搜索到
2
篇与
图像生成
的结果
-
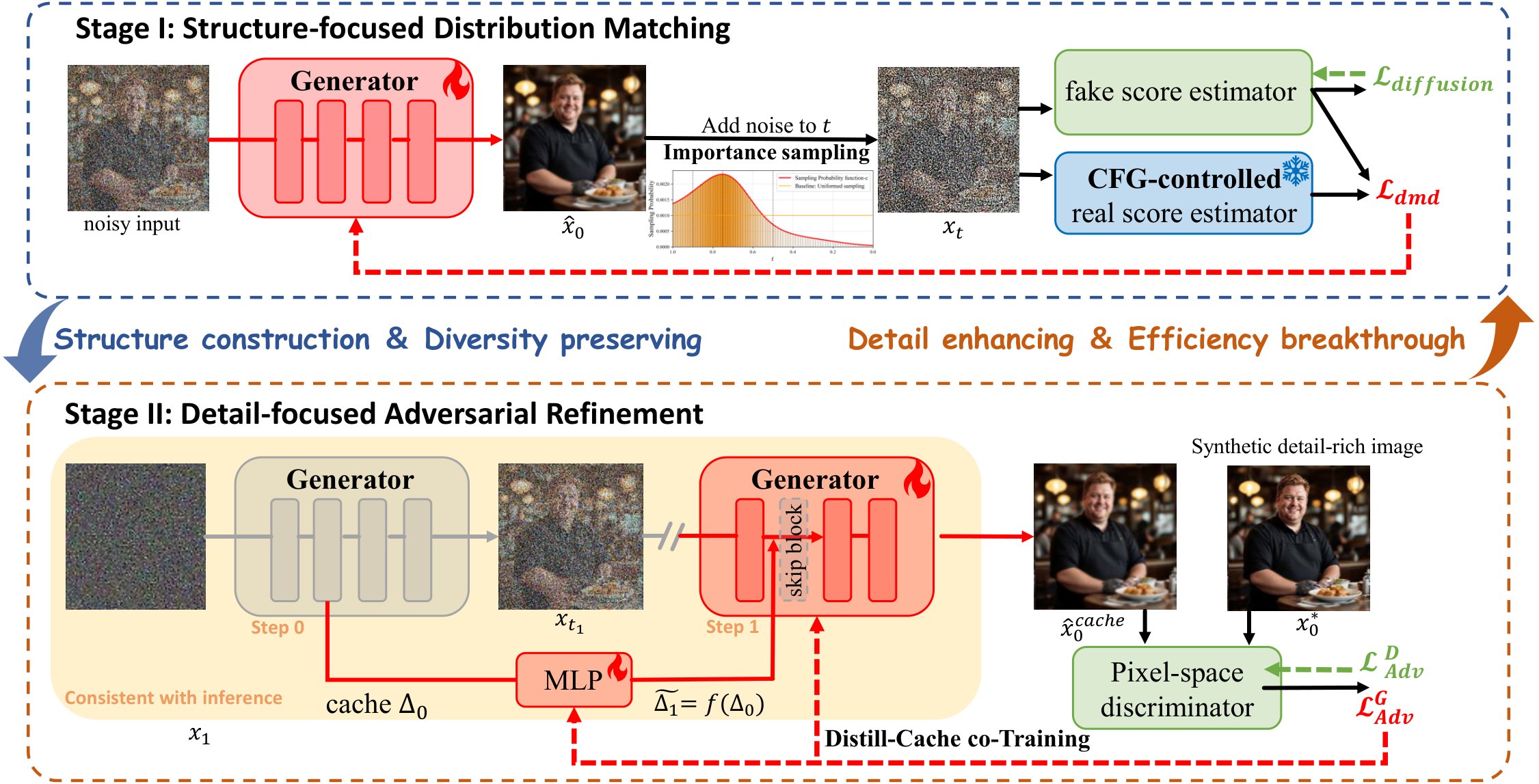
 AIGC 每日速读|2026-04-08|分数步蒸馏(1.x-Distill)实现33x推理加速 今日核心看点 分数步蒸馏(1.x-Distill) 空间编辑基准(SpatialEdit) 通用音频生成(OmniSonic) 视频DiT缓存(Chorus) 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成推理加速: 3篇 (1.x-Distill, Chorus, OP-GRPO) 图像编辑与评测: 3篇 (SpatialEdit, VicoEdit, Think-in-Strokes) 音频生成: 1篇 (OmniSonic, CVPR 2026) 视频生成: 1篇 (Vanast, CVPR 2026) 生成理解一体化: 1篇 (退化图像理解CLEAR) 含 3 篇 CVPR 2026 接收论文 重点论文深度解读 1. 1.x-Distill 首个分数步蒸馏框架——打破整数步约束实现33倍加速 | Unknown | arXiv:2604.04018 关键词: 蒸馏加速, 分布匹配蒸馏, 分数步推理, CFG控制, 块级缓存, SD3 研究动机 核心问题: 扩散模型迭代去噪计算量大,分布匹配蒸馏在极端少步时多样性崩溃 扩散模型生成高质量图像,但迭代去噪计算量大。分布匹配蒸馏(DMD)是少步蒸馏的有前途路径,但在 2 步或更少时遭遇多样性崩溃和保真度下降。作者发现两个核心问题:(1) 教师模型 CFG 在高噪声时域驱使学生过早坍缩到少数主导模式;(2) 极端少步蒸馏下,单一目标函数无法同时兼顾全局结构和细节。 前序工作及局限: DMD/DMD2:分布匹配蒸馏的先驱,但 2 步以下多样性严重崩溃 TDM/SenseFlow:无图像训练蒸馏,但未发现 CFG 导致模式坍缩的根因 DDIM/一致性模型:少步采样加速,但受限于整数步约束 DeepCache/Learning-to-Cache:DiT 块级缓存加速,但未与蒸馏训练过程整合 与前序工作的本质区别: 首次将分布匹配蒸馏与块级缓存统一,发现并解决 CFG 导致模式崩溃的根因,提出分数步蒸馏打破整数步约束 方法原理 1.x-Distill 框架包含三个核心创新: (1) 时间步感知 CFG 控制:在高噪声时域(t>alpha)禁用教师 CFG,使用纯条件分数引导学生覆盖更多模式;低噪声时域保留 CFG 保证细节质量。alpha=0.94 为最优阈值。 (2) 分阶段聚焦蒸馏(SFD):Stage I 结构导向分布匹配,采用重要性采样偏向 t=0.75 附近结构信息丰富的时域,避免低噪声区的过度纹理扰动;Stage II 细节导向对抗精炼,在学生的少步推理路径上生成样本,使用冻结 ConvNeXt 特征提取器 + 可训练分类头作为判别器,无需外部图像数据集。 (3) 蒸馏-缓存协同训练(DCT):观察到早期 DiT 块跨步骤时间冗余大,缓存块贡献 Delta_t = O_m - I_n,第二步跳过 6-8 个块。引入轻量级残差 MLP 预测修正缓存误差。Stage II 自然支持缓存训练,对抗损失直接监督缓存加速推理。 核心创新 首次提出分数步蒸馏概念,打破先前少步方法的整数步约束 发现并解决 DMD 中教师 CFG 导致模式崩溃的关键问题 提出分阶段聚焦蒸馏(SFD):结构导向分布匹配 + 细节导向对抗精炼 设计蒸馏-缓存协同训练(DCT),将块级缓存融入蒸馏流程 在 SD3-Medium 和 SD3.5-Large 上实现 1.67/1.74 有效 NFE,最高 33 倍加速 实验结果 SD3-Medium (24 DiT blocks): SFD 4步:FID 14.13(最佳),HPSv2 32.53,ImageReward 1.12 1.x-Distill-slow (NFE=1.75):FID 15.79,HPSv2 32.26,超越所有 2 步和大部分 4 步基线 1.x-Distill-fast (NFE=1.67):FID 16.72,HPSv2 31.69,比原始 28x2 采样加速 33 倍 SD3.5-Large (38 DiT blocks): SFD 4步:HPSv2 32.90,ImageReward 1.20(最佳) 1.x-Distill (NFE=1.74):FID 22.05,HPSv2 32.01,超越 TDM 2步基线 3.5+ HPSv2 DPG-Bench:蒸馏模型在复杂提示下总分超越多步教师模型 多样性(LPIPS):显著高于 Flash 和 TDM 等基线 用户研究:20 位评估者在 3200 提示上明确偏好 1.x-Distill 图表详解 方法核心:块级缓存设计 左图展示各 DiT 块的跨步复用误差(早期块冗余大),右图展示缓存机制:第一步完整计算并缓存块贡献,第二步跳过并用 MLP 修正恢复 CFG 在蒸馏中的作用分析 高噪声时域强 CFG 驱使学生过早模式坍缩;1.x-Distill 在高噪声区禁用 CFG,低噪声区保留 CFG 定性对比结果 SD3-Medium 上多种方法的生成质量对比,1.x-Distill 在 1.67 NFE 下仍保持连贯结构和丰富细节 批判性点评 新颖性: 首次提出分数步蒸馏概念,打破整数步约束。时域感知 CFG 控制、分阶段聚焦蒸馏、蒸馏-缓存协同训练三个创新点紧密配合。 可复现性: 代码和权重将公开。训练仅需 JourneyDB 提示数据,无需外部图像数据集。但具体训练超参数和缓存块选择策略的细节需参考附录。 影响力: 高——开辟 1.x 步蒸馏新范式,33x 加速具有重大实用价值。但目前仅验证 SD3 系列,Flux/SDXL 等架构的通用性有待考验。 深度点评: 首创分数步蒸馏 — 1.x-Distill 首次突破整数步约束,SD3 上仅 1.67 NFE 实现 33x 加速,FID 和人类偏好全面领先 推理加速三路并进 — 蒸馏(1.x-Distill) + 系统缓存(Chorus) + 训练效率(OP-GRPO),三维度全面提速 免训练方法降低门槛 — FDS(Flow Matching) 和 VicoEdit(图像编辑) 无需额外训练即可大幅提升质量 技术演进定位: 分布匹配蒸馏领域的重要推进,开辟 1.x 步生成新范式 可能的后续方向: 推广到 Flux/SDXL/视频扩散模型 自适应缓存块选择 与推理系统优化结合 其余论文速览 1. SpatialEdit:提出首个专门评估细粒度空间编辑的基准Sp SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing 关键词: 图像编辑·空间变换·几何保真度·合成数据·基准评测 贡献: 提出首个专门评估细粒度空间编辑的基准SpatialEdit-Bench,通过联合度量感知合理性和几何保真度系统评估空间操作能力。构建500K合成训练数据集SpatialEdit-500k,使用可控Blender管线生成精确的相机轨迹和物体变换真值。基于此训练16B参数的SpatialEdit-16B基线模型。 效果: SpatialEdit-16B在通用编辑任务中取得有竞争力的性能,同时在空间操作任务上大幅超越现有方法。 2. FDS:提出流分歧采样器FDS Training-Free Refinement of Flow Matching with Divergence-based Sampling 关键词: Flow Matching·采样优化·无训练·散度引导·即插即用 贡献: 提出流分歧采样器FDS,无需训练即可提升Flow Matching模型质量。核心发现:边缘速度场的散度可量化采样误导程度,利用该信号在每个求解步骤前将中间状态引导至歧义更小的区域。 效果: 作为即插即用框架,FDS兼容标准求解器和现有Flow模型,在文本到图像合成和逆问题等多种任务中一致提升保真度。 3. OmniSonic:提出通用整体音频生成任务UniHAGen OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text 关键词: 音频生成·视频到音频·Flow Matching·MoE·CVPR 2026 贡献: 提出通用整体音频生成任务UniHAGen,首次统一生成屏幕内环境音、屏幕外环境音和人类语音。设计TriAttn-DiT架构,通过三路交叉注意力同时处理三种音频条件,配合MoE门控机制自适应平衡。构建UniHAGen-Bench基准覆盖三种代表性场景。CVPR 2026。 效果: 在客观指标和人类评估上均一致超越现有最先进方法,建立了通用整体音频生成的强基线。 4. OP-GRPO:首个专为Flow-Matching模型设 OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models 关键词: GRPO·Flow Matching·离线策略·训练效率·后训练优化 贡献: 首个专为Flow-Matching模型设计的离线GRPO框架。主动选择高质量轨迹并自适应加入回放缓冲区重复使用;提出序列级重要性采样修正减轻分布偏移;发现并解决晚期去噪步骤的病态离线比率问题。 效果: 仅用平均34.2%的训练步骤即达到Flow-GRPO同等或更优性能,在图像和视频生成基准上均验证有效。 5. Vanast:提出统一框架从单张人像、服装图和姿态视频 Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision 关键词: 虚拟试穿·视频生成·扩散Transformer·人体动画·CVPR 2026 贡献: 提出统一框架从单张人像、服装图和姿态视频一步生成换装动画视频。构建大规模三元组监督数据,引入视频扩散Transformer的双模块架构稳定训练,支持零样本服装插值。CVPR 2026。 效果: 克服传统两阶段方案的身份漂移和服装扭曲问题,实现高保真、身份一致的服装迁移动画。 6. VicoEdit:提出VicoEdit——免训练且无需反演 Training-Free Image Editing with Visual Context Integration and Concept Alignment 关键词: 图像编辑·免训练·视觉上下文·概念对齐·后验采样 贡献: 提出VicoEdit——免训练且无需反演的视觉上下文注入图像编辑方法。直接基于视觉上下文将源图转换为目标图,消除扩散反演可能导致的轨迹偏离。设计概念对齐引导的后验采样方法增强编辑一致性。 效果: 免训练方法在编辑性能上甚至超越最先进的基于训练的模型。 7. Think-in-Strokes:提出过程驱动图像生成范式 Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning 关键词: 图像生成·推理过程·交错生成·可解释AI·多步细化 贡献: 提出过程驱动图像生成范式,将合成分解为思想-动作交错推理轨迹。每次迭代包含文本规划、视觉草拟、文本反思、视觉细化四个阶段。通过密集逐步监督维持空间和语义一致性。 效果: 使生成过程变得明确、可解释且可直接监督,在多种文本到图像基准上验证有效性。 8. Chorus:提出Chorus——利用跨请求相似性加速 Beyond Few-Step Inference: Accelerating Video Diffusion Transformer Model Serving with Inter-Request Caching Reuse 关键词: 视频生成·推理加速·跨请求缓存·DiT·模型服务 贡献: 提出Chorus——利用跨请求相似性加速视频扩散Transformer服务的缓存方法。采用三阶段缓存策略:完全复用阶段、区域级跨请求缓存阶段和令牌引导注意力放大阶段。在单请求内缓存无效的4步蒸馏模型上仍有效。 效果: 在工业级4步蒸馏视频DiT模型上实现高达45%的推理加速,同时维持语义对齐质量。 9. CLEAR:提出CLEAR框架连接统一多模态模型的生 CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models 关键词: 生成理解一体化·退化图像·统一多模态·强化学习·GRPO 贡献: 提出CLEAR框架连接统一多模态模型的生成和理解能力以处理退化图像。三步渐进策略:感知退化SFT建立先生成后回答推理模式;潜在表示桥替代解码-重编码绕路;交错GRPO联合优化文本推理和视觉生成。构建MMD-Bench覆盖六个基准三级退化。 效果: 显著提升退化输入鲁棒性同时保持清晰图像性能。发现移除像素级重建监督可获得更高感知质量的中间视觉状态。 趋势观察 推理加速多路径并进 — 分数步蒸馏(1.x-Distill)、跨请求缓存(Chorus)、离线GRPO(OP-GRPO)——从模型压缩、系统优化到训练效率三个维度全面提速 免训练方法持续升温 — FDS和VicoEdit均无需额外训练即可提升Flow Matching和图像编辑质量,降低部署门槛 人工智能炼丹师 整理 | 2026-04-08 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
AIGC 每日速读|2026-04-08|分数步蒸馏(1.x-Distill)实现33x推理加速 今日核心看点 分数步蒸馏(1.x-Distill) 空间编辑基准(SpatialEdit) 通用音频生成(OmniSonic) 视频DiT缓存(Chorus) 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成推理加速: 3篇 (1.x-Distill, Chorus, OP-GRPO) 图像编辑与评测: 3篇 (SpatialEdit, VicoEdit, Think-in-Strokes) 音频生成: 1篇 (OmniSonic, CVPR 2026) 视频生成: 1篇 (Vanast, CVPR 2026) 生成理解一体化: 1篇 (退化图像理解CLEAR) 含 3 篇 CVPR 2026 接收论文 重点论文深度解读 1. 1.x-Distill 首个分数步蒸馏框架——打破整数步约束实现33倍加速 | Unknown | arXiv:2604.04018 关键词: 蒸馏加速, 分布匹配蒸馏, 分数步推理, CFG控制, 块级缓存, SD3 研究动机 核心问题: 扩散模型迭代去噪计算量大,分布匹配蒸馏在极端少步时多样性崩溃 扩散模型生成高质量图像,但迭代去噪计算量大。分布匹配蒸馏(DMD)是少步蒸馏的有前途路径,但在 2 步或更少时遭遇多样性崩溃和保真度下降。作者发现两个核心问题:(1) 教师模型 CFG 在高噪声时域驱使学生过早坍缩到少数主导模式;(2) 极端少步蒸馏下,单一目标函数无法同时兼顾全局结构和细节。 前序工作及局限: DMD/DMD2:分布匹配蒸馏的先驱,但 2 步以下多样性严重崩溃 TDM/SenseFlow:无图像训练蒸馏,但未发现 CFG 导致模式坍缩的根因 DDIM/一致性模型:少步采样加速,但受限于整数步约束 DeepCache/Learning-to-Cache:DiT 块级缓存加速,但未与蒸馏训练过程整合 与前序工作的本质区别: 首次将分布匹配蒸馏与块级缓存统一,发现并解决 CFG 导致模式崩溃的根因,提出分数步蒸馏打破整数步约束 方法原理 1.x-Distill 框架包含三个核心创新: (1) 时间步感知 CFG 控制:在高噪声时域(t>alpha)禁用教师 CFG,使用纯条件分数引导学生覆盖更多模式;低噪声时域保留 CFG 保证细节质量。alpha=0.94 为最优阈值。 (2) 分阶段聚焦蒸馏(SFD):Stage I 结构导向分布匹配,采用重要性采样偏向 t=0.75 附近结构信息丰富的时域,避免低噪声区的过度纹理扰动;Stage II 细节导向对抗精炼,在学生的少步推理路径上生成样本,使用冻结 ConvNeXt 特征提取器 + 可训练分类头作为判别器,无需外部图像数据集。 (3) 蒸馏-缓存协同训练(DCT):观察到早期 DiT 块跨步骤时间冗余大,缓存块贡献 Delta_t = O_m - I_n,第二步跳过 6-8 个块。引入轻量级残差 MLP 预测修正缓存误差。Stage II 自然支持缓存训练,对抗损失直接监督缓存加速推理。 核心创新 首次提出分数步蒸馏概念,打破先前少步方法的整数步约束 发现并解决 DMD 中教师 CFG 导致模式崩溃的关键问题 提出分阶段聚焦蒸馏(SFD):结构导向分布匹配 + 细节导向对抗精炼 设计蒸馏-缓存协同训练(DCT),将块级缓存融入蒸馏流程 在 SD3-Medium 和 SD3.5-Large 上实现 1.67/1.74 有效 NFE,最高 33 倍加速 实验结果 SD3-Medium (24 DiT blocks): SFD 4步:FID 14.13(最佳),HPSv2 32.53,ImageReward 1.12 1.x-Distill-slow (NFE=1.75):FID 15.79,HPSv2 32.26,超越所有 2 步和大部分 4 步基线 1.x-Distill-fast (NFE=1.67):FID 16.72,HPSv2 31.69,比原始 28x2 采样加速 33 倍 SD3.5-Large (38 DiT blocks): SFD 4步:HPSv2 32.90,ImageReward 1.20(最佳) 1.x-Distill (NFE=1.74):FID 22.05,HPSv2 32.01,超越 TDM 2步基线 3.5+ HPSv2 DPG-Bench:蒸馏模型在复杂提示下总分超越多步教师模型 多样性(LPIPS):显著高于 Flash 和 TDM 等基线 用户研究:20 位评估者在 3200 提示上明确偏好 1.x-Distill 图表详解 方法核心:块级缓存设计 左图展示各 DiT 块的跨步复用误差(早期块冗余大),右图展示缓存机制:第一步完整计算并缓存块贡献,第二步跳过并用 MLP 修正恢复 CFG 在蒸馏中的作用分析 高噪声时域强 CFG 驱使学生过早模式坍缩;1.x-Distill 在高噪声区禁用 CFG,低噪声区保留 CFG 定性对比结果 SD3-Medium 上多种方法的生成质量对比,1.x-Distill 在 1.67 NFE 下仍保持连贯结构和丰富细节 批判性点评 新颖性: 首次提出分数步蒸馏概念,打破整数步约束。时域感知 CFG 控制、分阶段聚焦蒸馏、蒸馏-缓存协同训练三个创新点紧密配合。 可复现性: 代码和权重将公开。训练仅需 JourneyDB 提示数据,无需外部图像数据集。但具体训练超参数和缓存块选择策略的细节需参考附录。 影响力: 高——开辟 1.x 步蒸馏新范式,33x 加速具有重大实用价值。但目前仅验证 SD3 系列,Flux/SDXL 等架构的通用性有待考验。 深度点评: 首创分数步蒸馏 — 1.x-Distill 首次突破整数步约束,SD3 上仅 1.67 NFE 实现 33x 加速,FID 和人类偏好全面领先 推理加速三路并进 — 蒸馏(1.x-Distill) + 系统缓存(Chorus) + 训练效率(OP-GRPO),三维度全面提速 免训练方法降低门槛 — FDS(Flow Matching) 和 VicoEdit(图像编辑) 无需额外训练即可大幅提升质量 技术演进定位: 分布匹配蒸馏领域的重要推进,开辟 1.x 步生成新范式 可能的后续方向: 推广到 Flux/SDXL/视频扩散模型 自适应缓存块选择 与推理系统优化结合 其余论文速览 1. SpatialEdit:提出首个专门评估细粒度空间编辑的基准Sp SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing 关键词: 图像编辑·空间变换·几何保真度·合成数据·基准评测 贡献: 提出首个专门评估细粒度空间编辑的基准SpatialEdit-Bench,通过联合度量感知合理性和几何保真度系统评估空间操作能力。构建500K合成训练数据集SpatialEdit-500k,使用可控Blender管线生成精确的相机轨迹和物体变换真值。基于此训练16B参数的SpatialEdit-16B基线模型。 效果: SpatialEdit-16B在通用编辑任务中取得有竞争力的性能,同时在空间操作任务上大幅超越现有方法。 2. FDS:提出流分歧采样器FDS Training-Free Refinement of Flow Matching with Divergence-based Sampling 关键词: Flow Matching·采样优化·无训练·散度引导·即插即用 贡献: 提出流分歧采样器FDS,无需训练即可提升Flow Matching模型质量。核心发现:边缘速度场的散度可量化采样误导程度,利用该信号在每个求解步骤前将中间状态引导至歧义更小的区域。 效果: 作为即插即用框架,FDS兼容标准求解器和现有Flow模型,在文本到图像合成和逆问题等多种任务中一致提升保真度。 3. OmniSonic:提出通用整体音频生成任务UniHAGen OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text 关键词: 音频生成·视频到音频·Flow Matching·MoE·CVPR 2026 贡献: 提出通用整体音频生成任务UniHAGen,首次统一生成屏幕内环境音、屏幕外环境音和人类语音。设计TriAttn-DiT架构,通过三路交叉注意力同时处理三种音频条件,配合MoE门控机制自适应平衡。构建UniHAGen-Bench基准覆盖三种代表性场景。CVPR 2026。 效果: 在客观指标和人类评估上均一致超越现有最先进方法,建立了通用整体音频生成的强基线。 4. OP-GRPO:首个专为Flow-Matching模型设 OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models 关键词: GRPO·Flow Matching·离线策略·训练效率·后训练优化 贡献: 首个专为Flow-Matching模型设计的离线GRPO框架。主动选择高质量轨迹并自适应加入回放缓冲区重复使用;提出序列级重要性采样修正减轻分布偏移;发现并解决晚期去噪步骤的病态离线比率问题。 效果: 仅用平均34.2%的训练步骤即达到Flow-GRPO同等或更优性能,在图像和视频生成基准上均验证有效。 5. Vanast:提出统一框架从单张人像、服装图和姿态视频 Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision 关键词: 虚拟试穿·视频生成·扩散Transformer·人体动画·CVPR 2026 贡献: 提出统一框架从单张人像、服装图和姿态视频一步生成换装动画视频。构建大规模三元组监督数据,引入视频扩散Transformer的双模块架构稳定训练,支持零样本服装插值。CVPR 2026。 效果: 克服传统两阶段方案的身份漂移和服装扭曲问题,实现高保真、身份一致的服装迁移动画。 6. VicoEdit:提出VicoEdit——免训练且无需反演 Training-Free Image Editing with Visual Context Integration and Concept Alignment 关键词: 图像编辑·免训练·视觉上下文·概念对齐·后验采样 贡献: 提出VicoEdit——免训练且无需反演的视觉上下文注入图像编辑方法。直接基于视觉上下文将源图转换为目标图,消除扩散反演可能导致的轨迹偏离。设计概念对齐引导的后验采样方法增强编辑一致性。 效果: 免训练方法在编辑性能上甚至超越最先进的基于训练的模型。 7. Think-in-Strokes:提出过程驱动图像生成范式 Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning 关键词: 图像生成·推理过程·交错生成·可解释AI·多步细化 贡献: 提出过程驱动图像生成范式,将合成分解为思想-动作交错推理轨迹。每次迭代包含文本规划、视觉草拟、文本反思、视觉细化四个阶段。通过密集逐步监督维持空间和语义一致性。 效果: 使生成过程变得明确、可解释且可直接监督,在多种文本到图像基准上验证有效性。 8. Chorus:提出Chorus——利用跨请求相似性加速 Beyond Few-Step Inference: Accelerating Video Diffusion Transformer Model Serving with Inter-Request Caching Reuse 关键词: 视频生成·推理加速·跨请求缓存·DiT·模型服务 贡献: 提出Chorus——利用跨请求相似性加速视频扩散Transformer服务的缓存方法。采用三阶段缓存策略:完全复用阶段、区域级跨请求缓存阶段和令牌引导注意力放大阶段。在单请求内缓存无效的4步蒸馏模型上仍有效。 效果: 在工业级4步蒸馏视频DiT模型上实现高达45%的推理加速,同时维持语义对齐质量。 9. CLEAR:提出CLEAR框架连接统一多模态模型的生 CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models 关键词: 生成理解一体化·退化图像·统一多模态·强化学习·GRPO 贡献: 提出CLEAR框架连接统一多模态模型的生成和理解能力以处理退化图像。三步渐进策略:感知退化SFT建立先生成后回答推理模式;潜在表示桥替代解码-重编码绕路;交错GRPO联合优化文本推理和视觉生成。构建MMD-Bench覆盖六个基准三级退化。 效果: 显著提升退化输入鲁棒性同时保持清晰图像性能。发现移除像素级重建监督可获得更高感知质量的中间视觉状态。 趋势观察 推理加速多路径并进 — 分数步蒸馏(1.x-Distill)、跨请求缓存(Chorus)、离线GRPO(OP-GRPO)——从模型压缩、系统优化到训练效率三个维度全面提速 免训练方法持续升温 — FDS和VicoEdit均无需额外训练即可提升Flow Matching和图像编辑质量,降低部署门槛 人工智能炼丹师 整理 | 2026-04-08 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注 -
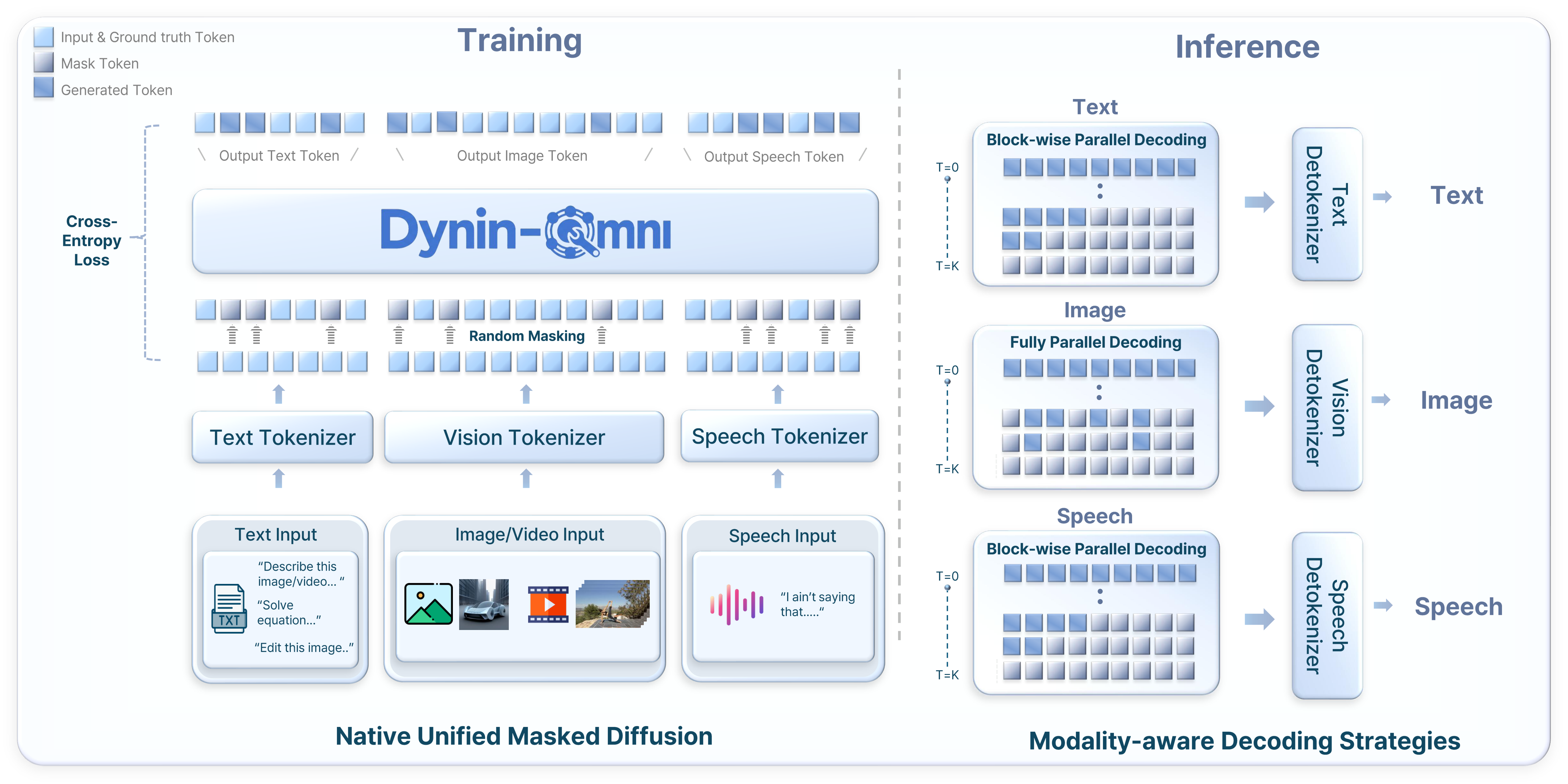
AIGC 每日速读|2026-04-03|Dynin-Omni|OmniVoice AIGC 视觉生成领域 · 每日论文解读 (2026-04-03) 人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇 今日核心看点 全模态统一 掩码扩散 600+语言TTS Mamba-TTS 智能调色 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成理解一体化模型 — 3 篇 音频/语音生成 — 4 篇 图片生成与编辑 — 2 篇 生成模型评测 — 1 篇 重点论文深度解读 1. Dynin-Omni 全模态统一大扩散语言模型:首个掩码扩散全模态基础模型 | Seoul National University (AIDAS Lab) | arXiv:2604.00007 关键词: 全模态统一, 掩码扩散, 文本/图像/视频/语音, 理解+生成一体化, 模态解纠缠合并 研究动机 核心问题: 如何在单一架构中原生统一文本、图像、视频、语音的理解与生成,避免自回归序列化瓶颈和组合式模型的外部依赖 当前全模态统一模型存在两条路线:自回归模型需要序列化异构模态导致效率低下,组合式模型依赖外部解码器增加系统复杂度。Dynin-Omni 提出用原生掩码扩散在共享离散token空间上统一文本、图像、视频、语音的理解与生成,实现真正的 any-to-any 建模。 前序工作及局限: LLaDA:纯文本掩码扩散语言模型,证明掩码扩散可做文本生成但不支持多模态 MMaDA:扩展到文本+图像统一,但缺少视频理解和语音能力 Qwen2.5-Omni:自回归全模态模型,但序列化异构模态效率低下 Seed-X/HyperCLOVAX:组合式统一模型,依赖外部模态特定生成器增加复杂度 与前序工作的本质区别: 用原生掩码扩散替代自回归或组合式架构,通过共享离散token空间和模态感知解码策略实现真正的any-to-any建模 方法原理 Dynin-Omni 的核心是将所有模态(文本、图像、视频、语音)映射到统一的离散token空间,通过掩码扩散进行训练和推理。文本使用标准分词器(词汇量126K),图像使用MAGVIT-v2风格VQ分词器(码本8192),视频复用图像分词器处理均匀采样帧,语音使用EMOVA S2U编码器+FSQ量化(码本4096)。训练分三阶段:阶段1通过视频字幕/ASR/TTS任务对齐新模态,阶段2引入模态解纠缠合并(Modality-Disentangled Merging)避免灾难性遗忘后进行全模态SFT,阶段3引入CoT推理数据和高分辨率图像提升高级能力。推理时采用模态感知解码策略:文本和语音用块状并行解码,图像用全并行解码,配合置信度重掩码机制迭代细化。 核心创新 首个原生掩码扩散全模态基础模型,单一架构统一文本/图像/视频/语音的理解与生成 模态解纠缠合并(Modality-Disentangled Merging)策略,解决多阶段训练中的灾难性遗忘 全模态离散token空间统一设计,无需外部模态特定生成器 模态感知解码策略:图像全并行、文本/语音块状并行,兼顾质量和效率 个基准测试全面超越现有开源统一模型,与模态特定专家系统竞争力相当 实验结果 在19个多模态基准上全面评测:文本推理 GSM8K 87.6、MATH 49.6;图像理解 MME-P 1733.6;视频理解 VideoMME 61.4;语音识别 LibriSpeech test-clean WER 2.1;图像生成 GenEval 0.87、DPG-Bench 86.3;图像编辑 ImgEdit 3.77;TTS WER 2.1。全面超越 HyperCLOVAX-Omni、Show-o2、BAGLE 等同类统一模型。消融实验证明模态解纠缠合并策略在第一阶段显著降低了各任务的训练损失。 图表详解 全模态架构对比:三种统一建模范式 对比了三种全模态建模范式:(a)感知中心模型如Qwen2.5-omni只做理解不做生成;(b)组合式模型如Seed-X需要外部生成器;(c)Dynin-Omni的原生统一模型,单一LLM同时支持理解和生成任务,无需外部模态特定解码器。 全模态性能对比:理解与生成双维度 展示Dynin-Omni在7个核心基准上与HyperCLOVAX-Omni、Qwen2.5-Omni、Show-o2、BAGLE的对比。理解维度:GSM8K 87.6、MME 1734、VideoMME 61.4;生成维度:GenEval 87.0、ImgEdit 3.77、TTS 97.9。 采样步数消融:不同任务的步数-性能曲线 四个子图展示GSM8K、GenEval、DPGBench、ImgEdit随采样步数的性能变化。文本推理需512+步才收敛,图像生成32-64步饱和,图像编辑8-32步即可保持强劲性能。 批判性点评 新颖性: 首个原生掩码扩散全模态基础模型,模态解纠缠合并策略是实用创新。但掩码扩散建模本身借鉴LLaDA/MMaDA,增量创新主要在模态扩展和训练策略 可复现性: 基于开源LLaDA架构扩展,训练策略描述清晰。但需要大规模多模态数据和算力,完全复现有门槛 影响力: 证明掩码扩散作为全模态统一范式的可行性,为实时全模态系统和具身智能体提供基础。图像生成质量(GenEval 0.87)仍落后FLUX.1(0.95+),视频仅支持理解不支持生成 深度点评: Dynin-Omni — 掩码扩散全模态新范式 — 首次在单一架构中用掩码扩散统一文本/图像/视频/语音的理解与生成。模态解纠缠合并有效缓解灾难性遗忘。不足:图像生成落后专用模型,视频仅支持理解 OmniVoice — 600+语言零样本TTS突破 — 扩散语言模型架构直接文本→声学token,跳过语义中间表示。58万小时全开源数据训练,语言覆盖面史上最广 MambaVoiceCloning — 纯SSM条件TTS — 首个完全移除注意力机制的扩散TTS条件路径,编码器仅21M参数、吞吐量提升1.6x。ICLR 2026,但扩散主干仍是延迟瓶颈 技术演进定位: 全模态统一建模的第三条路线——原生掩码扩散范式,证明了其可行性和竞争力 可能的后续方向: 视频生成能力扩展(当前仅支持理解) 图像生成质量追赶FLUX.1等专用模型 文本推理步数优化(当前需512+步) 实时全模态交互系统和具身智能体 其余论文速览 1. OmniVoice OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models 关键词: TTS·600+语言·扩散语言模型·零样本·多码本 贡献: 首个支持600+语言的大规模零样本TTS模型,直接文本→多码本声学token映射,跳过语义中间表示 效果: 基于58.1万小时开源多语言数据训练,中英文及多语种基准SOTA。全码本随机掩码策略+预训练LLM初始化确保清晰度 2. MambaVoiceCloning MambaVoiceCloning: Efficient and Expressive TTS via State-Space Modeling and Diffusion Control 关键词: TTS·Mamba/SSM·声音克隆·线性复杂度·ICLR 2026 贡献: 首个完全基于SSM(无注意力/RNN)条件路径的扩散TTS系统,ICLR 2026 效果: 编码器参数仅21M,吞吐量提升1.6x。MOS/CMOS/F0 RMSE/MCD均优于StyleTTS2和VITS 3. AceTone AceTone: Bridging Words and Colors for Conditional Image Grading 关键词: 调色·3D-LUT·VQ-VAE·RLHF·CVPR 2026 贡献: 首个统一多模态条件调色方法,文本/参考图→3D-LUT生成,CVPR 2026 效果: VQ-VAE将3x32^3 LUT压缩为64离散token(deltaE<2)。800K数据集+VLM预测+RL对齐,LPIPS提升50% 4. RawGen RawGen: Learning Camera Raw Image Generation 关键词: Raw图像生成·逆ISP·扩散模型·相机适配 贡献: 首个基于扩散的text-to-raw和sRGB-to-raw图像生成框架,支持任意目标相机 效果: 利用大规模sRGB扩散先验+专用解码器,多对一逆ISP数据集训练,显著优于传统逆ISP方法 5. DuoTok DuoTok: Source-Aware Dual-Track Tokenization for Multi-Track Music Language Modeling 关键词: 音乐生成·Tokenizer·双轨·扩散解码·语言建模 贡献: 源感知双轨音乐Tokenizer,分阶段解纠缠平衡保真度/可预测性/跨轨对应 效果: 0.75kbps比特率下竞争力重建+最低cnBPT,扩散解码器重建高频细节 6. Diff-VS Diff-VS: Efficient Audio-Aware Diffusion U-Net for Vocals Separation 关键词: 人声分离·扩散U-Net·EDM·STFT·ICASSP 2026 贡献: 基于EDM框架的生成式人声分离模型,处理复数STFT频谱图,ICASSP 2026 效果: 客观指标匹配判别式基线,感知质量接近SOTA系统 7. MMaDA-VLA MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation 关键词: VLA·扩散模型·多模态统一·指令跟随·西湖大学 贡献: 统一多模态指令和生成的大型扩散VLA模型(西湖大学) 效果: 单一扩散模型框架同时处理视觉理解、语言生成和动作预测 8. ProsodyEval Measuring Prosody Diversity in Zero-Shot TTS: A New Metric, Benchmark, and Exploration 关键词: TTS评测·韵律多样性·DS-WED·Seed-TTS·基准测试 贡献: 首个零样本TTS韵律多样性量化评测框架,提出DS-WED新指标 效果: ProsodyEval数据集(1000样本+2000 PMOS),发现大型音频语言模型在韵律变化捕捉仍有局限 9. ViGoR-Bench ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners? 关键词: 生成模型评测·视觉推理·I2I·视频·压力测试 贡献: 视觉生成模型推理能力统一评测框架,跨I2I/视频双轨评估+证据锚定自动评判 效果: 测试20+领先模型,揭示SOTA系统仍存在显著推理缺陷(美团等机构) 趋势观察 掩码扩散崛起 — Dynin-Omni证明掩码扩散可作为全模态统一建模的新范式,与自回归模型分庭抗礼 TTS走向极致效率 — MambaVoiceCloning用纯SSM替代所有注意力机制,OmniVoice覆盖600+语言,效率与覆盖面双突破 生成模型走向物理/审美对齐 — AceTone用RLHF对齐调色审美,RawGen生成物理一致的Raw图像,生成不再只追求逼真 人工智能炼丹师 整理 | 2026-04-03 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注