搜索到
3
篇与
推理加速
的结果
-
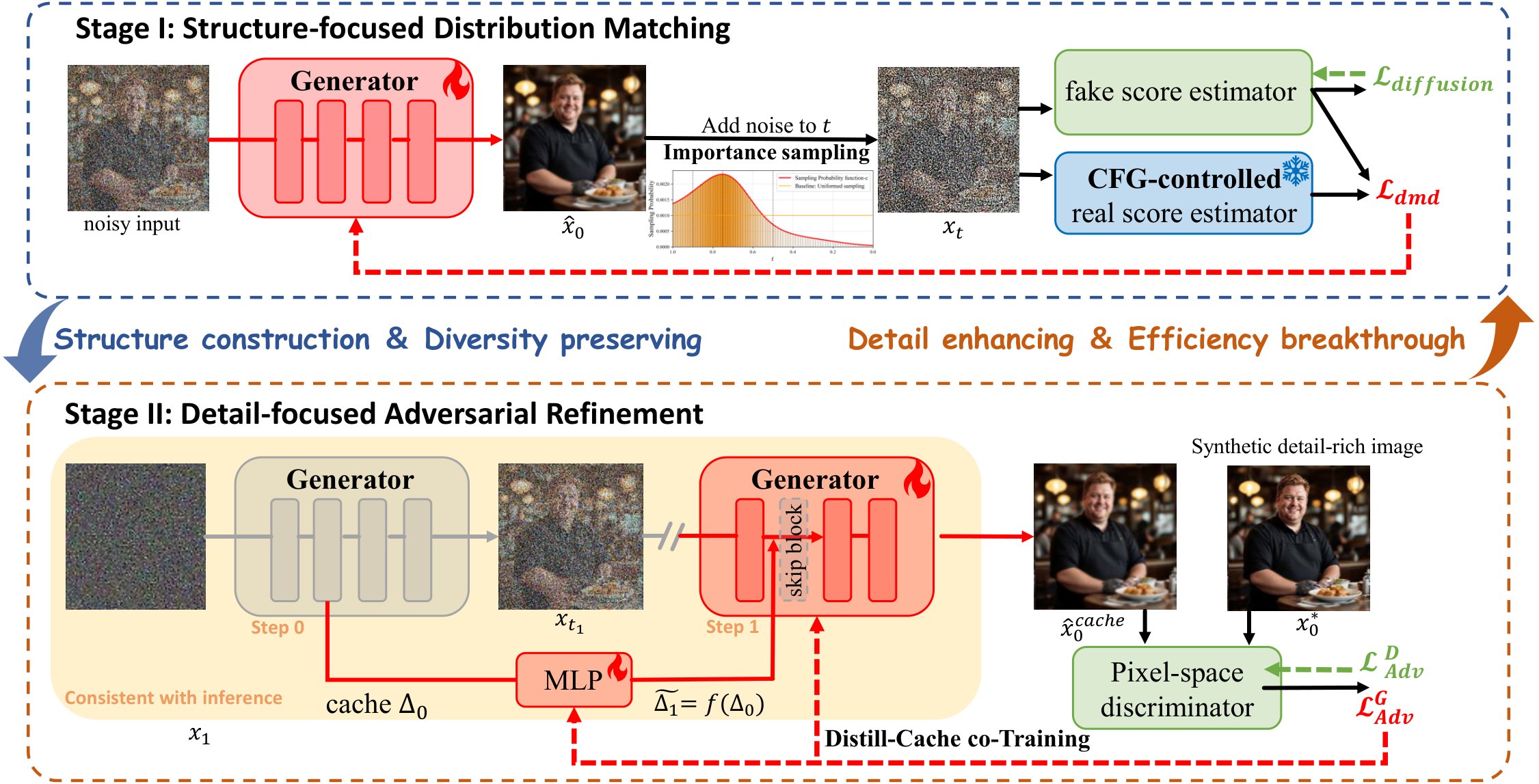
 AIGC 每日速读|2026-04-08|分数步蒸馏(1.x-Distill)实现33x推理加速 今日核心看点 分数步蒸馏(1.x-Distill) 空间编辑基准(SpatialEdit) 通用音频生成(OmniSonic) 视频DiT缓存(Chorus) 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成推理加速: 3篇 (1.x-Distill, Chorus, OP-GRPO) 图像编辑与评测: 3篇 (SpatialEdit, VicoEdit, Think-in-Strokes) 音频生成: 1篇 (OmniSonic, CVPR 2026) 视频生成: 1篇 (Vanast, CVPR 2026) 生成理解一体化: 1篇 (退化图像理解CLEAR) 含 3 篇 CVPR 2026 接收论文 重点论文深度解读 1. 1.x-Distill 首个分数步蒸馏框架——打破整数步约束实现33倍加速 | Unknown | arXiv:2604.04018 关键词: 蒸馏加速, 分布匹配蒸馏, 分数步推理, CFG控制, 块级缓存, SD3 研究动机 核心问题: 扩散模型迭代去噪计算量大,分布匹配蒸馏在极端少步时多样性崩溃 扩散模型生成高质量图像,但迭代去噪计算量大。分布匹配蒸馏(DMD)是少步蒸馏的有前途路径,但在 2 步或更少时遭遇多样性崩溃和保真度下降。作者发现两个核心问题:(1) 教师模型 CFG 在高噪声时域驱使学生过早坍缩到少数主导模式;(2) 极端少步蒸馏下,单一目标函数无法同时兼顾全局结构和细节。 前序工作及局限: DMD/DMD2:分布匹配蒸馏的先驱,但 2 步以下多样性严重崩溃 TDM/SenseFlow:无图像训练蒸馏,但未发现 CFG 导致模式坍缩的根因 DDIM/一致性模型:少步采样加速,但受限于整数步约束 DeepCache/Learning-to-Cache:DiT 块级缓存加速,但未与蒸馏训练过程整合 与前序工作的本质区别: 首次将分布匹配蒸馏与块级缓存统一,发现并解决 CFG 导致模式崩溃的根因,提出分数步蒸馏打破整数步约束 方法原理 1.x-Distill 框架包含三个核心创新: (1) 时间步感知 CFG 控制:在高噪声时域(t>alpha)禁用教师 CFG,使用纯条件分数引导学生覆盖更多模式;低噪声时域保留 CFG 保证细节质量。alpha=0.94 为最优阈值。 (2) 分阶段聚焦蒸馏(SFD):Stage I 结构导向分布匹配,采用重要性采样偏向 t=0.75 附近结构信息丰富的时域,避免低噪声区的过度纹理扰动;Stage II 细节导向对抗精炼,在学生的少步推理路径上生成样本,使用冻结 ConvNeXt 特征提取器 + 可训练分类头作为判别器,无需外部图像数据集。 (3) 蒸馏-缓存协同训练(DCT):观察到早期 DiT 块跨步骤时间冗余大,缓存块贡献 Delta_t = O_m - I_n,第二步跳过 6-8 个块。引入轻量级残差 MLP 预测修正缓存误差。Stage II 自然支持缓存训练,对抗损失直接监督缓存加速推理。 核心创新 首次提出分数步蒸馏概念,打破先前少步方法的整数步约束 发现并解决 DMD 中教师 CFG 导致模式崩溃的关键问题 提出分阶段聚焦蒸馏(SFD):结构导向分布匹配 + 细节导向对抗精炼 设计蒸馏-缓存协同训练(DCT),将块级缓存融入蒸馏流程 在 SD3-Medium 和 SD3.5-Large 上实现 1.67/1.74 有效 NFE,最高 33 倍加速 实验结果 SD3-Medium (24 DiT blocks): SFD 4步:FID 14.13(最佳),HPSv2 32.53,ImageReward 1.12 1.x-Distill-slow (NFE=1.75):FID 15.79,HPSv2 32.26,超越所有 2 步和大部分 4 步基线 1.x-Distill-fast (NFE=1.67):FID 16.72,HPSv2 31.69,比原始 28x2 采样加速 33 倍 SD3.5-Large (38 DiT blocks): SFD 4步:HPSv2 32.90,ImageReward 1.20(最佳) 1.x-Distill (NFE=1.74):FID 22.05,HPSv2 32.01,超越 TDM 2步基线 3.5+ HPSv2 DPG-Bench:蒸馏模型在复杂提示下总分超越多步教师模型 多样性(LPIPS):显著高于 Flash 和 TDM 等基线 用户研究:20 位评估者在 3200 提示上明确偏好 1.x-Distill 图表详解 方法核心:块级缓存设计 左图展示各 DiT 块的跨步复用误差(早期块冗余大),右图展示缓存机制:第一步完整计算并缓存块贡献,第二步跳过并用 MLP 修正恢复 CFG 在蒸馏中的作用分析 高噪声时域强 CFG 驱使学生过早模式坍缩;1.x-Distill 在高噪声区禁用 CFG,低噪声区保留 CFG 定性对比结果 SD3-Medium 上多种方法的生成质量对比,1.x-Distill 在 1.67 NFE 下仍保持连贯结构和丰富细节 批判性点评 新颖性: 首次提出分数步蒸馏概念,打破整数步约束。时域感知 CFG 控制、分阶段聚焦蒸馏、蒸馏-缓存协同训练三个创新点紧密配合。 可复现性: 代码和权重将公开。训练仅需 JourneyDB 提示数据,无需外部图像数据集。但具体训练超参数和缓存块选择策略的细节需参考附录。 影响力: 高——开辟 1.x 步蒸馏新范式,33x 加速具有重大实用价值。但目前仅验证 SD3 系列,Flux/SDXL 等架构的通用性有待考验。 深度点评: 首创分数步蒸馏 — 1.x-Distill 首次突破整数步约束,SD3 上仅 1.67 NFE 实现 33x 加速,FID 和人类偏好全面领先 推理加速三路并进 — 蒸馏(1.x-Distill) + 系统缓存(Chorus) + 训练效率(OP-GRPO),三维度全面提速 免训练方法降低门槛 — FDS(Flow Matching) 和 VicoEdit(图像编辑) 无需额外训练即可大幅提升质量 技术演进定位: 分布匹配蒸馏领域的重要推进,开辟 1.x 步生成新范式 可能的后续方向: 推广到 Flux/SDXL/视频扩散模型 自适应缓存块选择 与推理系统优化结合 其余论文速览 1. SpatialEdit:提出首个专门评估细粒度空间编辑的基准Sp SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing 关键词: 图像编辑·空间变换·几何保真度·合成数据·基准评测 贡献: 提出首个专门评估细粒度空间编辑的基准SpatialEdit-Bench,通过联合度量感知合理性和几何保真度系统评估空间操作能力。构建500K合成训练数据集SpatialEdit-500k,使用可控Blender管线生成精确的相机轨迹和物体变换真值。基于此训练16B参数的SpatialEdit-16B基线模型。 效果: SpatialEdit-16B在通用编辑任务中取得有竞争力的性能,同时在空间操作任务上大幅超越现有方法。 2. FDS:提出流分歧采样器FDS Training-Free Refinement of Flow Matching with Divergence-based Sampling 关键词: Flow Matching·采样优化·无训练·散度引导·即插即用 贡献: 提出流分歧采样器FDS,无需训练即可提升Flow Matching模型质量。核心发现:边缘速度场的散度可量化采样误导程度,利用该信号在每个求解步骤前将中间状态引导至歧义更小的区域。 效果: 作为即插即用框架,FDS兼容标准求解器和现有Flow模型,在文本到图像合成和逆问题等多种任务中一致提升保真度。 3. OmniSonic:提出通用整体音频生成任务UniHAGen OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text 关键词: 音频生成·视频到音频·Flow Matching·MoE·CVPR 2026 贡献: 提出通用整体音频生成任务UniHAGen,首次统一生成屏幕内环境音、屏幕外环境音和人类语音。设计TriAttn-DiT架构,通过三路交叉注意力同时处理三种音频条件,配合MoE门控机制自适应平衡。构建UniHAGen-Bench基准覆盖三种代表性场景。CVPR 2026。 效果: 在客观指标和人类评估上均一致超越现有最先进方法,建立了通用整体音频生成的强基线。 4. OP-GRPO:首个专为Flow-Matching模型设 OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models 关键词: GRPO·Flow Matching·离线策略·训练效率·后训练优化 贡献: 首个专为Flow-Matching模型设计的离线GRPO框架。主动选择高质量轨迹并自适应加入回放缓冲区重复使用;提出序列级重要性采样修正减轻分布偏移;发现并解决晚期去噪步骤的病态离线比率问题。 效果: 仅用平均34.2%的训练步骤即达到Flow-GRPO同等或更优性能,在图像和视频生成基准上均验证有效。 5. Vanast:提出统一框架从单张人像、服装图和姿态视频 Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision 关键词: 虚拟试穿·视频生成·扩散Transformer·人体动画·CVPR 2026 贡献: 提出统一框架从单张人像、服装图和姿态视频一步生成换装动画视频。构建大规模三元组监督数据,引入视频扩散Transformer的双模块架构稳定训练,支持零样本服装插值。CVPR 2026。 效果: 克服传统两阶段方案的身份漂移和服装扭曲问题,实现高保真、身份一致的服装迁移动画。 6. VicoEdit:提出VicoEdit——免训练且无需反演 Training-Free Image Editing with Visual Context Integration and Concept Alignment 关键词: 图像编辑·免训练·视觉上下文·概念对齐·后验采样 贡献: 提出VicoEdit——免训练且无需反演的视觉上下文注入图像编辑方法。直接基于视觉上下文将源图转换为目标图,消除扩散反演可能导致的轨迹偏离。设计概念对齐引导的后验采样方法增强编辑一致性。 效果: 免训练方法在编辑性能上甚至超越最先进的基于训练的模型。 7. Think-in-Strokes:提出过程驱动图像生成范式 Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning 关键词: 图像生成·推理过程·交错生成·可解释AI·多步细化 贡献: 提出过程驱动图像生成范式,将合成分解为思想-动作交错推理轨迹。每次迭代包含文本规划、视觉草拟、文本反思、视觉细化四个阶段。通过密集逐步监督维持空间和语义一致性。 效果: 使生成过程变得明确、可解释且可直接监督,在多种文本到图像基准上验证有效性。 8. Chorus:提出Chorus——利用跨请求相似性加速 Beyond Few-Step Inference: Accelerating Video Diffusion Transformer Model Serving with Inter-Request Caching Reuse 关键词: 视频生成·推理加速·跨请求缓存·DiT·模型服务 贡献: 提出Chorus——利用跨请求相似性加速视频扩散Transformer服务的缓存方法。采用三阶段缓存策略:完全复用阶段、区域级跨请求缓存阶段和令牌引导注意力放大阶段。在单请求内缓存无效的4步蒸馏模型上仍有效。 效果: 在工业级4步蒸馏视频DiT模型上实现高达45%的推理加速,同时维持语义对齐质量。 9. CLEAR:提出CLEAR框架连接统一多模态模型的生 CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models 关键词: 生成理解一体化·退化图像·统一多模态·强化学习·GRPO 贡献: 提出CLEAR框架连接统一多模态模型的生成和理解能力以处理退化图像。三步渐进策略:感知退化SFT建立先生成后回答推理模式;潜在表示桥替代解码-重编码绕路;交错GRPO联合优化文本推理和视觉生成。构建MMD-Bench覆盖六个基准三级退化。 效果: 显著提升退化输入鲁棒性同时保持清晰图像性能。发现移除像素级重建监督可获得更高感知质量的中间视觉状态。 趋势观察 推理加速多路径并进 — 分数步蒸馏(1.x-Distill)、跨请求缓存(Chorus)、离线GRPO(OP-GRPO)——从模型压缩、系统优化到训练效率三个维度全面提速 免训练方法持续升温 — FDS和VicoEdit均无需额外训练即可提升Flow Matching和图像编辑质量,降低部署门槛 人工智能炼丹师 整理 | 2026-04-08 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
AIGC 每日速读|2026-04-08|分数步蒸馏(1.x-Distill)实现33x推理加速 今日核心看点 分数步蒸馏(1.x-Distill) 空间编辑基准(SpatialEdit) 通用音频生成(OmniSonic) 视频DiT缓存(Chorus) 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 生成推理加速: 3篇 (1.x-Distill, Chorus, OP-GRPO) 图像编辑与评测: 3篇 (SpatialEdit, VicoEdit, Think-in-Strokes) 音频生成: 1篇 (OmniSonic, CVPR 2026) 视频生成: 1篇 (Vanast, CVPR 2026) 生成理解一体化: 1篇 (退化图像理解CLEAR) 含 3 篇 CVPR 2026 接收论文 重点论文深度解读 1. 1.x-Distill 首个分数步蒸馏框架——打破整数步约束实现33倍加速 | Unknown | arXiv:2604.04018 关键词: 蒸馏加速, 分布匹配蒸馏, 分数步推理, CFG控制, 块级缓存, SD3 研究动机 核心问题: 扩散模型迭代去噪计算量大,分布匹配蒸馏在极端少步时多样性崩溃 扩散模型生成高质量图像,但迭代去噪计算量大。分布匹配蒸馏(DMD)是少步蒸馏的有前途路径,但在 2 步或更少时遭遇多样性崩溃和保真度下降。作者发现两个核心问题:(1) 教师模型 CFG 在高噪声时域驱使学生过早坍缩到少数主导模式;(2) 极端少步蒸馏下,单一目标函数无法同时兼顾全局结构和细节。 前序工作及局限: DMD/DMD2:分布匹配蒸馏的先驱,但 2 步以下多样性严重崩溃 TDM/SenseFlow:无图像训练蒸馏,但未发现 CFG 导致模式坍缩的根因 DDIM/一致性模型:少步采样加速,但受限于整数步约束 DeepCache/Learning-to-Cache:DiT 块级缓存加速,但未与蒸馏训练过程整合 与前序工作的本质区别: 首次将分布匹配蒸馏与块级缓存统一,发现并解决 CFG 导致模式崩溃的根因,提出分数步蒸馏打破整数步约束 方法原理 1.x-Distill 框架包含三个核心创新: (1) 时间步感知 CFG 控制:在高噪声时域(t>alpha)禁用教师 CFG,使用纯条件分数引导学生覆盖更多模式;低噪声时域保留 CFG 保证细节质量。alpha=0.94 为最优阈值。 (2) 分阶段聚焦蒸馏(SFD):Stage I 结构导向分布匹配,采用重要性采样偏向 t=0.75 附近结构信息丰富的时域,避免低噪声区的过度纹理扰动;Stage II 细节导向对抗精炼,在学生的少步推理路径上生成样本,使用冻结 ConvNeXt 特征提取器 + 可训练分类头作为判别器,无需外部图像数据集。 (3) 蒸馏-缓存协同训练(DCT):观察到早期 DiT 块跨步骤时间冗余大,缓存块贡献 Delta_t = O_m - I_n,第二步跳过 6-8 个块。引入轻量级残差 MLP 预测修正缓存误差。Stage II 自然支持缓存训练,对抗损失直接监督缓存加速推理。 核心创新 首次提出分数步蒸馏概念,打破先前少步方法的整数步约束 发现并解决 DMD 中教师 CFG 导致模式崩溃的关键问题 提出分阶段聚焦蒸馏(SFD):结构导向分布匹配 + 细节导向对抗精炼 设计蒸馏-缓存协同训练(DCT),将块级缓存融入蒸馏流程 在 SD3-Medium 和 SD3.5-Large 上实现 1.67/1.74 有效 NFE,最高 33 倍加速 实验结果 SD3-Medium (24 DiT blocks): SFD 4步:FID 14.13(最佳),HPSv2 32.53,ImageReward 1.12 1.x-Distill-slow (NFE=1.75):FID 15.79,HPSv2 32.26,超越所有 2 步和大部分 4 步基线 1.x-Distill-fast (NFE=1.67):FID 16.72,HPSv2 31.69,比原始 28x2 采样加速 33 倍 SD3.5-Large (38 DiT blocks): SFD 4步:HPSv2 32.90,ImageReward 1.20(最佳) 1.x-Distill (NFE=1.74):FID 22.05,HPSv2 32.01,超越 TDM 2步基线 3.5+ HPSv2 DPG-Bench:蒸馏模型在复杂提示下总分超越多步教师模型 多样性(LPIPS):显著高于 Flash 和 TDM 等基线 用户研究:20 位评估者在 3200 提示上明确偏好 1.x-Distill 图表详解 方法核心:块级缓存设计 左图展示各 DiT 块的跨步复用误差(早期块冗余大),右图展示缓存机制:第一步完整计算并缓存块贡献,第二步跳过并用 MLP 修正恢复 CFG 在蒸馏中的作用分析 高噪声时域强 CFG 驱使学生过早模式坍缩;1.x-Distill 在高噪声区禁用 CFG,低噪声区保留 CFG 定性对比结果 SD3-Medium 上多种方法的生成质量对比,1.x-Distill 在 1.67 NFE 下仍保持连贯结构和丰富细节 批判性点评 新颖性: 首次提出分数步蒸馏概念,打破整数步约束。时域感知 CFG 控制、分阶段聚焦蒸馏、蒸馏-缓存协同训练三个创新点紧密配合。 可复现性: 代码和权重将公开。训练仅需 JourneyDB 提示数据,无需外部图像数据集。但具体训练超参数和缓存块选择策略的细节需参考附录。 影响力: 高——开辟 1.x 步蒸馏新范式,33x 加速具有重大实用价值。但目前仅验证 SD3 系列,Flux/SDXL 等架构的通用性有待考验。 深度点评: 首创分数步蒸馏 — 1.x-Distill 首次突破整数步约束,SD3 上仅 1.67 NFE 实现 33x 加速,FID 和人类偏好全面领先 推理加速三路并进 — 蒸馏(1.x-Distill) + 系统缓存(Chorus) + 训练效率(OP-GRPO),三维度全面提速 免训练方法降低门槛 — FDS(Flow Matching) 和 VicoEdit(图像编辑) 无需额外训练即可大幅提升质量 技术演进定位: 分布匹配蒸馏领域的重要推进,开辟 1.x 步生成新范式 可能的后续方向: 推广到 Flux/SDXL/视频扩散模型 自适应缓存块选择 与推理系统优化结合 其余论文速览 1. SpatialEdit:提出首个专门评估细粒度空间编辑的基准Sp SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing 关键词: 图像编辑·空间变换·几何保真度·合成数据·基准评测 贡献: 提出首个专门评估细粒度空间编辑的基准SpatialEdit-Bench,通过联合度量感知合理性和几何保真度系统评估空间操作能力。构建500K合成训练数据集SpatialEdit-500k,使用可控Blender管线生成精确的相机轨迹和物体变换真值。基于此训练16B参数的SpatialEdit-16B基线模型。 效果: SpatialEdit-16B在通用编辑任务中取得有竞争力的性能,同时在空间操作任务上大幅超越现有方法。 2. FDS:提出流分歧采样器FDS Training-Free Refinement of Flow Matching with Divergence-based Sampling 关键词: Flow Matching·采样优化·无训练·散度引导·即插即用 贡献: 提出流分歧采样器FDS,无需训练即可提升Flow Matching模型质量。核心发现:边缘速度场的散度可量化采样误导程度,利用该信号在每个求解步骤前将中间状态引导至歧义更小的区域。 效果: 作为即插即用框架,FDS兼容标准求解器和现有Flow模型,在文本到图像合成和逆问题等多种任务中一致提升保真度。 3. OmniSonic:提出通用整体音频生成任务UniHAGen OmniSonic: Towards Universal and Holistic Audio Generation from Video and Text 关键词: 音频生成·视频到音频·Flow Matching·MoE·CVPR 2026 贡献: 提出通用整体音频生成任务UniHAGen,首次统一生成屏幕内环境音、屏幕外环境音和人类语音。设计TriAttn-DiT架构,通过三路交叉注意力同时处理三种音频条件,配合MoE门控机制自适应平衡。构建UniHAGen-Bench基准覆盖三种代表性场景。CVPR 2026。 效果: 在客观指标和人类评估上均一致超越现有最先进方法,建立了通用整体音频生成的强基线。 4. OP-GRPO:首个专为Flow-Matching模型设 OP-GRPO: Efficient Off-Policy GRPO for Flow-Matching Models 关键词: GRPO·Flow Matching·离线策略·训练效率·后训练优化 贡献: 首个专为Flow-Matching模型设计的离线GRPO框架。主动选择高质量轨迹并自适应加入回放缓冲区重复使用;提出序列级重要性采样修正减轻分布偏移;发现并解决晚期去噪步骤的病态离线比率问题。 效果: 仅用平均34.2%的训练步骤即达到Flow-GRPO同等或更优性能,在图像和视频生成基准上均验证有效。 5. Vanast:提出统一框架从单张人像、服装图和姿态视频 Vanast: Virtual Try-On with Human Image Animation via Synthetic Triplet Supervision 关键词: 虚拟试穿·视频生成·扩散Transformer·人体动画·CVPR 2026 贡献: 提出统一框架从单张人像、服装图和姿态视频一步生成换装动画视频。构建大规模三元组监督数据,引入视频扩散Transformer的双模块架构稳定训练,支持零样本服装插值。CVPR 2026。 效果: 克服传统两阶段方案的身份漂移和服装扭曲问题,实现高保真、身份一致的服装迁移动画。 6. VicoEdit:提出VicoEdit——免训练且无需反演 Training-Free Image Editing with Visual Context Integration and Concept Alignment 关键词: 图像编辑·免训练·视觉上下文·概念对齐·后验采样 贡献: 提出VicoEdit——免训练且无需反演的视觉上下文注入图像编辑方法。直接基于视觉上下文将源图转换为目标图,消除扩散反演可能导致的轨迹偏离。设计概念对齐引导的后验采样方法增强编辑一致性。 效果: 免训练方法在编辑性能上甚至超越最先进的基于训练的模型。 7. Think-in-Strokes:提出过程驱动图像生成范式 Think in Strokes, Not Pixels: Process-Driven Image Generation via Interleaved Reasoning 关键词: 图像生成·推理过程·交错生成·可解释AI·多步细化 贡献: 提出过程驱动图像生成范式,将合成分解为思想-动作交错推理轨迹。每次迭代包含文本规划、视觉草拟、文本反思、视觉细化四个阶段。通过密集逐步监督维持空间和语义一致性。 效果: 使生成过程变得明确、可解释且可直接监督,在多种文本到图像基准上验证有效性。 8. Chorus:提出Chorus——利用跨请求相似性加速 Beyond Few-Step Inference: Accelerating Video Diffusion Transformer Model Serving with Inter-Request Caching Reuse 关键词: 视频生成·推理加速·跨请求缓存·DiT·模型服务 贡献: 提出Chorus——利用跨请求相似性加速视频扩散Transformer服务的缓存方法。采用三阶段缓存策略:完全复用阶段、区域级跨请求缓存阶段和令牌引导注意力放大阶段。在单请求内缓存无效的4步蒸馏模型上仍有效。 效果: 在工业级4步蒸馏视频DiT模型上实现高达45%的推理加速,同时维持语义对齐质量。 9. CLEAR:提出CLEAR框架连接统一多模态模型的生 CLEAR: Unlocking Generative Potential for Degraded Image Understanding in Unified Multimodal Models 关键词: 生成理解一体化·退化图像·统一多模态·强化学习·GRPO 贡献: 提出CLEAR框架连接统一多模态模型的生成和理解能力以处理退化图像。三步渐进策略:感知退化SFT建立先生成后回答推理模式;潜在表示桥替代解码-重编码绕路;交错GRPO联合优化文本推理和视觉生成。构建MMD-Bench覆盖六个基准三级退化。 效果: 显著提升退化输入鲁棒性同时保持清晰图像性能。发现移除像素级重建监督可获得更高感知质量的中间视觉状态。 趋势观察 推理加速多路径并进 — 分数步蒸馏(1.x-Distill)、跨请求缓存(Chorus)、离线GRPO(OP-GRPO)——从模型压缩、系统优化到训练效率三个维度全面提速 免训练方法持续升温 — FDS和VicoEdit均无需额外训练即可提升Flow Matching和图像编辑质量,降低部署门槛 人工智能炼丹师 整理 | 2026-04-08 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注 -
AIGC 周末专题深度解读:视频生成与编辑前沿进展|2026-03-22|SAMA|DynaEdit|PhysVideo| AIGC 周末专题深度解读 | 2026-03-22 | 视频生成与编辑前沿进展 人工智能炼丹师 整理 | 本期专题聚焦 2026 年 3 月第三周(3.15-3.22)视频生成与编辑领域的最新突破,涵盖物理一致生成、无训练编辑、高分辨率合成、推理加速、联合音视频生成等多个前沿方向。 专题概述 视频生成与编辑是当前 AIGC 领域最活跃的研究方向之一。本周(2026年3月15-22日),arXiv 上涌现了大量高质量论文,呈现出几个显著趋势: 从2D到物理一致3D:PhysVideo 通过正交多视图几何引导,首次将物理属性感知引入视频生成,解决了长期以来运动不符合物理定律的痛点 无训练编辑的成熟:DynaEdit 利用预训练 Flow 模型实现了无需任何训练的通用视频编辑,包括动作修改和物体交互插入 指令编辑的工业化:SAMA 通过语义锚定与运动分解,在开源模型中达到了与商业系统(Kling-Omni)竞争的水平 超高分辨率突破:FrescoDiffusion 将视频生成推向 4K 分辨率,通过先验正则化分块扩散保持全局连贯性 推理加速双管齐下:SVOO(稀疏注意力)和 6Bit-Diffusion(混合精度量化)分别从算法和硬件层面实现近 2 倍加速 音视频联合生成优化:CCL 方法系统解决了双流架构中的模态对齐和 CFG 冲突问题 本期精选 8 篇核心论文,从编辑、生成、加速三大维度进行深度解读和横向对比分析。 1. SAMA:分解语义锚定与运动对齐的指令引导视频编辑 论文信息 标题:SAMA: Factorized Semantic Anchoring and Motion Alignment for Instruction-Guided Video Editing 作者:Xinyao Zhang, Wenkai Dong, Yuxin Song, Bo Fang 等(字节跳动/清华大学) arXiv:2603.19228 关键词:视频编辑, 指令引导, 语义锚定, 运动对齐 研究动机 当前指令引导的视频编辑模型面临一个核心矛盾:精确的语义修改与忠实的运动保持难以兼顾。现有方法依赖注入外部先验(VLM 特征、结构条件)来缓解这一问题,但外部先验的引入严重限制了模型的鲁棒性和泛化能力。SAMA 提出了一个根本性的解决思路——将视频编辑分解为两个正交的子任务。 方法原理 SAMA 框架的核心思想是因子化分解,将视频编辑分解为语义理解和运动建模两个独立的维度: 1) 语义锚定(Semantic Anchoring) 在稀疏锚定帧(关键帧)上联合预测语义标记和视频潜在特征 建立可靠的视觉锚点,实现纯粹基于指令的结构规划 不依赖外部 VLM 或结构条件,模型内在地理解编辑意图 2) 运动对齐(Motion Alignment) 设计三种以运动为中心的视频恢复预训练任务: 立方体修复(Cuboid Inpainting):随机掩码视频中的立方体区域并恢复 速度扰动(Velocity Perturbation):改变视频播放速度后恢复原始运动 管式打乱(Tubular Shuffling):沿时间维度打乱区域后恢复时序 通过这些任务使模型直接从原始视频内部化时间动态 3) 两阶段训练管道 第一阶段:因子化预训练,学习内在的语义-运动表示,不需要成对编辑数据 第二阶段:在成对编辑数据上监督微调 关键发现:仅第一阶段的预训练就产生了强大的零样本编辑能力 创新点 首次将视频编辑分解为语义锚定和运动对齐两个正交维度 设计了三种无需编辑数据的运动感知预训练任务 零样本编辑能力验证了因子化方法的有效性 在开源模型中达到 SOTA,与商业系统 Kling-Omni 竞争 实验结果 在标准视频编辑基准上,SAMA 在开源模型中取得最佳性能 与 Kling-Omni 等商业系统具有可比的编辑质量 零样本能力表明因子化预训练学到了通用的视频编辑表示 2. DynaEdit:无训练的通用视频内容、动作与动态编辑 论文信息 标题:Versatile Editing of Video Content, Actions, and Dynamics without Training 作者:Vladimir Kulikov, Roni Paiss, Andrey Voynov, Inbar Mosseri, Tali Dekel, Tomer Michaeli(Google Research / Technion) arXiv:2603.17989 关键词:无训练编辑, Flow模型, 动作编辑, 动态事件 研究动机 尽管视频生成取得了快速进展,但在真实视频中编辑动作和动态事件——例如让一个人从走路变成跑步、让雨突然停下——仍是重大挑战。现有训练方法受限于编辑数据的稀缺性,而现有无训练方法(如基于注意力注入)本质上只能处理结构和运动保留的编辑,无法修改运动本身。 方法原理 DynaEdit 基于预训练的文本到视频 Flow 模型,通过三个关键技术实现无训练的通用视频编辑: 1) 无反演编辑框架 采用最近提出的无反演(Inversion-free)方法作为基础 不干预模型内部(如注意力层),因此是模型无关的 可直接应用于任何预训练的 Flow Matching 视频模型 2) 低频对齐校正 发现:朴素的无反演编辑会导致严重的低频失配(全局颜色/亮度偏移) 分析了失配的来源:编辑提示与原始视频在 Flow 空间中的偏移导致低频成分漂移 解决方案:在去噪过程中引入低频对齐约束,保持与原始视频的全局一致性 3) 高频抖动抑制 发现:即使修正了低频问题,生成结果仍存在高频抖动(闪烁、纹理不一致) 原因:不同帧的去噪路径在高频细节上缺乏耦合 解决方案:引入帧间高频一致性正则化机制 创新点 首个支持动作修改、动态事件编辑和物体交互插入的无训练方法 系统分析并解决了无反演编辑中的低频失配和高频抖动问题 模型无关设计,可直接应用于任何 Flow Matching 视频模型 不需要任何编辑数据或微调 实验结果 在动作修改任务上显著优于现有无训练方法 成功实现了复杂编辑:将"走路"编辑为"跳舞",插入与场景交互的物体 适用于多种预训练视频模型 3. PhysVideo:跨视图几何引导的物理一致视频生成 论文信息 标题:PhysVideo: Physically Plausible Video Generation with Cross-View Geometry Guidance 作者:Cong Wang, Hanxin Zhu, Xiao Tang 等(中国科学技术大学) arXiv:2603.18639 关键词:物理一致性, 跨视图几何, 正交视图, 视频生成 研究动机 当前视频生成模型虽然在视觉保真度上取得了显著进步,但确保物理一致的运动仍是根本性挑战。核心原因在于:真实世界的物体运动在三维空间中展开,而视频观察仅提供了这些动力学的局部、视角依赖的投影。这导致模型容易生成违反物理定律的运动——球在空中突然变向、物体穿过墙壁等。 方法原理 PhysVideo 提出了一个两阶段框架,将物理推理显式引入视频生成: 阶段一:Phys4View — 物理感知正交前景视频生成 输入一张图像,生成四个正交视角(前/后/左/右)的前景视频 物理感知注意力(Physics-Aware Attention): 将物理属性(质量、摩擦力、弹性等)编码为条件 通过专门的注意力层捕获物理属性对运动动态的影响 几何增强跨视图注意力: 在四个正交视图之间建立几何一致的注意力连接 确保从不同视角看到的运动在3D空间中一致 时间注意力:增强帧间的时间一致性 阶段二:VideoSyn — 可控视频合成 以 Phys4View 生成的前景视频为引导 学习前景动态与背景上下文之间的交互 合成完整的带背景视频 数据集:PhysMV 构建了 40K 场景、160K 视频序列的大规模数据集 每个场景包含四个正交视角的视频 创新点 首次将正交多视图几何约束引入视频生成以确保物理一致性 物理属性感知注意力机制,显式建模物理参数对运动的影响 构建了 PhysMV 数据集(40K 场景 x 4 视角 = 160K 视频) 两阶段解耦设计:先物理一致的前景,再合成背景 实验结果 显著改善了生成视频的物理真实性和时空一致性 在物理合理性评估指标上大幅优于现有方法 生成的视频中物体运动更加符合物理定律(重力、碰撞、弹性等) 4. EffectErase:视频物体移除与效果擦除的联合框架 论文信息 标题:EffectErase: Joint Video Object Removal and Insertion for High-Quality Effect Erasing 作者:Yang Fu, Yike Zheng, Ziyun Dai, Henghui Ding arXiv:2603.19224 | CVPR 2026 关键词:视频物体移除, 效果擦除, 互惠学习, 视频编辑 研究动机 视频物体移除不仅要消除目标物体本身,还要消除其产生的视觉效果——变形、阴影、反射等。现有基于扩散的视频修复方法虽然能移除物体,但通常难以消除这些附带效果,留下不自然的痕迹。此外,该领域缺乏系统涵盖各种物体效果的大规模数据集。 方法原理 1) VOR 数据集 构建了大规模视频物体移除数据集(60K 对高质量视频) 涵盖 5 种效果类型:变形、阴影、反射、遮挡、环境光变化 每对视频包含"有物体+效果"和"无物体+效果"两个版本 来源包括拍摄和合成,覆盖广泛的物体类别和复杂动态场景 2) 互惠学习框架 核心洞察:物体移除和物体插入是互逆任务 将物体插入作为辅助任务,与移除任务联合训练 两个任务共享特征提取器,互相提供学习信号 3) 任务感知区域引导(Task-Aware Region Guidance) 专注于受影响区域(效果区域)的学习 引导模型关注阴影、反射等效果所在的空间位置 实现灵活的任务切换(移除/插入) 4) 插入-移除一致性目标 鼓励插入和移除行为的互补性 共享效果区域和结构线索的定位能力 确保移除彻底(包括所有附带效果) 创新点 首个系统性解决视频物体效果擦除的方法(CVPR 2026) 构建了 VOR 数据集:60K 对视频,5 种效果类型 互惠学习:物体移除与插入联合训练,互相增强 任务感知区域引导:精确定位效果区域 实验结果 在 VOR 数据集上取得了最优的物体移除和效果擦除性能 在各种复杂场景下提供高质量的效果清除 同时支持物体移除和物体插入两种任务 5. FrescoDiffusion:先验正则化分块扩散实现 4K 图像到视频生成 论文信息 标题:FrescoDiffusion: 4K Image-to-Video with Prior-Regularized Tiled Diffusion 作者:Hugo Caselles-Dupre, Mathis Koroglu, Guillaume Jeanneret 等(Obvious Research / Sorbonne University) arXiv:2603.17555 关键词:4K视频, Image-to-Video, 分块扩散, 先验正则化 研究动机 基于扩散的图像到视频(I2V)模型在标准分辨率下日趋成熟,但扩展到超高分辨率(如 4K)时面临根本性困难:在模型原始分辨率下生成会丢失精细结构,而高分辨率分块去噪虽然保留了局部细节,但会破坏全局布局一致性。这个问题在"湿壁画动画"场景中尤为严重——包含多个角色、物体和语义子场景的巨型艺术品必须在时间上保持空间连贯性。 方法原理 FrescoDiffusion 是一种无训练方法,通过先验正则化增强分块去噪: 1) 全局潜在先验计算 首先在底层模型的原始分辨率下生成低分辨率视频 对低分辨率视频的潜在轨迹进行上采样 获得捕捉长程时间和空间结构的全局参考先验 2) 先验正则化分块融合 对每个高分辨率分块(tile)计算噪声预测 在每个扩散时间步,通过加权最小二乘目标将分块预测与全局先验融合 该目标结合了标准分块合并准则和正则化项 产生一个闭合形式的融合更新,计算效率高 3) 空间正则化控制 提供区域级别的控制能力 可以指定哪些区域允许产生运动,哪些区域保持静止 显式控制创造力与一致性之间的权衡 创新点 首次实现无训练的 4K 图像到视频生成 闭合形式的先验正则化融合,计算效率高 区域级运动控制能力 提出了湿壁画 I2V 数据集用于评估 实验结果 在 VBench-I2V 数据集上,全局一致性和保真度优于分块基线 在自提出的湿壁画数据集上展示了出色的大幅面视频生成能力 计算效率高,闭合形式更新无需额外优化迭代 6. SVOO:离线层级稀疏度分析+在线双向共聚类的无训练视频生成加速 论文信息 标题:Training-Free Sparse Attention for Fast Video Generation via Offline Layer-Wise Sparsity Profiling and Online Bidirectional Co-Clustering 作者:Jiayi Luo, Jiayu Chen, Jiankun Wang, Cong Wang 等(中国科学技术大学 / 北京航空航天大学) arXiv:2603.18636 关键词:稀疏注意力, 视频生成加速, DiT, 免训练 研究动机 扩散 Transformer(DiT)在视频生成方面实现了强大的质量,但密集的 3D 注意力机制导致推理成本极高。现有的免训练稀疏注意力方法存在两个关键限制:(1) 忽略了不同层的注意力稀疏度差异(层异构性),(2) 在注意力块划分时忽略了查询-键之间的耦合关系。 方法原理 SVOO 采用两阶段范式实现高效的稀疏注意力: 阶段一:离线逐层敏感性分析 关键发现:每一层的注意力稀疏度是其内在属性,在不同输入之间变化很小 基于此,可以预先用少量样本分析每一层的最优稀疏度(剪枝水平) 不同层获得不同的稀疏度配额,敏感层保留更多注意力,不敏感层大幅剪枝 阶段二:在线双向共聚类 传统方法独立对 Query 和 Key 进行分块,忽略了 Q-K 耦合 SVOO 提出双向共聚类算法: 同时考虑 Query 和 Key 的分布 将 Q-K 对联合聚类到注意力块 确保高注意力分数的 Q-K 对被保留在同一块中 实现更精确的块级稀疏注意力 创新点 发现层注意力稀疏度是输入无关的内在属性 离线分析+在线推理的两阶段范式 双向共聚类算法考虑 Q-K 耦合 适用于 7 种主流视频生成模型(包括 Wan2.1) 实验结果 在 Wan2.1 上实现 1.93x 加速,同时保持 29 dB 的 PSNR 在 7 个视频生成模型上一致优于现有稀疏注意力方法 质量-速度权衡显著优于对比方法 7. 6Bit-Diffusion:视频 DiT 的推理时混合精度量化 论文信息 标题:6Bit-Diffusion: Inference-Time Mixed-Precision Quantization for Video Diffusion Models 作者:Rundong Su, Jintao Zhang, Zhihang Yuan 等(清华大学) arXiv:2603.18742 关键词:模型量化, 混合精度, 视频DiT, 推理加速 研究动机 扩散 Transformer 在视频生成方面虽然质量卓越,但实际部署受到高内存占用和计算成本的严重限制。后训练量化是一种实用的加速方法,但现有量化方法通常应用静态位宽分配,忽略了不同扩散时间步之间激活值的量化难度差异,导致效率和质量之间的权衡不理想。 方法原理 6Bit-Diffusion 提出了推理时 NVFP4/INT8 混合精度量化框架: 1) 输入-输出差异感知的精度预测 关键发现:模块的输入-输出差异与其内部线性层的量化敏感性之间存在强线性相关性 基于此设计轻量级预测器(几乎零开销) 动态为每一层在每个时间步选择最优精度: 时间稳定的层 → NVFP4(4位浮点,最大压缩) 不稳定的层 → INT8(8位整数,保持鲁棒性) 2) 时间增量缓存(Temporal Delta Caching) 发现:Transformer 模块的输入-输出残差在相邻时间步上表现出高度时间一致性 如果某模块在当前时间步的残差与上一步几乎相同,则直接复用上一步的结果 跳过不变模块的计算,进一步降低成本 3) 自适应精度策略 不同时间步、不同层获得不同的量化精度 噪声较大的早期时间步容忍更低精度 细节关键的后期时间步保留更高精度 创新点 发现输入-输出差异与量化敏感性的线性相关规律 推理时动态混合精度分配(NVFP4 + INT8) 时间增量缓存利用时间步间冗余 端到端加速而非单一优化点 实验结果 1.92x 端到端加速 3.32x 内存减少 生成质量与全精度模型几乎无差异 为高效视频 DiT 推理设立了新基准 8. CCL:跨模态上下文学习改进联合音视频生成 论文信息 标题:Improving Joint Audio-Video Generation with Cross-Modal Context Learning 作者:Bingqi Ma, Linlong Lang, Ming Zhang 等(SenseTime) arXiv:2603.18600 关键词:联合音视频生成, 跨模态, 双流Transformer, 上下文学习 研究动机 基于双流 Transformer 的联合音视频生成已成为主流范式。通过结合预训练的视频和音频扩散模型,加上跨模态交互注意力,可以用最少的训练数据生成高质量同步音视频。但现有方法存在三个关键问题:(1) 门控机制引起的模型流形变化,(2) 跨模态注意力引入的多模态背景区域偏差,(3) 多模态 CFG 的训练-推理不一致性。 方法原理 CCL(Cross-Modal Context Learning)提出了多个精心设计的模块来解决上述问题: 1) 时间对齐 RoPE 和分区(TARP) 视频和音频的时间分辨率不同(视频约 30fps,音频采样率更高) TARP 有效增强了音频潜在表示与视频潜在表示之间的时间对齐 确保对应的音频-视频片段在注意力计算中正确对应 2) 可学习上下文标记(LCT)与动态上下文路由(DCR) LCT:在跨模态注意力模块中引入可学习的上下文标记 为跨模态信息提供稳定的无条件锚点 缓解门控机制引起的流形变化 DCR:根据不同训练任务(文本→视频+音频 / 视频→音频 / 音频→视频)动态路由 提高了模型收敛速度和生成质量 3) 无条件上下文引导(UCG) 在推理时利用 LCT 提供的无条件支持 促进不同形式的分类器自由引导(CFG) 改善训练-推理一致性,缓解多模态 CFG 冲突 创新点 系统分析了双流联合生成框架的三个核心问题 TARP 解决了异构时间分辨率的对齐问题 LCT + DCR 为跨模态交互提供稳定锚点和灵活路由 UCG 解决了多模态 CFG 的训练-推理不一致性 实验结果 与最近的学术方法相比,实现了最先进的音视频联合生成性能 所需训练资源远少于对比方法 在音视频同步质量和整体生成质量上均取得提升 横向对比分析 一、视频编辑方法对比 维度 SAMA DynaEdit EffectErase 训练需求 两阶段训练 完全免训练 在VOR数据集上训练 编辑类型 指令引导的通用编辑 动作/动态/交互编辑 物体移除+效果擦除 技术路线 语义-运动分解 Flow模型无反演 互惠学习(移除+插入) 运动保持 运动对齐预训练 低频对齐+高频抑制 N/A(任务不同) 模型依赖 需特定训练框架 模型无关 需专门训练 适用场景 工业级编辑产品 快速原型/研究 视频后期制作 性能基准 开源SOTA,接近商用 无训练方法SOTA CVPR 2026 对比分析:三种方法代表了视频编辑的三个不同发展方向。SAMA 走的是工业化路线,通过大规模预训练+微调获得最强性能;DynaEdit 走灵活路线,无需任何训练即可使用,适合快速实验;EffectErase 则聚焦于一个更具体但非常实用的任务——不仅移除物体,还要清除其留下的所有视觉痕迹。 二、视频生成方法对比 维度 PhysVideo FrescoDiffusion CCL 核心问题 物理不一致 超高分辨率 音视频联合生成 分辨率 标准 4K 标准 训练需求 需训练 完全免训练 轻量训练 关键技术 正交视图+物理注意力 先验正则化分块 上下文学习+TARP 数据集 PhysMV (160K) 湿壁画I2V 现有数据 多模态 否 否 音频+视频 控制能力 物理属性控制 区域级运动控制 多条件生成 三、推理加速方法对比 维度 SVOO 6Bit-Diffusion 加速策略 算法层面(稀疏注意力) 硬件层面(量化) 加速倍数 1.93x 1.92x 内存优化 有限 3.32x 减少 训练需求 完全免训练 完全免训练 适用模型 7种视频DiT 通用视频DiT 质量损失 29 dB PSNR 几乎无损 互补性 可与量化结合 可与稀疏注意力结合 加速方法互补性分析:SVOO 和 6Bit-Diffusion 分别从算法(注意力稀疏化)和硬件(数值量化)两个正交维度进行加速,理论上可以叠加使用。如果将两者结合,有望实现接近 4x 的加速,同时内存减少超过 3x。这为视频 DiT 的实际部署打开了大门。 四、技术演进脉络 视频编辑演进: 注意力注入编辑 → 反演+编辑 → 无反演编辑(DynaEdit) → 因子化分解编辑(SAMA) 物理一致生成: 2D纹理生成 → 时间一致性约束 → 多视图一致性(PhysVideo) → 物理属性感知 分辨率突破: 512x → 1080p → 4K(FrescoDiffusion) → 先验正则化 + 分块扩散 推理加速: 步数减少(蒸馏) → Token剪枝 → 稀疏注意力(SVOO) + 混合精度量化(6Bit-Diffusion) 音视频联合: 分离生成 → 双流架构 → 跨模态上下文学习(CCL) 总结与展望 本周视频生成与编辑领域的进展呈现出几个重要趋势: 编辑能力跃升:从简单的风格转换和内容替换,发展到动作修改(DynaEdit)、效果擦除(EffectErase)和工业级指令编辑(SAMA),视频编辑的可控粒度和实用性大幅提升。 物理世界建模:PhysVideo 通过引入正交多视图约束和物理属性感知,标志着视频生成开始从"看起来像"向"符合物理规律"转变。这是迈向世界模型的重要一步。 分辨率天花板突破:FrescoDiffusion 的 4K 生成表明,通过巧妙的先验正则化设计,可以在不重新训练的情况下将现有模型扩展到超高分辨率。 部署友好化:SVOO 和 6Bit-Diffusion 从算法和硬件两个维度各自实现了约 2x 的加速,且两者互补可叠加。这使得高质量视频 DiT 在消费级硬件上运行成为可能。 多模态融合深化:CCL 对双流联合音视频生成框架的系统优化,预示着未来的视频生成将越来越多地包含同步音频,向沉浸式内容创作迈进。 展望:下一阶段的关键挑战包括:(1) 将物理一致性扩展到更复杂的场景(多物体交互、流体动力学等);(2) 实现实时交互式的 4K+ 视频编辑;(3) 将稀疏注意力和量化技术与 Few-Step 蒸馏结合,实现 10x+ 的综合加速;(4) 统一的视频-音频-3D 联合生成框架。 本报告由人工智能炼丹师自动整理生成,基于 arXiv 2026年3月第三周公开论文。
-
AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 专题方向:视频 DiT 中的稀疏注意力、线性注意力与推理加速 覆盖时间:2026年3月2日 — 2026年3月13日 整理:人工智能炼丹师 日期:2026年3月14日(周六) 一、专题概览 本周是视频扩散 Transformer(Video DiT)高效推理方向的"论文爆发周"。短短一周内,arXiv 上出现了 9 篇 高度聚焦于视频 DiT 注意力加速与推理优化的论文,覆盖了从稀疏注意力、线性注意力、结构化注意力,到蒸馏压缩、缓存+剪枝、系统级并行优化的完整技术栈。 核心背景 当前主流视频生成模型(Wan 2.1/2.2、HunyuanVideo、Mochi 等)均采用 Diffusion Transformer(DiT)架构,其核心瓶颈在于 全注意力(Full 3D Attention)的 O(N²) 复杂度。一段 5 秒 720P 视频的 token 序列长度可达数十万,全注意力的计算量和显存占用极其惊人。因此,如何在保持生成质量的前提下大幅降低注意力计算成本,成为本周研究的核心主题。 本周论文全景 # 论文 方法类别 核心思路 加速比 提交日期 1 CalibAtt 稀疏注意力(免训练) 离线校准块级稀疏模式 1.58x E2E 3月5日 2 SVG-EAR 稀疏注意力 + 线性补偿(免训练) 误差感知路由 + 聚类质心补偿 1.77-1.93x 3月9日 3 SODA 缓存 + 剪枝(免训练) 敏感度导向的动态加速 SOTA fidelity 3月7日 4 FrameDiT 结构化注意力(需训练) 帧级矩阵注意力 ~Local FA 3月10日 5 VMonarch 结构化注意力(轻量微调) Monarch 矩阵分解 5x attn, 17.5x FLOPs↓ 1月29日 6 SALAD 稀疏 + 线性混合(轻量微调) 门控线性注意力并行分支 1.72x, 90%稀疏 1月23日 7 SLA 稀疏 + 线性融合(微调) 三级权重分类 + 自定义 kernel 2.2x E2E, 13.7x attn 2025.9 (ICLR'26) 8 FastLightGen 蒸馏 + 剪枝 步数+参数同时压缩 4步+30%剪枝 3月2日 9 Diagonal Distillation 自回归蒸馏 对角蒸馏 + 隐式光流 277.3x, 31 FPS 3月10日 二、重点论文深度解读 论文 1:CalibAtt — 校准稀疏注意力加速视频生成 标题:Accelerating Text-to-Video Generation with Calibrated Sparse Attention 作者:Shai Yehezkel, Shahar Yadin, Noam Elata 等 机构:以色列理工 日期:2026年3月5日 arXiv:2603.05503 关键词:稀疏注意力 免训练 离线校准 块级模式 Wan 2.1 Mochi 研究动机 视频 DiT 中的全注意力计算是推理速度的主要瓶颈。已有的稀疏注意力方法要么需要训练(如 SLA、SALAD),要么是在线动态判断每个 token 的重要性(开销大)。作者观察到一个关键现象:大量 token-to-token 连接在不同输入上一致地产生可忽略的注意力分数,且这些模式在不同查询间重复出现。 方法原理 CalibAtt 采用"离线校准 + 在线高效推理"的两阶段策略: 离线校准阶段:在少量参考视频上运行全注意力,统计每一层、每个注意力头、每个扩散时间步的块级(block-level)稀疏模式和重复模式 模式编译:将稳定的稀疏模式编译为优化的注意力操作(类似于"稀疏注意力的 JIT 编译") 在线推理:只计算被选中的输入相关连接,以硬件友好的方式跳过未选中的连接 核心创新 块级粒度:不做 token 级稀疏(开销大),而是以 token block 为单位,兼顾精度和效率 跨输入稳定性:发现稀疏模式对输入不敏感,可以离线固定 层-头-时间步三维校准:不同层/头/时间步的稀疏模式不同,细粒度适配 实验结果 在 Wan 2.1 14B、Mochi 1 及其蒸馏版本上测试 实现 1.58x 端到端加速 在视频生成质量和文本-视频对齐度上优于已有免训练方法 支持多种分辨率 技术脉络 Sparse VideoGen (2024) → Sparse VideoGen2 (2025.5) → CalibAtt (2026.3)。从在线动态稀疏 → 离线校准静态稀疏,核心洞察是"稀疏模式跨输入稳定"。 批判性点评 优势:完全免训练,直接即插即用;离线校准成本低;硬件友好 局限:1.58x 的加速比在本周论文中并不突出;块级粒度可能丢失细粒度信息;对新架构需要重新校准 创新性评分:3/5 — 洞察有价值但方法相对直接 论文 2:SVG-EAR — 无参数线性补偿的误差感知路由 标题:SVG-EAR: Parameter-Free Linear Compensation for Sparse Video Generation via Error-aware Routing 作者:Xuanyi Zhou, Qiuyang Mang, Shuo Yang 等 (UC Berkeley, Ion Stoica 组) 日期:2026年3月9日 arXiv:2603.08982 关键词:稀疏注意力 线性补偿 误差感知路由 聚类质心 免训练 Wan 2.2 HunyuanVideo 研究动机 现有稀疏注意力方法面临两难:(1) 直接丢弃被跳过的注意力块会丢失信息;(2) 用学习型预测器来近似它们又引入训练开销和分布偏移。能否在不训练的情况下恢复被跳过块的贡献? 方法原理 SVG-EAR 的核心洞察:经过语义聚类后,同一块内的 key 和 value 具有高度相似性,可以用少量聚类质心准确概括。 聚类质心补偿:对被跳过的注意力块,用 key/value 的聚类质心做线性(O(N))近似,恢复其对输出的贡献 误差感知路由:传统方法按注意力分数选择需要精确计算的块,但高注意力分数 ≠ 高近似误差。SVG-EAR 用一个轻量探测器估计每个块的补偿误差,选择"误差-成本比"最高的块做精确计算 理论保证:提供了注意力重建误差与聚类质量之间的理论上界 核心创新 误差感知 vs 分数感知:颠覆了传统"高注意力分数 = 重要"的假设,改为"高近似误差 = 需要精确计算" 无参数线性补偿:用聚类质心做 O(N) 补偿,不需要任何训练 帕累托最优:在所有免训练方法中建立了新的帕累托前沿 实验结果 Wan 2.2:1.77x 加速,PSNR 29.759 HunyuanVideo:1.93x 加速,PSNR 31.043 显著优于 Sparse VideoGen2 和 CalibAtt 技术脉络 Sparse VideoGen → SVG2 → SVG-EAR(同一系列的第三代,Ion Stoica / Berkeley 团队的持续推进) 批判性点评 优势:免训练、有理论保证、误差感知路由的思路很优雅 局限:聚类质心计算本身有开销;实际 wall-clock 加速受限于聚类效率;PSNR 不是视频生成的最佳指标 创新性评分:4/5 — 误差感知路由是本周最有洞察的方法论创新 论文 3:SODA — 敏感度导向的动态加速 标题:SODA: Sensitivity-Oriented Dynamic Acceleration for Diffusion Transformer 作者:Tong Shao, Yusen Fu 等 日期:2026年3月7日 arXiv:2603.07057 关键词:缓存 剪枝 敏感度分析 动态规划 免训练 DiT-XL PixArt-α OpenSora 研究动机 特征缓存(caching)和 token 剪枝(pruning)是两种互补的加速手段:缓存加速效率高但影响保真度,剪枝相反。现有方法用固定的启发式策略组合两者,无法捕捉模型对加速操作的细粒度敏感度变化。 方法原理 离线敏感度建模:构建跨时间步、层、模块的敏感度误差模型,量化每个计算单元对缓存/剪枝操作的敏感程度 动态规划优化缓存间隔:以敏感度误差为代价函数,用 DP 求解最优缓存时间点 自适应剪枝:在缓存复用阶段,根据 token 敏感度动态决定剪枝时机和比例 核心创新 敏感度误差建模:不是简单地均匀缓存/剪枝,而是"在最不敏感处缓存,在最不敏感的 token 处剪枝" DP 最优化:缓存间隔不再是超参数,而是通过动态规划自动求解 实验结果 在 DiT-XL/2、PixArt-α、OpenSora 上实现 SOTA 生成保真度 在可控加速比下保真度显著优于 PAB、∆-DiT 等基线 技术脉络 FasterCache (2024) → ∆-DiT (2024) → PAB → SODA (2026.3) 批判性点评 优势:缓存+剪枝的统一框架,敏感度建模理论扎实 局限:离线敏感度分析需要额外推理开销;DP 只优化缓存间隔,未联合优化剪枝策略;仅测试了较小的模型(DiT-XL/2),未在 Wan/HunyuanVideo 等大模型上验证 创新性评分:3.5/5 论文 4:VMonarch — Monarch 矩阵结构化注意力 标题:VMonarch: Efficient Video Diffusion Transformers with Structured Attention 作者:Cheng Liang, Haoxian Chen, Liang Hou 等 (南京大学 + 腾讯) 日期:2026年1月29日 arXiv:2601.22275 关键词:Monarch矩阵 结构化稀疏 交替最小化 FlashAttention 在线熵 5x加速 研究动机 视频 DiT 的注意力模式天然具有高度稀疏的时空结构,但现有稀疏方法(Top-K、局部窗口)要么不灵活,要么丢失全局信息。能否找到一种数学上优雅的方式来表示这些稀疏模式? 方法原理 VMonarch 将视频 DiT 的稀疏注意力模式建模为 Monarch 矩阵 —— 一类具有灵活稀疏性的结构化矩阵。 时空 Monarch 分解:将全注意力矩阵分解为帧内(空间)和帧间(时间)两组 Monarch 因子,分别捕捉空间和时间相关性 交替最小化:通过交替优化两组因子来逼近原始全注意力 重计算策略:解决交替最小化不稳定导致的伪影问题 在线熵算法:融入 FlashAttention 的在线熵计算,支持长序列高效更新 核心创新 Monarch 矩阵在视频 DiT 中的首次应用:优雅地统一了稀疏和结构化的优势 在线熵 + FlashAttention 融合:使得 Monarch 矩阵更新在长序列上也可行 实验结果 注意力 FLOPs 减少 17.5 倍 注意力计算加速 5 倍以上 在 VBench 上轻量微调后质量与全注意力相当 90% 稀疏度下超越所有 SOTA 稀疏注意力方法 技术脉络 Monarch Mixer (2023) → Monarch in LLM → VMonarch (视频 DiT 首次应用) 批判性点评 优势:数学上最优雅的方案;17.5x FLOPs 减少是本周最极端的数字;与 FlashAttention 兼容 局限:交替最小化的收敛性依赖初始化;需要轻量微调(非完全免训练);实际 wall-clock 加速(5x)远小于理论 FLOPs 减少(17.5x),说明实现上有瓶颈 创新性评分:4.5/5 — 本周最具理论深度的工作 论文 5:SLA — 稀疏-线性注意力融合 标题:SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention 作者:Jintao Zhang 等 (清华 + Berkeley) 日期:2025年9月28日(ICLR 2026 Oral) arXiv:2509.24006 关键词:稀疏注意力 线性注意力 融合 自定义GPU kernel 95%计算减少 ICLR 2026 研究动机 注意力权重可以分为两部分:少量大权重(高秩)和大量小权重(低秩)。这天然暗示:对大权重用稀疏注意力(O(N²) 但只算少量),对小权重用线性注意力(O(N))。 方法原理 三级分类:将注意力权重分为 Critical(O(N²) 精确计算)、Marginal(O(N) 线性注意力)、Negligible(跳过) 融合 GPU kernel:将稀疏和线性注意力的计算融合到单个 GPU kernel 中,支持前向和反向传播 轻量微调:仅需少量微调步就能适配 核心创新 稀疏+线性的系统性融合:不是简单的 fallback,而是基于权重分布的最优分配 自定义 GPU kernel:工程实现极其扎实,直接转化为实际加速 实验结果 注意力计算减少 95%(20 倍) 注意力加速 13.7 倍 端到端加速 2.2 倍(Wan 2.1-1.3B) 生成质量无损 技术脉络 稀疏注意力 + 线性注意力两条独立技术路线 → SLA 首次统一融合(ICLR 2026 Oral) 批判性点评 优势:ICLR 2026 Oral,学术认可度最高;2.2x E2E 加速是免训练之外的最佳实际数字;自定义 kernel 可直接落地 局限:需要微调(虽然很轻量);目前只在 1.3B 模型上测试,14B 模型的效果未知;kernel 需要针对不同硬件调优 创新性评分:4.5/5 论文 6:SALAD — 高稀疏度线性注意力微调 标题:SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer 作者:Tongcheng Fang 等 (清华 + 腾讯) 日期:2026年1月23日 arXiv:2601.16515 关键词:线性注意力 门控机制 高稀疏度 轻量微调 2000样本 研究动机 免训练稀疏注意力受限于有限的稀疏度(通常 50-70%),而训练型方法需要大量数据和计算。能否用极轻量的微调达到极高稀疏度? 方法原理 双分支并行:在稀疏注意力旁边添加一个轻量线性注意力分支 输入依赖门控:用门控机制动态平衡两个分支的贡献 极轻量微调:仅需 2000 个视频样本和 1600 步训练 实验结果 90% 稀疏度,1.72x 推理加速 生成质量与全注意力基线相当 批判性点评 思路与 SLA 类似但更轻量;微调效率极高(2000 样本);但 1.72x 加速低于 SLA 的 2.2x 创新性评分:3.5/5 论文 7:FastLightGen — 步数 + 参数同时压缩 标题:FastLightGen: Fast and Light Video Generation with Fewer Steps and Parameters 作者:Shitong Shao, Yufei Gu, Zeke Xie 日期:2026年3月2日 arXiv:2603.01685 关键词:蒸馏 剪枝 步数压缩 参数压缩 HunyuanVideo WanX 研究动机 以往的加速研究要么减少采样步数(蒸馏),要么减少模型参数(剪枝),但从未同时压缩两者。 方法原理 FastLightGen 的核心:构建一个"最优教师模型",在协同框架中同时蒸馏步数和参数。 协同蒸馏框架:同时优化步数减少和参数剪枝 最优教师构建:教师模型本身经过优化,以最大化学生模型的性能 实验结果 4 步采样 + 30% 参数剪枝 = 最佳视觉质量(在约束推理预算下) 在 HunyuanVideo-ATI2V 和 WanX-TI2V 上优于所有竞争方法 批判性点评 首次探索步数+参数的联合压缩,填补了研究空白 但 30% 剪枝比较保守;缺少与纯蒸馏方法的详细对比 创新性评分:3.5/5 论文 8:Diagonal Distillation — 对角蒸馏实现流式视频生成 标题:Streaming Autoregressive Video Generation via Diagonal Distillation 作者:Jinxiu Liu 等 (HKUST, Ming-Hsuan Yang) 日期:2026年3月10日 arXiv:2603.09488 关键词:自回归 蒸馏 流式生成 光流建模 277x加速 31 FPS 研究动机 扩散蒸馏将多步模型压缩为少步变体,但现有方法主要针对图像设计,忽略了视频的时间依赖性,导致运动不连贯和长序列误差累积。 方法原理 对角蒸馏:不同于传统的逐 chunk 独立蒸馏,Diagonal Distillation 沿"视频 chunk × 去噪步"的对角线方向进行蒸馏 非对称生成策略:前面的 chunk 用更多步、后面的 chunk 用更少步。后面的 chunk 可以继承前面已充分处理的外观信息 隐式光流建模:在严格步数约束下保持运动质量 核心创新 对角蒸馏:沿时间-步数对角线操作,充分利用时间上下文 非对称步数分配:打破"每个 chunk 步数相同"的假设 曝光偏差缓解:将训练时的噪声条件与推理时对齐 实验结果 5 秒视频 2.61 秒生成(31 FPS) 相比原始模型 277.3 倍加速 运动连贯性和长序列质量显著优于图像蒸馏方法 批判性点评 优势:277x 是本周最震撼的加速数字;流式生成对实时应用极其重要 局限:目前仅适用于自回归视频模型;生成质量与原始多步模型仍有差距;FPS 数字的分辨率条件未详细说明 创新性评分:4/5 论文 9:FrameDiT — 帧级矩阵注意力 标题:FrameDiT: Diffusion Transformer with Frame-Level Matrix Attention for Efficient Video Generation 作者:Minh Khoa Le 等 日期:2026年3月10日 arXiv:2603.09721 关键词:帧级注意力 矩阵注意力 时空结构 Local Factorized 研究动机 现有方法面临 Full 3D Attention(强但贵)vs Local Factorized Attention(快但丢失全局信息)的两难。 方法原理 Matrix Attention:将整帧作为矩阵处理,通过矩阵原生操作生成 Q/K/V 帧间注意力:在帧级别而非 token 级别做跨帧注意力,保持全局时空结构 FrameDiT-H:混合 Matrix Attention + Local Factorized Attention,同时捕捉大运动和小运动 实验结果 多个视频生成 benchmark 上达到 SOTA 效率与 Local Factorized Attention 相当 批判性点评 帧级注意力的粒度介于 Full 3D 和 Local Factorized 之间,是一个有趣的中间地带 但"矩阵注意力"的具体实现细节(矩阵原生操作是什么?)缺乏清晰的数学定义 创新性评分:3/5 三、横向对比分析 3.1 方法分类体系 本周的 9 篇论文可以按 "是否需要训练" 和 "加速策略" 两个维度分类: 免训练 轻量微调 训练/蒸馏 ┌─────────┐ ┌─────────┐ ┌─────────┐ 稀疏注意力 │CalibAtt │ │ SALAD │ │ SLA │ │SVG-EAR │ │VMonarch │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 缓存+剪枝 │ SODA │ │ │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 蒸馏+压缩 │ │ │ │ │FastLight│ │ │ │ │ │DiagDist │ ├─────────┤ ├─────────┤ ├─────────┤ 结构化注意力 │ │ │ │ │FrameDiT │ └─────────┘ └─────────┘ └─────────┘ 3.2 性能对比 方法 注意力加速 端到端加速 需要训练? 测试模型 质量保持 CalibAtt - 1.58x 否 Wan 2.1 14B, Mochi ★★★★ SVG-EAR - 1.77-1.93x 否 Wan 2.2, HunyuanVideo ★★★★ SODA - 可控 否 DiT-XL, PixArt-α, OpenSora ★★★★★ VMonarch 5x - 轻量微调 VBench ★★★★ SALAD - 1.72x 2000样本 - ★★★★ SLA 13.7x 2.2x 少量微调 Wan 2.1 1.3B ★★★★★ FastLightGen - 显著 蒸馏 HunyuanVideo, WanX ★★★★ Diagonal Dist. - 277.3x 蒸馏 自回归模型 ★★★ FrameDiT ~FA级 ~FA级 训练 多个benchmark ★★★★ 3.3 技术路线演进 本周的论文清晰地展现了四条技术路线的演进: 路线 A:免训练稀疏注意力 核心思想:发现并利用注意力的天然稀疏性 演进:Token-level Top-K → Block-level 静态模式 (CalibAtt) → 误差感知动态路由 (SVG-EAR) 加速上限:~2x(受限于稀疏度无法无限提高) 路线 B:稀疏 + 线性注意力融合 核心思想:对不同重要性的注意力权重使用不同计算策略 演进:纯稀疏 / 纯线性 → 并行双分支 (SALAD) → 融合 kernel (SLA) → Monarch 结构化 (VMonarch) 加速上限:~2-5x(取决于 kernel 效率) 路线 C:缓存 + 剪枝 核心思想:利用扩散过程中相邻时间步的特征相似性 演进:均匀缓存 → 启发式组合 → 敏感度导向 DP 优化 (SODA) 加速上限:~2-3x(缓存复用比例有限) 路线 D:蒸馏 + 压缩 核心思想:用小模型/少步数逼近大模型/多步数 演进:步数蒸馏 → 参数剪枝 → 联合压缩 (FastLightGen) → 对角蒸馏 (Diagonal Distillation) 加速上限:100x+(但质量损失更大) 3.4 关键洞察与趋势 免训练方法的天花板在 ~2x:CalibAtt (1.58x) 和 SVG-EAR (1.93x) 代表了免训练稀疏注意力的当前上限。突破需要引入轻量训练。 稀疏 + 线性融合是最佳平衡点:SLA 通过自定义 kernel 实现 2.2x E2E 加速且质量无损,是目前注意力加速的最优解。ICLR 2026 Oral 的认可也说明了这一点。 蒸馏方法的加速比远超注意力优化:Diagonal Distillation 的 277x 说明,如果能接受一定质量损失,蒸馏是最强力的加速手段。但注意力优化的优势是"质量无损"。 多种方法可叠加:注意力优化 + 蒸馏可以叠加使用。CalibAtt 已在蒸馏模型上验证有效。理论上 SLA + 步数蒸馏可能实现 5-10x 无损加速。 Wan 和 HunyuanVideo 成为标准测试平台:本周几乎所有论文都在这两个模型上测试,说明它们已成为视频生成的事实标准。 从算法到系统的全栈优化:SODA 的序列并行推理提醒我们,纯算法优化之外,系统级优化(多 GPU 并行、算子融合等)同样重要。 四、总结与展望 本周最值得关注的 3 篇 SLA (ICLR 2026 Oral):稀疏-线性融合的里程碑工作,自定义 kernel 的工程深度令人印象深刻 SVG-EAR:误差感知路由的洞察非常深刻,免训练方法的新标杆 VMonarch:Monarch 矩阵的引入为结构化注意力开辟了全新方向 未来研究方向预判 注意力优化 + 蒸馏的联合框架:将 SLA/SVG-EAR 与 FastLightGen/Diagonal Distillation 结合 更大规模模型验证:SLA 仅在 1.3B 上测试,14B+ 模型上的表现待验证 长视频生成的特化优化:随着视频长度增长到分钟级,注意力优化的重要性进一步凸显 硬件协同设计:自定义 kernel(SLA)和结构化矩阵(VMonarch)需要与硬件特性深度适配 人工智能炼丹师 整理 | 2026-03-14