搜索到
64
篇与
人工智能炼丹师
的结果
-
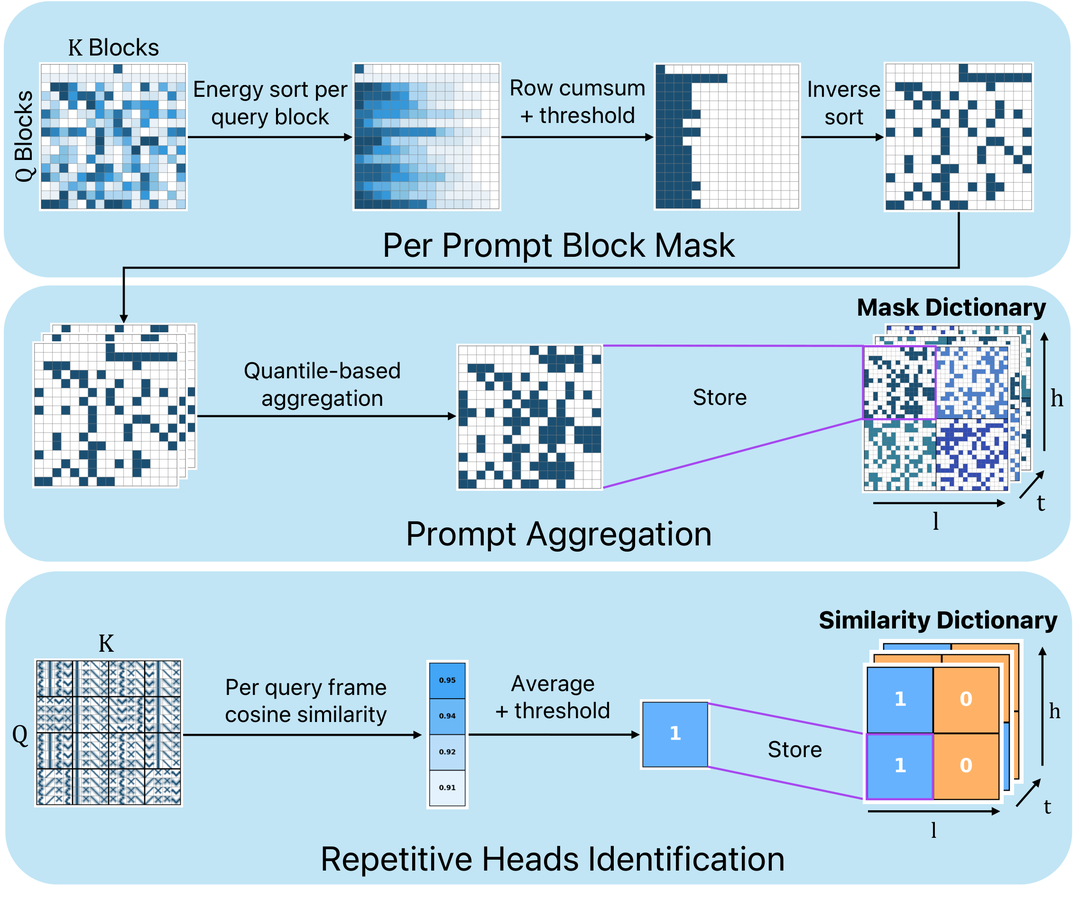
 AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 专题方向:视频 DiT 中的稀疏注意力、线性注意力与推理加速 覆盖时间:2026年3月2日 — 2026年3月13日 整理:人工智能炼丹师 日期:2026年3月14日(周六) 一、专题概览 本周是视频扩散 Transformer(Video DiT)高效推理方向的"论文爆发周"。短短一周内,arXiv 上出现了 9 篇 高度聚焦于视频 DiT 注意力加速与推理优化的论文,覆盖了从稀疏注意力、线性注意力、结构化注意力,到蒸馏压缩、缓存+剪枝、系统级并行优化的完整技术栈。 核心背景 当前主流视频生成模型(Wan 2.1/2.2、HunyuanVideo、Mochi 等)均采用 Diffusion Transformer(DiT)架构,其核心瓶颈在于 全注意力(Full 3D Attention)的 O(N²) 复杂度。一段 5 秒 720P 视频的 token 序列长度可达数十万,全注意力的计算量和显存占用极其惊人。因此,如何在保持生成质量的前提下大幅降低注意力计算成本,成为本周研究的核心主题。 本周论文全景 # 论文 方法类别 核心思路 加速比 提交日期 1 CalibAtt 稀疏注意力(免训练) 离线校准块级稀疏模式 1.58x E2E 3月5日 2 SVG-EAR 稀疏注意力 + 线性补偿(免训练) 误差感知路由 + 聚类质心补偿 1.77-1.93x 3月9日 3 SODA 缓存 + 剪枝(免训练) 敏感度导向的动态加速 SOTA fidelity 3月7日 4 FrameDiT 结构化注意力(需训练) 帧级矩阵注意力 ~Local FA 3月10日 5 VMonarch 结构化注意力(轻量微调) Monarch 矩阵分解 5x attn, 17.5x FLOPs↓ 1月29日 6 SALAD 稀疏 + 线性混合(轻量微调) 门控线性注意力并行分支 1.72x, 90%稀疏 1月23日 7 SLA 稀疏 + 线性融合(微调) 三级权重分类 + 自定义 kernel 2.2x E2E, 13.7x attn 2025.9 (ICLR'26) 8 FastLightGen 蒸馏 + 剪枝 步数+参数同时压缩 4步+30%剪枝 3月2日 9 Diagonal Distillation 自回归蒸馏 对角蒸馏 + 隐式光流 277.3x, 31 FPS 3月10日 二、重点论文深度解读 论文 1:CalibAtt — 校准稀疏注意力加速视频生成 标题:Accelerating Text-to-Video Generation with Calibrated Sparse Attention 作者:Shai Yehezkel, Shahar Yadin, Noam Elata 等 机构:以色列理工 日期:2026年3月5日 arXiv:2603.05503 关键词:稀疏注意力 免训练 离线校准 块级模式 Wan 2.1 Mochi 研究动机 视频 DiT 中的全注意力计算是推理速度的主要瓶颈。已有的稀疏注意力方法要么需要训练(如 SLA、SALAD),要么是在线动态判断每个 token 的重要性(开销大)。作者观察到一个关键现象:大量 token-to-token 连接在不同输入上一致地产生可忽略的注意力分数,且这些模式在不同查询间重复出现。 方法原理 CalibAtt 采用"离线校准 + 在线高效推理"的两阶段策略: 离线校准阶段:在少量参考视频上运行全注意力,统计每一层、每个注意力头、每个扩散时间步的块级(block-level)稀疏模式和重复模式 模式编译:将稳定的稀疏模式编译为优化的注意力操作(类似于"稀疏注意力的 JIT 编译") 在线推理:只计算被选中的输入相关连接,以硬件友好的方式跳过未选中的连接 核心创新 块级粒度:不做 token 级稀疏(开销大),而是以 token block 为单位,兼顾精度和效率 跨输入稳定性:发现稀疏模式对输入不敏感,可以离线固定 层-头-时间步三维校准:不同层/头/时间步的稀疏模式不同,细粒度适配 实验结果 在 Wan 2.1 14B、Mochi 1 及其蒸馏版本上测试 实现 1.58x 端到端加速 在视频生成质量和文本-视频对齐度上优于已有免训练方法 支持多种分辨率 技术脉络 Sparse VideoGen (2024) → Sparse VideoGen2 (2025.5) → CalibAtt (2026.3)。从在线动态稀疏 → 离线校准静态稀疏,核心洞察是"稀疏模式跨输入稳定"。 批判性点评 优势:完全免训练,直接即插即用;离线校准成本低;硬件友好 局限:1.58x 的加速比在本周论文中并不突出;块级粒度可能丢失细粒度信息;对新架构需要重新校准 创新性评分:3/5 — 洞察有价值但方法相对直接 论文 2:SVG-EAR — 无参数线性补偿的误差感知路由 标题:SVG-EAR: Parameter-Free Linear Compensation for Sparse Video Generation via Error-aware Routing 作者:Xuanyi Zhou, Qiuyang Mang, Shuo Yang 等 (UC Berkeley, Ion Stoica 组) 日期:2026年3月9日 arXiv:2603.08982 关键词:稀疏注意力 线性补偿 误差感知路由 聚类质心 免训练 Wan 2.2 HunyuanVideo 研究动机 现有稀疏注意力方法面临两难:(1) 直接丢弃被跳过的注意力块会丢失信息;(2) 用学习型预测器来近似它们又引入训练开销和分布偏移。能否在不训练的情况下恢复被跳过块的贡献? 方法原理 SVG-EAR 的核心洞察:经过语义聚类后,同一块内的 key 和 value 具有高度相似性,可以用少量聚类质心准确概括。 聚类质心补偿:对被跳过的注意力块,用 key/value 的聚类质心做线性(O(N))近似,恢复其对输出的贡献 误差感知路由:传统方法按注意力分数选择需要精确计算的块,但高注意力分数 ≠ 高近似误差。SVG-EAR 用一个轻量探测器估计每个块的补偿误差,选择"误差-成本比"最高的块做精确计算 理论保证:提供了注意力重建误差与聚类质量之间的理论上界 核心创新 误差感知 vs 分数感知:颠覆了传统"高注意力分数 = 重要"的假设,改为"高近似误差 = 需要精确计算" 无参数线性补偿:用聚类质心做 O(N) 补偿,不需要任何训练 帕累托最优:在所有免训练方法中建立了新的帕累托前沿 实验结果 Wan 2.2:1.77x 加速,PSNR 29.759 HunyuanVideo:1.93x 加速,PSNR 31.043 显著优于 Sparse VideoGen2 和 CalibAtt 技术脉络 Sparse VideoGen → SVG2 → SVG-EAR(同一系列的第三代,Ion Stoica / Berkeley 团队的持续推进) 批判性点评 优势:免训练、有理论保证、误差感知路由的思路很优雅 局限:聚类质心计算本身有开销;实际 wall-clock 加速受限于聚类效率;PSNR 不是视频生成的最佳指标 创新性评分:4/5 — 误差感知路由是本周最有洞察的方法论创新 论文 3:SODA — 敏感度导向的动态加速 标题:SODA: Sensitivity-Oriented Dynamic Acceleration for Diffusion Transformer 作者:Tong Shao, Yusen Fu 等 日期:2026年3月7日 arXiv:2603.07057 关键词:缓存 剪枝 敏感度分析 动态规划 免训练 DiT-XL PixArt-α OpenSora 研究动机 特征缓存(caching)和 token 剪枝(pruning)是两种互补的加速手段:缓存加速效率高但影响保真度,剪枝相反。现有方法用固定的启发式策略组合两者,无法捕捉模型对加速操作的细粒度敏感度变化。 方法原理 离线敏感度建模:构建跨时间步、层、模块的敏感度误差模型,量化每个计算单元对缓存/剪枝操作的敏感程度 动态规划优化缓存间隔:以敏感度误差为代价函数,用 DP 求解最优缓存时间点 自适应剪枝:在缓存复用阶段,根据 token 敏感度动态决定剪枝时机和比例 核心创新 敏感度误差建模:不是简单地均匀缓存/剪枝,而是"在最不敏感处缓存,在最不敏感的 token 处剪枝" DP 最优化:缓存间隔不再是超参数,而是通过动态规划自动求解 实验结果 在 DiT-XL/2、PixArt-α、OpenSora 上实现 SOTA 生成保真度 在可控加速比下保真度显著优于 PAB、∆-DiT 等基线 技术脉络 FasterCache (2024) → ∆-DiT (2024) → PAB → SODA (2026.3) 批判性点评 优势:缓存+剪枝的统一框架,敏感度建模理论扎实 局限:离线敏感度分析需要额外推理开销;DP 只优化缓存间隔,未联合优化剪枝策略;仅测试了较小的模型(DiT-XL/2),未在 Wan/HunyuanVideo 等大模型上验证 创新性评分:3.5/5 论文 4:VMonarch — Monarch 矩阵结构化注意力 标题:VMonarch: Efficient Video Diffusion Transformers with Structured Attention 作者:Cheng Liang, Haoxian Chen, Liang Hou 等 (南京大学 + 腾讯) 日期:2026年1月29日 arXiv:2601.22275 关键词:Monarch矩阵 结构化稀疏 交替最小化 FlashAttention 在线熵 5x加速 研究动机 视频 DiT 的注意力模式天然具有高度稀疏的时空结构,但现有稀疏方法(Top-K、局部窗口)要么不灵活,要么丢失全局信息。能否找到一种数学上优雅的方式来表示这些稀疏模式? 方法原理 VMonarch 将视频 DiT 的稀疏注意力模式建模为 Monarch 矩阵 —— 一类具有灵活稀疏性的结构化矩阵。 时空 Monarch 分解:将全注意力矩阵分解为帧内(空间)和帧间(时间)两组 Monarch 因子,分别捕捉空间和时间相关性 交替最小化:通过交替优化两组因子来逼近原始全注意力 重计算策略:解决交替最小化不稳定导致的伪影问题 在线熵算法:融入 FlashAttention 的在线熵计算,支持长序列高效更新 核心创新 Monarch 矩阵在视频 DiT 中的首次应用:优雅地统一了稀疏和结构化的优势 在线熵 + FlashAttention 融合:使得 Monarch 矩阵更新在长序列上也可行 实验结果 注意力 FLOPs 减少 17.5 倍 注意力计算加速 5 倍以上 在 VBench 上轻量微调后质量与全注意力相当 90% 稀疏度下超越所有 SOTA 稀疏注意力方法 技术脉络 Monarch Mixer (2023) → Monarch in LLM → VMonarch (视频 DiT 首次应用) 批判性点评 优势:数学上最优雅的方案;17.5x FLOPs 减少是本周最极端的数字;与 FlashAttention 兼容 局限:交替最小化的收敛性依赖初始化;需要轻量微调(非完全免训练);实际 wall-clock 加速(5x)远小于理论 FLOPs 减少(17.5x),说明实现上有瓶颈 创新性评分:4.5/5 — 本周最具理论深度的工作 论文 5:SLA — 稀疏-线性注意力融合 标题:SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention 作者:Jintao Zhang 等 (清华 + Berkeley) 日期:2025年9月28日(ICLR 2026 Oral) arXiv:2509.24006 关键词:稀疏注意力 线性注意力 融合 自定义GPU kernel 95%计算减少 ICLR 2026 研究动机 注意力权重可以分为两部分:少量大权重(高秩)和大量小权重(低秩)。这天然暗示:对大权重用稀疏注意力(O(N²) 但只算少量),对小权重用线性注意力(O(N))。 方法原理 三级分类:将注意力权重分为 Critical(O(N²) 精确计算)、Marginal(O(N) 线性注意力)、Negligible(跳过) 融合 GPU kernel:将稀疏和线性注意力的计算融合到单个 GPU kernel 中,支持前向和反向传播 轻量微调:仅需少量微调步就能适配 核心创新 稀疏+线性的系统性融合:不是简单的 fallback,而是基于权重分布的最优分配 自定义 GPU kernel:工程实现极其扎实,直接转化为实际加速 实验结果 注意力计算减少 95%(20 倍) 注意力加速 13.7 倍 端到端加速 2.2 倍(Wan 2.1-1.3B) 生成质量无损 技术脉络 稀疏注意力 + 线性注意力两条独立技术路线 → SLA 首次统一融合(ICLR 2026 Oral) 批判性点评 优势:ICLR 2026 Oral,学术认可度最高;2.2x E2E 加速是免训练之外的最佳实际数字;自定义 kernel 可直接落地 局限:需要微调(虽然很轻量);目前只在 1.3B 模型上测试,14B 模型的效果未知;kernel 需要针对不同硬件调优 创新性评分:4.5/5 论文 6:SALAD — 高稀疏度线性注意力微调 标题:SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer 作者:Tongcheng Fang 等 (清华 + 腾讯) 日期:2026年1月23日 arXiv:2601.16515 关键词:线性注意力 门控机制 高稀疏度 轻量微调 2000样本 研究动机 免训练稀疏注意力受限于有限的稀疏度(通常 50-70%),而训练型方法需要大量数据和计算。能否用极轻量的微调达到极高稀疏度? 方法原理 双分支并行:在稀疏注意力旁边添加一个轻量线性注意力分支 输入依赖门控:用门控机制动态平衡两个分支的贡献 极轻量微调:仅需 2000 个视频样本和 1600 步训练 实验结果 90% 稀疏度,1.72x 推理加速 生成质量与全注意力基线相当 批判性点评 思路与 SLA 类似但更轻量;微调效率极高(2000 样本);但 1.72x 加速低于 SLA 的 2.2x 创新性评分:3.5/5 论文 7:FastLightGen — 步数 + 参数同时压缩 标题:FastLightGen: Fast and Light Video Generation with Fewer Steps and Parameters 作者:Shitong Shao, Yufei Gu, Zeke Xie 日期:2026年3月2日 arXiv:2603.01685 关键词:蒸馏 剪枝 步数压缩 参数压缩 HunyuanVideo WanX 研究动机 以往的加速研究要么减少采样步数(蒸馏),要么减少模型参数(剪枝),但从未同时压缩两者。 方法原理 FastLightGen 的核心:构建一个"最优教师模型",在协同框架中同时蒸馏步数和参数。 协同蒸馏框架:同时优化步数减少和参数剪枝 最优教师构建:教师模型本身经过优化,以最大化学生模型的性能 实验结果 4 步采样 + 30% 参数剪枝 = 最佳视觉质量(在约束推理预算下) 在 HunyuanVideo-ATI2V 和 WanX-TI2V 上优于所有竞争方法 批判性点评 首次探索步数+参数的联合压缩,填补了研究空白 但 30% 剪枝比较保守;缺少与纯蒸馏方法的详细对比 创新性评分:3.5/5 论文 8:Diagonal Distillation — 对角蒸馏实现流式视频生成 标题:Streaming Autoregressive Video Generation via Diagonal Distillation 作者:Jinxiu Liu 等 (HKUST, Ming-Hsuan Yang) 日期:2026年3月10日 arXiv:2603.09488 关键词:自回归 蒸馏 流式生成 光流建模 277x加速 31 FPS 研究动机 扩散蒸馏将多步模型压缩为少步变体,但现有方法主要针对图像设计,忽略了视频的时间依赖性,导致运动不连贯和长序列误差累积。 方法原理 对角蒸馏:不同于传统的逐 chunk 独立蒸馏,Diagonal Distillation 沿"视频 chunk × 去噪步"的对角线方向进行蒸馏 非对称生成策略:前面的 chunk 用更多步、后面的 chunk 用更少步。后面的 chunk 可以继承前面已充分处理的外观信息 隐式光流建模:在严格步数约束下保持运动质量 核心创新 对角蒸馏:沿时间-步数对角线操作,充分利用时间上下文 非对称步数分配:打破"每个 chunk 步数相同"的假设 曝光偏差缓解:将训练时的噪声条件与推理时对齐 实验结果 5 秒视频 2.61 秒生成(31 FPS) 相比原始模型 277.3 倍加速 运动连贯性和长序列质量显著优于图像蒸馏方法 批判性点评 优势:277x 是本周最震撼的加速数字;流式生成对实时应用极其重要 局限:目前仅适用于自回归视频模型;生成质量与原始多步模型仍有差距;FPS 数字的分辨率条件未详细说明 创新性评分:4/5 论文 9:FrameDiT — 帧级矩阵注意力 标题:FrameDiT: Diffusion Transformer with Frame-Level Matrix Attention for Efficient Video Generation 作者:Minh Khoa Le 等 日期:2026年3月10日 arXiv:2603.09721 关键词:帧级注意力 矩阵注意力 时空结构 Local Factorized 研究动机 现有方法面临 Full 3D Attention(强但贵)vs Local Factorized Attention(快但丢失全局信息)的两难。 方法原理 Matrix Attention:将整帧作为矩阵处理,通过矩阵原生操作生成 Q/K/V 帧间注意力:在帧级别而非 token 级别做跨帧注意力,保持全局时空结构 FrameDiT-H:混合 Matrix Attention + Local Factorized Attention,同时捕捉大运动和小运动 实验结果 多个视频生成 benchmark 上达到 SOTA 效率与 Local Factorized Attention 相当 批判性点评 帧级注意力的粒度介于 Full 3D 和 Local Factorized 之间,是一个有趣的中间地带 但"矩阵注意力"的具体实现细节(矩阵原生操作是什么?)缺乏清晰的数学定义 创新性评分:3/5 三、横向对比分析 3.1 方法分类体系 本周的 9 篇论文可以按 "是否需要训练" 和 "加速策略" 两个维度分类: 免训练 轻量微调 训练/蒸馏 ┌─────────┐ ┌─────────┐ ┌─────────┐ 稀疏注意力 │CalibAtt │ │ SALAD │ │ SLA │ │SVG-EAR │ │VMonarch │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 缓存+剪枝 │ SODA │ │ │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 蒸馏+压缩 │ │ │ │ │FastLight│ │ │ │ │ │DiagDist │ ├─────────┤ ├─────────┤ ├─────────┤ 结构化注意力 │ │ │ │ │FrameDiT │ └─────────┘ └─────────┘ └─────────┘ 3.2 性能对比 方法 注意力加速 端到端加速 需要训练? 测试模型 质量保持 CalibAtt - 1.58x 否 Wan 2.1 14B, Mochi ★★★★ SVG-EAR - 1.77-1.93x 否 Wan 2.2, HunyuanVideo ★★★★ SODA - 可控 否 DiT-XL, PixArt-α, OpenSora ★★★★★ VMonarch 5x - 轻量微调 VBench ★★★★ SALAD - 1.72x 2000样本 - ★★★★ SLA 13.7x 2.2x 少量微调 Wan 2.1 1.3B ★★★★★ FastLightGen - 显著 蒸馏 HunyuanVideo, WanX ★★★★ Diagonal Dist. - 277.3x 蒸馏 自回归模型 ★★★ FrameDiT ~FA级 ~FA级 训练 多个benchmark ★★★★ 3.3 技术路线演进 本周的论文清晰地展现了四条技术路线的演进: 路线 A:免训练稀疏注意力 核心思想:发现并利用注意力的天然稀疏性 演进:Token-level Top-K → Block-level 静态模式 (CalibAtt) → 误差感知动态路由 (SVG-EAR) 加速上限:~2x(受限于稀疏度无法无限提高) 路线 B:稀疏 + 线性注意力融合 核心思想:对不同重要性的注意力权重使用不同计算策略 演进:纯稀疏 / 纯线性 → 并行双分支 (SALAD) → 融合 kernel (SLA) → Monarch 结构化 (VMonarch) 加速上限:~2-5x(取决于 kernel 效率) 路线 C:缓存 + 剪枝 核心思想:利用扩散过程中相邻时间步的特征相似性 演进:均匀缓存 → 启发式组合 → 敏感度导向 DP 优化 (SODA) 加速上限:~2-3x(缓存复用比例有限) 路线 D:蒸馏 + 压缩 核心思想:用小模型/少步数逼近大模型/多步数 演进:步数蒸馏 → 参数剪枝 → 联合压缩 (FastLightGen) → 对角蒸馏 (Diagonal Distillation) 加速上限:100x+(但质量损失更大) 3.4 关键洞察与趋势 免训练方法的天花板在 ~2x:CalibAtt (1.58x) 和 SVG-EAR (1.93x) 代表了免训练稀疏注意力的当前上限。突破需要引入轻量训练。 稀疏 + 线性融合是最佳平衡点:SLA 通过自定义 kernel 实现 2.2x E2E 加速且质量无损,是目前注意力加速的最优解。ICLR 2026 Oral 的认可也说明了这一点。 蒸馏方法的加速比远超注意力优化:Diagonal Distillation 的 277x 说明,如果能接受一定质量损失,蒸馏是最强力的加速手段。但注意力优化的优势是"质量无损"。 多种方法可叠加:注意力优化 + 蒸馏可以叠加使用。CalibAtt 已在蒸馏模型上验证有效。理论上 SLA + 步数蒸馏可能实现 5-10x 无损加速。 Wan 和 HunyuanVideo 成为标准测试平台:本周几乎所有论文都在这两个模型上测试,说明它们已成为视频生成的事实标准。 从算法到系统的全栈优化:SODA 的序列并行推理提醒我们,纯算法优化之外,系统级优化(多 GPU 并行、算子融合等)同样重要。 四、总结与展望 本周最值得关注的 3 篇 SLA (ICLR 2026 Oral):稀疏-线性融合的里程碑工作,自定义 kernel 的工程深度令人印象深刻 SVG-EAR:误差感知路由的洞察非常深刻,免训练方法的新标杆 VMonarch:Monarch 矩阵的引入为结构化注意力开辟了全新方向 未来研究方向预判 注意力优化 + 蒸馏的联合框架:将 SLA/SVG-EAR 与 FastLightGen/Diagonal Distillation 结合 更大规模模型验证:SLA 仅在 1.3B 上测试,14B+ 模型上的表现待验证 长视频生成的特化优化:随着视频长度增长到分钟级,注意力优化的重要性进一步凸显 硬件协同设计:自定义 kernel(SLA)和结构化矩阵(VMonarch)需要与硬件特性深度适配 人工智能炼丹师 整理 | 2026-03-14
AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 AIGC 周末专题深度解读:视频扩散 Transformer 高效推理 专题方向:视频 DiT 中的稀疏注意力、线性注意力与推理加速 覆盖时间:2026年3月2日 — 2026年3月13日 整理:人工智能炼丹师 日期:2026年3月14日(周六) 一、专题概览 本周是视频扩散 Transformer(Video DiT)高效推理方向的"论文爆发周"。短短一周内,arXiv 上出现了 9 篇 高度聚焦于视频 DiT 注意力加速与推理优化的论文,覆盖了从稀疏注意力、线性注意力、结构化注意力,到蒸馏压缩、缓存+剪枝、系统级并行优化的完整技术栈。 核心背景 当前主流视频生成模型(Wan 2.1/2.2、HunyuanVideo、Mochi 等)均采用 Diffusion Transformer(DiT)架构,其核心瓶颈在于 全注意力(Full 3D Attention)的 O(N²) 复杂度。一段 5 秒 720P 视频的 token 序列长度可达数十万,全注意力的计算量和显存占用极其惊人。因此,如何在保持生成质量的前提下大幅降低注意力计算成本,成为本周研究的核心主题。 本周论文全景 # 论文 方法类别 核心思路 加速比 提交日期 1 CalibAtt 稀疏注意力(免训练) 离线校准块级稀疏模式 1.58x E2E 3月5日 2 SVG-EAR 稀疏注意力 + 线性补偿(免训练) 误差感知路由 + 聚类质心补偿 1.77-1.93x 3月9日 3 SODA 缓存 + 剪枝(免训练) 敏感度导向的动态加速 SOTA fidelity 3月7日 4 FrameDiT 结构化注意力(需训练) 帧级矩阵注意力 ~Local FA 3月10日 5 VMonarch 结构化注意力(轻量微调) Monarch 矩阵分解 5x attn, 17.5x FLOPs↓ 1月29日 6 SALAD 稀疏 + 线性混合(轻量微调) 门控线性注意力并行分支 1.72x, 90%稀疏 1月23日 7 SLA 稀疏 + 线性融合(微调) 三级权重分类 + 自定义 kernel 2.2x E2E, 13.7x attn 2025.9 (ICLR'26) 8 FastLightGen 蒸馏 + 剪枝 步数+参数同时压缩 4步+30%剪枝 3月2日 9 Diagonal Distillation 自回归蒸馏 对角蒸馏 + 隐式光流 277.3x, 31 FPS 3月10日 二、重点论文深度解读 论文 1:CalibAtt — 校准稀疏注意力加速视频生成 标题:Accelerating Text-to-Video Generation with Calibrated Sparse Attention 作者:Shai Yehezkel, Shahar Yadin, Noam Elata 等 机构:以色列理工 日期:2026年3月5日 arXiv:2603.05503 关键词:稀疏注意力 免训练 离线校准 块级模式 Wan 2.1 Mochi 研究动机 视频 DiT 中的全注意力计算是推理速度的主要瓶颈。已有的稀疏注意力方法要么需要训练(如 SLA、SALAD),要么是在线动态判断每个 token 的重要性(开销大)。作者观察到一个关键现象:大量 token-to-token 连接在不同输入上一致地产生可忽略的注意力分数,且这些模式在不同查询间重复出现。 方法原理 CalibAtt 采用"离线校准 + 在线高效推理"的两阶段策略: 离线校准阶段:在少量参考视频上运行全注意力,统计每一层、每个注意力头、每个扩散时间步的块级(block-level)稀疏模式和重复模式 模式编译:将稳定的稀疏模式编译为优化的注意力操作(类似于"稀疏注意力的 JIT 编译") 在线推理:只计算被选中的输入相关连接,以硬件友好的方式跳过未选中的连接 核心创新 块级粒度:不做 token 级稀疏(开销大),而是以 token block 为单位,兼顾精度和效率 跨输入稳定性:发现稀疏模式对输入不敏感,可以离线固定 层-头-时间步三维校准:不同层/头/时间步的稀疏模式不同,细粒度适配 实验结果 在 Wan 2.1 14B、Mochi 1 及其蒸馏版本上测试 实现 1.58x 端到端加速 在视频生成质量和文本-视频对齐度上优于已有免训练方法 支持多种分辨率 技术脉络 Sparse VideoGen (2024) → Sparse VideoGen2 (2025.5) → CalibAtt (2026.3)。从在线动态稀疏 → 离线校准静态稀疏,核心洞察是"稀疏模式跨输入稳定"。 批判性点评 优势:完全免训练,直接即插即用;离线校准成本低;硬件友好 局限:1.58x 的加速比在本周论文中并不突出;块级粒度可能丢失细粒度信息;对新架构需要重新校准 创新性评分:3/5 — 洞察有价值但方法相对直接 论文 2:SVG-EAR — 无参数线性补偿的误差感知路由 标题:SVG-EAR: Parameter-Free Linear Compensation for Sparse Video Generation via Error-aware Routing 作者:Xuanyi Zhou, Qiuyang Mang, Shuo Yang 等 (UC Berkeley, Ion Stoica 组) 日期:2026年3月9日 arXiv:2603.08982 关键词:稀疏注意力 线性补偿 误差感知路由 聚类质心 免训练 Wan 2.2 HunyuanVideo 研究动机 现有稀疏注意力方法面临两难:(1) 直接丢弃被跳过的注意力块会丢失信息;(2) 用学习型预测器来近似它们又引入训练开销和分布偏移。能否在不训练的情况下恢复被跳过块的贡献? 方法原理 SVG-EAR 的核心洞察:经过语义聚类后,同一块内的 key 和 value 具有高度相似性,可以用少量聚类质心准确概括。 聚类质心补偿:对被跳过的注意力块,用 key/value 的聚类质心做线性(O(N))近似,恢复其对输出的贡献 误差感知路由:传统方法按注意力分数选择需要精确计算的块,但高注意力分数 ≠ 高近似误差。SVG-EAR 用一个轻量探测器估计每个块的补偿误差,选择"误差-成本比"最高的块做精确计算 理论保证:提供了注意力重建误差与聚类质量之间的理论上界 核心创新 误差感知 vs 分数感知:颠覆了传统"高注意力分数 = 重要"的假设,改为"高近似误差 = 需要精确计算" 无参数线性补偿:用聚类质心做 O(N) 补偿,不需要任何训练 帕累托最优:在所有免训练方法中建立了新的帕累托前沿 实验结果 Wan 2.2:1.77x 加速,PSNR 29.759 HunyuanVideo:1.93x 加速,PSNR 31.043 显著优于 Sparse VideoGen2 和 CalibAtt 技术脉络 Sparse VideoGen → SVG2 → SVG-EAR(同一系列的第三代,Ion Stoica / Berkeley 团队的持续推进) 批判性点评 优势:免训练、有理论保证、误差感知路由的思路很优雅 局限:聚类质心计算本身有开销;实际 wall-clock 加速受限于聚类效率;PSNR 不是视频生成的最佳指标 创新性评分:4/5 — 误差感知路由是本周最有洞察的方法论创新 论文 3:SODA — 敏感度导向的动态加速 标题:SODA: Sensitivity-Oriented Dynamic Acceleration for Diffusion Transformer 作者:Tong Shao, Yusen Fu 等 日期:2026年3月7日 arXiv:2603.07057 关键词:缓存 剪枝 敏感度分析 动态规划 免训练 DiT-XL PixArt-α OpenSora 研究动机 特征缓存(caching)和 token 剪枝(pruning)是两种互补的加速手段:缓存加速效率高但影响保真度,剪枝相反。现有方法用固定的启发式策略组合两者,无法捕捉模型对加速操作的细粒度敏感度变化。 方法原理 离线敏感度建模:构建跨时间步、层、模块的敏感度误差模型,量化每个计算单元对缓存/剪枝操作的敏感程度 动态规划优化缓存间隔:以敏感度误差为代价函数,用 DP 求解最优缓存时间点 自适应剪枝:在缓存复用阶段,根据 token 敏感度动态决定剪枝时机和比例 核心创新 敏感度误差建模:不是简单地均匀缓存/剪枝,而是"在最不敏感处缓存,在最不敏感的 token 处剪枝" DP 最优化:缓存间隔不再是超参数,而是通过动态规划自动求解 实验结果 在 DiT-XL/2、PixArt-α、OpenSora 上实现 SOTA 生成保真度 在可控加速比下保真度显著优于 PAB、∆-DiT 等基线 技术脉络 FasterCache (2024) → ∆-DiT (2024) → PAB → SODA (2026.3) 批判性点评 优势:缓存+剪枝的统一框架,敏感度建模理论扎实 局限:离线敏感度分析需要额外推理开销;DP 只优化缓存间隔,未联合优化剪枝策略;仅测试了较小的模型(DiT-XL/2),未在 Wan/HunyuanVideo 等大模型上验证 创新性评分:3.5/5 论文 4:VMonarch — Monarch 矩阵结构化注意力 标题:VMonarch: Efficient Video Diffusion Transformers with Structured Attention 作者:Cheng Liang, Haoxian Chen, Liang Hou 等 (南京大学 + 腾讯) 日期:2026年1月29日 arXiv:2601.22275 关键词:Monarch矩阵 结构化稀疏 交替最小化 FlashAttention 在线熵 5x加速 研究动机 视频 DiT 的注意力模式天然具有高度稀疏的时空结构,但现有稀疏方法(Top-K、局部窗口)要么不灵活,要么丢失全局信息。能否找到一种数学上优雅的方式来表示这些稀疏模式? 方法原理 VMonarch 将视频 DiT 的稀疏注意力模式建模为 Monarch 矩阵 —— 一类具有灵活稀疏性的结构化矩阵。 时空 Monarch 分解:将全注意力矩阵分解为帧内(空间)和帧间(时间)两组 Monarch 因子,分别捕捉空间和时间相关性 交替最小化:通过交替优化两组因子来逼近原始全注意力 重计算策略:解决交替最小化不稳定导致的伪影问题 在线熵算法:融入 FlashAttention 的在线熵计算,支持长序列高效更新 核心创新 Monarch 矩阵在视频 DiT 中的首次应用:优雅地统一了稀疏和结构化的优势 在线熵 + FlashAttention 融合:使得 Monarch 矩阵更新在长序列上也可行 实验结果 注意力 FLOPs 减少 17.5 倍 注意力计算加速 5 倍以上 在 VBench 上轻量微调后质量与全注意力相当 90% 稀疏度下超越所有 SOTA 稀疏注意力方法 技术脉络 Monarch Mixer (2023) → Monarch in LLM → VMonarch (视频 DiT 首次应用) 批判性点评 优势:数学上最优雅的方案;17.5x FLOPs 减少是本周最极端的数字;与 FlashAttention 兼容 局限:交替最小化的收敛性依赖初始化;需要轻量微调(非完全免训练);实际 wall-clock 加速(5x)远小于理论 FLOPs 减少(17.5x),说明实现上有瓶颈 创新性评分:4.5/5 — 本周最具理论深度的工作 论文 5:SLA — 稀疏-线性注意力融合 标题:SLA: Beyond Sparsity in Diffusion Transformers via Fine-Tunable Sparse-Linear Attention 作者:Jintao Zhang 等 (清华 + Berkeley) 日期:2025年9月28日(ICLR 2026 Oral) arXiv:2509.24006 关键词:稀疏注意力 线性注意力 融合 自定义GPU kernel 95%计算减少 ICLR 2026 研究动机 注意力权重可以分为两部分:少量大权重(高秩)和大量小权重(低秩)。这天然暗示:对大权重用稀疏注意力(O(N²) 但只算少量),对小权重用线性注意力(O(N))。 方法原理 三级分类:将注意力权重分为 Critical(O(N²) 精确计算)、Marginal(O(N) 线性注意力)、Negligible(跳过) 融合 GPU kernel:将稀疏和线性注意力的计算融合到单个 GPU kernel 中,支持前向和反向传播 轻量微调:仅需少量微调步就能适配 核心创新 稀疏+线性的系统性融合:不是简单的 fallback,而是基于权重分布的最优分配 自定义 GPU kernel:工程实现极其扎实,直接转化为实际加速 实验结果 注意力计算减少 95%(20 倍) 注意力加速 13.7 倍 端到端加速 2.2 倍(Wan 2.1-1.3B) 生成质量无损 技术脉络 稀疏注意力 + 线性注意力两条独立技术路线 → SLA 首次统一融合(ICLR 2026 Oral) 批判性点评 优势:ICLR 2026 Oral,学术认可度最高;2.2x E2E 加速是免训练之外的最佳实际数字;自定义 kernel 可直接落地 局限:需要微调(虽然很轻量);目前只在 1.3B 模型上测试,14B 模型的效果未知;kernel 需要针对不同硬件调优 创新性评分:4.5/5 论文 6:SALAD — 高稀疏度线性注意力微调 标题:SALAD: Achieve High-Sparsity Attention via Efficient Linear Attention Tuning for Video Diffusion Transformer 作者:Tongcheng Fang 等 (清华 + 腾讯) 日期:2026年1月23日 arXiv:2601.16515 关键词:线性注意力 门控机制 高稀疏度 轻量微调 2000样本 研究动机 免训练稀疏注意力受限于有限的稀疏度(通常 50-70%),而训练型方法需要大量数据和计算。能否用极轻量的微调达到极高稀疏度? 方法原理 双分支并行:在稀疏注意力旁边添加一个轻量线性注意力分支 输入依赖门控:用门控机制动态平衡两个分支的贡献 极轻量微调:仅需 2000 个视频样本和 1600 步训练 实验结果 90% 稀疏度,1.72x 推理加速 生成质量与全注意力基线相当 批判性点评 思路与 SLA 类似但更轻量;微调效率极高(2000 样本);但 1.72x 加速低于 SLA 的 2.2x 创新性评分:3.5/5 论文 7:FastLightGen — 步数 + 参数同时压缩 标题:FastLightGen: Fast and Light Video Generation with Fewer Steps and Parameters 作者:Shitong Shao, Yufei Gu, Zeke Xie 日期:2026年3月2日 arXiv:2603.01685 关键词:蒸馏 剪枝 步数压缩 参数压缩 HunyuanVideo WanX 研究动机 以往的加速研究要么减少采样步数(蒸馏),要么减少模型参数(剪枝),但从未同时压缩两者。 方法原理 FastLightGen 的核心:构建一个"最优教师模型",在协同框架中同时蒸馏步数和参数。 协同蒸馏框架:同时优化步数减少和参数剪枝 最优教师构建:教师模型本身经过优化,以最大化学生模型的性能 实验结果 4 步采样 + 30% 参数剪枝 = 最佳视觉质量(在约束推理预算下) 在 HunyuanVideo-ATI2V 和 WanX-TI2V 上优于所有竞争方法 批判性点评 首次探索步数+参数的联合压缩,填补了研究空白 但 30% 剪枝比较保守;缺少与纯蒸馏方法的详细对比 创新性评分:3.5/5 论文 8:Diagonal Distillation — 对角蒸馏实现流式视频生成 标题:Streaming Autoregressive Video Generation via Diagonal Distillation 作者:Jinxiu Liu 等 (HKUST, Ming-Hsuan Yang) 日期:2026年3月10日 arXiv:2603.09488 关键词:自回归 蒸馏 流式生成 光流建模 277x加速 31 FPS 研究动机 扩散蒸馏将多步模型压缩为少步变体,但现有方法主要针对图像设计,忽略了视频的时间依赖性,导致运动不连贯和长序列误差累积。 方法原理 对角蒸馏:不同于传统的逐 chunk 独立蒸馏,Diagonal Distillation 沿"视频 chunk × 去噪步"的对角线方向进行蒸馏 非对称生成策略:前面的 chunk 用更多步、后面的 chunk 用更少步。后面的 chunk 可以继承前面已充分处理的外观信息 隐式光流建模:在严格步数约束下保持运动质量 核心创新 对角蒸馏:沿时间-步数对角线操作,充分利用时间上下文 非对称步数分配:打破"每个 chunk 步数相同"的假设 曝光偏差缓解:将训练时的噪声条件与推理时对齐 实验结果 5 秒视频 2.61 秒生成(31 FPS) 相比原始模型 277.3 倍加速 运动连贯性和长序列质量显著优于图像蒸馏方法 批判性点评 优势:277x 是本周最震撼的加速数字;流式生成对实时应用极其重要 局限:目前仅适用于自回归视频模型;生成质量与原始多步模型仍有差距;FPS 数字的分辨率条件未详细说明 创新性评分:4/5 论文 9:FrameDiT — 帧级矩阵注意力 标题:FrameDiT: Diffusion Transformer with Frame-Level Matrix Attention for Efficient Video Generation 作者:Minh Khoa Le 等 日期:2026年3月10日 arXiv:2603.09721 关键词:帧级注意力 矩阵注意力 时空结构 Local Factorized 研究动机 现有方法面临 Full 3D Attention(强但贵)vs Local Factorized Attention(快但丢失全局信息)的两难。 方法原理 Matrix Attention:将整帧作为矩阵处理,通过矩阵原生操作生成 Q/K/V 帧间注意力:在帧级别而非 token 级别做跨帧注意力,保持全局时空结构 FrameDiT-H:混合 Matrix Attention + Local Factorized Attention,同时捕捉大运动和小运动 实验结果 多个视频生成 benchmark 上达到 SOTA 效率与 Local Factorized Attention 相当 批判性点评 帧级注意力的粒度介于 Full 3D 和 Local Factorized 之间,是一个有趣的中间地带 但"矩阵注意力"的具体实现细节(矩阵原生操作是什么?)缺乏清晰的数学定义 创新性评分:3/5 三、横向对比分析 3.1 方法分类体系 本周的 9 篇论文可以按 "是否需要训练" 和 "加速策略" 两个维度分类: 免训练 轻量微调 训练/蒸馏 ┌─────────┐ ┌─────────┐ ┌─────────┐ 稀疏注意力 │CalibAtt │ │ SALAD │ │ SLA │ │SVG-EAR │ │VMonarch │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 缓存+剪枝 │ SODA │ │ │ │ │ ├─────────┤ ├─────────┤ ├─────────┤ 蒸馏+压缩 │ │ │ │ │FastLight│ │ │ │ │ │DiagDist │ ├─────────┤ ├─────────┤ ├─────────┤ 结构化注意力 │ │ │ │ │FrameDiT │ └─────────┘ └─────────┘ └─────────┘ 3.2 性能对比 方法 注意力加速 端到端加速 需要训练? 测试模型 质量保持 CalibAtt - 1.58x 否 Wan 2.1 14B, Mochi ★★★★ SVG-EAR - 1.77-1.93x 否 Wan 2.2, HunyuanVideo ★★★★ SODA - 可控 否 DiT-XL, PixArt-α, OpenSora ★★★★★ VMonarch 5x - 轻量微调 VBench ★★★★ SALAD - 1.72x 2000样本 - ★★★★ SLA 13.7x 2.2x 少量微调 Wan 2.1 1.3B ★★★★★ FastLightGen - 显著 蒸馏 HunyuanVideo, WanX ★★★★ Diagonal Dist. - 277.3x 蒸馏 自回归模型 ★★★ FrameDiT ~FA级 ~FA级 训练 多个benchmark ★★★★ 3.3 技术路线演进 本周的论文清晰地展现了四条技术路线的演进: 路线 A:免训练稀疏注意力 核心思想:发现并利用注意力的天然稀疏性 演进:Token-level Top-K → Block-level 静态模式 (CalibAtt) → 误差感知动态路由 (SVG-EAR) 加速上限:~2x(受限于稀疏度无法无限提高) 路线 B:稀疏 + 线性注意力融合 核心思想:对不同重要性的注意力权重使用不同计算策略 演进:纯稀疏 / 纯线性 → 并行双分支 (SALAD) → 融合 kernel (SLA) → Monarch 结构化 (VMonarch) 加速上限:~2-5x(取决于 kernel 效率) 路线 C:缓存 + 剪枝 核心思想:利用扩散过程中相邻时间步的特征相似性 演进:均匀缓存 → 启发式组合 → 敏感度导向 DP 优化 (SODA) 加速上限:~2-3x(缓存复用比例有限) 路线 D:蒸馏 + 压缩 核心思想:用小模型/少步数逼近大模型/多步数 演进:步数蒸馏 → 参数剪枝 → 联合压缩 (FastLightGen) → 对角蒸馏 (Diagonal Distillation) 加速上限:100x+(但质量损失更大) 3.4 关键洞察与趋势 免训练方法的天花板在 ~2x:CalibAtt (1.58x) 和 SVG-EAR (1.93x) 代表了免训练稀疏注意力的当前上限。突破需要引入轻量训练。 稀疏 + 线性融合是最佳平衡点:SLA 通过自定义 kernel 实现 2.2x E2E 加速且质量无损,是目前注意力加速的最优解。ICLR 2026 Oral 的认可也说明了这一点。 蒸馏方法的加速比远超注意力优化:Diagonal Distillation 的 277x 说明,如果能接受一定质量损失,蒸馏是最强力的加速手段。但注意力优化的优势是"质量无损"。 多种方法可叠加:注意力优化 + 蒸馏可以叠加使用。CalibAtt 已在蒸馏模型上验证有效。理论上 SLA + 步数蒸馏可能实现 5-10x 无损加速。 Wan 和 HunyuanVideo 成为标准测试平台:本周几乎所有论文都在这两个模型上测试,说明它们已成为视频生成的事实标准。 从算法到系统的全栈优化:SODA 的序列并行推理提醒我们,纯算法优化之外,系统级优化(多 GPU 并行、算子融合等)同样重要。 四、总结与展望 本周最值得关注的 3 篇 SLA (ICLR 2026 Oral):稀疏-线性融合的里程碑工作,自定义 kernel 的工程深度令人印象深刻 SVG-EAR:误差感知路由的洞察非常深刻,免训练方法的新标杆 VMonarch:Monarch 矩阵的引入为结构化注意力开辟了全新方向 未来研究方向预判 注意力优化 + 蒸馏的联合框架:将 SLA/SVG-EAR 与 FastLightGen/Diagonal Distillation 结合 更大规模模型验证:SLA 仅在 1.3B 上测试,14B+ 模型上的表现待验证 长视频生成的特化优化:随着视频长度增长到分钟级,注意力优化的重要性进一步凸显 硬件协同设计:自定义 kernel(SLA)和结构化矩阵(VMonarch)需要与硬件特性深度适配 人工智能炼丹师 整理 | 2026-03-14 -
多模态预训练模型之CogVLM CogVLM:VISUAL EXPERT FOR LARGE LANGUAGE MODELS 被多个文生图模型广泛使用,包括SD3、可图用作Caption模型 图像 & 文本分别建模的思想在SD3中的MMDIT中也被应用到 1. Motivation 浅层对齐的缺陷:例如BLIP2的QFormer或者LLAVA的MLP,作者认为是导致幻觉的一个重要原因 浅层对齐 + 图文联合训练(LLM+Vision+adapter)会损害NLP的能力: Qwen-VL 等模型,会导致文本理解能力的灾难性遗忘【只要训练数据配比得当,就能避免这个问题?】 2. 主要贡献 模型结构: 引入视觉专家(QKV matrix+ FFN): 冻结LLM,100%保留文本对话能力 视觉位置编码:图像特征共享一个位置编码,对于高分辨率理解有帮助。 3. 一些细节 3.1 消融实验(caption 任务 + VQA任务) 模型结构 & 微调的部分:【视觉专家 + MLP adapater】比其他更好,(为什么没有微调视觉+LLM+adapter全量实验,在下游任务上全量FT应该可以更好),该部分影响最大 采用LLM的权重来初始化Visual Expert能够提升性能(应该能加速训练,和LLM expert融合会更容易) 视觉部分,单向注意 or 双向注意的影响,使用单向注意反而更好 视觉部分的自回归监督,没有提升 EMA可以多数任务上均能带来提升 3.3 训练数据细节 3.3.1 预训练数据 LAION-2B + COYO-700M-> 1.5B Visual grouding: 40M(GLIP v2预测的bounding box作为GT),从LAION-115M中过滤出来的40M(75%的图片包含至少两个目标框) 3.3.2 SFT数据(50w) LLaVA-Instruct (corrected) LRV-Instruction LLaVAR in-house data 3.4 训练细节 在SFT阶段,对LLM进行训练,学习率为base其他参数的10%,VIT始终保持固定
-
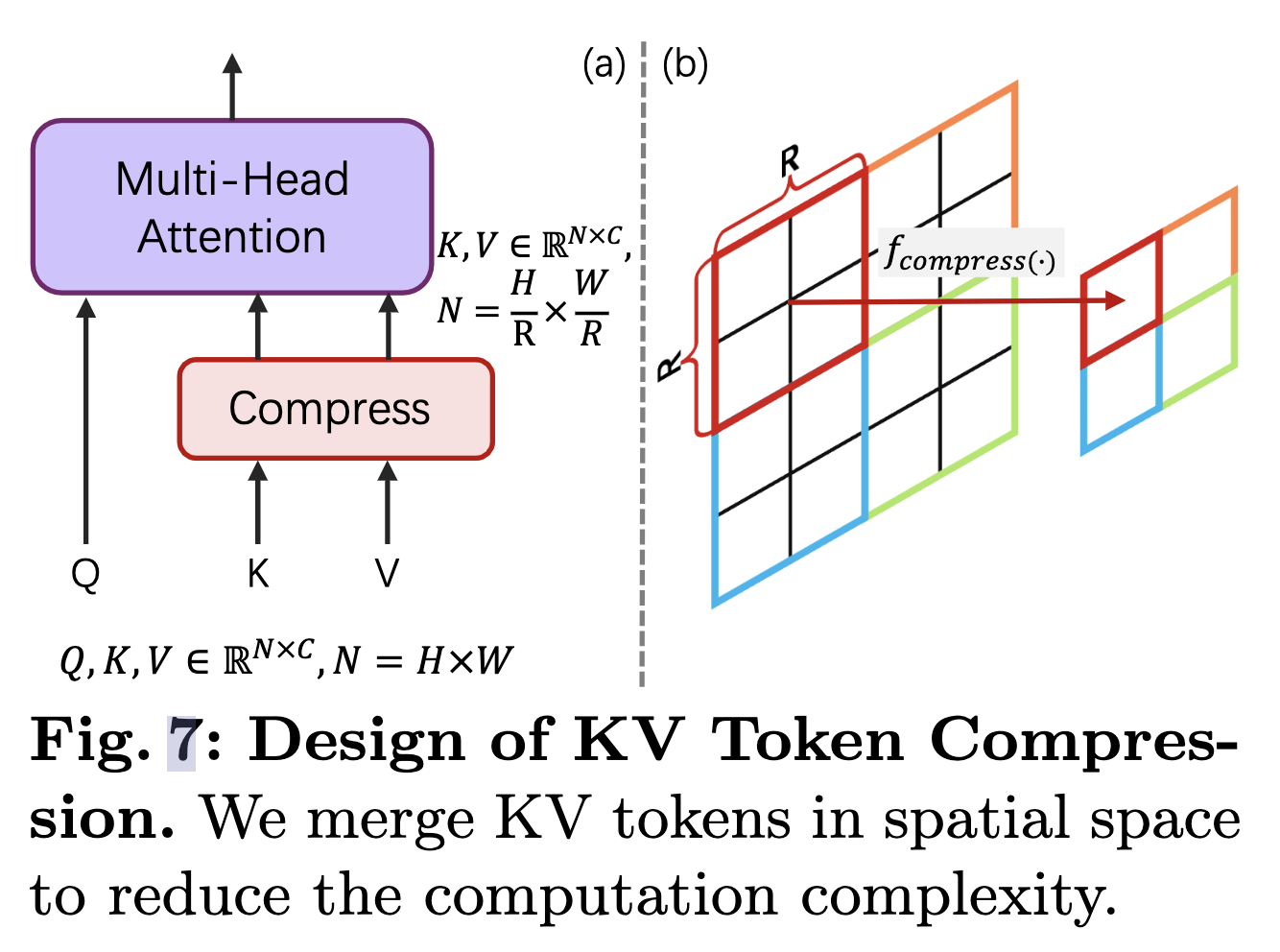
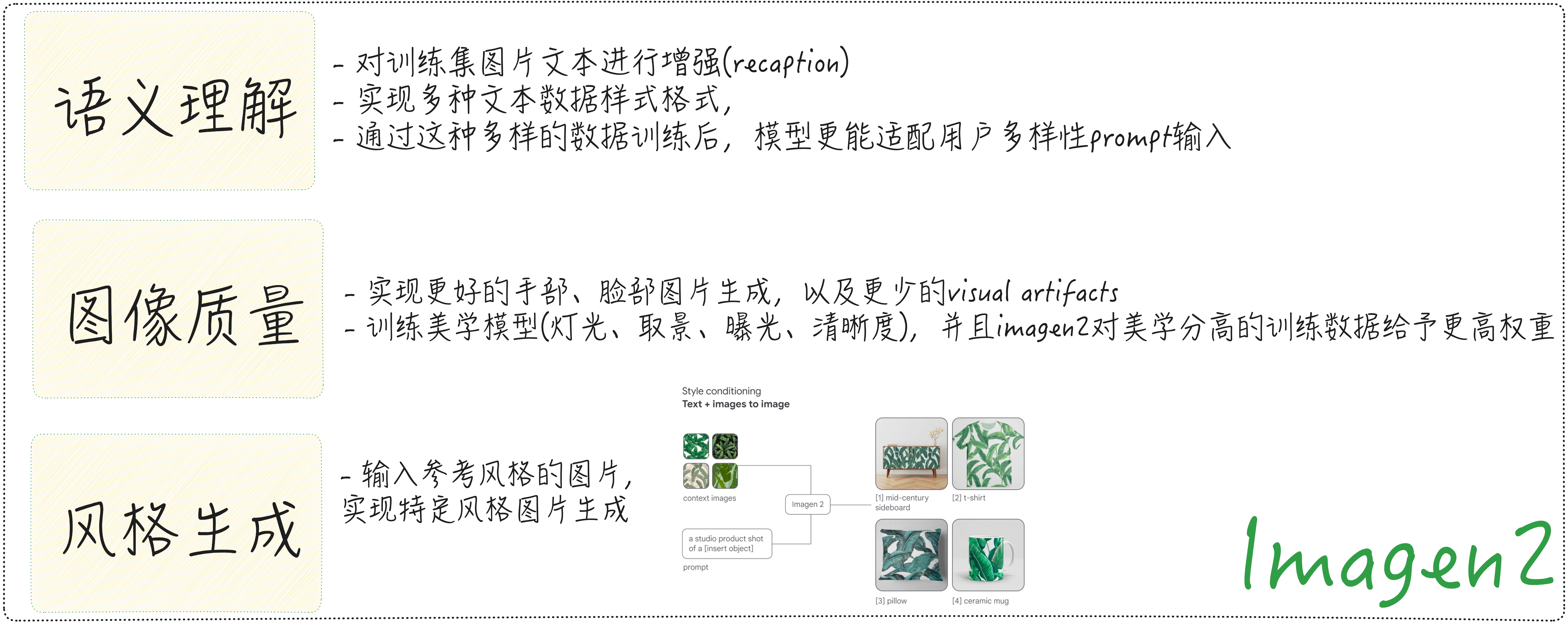
DiT文生图系列之Pixart-∑ PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation Motivation 高分辩率图像生成: Transformer架构中序列越长,计算复杂度是O(n^2),越长的分辨率,对于计算推理时间和训练成本来说就越高。如何实现更好更快的生成是一大难点。 高质量的图文对数据:爬虫图文对在图片质量和文本质量上都存在问题,不够美观,图文相关性弱。利用MLLM进行recaption通常会出现幻觉问题,提升MLLM的精度对于图文一致性非常重要。 从弱到强的训练策略:对于低分辨率训练模型、vae模型切换,从已经训练好的base模型,继承之前的训练权重,如何更好的迁移到新模型非常重要,节约训练成本。 主要贡献 高分辩率图像生成 根据self-attention的计算原理,KV矩阵的长度可以比原序列更短。注意力维度由NxN变成Nx(N/(RxR)): $QK^{T}$的维度变换(NC) (CxN/(RxR))-> N x (N/(RxR))。这样可以实现计算的压缩,并且相邻token存在语义的相似性,这样相当于引入了空间的局部先验。这里压缩的函数$f_{compress}$可以是global average pooling或者是stride为R的卷积层(可以用avg的kernel初始化加速训练)。 高质量的图文对数据 PixArt-Σ采用更好的ShareCaptioner替代原始的LLava模型,幻觉率更低,训练时采用60%概率选择,让模型能够适用caption文本和更多样范式的其他文本。收集了8百万4K分辨率的真实摄影图片。 从弱到强的训练策略: VAE: 从SD1.5的VAE替换到SDXL的VAE,2k训练steps 512分辨率提升到1024分辨率:结合位置编码插值(PE Interp),可以实现更快的尺度适应 KV压缩并采用avg的kernel权重初始化可以加速训练 继承原有的权重训练,PixArt-Σ具有非常高的训练效率 一些思考 局部窗口进行kv的压缩对于用Transformer架构的生成模型来说都是适用的,也可以用于自回归范式的图像生成模型
-
基于LLM做多模态生成系列文章-Make-A-Scene 基于LLM做多模态生成系列文章-Make-A-Scene Make a Scene (Meta-2022): Make-A-Scene: Scene-Based Text-to-Image Generation with Human Priors Motivation 提升生成的可控性:Make-A-Scene同期工作主要以文生图为主,生成结果的可控性低。(ControlNet之前的工作) 人类感知优化:人类对于人脸/人体显著物体的畸形容忍程度较低,生成图片需要增强这些方面的能力 主要贡献 1. 可控生成:实现除文本控制外,增加图片分割图的可控生成,结构一致性 2. 压缩优化:优化图片tokenizer,增强对显著物体(人脸/人体等)的重建效果 3. 推理优化:提出针对自回归图片生成模型的CFG方案【可以舍弃CLIP rerank的环节】,极大提升FID和图文对齐 一些思考 分割图与类别相关,推理过程中有OOD的类别,有一定的限制性 提高对显著物体的重建效果,通过加入“感知Loss”实现,Face Embedding or Vgg Embedding进行约束 CFG对于提升图文一致性效果非常显著。 其中系数经验值取3-5
-
基于LLM做多模态生成系列文章-Parti和Dalle 基于LLM做多模态生成系列文章-Parti和Dalle Parti: Scaling Autoregressive Models for Content-Rich Text-to-Image Generation Dalle: Zero-Shot Text-to-Image Generation 基于LLM的图片生成预期达成目标:复杂指令生成(多主体,属性绑定、空间位置关系等)、世界性知识 模型 模型结构图 图片离散化方式 自回归网络 参数量 生成图片大小 Dalle d-VAE Decoder-only 12B 256x256 Parti vit-VQGAN Encoder-Decoder 350M、750M、3B、20B 1024 = 256 + 4倍SR 参考链接 -知乎 多模态预训练:DALL-E
-
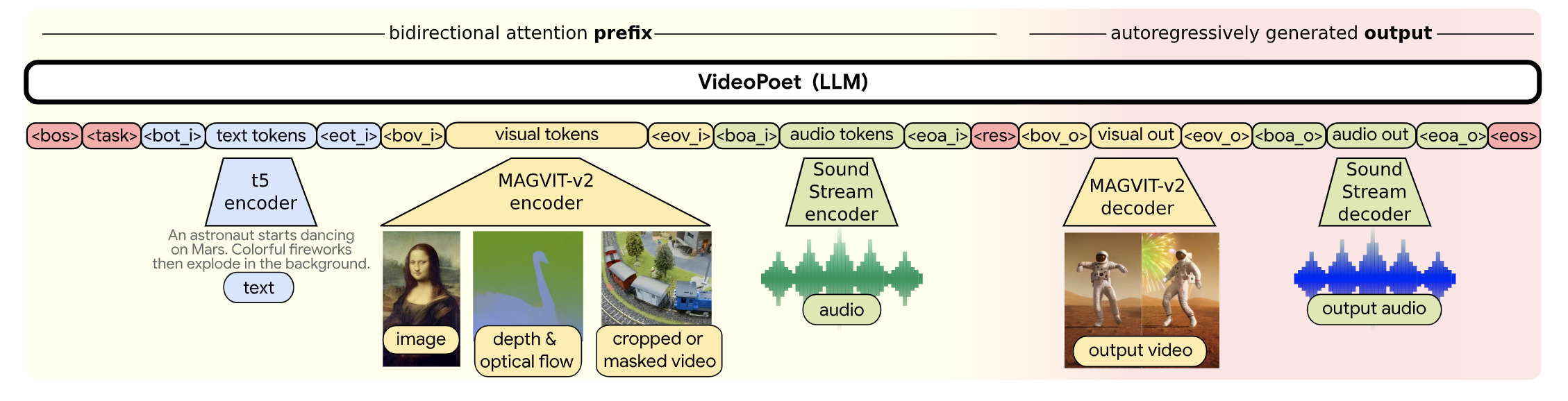
基于LLM做多模态生成系列文章-VideoPoet VideoPoet: A Large Language Model for Zero-Shot Video Generation Motivation 用扩散模型还是LLM做视觉生成?:LLM相比于Diffusion的优势,基设好,模型架构统一,多任务友好。但是当前主流的视觉生成还是以扩散模型为主,主要的原因在于训练一个基础模型的成本很高,以SD开源模型为代表。基于开源SD进行优化实现成本小很多,通过各种adapter在下游任务做适配。扩散模型对于任意多模态生成不利于统一(比如,如何用扩散模型做QA问答?),LLM会更友好。 主要贡献 多模态生成统一架构,实现图片、视频、音频的自回归生成,其中文本采用T5,视觉采用Magvit-v2,音频采用SoundStream Encoder进行离散化 级连的两阶段超分(两个2x超分):超分辨率受限于token长度,采用局部窗口的attention方式。采用将水平、垂直、时间三个维度解耦。 一些细节 模型参数量:8B模型 语言模型选择:UL2: Unifying Language Learning Paradigms 图文数据量:1B 视频数据量:270M(其中100M带有文字描述) tokeinzer词表:视觉采用Magvit-v2【26w词表】、音频:SoundStream Encoder【4096词表】 一些思考 关于文本编码:只用64个Token进行文字编码,并且使用预训练的文本编码器(T5-XL)。虽然提高了效率,但是受限预训练模型,并且转换到中文场景也会有限制(中文语义编码不准确)。端到端训练时,能够训练文本编码,如果有足够的数据量,理论上应该是更适配的。另外,该设计方案不考虑文本生成,不太符合全模态输出的设计。 视觉Tokenizer:Tokenizer在整个框架中非常重要,提升压缩率,能用更少的token来表示,以提升自回归的效率。Tokenizer应该是分层级的,有些场景对细节要求很高,则需要非常低损失的压缩,如小人脸、文字。对于风景,需要压缩损失可以更大些,提升自回归的效率。 预训练任务+下游多任务Finetune: 预训练任务越多越丰富,在使用时zero-shot性能和需要的下游数据量越少。具体需要哪些预训练任务,需要仔细考量。
-
-
Emu & Emu-edit (Meta) Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack Emu的主要发现: 采用少量的人工挑选标注数据(2k),即可大幅提升生成图像的美学质量。可能存在的问题:在少量数据集下Finetune需要严格控制训练steps,否则可能会出现过拟合问题、主体概念遗忘问题 Emu 训练测试流程 Emu 模型结构 模型结构主要改进点: 文本Encoder集成 CLIP和T5-XXL两种不同类型特征 提升VAE编码的特征通道数,让有损压缩丢失的信息更少 参考之前工作,利用noise-offset & 分尺度多阶段训练方法。前期学习语义生成,后期提升生成细节。 Emu Edit: Precise Image Editing via Recognition and Generation Tasks TODO
-
-
中文场景下的CLIP图文预训练 1. 写在前面 被广泛使用的CLIP模型,采用英文描述和图片对数据集(WebImageText 400M),进行对比学习训练,限制了其在中文场景下的应用。例如,在文生图应用中,国外开源模型Stable Diffusion需要采用英文作为输入,要支持中文描述生成图片得先翻译为英文。此外利用英文语料库训练的模型,对于【红烧狮子头、佛跳墙、对联和中文的成语、历史典故等】中文语境理解不够 在中文场景下的图文理解,近期也有相应的算法提出,包括智源的AltCLIP、阿里的ChinseCLIP、IDEA研究院的Taiyi、Wenlan、Wukong、R2D2等。这些算法各有优劣,本文将对上述算法和相关的数据集进行总结对比。 2. 中文-图文数据集 数据集 说明 机构 下载链接 WuKong 100M 数据集大小100M 华为 https://wukong-dataset.github.io/wukong-dataset/ Zero-Corpus 开源数据集大小23M(共250M) ,通过用户CTR行为数据进行过滤匹配的图文对 360 https://zero.so.com/index.html Laion5B-CN 包含多语言的图文数据,其中中文约143M LAION https://laion.ai/blog/laion-5b/ M6-Corpus 60M 阿里 数据未开源 TaiSu 166M 中科院自动化所 https://github.com/ksOAn6g5/TaiSu 3. 现有中文CLIP综合对比 多数的中文CLIP均采用固定图像侧模型参数,只训练文本Encoder的方法。为进一步提升性能,ChinseCLIP 采用两阶段训练方案:先只训练文本Encoder,再联合训练图像Encoder+文本Encoder; AltCLIP也采用两阶段训练方案: 利用模型蒸馏,学习不同语种之间的文本语义对齐,再利用图文对对比学习,Finetune文本Encoder。 多数方法虽然提升了模型在中文数据上的指标,但是同时在英文数据上的性能(zero-shot 检索任务)却下降了。截止到目前(2023/04),AltCLIP方法能够在中文和英文数据集上均取得SOTA的结果。 算法 开源日期 训练集 算法概括 Wukong-CLIP 2022-02 Wukong(100M/500M) 冻结图像encoder(ResNet50/VIT/Swin), 只训练文本Encoder,对比学习损失参照FILIP的方式学习细粒度的文本和图像块对齐 Taiyi-CLIP 2022-09 Wukong(100M)+Zero(23M) 基于OpenCLIP,冻结视觉编码器并且只微调语言编码器 ChinseCLIP 2022-11 LAION-CN(108M)+Wukong(72M)+翻译数据(20M, Visual Genome/MSCOCO) 基于OpenCLIP,两阶段训练方案: 1) 先Finetune文本Encoder2) 再结合ImageEncoder联合训练; 模型的缺点: 在英文任务上的指标大幅下降 AltCLIP 2022-12 Wudao + LAION 基于XLM-R文本Encoder+OpenCLIP图像Encoer,两阶段训练方案: 1) 先只是使用平行语料文本(相同含义的中英文数据)来进行蒸馏(平行语料相对于图文对更容易获取且数量更大)2) 再使用少量的2M中/英图像-文本对来训练文本编码器(图像侧固定)
-
生成内容真实度判别调研 & 模型选型 1. 背景概述 调研出发点: 利用判别模型对生成内容进行真假打分,根据模型输出属于“真”类的得分进行排序,可以筛选出生成“质量”更高的内容 任务难点: 简单的二分类任务(真假判别),泛化性能不足(没学到期望的关键信息) 简单整图二分类模型的解释性不强。如果能够在空间上“检测”到不真实部分的位置,则模型的可解释性更强 本文主要围绕DeepFake相关工作和近期文本/图像生成模型和强化学习结合的Reward函数设计两方面展开调研 2. 相关工作 2.1 真假图像鉴别 2.1.1 粗暴二分类方案 【CVPR 2020】【Adobe Research】CNN-generated images are surprisingly easy to spot... for now Motivation:提升真假鉴别器在不同数据集上的泛化性,实验分析影响模型泛化性的因素 Method & Results: 模型结构:利用ImageNet预训练的ResNet50进行真假鉴别二分类训练 数据增广:Gaussian blur、JPEG压缩的数据增广,提升模型在不同数据集下的泛化性能 定性分析: 鉴别器不能稳定表征图像的真实度/虚假度,在部分数据集上可观测到规律 4. 生成图片 vs 真实图片频域差异:大部分生成图片在频域有棋盘效应(low-level CNN artifacts) 5. 在PS结果上的泛化性:模型在Photoshope处理过的数据集上预测结果近乎随机 2.1.2 关注局部细节的鉴别方法 【CVPR 2021】【Microsoft Cloud AI】Multi-attentional Deepfake Detection Motivation:真假图片分类和Fine-grained图片分类相似,更关注图像的局部细节,而不是整体轮廓 or 背景语义信息。借鉴Fine-grained classification中的part-based方法提升细节鉴别能力 Method & Results:采用浅层纹理特征 & 深层语义特征融合的方式,进行二分类网络训练 局部边缘纹理增强模块(Texture enhancement block): 输入浅层特征Feature map,减去模糊(pooling)后的Feature mAP得到边缘纹理 空间局部注意力模块[Attnetion Module] & Bilinear Attention Pooling:输入高层语义特征,经过1x1卷积获得M个不同的Attention Map(Fk),利用这些注意力引导浅层&深层特征 增强注意力多样性: 基于注意力的显著性区域模糊AGDA(Attention Guided Data Augmentations):I′ = I × (1 − A) + Id × A (Id为高斯模糊图像,A为随机一张attention MAP) 注意力特征图metric learning约束(Regional Independence Loss):同一个注意力图关注区域特征相近,不同注意力图关注区域特征远离 【CVPR 2022】【Youtu Lab, Tencent】End-to-End Reconstruction-Classification Learning for Face Forgery Detection Motivation:当训练集中Fake类别图像分布不够丰富时(Fake图片的种类通常是多样且日益增长),判别式模型的泛化性能存在问题 Method & Results:通过生成式模型AutoEncoder进行像素级重建,学习真实图像的数据分布 模型结构优化: 像素级AutoEncoder重建(只对真实样本进行) & 重建误差注意力引导 在多个图像尺度下进行Encoder、Decoder之间的信息聚合: 度量学习损失优化:只约束真实样本特征之间尽可能接近(不同方法生成样本分布差异大),约束真假图像之间距离远离 模型泛化能力验证:训练不做数据扰动,测试时进数据增广,验证模型性能 2.1.3 基于频域的检测方法 【ECCV 2020】【SenseTime】Thinking in Frequency: Face Forgery Detection by Mining Frequency-aware Clues Motivation: 生成图像的“伪影”在频域更为明显,通过引入频域特征,提升模型鉴别能力;当图像被JPEG压缩后,伪影在像素空间上不显著,但在频域响应中可见 Method & Results: 论文方法整体还是一个二分类的框架,为了能够充分利用频域信息,作者采用了FAD提取空间域特征,LFS提取频域特征,最后再进行两类特征融合。 Frequency-aware 空间域特征(FAD):利用DCT将输入图像转换到频域,在频域进行高通、低通、和带通滤波,每个频带的滤波结果转换回空间域之后,就实现了图像分解,图像分解之后再进行CNN特征提取。 Local Frequency Statistics (LFS频域特征):利用滑动窗口DCT,对空间局部快进行频域分布统计特征 LFS 与FAD虽然都利用了频域信息,但是LFS是显式地以频域幅值作为特征,而FAD则通过DCT反变换回空间域再进行CNN特征提取。局部窗口统计特征 & 空间像素特征具有平移不变形,所以能适用CNN。(不直接在整图的频域上使用CNN) two-stream融合模块:Cross Attnetion 进行两类特征融合 模型优点 & 实验验证:在低画质图像上(压缩),模型的性能优越 【CVPR 2021】【Kuaishou】Frequency-aware Discriminative Feature Learning Supervised by Single-Center Loss for Face Forgery Detection Motivation: 1)基于softmax的分类损失没有约束类内距离紧凑 & 类间距离尽可能远离,为了实现这一目标提升鉴别器模型的泛化能力,作者提出针对真假二分类的度量学习损失函数;2)频域与像素空间域特征互补,提升精度 Method & Results: 模型整体流程:输入RGB图像,分别提取空间像素域和频域特征,对融合后的特征进行Softmax loss和Single-Center Loss两种损失函数进行监督: 频域特征提取:与JPEG压缩的方法类似,将RGB-〉YCbCr后,对局部块(8*8)进行DCT变换,并合并相同频率系数到当个channel(局部块 & reshape等操作和F3Net相似) Single-Center Loss:最小化真实图像特征与Natural(真实图像)类中心之间的距离 & 最大化,最大化每个生成图像与Natural类别中心之间的相对距离 模型效果验证: 2.2 生成内容排序 2.2.1 文本生成 【InstructGPT】【OpenAI】Training language models to follow instructions with human feedback Reward Model方法:对于一个prompt生成N个结果,让标注员对生成内容进行排序。对于一条排序好的标注数据,选择组样本对,并构建pairwise网络,学习对选择的两个生成内容进行质量高低判断。不做绝对打分而做排序的原因:排序标注更容易达成一致意见,标准更统一,而打绝对分数标注更困难(进而导致标注质量低,模型训练困难)。 2.2.2 图片生成 【Google】 Aligning Text-to-Image Models using Human Feedback Reward Function:学习文本与生成图像之间的匹配程度,采用0/1二分进行监督(背景/计数/颜色三方面综合考量) 模型输入:prompt T + 生成图像 I 模型输出:利用clip的文本 & 视觉 encoder分别提取文本和图像特征,经过两层MLP直接输出匹配度 监督目标:监督信号包含有监督和自监督两种 有监督:Reward模型输出的匹配度与人工标注的0/1匹配值,进行MSEloss监督 自监督:随机采样N个文本与生成图像I计算匹配度,最后得到N+1个匹配度score,进行CrossEntropy损失函数监督 3. 方案选型 3.1 网络结构选型 3.2 监督目标选型 4. 参考文献 https://github.com/Daisy-Zhang/Awesome-Deepfakes-Detection https://docs.qq.com/doc/DVG9pRHBFTUxYa0t1?&u=b0613c6debd74375ab98960a2d73d708
-
公开音频数据集和语音预训练模型总结 开源数据集 数据集 说明 Google-AudioSet 2084k, 527个类别, youtube视频 Youtube-100M 100M Youtube视频,根据标题/描述/评论自动生成的标签,标签集合约3w WeneSpeech 中文1w小时+音频数据集, 包括有声书、解说、纪录片、电视剧、访谈、新闻、朗读、演讲、综艺和其他等10大场景 VGG-Sound short clips of audio sounds, 200k个Youtube视频, 310个类别 LibriSpeech Large-scale (1000 hours) corpus of read English speech Libri-Light open-source audio books from the LibriVox project GigaSpeech audiobooks, podcasts and YouTube VoxPopuli multilingual corpus, 23种语言,100k小时 开源预训练模型 模型 训练数据 备注 Vggish YouTube-100M 2017年 腾讯游戏开源wav2vec2.0 & hubert WeneSpeech 2021年 FaceBook data2vec LibriSpeech 2022年 MSRA WavLM Libri-Light, GigaSpeech, VoxPopuli 2021年