2) 分阶段聚焦蒸馏(SFD):Stage I 结构导向分布匹配,采用重要性采样偏向 t=0.75 附近结构信息丰富的时域,避免低噪声区的过度纹理扰动;Stage II 细节导向对抗精炼,在学生的少步推理路径上生成样本,使用冻结 ConvNeXt 特征提取器 + 可训练分类头作为判别器,无需外部图像数据集。 (3) 蒸馏-缓存协同训练(DCT):观察到早期 DiT 块跨步骤时间冗余大,缓存块贡献 Delta_t = O_m - I_n,第二步跳过 6-8 个块。引入轻量级残差 MLP 预测修正缓存误差。Stage II 自然支持缓存训练,对抗损失直接监督缓存加速推理。 核心创新 首次提出分数步蒸馏概念,打破先前少步方法的整数步约束 发现并解决 DMD 中教师 CFG 导致模式崩溃的关键问题 提出分阶段聚焦蒸馏(SFD):结构导向分布匹配 + 细节导向对抗精炼 设计蒸馏-缓存协同训练(DCT),将块级缓存融入蒸馏流程 在 SD3-Medium 和 SD3.5-Large 上实现 1.67/1.74 有效 NFE,最高 33 倍加速 实验结果 SD3-Medium (24 DiT blocks): SFD 4步:FID 14.13(最佳),HPSv2 32.53,ImageReward 1.12 1.x-Distill-slow (NFE=1.75):FID 15.79,HPSv2 32.26,超越所有 2 步和大部分 4 步基线 1.x-Distill-fast (NFE=1.67):FID 16.72,HPSv2 31.69,比原始 28x2 采样加速 33 倍 SD3.5-Large (38 DiT blocks): SFD 4步:HPSv2 32.90,ImageReward 1.20(最佳) 1.x-Distill (NFE=1.74):FID 22.05,HPSv2 32.01,超越 TDM 2步基线 3.5+ HPSv2 DPG-Bench:蒸馏模型在复杂提示下总分超越多步教师模型 多样性(LPIPS):显著高于 Flash 和 TDM 等基线 用户研究:20 位评估者在 3200 提示上明确偏好 1.x-Distill 图表详解 方法核心:块级缓存设计 左图展示各 DiT 块的跨步复用误差(早期块冗余大),右图展示缓存机制:第一步完整计算并缓存块贡献,第二步跳过并用 MLP 修正恢复 CFG 在蒸馏中的作用分析 高噪声时域强 CFG 驱使学生过早模式坍缩;1.x-Distill 在高噪声区禁用 CFG,低噪声区保留 CFG 定性对比结果 SD3-Medium 上多种方法的生成质量对比,1.x-Distill 在 1.67 NFE 下仍保持连贯结构和丰富细节 批判性点评 新颖性: 首次提出分数步蒸馏概念,打破整数步约束。时域感知 CFG 控制、分阶段聚焦蒸馏、蒸馏-缓存协同训练三个创新点紧密配合。 可复现性: 代码和权重将公开。训练仅需 JourneyDB 提示数据,无需外部图像数据集。但具体训练超参数和缓存块选择策略的细节需参考附录。 影响力: 高——开辟 1.x 步蒸馏新范式,33x 加速具有重大实用价值。但目前仅验证 SD3 系列,Flux/SDXL 等架构的通用性有待考验。 深度点评: 首创分数步蒸馏 — 1.x-Distill 首次突破整数步约束,SD3 上仅 1.67 NFE 实现 33x 加速,FID 和人类偏好全面领先 推理加速三路并进 — 蒸馏(1.x-Distill) + 系统缓存(Chorus) + 训练效率(OP-GRPO),三维度全面提速 免训练方法降低门槛 — FDS(Flow Matching) 和 VicoEdit(图像编辑) 无需额外训练即可大幅提升质量 技术演进定位: 分布匹配蒸馏领域的重要推进,开辟 1.x 步生成新范式 可能的后续方向: 推广到 Flux/SDXL/视频扩散模型 自适应缓存块选择 与推理系统优化结合 其余论文速览 1. SpatialEdit:提出首个专门评估细粒度空间编辑的基准Sp SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing 关键词: 图像编辑·空间变换·几何保真度·合成数据·基准评测 贡献: 提出首个专门评估细粒度空间编辑的基准SpatialEdit-Bench,通过联合度量感知合理性和几何保真度系统评估空间操作能力。构建500K合成训练数据集SpatialEdit-500k,使用可控Blender管线生成精确的相机轨迹和物体变换真值。基于此训练16B参数的SpatialEdit-16B基线模型。 效果: SpatialEdit-16B在通用编辑任务中取得有竞争力的性能,同时在空间操作任务上大幅超越现有方法。 2. FDS:提出流分歧采样器FDS Training-Free Refinement of Flow Matching with Divergence-based Sampling 关键词: Flow Matching·采样优化·无训练·散度引导·即插即用 贡献: 提出流分歧采样器FDS,无需训练即可提升Flow Matching模型质量。核心发现:边缘速度场的散度可量化采样误导程度,利用该信号在每个求解步骤前将中间状态引导至歧义更小的区域。 效果: 作为即插即用框架,FDS兼容标准求解器和现有Flow模型,在文本到图像合成和逆问题等多种任务中一致提升保真度。 3. OmniSonic:提出通用整体音频生成任务UniHAGen OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text 关键词: 音频生成·视频到音频·Flow Matching·MoE·CVPR 2026 贡献: 提出通用整体音频生成任务UniHAGen,首次统一生成屏幕内环境音、屏幕外环境音和人类语音。设计TriAttn-DiT架构,通过三路交叉注意力同时处理三种音频条件,配合MoE门控机制自适应平衡。构建UniHAGen-Bench基准覆盖三种代表性场景。CVPR 2026。 效果: 在客观指标和人类评估上均一致超越现有最先进方法,建立了通用整体音频生成的强基线。 4. OP-GRPO:首个专为Flow-Matching模型设 OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models 关键词: GRPO·Flow Matching·离线策略·训练效率·后训练优化 贡献: 首个专为Flow-Matching模型设计的离线GRPO框架。主动选择高质量轨迹并自适应加入回放缓冲区重复使用;提出序列级重要性采样修正减轻分布偏移;发现并解决晚期去噪步骤的病态离线比率问题。 效果: 仅用平均34.2%的训练步骤即达到Flow-GRPO同等或更优性能,在图像和视频生成基准上均验证有效。 5. Vanast:提出统一框架从单张人像、服装图和姿态视频 Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision 关键词: 虚拟试穿·视频生成·扩散Transformer·人体动画·CVPR 2026 贡献: 提出统一框架从单张人像、服装图和姿态视频一步生成换装动画视频。构建大规模三元组监督数据,引入视频扩散Transformer的双模块架构稳定训练,支持零样本服装插值。CVPR 2026。 效果: 克服传统两阶段方案的身份漂移和服装扭曲问题,实现高保真、身份一致的服装迁移动画。 6. VicoEdit:提出VicoEdit——免训练且无需反演 Training-Free Image Editing with Visual Context Integration and Concept Alignment 关键词: 图像编辑·免训练·视觉上下文·概念对齐·后验采样 贡献: 提出VicoEdit——免训练且无需反演的视觉上下文注入图像编辑方法。直接基于视觉上下文将源图转换为目标图,消除扩散反演可能导致的轨迹偏离。设计概念对齐引导的后验采样方法增强编辑一致性。 效果: 免训练方法在编辑性能上甚至超越最先进的基于训练的模型。 7. Think-in-Strokes:提出过程驱动图像生成范式 Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning 关键词: 图像生成·推理过程·交错生成·可解释AI·多步细化 贡献: 提出过程驱动图像生成范式,将合成分解为思想-动作交错推理轨迹。每次迭代包含文本规划、视觉草拟、文本反思、视觉细化四个阶段。通过密集逐步监督维持空间和语义一致性。 效果: 使生成过程变得明确、可解释且可直接监督,在多种文本到图像基准上验证有效性。 8. Chorus:提出Chorus——利用跨请求相似性加速 Beyond Few-Step Inference: Accelerating Video Diffusion Transformer Model Serving with Inter-Request Caching Reuse 关键词: 视频生成·推理加速·跨请求缓存·DiT·模型服务 贡献: 提出Chorus——利用跨请求相似性加速视频扩散Transformer服务的缓存方法。采用三阶段缓存策略:完全复用阶段、区域级跨请求缓存阶段和令牌引导注意力放大阶段。在单请求内缓存无效的4步蒸馏模型上仍有效。 效果: 在工业级4步蒸馏视频DiT模型上实现高达45%的推理加速,同时维持语义对齐质量。 9. CLEAR:提出CLEAR框架连接统一多模态模型的生 CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models 关键词: 生成理解一体化·退化图像·统一多模态·强化学习·GRPO 贡献: 提出CLEAR框架连接统一多模态模型的生成和理解能力以处理退化图像。三步渐进策略:感知退化SFT建立先生成后回答推理模式;潜在表示桥替代解码-重编码绕路;交错GRPO联合优化文本推理和视觉生成。构建MMD-Bench覆盖六个基准三级退化。 效果: 显著提升退化输入鲁棒性同时保持清晰图像性能。发现移除像素级重建监督可获得更高感知质量的中间视觉状态。 趋势观察 推理加速多路径并进 — 分数步蒸馏(1.x-Distill)、跨请求缓存(Chorus)、离线GRPO(OP-GRPO)——从模型压缩、系统优化到训练效率三个维度全面提速 免训练方法持续升温 — FDS和VicoEdit均无需额外训练即可提升Flow Matching和图像编辑质量,降低部署门槛 人工智能炼丹师 整理 | 2026-04-08 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
AIGC 每日速读|2026-04-08|分数步蒸馏(1.x-Distill)实现33x推理加速 今日核心看点 分数步蒸馏(1.x-Distill) 空间编辑基准(SpatialEdit) 通用音频生成(OmniSonic) 视频DiT缓存(Chorus) 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成推理加速: 3篇 (1.x-Distill, Chorus, OP-GRPO) 图像编辑与评测: 3篇 (SpatialEdit, VicoEdit, Think-in-Strokes) 音频生成: 1篇 (OmniSonic, CVPR 2026) 视频生成: 1篇 (Vanast, CVPR 2026) 生成理解一体化: 1篇 (退化图像理解CLEAR) 含 3 篇 CVPR 2026 接收论文 重点论文深度解读 1. 1.x-Distill 首个分数步蒸馏框架——打破整数步约束实现33倍加速 | Unknown | arXiv:2604.04018 关键词: 蒸馏加速, 分布匹配蒸馏, 分数步推理, CFG控制, 块级缓存, SD3 研究动机 核心问题: 扩散模型迭代去噪计算量大,分布匹配蒸馏在极端少步时多样性崩溃 扩散模型生成高质量图像,但迭代去噪计算量大。分布匹配蒸馏(DMD)是少步蒸馏的有前途路径,但在 2 步或更少时遭遇多样性崩溃和保真度下降。作者发现两个核心问题:(1) 教师模型 CFG 在高噪声时域驱使学生过早坍缩到少数主导模式;(2) 极端少步蒸馏下,单一目标函数无法同时兼顾全局结构和细节。 前序工作及局限: DMD/DMD2:分布匹配蒸馏的先驱,但 2 步以下多样性严重崩溃 TDM/SenseFlow:无图像训练蒸馏,但未发现 CFG 导致模式坍缩的根因 DDIM/一致性模型:少步采样加速,但受限于整数步约束 DeepCache/Learning-to-Cache:DiT 块级缓存加速,但未与蒸馏训练过程整合 与前序工作的本质区别: 首次将分布匹配蒸馏与块级缓存统一,发现并解决 CFG 导致模式崩溃的根因,提出分数步蒸馏打破整数步约束 方法原理 1.x-Distill 框架包含三个核心创新: (1) 时间步感知 CFG 控制:在高噪声时域(t>alpha)禁用教师 CFG,使用纯条件分数引导学生覆盖更多模式;低噪声时域保留 CFG 保证细节质量。alpha=0.94 为最优阈值。 (2) 分阶段聚焦蒸馏(SFD):Stage I 结构导向分布匹配,采用重要性采样偏向 t=0.75 附近结构信息丰富的时域,避免低噪声区的过度纹理扰动;Stage II 细节导向对抗精炼,在学生的少步推理路径上生成样本,使用冻结 ConvNeXt 特征提取器 + 可训练分类头作为判别器,无需外部图像数据集。 (3) 蒸馏-缓存协同训练(DCT):观察到早期 DiT 块跨步骤时间冗余大,缓存块贡献 Delta_t = O_m - I_n,第二步跳过 6-8 个块。引入轻量级残差 MLP 预测修正缓存误差。Stage II 自然支持缓存训练,对抗损失直接监督缓存加速推理。 核心创新 首次提出分数步蒸馏概念,打破先前少步方法的整数步约束 发现并解决 DMD 中教师 CFG 导致模式崩溃的关键问题 提出分阶段聚焦蒸馏(SFD):结构导向分布匹配 + 细节导向对抗精炼 设计蒸馏-缓存协同训练(DCT),将块级缓存融入蒸馏流程 在 SD3-Medium 和 SD3.5-Large 上实现 1.67/1.74 有效 NFE,最高 33 倍加速 实验结果 SD3-Medium (24 DiT blocks): SFD 4步:FID 14.13(最佳),HPSv2 32.53,ImageReward 1.12 1.x-Distill-slow (NFE=1.75):FID 15.79,HPSv2 32.26,超越所有 2 步和大部分 4 步基线 1.x-Distill-fast (NFE=1.67):FID 16.72,HPSv2 31.69,比原始 28x2 采样加速 33 倍 SD3.5-Large (38 DiT blocks): SFD 4步:HPSv2 32.90,ImageReward 1.20(最佳) 1.x-Distill (NFE=1.74):FID 22.05,HPSv2 32.01,超越 TDM 2步基线 3.5+ HPSv2 DPG-Bench:蒸馏模型在复杂提示下总分超越多步教师模型 多样性(LPIPS):显著高于 Flash 和 TDM 等基线 用户研究:20 位评估者在 3200 提示上明确偏好 1.x-Distill 图表详解 方法核心:块级缓存设计 左图展示各 DiT 块的跨步复用误差(早期块冗余大),右图展示缓存机制:第一步完整计算并缓存块贡献,第二步跳过并用 MLP 修正恢复 CFG 在蒸馏中的作用分析 高噪声时域强 CFG 驱使学生过早模式坍缩;1.x-Distill 在高噪声区禁用 CFG,低噪声区保留 CFG 定性对比结果 SD3-Medium 上多种方法的生成质量对比,1.x-Distill 在 1.67 NFE 下仍保持连贯结构和丰富细节 批判性点评 新颖性: 首次提出分数步蒸馏概念,打破整数步约束。时域感知 CFG 控制、分阶段聚焦蒸馏、蒸馏-缓存协同训练三个创新点紧密配合。 可复现性: 代码和权重将公开。训练仅需 JourneyDB 提示数据,无需外部图像数据集。但具体训练超参数和缓存块选择策略的细节需参考附录。 影响力: 高——开辟 1.x 步蒸馏新范式,33x 加速具有重大实用价值。但目前仅验证 SD3 系列,Flux/SDXL 等架构的通用性有待考验。 深度点评: 首创分数步蒸馏 — 1.x-Distill 首次突破整数步约束,SD3 上仅 1.67 NFE 实现 33x 加速,FID 和人类偏好全面领先 推理加速三路并进 — 蒸馏(1.x-Distill) + 系统缓存(Chorus) + 训练效率(OP-GRPO),三维度全面提速 免训练方法降低门槛 — FDS(Flow Matching) 和 VicoEdit(图像编辑) 无需额外训练即可大幅提升质量 技术演进定位: 分布匹配蒸馏领域的重要推进,开辟 1.x 步生成新范式 可能的后续方向: 推广到 Flux/SDXL/视频扩散模型 自适应缓存块选择 与推理系统优化结合 其余论文速览 1. SpatialEdit:提出首个专门评估细粒度空间编辑的基准Sp SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing 关键词: 图像编辑·空间变换·几何保真度·合成数据·基准评测 贡献: 提出首个专门评估细粒度空间编辑的基准SpatialEdit-Bench,通过联合度量感知合理性和几何保真度系统评估空间操作能力。构建500K合成训练数据集SpatialEdit-500k,使用可控Blender管线生成精确的相机轨迹和物体变换真值。基于此训练16B参数的SpatialEdit-16B基线模型。 效果: SpatialEdit-16B在通用编辑任务中取得有竞争力的性能,同时在空间操作任务上大幅超越现有方法。 2. FDS:提出流分歧采样器FDS Training-Free Refinement of Flow Matching with Divergence-based Sampling 关键词: Flow Matching·采样优化·无训练·散度引导·即插即用 贡献: 提出流分歧采样器FDS,无需训练即可提升Flow Matching模型质量。核心发现:边缘速度场的散度可量化采样误导程度,利用该信号在每个求解步骤前将中间状态引导至歧义更小的区域。 效果: 作为即插即用框架,FDS兼容标准求解器和现有Flow模型,在文本到图像合成和逆问题等多种任务中一致提升保真度。 3. OmniSonic:提出通用整体音频生成任务UniHAGen OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text 关键词: 音频生成·视频到音频·Flow Matching·MoE·CVPR 2026 贡献: 提出通用整体音频生成任务UniHAGen,首次统一生成屏幕内环境音、屏幕外环境音和人类语音。设计TriAttn-DiT架构,通过三路交叉注意力同时处理三种音频条件,配合MoE门控机制自适应平衡。构建UniHAGen-Bench基准覆盖三种代表性场景。CVPR 2026。 效果: 在客观指标和人类评估上均一致超越现有最先进方法,建立了通用整体音频生成的强基线。 4. OP-GRPO:首个专为Flow-Matching模型设 OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models 关键词: GRPO·Flow Matching·离线策略·训练效率·后训练优化 贡献: 首个专为Flow-Matching模型设计的离线GRPO框架。主动选择高质量轨迹并自适应加入回放缓冲区重复使用;提出序列级重要性采样修正减轻分布偏移;发现并解决晚期去噪步骤的病态离线比率问题。 效果: 仅用平均34.2%的训练步骤即达到Flow-GRPO同等或更优性能,在图像和视频生成基准上均验证有效。 5. Vanast:提出统一框架从单张人像、服装图和姿态视频 Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision 关键词: 虚拟试穿·视频生成·扩散Transformer·人体动画·CVPR 2026 贡献: 提出统一框架从单张人像、服装图和姿态视频一步生成换装动画视频。构建大规模三元组监督数据,引入视频扩散Transformer的双模块架构稳定训练,支持零样本服装插值。CVPR 2026。 效果: 克服传统两阶段方案的身份漂移和服装扭曲问题,实现高保真、身份一致的服装迁移动画。 6. VicoEdit:提出VicoEdit——免训练且无需反演 Training-Free Image Editing with Visual Context Integration and Concept Alignment 关键词: 图像编辑·免训练·视觉上下文·概念对齐·后验采样 贡献: 提出VicoEdit——免训练且无需反演的视觉上下文注入图像编辑方法。直接基于视觉上下文将源图转换为目标图,消除扩散反演可能导致的轨迹偏离。设计概念对齐引导的后验采样方法增强编辑一致性。 效果: 免训练方法在编辑性能上甚至超越最先进的基于训练的模型。 7. Think-in-Strokes:提出过程驱动图像生成范式 Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning 关键词: 图像生成·推理过程·交错生成·可解释AI·多步细化 贡献: 提出过程驱动图像生成范式,将合成分解为思想-动作交错推理轨迹。每次迭代包含文本规划、视觉草拟、文本反思、视觉细化四个阶段。通过密集逐步监督维持空间和语义一致性。 效果: 使生成过程变得明确、可解释且可直接监督,在多种文本到图像基准上验证有效性。 8. Chorus:提出Chorus——利用跨请求相似性加速 Beyond Few-Step Inference: Accelerating Video Diffusion Transformer Model Serving with Inter-Request Caching Reuse 关键词: 视频生成·推理加速·跨请求缓存·DiT·模型服务 贡献: 提出Chorus——利用跨请求相似性加速视频扩散Transformer服务的缓存方法。采用三阶段缓存策略:完全复用阶段、区域级跨请求缓存阶段和令牌引导注意力放大阶段。在单请求内缓存无效的4步蒸馏模型上仍有效。 效果: 在工业级4步蒸馏视频DiT模型上实现高达45%的推理加速,同时维持语义对齐质量。 9. CLEAR:提出CLEAR框架连接统一多模态模型的生 CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models 关键词: 生成理解一体化·退化图像·统一多模态·强化学习·GRPO 贡献: 提出CLEAR框架连接统一多模态模型的生成和理解能力以处理退化图像。三步渐进策略:感知退化SFT建立先生成后回答推理模式;潜在表示桥替代解码-重编码绕路;交错GRPO联合优化文本推理和视觉生成。构建MMD-Bench覆盖六个基准三级退化。 效果: 显著提升退化输入鲁棒性同时保持清晰图像性能。发现移除像素级重建监督可获得更高感知质量的中间视觉状态。 趋势观察 推理加速多路径并进 — 分数步蒸馏(1.x-Distill)、跨请求缓存(Chorus)、离线GRPO(OP-GRPO)——从模型压缩、系统优化到训练效率三个维度全面提速 免训练方法持续升温 — FDS和VicoEdit均无需额外训练即可提升Flow Matching和图像编辑质量,降低部署门槛 人工智能炼丹师 整理 | 2026-04-08 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注 -
AIGC 周末专题|2026-04-04|视频生成前沿|统一框架|长视频|物理一致性 AIGC 周末专题深度解读:视频生成与编辑前沿:从统一框架到长视频、物理一致性与高效推理 人工智能炼丹师 整理 | 2026年4月4日(周六) 覆盖时间:2026年3月29日 — 2026年4月4日 本期概述 本期 AIGC 周末专题聚焦视频生成与编辑前沿:从统一框架到长视频、物理一致性与高效推理方向,精选 6 篇代表性论文进行深度解读。 方向分布: 统一视频生成框架 — 1篇 长视频生成 — 1篇 物理一致性与几何对齐 — 1篇 高效少步训练 — 1篇 多镜头流式叙事 — 1篇 角色一致性生成 — 1篇 本期论文一览 # 论文 机构 核心贡献 arXiv ID 1 OmniWeaving Tencent Hunyuan, Zhejiang University 提出 OmniWeaving 统一视频生成框架,通过 MLLM 实现多模态理解与推理,支持文本、多图像、视频的自由组合输 2603.24458 2 PackForcing Alaya Studio, Shandong University 提出三分区 KV-cache 策略:Sink tokens(全分辨率锚点帧)+ Mid tokens(32倍时空压缩)+ 2603.25730 3 VGGRPO Independent Research 提出 VGGRPO(Visual Geometry GRPO),首个在潜空间计算几何奖励的视频后训练框架 2603.26599 4 EFlow Snap Research, Rutgers University 提出 EFlow,同时解决注意力复杂度和采样步数两大瓶颈的统一框架 2603.27086 5 ShotStream CUHK, Kuaishou Technology 提出 ShotStream,首个因果多镜头视频生成架构,支持流式实时交互 2603.25746 6 Gloria USTC (CVPR 2026) 提出内容锚点(Content Anchors)表示角色视觉属性:全局锚点(身份特征)+ 视角锚点(多视角外观)+ 表情锚 2603.29931 1. OmniWeaving:统一视频生成:自由组合与推理驱动的全能框架 论文: OmniWeaving arXiv: 2603.24458 机构: Tencent Hunyuan, Zhejiang University 1.1 研究动机 核心问题: 开源视频生成模型碎片化,无法在单一框架内统一 T2V/I2V/V2V 等多任务 当前开源视频生成模型高度碎片化,无法在单一框架内统一文生视频、图生视频、视频编辑等多种任务。商业系统(如 Seedance-2.0)遥遥领先,开源社区急需一个全能统一方案。 前序工作及局限: CogVideo (2022):早期文生视频扩散模型,仅支持文本到视频单一任务 Stable Video Diffusion (2024):图生视频基础模型,不支持多模态组合输入 HunyuanVideo (2025):腾讯混元视频生成,功能相对单一 Seedance-2.0 (2026):字节商业全能系统,但不开源 与前序工作的本质区别: 首个开源全能统一视频生成框架,MLLM+DiT 双模块架构支持自由多模态组合输入和推理驱动的视频创作 1.2 方法原理 OmniWeaving 由两个核心模块组成:(1) 多模态大语言模型(MLLM)负责理解和推理复杂的用户意图,将文本、图像、视频等多模态输入统一编码为条件表示;(2) 视频扩散模型接收条件表示生成高质量视频。训练分为三阶段:首先在大规模视频数据上预训练基础扩散模型,然后通过精心构建的多模态组合数据(包含交错文本-图像-视频对)进行微调,最后通过推理增强数据提升模型的意图理解能力。关键创新在于训练数据构建管线:自动从海量视频中提取多模态组合场景,生成需要推理才能完成的复杂视频创作任务。 1.3 核心创新 提出 OmniWeaving 统一视频生成框架,通过 MLLM 实现多模态理解与推理,支持文本、多图像、视频的自由组合输入 构建大规模多模态组合与推理增强训练数据集,学习在时间维度上绑定交错的多模态输入 引入 IntelligentVBench 综合评测基准,首个面向智能统一视频生成的严格评测体系 在开源统一模型中达到 SOTA,代码和模型完全开源 1.4 实验结果 在文生视频(T2V)、图生视频(I2V)、视频到视频(V2V)等多个任务上均达到开源 SOTA。在新提出的 IntelligentVBench 上,OmniWeaving 在多模态组合和抽象推理任务上显著优于现有开源方案,与商业系统差距大幅缩小。 1.5 关键洞察 训练数据构建管线依赖大量自动化标注,数据质量可能存在噪声。IntelligentVBench 作为自家提出的评测基准,客观性有待社区验证。与 Seedance-2.0 等商业系统相比仍有差距,但开源意义重大。 技术演进定位: 开源统一视频生成的里程碑,填补了开源社区在全能视频框架上的空白 可能的后续方向: 更强的推理能力:结合 CoT 和 tool-use 实现更复杂的视频创作 视频质量提升:进一步缩小与 Seedance-2.0 等商业系统的差距 社区生态建设:作为开源基座支持下游任务微调和插件开发 2. PackForcing:短视频训练即可生成连贯2分钟长视频 论文: PackForcing arXiv: 2603.25730 机构: Alaya Studio, Shandong University 2.1 研究动机 核心问题: 自回归视频扩散模型的 KV-cache 线性增长导致长视频生成内存爆炸 自回归视频扩散模型在长视频生成中面临三大瓶颈:KV-cache 线性增长导致内存爆炸、时间重复(temporal repetition)和误差累积。现有方法无法在有限 GPU 内存下生成超过30秒的连贯视频。 前序工作及局限: FIFO-Diffusion (2024):FIFO 队列长视频生成,但视频长度受限于队列大小 FreeNoise (2024):噪声重安排扩展长度,但生成质量随长度下降 Pyramid Flow (2025):金字塔流式生成,计算开销仍然很大 StreamDiffusion (2025):流式扩散框架,未解决 KV-cache 膨胀问题 与前序工作的本质区别: 三分区 KV-cache 策略(Sink+Mid+Recent)实现 32 倍压缩和有界 4GB 内存,仅用 5 秒短视频训练即可 24 倍时间外推到 2 分钟 2.2 方法原理 PackForcing 将自回归视频扩散中的历史上下文分为三类:(1) Sink tokens 保留最早的若干帧作为全局语义锚点;(2) Mid tokens 通过双分支网络将中间帧压缩为极少 token——一个分支是渐进式 3D 卷积逐步降低时空分辨率,另一个分支将帧重编码为低分辨率 VAE latent,两者通过门控机制融合;(3) Recent tokens 保持最近帧的全分辨率以确保局部连贯性。当 Mid tokens 过多时,动态 top-k 机制选择最重要的 token 保留,同时通过连续 RoPE 重编码消除位置间隙。整个框架可在仅 5 秒短视频片段上训练,推理时自回归扩展到 2 分钟。 2.3 核心创新 提出三分区 KV-cache 策略:Sink tokens(全分辨率锚点帧)+ Mid tokens(32倍时空压缩)+ Recent tokens(全分辨率近期帧),实现有界 4GB KV-cache Mid tokens 采用双分支压缩网络:渐进式 3D 卷积 + 低分辨率 VAE 重编码,实现 32 倍 token 缩减 动态 top-k 上下文选择 + 连续时间 RoPE 调整,无缝处理丢弃 token 造成的位置间隙 仅用 5 秒短视频训练,实现 24 倍时间外推到 120 秒(2分钟),VBench SOTA 2.4 实验结果 在单个 H200 GPU 上生成 832x480/16FPS 的 2 分钟连贯视频,KV-cache 仅占 4GB。VBench 时间一致性达 26.07,动态度 56.25,均为 SOTA。实现 24 倍时间外推(5秒→120秒)。 2.5 关键洞察 双分支 Mid token 压缩引入额外计算开销,需要验证其在更高分辨率(1080p+)下的可扩展性。目前仅在 16FPS 下验证,更高帧率场景待测试。分区策略中的超参数(Sink/Mid/Recent 比例)需要仔细调节。 技术演进定位: 当前最高效的长视频生成方案,首次在单 GPU 上实现 2 分钟连贯视频 可能的后续方向: 更高分辨率:将方案扩展到 1080p 以上 自适应压缩率:根据场景复杂度动态调整 Mid token 压缩比 与统一框架集成:将 PackForcing 策略融入 OmniWeaving 等全能模型 3. VGGRPO:4D潜空间奖励驱动的世界一致性视频生成 论文: VGGRPO arXiv: 2603.26599 机构: Independent Research 3.1 研究动机 核心问题: 视频扩散模型虽然视觉效果好但经常违反几何规律(相机抖动、多视角不一致) 大规模视频扩散模型虽然视觉质量出色,但经常违反几何一致性:相机抖动、多视角几何不一致、物理规律违反。现有方法要么修改架构(损害泛化能力),要么在 RGB 空间计算几何奖励(昂贵且仅限静态场景)。需要一种不修改架构、计算高效且支持动态场景的方案。 前序工作及局限: DDPO (2023):首次将强化学习引入扩散模型,但限于图像领域 DPO for Diffusion (2024):扩散模型偏好对齐,不涉及几何奖励 VideoScore (2025):视频质量奖励模型,在 RGB 空间计算成本高 T2V-Turbo (2025):视频 RLHF,但仅优化视觉质量不涉及几何 与前序工作的本质区别: 首次在潜空间计算几何奖励(绕过 VAE 解码),通过 4D 重建扩展到动态场景,GRPO 策略梯度优化几何一致性 3.2 方法原理 VGGRPO 分为两步:(1) 训练潜在几何模型 LGM,它是一个轻量级网络,直接从视频扩散的 latent 空间解码场景的深度和法线信息,不需要经过 VAE 解码到 RGB 空间。LGM 通过冻结 VAE encoder-decoder 对和几何基础模型(如 DPT/Metric3D)蒸馏训练。(2) 使用 Group Relative Policy Optimization(GRPO)进行视频扩散模型的后训练。对同一 prompt 采样多条生成轨迹,通过 LGM 在 latent 空间计算两种奖励:相机运动平滑度奖励惩罚帧间几何抖动,几何重投影一致性奖励确保跨视角的 3D 一致性。GRPO 根据奖励差异更新策略梯度。4D 扩展通过时序多帧几何重建实现。 3.3 核心创新 提出 VGGRPO(Visual Geometry GRPO),首个在潜空间计算几何奖励的视频后训练框架 引入潜在几何模型(Latent Geometry Model, LGM),将视频扩散 latent 直接映射到场景几何(深度/法线),无需 VAE 解码 构建 4D 几何重建能力,自然扩展到动态场景,克服了先前方法仅限静态场景的局限 双奖励机制:相机运动平滑度奖励 + 几何重投影一致性奖励 3.4 实验结果 在静态场景(RealEstate10K)和动态场景(WebVid)上均显著提升几何一致性。相机稳定性提升 23%,几何重投影误差下降 31%。推理成本与基线相同(LGM 仅训练时使用),避免了 VAE 解码的计算开销。 3.5 关键洞察 LGM 的训练质量直接影响奖励信号的准确性,如果几何基础模型本身有偏差会传播到视频模型。当前奖励仅考虑几何一致性,未涉及物理动力学(如碰撞、重力)。GRPO 的多轨迹采样增加了训练成本。 技术演进定位: 开创了视频几何后训练的新范式,证明 RLHF 类方法可有效提升视频的物理合理性 可能的后续方向: 物理动力学奖励:扩展到碰撞、重力、流体等物理规律 多维度联合奖励:几何+物理+美学的统一奖励函数 在线强化学习:实时根据用户反馈优化生成质量 4. EFlow:高效少步视频生成器:从头训练的突破 论文: EFlow arXiv: 2603.27086 机构: Snap Research, Rutgers University 4.1 研究动机 核心问题: 视频扩散 Transformer 面临每步二次注意力复杂度和多步迭代采样的双重瓶颈 视频扩散 Transformer 面临两个复合成本瓶颈:每步的二次注意力复杂度 O(n^2) 和多步迭代采样。现有加速方法通常只解决其中一个——蒸馏减少步数但不降低单步成本,高效注意力降低单步成本但不减少步数。需要同时解决两个瓶颈的统一方案。 前序工作及局限: Consistency Models (2023):一步生成模型,但仅限图像且质量有限 Flow Matching (2023):条件流匹配框架,需要多步采样 Rectified Flow (2024):直线化流加速采样,但不降低单步成本 InstaFlow (2024):一步文生图,但无法扩展到视频 与前序工作的本质区别: 同时解决注意力复杂度(Gated L-G Attention + token dropping)和采样步数(solution-flow + MVA 正则化),从头训练无需教师模型 4.2 方法原理 EFlow 基于 solution-flow 目标,学习将时刻 t 的噪声状态直接映射到时刻 s(跨越多个扩散步)。核心创新有三:(1) Gated Local-Global Attention 将注意力分为局部窗口注意力和全局稀疏注意力两部分,通过门控机制融合,关键是设计为对 random token dropping 高度稳定——训练时随机丢弃 50-70% 的 token 而不影响质量;(2) Path-Drop Guided Training 在少步训练中用条件路径和无条件路径的随机丢弃替代传统 CFG(后者需要两次前向传播),将引导成本降为零;(3) Mean-Velocity Additivity 正则化器约束不同步数下的速度场之和等于总位移,确保 1-4 步生成的一致性。从头训练流程支持直接训练少步模型,无需先训练多步模型再蒸馏。 4.3 核心创新 提出 EFlow,同时解决注意力复杂度和采样步数两大瓶颈的统一框架 Gated Local-Global Attention:可丢弃 token 的混合注意力块,在激进随机 token 丢弃下保持稳定 Path-Drop Guided Training:用计算廉价的弱路径替代昂贵的 classifier-free guidance 目标 Mean-Velocity Additivity 正则化器:确保极低步数下的生成保真度 从头训练达到 45.3 倍推理加速,2.5 倍训练吞吐量提升 4.4 实验结果 在 Kinetics-600 和大规模 T2V 数据集上验证。4步生成质量与标准 50 步模型相当。训练吞吐量比标准 solution-flow 提升 2.5 倍。推理延迟降低 45.3 倍。生成质量 FVD 与多步基线竞争。 4.5 关键洞察 随机 token dropping 在极端比例下可能影响细节质量。Path-Drop Guided 是否在所有场景下都能替代 CFG 有待更多验证。从头训练的计算量仍然很大(虽然吞吐量提升了2.5倍)。目前主要在较短视频上验证。 技术演进定位: 首个同时解决两大瓶颈的统一加速框架,45.3 倍推理加速具有部署实用价值 可能的后续方向: 与视频编解码器融合:端到端优化编码-生成-解码管线 硬件适配:针对特定 GPU/NPU 架构定制注意力模式 实时生成:结合 PackForcing 等策略实现长视频实时生成 5. ShotStream:流式多镜头视频生成:实时交互式叙事 论文: ShotStream arXiv: 2603.25746 机构: CUHK, Kuaishou Technology 5.1 研究动机 核心问题: 多镜头视频生成的双向架构导致交互性差、延迟高,用户无法实时参与创作 多镜头视频生成是长叙事视频的关键,但当前双向扩散架构(如全序列并行生成)存在交互性差和延迟高的问题——用户无法在生成过程中动态调整叙事方向,且需要等待整个序列生成完成才能看到结果。 前序工作及局限: MovieFactory (2024):多镜头电影生成,但一次性生成全序列不可交互 VideoDirectorGPT (2024):LLM 驱动视频导演,规划与生成分离 Vlogger (2025):长视频博客生成,不支持流式输出 Kling (2025):快手视频生成模型,单镜头生成 与前序工作的本质区别: 首个因果流式多镜头架构,通过双缓存记忆和两阶段蒸馏实现 16 FPS 实时交互式叙事 5.2 方法原理 ShotStream 的流程分为训练和推理两阶段。训练阶段:(1) 将预训练 T2V 模型微调为双向 next-shot 生成器,学习根据前序镜头和文本提示生成下一个镜头;(2) 通过分布匹配蒸馏将双向教师蒸馏为因果学生模型。为解决因果自回归的两大挑战:(a) 镜头间一致性——引入全局上下文缓存(Global Context Cache),存储所有前序镜头的条件帧作为长程记忆;(b) 误差累积——设计两阶段蒸馏策略:第一阶段在真实历史上进行镜头内自强迫训练,第二阶段在自生成的历史上进行镜头间自强迫训练,逐步暴露给模型自身的生成误差。RoPE 不连续性指示器通过在全局和局部缓存之间插入位置编码跳跃来消除歧义。 5.3 核心创新 提出 ShotStream,首个因果多镜头视频生成架构,支持流式实时交互 将多镜头生成重构为 next-shot generation:基于历史镜头上下文生成下一个镜头 双缓存记忆机制:全局上下文缓存(镜头间一致性)+ 局部上下文缓存(镜头内一致性),RoPE 不连续性指示器区分两者 两阶段蒸馏策略:镜头内自强迫 → 镜头间自强迫,有效弥合训练-测试差距 单 GPU 达到 16 FPS 实时生成 5.4 实验结果 在 MovieGen 和 StoryBench 上评测。亚秒级延迟,单 GPU 16 FPS。多镜头连贯性指标(FCD、IC-LPIPS)与双向模型持平甚至更优。支持用户中途修改叙事提示,实现真正的交互式叙事。 5.5 关键洞察 因果架构天然信息量少于双向架构,长程一致性在超长叙事(10+镜头)下可能衰减。蒸馏质量依赖双向教师模型。全局上下文缓存随镜头数增长可能成为新的内存瓶颈。 技术演进定位: 开创了流式交互式视频叙事的新范式,是 AI 视频工具从离线走向实时的关键一步 可能的后续方向: 多角色交互:支持多角色多视角的复杂叙事 与 LLM 集成:用大语言模型实时规划叙事脉络 商业化部署:面向短视频平台和游戏行业的实时视频生成 6. Gloria:基于内容锚点的长时角色一致性视频生成 论文: Gloria arXiv: 2603.29931 机构: USTC (CVPR 2026) 6.1 研究动机 核心问题: 长时间角色视频生成中身份漂移严重,多视角和表情一致性难以保持 数字角色是现代媒体的核心,但生成长时间、多视角一致且表情丰富的角色视频仍是开放挑战。现有方法面临两类问题:要么参考信息不足导致身份漂移,要么使用非角色中心的记忆信息导致一致性次优。 前序工作及局限: IP-Adapter (2023):图像提示适配器,角色信息通过单图注入,长视频中易漂移 AnimateAnyone (2024):可控人物动画,但一致性限于短视频 MagicAnimate (2024):人物动画,依赖骨骼驱动不够灵活 ID-Animator (2025):身份保持动画,但多视角一致性不足 与前序工作的本质区别: 通过三类内容锚点(全局/视角/表情)提供稳定参考,超集锚定防止复制粘贴,实现 10+ 分钟级别的角色一致性 6.2 方法原理 Gloria 将角色视频生成类比为由外向内观察的场景。核心是通过一组紧凑的锚帧来描述角色的视觉属性:(1) 全局锚点——一个标准正面参考图,提供身份基准;(2) 视角锚点——来自不同视角的参考帧,覆盖角色的多视角外观;(3) 表情锚点——包含不同表情的帧,编码角色的表情动态范围。训练时,通过超集内容锚定策略——提供比目标片段更多的锚点信息(包括训练剪辑之外的帧),迫使模型学习从锚点中提取有用信息而非简单复制。同时使用 RoPE 位置偏移作为弱条件区分不同锚点帧,让模型知道哪些帧来自哪个视角。数据管线方面,从海量视频中自动检测角色区域、跟踪身份、提取关键帧作为锚点。 6.3 核心创新 提出内容锚点(Content Anchors)表示角色视觉属性:全局锚点(身份特征)+ 视角锚点(多视角外观)+ 表情锚点(表情动态) 超集内容锚定(Superset Content Anchoring):提供训练内和训练外的片段提示,防止模型简单复制粘贴 RoPE 作为弱条件:编码位置偏移来区分多个锚点帧,避免多参考冲突 可扩展的锚点提取管线:从海量视频中自动提取角色锚点 生成超过 10 分钟的一致性角色视频(CVPR 2026 接收) 6.4 实验结果 生成超过 10 分钟的长视频,保持角色身份、多视角外观和表情一致性。在人类评估中,ID 一致性和外观多样性均超过 SOTA 方法(包括 IP-Adapter、AnimateAnyone 等)。被 CVPR 2026 主会议接收。 6.5 关键洞察 锚点提取管线依赖角色检测和跟踪的准确性,遮挡严重的场景可能失败。超集锚定策略增加了训练复杂度。对非人物角色(如动漫、卡通角色)的泛化能力需要更多验证。10 分钟的一致性主要在受控场景下验证。 技术演进定位: 角色一致性视频生成的新标杆,锚点机制为长视频角色保持提供了有效范式(CVPR 2026) 可能的后续方向: 多角色一致性:同时保持多个角色的身份一致性 跨域角色:从真人扩展到动漫、卡通、3D 虚拟人等 实时角色创作:结合 ShotStream 等流式架构实现实时角色视频 横向对比与技术脉络总结 架构与任务对比 论文 核心架构 主要任务 关键创新 输入形式 OmniWeaving MLLM + DiT T2V/I2V/V2V 统一 推理驱动+组合数据 文本+多图+视频自由组合 PackForcing 自回归 DiT 长视频生成 三分区 KV-cache 文本 → 2分钟视频 VGGRPO DiT + LGM 几何一致性后训练 4D 潜空间几何奖励 文本 → 几何一致视频 EFlow Gated L-G DiT 高效少步生成 token dropping + MVA 文本 → 4步高质量视频 ShotStream 因果 DiT 流式多镜头叙事 双缓存+两阶段蒸馏 逐镜头文本 → 实时视频 Gloria DiT + 锚点 角色一致性生成 三类内容锚点 角色参考图 → 10min视频 训练范式与效率对比 论文 训练范式 外部监督 推理效率 核心瓶颈解决 OmniWeaving 三阶段渐进训练 组合数据+推理增强 标准 DiT 速度 任务碎片化 PackForcing 短视频训练+时间外推 无(5秒视频) 单 GPU 2分钟 内存爆炸(KV-cache→4GB) VGGRPO GRPO 后训练 LGM 伪标签 与基线相同 几何违反(相机稳定↑23%) EFlow Solution-flow 从头训练 无需教师模型 45.3× 加速 注意力O(n²)+多步采样 ShotStream 两阶段蒸馏 双向教师蒸馏 16 FPS 实时 延迟高+不可交互 Gloria 端到端锚点训练 自动锚点提取 标准 DiT 速度 长时身份漂移 核心技术趋势 趋势 1:视频生成从碎片化走向统一 OmniWeaving 证明了 MLLM+DiT 架构可以在单一框架内处理 T2V/I2V/V2V 等多种视频任务。推理驱动的数据构建策略使模型能理解复杂的多模态组合意图,这预示着未来的视频 AI 将是全能型的。 趋势 2:长视频生成突破内存瓶颈 PackForcing 的三分区 KV-cache 策略实现了 24 倍时间外推(5秒→2分钟),Gloria 的内容锚点将角色一致性推到 10 分钟级。两者共同表明长视频生成的关键不在于生成能力本身,而在于上下文管理和信息压缩。 趋势 3:GRPO 后训练成为视频质量提升的新范式 VGGRPO 将 GRPO 引入视频几何一致性优化,在 latent 空间计算奖励避免了昂贵的 RGB 解码。这延续了 LLM 领域 RLHF/DPO 的成功经验,后训练对齐正成为视频扩散模型质量提升的关键杠杆。 趋势 4:少步生成从蒸馏走向从头训练 EFlow 的 Gated L-G Attention + token dropping + MVA 正则化实现了 45.3 倍推理加速,且无需教师模型。这种从头训练少步模型的路线比蒸馏更灵活,可能成为效率优化的主流方案。 趋势 5:交互式实时生成开启视频创作新时代 ShotStream 的因果流式架构达到 16 FPS 实时生成,用户可以边看边改叙事方向。这标志着视频 AI 从「离线工具」向「实时合作者」的转变,对短视频平台和游戏行业有重要意义。 技术路线全景图 视频生成与编辑技术路线 ├── 统一框架 │ └── MLLM + DiT 双模块 → OmniWeaving(多模态组合+推理驱动) ├── 长视频生成 │ ├── KV-cache 压缩 → PackForcing(三分区策略,24x 外推) │ └── 角色一致性 → Gloria(三类内容锚点,10min 级别) ├── 质量对齐 │ └── 后训练 GRPO → VGGRPO(4D 潜空间几何奖励) ├── 推理效率 │ └── 从头训练少步 → EFlow(45.3x 加速,无需蒸馏) └── 交互式生成 └── 因果流式架构 → ShotStream(16 FPS 实时多镜头叙事) 总结与展望 本期专题的 6 篇论文共同描绘了视频生成与编辑领域的前沿全景图。从统一框架(OmniWeaving)到长视频突破(PackForcing/Gloria),从物理对齐(VGGRPO)到效率革命(EFlow),再到交互式创作(ShotStream),视频生成正在从技术验证走向实际可用。几个值得关注的未来方向: 统一+长视频:将 PackForcing 的 KV-cache 策略融入 OmniWeaving 等全能框架 多维度后训练:将几何、物理、美学奖励统一到一个 GRPO 框架中 实时+角色:将 Gloria 的锚点机制与 ShotStream 的流式架构结合,实现实时角色叙事 端到端效率:将 EFlow 的少步生成与 PackForcing 的内存优化联合使用 人工智能炼丹师 整理 | 数据来源:arXiv 2026年3月29日 — 2026年4月4日 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注