搜索到
2
篇与
diffusion
的结果
-
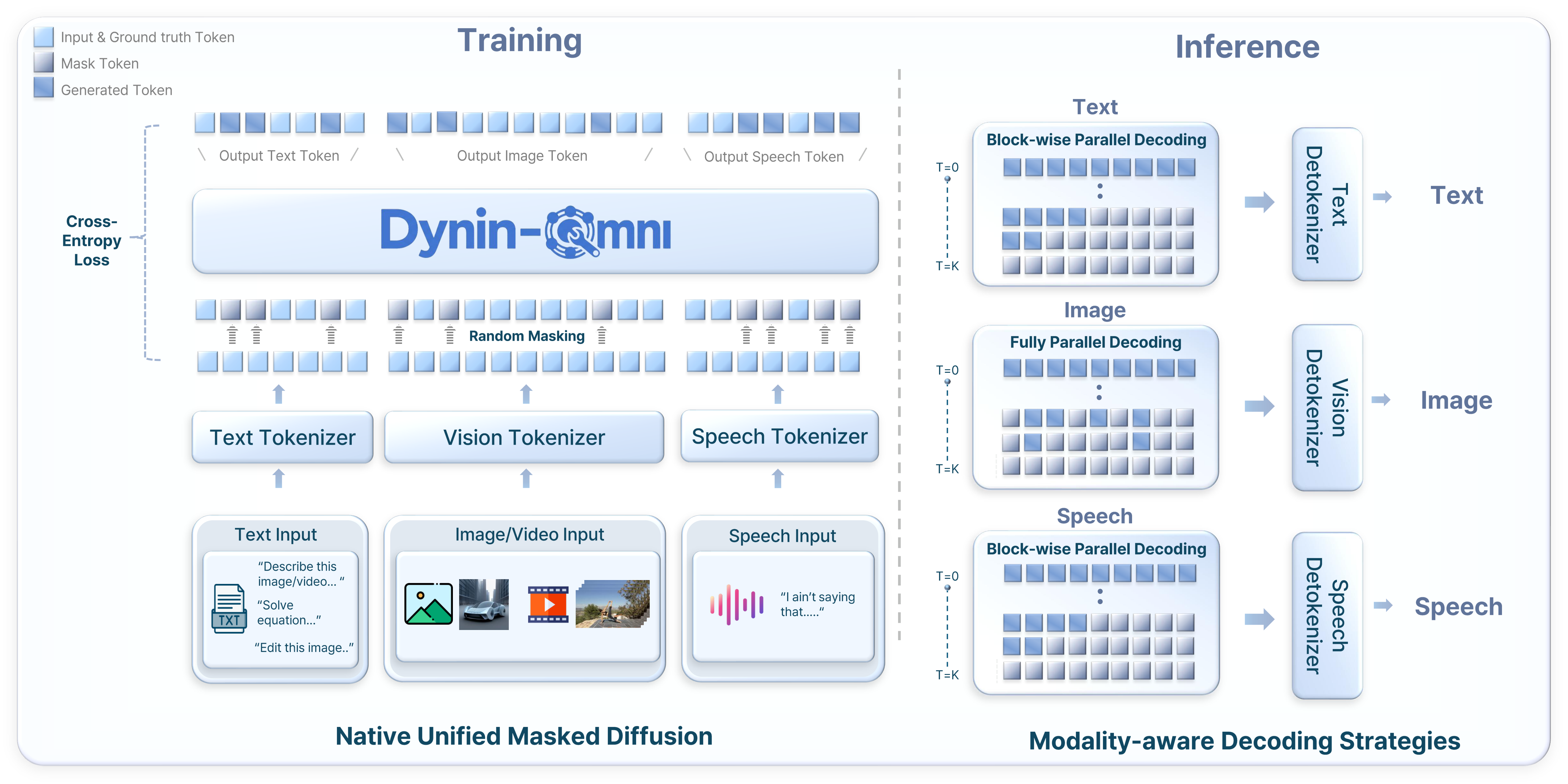
 AIGC 每日速读|2026-04-03|Dynin-Omni|OmniVoice AIGC 视觉生成领域 · 每日论文解读 (2026-04-03) 人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇 今日核心看点 全模态统一 掩码扩散 600+语言TTS Mamba-TTS 智能调色 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成理解一体化模型 — 3 篇 音频/语音生成 — 4 篇 图片生成与编辑 — 2 篇 生成模型评测 — 1 篇 重点论文深度解读 1. Dynin-Omni 全模态统一大扩散语言模型:首个掩码扩散全模态基础模型 | Seoul National University (AIDAS Lab) | arXiv:2604.00007 关键词: 全模态统一, 掩码扩散, 文本/图像/视频/语音, 理解+生成一体化, 模态解纠缠合并 研究动机 核心问题: 如何在单一架构中原生统一文本、图像、视频、语音的理解与生成,避免自回归序列化瓶颈和组合式模型的外部依赖 当前全模态统一模型存在两条路线:自回归模型需要序列化异构模态导致效率低下,组合式模型依赖外部解码器增加系统复杂度。Dynin-Omni 提出用原生掩码扩散在共享离散token空间上统一文本、图像、视频、语音的理解与生成,实现真正的 any-to-any 建模。 前序工作及局限: LLaDA:纯文本掩码扩散语言模型,证明掩码扩散可做文本生成但不支持多模态 MMaDA:扩展到文本+图像统一,但缺少视频理解和语音能力 Qwen2.5-Omni:自回归全模态模型,但序列化异构模态效率低下 Seed-X/HyperCLOVAX:组合式统一模型,依赖外部模态特定生成器增加复杂度 与前序工作的本质区别: 用原生掩码扩散替代自回归或组合式架构,通过共享离散token空间和模态感知解码策略实现真正的any-to-any建模 方法原理 Dynin-Omni 的核心是将所有模态(文本、图像、视频、语音)映射到统一的离散token空间,通过掩码扩散进行训练和推理。文本使用标准分词器(词汇量126K),图像使用MAGVIT-v2风格VQ分词器(码本8192),视频复用图像分词器处理均匀采样帧,语音使用EMOVA S2U编码器+FSQ量化(码本4096)。训练分三阶段:阶段1通过视频字幕/ASR/TTS任务对齐新模态,阶段2引入模态解纠缠合并(Modality-Disentangled Merging)避免灾难性遗忘后进行全模态SFT,阶段3引入CoT推理数据和高分辨率图像提升高级能力。推理时采用模态感知解码策略:文本和语音用块状并行解码,图像用全并行解码,配合置信度重掩码机制迭代细化。 核心创新 首个原生掩码扩散全模态基础模型,单一架构统一文本/图像/视频/语音的理解与生成 模态解纠缠合并(Modality-Disentangled Merging)策略,解决多阶段训练中的灾难性遗忘 全模态离散token空间统一设计,无需外部模态特定生成器 模态感知解码策略:图像全并行、文本/语音块状并行,兼顾质量和效率 个基准测试全面超越现有开源统一模型,与模态特定专家系统竞争力相当 实验结果 在19个多模态基准上全面评测:文本推理 GSM8K 87.6、MATH 49.6;图像理解 MME-P 1733.6;视频理解 VideoMME 61.4;语音识别 LibriSpeech test-clean WER 2.1;图像生成 GenEval 0.87、DPG-Bench 86.3;图像编辑 ImgEdit 3.77;TTS WER 2.1。全面超越 HyperCLOVAX-Omni、Show-o2、BAGLE 等同类统一模型。消融实验证明模态解纠缠合并策略在第一阶段显著降低了各任务的训练损失。 图表详解 全模态架构对比:三种统一建模范式 对比了三种全模态建模范式:(a)感知中心模型如Qwen2.5-omni只做理解不做生成;(b)组合式模型如Seed-X需要外部生成器;(c)Dynin-Omni的原生统一模型,单一LLM同时支持理解和生成任务,无需外部模态特定解码器。 全模态性能对比:理解与生成双维度 展示Dynin-Omni在7个核心基准上与HyperCLOVAX-Omni、Qwen2.5-Omni、Show-o2、BAGLE的对比。理解维度:GSM8K 87.6、MME 1734、VideoMME 61.4;生成维度:GenEval 87.0、ImgEdit 3.77、TTS 97.9。 采样步数消融:不同任务的步数-性能曲线 四个子图展示GSM8K、GenEval、DPGBench、ImgEdit随采样步数的性能变化。文本推理需512+步才收敛,图像生成32-64步饱和,图像编辑8-32步即可保持强劲性能。 批判性点评 新颖性: 首个原生掩码扩散全模态基础模型,模态解纠缠合并策略是实用创新。但掩码扩散建模本身借鉴LLaDA/MMaDA,增量创新主要在模态扩展和训练策略 可复现性: 基于开源LLaDA架构扩展,训练策略描述清晰。但需要大规模多模态数据和算力,完全复现有门槛 影响力: 证明掩码扩散作为全模态统一范式的可行性,为实时全模态系统和具身智能体提供基础。图像生成质量(GenEval 0.87)仍落后FLUX.1(0.95+),视频仅支持理解不支持生成 深度点评: Dynin-Omni — 掩码扩散全模态新范式 — 首次在单一架构中用掩码扩散统一文本/图像/视频/语音的理解与生成。模态解纠缠合并有效缓解灾难性遗忘。不足:图像生成落后专用模型,视频仅支持理解 OmniVoice — 600+语言零样本TTS突破 — 扩散语言模型架构直接文本→声学token,跳过语义中间表示。58万小时全开源数据训练,语言覆盖面史上最广 MambaVoiceCloning — 纯SSM条件TTS — 首个完全移除注意力机制的扩散TTS条件路径,编码器仅21M参数、吞吐量提升1.6x。ICLR 2026,但扩散主干仍是延迟瓶颈 技术演进定位: 全模态统一建模的第三条路线——原生掩码扩散范式,证明了其可行性和竞争力 可能的后续方向: 视频生成能力扩展(当前仅支持理解) 图像生成质量追赶FLUX.1等专用模型 文本推理步数优化(当前需512+步) 实时全模态交互系统和具身智能体 其余论文速览 1. OmniVoice OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models 关键词: TTS·600+语言·扩散语言模型·零样本·多码本 贡献: 首个支持600+语言的大规模零样本TTS模型,直接文本→多码本声学token映射,跳过语义中间表示 效果: 基于58.1万小时开源多语言数据训练,中英文及多语种基准SOTA。全码本随机掩码策略+预训练LLM初始化确保清晰度 2. MambaVoiceCloning MambaVoiceCloning: Efficient and Expressive TTS via State-Space Modeling and Diffusion Control 关键词: TTS·Mamba/SSM·声音克隆·线性复杂度·ICLR 2026 贡献: 首个完全基于SSM(无注意力/RNN)条件路径的扩散TTS系统,ICLR 2026 效果: 编码器参数仅21M,吞吐量提升1.6x。MOS/CMOS/F0 RMSE/MCD均优于StyleTTS2和VITS 3. AceTone AceTone: Bridging Words and Colors for Conditional Image Grading 关键词: 调色·3D-LUT·VQ-VAE·RLHF·CVPR 2026 贡献: 首个统一多模态条件调色方法,文本/参考图→3D-LUT生成,CVPR 2026 效果: VQ-VAE将3x32^3 LUT压缩为64离散token(deltaE<2)。800K数据集+VLM预测+RL对齐,LPIPS提升50% 4. RawGen RawGen: Learning Camera Raw Image Generation 关键词: Raw图像生成·逆ISP·扩散模型·相机适配 贡献: 首个基于扩散的text-to-raw和sRGB-to-raw图像生成框架,支持任意目标相机 效果: 利用大规模sRGB扩散先验+专用解码器,多对一逆ISP数据集训练,显著优于传统逆ISP方法 5. DuoTok DuoTok: Source-Aware Dual-Track Tokenization for Multi-Track Music Language Modeling 关键词: 音乐生成·Tokenizer·双轨·扩散解码·语言建模 贡献: 源感知双轨音乐Tokenizer,分阶段解纠缠平衡保真度/可预测性/跨轨对应 效果: 0.75kbps比特率下竞争力重建+最低cnBPT,扩散解码器重建高频细节 6. Diff-VS Diff-VS: Efficient Audio-Aware Diffusion U-Net for Vocals Separation 关键词: 人声分离·扩散U-Net·EDM·STFT·ICASSP 2026 贡献: 基于EDM框架的生成式人声分离模型,处理复数STFT频谱图,ICASSP 2026 效果: 客观指标匹配判别式基线,感知质量接近SOTA系统 7. MMaDA-VLA MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation 关键词: VLA·扩散模型·多模态统一·指令跟随·西湖大学 贡献: 统一多模态指令和生成的大型扩散VLA模型(西湖大学) 效果: 单一扩散模型框架同时处理视觉理解、语言生成和动作预测 8. ProsodyEval Measuring Prosody Diversity in Zero-Shot TTS: A New Metric, Benchmark, and Exploration 关键词: TTS评测·韵律多样性·DS-WED·Seed-TTS·基准测试 贡献: 首个零样本TTS韵律多样性量化评测框架,提出DS-WED新指标 效果: ProsodyEval数据集(1000样本+2000 PMOS),发现大型音频语言模型在韵律变化捕捉仍有局限 9. ViGoR-Bench ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners? 关键词: 生成模型评测·视觉推理·I2I·视频·压力测试 贡献: 视觉生成模型推理能力统一评测框架,跨I2I/视频双轨评估+证据锚定自动评判 效果: 测试20+领先模型,揭示SOTA系统仍存在显著推理缺陷(美团等机构) 趋势观察 掩码扩散崛起 — Dynin-Omni证明掩码扩散可作为全模态统一建模的新范式,与自回归模型分庭抗礼 TTS走向极致效率 — MambaVoiceCloning用纯SSM替代所有注意力机制,OmniVoice覆盖600+语言,效率与覆盖面双突破 生成模型走向物理/审美对齐 — AceTone用RLHF对齐调色审美,RawGen生成物理一致的Raw图像,生成不再只追求逼真 人工智能炼丹师 整理 | 2026-04-03 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
AIGC 每日速读|2026-04-03|Dynin-Omni|OmniVoice AIGC 视觉生成领域 · 每日论文解读 (2026-04-03) 人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇 今日核心看点 全模态统一 掩码扩散 600+语言TTS Mamba-TTS 智能调色 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成理解一体化模型 — 3 篇 音频/语音生成 — 4 篇 图片生成与编辑 — 2 篇 生成模型评测 — 1 篇 重点论文深度解读 1. Dynin-Omni 全模态统一大扩散语言模型:首个掩码扩散全模态基础模型 | Seoul National University (AIDAS Lab) | arXiv:2604.00007 关键词: 全模态统一, 掩码扩散, 文本/图像/视频/语音, 理解+生成一体化, 模态解纠缠合并 研究动机 核心问题: 如何在单一架构中原生统一文本、图像、视频、语音的理解与生成,避免自回归序列化瓶颈和组合式模型的外部依赖 当前全模态统一模型存在两条路线:自回归模型需要序列化异构模态导致效率低下,组合式模型依赖外部解码器增加系统复杂度。Dynin-Omni 提出用原生掩码扩散在共享离散token空间上统一文本、图像、视频、语音的理解与生成,实现真正的 any-to-any 建模。 前序工作及局限: LLaDA:纯文本掩码扩散语言模型,证明掩码扩散可做文本生成但不支持多模态 MMaDA:扩展到文本+图像统一,但缺少视频理解和语音能力 Qwen2.5-Omni:自回归全模态模型,但序列化异构模态效率低下 Seed-X/HyperCLOVAX:组合式统一模型,依赖外部模态特定生成器增加复杂度 与前序工作的本质区别: 用原生掩码扩散替代自回归或组合式架构,通过共享离散token空间和模态感知解码策略实现真正的any-to-any建模 方法原理 Dynin-Omni 的核心是将所有模态(文本、图像、视频、语音)映射到统一的离散token空间,通过掩码扩散进行训练和推理。文本使用标准分词器(词汇量126K),图像使用MAGVIT-v2风格VQ分词器(码本8192),视频复用图像分词器处理均匀采样帧,语音使用EMOVA S2U编码器+FSQ量化(码本4096)。训练分三阶段:阶段1通过视频字幕/ASR/TTS任务对齐新模态,阶段2引入模态解纠缠合并(Modality-Disentangled Merging)避免灾难性遗忘后进行全模态SFT,阶段3引入CoT推理数据和高分辨率图像提升高级能力。推理时采用模态感知解码策略:文本和语音用块状并行解码,图像用全并行解码,配合置信度重掩码机制迭代细化。 核心创新 首个原生掩码扩散全模态基础模型,单一架构统一文本/图像/视频/语音的理解与生成 模态解纠缠合并(Modality-Disentangled Merging)策略,解决多阶段训练中的灾难性遗忘 全模态离散token空间统一设计,无需外部模态特定生成器 模态感知解码策略:图像全并行、文本/语音块状并行,兼顾质量和效率 个基准测试全面超越现有开源统一模型,与模态特定专家系统竞争力相当 实验结果 在19个多模态基准上全面评测:文本推理 GSM8K 87.6、MATH 49.6;图像理解 MME-P 1733.6;视频理解 VideoMME 61.4;语音识别 LibriSpeech test-clean WER 2.1;图像生成 GenEval 0.87、DPG-Bench 86.3;图像编辑 ImgEdit 3.77;TTS WER 2.1。全面超越 HyperCLOVAX-Omni、Show-o2、BAGLE 等同类统一模型。消融实验证明模态解纠缠合并策略在第一阶段显著降低了各任务的训练损失。 图表详解 全模态架构对比:三种统一建模范式 对比了三种全模态建模范式:(a)感知中心模型如Qwen2.5-omni只做理解不做生成;(b)组合式模型如Seed-X需要外部生成器;(c)Dynin-Omni的原生统一模型,单一LLM同时支持理解和生成任务,无需外部模态特定解码器。 全模态性能对比:理解与生成双维度 展示Dynin-Omni在7个核心基准上与HyperCLOVAX-Omni、Qwen2.5-Omni、Show-o2、BAGLE的对比。理解维度:GSM8K 87.6、MME 1734、VideoMME 61.4;生成维度:GenEval 87.0、ImgEdit 3.77、TTS 97.9。 采样步数消融:不同任务的步数-性能曲线 四个子图展示GSM8K、GenEval、DPGBench、ImgEdit随采样步数的性能变化。文本推理需512+步才收敛,图像生成32-64步饱和,图像编辑8-32步即可保持强劲性能。 批判性点评 新颖性: 首个原生掩码扩散全模态基础模型,模态解纠缠合并策略是实用创新。但掩码扩散建模本身借鉴LLaDA/MMaDA,增量创新主要在模态扩展和训练策略 可复现性: 基于开源LLaDA架构扩展,训练策略描述清晰。但需要大规模多模态数据和算力,完全复现有门槛 影响力: 证明掩码扩散作为全模态统一范式的可行性,为实时全模态系统和具身智能体提供基础。图像生成质量(GenEval 0.87)仍落后FLUX.1(0.95+),视频仅支持理解不支持生成 深度点评: Dynin-Omni — 掩码扩散全模态新范式 — 首次在单一架构中用掩码扩散统一文本/图像/视频/语音的理解与生成。模态解纠缠合并有效缓解灾难性遗忘。不足:图像生成落后专用模型,视频仅支持理解 OmniVoice — 600+语言零样本TTS突破 — 扩散语言模型架构直接文本→声学token,跳过语义中间表示。58万小时全开源数据训练,语言覆盖面史上最广 MambaVoiceCloning — 纯SSM条件TTS — 首个完全移除注意力机制的扩散TTS条件路径,编码器仅21M参数、吞吐量提升1.6x。ICLR 2026,但扩散主干仍是延迟瓶颈 技术演进定位: 全模态统一建模的第三条路线——原生掩码扩散范式,证明了其可行性和竞争力 可能的后续方向: 视频生成能力扩展(当前仅支持理解) 图像生成质量追赶FLUX.1等专用模型 文本推理步数优化(当前需512+步) 实时全模态交互系统和具身智能体 其余论文速览 1. OmniVoice OmniVoice: Towards Omnilingual Zero-Shot Text-to-Speech with Diffusion Language Models 关键词: TTS·600+语言·扩散语言模型·零样本·多码本 贡献: 首个支持600+语言的大规模零样本TTS模型,直接文本→多码本声学token映射,跳过语义中间表示 效果: 基于58.1万小时开源多语言数据训练,中英文及多语种基准SOTA。全码本随机掩码策略+预训练LLM初始化确保清晰度 2. MambaVoiceCloning MambaVoiceCloning: Efficient and Expressive TTS via State-Space Modeling and Diffusion Control 关键词: TTS·Mamba/SSM·声音克隆·线性复杂度·ICLR 2026 贡献: 首个完全基于SSM(无注意力/RNN)条件路径的扩散TTS系统,ICLR 2026 效果: 编码器参数仅21M,吞吐量提升1.6x。MOS/CMOS/F0 RMSE/MCD均优于StyleTTS2和VITS 3. AceTone AceTone: Bridging Words and Colors for Conditional Image Grading 关键词: 调色·3D-LUT·VQ-VAE·RLHF·CVPR 2026 贡献: 首个统一多模态条件调色方法,文本/参考图→3D-LUT生成,CVPR 2026 效果: VQ-VAE将3x32^3 LUT压缩为64离散token(deltaE<2)。800K数据集+VLM预测+RL对齐,LPIPS提升50% 4. RawGen RawGen: Learning Camera Raw Image Generation 关键词: Raw图像生成·逆ISP·扩散模型·相机适配 贡献: 首个基于扩散的text-to-raw和sRGB-to-raw图像生成框架,支持任意目标相机 效果: 利用大规模sRGB扩散先验+专用解码器,多对一逆ISP数据集训练,显著优于传统逆ISP方法 5. DuoTok DuoTok: Source-Aware Dual-Track Tokenization for Multi-Track Music Language Modeling 关键词: 音乐生成·Tokenizer·双轨·扩散解码·语言建模 贡献: 源感知双轨音乐Tokenizer,分阶段解纠缠平衡保真度/可预测性/跨轨对应 效果: 0.75kbps比特率下竞争力重建+最低cnBPT,扩散解码器重建高频细节 6. Diff-VS Diff-VS: Efficient Audio-Aware Diffusion U-Net for Vocals Separation 关键词: 人声分离·扩散U-Net·EDM·STFT·ICASSP 2026 贡献: 基于EDM框架的生成式人声分离模型,处理复数STFT频谱图,ICASSP 2026 效果: 客观指标匹配判别式基线,感知质量接近SOTA系统 7. MMaDA-VLA MMaDA-VLA: Large Diffusion Vision-Language-Action Model with Unified Multi-Modal Instruction and Generation 关键词: VLA·扩散模型·多模态统一·指令跟随·西湖大学 贡献: 统一多模态指令和生成的大型扩散VLA模型(西湖大学) 效果: 单一扩散模型框架同时处理视觉理解、语言生成和动作预测 8. ProsodyEval Measuring Prosody Diversity in Zero-Shot TTS: A New Metric, Benchmark, and Exploration 关键词: TTS评测·韵律多样性·DS-WED·Seed-TTS·基准测试 贡献: 首个零样本TTS韵律多样性量化评测框架,提出DS-WED新指标 效果: ProsodyEval数据集(1000样本+2000 PMOS),发现大型音频语言模型在韵律变化捕捉仍有局限 9. ViGoR-Bench ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners? 关键词: 生成模型评测·视觉推理·I2I·视频·压力测试 贡献: 视觉生成模型推理能力统一评测框架,跨I2I/视频双轨评估+证据锚定自动评判 效果: 测试20+领先模型,揭示SOTA系统仍存在显著推理缺陷(美团等机构) 趋势观察 掩码扩散崛起 — Dynin-Omni证明掩码扩散可作为全模态统一建模的新范式,与自回归模型分庭抗礼 TTS走向极致效率 — MambaVoiceCloning用纯SSM替代所有注意力机制,OmniVoice覆盖600+语言,效率与覆盖面双突破 生成模型走向物理/审美对齐 — AceTone用RLHF对齐调色审美,RawGen生成物理一致的Raw图像,生成不再只追求逼真 人工智能炼丹师 整理 | 2026-04-03 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注 -
AIGC 周末专题深度解读:视频生成与编辑前沿进展|2026-03-22|SAMA|DynaEdit|PhysVideo| AIGC 周末专题深度解读 | 2026-03-22 | 视频生成与编辑前沿进展 人工智能炼丹师 整理 | 本期专题聚焦 2026 年 3 月第三周(3.15-3.22)视频生成与编辑领域的最新突破,涵盖物理一致生成、无训练编辑、高分辨率合成、推理加速、联合音视频生成等多个前沿方向。 专题概述 视频生成与编辑是当前 AIGC 领域最活跃的研究方向之一。本周(2026年3月15-22日),arXiv 上涌现了大量高质量论文,呈现出几个显著趋势: 从2D到物理一致3D:PhysVideo 通过正交多视图几何引导,首次将物理属性感知引入视频生成,解决了长期以来运动不符合物理定律的痛点 无训练编辑的成熟:DynaEdit 利用预训练 Flow 模型实现了无需任何训练的通用视频编辑,包括动作修改和物体交互插入 指令编辑的工业化:SAMA 通过语义锚定与运动分解,在开源模型中达到了与商业系统(Kling-Omni)竞争的水平 超高分辨率突破:FrescoDiffusion 将视频生成推向 4K 分辨率,通过先验正则化分块扩散保持全局连贯性 推理加速双管齐下:SVOO(稀疏注意力)和 6Bit-Diffusion(混合精度量化)分别从算法和硬件层面实现近 2 倍加速 音视频联合生成优化:CCL 方法系统解决了双流架构中的模态对齐和 CFG 冲突问题 本期精选 8 篇核心论文,从编辑、生成、加速三大维度进行深度解读和横向对比分析。 1. SAMA:分解语义锚定与运动对齐的指令引导视频编辑 论文信息 标题:SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing 作者:Xinyao Zhang, Wenkai Dong, Yuxin Song, Bo Fang 等(字节跳动/清华大学) arXiv:2603.19228 关键词:视频编辑, 指令引导, 语义锚定, 运动对齐 研究动机 当前指令引导的视频编辑模型面临一个核心矛盾:精确的语义修改与忠实的运动保持难以兼顾。现有方法依赖注入外部先验(VLM 特征、结构条件)来缓解这一问题,但外部先验的引入严重限制了模型的鲁棒性和泛化能力。SAMA 提出了一个根本性的解决思路——将视频编辑分解为两个正交的子任务。 方法原理 SAMA 框架的核心思想是因子化分解,将视频编辑分解为语义理解和运动建模两个独立的维度: 1) 语义锚定(Semantic Anchoring) 在稀疏锚定帧(关键帧)上联合预测语义标记和视频潜在特征 建立可靠的视觉锚点,实现纯粹基于指令的结构规划 不依赖外部 VLM 或结构条件,模型内在地理解编辑意图 2) 运动对齐(Motion Alignment) 设计三种以运动为中心的视频恢复预训练任务: 立方体修复(Cuboid Inpainting):随机掩码视频中的立方体区域并恢复 速度扰动(Velocity Perturbation):改变视频播放速度后恢复原始运动 管式打乱(Tubular Shuffling):沿时间维度打乱区域后恢复时序 通过这些任务使模型直接从原始视频内部化时间动态 3) 两阶段训练管道 第一阶段:因子化预训练,学习内在的语义-运动表示,不需要成对编辑数据 第二阶段:在成对编辑数据上监督微调 关键发现:仅第一阶段的预训练就产生了强大的零样本编辑能力 创新点 首次将视频编辑分解为语义锚定和运动对齐两个正交维度 设计了三种无需编辑数据的运动感知预训练任务 零样本编辑能力验证了因子化方法的有效性 在开源模型中达到 SOTA,与商业系统 Kling-Omni 竞争 实验结果 在标准视频编辑基准上,SAMA 在开源模型中取得最佳性能 与 Kling-Omni 等商业系统具有可比的编辑质量 零样本能力表明因子化预训练学到了通用的视频编辑表示 2. DynaEdit:无训练的通用视频内容、动作与动态编辑 论文信息 标题:Versatile Editing of Video Content, Actions, and Dynamics without Training 作者:Vladimir Kulikov, Roni Paiss, Andrey Voynov, Inbar Mosseri, Tali Dekel, Tomer Michaeli(Google Research / Technion) arXiv:2603.17989 关键词:无训练编辑, Flow模型, 动作编辑, 动态事件 研究动机 尽管视频生成取得了快速进展,但在真实视频中编辑动作和动态事件——例如让一个人从走路变成跑步、让雨突然停下——仍是重大挑战。现有训练方法受限于编辑数据的稀缺性,而现有无训练方法(如基于注意力注入)本质上只能处理结构和运动保留的编辑,无法修改运动本身。 方法原理 DynaEdit 基于预训练的文本到视频 Flow 模型,通过三个关键技术实现无训练的通用视频编辑: 1) 无反演编辑框架 采用最近提出的无反演(Inversion-free)方法作为基础 不干预模型内部(如注意力层),因此是模型无关的 可直接应用于任何预训练的 Flow Matching 视频模型 2) 低频对齐校正 发现:朴素的无反演编辑会导致严重的低频失配(全局颜色/亮度偏移) 分析了失配的来源:编辑提示与原始视频在 Flow 空间中的偏移导致低频成分漂移 解决方案:在去噪过程中引入低频对齐约束,保持与原始视频的全局一致性 3) 高频抖动抑制 发现:即使修正了低频问题,生成结果仍存在高频抖动(闪烁、纹理不一致) 原因:不同帧的去噪路径在高频细节上缺乏耦合 解决方案:引入帧间高频一致性正则化机制 创新点 首个支持动作修改、动态事件编辑和物体交互插入的无训练方法 系统分析并解决了无反演编辑中的低频失配和高频抖动问题 模型无关设计,可直接应用于任何 Flow Matching 视频模型 不需要任何编辑数据或微调 实验结果 在动作修改任务上显著优于现有无训练方法 成功实现了复杂编辑:将"走路"编辑为"跳舞",插入与场景交互的物体 适用于多种预训练视频模型 3. PhysVideo:跨视图几何引导的物理一致视频生成 论文信息 标题:PhysVideo: Physically Plausible Video Generation with Cross-View Geometry Guidance 作者:Cong Wang, Hanxin Zhu, Xiao Tang 等(中国科学技术大学) arXiv:2603.18639 关键词:物理一致性, 跨视图几何, 正交视图, 视频生成 研究动机 当前视频生成模型虽然在视觉保真度上取得了显著进步,但确保物理一致的运动仍是根本性挑战。核心原因在于:真实世界的物体运动在三维空间中展开,而视频观察仅提供了这些动力学的局部、视角依赖的投影。这导致模型容易生成违反物理定律的运动——球在空中突然变向、物体穿过墙壁等。 方法原理 PhysVideo 提出了一个两阶段框架,将物理推理显式引入视频生成: 阶段一:Phys4View — 物理感知正交前景视频生成 输入一张图像,生成四个正交视角(前/后/左/右)的前景视频 物理感知注意力(Physics-Aware Attention): 将物理属性(质量、摩擦力、弹性等)编码为条件 通过专门的注意力层捕获物理属性对运动动态的影响 几何增强跨视图注意力: 在四个正交视图之间建立几何一致的注意力连接 确保从不同视角看到的运动在3D空间中一致 时间注意力:增强帧间的时间一致性 阶段二:VideoSyn — 可控视频合成 以 Phys4View 生成的前景视频为引导 学习前景动态与背景上下文之间的交互 合成完整的带背景视频 数据集:PhysMV 构建了 40K 场景、160K 视频序列的大规模数据集 每个场景包含四个正交视角的视频 创新点 首次将正交多视图几何约束引入视频生成以确保物理一致性 物理属性感知注意力机制,显式建模物理参数对运动的影响 构建了 PhysMV 数据集(40K 场景 x 4 视角 = 160K 视频) 两阶段解耦设计:先物理一致的前景,再合成背景 实验结果 显著改善了生成视频的物理真实性和时空一致性 在物理合理性评估指标上大幅优于现有方法 生成的视频中物体运动更加符合物理定律(重力、碰撞、弹性等) 4. EffectErase:视频物体移除与效果擦除的联合框架 论文信息 标题:EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing 作者:Yang Fu, Yike Zheng, Ziyun Dai, Henghui Ding arXiv:2603.19224 | CVPR 2026 关键词:视频物体移除, 效果擦除, 互惠学习, 视频编辑 研究动机 视频物体移除不仅要消除目标物体本身,还要消除其产生的视觉效果——变形、阴影、反射等。现有基于扩散的视频修复方法虽然能移除物体,但通常难以消除这些附带效果,留下不自然的痕迹。此外,该领域缺乏系统涵盖各种物体效果的大规模数据集。 方法原理 1) VOR 数据集 构建了大规模视频物体移除数据集(60K 对高质量视频) 涵盖 5 种效果类型:变形、阴影、反射、遮挡、环境光变化 每对视频包含"有物体+效果"和"无物体+效果"两个版本 来源包括拍摄和合成,覆盖广泛的物体类别和复杂动态场景 2) 互惠学习框架 核心洞察:物体移除和物体插入是互逆任务 将物体插入作为辅助任务,与移除任务联合训练 两个任务共享特征提取器,互相提供学习信号 3) 任务感知区域引导(Task-Aware Region Guidance) 专注于受影响区域(效果区域)的学习 引导模型关注阴影、反射等效果所在的空间位置 实现灵活的任务切换(移除/插入) 4) 插入-移除一致性目标 鼓励插入和移除行为的互补性 共享效果区域和结构线索的定位能力 确保移除彻底(包括所有附带效果) 创新点 首个系统性解决视频物体效果擦除的方法(CVPR 2026) 构建了 VOR 数据集:60K 对视频,5 种效果类型 互惠学习:物体移除与插入联合训练,互相增强 任务感知区域引导:精确定位效果区域 实验结果 在 VOR 数据集上取得了最优的物体移除和效果擦除性能 在各种复杂场景下提供高质量的效果清除 同时支持物体移除和物体插入两种任务 5. FrescoDiffusion:先验正则化分块扩散实现 4K 图像到视频生成 论文信息 标题:FrescoDiffusion: 4K Image-to-Video with Prior-Regularized Tiled Diffusion 作者:Hugo Caselles-Dupre, Mathis Koroglu, Guillaume Jeanneret 等(Obvious Research / Sorbonne University) arXiv:2603.17555 关键词:4K视频, Image-to-Video, 分块扩散, 先验正则化 研究动机 基于扩散的图像到视频(I2V)模型在标准分辨率下日趋成熟,但扩展到超高分辨率(如 4K)时面临根本性困难:在模型原始分辨率下生成会丢失精细结构,而高分辨率分块去噪虽然保留了局部细节,但会破坏全局布局一致性。这个问题在"湿壁画动画"场景中尤为严重——包含多个角色、物体和语义子场景的巨型艺术品必须在时间上保持空间连贯性。 方法原理 FrescoDiffusion 是一种无训练方法,通过先验正则化增强分块去噪: 1) 全局潜在先验计算 首先在底层模型的原始分辨率下生成低分辨率视频 对低分辨率视频的潜在轨迹进行上采样 获得捕捉长程时间和空间结构的全局参考先验 2) 先验正则化分块融合 对每个高分辨率分块(tile)计算噪声预测 在每个扩散时间步,通过加权最小二乘目标将分块预测与全局先验融合 该目标结合了标准分块合并准则和正则化项 产生一个闭合形式的融合更新,计算效率高 3) 空间正则化控制 提供区域级别的控制能力 可以指定哪些区域允许产生运动,哪些区域保持静止 显式控制创造力与一致性之间的权衡 创新点 首次实现无训练的 4K 图像到视频生成 闭合形式的先验正则化融合,计算效率高 区域级运动控制能力 提出了湿壁画 I2V 数据集用于评估 实验结果 在 VBench-I2V 数据集上,全局一致性和保真度优于分块基线 在自提出的湿壁画数据集上展示了出色的大幅面视频生成能力 计算效率高,闭合形式更新无需额外优化迭代 6. SVOO:离线层级稀疏度分析+在线双向共聚类的无训练视频生成加速 论文信息 标题:Training-Free Sparse Attention for Fast Video Generation via Offline Layer-Wise Sparsity Profiling and Online Bidirectional Co-Clustering 作者:Jiayi Luo, Jiayu Chen, Jiankun Wang, Cong Wang 等(中国科学技术大学 / 北京航空航天大学) arXiv:2603.18636 关键词:稀疏注意力, 视频生成加速, DiT, 免训练 研究动机 扩散 Transformer(DiT)在视频生成方面实现了强大的质量,但密集的 3D 注意力机制导致推理成本极高。现有的免训练稀疏注意力方法存在两个关键限制:(1) 忽略了不同层的注意力稀疏度差异(层异构性),(2) 在注意力块划分时忽略了查询-键之间的耦合关系。 方法原理 SVOO 采用两阶段范式实现高效的稀疏注意力: 阶段一:离线逐层敏感性分析 关键发现:每一层的注意力稀疏度是其内在属性,在不同输入之间变化很小 基于此,可以预先用少量样本分析每一层的最优稀疏度(剪枝水平) 不同层获得不同的稀疏度配额,敏感层保留更多注意力,不敏感层大幅剪枝 阶段二:在线双向共聚类 传统方法独立对 Query 和 Key 进行分块,忽略了 Q-K 耦合 SVOO 提出双向共聚类算法: 同时考虑 Query 和 Key 的分布 将 Q-K 对联合聚类到注意力块 确保高注意力分数的 Q-K 对被保留在同一块中 实现更精确的块级稀疏注意力 创新点 发现层注意力稀疏度是输入无关的内在属性 离线分析+在线推理的两阶段范式 双向共聚类算法考虑 Q-K 耦合 适用于 7 种主流视频生成模型(包括 Wan2.1) 实验结果 在 Wan2.1 上实现 1.93x 加速,同时保持 29 dB 的 PSNR 在 7 个视频生成模型上一致优于现有稀疏注意力方法 质量-速度权衡显著优于对比方法 7. 6Bit-Diffusion:视频 DiT 的推理时混合精度量化 论文信息 标题:6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models 作者:Rundong Su, Jintao Zhang, Zhihang Yuan 等(清华大学) arXiv:2603.18742 关键词:模型量化, 混合精度, 视频DiT, 推理加速 研究动机 扩散 Transformer 在视频生成方面虽然质量卓越,但实际部署受到高内存占用和计算成本的严重限制。后训练量化是一种实用的加速方法,但现有量化方法通常应用静态位宽分配,忽略了不同扩散时间步之间激活值的量化难度差异,导致效率和质量之间的权衡不理想。 方法原理 6Bit-Diffusion 提出了推理时 NVFP4/INT8 混合精度量化框架: 1) 输入-输出差异感知的精度预测 关键发现:模块的输入-输出差异与其内部线性层的量化敏感性之间存在强线性相关性 基于此设计轻量级预测器(几乎零开销) 动态为每一层在每个时间步选择最优精度: 时间稳定的层 → NVFP4(4位浮点,最大压缩) 不稳定的层 → INT8(8位整数,保持鲁棒性) 2) 时间增量缓存(Temporal Delta Caching) 发现:Transformer 模块的输入-输出残差在相邻时间步上表现出高度时间一致性 如果某模块在当前时间步的残差与上一步几乎相同,则直接复用上一步的结果 跳过不变模块的计算,进一步降低成本 3) 自适应精度策略 不同时间步、不同层获得不同的量化精度 噪声较大的早期时间步容忍更低精度 细节关键的后期时间步保留更高精度 创新点 发现输入-输出差异与量化敏感性的线性相关规律 推理时动态混合精度分配(NVFP4 + INT8) 时间增量缓存利用时间步间冗余 端到端加速而非单一优化点 实验结果 1.92x 端到端加速 3.32x 内存减少 生成质量与全精度模型几乎无差异 为高效视频 DiT 推理设立了新基准 8. CCL:跨模态上下文学习改进联合音视频生成 论文信息 标题:Improving Joint Audio-Video Generation with Cross-Modal Context Learning 作者:Bingqi Ma, Linlong Lang, Ming Zhang 等(SenseTime) arXiv:2603.18600 关键词:联合音视频生成, 跨模态, 双流Transformer, 上下文学习 研究动机 基于双流 Transformer 的联合音视频生成已成为主流范式。通过结合预训练的视频和音频扩散模型,加上跨模态交互注意力,可以用最少的训练数据生成高质量同步音视频。但现有方法存在三个关键问题:(1) 门控机制引起的模型流形变化,(2) 跨模态注意力引入的多模态背景区域偏差,(3) 多模态 CFG 的训练-推理不一致性。 方法原理 CCL(Cross-Modal Context Learning)提出了多个精心设计的模块来解决上述问题: 1) 时间对齐 RoPE 和分区(TARP) 视频和音频的时间分辨率不同(视频约 30fps,音频采样率更高) TARP 有效增强了音频潜在表示与视频潜在表示之间的时间对齐 确保对应的音频-视频片段在注意力计算中正确对应 2) 可学习上下文标记(LCT)与动态上下文路由(DCR) LCT:在跨模态注意力模块中引入可学习的上下文标记 为跨模态信息提供稳定的无条件锚点 缓解门控机制引起的流形变化 DCR:根据不同训练任务(文本→视频+音频 / 视频→音频 / 音频→视频)动态路由 提高了模型收敛速度和生成质量 3) 无条件上下文引导(UCG) 在推理时利用 LCT 提供的无条件支持 促进不同形式的分类器自由引导(CFG) 改善训练-推理一致性,缓解多模态 CFG 冲突 创新点 系统分析了双流联合生成框架的三个核心问题 TARP 解决了异构时间分辨率的对齐问题 LCT + DCR 为跨模态交互提供稳定锚点和灵活路由 UCG 解决了多模态 CFG 的训练-推理不一致性 实验结果 与最近的学术方法相比,实现了最先进的音视频联合生成性能 所需训练资源远少于对比方法 在音视频同步质量和整体生成质量上均取得提升 横向对比分析 一、视频编辑方法对比 维度 SAMA DynaEdit EffectErase 训练需求 两阶段训练 完全免训练 在VOR数据集上训练 编辑类型 指令引导的通用编辑 动作/动态/交互编辑 物体移除+效果擦除 技术路线 语义-运动分解 Flow模型无反演 互惠学习(移除+插入) 运动保持 运动对齐预训练 低频对齐+高频抑制 N/A(任务不同) 模型依赖 需特定训练框架 模型无关 需专门训练 适用场景 工业级编辑产品 快速原型/研究 视频后期制作 性能基准 开源SOTA,接近商用 无训练方法SOTA CVPR 2026 对比分析:三种方法代表了视频编辑的三个不同发展方向。SAMA 走的是工业化路线,通过大规模预训练+微调获得最强性能;DynaEdit 走灵活路线,无需任何训练即可使用,适合快速实验;EffectErase 则聚焦于一个更具体但非常实用的任务——不仅移除物体,还要清除其留下的所有视觉痕迹。 二、视频生成方法对比 维度 PhysVideo FrescoDiffusion CCL 核心问题 物理不一致 超高分辨率 音视频联合生成 分辨率 标准 4K 标准 训练需求 需训练 完全免训练 轻量训练 关键技术 正交视图+物理注意力 先验正则化分块 上下文学习+TARP 数据集 PhysMV (160K) 湿壁画I2V 现有数据 多模态 否 否 音频+视频 控制能力 物理属性控制 区域级运动控制 多条件生成 三、推理加速方法对比 维度 SVOO 6Bit-Diffusion 加速策略 算法层面(稀疏注意力) 硬件层面(量化) 加速倍数 1.93x 1.92x 内存优化 有限 3.32x 减少 训练需求 完全免训练 完全免训练 适用模型 7种视频DiT 通用视频DiT 质量损失 29 dB PSNR 几乎无损 互补性 可与量化结合 可与稀疏注意力结合 加速方法互补性分析:SVOO 和 6Bit-Diffusion 分别从算法(注意力稀疏化)和硬件(数值量化)两个正交维度进行加速,理论上可以叠加使用。如果将两者结合,有望实现接近 4x 的加速,同时内存减少超过 3x。这为视频 DiT 的实际部署打开了大门。 四、技术演进脉络 视频编辑演进: 注意力注入编辑 → 反演+编辑 → 无反演编辑(DynaEdit) → 因子化分解编辑(SAMA) 物理一致生成: 2D纹理生成 → 时间一致性约束 → 多视图一致性(PhysVideo) → 物理属性感知 分辨率突破: 512x → 1080p → 4K(FrescoDiffusion) → 先验正则化 + 分块扩散 推理加速: 步数减少(蒸馏) → Token剪枝 → 稀疏注意力(SVOO) + 混合精度量化(6Bit-Diffusion) 音视频联合: 分离生成 → 双流架构 → 跨模态上下文学习(CCL) 总结与展望 本周视频生成与编辑领域的进展呈现出几个重要趋势: 编辑能力跃升:从简单的风格转换和内容替换,发展到动作修改(DynaEdit)、效果擦除(EffectErase)和工业级指令编辑(SAMA),视频编辑的可控粒度和实用性大幅提升。 物理世界建模:PhysVideo 通过引入正交多视图约束和物理属性感知,标志着视频生成开始从"看起来像"向"符合物理规律"转变。这是迈向世界模型的重要一步。 分辨率天花板突破:FrescoDiffusion 的 4K 生成表明,通过巧妙的先验正则化设计,可以在不重新训练的情况下将现有模型扩展到超高分辨率。 部署友好化:SVOO 和 6Bit-Diffusion 从算法和硬件两个维度各自实现了约 2x 的加速,且两者互补可叠加。这使得高质量视频 DiT 在消费级硬件上运行成为可能。 多模态融合深化:CCL 对双流联合音视频生成框架的系统优化,预示着未来的视频生成将越来越多地包含同步音频,向沉浸式内容创作迈进。 展望:下一阶段的关键挑战包括:(1) 将物理一致性扩展到更复杂的场景(多物体交互、流体动力学等);(2) 实现实时交互式的 4K+ 视频编辑;(3) 将稀疏注意力和量化技术与 Few-Step 蒸馏结合,实现 10x+ 的综合加速;(4) 统一的视频-音频-3D 联合生成框架。 本报告由人工智能炼丹师自动整理生成,基于 arXiv 2026年3月第三周公开论文。