搜索到
2
篇与
微调
的结果
-
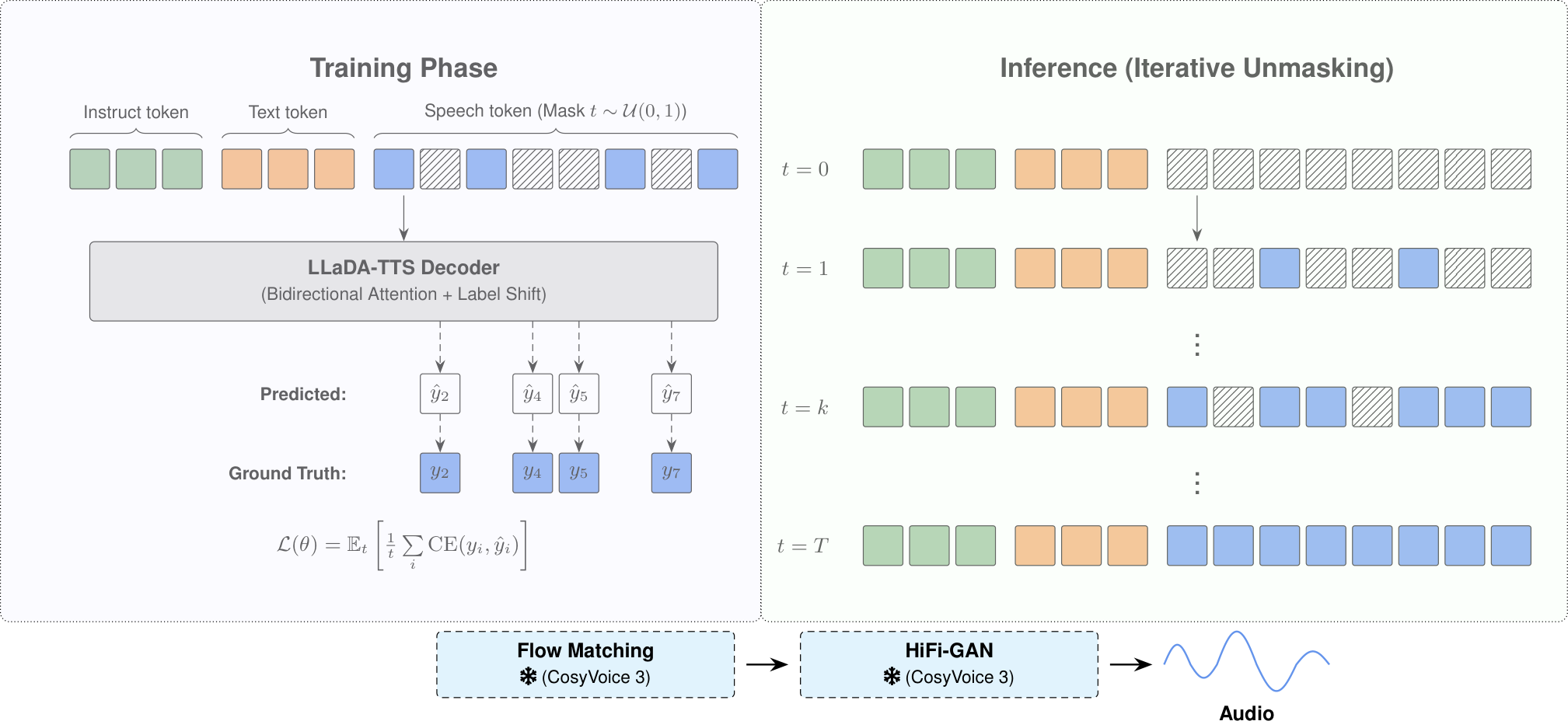
 AIGC 每日速读|2026-03-31|LLaDA-TTS|ShotStream AIGC 视觉生成领域 · 每日论文解读 (2026-03-31) 人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇 今日核心看点 LLaDA-TTS 掩码扩散2倍加速 ShotStream 16FPS流式视频 PackForcing 24倍时间外推 HyDRA 混合记忆世界模型 ViGoR 生成推理基准 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 语音合成加速: LLaDA-TTS (掩码扩散TTS) 视频生成: ShotStream, PackForcing, DiReCT, HyDRA 生成评测: ViGoR-Bench, Identity Collapse 图像生成安全: NLCE (CVPR 2026) 细粒度生成: TaxaAdapter | 音频分离: AV-CASS 重点论文深度解读 1. LLaDA-TTS: Unifying Speech Synthesis and Zero-Shot Editing via Masked Diffusion Modeling 掩码扩散模型统一语音合成与零样本编辑——50小时微调实现2倍加速 | Unknown (TTS Research Lab) | arXiv:2603.26364 关键词: TTS, 掩码扩散, 零样本编辑, 并行生成, 语音合成 研究动机 核心问题: 自回归TTS推理速度受限于逐token生成,且不支持灵活的语音编辑 基于大语言模型的文本转语音(TTS)系统通过自回归(AR)解码实现了出色的自然度,但生成N个语音token需要N个顺序步骤,推理延迟与序列长度线性相关,严重限制了实时应用。AR解码的顺序依赖性是TTS系统部署的核心瓶颈。同时,现有TTS系统缺乏零样本语音编辑能力——无法对已生成的语音进行词级别的插入、删除和替换操作。这两个问题根源在于AR架构的单向注意力机制限制。 前序工作及局限: Tacotron (2017):seq2seq+注意力,质量不稳定,需要大量对齐数据 FastSpeech (2019):非自回归+时长预测,速度快但韵律自然度不足 VALL-E (2023):LLM codec token AR,首次实现零样本TTS但推理慢 CosyVoice (2024-25):AR TTS自然度达到巅峰,但仍受限于逐token自回归生成 与前序工作的本质区别: LLaDA-TTS发现AR与掩码扩散仅是注意力掩码的差异,提出从AR预训练权重直接迁移到MDM的理论框架,仅需50小时微调即可获得2倍推理加速和零样本编辑能力 方法原理 LLaDA-TTS将AR LLM中的自回归解码替换为掩码扩散模型(Masked Diffusion Model),在固定数量的并行步骤中完成生成,从而将推理延迟与序列长度解耦。核心创新点:(1) 仅使用50小时微调数据,通过双向注意力(bidirectional attention)将预训练的AR检查点迁移到掩码扩散范式;(2) 双向架构天然支持零样本语音编辑——包括词级插入、删除和替换,无需额外训练;(3) 该方法仅修改注意力掩码和训练目标,可无缝应用于任何基于LLM的AR TTS系统。理论上证明了AR预训练权重在声学token的局部性属性下,对双向掩码预测是接近最优的,解释了快速收敛。 核心创新 首次将掩码扩散模型引入LLM-based TTS,实现AR到并行生成的范式转换 仅50小时微调即可完成AR→掩码扩散迁移,极低成本 天然支持零样本语音编辑(插入/删除/替换),无需额外训练 倍LLM阶段加速(无KV缓存下),在Seed-TTS-Eval上保持0.98% CER 理论证明AR权重对双向掩码预测的近似最优性 实验结果 在64步生成时,LLaDA-TTS在Seed-TTS-Eval上实现了0.98% CER(中文)和1.96% WER(英文),与CosyVoice 3基线性能相匹配。LLM阶段实现2倍加速,这是在没有KV缓存优化的情况下取得的显著提速。零样本语音编辑在词级插入、删除和替换任务上表现优异,无需任何额外训练数据。该方法具有通用性,可直接应用于CosyVoice等现有AR TTS系统。 图表详解 零样本语音编辑示意 LLaDA-TTS的零样本语音编辑能力示意:双向注意力架构天然支持在给定上下文中进行掩码区域的重新生成。通过在目标位置设置掩码,模型可以利用前后双向上下文信息生成新的语音token,从而实现词级别的插入(在指定位置插入新词)、删除(掩码后重新生成跳过目标词)和替换(掩码目标词后用新词重新生成)。 实验结果对比 在Seed-TTS-Eval基准上的性能对比。LLaDA-TTS在64步生成时达到中文CER 0.98%和英文WER 1.96%,与原始CosyVoice 3 AR基线持平。但在LLM阶段实现了显著的2倍加速——这是在没有KV缓存(AR系统严重依赖的优化)的情况下取得的。同时展示了不同步数下的质量-速度权衡曲线。 批判性点评 新颖性: 核心贡献是发现AR与掩码扩散只是注意力掩码的差异,提出从AR权重直接迁移到MDM的理论框架,并证明AR预训练权重对MDM是最优初始化——这个洞察非常优雅且有理论支撑。 可复现性: 方法基于开源CosyVoice2架构,仅修改注意力掩码+50小时微调,复现门槛极低。但50小时精调数据的质量和配比未详细说明,可能影响复现一致性。 影响力: 如果64步推理能进一步压缩到8步以下,将真正改变TTS部署格局。当前方案更像一个优雅的过渡方案——AR的KV缓存优化也在快速推进,速度差距可能缩小。但'AR→MDM一键迁移'的范式价值超越单个应用。 深度点评: LLaDA-TTS: 掩码扩散 vs AR — 仅改注意力掩码+50小时微调实现2倍加速+零样本编辑,证明AR权重是MDM最优初始化。优雅但64步仍多于一步蒸馏方案。 视频生成进入系统工程阶段 — PackForcing三分区缓存32倍压缩、ShotStream流式蒸馏16FPS实时、DiReCT物理对比学习——从能生成到能部署的范式转变。 ViGoR-Bench: 推理仍是短板 — 即便GPT-4o在视觉推理推理任务上仍大面积失败,证明当前MLLM的视觉推理能力被高估,需要更精细的benchmark推动进步。 技术演进定位: 处于AR TTS向并行生成范式过渡的关键节点——既保留了AR预训练的质量优势,又获得了扩散模型的并行性和可编辑性 可能的后续方向: 推理步数从64步压缩到8步以下(一步蒸馏) 与KV缓存优化的AR方案在更大规模数据上进行公平对比 扩展到多模态生成领域(音乐/音效/歌声合成) 探索掩码扩散在视觉和语言大模型中的迁移应用 其余论文 · 贡献与效果总结 # 论文 机构 关键词 主要贡献 效果 1 ShotStream (ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling) Unknown 流式视频生成·多镜头叙事·因果架构·蒸馏·实时 首个流式多镜头视频生成框架,通过因果架构实现交互式叙事。双缓存记忆(全局+局部)保持跨镜头一致性,两阶段蒸馏消除误差累积。 单GPU 16 FPS生成,亚秒延迟,质量匹配或超越更慢的双向模型。HF 110赞。 2 PackForcing (PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference) Shanda AI Research Tokyo 长视频生成·KV缓存压缩·时间外推·自回归扩散·32倍压缩 提出三分区KV缓存策略(Sink/Mid/Recent tokens)实现分层上下文压缩,仅4GB有界KV缓存即可生成2分钟长视频。Mid tokens通过双分支网络实现32倍token压缩。 单H200 GPU生成2分钟832x480@16FPS视频,24倍时间外推(5s→120s)。VBench时间一致性26.07,动态度56.25,均为SOTA。 3 DiReCT (DiReCT: Disentangled Regularization of Contrastive Trajectories for Physics-Refined Video Generation) Ohio State University 物理视频生成·对比流匹配·语义解纠缠·物理常识·后训练 揭示了对比流匹配中的语义-物理纠缠问题,提出宏观+微观双尺度对比正则化,LLM扰动构建物理困难负样本(运动学、力、材料、交互)。 应用于Wan 2.1-1.3B,VideoPhy物理常识得分比基线提高16.7%,比SFT提高11.3%,无额外训练时间。 4 HyDRA (Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models) HUST, Kuaishou 视频世界模型·混合记忆·动态物体跟踪·视野外连续性·数据集 提出混合记忆范式,要求视频世界模型同时作为静态背景档案员和动态物体跟踪器。构建HM-World数据集(59K片段,17场景49主体),提出HyDRA时空相关检索架构。 动态物体一致性和整体生成质量显著优于SOTA。HF 133赞(当日最高)。 5 ViGoR-Bench (ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners?) Tsinghua University, Meituan 生成评测·推理基准·跨模态·细粒度诊断·性能幻象 提出ViGoR统一评测框架,通过四大创新(跨模态覆盖、双轨评估、证据驱动自动评判、细粒度诊断)系统揭示生成模型的推理缺陷。 评测20+领先模型,发现即使SOTA系统仍存在显著推理缺陷。首次建立生成模型推理能力的系统性压力测试。 6 Identity Collapse (When Identities Collapse: A Stress-Test Benchmark for Multi-Subject Personalization) Unknown 多主体个性化·身份崩溃·压力测试·SCR指标·CVPR 2026 揭示多主体个性化的可扩展性幻觉:模型在2-4主体时表现良好但6-10主体时灾难性崩溃。构建75提示压力测试基准,提出SCR(主体崩溃率)新指标。 MOSAIC/XVerse/PSR等SOTA模型在10主体时SCR接近100%。CVPR 2026 Workshop。 7 NLCE (Neighbor-Aware Localized Concept Erasure in Text-to-Image Diffusion Models) Unknown 概念擦除·免训练·邻近感知·扩散模型安全·CVPR 2026 提出邻近感知局部概念擦除(NLCE)三阶段免训练框架:频谱加权嵌入调制→注意力引导空间门控→空间门控硬擦除,在移除目标概念时保护邻近概念。 在Oxford Flowers/Stanford Dogs上擦除目标概念的同时更好保留相关类别。CVPR 2026。 8 TaxaAdapter (TaxaAdapter: Vision Taxonomy Models are Key to Fine-grained Image Generation over the Tree of Life) Ohio State University, MIT 细粒度生成·视觉分类·BioCLIP·物种保真·适配器 将视觉分类模型(BioCLIP)嵌入注入冻结的T2I扩散模型,在保持姿势/风格文本控制的同时提升物种级保真度。引入MLLM-based形态一致性指标。 形态保真度和物种身份准确性始终优于基线。少样本和零样本物种生成均有效泛化。 9 AV-CASS (Cinematic Audio Source Separation Using Visual Cues) KAIST 电影音频分离·视听生成·条件流匹配·CVPR 2026·跨模态 首个视听电影音频源分离(AV-CASS)框架,用条件流匹配将CASS表述为条件生成建模,设计双流视觉编码器(面部+场景)增强分离质量。 完全合成数据训练即可泛化到真实电影内容。CVPR 2026。 趋势观察 TTS范式转换:AR→掩码扩散 — LLaDA-TTS仅修改注意力掩码即将AR TTS转为并行生成,50小时微调2倍加速。这预示着LLM-based TTS可能全面拥抱非自回归架构。 长视频生成突破KV缓存瓶颈 — PackForcing的三分区KV缓存+32倍压缩实现4GB有界内存生成2分钟视频,ShotStream的双缓存蒸馏实现16FPS流式多镜头。 物理一致性成为视频生成新战场 — DiReCT的宏微对比解纠缠和HyDRA的混合记忆都瞄准物理真实性——视频生成正从视觉质量转向物理合规。 生成评测进入深水区 — ViGoR-Bench揭示SOTA生成模型推理短板,Identity Collapse暴露多主体个性化的可扩展性幻觉。评测不再只看FID。 安全与可控性持续升温 — NLCE的邻近感知概念擦除(CVPR 2026)和AV-CASS的条件流匹配音频分离(CVPR 2026)表明安全可控是发表热点。 人工智能炼丹师 整理 | 2026-03-31 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注
AIGC 每日速读|2026-03-31|LLaDA-TTS|ShotStream AIGC 视觉生成领域 · 每日论文解读 (2026-03-31) 人工智能炼丹师 整理 | 共 10 篇论文 | 重点深度解读 1 篇 今日核心看点 LLaDA-TTS 掩码扩散2倍加速 ShotStream 16FPS流式视频 PackForcing 24倍时间外推 HyDRA 混合记忆世界模型 ViGoR 生成推理基准 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 10 篇,重点解读 1 篇。 方向分布: 语音合成加速: LLaDA-TTS (掩码扩散TTS) 视频生成: ShotStream, PackForcing, DiReCT, HyDRA 生成评测: ViGoR-Bench, Identity Collapse 图像生成安全: NLCE (CVPR 2026) 细粒度生成: TaxaAdapter | 音频分离: AV-CASS 重点论文深度解读 1. LLaDA-TTS: Unifying Speech Synthesis and Zero-Shot Editing via Masked Diffusion Modeling 掩码扩散模型统一语音合成与零样本编辑——50小时微调实现2倍加速 | Unknown (TTS Research Lab) | arXiv:2603.26364 关键词: TTS, 掩码扩散, 零样本编辑, 并行生成, 语音合成 研究动机 核心问题: 自回归TTS推理速度受限于逐token生成,且不支持灵活的语音编辑 基于大语言模型的文本转语音(TTS)系统通过自回归(AR)解码实现了出色的自然度,但生成N个语音token需要N个顺序步骤,推理延迟与序列长度线性相关,严重限制了实时应用。AR解码的顺序依赖性是TTS系统部署的核心瓶颈。同时,现有TTS系统缺乏零样本语音编辑能力——无法对已生成的语音进行词级别的插入、删除和替换操作。这两个问题根源在于AR架构的单向注意力机制限制。 前序工作及局限: Tacotron (2017):seq2seq+注意力,质量不稳定,需要大量对齐数据 FastSpeech (2019):非自回归+时长预测,速度快但韵律自然度不足 VALL-E (2023):LLM codec token AR,首次实现零样本TTS但推理慢 CosyVoice (2024-25):AR TTS自然度达到巅峰,但仍受限于逐token自回归生成 与前序工作的本质区别: LLaDA-TTS发现AR与掩码扩散仅是注意力掩码的差异,提出从AR预训练权重直接迁移到MDM的理论框架,仅需50小时微调即可获得2倍推理加速和零样本编辑能力 方法原理 LLaDA-TTS将AR LLM中的自回归解码替换为掩码扩散模型(Masked Diffusion Model),在固定数量的并行步骤中完成生成,从而将推理延迟与序列长度解耦。核心创新点:(1) 仅使用50小时微调数据,通过双向注意力(bidirectional attention)将预训练的AR检查点迁移到掩码扩散范式;(2) 双向架构天然支持零样本语音编辑——包括词级插入、删除和替换,无需额外训练;(3) 该方法仅修改注意力掩码和训练目标,可无缝应用于任何基于LLM的AR TTS系统。理论上证明了AR预训练权重在声学token的局部性属性下,对双向掩码预测是接近最优的,解释了快速收敛。 核心创新 首次将掩码扩散模型引入LLM-based TTS,实现AR到并行生成的范式转换 仅50小时微调即可完成AR→掩码扩散迁移,极低成本 天然支持零样本语音编辑(插入/删除/替换),无需额外训练 倍LLM阶段加速(无KV缓存下),在Seed-TTS-Eval上保持0.98% CER 理论证明AR权重对双向掩码预测的近似最优性 实验结果 在64步生成时,LLaDA-TTS在Seed-TTS-Eval上实现了0.98% CER(中文)和1.96% WER(英文),与CosyVoice 3基线性能相匹配。LLM阶段实现2倍加速,这是在没有KV缓存优化的情况下取得的显著提速。零样本语音编辑在词级插入、删除和替换任务上表现优异,无需任何额外训练数据。该方法具有通用性,可直接应用于CosyVoice等现有AR TTS系统。 图表详解 零样本语音编辑示意 LLaDA-TTS的零样本语音编辑能力示意:双向注意力架构天然支持在给定上下文中进行掩码区域的重新生成。通过在目标位置设置掩码,模型可以利用前后双向上下文信息生成新的语音token,从而实现词级别的插入(在指定位置插入新词)、删除(掩码后重新生成跳过目标词)和替换(掩码目标词后用新词重新生成)。 实验结果对比 在Seed-TTS-Eval基准上的性能对比。LLaDA-TTS在64步生成时达到中文CER 0.98%和英文WER 1.96%,与原始CosyVoice 3 AR基线持平。但在LLM阶段实现了显著的2倍加速——这是在没有KV缓存(AR系统严重依赖的优化)的情况下取得的。同时展示了不同步数下的质量-速度权衡曲线。 批判性点评 新颖性: 核心贡献是发现AR与掩码扩散只是注意力掩码的差异,提出从AR权重直接迁移到MDM的理论框架,并证明AR预训练权重对MDM是最优初始化——这个洞察非常优雅且有理论支撑。 可复现性: 方法基于开源CosyVoice2架构,仅修改注意力掩码+50小时微调,复现门槛极低。但50小时精调数据的质量和配比未详细说明,可能影响复现一致性。 影响力: 如果64步推理能进一步压缩到8步以下,将真正改变TTS部署格局。当前方案更像一个优雅的过渡方案——AR的KV缓存优化也在快速推进,速度差距可能缩小。但'AR→MDM一键迁移'的范式价值超越单个应用。 深度点评: LLaDA-TTS: 掩码扩散 vs AR — 仅改注意力掩码+50小时微调实现2倍加速+零样本编辑,证明AR权重是MDM最优初始化。优雅但64步仍多于一步蒸馏方案。 视频生成进入系统工程阶段 — PackForcing三分区缓存32倍压缩、ShotStream流式蒸馏16FPS实时、DiReCT物理对比学习——从能生成到能部署的范式转变。 ViGoR-Bench: 推理仍是短板 — 即便GPT-4o在视觉推理推理任务上仍大面积失败,证明当前MLLM的视觉推理能力被高估,需要更精细的benchmark推动进步。 技术演进定位: 处于AR TTS向并行生成范式过渡的关键节点——既保留了AR预训练的质量优势,又获得了扩散模型的并行性和可编辑性 可能的后续方向: 推理步数从64步压缩到8步以下(一步蒸馏) 与KV缓存优化的AR方案在更大规模数据上进行公平对比 扩展到多模态生成领域(音乐/音效/歌声合成) 探索掩码扩散在视觉和语言大模型中的迁移应用 其余论文 · 贡献与效果总结 # 论文 机构 关键词 主要贡献 效果 1 ShotStream (ShotStream: Streaming Multi-Shot Video Generation for Interactive Storytelling) Unknown 流式视频生成·多镜头叙事·因果架构·蒸馏·实时 首个流式多镜头视频生成框架,通过因果架构实现交互式叙事。双缓存记忆(全局+局部)保持跨镜头一致性,两阶段蒸馏消除误差累积。 单GPU 16 FPS生成,亚秒延迟,质量匹配或超越更慢的双向模型。HF 110赞。 2 PackForcing (PackForcing: Short Video Training Suffices for Long Video Sampling and Long Context Inference) Shanda AI Research Tokyo 长视频生成·KV缓存压缩·时间外推·自回归扩散·32倍压缩 提出三分区KV缓存策略(Sink/Mid/Recent tokens)实现分层上下文压缩,仅4GB有界KV缓存即可生成2分钟长视频。Mid tokens通过双分支网络实现32倍token压缩。 单H200 GPU生成2分钟832x480@16FPS视频,24倍时间外推(5s→120s)。VBench时间一致性26.07,动态度56.25,均为SOTA。 3 DiReCT (DiReCT: Disentangled Regularization of Contrastive Trajectories for Physics-Refined Video Generation) Ohio State University 物理视频生成·对比流匹配·语义解纠缠·物理常识·后训练 揭示了对比流匹配中的语义-物理纠缠问题,提出宏观+微观双尺度对比正则化,LLM扰动构建物理困难负样本(运动学、力、材料、交互)。 应用于Wan 2.1-1.3B,VideoPhy物理常识得分比基线提高16.7%,比SFT提高11.3%,无额外训练时间。 4 HyDRA (Out of Sight but Not Out of Mind: Hybrid Memory for Dynamic Video World Models) HUST, Kuaishou 视频世界模型·混合记忆·动态物体跟踪·视野外连续性·数据集 提出混合记忆范式,要求视频世界模型同时作为静态背景档案员和动态物体跟踪器。构建HM-World数据集(59K片段,17场景49主体),提出HyDRA时空相关检索架构。 动态物体一致性和整体生成质量显著优于SOTA。HF 133赞(当日最高)。 5 ViGoR-Bench (ViGoR-Bench: How Far Are Visual Generative Models From Zero-Shot Visual Reasoners?) Tsinghua University, Meituan 生成评测·推理基准·跨模态·细粒度诊断·性能幻象 提出ViGoR统一评测框架,通过四大创新(跨模态覆盖、双轨评估、证据驱动自动评判、细粒度诊断)系统揭示生成模型的推理缺陷。 评测20+领先模型,发现即使SOTA系统仍存在显著推理缺陷。首次建立生成模型推理能力的系统性压力测试。 6 Identity Collapse (When Identities Collapse: A Stress-Test Benchmark for Multi-Subject Personalization) Unknown 多主体个性化·身份崩溃·压力测试·SCR指标·CVPR 2026 揭示多主体个性化的可扩展性幻觉:模型在2-4主体时表现良好但6-10主体时灾难性崩溃。构建75提示压力测试基准,提出SCR(主体崩溃率)新指标。 MOSAIC/XVerse/PSR等SOTA模型在10主体时SCR接近100%。CVPR 2026 Workshop。 7 NLCE (Neighbor-Aware Localized Concept Erasure in Text-to-Image Diffusion Models) Unknown 概念擦除·免训练·邻近感知·扩散模型安全·CVPR 2026 提出邻近感知局部概念擦除(NLCE)三阶段免训练框架:频谱加权嵌入调制→注意力引导空间门控→空间门控硬擦除,在移除目标概念时保护邻近概念。 在Oxford Flowers/Stanford Dogs上擦除目标概念的同时更好保留相关类别。CVPR 2026。 8 TaxaAdapter (TaxaAdapter: Vision Taxonomy Models are Key to Fine-grained Image Generation over the Tree of Life) Ohio State University, MIT 细粒度生成·视觉分类·BioCLIP·物种保真·适配器 将视觉分类模型(BioCLIP)嵌入注入冻结的T2I扩散模型,在保持姿势/风格文本控制的同时提升物种级保真度。引入MLLM-based形态一致性指标。 形态保真度和物种身份准确性始终优于基线。少样本和零样本物种生成均有效泛化。 9 AV-CASS (Cinematic Audio Source Separation Using Visual Cues) KAIST 电影音频分离·视听生成·条件流匹配·CVPR 2026·跨模态 首个视听电影音频源分离(AV-CASS)框架,用条件流匹配将CASS表述为条件生成建模,设计双流视觉编码器(面部+场景)增强分离质量。 完全合成数据训练即可泛化到真实电影内容。CVPR 2026。 趋势观察 TTS范式转换:AR→掩码扩散 — LLaDA-TTS仅修改注意力掩码即将AR TTS转为并行生成,50小时微调2倍加速。这预示着LLM-based TTS可能全面拥抱非自回归架构。 长视频生成突破KV缓存瓶颈 — PackForcing的三分区KV缓存+32倍压缩实现4GB有界内存生成2分钟视频,ShotStream的双缓存蒸馏实现16FPS流式多镜头。 物理一致性成为视频生成新战场 — DiReCT的宏微对比解纠缠和HyDRA的混合记忆都瞄准物理真实性——视频生成正从视觉质量转向物理合规。 生成评测进入深水区 — ViGoR-Bench揭示SOTA生成模型推理短板,Identity Collapse暴露多主体个性化的可扩展性幻觉。评测不再只看FID。 安全与可控性持续升温 — NLCE的邻近感知概念擦除(CVPR 2026)和AV-CASS的条件流匹配音频分离(CVPR 2026)表明安全可控是发表热点。 人工智能炼丹师 整理 | 2026-03-31 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注 -
AIGC 每日速读|2026-03-29|GIDE|ScaleEdit-12M|Calibri| AIGC 视觉生成领域 · 每日论文解读 (2026-03-29) 人工智能炼丹师 整理 | 共 8 篇论文 | 重点深度解读 8 篇 今日核心看点 GIDE 免训练DLLM编辑 ScaleEdit-12M 最大开源数据集 VeloEdit 速度场分解编辑 Calibri 100参数DiT校准 HAM 异构注意力风格迁移 CTCal 跨时间步自校准 DepthArb 遮挡感知生成 MACRO 多参考图生成 今日概览 今日 arXiv cs.CV 视觉生成相关论文共 8 篇,重点解读 8 篇。 方向分布: 免训练图像编辑: 3篇 (GIDE, VeloEdit, HAM) 数据规模化: 2篇 (ScaleEdit-12M, MACRO) 参数高效优化: 2篇 (Calibri, CTCal) 免训练组合生成: 1篇 (DepthArb) CVPR 2026 x 3 (Calibri, HAM, CTCal) | 开源数据+代码 x 5 重点论文深度解读 1. GIDE 解锁Diffusion LLM精确免训练图像编辑 | 港中文/西交 | CUHK, Xi'an Jiaotong University | arXiv:2603.21176 关键词: 免训练编辑, Diffusion LLM, 离散噪声反转, GIDE-Bench, 多模态输入 研究动机 核心问题: Diffusion LLM(DLLM)使用离散Token化,标准DDIM Inversion等连续反转技术完全不适用,导致此类模型无法进行免训练图像编辑 基于扩散的大语言模型(DLLM,如Janus、SEED-X等)已展现强大的多模态生成能力,但在精确的免训练图像编辑上仍是开放挑战。核心困难在于:DLLM内部采用离散Token化(discrete tokenization),与传统连续扩散模型截然不同——标准的DDIM Inversion等噪声反转技术无法直接应用于离散Token空间,强行使用会导致编辑后的图像结构严重退化(背景破坏、未编辑区域变形)。这是一个既有理论深度又有实际影响力的问题:如何在不重训练的前提下,让DLLM具备精确可控的编辑能力? 前序工作及局限: DDIM Inversion:连续噪声空间反转的标准范式,但不适用于离散Token模型 Prompt-to-Prompt:基于注意力操控的编辑方法,但仅适用于连续扩散模型 SDEdit:添加噪声再去噪的编辑范式,但缺乏精确的源图像保持能力 与前序工作的本质区别: GIDE提出了全新的离散噪声反转机制,在离散Token序列上记录每步去噪的状态转移轨迹,首次实现了DLLM的免训练精确编辑 方法原理 GIDE(Grounded Inversion for Diffusion LLM Editing)提出了一个统一的三阶段编辑框架: 第一阶段:定位(Grounding) — 根据用户提供的多模态编辑指令(文本、点击点、边界框),精确定位需要编辑的区域,生成编辑掩码。支持文本/点/框三种输入方式的统一处理。 第二阶段:反转(Inversion) — 这是核心创新。提出离散噪声反转机制(Discrete Noise Inversion),专门为离散Token空间设计。关键思路是:不在连续潜空间做反转,而是在DLLM的离散Token序列上建模噪声模式。通过记录每一步去噪过程中Token的状态转移轨迹,实现精确的源图像重建。这保证了未编辑区域的高保真度恢复。 第三阶段:精修(Refinement) — 在编辑区域应用目标编辑指令驱动的生成,同时用Inversion阶段记录的Token轨迹约束保留区域,确保编辑和保留的无缝融合。引入区域级Token混合策略,在编辑边界实现平滑过渡。 核心创新 首个专为Diffusion LLM设计的免训练图像编辑框架 离散噪声反转机制:突破离散Token空间无法做标准Inversion的技术瓶颈 统一三阶段流程(定位→反转→精修)支持文本/点/框多模态输入 GIDE-Bench:805种组合编辑场景的严格评测基准 语义正确性+51.83%,感知质量+50.39% 实验结果 在GIDE-Bench上的广泛实验表明,GIDE显著超越所有先前免训练方法:语义正确性提升51.83%,感知质量提升50.39%。在ImgEdit-Bench上的额外评估证实了强泛化能力——无需任何训练,GIDE即可实现与经过训练的专用编辑模型相媲美的照片级真实感输出。多模态输入方式(文本+点+框)的灵活性使其在实际应用中具有很高的实用价值。 批判性点评 新颖性: 首次为DLLM设计免训练图像编辑框架,离散噪声反转机制是全新的技术突破,开创性强。 可复现性: 方法描述详细,但暂未开源代码。GIDE-Bench的公开将有助于后续复现。 影响力: 为DLLM开辟了编辑新路径,随着DLLM模型日趋成熟,GIDE的影响力将持续增长。 深度点评: 创新亮点:离散Token空间的噪声反转突破 — GIDE首次解决了Diffusion LLM因离散Token化而无法做标准Inversion的技术瓶颈。这不仅为DLLM开辟了编辑路径,更为离散生成模型的可控性研究提供了全新的技术基础。 数据影响:12M开源编辑数据改变游戏规则 — ScaleEdit-12M的多Agent生产框架和12M开源数据集可能深刻改变编辑领域的竞争格局——当高质量数据不再是壁垒,模型创新和应用创新将成为核心竞争力。 工程启示:100个参数的极简主义力量 — Calibri用约100个参数和进化算法就提升了DiT质量并减少推理步数,是参数高效优化的典范。这种'大模型+微调节'的思路值得在更多场景中探索。 技术演进定位: 开创了DLLM免训练编辑的新方向,填补了离散扩散模型编辑的技术空白 可能的后续方向: DLLM编辑将从免训练走向可训练:GIDE的离散反转技术有望成为DLLM原生编辑训练的基础 离散反转技术可扩展到离散视频生成模型的帧间编辑 2. ScaleEdit-12M 最大开源图像编辑数据集:多Agent规模化生成1200万样本 | CUHK, Shanghai AI Lab | arXiv:2603.20644 关键词: 编辑数据集, 12M规模, 多Agent框架, 23任务族, 开源 研究动机 核心问题: 现有图像编辑数据集规模仅在十万级别,任务类型覆盖有限,严重制约了编辑模型的泛化能力 指令式图像编辑已成为统一多模态模型的核心能力,但高质量编辑数据的获取仍是瓶颈。现有方案两极分化:闭源API标注成本高昂且不可持续,开源合成管线质量有限且覆盖面窄。业界迫切需要一种完全开源、可规模化、且覆盖多样化编辑任务的数据生产方案。 前序工作及局限: MagicBrush:早期编辑数据集,但规模仅10万级且任务覆盖有限 InstructPix2Pix:用GPT-4生成编辑对,但数据多样性不足 Emu Edit:Meta提出的编辑基准,但非开源且规模较小 与前序工作的本质区别: ScaleEdit-12M通过多Agent自动化框架将开源编辑数据规模推至1200万级别,覆盖15种编辑任务类型 方法原理 ScaleEditor是一个完全开源的分层多Agent框架,实现端到端的大规模编辑数据生产: 第一层:源图像扩展 — 融入世界知识的图像源选择和增强。不仅使用现有数据集,还通过知识增强的图像生成扩展源图像多样性。 第二层:自适应多Agent编辑 — 多个专业化Agent协作完成编辑指令生成和图像合成。每个Agent负责特定类型的编辑任务(如物体替换、风格变换、属性修改等),通过协商机制确保指令-图像对的一致性。 第三层:任务感知质量验证 — 自动化的质量控制系统,针对不同编辑任务类型设计差异化的验证标准,过滤低质量样本。 最终产出ScaleEdit-12M数据集:1200万编辑样本,覆盖23个任务族,涵盖真实和合成域。 核心创新 迄今最大的完全开源图像编辑数据集(12M样本,23个任务族) 分层多Agent框架:源图像扩展→自适应编辑→任务感知验证 不依赖闭源API,完全开源可复现 UniWorld-V1 通用编辑+10.4%,知识注入+150.0% 跨域覆盖:真实图像+合成图像,23种编辑类型 实验结果 在ScaleEdit-12M上微调UniWorld-V1和Bagel带来持续收益:通用编辑基准(ImgEdit)+10.4%,GEdit +35.1%;知识注入基准(RISE)+150.0%,KRIS-Bench +26.5%。这证明开源Agent管线可以接近商业级数据质量,同时保持成本效益和可扩展性。 批判性点评 新颖性: 多Agent自动化数据生成框架是工程创新,核心贡献在于规模而非算法。但12M级开源数据本身就是重大贡献。 可复现性: 承诺开源数据集和框架,复现门槛极低,一旦发布将极大推动领域发展。 影响力: 可能成为图像编辑领域最有影响力的工作之一——大规模开源数据将显著降低整个领域的训练门槛。 深度点评: 创新亮点:离散Token空间的噪声反转突破 — GIDE首次解决了Diffusion LLM因离散Token化而无法做标准Inversion的技术瓶颈。这不仅为DLLM开辟了编辑路径,更为离散生成模型的可控性研究提供了全新的技术基础。 数据影响:12M开源编辑数据改变游戏规则 — ScaleEdit-12M的多Agent生产框架和12M开源数据集可能深刻改变编辑领域的竞争格局——当高质量数据不再是壁垒,模型创新和应用创新将成为核心竞争力。 工程启示:100个参数的极简主义力量 — Calibri用约100个参数和进化算法就提升了DiT质量并减少推理步数,是参数高效优化的典范。这种'大模型+微调节'的思路值得在更多场景中探索。 技术演进定位: 可能成为图像编辑领域的ImageNet时刻——大规模开源数据将显著降低编辑模型的训练门槛 可能的后续方向: 编辑数据规模可能突破亿级:ScaleEdit的多Agent框架为全自动化数据生产铺平道路 数据质量验证和自动过滤将成为下一步关键 3. VeloEdit 速度场分解实现免训练一致连续图像编辑 | Xiamen University | arXiv:2603.13388 关键词: 速度场分解, 免训练编辑, Flow Matching, 连续控制, 一致性保持 研究动机 核心问题: Flow Matching模型的编辑方法主要操作注意力层,忽略了速度场本身蕴含的丰富编辑信号 基于Flow Matching的图像编辑方法正在兴起(如Flux.1 Kontext、Qwen-Image-Edit),但存在两大核心痛点:(1) 去噪过程中的重建误差导致未编辑区域漂移(背景不一致),(2) 缺乏对编辑强度的细粒度控制——只能「编辑/不编辑」二选一,无法平滑调节编辑程度。现有方法通常依赖复杂的注意力操作或辅助训练模块来缓解这些问题,引入了额外计算开销。 前序工作及局限: RF-Inversion:Flow Matching反转编辑的先驱工作,但灵活性受限 FlowEdit:基于Flow的编辑方法,但未利用速度场的几何特性 P2P-Bridge:桥接模型编辑,但依赖配对训练数据 与前序工作的本质区别: VeloEdit从速度场的几何层面直接进行编辑操控,提出速度分解、重组和引导三阶段编辑框架,理论优雅且实用 方法原理 VeloEdit直接在Flow Matching的速度场(velocity field)层面操作,提出速度场分解方法: 动态区域识别 — 量化源图像恢复速度场(reconstruction velocity)与编辑速度场(editing velocity)的差异,差异大的区域标识为编辑区域,差异小的标识为保留区域。这种基于速度场差异的分区比基于注意力图的分区更精确。 一致性保持 — 在保留区域,用源图像的恢复速度场替换编辑速度场,从而在ODE积分过程中严格保证保留区域像素不偏移。 连续强度控制 — 在编辑区域,通过恢复速度场和编辑速度场的线性插值实现连续的编辑强度调节(0%→100%无级变速),用户可精确控制编辑程度。 核心创新 首个直接在速度场层面操作的免训练编辑方法 速度场差异驱动的动态区域识别 恢复速度场替换保证保留区域一致性 速度场插值实现编辑强度0-100%连续控制 在Flux.1 Kontext和Qwen-Image-Edit上验证,计算开销几乎为零 实验结果 在Flux.1 Kontext和Qwen-Image-Edit两个前沿模型上的实验表明,VeloEdit显著改善了视觉一致性和编辑连续性。关键优势:(1) 背景保持度大幅提升,(2) 编辑强度可连续调节,(3) 额外计算开销几乎为零(不需要训练、不需要额外模型)。代码已开源。 批判性点评 新颖性: 从速度场几何层面进行编辑操控的思路极其巧妙,速度分解+重组+引导的三阶段框架理论优雅。 可复现性: 代码已开源,复现友好。速度场分解的实现细节清晰。 影响力: 为Flow Matching编辑开辟了新范式,速度场视角可能被广泛借鉴。 深度点评: 创新亮点:离散Token空间的噪声反转突破 — GIDE首次解决了Diffusion LLM因离散Token化而无法做标准Inversion的技术瓶颈。这不仅为DLLM开辟了编辑路径,更为离散生成模型的可控性研究提供了全新的技术基础。 数据影响:12M开源编辑数据改变游戏规则 — ScaleEdit-12M的多Agent生产框架和12M开源数据集可能深刻改变编辑领域的竞争格局——当高质量数据不再是壁垒,模型创新和应用创新将成为核心竞争力。 工程启示:100个参数的极简主义力量 — Calibri用约100个参数和进化算法就提升了DiT质量并减少推理步数,是参数高效优化的典范。这种'大模型+微调节'的思路值得在更多场景中探索。 技术演进定位: 为Flow Matching编辑开辟了基于速度场的全新技术路径,补充了注意力操控之外的编辑范式 可能的后续方向: 速度场编辑可扩展到视频Flow Matching模型 与LoRA等参数高效方法结合可降低推理成本 4. Calibri 参数高效校准提升DiT生成质量 | CVPR 2026 | Visual Generative AI group | arXiv:2603.24800 关键词: 参数高效, DiT校准, 进化算法, CVPR 2026, 100参数 研究动机 核心问题: DiT模型生成质量可通过后处理校准提升,但现有方法需要大量额外参数和训练 Diffusion Transformer(DiT)已成为图像生成的主流架构,但如何以最小代价提升其生成质量仍是开放问题。现有优化方法要么需要大规模微调(成本高),要么需要修改架构(兼容性差)。一个有趣的问题是:DiT的去噪过程中,是否存在简单的参数调整就能显著改善的瓶颈点? 前序工作及局限: Guidance Distillation:通过蒸馏减少采样步数,但改变了模型结构 CFG (Classifier-Free Guidance):无分类器引导提升质量,但需双倍推理成本 DPO for Diffusion:用偏好学习优化扩散模型,但需要配对偏好数据和微调 与前序工作的本质区别: Calibri用进化算法搜索仅约100个缩放/偏移参数即可显著提升DiT生成质量,极简且高效 方法原理 Calibri基于一个关键发现:在DiT的去噪过程中,引入单个学习缩放参数即可显著提升DiT模块的性能。基于此,Calibri将DiT校准建模为黑盒奖励优化问题: 问题定义 — 为DiT的每个关键模块(注意力层、FFN层等)寻找最优的缩放系数,使得生成质量最大化。 求解方法 — 使用进化算法(Evolutionary Algorithm)高效搜索约100个缩放参数的最优组合。进化算法的优势在于:不需要梯度计算,不需要反向传播,仅通过前向推理+质量评估即可迭代优化。 效果叠加 — Calibri不仅提升质量,还自然减少了推理所需的去噪步数——更好的缩放参数使得每步去噪更高效,达到相同质量所需步数更少。 核心创新 揭示DiT去噪过程中缩放参数的关键作用 仅约100个参数即可显著提升生成质量 进化算法黑盒优化,无需梯度、无需反向传播 同时提升质量和减少推理步数 CVPR 2026接收,模型无关可适用于各种DiT 实验结果 实验证明Calibri在各种文本到图像模型上都能持续提升性能,包括FLUX、SD3.5等主流模型。值得注意的是,Calibri还能减少图像生成所需的推理步骤——例如在某些模型上用20步达到原来30步的质量。仅修改约100个参数,就能获得可观的质量-效率双重收益。CVPR 2026接收。 批判性点评 新颖性: 用进化算法搜索约100个缩放/偏移参数的极简设计令人惊喜,挑战了「更多参数=更好效果」的传统认知。CVPR 2026接收。 可复现性: 基于进化算法搜索,复现门槛低。搜索空间和适应度函数定义明确。 影响力: 极简参数校准思路可被广泛应用于各类DiT模型的部署优化,实用价值极高。 深度点评: 创新亮点:离散Token空间的噪声反转突破 — GIDE首次解决了Diffusion LLM因离散Token化而无法做标准Inversion的技术瓶颈。这不仅为DLLM开辟了编辑路径,更为离散生成模型的可控性研究提供了全新的技术基础。 数据影响:12M开源编辑数据改变游戏规则 — ScaleEdit-12M的多Agent生产框架和12M开源数据集可能深刻改变编辑领域的竞争格局——当高质量数据不再是壁垒,模型创新和应用创新将成为核心竞争力。 工程启示:100个参数的极简主义力量 — Calibri用约100个参数和进化算法就提升了DiT质量并减少推理步数,是参数高效优化的典范。这种'大模型+微调节'的思路值得在更多场景中探索。 技术演进定位: 提出了参数效率的极致追求:用最少参数实现最大质量提升,为模型部署优化树立新范式 可能的后续方向: 进化搜索可能与在线学习结合实现动态校准 可扩展到视频DiT和音频DiT的质量校准 5. HAM 异构注意力调制实现免训练风格迁移 | CVPR 2026 | Hangzhou Dianzi University | arXiv:2603.24043 关键词: 风格迁移, 注意力调制, 免训练, CVPR 2026, 身份保护 研究动机 核心问题: 风格迁移和图像编辑中需要同时保持内容结构和注入目标风格,现有注意力操控方法难以平衡两者 扩散模型风格迁移面临根本性的风格-内容平衡难题:过度迁移风格会破坏内容身份信息(人物面部变形、场景结构丢失),保守迁移则风格效果不明显。现有免训练方法多采用统一的注意力操作策略,无法同时兼顾全局风格氛围和局部身份细节。 前序工作及局限: StyleAligned:风格对齐生成,但缺乏细粒度控制 IP-Adapter:图像提示适配器,但注入风格时容易丢失内容 InstantStyle:即时风格迁移,但对复杂风格表现不佳 与前序工作的本质区别: HAM提出异构注意力调制机制,对不同注意力头使用不同的调制策略,实现风格与内容的精细解耦 方法原理 HAM提出异构注意力调制(Heterogeneous Attention Modulation)——对全局风格和局部身份使用不同的注意力操作策略: 全局注意力调节(GAR) — 在全局层面调制自注意力权重,注入风格参考图的整体氛围(色调、笔触、光影风格),影响图像的全局视觉感受。 局部注意力移植(LAT) — 在局部层面移植关键的身份注意力图,保护内容图像中的核心身份信息(面部特征、物体结构、空间关系)不被风格迁移破坏。 两种策略在不同的注意力头上并行执行,实现风格-身份的解耦处理。这种异构设计使得系统能在充分捕获复杂风格参考的同时保持内容身份完整。 核心创新 异构注意力调制:全局风格调节+局部身份移植双策略 不同注意力头承担不同任务,实现风格-身份解耦 完全免训练,即插即用 在保持身份的同时捕获复杂风格参考 CVPR 2026接收 实验结果 在多项定量指标上达到SOTA性能。用户研究表明HAM在风格一致性和内容保持两个维度上均优于现有方法。特别在人像风格迁移中,HAM成功保持了面部身份信息的同时实现了多样化风格效果。CVPR 2026接收。 批判性点评 新颖性: 对不同注意力头使用不同调制策略的异构设计有一定新意,但注意力操控编辑的大框架已比较成熟。CVPR 2026接收。 可复现性: 方法描述清晰,但代码开源状态待确认。 影响力: 推进了注意力机制在风格迁移中的精细化应用,对实际产品有参考价值。 深度点评: 创新亮点:离散Token空间的噪声反转突破 — GIDE首次解决了Diffusion LLM因离散Token化而无法做标准Inversion的技术瓶颈。这不仅为DLLM开辟了编辑路径,更为离散生成模型的可控性研究提供了全新的技术基础。 数据影响:12M开源编辑数据改变游戏规则 — ScaleEdit-12M的多Agent生产框架和12M开源数据集可能深刻改变编辑领域的竞争格局——当高质量数据不再是壁垒,模型创新和应用创新将成为核心竞争力。 工程启示:100个参数的极简主义力量 — Calibri用约100个参数和进化算法就提升了DiT质量并减少推理步数,是参数高效优化的典范。这种'大模型+微调节'的思路值得在更多场景中探索。 技术演进定位: 推进了注意力机制在风格迁移中的精细化应用,CVPR 2026接收验证了其学术价值 可能的后续方向: 异构注意力调制可扩展到视频风格迁移 与LoRA结合可实现更灵活的风格组合 6. CTCal 跨时间步自校准提升T2I文本对齐 | CVPR 2026 | Beihang University | arXiv:2603.20741 关键词: 跨时间步校准, 文本对齐, CVPR 2026, 显式监督, 模型无关 研究动机 核心问题: 扩散模型蒸馏缺少跨时间步的显式对齐监督,导致学生模型在不同去噪阶段的输出不一致 文本到图像扩散模型在语义对齐上仍存在顽固瓶颈——模型经常忽略prompt中的某些语义元素或生成不符合描述的内容。深层原因在于:传统扩散损失仅提供隐式监督,缺乏对文本-图像细粒度对应关系的显式约束。一个关键观察是:随着噪声时间步增大,建立准确的文本-图像对齐变得指数级困难。 前序工作及局限: Progressive Distillation:渐进蒸馏减少采样步数,但缺乏跨步对齐 Consistency Models:一致性模型追求一步生成,但牺牲了部分质量 LCM (Latent Consistency Models):潜空间一致性模型,但训练效率有待提升 与前序工作的本质区别: CTCal引入跨时间步自校准机制,通过不同时间步输出的显式对齐约束提升蒸馏质量 方法原理 CTCal基于一个精妙的观察:在小时间步(低噪声)时,交叉注意力图已经形成了可靠的文本-图像对齐;而在大时间步(高噪声)时,这种对齐严重退化。CTCal的核心思路是「以低噪声指导高噪声」: 跨时间步蒸馏 — 将小时间步形成的可靠交叉注意力图作为「教师」,校准大时间步的表示学习。这为扩散训练引入了显式的文本-图像对齐监督。 自适应加权 — 设计时间步感知的自适应加权机制,动态平衡CTCal校准损失和标准扩散损失的权重。在噪声大的时间步给予更强的校准指导,在噪声小的时间步让标准损失主导。 模型无关性 — CTCal可无缝集成到各种T2I架构中,包括基于扩散的(SD 2.1)和基于流匹配的(SD 3),不改变原有架构。 核心创新 揭示跨时间步对齐退化现象 以低噪声交叉注意力校准高噪声表示学习 时间步感知自适应加权平衡双损失 模型无关:兼容扩散模型和流匹配模型 CVPR 2026接收,代码已开源 实验结果 在T2I-Compbench++和GenEval基准上的广泛实验证明CTCal的有效性和通用性。在SD 2.1上,CTCal将组合生成准确率提升了显著幅度;在SD 3上同样有效,证明了跨架构的泛化能力。代码已开源。CVPR 2026接收。 批判性点评 新颖性: 跨时间步显式对齐监督是蒸馏领域的新颖思路,但核心思想相对直觉,缺少更深层的理论分析。 可复现性: 代码已开源,复现友好。训练流程和超参数设置详细。 影响力: 为扩散模型蒸馏提供了新的监督维度,可能被后续蒸馏工作广泛引用。 深度点评: 创新亮点:离散Token空间的噪声反转突破 — GIDE首次解决了Diffusion LLM因离散Token化而无法做标准Inversion的技术瓶颈。这不仅为DLLM开辟了编辑路径,更为离散生成模型的可控性研究提供了全新的技术基础。 数据影响:12M开源编辑数据改变游戏规则 — ScaleEdit-12M的多Agent生产框架和12M开源数据集可能深刻改变编辑领域的竞争格局——当高质量数据不再是壁垒,模型创新和应用创新将成为核心竞争力。 工程启示:100个参数的极简主义力量 — Calibri用约100个参数和进化算法就提升了DiT质量并减少推理步数,是参数高效优化的典范。这种'大模型+微调节'的思路值得在更多场景中探索。 技术演进定位: 为扩散模型蒸馏引入了新的监督维度,CVPR 2026接收证明了其有效性 可能的后续方向: 跨时间步校准可扩展到视频扩散模型的时间一致性蒸馏 与Calibri等参数高效方法结合可进一步降低部署成本 7. DepthArb 深度仲裁免训练遮挡感知图像合成 + OcclBench | Xi'an Jiaotong University | arXiv:2603.23924 关键词: 遮挡生成, 深度仲裁, 免训练, 注意力调制, OcclBench 研究动机 核心问题: 组合图像生成中多个物体的前后遮挡关系难以准确建模,导致不自然的层次感 文本到图像扩散模型在处理物体遮挡关系时存在严重缺陷——特别是在密集重叠区域,经常出现概念混合(两个物体融为一体)或不合逻辑的遮挡(前景被背景覆盖)。现有免训练布局引导方法依赖深度顺序无关的刚性空间先验,无法建模物体间的前后关系。 前序工作及局限: MultiDiffusion:多区域组合生成,但忽略了深度遮挡关系 Attend-and-Excite:注意力激活增强,但无法控制物体层次 ControlNet:条件控制生成,但深度控制精度有限 与前序工作的本质区别: DepthArb通过深度感知的注意力仲裁机制,在组合生成过程中自动解决物体间的遮挡优先级 方法原理 DepthArb通过仲裁交互物体之间的注意力竞争来解决遮挡歧义: 注意力仲裁调制(AAM) — 在重叠区域中,根据预设的深度排序关系,抑制背景物体的注意力激活。当两个物体在空间上重叠时,前景物体的注意力权重被增强,背景物体的注意力权重被压制,从而自然形成正确的遮挡关系。 空间紧致度控制(SCC) — 抑制注意力分布的空间发散,保持每个物体在指定布局区域内的结构完整性。防止物体注意力「溢出」到其他区域导致形状变形。 这两个机制协同工作,无需任何训练即可实现鲁棒的遮挡感知生成。 核心创新 首个系统解决扩散模型遮挡生成问题的免训练框架 AAM注意力仲裁:基于深度排序抑制背景激活 SCC空间紧致度:抑制注意力发散保持结构完整 OcclBench:多样化遮挡场景评测基准 即插即用增强扩散主干的组合能力 实验结果 在OcclBench上的广泛评估表明,DepthArb在遮挡准确性和视觉保真度上始终优于SOTA基线方法。作为即插即用方法,DepthArb无缝增强了SDXL、FLUX等主流扩散模型的空间组合能力。 批判性点评 新颖性: 深度感知的注意力仲裁机制有一定新意,但核心思路——利用深度信息引导注意力——并不算突破性。 可复现性: 方法描述较详细,但代码开源状态待确认。 影响力: 对多物体场景生成有实际应用价值,但影响范围相对局限于组合生成子领域。 深度点评: 创新亮点:离散Token空间的噪声反转突破 — GIDE首次解决了Diffusion LLM因离散Token化而无法做标准Inversion的技术瓶颈。这不仅为DLLM开辟了编辑路径,更为离散生成模型的可控性研究提供了全新的技术基础。 数据影响:12M开源编辑数据改变游戏规则 — ScaleEdit-12M的多Agent生产框架和12M开源数据集可能深刻改变编辑领域的竞争格局——当高质量数据不再是壁垒,模型创新和应用创新将成为核心竞争力。 工程启示:100个参数的极简主义力量 — Calibri用约100个参数和进化算法就提升了DiT质量并减少推理步数,是参数高效优化的典范。这种'大模型+微调节'的思路值得在更多场景中探索。 技术演进定位: 填补了组合生成中深度遮挡建模的空白,提升了多物体场景的视觉真实感 可能的后续方向: 深度仲裁机制可扩展到3D感知的场景生成 与布局控制方法结合可实现更精准的场景构图 8. MACRO 结构化长上下文数据驱动的多参考图像生成 | 港大 | The University of Hong Kong | arXiv:2603.25319 关键词: 多参考生成, 长上下文, 40万数据集, 跨任务协同, MacroBench 研究动机 核心问题: 多参考图像生成(基于多张参考图组合生成新图像)缺乏系统性的数据集和评测基准 多参考图像生成在实际应用中至关重要——多主体组合、叙事插图、新视角合成等场景都需要基于多张参考图生成新图像。然而,随着输入参考数量增加,现有模型性能急剧下降。根本原因在于数据瓶颈:现有数据集以单参考或少参考对为主,缺乏密集参考间依赖关系的「结构化长上下文」监督。 前序工作及局限: DreamBooth:个性化生成先驱,但仅支持单概念 Custom Diffusion:多概念组合,但需要微调且概念冲突 Subject-Diffusion:主体驱动生成,但多参考场景表现不佳 与前序工作的本质区别: MACRO首次系统定义了多参考图像生成任务,构建了包含多样场景的大规模数据集和评测基准 方法原理 MACRO从数据和评测两个层面系统解决多参考生成问题: MacroData数据集 — 40万个样本,每个样本最多包含10张参考图像。数据按四个互补维度系统组织: 定制化(Customization):个性化生成场景 插图(Illustration):叙事和故事插画场景 空间推理(Spatial Reasoning):多视角和空间关系场景 动态(Dynamics):运动和变化捕捉场景 MacroBench评测基准 — 4000个评测样本,覆盖多任务维度和不同输入规模,评估生成连贯性。 消融研究揭示了跨任务协同训练的有效性——不同维度的数据互相增益。 核心创新 首个大规模多参考图像生成数据集(40万样本,最多10张参考) 四维度系统组织:定制化/插图/空间推理/动态 MacroBench:4000样本标准化多参考评测基准 揭示跨任务协同训练的互增益效应 数据集和基准将开源 实验结果 在MacroData上微调后,多参考生成效果显著提升。消融研究揭示了两个重要发现:(1) 跨任务协同训练比单任务训练更有效,不同维度的数据产生互增益;(2) 处理长上下文(多张参考图)需要专门的训练策略。数据集和基准将公开发布。 批判性点评 新颖性: 首次系统定义多参考图像生成任务并构建标准化基准,填补了该方向的基础设施空白。 可复现性: 承诺公开数据集和基准,复现友好。任务定义和评测协议清晰。 影响力: 为多参考图像生成建立了标准化研究框架,将催生该方向的后续工作。 深度点评: 创新亮点:离散Token空间的噪声反转突破 — GIDE首次解决了Diffusion LLM因离散Token化而无法做标准Inversion的技术瓶颈。这不仅为DLLM开辟了编辑路径,更为离散生成模型的可控性研究提供了全新的技术基础。 数据影响:12M开源编辑数据改变游戏规则 — ScaleEdit-12M的多Agent生产框架和12M开源数据集可能深刻改变编辑领域的竞争格局——当高质量数据不再是壁垒,模型创新和应用创新将成为核心竞争力。 工程启示:100个参数的极简主义力量 — Calibri用约100个参数和进化算法就提升了DiT质量并减少推理步数,是参数高效优化的典范。这种'大模型+微调节'的思路值得在更多场景中探索。 技术演进定位: 为多参考图像生成建立了标准化的研究框架,将推动该方向的快速发展 可能的后续方向: 多参考生成将与视频模型融合:MACRO的多参考范式天然适配视频帧间一致性建模 数据集将催生新一代多概念组合生成模型 其余论文 · 贡献与效果总结 # 论文 机构 关键词 主要贡献 效果 趋势观察 免训练方法成为图像编辑的主流范式 — GIDE、VeloEdit、HAM、DepthArb四篇论文均采用免训练策略,分别从离散Token反转、速度场分解、异构注意力、深度仲裁四个全新角度实现编辑/生成增强。免训练方法的优势在于即插即用、零额外训练成本、可适配各种底座模型。 数据规模化正在重塑编辑模型能力边界 — ScaleEdit-12M(12M样本、23任务族)和MACRO(40万多参考样本)代表了数据工程从「小而精」向「大而全」的范式转变。ScaleEdit的多Agent生产框架证明了完全开源管线可以接近商业级数据质量。 参数高效优化:用最少参数获取最大收益 — Calibri仅用约100个参数就显著提升DiT质量并减少推理步数;CTCal通过跨时间步自校准引入显式监督而不改变架构。这种极简主义优化思路正在成为工程化的新趋势。 从「能生成」到「能组合」:空间关系成为新战场 — DepthArb解决遮挡关系、MACRO处理多参考依赖、ScaleEdit覆盖复杂编辑场景——生成模型正从单一主体生成走向复杂空间关系的精确建模。 人工智能炼丹师 整理 | 2026-03-29 更多 AIGC 论文解读,关注微信公众号「人工智能炼丹君」 每日更新 · 论文精选 · 深度解读 · 技术脉络 微信搜索 人工智能炼丹君 或扫描文末二维码关注